Chapter 4. Data Governance over a Data Life Cycle
In previous chapters, we introduced governance, what it means, and the tools and processes that make governance a reality, as well as the people and process aspects of governance. This chapter will bring together those concepts and provide a data life cycle approach to operationalize governance within your organization.
You will learn about a data life cycle, the different phases of a data life cycle, data life cycle management, applying data governance over a data life cycle, crafting a data governance policy, best practices along each life cycle phase, applicable examples, and considerations for implementing governance. For some, this chapter will validate what you already know; for others, it will help you ponder, plant seeds, and consider how these learnings can be applied within your organization. This chapter will introduce and address a lot of concepts that will help you get started on the journey to making governance a reality. Before getting into the detailed aspects of governance, it’s important to center our understanding on data life cycle management and what it means for governance.
What Is a Data Life Cycle?
Defining what a data life cycle is should be easy—but in reality, it’s quite complex. If you look up the definition of a data life cycle and its phases, you quickly realize that it varies from one author to another, and from one organization to another. There’s honestly not one right way to think about the different stages a piece of data goes through; however, we can all agree that each phase that is defined has certain characteristics that are important in distinguishing it from the other phases. And because of these different characteristics within each phase, the way to think about governance will also vary as each piece of data moves through the data life cycle. In this chapter, we will define a data life cycle as the order of stages a piece of data goes through from its initial generation or capture to its eventual archival or deletion at the end of its useful life.
It’s important to quickly point out that this definition tries to capture the essence of what happens to a piece of data; however, not all data goes through each phase, and these phases are simply logical dependencies and not actual data flows.
Organizations work with transactional data as well as with analytical data. In this chapter, we will primarily focus on the analytics data life cycle, from the point when data is ingested into a platform all the way to when it is analyzed, visualized, purged, and archived.
Transactional systems are databases that are optimized to run day-to-day transactional operations. These are fully optimized systems that allow for a high number of concurrent users and transaction types. Even though these systems generate data, most are not optimized to run analytics processes. On the other hand, analytical systems are optimized to run analytical processes. These databases store historical data from various sources, including CRM, IOT sensors, logs, transactional data (sales, inventory), and many more. These systems allow data analysts, business analysts, and even executives to run queries and reports against the data stored in the analytic database.
As you can quickly see, transactional data and analytical data can have completely different data life cycles depending on what an organization chooses to do. That said, for many organizations, transactional data is usually moved to an analytics system for analysis and will therefore undergo the phases of a data life cycle that we will outline in the following section.
Proper oversight of data throughout its life cycle is essential for optimizing its usefulness and minimizing the potential for errors. Data governance is at the core of making data work for businesses. Defining this process end-to-end across the data life cycle is needed to operationalize data governance and make it a reality. And because each phase has distinct governance needs, this ultimately helps the mission of data governance.
Phases of a Data Life Cycle
As mentioned earlier, you will see a data life cycle represented in many different ways, and there’s no right or wrong answer. Whichever framework you choose to use for your organization has to be the one guiding the processes and procedures you put in place. Each phase of the data life cycle as shown in Figure 4-1 has distinct characteristics. In this section, we will go through each phase of the life cycle as we define it, delve into what each phase means, and walk through the implications for each phase as you think about governance.

Figure 4-1. Phases of a data life cycle
Data Creation
The first phase of the data life cycle is the creation or capture of data. Data is generated from multiple sources, in different formats such as structured or unstructured data, and in different frequencies (batch or stream). Customers can choose to use existing data connectors, build ETL pipelines, and/or leverage third-party ingestion tools to load data into a data platform or storage system. Metadata—data about data—can also be created and captured in this phase. You will notice data creation and data capture used interchangeably, mostly because of the source of data. When new data is created, that is referred to as data creation, and when existing data is funneled into a system, it is referred to as data capture.
In Chapter 1, we mentioned that the rate at which data is generated is growing exponentially, with IDC predicting that worldwide data will grow to 175 zettabytes by 2025.1 This is enormous! Data is typically created in one of these three ways:
- Data acquisition
- When an organization acquires data that has been produced by a third-party organization
- Data entry
- When new data is manually entered by humans or devices within the organization
- Data capture
- When data generated by various devices in an organization, such as IOT sensors, is captured
It’s important to mention that each of these ways of generating data offers significant data governance challenges. For example, what are the different checks and balances for data acquired from outside your organization? There are probably contracts and agreements that outline how the enterprise is allowed to use this data and for what purposes. There might also be limitations as to who can access that specific data. All these offer considerations and implications for governance. Later in the chapter, we will look at how to think about governance during this phase, and we will call out the different tools you should think about when designing your governance strategy.
Data Processing
Once data has been captured, it is then processed, without yet deriving any value from it for the enterprise. This is done prior to its use. Data processing is also referred to as data maintenance, and this is when data goes through processes such as integration, cleaning, scrubbing, or extract-transform-load (ETL) to get it ready for storage and eventual analysis.
In this phase, some of the governance implications that you will come across are data lineage, data quality, and data classification. All these have been discussed in much more detail in Chapter 2. To make governance a reality, how do you make sure that as data is being processed, its lineage is tracked and maintained? In addition, checking data quality is very important to make sure you’re not missing any important values before storing this data. You should also think about data classification. How are you dealing with sensitive information? What is it? How are you ensuring management of and access to this data so it doesn’t get into the wrong hands? Finally, as this data is moving, it needs to be encrypted in transit and then later at rest. There are a lot of governance considerations during this phase. We will delve into these concepts later in the chapter.
Data Storage
The third phase in the data life cycle is data storage, where both data and metadata are stored on storage systems and devices with the appropriate levels of protection. Because we’re focusing on the analytics data life cycle, a storage system could be a data warehouse, a data mart, or a data lake. Data should be encrypted at rest to protect it from intrusions and attacks. In addition, data needs to be backed up to ensure redundancy in the event of a data loss, accidental deletion, or disaster.
Data Usage
The data usage phase is important to understanding how data is consumed within an organization to support the organization’s objectives and operations. In this phase, data becomes truly useful and empowers the organization to make informed business decisions when it can be viewed, analyzed, and/or visualized for insights. In this phase, users get to ask all types of questions of the data, via a user interface or business intelligence tools, with the hope of getting “good” answers. This is where the rubber meets the road, especially when confirming whether the governance processes already instituted in previous phases truly work. If data quality is not implemented correctly, the types of answers you receive will be incorrect or might not make too much sense, and this could potentially jeopardize your business operations.
In this phase, data itself may be the product or service that the organization offers. If data is indeed the product, then different governance policies need to be enacted to ensure proper handling of this data.
Because data is consumed by multiple internal and external stakeholders and processes during this phase, proper access management and audits are key. In addition, there might be regulatory or contractual constraints on how data may actually be used, and part of the role of data governance is to ensure that these constraints are observed accordingly.
Data Archiving
In the data archiving phase, data is removed from all active production environments and copied to another environment. It is no longer processed, used, or published, but is stored in case it is needed again in an active production environment. Because the volume of data generated is growing, it’s inevitable that the volume of archived data grows. In this phase, no maintenance or general usage occurs. A data governance plan should guide the retention of this data and define the length of time it will be stored, including the different controls that will be applied to this data.
Data Destruction
In this final phase, data is destroyed. Data destruction, or purging, refers to the removal of every copy of data from an organization, typically done from an archive storage location. Even if you wanted to save all your data forever, it’s just not feasible. It’s very expensive to store data that is not in use, and compliance issues create the need to get rid of data you no longer need. The primary challenge of this phase is ensuring that all the data is properly destroyed and at the right time.
Before destroying any data, it is critical to confirm whether there are any policies in place that would require you to retain the data for a certain period of time. Coming up with the right timeline for this cycle means understanding state and federal regulations, industry standards, and governance policies to ensure that the right steps are taken. You will also need to prove that the purge has been done properly, which ensures that data doesn’t consume more resources than necessary at the end of its useful life.
You should now have a solid understanding about the different phases of a data life cycle and what some of the governance implications are. As stated previously, these phases are logical dependencies and not necessarily actual data flows. Some pieces of data might go back and forth between different processing systems before being stored. And some that are stored in a data lake might skip processing altogether and get stored first, and then get processed later. Data does not need to pass through all the phases.
We’re sure you’ve heard the phrase “Rome was not built in a day,” but that’s really what this data life cycle is trying to do. Applying data governance in an organization is a daunting task and can be very overwhelming. However, if you think about your data within these logical data life cycle phases, implementing governance can be a task that can be broken down into each phase and then thought through and implemented accordingly.
Data Life Cycle Management
Now that you understand the data life cycle, another common term you will run into is data life cycle management (DLM). What’s interesting is that many authors will refer to data life cycle and data life cycle management interchangeably. Even though there might be a need or desire to bundle them together, it’s important to realize that a data life cycle can exist without data life cycle management. DLM, therefore, refers to a comprehensive policy-based approach to manage the flow of data throughout its life cycle, from creation to the time when it becomes obsolete and is purged. When an organization is able to define and organize the life cycle processes and practices into repeatable steps for the company, this refers to DLM. As you start learning about DLM, you will quickly run into a data management plan. So let’s quickly look at what that means and what it entails.
Data Management Plan
A data management plan (DMP) defines how data will be managed, described, and stored. In addition, it defines standards you will use and how data will be handled and protected throughout its life cycle. You will primarily see data management plans required to drive research projects within institutions, but the concepts of the process are fundamental to implementing governance. Because of this, it’s worth us doing a deep dive into them and seeing how these could be applied to implement governance within an organization.
With governance, you will quickly realize that there is no a lack of templates and frameworks—see, for example, the DMPTool from Massachusetts Institute of Technology. You simply need to pick a plan or framework that works for your project and organization and march ahead; there’s not one right or wrong way to do it. If you choose to use a data management plan, here is some quick guidance to get you started. The concepts here are much more fundamental than the template or framework, so if you were able to capture these in a document, then you’d be ahead of the curve.
Guidance 1: Identify the data to be captured or collected
Data volume is important to helping you determine infrastructure costs and people time. You need to know how much data you’re expecting and the types of data you will be collecting:
- Types
- Outline the various types of data you will be collecting. Are they structured or unstructured? This will help determine the right infrastructure to use.
- Sources
- Where is the data coming from? Are there restrictions on how this data can be used or manipulated? What are those rules? All of these need to be documented.
- Volume
- This can be a little difficult to predict, especially with the exponential growth in data; however, planning for that increase early on and projecting what it could be would set you apart and help you be prepared for the future.
Guidance 2: Define how the data will be organized
Now that you know the type, sources, and volume of data you’re collecting, you need to determine how that data will be managed. What tools do you need across the data life cycle? Do you need a data warehouse? Which type, and from which vendor? Or do you need a data lake? Or do you need both? Understanding these implications and what each means will allow you to better define what your governance policies should be. There are many regulations that govern how data can and cannot be used, and understanding them is vital.
Guidance 3: Document a data storage and preservation strategy
Disasters happen, and ensuring that you’ve adequately prepared for one is very important. How long will a piece of data be accessible, and by whom? How will the data be stored and protected over its life? As we mentioned previously, data purging needs to happen according to the rules set forth. In addition, understanding what your systems’ backup and retention policies are, is important.
Guidance 4: Define data policies
It’s important to document how data will be managed and shared. Identify the licensing and sharing agreements that pertain to the data you’re collecting. Are there restrictions that the organization should adhere to? What are the legal and ethical restrictions on access to and use of sensitive data, for example? Regulations like GDPR and CCPA can easily get confusing and can even become contradictory. In this step, ensure that all the applicable data policies are captured accordingly. This also helps in case you’re audited.
Guidance 5: Define roles and responsibilities
Chapter 3 defined roles and responsibilities. With those roles in mind, determine which are the right ones for your organization and what each one means for you. Which teams will be responsible for metadata management and data discovery? Who will ensure governance policies are followed all the way? And there are many more roles that you can define.
A DMP should provide your organization with an easy-to-follow roadmap that will guide others and explain how data will be treated throughout its life cycle. Think of this as a living document that evolves with your organization as new datasets are captured, and as new laws and regulations are enacted.
If this was a data management plan for a research project, it would have included a lot more steps and items for consideration. Those plans tend to be more robust because they guide the entire research project and data end-to-end. We will cover a lot more concepts later in the chapter, so we chose to select items that were easily transferable to creating a governance policy and plan for your organization.
Applying Governance over the Data Life Cycle
We’ve gone through fundamental concepts thus far; now let’s bring everything together and look at how you can apply governance over the data life cycle. Governance needs to bring together people, processes, and technology to govern data throughout its life cycle. In Chapter 2, we outlined a robust set of tools to make governance a reality, and Chapter 3 focused on the people and process side of things. It’s important to point out that implementing governance is complicated; there’s no easy way to simply apply everything and consider he job done. Most technologies need to be stitched together, and as you can imagine, they’re all coming from different vendors with different implementations. You would need to integrate the best-in-class suite of products and services to make things work. Another option is to purchase a fully integrated data platform or governance platform. This is not a trivial task.
Data Governance Framework
Frameworks help you visualize the plan, and there are several frameworks that can help you think about governance across the data life cycle. Figure 4-2 is one such framework in which we highlight all the concepts from Chapter 2, overlaid with the concepts we’ve discussed in this chapter.
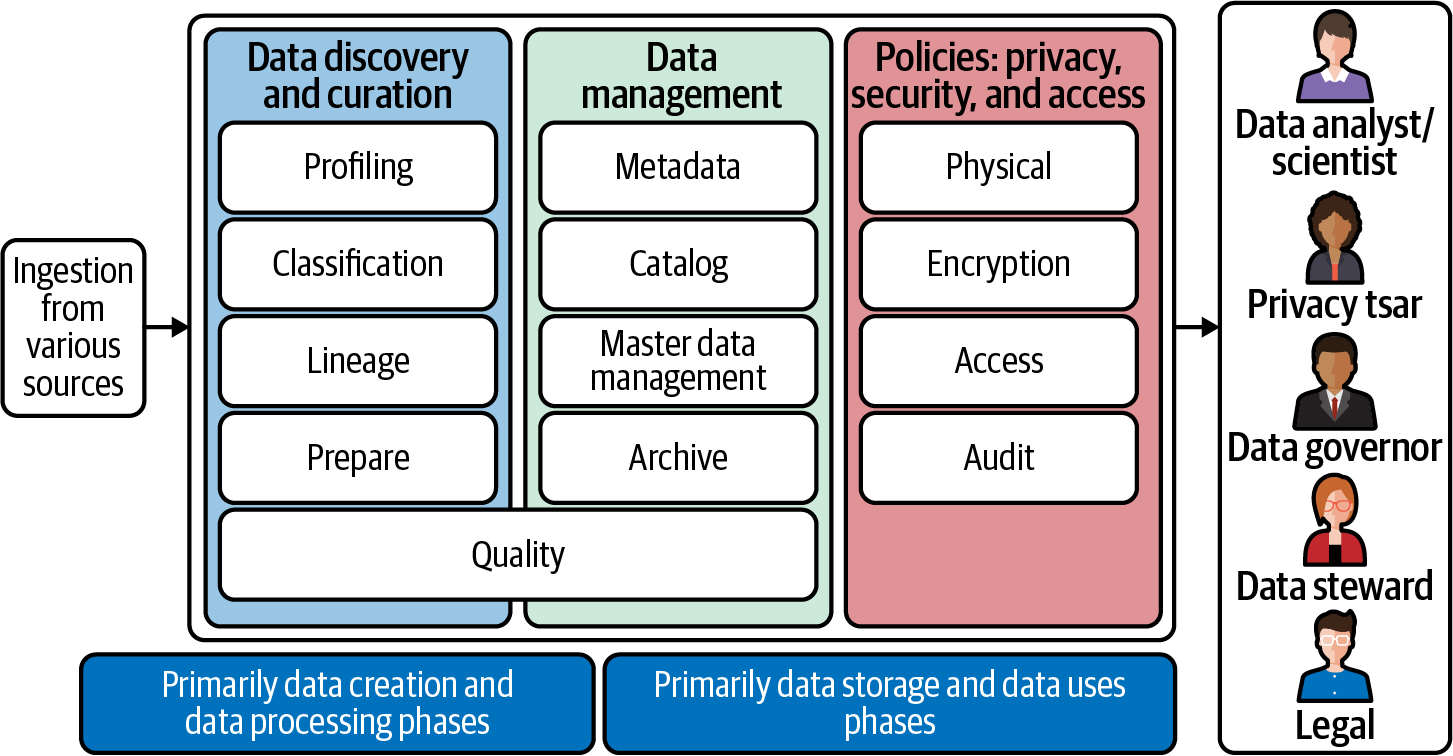
Figure 4-2. Governance over a data life cycle
This framework oversimplifies things to make them easier to understand; it assumes things are linear, from left to right, which is usually not the case. When data is ingested from various sources on the left, this is simply at the point of data creation or capture. That data is then processed and stored, and then it is consumed by the different stakeholders, including data analysts, data engineers, data stewards, and so on.
Data archiving and data destruction are not reflected in this framework because those take place beyond the point when data is used. As we previously outlined, during archiving, data is removed from all active production environments. It is no longer processed, used, or published but is stored in case it is needed again in the future. Destruction is when data comes to the end of its life and is removed according to guidelines and procedures that have been set forth.
One discrepancy that you will quickly notice is that metadata management should be considered from the point of data creation—where enterprises need to discover and curate the data as it’s ingested (especially for sensitive data)—to when data is stored and discovered in the applicable storage system. Archiving, even though mentioned within data management, tends to happen when the data’s usefulness is done and it is removed from production environments. Though archiving is an important part of governance, this diagram implies that it is taking place in the middle of the data life cycle. That said, it’s also possible to have an archiving strategy when data is simply stored in the applicable storage systems, so we cannot completely rule this out.
We want to reiterate that Figure 4-2 provides a logical representation of the phases a piece of data goes through, from left to right, and not necessarily the actual step-by-step flow of the data. There’s a lot of back and forth that happens between each phase, and not all pieces of data go through each one of these phases.
Frameworks are good at providing a holistic view of things. However, they are not the be-all, end-all. Make sure whichever framework you select works for your organization and your data.
Note
We’ve mentioned it already, but would like to emphasize again the idea of selecting a framework that work for your organization. This can include considerations around the kind of data you collect or work with, as well as what kind of personnel you have dedicated to your data governance efforts. One thing we challenge you to consider is how to take what you have and fit enough framework around it. Take these ideas as laid out (noting that not each step is required or even necessary) and layer on what you have to work with currently as a place to start. More pieces (and people, for that matter) can be added later, but if you focus on at least laying the groundwork—the foundation—you will be in a much better position if or when you do have more pieces to add to your framework.
Data Governance in Practice
OpenStreetMap (OSM) was created by Steve Coast in the UK in 2004 and was inspired by the success of Wikipedia. It is open source, which means it is created by people like you and is free to use under an open license. It was a response to the proliferation of siloed, proprietary international geographical data sources and dozens of mapping software products that didn’t talk to each other. OSM has grown significantly to over two million contributors, and what’s amazing is that it works. In fact, it works well enough to be the trusted source of data for a number of Fortune 500 companies, including other small and medium-sized businesses. With so many contributors, OSM is successful because it was able to establish data standards early in the process and ensured contributors adhered to them. As you can imagine, a crowdsourced mapping system without a way to standardize contributor data could go wrong very quickly. Defining governance standards can bring value to your organization and provide trusted data for your users.
And now that you have an understanding of the data life cycle with an overlay of the different governance tools, let’s delve further into how the different data governance tools we outlined in Chapters 1 and 2 can be applied and used across this life cycle. This section also includes best practices, which can help you start to define your organization’s data standards.
Data creation
As previously mentioned, this is the initial phase of the data life cycle, where data is created or captured. During this phase, an organization can choose to capture both the metadata, and the lineage of the data. Metadata describes the data, while the lineage describes the where of the data and how it will flow and be transformed and used downstream. Trying to capture these during this initial phase sets you up well for the later phases.
In addition, processes such as classification and profiling can be employed, especially if you’re dealing with sensitive data assets. Data should also be encrypted in transit to offer protection from intrusions and attacks. Cloud service providers such as Google Cloud offer encryption in transit and at rest by default.
Data processing
During this phase, data goes through processes such as integration, cleaning, scrubbing, or extract-transform-load (ETL) prior to its use, to get it ready for storage and eventual analysis. It’s important that the integrity of the data is preserved during this phase; that is why data quality plays a critical role.
Lineage needs to be captured and tracked here also, to ensure that the end users understand which processes led to which transformation and where the data originated from. We heard this from one user: “It would be nice to have a better understanding of the lineage of data. When finding where a certain column in a table comes from, I need to manually dig through the source code of that table and follow that trail (if I have access). Automate this process.” This is a common pain point felt by many, and one in which DLM and governance are critical.
Document Data Quality Expectations
Different data consumers may have different data quality requirements, so it’s important to provide a means to document data quality expectations while the data is being captured and processed, as well as techniques and tools for supporting the data’s validation and monitoring as it goes through the data life cycle. The right processes for data quality management will provide measurable and trustworthy data for analysis.
Data storage
In this phase, both data and metadata are stored and made ready for analysis. Data should be encrypted at rest to protect it from intrusions and attacks. In addition, data needs to be backed up to ensure redundancy.
Automated Data Protection and Recovery
Because data is stored in storage devices in this phase, find solutions and products that provide automated data protection to ensure that exposed data cannot be read, including encryption at rest, encryption in transit, data masking, and permanent deletion. In addition, implement a robust recovery plan to protect your business when a disaster strikes.
Data usage
In this phase, data is analyzed and consumed for insights and consumed by multiple internal and external stakeholders and processes in the organization. In addition, analyzed data is visualized and used to support the organization’s objectives and operations; business intelligence tools play a critical role in this phase.
A data catalog is vital to helping users discover data assets using captured metadata. Privacy, access management, and auditing are paramount at this stage, which ensures that the right people and systems are accessing and sharing the data for analysis. Furthermore, there might be regulatory or contractual constraints on how data may actually be used, and part of the role of data governance is to ensure that these constraints are observed.
Data Access Management
It is important to provide data services that allow data consumers to access their data with ease. Documenting what and how the data will be used, and for what purposes, can help you define identities, groups, and roles and assign access rights to establish a level of managed access. This ensures that only authorized and authenticated individuals and systems are able to access data assets according to defined rules.
Data archiving
In this phase, data is removed from all active production environments. It is no longer processed, used, or published but is stored in case it is needed again in the future. Data classification should guide the retention and disposal method of data.
Automated Data Protection Plan
Beyond being a way to prevent unauthorized individuals from accessing data, perimeter security is not and never has been sufficient for protecting data. The same protections applied in data storage would apply here as well to ensure that exposed data cannot be read, including encryption at rest, data masking, and permanent deletion. In addition, in case of a disaster, or in the event that archive data is needed again in a production environment, it’s important to have a well-defined process to revive this data and make it useful.
Data destruction
Finally, data is destroyed, or rather, it is removed from the enterprise at the end of its useful life. Before purging any data, it is critical to confirm whether there are any policies in place that would require you to retain the data for a certain period of time. Data classification should guide the retention and disposal method of data.
Create a Compliance Policy
Coming up with the right timeline for this cycle means understanding state and federal regulations, industry standards, and governance policies and staying up to date on any changes. Doing so helps to ensure that the right steps are taken and that the purge has been done properly. It also ensures that data doesn’t consume more resources than necessary at the end of its useful life.
IT stakeholders are urged to revisit the guidelines for destroying data every 12–18 months to ensure compliance, since rules change often.
Example of How Data Moves Through a Data Platform
Here’s an example scenario of how data could move through a data platform with the framework in Figure 4-2.
Scenario
Let’s say that a business wants to ingest data onto a cloud-data platform, like Google Cloud, AWS, or Azure, and share it with data analysts. This data may include sensitive elements such as US social security numbers, phone numbers, and email addresses. Here are the different pieces it might go through:
Business configures an ingestion data pipeline using a batch or streaming service:
Goal: As they move raw data into the platform, it will need to be scanned, classified, and tagged before it can be processed, manipulated, and stored.
Staged ingestion buckets:
Ingest: heavily restricted
Released: processed data
Admin quarantine: needs review
Data is then scanned and classified for sensitive information such as PII.
Some data may be redacted, obfuscated, or anonymized/de-identified. This process may generate new metadata, such as what keys were used for tokenization. This metadata would be captured at this stage.
Data is tagged with PII tags/labels.
Aspects of data quality can be accessed—that is, are there any missing values, are primary keys in the right format, etc.
Start to capture data provenance information for lineage.
As data moves between the different services along the life cycle, it is encrypted in transit.
Once ingestion and processing are complete, the data will need to be stored in a data warehouse and/or a data lake, where it is encrypted at rest. Backup and recovery processes need to be employed as well, in case of a disaster.
While in storage, additional business and technical metadata can be added to the data and cataloged, and users need to be able to discover and find the data.
Audit trails need to be captured throughout this data life cycle and made visible as needed. Audits allow you to check the effectiveness of controls in order to quickly mitigate threats and evaluate overall security health.
Throughout this process, it is important to ensure that the right people and services have access and permissions to the right data across the data platform using a robust identity and access management (IAM) solution.
You need to be able to run analytics and visualize the results for use. In addition to access management, additional privacy, de-identification, and anonymization tools may be employed.
Once this data is no longer needed in a production environment, it is archived for a determined period of time to maintain compliance.
At the end of its useful life, it is completely removed from the data platform and destroyed.
Operationalizing Data Governance
It’s one thing to have a plan, but it’s something else to ensure that plan works for your organization. NASA learned things the hard way. In September 1999, after almost 10 months of travel to Mars, the $125-million Mars Climate Orbiter lost communication and then burned and broke into pieces a mere 37 miles away from the planet’s surface. The analysis found out that, while NASA had used the metric system, one of its partners had used the International System of Units (SI). This inconsistency was not discovered until it was time to land the orbiter, leading to a complete loss of the satellite. This of course was crushing to the team. After this incident, proper checks and balances were implemented to ensure that something similar did not happen again.
Bringing things together so that issues such as the one NASA experienced are caught early and rectified before a disaster happens starts with the creatiion of a data governance policy. A data governance policy is a living, breathing document that provides a set of rules, policies, and guidance for safeguarding an organization’s data assets.
What Is a Data Governance Policy?
A data governance policy is a documented set of guidelines for ensuring that an organization’s data and information assets are managed consistently and used properly. A data governance policy is essential in order to implement governance. The guidelines will include individual policies for data quality, access, security, privacy, and usage, which are paramount for managing data across its life cycle. In addition, data governance policies center on establishing roles and responsibilities for data that include access, disposal, storage, backup, and protection, which should all be familiar concepts. This document helps to bring everything together toward a common goal.
The data governance policy is usually created by a data governance committee or data governance council, which is made up of business executives and other data owners. This policy document defines a clear data governance structure for the executive team, managers, and line workers to follow in their daily operations.
To get started operationalizing governance, a data governance charter template could be useful. Figure 4-4 shows an example template that could help you socialize your ideas across the organization and get the conversation started. Information in this template will funnel directly into your data governance policy.
Use the data governance charter template to kick off the conversation and get your team assembled. Once it has bought into your vision, mission, and goals, that is the team that will help you create and define your governance policy.

Figure 4-4. Data governance charter template
Importance of a Data Governance Policy
When you have a business idea and are going to friends to socialize the idea and possibly get them to buy into it, you will quickly run into someone who asks for a business plan. “Do you have a business plan you can share so I can read more about this idea and what your plans are?” A data governance policy allows you to have all the important elements of operationalizing governance documented according to your organization’s needs and objectives. It also allows consistency within the organization over a long period of time. It is the document that everyone will refer to when questions and issues arise. It should be reviewed regularly and updated when things in the organization change. You can consider it your business plan—or to another extreme, it can also be your governance bible.
When a data governance policy is well drafted, it will ensure:
Consistent, efficient, and effective management of the data assets throughout the organization and data life cycle and over time.
The appropriate level of protection of the organization’s data assets based on their value and risk as determined by the data governance committee.
The appropriate protection and security levels for different categories of data as established by the governance committee.
Developing a Data Governance Policy
A data governance policy is usually authored by the data governance committee or appointed data governance council. This committee will establish comprehensive policies for the data program that outline how data will be collected, stored, used, and protected. The committee will identify risks and regulatory requirements and look into how they will impact or disrupt the business.
Once all the risks and assessments have been identified, the data governance committee will then draft policy guidelines and procedures that will ensure the organization has the data program that was envisioned. When a policy is well written, it helps capture the strategic vision of the data program. The vision for the governance program could be to drive digital transformation for the organization, or possibly to get insights to drive new revenue or even to use data to provide new products or services. Whichever is the case for your organization, the policies drafted should all coalesce toward the articulated vision and mission as outlined in the data governance charter template.
Part of the process of developing a data governance policy is establishing the expectations, wants, and needs of key stakeholders through interviews, meetings, and informal conversations. This will help you get valuable input, but it’s also an opportunity to secure additional buy-in for the program.
Data Governance Policy Structure
A well-crafted policy should be unique to your organization’s vision, mission, and goals. Don’t get hung up on every single piece of information on this template, however; use it more like a guide to help you think things through. With that in mind, your governance policy should address:
- Vision and mission for the program
- If you used a data governance charter template as outlined in Figure 4-4 to get buy-in from other stakeholders, that means you already have this information readily available. As mentioned before, the vision for the governance program could be to drive digital transformation for the organization, or to get insights to drive new revenue, or even to use data to provide new products or services.
- Policy purpose
- Capture goals for your organization’s data governance program, as well as metrics for determining success. The mission and vision of the program should drive the goals and success metrics.
- Policy scope
- Document the data assets covered by this governance policy. In addition, inventory the data sources and determine data classifications based on whether data is sensitive, confidential, or publicly available, along with the levels of security and protection required at the different levels.
- Definitions and terms
- The data governance policy is usually viewed by stakeholders across the organization who might not be familiar with certain terms. Use this section to document terms and definitions to ensure everyone is on the same page.
- Policy principles
- Define rules and standards for the governance program you’re looking to set up along with the procedures and programs to enforce them. The rules could cover data access (who has access to what data), data usage (how the data will be used and details around what’s acceptable), data integration (what transformations the data will undergo), and data integrity (expectations around data quality). Develop best practices to protect data and to ensure regulations and compliance are effectively documented.
- Program structure
- Define roles and responsibilities (R&Rs), which are positions within the organization that will oversee elements of the governance program. A RACI chart could help you map out who is responsible, who is accountable, who needs to be consulted, and who should be kept informed about changes. Information on governance R&Rs can be found in Chapter 3 of the book.
- Policy review
- Determine when the policy will be reviewed and updated and how adherence to the policy will be monitored, measured, and remedied.
- Further assistance
- Document the right people to address questions from the team and other stakeholders.
It’s not enough to document a data governance policy as outlined in Figure 4-5, communicating it to all stakeholders is equally important. This could happen through a combination of group meetings and training, one-on-one conversations, recorded training videos, and written communication.

Figure 4-5. Example data governance policy template
In addition, review performance regularly with your data governance team to ensure that you’re still on the right track. This also means regularly reviewing your data governance policy to make sure it still reflects the current needs of the organization and program.
Roles and Responsibilities
When operationalizing governance over a data life cycle, you will interact with many stakeholders within the organization, and you will need to bring them together to work on this common goal. While it might be tempting to definitively say which roles do what at which part of the data life cycle, as outlined in Chapter 3, many data governance frameworks revolve around a complex interplay of roles and responsibilities. The reality is that most companies rarely are able to exactly or fully staff governance roles due to lack of employee skill set or, more commonly, a simple lack of headcount. For this reason, employees working in the information and data space of their company often wear different user “hats.”
We will not go into detail about roles and responsibilities in this chapter, because they’re well outlined in Chapter 3. You still need to define what these look like within your organization and how they will interplay with each other to make governance a reality for you. This will typically be outlined in a RACI matrix describing who is “responsible, accountable, to be consulted, and to be informed” within a certain enforcement, process, policy, or standard.
Step-by-Step Guidance
By this section of the book, you should know that data governance goes beyond the selection and implementation of products and tools. The success of a data governance program depends on the combination of people, processes, and tools all working together to make governance a reality. This section will feel very familiar, because it gathers all the elements discussed in the previous section on data governance policy and puts them in a step-by-step process to show you how to get started. It further double clicks into the concepts as well.
- Build the business case
- As previously mentioned, data governance takes time and is expensive. If done correctly, it can be automated as part of the application design done at the source with a focus on business value. That said, data governance initiatives will often vary in scope and objectives. Depending on where the initiative is originating from, you need to be able to build a business case that will identify critical business drivers and justify the effort and investment of data governance. It should identify the pain points, outline perceived data risks, and indicate how governance helps the organization mitigate those risks and enable better business outcomes. It’s OK to start small, strive for quick wins, and build up ambitions over time. Set clear, measurable, and specific goals. You cannot control what you cannot measure; therefore you need to outline success metrics. The data governance charter template in Figure 4-4 is perfect for helping you get started.
- Document guiding principles
- Develop and document core principles associated with governance and, of course, associated with the project you’re looking to get off the ground. A core principle of your governance strategy could be to make consistent and confident business decisions based on trustworthy data aligned with all the various purposes for the use of the data assets. Another core principle could be to meet regulatory requirements and avoid fines or even to optimize staff effectiveness by providing data assets that meet the desired data quality thresholds. Define principles that are core to your business and project. If you’re still new to this area, there are a lot of resources available. If you are looking online, there are several vendor-agnostic, not-for-profit associations, such as the Data Governance Institute (DGI), the Data Management Association (DAMA), the Data Governance Professionals Organization (DGPO), and the Enterprise Data Management Council, all of which provide great resources for business, IT, and data professionals dedicated to advancing the discipline of data governance. In addition, identify whether there are any local data governance meetup groups or conferences that you can possibly attend, such as the Data Governance and Information Quality Conference, DAMA International Events, or a Financial Information Summit.
- Get management buy-in
- It should be no surprise that without management buy-in, your governance initiative can easily be dead from the get-go. Management controls the big decisions and funding that you need. Outlining important KPIs, and how your plan helps to move them, will get management to be all ears. Engage data governance champions and get buy-in from the key senior stakeholders. Present your business case and guiding principles to C-level management for approval. You need allies on your side to help make the case. And once the project has gotten off the ground, communicate frequently.
- Develop an operating model
- Once you have management approval, it’s time to get to work. How do you integrate this governance plan into the way of doing business in your enterprise? We introduced you to the data governance policy, which can come in very handy during this process. During this stage, define the data governance roles and responsibilities, and then describe the processes and procedures for the data governance council and data stewardship teams who will define processes for defining and implementing policies as well as for reviewing and remediating identified data issues. Leverage the content from the data management policy plan to help you define your operating model. Data governance is a team sport, with deliverables from all parts of the business.
- Develop a framework for accountability
- As with any project you’re looking to bring to market, establishing a framework for assigning custodianship and responsibility for critical data domains is paramount. Define ownership. Make sure there is visibility to the “data owners” across the data landscape. Provide a methodology to ensure that everyone is accountable for contributing to data usability. Refer back to your data management policy, as it probably started to capture some of these dependencies.
- Develop taxonomies and ontologies
- This is where a lot of the education you’ve collected thus far comes in handy. Working closely with governance associations, leaning in on your peers, and simply learning about things online will help you with this step. There may be a number of governance directives associated with data classification, organization, and, in the case of sensitive information, data protection. To enable your data consumers to comply with those directives, there must be a clear definition of the categories (for organizational structure) and classifications (for assessing data sensitivity). These should be captured in your data governance policy.
- Assemble the right technology stack
- Once you’ve assigned data governance roles to your staff and defined and approved your processes and procedures, you should then assemble a suite of tools that facilitates implementation and ongoing validation of compliance with data policies and accurate compliance reporting. Map infrastructure, architecture, and tools. Your data governance framework must be a sensible part of your enterprise architecture, the IT landscape, and the tools needed. We talked about technology in previous sections, so we won’t go into detail about it here. Finding tools and technology that work for you and satisfy the organizational objectives you laid out is what’s important.
- Establish education and training
- As highlighted earlier, for data governance to work, it needs buy-in across the organization. You need to ensure that your organization is keeping up and is still buying into the project you presented. It’s therefore important to raise awareness of the value of data governance by developing educational materials highlighting data governance practices, procedures, and the use of supporting technology. Plan for regular training sessions to reinforce good data governance practices. Wherever possible, use business terms, and translate the academic parts of the data governance discipline into meaningful content in the business context.
Considerations for Governance Across a Data Life Cycle
Data governance has been around since there was data to govern, but it was mostly viewed as an IT function. Implementing data governance across the data life cycle is no walk in the park. Here are some considerations you will need to think about as you implement governance in your organization. These should not be surprising to you, because you will quickly notice that they touch on a lot of aspects we introduced in Chapters 1 and 2, as well as in this chapter.
Deployment time
Crafting and setting up governance processes across the data life cycle takes a lot of time, effort, and resources. In this chapter, we have introduced a lot of concepts, ideas, and ways to think about operationalizing governance across the data life cycle, and you can see it gets overwhelming very quickly. There’s not a one-size-fits-all solution; you need to identify what is unique about your business and then forge a plan that works for you. Automation can reduce the deployment time compared with hand-coded governance processes. In addition, artificial intelligence is seen as a way to get arms around data governance in the future, especially for things like autodiscovery of sensitive data and metadata management. That means that as you look for solutions in the market, you will need to find out how much automation and integration is built into it, how well it works for your environment and situation, and whether that is the most difficult part of the workflow that could use automation. In a hybrid or even a multi-cloud world, this becomes even more complex and further increases the deployment time.
Complexity and cost
Complexity comes in many forms. In Chapter 1, we talked about how much the data landscape is and about just how quickly data was being produced in the world. Another complexity is a lack of defined industry standards for things like metadata. We touched on this in Chapter 2. In most cases, metadata does not obey the same policies and controls as the underlying data itself, and a lack of standardized metadata specifications means that different products and processes will have different ways of presenting this information. Still another complexity is the sheer amount of tools, processes, and infrastructure needed to make governance a reality. In order to deliver comprehensive governance, organizations must either integrate best-of-breed solutions, which are often complex and very expensive (with high license and maintenance costs), or buy turnkey, integrated solutions, which are expensive and fewer in the market. With this in mind, cloud service providers (CSPs) are building data platforms with all these governance capabilities built in, thus creating a one-stop shop and simplifying the process for customers. As an organization, research and compare the different data platforms provided by CSPs and see which one works for you. Some businesses choose to leave some of their data on-premises; however, for the data that can move to the cloud, these CSPs are now building robust tools and processes to help customers govern their data end-to-end on the platform. In addition, companies such as Informatica, Alation, and Collibra offer governance-specific platforms and products that can be implemented in your organization.
Changing regulation environment
In previous chapters, we’ve clearly outlined the implications of a constantly changing regulatory environment with the introduction of GDPR and CCPA. We will not go into the same detail here; however, regulations define a lot of what must be done and implemented to ensure governance. They will outline how certain types of data need to be handled and which types of controls need to be in place, and they sometimes will even go as far as outlining what the repercussions are when these things are not complied with. Complying with regulations is absolutely something your organization needs to think about as you implement data governance over the data life cycle.
Note
In our discussions with many different companies, we’ve heard of two very different philosophies when it comes to considering changes to the regulatory environment. One strategy is to assume that, in the future, the most restrictive regulations that are present now will cascade and be required everywhere (like CCPA being required across the entire US and not just in California), and that ensuring compliance now, even though not required, is a top priority. Conversely, we’ve also heard the strategy of complying only with what’s required right now and dealing with regulations only if they become required. We strongly suggest you take the former approach, because a proper and well-thought-out governance program not only ensures compliance with ever-changing regulations; it also enables many of the other benefits we’ve outlined thus far, such as better findability, better security, and more accurate analytics from higher-quality data.
Location of data
In order to fully implement governance over a data life cycle, understanding which data is on-premises versus in the cloud is very important. Furthermore, understanding how data will interact with other data along the life cycle does create complexity. In the current paradigm, most organizational data lives both on-premises and in the cloud, and having systems and tools that allow for hybrid and even multicloud scenarios is paramount. In Chapter 1, we talked about why governance is easier in the public cloud—it’sprimarily because the public cloud has several features that make data governance easier to implement, monitor, and update. In many cases, these features are unavailable or cost-prohibitive in on-premises systems. Data should be protected no matter where it is located, so a viable data life cycle management plan will incorporate governance for all data at all times.
Organizational culture
As you know, culture is one of those intangible things in an organization that plays an important role in how the organization functions. In Chapter 3, we touched on how an organization can create a culture of privacy and security, which allows employees to understand how data should be managed and treated so that they are good stewards of proper data handling and usage. In this section, we’re referring to organizational culture, which often dictates what people do and how they behave. Your organization might be free, allowing folks to easily raise questions and concerns, and in such an environment, when something goes wrong, people are more likely to speak up. In organizations in which people are reprimanded for every little thing, they will be more afraid to speak up and report when things are not working or even when things go wrong. In these environments, governance is a little difficult to implement, because without transparency and proper reporting, mistakes are usually not discovered until much later. In the NASA example we provided earlier in this chapter, there were a couple of people within the organization who noticed the discrepancy in the data and even reported it. Their reports were ignored by management, and we all know what happened. Things did not end well for NASA. Remember, instituting governance in an organization is often met with resistance, especially if the organization is accustomed to decentralized operations. Creating an environment in which functions are centralized across the data life cycle simply means that these areas have to adhere to processes that they might not have been used to in the past but that are for the larger good of the organization.
Summary
Data life cycle management is paramount to implementing governance and ensures that useful data is clean, accurate, and readily available to users. In addition, it ensures that your organization remains compliant at all times.
In this chapter, we introduced you to data life cycle management, and how to apply governance over the data life cycle. We then looked into operationalizing governance and how the role of a data governance policy is to ensure that an organization’s data and information assets are managed consistently and used properly. Finally, we provided step-by-step guidance for implementing governance and finished with the considerations for governance across the data life cycle, including deployment time, complexity and cost, and organizational culture.
1 Andy Patrizio, “IDC: Expect 175 Zettabytes of Data Worldwide by 2025”, Network World, December 3, 2018.
2 A natural experiment is a situation in which you can identify experimental and control groups determined by factors outside the control of the investigators. In our example here, the runners naturally fell into groups defined by the shoes they wore, rather than being assigned shoes externally. The groups of runners were large enough to qualify for good “experimental” and “control” groups with controlled number of external factors.
Get Data Governance: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

