Kapitel 4. Entscheidungsmodellierung: Der Prozess zur Untersuchung von Entscheidungswerten
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Ertrinken wir in Daten? Die Welt erzeugt mittlerweile mehr als 100 Zettabytes (ZB)1 an Daten pro Jahr, "das entspricht in etwa der Menge, die jeder Mensch jedes Jahr in der Library of Congress erzeugt", so Marc Warner in Computer Weekly. Aber hilft uns das wirklich weiter? "Wenn die datengesteuerte Entscheidungsfindung richtig wäre", fügt Warner hinzu, "sollte dieses Wachstum zu einer erheblich verbesserten Unternehmensleistung führen.... Ist das geschehen? Offensichtlich nicht." Was ist da los?
Daten können uns nur dann helfen, zu denken oder etwas effizienter zu tun, wenn es die richtigen Daten sind, in der richtigen Form, zur richtigen Zeit. Zettabytes falscher Daten in der falschen Form helfen uns nicht dabei, unsere Ziele zu erreichen; im Gegenteil, Daten können uns im Weg stehen. Deshalb sagen so viele Entscheidungsträger/innen routinemäßig Dinge wie: "Bitte schicken Sie mir keine Daten. Ich bin einfach nicht interessiert."
Entscheidungsintelligenz behebt dieses Problem, indem sie deine Daten in eine besser nutzbare Form umwandelt. Der Prozess der Entscheidungsfindung (Prozess B2, siehe Abbildung 4-1) ist der erste Schritt auf dem Weg zur Erstellung einer Softwaresimulation des Pfades/der Pfade von den Aktionen zu den Ergebnissen, die dir hilft, die besten Aktionen zu bestimmen. Die CDD dient als "Gerüst", das dir zeigt, wo die Daten diese Simulation unterstützen. Die Untersuchung von Entscheidungswerten beginnt mit deiner anfänglichen CDD und nutzt sie als Leitfaden für deine Untersuchung, um mehrere Werte zu finden, die für eine evidenzbasierte Entscheidungsfindung genutzt werden können. Hier fragst du dich insbesondere: "Wenn ich das Element auf der linken Seite dieser Abhängigkeit ändere, was passiert dann mit dem Element auf der rechten Seite?"
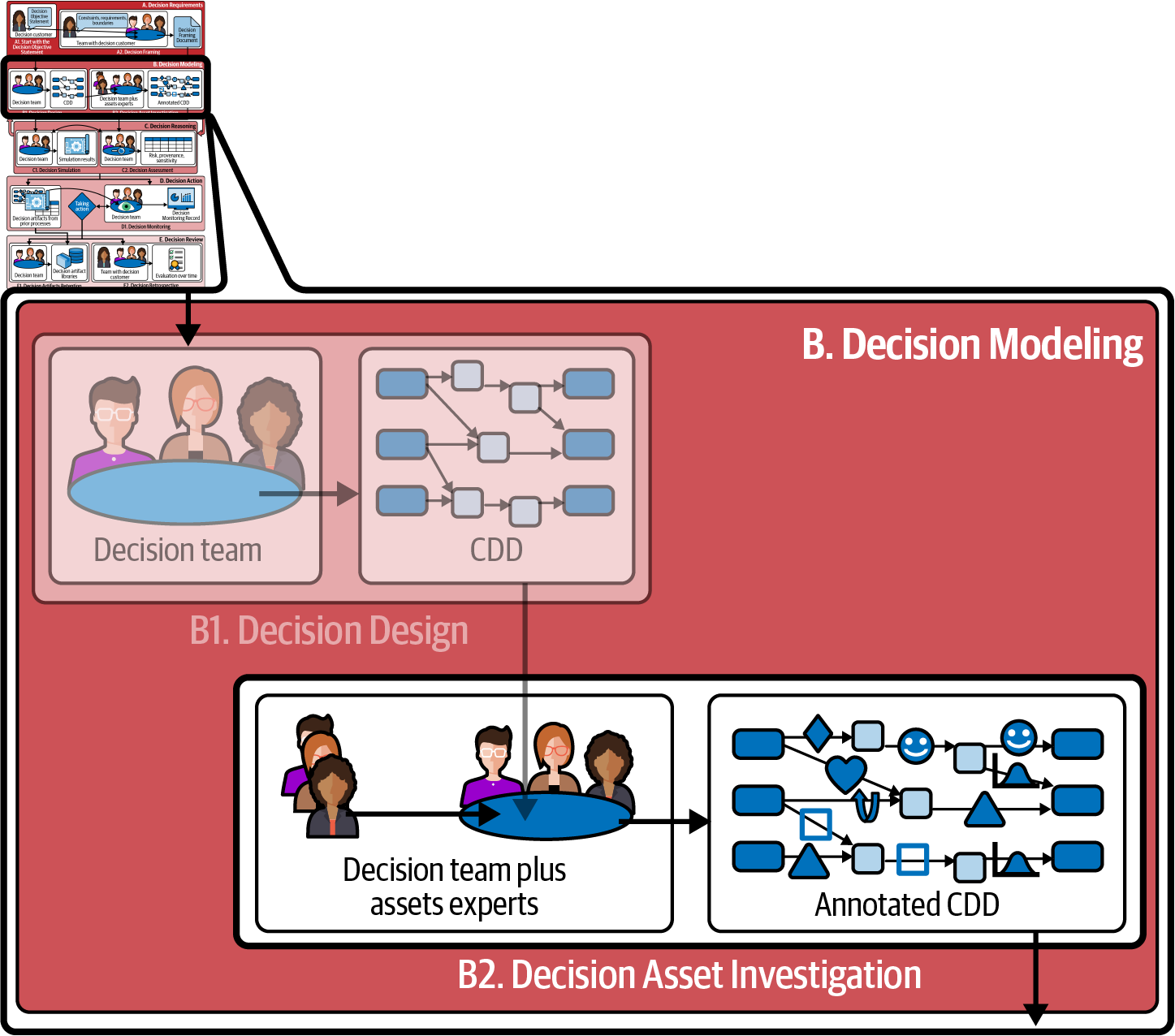
Abbildung 4-1. Der Zusammenhang zwischen Decision Asset Investigation und den anderen Prozessen in diesem Buch.
Wie du in Kapitel 3 gelernt hast, konzentriert sich Prozess B1, das Entscheidungsdesign, auf die Ausrichtung auf die Ergebnisse, die Identifizierung von Hebeln, die diese Ergebnisse bewirken können, das Verständnis von externen Faktoren, die diese Ergebnisse beeinflussen, und den Aufbau der Kausalketten von den Hebeln und externen Faktoren zu den Ergebnissen. Prozess B2, Decision Asset Investigation, konzentriert sich dagegen auf die Identifizierung der Assets, die dir helfen, diese Kausalketten in Software umzusetzen. Am Ende hast du ein Werkzeug, mit dem du sagen kannst: "Wenn ich diese Hebel wähle und diese Annahmen über externe Faktoren treffe, erwarte ich, dass ich dieses Ergebnis messen kann."
Dieses Kapitel führt dich Schritt für Schritt durch den Prozess der Nutzung und Kommentierung deines CDD, um Entscheidungsressourcen - Daten und andere Arten von Technologien - zu identifizieren, die die Simulation, die du in Kapitel 5 erstellen wirst, unterstützen und das Gespräch mit deinem Datenteam erleichtern können. Dieses Gespräch unterscheidet sich deutlich von den üblichen "Back-to-Front"-Entscheidungsgesprächen. Durch diese Arbeit wird deine "Entscheidungsvorlage" in eine Spezifikation für einen "digitalen Zwilling der Entscheidung" umgewandelt, die für die Simulation bereit ist.
Die Entscheidung für die Digitalisierung
Wann lohnt es sich, über die CDD hinauszugehen und eine Entscheidung in Software zu modellieren? Die einfache Antwort lautet: Das hängt davon ab, welchen Return on Investment (ROI) du von dieser Übung erwartest. Vielleicht stellst du - wie einige unserer Kunden - fest, dass die CDD allein schon ein großer Gewinn ist und dein Unternehmen noch nicht bereit ist, den nächsten Schritt zu tun. Oder du stellst fest, nachdem du ein wenig mit dem CDD gearbeitet hast, dass entweder (a) deine Entscheidungskunden es einfach nicht "kapieren" oder (b) die Entscheidung so komplex und wertvoll ist, dass du glaubst, dass es sich lohnt, eine Simulation dafür zu entwickeln. Wenn der Lebensunterhalt von Menschen und/oder große Geldbeträge von einer Entscheidung abhängen, haben unsere Kunden festgestellt, dass sich die Investition in die Implementierung von Entscheidungssoftware lohnen kann. Und wenn du möchtest, kannst du mit einer einfachen Simulation - manchmal auch "Low-Fidelity-Simulation" genannt - "den Zeh ins Wasser halten", bevor du den ganzen Schnickschnack mit Daten und Analysen einführst.
Wenn du dich dafür entscheidest, weiterzumachen, wirst du feststellen, dass der Aufwand für die Ermittlung von Entscheidungswerten sehr unterschiedlich ist. Manchmal ist dein Entscheidungsasset sehr einfach - es ist nur das Wissen, dass, wenn das Element auf der linken Seite steigt, auch das Element auf der rechten Seite steigt (oder fällt). In anderen Fällen kann es sich um ein statistisches Modell, ein ML-Modell, ein verhaltensorientiertes, kognitives und/oder mathematisches Modell oder um menschliches Fachwissen handeln, das detaillierte Informationen über eine bestimmte Abhängigkeit liefern kann. Eine der wichtigsten Fragen, die du bei der Untersuchung von Entscheidungsressourcen beantworten musst, lautet: "Wo befindet sich das Modell, das diesem Abhängigkeitspfeil zugrunde liegt?"
Einführung in den Prozess B2: Entscheidung Asset Investigation
Dieses Kapitel zeigt, wie Entscheidungsteams mit Analysten zusammenarbeiten können, um Entscheidungswerte zu ermitteln. Du lernst, wie du den Prozess der Entscheidungs-Asset-Untersuchung anwendest und ein Entscheidungs-Asset-Register führst, in dem du die Assets und die für sie verantwortlichen Personen festhältst. Im Anwendungsfall "Versuchen Sie es selbst" am Ende des Kapitels übst du, Entscheidungswerte zu identifizieren, sie einem CDD zuzuordnen und sie in das Register einzutragen.
Unter findest du im Anhang eine vollständige Liste, wie Daten sowohl bei der Entscheidungsfindung als auch bei der Umsetzung der Entscheidung verwendet werden können. Du brauchst diese vollständige Liste nicht, um mit dem Sammeln von Entscheidungsgrundlagen zu beginnen; du kannst auch ohne sie loslegen. Im Wesentlichen besagt sie, dass Daten viele der Entscheidungselemente beeinflussen können: Sie liefern Vorhersagen oder Annahmen über externe Faktoren, liefern erwartete Bereiche für Zwischenergebnisse und (am wichtigsten) steuern die Modelle, die die Abhängigkeitspfeile bestimmen. Diese Daten sind bei der Entscheidungsfindung und im Verlauf der Entscheidungsfindung nützlich.
Dieser Prozess hat zwei Ziele. Erstens hilft er dir dabei, die Entscheidungsgrundlagen (wie Daten, Wissen und Teilmodelle) zu dokumentieren, die später in deine Simulation einfließen werden. Zweitens hilft er dir, fehlende Ressourcen zu identifizieren, damit du diese Ressourcen vorrangig finden oder durch die Vorbereitung und Sammlung neuer Daten, Modellierung und/oder Forschungsinitiativen schaffen kannst.
Es kommt häufig vor, dass man im Laufe dieses Prozesses feststellt, dass man wichtige Elemente in der CDD vergessen hat, wie z.B. eine externe Komponente, die den Wert eines Zwischenprodukts bestimmt. Zögere nicht, diese Elemente hinzuzufügen, wenn du sie gefunden hast, und knüpfe damit an das Decision Design aus dem letzten Kapitel an. Wenn dein Unternehmen schon eine Weile mit DI arbeitet, wirst du vielleicht feststellen, dass jemand anderes einen Teil deiner CDD modelliert und sogar simuliert hat, so dass du sehen kannst, welche Daten und Modelle sie verwendet haben. Je mehr du DI anwendest und alle von dir erstellten Artefakte aufbewahrst (siehe Kapitel 8), desto mehr kannst du auf der Arbeit anderer aufbauen und desto einfacher wird es.
Vom einfachen zum anspruchsvollen Vermögen
Wenn du dein Vermögen dokumentierst, wirst du wahrscheinlich feststellen, dass die Genauigkeit der Angaben sehr unterschiedlich ist. Vielleicht weißt du nur, dass "wenn dieses Element steigt, das andere sinkt". Oder - eine Stufe anspruchsvoller - vielleicht kannst du ein einfaches X/Y-Diagramm(Skizzen-Diagramm) zeichnen, das zeigt, wie die beiden zusammenhängen. Im Extremfall könntest du über eine Bibliothek mit 30 Forschungsarbeiten verfügen, die sich auf einen Vermögenswert beziehen , z. B. wie Nematoden auf verschiedene Behandlungen bei unterschiedlichen Boden- und Wetterbedingungen reagieren. Du könntest über eine Software verfügen, die die Abhängigkeiten berechnet, oder über eine einfache oder komplizierte mathematische Funktion. Abbildung 4-2 veranschaulicht die verschiedenen Stufen der Modellierung von Vermögenswerten. Tabelle 4-2 enthält Symbole für viele Arten von komplexen Modellen.

Abbildung 4-2. Ein paar verschiedene Stufen der Ausgereiftheit von Vermögenswerten, die über Abhängigkeiten informieren können.
Dokumentieren von Entscheidungswerten
Wenn du Entscheidungswerte identifizierst, empfehlen wir, sie in einem Entscheidungswerte-Register aufzulisten. Eine Vorlage (Phase B, Arbeitsblatt 2: Register der Entscheidungsgüter) findest du in den ergänzenden Materialien. Tabelle 4-1 zeigt ein Beispiel für ein Register der Entscheidungswerte.
| Entscheidungselement | Entscheidung Vermögenswert | Asset-Typ | Asset-Quelle und Kontakt |
|---|---|---|---|
| <Hier gibst du entweder eine Beschreibung des zugehörigen Entscheidungselements ein, z. B. "Abhängigkeit von der Preisgestaltung zum Volumen", oder du kannst die CDD mit Zahlen beschriften und nur diese Zahl hier einfügen, z. B. "(1)">. | <Name oder Beschreibung des zu verwendenden Entscheidungsassets, z. B. "Preis-Mengen-Kurve" oder "Modell namens PV_33B im Data Warehouse">. | <Dies kann eine von vielen Arten von Vermögenswerten sein, z. B. eine Skizze, ein Datensatz, ein ökonometrisches Modell, eine Beobachtung, menschliches Wissen und vieles mehr> | <Wer ist für die Wartung/Bereitstellung dieses Vermögenswerts verantwortlich? |
| <Füge so viele Zeilen in die Tabelle ein, wie es Assets zu verfolgen gibt>. |
|
|
|
CDD-Anmerkungen
Wenn du das Vermögensverzeichnis ausfüllst, ist es eine gute Idee, dein CDD zu kommentieren, um die verschiedenen Arten von Vermögenswerten zu kennzeichnen, die du zum Einsatz bringst. Damit das Diagramm nicht zu unübersichtlich wird, kannst du ein Symbol einzeichnen, das die Art des Vermögenswerts kennzeichnet. Tabelle 4-2 enthält Beispiele für Symbole, die wir bereits verwendet haben, und Abbildung 4-3 zeigt einen Teil eines Entscheidungsmodells, das mit Symbolen für einige verschiedene Arten von Vermögenswerten versehen ist.
| Symbol | Art der Entscheidungsgrundlage |
|---|---|
| Mathematisches Modell (finanziell oder ökonometrisch) | |
| Mathematisches Modell (nicht finanziell oder ökonometrisch) | |
| ML-Modell | |
| Statistisches Modell | |
| Verhaltensmuster oder psychologisches Modell | |
| Wissensgraph / Inferenzmodell | |
| Medizinisches Modell | |
| Digitales Zwillingsmodell (menschliche oder nicht-menschliche Expertise in einem Bereich) | |
| Skizzengrafik unter Einbeziehung menschlicher Expertise | |
| Menschliches Fachwissen, das nicht in ein Modell oder eine Skizzengrafik einfließt | |
| Datenquelle für Daten, die nicht in ein Modell oder eine Skizze integriert sind | |
| Informationsquelle für Informationen, die nicht in einem Modell oder einer Skizze enthalten sind | |
| Agentenbasiertes menschliches Bewegungsmodell | |
| System zur Beobachtung, Datenerfassung, Messung oder Überwachung | |
| Einschränkung | |
| Vermutung (in der Regel basierend auf menschlichem Wissen, Intuition oder einer Informationsquelle) | |
| Entscheidung Teilmodell |
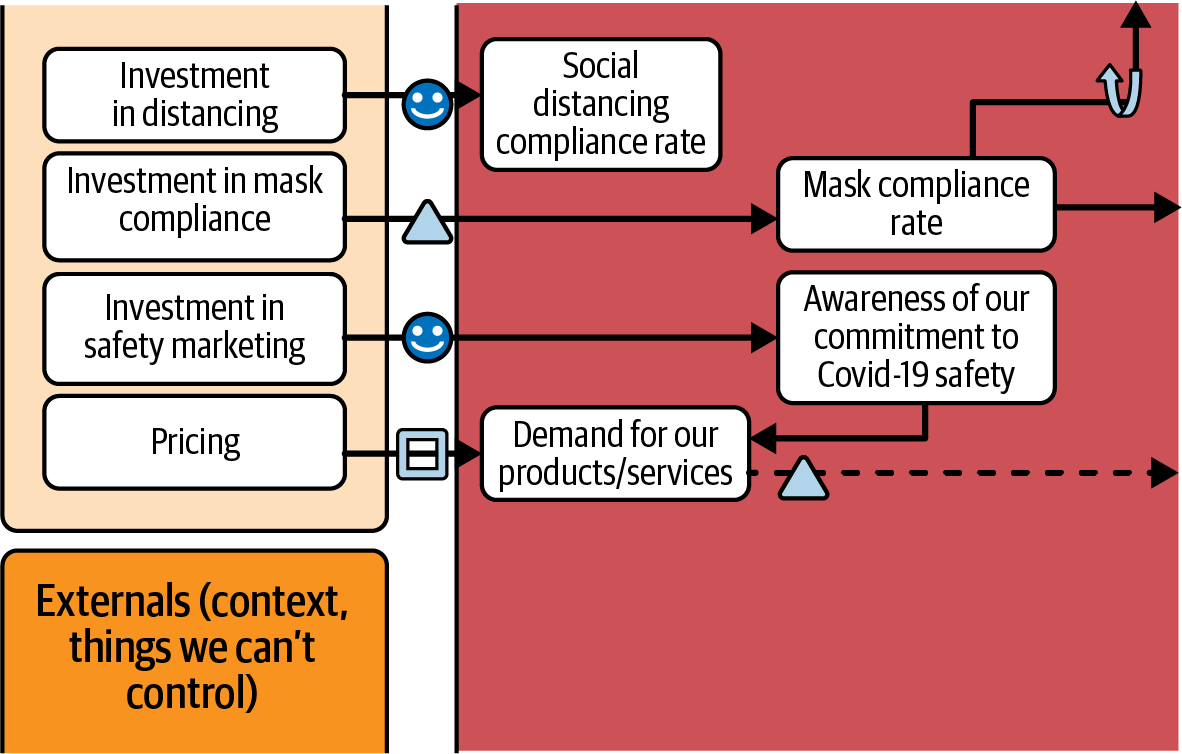
Abbildung 4-3. Ausschnitt aus einem CDD, der verschiedene Arten von Daten und Technologien zeigt, die seiner Struktur zugrunde liegen. Dieses Verhaltensmodell sagt voraus, wie sich die Investition in ein Marketingprogramm zur Förderung der sozialen Distanzierung auf die Einhaltung der sozialen Distanzierung auswirkt. Das ökonometrische Modell zeigt, wie die Preisgestaltung zur Nachfrage führt, und das ML-Modell sagt voraus, wie sich die Investition in ein Marketingprogramm auf die Einhaltung der Maske auswirkt. Das vollständige Entscheidungsmodell findest du in Abbildung P-2 oder im ergänzenden Materialarchiv.
In diesem Sinne: Siehe "Formale Prozessbeschreibung": Prozess B2: Untersuchung des Entscheidungsgegenstands" (einschließlich des Ausfüllens des Registers und der Kommentierung der CDD), gefolgt von einigen Hinweisen, wie dies zu tun ist. Beachte, dass sich dieser Prozess von Schritt 12, der die Bewertung von Fachwissen beinhaltet, aus Prozess B1, Entscheidungsdesign(Kapitel 3), unterscheidet, weil er eine vollständige CDD als Input für den Prozess voraussetzt. Außerdem geht es darum, technische Elemente zu entdecken, die das CDD von einem Diagramm zu einem computergestützten Modell überbrücken, und nicht darum, neue Elemente für das CDD zu untersuchen. Beide Prozesse verbessern das CDD, nur auf unterschiedliche Weise.
Aufzeichnung der Entscheidungswerte
Du musst mehr Informationen über jedes Entscheidungsgut aufzeichnen, als du auf einer CDD zeigen kannst. Wie du sie aufzeichnest, hängt davon ab, wie deine Organisation Daten und Wissen verwaltet. Wenn du Daten und Wissen auf Abteilungsebene verwaltest, kannst du ein Tabellenblatt oder eine Tabelle wie Tabelle 4-3 als Decision Asset Register verwenden, um die Standorte und Eigentümer der mit deinen CDD-Elementen verbundenen Assets zu erfassen.
Andererseits kann dein Lexikon, wenn du über eine ausgereifte Data-Governance-Architektur verfügst, jeden Datenbegriff genau definieren und die maßgebliche Quelle für die Beschaffung oder Berechnung seines Wertes dokumentieren. Du kannst Lexikoneinträge in einer Tabelle referenzieren, aber wenn du CDDs erstellst, könntest du auch ein Abhängigkeitslexikon erstellen, das Elemente, die als Zwischenstufen oder Ergebnisse auftreten, und ihre Abhängigkeiten, die Pfeile zu ihnen und die Elemente auf der linken Seite dieser Pfeile mit Verweisen auf dein Datenlexikon für die Daten, die diese Abhängigkeiten begründen, dokumentiert. So sind die Abhängigkeiten für zukünftige CDDs leicht verfügbar.
Wenn du dich für diesen eher formalen Weg entscheidest, kannst du mit einem Abhängigkeitslexikon Fragen beantworten wie: "Welche organisatorischen Ergebnisse werden durch diese Daten beeinflusst? Wenn dein Unternehmen über ausgereifte Wissensmanagementsysteme, -standards und/oder -prozesse verfügt, kannst du dein Abhängigkeitslexikon auch mit diesen verknüpfen, um Abhängigkeiten zu ermitteln, die auf menschlichem Wissen basieren.
Du könntest auch darüber nachdenken, zu untersuchen, wie LLMs wie ChatGPT und/oder semantische Suchwerkzeuge dir helfen können, Elemente innerhalb deines formalen Lexikons zu finden: Das könnte die Zukunft des KM sein, das nun Entscheidungsmodelle als wertvolles Unternehmensvermögen behandeln kann, das es zu speichern und kontinuierlich zu verbessern gilt. Du könntest LLMs und die semantische Suche nutzen, um Entscheidungselemente zu identifizieren, die in deiner Wissensbasis gespeichert sind.
Formale Prozessbeschreibung: Prozess B2: Entscheidung Asset-Untersuchung
- Beschreibung
Identifiziere und dokumentiere vorhandene und fehlende Daten, Informationen, menschliches Wissen und andere Technologien, die als Entscheidungsgrundlage für die CDD dienen, um sie in ein computergestütztes Entscheidungsmodell zu integrieren.
- Voraussetzungen
Die CDD, die während des Entscheidungsdesigns erstellt wurde.
Ein Auftrag (in der Regel vom Entscheidungskunden) zur Erstellung einer automatisierten Simulation auf der Grundlage des CDD.
Hinweise zu Zeit, Aufwand und Treue, die für diesen Prozess erforderlich sind.
Ziehe es in Erwägung, den Anhang zu lesen.
Erstelle ein leeres Decision Asset Register, in dem du deine Ergebnisse festhältst, oder verwende Phase B, Arbeitsblatt 2: Decision Asset Register, das du in den ergänzenden Materialien findest, oder verstehe, wie du organisatorische Tools nutzen kannst, die CDDs mit deinem Data Governance System und deinem Wissensmanagementsystem verbinden.
- Verantwortliche Rolle
Leiter des Entscheidungsteams. Sie werden von Personen innerhalb und außerhalb des Entscheidungsteams unterstützt, die Daten, Informationen, Modelle, Dokumente oder andere Formen menschlichen Wissens im Zusammenhang mit der CDD bereitstellen können.
- Steps
Lies dir diesen Prozess durch und passe ihn ggf. an dein Team an.
Überprüfe in einem ersten Schritt das CDD, das du während des Entscheidungsdesigns erstellt hast:
Beginne damit, die "niedrig hängenden Früchte" zu dokumentieren: die Entscheidungswerte, die du bereits während der CDD-Erhebung identifiziert hast (vielleicht hast du sie auf einem "Parkplatz" erfasst). Füge sie dem Register der Entscheidungswerte hinzu.
Bitte dein Team, sich die CDD noch einmal anzusehen und die Kausalketten zu identifizieren, von denen sie glauben, dass sie den größten Einfluss auf die Ergebnisse haben werden. Dokumentiere sie, einschließlich der Hebel, externen Faktoren, Zwischenstufen und/oder Ergebnisse. Wie bei den Ergebnissen und Hebeln kannst du auch nach den drei wichtigsten Ketten fragen, die deiner Meinung nach den größten Einfluss haben.
Untersuche für jedes Zwischenprodukt und jedes Ergebnis, insbesondere für die drei wichtigsten Kausalketten, ob es ein Modell oder eine Funktion gibt, die Aufschluss darüber gibt, wie es von dem/den unmittelbar vorangehenden Element(en) abhängt. Welche Daten liefert jedes Element für das Modell oder die Funktion? Fehlen irgendwelche externen Faktoren, Hebel oder Zwischenstufen?
Frage für jede Zwischenstufe:
Gibt es Beschränkungen für die zulässigen Werte? Diese werden in deine Simulation einfließen und zeigen dir, wie du die Entscheidung im Laufe der Zeit überwachen kannst.
Gibt es Systeme, die dieses Zwischenprodukt beobachten oder messen (z. B. ein BI-Tool)?
Trage deine Antworten in das Register der Entscheidungsgüter ein und beschrifte die CDD, damit du eine klare Verbindung zwischen jedem Gut und dem Ort innerhalb der CDD herstellen kannst, für den es gilt.
Dokumentiere für jeden Externen seine:
Angenommene(r) Wert(e)
Zwänge
Relevante Datensätze
Beobachtungen
Mess- oder Überwachungssysteme
Modelle (z.B. ein Prognosemodell für das BIP in Indien für die nächsten fünf Jahre)
Dokumentiere, wo du denkst, dass es fehlende Mittel gibt, die benötigt werden, aber noch nicht beschafft wurden.
- Liefergegenstände
Entscheidung Asset Investigation: Eine Süßkartoffel CDD treibt Datenerhebung und Forschung voran
Wie bereits erläutert, dient der Decision Asset Investigation-Prozess zwei Zwecken: der Identifizierung vorhandener Ressourcen und der Festlegung von Prioritäten für die Sammlung neuer Daten oder die Erstellung von Modellen. Hier ist eine Geschichte darüber, wie sich dies in einem kürzlich durchgeführten Projekt abgespielt hat.
Vor ein paar Jahren hatten die Süßkartoffelanbauer in den USA mit einer neuen Art von landwirtschaftlichem Schädling zu kämpfen, der Nematode. Im Grunde ist es eine hässliche Art von Wurm. Die Verbraucher im Einzelhandel bevorzugen in der Regel makellose Produkte, aber Nematoden lassen sie kosmetisch unansehnlich aussehen. Auch wenn die Kartoffeln durchaus genießbar sind, ist diese "hässliche" Ware für den Verkauf an die Verbraucher ungeeignet und muss zu einem viel niedrigeren Preis an Konservenfabriken oder Tierfutterhersteller verkauft werden - ein erheblicher finanzieller Schaden für die Erzeuger.
Landwirte können Nematoden auf verschiedene Weise bekämpfen. Die gebräuchlichsten Methoden sind die Fruchtfolge (d.h. der Anbau einer anderen Kultur, z.B. Erdnüsse, auf einem nematodenbelasteten Feld für eine Saison), der Einsatz von Pestiziden oder beides. Beide Methoden sind mit Kosten verbunden, und die Fruchtfolgekulturen sind deutlich weniger rentabel als der Süßkartoffelanbau. Die Wahl der besten Maßnahme ist eine komplexe Entscheidung in einem unbeständigen Umfeld, die große finanzielle Auswirkungen haben kann.
Im Rahmen eines Projekts des US-Landwirtschaftsministeriums (USDA), das Süßkartoffelanbauern helfen soll, mit Hilfe von DI bessere Entscheidungen zu treffen, haben wir ein Entscheidungsmodell für dieses Problem entwickelt. In Zusammenarbeit mit einer Gruppe von Süßkartoffel-Experten unter der Leitung von Dr. David Roberts und Dr. Michael Kudenov, , sowie der Pflanzenpathologin Dr. Adrienne Gorny haben wir die Ergebnisse, Hebel und externen Faktoren ermittelt, das CDD erstellt und einige Male wiederholt, um sicherzustellen, dass wir nichts Wichtiges übersehen haben. Das Ergebnis war das in Abbildung 4-4 dargestellte CDD.
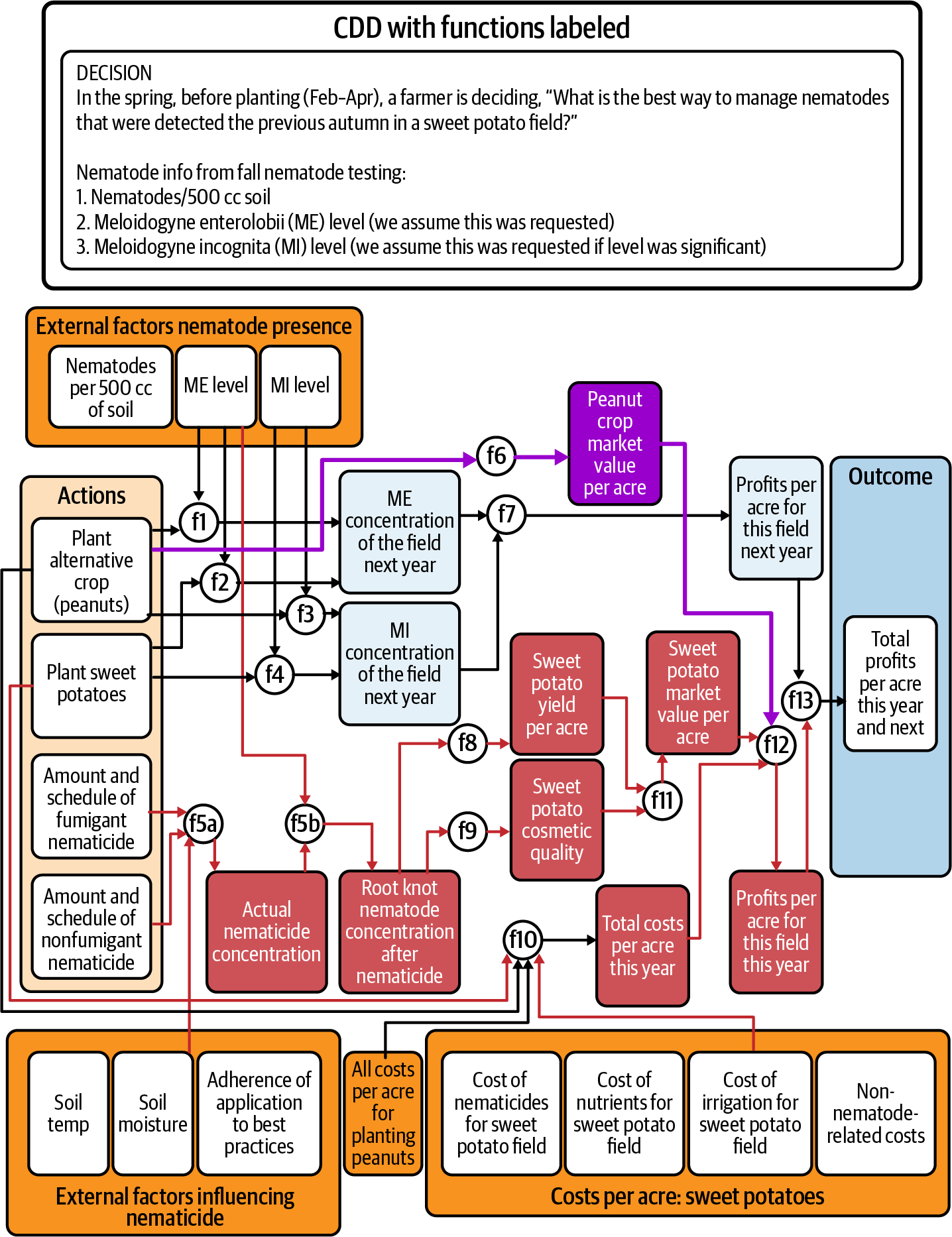
Abbildung 4-4. Das Modell der Süßkartoffelnematoden mit den angegebenen Funktionen (mit freundlicher Genehmigung des von der USDA Agriculture and Food Research Initiative finanzierten Projekts DECIDE-SMARTER).
Nach dem Prozess der Entscheidungsfindung gingen wir zur Untersuchung der Entscheidungsgrundlage über. Unsere Experten schickten uns mehrere Listen mit Datenquellen. Wir glichen sie mit dem CDD ab und stellten zu unserer großen Überraschung fest, dass es eine Menge Forschung und Daten gab, die einen Teil des CDD unterstützten, aber überhaupt keine Forschung, um einige andere Teile zu unterstützen. Insbesondere die Verknüpfung der Nematizidkonzentration (in Abbildung 4-4 mit f5a gekennzeichnet) und die Verknüpfungen von Ertrag, Preis und Gewinn (mit f6 bis f13 gekennzeichnet) waren gut erforscht, aber für die übrigen Verknüpfungen gab es nur sehr wenige Forschungsergebnisse.
Wie sich herausstellte, hatten die Forscher/innen ohne das CDD zur visuellen Darstellung der Entscheidungsstruktur nicht bemerkt, dass sie nur Daten erstellten und Forschung betrieben, um einen Teil davon zu unterstützen!
Wenn du noch nie mit dieser Situation konfrontiert warst, wirst du dich vielleicht wundern, dass das passiert ist. Wir waren auch überrascht: Wie kann es sein, dass so viele Daten nicht in das gesamte Entscheidungsmodell einfließen und dass es so große Lücken zwischen dem, was die Entscheidungsträger brauchen, und dem, was untersucht wurde, gibt? Aber wir haben gesehen, dass sich dieses Muster immer wieder wiederholt: Die heutigen Datensysteme sind darauf ausgelegt, Fragen zu beantworten und Erkenntnisse zu liefern, aber nicht darauf, Handlungen mit Ergebnissen zu verbinden. Da ihnen die Perspektive von Aktion und Ergebnis fehlt, bleiben sie oft hinter dem zurück, was nötig ist.
Zurück zum aktuellen Prozess: Das vorherige Beispiel zeigt, dass die CDD-Analyse dir nicht nur sagen kann, wann du über die nötigen Informationen für eine Entscheidung verfügst, sondern auch, wann nicht: Du musst neue Recherchen anstellen, eine neue Datenquelle finden und/oder die CDD als Low-Fidelity-Modell verwenden.
Daten für Externe
Zuvor hast du gelernt, wie man Daten untersucht, die helfen können, Abhängigkeiten zu erkennen. Auch Externe brauchen Daten. Man kann Externe in vier Kategorien einteilen:
Dinge, die sich nie ändern, wie der Durchmesser der Erde
Einzelne sich ändernde Werte, die du messen kannst, wie die aktuelle Temperatur
Werte, die sich in Zukunft ändern werden und die du vorhersagen kannst, wie die morgige Höchsttemperatur
Gruppen von Werten, die du für die Zukunft vorhersagen kannst, wie die tägliche Höchsttemperatur für die nächsten sechs Monate
Tipp
Werte, die sich in der Zukunft ändern werden und die du für die Zukunft vorhersagen kannst, nennen wir oft "Annahmen" oder "Vorhersagen". Beachte, dass die englische Sprache diese Wörter auch für Zwischenwerte und Ergebnisse verwendet, zum Beispiel: "Wir sagen voraus, dass unser Unternehmen im nächsten Monat um 20 % wachsen wird." Als Entscheidungsmodellierer/in weißt du aber, dass es sehr hilfreich ist, zwischen Dingen zu unterscheiden, die du durch dein Handeln beeinflussen kannst (Ergebnisse) und Dingen, auf die du keinen Einfluss hast (Externa). Wir empfehlen daher, dass du deinen Teams beibringst, statt "Annahme" oder "Vorhersage" den eindeutigeren Begriff "Zwischenergebnisse" (oder "Frühindikator" oder "Prozesskennzahl") zu verwenden, um Verwirrung zu vermeiden.
Aber zurück zu Vorhersagen über externe Faktoren. Oft verwenden Analysten und Statistiker Informationen aus der Vergangenheit, die sie in die Zukunft extrapolieren, um diese Art von Vorhersagen zu treffen. Manchmal funktioniert das, manchmal aber auch nicht.
Um nur ein berühmtes Beispiel zu nennen: Toilettenpapierhersteller hatten jahrelang sehr stabile Daten über die Verbrauchernachfrage und die Unternehmensnachfrage. Sie hatten jahrelang datengestützte Entscheidungen über Produktionslinien und Vertriebskanäle getroffen. Sie nutzten ihre vorhandenen Daten, um Vorhersagen über das Angebot und die Nachfrage von Toilettenpapier im Jahr 2020 zu treffen. Aufgrund der Covid-19-Pandemie wäre es jedoch schwer zu behaupten, dass 2020 "genauso" wie 2019 sein würde! Und weil sich viele Entscheidungen, die 2019 getroffen wurden, im Jahr 2020 auswirkten, änderten sich viele Dinge - einschließlich eines40%igen Anstiegs der Verbrauchernachfrage gegenüber der kommerziellen Nachfrage nach Toilettenpapier, ganz zu schweigen von Panikkäufen und Hortungen. Die Just-in-Time-Vertriebsketten im Einzelhandel, auf die sich die Toilettenpapierhersteller verlassen, um ihr Produkt zu den Verbrauchern zu bringen, konnten die gestiegene Last nicht bewältigen, und das System brach zusammen. Die Lehre daraus ist, dass große, stabile Datensätze nur dann "harte Daten" sind, wenn es um die Vergangenheit geht. Wenn es um die Zukunft geht, können wir nur Vorhersagen machen.
Eng verbunden mit der Idee einer Vorhersage ist das Konzept einer externen Annahme. Eine Annahme ist eine Vermutung über den Wert eines externen Faktors, über den du dir nicht sicher bist, entweder weil er sich auf eine ungewisse Zukunft bezieht oder weil du dir nicht sicher bist, ob du ihn in der Gegenwart genau messen kannst. Unsere Süßkartoffelbauern könnten zum Beispiel annehmen, dass jedes Feld eine gewisse Konzentration von Nematoden aufweist, weil sie der Meinung sind, dass sich die Kosten für die eigentliche Untersuchung nicht lohnen. Alle Vorhersagen sind Annahmen, aber nicht alle Annahmen sind Vorhersagen.
Hier findest du einige Daten, die dir bei externen Annahmen helfen können:
Spezifische Werte oder Wertespannen, wie z. B. "Es wird angenommen, dass die Treibhausgasemissionen zwischen 60 und 70 Gramm pro verkauftem Passagierkilometer liegen".
Vorhersagen und Modelle, einschließlich vorhergesagter numerischer Werte oder Wahrscheinlichkeitsverteilungen aus mathematischen oder ML-Modellen
Datensätze, wie z. B. die täglichen Höchst- und Tiefsttemperaturen für einen bestimmten Ort für die letzten 100 Jahre
Es kann auch nützlich sein, Einschränkungen für externe Faktoren zu dokumentieren: Bereiche oder Werte, von denen du glaubst, dass sie das Erreichen deines Ziels unmöglich machen würden. Zum Beispiel: "Wenn die Temperatur für mehr als eine Stunde über den Bereich von 0 Grad Celsius bis 40 Grad Celsius hinausgeht, wird diese Pflanze sterben."
Der Puzzle-Spielzeug-Anwendungsfall: Das Gespräch über die Entscheidungsgrundlage
Herzlichen Glückwunsch! Das neue Schreibtischspielzeug deines Unternehmens - ein dreidimensionales Puzzle - ist bereit für die Markteinführung! Nachdem du und dein Team das Erreichen dieses Meilensteins gefeiert habt, müsst ihr entscheiden, wie ihr euer glänzendes neues Puzzle auf den Markt bringen wollt.
Du hast ein paar Entscheidungen zu treffen:
Wie viel solltest du für jedes Rätsel verlangen?
Wie viele Einheiten solltest du für die erste Produktionsserie bestellen?
Wie viel solltest du in die Vermarktung des Puzzles investieren?
Du musst deine Entscheidungen der Geschäftsführung zur Genehmigung vorlegen, und du weißt, dass sie harte Beweise dafür verlangen werden, dass dein Plan profitabel sein wird und dass deine Entscheidungen das Unternehmen keinen inakzeptablen Risiken aussetzen werden.
Glücklicherweise hast du Zugang zu den besten Analytikern und Datenwissenschaftlern deines Unternehmens und zu modernster BI-Software. Du berufst ein "War Room"-Treffen mit deinem Analystenteam ein, um die drei Entscheidungen zu erläutern und mit der Ausarbeitung zu beginnen. Die Analysten beginnen, dein Whiteboard mit Diagrammen von Data Lakes zu füllen. Sie erzählen dir von dem KI-Algorithmus, den sie verwenden werden, und öffnen ihre Laptops, um dir eine Tabelle mit 20 Arbeitsblättern, ihre erstaunlichen Analysetools und die noch erstaunlicheren Erkenntnisse zu zeigen, die sie liefern. Im Laufe der nächsten Woche fügen sie ihre besten Informationen zusammen und erstellen das Dashboard in Abbildung 4-5.
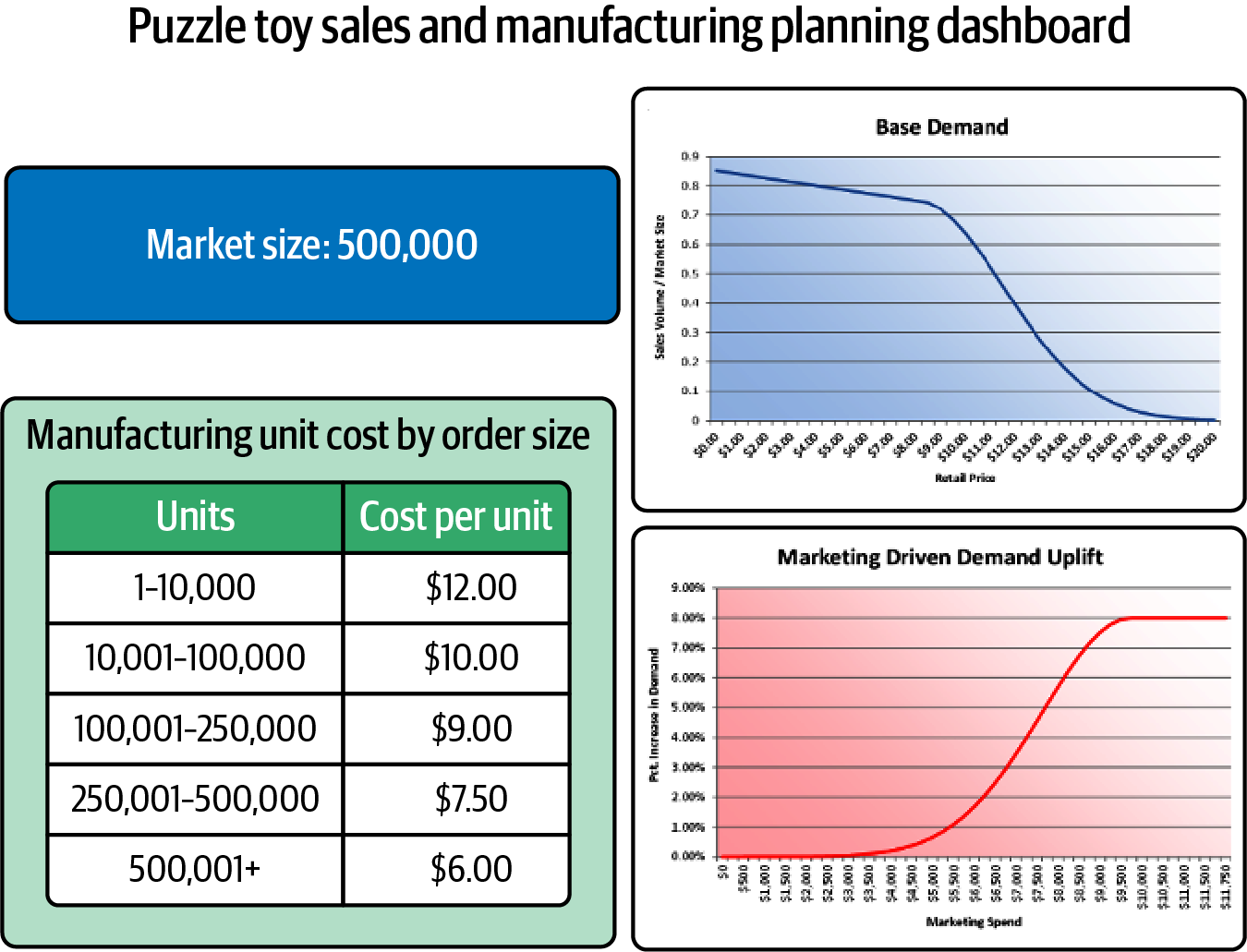
Abbildung 4-5. Ein Dashboard für die Produkteinführung des Puzzlespielzeugs.
Es ist ziemlich beeindruckend, aber du musst fragen: "Wie beantwortet dieses Dashboard meine drei Fragen?" Die Datenwissenschaftler schauen verwirrt. Da das Unternehmen noch nie ein solches Produkt auf den Markt gebracht hat, gibt es keine Diagramme, die deine drei Entscheidungsmöglichkeiten mit dem Ergebnis in Verbindung bringen, das du messen willst.
Die Datenwissenschaftler sind verwirrt und ein bisschen frustriert. Das Unternehmen hat viel Geld ausgegeben, um eine riesige Sammlung von Daten zu sammeln, aufzubereiten und zu verwalten. Schließlich gilt: "Deine Entscheidung ist nur so gut wie deine Daten", oder? Die Antworten auf diese scheinbar einfachen Fragen müssen doch irgendwo in all der Technik stecken. Aber wo?
Zum Glück hast du zu Beginn des Projekts eine CDD benutzt, um zu entscheiden, was für ein Spielzeug du bauen willst. Jetzt erkennst du, dass ein neues CDD deine Fragen beantworten kann. Die drei Fragen deuten auf drei Dinge hin, die du kontrollieren kannst, deine drei Hebel: Verkaufspreis, Größe des Produktionsauftrags und Marketingausgaben in Prozent des Gewinns. Das Ergebnis ist einfach: Gewinn. Dein Ziel ist es, diesen Gewinn zu maximieren. Mit ein wenig Hilfe deines Teams skizzierst du auf schnell das in Abbildung 4-6 gezeigte CDD.
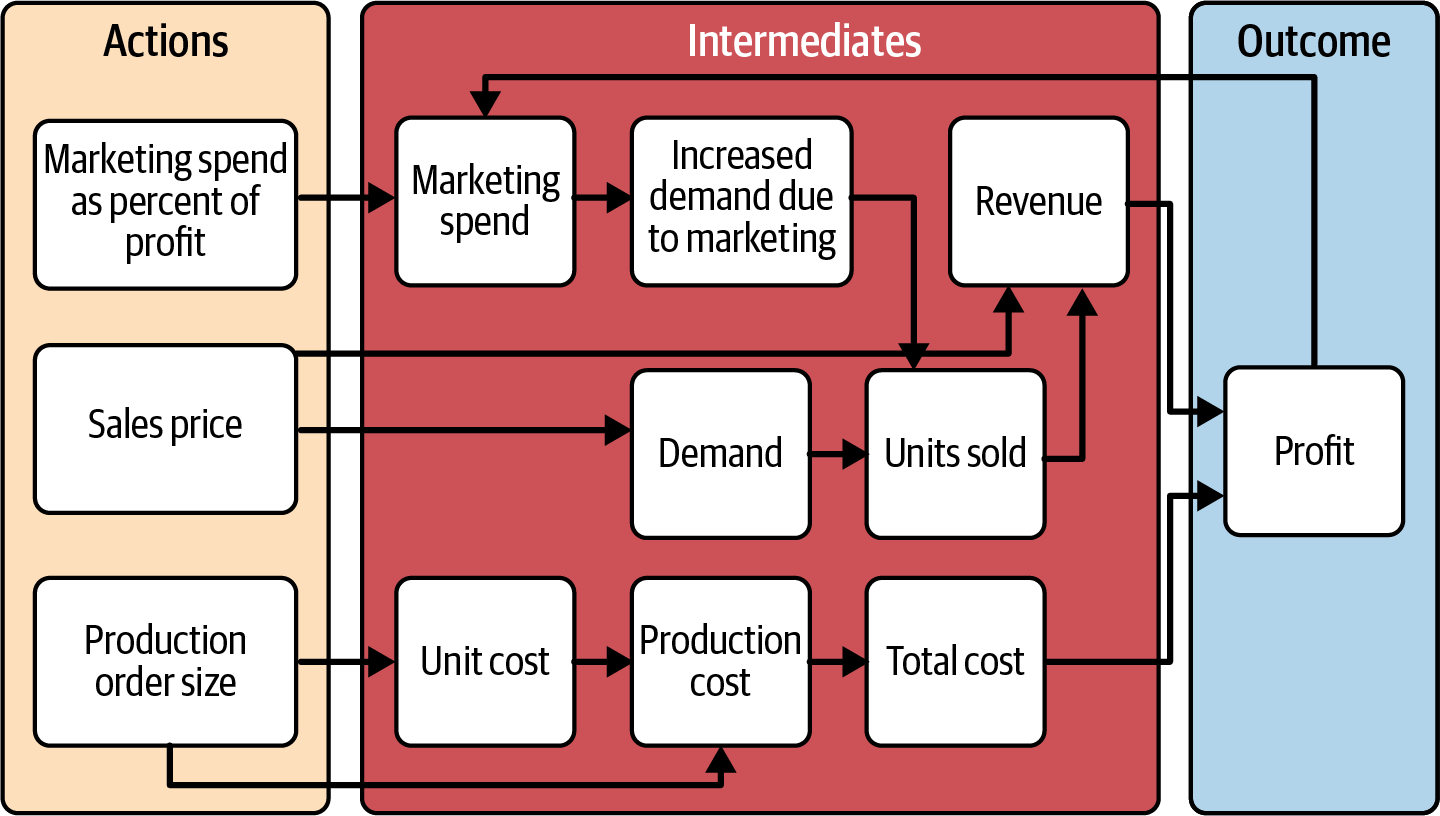
Abbildung 4-6. Das CDD zur Produkteinführung, bereit für die Entscheidungsfindung.
Jetzt kannst du dir die Abhängigkeitspfeile auf ansehen und nach Daten und Modellen suchen, die sie erklären. Du stellst schnell fest, dass die Stückkosten umgekehrt proportional zur Größe des Produktionsauftrags sind; je mehr du kaufst, desto billiger ist jede Einheit. Du erkennst auch, dass du keine Kontrolle über die Produktionskosten hast. Diese werden von der Fertigung kontrolliert, einer anderen Abteilung deines Unternehmens. Du hast also eine neue externe Größe: Stückkosten im Verhältnis zur produzierten Stückzahl. Und dein Analyseteam verfügt über Produktionsdaten, die die Kosten im Verhältnis zur Stückzahl für andere Tischspielzeugprodukte vorhersagen. Sie stehen sogar auf dem Dashboard, das sie dir gegeben haben. Jetzt hast du also ein External und den dazugehörigen Datensatz zum CDD hinzugefügt, wie in Abbildung 4-7 dargestellt.
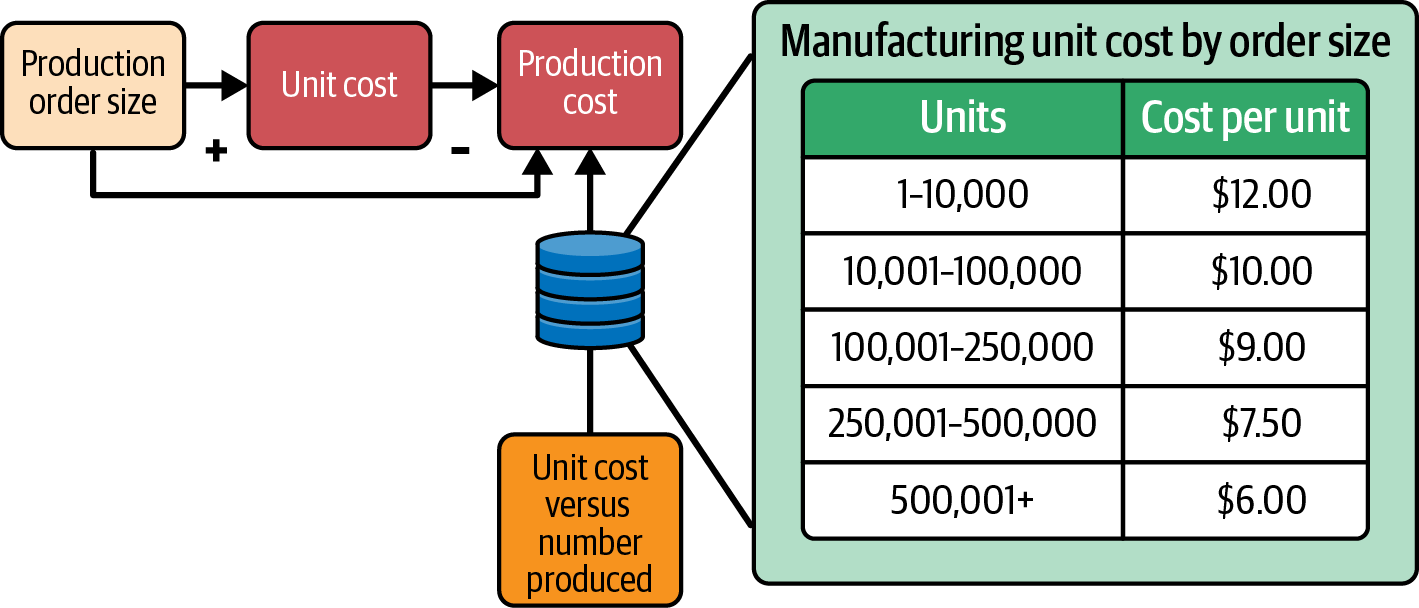
Abbildung 4-7. Hinzufügen eines Externen und seiner zugehörigen Daten.
Als Nächstes betrachtest du die Beziehung zwischen dem Verkaufspreis und den verkauften Einheiten. Die verkauften Stückzahlen hängen von einer anderen externen Größe ab, dem Kundenverhalten. Genauer gesagt hängt er von einer bestimmten Komponente des Kundenverhaltens ab, der Nachfrage im Verhältnis zum Preis. Dein Analyseteam verfügt über ein ML-Modell, das die Nachfrage nach ähnlichen Produkten vorhersagt, und hat es auf dem Dashboard grafisch als Basisnachfrage dargestellt, eine Kurve, die die Marktdurchdringungsrate im Verhältnis zum Verkaufspreis zeigt. Die Marktdurchdringungsrate ist die Anzahl der verkauften Einheiten geteilt durch die Marktgröße. Um die Beziehung zwischen Verkaufspreis und verkauften Einheiten zu verstehen, brauchst du also noch eine weitere externe Größe, die Marktgröße. Das Analyseteam hat Marketinginformationen gefunden, die deine Marktgröße auf 500.000 Einheiten schätzen. Der Teil "Verkaufspreis zu verkauften Einheiten" der CDD sieht jetzt wie in Abbildung 4-8 aus.
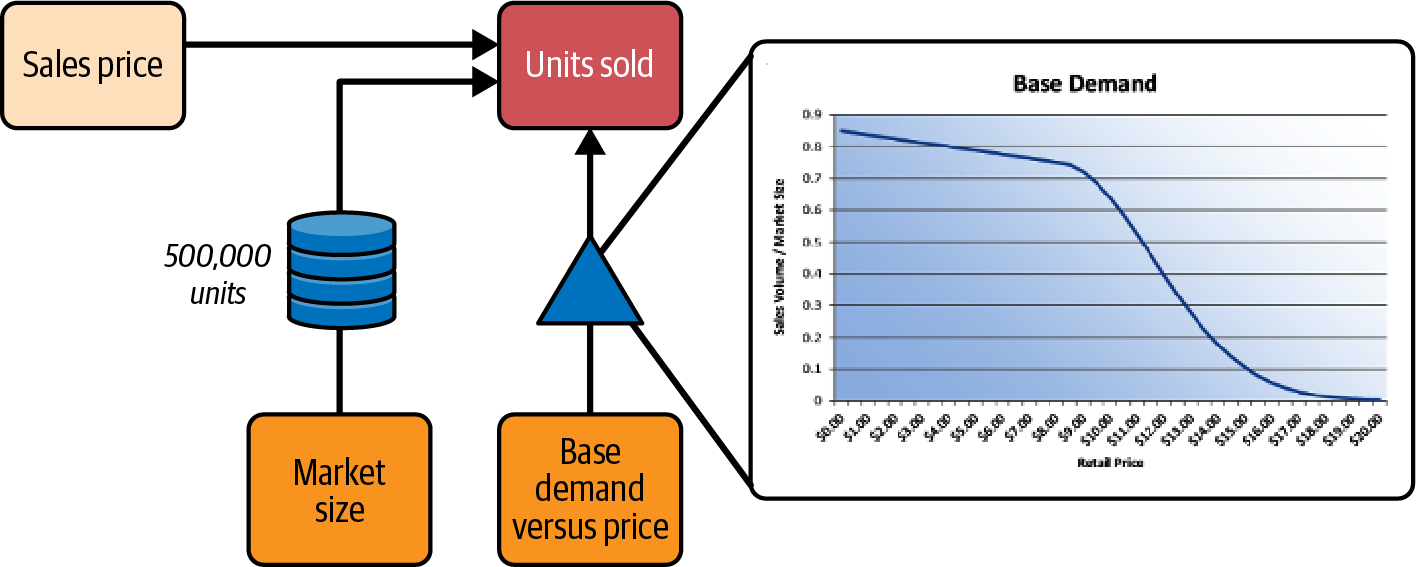
Abbildung 4-8. Hinzufügen von Externa und Daten, die das Verhältnis zwischen Verkaufspreis und verkauften Einheiten zeigen.
Du erkennst, dass die Marketingausgaben auch die Nachfrage ankurbeln, und wendest dich der Kausalkette zu, die mit den Marketingausgaben in Prozent des Gewinns beginnt. Du brauchst noch eine weitere Kennzahl: die erhöhte Nachfrage im Vergleich zu den Marketingausgaben. Das Analyseteam hat eine Vorhersagefunktion erstellt, die auf dem Dashboard durch das Diagramm "Marketing-Driven Demand Uplift" dargestellt wird. Sie zeigt den prozentualen Anstieg der Nachfrage als Funktion der Marketingausgaben. Wenn du das addierst, erhältst du die in Abbildung 4-9 dargestellte CDD.
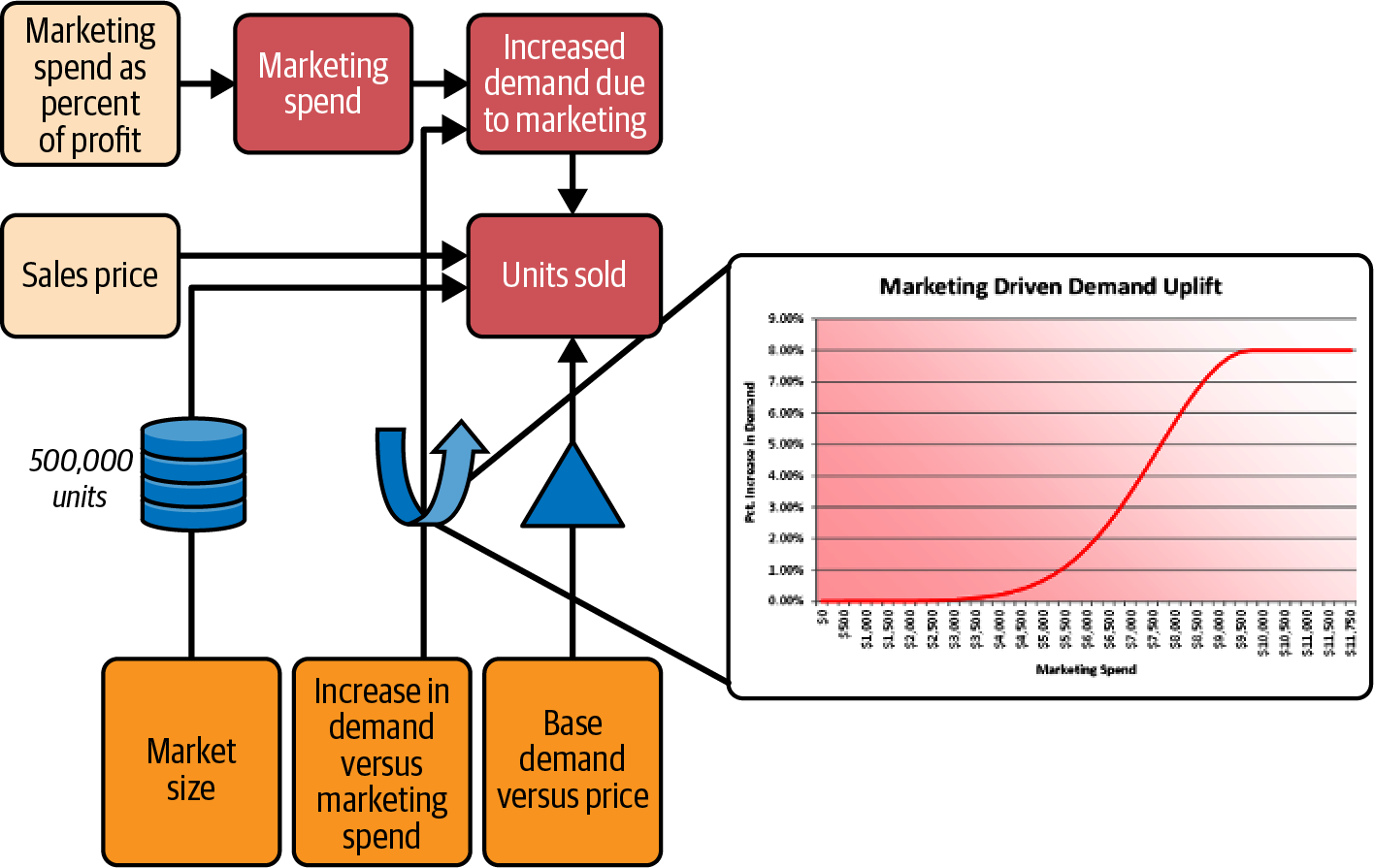
Abbildung 4-9. Hinzufügen des Marketing-Uplifts extern.
Wenn du das CDD verfeinerst, um alle Stellen anzuzeigen, an denen Daten benötigt werden, entsteht das kommentierte CDD in Abbildung 4-10.
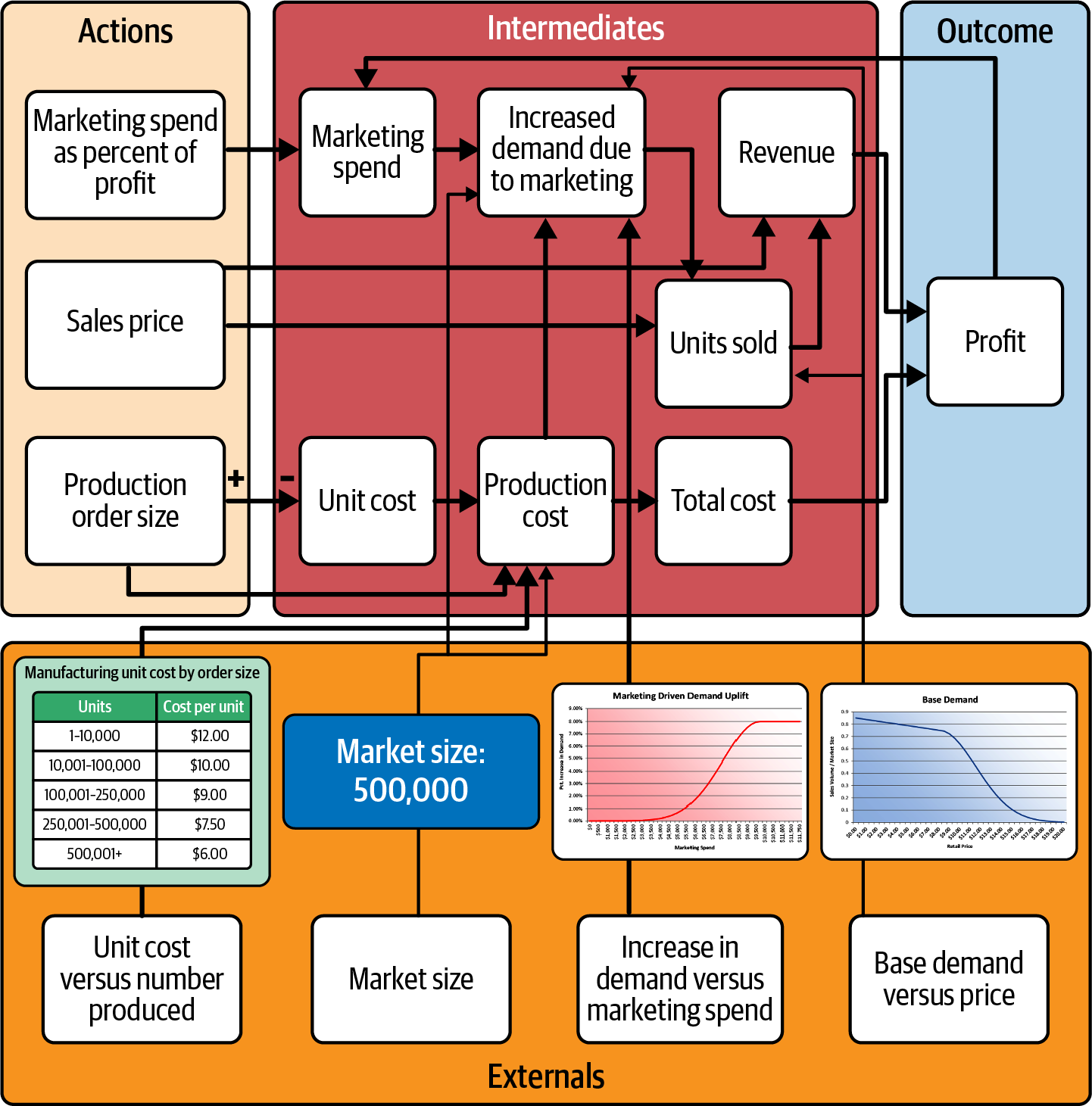
Abbildung 4-10. Die CDD am Ende der Decision Asset Investigation.
Versuch es selbst: Decision Asset Investigation für den Anwendungsfall Telekommunikation
Du hast ein CDD in "Try It Yourself: Entscheidungsdesign für einen Anwendungsfall der Telekommunikation". In diesem Abschnitt führst du einen kleinen Decision Asset Investigation-Prozess für diesen Anwendungsfall durch.
Wir beginnen mit einem sehr einfachen Ansatz zur Identifizierung von Vermögenswerten, nämlich dem "Finden" von Wissen in deinem eigenen Gehirn über die Richtung einiger Abhängigkeiten.
In deiner nächsten Sitzung leitest du das Telekom-Entscheidungsteam dabei an, gemeinsam die Prozessbeschreibung der Decision Asset Investigation durchzulesen. Als ersten Schritt bei der Durchsicht der CDD beschließt du, dir die Abhängigkeitspfeile anzusehen. Du stellst fest, dass bei den meisten Abhängigkeiten in diesem Diagramm, wenn das Element auf der linken Seite zunimmt, auch das Element auf der rechten Seite zunimmt (das sind die sogenannten direkten Abhängigkeiten). Du bittest das Team, nach Ausnahmen zu suchen: Gibt es auch umgekehrte Abhängigkeiten, bei denen die Veränderungen in die entgegengesetzte Richtung gehen? Das Team erkennt schnell, dass der Pfeil von "Preis" zu "Volumen" eine umgekehrte Abhängigkeit darstellt und markiert ihn im CDD, wie in Abbildung 4-11 dargestellt. Dann findet das Team zwei weitere umgekehrte Abhängigkeiten und markiert sie im CDD.
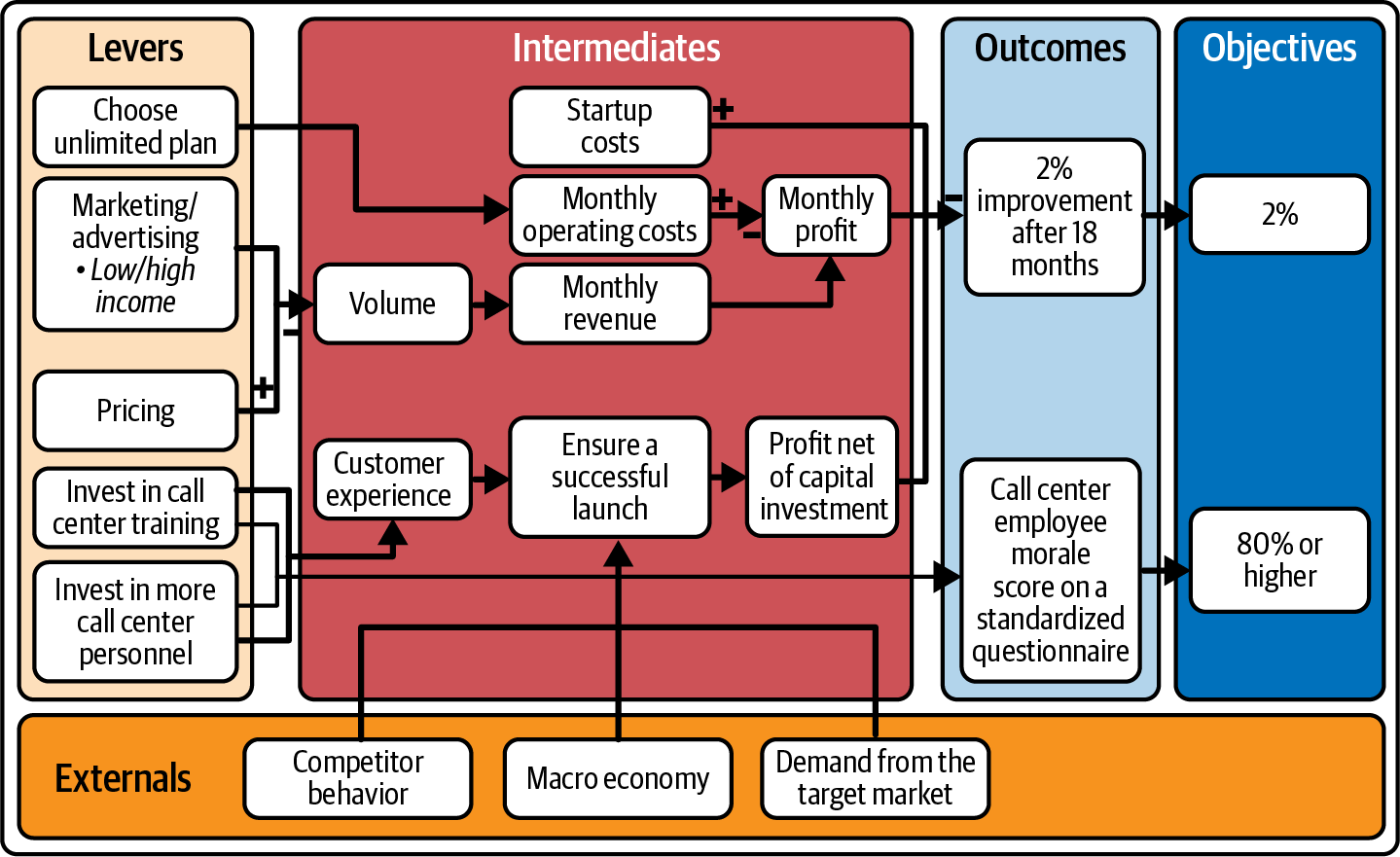
Abbildung 4-11. Der CDD für den unbegrenzten Nutzungsplan mit umgekehrten Abhängigkeiten kommentiert.
Du wirst vielleicht Unstimmigkeiten darüber hören, wie bestimmte Abhängigkeiten funktionieren, z. B. die Form des Skizzengraphen. Je nach Art der Verknüpfung erfordert die Lösung unterschiedliche Ansätze: Eine Verknüpfung, die auf einer einfachen Formel beruht, kann bedeuten, dass du mit Experten in der Finanzabteilung sprechen musst, während eine Verknüpfung, die auf ML basiert, den Aufbau eines neuen Modells erfordert. Vielleicht möchtest du auch verschiedene Gruppen von Vermögenswerten in zwei verschiedenen Listen erfassen, damit du beide ausprobieren kannst, um zu sehen, ob sie zu unterschiedlichen Entscheidungen führen.
Du fragst das Team, ob sie von bestehenden Anlagen wissen, die mehr Informationen über eine der Abhängigkeiten in ihrer CDD liefern würden. Ein Produktmanager weist darauf hin, dass das Verhältnis von Preis und Menge selten eine einfache Gerade ist. Zur Veranschaulichung erstellt er eine Schnellskizze wie die in Abbildung 4-12. Du machst einen entsprechenden Eintrag in Zeile 1 des Decision Asset Registers, wie in Tabelle 4-3 dargestellt.
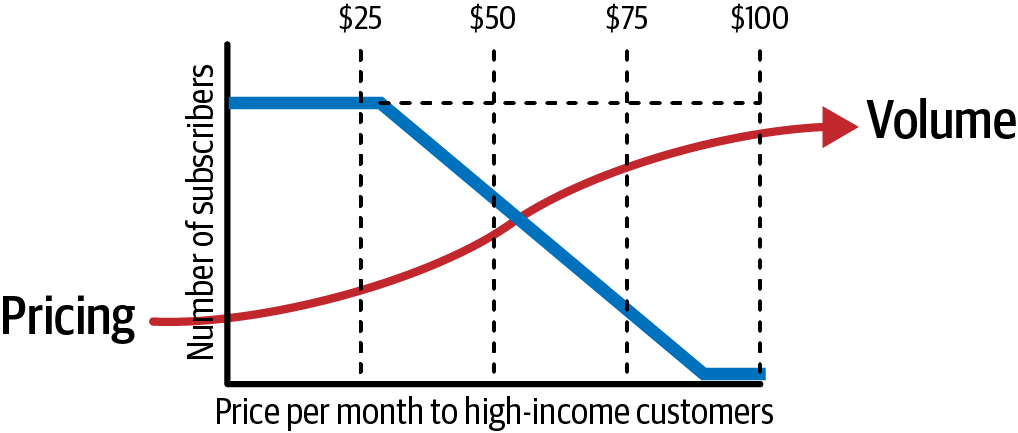
Abbildung 4-12. Ein skizzenhaftes Diagramm, das zeigt, wie der Preis die Nachfrage beeinflusst.
| Entscheidungselement | Entscheidung Vermögenswert | Asset-Typ | Asset-Quelle und Kontakt |
|---|---|---|---|
| Abhängigkeit von Preis und Volumen | Preis-/Volumenkurve | Diagramm skizzieren | Joe Smith, Product Mgr., Marketing |
| Abhängigkeit von Preis und Volumen | Ergebnisse des Verbraucherpreistests | ML-Modell, basierend auf einem Datensatz | Mary Brown, Sr. Datenwissenschaftlerin, ML-Gruppe |
| Hebel für Marketing/Werbung | Historische Werbewirksamkeit | Menschliches Wissen | Shanice Johnson, Werbeleiterin, Marketing |
| Makroökonomie extern | Econ. Dept. Modell 1042 | Ökonometrisches Modell | Prof. Sara García, Econ. Abt., UXY |
| Externes Verhalten der Wettbewerber | Competitive Intelligence | Beobachtung | John Wu, Sr. Forschungsanalyst, Marketing |
Der ML-Experte des Teams antwortet und meldet sich zum ersten Mal zu Wort: "Ich habe einen Datensatz von einem ähnlichen Produkt, bei dem wir verschiedene Preisniveaus an mehreren tausend potenziellen Kunden mit unterschiedlichen Eigenschaften getestet haben. Daraus geht hervor, dass das Verhältnis zwischen Preis und Volumen nicht einfach eine gerade Linie ist. Ich wette, dass ich mit diesem Datensatz ein erstes Modell erstellen könnte, das zeigt, wie verschiedene Preisentscheidungen die Produktnachfrage verändern würden - eine Art maschinelles Lernen, das die Nachfrage präzise abschätzt." Das Team ist gerne bereit, einen bestehenden Datensatz zu identifizieren, der für die Entscheidung nützlich sein könnte, und du kennzeichnest die Abhängigkeit, um dies zu zeigen (siehe Abbildung 4-13), und machst einen entsprechenden Eintrag im Register der Entscheidungsressourcen (siehe zweite Zeile in Tabelle 4-3).
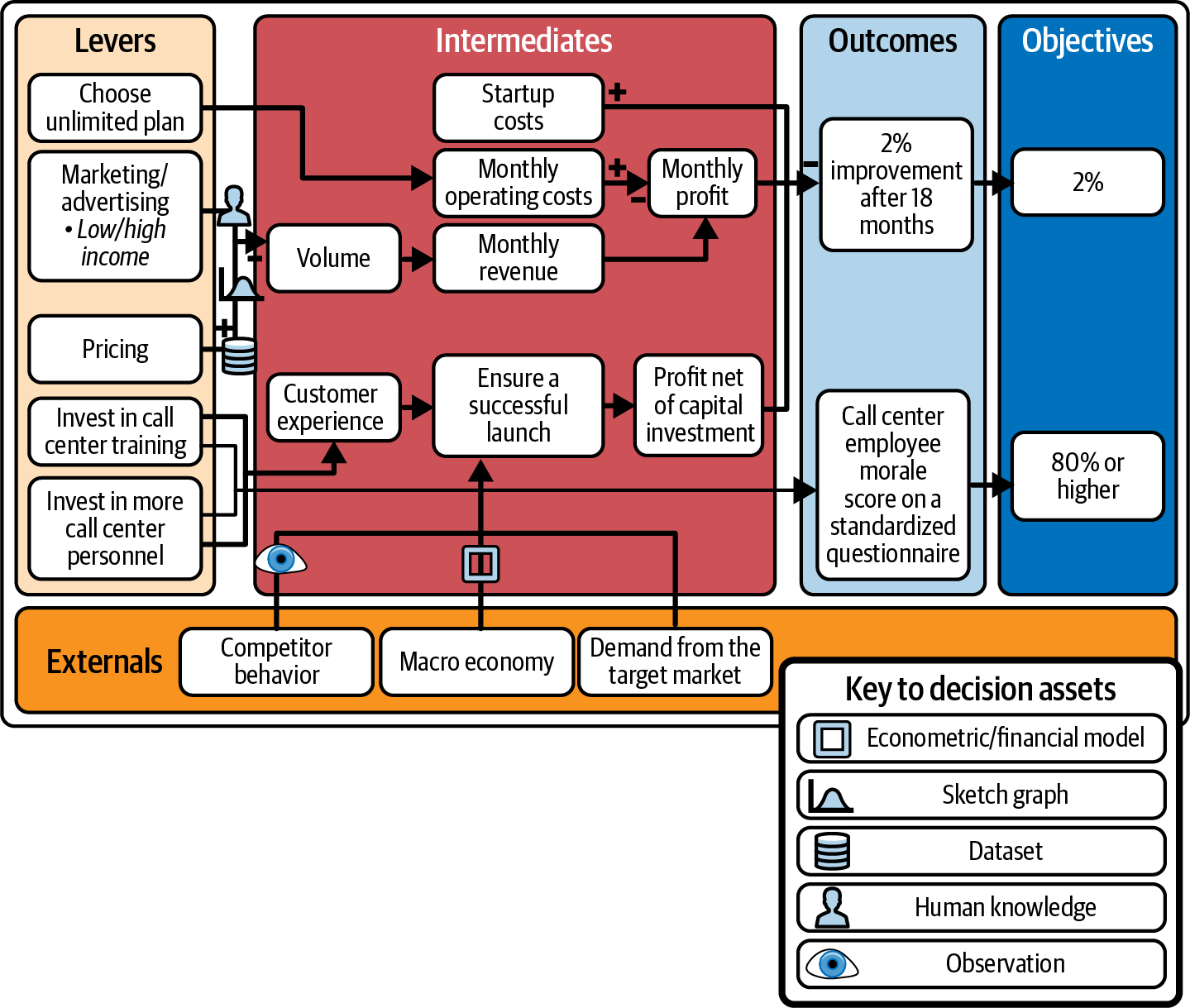
Abbildung 4-13. Der CDD für den unbegrenzten Nutzungsplan, kommentiert mit den Entscheidungswerten.
Der Produktmanager meldet sich wieder zu Wort und erklärt, dass er gerade einer Kollegin aus der Werbeabteilung eine SMS geschickt und sie gebeten hat, der Gruppe beizutreten. Als sie eintrifft, erklärt sie, dass es "allgemein bekannt" ist, dass eine gezielte Werbekampagne etwa 2% der potenziellen Kunden davon überzeugt, zu dem Unternehmen zu wechseln, das die Kampagne durchführt. Du vermerkst diesen Teil des menschlichen Fachwissens in der CDD und fügst die dritte Zeile zum Register der Entscheidungswerte hinzu.
Du gehst nun dazu über, die externen Faktoren zu betrachten. Du bittest das Team, die Annahmen in deinen externen Daten zu identifizieren und sich zu überlegen, welche Assets diese Annahmen unterstützen könnten. Ein Datenwissenschaftler empfiehlt ein öffentlich zugängliches makroökonomisches Modell einer nahegelegenen Universität (Zeile 4 des Decision Asset Registers); jemand aus dem Marketing erklärt, dass es in seiner Abteilung eine Wettbewerbsforschungsgruppe gibt, die sofort weiß, wenn ein Konkurrent ein ähnliches Produkt auf den Markt bringt (Zeile 5 des Decision Asset Registers). Dies ist eine Beobachtung, die du nutzen kannst, um das Verhalten der Wettbewerber zu verfolgen.
Du fügst die Assets wie in Abbildung 4-13 gezeigt zum CDD hinzu und beglückwünschst das Team zu seiner Arbeit, aber du stellst fest, dass sie nicht alle möglichen Entscheidungs-Assets gefunden haben. Du hast gerade den ersten Durchgang gemacht, bei dem nur nach den leicht zu findenden Assets gesucht wurde: die "niedrig hängenden Früchte". Später wirst du einen weiteren Durchgang machen, um nach zusätzlichen Entscheidungswerten zu suchen, die du für die Erstellung einer Entscheidungssimulation oder für die Entscheidungsfindung brauchst; du könntest die CDD auch an andere im Unternehmen weitergeben, um deren Expertise einzuholen. Vielleicht beauftragst du sogar einen Praktikanten mit der Suche nach potenziellen Hilfsmitteln für die CDD.
Fazit
In diesem Kapitel über den Prozess B2, die Untersuchung von Entscheidungswerten, hast du gelernt, wie du eine Liste von Werten sammelst, die dir dabei helfen, ein Computermodell zu erstellen, das zeigt, wie Handlungen zu Ergebnissen führen, und schließlich Seite an Seite mit einem Computer zu arbeiten, um die besten Handlungen zu wählen. Du hast diese Werte erfasst, indem du das CDD aus Kapitel 3 mit Anmerkungen versehen und sie in einem Werteverzeichnis aufgelistet hast. In Kapitel 5 wirst du das Register und das kommentierte CDD nutzen, um Entscheidungen zu simulieren und zu verfolgen.
1 Das ist eine sehr, sehr große Zahl: 1.000.000.000.000.000.000.000 (1021) Bytes.
Get Das Handbuch der Entscheidungsintelligenz now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

