Chapter 1. Introduction
Before we dive into the internals of Chef and look at all the different things we can customize, let’s take a step back, remind ourselves what we’re dealing with when we talk about configuration management, and look at why you might want or need to customize Chef in the first place and what you need to know to get the most out of this book.
What Is Configuration Management?
Time stands still for no man.
— Anonymous
The term configuration management has been in common usage since the 1950s, when the US Air Force developed an approach to managing the extremely complex manufacturing processes involved in producing military equipment. The USAF needed a way to make sure that its equipment performed as required, while also functioning as expected and complying with the relevant military equipment standards. The term was codified as an actual standard in the early 1960s, and the ideas underpinning CM have since been adopted by a number of other industries, such as civil and industrial engineering and, of course, computing.
What we think of as configuration management in the IT sense has been around in one form or another for as long as people have been running more than one computer, although it was not always recognized as such. Looking back through the mists of time to the era of mainframes and minicomputers, we find system administrators tending single, monolithic systems, every tunable setting and parameter committed to memory or to multivolume technical manuals. Computers of any description were far outside the reach of most companies—only the largest corporations and university labs could afford the asking price. Soon, however, as computing hardware became more common, prices dropped to within the reach of more and more companies, and commoditized “cloud” computing became commonplace. The exploding usage of computers and the corresponding increase in the number of sysadmins that were needed to look after them began to make this model of a single repository of knowledge unsustainable.
The industry quickly recognized this problem, and started to document everything. Thus was born the era of internal configuration guides, document stores, and wikis full of all the information a new hire might need to get up to speed on the employer’s infrastructure and systems. This approach, however, also had its limits. As the usage of computers expanded across the globe and more and more companies started developing software systems, manually updated documentation became more and more of a chore to keep relevant and up-to-date. So, people started automating configuration tasks using whatever scripting languages they had on hand. These custom scripts worked perfectly well for a while. They made configuring systems and software much easier because people didn’t have to copy and paste from the manual any more.
Eventually, though, progress overtook the industry again. Individuals within the same infrastructure started using different architectures, software versions, and configuration settings. All of a sudden, people found themselves having to maintain an increasing number of very complex scripts to manage all the different permutations they required, cater to all the possible ways these scripted processes could fail, and so on. It was this very problem that led to the development of what we now recognize as CM in the operations sense.
In 1993, a postdoc at Oslo University in Norway named Mark Burgess decided that he’d had quite enough of managing all of these scripts, thank you very much. Mark wrote the very first version of the configuration engine, CFEngine, to provide an architecture- and OS-independent way of managing the Unix workstations he was responsible for at the time. This was the first of what we now recognize as configuration management systems.
In the years since CFEngine was first developed, a number of other CM systems were developed to satisfy various requirements that existing tools did not provide for. In 2005 Luke Kanies released Puppet, which was the predominant alternative to CFEngine until Chef came along in 2009. Since then, a number of other CM systems (such as Ansible and SaltStack) have been released, but at the time of this writing, CFEngine, Puppet, and Chef are the dominant players in the space.
So Why Chef?
Why, then, did Chef get written when there were already two well-established and relatively mature CM systems to choose from?
The foundation of Chef can be traced back to a consulting company named HJK Solutions (now better known as Chef, Inc.) that specialized in automating the configuration of infrastructure for startup companies. Through this work, HJK Solutions came to realize that the utopia of fully automated infrastructures was becoming a real possibility, even for companies without a staff of highly experienced operations engineers. But things weren’t quite at that stage yet—HJK observed a number of problems with what could be achieved with existing CM systems that needed to be solved first. Here were a few of the main concerns:
- Service-oriented architecture
- In order for fully automated infrastructure to become a possibility, configuration management systems needed to move toward a service-oriented architecture instead of defining a canonical model of infrastructure. That is, rather than defining the infrastructure configuration in stone, CM systems needed to be able to expose as much data as possible about the state of the infrastructure to allow you to better manage its automation.
- Sharable code
- For infrastructure as code to work effectively, people needed to be able to share the code that built their infrastructure. This is a principle found in traditional software development too—code should be modular, clean, and not repetitive. HJK found that the existing tools didn’t provide the sort of generic, reusable building blocks necessary to allow people to effectively share and reuse their infrastructure code.
The folks at HJK didn’t think that any other open source CM systems met the requirements they saw as necessary to achieve fully automated infrastructure, so they created Chef. But did they succeed? What makes Chef different from the other CM systems out there, and why might you want to use it? Because you’re reading this book, you likely already have an idea of the reasons Chef was chosen by your organization and the key differentiators between Chef and its contemporaries, but I’d like to highlight a few of them anyway:
- Chef frees people up where possible
- Like other CM systems, Chef aims to help remove people from the process of automating infrastructure whenever possible. This may sound like the classic joke about replacing yourself with a very small shell script, but think about it—the less time you spend having to keep your server configurations in sync, installing the right combinations of packages, and so on, the more time you have to spend doing far more interesting things! You still have to write your infrastructure automation code, of course, but after you’ve done that Chef takes care of the rest.
- Everything is Ruby
- Chef uses Ruby as its configuration language, as opposed to a custom DSL. On the surface, the language used to write Chef cookbooks might not always look like regular Ruby, but it is.
- Chef is infinitely extensible
- Chef is infinitely extensible. Right from the outset, Chef was designed to integrate with any system you choose to use, and to allow any system to integrate with it. The people at Chef, Inc. don’t see Chef as a carved stone tablet that represents your infrastructure; they see it as a service layer that exposes data about how your infrastructure is behaving and what it looks like. It is this extensibility and data service that allow the sorts of customizations we’ll look at in this book.
- Chef is modular
- Chef was also designed from the ground up to allow you to build your automated infrastructure using modular, reusable components. Chef cookbooks are formed out of discrete “chunks” of automation behavior that can be extended, shared, and reused across your infrastructure.
- In Chef, order matters
- Chef guarantees that it will run things in the same order, every time. If you define a run list in Chef, no matter how many Chef runs you perform, the resources in that run list will always be applied in the same order. See Chapter 3 for more on how Chef runs are executed.
- Thick client, thin server
- Chef does as much work as it can on the node being configured rather than the server. The Chef server is responsible for storing, managing, and shipping cookbooks, files, and other data to client nodes, which then run your infrastructure code. Although all of the out-of-the-box client tools supplied with Chef are written in Ruby, the HTTP-based API of the Chef servers means that it can also be accessed using variety of programming languages—some of these client libraries are discussed in Chapter 11.
- Chef is a system state service
- The thin server model allows Chef to store a copy of the “state” of each node on the server, which includes data like the recipes applied to the server, when it last completed a Chef run, its hardware configuration, etc. By capturing this information in a central location, the Chef server is able to provide us with a “system state” service that can tell us the current state of the node, what the state of the node was at the end of the last chef-client run, and what the state of the node should be at the end of the current chef-client run.
- Resource signals
- Resources in Chef cookbooks are able to “signal” other resources to perform particular actions, allowing you to add conditional logic paths into your infrastructure code while still retaining the modularity and reusability that Chef was designed to provide. You are also able to reuse the same resource several times without redefining it—for example, you can define a “service” resource to control your MySQL server and then use that resource to stop and start your MySQL server by simply instructing the resource to perform different actions.
Chef gives you nearly limitless flexibility to automate your infrastructure as you see fit. It has never been positioned as a panacea to cure all your ills, or magically automate all of the legacy cruft out of that eight-year-old server in the corner. What Chef is, however, is a framework designed to give you all of the tools you need to automate your infrastructure however you want.
Think Critically
Ultimately, as technology professionals, our primary function is to add value to our businesses, regardless of how much time we spend writing code or configuring servers. This is just as true for operations engineers and developers as it is for frontline sales and marketing staff. Developers might not be on the front lines shifting product or selling to customers, but we code and configure the infrastructure and platforms that allow our businesses to function in the Internet age. Every business is different, and only that business can make the decisions about what will add value and what won’t. As a technical expert in your company, you know better than me, or Chef, Inc., or anyone else for that matter about what adds value to your particular company.
This is worth remembering, as it is the principal reason that Chef, Inc. will not typically advocate particular workflows or tooling combinations as the “canonical” Chef way of doing things, and also the reason that I will not do so in this book. The instant a methodology or technique is declared canonical, anything else is considered to be wrong—even if it might be what makes the most sense for your particular use case. Chef is categorically not a system that requires you to do anything in a particular way; rather, it provides you with everything you need to make those decisions for yourself and for the good of your business. As with all systems, however, there are some best practices—we’ll look at some of those throughout the course of this book.
Simply put, Chef gives you the tools and flexibility to craft infrastructure code that is right for you, your team, and your business. It won’t get in the way and it won’t try and force you down a particular path. My aim for this book is to help you gain a deeper understanding of how you can make use of this flexibility and extensibility so you can take what you learn and add even more value to your business. To this end, I want you to question everything you read in this book and ask yourself if it’s right for you.
I can certainly guarantee that the content of this book will be technically accurate and as comprehensive as I can possibly make it, but just as Chef cannot automate your business needs automatically, I cannot tell you what is best for your company or what will solve your specific infrastructure automation problems. What I can do is give you the knowledge and techniques to make you better able to solve those problems for yourself.
In my day job, I work in operations for Etsy, an online marketplace where people around the world connect to buy and sell unique goods. Etsy is fairly well known for its engineering culture, which is rooted in the DevOps movement. We are not particularly driven by procedures or rigid workflows. I usually don’t have to deal with committees to get things done, and am given a high degree of autonomy to perform my job. I think it’s important to frame the employment background I come from because yours may be very different.
You may work for a small startup where you are the only operations engineer and have very little time for anything but the most crucial work. You may work for a large multinational corporation with a many-layered change control process and ITIL compliance to worry about. You may work for a company that stores credit card data and has to maintain PCI-DSS compliance, with all the procedural and auditing headaches that entails. Every single one of you reading this book comes from a different employment background, and you’re all using Chef to solve different problems.
So I propose a pact. I promise to do my best to write an interesting, relevant book that is full of helpful information, useful code snippets, and practical advice for how to approach customizing Chef. And in turn, after I’ve armed you with all of the knowledge and techniques that I can, you promise to carefully look at the problems you’re trying to solve and think critically about the best way to do that. What I’m asking you to consider when looking at customizing your Chef setup is not whether you can do something, but whether you should. And I have a couple of suggestions to help you do that…
Meet AwesomeInc
To help with the process of critically examining the material covered in this book from the perspective of a business trying to solve real problems, I’d like to introduce AwesomeInc, a fictional company whose operations team and developers will be working through a project to customize various aspects of their Chef infrastructure.
AwesomeInc is a midsize company of around 200 staff based in California that produces and sells custom car parts. It was founded in 2005 by two siblings, Chad and Kate Awesome, who started a small business customizing their friends’ cars in their parents’ driveway. The business grew rapidly as word spread, and AwesomeInc now ships its own line of custom car parts all across the US and Canada. Business has been so good recently that the executive team decided that this is the year to go international!
AwesomeInc has 3 dedicated operations engineers and 15 full-time development staff, all led by Mike, the straight-shooting, hard-negotiating but secretly lovable Director of Engineering. They’ve already rolled out Chef across their suite of 150 servers, a mix of both physical hardware and virtualized servers in the cloud. They’re using the open source version of Chef server, hosted internally.
Their ops staff and developers are well versed in writing basic cookbooks, and have been through Chef, Inc.’s “Chef fundamentals” training. But now the word has come down from on high that with the push to go international, AwesomeInc’s infrastructure will be moving from a single system to separate geographically diverse systems, linking back to a central stock database in the US.
Spotting a chance to get ahead of the game, Mike instructs his team to do an audit of their servers and make sure that all of their cookbooks are up-to-date prior to commencing the work to support multiple locations. When the team completes its audit, however, it turns out that things aren’t quite as rosy as they’d hoped.
Although the majority of AwesomeInc’s cookbooks are working perfectly and are up-to-date, there are a few cookbooks that have been modified and not tested properly, and that have been causing Chef runs to fail silently on a number of AwesomeInc’s servers. Additionally, AwesomeInc developers are developing a customized stock management tool to distribute to each new location and are struggling with duplicated recipe code to handle the different permutations supported by the tool.
Mike decides to get a grip on the situation and calls a team meeting to ticket up the cleanup work that’s needed to bring the cookbooks back up to snuff, and look at ways to avoid the issues they’ve been seeing. During the meeting, a number of his operations team members express concern about how they’ll cope with the increased headcount that will follow AwesomeInc’s international expansion. It turns out that operations staff and developers are already beginning to find themselves treading on each other’s toes when they make Chef changes, and it’s becoming increasingly hard to keep track of what has been changed by whom. The team is worried that with the increased frequency of changes that will likely follow the hiring of more engineering staff, it will become harder and harder to maintain stable systems.
They mull over these issues for a few days, and quickly come to the consensus that things need to change. But then Mike asks the million-dollar question: how do we fix this? The team rapidly realize that out of the box, Chef won’t fix these problems for them. Their only option is to customize Chef to give them more visibility into how it’s running on their servers, who is making changes and when, and what those changes are doing.
As we work through the material in this book, we’ll follow the team at AwesomeInc as they learn about the possibilities for customizing Chef, and what they can do to solve the specific problems they’ve encountered in the past. We’ll focus on what solutions they can make use of as well as why each might be a good or bad idea. In addition, we’ll look at what members of the Chef community have done to solve the same problems in the real world—these techniques are no use, after all, if they don’t transfer to real life.
Criteria for Customization
With great power comes great responsibility.
— Voltaire (François-Marie Arouet)
You could be forgiven for thinking that having written a book called Customizing Chef, my advice to you would always be to customize Chef. It isn’t. I’d much rather you carefully consider each customization you’re thinking about making, possibly deciding that maybe it’s not the best idea, than make a whole bunch of customizations that don’t really help you.
One of the recurring problems that our industry as a whole suffers from is a terminal case of the “new shinies.” We’re all of us somewhat prone to taking a new methodology or tool and trying to make it do everything, regardless of whether or not it is actually well-suited to those things.
With a system as flexible and customizable as Chef, you’re more limited by your imagination than by anything technical, and that carries with it the risk of new-shiny overtaking a rational decision-making process. So how do you make sure that when you customize Chef, you’re doing it for well-thought-out reasons that will ultimately add value to your business? We’ve met AwesomeInc and begun to explore the challenges they’re dealing with, but what happens when your specific challenges don’t mesh nicely with my carefully selected examples?
Let’s look at some more general criteria you can use to vet proposed customizations. When you’re thinking about developing or implementing customizations to your Chef setup, I want you to come back to this list and mentally check off how many criteria are satisfied. If the answer is none, it’s probably time to take a really careful look at why you’re considering the customization—you might be doing it because you can, rather than because you should. If you’re like me and enjoy symmetry and easy-to-remember acronyms, remember SMVMS:
- Simplicity
- Will the customization you’re considering make something simpler? This could range from simplifying your deployment process by automating cookbook upload and testing, through cleaning up an old legacy recipe full of labyrinthine control statements, all the way to making it easier for a new hire to work with your Apache configurations.
- Modularity
- Will the customization you’re considering make your infrastructure code more modular and reusable? Are you taking multiple slightly modified chunks of “copypasta” code and refining them into a more generic modular resource that can be defined once and then called from the various places that need it?
- Visibility
- Will the customization you’re considering increase your visibility into your Chef infrastructure? Will it let you introspect deeper into your Chef runs than you’ve ever been able to before? Will it generate metrics for you so you can tell at a glance whether your Chef runs are getting slower or faster? Will people be able to gain greater awareness of when Chef changes have gone live and what exactly they did?
- Maintainability
- Will the customization you’re considering make it easier for your Chef users to maintain your infrastructure codebase? Will it make people less afraid to change the one cookbook that runs on all of your servers? When a new hire starts, will she be able to tear up the manual of voodoo incantations previously required to work with this code?
- Scalability
- Will the customization you’re considering help your infrastructure scale to meet your business’s growth needs? Have you hit the point where you need to diversify your infrastructure from a single data center, and all of a sudden the assumptions you made in your recipes about server naming conventions break down? Are you building out a small software stack into a much larger n-tier cluster?
Let’s look in a little more detail at some questions the folks at AwesomeInc asked themselves when looking at how to solve the problems they identified and how they map to the “Criteria for Customization” just discussed—all are excellent candidates for a sound decision to customize, but for different reasons.
How Do We Find Out When Our Chef Runs Are Failing, and Why?
The folks at AwesomeInc are looking to improve the visibility they have into Chef and how it’s performing. Out of the box, Chef will expose some information to you through both the web UI and the command line on when a particular node last checked in with the Chef server and what its current run list is, but it won’t tell you whether or not the last Chef run failed or the causes of any failures. This might sound like somewhat of an omission, but look at it this way: bearing in mind the wide variety of notification and alerting systems out there, how should Chef expose this information to a Windows user? A Linux user? Should it always alert on every failed run?
Rather than trying to solve all possible use cases, Chef, Inc. has made it extremely easy to capture this information in Chef so that you can handle it in a way that works well with your particular choice of monitoring and alerting software. We’ll look in more detail at how you can capture and make use of this information in Chapter 5.
Caution
Some Chef setups, such as chef-solo, do not use a centralized Chef server and will not support some types of customization, such as those making use of persistent node attributes. Please see Chef Installation Types and Limitations for more details.
How Do We Simplify Our Recipes to Reduce the Amount of Replicated Code?
The team at AwesomeInc are looking to improve both the modularity and the simplicity of their infrastructure code. As we’ve already seen, Chef provides building blocks and tools to let you automate your infrastructure however you want. Out of the box it provides resources for a number of operations, from configuring users through downloading remote files to managing packages and services. But like Chef itself, these resources are designed to be as simple and generic as possible. Chef doesn’t provide a built-in resource for configuring a virtual host in Apache, for example, although this can still be done with a combination of out-of-the-box resources.
Again, though, this is where the extensibility and flexibility of Chef really come in handy. There is nothing to stop you from writing your own resource to configure Apache virtual hosts, or set up Ruby Version Manager (RVM) on your development workstations, or configure access to your MySQL databases. The sky is the limit here—Chef gives you the framework and lets you decide for yourself. We’ll look at how to write your own resources and recipe logic in Part III.
How Do We Stop Our Developers and Ops Staff from Treading All over Each Other’s Changes?
The people at AwesomeInc are looking to improve the visibility they have into Chef changes and the scalability of their engineering organization so that they can increase their headcount without compromising the stability of their infrastructure with a sudden increase in the volume of Chef changes. Out of the box, Chef comes with Knife, a command-line tool that lets you perform a number of operations such as uploading cookbooks, configuring node run lists, running commands across a group of servers, and running search queries against your infrastructure. The team at AwesomeInc have been using these built-in Knife commands to work with Chef.
Knife ships with a powerful set of features, but once again, it is specifically designed to be as generic as possible. Knife does not ship with built-in functionality to spin up nodes on Amazon EC2. It does not ship with functionality to stop teams with large numbers of Chef users from treading on each other’s toes (although it does have a flag to stop you from uploading the same cookbook version twice). What Knife does ship with is a design that allows it to be customized easily and extensively. We’ll look at how to customize Knife in Chapter 10.
Caution
Some Chef setups, such as chef-solo, do not use a centralized Chef server and will not work with some Knife commands or plugins. Please see Chef Installation Types and Limitations for more details.
State of the Customization Nation
Now that we’ve examined the example scenarios we’ll be working through in this book and looked at some general criteria to weigh your customization ideas against, let’s get those creative juices flowing and have a brief look at some of the customizations the Chef community have already produced and the problems they were trying to solve. This is by no means an exhaustive list, and my inclusion (or exclusion) of a tool by no means implies that I’m passing judgment on it or recommending it—my aim is simply to take you on a whistle-stop tour of some of the Chef customizations to be found in the wild today to get you thinking about what is possible. The discussion may also help you identify particular chapters of this book to read first.
Chef Supermarket
One of the most comprehensive and extensive Chef resources available today is the Chef Supermarket (formerly “Community Cookbooks”) site. It is a publicly accessible website hosted by Chef, Inc. where Chef users can upload their cookbooks and share them with the wider community. You’ll find cookbooks for a decent proportion of the software package systems you’re likely to want to use, varying from simple cookbooks containing one or two recipes all the way through to more advanced cookbooks containing custom providers and resources for a wide range of tasks (see Part III for more details on how to write resources and providers).
It’s important to remember that the majority of the cookbooks are open source code uploaded by members of the Chef community. They are not supported or warrantied by Chef, Inc., and their presence on the Chef Supermarket site is not an indication of quality or correctness—as we’ve already discussed, as with all solutions it’s very important that you make sure these cookbooks are right for your infrastructure. For example, some cookbooks may only support a particular Linux distribution, or make certain assumptions about how you configure your software. Community members are able to review and comment on cookbooks, however, which can be a good starting point for evaluating suitability.
Development Tooling
Although more strictly tooling built around Chef than direct customizations, a number of tools have been written to help support the Chef development process. One of the benefits of “infrastructure as code” is that we get to benefit from the expertise and experience of the wider development community, and adopt software engineering best practices to write awesome infrastructure code. The following tools are some of the fruits of this way of thinking:
- Foodcritic
- Foodcritic is a lint checker that checks your cookbooks against a set of “best practice” rules as well as letting you define your own rules. Foodcritic can check for coding style as well as the actual correctness of your cookbooks.
- Test Kitchen
- Test Kitchen is a tool created by Fletcher Nichol that lets you write integration tests for your Chef cookbooks. It uses the Vagrant virtualization software to spin up “test” nodes that run your integration tests and produce a report after.
- ChefSpec
- ChefSpec is a unit testing framework that allows you to write RSpec-style tests for testing Chef cookbooks and verifying that they behave as expected.
- Leibniz
- Leibniz is an acceptance testing tool that leverages the provisioning features of Test Kitchen to allow you to run acceptance tests against your infrastructure using Cucumber/Gherkin features.
- Jenkins chef-plugin
- chef-plugin is a plugin for the Jenkins continuous integration (CI) tool that allows you to initiate a Chef run on a remote host with the specified configuration and report its status.
Workflow Tooling
Cookbooks aside, some of the most popular tooling written for Chef has been to support different workflows for working with Chef. As we’ve already seen, Chef, Inc. intends Chef to be as generic as possible and correspondingly will not generally advocate a particular workflow or methodology—if it did, as soon as your requirements fell outside of that “one true way,” you’d be doing it wrong. The workflow tools described in this section are good examples of members of the Chef community producing tools to fulfill business requirements that were not satisfied by Chef out of the box. In the three particular cases mentioned here, it turns out that a decent chunk of the community had the same requirements and adopted one or the other of these tools, so they’ve become relatively well known as a result:
- Berkshelf
- Berkshelf was initially developed by the engineering team at Riot Games to solve some of the issues they were experiencing around managing cookbook dependencies. Berkshelf is essentially a bundler for Chef—it allows you to quickly and simply install all the cookbook dependencies your own cookbook has, and stores them in a special “berkshelf” in a similar way to how Ruby installs gems. Berkshelf treats cookbook dependencies as libraries to be utilized and extended by your cookbooks, rather than adding them into your main cookbook repository to be customized themselves.
- Librarian-Chef
- Librarian-Chef is based on a similar idea to Berkshelf: that of managing cookbook dependencies. Rather than storing cookbook dependencies in a separate area, however, Librarian-Chef effectively takes control of the /cookbooks directory in your Chef repository and uses a special “Cheffile” to specify what cookbooks should be installed and from where. Librarian-Chef is designed to work with cookbooks that are each separate projects (like those on the Chef Supermarket site) rather than cookbooks that are solely stored in your Chef repository.
- knife-spork
- knife-spork (disclosure: written by me) was developed at Etsy to support the unusually large number of developers and operations staff who were regularly making Chef changes. At Etsy, we found that having 30 or 40 Chef users regularly changing and uploading the same environment files resulted in uncertainty over whether or not changes had gone “live,” been overwritten by subsequent changes, or just flat out been lost in the noise. Since its initial release, knife-spork has been extended to include plugins for various tasks, such as automatically running Foodcritic prior to uploading cookbooks and broadcasting Chef changes to a number of different systems, including IRC, HipChat, Campfire, and Graphite.
Knife Plugins
Caution
Some Chef setups, such as chef-solo, do not use a centralized Chef server and will not work with some Knife commands or plugins. Please see Chef Installation Types and Limitations for more details.
Knife is one of the most versatile tools provided with Chef, and the community has been quick to take advantage of this. Out of the box, it supports a number of built-in commands for uploading, editing, and deleting a variety of Chef objects such as cookbooks, roles, users, and clients. But Knife’s main strength is its flexibility and customizability. Knife provides an extremely powerful interface to Chef and its underlying functionality that can be leveraged in any number of ways. We’ll look in much greater detail at how you can write your own Knife plugins in Chapter 10.
One of the categories of Knife plugin that has seen the most development activity is that surrounding working with cloud providers. Plugins already exist for provisioning nodes on a number of different cloud providers (Amazon EC2, Rackspace, and Joyent, to mention but a few). Knife ships with the “bootstrap” command, which is used to install and configure Chef on nodes that are already running an OS, and as more and more people started to use cloud infrastructure, it was a logical progression that Knife plugins be written to handle the provisioning of cloud instances prior to setting up Chef.
Here’s a quick sampling of some of the other Knife plugins that have been created by the Chef community, and what they’re for (the knife- prefix is a naming convention rather than a functional requirement):
- knife-elb
- The knife-elb plugin automates the adding and removing of nodes to and from Elastic Load Balancers on Amazon’s EC2 service.
- knife-kvm
- knife-kvm gives you the ability to provision, manage, and bootstrap Chef on virtual machines using the open source KVM virtualization platform.
- knife-rhn
- knife-rhn is a Knife plugin for managing your nodes within the Red Hat Satellite systems management platform. The plugin lets you add nodes to and remove them from Red Hat Network, as well as manage system groups.
- knife-block
- knife-block allows you to configure and manage multiple Knife configuration files, if you’re using multiple Chef servers.
- knife-crawl
- knife-crawl is a Knife plugin to display role hierarchies. It will show you all the roles that are included within the specified role, and optionally all roles that in turn include the specified role.
- knife-community
- knife-community is a Knife plugin that assists with deploying Chef cookbooks to the Chef Supermarket site. This plugin aims to help users comply with a number of best practices for submitting community cookbooks, such as correct cookbook version numbering and Git-tagging new cookbook releases.
Handlers
Handlers in Chef are extensions that can be triggered in response to specific situations to carry out a variety of tasks. Handlers are typically integrated with the chef-client run process and are called depending on whether or not errors occurred during the Chef run, as shown in Figure 1-1.
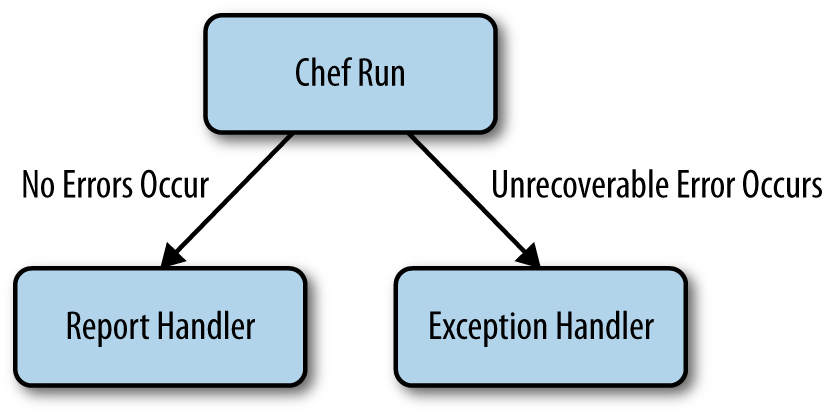
There are two main types of handler:
- Report handlers
- As shown in Figure 1-1, report handlers are used to carry out actions when the chef-client run has succeeded without error.
- Exception handlers
- As shown in Figure 1-1, exception handlers are used to carry out actions when an error has occurred during the chef-client run that cannot be recovered from.
Handlers allow you to capture all sorts of data about how Chef runs are behaving. We will look at these further in Chapter 5, but in the meantime let’s look at some of the ways that the members of the Chef community have made use of this information:
- chef-graphite_handler
- chef-graphite_handler is a report handler (provided as a cookbook) for sending Chef run results to the open source Graphite graphing system.
- chef-handler-splunkstorm
- chef-handler-splunkstorm is a combination report and exception handler that reports Chef run statuses to Splunk. It will also log full stack traces in the event of a run failure.
- chef-irc-snitch
- chef-irc-snitch is an exception handler that sends notifications of Chef run failures to an IRC channel, complete with a GitHub gist containing node information, the exception message itself, and the backtrace to assist in debugging.
Recipes and Resources
In addition to publishing cookbooks on Chef Supermarket, a number of community members have created open source libraries and providers that are more generally useful to the community than to users of a specific cookbook. We’ll look at how to write providers in Chapters 8 and 9, but until then here’s a taste of what’s currently available:
- chef-whitelist
- chef-whitelist is a library developed at Etsy to allow host-based rollouts of changes. It allows you to define a whitelist (containing hostnames, roles, or wildcard pattern matches) in a data bag, and then add simple control statements to your cookbooks to apply different logic to roles that match an entry in the whitelist.
- chef-deploy
- chef-deploy is a Ruby gem that provides Chef resources and providers to allow you to deploy Ruby web applications without using Capistrano. It maintains forward and backward compatibility with Capistrano by using the same directory structure and deployment strategy.
Chef Installation Types and Limitations
Before we move on to the technical portion of the book, it’s worth noting that not all of the material covered will work on all types of Chef setup. Throughout the book, when I list examples of techniques I’ll note whether or not there are any compatibility issues with different types of Chef install; here, I list each type of install along with details on how they differ and which features are not supported.
Tip
Although both variants of Enterprise Chef listed here are commercial products, all of the material in this book is fully compatible with the open source version of Chef server. You do not need a paid-for version of Chef to work through this book.
chef-solo
chef-solo is the simplest Chef setup you can run. It is a function-limited version of chef-client, and you have no central Chef server. chef-solo requires a copy of all your cookbooks on each node (including all cookbook dependencies); it reads each cookbook from the local disk and applies it to your server.
You would typically use chef-solo if for some reason you didn’t want to use a central Chef server—say, when initially evaluating Chef, or when configuring appliance-type systems that may not have network access.
As there is no central Chef server in a chef-solo setup, the following features are not supported:
- Node data
- Nodes do not save state when they finish a run.
- Persistent attributes
- Attributes do not persist across Chef runs. Any attributes needed by a chef-solo run should be set either in cookbooks, or in a JSON configuration file passed to chef-solo.
- Search
- chef-solo does not allow you to use search in your recipes (or by using Knife), as there is no central server to store node state or attributes in search indexes.
- Centralized cookbooks
- chef-solo doesn’t support centralized cookbook storage and distribution. You must have a separate copy of each of your cookbooks, roles, environments, etc. on each node. This also means that you need to make sure you keep all of the copies in sync to ensure your changes are applied consistently across your infrastructure.
- Centralized API
- The lack of a centralized Chef server in chef-solo means that you don’t have access to the Chef Server API, which is the interface used to access the “system state” service that Chef provides.
- Authentication
- Because chef-solo runs entirely self-contained on the node, you don’t have the authentication controls that the Chef server provides to determine whether or not a client on a node is authorized to download and run cookbooks, roles, and environments, etc. Any node with a copy of your cookbook data can run those cookbooks; all you need is access to log onto the node itself to initiate a Chef run.
Open Source Chef
Chef, Inc. provides a free and open source version of Chef server that stores cookbooks, node run lists, and attributes, and provides a centralized API. Each node runs chef-client and queries the server to obtain information about the configuration to be applied during the run. chef-client then performs the run on the node, using locally cached copies of the cookbooks (which are synced with the copies stored on the server at the start of the run). When the run concludes, chef-client saves the node state and updated attributes back to the central server.
The open source version of Chef server has to be configured, installed, and updated locally by the user and will not automatically scale. It is entirely possible to scale out components, but the user must do this manually. Chef, Inc. can provide optional paid support for open source Chef servers, but the Chef community is the more usual source of technical advice. Open source Chef is recommended for advanced users, or at the very least those comfortable with manually maintaining the respective components.
All material covered in this book is fully compatible with the open source version of Chef server.
Local Mode
Introduced in Chef version 11.8, local mode is an extension to chef-client designed to fill the gap between chef-solo and running with a full Chef server. chef-solo is ideal for quickly testing cookbooks, or situations where Chef needs to run in total isolation without access to a Chef server (embedded appliances, for example). Sometimes, however, you might find yourself wishing to test out features usually provided by the Chef server (like search) without the hassle of having to set up a full Chef server, or to test in a sandbox environment isolated from your production Chef server. This is where local mode comes in!
Local mode makes use of an open source tool created by Chef, Inc. called chef-zero. chef-zero provides an extremely simple memory-resident Chef server that supports many of the commands and features that can be run against a full Chef server. It’s very lightweight and easy to use, but it does not perform any input validation or authorization checking, and it does not save any “state” data in the way a full Chef server would. Every time chef-zero starts up, it is completely empty and contains no cookbooks or saved node data. Provided that you bear these limitations in mind, it can be an extremely useful tool for testing more advanced cookbook features. It’s important to remember that chef-zero is not intended to be used as a production replacement for the open source Chef server or any of the Enterprise Chef servers.
To run chef-client under local mode, you simply run it with the -z option. This will start up a chef-zero server, and your Chef run will communicate with chef-zero instead of any Chef server specified in the client.rb configuration file. We’ll look more at how this functionality is implemented in Tracing a chef-client Run, and you can find out more about how to use chef-zero in your cookbook testing workflow on the Chef blog.
chef-zero provides a lightweight implementation of a Chef server, and supports all of the same commands and operations as the open source Chef server.
Private Enterprise Chef
Enterprise Chef is the commercial version of the open source Chef server. The private version of Enterprise Chef is hosted inside your firewall on your own hardware and provides clustering support out of the box. After hosted Enterprise Chef (discussed next), private Enterprise Chef is the next-easiest option to get up and running with, and is particularly recommended for those new to Chef or looking to evaluate it in a setting with the budget to accommodate the hardware and licensing costs of running a private Chef appliance. Along with the features provided in the open source version, Enterprise Chef provides a number of additional features, some of which are touched on elsewhere in this book. These include:
- Role-based access control
- Enterprise Chef provides more fine-grained access control than the open source version. Whereas open source Chef will give access to all objects (cookbooks, nodes, users, roles, etc.) to any properly authenticated user, Enterprise Chef allows you to refine this permissions model to grant different permission levels (for example, create, read, update) to different users or groups of users.
- Multitenancy
- Enterprise Chef allows a user to maintain totally distinct Chef setups for different “tenants.” For example, if you were running a Chef server that served a number of companies, Enterprise Chef would allow you to keep functionally separate Chef “environments” for each client—cookbooks, node data, attributes, search indexes, etc. would all be separated per client.
- Push client runs
- Under the open source version of Chef server, chef-client runs on a “pull” model. This means that chef-client typically runs in daemonized mode, and queries the server for details on what it should run on the node at a configurable interval. When you make a change, unless you script a manual Chef run on all of your nodes, you have to wait until the next Chef run for the changes to go out. Enterprise Chef allows you to push runs out to your nodes, which means that if you so desire you can kick off chef-client runs as soon as a change has gone out without the need for any manual scripting.
Tip
All material covered in this book is fully compatible with private Enterprise Chef.
Hosted Enterprise Chef
The hosted version of Enterprise Chef provides all of the same features as the private version, with the addition that it is not hosted inside your organization but rather managed by Chef, Inc. This means that Chef, Inc. hosts the systems that power hosted Chef and handles all updating, scaling, and support.
Hosted Enterprise Chef is the easiest option to get up and running with, and is particularly recommended for those new to Chef or looking to evaluate it.
Tip
All material covered in this book is fully compatible with hosted Enterprise Chef.
Prerequisites
The last thing I’d like to cover in this chapter is a quick note on the prerequisite tooling and knowledge I’m assuming in my readers. This book is aimed at people who are already comfortable using Chef and want to level up their skills; it assumes that if you’re not using hosted Enterprise Chef, you already have a Chef server installed and configured, or are using chef-solo.
Although advanced Chef knowledge is not a prerequisite for this material, you should ideally have read or be familiar with the concepts covered in Mischa Taylor and Seth Vargo’s book Learning Chef, and be familiar with most of the topics mentioned in this section.
Knife
Although you don’t have to be familiar with every supported Knife command, you should be comfortable with how to configure and install Knife and run basic commands for tasks such as:
- Uploading cookbooks
- Creating clients
- Uploading and editing roles and environments
Nodes and Clients
You should understand how to register nodes with Chef, how to configure the run list of a node, and how to run chef-client. You should be at least roughly familiar with the anatomy of a Chef run and be able to interpret basic errors when a run fails.
Cookbooks, Attributes, Roles, Environments, and Data Bags
You should be comfortable writing recipes using the resources provided by out-of-the-box Chef, using notifies to initiate actions on other resources, and combining those recipes into a cookbook. You should have a basic understanding of the concept of attributes in Chef and how to set and read them.
You should at least roughly understand how to edit and use roles, environments, and data bags. Advanced knowledge isn’t necessary, but you should be aware of the concepts and how they integrate with the rest of Chef.
Chef Search
You should understand how to perform simple searches in Chef, either in recipes or using Knife, such as finding a list of all nodes containing “foo” in their names.
Ruby
You don’t need to be a Ruby expert to work through the material in this book, but you should be comfortable with the level of Ruby covered in Learning Chef or on Chef, Inc.’s “Just Enough Ruby for Chef” page. We’ll cover all of the Ruby concepts you’ll need for this book in Chapter 2, but if you’d like a more comprehensive Ruby reference to help you along I’d recommend either The Ruby Programming Language by David Flanagan and Yukihiro Matsumoto, or Learning Ruby by Michael Fitzgerald (both from O’Reilly). Both are excellent and extremely comprehensive books, and although they contain far more Ruby than is necessary to follow the material in this book, they cover a lot more about writing “correct” Ruby and how to stick to Ruby best practices than we do here.
Assumptions
As Chef is supported on a number of different platforms, throughout this book I’ve had to make several assumptions about the environment in which you’re running Chef in order to keep the examples as readable and simple as possible. I assume that:
- You’re running on a Linux/Unix-based operating system (this includes Mac OS X).
- You installed Chef via the omnibus installer documented on the Chef, Inc. “Install Chef” page.
- You’re running at least chef-client version 11.10.0.
- You have at least version 1.9.2 of Ruby installed—many of the examples in this book will not work with Ruby 1.8.
- You have the Git source code management system installed.
- You’re familiar with the use of a programmer’s text editor such as Vim, Emacs, or TextMate.
If any of these assumptions do not apply to you (for example, if you’re running Windows or installed Chef from RubyGems), you may find that some of the directory paths and commands used throughout the book require a little tweaking to work in your environment. I’ve done my best to indicate when this is likely to be the case.
Get Customizing Chef now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

