Capítulo 1. Del objetivo del producto al marco del ML
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
ML permite a las máquinas aprender de los datos y comportarse de forma probabilística para resolver problemas optimizando para un objetivo dado. Esto se opone a la programación tradicional, en la que un programador escribe instrucciones paso a paso que describen cómo resolver un problema. Esto hace que el ML sea especialmente útil para construir sistemas para los que no podemos definir una solución heurística.
La Figura 1-1 describe dos formas de escribir un sistema para detectar gatos. A la izquierda, un programa consiste en un procedimiento que se ha escrito manualmente. A la derecha, un enfoque ML aprovecha un conjunto de datos de fotos de gatos y perros etiquetadas con el animal correspondiente para permitir que un modelo aprenda el mapeo de la imagen a la categoría. En el enfoque ML, no hay ninguna especificación de cómo debe conseguirse el resultado, sólo un conjunto de entradas y salidas de ejemplo.

Figura 1-1. De definir procedimientos a mostrar ejemplos
El ML es potente y puede desbloquear productos totalmente nuevos, pero como se basa en el reconocimiento de patrones, introduce un nivel de incertidumbre. Es importante identificar qué partes de un producto se beneficiarían del ML y cómo enmarcar un objetivo de aprendizaje de forma que se minimicen los riesgos de que los usuarios tengan una mala experiencia.
Por ejemplo, es casi imposible (y lleva muchísimo tiempo intentarlo) que los humanos escriban instrucciones paso a paso para detectar automáticamente qué animal hay en una imagen basándose en los valores de los píxeles. Sin embargo, alimentando una red neuronal convolucional (CNN) con miles de imágenes de distintos animales, podemos construir un modelo que realice esta clasificación con más precisión que un humano. Esto hace que sea una tarea atractiva para abordar con ML.
Por otro lado, una aplicación que calcule tus impuestos automáticamente debe basarse en las directrices proporcionadas por el gobierno. Como habrás oído, tener errores en tu declaración de la renta está generalmente mal visto. Esto hace que el uso de ML para generar automáticamente declaraciones de la renta sea una propuesta dudosa.
Nunca querrás utilizar ML cuando puedas resolver tu problema con un conjunto manejable de reglas deterministas. Por manejable me refiero a un conjunto de reglas que puedas escribir con confianza y cuyo mantenimiento no sea demasiado complejo.
Así que, aunque el ML abre un mundo de aplicaciones diferentes, es importante pensar qué tareas pueden y deben resolverse mediante ML. Cuando construyas productos, debes partir de un problema empresarial concreto, determinar si requiere ML, y luego trabajar para encontrar el enfoque de ML que te permita iterar lo más rápidamente posible.
Cubriremos este proceso en este capítulo, empezando por los métodos para estimar qué tareas pueden resolverse mediante ML, qué enfoques de ML son apropiados para qué objetivos de producto, y cómo abordar los requisitos de datos. Ilustraré estos métodos con el caso práctico del Editor ML que mencionamos en "Nuestro caso práctico: Redacción asistida por ML", y una entrevista con Monica Rogati.
Estima lo que es posible
Dado que los modelos ML de pueden abordar tareas sin necesidad de que los humanos les den instrucciones paso a paso, eso significa que son capaces de realizar algunas tareas mejor que los expertos humanos (como detectar tumores a partir de imágenes radiológicas o jugar al Go) y otras que son totalmente inaccesibles para los humanos (como recomendar artículos entre millones o cambiar la voz de un orador para que suene como otra persona).
La capacidad del ML para aprender directamente de los datos lo hace útil en una amplia gama de aplicaciones, pero hace más difícil para los humanos distinguir con precisión qué problemas pueden resolverse con ML. Por cada resultado exitoso publicado en un artículo de investigación o en un blog corporativo, hay cientos de ideas que parecen razonables pero que han fracasado por completo.
Aunque actualmente no existe una forma segura de predecir el éxito del ML, hay pautas que pueden ayudarte a reducir el riesgo asociado a abordar un proyecto de ML. Lo más importante es que siempre debes empezar con un objetivo de producto para luego decidir cuál es la mejor forma de resolverlo. En esta fase, estate abierto a cualquier enfoque, requiera o no ML. Cuando consideres enfoques de ML, asegúrate de evaluarlos en función de lo apropiados que sean para el producto, no simplemente en función de lo interesantes que sean los métodos en el vacío.
La mejor manera de hacerlo es siguiendo dos pasos sucesivos: (1) enmarcar el objetivo de tu producto en un paradigma de ML, y (2) evaluar la viabilidad de esa tarea de ML. En función de tu evaluación, puedes reajustar tu encuadre hasta que estemos satisfechos. Exploremos lo que significan realmente estos pasos.
-
Enmarcar el objetivo de un producto en un paradigma de ML: Cuando construimos un producto, empezamos por pensar qué servicio queremos prestar a los usuarios. Como mencionamos en la introducción, ilustraremos los conceptos de este libro utilizando el caso práctico de un editor que ayuda a los usuarios a escribir mejores preguntas. El objetivo de este producto es claro: queremos que los usuarios reciban consejos procesables y útiles sobre el contenido que escriben. Los problemas de ML, sin embargo, se plantean de una forma totalmente distinta. Un problema de ML consiste en aprender una función a partir de datos. Un ejemplo es aprender a tomar una frase en un idioma y emitirla en otro. Para un objetivo de producto, suele haber muchas formulaciones de ML diferentes, con distintos niveles de dificultad de implementación.
-
Evaluar la viabilidad del ML: ¡No todos los problemas de ML de son iguales! A medida que ha evolucionado nuestra comprensión del ML, problemas como crear un modelo para clasificar correctamente fotos de gatos y perros se han podido resolver en cuestión de horas, mientras que otros, como crear un sistema capaz de mantener una conversación, siguen siendo problemas de investigación abiertos. Para construir aplicaciones de ML de forma eficiente, es importante considerar múltiples marcos potenciales de ML y empezar por los que juzguemos más sencillos. Una de las mejores formas de evaluar la dificultad de un problema de ML es fijarse tanto en el tipo de datos que requiere como en los modelos existentes que podrían aprovechar dichos datos.
Para sugerir diferentes encuadres y evaluar su viabilidad, debemos examinar dos aspectos centrales de un problema de ML: los datos y los modelos.
Modelos
Hay muchos modelos de uso común en ML, y nos abstendremos de dar una visión general de todos ellos aquí. No dudes en consultar los libros enumerados en "Recursos adicionales" para obtener una visión más completa. Además de los modelos comunes, cada semana se publican muchas variaciones de modelos, arquitecturas novedosas y estrategias de optimización. Sólo en mayo de 2019, se enviaron más de 13.000 artículos a ArXiv, un popular archivo electrónico de investigación donde se envían con frecuencia artículos sobre nuevos modelos.
Sin embargo, es útil compartir una visión general de las distintas categorías de modelos y de cómo pueden aplicarse a distintos problemas. Para ello, propongo aquí una sencilla taxonomía de modelos basada en cómo abordan un problema. Puedes utilizarla como guía para seleccionar un enfoque con el que abordar un determinado problema de ML. Dado que los modelos y los datos están estrechamente relacionados en el ML, notarás cierto solapamiento entre esta sección y "Tipos de datos".
Los algoritmos ML pueden clasificarse en función de si requieren etiquetas. Aquí, una etiqueta se refiere a la presencia en los datos de una salida ideal que un modelo debería producir para un ejemplo dado. Los algoritmos supervisados aprovechan conjuntos de datos que contienen etiquetas para las entradas, y su objetivo es aprender una correspondencia entre las entradas y las etiquetas. En cambio, los algoritmos no supervisados no necesitan etiquetas. Por último, los algoritmos débilmente supervisados aprovechan etiquetas que no son exactamente la salida deseada, pero que se parecen a ella de alguna manera.
Muchos objetivos de los productos pueden abordarse mediante algoritmos supervisados y no supervisados. Un sistema de detección de fraudes puede construirse entrenando un modelo para detectar transacciones que difieran de la media, sin necesidad de etiquetas. Un sistema así también podría construirse etiquetando manualmente las transacciones como fraudulentas o legítimas, y entrenando un modelo para que aprenda de dichas etiquetas.
Para la mayoría de las aplicaciones, los enfoques supervisados son más fáciles de validar, ya que tenemos acceso a etiquetas para evaluar la calidad de la predicción de un modelo. Esto también facilita el entrenamiento de los modelos, ya que tenemos acceso a los resultados deseados. Aunque crear un conjunto de datos etiquetados a veces puede llevar mucho tiempo al principio, facilita mucho la creación y validación de modelos. Por este motivo, este libro tratará principalmente de enfoques supervisados.
Con dicho esto, determinar qué tipo de entradas tomará tu modelo y qué salidas producirá te ayudará a reducir significativamente los enfoques potenciales. En función de estos tipos, cualquiera de las siguientes categorías de enfoques de ML podría ser una buena opción:
-
Clasificación y regresión
-
Extracción de conocimientos
-
Organización del catálogo
-
Modelos generativos
Me extenderé más sobre ellos en la siguiente sección. Mientras exploramos estos distintos enfoques de modelización, recomiendo a que pienses qué tipo de datos tienes a tu disposición o podrías reunir. A menudo, la disponibilidad de datos acaba siendo el factor limitante en la selección del modelo.
Clasificación y regresión
Algunos proyectos de se centran en clasificar eficazmente puntos de datos entre dos o más categorías o atribuirles un valor en una escala continua (lo que se denomina regresión en lugar de clasificación). La regresión y la clasificación son técnicamente diferentes, pero a menudo los métodos para abordarlas se solapan significativamente, por lo que las agrupamos aquí.
Una de las razones por las que la clasificación y la regresión son similares es porque la mayoría de los modelos de clasificación emiten una puntuación de probabilidad para que un modelo pertenezca a una categoría. El aspecto de la clasificación se reduce entonces a decidir cómo atribuir un objeto a una categoría basándose en dichas puntuaciones. A un alto nivel, un modelo de clasificación puede verse como una regresión sobre valores de probabilidad.
Normalmente, clasificamos o puntuamos ejemplos individuales, como los filtros de spam que clasifican cada correo electrónico como válido o basura, los sistemas de detección de fraudes que clasifican a los usuarios como fraudulentos o legítimos, o los modelos radiológicos de visión por ordenador que clasifican los huesos como fracturados o sanos.
En la Figura 1-2, puedes ver un ejemplo de clasificando una frase según su sentimiento y el tema que trata.
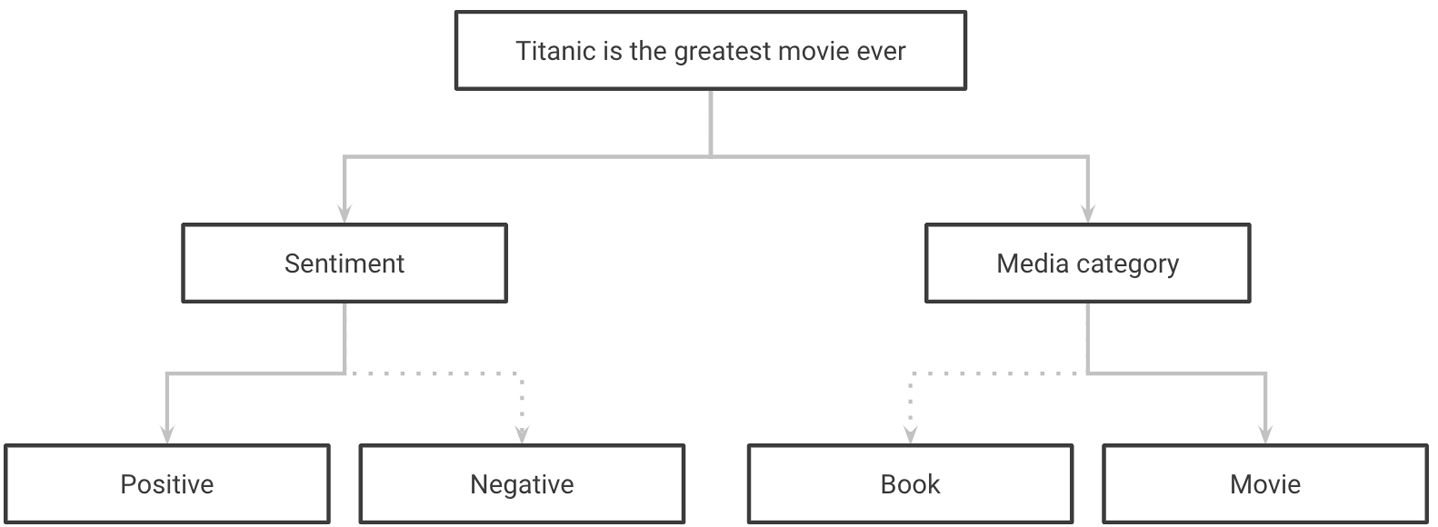
Figura 1-2. Clasificar una frase en varias categorías
En los proyectos de regresión, en lugar de atribuir una clase a cada ejemplo, les damos un valor. Predecir el precio de venta de una vivienda a partir de atributos como cuántas habitaciones tiene y dónde está situada es un ejemplo de problema de regresión.
En algunos casos, tenemos acceso a una serie de puntos de datos pasados (en lugar de uno) para predecir un acontecimiento en el futuro. Este tipo de datos suele denominarse una serie temporal, y hacer predicciones a partir de una serie de puntos de datos se denomina previsión. Los datos de series temporales podrían representar el historial médico de un paciente o una serie de mediciones de asistencia a parques nacionales. Estos proyectos suelen beneficiarse de modelos y funciones que pueden aprovechar esta dimensión temporal añadida.
En otros casos, intentamos detectar sucesos inusuales en un conjunto de datos. Esto se denomina detección de anomalías. Cuando un problema de clasificación trata de detectar sucesos que representan una pequeña minoría de los datos y, por tanto, son difíciles de detectar con precisión, a menudo se requiere un conjunto diferente de métodos. Escoger una aguja de un pajar es una buena analogía en este caso.
Un buen trabajo de clasificación y regresión suele requerir un importante trabajo de selección de características y de ingeniería de características. La selección de características consiste en identificar un subconjunto de características que tengan el mayor valor predictivo. La generación de características es la tarea de identificar y generar buenos predictores de un objetivo modificando y combinando las características existentes de un conjunto de datos. Trataremos ambos temas con más profundidad en la Parte III.
Recientemente, el aprendizaje profundo ha demostrado una prometedora capacidad para generar automáticamente características útiles a partir de imágenes, texto y audio. En el futuro, puede desempeñar un papel más importante en la simplificación de la generación y selección de características, pero por ahora, siguen siendo partes integrales del flujo de trabajo de ML.
Por último, a menudo podemos basarnos en la clasificación o puntuación descrita anteriormente para proporcionar consejos útiles. Esto requiere construir un modelo de clasificación interpretable y utilizar sus características para generar consejos procesables. Más adelante hablaremos de ello.
No todos los problemas pretenden atribuir un conjunto de categorías o valores a un ejemplo. En algunos casos, nos gustaría operar a un nivel más granular y extraer información de partes de una entrada, como saber dónde está un objeto en una imagen, por ejemplo.
Extracción de conocimientos a partir de datos no estructurados
Losdatos estructurados son datos que se almacenan en un formato tabular. Las tablas de bases de datos y las hojas de Excel son buenos ejemplos de datos estructurados. Los datos no estructurados se refieren a conjuntos de datos que no están en formato tabular. Esto incluye texto (de artículos, reseñas, Wikipedia, etc.), música, vídeos y canciones.
En la Figura 1-3, puedes ver un ejemplo de datos estructurados a la izquierda y de datos no estructurados a la derecha. Los modelos de extracción de conocimiento se centran en tomar una fuente de datos no estructurados y extraer su estructura mediante ML.
En el caso del texto, la extracción de conocimiento puede utilizarse para añadir estructura a las reseñas, por ejemplo. Se puede entrenar un modelo para extraer de las reseñas aspectos como la limpieza, la calidad del servicio y el precio. Así, los usuarios podrían acceder fácilmente a las reseñas que mencionan temas de su interés.
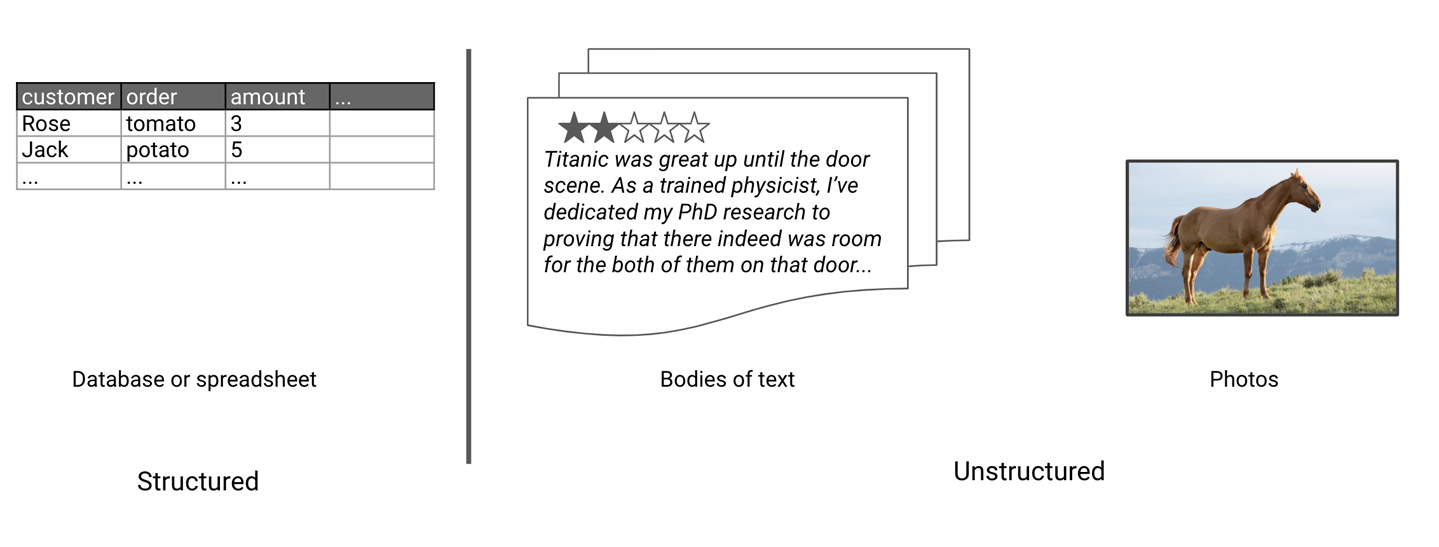
Figura 1-3. Ejemplos de tipos de datos estructurados y no estructurados
En el ámbito médico, se podría construir un modelo de extracción de conocimientos que tomara como entrada el texto en bruto de artículos médicos y extrajera información como la enfermedad de la que se habla en el artículo, así como el diagnóstico asociado y su rendimiento. En la Figura 1-4, un modelo toma una frase como entrada y extrae qué palabras se refieren a un tipo de medio y qué palabras se refieren al título de un medio. Utilizar un modelo de este tipo en los comentarios de un foro de fans, por ejemplo, nos permitiría generar resúmenes de qué películas se discuten con frecuencia.
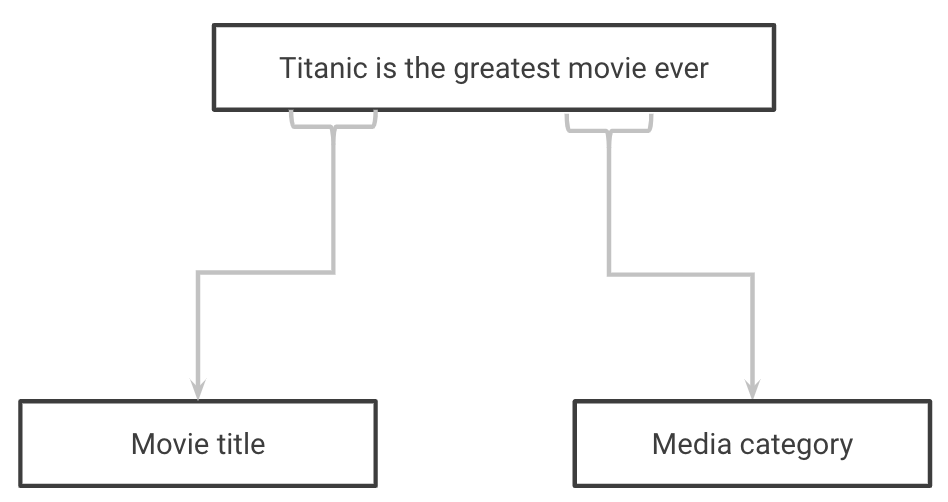
Figura 1-4. Extraer el tipo de medio y el título de una frase
En las imágenes de, las tareas de extracción de conocimiento suelen consistir en encontrar áreas de interés en una imagen y categorizarlas. En la Figura 1-5 se representan dos enfoques comunes : la detección de objetos es un enfoque más tosco que consiste en dibujar rectángulos (denominados cuadros delimitadores) alrededor de las zonas de interés, mientras que la segmentación atribuye con precisión cada píxel de una imagen a una categoría determinada.
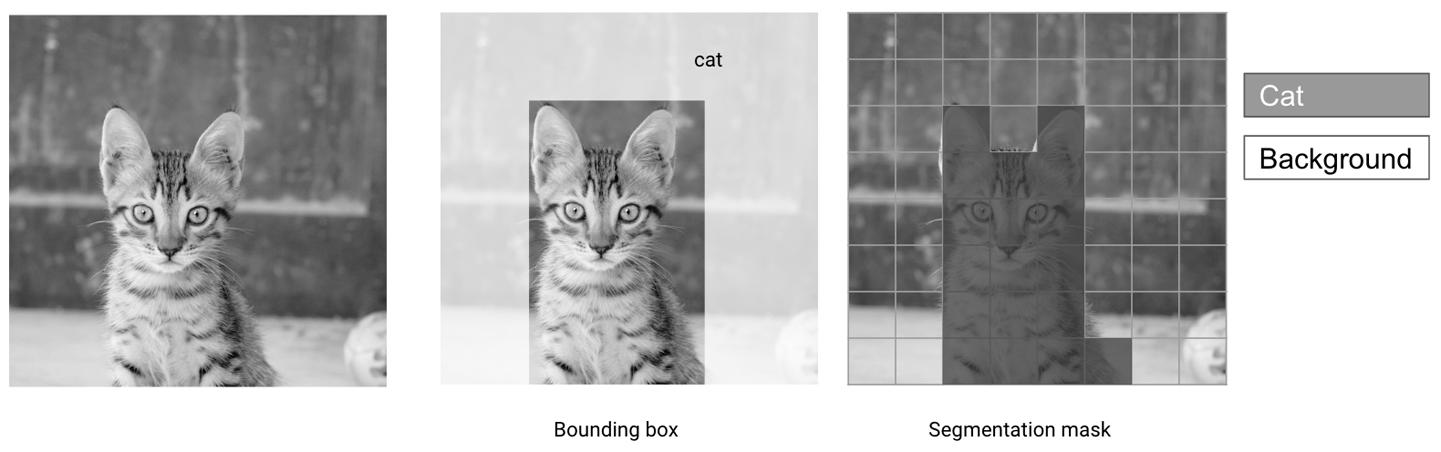
Figura 1-5. Cuadros delimitadores y máscaras de segmentación
A veces, esta información extraída puede utilizarse como entrada para otro modelo. Un ejemplo es utilizar un modelo de detección de poses para extraer puntos clave de un vídeo de un yogui, y alimentar con esos puntos clave un segundo modelo que clasifique la pose como correcta o no basándose en datos etiquetados. La Figura 1-6 muestra un ejemplo de una serie de dos modelos que podrían hacer precisamente esto. El primer modelo extrae información estructurada (las coordenadas de las articulaciones) de datos no estructurados (una foto), y el segundo toma esas coordenadas y las clasifica como una pose de yoga.
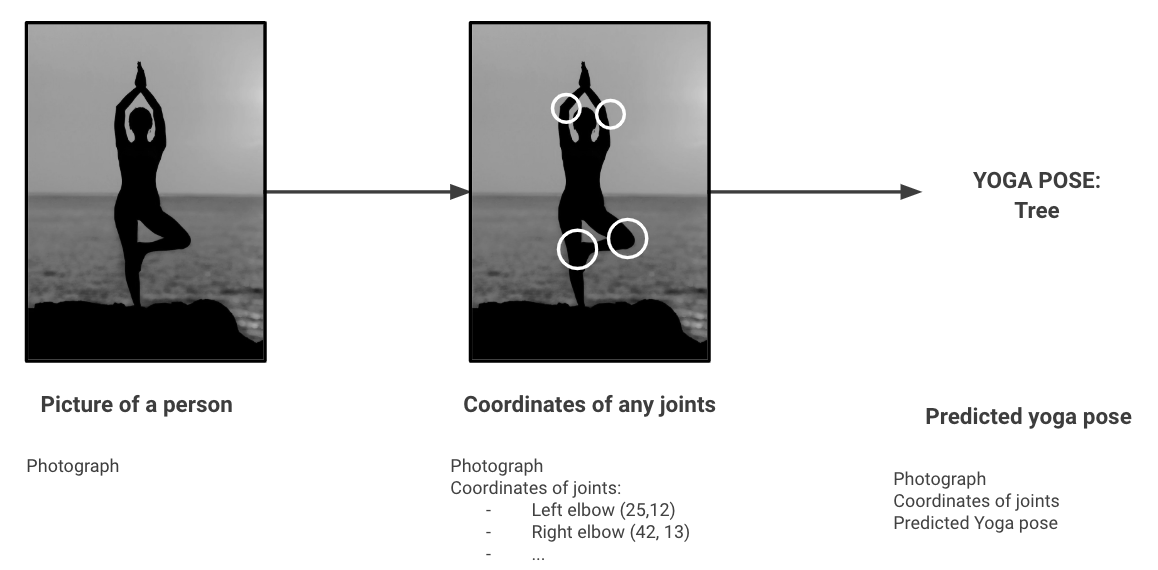
Figura 1-6. Detección de posturas de yoga
Los modelos que hemos visto hasta ahora se centran en generar salidas condicionadas a una entrada dada. En algunos casos, como los motores de búsqueda o los sistemas de recomendación, el objetivo del producto consiste en hacer emerger elementos relevantes. Esto es lo que trataremos en la siguiente categoría.
Organización del catálogo
Catálogo Los modelos de organización suelen producir un conjunto de resultados para presentar a los usuarios. Estos resultados pueden estar condicionados por una cadena de entrada tecleada en una barra de búsqueda, una imagen cargada o una frase pronunciada a un asistente doméstico. En muchos casos, como en los servicios de streaming, este conjunto de resultados también se puede presentar proactivamente al usuario como contenido que le puede gustar sin que haga ninguna solicitud.
La Figura 1-7 muestra un ejemplo de un sistema de este tipo que ofrece voluntariamente posibles películas candidatas para ver basándose en una película que el usuario acaba de ver, pero sin que el usuario realice ningún tipo de búsqueda.
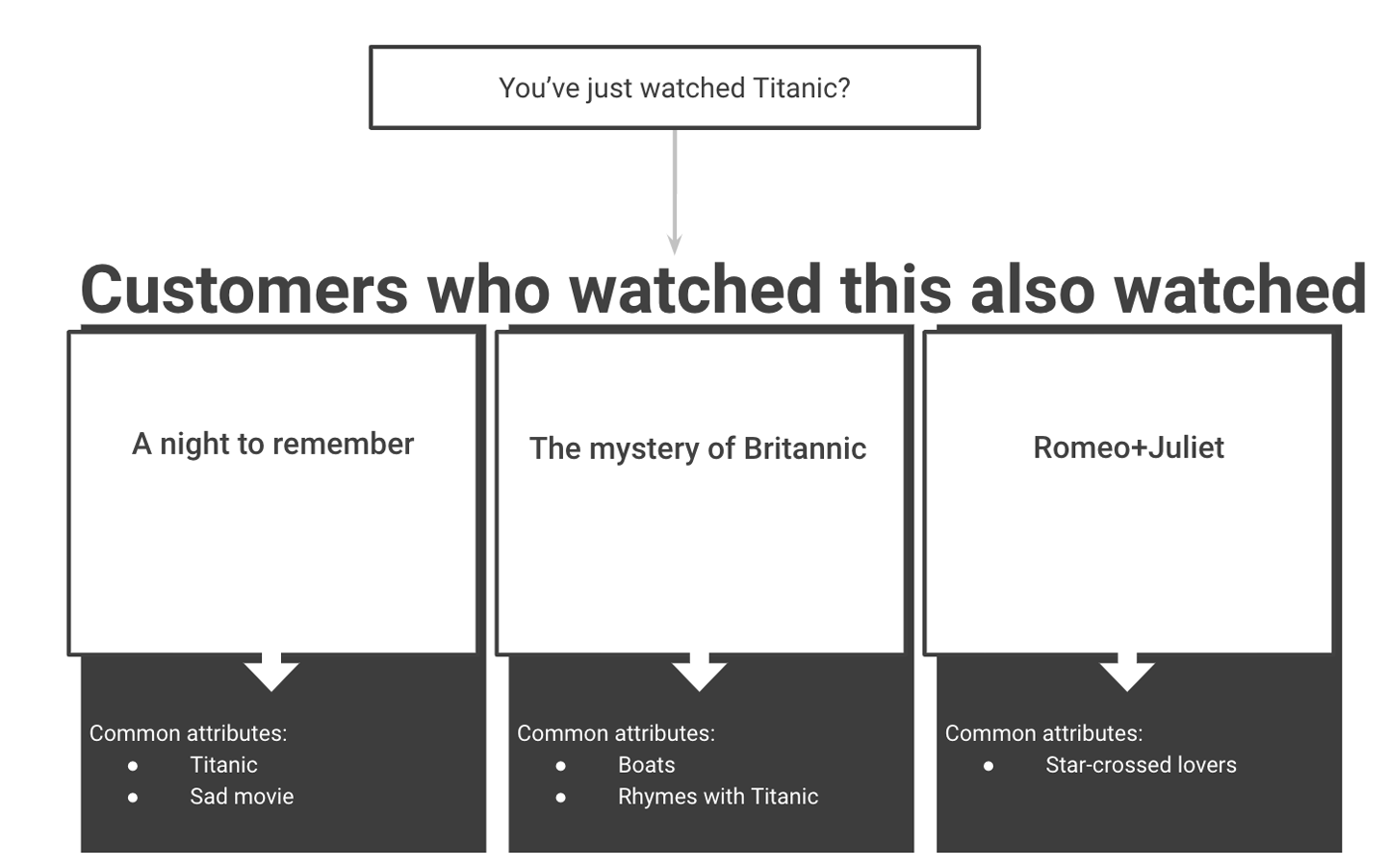
Figura 1-7. Recomendaciones de películas
Así, estos modelos recomiendan artículos que están relacionados con un artículo por el que el usuario ya ha expresado interés (artículos similares de Medium o productos de Amazon) o proporcionan una forma útil de buscar en un catálogo (permitiendo a los usuarios buscar artículos escribiendo texto o enviando sus propias fotos).
Estas recomendaciones de suelen basarse en el aprendizaje a partir de patrones previos de los usuarios, en cuyo caso se denominan sistemas de recomendación colaborativa. A veces, se basan en atributos concretos de los artículos, en cuyo caso se denominan sistemas de recomendación basados en el contenido. Algunos sistemas aprovechan tanto los enfoques colaborativos como los basados en el contenido.
Por último, el ML también puede utilizarse con fines creativos. Los modelos pueden aprender a generar imágenes estéticamente agradables, audio e incluso texto divertido. Estos modelos se denominan modelos generativos.
Modelos generativos
Modelos generativos se centran en generar datos, potencialmente dependientes de la entrada del usuario. Como estos modelos se centran en generar datos en lugar de clasificarlos en categorías, puntuarlos, extraer información de ellos u organizarlos, suelen tener una amplia gama de salidas. Esto significa que los modelos generativos están especialmente indicados para tareas como la traducción, en la que los resultados son inmensamente variados.
Por otro lado, los modelos generativos se utilizan a menudo para entrenar y tienen salidas que están menos restringidas, lo que los convierte en una opción más arriesgada para la producción. Por eso, a menos que sean necesarios para alcanzar tu objetivo, recomiendo empezar primero con otros modelos. Sin embargo, a los lectores que deseen profundizar en los modelos generativos, les recomiendo el libro Generative Deep Learning, de David Foster.
Algunos ejemplos prácticos de son la traducción, que asigna frases de un idioma a otro; el resumen; la generación de subtítulos, que asigna vídeos y pistas de audio a transcripciones; y la transferencia neuronal de estilo (véase Gatys et al., "A Neural Algorithm of Artistic Style"), que asigna imágenes a interpretaciones estilizadas.
La Figura 1-8 muestra un ejemplo de un modelo generativo que transforma una fotografía de la izquierda dándole un estilo similar al de una pintura mostrada en la viñeta de la derecha.

Figura 1-8. Ejemplo de transferencia de estilo de Gatys et al., "A Neural Algorithm of Artistic Style" (Un algoritmo neuronal del estilo artístico)
Como puedes deducir a estas alturas, cada tipo de modelo requiere un tipo diferente de datos para ser entrenado. Por lo general, la elección de un modelo dependerá en gran medida de los datos que puedas obtener: la disponibilidad de datos suele determinar la selección del modelo.
Veamos algunos escenarios de datos habituales y los modelos asociados.
Datos
Supervisado Los modelos ML aprovechan los patrones de los datos para aprender mapeos útiles entre entradas y salidas. Si un conjunto de datos contiene características que son predictivas de la salida objetivo, debería ser posible que un modelo adecuado aprendiera de él. Sin embargo, lo más frecuente es que no dispongamos inicialmente de los datos adecuados para entrenar un modelo que resuelva un caso de uso de un producto de principio a fin.
Por ejemplo, supongamos que estamos entrenando un sistema de reconocimiento de voz que escuchará las peticiones de los clientes, comprenderá su intención y realizará acciones en función de dicha intención. Cuando empezamos a trabajar en este proyecto, podemos definir un conjunto de intenciones que querríamos comprender, como "reproducir una película en el televisor".
Para entrenar un modelo ML que realice esta tarea, necesitaríamos tener un conjunto de datos que contenga clips de audio de usuarios de diversos orígenes pidiendo en sus propios términos que el sistema reproduzca una película. Disponer de un conjunto representativo de entradas es crucial, ya que cualquier modelo sólo podrá aprender de los datos que le presentemos. Si un conjunto de datos contiene ejemplos de sólo un subconjunto de la población, un producto sólo será útil para ese subconjunto. Teniendo esto en cuenta, debido al dominio especializado que hemos seleccionado, es muy poco probable que ya exista un conjunto de datos con ejemplos de este tipo.
Para la mayoría de las aplicaciones que queramos abordar, necesitaremos buscar, conservar y recopilar datos adicionales. El proceso de adquisición de datos puede variar mucho en alcance y complejidad dependiendo de las características específicas de un proyecto, y estimar el reto con antelación es crucial para tener éxito.
Para empezar, definamos algunas situaciones diferentes en las que puedes encontrarte al buscar un conjunto de datos. Esta situación inicial debe ser un factor clave a la hora de decidir cómo proceder.
Tipos de datos
Una vez que hemos definido un problema como un mapeo de entradas a salidas, podemos buscar fuentes de datos que sigan este mapeo.
Para la detección de fraudes, podrían ser ejemplos de usuarios fraudulentos e inocentes, junto con características de su cuenta que pudiéramos utilizar para predecir su comportamiento. Para la traducción, sería un corpus de pares de frases en los dominios de origen y destino. Para la organización y búsqueda de contenidos, podría ser un historial de búsquedas y clics anteriores.
Rara vez podremos encontrar la cartografía exacta que buscamos. Por eso, es útil considerar algunos casos diferentes. Piensa en esto como una jerarquía de necesidades de datos.
Disponibilidad de datos
En hay aproximadamente tres niveles de disponibilidad de datos, desde el mejor de los casos hasta el más difícil. Desgraciadamente, como ocurre con la mayoría de las demás tareas, en general puedes suponer que el tipo de datos más útil será el más difícil de encontrar. Vamos a repasarlos.
- Existen datos etiquetados
-
Se trata de la categoría situada más a la izquierda en la Figura 1-9. Cuando se trabaja en un modelo supervisado, encontrar un conjunto de datos etiquetados es el sueño de todo profesional. Etiquetado significa que muchos puntos de datos contienen el valor objetivo que el modelo intenta predecir. Esto facilita el entrenamiento y la evaluación de la calidad del modelo, ya que las etiquetas proporcionan respuestas reales. Encontrar un conjunto de datos etiquetados que se ajuste a tus necesidades y esté disponible gratuitamente en la web es raro en la práctica. Sin embargo, es habitual confundir el conjunto de datos que encuentras con el conjunto de datos que necesitas.
- Existen datos débilmente etiquetados
-
Este es la categoría intermedia de la Figura 1-9. Algunos conjuntos de datos contienen etiquetas que no son exactamente un objetivo de modelado, pero están algo correlacionadas con él. El historial de reproducciones y saltos de un servicio de streaming de música son ejemplos de un conjunto de datos débilmente etiquetado para predecir si a un usuario no le gusta una canción. Aunque un oyente no haya marcado una canción como que no le gusta, si se la saltó mientras sonaba, es un indicio de que puede no haberle gustado. Las etiquetas débiles son menos precisas por definición, pero a menudo más fáciles de encontrar que las etiquetas perfectas.
- Existen datos sin etiquetar
-
Esta categoría se encuentra a la derecha de la Figura 1-9. En algunos casos, aunque no dispongamos de un conjunto de datos etiquetados que mapee las entradas deseadas con las salidas, al menos tenemos acceso a un conjunto de datos que contiene ejemplos relevantes. Para el ejemplo de la traducción de texto, podríamos tener acceso a grandes colecciones de texto en ambas lenguas, pero sin una correspondencia directa entre ellas. Esto significa que tenemos que etiquetar el conjunto de datos, encontrar un modelo que pueda aprender de datos no etiquetados, o hacer un poco de ambas cosas.
- Necesitamos adquirir datos
-
En algunos casos, estamos a un paso de los datos no etiquetados, ya que primero tenemos que adquirirlos. En muchos casos, no disponemos de un conjunto de datos para lo que necesitamos y, por tanto, tendremos que encontrar la forma de adquirir dichos datos. Esto suele considerarse una tarea insuperable, pero ahora existen muchos métodos para recopilar y etiquetar datos rápidamente. Éste será el tema central del Capítulo 4.
Para nuestro caso de estudio, un conjunto de datos ideal sería un conjunto de preguntas escritas por el usuario, junto con un conjunto de preguntas mejor redactadas. Un conjunto de datos débilmente etiquetado sería un conjunto de datos de muchas preguntas con algunas etiquetas débiles indicativas de su calidad, como "me gusta" o "upvotes". Esto ayudaría a un modelo a aprender qué hace que las preguntas sean buenas y malas, pero no proporcionaría ejemplos paralelos de la misma pregunta. Puedes ver ambos ejemplos en la Figura 1-9.
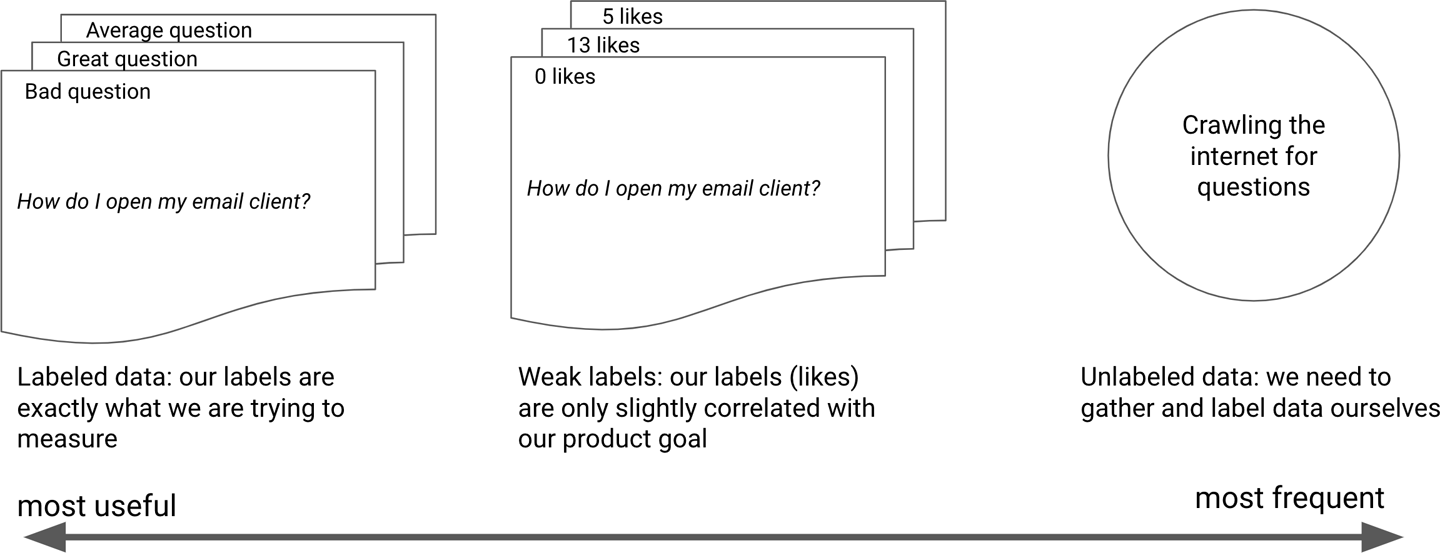
Figura 1-9. Disponibilidad de datos frente a utilidad de los datos
En general, en ML, un conjunto de datos débilmente etiquetado se refiere a un conjunto de datos que contiene información que ayudará a un modelo a aprender, pero no la verdad básica exacta. En la práctica, la mayoría de los conjuntos de datos que podemos reunir están débilmente etiquetados.
Tener un conjunto de datos imperfecto está totalmente bien y no debería detenerte. El proceso de ML es iterativo por naturaleza, así que empezar con un conjunto de datos y obtener algunos resultados iniciales es la mejor forma de avanzar, independientemente de la calidad de los datos.
Los conjuntos de datos son iterativos
En muchos casos, dado que no podrás encontrar inmediatamente un conjunto de datos que contenga una correspondencia directa entre las entradas y la salida deseada, te sugiero que vayas iterando progresivamente en la forma de formular el problema, para que te resulte más fácil encontrar un conjunto de datos adecuado para empezar. Cada conjunto de datos que explores y utilices te proporcionará información valiosa que podrás utilizar para curar la siguiente versión de tu conjunto de datos y generar características útiles para tus modelos.
Sumerjámonos ahora en el caso práctico y veamos cómo podemos utilizar lo que hemos aprendido para identificar los distintos modelos y conjuntos de datos que podríamos utilizar, y elegir el más adecuado.
Enmarcar el Editor de ML
Veamos en cómo podríamos iterar a través de un caso de uso de un producto para encontrar el encuadre de ML adecuado. Pasaremos por este proceso esbozando un método para progresar desde un objetivo de producto (ayudar a los usuarios a escribir mejores preguntas) hasta un paradigma de ML.
Nos gustaría construir un editor que acepte las preguntas de los usuarios y las mejore para que estén mejor escritas, pero ¿qué significa "mejor" en este caso? Empecemos por definir un poco más claramente el objetivo de producto del asistente de redacción.
Muchas personas de utilizan foros, redes sociales y sitios web como Stack Overflow para encontrar respuestas a sus preguntas. Sin embargo, la forma en que la gente hace las preguntas tiene un impacto dramático sobre si reciben una respuesta útil. Esto es desafortunado tanto para el usuario que busca respuesta a su pregunta como para futuros usuarios que puedan tener el mismo problema y podrían haber encontrado útil una respuesta existente. Para ello, nuestro objetivo será construir un asistente que pueda ayudar a los usuarios a escribir mejores preguntas.
Tenemos un objetivo de producto y ahora tenemos que decidir qué enfoque de modelado utilizar. Para tomar esta decisión, pasaremos por el bucle de iteración de selección de modelos y validación de datos mencionado anteriormente.
Intentar hacerlo todo con ML: un marco de principio a fin
En este contexto, de extremo a extremo significa utilizar un único modelo para ir de la entrada a la salida sin pasos intermedios. Dado que la mayoría de los objetivos de los productos son muy específicos, intentar resolver un caso de uso completo aprendiéndolo de extremo a extremo suele requerir modelos ML de perímetro personalizados. Ésta puede ser la solución adecuada para los equipos que disponen de los recursos para desarrollar y mantener tales modelos, pero a menudo merece la pena empezar primero con modelos más conocidos.
En nuestro caso, podríamos intentar reunir un conjunto de datos de preguntas mal formuladas, así como sus versiones editadas profesionalmente. Entonces podríamos utilizar un modelo generativo para pasar directamente de un texto a otro.
La Figura 1-10 muestra cómo sería esto en la práctica. Muestra un diagrama sencillo con la entrada del usuario a la izquierda, la salida deseada a la derecha y un modelo en medio.

Figura 1-10. Enfoque de extremo a extremo
Como verás, este enfoque conlleva importantes retos:
- Datos
-
Para adquirir un conjunto de datos de este tipo, tendríamos que encontrar pares de preguntas con la misma intención pero de diferente calidad de redacción. Se trata de un conjunto de datos bastante raro de encontrar tal cual. Construirlo nosotros mismos también sería costoso, ya que necesitaríamos la ayuda de redactores profesionales para generar estos datos.
- Modelo
-
Los modelos que van de una secuencia de texto a otra, vistos en la categoría de modelos generativos comentada anteriormente, han progresado enormemente en los últimos años. Los modelos secuencia a secuencia (como se describen en el artículo de I. Sutskever et al., "Sequence to Sequence Learning with Neural Networks") se propusieron originalmente en 2014 para las tareas de traducción de y están acortando distancias entre la traducción automática y la humana. El éxito de estos modelos, sin embargo, se ha producido sobre todo en tareas a nivel de frase, y no se han utilizado con frecuencia para procesar textos de más de un párrafo. Esto se debe a que, hasta ahora, no han sido capaces de captar el contexto a largo plazo de un párrafo a otro. Además, como suelen tener un gran número de parámetros, son algunos de los modelos más lentos de entrenar. Si un modelo se entrena una sola vez, esto no es necesariamente un problema. Si hay que volver a entrenarlo cada hora o cada día, el tiempo de entrenamiento puede convertirse en un factor importante.
- Latencia
-
Modelos secuencia a secuencia suelen ser modelos autorregresivos, lo que significa que necesitan la salida del modelo de la palabra anterior para empezar a trabajar en la siguiente. Esto les permite aprovechar la información de las palabras vecinas, pero hace que sean más lentos de entrenar y de ejecutar la inferencia que los modelos más sencillos. Tales modelos pueden tardar unos segundos en producir una respuesta en el momento de la inferencia, frente a la latencia de subsegundos de los modelos más sencillos. Aunque es posible optimizar un modelo de este tipo para que funcione con suficiente rapidez, requerirá un trabajo de ingeniería adicional.
- Facilidad de aplicación
-
Entrenar modelos complejos de extremo a extremo es un proceso muy delicado y propenso a errores, ya que tienen muchas piezas móviles. Esto significa que tenemos que considerar el equilibrio entre el rendimiento potencial de un modelo y la complejidad que añade a una cadena. Esta complejidad nos ralentizará a la hora de construir una canalización, pero también introduce una carga de mantenimiento. Si prevemos que otros compañeros de equipo pueden necesitar iterar sobre tu modelo y mejorarlo, puede merecer la pena elegir un conjunto de modelos más sencillos y mejor comprendidos.
Este planteamiento de principio a fin podría funcionar, pero requerirá mucho esfuerzo inicial de recopilación de datos e ingeniería, sin garantía de éxito, por lo que merecería la pena explorar otras alternativas, como veremos a continuación.
El método más sencillo: Ser el Algoritmo
Como verás en la entrevista al final de esta sección, a menudo es una gran idea que los científicos de datos sean el algoritmo antes de ponerlo en práctica. En otras palabras, para comprender cómo automatizar mejor un problema, empieza por intentar resolverlo manualmente. Entonces, si nosotros mismos editáramos las preguntas para mejorar la legibilidad y las probabilidades de obtener una respuesta, ¿cómo lo haríamos?
Un primer enfoque sería no utilizar datos en absoluto, sino aprovechar el estado de la técnica para definir qué hace que una pregunta o un cuerpo de texto estén bien escritos. Para obtener consejos generales de redacción, podríamos ponernos en contacto con un redactor profesional o investigar las guías de estilo de los periódicos para saber más.
Además, deberíamos sumergirnos en un conjunto de datos para observar ejemplos individuales y tendencias, y dejar que éstos informen nuestra estrategia de modelado. Nos saltaremos esto por ahora, ya que trataremos cómo hacerlo con más profundidad en el Capítulo 4.
Para empezar, podríamos examinar la investigación existente para identificar algunos atributos que podríamos utilizar para ayudar a la gente a escribir con más claridad. Estas características de podrían incluir factores como
- Simplicidad en prosa
-
A menudo aconsejamos a los nuevos escritores que utilicen palabras y estructuras de frases más sencillas. Así, podríamos establecer una serie de criterios sobre la longitud adecuada de las frases y las palabras, y recomendar los cambios que sean necesarios.
- Tono
-
Podríamos medir el uso de adverbios, superlativos y signos de puntuación para medir la polaridad del texto. Dependiendo del contexto, las preguntas con más opiniones pueden recibir menos respuestas.
- Características estructurales
-
Por último, podríamos intentar extraer la presencia de atributos estructurales importantes, como el uso de saludos o signos de interrogación.
Una vez que hayamos identificado y generado características útiles, podemos construir una solución sencilla que las utilice para ofrecer recomendaciones. Aquí no hay nada de ML, pero esta fase es crucial por dos razones: proporciona una línea de base que es muy rápida de implementar y servirá como criterio para medir los modelos.
Para validar nuestra intuición sobre cómo detectar la buena escritura, podemos reunir un conjunto de datos de texto "bueno" y "malo" y ver si podemos distinguir el bueno del malo utilizando estas características.
El término medio: Aprender de nuestra experiencia
Ahora que tenemos un conjunto básico de características, podemos intentar utilizarlas para aprender un modelo de estilo a partir de un conjunto de datos. Para ello, podemos reunir un conjunto de datos, extraer de él las características que hemos descrito antes y entrenar en él un clasificador para separar los ejemplos buenos de los malos.
Una vez que tenemos un modelo que puede clasificar el texto escrito, podemos inspeccionarlo para identificar qué características son altamente predictivas y utilizarlas como recomendaciones. Veremos cómo hacerlo en la práctica en el Capítulo 7.
La Figura 1-11 describe este enfoque. A la izquierda, se entrena un modelo para clasificar una pregunta como buena o mala. A la derecha, el modelo entrenado recibe una pregunta y puntúa las reformulaciones candidatas de esta pregunta que harán que reciba una mejor puntuación. La reformulación con la puntuación más alta se recomienda al usuario.
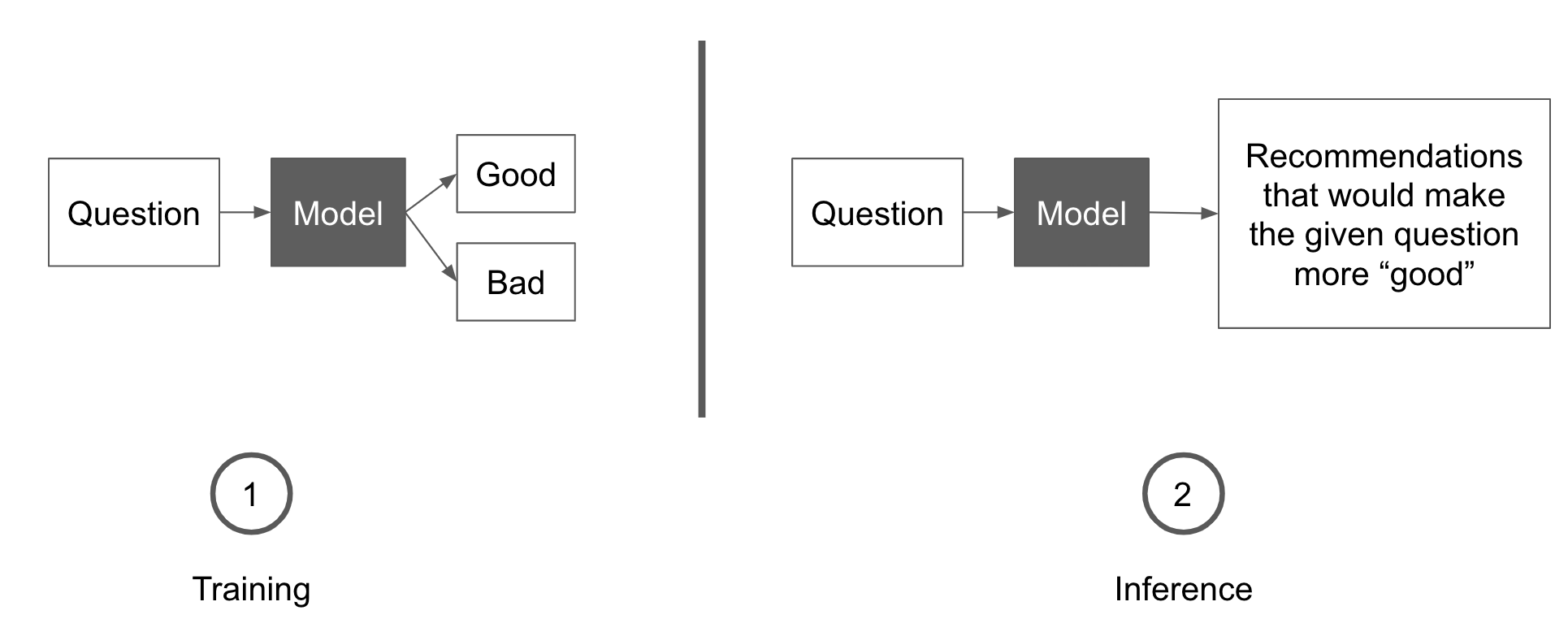
Figura 1-11. Un término medio entre lo manual y lo integral
Examinemos los retos que esbozamos en "Intentar hacerlo todo con ML: un marco de principio a fin" y veamos si el enfoque del clasificador los facilita:
- Conjunto de datos
-
Podríamos obtener un conjunto de datos de ejemplos buenos y malos recopilando preguntas de un foro online junto con alguna medida de su calidad, como el número de vistas o upvotes. A diferencia del enfoque de extremo a extremo, esto no requiere que tengamos acceso a revisiones de las mismas preguntas. Simplemente necesitamos un conjunto de ejemplos buenos y malos de los que podamos esperar aprender características agregadas, que es un conjunto de datos más fácil de encontrar.
- Modelo
-
Aquí tenemos que tener en cuenta dos cosas: lo predictivo que es un modelo (¿puede separar eficazmente los artículos buenos de los malos?) y la facilidad con que se pueden extraer características de él (¿podemos ver qué atributos se utilizaron para clasificar un ejemplo?). Hay muchos modelos potenciales que podríamos utilizar aquí, junto con diferentes características que podríamos extraer del texto para hacerlo más explicable.
- Latencia
-
La mayoría de los clasificadores de texto son bastante rápidos. Podríamos empezar con un modelo sencillo como un bosque aleatorio, que puede devolver resultados en menos de una décima de segundo en hardware normal, y pasar a arquitecturas más complejas si fuera necesario.
- Facilidad de aplicación
-
En comparación con la generación de textos, la clasificación de textos se entiende relativamente bien, lo que significa que construir un modelo de este tipo debería ser relativamente rápido. Existen muchos ejemplos en línea de cadenas de clasificación de textos que funcionan, y muchos de estos modelos ya se han implementado en la producción.
Si empezamos con una heurística humana y luego construimos este sencillo modelo, podremos tener rápidamente una línea de base inicial, y el primer paso hacia una solución. Además, el modelo inicial será una forma estupenda de informar sobre lo que hay que construir a continuación (más sobre esto en la Parte III).
Para saber más sobre la importancia de empezar con líneas de base sencillas, me senté con Monica Rogati, que comparte algunas de las lecciones que ha aprendido ayudando a los equipos de datos a entregar productos.
Monica Rogati: Cómo elegir y priorizar proyectos de ML
Tras obtener su doctorado en informática en , Monica Rogati comenzó su carrera en LinkedIn, donde trabajó en productos básicos como la integración de ML en el algoritmo People You May Know y construyó la primera versión del emparejamiento entre empleos y candidatos. Después se convirtió en vicepresidenta de datos en Jawbone, donde creó y dirigió todo el equipo de datos. Monica es ahora asesora de docenas de empresas cuyo número de empleados oscila entre 5 y 8.000. Ha accedido amablemente a compartir algunos de los consejos que suele dar a los equipos cuando se trata de diseñar y ejecutar productos de ML.
P: ¿Cómo se determina el alcance de un producto ML?
R: Tienes que recordar que estás intentando utilizar las mejores herramientas para resolver un problema, y sólo utilizar el ML si tiene sentido.
Supongamos que quieres predecir lo que hará un usuario de una aplicación y mostrárselo como sugerencia. Deberías empezar por combinar los debates sobre el modelado y el producto. Entre otras cosas, esto incluye diseñar el producto en torno al manejo de los fallos de ML con elegancia.
Podríamos empezar teniendo en cuenta la confianza que tiene nuestro modelo en su predicción. Entonces podríamos formular nuestras sugerencias de forma diferente en función de la puntuación de confianza. Si la confianza es superior al 90%, presentamos la sugerencia de forma destacada; si es superior al 50%, seguimos mostrándola pero con menos énfasis, y no mostramos nada si la confianza es inferior a esta puntuación.
P: ¿Cómo decides en qué centrarte en un proyecto de ML?
R: En tienes que encontrar el cuello de botella del impacto, es decir, la pieza de tu pipeline que podría aportar más valor si la mejoras. Cuando trabajo con empresas, a menudo descubro que puede que no estén trabajando en el problema correcto o que no se encuentren en la fase de crecimiento adecuada para ello.
A menudo hay problemas en torno al modelo. La mejor forma de averiguarlo es sustituir el modelo por algo sencillo y depurar toda la tubería. Con frecuencia, los problemas no estarán en la precisión de tu modelo. Con frecuencia, tu producto está muerto aunque tu modelo tenga éxito.
P: ¿Por qué sueles recomendar empezar con un modelo sencillo?
R: El objetivo de nuestro plan debe ser reducir de algún modo el riesgo de nuestro modelo. La mejor forma de hacerlo es empezar con un "modelo de referencia" para evaluar el rendimiento en el peor de los casos. Para nuestro ejemplo anterior, esto podría ser simplemente sugerir cualquier acción que el usuario haya realizado previamente.
Si hiciéramos esto, ¿con qué frecuencia nuestra predicción sería correcta, y cómo de molesto sería nuestro modelo para el usuario si nos equivocáramos? Suponiendo que nuestro modelo no fuera mucho mejor que esta línea de base, ¿seguiría siendo valioso nuestro producto?
Esto se aplica bien a ejemplos de comprensión y generación del lenguaje natural, como los chatbots, la traducción, las preguntas y respuestas, y el resumen. A menudo, en la síntesis, por ejemplo, basta con extraer las principales palabras clave y categorías de un artículo para satisfacer las necesidades de la mayoría de los usuarios.
P: Una vez que tienes todo tu pipeline, ¿cómo identificas el cuello de botella del impacto?
R: Deberías empezar imaginando que el cuello de botella del impacto está resuelto, y preguntarte si ha merecido la pena el esfuerzo que estimaste que llevaría. Animo a los científicos de datos a redactar un tweet y a las empresas a escribir un comunicado de prensa antes incluso de empezar un proyecto. Eso les ayuda a evitar trabajar en algo sólo porque les pareció guay y pone en contexto el impacto de los resultados en función del esfuerzo.
El caso ideal es que puedas presentar los resultados independientemente del resultado: si no obtienes el mejor resultado, ¿sigue siendo impactante? ¿Has aprendido algo o validado algunas suposiciones? Una forma de contribuir a ello es crear una infraestructura que ayude a reducir el esfuerzo necesario para la implementación.
En LinkedIn, teníamos acceso a un elemento de diseño muy útil, una ventanita con unas cuantas filas de texto e hipervínculos, que podíamos personalizar con nuestros datos. Esto facilitó el lanzamiento de experimentos para proyectos como las recomendaciones de empleo, ya que el diseño ya estaba aprobado. Como la inversión de recursos era baja, el impacto no tenía que ser tan grande, lo que permitía un ciclo de iteración más rápido. La barrera pasa a ser entonces la de las preocupaciones no relacionadas con la ingeniería, como la ética, la equidad y la marca.
P: ¿Cómo decides qué técnicas de modelado utilizar?
R: La primera línea de defensa es examinar tú mismo los datos. Supongamos que queremos construir un modelo para recomendar grupos a los usuarios de LinkedIn. Una forma ingenua sería recomendar el grupo más popular que contenga el nombre de su empresa en el título del grupo. Después de mirar unos cuantos ejemplos, descubrimos que uno de los grupos populares de la empresa Oracle era "¡Oracle apesta!", que sería un grupo terrible para recomendar a los empleados de Oracle.
Siempre es valioso dedicar el esfuerzo manual a mirar las entradas y salidas de tu modelo. Desplázate por un montón de ejemplos para ver si algo parece raro. El jefe de mi departamento en IBM tenía el mantra de hacer algo manualmente durante una hora antes de poner nada de trabajo.
Observar tus datos te ayuda a pensar en buenas heurísticas, modelos y formas de replantear el producto. Si clasificas los ejemplos de tu conjunto de datos por frecuencia, puede que incluso seas capaz de identificar y etiquetar rápidamente el 80% de tus casos de uso.
En Jawbone, por ejemplo, la gente introducía "frases" para registrar el contenido de sus comidas. Para cuando etiquetamos a mano las 100 mejores, habíamos cubierto el 80% de las frases y teníamos ideas claras de cuáles serían los principales problemas que tendríamos que resolver, como las variedades de codificación del texto y los idiomas.
La última línea de defensa es contar con una plantilla diversa que examine los resultados. Esto te permitirá detectar los casos en los que un modelo muestra un comportamiento discriminatorio, como etiquetar a tus amigos como gorilas, o es insensible al sacar a la luz experiencias pasadas dolorosas con su inteligente retrospectiva "el año pasado por estas fechas".
Conclusión
Como hemos visto en, la creación de una aplicación potenciada por ML empieza por juzgar la viabilidad y elegir un enfoque. La mayoría de las veces, elegir un enfoque supervisado es la forma más sencilla de empezar. Entre ellos, la clasificación, la extracción de conocimientos, la organización de catálogos o los modelos generativos son los paradigmas más comunes en la práctica.
A la hora de elegir un enfoque, debes identificar la facilidad con la que podrás acceder a datos con etiquetas fuertes o débiles, o a cualquier tipo de datos. A continuación, debes comparar los posibles modelos y conjuntos de datos definiendo un objetivo de producto y eligiendo el enfoque de modelado que mejor te permita alcanzar dicho objetivo.
Ilustramos estos pasos para el Editor de ML, optando por empezar con una heurística sencilla y un enfoque basado en la clasificación. Y finalmente, cubrimos cómo líderes como Monica Rogati han estado aplicando estas prácticas para enviar con éxito modelos ML a los usuarios.
Ahora que hemos elegido un enfoque inicial, es hora de definir las métricas de éxito y crear un plan de acción para progresar regularmente. Esto implicará establecer unos requisitos mínimos de rendimiento, hacer una inmersión profunda en los recursos de modelado y datos disponibles, y construir un prototipo sencillo.
Trataremos todos ellos en el Capítulo 2.
Get Creación de aplicaciones basadas en el aprendizaje automático now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

