Parte III. Iterar sobre modelos
La Parte I cubría las buenas prácticas para poner en marcha un proyecto de ML y seguir su progreso. En la Parte II, vimos el valor de construir una tubería de extremo a extremo lo más rápido posible junto con la exploración de un conjunto de datos inicial.
Debido a su naturaleza experimental, el ML es en gran medida un proceso iterativo. Deberías planear iterar repetidamente sobre modelos y datos, siguiendo un bucle experimental como el de la Figura III-1.
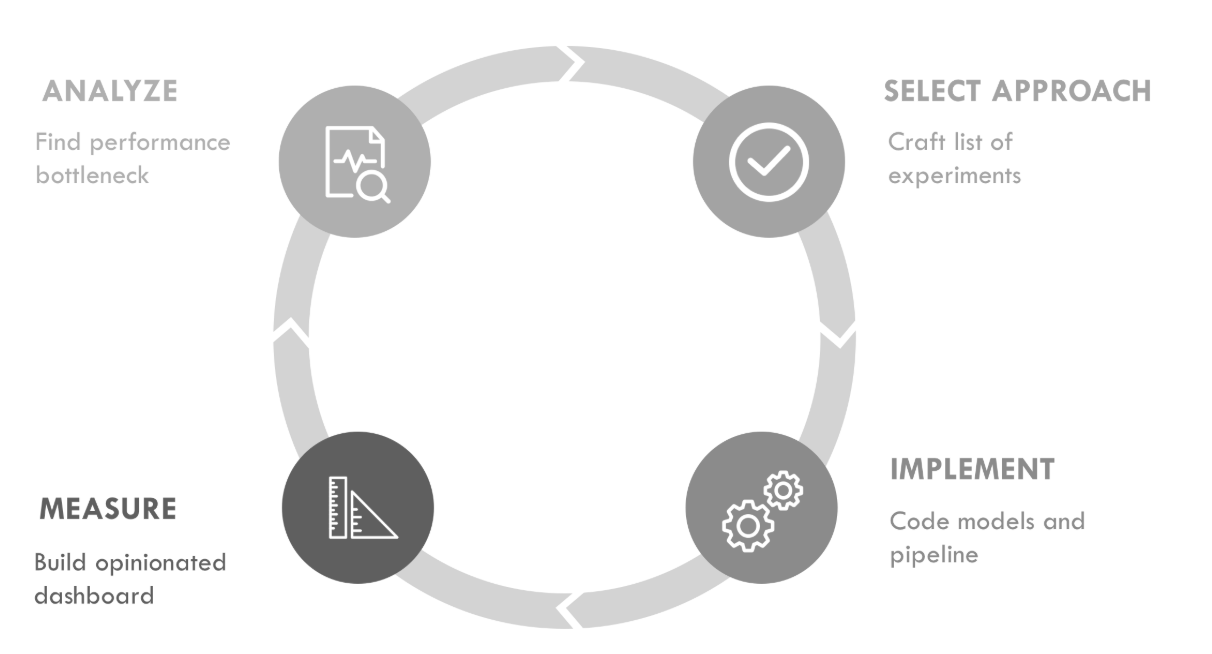
Figura III-1. El bucle ML
La Parte III describirá una iteración del bucle. Cuando trabajes en proyectos de ML, debes planificar pasar por múltiples iteraciones de este tipo antes de esperar alcanzar un rendimiento satisfactorio. Aquí tienes un resumen de los capítulos de esta parte del libro:
- Capítulo 5
-
En este capítulo, entrenaremos un primer modelo y lo evaluaremos comparativamente. Después, analizaremos su rendimiento en profundidad e identificaremos cómo podría mejorarse.
- Capítulo 6
-
Este capítulo trata de las técnicas para construir y depurar modelos rápidamente y evitar errores que llevan mucho tiempo.
- Capítulo 7
-
En este capítulo, utilizaremos el Editor ML como caso de estudio para mostrar cómo aprovechar un clasificador entrenado para proporcionar sugerencias a los usuarios y construir un modelo de sugerencias totalmente funcional.
Get Creación de aplicaciones basadas en el aprendizaje automático now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

