Capítulo 1. Introducción Introducción
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En este primer capítulo, presentaremos las canalizaciones de aprendizaje automático y esbozaremos todos los pasos necesarios para construirlas. Explicaremos lo que debe ocurrir para que tu modelo de aprendizaje automático pase de ser un experimento a un sólido sistema de producción. También presentaremos nuestro proyecto de ejemplo que utilizaremos a lo largo del resto del libro para demostrar los principios que describimos.
¿Por qué tuberías de aprendizaje automático?
La principal ventaja de los conductos de aprendizaje automático reside en la automatización de los pasos del ciclo de vida del modelo. Cuando se dispone de nuevos datos de entrenamiento, debe activarse un flujo de trabajo que incluya la validación de los datos, el preprocesamiento, el entrenamiento del modelo, el análisis y la implementación. Hemos observado que demasiados equipos de ciencia de datos realizan manualmente estos pasos, lo que es costoso y también una fuente de errores. Veamos algunos detalles de las ventajas de los pipelines de aprendizaje automático:
- Capacidad para centrarse en nuevos modelos, no en mantener los modelos existentes
-
Los conductos automatizados de aprendizaje automático liberarán a los científicos de datos del mantenimiento de los modelos existentes. Hemos observado que demasiados científicos de datos dedican sus días a mantener actualizados los modelos desarrollados previamente. Ejecutan scripts manualmente para preprocesar sus datos de entrenamiento, escriben scripts de implementación puntuales o ajustan manualmente sus modelos. Los pipelines automatizados permiten a los científicos de datos desarrollar nuevos modelos, la parte divertida de su trabajo. En última instancia, esto conducirá a una mayor satisfacción laboral y retención en un mercado de trabajo competitivo.
- Prevención de fallos
-
Las canalizaciones automatizadas pueden evitar errores. Como veremos en capítulos posteriores, los modelos recién creados estarán vinculados a un conjunto de datos versionados y los pasos de preprocesamiento estarán vinculados al modelo desarrollado. Esto significa que si se recogen nuevos datos, se generará un nuevo modelo. Si se actualizan los pasos de preprocesamiento, los datos de entrenamiento dejarán de ser válidos y se generará un nuevo modelo. En los flujos de trabajo manuales de aprendizaje automático, una fuente común de errores es un cambio en el paso de preprocesamiento después de que se haya entrenado un modelo. En este caso, desplegaríamos un modelo con instrucciones de procesamiento diferentes a aquellas con las que entrenamos el modelo. Estos errores pueden ser realmente difíciles de depurar, ya que la inferencia del modelo sigue siendo posible, pero simplemente incorrecta. Con flujos de trabajo automatizados, estos errores pueden evitarse.
- Seguimiento útil en papel
-
El seguimiento del experimento y la gestión de la liberación del modelo generan un rastro documental de los cambios del modelo. El experimento registrará los cambios en los hiperparámetros del modelo, los conjuntos de datos utilizados y las métricas resultantes del modelo (por ejemplo, pérdida o precisión). La gestión de la publicación del modelo llevará un registro de qué modelo se seleccionó e implementó finalmente. Este rastro en papel es especialmente valioso si el equipo de ciencia de datos necesita volver a crear un modelo o realizar un seguimiento del rendimiento del modelo.
- Normalización
-
Las canalizaciones estandarizadas de aprendizaje automático mejoran la experiencia de un equipo de ciencia de datos. Gracias a las configuraciones estandarizadas, los científicos de datos pueden incorporarse rápidamente o moverse entre equipos y encontrar los mismos entornos de desarrollo. Esto mejora la eficiencia y reduce el tiempo empleado en la configuración de un nuevo proyecto. La inversión de tiempo en la configuración de los conductos de aprendizaje automático también puede conducir a una mejora de la tasa de retención.
- El argumento comercial a favor de las tuberías
-
La implantación de canalizaciones automatizadas de aprendizaje automático tendrá tres impactos clave para un equipo de ciencia de datos:
-
Más tiempo de desarrollo para nuevos modelos
-
Procesos más sencillos para actualizar los modelos existentes
-
Menos tiempo dedicado a reproducir modelos
-
Todos estos aspectos reducirán los costes de los proyectos de ciencia de datos. Pero además, lo harán las canalizaciones automatizadas de aprendizaje automático:
-
Ayudan a detectar posibles sesgos en los conjuntos de datos o en los modelos entrenados. Detectar los sesgos puede evitar daños a las personas que interactúan con el modelo. Por ejemplo, se descubrió que el sistema de selección de currículos de Amazon, basado en el aprendizaje automático, tenía un sesgo en contra de las mujeres.
-
Crea un rastro en papel (mediante el seguimiento de experimentos y la gestión de la publicación de modelos) que te ayude si surgen preguntas sobre las leyes de protección de datos, como el Reglamento General de Protección de Datos (RGPD) de Europa.
-
Libera tiempo de desarrollo para los científicos de datos y aumenta su satisfacción laboral.
Cuándo pensar en tuberías de aprendizaje automático
Los pipelines de aprendizaje automático proporcionan una serie de ventajas, pero no todos los proyectos de ciencia de datos necesitan un pipeline. A veces, los científicos de datos simplemente quieren experimentar con un nuevo modelo, investigar una nueva arquitectura de modelo o reproducir una publicación reciente. Las pipelines no serían útiles en estos casos. Sin embargo, en cuanto un modelo tenga usuarios (por ejemplo, se esté utilizando en una app), requerirá actualizaciones y ajustes continuos. En estas situaciones, volvemos a los escenarios que comentábamos antes sobre la actualización continua de los modelos y la reducción de la carga de estas tareas para los científicos de datos.
Las canalizaciones también adquieren importancia a medida que crece un proyecto de aprendizaje automático. Si el conjunto de datos o los requisitos de recursos son grandes, los enfoques que comentamos permiten escalar fácilmente la infraestructura. Si la repetibilidad es importante, se consigue mediante la automatización y el seguimiento de auditoría de los conductos de aprendizaje automático.
Visión general de los pasos de un proceso de aprendizaje automático
Un proceso de aprendizaje automático comienza con la ingestión de nuevos datos de entrenamiento y termina con la recepción de algún tipo de información sobre el rendimiento de tu modelo recién entrenado. Esta información puede ser una métrica de rendimiento de producción o la opinión de los usuarios de tu producto. El proceso incluye una serie de pasos, como el preprocesamiento de los datos, el entrenamiento del modelo y su análisis, así como la implementación del modelo. Puedes imaginar que realizar estos pasos manualmente es engorroso y muy propenso a errores. A lo largo de este libro, te presentaremos herramientas y soluciones para automatizar tu proceso de aprendizaje automático.
Como puedes ver en la Figura 1-1, el pipeline es en realidad un ciclo recurrente. Los datos pueden recogerse continuamente y, por tanto, los modelos de aprendizaje automático pueden actualizarse. Más datos significa generalmente modelos mejorados. Y debido a esta afluencia constante de datos, la automatización es clave. En las aplicaciones del mundo real, querrás volver a entrenar tus modelos con frecuencia. Si no lo haces, en muchos casos la precisión disminuirá porque los datos de entrenamiento son diferentes de los nuevos datos sobre los que el modelo está haciendo predicciones. Si el reentrenamiento es un proceso manual, en el que es necesario validar manualmente los nuevos datos de entrenamiento o analizar los modelos actualizados, un científico de datos o un ingeniero de aprendizaje automático no tendría tiempo de desarrollar nuevos modelos para problemas empresariales totalmente distintos.
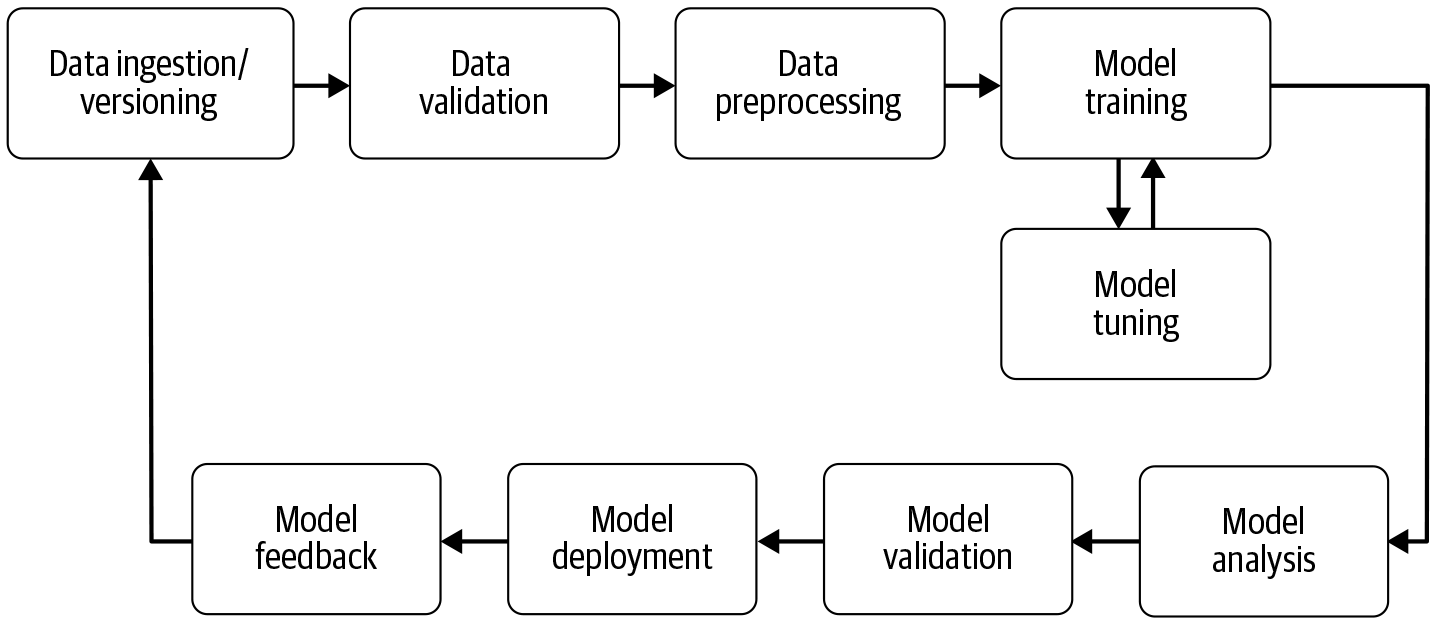
Figura 1-1. Ciclo de vida del modelo
Un proceso de aprendizaje automático suele incluir los pasos de las siguientes secciones.
Ingestión y versionado de datos
La ingesta de datos, como describimos en el Capítulo 3, es el principio de toda cadena de aprendizaje automático. En este paso, procesamos los datos en un formato que los siguientes componentes puedan digerir. El paso de ingestión de datos no realiza ninguna ingeniería de características (esto ocurre después del paso de validación de datos). También es un buen momento para versionar los datos de entrada para conectar una instantánea de datos con el modelo entrenado al final de la canalización.
Validación de datos
Antes de entrenar una nueva versión del modelo, necesitamos validar los nuevos datos. La validación de datos(Capítulo 4) se centra en comprobar que las estadísticas de los nuevos datos son las esperadas (por ejemplo, el rango, el número de categorías y la distribución de las categorías). También alerta al científico de datos si se detectan anomalías. Por ejemplo, si estás entrenando un modelo de clasificación binaria, tus datos de entrenamiento podrían contener un 50% de muestras de la Clase X y un 50% de muestras de la Clase Y. Las herramientas de validación de datos proporcionan alertas si cambia la división entre estas clases, donde quizás los datos recién recogidos se dividen 70/30 entre las dos clases. Si se entrena un modelo con un conjunto de entrenamiento tan desequilibrado y el científico de datos no ha ajustado la función de pérdida del modelo, o ha tomado muestras excesivas o insuficientes de la categoría X o Y, las predicciones del modelo podrían estar sesgadas hacia la categoría dominante.
Las herramientas habituales de validación de datos también te permitirán comparar conjuntos de datos diferentes. Si tienes un conjunto de datos con una etiqueta dominante y lo divides en un conjunto de entrenamiento y otro de validación, tienes que asegurarte de que la división de etiquetas es aproximadamente la misma entre los dos conjuntos de datos. Las herramientas de validación de datos te permitirán comparar conjuntos de datos y poner de relieve las anomalías.
Si la validación pone de manifiesto algo fuera de lo normal, se puede detener aquí la canalización y alertar al científico de datos. Si se detecta un cambio en los datos, el científico de datos o el ingeniero de aprendizaje automático pueden cambiar el muestreo de las clases individuales (por ejemplo, elegir sólo el mismo número de ejemplos de cada clase), o cambiar la función de pérdida del modelo, iniciar una nueva canalización de construcción del modelo y reiniciar el ciclo de vida.
Preprocesamiento de datos
Es muy probable que no puedas utilizar tus datos recién recogidos y entrenar directamente tu modelo de aprendizaje automático. En casi todos los casos, necesitarás preprocesar los datos para utilizarlos en tus ejecuciones de entrenamiento. A menudo hay que convertir las etiquetas en uno o varios vectores calientes.1 Lo mismo ocurre con las entradas del modelo. Si entrenas un modelo a partir de datos de texto, querrás convertir los caracteres del texto en índices o los tokens del texto en vectores de palabras. Como el preprocesamiento sólo es necesario antes del entrenamiento del modelo y no con cada época de entrenamiento, lo más lógico es ejecutar el preprocesamiento en su propio paso del ciclo vital antes de entrenar el modelo.
Las herramientas de preprocesamiento de datos pueden ir desde un simple script de Python hasta elaborados modelos de gráficos. Aunque la mayoría de los científicos de datos se centran en las capacidades de procesamiento de sus herramientas preferidas, también es importante que las modificaciones de los pasos de preprocesamiento puedan vincularse a los datos procesados y viceversa. Esto significa que si alguien modifica un paso de procesamiento (por ejemplo, permitiendo una etiqueta adicional en una conversión vectorial de un solo paso), los datos de entrenamiento anteriores deberían dejar de ser válidos y forzar una actualización de toda la tubería. Describimos este paso del proceso en el Capítulo 5.
Entrenamiento y ajuste del modelo
El paso de entrenamiento del modelo(Capítulo 6) es el núcleo del proceso de aprendizaje automático. En este paso, entrenamos un modelo para que tome entradas y prediga una salida con el menor error posible. Con modelos grandes, y especialmente con grandes conjuntos de entrenamiento, este paso puede volverse rápidamente difícil de gestionar. Como la memoria suele ser un recurso finito para nuestros cálculos, la distribución eficiente del entrenamiento del modelo es crucial.
Últimamente se presta mucha atención al ajuste de modelos, porque puede producir mejoras significativas en el rendimiento y proporcionar un perímetro competitivo. Dependiendo de tu proyecto de aprendizaje automático, puedes optar por afinar tu modelo antes de empezar a pensar en los conductos de aprendizaje automático o puedes querer afinarlo como parte de tu conducto. Dado que nuestros pipelines son escalables, gracias a su arquitectura subyacente, podemos hacer girar un gran número de modelos en paralelo o en secuencia. Esto nos permite elegir los hiperparámetros óptimos del modelo para nuestro modelo de producción final.
Análisis de modelos
Generalmente, utilizaríamos la precisión o la pérdida para determinar el conjunto óptimo de parámetros del modelo. Pero una vez que nos hayamos decidido por la versión final del modelo, es muy útil realizar un análisis más profundo del rendimiento del modelo (descrito en el Capítulo 7). Esto puede incluir el cálculo de otras métricas como la precisión, la recuperación y el AUC (área bajo la curva), o el cálculo del rendimiento en un conjunto de datos mayor que el conjunto de validación utilizado en el entrenamiento.
Otra razón para realizar un análisis en profundidad del modelo es comprobar que sus predicciones son justas. Es imposible saber cómo funcionará el modelo con distintos grupos de usuarios a menos que se corte el conjunto de datos y se calcule el rendimiento de cada corte. También podemos investigar la dependencia del modelo de las características utilizadas en el entrenamiento y explorar cómo cambiarían las predicciones del modelo si alteráramos las características de un solo ejemplo de entrenamiento.
Al igual que el paso de ajuste del modelo y la selección final del modelo de mejor rendimiento, este paso del flujo de trabajo requiere una revisión por parte de un científico de datos. Sin embargo, demostraremos cómo se puede automatizar todo el análisis y que sólo un humano realice la revisión final. La automatización mantendrá el análisis de los modelos coherente y comparable con otros análisis.
Versionado de modelos
La finalidad del paso de versionado y validación del modelo es llevar un registro de qué modelo, conjunto de hiperparámetros y conjuntos de datos se han seleccionado como la siguiente versión que se va a implementar.
El versionado semántico en ingeniería de software requiere que aumentes el número de versión mayor cuando hagas un cambio incompatible en tu API o cuando añadas funciones mayores. De lo contrario, aumentas el número de versión menor. La gestión de versiones de modelos tiene otro grado de libertad: el conjunto de datos. Hay situaciones en las que puedes conseguir una diferencia significativa del rendimiento del modelo sin cambiar ni un solo parámetro del modelo ni la descripción de la arquitectura, proporcionando muchos más datos y/o datos mejores para el proceso de entrenamiento. ¿Ese aumento del rendimiento justifica una actualización importante de la versión?
Aunque la respuesta a esta pregunta puede ser diferente para cada equipo de ciencia de datos, es esencial documentar todas las aportaciones a una nueva versión del modelo (hiperparámetros, conjuntos de datos, arquitectura) y hacer un seguimiento de ellas como parte de este paso de lanzamiento.
Implementación de modelos
Una vez que has entrenado, ajustado y analizado tu modelo, está listo para el prime time. Por desgracia, demasiados modelos se despliegan con implementaciones únicas, lo que hace que la actualización de los modelos sea un proceso frágil.
Los servidores de modelos modernos te permiten implementar tus modelos sin escribir código de aplicación web. A menudo, proporcionan múltiples interfaces API, como los protocolos de transferencia de estado representacional (REST) o de llamada a procedimiento remoto (RPC), y te permiten alojar varias versiones del mismo modelo simultáneamente. Alojar varias versiones al mismo tiempo te permitirá realizar pruebas A/B con tus modelos y te proporcionará valiosos comentarios sobre las mejoras de tus modelos.
Los servidores de modelos también te permiten actualizar una versión del modelo sin volver a desplegar tu aplicación, lo que reducirá el tiempo de inactividad de tu aplicación y la comunicación entre los equipos de desarrollo de la aplicación y de aprendizaje automático. Describimos la implementación de modelos en los capítulos 8 y 9.
Bucles de realimentación
A menudo se olvida el último paso del proceso de aprendizaje automático, pero es crucial para el éxito de los proyectos de ciencia de datos. Tenemos que cerrar el bucle. A continuación, podemos medir la eficacia y el rendimiento del modelo recién implementado. Durante este paso, podemos capturar información valiosa sobre el rendimiento del modelo. En algunas situaciones, también podemos capturar nuevos datos de entrenamiento para aumentar nuestros conjuntos de datos y actualizar nuestro modelo. Esto puede implicar a un humano en el bucle, o puede ser automático. Hablaremos de los bucles de retroalimentación en el Capítulo 13.
Excepto los dos pasos de revisión manual (el paso de análisis del modelo y el paso de retroalimentación), podemos automatizar todo el proceso. Los científicos de datos deberían poder centrarse en el desarrollo de nuevos modelos, no en la actualización y el mantenimiento de los modelos existentes.
Protección de datos
En el momento de escribir estas líneas, las consideraciones sobre la privacidad de los datos quedan fuera del proceso estándar de aprendizaje automático. Esperamos que esto cambie en el futuro, a medida que aumente la preocupación de los consumidores por el uso de sus datos y se promulguen nuevas leyes que restrinjan el uso de los datos personales. Esto hará que los métodos de preservación de la privacidad se integren en las herramientas para construir canalizaciones de aprendizaje automático.
En el Capítulo 14 tratamos varias opciones actuales para aumentar la privacidad en los modelos de aprendizaje automático:
-
Privacidad diferencial, donde las matemáticas garantizan que las predicciones del modelo no exponen los datos de un usuario
-
Aprendizaje federado, en el que los datos brutos no salen del dispositivo del usuario
-
Aprendizaje automático encriptado, donde todo el proceso de entrenamiento puede ejecutarse en el espacio encriptado o puede encriptarse un modelo entrenado con datos brutos.
Orquestación de tuberías
Todos los componentes de una cadena de aprendizaje automático descritos en el apartado anterior necesitan para ejecutarse o, como decimos nosotros, orquestarse, de modo que los componentes se ejecuten en el orden correcto. Las entradas de un componente deben calcularse antes de ejecutarlo. La orquestación de estos pasos se realiza mediante herramientas como Apache Beam, Apache Airflow (tratadas en el Capítulo 11), o Kubeflow Pipelines para la infraestructura Kubernetes (tratada en el Capítulo 12).
Mientras que las herramientas de canalización de datos coordinan los pasos de la canalización de aprendizaje automático, los almacenes de artefactos de canalización, como el Almacén de Metadatos de TensorFlow ML, capturan los resultados de los procesos individuales. En el Capítulo 2, daremos una visión general de la MetadataStore de TFX y miraremos entre bastidores de TFX y sus componentes de canalización.
¿Por qué orquestación de canalizaciones?
En 2015, un grupo de ingenieros de aprendizaje automático de Google llegó a la conclusión de que una de las razones por las que los proyectos de aprendizaje automático suelen fracasar es que la mayoría de los proyectos vienen con código personalizado para salvar las distancias entre los pasos del proceso de aprendizaje automático.2 Sin embargo, este código personalizado no se transfiere fácilmente de un proyecto a otro. Los investigadores resumieron sus hallazgos en el documento "Hidden Technical Debt in Machine Learning Systems" (Deuda técnica oculta en los sistemas de aprendizaje automático).3 Los autores argumentan en este documento que el código de unión entre los pasos del pipeline suele ser frágil y que los scripts personalizados no escalan más allá de casos específicos. Con el tiempo, se han desarrollado herramientas como Apache Beam, Apache Airflow o Kubeflow Pipelines. Estas herramientas pueden utilizarse para gestionar las tareas de la tubería de aprendizaje automático; permiten una orquestación estandarizada y una abstracción del código de unión entre tareas.
Aunque al principio pueda parecer engorroso aprender una nueva herramienta (por ejemplo, Beam o Airflow) o un nuevo marco (por ejemplo, Kubeflow) y configurar una infraestructura adicional de aprendizaje automático (por ejemplo, Kubernetes), la inversión de tiempo se amortizará muy pronto. Al no adoptar canalizaciones estandarizadas de aprendizaje automático, los equipos de ciencia de datos se enfrentarán a configuraciones de proyecto únicas, ubicaciones arbitrarias de archivos de registro, pasos de depuración únicos, etc. La lista de complicaciones puede ser interminable.
Grafos acíclicos dirigidos
Las herramientas de canalización como Apache Beam, Apache Airflow y Kubeflow Pipelines gestionan el flujo de tareas mediante una representación gráfica de las dependencias de las tareas.
Como muestra el gráfico de ejemplo de la Figura 1-2, los pasos del pipeline son dirigidos. Esto significa que un pipeline comienza con la Tarea A y termina con la Tarea E, lo que garantiza que la ruta de ejecución está claramente definida por las dependencias de las tareas. Los grafos dirigidos evitan situaciones en las que algunas tareas comienzan sin que todas las dependencias estén totalmente calculadas. Como sabemos que debemos preprocesar nuestros datos de entrenamiento antes de entrenar un modelo, la representación como un grafo dirigido evita que la tarea de entrenamiento se ejecute antes de que se complete el paso de preprocesamiento.
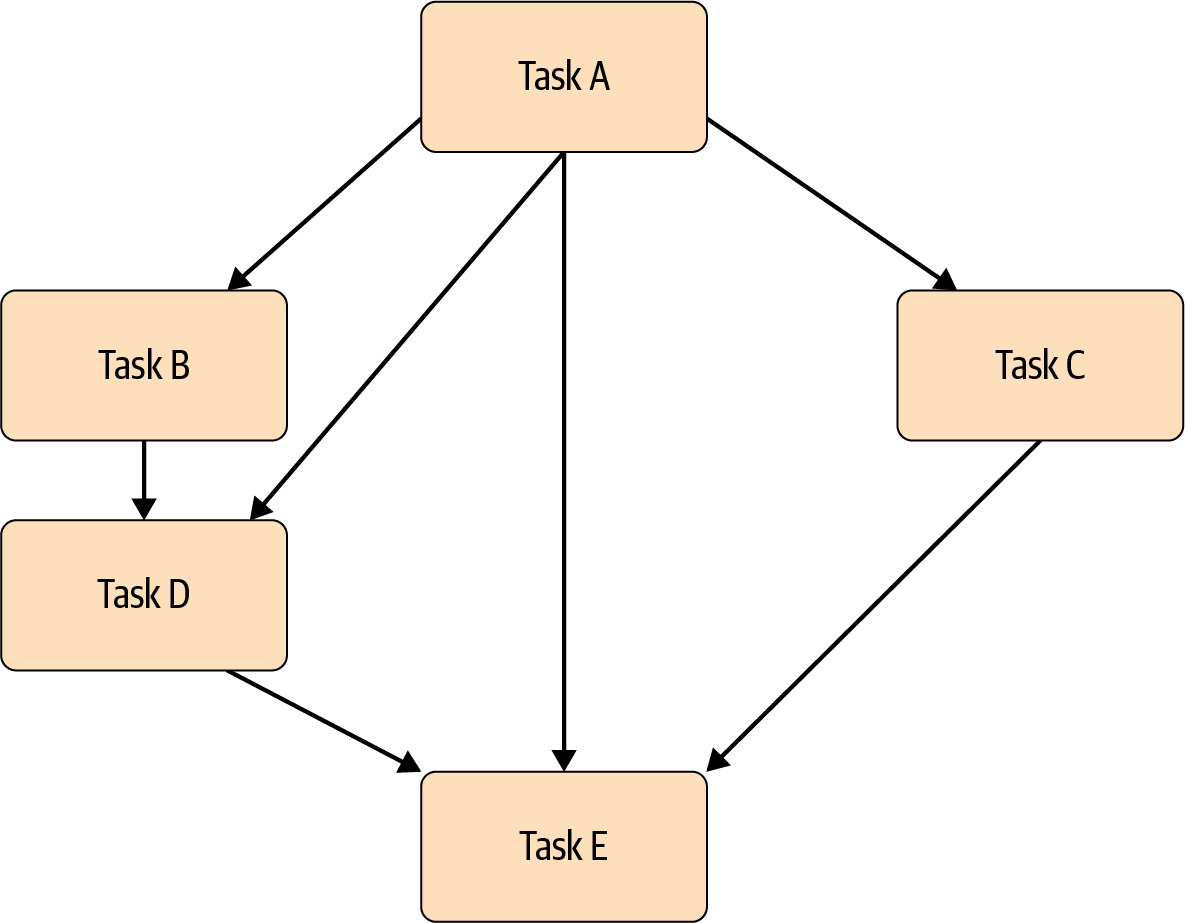
Figura 1-2. Ejemplo de grafo acíclico dirigido
Los grafos de las canalizaciones también deben ser acíclicos, lo que significa que un grafo no está vinculado a una tarea completada previamente. Esto significaría que la tubería podría ejecutarse sin fin y, por tanto, no terminaría el flujo de trabajo.
Debido a las dos condiciones (ser dirigidos y acíclicos), los grafos de flujo de trabajo se denominan grafos acíclicos dirigidos (DAG). Descubrirás que los DAG son un concepto central de la mayoría de las herramientas de flujo de trabajo. Trataremos más detalles sobre cómo se ejecutan estos grafos en los Capítulos 11 y 12.
Nuestro Proyecto Ejemplo
Para seguir con este libro, hemos creado un proyecto de ejemplo utilizando datos de código abierto. El conjunto de datos es una colección de reclamaciones de consumidores sobre productos financieros en Estados Unidos, y contiene una mezcla de datos estructurados (datos categóricos/numéricos) y datos no estructurados (texto). Los datos proceden de la Oficina de Protección Financiera del Consumidor.
La Figura 1-3 muestra una muestra de este conjunto de datos.
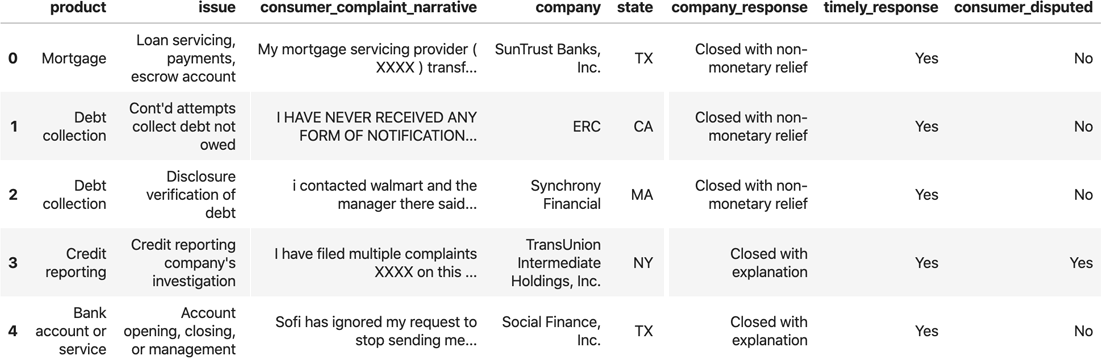
Figura 1-3. Muestra de datos
El problema del aprendizaje automático es, dados los datos sobre la reclamación, predecir si el consumidor ha impugnado la reclamación. En este conjunto de datos, el 30% de las reclamaciones son impugnadas, por lo que el conjunto de datos no está equilibrado.
Estructura del proyecto
Hemos proporcionado nuestro proyecto de ejemplo como repositorio de GitHub, y puedes clonarlo normalmente utilizando el siguiente comando:
$git clone https://github.com/Building-ML-Pipelines/\building-machine-learning-pipelines.git
Versiones del paquete Python
Para construir nuestro proyecto de ejemplo, utilizamos Python 3.6-3.8. Hemos utilizado la versión 2.2.0 de TensorFlow y la versión 0.22.0 de TFX. Haremos todo lo posible por actualizar nuestro repositorio de GitHub con futuras versiones, pero no podemos garantizar que el proyecto funcione con otras versiones de lenguajes o paquetes.
Nuestro proyecto de ejemplo contiene lo siguiente:
-
Una carpeta de capítulos que contiene cuadernos para ejemplos independientes de los capítulos 3, 4, 7 y 14
-
Una carpeta de componentes con el código de los componentes comunes, como la definición del modelo
-
Una tubería interactiva completa
-
Un ejemplo de experimento de aprendizaje automático, que es el punto de partida de la canalización
-
Ejemplos completos de pipelines orquestados por Apache Beam, Apache Airflow y Kubeflow Pipelines
-
Una carpeta de utilidades con un script para descargar los datos
En los capítulos siguientes te guiaremos por los pasos necesarios para convertir el experimento de aprendizaje automático de ejemplo, en nuestro caso un cuaderno Jupyter con una arquitectura de modelo Keras, en una cadena completa de aprendizaje automático de principio a fin.
Nuestro modelo de aprendizaje automático
El núcleo de nuestro proyecto de aprendizaje profundo de ejemplo es el modelo generado por la función get_model en el script components/module.py de nuestro proyecto de ejemplo. El modelo predice si un consumidor impugnó una reclamación utilizando las siguientes características:
-
El producto financiero
-
El subproducto
-
Respuesta de la empresa a la denuncia
-
El problema por el que se quejó el consumidor
-
El estado de EE.UU.
-
El código postal
-
El texto de la denuncia (el relato)
A efectos de construir el conducto de aprendizaje automático, suponemos que el diseño de la arquitectura del modelo está hecho y no modificaremos el modelo. Discutiremos la arquitectura del modelo con más detalle en el Capítulo 6. Pero para este libro, la arquitectura del modelo es un punto muy secundario. Este libro trata de lo que puedes hacer con tu modelo una vez que lo tengas.
Objetivo del Proyecto Ejemplo
A lo largo de este libro, demostraremos los marcos, componentes y elementos de infraestructura necesarios para entrenar continuamente nuestro modelo de aprendizaje automático de ejemplo. Utilizaremos la pila del diagrama de arquitectura que se muestra en la Figura 1-4.
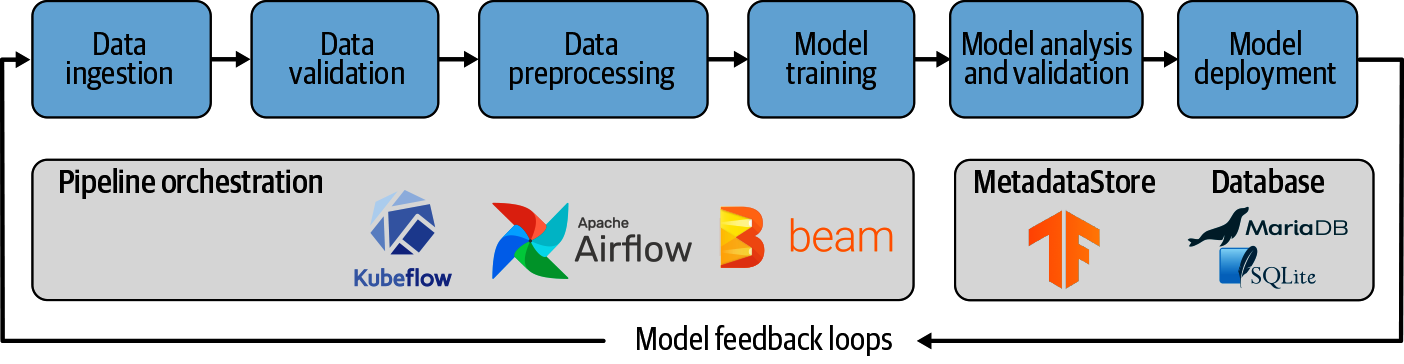
Figura 1-4. Arquitectura del proceso de aprendizaje automático de nuestro proyecto de ejemplo
Hemos intentado implementar un problema genérico de aprendizaje automático que puede sustituirse fácilmente por tu problema específico de aprendizaje automático. La estructura y la configuración básica de la canalización del aprendizaje automático siguen siendo las mismas y pueden trasladarse a tu caso de uso. Cada componente requerirá cierta personalización (por ejemplo, desde dónde ingerir los datos), pero como veremos, las necesidades de personalización serán limitadas.
Resumen
En este capítulo, hemos introducido el concepto de tuberías de aprendizaje automático y explicado los pasos individuales. También hemos mostrado las ventajas de automatizar este proceso. Además, hemos sentado las bases para los capítulos siguientes y hemos incluido un breve resumen de cada capítulo junto con una introducción de nuestro proyecto de ejemplo. En el próximo capítulo, ¡empezaremos a construir nuestra canalización!
1 En los problemas de clasificación supervisada con múltiples clases como salidas, a menudo es necesario convertir de una categoría a un vector como (0,1,0), que es un vector de una sola salida, o de una lista de categorías a un vector como (1,1,0), que es un vector de varias salidas.
2 Google inició un proyecto interno llamado Sibyl en 2007 para gestionar una canalización interna de producción de aprendizaje automático. Sin embargo, en 2015, el tema recibió una mayor atención cuando D. Sculley et al. publicaron sus aprendizajes sobre los pipelines de aprendizaje automático, "Hidden Technical Debt in Machine Learning Systems" (Deuda técnica oculta en los sistemas de aprendizaje automático).
3 D. Sculley et al., "Deuda técnica oculta en los sistemas de aprendizaje automático", Google, Inc. (2015).
Get Construir Pipelines de Aprendizaje Automático now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

