Kapitel 1. Einführung in CockroachDB
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
CockroachDB ist ein verteiltes, transaktionales, relationales, cloud-natives SQL-Datenbanksystem. Das ist ein ganz schöner Brocken! Aber kurz gesagt, CockroachDB nutzt sowohl die Stärken der vorherigen Generation relationaler Datenbanksysteme - starke Konsistenz, die Leistungsfähigkeit von SQL und das relationale Datenmodell - als auch die Stärken moderner verteilter Cloud-Prinzipien. Das Ergebnis ist ein Datenbanksystem, das im Großen und Ganzen mit anderen SQL-basierten Transaktionsdatenbanken kompatibel ist, aber eine viel höhere Skalierbarkeit und Verfügbarkeit bietet.
In diesem Kapitel werfen wir einen Blick auf die Geschichte der Datenbankmanagementsysteme (DBMS) und erfahren, wie CockroachDB die technologischen Fortschritte der letzten Jahrzehnte nutzt, um seine ehrgeizigen Ziele zu erreichen.
Eine kurze Geschichte der Datenbanken
Datenspeicherung und Datenverarbeitung sind die "Killer-Apps" der menschlichen Zivilisation. Die verbale Sprache verschaffte uns einen enormen Vorteil bei der Zusammenarbeit in der Gemeinschaft. Doch erst als wir die Speicherung von Daten entwickelten - z. B. die Schriftsprache - konnte jede Generation auf den Erfahrungen der vorangegangenen Generationen aufbauen.
Die frühesten schriftlichen Aufzeichnungen, die fast 10.000 Jahre zurückliegen, sind landwirtschaftliche Buchhaltungsunterlagen. Diese Keilschriftaufzeichnungen, die auf Tontafeln aufgezeichnet wurden(Abbildung 1-1), dienen demselben Zweck wie die Datenbanken, die moderne Buchhaltungssysteme unterstützen.
Die Technologien zur Speicherung von Informationen haben sich über Jahrtausende hinweg nur langsam weiterentwickelt. Die Verwendung von billigen, tragbaren und einigermaßen haltbaren Papiermedien, die in Bibliotheken und Schränken aufbewahrt wurden, war fast ein Jahrtausend lang die bewährte Methode.

Abbildung 1-1. Keilschrifttafel, ca. 3000 v. Chr. (Quelle: Wikipedia)
Das Aufkommen der digitalen Datenverarbeitung hat zu einer wahren Informationsrevolution geführt. Innerhalb einer einzigen menschlichen Lebensspanne haben digitale Informationssysteme zu einem exponentiellen Wachstum von Umfang und Geschwindigkeit der Speicherung von Informationen geführt. Heute wird der größte Teil der menschlichen Informationen in digitalen Formaten gespeichert, ein Großteil davon in Datenbanksystemen.
Vor-relationale Datenbanken
Die ersten Digitalcomputer hatten eine vernachlässigbare Speicherkapazität und wurden vor allem für Berechnungen eingesetzt, z. B. zum Erstellen von ballistischen Tabellen, Entschlüsseln von Codes und für wissenschaftliche Berechnungen. Als sich jedoch in den 1950er Jahren Magnetbänder und -platten durchsetzten, wurde es zunehmend möglich, mit Computern Datenmengen zu speichern und zu verarbeiten, die mit anderen Mitteln nicht zu bewältigen gewesen wären.
Die ersten Anwendungen nutzten einfache Flat Files zur Speicherung der Daten. Doch schon bald wurde klar, dass die Komplexität des zuverlässigen und effizienten Umgangs mit großen Datenmengen spezielle und dedizierte Softwareplattformen erforderte - und diese wurden zu den ersten Datensystemen.
Frühe Datenbanksysteme liefen auf monolithischen Großrechnern, die auch für den Anwendungscode verantwortlich waren. Die Anwendungen waren eng mit den Datenbanksystemen gekoppelt und verarbeiteten die Daten direkt über prozedurale Sprachbefehle. In den 1970er Jahren wetteiferten zwei Modelle von Datenbanksystemen um die Vorherrschaft: das Netzwerk- und das hierarchische Modell. Diese Modelle wurden von den damals wichtigsten Datenbanken, IMS (Information Management System) und IDMS (Integrated Database Management System), repräsentiert.
Diese Systeme waren ein großer Fortschritt gegenüber ihren Vorgängern, hatten aber auch erhebliche Nachteile. Abfragen mussten im Voraus geplant werden, und es konnten nur einzelne Datensätze verarbeitet werden. Selbst der einfachste Bericht erforderte Programmierressourcen, um ihn zu implementieren, und alle IT-Abteilungen litten unter einem enormen Rückstau an Berichtsanfragen.
Das relationale Modell
Wahrscheinlich hat niemand mehr Einfluss auf die Datenbanktechnologie gehabt als Edgar Codd (was auch immer Larry Ellison denken mag). Codd war ein "Programmiermathematiker" - das, was wir heute als Datenwissenschaftler bezeichnen würden - der seit 1949 mit Unterbrechungen bei IBM gearbeitet hat. 1970 schrieb Codd seine bahnbrechende Arbeit "A Relational Model of Data for Large Shared Data Banks". Darin legte er dar, was Codd als grundlegende Probleme bei der Entwicklung bestehender Datenbanksysteme ansah:
-
Bestehende Datenbanksysteme verschmolzen physische und logische Repräsentationen von Daten auf eine Art und Weise, die Datenanfragen oft verkomplizierte und zu Schwierigkeiten bei der Beantwortung von Anfragen führte, die während des Datenbankdesigns nicht vorhergesehen wurden.
-
Es gab keinen formalen Standard für die Datendarstellung. Als Mathematiker war Codd mit theoretischen Modellen zur Darstellung von Daten vertraut - er war der Meinung, dass diese Prinzipien auch auf Datenbanksysteme angewendet werden sollten.
-
Bestehende Datenbanksysteme waren zu schwer zu bedienen. Nur Programmierer waren in der Lage, Daten aus diesen Systemen abzurufen, und der Prozess des Datenabrufs war unnötig komplex. Codd war der Meinung, dass es eine leicht zugängliche Methode zum Abrufen von Daten geben musste.
Codds relationales Modell beschreibt eine Methode zur logischen Darstellung von Daten, die unabhängig von der zugrunde liegenden Speicherung ist. Es erforderte eine Abfragesprache, mit der jede Frage beantwortet werden konnte, die sich mit den Daten beantworten ließ.
Das relationale Modell definiert die grundlegenden Bausteine einer relationalen Datenbank:
-
Tupel sind eine Menge von Attributwerten. Die Attribute werden als skalare (eindimensionale) Werte bezeichnet. Ein Tupel kann als ein einzelner "Datensatz" oder eine "Zeile" betrachtet werden.
-
Eine Relation ist eine Sammlung von eindeutigen Tupeln der gleichen Form. Eine Relation stellt einen zweidimensionalen Datensatz mit einer festen Anzahl von Attributen und einer beliebigen Anzahl von Tupeln dar. Eine Tabelle in einer Datenbank ist ein Beispiel für eine Relation.
-
Constraints erzwingen Konsistenz und definieren Beziehungen zwischen Tupeln.
-
Es werden verschiedene Operationen definiert, z.B. wie Joins, Projektionen und Unions. Operationen auf Beziehungen führen immer zu Beziehungen. Wenn du zum Beispiel zwei Relationen verbindest, ist das Ergebnis selbst eine Relation.
-
Ein Schlüssel besteht aus einem oder mehreren Attributen, die zur Identifizierung eines Tupels verwendet werden können. Es kann mehr als einen Schlüssel geben, und ein Schlüssel kann aus mehreren Attributen bestehen.
Das relationale Modell definiert darüber hinaus eine Reihe von "Normalformen", die den Grad der Redundanz im Modell verringern. Eine Beziehung befindet sich in der dritten Normalform, wenn alle Daten in jedem Tupel vom gesamten Primärschlüssel dieses Tupels und von keinem anderen Attribut abhängig sind. Wir erinnern uns daran mit dem Sprichwort: "Der Schlüssel, der ganze Schlüssel und nichts als der Schlüssel (so wahr mir Codd helfe)".
Die dritte Normalform ist im Allgemeinen der Ausgangspunkt für die Konstruktion eines effizienten und leistungsfähigen Datenmodells. Wir werden auf die dritte Normalform in Kapitel 5 zurückkommen. Abbildung 1-2 veranschaulicht Daten in dritter Normalform.
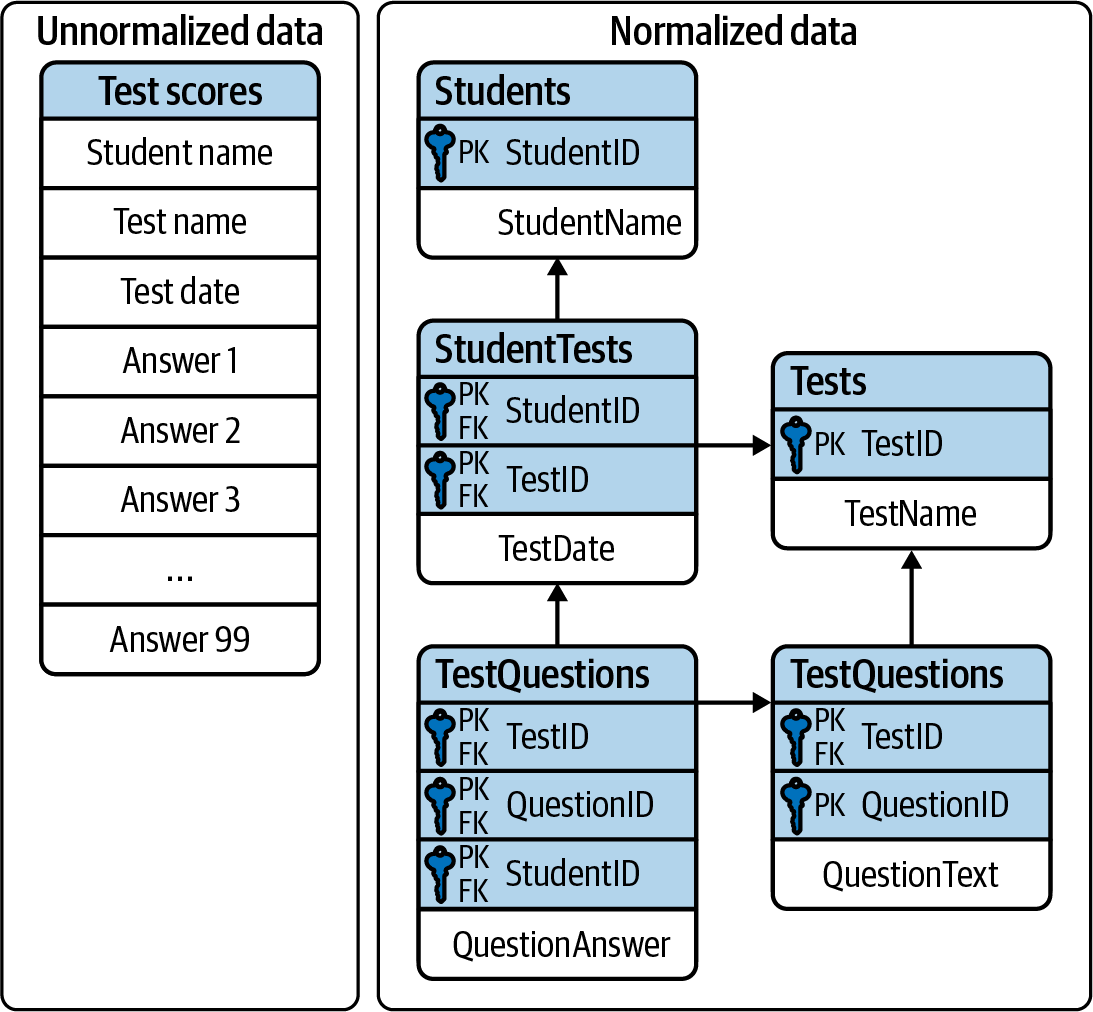
Abbildung 1-2. Daten, die in einer relationalen "dritten Normalform"-Struktur dargestellt werden
Implementierung des relationalen Modells
Das relationale Modell diente als Grundlage für die bekannten Strukturen, die heute in allen relationalen Datenbanken zu finden sind. Tupel werden als Zeilen und Beziehungen als Tabellen dargestellt.
Eine Tabelle ist eine Beziehung, die eine physische Speicherung erhalten hat. Die zugrunde liegende Speicherung kann verschiedene Formen annehmen. Zusätzlich zur physischen Darstellung der Daten wurden Indizierungs- und Clustering-Schemata eingeführt, um eine effiziente Datenverarbeitung zu ermöglichen und Einschränkungen umzusetzen.
Indizes und geclusterte Speicherung waren nicht Teil des relationalen Modells, sondern wurden in relationale Datenbanken integriert, um die Abfrageleistung transparent zu verbessern, ohne die Arten von Abfragen zu verändern. So war die logische Darstellung der Daten, die der Anwendung präsentiert wurde, unabhängig vom zugrunde liegenden physischen Modell.
In einigen relationalen Implementierungen kann eine Tabelle sogar durch mehrere indizierte Strukturen implementiert werden, die unterschiedliche Zugriffswege auf die Daten ermöglichen.
Transaktionen
Eine Transaktion ist eine logische Arbeitseinheit, die als Ganzes erfolgreich sein oder fehlschlagen muss. Transaktionen gab es schon vor dem relationalen Modell, aber in vor-relationalen Systemen waren Transaktionen oft in der Verantwortung der Anwendungsschicht. Im relationalen Modell von Codd übernahm die Datenbank die formale Verantwortung für die Transaktionsverarbeitung.1 Nach Codds Formulierung bietet ein relationales System explizite Unterstützung für das Starten einer Transaktion und das Bestätigen oder Abbrechen dieser Transaktion.
Die Verwendung von Transaktionen zur Wahrung der Konsistenz von Anwendungsdaten wurde auch intern genutzt, um die Konsistenz zwischen den verschiedenen physischen Strukturen, die Tabellen darstellen, zu wahren. Wenn eine Tabelle zum Beispiel durch mehrere Indizes repräsentiert wird, müssen alle diese Indizes auf transaktionale Weise synchronisiert werden.
Das relationale Modell von Codd definierte nicht alle Aspekte desTransaktionsverhaltens, die in den meisten relationalen Datenbanksystemen zum Einsatz kommen. 1981 formulierte Jim Gray die Grundprinzipien der Transaktionsverarbeitung, die wir heute noch verwenden. Diese Prinzipien wurden später alsACID-Transaktionen (atomic, consistent, isolated and durable) bekannt.
Gray drückt es so aus: "Eine Transaktion ist eine Zustandsänderung, die die Eigenschaften Atomarität (alles oder nichts), Dauerhaftigkeit (Auswirkungen überleben Ausfälle) und Konsistenz (eine korrekte Änderung) hat." Das Prinzip der Isolation, dasin einer späteren Überarbeitung hinzugefügt wurde, besagt, dass eine Transaktion nicht in der Lage sein sollte, die Auswirkungen anderer laufenderTransaktionen zu sehen.
Die perfekte Isolierung zwischen Transaktionen - die serielle Isolierung - führt zu einigen Einschränkungen bei der gleichzeitigen Datenverarbeitung. Viele Datenbanken haben niedrigere Isolationsstufen eingeführt oder den Anwendungen die Möglichkeit gegeben, aus verschiedenen Isolationsstufen zu wählen. Auf diese Auswirkungen wird in Kapitel 2 näher eingegangen.
Die SQL-Sprache
Codd legte fest, dass ein relationales System eine "Datenbank-Subsprache" unterstützen sollte, um relationale Daten zu navigieren und zu verändern. Er schlug 1971 die Alpha-Sprache vor, die die QUEL-Sprache beeinflusste, die von den Schöpfern von Ingres entwickelt wurde - ein frühes relationales Datenbanksystem, das an der University of California entwickelt wurde und die Open-Source-Datenbank PostgreSQL beeinflusst hat.
In der Zwischenzeit entwickelten Forscher bei IBM das System R, einen Prototyp eines DBMS, das auf Codds relationalem Modell basierte. Sie entwickelten die Sprache SEQUEL als Daten-Subsprache für das Projekt. SEQUEL wurde schließlich in SQL umbenannt und in die kommerziellen IBM-Datenbanken, einschließlich IBM DB2, übernommen.
Oracle wählte SQL als die Abfragesprache für sein bahnbrechendes relationales Datenbankmanagementsystem (RDBMS), und Ende der 1970er Jahre hatte sich SQL als relationale Abfragesprache gegen QUEL durchgesetzt und wurde 1986 zur ANSI (American National Standards Institute) Standardsprache.
SQL braucht kaum eine Einführung. Es ist heute eine der am häufigsten verwendeten Computersprachen der Welt. Wir werden uns in Kapitel 4 mit der SQL-Implementierung von CockroachDB befassen. Es ist jedoch erwähnenswert, dass die relative Benutzerfreundlichkeit von SQL die Zielgruppe der Datenbankbenutzer/innen drastisch erweitert hat. Man musste kein sehr erfahrener Datenbankprogrammierer mehr sein, um Daten aus einer Datenbank abzurufen: SQL konnte auch Gelegenheitsnutzern von Datenbanken, wie Analysten und Statistikern, beigebracht werden. Man kann mit Fug und Recht behaupten, dass SQL Datenbanken in die Reichweite von Geschäftsanwendern brachte.
Die RDBMS-Hegemonie
Die Kombination aus dem relationalen Modell, der SQL-Sprache und ACID-Transaktionen wurde von den frühen 1980er Jahren bis in die frühen 2000er Jahre zum dominierenden Modell für neue Datenbanksysteme. Diese Systeme wurden allgemein als RDBMS bekannt.
Das RDBMS kam etwa zur gleichen Zeit auf den Markt, als sich ein Paradigmenwechsel in der Anwendungsarchitektur vollzog. Die Welt der Mainframe-Anwendungen wich dem Client/Server-Modell. Im Client/Server-Modell lief der Anwendungscode auf Mikrocomputern (PCs), während die Datenbank auf einem Minicomputer lief, der zunehmend mit dem Betriebssystem Unix betrieben wurde. Während der Umstellung auf das Client/Server-Modell wurden die prä-relationalen Mainframe-Datenbanken weitgehend zugunsten der neuen RDBMS aufgegeben.
Am Ende des 20. Jahrhunderts war das RDBMS das Maß aller Dinge. Die führenden kommerziellen Datenbanken dieser Zeit - Oracle, Sybase, SQL Server, Informix und DB2 - konkurrierten in Bezug auf Leistung, Funktionalität oder Preis, aber alle waren praktisch identisch in ihrer Anwendung des relationalen Modells, SQL und ACID-Transaktionen. Mit der zunehmenden Beliebtheit von Open-Source-Software gewannen Open-Source-Datenbankmanagementsysteme wie MySQL und PostgreSQL an Bedeutung und an Zugkraft.
Betritt das Internet
Um die Wende zum 21. Jahrhundert gab es eine noch wichtigere Veränderung der Anwendungsarchitekturen. Diese Veränderung war natürlich das Internet. Ursprünglich liefen Internetanwendungen auf einem Software-Stack, der einer Client/Server-Anwendung nicht unähnlich war. Ein einziger großer Server beherbergte die Datenbank der Anwendung, während der Anwendungscode auf einem "Middle Tier"-Server lief und die Endnutzer/innen über Webbrowser mit der Anwendung interagierten.
In den Anfängen des Internets genügte diese Architektur - wenn auch oft nur knapp. Die monolithischen Datenbankserver waren oft ein Leistungsengpass, und obwohl Standby-Datenbanken routinemäßig eingesetzt wurden, war ein Datenbankausfall eine der häufigsten Ursachen für das Versagen von Anwendungen.
Als das Web wuchs, wurden die Grenzen des zentralisierten RDBMS unhaltbar. Die aufkommenden sozialen Netzwerke und E-Commerce-Websites des "Web 2.0" hatten zwei Eigenschaften, die immer schwieriger zu unterstützen waren:
-
Diese Systeme hatten eine globale oder fast globale Dimension. Nutzer auf mehreren Kontinenten brauchten gleichzeitigen Zugriff auf die Anwendung.
-
Jede Art von Ausfallzeit war unerwünscht. Das alte Modell der "Wochenend-Upgrades" war nicht mehr akzeptabel. Es gab kein Wartungsfenster, in dem es nicht zu erheblichen Betriebsunterbrechungen kam.
Alle Beteiligten waren sich einig, dass das monolithische, einzelne Datenbanksystem weichen musste, wenn die Anforderungen der neuen Art von Internetanwendungen erfüllt werden sollten. Es wurde erkannt, dass ein sehr bedeutendes und potenziell unüberwindbares Hindernis im Weg stand: Das CAP-Theorem- oder Brewer's-Theorem -besagt, dass ein verteiltes System höchstens zwei von drei wünschenswerten Eigenschaften haben kann (siehe Abbildung 1-3):
- Konsistenz
-
Jeder Nutzer sieht die gleiche Ansicht des Datenbankstatus.
- Verfügbarkeit
-
Die Datenbank bleibt verfügbar, solange nicht alle Elemente des verteilten Systems fehlschlagen.
- Teilungstoleranz
-
Das System läuft in einer Umgebung, in der eine Netzwerkpartition das verteilte System in zwei Hälften teilen könnte, oder wenn zwei Knoten im Netzwerk nicht miteinander kommunizieren können. Ein partitionstolerantes System arbeitet weiter, auch wenn das Netzwerk zwischen den Knoten eine beliebige Anzahl von Nachrichten fallen lässt (oder verzögert).
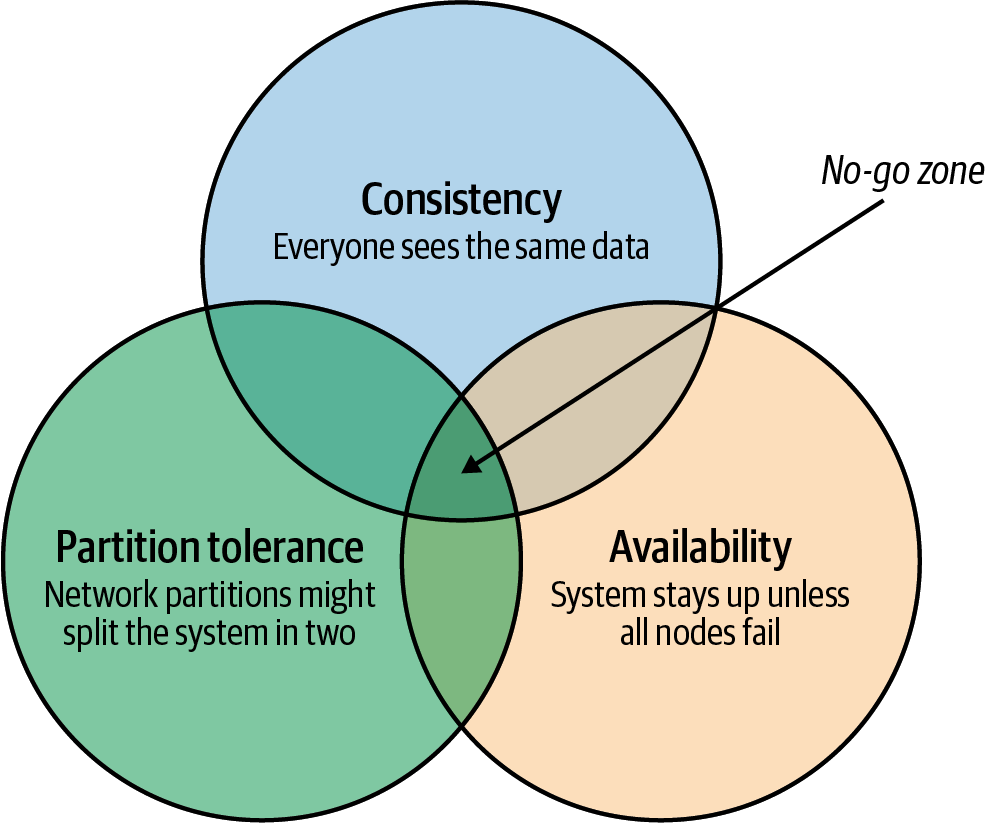
Abbildung 1-3. Das CAP-Theorem besagt, dass ein System nicht alle drei Eigenschaften von Konsistenz, Verfügbarkeit und Partitionstoleranz unterstützen kann
Nehmen wir zum Beispiel den Fall eines globalen E-Commerce-Systems mit Nutzern in Nordamerika und Europa. Wenn das Netzwerk zwischen den beiden Kontinenten fehlschlägt (eine Netzwerkpartition), musst du eines der folgenden Ergebnisse wählen:
-
Nutzer/innen in Europa und Nordamerika sehen möglicherweise unterschiedliche Versionen der Datenbank: Das geht zu Lasten der Konsistenz.
-
Eine der beiden Regionen muss abgeschaltet (oder schreibgeschützt) werden, was dieVerfügbarkeit beeinträchtigt.
Geclusterte RDBMS zu dieser Zeit würden in der Regel die Verfügbarkeit beeinträchtigen. In Oracles Real Application Clusters (RAC) geclusterter Datenbank zum Beispiel würde eine Netzwerkpartition zwischen den Knoten dazu führen, dass alle Knoten in einer der Partitionen abgeschaltet werden.
Internet-Pioniere wie Amazon waren jedoch der Meinung, dass Verfügbarkeit wichtiger ist als strikte Konsistenz. Amazon entwickelte ein Datenbanksystem -Dynamo -, das "eventuelle Konsistenz" implementierte. Im Falle einer Partition hatten alle Zonen weiterhin Zugriff auf das System, aber wenn die Partition aufgelöst war, mussten die Inkonsistenzen ausgeglichen werden - und dabei gingen möglicherweise Daten verloren.
Die NoSQL-Bewegung
Zwischen 2008 und 2010 entstanden Dutzende neuer Datenbanksysteme, die alle die drei Säulen des RDBMS aufgaben: das relationale Datenmodell, die SQL-Sprache und ACID-Transaktionen. Einige dieser neuen Systeme - Cassandra, Riak, Project Voldemort und HBase zum Beispiel - wurden direkt von nicht-relationalen Technologien beeinflusst, die bei Amazon und Google entwickelt wurden.
Viele dieser Systeme waren im Wesentlichen "schema-frei", d. h. sie unterstützten keine spezifische Struktur für die gespeicherten Daten oder erforderten sie sogar. In Key-Value-Datenbanken ermöglicht ein beliebiger Schlüssel den programmatischen Zugriff auf einen beliebig strukturierten "Wert". Die Datenbank weiß nicht, was in diesem Wert enthalten ist. Aus Sicht der Datenbank ist der Wert nur eine unstrukturierte Menge von Bits. Andere nicht-relationale Systeme stellen Daten in halbtabellarischen Formaten oder als JSON-Dokumente (JavaScript Object Notation) dar. Keine dieser neuen Datenbanken setzte jedoch die Prinzipien des relationalen Modells um.
Diese Systeme wurden zunächst als verteilte nicht-relationale Datenbanksysteme (DNRDBMS) bezeichnet, wurden aber - da sie die SQL-Sprache nicht enthalten - schnell unter dem weitaus einprägsameren Begriff "NoSQL"-Datenbanken bekannt.
NoSQL war schon immer ein fragwürdiger Begriff. Er definierte eher, was die Klasse von Systemen verwirft, als dass er ihre einzigartigen Unterscheidungsmerkmale beschreibt. Nichtsdestotrotz hat sich der Begriff "NoSQL" durchgesetzt, und in den folgenden zehn Jahren haben sich NoSQL-Datenbanken wie Cassandra, DynamoDB und MongoDB als eigenständiges und wichtiges Segment der Datenbanklandschaft etabliert.
Das Aufkommen von verteiltem SQL
Vor allem die Herausforderungen bei der Implementierung von verteilten Transaktionen im Web führten zu einer Spaltung der modernen Datenbankmanagementsysteme. Mit dem Aufkommen globaler Anwendungen mit extrem hohen Anforderungen an die Betriebszeit wurde es undenkbar, die Verfügbarkeit für perfekte Konsistenz zu opfern. Fast unisono führten die führenden Web 2.0-Unternehmen wie Amazon, Google und Facebook neue Datenbankdienste ein, die nur "eventuell" oder "schwach" konsistent, aber dafür global und hochverfügbar sind, und die Open-Source-Gemeinde reagierte mit Datenbanken, die auf diesen Prinzipien basieren.
NoSQL-Datenbanken hatten jedoch ihre eigenen starken Einschränkungen. Die SQL-Sprache war weithin bekannt und bildete die Grundlage für fast alle Business Intelligence-Tools. NoSQL-Datenbanken sahen sich gezwungen, eine gewisse SQL-Kompatibilität zu bieten, und so fügten viele einen SQL-ähnlichen Dialekt hinzu, was zur Neudefinition von NoSQL als "nicht nur SQL" führte. In vielen Fällen waren diese SQL-Implementierungen reine Abfragesprachen und dienten nur der Unterstützung von Business Intelligence-Funktionen. In anderen Fällen unterstützte eine SQL-ähnliche Sprache die Transaktionsverarbeitung, bot aber nur eine begrenzte Teilmenge der SQL-Funktionen.
Die Probleme, die durch eine schwächere Konsistenz verursacht werden, waren jedoch schwerer zu ignorieren. Konsistenz und Korrektheit von Daten sind bei geschäftskritischen Anwendungen oft nicht verhandelbar. Während es unter bestimmten Umständen - z. B. in den sozialen Medien - akzeptabel sein kann, dass verschiedene Benutzer leicht unterschiedliche Ansichten desselben Themas sehen, ist in anderen Kontexten - z. B. in der Logistik - jede Inkonsistenz inakzeptabel. Fortschrittliche nicht-relationale Datenbanken verwenden abstimmbare Konsistenz und ausgeklügelte Algorithmen zur Konfliktlösung, um Dateninkonsistenzen zu verringern. Jede Datenbank, die auf strikte Konsistenz verzichtet, muss jedoch Szenarien in Kauf nehmen, in denen Daten während des Abgleichs von Netzwerkpartitionen oder aufgrund von konkurrierendenTransaktionen mit unklarem Zeitplan verloren gehen oder beschädigt werden können.
Google war Vorreiter für viele der Technologien, die wichtigen Open-Source-NoSQL-Systemen zugrunde liegen. So führten das Google File System und die MapReduce-Technologien direkt zu Apache Hadoop und Google Bigtable zu Apache HBase. Google war sich also der Grenzen dieser neuen Datenspeicher durchaus bewusst.
Das Spanner-Projekt wurde als Versuch gestartet, eine verteilte Datenbank zu bauen, die ähnlich wie Googles bestehendes Bigtable-System sowohl starke Konsistenz als auch hohe Verfügbarkeit unterstützt.
Spanner profitierte von Googles hochredundantem Netzwerk, was die Wahrscheinlichkeit von netzwerkbasierten Verfügbarkeitsproblemen verringerte, aber die wirklich neue Funktion von Spanner war sein TrueTime-System. TrueTime modelliert explizit die Unsicherheit der Zeitmessung in einem verteilten System, so dass sie in das Transaktionsprotokoll integriert werden kann. Verteilte Datenbanken unternehmen große Anstrengungen, um konsistente Informationen von den Replikaten im System zu erhalten. Sperren sind der wichtigste Mechanismus, um zu verhindern, dass inkonsistente Informationen in der Datenbank erstellt werden, während Snapshots der wichtigste Mechanismus für die Rückgabe konsistenter Informationen sind. Abfragen sehen keine Änderungen an den Daten, die während ihrer Ausführung auftreten, weil sie von einem konsistenten "Snapshot" der Daten lesen. Die Aufrechterhaltung von Snapshots in verteilten Datenbanken kann schwierig sein: Normalerweise ist eine umfangreiche Kommunikation zwischen den Knoten erforderlich, um die Reihenfolge der Transaktionen und Abfragen abzustimmen. Die von TrueTime bereitgestellten Zeitinformationen ermöglichen die Verwendung von Snapshots mit minimaler Kommunikation zwischen den Knoten.
Google Spanner optimiert den Snapshot-Mechanismus durch die Verwendung von GPS-Empfängern und Atomuhren, die in jedem Rechenzentrum installiert sind, weiter. GPS liefert einen extern validierten Zeitstempel, während die Atomuhr eine hochauflösende Zeit zwischen den GPS-"Fixes" liefert. Das Ergebnis ist, dass jeder Spanner-Server auf der ganzen Welt fast die gleiche Uhrzeit hat. Dadurch kann Spanner Transaktionen und Abfragen präzise anordnen, ohne dass eine übermäßige Kommunikation zwischen den Knoten oder Verzögerungen aufgrund zu großer Uhrunsicherheit erforderlich sind.
Hinweis
Spanner ist in hohem Maße von Googles redundantem Netzwerk und spezialisierter Server-Hardware abhängig. Spanner kann nicht unabhängig vom Google-Netzwerk arbeiten.
In der ersten Version von Spanner wurden die Grenzen des CAP-Theorems so weit hinausgeschoben, wie es die Technologie zuließ. Sie stellte ein verteiltes Datenbanksystem dar, in dem die Konsistenz garantiert, die Verfügbarkeit maximiert und Netzwerkpartitionen so weit wie möglich vermieden wurden. Im Laufe der Zeit fügte Google dem Datenmodell von Spanner relationale Funktionen und die Unterstützung der SQL-Sprache hinzu. Bis 2017 hatte sich Spanner zu einer verteilten Datenbank entwickelt, die alle drei Säulen eines RDBMS unterstützte: die SQL-Sprache, das relationale Datenmodell und ACID-Transaktionen.
Die Ankunft von CockroachDB
Mit Spanner demonstrierte Google überzeugend den Nutzen einer hochkonsistenten verteilten Datenbank. Allerdings war Spanner eng an die Google Cloud Platform (GCP) gekoppelt und - zumindest anfangs - nicht öffentlich zugänglich.
Es lag auf der Hand, dass die von Spanner entwickelten Technologien einer breiteren Öffentlichkeit zugänglich gemacht werden sollten. Im Jahr 2015 gründete ein Trio von Google-Alumni - Spencer Kimball, Peter Mattis und Ben Darnell - Cockroach Labs mit mit dem Ziel, eine quelloffene, geoskalierbare und ACID-kompatible Datenbank zu entwickeln.
Spencer, Peter und Ben wählten den Namen "CockroachDB" ( ) zu Ehren der bescheidenen Kakerlake, von der es heißt, sie sei so widerstandsfähig, dass sie sogar einen Atomkrieg überleben würde(Abbildung 1-4).
Abbildung 1-4. Das ursprüngliche CockroachDB-Logo
CockroachDB Design Ziele
CockroachDB wurde entwickelt, um die folgenden Attribute zu unterstützen:
- Skalierbarkeit
-
Die verteilte Architektur von CockroachDB ermöglicht die nahtlose Skalierung eines Clusters bei steigender oder sinkender Arbeitslast. Einem Cluster können Knoten hinzugefügt werden, ohne dass eine manuelle Anpassung erforderlich ist, und die Leistung steigt vorhersehbar mit der Anzahl der Knoten.
- Hohe Verfügbarkeit
-
Ein CockroachDB-Cluster hat keinen Single Point of Failure. CockroachDB kann weiterarbeiten, wenn ein Knoten, eine Zone oder eine Region fehlschlägt, ohne die Verfügbarkeit zu beeinträchtigen.
- Konsistenz
-
CockroachDB bietet den höchsten praktischen Grad an transaktionaler Isolation und Konsistenz. Transaktionen arbeiten unabhängig voneinander und sind nach dem Commit garantiert dauerhaft und für alle Sitzungen sichtbar.
- Leistung
-
Die CockroachDB-Architektur wurde entwickelt, um transaktionale Arbeitslasten mit niedriger Latenz und hohem Durchsatz zu unterstützen . Es wurden alle Anstrengungen unternommen, um bewährte Methoden zur Indizierung, Zwischenspeicherung und andere Optimierungsstrategien für Datenbanken zu übernehmen.
- Geopartitionierung
-
CockroachDB ermöglicht es, die Daten an bestimmten Orten zu platzieren, um die Leistung für "lokalisierte" Anwendungen zu verbessern und dieAnforderungen der Datenhoheit zu erfüllen.
- Kompatibilität
-
CockroachDB implementiert ANSI-Standard-SQL und ist mit dem Wire-Protokoll von PostgreSQL kompatibel. Das bedeutet, dass die meisten Datenbanktreiber und Frameworks, die mit PostgreSQL funktionieren, auch mit CockroachDB funktionieren. Viele PostgreSQL-Anwendungen können auf CockroachDB portiert werden, ohne dass wesentliche Änderungen am Programmcode erforderlich sind.
- Tragbarkeit
-
CockroachDB wird als vollständig verwalteter Datenbankdienst angeboten, was in vielen Fällen die einfachste und kostengünstigste Art der Bereitstellung ist. Sie kann aber auch auf so ziemlich jeder Plattform laufen, die du dir vorstellen kannst, vom Laptop eines Entwicklers bis hin zu einem großen Cloud-Einsatz. Die Architektur von CockroachDB ist sehr gut auf die Einsatzmöglichkeiten von Containern und insbesondere auf Kubernetes abgestimmt. CockroachDB bietet einen Kubernetes-Operator, der einen Großteil der Komplexität eines Kubernetes-Einsatzes eliminiert.
Du denkst jetzt vielleicht: "Das Ding kann alles!" Es ist jedoch wichtig, darauf hinzuweisen, dass CockroachDB nicht dazu gedacht war, alles für alle Menschen zu sein. Im Besonderen:
- CockroachDB priorisiert Konsistenz vor Verfügbarkeit
-
Wir haben bereits gesehen, wie das CAP-Theorem besagt, dass du dich bei einer Netzwerkpartition entweder für die Konsistenz oder die Verfügbarkeit entscheiden musst. Im Gegensatz zu "eventuell" konsistenten Datenbanken wie DynamoDB oder Cassandra garantiert CockroachDB Konsistenz um jeden Preis. Das bedeutet, dass sich ein CockroachDB-Knoten unter Umständen weigert, Anfragen zu bearbeiten, wenn er von seinen Peers abgeschnitten ist. Ein Cassandra-Knoten könnte unter ähnlichen Umständen eine Anfrage annehmen, auch wenn die Möglichkeit besteht, dass die Daten in der Anfrage später verworfen werden müssen.
- Die CockroachDB-Architektur priorisiert transaktionale Workloads
-
CockroachDB enthält die SQL-Konstrukte für die Erstellung von Aggregationen und die analytischen "Windowing"-Funktionen von SQL 2003, und CockroachDB ist sicherlich in der Lage, sich in beliebte Business Intelligence-Tools wie Tableau zu integrieren. Es gibt keinen besonderen Grund, warum CockroachDB nicht für analytische Anwendungen genutzt werden könnte. Allerdings sind die einzigartigen Funktionen von CockroachDB eher auf transaktionale Arbeitslasten ausgerichtet. Für rein analytische Arbeitslasten, die keine Transaktionen erfordern, bieten andere Datenbankplattformen möglicherweise eine bessere Leistung.
Es ist wichtig, sich daran zu erinnern, dass CockroachDB zwar von Spanner inspiriert wurde, aber in keiner Weise ein "Spanner-Klon" ist. Das CockroachDB-Team hat viele Konzepte des Spanner-Teams übernommen, ist aber in einigen wichtigen Punkten von Spanner abgewichen.
Erstens wurde Spanner für den Betrieb auf sehr spezieller Hardware entwickelt. Spanner-Knoten haben Zugang zu einer Atomuhr und einem GPS-Gerät, was unglaublich genaue Zeitstempel ermöglicht. CockroachDB wurde für den Betrieb auf Standard-Hardware und in Container-Umgebungen (wie Kubernetes) entwickelt und kann sich daher nicht auf die Synchronisierung mit einer Atomuhr verlassen. Wie wir in Kapitel 2 sehen werden, verlässt sich CockroachDB auf eine gute Taktsynchronisation zwischen den Knoten, ist aber viel toleranter gegenüber Taktverschiebungen als Spanner. Daher kann CockroachDB überall laufen, auch bei einem Cloud-Provider oder in einem Rechenzentrum vor Ort (und ein CockroachDB-Cluster kann sogar mehrere Cloud-Umgebungen umfassen).
Zweitens: Während die verteilte Speicherung von CockroachDB von Spanner inspiriert ist, sind die SQL-Engine und die APIs so konzipiert, dass sie mit PostgreSQL kompatibel sind. PostgreSQL ist heute eines der am häufigsten eingesetzten RDBMS und wird von einem umfangreichen Ökosystem von Treibern und Frameworks unterstützt. Das "Drahtprotokoll" von CockroachDB ist vollständig kompatibel mit PostgreSQL, d.h. jeder Treiber, der mit PostgreSQL funktioniert, funktioniert auch mit CockroachDB. Auf der SQL-Sprachebene wird es aufgrund der Unterschiede in den zugrunde liegenden Speicherungs- und Transaktionsmodellen immer Unterschiede zwischen PostgreSQL und CockroachDB geben. Die am häufigsten verwendete SQL-Syntax ist jedoch für beide Datenbanken gleich.
Drittens hat sich CockroachDB weiterentwickelt, um die Bedürfnisse der Community zu befriedigen, und hat viele Funktionen eingeführt, die das Spanner-Projekt nie vorgesehen hatte. Heute ist CockroachDB eine florierende Datenbankplattform, deren Verbindung zu Spanner nur noch von historischem Interesse ist.
CockroachDB Veröffentlichungen
Die erste Produktionsversion von CockroachDB erschien im Mai 2017. Mit dieser Version wurden die Kernfunktionen der verteilten transaktionalen SQL-Datenbanken eingeführt, wenn auch mit einigen Einschränkungen hinsichtlich Leistung und Skalierung. Version 2.0, die 2018 veröffentlicht wurde, enthielt neue Partitionierungsfunktionen für geografisch verteilte Einsätze, Unterstützung für JSON-Daten und massive Leistungsverbesserungen.
2019 ist CockroachDB mutig von Version 2 auf Version 19 gesprungen! Das lag nicht an den 17 fehlgeschlagenen Versionen zwischen 2 und 19, sondern an einer Änderung der Nummerierungsstrategie, bei der jede Version mit ihrem Versionsjahr verknüpft wird, anstatt die Versionen als "Major" oder "Minor" zu bezeichnen.
Einige Highlights der vergangenen Veröffentlichungen sind:
-
Mit Version 19.1 (April 2019) wurden Sicherheitsfunktionen wie die Verschlüsselung im Ruhezustand und die Integration von LDAP (Lightweight Directory Access Protocol), die in Kapitel 7 beschriebene Änderungsdatenerfassung und Optimierungen für mehrere Regionen eingeführt.
-
Mit Version 19.2 (November 2019) wurden das Transaktionsprotokoll Parallel Commits und weitere Leistungsverbesserungen eingeführt.
-
Mit Version 20.1 (Mai 2020) wurden viele SQL-Funktionen eingeführt, darunter
ALTERPRIMARYKEY,SELECTFORUPDATE, verschachtelte Transaktionen und temporäre Tabellen. -
Mit Version 20.2 (November 2020) wurden Unterstützung für räumliche Datentypen, neue Transaktionsdetailseiten in der DB-Konsole und die kostenlose Bereitstellung der verteilten Funktionen
BACKUPundRESTOREhinzugefügt. -
Version 21.1 (Mai 2021) vereinfacht die Nutzung der Multiregionen-Funktionalität und erweitert die Konfigurationsoptionen für die Protokollierung.
-
Mit Version 21.2 (November 2021) wurden "Bounded Staleness Reads" und zahlreiche Stabilitäts- und Leistungsverbesserungen eingeführt, darunter ein Zulassungskontrollsystem, das eine Überlastung des Clusters verhindert.
CockroachDB in Aktion
CockroachDB hat in einem überfüllten Datenbankmarkt eine starke und wachsende Anziehungskraft gewonnen. Nutzer, die durch die Skalierbarkeit traditioneller relationaler Datenbanken wie PostgreSQL und MySQL eingeschränkt waren, werden von der größeren Skalierbarkeit von CockroachDB angezogen. Diejenigen, die bisher verteilte NoSQL-Lösungen wie Cassandra genutzt haben, werden von der größeren Transaktionskonsistenz und SQL-Kompatibilität von CockroachDB angezogen. Und diejenigen, die auf moderne containerisierte und cloud-native Architekturen umstellen, schätzen die Cloud- und Container-Fähigkeit der Plattform.
Heute kann sich CockroachDB rühmen, in großem Umfang in verschiedenen Branchen eingesetzt zu werden. Werfen wir einen Blick auf einige dieser Fallstudien.2
CockroachDB bei DevSisters
DevSisters ist ein in Südkorea ansässiges Spieleentwicklungsunternehmen, das für Spiele wie das Handyspiel Cookie Run verantwortlich ist : Kingdom. Ursprünglich nutzte DevSisters Couchbase für seine Persistenzschicht, hatte aber Probleme mit der Transaktionsintegrität und Skalierbarkeit. Bei der Suche nach einer neuen Datenbanklösung waren die Anforderungen von DevSisters unter anderem Skalierbarkeit, Transaktionskonsistenz und die Unterstützung eines sehr hohen Durchsatzes.
DevSisters zog sowohl Amazon Aurora und DynamoDB als auch CockroachDB in Betracht, entschied sich aber schließlich für CockroachDB. Sungyoon Jeong aus dem DevOps-Team sagt: "Es wäre unmöglich gewesen, dieses Spiel mit MySQL oder Aurora zu skalieren. Wir erlebten mehr als das Sechsfache der erwarteten Arbeitslast und CockroachDB war in der Lage, während dieser Reise mit uns zu skalieren."
CockroachDB bei DoorDash
DoorDash ist eine lokale Handelsplattform, die Verbraucher mit ihren Lieblingsgeschäften in den Vereinigten Staaten, Kanada, Australien, Japan und Deutschland verbindet. Heute hat DoorDash mehr als 160 CockroachDB-Cluster für seine Entwickler für verschiedene kundenorientierte, Backend-Analyse- und interne Workloads eingerichtet.
Das DoorDash-Team schätzt an CockroachDB, dass sie horizontal skaliert, SQL spricht und Postgres-kompatibel ist und schwere Lese- und Schreibvorgänge ohne Leistungseinbußen bewältigt. Die robuste Architektur von CockroachDB und die Live-Schemaänderungen sind ebenfalls ein großer Vorteil für das Team. "DoorDash konnte mit CockroachDB zahlreiche Workloads migrieren und skalieren, ohne die Anwendungen neu schreiben zu müssen - es waren nur kleine Index- oder Schemaänderungen nötig", sagt Sean Chittenden, Engineering Lead für das Core Infrastructure-Team bei DoorDash.
CockroachDB bei Bose
Bose ist ein weltweit führendes Unternehmen der Unterhaltungselektronik besonders bekannt als Anbieter von High-Fidelity-Audiogeräten.
Der Kundenstamm von Bose erstreckt sich über den ganzen Globus, und Bose möchte diesen Kunden die besten Cloud-basierten Support-Lösungen bieten.
Bose hat sich eine moderne, auf Microservices basierende Softwarearchitektur zu eigen gemacht. Das Rückgrat der Bose-Plattform ist Kubernetes, das den Anwendungen den Zugriff auf Low-Level-Dienste - containerisierte Berechnungen - und auf Higher-Level-Dienste wie Elasticsearch, Kafka und Redis ermöglicht. CockroachDB wurde zur Grundlage der Datenbankplattform für diese containerisierte Microservice-Plattform.
Neben der Ausfallsicherheit und Skalierbarkeit von CockroachDB war die Fähigkeit von CockroachDB, in einer Kubernetes-Umgebung gehostet zu werden, entscheidend.
Durch den Betrieb von CockroachDB in einer Kubernetes-Umgebung hat Bose den Entwicklern eine Self-Service-Datenbank auf Abruf zur Verfügung gestellt. Entwickler können CockroachDB-Cluster für die Entwicklung oder für Tests einfach und schnell in einer Kubernetes-Umgebung aufsetzen. In der Produktion bietet CockroachDB mit Kubernetes umfassende Skalierbarkeit, Redundanz und hohe Verfügbarkeit.
Zusammenfassung
In diesem Kapitel haben wir CockroachDB in einen historischen Kontext gestellt und die Ziele und Möglichkeiten der Datenbank CockroachDB vorgestellt.
Die RDBMS, die in den 1970er und 1980er Jahren aufkamen, waren ein Triumph der Softwareentwicklung, der Softwareanwendungen von Client/Server bis hin zum frühen Internet ermöglichte. Die Anforderungen an global skalierbare, stets verfügbare Internetanwendungen waren jedoch unvereinbar mit den monolithischen, streng konsistenten RDBMS-Architekturen der damaligen Zeit. Daher entstand um 2010 eine Vielzahl von verteilten, "letztendlich konsistenten" NoSQL-Systemen, die die Anforderungen einer neuen Generation von internen Anwendungen erfüllen.
Obwohl diese NoSQL-Lösungen ihre Vorteile haben, sind sie für viele oder die meisten Anwendungen ein Rückschritt. Die Unfähigkeit, die Korrektheit der Daten zu garantieren, und der Verlust der sehr vertrauten und produktiven SQL-Sprache waren in vielerlei Hinsicht ein Rückschritt. CockroachDB wurde als hochgradig konsistente und hochverfügbare SQL-basierte Transaktionsdatenbank entwickelt, die einen besseren Kompromiss zwischen Verfügbarkeit und Konsistenz bietet - wobei die Konsistenz an erster Stelle steht, die Verfügbarkeit aber sehr hoch ist.
CockroachDB ist eine hochverfügbare, transaktionskonsistente SQL-Datenbank, die mit bestehenden Entwicklungsframeworks und den immer wichtiger werdenden containerisierten Bereitstellungsmodellen und Cloud-Architekturen kompatibel ist. CockroachDB wurde bereits in großem Umfang in einer Vielzahl von Branchen und unter verschiedenen Bedingungen eingesetzt.
Im nächsten Kapitel werden wir die Architektur von CockroachDB untersuchen und genau sehen, wie sie ihre ehrgeizigen Designziele erreicht.
1 Aus "Regel 5" in den 12 Regeln von Codd, die Anfang der 80er Jahre veröffentlicht wurden.
2 Cockroach Labs unterhält eine wachsende Liste von CockroachDB-Fallstudien.
Get CockroachDB: Der endgültige Leitfaden now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

