Chapter 4. Cloud Native Patterns
Progress is possible only if we train ourselves to think about programs without thinking of them as pieces of executable code.1
Edsger W. Dijkstra, August 1979
In 1991, while still at Sun Microsystems, L Peter Deutsch2 formulated the “fallacies of distributed computing,” which lists some of the false assumptions that programmers new (and not so new) to distributed applications often make:
-
The network is reliable: switches fail, routers get misconfigured
-
Latency is zero: it takes time to move data across a network
-
Bandwidth is infinite: a network can handle only so much data at a time
-
The network is secure: don’t share secrets in plain text; encrypt everything
-
Topology doesn’t change: servers and services come and go
-
There is one administrator: multiple admins lead to heterogeneous solutions
-
Transport cost is zero: moving data around costs time and money
-
The network is homogeneous: every network is (sometimes very) different
If I might be so audacious, I’d like to add a ninth one:
-
Services are reliable: services that you depend on can fail at any time
In this chapter, I’ll present a selection of idiomatic patterns—tested, proven development paradigms—designed to address one or more of the conditions described in Deutsch’s fallacies and demonstrate how to implement them in Go. None of the patterns discussed in this book are original to this book—some have been around for as long as distributed applications have existed—but most haven’t been previously published together in a single work. Many of them are unique to Go or have novel implementations in Go relative to other languages.
Unfortunately, this book won’t cover infrastructure-level patterns like the Bulkhead or Gatekeeper patterns. Largely, this is because our focus is on application-layer development in Go, and those patterns, while indispensable, function at an entirely different abstraction level. If you’re interested in learning more, I recommend Cloud Native Infrastructure by Justin Garrison and Kris Nova (O’Reilly) and Designing Distributed Systems by Brendan Burns (O’Reilly).
The Context Package
Most of the code examples in this chapter make use of the context package, which was introduced in Go 1.7 to provide an idiomatic means of carrying deadlines, cancellation signals, and request-scoped values between processes. It contains a single interface, context.Context, whose methods are listed in the following:
typeContextinterface{// Deadline returns the time when this Context should be canceled; it// returns ok==false if no deadline is set.Deadline()(deadlinetime.Time,okbool)// Done returns a channel that's closed when this Context is canceled.Done()<-chanstruct{}// Err indicates why this context was canceled after the Done channel is// closed. If Done is not yet closed, Err returns nil.Err()error// Value returns the value associated with this context for key, or nil// if no value is associated with key. Use with care.Value(keyany)any}
Three of these methods can be used to learn something about a Context value’s cancellation status or behavior. The fourth, Value, can be used to retrieve a value associated with an arbitrary key. Context’s Value method is the focus of some controversy in the Go world and will be discussed more in “Defining Request-Scoped Values”.
What Context Can Do for You
A context.Context value is used by passing it directly to a service request, which may in turn pass it to one or more subrequests. What makes this useful is that when a Context is canceled, all functions holding it (or a derived Context; more on this in “Defining Context Deadlines and Timeouts”) will receive the signal, allowing them to coordinate their cancellation and reduce wasted effort.
Take, for example, a request from a user to a service, which in turn makes a request to a database. In an ideal scenario, the user, application, and database requests can be diagrammed as in Figure 4-1.

Figure 4-1. A successful request from a user, to a service, to a database.
But what if the user terminates their request before it’s fully completed? In most cases, oblivious to the overall context of the request, the processes will continue to live on anyway (Figure 4-2), consuming resources in order to provide a result that’ll never be used.

Figure 4-2. Subprocesses, unaware of a canceled user request, will continue anyway.
However, by sharing a Context to each subsequent request, all long-running processes can be sent a simultaneous “done” signal, allowing the cancellation signal to be coordinated among each of the processes (Figure 4-3).

Figure 4-3. By sharing context, cancellation signals can be coordinated among processes.
Importantly, Context values are also thread safe: they can be safely used by multiple concurrently executing goroutines without fear of unexpected behaviors.
Creating Context
A brand-new context.Context can be obtained using one of two functions:
Background() Context-
Returns an empty
Contextthat’s never canceled, has no values, and has no deadline. It’s typically used by the main function, initialization, and tests and as the top-levelContextfor incoming requests. TODO() Context-
Also provides an empty
Context, but it’s intended to be used as a placeholder when it’s unclear whichContextto use or when a parentContextis not yet available.
Defining Context Deadlines and Timeouts
The context package also includes a number of methods for creating derived Context values that allow you to direct cancellation behavior, either by applying a timeout or by a function hook that can explicitly trigger a cancellation:
WithDeadline(Context, time.Time) (Context, CancelFunc)-
Accepts a specific time at which the
Contextwill be canceled and theDonechannel will be closed. WithTimeout(Context, time.Duration) (Context, CancelFunc)-
Accepts a duration after which the
Contextwill be canceled and theDonechannel will be closed. WithCancel(Context) (Context, CancelFunc)-
Unlike the previous functions,
WithCancelaccepts nothing additional and only returns a function that can be called to explicitly cancel theContext.
All three of these functions return a derived Context that includes any requested decoration and a context.CancelFunc, a zero-parameter function that can be called to explicitly cancel the Context and all of its derived values.
Tip
When a Context is canceled, all Contexts that are derived from it are also canceled. Contexts that it was derived from are not.
For the sake of completion, it’s worth mentioning that there are also three recently introduced functions that parallel the three just mentioned but that also allow you to specify a specific error value as the cancellation cause:
WithDeadlineCause(Context, time.Time, error) (Context, CancelFunc)-
Introduced in Go 1.21. Behaves like
WithDeadlinebut also sets the cause of the returnedContextwhen the deadline is exceeded. The returnedCancelFuncdoes not set the cause. WithTimeoutCause(Context, time.Duration, error) (Context, CancelFunc)-
Introduced in Go 1.21. Behaves like
WithTimeoutbut also sets the cause of the returnedContextwhen the timeout expires. The returnedCancelFuncdoes not set the cause. WithCancelCause(Context) (Context, CancelCauseFunc)-
Introduced in Go 1.20. Behaves like
WithCancelbut returns aCancelCauseFuncinstead of aCancelFunc. Callingcancelwith a non-nilerror(the “cause”) records thaterrorinctx; it can then be retrieved usingCause(ctx).
The ability to explicitly define a cause can provide useful context3 for logging or otherwise deciding on an appropriate response.
Defining Request-Scoped Values
Finally, the context package includes a function that can be used to define an arbitrary request-scoped key-value pair that can be accessed from the returned Context—and all Context values derived from it—via the Value method:
WithValue(parent Context, key, val any) Context-
WithValuereturns a derivation ofparentin whichkeyis associated with the valueval.
Using a Context
When a service request is initiated, either by an incoming request or triggered by the main function, the top-level process will use the Background function to create a new Context value, possibly decorating it with one or more of the context.With* functions, before passing it along to any subrequests. Those subrequests then need only watch the Done channel for cancellation signals.
For example, take a look at the following Stream function:
funcStream(ctxcontext.Context,outchan<-Value)error{// Create a derived Context with a 10s timeout; dctx// will be canceled upon timeout, but ctx will not.// cancel is a function that will explicitly cancel dctx.dctx,cancel:=context.WithTimeout(ctx,10*time.Second)// Release resources if SlowOperation completes before timeoutdefercancel()res,err:=SlowOperation(dctx)// res is a Value channeliferr!=nil{// True if dctx times outreturnerr}for{select{caseout<-<-res:// Read from res; send to outcase<-ctx.Done():// Triggered if ctx is canceledreturnctx.Err()// but not if dctx is canceled}}}
Stream receives a ctx Context as an input parameter, which it sends to WithTimeout to create dctx, a derived Context with a 10-second timeout. Because of this decoration, the SlowOperation(dctx) call could possibly time out after 10 seconds and return an error. Functions using the original ctx, however, will not have this timeout decoration and will not time out.
Further down, the original ctx value is used in a for loop around a select statement to retrieve values from the res channel provided by the SlowOperation function. Note the case <-ctx.Done() statement, which is executed when the ctx.Done channel closes to return an appropriate error value.
Layout of This Chapter
The general presentation of each pattern in this chapter is loosely based on the one used in the famous “Gang of Four” Design Patterns book4 but is simpler and less formal. Each pattern opens with a very brief description of its purpose and the reasons for using it and is followed by the following sections:
- Applicability
-
Context and descriptions of where this pattern may be applied.
- Participants
-
A listing of the components of the pattern and their roles.
- Implementation
-
A discussion of the solution and its implementation.
- Sample code
-
A demonstration of how the code may be implemented in Go.
Stability Patterns
The stability patterns presented here address one or more of the assumptions called out by the fallacies of distributed computing. They’re generally intended to be applied by distributed applications to improve their own stability and the stability of the larger system they’re a part of.
Circuit Breaker
Circuit Breaker automatically degrades service functions in response to a likely fault, preventing larger or cascading failures by eliminating recurring errors and providing reasonable error responses.
Applicability
If the fallacies of distributed computing were to be distilled to one point, it would be that errors and failures are an undeniable fact of life for distributed, cloud native systems. Services become misconfigured, databases crash, networks partition. We can’t prevent it; we can only accept and account for it.
Failing to do so can have some rather unpleasant consequences. We’ve all seen them, and they aren’t pretty. Some services might keep futilely trying to do their job and returning nonsense to their client; others might fail catastrophically and maybe even fall into a crash/restart death spiral. It doesn’t matter, because in the end they’re all wasting resources, obscuring the source of original failure, and making cascading failures even more likely.
On the other hand, a service that’s designed with the assumption that its dependencies can fail at any time can respond reasonably when they do. The Circuit Breaker allows a service to detect such failures and to “open the circuit” by temporarily ceasing to execute requests, instead providing clients with an error message consistent with the service’s communication contract.
For example, imagine a service that (ideally) receives a request from a client, executes a database query, and returns a response. What if the database fails? The service might continue futilely trying to query it anyway, flooding the logs with error messages and eventually timing out or returning useless errors. Such a service can use a Circuit Breaker to “open the circuit” when the database fails, preventing the service from making any more doomed database requests (at least for a while) and allowing it to respond to the client immediately with a meaningful notification.
Participants
This pattern includes the following participants:
- Circuit
-
The function that interacts with the service.
- Breaker
-
A closure with the same function signature as Circuit.
Implementation
Essentially, the Circuit Breaker is just a specialized Adapter pattern, with Breaker wrapping Circuit to add some additional error handling logic.
Like the electrical switch from which this pattern derives its name, Breaker has two possible states: closed and open. In the closed state, everything is functioning normally. All requests received from the client by Breaker are forwarded unchanged to Circuit, and all responses from Circuit are forwarded back to the client. In the open state, Breaker doesn’t forward requests to Circuit. Instead it “fails fast” by responding with an informative error message.
Breaker internally tracks the errors returned by Circuit; if the number of consecutive errors returned by Circuit exceeds a defined threshold, Breaker trips and its state switches to open.
Most implementations of Circuit Breaker include some logic to automatically close the circuit after some period of time. Keep in mind, though, that hammering an already malfunctioning service with lots of retries can cause its own problems, so it’s standard to include some kind of backoff logic that reduces the rate of retries over time. The subject of backoff is actually fairly nuanced, but it will be covered in detail in “Play It Again: Retrying Requests”.
In a multinode service, this implementation can be extended to include some shared storage mechanism, such as a Memcached or Redis network cache, to track the circuit state.
Sample code
We begin by creating a Circuit type that specifies the signature of the function that’s interacting with your database or other upstream service. In practice, this can take whatever form is appropriate for your functionality. It should include an error in its return list, however:
typeCircuitfunc(context.Context)(string,error)
In this example, Circuit is a function that accepts a Context value, which was described in depth in “The Context Package”. Your implementation may vary.
The Breaker function accepts any function that conforms to the Circuit type definition, and an integer representing the number of consecutive failures allowed before the circuit automatically opens. In return it provides another function, which also conforms to the Circuit type definition:
funcBreaker(circuitCircuit,thresholdint)Circuit{varfailuresintvarlast=time.Now()varmsync.RWMutexreturnfunc(ctxcontext.Context)(string,error){m.RLock()// Establish a "read lock"d:=failures-thresholdifd>=0{shouldRetryAt:=last.Add((2<<d)*time.Second)if!time.Now().After(shouldRetryAt){m.RUnlock()return"",errors.New("service unavailable")}}m.RUnlock()// Release read `lock`response,err:=circuit(ctx)// Issue the request properm.Lock()// Lock around shared resourcesdeferm.Unlock()last=time.Now()// Record time of attemptiferr!=nil{// Circuit returned an error,failures++// so we count the failurereturnresponse,err// and return}failures=0// Reset failures counterreturnresponse,nil}}
The Breaker function constructs another function, also of type Circuit, which wraps circuit to provide the desired functionality. You may recognize this from “Anonymous Functions and Closures” as a closure: a nested function with access to the variables of its parent function. As you will see, all of the “stability” functions implemented for this chapter work this way.
The closure works by counting the number of consecutive errors returned by
circuit. If that value meets the failure threshold, then it returns the error “service unreachable” without actually calling circuit. Any successful calls to circuit cause failures to reset to 0, and the cycle begins again.
The closure even includes an automatic reset mechanism that allows requests to call circuit again after several seconds, with an exponential backoff in which the durations of the delays between retries roughly doubles with each attempt. Though simple and quite common, this actually isn’t the ideal backoff algorithm. We’ll review exactly why in “Backoff Algorithms”.
This function also includes our first use of a mutex (also known as a lock).5 Mutexes are a common idiom in concurrent programming, and we’re going to use them quite a bit in this chapter, so if you’re fuzzy on mutexes in Go, see “Mutexes”.
Debounce
Debounce limits the frequency of a function invocation so that only the first or last in a cluster of calls is actually performed.
Applicability
Debounce is the second of our patterns to be labeled with an electrical circuit theme. Specifically, it’s named after a phenomenon in which a switch’s contacts “bounce” when they’re opened or closed, causing the circuit to fluctuate a bit before settling down. It’s usually no big deal, but this “contact bounce” can be a real problem in logic circuits where a series of on/off pulses can be interpreted as a data stream. The practice of eliminating contact bounce so that only one signal is transmitted by an opening or closing contact is called debouncing.
In the world of services, we sometimes find ourselves performing a cluster of potentially slow or costly operations where only one would do. Using the Debounce pattern, a series of similar calls that are tightly clustered in time are restricted to only one call, typically the first or last in a batch.
This technique has been used in the JavaScript world for years to limit the number of operations that could slow the browser by taking only the first in a series of user events, or to delay a call until a user is ready. You’ve probably seen an application of this technique in practice before. We’re all familiar with the experience of using a search bar whose autocomplete pop-up doesn’t display until after you pause typing, or spam-clicking a button only to see the clicks after the first ignored.
Those of us who specialize in backend services can learn a lot from our frontend colleagues, who have been working for years to account for the reliability, latency, and bandwidth issues inherent to distributed systems. For example, this approach could be used to retrieve some slowly updating remote resource without bogging down, wasting both client and server time with wasteful requests.
This pattern is similar to “Throttle”, in that it limits how often a function can be called. But where Debounce restricts clusters of invocations, Throttle simply limits according to time period. For more on the difference between the Debounce and Throttle patterns, see “What’s the Difference Between Throttle and Debounce?”.
Participants
This pattern includes the following participants:
- Circuit
-
The function to regulate
- Debounce
-
A closure with the same function signature as Circuit
Implementation
The Debounce implementation is actually very similar to the one for Circuit Breaker in that it wraps Circuit to provide the rate-limiting logic. That logic is actually quite straightforward: on each call of the outer function—regardless of its outcome—a time interval is set. Any subsequent call made before that time interval expires is ignored; any call made afterward is passed along to the inner function. This implementation, in which the inner function is called once and subsequent calls are ignored, is called function-first and is useful because it allows the initial response from the inner function to be cached and returned.
A function-last implementation will wait for a pause after a series of calls before calling the inner function. This variant is common in the JavaScript world when a programmer wants a certain amount of input before making a function call, such as when a search bar waits for a pause in typing before autocompleting. Function-last tends to be less common in backend services because it doesn’t provide an immediate response, but it can be useful if your function doesn’t need results right away.
Sample code
Just like in the Circuit Breaker implementation, we start by defining a derived function type with the signature of the function we want to limit. Also like Circuit Breaker, we call it Circuit; it’s identical to the one declared in that example. Again, Circuit can take whatever form is appropriate for your functionality, but it should include an error in its returns:
typeCircuitfunc(context.Context)(string,error)
The similarity with the Circuit Breaker implementation is quite intentional: their compatibility makes them “chainable,” as demonstrated in the following:
funcmyFunction(ctxcontext.Context)(string,error){/* ... */}wrapped:=Breaker(Debounce(myFunction))response,err:=wrapped(ctx)
The function-first implementation of Debounce—DebounceFirst—is very straightforward compared to function-last because it needs to track only the last time it was called and return a cached result if it’s called again less than d duration after:
funcDebounceFirst(circuitCircuit,dtime.Duration)Circuit{varthresholdtime.Timevarresultstringvarerrerrorvarmsync.Mutexreturnfunc(ctxcontext.Context)(string,error){m.Lock()deferm.Unlock()iftime.Now().Before(threshold){returnresult,err}result,err=circuit(ctx)threshold=time.Now().Add(d)returnresult,err}}
This implementation of DebounceFirst takes pains to ensure thread safety by wrapping the entire function in a mutex. While this will force overlapping calls at the start of a cluster to have to wait until the result is cached, it also guarantees that circuit is called exactly once, at the very beginning of a cluster. A defer ensures that the value of threshold, representing the time when a cluster ends (if there are no further calls), is reset with every call.
There’s a potential problem with this approach: it effectively just caches the result of the function and returns it if it’s called again. But what if the circuit function has important side effects? The following variation, DebounceFirstContext, is a little more sophisticated in that every call to it produces a call to circuit, but each call after the first context cancels the one before it:
funcDebounceFirstContext(circuitCircuit,dtime.Duration)Circuit{varthresholdtime.Timevarmsync.MutexvarlastCtxcontext.ContextvarlastCancelcontext.CancelFuncreturnfunc(ctxcontext.Context)(string,error){m.Lock()iftime.Now().Before(threshold){lastCancel()}lastCtx,lastCancel=context.WithCancel(ctx)threshold=time.Now().Add(d)m.Unlock()result,err:=circuit(lastCtx)returnresult,err}}
In DebounceFirstContext we use the same general structure and locking scheme as in DebounceFirst, but this time we set aside a Context and CancelFunc for circuit, which allows us to explicitly cancel circuit with each subsequent invocation before calling it again. In this way, circuit is still called (and any expected side effects triggered) each time while explicitly canceling any prior calls.
What if we want to call our Circuit function at the end of a cluster of calls? For this we’ll use a function-last implementation. Unfortunately, it’s a bit more awkward because it involves the use of a timer function to determine whether enough time has passed since the function was last called, and to call only circuit when it has:
typeCircuitfunc(context.Context)(string,error)funcDebounceLast(circuitCircuit,dtime.Duration)Circuit{varmsync.Mutexvartimer*time.Timervarcctxcontext.Contextvarcancelcontext.CancelFuncreturnfunc(ctxcontext.Context)(string,error){m.Lock()iftimer!=nil{timer.Stop()cancel()}cctx,cancel=context.WithCancel(ctx)ch:=make(chanstruct{resultstringerrerror},1)timer=time.AfterFunc(d,func(){r,e:=circuit(cctx)ch<-struct{resultstringerrerror}{r,e}})m.Unlock()select{caseres:=<-ch:returnres.result,res.errcase<-cctx.Done():return"",cctx.Err()}}}
In this implementation, a call to DebounceLast uses time.AfterFunc to execute the circuit function after the specified duration. This useful function lets us call an arbitrary function after a specific duration. It also provides a time.Timer value that can be used to cancel it. This is exactly what we need: you’ll notice that any already-existing timer is stopped (via its Stop method) before starting a new one, ensuring that circuit is called only once.
You’ve probably noticed that we also use a channel to send an anonymous struct (yes, you can do that!). This not only allows us to transmit both of the return values of circuit beyond the asynchronous function it’s called in, but it also conveniently allows us to use a select statement to react appropriately to a context cancellation event.
Retry
Retry accounts for a possible transient fault in a distributed system by transparently retrying a failed operation.
Applicability
Transient errors are a fact of life when working with complex distributed systems. These can be caused by any number of (hopefully) temporary conditions, especially if the downstream service or network resource has protective strategies in place, such as throttling that temporarily rejects requests under high workload, or adaptive strategies like autoscaling that can add capacity when needed.
These faults often resolve themselves after a bit of time, so repeating the request after a reasonable delay is likely (but not guaranteed) to be successful. Failing to account for transient faults can lead to a system that’s unnecessarily brittle. On the other hand, implementing an automatic retry strategy can considerably improve the stability of the service that can benefit both it and its upstream consumers.
Warning
Retry should be used with only idempotent operations. If you are not familiar with the concept of idempotence, we will cover it in detail in “What Is Idempotence and Why Does It Matter?”.
Participants
This pattern includes the following participants:
- Effector
-
The function that interacts with the service.
- Retry
-
A function that accepts Effector and returns a closure with the same function signature as Effector.
Implementation
This pattern works similarly to Circuit Breaker or Debounce in that there is a derived function type, Effector, that defines a function signature. This signature can take whatever form is appropriate for your implementation, but when the function executing the potentially failing operation is implemented, it must match the signature defined by Effector.
The Retry function accepts the user-defined Effector function and returns an Effector function that wraps the user-defined function to provide the retry logic. Along with the user-defined function, Retry also accepts an integer describing the maximum number of retry attempts that it will make and a time.Duration that describes how long it’ll wait between each retry attempt. If the retries parameter is 0, then the retry logic will effectively become a no-op.
Note
Although not included here, most retry implementations will include some kind of backoff logic.
Sample code
The signature for function argument of the Retry function is Effector. It looks exactly like the function types for the previous patterns:
typeEffectorfunc(context.Context)(string,error)
The Retry function itself is relatively straightforward, at least compared to the functions we’ve seen so far in this chapter:
funcRetry(effectorEffector,maxRetriesint,delaytime.Duration)Effector{returnfunc(ctxcontext.Context)(string,error){forr:=0;;r++{response,err:=effector(ctx)iferr==nil||r>=maxRetries{returnresponse,err}log.Printf("Attempt %d failed; retrying in %v",r+1,delay)select{case<-time.After(delay):case<-ctx.Done():return"",ctx.Err()}}}}
You may have already noticed what it is that keeps the Retry function so slender: although it returns a function, that function doesn’t have any external state. This means we don’t need any elaborate mechanisms to manage concurrency.
Note the contents of the select block, which demonstrates a common idiom for implementing a channel read timeout in Go based on the time.After function, similar to the example in “Implementing channel timeouts”. This very useful function returns a channel that emits a message after the specified time has elapsed, which activates its case and ends the current iteration of the retry loop.
To use Retry, we can implement the function that executes the potentially failing operation and whose signature matches the Effector type; this role is played by
EmulateTransientError in the following example:
varcountintfuncEmulateTransientError(ctxcontext.Context)(string,error){count++ifcount<=3{return"intentional fail",errors.New("error")}else{return"success",nil}}funcmain(){r:=Retry(EmulateTransientError,5,2*time.Second)res,err:=r(context.Background())fmt.Println(res,err)}
In the main function, the EmulateTransientError function is passed to Retry, providing the function variable r. When r is called, EmulateTransientError is called, and called again after a delay if it returns an error, according to the retry logic shown previously. Finally, after the fourth attempt, EmulateTransientError returns a nil error, and the Retry function exits.
Throttle
Throttle limits the frequency of a function call to some maximum number of invocations per unit of time.
Applicability
The Throttle pattern is named after a device used to manage the flow of a fluid, such as the amount of fuel going into a car engine. Like its namesake mechanism, Throttle restricts the number of times that a function can be called over a period of time. For example:
-
A user may be allowed only 10 service requests per second.
-
A client may restrict itself to call a particular function once every 500 milliseconds.
-
An account may be allowed only three failed login attempts in a 24-hour period.
Perhaps the most common reason to apply a Throttle is to account for sharp activity spikes that could saturate the system with a possibly unreasonable number of requests that may be expensive to satisfy, or lead to service degradation and eventually failure. While it may be possible for a system to scale up to add sufficient capacity to meet user demand, this takes time, and the system may not be able to react quickly enough.
Participants
This pattern includes the following participants:
- Effector
-
The function to regulate
- Throttle
-
A function that accepts Effector and returns a closure with the same function signature as Effector
Implementation
The Throttle pattern is similar to many of the other patterns described in this chapter: it’s implemented as a function that accepts an effector function and returns a Throttle closure with the same signature that provides the rate-limiting logic.
The most common algorithm for implementing rate-limiting behavior is the token bucket, which uses the analogy of a bucket that can hold some maximum number of tokens. When a function is called, a token is taken from the bucket, which then refills at some fixed rate.
The way that a Throttle treats requests when there are insufficient tokens in the bucket to pay for it can vary depending on the needs of the developer. Some common strategies are as follows:
- Return an error
-
This is the most basic strategy and is common when you’re only trying to restrict unreasonable or potentially abusive numbers of client requests. A RESTful service adopting this strategy might respond with a status
429 (Too Many Requests). - Replay the response of the last successful function call
-
This strategy can be useful when a service or expensive function call is likely to provide an identical result if called too soon. It’s commonly used in the JavaScript world.
- Enqueue the request for execution when sufficient tokens are available
-
This approach can be useful when you want to eventually handle all requests, but it’s also more complex and may require taking care to ensure that memory isn’t exhausted.
Sample code
The following example implements a basic “token bucket” algorithm that uses the “error” strategy:
typeEffectorfunc(context.Context)(string,error)funcThrottle(eEffector,maxuint,refilluint,dtime.Duration)Effector{vartokens=maxvaroncesync.Oncevarmsync.Mutexreturnfunc(ctxcontext.Context)(string,error){ifctx.Err()!=nil{return"",ctx.Err()}once.Do(func(){ticker:=time.NewTicker(d)gofunc(){deferticker.Stop()for{select{case<-ctx.Done():returncase<-ticker.C:m.Lock()t:=tokens+refillift>max{t=max}tokens=tm.Unlock()}}}()})m.Lock()deferm.Unlock()iftokens<=0{return"",fmt.Errorf("too many calls")}tokens--returne(ctx)}}
This Throttle implementation is similar to our other examples in that it wraps an effector function e with a closure that contains the rate-limiting logic. The bucket is initially allocated max tokens; each time the closure is triggered, it checks whether it has any remaining tokens. If tokens are available, it decrements the token count by one and triggers the effector function. If not, an error is returned. Tokens are added at a rate of refill tokens every duration d.
Timeout
Timeout allows a process to stop waiting for an answer once it’s clear that an answer may not be coming.
Applicability
The first of the fallacies of distributed computing is that “the network is reliable,” and it’s first for a reason. Switches fail, routers and firewalls get misconfigured, packets get blackholed. Even if your network is working perfectly, not every service is thoughtful enough to guarantee a meaningful and timely response—or any response at all—if and when it malfunctions.
Timeout represents a common solution to this dilemma and is so beautifully simple that it barely even qualifies as a pattern at all: given a service request or function call that’s running for a longer-than-expected time, the caller simply…stops waiting.
However, don’t mistake “simple” or “common” for “useless.” On the contrary, the ubiquity of the timeout strategy is a testament to its usefulness. The judicious use of timeouts can provide a degree of fault isolation, preventing cascading failures and reducing the chance that a problem in a downstream resource becomes your problem.
Participants
This pattern includes the following participants:
- Client
-
The client who wants to execute SlowFunction
- SlowFunction
-
The long-running function that implements the functionality desired by Client
- Timeout
-
A wrapper function around SlowFunction that implements the timeout logic
Implementation
There are several ways to implement a timeout in Go, but the most idiomatic way is to use the functionality provided by the context package. See “The Context Package” for more information.
In an ideal world, any possibly long-running function will accept a context.Context parameter directly. If so, your work is fairly straightforward: you need only pass it a Context value decorated with the context.WithTimeout function:
ctx,cancel:=context.WithTimeout(context.Background(),10*time.Second)defercancel()result,err:=SomeFunction(ctx)
However, this isn’t always the case, and with third-party libraries you don’t always have the option of refactoring to accept a Context value. In these cases, the best course
of action may be to wrap the function call in such a way that it does respect your
Context.
For example, imagine you have a potentially long-running function that not only doesn’t accept a Context value but comes from a package you don’t control. If Client were to call SlowFunction directly, it would be forced to wait until the function completes, if indeed it ever does. Now what?
Instead of calling SlowFunction directly, you can call it in a goroutine. This way you can capture the results if it returns in an acceptable period of time, but you can also move on if it doesn’t.
Warning
Timing out doesn’t actually cancel SlowFunction. If it doesn’t end somehow, the result will be a goroutine leak. See “Goroutines” for more on this phenomenon.
To do this, we can leverage a few tools that we’ve seen before: context.Context for timeouts, channels for communicating results, and select to catch whichever one acts first.
Sample code
The following example imagines the existence of the fictional function, Slow, whose execution may or may not complete in some reasonable amount of time and whose signature conforms with the following type definition:
typeSlowFunctionfunc(string)(string,error)
Rather than calling Slow directly, we instead provide a Timeout function, which wraps a provided SlowFunction in a closure and returns a WithContext function, which adds a context.Context to the SlowFunction’s parameter list:
typeWithContextfunc(context.Context,string)(string,error)funcTimeout(fSlowFunction)WithContext{returnfunc(ctxcontext.Context,argstring)(string,error){ch:=make(chanstruct{resultstringerrerror},1)gofunc(){res,err:=f(arg)ch<-struct{resultstringerrerror}{res,err}}()select{caseres:=<-ch:returnres.result,res.errcase<-ctx.Done():return"",ctx.Err()}}}
Within the function that Timeout constructs, the SlowFunction is run in a goroutine, with its return values being wrapped in a struct and sent into a channel constructed for that purpose, assuming it completes in time.
The next statement select’s on two channels: the SlowFunction function response channel and the Context value’s Done channel. If the former completes first, the closure will return the SlowFunction’s return values; otherwise, it returns the error provided by the Context.
Tip
If the SlowFunction is slow because it’s expensive, a possible improvement would be to check whether ctx.Err() returns a non-nil value before calling the goroutine.
Using the Timeout function isn’t much more complicated than consuming Slow directly, except that instead of one function call, we have two: the call to Timeout to retrieve the closure and the call to the closure itself:
funcmain(){ctx,cancel:=context.WithTimeout(context.Background(),time.Second)defercancel()timeout:=Timeout(Slow)res,err:=timeout(ctx,"some input")fmt.Println(res,err)}
Finally, although it’s usually preferred to implement service timeouts using
context.Context, channel timeouts can also be implemented using the channel provided by the time.After function. See “Implementing channel timeouts” for an example of how this is done.
Concurrency Patterns
A cloud native service will often be called upon to efficiently juggle multiple processes and handle high (and highly variable) levels of load, ideally without having to suffer the trouble and expense of scaling up. As such, it needs to be highly concurrent and able to manage multiple simultaneous requests from multiple clients. While Go is known for its concurrency support, bottlenecks can and do happen. Some of the patterns that have been developed to prevent them are presented here.
For the sake of simplicity, the code examples in this section don’t implement context cancellation. Generally, you shouldn’t have too much difficulty adding it on your own.
Fan-In
Fan-in multiplexes multiple input channels onto one output channel.
Applicability
Services that have some number of workers that all generate output may find it useful to combine all of the workers’ outputs to be processed as a single unified stream. For these scenarios we use the fan-in pattern, which can read from multiple input channels by multiplexing them onto a single destination channel.
Participants
This pattern includes the following participants:
- Sources
-
A set of one or more input channels with the same type. Accepted by Funnel.
- Destination
-
An output channel of the same type as Sources. Created and provided by Funnel.
- Funnel
-
Accepts Sources and immediately returns Destination. Any input from any Sources will be output by Destination.
Implementation
Funnel is implemented as a function that receives zero to N input channels (Sources). For each input channel in Sources, the Funnel function starts a separate goroutine to read values from its assigned channel and forward them to a single output channel shared by all of the goroutines (Destination).
Sample code
The Funnel function is a variadic function that receives sources: zero to N channels of some type (int in the following example):
funcFunnel(sources...<-chanint)<-chanint{dest:=make(chanint)// The shared output channelwg:=sync.WaitGroup{}// Used to automatically close dest// when all sources are closedwg.Add(len(sources))// Set size of the WaitGroupfor_,ch:=rangesources{// Start a goroutine for each sourcegofunc(ch<-chanint){deferwg.Done()// Notify WaitGroup when ch closesforn:=rangech{dest<-n}}(ch)}gofunc(){// Start a goroutine to close destwg.Wait()// after all sources closeclose(dest)}()returndest}
For each channel in the list of sources, Funnel starts a dedicated goroutine that reads values from its assigned channel and forwards them to dest, a single-output channel shared by all of the goroutines.
Note the use of a sync.WaitGroup to ensure that the destination channel is closed appropriately. Initially, a WaitGroup is created and set to the total number of source channels. If a channel is closed, its associated goroutine exits, calling wg.Done. When all of the channels are closed, the WaitGroup’s counter reaches zero, the lock imposed by wg.Wait is released, and the dest channel is closed.
Using Funnel is reasonably straightforward: given N source channels (or a slice of N channels), pass the channels to Funnel. The returned destination channel may be read in the usual way and will close when all source channels close:
funcmain(){varsources[]<-chanint// Declare an empty channel slicefori:=0;i<3;i++{ch:=make(chanint)sources=append(sources,ch)// Create a channel; add to sourcesgofunc(){// Run a toy goroutine for eachdeferclose(ch)// Close ch when the routine endsfori:=1;i<=5;i++{ch<-itime.Sleep(time.Second)}}()}dest:=Funnel(sources...)ford:=rangedest{fmt.Println(d)}}
This example creates a slice of three int channels, into which the values from 1 to 5 are sent before being closed. In a separate goroutine, the outputs of the single dest channel are printed. Running this will result in the appropriate 15 lines being printed before dest closes and the function ends.
Fan-Out
Fan-out evenly distributes messages from an input channel to multiple output channels.
Applicability
Fan-out receives messages from an input channel, distributing them evenly among output channels, and is a useful pattern for parallelizing CPU and I/O utilization.
For example, imagine that you have an input source, such as a Reader on an input stream or a listener on a message broker that provides the inputs for some resource-intensive unit of work. Rather than coupling the input and computation processes, which would confine the effort to a single serial process, you might prefer to parallelize the workload by distributing it among some number of concurrent worker
processes.
Participants
This pattern includes the following participants:
- Source
-
An input channel. Accepted by Split.
- Destinations
-
An output channel of the same type as Source. Created and provided by Split.
- Split
-
A function that accepts Source and immediately returns Destinations. Any input from Source will be output to a Destination.
Implementation
Fan-out may be relatively conceptually straightforward, but the devil is in the details.
Typically, fan-out is implemented as a Split function, which accepts a single Source channel and integer representing the desired number of Destination channels. The Split function creates the Destination channels and executes some background process that retrieves values from Source channel and forwards them to one of the Destinations.
The implementation of the forwarding logic can be done in one of two ways:
-
Using a single goroutine that reads values from Source and forwards them to the Destinations in a round-robin fashion. This has the virtue of requiring only one master goroutine, but if the next channel isn’t ready to read yet, it’ll slow the entire process.
-
Using separate goroutines for each Destination that compete to read the next value from Source and forward it to their respective Destination. This requires slightly more resources but is less likely to get bogged down by a single slow-running worker.
The next example uses the latter approach.
Sample code
In this example, the Split function accepts a single receive-only channel, source, and an integer describing the number of channels to split the input into, n. It returns a slice of n send-only channels with the same type as source.
Internally, Split creates the destination channels. For each channel created, it executes a goroutine that retrieves values from source in a for loop and forwards them to their assigned output channel. Effectively, each goroutine competes for reads from source; if several are trying to read, the “winner” will be randomly determined. If source is closed, all goroutines terminate and all of the destination channels are closed:
funcSplit(source<-chanint,nint)[]<-chanint{vardests[]<-chanint// Declare the dests slicefori:=0;i<n;i++{// Create n destination channelsch:=make(chanint)dests=append(dests,ch)gofunc(){// Each channel gets a dedicateddeferclose(ch)// goroutine that competes for readsforval:=rangesource{ch<-val}}()}returndests}
Given a channel of some specific type, the Split function will return a number of destination channels. Typically, each will be passed to a separate goroutine, as demonstrated in the following example:
funcmain(){source:=make(chanint)// The input channeldests:=Split(source,5)// Retrieve 5 output channelsgofunc(){// Send the number 1..10 to sourcefori:=1;i<=10;i++{// and close it when we're donesource<-i}close(source)}()varwgsync.WaitGroup// Use WaitGroup to wait untilwg.Add(len(dests))// the output channels all closefori,d:=rangedests{gofunc(iint,d<-chanint){deferwg.Done()forval:=ranged{fmt.Printf("#%d got %d\n",i,val)}}(i,d)}wg.Wait()}
This example creates an input channel, source, which it passes to Split to receive its output channels. Concurrently, it passes the values 1 to 10 into source in a goroutine while receiving values from dests in 5 others. When the inputs are complete, the source channel is closed, which triggers closures in the output channels, which ends the read loops, which causes wg.Done to be called by each of the read goroutines, which releases the lock on wg.Wait and allows the function to end.
Future
Future provides a placeholder for a value that’s not yet known.
Applicability
Futures (also known as Promises or Delays)6 are a synchronization construct that provide a placeholder for a value that’s still being generated by an asynchronous process.
This pattern isn’t used as frequently in Go as in some other languages because channels can often be used in a similar way. For example, the long-running blocking function BlockingInverse (not shown) can be executed in a goroutine that returns the result (when it arrives) along a channel. The ConcurrentInverse function that follows does exactly that, returning a channel that can be read when a result becomes available:
funcConcurrentInverse(mMatrix)<-chanMatrix{out:=make(chanMatrix)gofunc(){out<-BlockingInverse(m)close(out)}()returnout}
Using ConcurrentInverse, one could then build a function to calculate the inverse product of two matrices:
funcInverseProduct(a,bMatrix)Matrix{inva:=ConcurrentInverse(a)invb:=ConcurrentInverse(b)returnProduct(<-inva,<-invb)}
This doesn’t seem so bad, but it comes with some baggage that makes it undesirable for something like a public API. First, the caller has to be careful to call
ConcurrentInverse with the correct timing. To see what I mean, take a close look at the following:
returnProduct(<-ConcurrentInverse(a),<-ConcurrentInverse(b))
See the problem? Since the computation isn’t started until ConcurrentInverse is actually called, this construct would be effectively executed serially, requiring twice the runtime.
What’s more, when using channels this way, functions with more than one return value will usually assign a dedicated channel to each member of the return list, which can become awkward as the return list grows or when the values need to be read by more than one goroutine.
The Future pattern contains this complexity by encapsulating it in an API that provides the consumer with a simple interface whose method can be called normally, blocking all calling routines until all of its results are resolved. The interface that the value satisfies doesn’t even have to be constructed specially for that purpose; any interface that’s convenient for the consumer can be used.
Participants
This pattern includes the following participants:
- Future
-
The interface that is received by the consumer to retrieve the eventual result
- SlowFunction
-
A wrapper function around some function to be asynchronously executed; provides Future
- InnerFuture
-
Satisfies the Future interface; includes an attached method that contains the result access logic
Implementation
The API presented to the consumer is fairly straightforward: the programmer calls SlowFunction, which returns a value that satisfies the Future interface. Future may be a bespoke interface, as in the following example, or it may be something more like an io.Reader that can be passed to its own functions.
In actuality, when SlowFunction is called, it executes the core function of interest as a goroutine. In doing so, it defines channels to capture the core function’s output, which it wraps in InnerFuture.
InnerFuture has one or more methods that satisfy the Future interface, which retrieve the values returned by the core function from the channels, cache them, and return them. If the values aren’t available on the channel, the request blocks. If they have already been retrieved, the cached values are returned.
Sample code
In this example, we use a Future interface that the InnerFuture will satisfy:
typeFutureinterface{Result()(string,error)}
The InnerFuture struct is used internally to provide the concurrent functionality. In this example, it satisfies the Future interface but could just as easily choose to satisfy something like io.Reader by attaching a Read method, if you prefer:
typeInnerFuturestruct{oncesync.Oncewgsync.WaitGroupresstringerrerrorresCh<-chanstringerrCh<-chanerror}func(f*InnerFuture)Result()(string,error){f.once.Do(func(){f.wg.Add(1)deferf.wg.Done()f.res=<-f.resChf.err=<-f.errCh})f.wg.Wait()returnf.res,f.err}
In this implementation, the struct itself contains a channel and a variable for each value returned by the Result method. When Result is first called, it attempts to read the results from the channels and send them back to the InnerFuture struct so that subsequent calls to Result can immediately return the cached values.
Note the use of sync.Once and sync.WaitGroup. The former does what it says on the tin: it ensures that the function that’s passed to it is called exactly once. The WaitGroup is used to make this function call thread safe: any calls after the first will be blocked at wg.Wait until the channel reads are complete.
SlowFunction is a wrapper around the core functionality that you want to run concurrently. It has the job of creating the results channels, running the core function in a goroutine, and creating and returning the Future implementation (InnerFuture, in this example):
funcSlowFunction(ctxcontext.Context)Future{resCh:=make(chanstring)errCh:=make(chanerror)gofunc(){select{case<-time.After(2*time.Second):resCh<-"I slept for 2 seconds"errCh<-nilcase<-ctx.Done():resCh<-""errCh<-ctx.Err()}}()return&InnerFuture{resCh:resCh,errCh:errCh}}
To make use of this pattern, you need only call the SlowFunction and use the returned Future as you would any other value:
funcmain(){ctx:=context.Background()future:=SlowFunction(ctx)// Do stuff while SlowFunction chugs along in the background.res,err:=future.Result()iferr!=nil{fmt.Println("error:",err)return}fmt.Println(res)}
This approach provides a reasonably good user experience. The programmer can create a Future and access it as they wish, and can even apply timeouts or deadlines with a Context.
Sharding
Sharding splits a large data structure into multiple partitions to localize the effects of read/write locks.
Applicability
The term sharding is typically used in the context of distributed state to describe data that is partitioned between server instances. This kind of horizontal sharding is commonly used by databases and other data stores to distribute load and provide redundancy.
A slightly different issue can sometimes affect highly concurrent services that have a shared data structure with a locking mechanism to protect it from conflicting writes. In this scenario, the locks that serve to ensure the fidelity of the data can also create a bottleneck when processes start to spend more time waiting for locks than they do doing their jobs. This unfortunate phenomenon is called lock contention.
While this might be resolved in some cases by scaling the number of instances, this also increases complexity and latency, because distributed locks need to be established, and writes need to establish consistency. An alternative strategy for reducing lock contention around shared data structures within an instance of a service is vertical sharding, in which a large data structure is partitioned into two or more structures, each representing a part of the whole. Using this strategy, only a portion of the overall structure needs to be locked at a time, decreasing overall lock contention.
Participants
This pattern includes the following participants:
- ShardedMap
-
An abstraction around one or more Shards providing read and write access as if the Shards were a single map
- Shard
-
An individually lockable collection representing a single data partition
Implementation
While idiomatic Go generally prefers the use of memory sharing via channels over using locks to protect shared resources,7 this isn’t always possible. Maps are particularly unsafe for concurrent use, making the use of locks as a synchronization mechanism a necessary evil. Fortunately, Go provides sync.RWMutex for precisely this purpose. You may recall sync.RWMutex from “Mutexes”.
This strategy generally works well enough. However, because locks allow access to only one process at a time, the average amount of time spent waiting for locks to clear in a read/write intensive application can increase dramatically with the number of concurrent processes acting on the resource. The resulting lock contention can potentially bottleneck key functionality.
Vertical sharding reduces lock contention by splitting the underlying data structure—usually a map—into several individually lockable maps. An abstraction layer provides access to the underlying shards as if they were a single structure (see Figure 4-5).
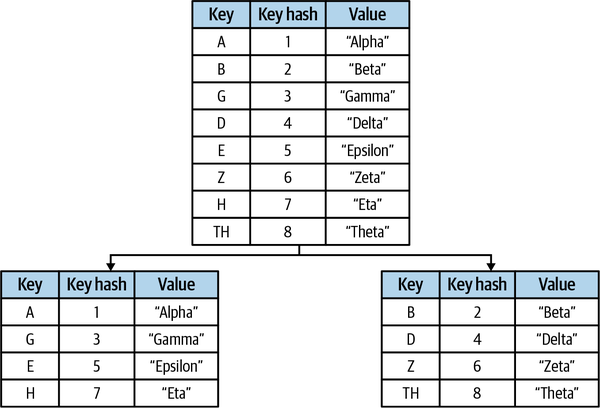
Figure 4-5. Vertically sharding a map by key hash.
Internally, this is accomplished by creating an abstraction layer around what is essentially a map of maps. Whenever a value is read or written to the map abstraction, a hash value is calculated for the key, which is then modded by the number of shards to generate a shard index. This allows the map abstraction to isolate the necessary locking to only the shard at that index.
Sample code
In the following example, we use the standard sync and hash/fnv packages to implement a basic sharded map: ShardedMap.
Internally, ShardedMap is just a slice of pointers to some number of Shard values, but we define it as a type so we can attach methods to it. Each Shard includes
a map[string]any that contains that shard’s data and a composed
sync.RWMutex so that it can be individually locked:
typeShard[Kcomparable,Vany]struct{sync.RWMutex// Compose from sync.RWMutexitemsmap[K]V// m contains the shard's data}typeShardedMap[Kcomparable,Vany][]*Shard[K,V]
Go doesn’t have Java-style constructors, so we provide a NewShardedMap function to retrieve a new ShardedMap:
funcNewShardedMap[Kcomparable,Vany](nshardsint)ShardedMap[K,V]{shards:=make([]*Shard[K,V],nshards)// Initialize a *Shards slicefori:=0;i<nshards;i++{shard:=make(map[K]V)shards[i]=&Shard[K,V]{items:shard}// A ShardedMap IS a slice!}returnshards}
ShardedMap has two unexported methods, getShardIndex and getShard, which are used to calculate a key’s shard index and retrieve a key’s correct shard, respectively. These could be easily combined into a single method, but splitting them this way makes them easier to test:8
func(mShardedMap[K,V])getShardIndex(keyK)int{str:=reflect.ValueOf(key).String()// Get string representation of keyhash:=fnv.New32a()// Get a hash implementationhash.Write([]byte(str))// Write bytes to the hashsum:=int(hash.Sum32())// Get the resulting checksumreturnsum%len(m)// Mod by len(m) to get index}func(mShardedMap[K,V])getShard(keyK)*Shard[K,V]{index:=m.getShardIndex(key)returnm[index]}
To get the index, we first compute the hash of the string representation of the value, from which we calculate our final value by modding it against the number of shards. This definitely isn’t the most computationally efficient way to go about generating a hash, but it’s conceptually simple and works well enough for an example.
The precise hash algorithm doesn’t really matter very much—we use the FNV-1a hash function in this example—as long as it’s deterministic and provides a reasonably uniform value distribution.
Finally, we add methods to ShardedMap to allow a user to read and write values. Obviously, these don’t demonstrate all of the functionality a map might need. The source for this example is in the GitHub repository associated with this book, however, so please feel free to implement them as an exercise. A Delete and a Contains method would be nice:
func(mShardedMap[K,V])Get(keyK)V{shard:=m.getShard(key)shard.RLock()defershard.RUnlock()returnshard.items[key]}func(mShardedMap[K,V])Set(keyK,valueV){shard:=m.getShard(key)shard.Lock()defershard.Unlock()shard.items[key]=value}
When you do need to establish locks on all of the tables, it’s generally best to do so concurrently. In the following, we implement a Keys function using goroutines and our old friend sync.WaitGroup:
func(mShardedMap[K,V])Keys()[]K{varkeys[]K// Declare an empty keys slicevarmutexsync.Mutex// Mutex for write safety to keysvarwgsync.WaitGroup// Create a wait group and add awg.Add(len(m))// wait value for each slicefor_,shard:=rangem{// Run a goroutine for each slice in mgofunc(s*Shard[K,V]){s.RLock()// Establish a read lock on sdeferwg.Done()// Release of the read lockdefers.RUnlock()// Tell the WaitGroup it's doneforkey,_:=ranges.items{// Get the slice's keysmutex.Lock()keys=append(keys,key)mutex.Unlock()}}(shard)}wg.Wait()// Block until all goroutines are donereturnkeys// Return combined keys slice}
Using ShardedMap isn’t quite like using a standard map, unfortunately, but while it’s different, it’s no more complicated:
funcmain(){m:=NewShardedMap[string,int](5)keys:=[]string{"alpha","beta","gamma"}fori,k:=rangekeys{m.Set(k,i+1)fmt.Printf("%5s: shard=%d value=%d\n",k,m.getShardIndex(k),m.Get(k))}fmt.Println(m.Keys())}
Output:
alpha: shard=3 value=1 beta: shard=2 value=2 gamma: shard=0 value=3 [gamma beta alpha]
Prior to Go 1.21 (and in the previous edition of this book), the ShardedMap had to be constructed with any type values, at least if it was going to be reusable. However, this came with the loss of type safety associated with the use of any and the subsequent requirement of type assertions. Fortunately, with the release of Go generics, this is a solved problem.
Worker Pool
A worker pool directs multiple processes to concurrently execute work on a collection of input.
Applicability
Probably one of the most commonly used of the patterns in this chapter, a worker pool (or a “thread pool” in pretty much any other language) is a pattern used in many languages to efficiently manage the execution of multiple concurrent tasks by using a fixed number of workers.
Worker pools are very good at managing tasks that you want to run concurrently, but only to a point. Common applications include things like handling multiple incoming requests, processing task queues, handling steps in data pipelines, and executing long-duration batch processing jobs.
Participants
This pattern includes the following participants:
- Worker
-
A function that does some work on items from Jobs and sends the results to Results
- Jobs
-
A channel from which Worker receives the raw data to be worked on
- Results
-
A channel into which Worker sends the results of its work
Implementation
Programmers coming from other languages may be familiar with the concept of the “thread pool”: a group of threads that are standing by to do some work. This is a useful concurrency pattern in any language, but thread pools can often be tedious and sometimes complicated to work with.9
Fortunately, Go’s concurrency features—goroutines and channels—make it especially well-suited for building something like this. As such, our implementation is rather straightforward relative to many other languages: what we call a “worker” is really just a goroutine10 (Worker) that receives input data on an input channel (Jobs) and returns that work along an output channel (Results).
Both channels are shared among all workers, so any work sent along the jobs channel will be done by the first available worker. Importantly, each worker lives only as long as the jobs channel is open: they’re designed to automatically terminate once their job is done.
Sample code
If you’re accustomed to working with thread pools in other languages, you’ll hopefully find our example of a worker pool to be refreshingly simple. In my opinion, this pattern highlights the elegance of the design around Go’s concurrency features particularly well.
The meat of the pattern is the worker, which (as its name implies) does the work. Below is the blueprint for a single worker function:
funcworker(idint,jobs<-chanint,resultschan<-int){forj:=rangejobs{fmt.Println("Worker",id,"started job",j)time.Sleep(time.Second)results<-j*2}}
As you can see, this example worker is a fairly standard function that accepts a job channel for sending work to it, and results channels for sending the results of the work out. This implementation also takes an id integer, which is just used for demonstration purposes.
This worker’s functionality is pretty trivial, reading an int value from the jobs channel and (after a brief pause to simulate effort) writing that value’s double out via the results channel. Note that it’ll automatically exit when the jobs channel closes.
Warning
You should always know how and when any goroutine you create is going to terminate, or you risk creating a goroutine leak.
Now, if we were using just one worker, this wouldn’t be much more useful than just looping over the inputs and doing the computation one by one. But of course, as you’ve probably already inferred, we won’t be using just one worker:
funcmain(){jobs:=make(chanint,10)results:=make(chanint)wg:=sync.WaitGroup{}forw:=1;w<=3;w++{// Spawn 3 workers processesgoworker(w,jobs,results)}forj:=1;j<=10;j++{// Send jobs to workerswg.Add(1)jobs<-j}gofunc(){wg.Wait()close(jobs)close(results)}()forr:=rangeresults{fmt.Println("Got result:",r)wg.Done()}}
In this example, we start by creating the two channels: job to put work into and results to receive the completed work from. We also create a sync.WaitGroup, which lets us pause until all the work is done.
Now the interesting bit: we use the go keyword to start three workers, passing both channels into each. We haven’t given them any work to do yet, so they’re all blocked waiting for jobs.
Now that we have the workers in place, let’s see what they can do by sending them some work units via the job channel. Each work unit is received and processed by exactly one of the three workers. Finally, we read the results coming from the results channel until it’s closed by the goroutine.
This pattern may strike you as trivial, and that’s okay. But it demonstrates how, with a couple of channels and goroutines, we can create a fully functional worker pool in Go.
Chord
The Chord (or Join) pattern performs an atomic consumption of messages from each member of a group of channels.
Applicability
In music, a chord is a group of multiple notes sounded together to produce a harmony. Like its namesake musical concept, the Chord pattern consists of multiple signals being sent together, in this case along channels, to produce a single output.
More specifically, the Chord pattern receives inputs from multiple channels but emits a value only when all its channels have emitted a value.
This could be a useful pattern if, for example, you need to receive inputs from multiple monitored data sources before acting.
Participants
This pattern includes the following participants:
- Sources
-
A set of one or more input channels with the same type. Accepted by Chord.
- Destination
-
An output channel of the same type as Sources. Created and provided by Chord.
- Chord
-
Accepts Sources and immediately returns Destination. Any input from any Sources will be output by Destination.
Implementation
The Chord pattern is very similar to “Fan-In” in that it concurrently reads inputs from multiple Sources channels and emits them back to the Destination channel, but that’s where the similarity ends. Where Fan-In immediately forwards all inputs, Chord waits to act until it’s received at least one value from each of its source channels, then it packages all the values into a slice and sends it on the Destination channel.
In fact, the first half of this pattern, which retrieves values from Sources and sends them into an intermediate channel for processing, looks and acts exactly like a Fan-In, to the extent that Chord can reasonably be considered an extension of Fan-In.
It’s that last half, though, that makes this pattern interesting. It’s this part that keeps track of which channels have sent messages since the last output, and for packaging the most recent inputs from each channel into a slice to be sent to Destination.
Sample code
Chord is probably the most conceptually complex pattern described in this chapter (which is why I saved it for last). However, as mentioned previously, the first half of the following example is taken directly from “Fan-In”.
Since you’re (hopefully) a Fan-in expert at this point, you’ll probably see that pattern in the first half or so of the following Chord function:
funcChord(sources...<-chanint)<-chan[]int{typeinputstruct{// Used to send inputsidx,inputint// between goroutines}dest:=make(chan[]int)// The output channelinputs:=make(chaninput)// An intermediate channelwg:=sync.WaitGroup{}// Used to close channels whenwg.Add(len(sources))// all sources are closedfori,ch:=rangesources{// Start goroutine for each sourcegofunc(iint,ch<-chanint){deferwg.Done()// Notify WaitGroup when ch closesforn:=rangech{inputs<-input{i,n}// Transfer input to next goroutine}}(i,ch)}gofunc(){wg.Wait()// Wait for all sources to closeclose(inputs)// then close inputs channel}()gofunc(){res:=make([]int,len(sources))// Slice for incoming inputssent:=make([]bool,len(sources))// Slice to track sent statuscount:=len(sources)// Counter for channelsforr:=rangeinputs{res[r.idx]=r.input// Update incoming inputif!sent[r.idx]{// First input from channel?sent[r.idx]=truecount--}ifcount==0{c:=make([]int,len(res))// Copy and send inputs slicecopy(c,res)dest<-ccount=len(sources)// Reset counterclear(sent)// Clear status tracker}}close(dest)}()returndest}
Looking closely, you’ll notice that Chord is composed of three key sections.
The first is a for loop that spawns a number of goroutines, one for each channel in sources. When any of these receives a value from its respective channel, it sends both its channel’s index and the value received to the intermediate inputs channel to be picked up by another goroutine. When a sources channel closes, the goroutine watching it ends as well, decrementing the WaitGroup counter in the process.
The next section is a goroutine whose only job is to wait for the WaitGroup. When all of the sources channels close, the lock is released, and the intermediate inputs channel is closed.
Finally, the last goroutine’s purpose is to read input values from the intermediate inputs channel and determine whether all channels in sources have sent a value yet. Whenever a value is received from an input channel, the res slice is updated at the appropriate index with the value. If this is the first time receiving a value from a particular channel, the count counter is decremented.
Once count hits zero, a few things happen: the res slice (which contains all of the most recent inputs from all the sources channels) is copied and sent into the destination channel, the count counter is reset, and the sent slice is cleared. With that, Chord is reset for another read cycle.
Note how we copy the res slice before sending it. This is a safety feature made necessary by the fact that slices are a pointer type, so if we don’t make a copy in this way, subsequent inputs could cause the slice to be modified as it’s being used elsewhere.
Now let’s see Chord in action:
funcmain(){ch1:=make(chanint)ch2:=make(chanint)ch3:=make(chanint)gofunc(){forn:=1;n<=4;n++{ch1<-nch1<-n*2// Writing twice to ch1!ch2<-nch3<-ntime.Sleep(time.Second)}close(ch1)// Closing all input channelsclose(ch2)// causes res to be closed asclose(ch3)// as well}()res:=Chord(ch1,ch2,ch3)fors:=rangeres{// Read resultsfmt.Println(s)}}
The first thing that this function does is create some input channels, which we’ll be sending some data to see how Chord behaves.
It then spawns a goroutine that sends some data into the channels, closing them all when it’s done sending. Note the double send to the ch1 channel.
Running this produces a nice, consistent output and terminates normally:
[2 1 1] [4 2 2] [6 3 3] [8 4 4]
This output tells us two things. First, the program terminated normally, so we know that the res channel indeed closed when all of the input channels closed, breaking the final for loop as expected. Second, the values in position 0 of each of the output slices reflects the second value sent into ch1, highlighting that this Chord implementation responds with the most recently sent values.
Summary
This chapter covered quite a few very interesting—and useful—idioms. There are probably many more,11 but these are the ones I felt were most important, either because they’re somehow practical in a directly applicable way or because they showcase some interesting feature of the Go language. Often both.
In Chapter 5, we’ll move on to the next level, taking some of the things we discussed in Chapters 3 and 4 and putting them into practice by building a simple key-value store from scratch!
1 Spoken August 1979. Attested to by Vicki Almstrum, Tony Hoare, Niklaus Wirth, Wim Feijen, and Rajeev Joshi. In Pursuit of Simplicity: A Symposium Honoring Professor Edsger Wybe Dijkstra, May 12–13, 2000.
2 L (yes, his legal name is L) is a brilliant and fascinating human being. Look him up some time.
3 Pun unavoidable.
4 Erich Gamma et al., Design Patterns: Elements of Reusable Object-Oriented Software, 1st ed. (Addison-Wesley Professional, 1994).
5 If you prefer boring names.
6 While these terms are often used interchangeably, they can also have shades of meaning depending on their context. I know. Please don’t write me any angry letters about this.
7 See the article, “Share Memory by Communicating”, The Go Blog.
8 If you’re into that kind of thing.
9 Java developers, you know what I’m talking about.
10 Which is why we call it a “worker pool” instead of a “thread pool.”
11 Did I leave out your favorite? Let me know, and I’ll try to include it in the next edition!
Get Cloud Native Go, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

