Capítulo 1. Tomar mejores decisiones basadas en datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
El objetivo principal del análisis de datos es tomar mejores decisiones. Rara vez tenemos necesidad de dedicar tiempo a analizar datos si no estamos bajo presión para tomar una decisión basada en los resultados de ese análisis. Cuando vas a comprar un coche, puedes preguntar al vendedor el año de fabricación y la lectura del cuentakilómetros. Conocer la antigüedad del coche te permite estimar su valor potencial. Dividir la lectura del cuentakilómetros entre la edad del coche te permite discernir cuánto se ha conducido el coche, y si es probable que dure los cinco años que piensas quedártelo. Si no te hubiera importado comprar el coche, no habrías tenido necesidad de hacer este análisis de datos.
De hecho, podemos ir más lejos: el objetivo de la recogida de datos es, en muchos casos, sólo para que luego puedas realizar un análisis de datos y tomar decisiones basadas en ese análisis (véase la Figura 1-1). Cuando preguntaste al vendedor la antigüedad del coche y su kilometraje, estabas recopilando datos para llevar a cabo tu análisis de datos. Pero va más allá de tu recogida de datos. En primer lugar, el coche tiene un cuentakilómetros porque muchas personas, no sólo los posibles compradores, tendrán que tomar decisiones basándose en el kilometraje del coche. La lectura del cuentakilómetros debe respaldar muchas decisiones: ¿debe el fabricante pagar por una transmisión averiada? ¿Es hora de cambiar el aceite? El análisis de cada una de estas decisiones es diferente, pero todas se basan en el hecho de que se han recogido los datos del kilometraje.
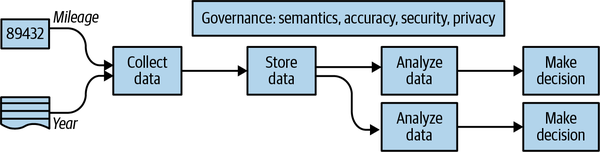
Figura 1-1. El objetivo de recopilar datos es tomar decisiones con ellos.
Si te dedicas a tomar muchas decisiones utilizando el kilometraje de tu coche, tiene sentido almacenar los datos que has recopilado para que sea más fácil tomar decisiones en el futuro. Recopilar datos requiere tiempo y esfuerzo, mientras que almacenarlos es relativamente barato. Por supuesto, tienes que planificar el almacenamiento de los datos de forma que sepas lo que significan cuando los necesites más adelante. Esto se llama capturar la semántica de los datos y es un aspecto importante de la gobernanza de datos, para garantizar que los datos sean útiles para la toma de decisiones.
La recogida de datos en una forma que permita tomar decisiones impone requisitos a la infraestructura de recogida y a la seguridad de dicha infraestructura. ¿Cómo sabe la compañía de seguros que recibe una reclamación por accidente y necesita pagar a su cliente el valor del coche que la lectura del cuentakilómetros es exacta? ¿Cómo se calibran los cuentakilómetros? ¿Qué tipo de salvaguardias existen para garantizar que el cuentakilómetros no ha sido manipulado? ¿Qué ocurre si la manipulación es involuntaria, como la instalación de neumáticos de un tamaño diferente al utilizado para calibrar el cuentakilómetros? La auditabilidad de los datos es importante siempre que haya varias partes implicadas, y la propiedad y el uso de los datos estén separados. Cuando los datos no son verificables, los mercados fracasan, no se pueden tomar decisiones óptimas, y las partes implicadas tienen que recurrir a la señalización y el escrutinio.1
No todos los datos son tan caros de recopilar y asegurar como la lectura del cuentakilómetros de un coche.2 El coste de los sensores se ha reducido drásticamente en las últimas décadas, y muchos de nuestros procesos cotidianos producen tantos datos que nos encontramos en posesión de datos que no teníamos intención de recoger explícitamente. Dado que el hardware para recopilar, ingerir y almacenar los datos se ha abaratado, a menudo optamos por retener los datos indefinidamente, manteniéndolos a nuestro alrededor sin ninguna razón discernible. A medida que aumenta el tamaño de los datos dentro de una organización, se hace cada vez más esencial organizarlos y catalogarlos cuidadosamente. Así que, si vamos a realizar análisis de todos estos datos que de alguna manera hemos conseguido recopilar y almacenar, más vale que tengamos un propósito para ellos. La mano de obra sigue siendo cara.
Otra razón para tener cuidado con los datos que recopilamos y almacenamos es que muchos de ellos son sobre personas. Conocer el kilometraje del coche que conduce alguien nos da mucha información sobre él, y es información que tal vez no quiera compartir más que con el fin específico de estimar el precio de mercado de su coche. La privacidad y la confidencialidad deben tenerse en cuenta incluso antes de recopilar los datos, para poder tomar las decisiones adecuadas sobre qué datos recopilar, cómo controlar el acceso a ellos y cuánto tiempo conservarlos. Esto es aún más importante cuando los datos se facilitan con un coste, un riesgo y/o una pérdida de autonomía corporal significativos, como es el caso de muchos datos biomédicos de pacientes. Contar con un experto en privacidad de datos para que examine tu esquema y tus prácticas de protección de datos es una inversión que se amortizará con creces en términos de cumplimiento normativo y relaciones públicas.
El análisis de datos suele desencadenarse porque hay que tomar una decisión. ¿Entrar en un mercado o no? ¿Pagar una comisión o no? ¿A cuánto subir el precio? ¿Cuántas bolsas comprar? ¿Comprar ahora o esperar una semana? Las decisiones se multiplican, y como ahora los datos son tan omnipresentes, ya no necesitamos tomar esas decisiones basándonos enla heurística de o en simples reglas empíricas. Ahora podemos tomar esas decisiones basándonos en datos.
Por supuesto, no necesitamos crear nosotros mismos los sistemas y herramientas para tomar todas las decisiones basadas en datos. El caso de uso de estimar el valor de un coche que ha sido conducido una cierta distancia es lo bastante común como para que haya varias empresas que lo ofrezcan como servicio: verificarán que el cuentakilómetros es exacto, confirmarán que el coche no ha tenido un accidente y compararán el precio de venta con el precio de venta típico de los coches de tu mercado. El valor real, por tanto, no está en tomar una decisión basada en datos una sola vez, sino en poder hacerlo sistemáticamente y ofrecerlo como un servicio.3 Esto también permite a las empresas especializarse en distintas áreas de negocio y mejorar continuamente la precisión y el valor de las decisiones que pueden tomarse.
Muchas decisiones similares
Debido a los bajos costes asociados a los sensores y el almacenamiento, hay muchas industrias y casos de uso que tienen el potencial de apoyar la toma de decisiones basada en datos. Si trabajas en una industria de este tipo, o quieres crear una empresa que se ocupe de un caso de uso de este tipo, las posibilidades de apoyar la toma de decisiones basada en datos acaban de ampliarse. En algunos casos, tendrás que recopilar los datos. En otros, tendrás acceso a datos ya recogidos y, en muchos casos, tendrás que complementar los datos que tienes con otros conjuntos de datos que tendrás que buscar. En todos estos casos, ser capaz de realizar análisis de datos para apoyar sistemáticamente la toma de decisiones en nombre de los usuarios es una de las habilidades más importantes que hay que poseer.
En este libro, tomaré una decisión que hay que tomar y aplicaré distintos métodos estadísticos y de aprendizaje automático para obtener información sobre la toma de esa decisión. Sin embargo, no queremos tomar esa decisión una sola vez, aunque de vez en cuando nos lo planteemos así. En lugar de eso, estudiaremos cómo tomar la decisión de forma sistemática, de modo que utilicemos el mismo algoritmo para tomar la decisión muchas, muchas, muchas veces. Nuestro objetivo final será proporcionar esta capacidad de decisión como un servicio a nuestros clientes: ellos nos dirán las cosas que razonablemente cabe esperar que sepan, y nosotros sabremos o deduciremos el resto (porque hemos estado recopilando datos sistemáticamente). Basándonos en estos datos, sugeriremos la decisión óptima.
Que una decisión sea o no puntual es la principal diferencia entre la analítica de datos y la ciencia de datos. La analítica de datos consiste en analizar manualmente los datos para tomar una única decisión o responder a una única pregunta. La ciencia de datos consiste en desarrollar una técnica (llamada modelo o algoritmo) para poder tomar decisiones similares de forma sistemática. A menudo, la ciencia de datos consiste en automatizar y optimizar el proceso de toma de decisiones que se determinó en primer lugar mediante el análisis de datos.4
Cuando recojamos los datos, tendremos que estudiar cómo hacer que los datos sean seguros. Esto incluirá cómo garantizar no sólo que los datos no han sido manipulados, sino también que la información privada de los usuarios no se ve comprometida: por ejemplo, si estamos recopilando sistemáticamente el kilometraje del cuentakilómetros y conocemos el kilometraje exacto del coche en cualquier momento, este conocimiento se convierte en información extremadamente sensible. Dada otra información suficiente sobre el cliente (como la dirección de su casa y los patrones de tráfico de la ciudad en la que vive), el kilometraje es suficiente para poder deducir la ubicación de esa persona en todo momento.5 Por tanto, las implicaciones para la privacidad de alojar algo tan aparentemente inocuo como el kilometraje de un coche pueden llegar a ser enormes. La seguridad implica que debemos controlar el acceso a los datos, y que debemos mantener registros de auditoría inmutables sobre quién ha visto o modificado los datos.
No basta con recoger los datos o utilizarlos tal cual. Debemos comprender los datos. Del mismo modo que necesitamos conocer los tipos de problemas asociados a la manipulación de cuentakilómetros para comprender los factores que intervienen en la estimación del valor de un vehículo en función del kilometraje, nuestros métodos de análisis tendrán que tener en cuenta cómo se recogieron los datos en tiempo real y los tipos de errores que podrían estar asociados a esos datos. El conocimiento íntimo de los datos y sus peculiaridades tiene un valor incalculable cuando se trata de hacer ciencia de datos: a menudo, la diferencia entre una idea para una startup de ciencia de datos que funciona y otra que no, es si se han evaluado y tenido en cuenta todos los matices apropiados.
Cuando se trata de proporcionar la capacidad de apoyo a la toma de decisiones como un servicio, no basta con tener una forma de hacerlo en algún sistema fuera de línea en algún lugar. Habilitarla como servicio implica toda una serie de otras preocupaciones. El primer conjunto de preocupaciones se refiere a la calidad de la propia decisión: ¿cuán precisa suele ser? ¿Cuáles son las fuentes típicas de error? ¿En qué situaciones no debería utilizarse este sistema? El siguiente conjunto de preocupaciones, sin embargo, se refiere a la calidad del servicio. ¿Cuál es su fiabilidad? ¿Cuántas consultas por segundo puede soportar? ¿Cuál es la latencia entre que un dato está disponible y se incorpora al modelo que se utiliza para tomar decisiones sistemáticas? En resumen, utilizaremos este único caso de uso como una forma de explorar muchas facetas diferentes de la ciencia de datos práctica.
El papel de los científicos de datos
"Espera un segundo", te imagino diciendo, "nunca me he apuntado a consultas por segundo de un servicio web. Tenemos gente que hace ese tipo de cosas. Mi trabajo consiste en escribir consultas SQL y crear informes. No reconozco esto de lo que hablas. No es lo que hago en absoluto". O quizá lo que te desconcertó fue la primera parte de la discusión. "¿Toma de decisiones? Eso es para los empresarios. ¿Yo? Lo que hago es diseñar sistemas de procesamiento de datos. Puedo aprovisionar infraestructuras, decirte lo que hacen nuestros sistemas en este momento y mantenerlo todo seguro. Ciencia de datos suena muy elegante, pero yo hago ingeniería. Cuando has dicho Ciencia de Datos en la Plataforma en la Nube de Google, pensaba que ibas a hablar de cómo mantener los sistemas en funcionamiento y cómo descargar ráfagas de actividad a la nube". Un tercer grupo de personas se pregunta: "¿Cómo es esto ciencia de datos? ¿Dónde está el debate sobre los distintos tipos de modelos y sobre cómo hacer inferencias estadísticas y evaluarlas? ¿Dónde están las matemáticas? ¿Por qué hablas con analistas de datos e ingenieros? Habla conmigo, que tengo un doctorado". Son puntos justos: parece que estoy mezclando los trabajos realizados por diferentes grupos de personas en tu organización.
En otras palabras, podrías estar de acuerdo con lo siguiente:
-
El análisis de datos está ahí para apoyar la toma de decisiones.
-
La toma de decisiones basada en datos puede ser superior a la heurística.
-
La precisión de los modelos de decisión depende de que elijas el enfoque estadístico o de aprendizaje automático adecuado.
-
Los matices en los datos pueden invalidar completamente tu modelización, por lo que comprender los datos y sus peculiaridades es crucial.
-
Existen grandes oportunidades de mercado en el apoyo sistemático a la toma de decisiones y en su prestación como servicio.
-
Tales servicios requieren una recogida de datos y una actualización de modelos continuas.
-
La recogida continua de datos implica una seguridad y una auditoría sólidas.
-
Los clientes del servicio exigen garantías de fiabilidad, precisión y latencia.
En lo que puede que no estés de acuerdo es en si todos estos aspectos son cosas de las que tú, personal y profesionalmente, debes preocuparte. En cambio, puede que te consideres un analista de datos, un ingeniero de datos o un científico de datos y no te importe cómo hacen las demás funciones lo que sea que hagan.
Hay tres respuestas a esta objeción:
-
En cualquier situación en la que tengas un pequeño número de personas haciendo cosas ambiciosas -una empresa pequeña, una startup innovadora, una organización sin ánimo de lucro con poca financiación o un laboratorio de investigación con demasiados recursos- te encontrarás desempeñando todos estos papeles, así que aprende el ciclo de vida completo.
-
La nube pública hace que sea relativamente fácil aprender todas las funciones, así que ¿por qué no ser un científico de datos de pila completa?
-
Incluso si trabajas en una gran empresa en la que estas tareas las llevan a cabo diferentes funciones, es útil comprender el proceso de principio a fin y las preocupaciones en cada etapa. Esto te ayudará a colaborar mejor con otros equipos.
Veamos estas respuestas una por una.
Entorno Scrappy
En Google, consideramos que el papel de un ingeniero de datos es bastante amplio. Al igual que nos referimos a todo nuestro personal técnico como ingenieros, consideramos a los ingenieros de datos como un término inclusivo para cualquier persona que pueda "dar forma a los resultados empresariales mediante la realización de análisis de datos". Para realizar análisis de datos, hay que empezar por preparar los datos para poder analizarlos a escala. No basta con contar, sumar y representar gráficamente los resultados mediante consultas SQL y software de gráficos: debes comprender los matices de los datos y el marco estadístico en el que interpretas los resultados. Esta capacidad de preparar los datos y llevar a cabo análisis de datos estadísticamente válidos para resolver problemas empresariales concretos es de vital importancia: las consultas, los informes y los gráficos no son el objetivo final. Una decisión precisa y verificable sí lo es.
Por supuesto, no basta con hacer análisis de datos puntuales. Ese análisis de datos debe ser escalable. En otras palabras, un proceso de toma de decisiones preciso debe ser repetible y poder ser realizado por muchos usuarios, no sólo por ti. La forma de ampliar los análisis de datos puntuales es automatizarlos. Después de que un ingeniero de datos haya ideado el algoritmo, debe ser capaz de hacerlo sistemático y repetible. Del mismo modo que es mucho más fácil cuando la gente encargada de la fiabilidad de los sistemas puede hacer cambios en el código por sí misma,6 es considerablemente más fácil cuando las personas que entienden de estadística y aprendizaje automático pueden codificar ellas mismas esos modelos. Google cree que un ingeniero de datos debe ser capaz de pasar de construir modelos estadísticos y de aprendizaje automático a automatizarlos. Sólo podrá hacerlo si es capaz de diseñar, construir y solucionar problemas de sistemas de procesamiento de datos que sean seguros, responsables, fiables, tolerantes a fallos, escalables y eficientes.
Este deseo de tener ingenieros que sepan de ciencia de datos y científicos de datos que sepan codificar no es sólo de Google: es común en organizaciones tecnológicamente sofisticadas y en pequeñas empresas. Cuando una empresa pequeña busca ingenieros de datos o científicos de datos, lo que busca es una persona que pueda realizar las tres tareas -preparación de datos, análisis de datos y automatización- necesarias para tomar decisiones repetibles y escalables a partir de los datos.
¿Hasta qué punto es realista que las empresas esperen una persona renacentista, un virtuoso en diferentes campos? ¿Pueden esperar razonablemente contratar ingenieros de datos que sepan hacer ciencia de datos? ¿Qué probabilidades hay de que encuentren a alguien capaz de diseñar un esquema de base de datos, escribir consultas SQL, entrenar modelos de aprendizaje automático, codificar una cadena de procesamiento de datos y averiguar cómo ampliarlo todo? Sorprendentemente, se trata de una expectativa muy razonable, porque la cantidad de conocimientos que necesitas para realizar estos trabajos es ahora mucho menor que la que necesitabas hace unos años.
Científicos de datos en la nube Full Stack
Debido al continuo movimiento hacia la nube, los científicos de datos pueden hacer el trabajo que antes hacían varias personas con diferentes conjuntos de habilidades. Con la llegada de la infraestructura autoescalable, sin servidor, gestionada y fácil de programar, cada vez hay más personas capaces de crear sistemas escalables. Por tanto, ahora es razonable esperar poder contratar a científicos de datos capaces de crear soluciones holísticas basadas en datos para tus problemas más espinosos. No necesitas ser un polímata para ser un científico de datos de pila completa: simplemente tienes que aprender a hacer ciencia de datos en la nube.
Decir que la nube es lo que hace posibles los científicos de datos de pila completa parece una afirmación muy elevada. Esto depende de lo que yo entienda por "nube": no me refiero simplemente a migrar las cargas de trabajo que se ejecutan en las instalaciones a una infraestructura propiedad de un proveedor de nubes públicas. Hablo, en cambio, de servicios gestionados y realmente autoescalables que automatizan gran parte del aprovisionamiento, monitoreo y gestión de la infraestructura: servicios como Google BigQuery, Vertex AI, Cloud Dataflow y Cloud Run en Google Cloud Platform. Si tenemos en cuenta que el escalado y la tolerancia a fallos de muchas cargas de trabajo de análisis y procesamiento de datos pueden automatizarse eficazmente, siempre que se utilice el conjunto adecuado de herramientas, está claro que la cantidad de apoyo informático que necesita un científico de datos se reduce drásticamente con una migración a la nube.
Al mismo tiempo, las herramientas de ciencia de datos son cada vez más sencillas de utilizar. La amplia disponibilidad de marcos como Spark, Pandas y Keras ha hecho que la ciencia de datos y las herramientas de ciencia de datos sean extremadamente accesibles para el desarrollador medio: ya no es necesario ser un especialista en ciencia de datos para crear un modelo estadístico o entrenar un bosque aleatorio. Esto ha abierto el campo de la ciencia de datos a las personas que desempeñan funciones informáticas más tradicionales.
Del mismo modo, los analistas de datos y los administradores de bases de datos de hoy en día pueden tener antecedentes y conjuntos de habilidades completamente diferentes, porque el análisis de datos normalmente ha implicado serios asistentes de SQL, y la administración de bases de datos normalmente ha implicado un profundo conocimiento de los índices y el ajuste de las bases de datos. Con la introducción de herramientas como BigQuery, en las que las tablas se desnormalizan y la sobrecarga de administración es mínima, el papel de un administrador de bases de datos disminuye considerablemente. La creciente disponibilidad de herramientas de visualización llave en mano, como Tableau y Looker, que se conectan a todos los almacenes de datos de una empresa, hace posible que un mayor número de personas interactúen directamente con los almacenes de la empresa y elaboren informes y perspectivas convincentes.
La razón por la que todas estas funciones relacionadas con los datos se están fusionando, por tanto, es porque el problema de la infraestructura es cada vez menos intenso y el ámbito del análisis y modelado de datos se está democratizando.
Si hoy te consideras un científico de datos, o un analista de datos, o un administrador de bases de datos, o un programador de sistemas, esto es totalmente estimulante o totalmente irrealista. Es estimulante si te mueres de ganas de hacer todas las demás tareas que considerabas fuera de tu alcance, si las barreras de entrada han caído tan bajo como afirmo que lo han hecho. Si estás entusiasmado y ansioso por aprender las cosas que necesitarás saber en este nuevo mundo de datos, ¡bienvenido!7 Este libro es para ti.
Si mi visión de una mezcla de roles te parece un futuro distópico improbable, escúchame. La visión de servicios autoescalables que requieren muy poco en forma de gestión de la infraestructura puede ser completamente ajena a tu experiencia si estás en un entorno empresarial que se mueve con notoria lentitud: es imposible, podrías pensar, que los roles de datos vayan a cambiar tan drásticamente como todo eso para cuando te jubiles.
Bueno, puede ser. No sé dónde trabajas ni lo abierta al cambio que está tu organización. Lo que creo, sin embargo, es que cada vez más organizaciones y cada vez más sectores van a ser como los nativos digitales. Cada vez habrá más vacantes para científicos de datos full stack, y los ingenieros de datos estarán tan solicitados como lo están hoy los científicos de datos. Esto se debe a que los ingenieros de datos serán personas que puedan hacer ciencia de datos y sepan lo suficiente sobre infraestructura como para poder ejecutar sus cargas de trabajo de ciencia de datos en la nube pública. Merecerá la pena que aprendas la terminología de la ciencia de datos y los marcos de la ciencia de datos, y que te hagas más valioso para la próxima década.
Colaboración
Aunque trabajes en una empresa con una estricta separación de responsabilidades, puede ser útil saber cómo hacen su trabajo los demás equipos. Esto se debe a que hay muchos artefactos que ellos crean y que tú utilizarás, o que tú crearás y ellos utilizarán. Conocer sus requisitos y limitaciones te ayudará a ser más eficaz en la comunicación a través de los límites de la organización.
En la Figura 1-2 se muestran los distintos roles laborales relacionados con los datos y el aprendizaje automático. Todas estas funciones colaboran en la creación de un modelo de aprendizaje automático de producción. Entre la ingesta de datos y la interfaz del usuario final, hay múltiples traspasos. Cada uno de estos traspasos supone una oportunidad para malinterpretar los requisitos de la siguiente etapa o para no poder hacerse cargo de lo que se ha creado en la etapa anterior.
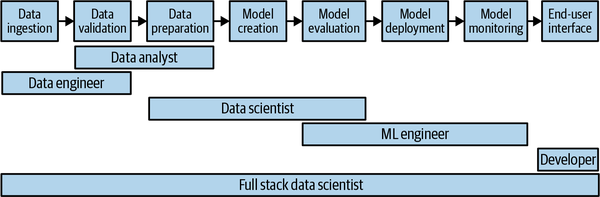
Figura 1-2. Hay muchas funciones que deben colaborar para llevar una solución de ciencia de datos de la idea a la producción. Cada traspaso conlleva un riesgo de fracaso.
Comprender las funciones adyacentes, las herramientas con las que trabajan y la infraestructura que utilizan puede ayudarte a reducir las posibilidades de que se les caiga el testigo.
Dicho esto, es muy difícil conseguir una separación limpia de responsabilidades: las mejores organizaciones que conozco, las que tienen cientos o miles de modelos de aprendizaje automático en producción, emplean científicos de datos de pila completa que trabajan en un problema desde el inicio hasta la producción. Pueden tener analistas de datos especializados, ingenieros de datos, científicos de datos o ingenieros de ML, pero sobre todo en calidad de mantenimiento: la innovación suele correr a cargo de la gente de la pila completa. Incluso los científicos de datos de pila completa tienen áreas en las que son más fuertes y áreas en las que colaboran con especialistas.
Buenas prácticas
Este libro entero consiste en un caso práctico ampliado. Resolver un problema práctico del mundo real te ayudará a atravesar todo el bombo y platillo que rodea a los macrodatos, el aprendizaje automático, la computación en nube, etc. Desmontar un caso práctico y ensamblarlo de múltiples maneras ilumina las capacidades y deficiencias de las distintas herramientas de big data y aprendizaje automático que tienes a tu disposición. Un caso práctico puede ayudarte a identificar los tipos de decisiones basadas en datos que puedes tomar en tu empresa e iluminar las consideraciones que hay detrás de los datos que necesitas recopilar y conservar, así como los tipos de modelos estadísticos y de aprendizaje automático que puedes utilizar. A lo largo de este libro intentaré aplicar las buenas prácticas actuales.
Soluciones de simples a complejas
Una de las formas en que este libro refleja la práctica es que utilizo un conjunto de datos del mundo real para resolver un escenario realista y abordar los problemas a medida que surgen. Así, empezaré con una decisión que hay que tomar y aplicaré diferentes métodos estadísticos y de aprendizaje automático para obtener información sobre cómo tomar esa decisión basándome en los datos. Esto te dará la capacidad de explorar otros problemas y la confianza para resolverlos a partir de los primeros principios. Como con la mayoría de las cosas, empezaré con soluciones sencillas y me iré abriendo camino hacia otras más complejas. Empezar con una solución compleja sólo oscurecerá detalles del problema que se comprenden mejor al resolverlo de forma más sencilla. Por supuesto, las soluciones más sencillas tendrán inconvenientes, y éstos ayudarán a motivar la necesidad de una complejidad adicional.
Una cosa que no hago, sin embargo, es volver atrás y retroadaptar soluciones anteriores basándome en los conocimientos que adquiero en el proceso de llevar a cabo planteamientos más sofisticados. En tu trabajo práctico, sin embargo, te recomiendo encarecidamente que mantengas el software asociado a los primeros intentos de resolver un problema, y que vuelvas atrás y mejores continuamente esos primeros intentos con lo que aprendas por el camino. La experimentación paralela es el nombre del juego. Debido a la naturaleza lineal de un libro, yo no lo hago, pero recomiendo encarecidamente que sigas manteniendo activamente varios modelos. Dada la posibilidad de elegir entre dos modelos con medidas de precisión similares, puedes elegir el más sencillo: no tiene sentido utilizar modelos más complejos si un enfoque más sencillo puede funcionar con algunas modificaciones.8 Otra razón para tener varios modelos es que resulta útil disponer de un sustituto si descubres que el modelo de producción actual pierde precisión o tiene comportamientos no deseados.
Computación en la nube
Antes de incorporarme a Google, era investigador científico y trabajaba en algoritmos de aprendizaje automático para el diagnóstico y la predicción meteorológicos. Los modelos de aprendizaje automático implicaban múltiples sensores meteorológicos, pero dependían en gran medida de los datos del radar meteorológico. Hace unos años, cuando emprendimos un proyecto para volver a analizar los datos históricos del radar meteorológico utilizando los algoritmos más recientes, tardamos cuatro años en hacerlo. Sin embargo, más recientemente, mi equipo pudo elaborar estimaciones de precipitaciones a partir del mismo conjunto de datos, pero pudo recorrerlo en unas dos semanas. Puedes imaginarte el ritmo de innovación que resulta cuando tomas algo que solía llevar cuatro años y lo haces factible en dos semanas.
De cuatro años a dos semanas. La razón era que gran parte del trabajo de hace tan sólo cinco años consistía en mover datos de un lado a otro. Recuperábamos los datos de las unidades de cinta, los pasábamos al disco, los procesábamos y los trasladábamos para dejar paso al siguiente conjunto de datos. Averiguar qué trabajos habían fallado llevaba mucho tiempo, y reintentar los trabajos fallidos implicaba múltiples pasos, incluido un humano en el bucle. Lo ejecutábamos en un clúster de máquinas de tamaño fijo. La combinación de todas estas cosas hacía que se tardara muchísimo tiempo en procesar el archivo histórico. Cuando empezamos a hacerlo todo en la nube pública, descubrimos que podíamos almacenar todos los datos del radar en el almacenamiento en la nube y, siempre que accediéramos a ellos desde máquinas virtuales (VM) de la misma región, las velocidades de transferencia de datos eran lo suficientemente rápidas. Aún teníamos que escenificar los datos en discos, realizar el cálculo y apagar las máquinas virtuales, pero esto era mucho más manejable. Simplemente reduciendo la cantidad de movimiento de datos entre la cinta y el disco y ejecutando los procesos en muchas más máquinas nos permitía llevar a cabo el procesamiento mucho más rápido; mérito de laelasticidad de (la capacidad de aumentar sin problemas el número de recursos que podemos asignar a un trabajo en la nube pública.
¿Era más caro ejecutar los trabajos en 10 veces más máquinas que cuando hacíamos el procesamiento in situ? No, porque la economía suele estar a favor de alquilar bajo demanda en lugar de comprar la potencia de procesamiento directamente, sobre todo si no vas a utilizar las máquinas 24 horas al día, 7 días a la semana. Tanto si utilizas 10 máquinas durante 10 horas como si utilizas 100 máquinas durante 1 hora, el coste sigue siendo el mismo. Entonces, ¿por qué no obtener tus respuestas en una hora en lugar de en 10 horas?
En este libro, haremos toda nuestra ciencia de datos en Google Cloud para aprovechar la escala casi infinita que ofrece la nube pública.
Sin servidor
Cuando hicimos nuestra preparación de datos meteorológicos utilizando máquinas virtuales basadas en la nube, aún no estábamos aprovechando todo lo que ésta puede ofrecer. Deberíamos haber renunciado por completo al proceso de hacer girar las máquinas virtuales, instalar software en ellas y buscar trabajos fallidos; lo que deberíamos haber hecho era utilizar un marco de procesamiento de datos de autoescalado como BigQuery o Cloud Dataflow. Si lo hubiéramos hecho, habríamos podido ejecutar nuestros trabajos en miles de máquinas y podríamos haber reducido el tiempo de procesamiento de dos semanas a unas pocas horas. No tener que gestionar ninguna infraestructura es en sí mismo una gran ventaja cuando se trata de rastrear terabytes de datos. Tener el procesamiento de datos, el análisis y el aprendizaje automático a escala de miles de máquinas es una ventaja adicional.
La principal ventaja de realizar ingeniería de datos en la nube es la cantidad de tiempo que te ahorra.9 No deberías tener que esperar días o meses; en cambio, como muchos trabajos son vergonzosamente paralelos, puedes obtener tus resultados en minutos u horas haciéndolos funcionar en miles de máquinas. Puede que no puedas permitirte poseer permanentemente tantas máquinas, pero sin duda es posible alquilarlas durante minutos cada vez. Este ahorro de tiempo hace que los servicios autoescalables en una nube pública sean la elección lógica para llevar a cabo el procesamiento de datos.
Ejecutar trabajos de datos en miles de máquinas durante minutos requiere servicios totalmente gestionados. Almacenar los datos localmente en las máquinas virtuales o en discos persistentes, como ocurre con el clúster Apache Hadoop, no es escalable a menos que sepas con precisión qué trabajos se van a ejecutar, cuándo y dónde. No podrás reducir el tamaño del clúster de máquinas si no tienes reintentos automáticos para los trabajos fallidos y, lo que es más importante, barajar los datos en los nodos de datos restantes (suponiendo que haya suficiente espacio libre). El tiempo total de cálculo será el tiempo empleado por el trabajador más sobrecargado, a menos que tengas un cambio dinámico de tareas entre los nodos del clúster. Todo esto apunta a la necesidad de servicios de autoescalado que redimensionen dinámicamente el clúster, dividan los trabajos en tareas, muevan las tareas entre los nodos de cálculo y puedan confiar en redes altamente eficientes para mover los datos a los nodos que están realizando el procesamiento.
En Google Cloud Platform, los principales servicios autoescalables, totalmente gestionados y "sin servidor" son BigQuery (para análisis de datos), Cloud Spanner (para bases de datos), Cloud Dataflow (para canalizaciones de procesamiento de datos), Cloud Pub/Sub (para sistemas basados en mensajes), Cloud Bigtable (para ingesta de alto rendimiento), Cloud Run o Cloud Functions (para aplicaciones, tareas) y Vertex AI (para aprendizaje automático).10 El uso de servicios autoescalables como éstos hace posible que un ingeniero de datos empiece a abordar problemas empresariales más complejos, porque se ha liberado del mundo de la gestión de sus propias máquinas e instalaciones de software, ya sea en forma de hardware desnudo, máquinas virtuales o contenedores. Si tienes que elegir entre un producto que te obliga a configurar primero un contenedor, un servidor o un clúster, y otro que te libera de esas consideraciones, elige el sin servidor. Tendrás más tiempo para resolver los problemas que realmente importan a tu empresa.
Una decisión probabilística
Imagina que estás a punto de coger un vuelo y, justo antes de que el vuelo despegue de la pista (y te pidan que apagues el teléfono), tienes la oportunidad de enviar un último mensaje de texto. Ya ha pasado la hora de salida publicada y estás un poco ansioso. La Figura 1-3 presenta una vista gráfica del escenario.
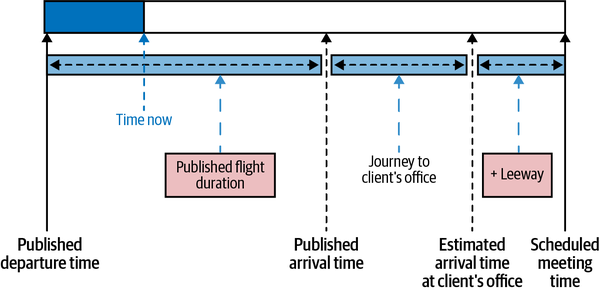
Figura 1-3. Ilustración gráfica del caso práctico: si el vuelo sale con retraso, ¿debe el guerrero de la carretera cancelar la reunión?
El motivo de tu ansiedad es que has programado una reunión importante con un cliente en sus oficinas. Como corresponde a un científico de datos racional11 has programado las cosas con bastante precisión. Le has tomado la palabra a la compañía aérea en cuanto a la hora de llegada del vuelo, has tenido en cuenta el tiempo necesario para llamar a un taxi y has utilizado una herramienta cartográfica en línea para calcular el tiempo necesario para llegar a la oficina del cliente. Después, añadiste algo de margen (digamos 30 minutos) y le dijiste al cliente a qué hora te reunirías con él. Y ahora resulta que el vuelo sale con retraso. Entonces, ¿debes enviar un mensaje de texto informando a tu cliente de que no podrás acudir a la reunión porque tu vuelo saldrá con retraso o no debes hacerlo?
Esta decisión podría tomarse de muchas maneras, incluyendo el instinto visceral y el uso de la heurística. Como somos personas muy racionales, nosotros (tú y yo) tomaremos esta decisión basándonos en datos. Además, vemos que es una decisión que toman muchos de los guerreros de la carretera de nuestra empresa día tras día. Sería bueno que pudiéramos hacerlo de forma sistemática y que un servidor corporativo enviara una alerta a los viajeros sobre los retrasos previstos si vemos eventos en su calendario que es probable que se pierdan. Construyamos un marco de datos para resolver este problema.
Enfoque Probabilístico
Si decidimos tomar la decisión en función de los datos, hay varios enfoques que podemos adoptar. ¿Deberíamos cancelar la reunión si hay más de un 30% de probabilidades de que falte? ¿O deberíamos asignar un coste al aplazamiento de la reunión (el cliente podría irse con nuestra competencia antes de que tengamos la oportunidad de demostrar nuestro gran producto) frente a no acudir a la reunión programada (el cliente podría no volver a atender nuestras llamadas) y minimizar nuestra pérdida esperada de ingresos? El enfoque probabilístico se traduce en riesgo, y muchas decisiones prácticas dependen del riesgo. Además, el enfoque probabilístico es más general, porque si conocemos la probabilidad y la pérdida monetaria asociada a faltar a la reunión, es posible calcular el valor esperado de cualquier decisión que tomemos. Por ejemplo, supongamos que la probabilidad de faltar a la reunión es del 20% y decidimos no cancelarla (porque el 20% es inferior a nuestro umbral de decisión del 30%). Pero sólo hay un 25% de probabilidades de que el cliente firme el gran acuerdo (por valor de un millón de dólares) por el que te vas a reunir con él. Como hay un 80% de posibilidades de que lleguemos a la reunión, el valor positivo esperado de no cancelar la reunión es 0,8 × 0,25 × 1 millón, o 200.000 $. El valor negativo de no cancelarla es que perdamos la reunión. Suponiendo que el cliente tenga un 90% de probabilidades de dejarnos plantados en el futuro si faltamos a una reunión con él, la desventaja esperada es de 0,2 × 0,9 × 0,25 × 1 millón, o 45.000 $. Esto arroja un valor esperado de 155.000 $ a favor de no cancelar la reunión. Podemos ajustar estas cifras para obtener un umbral de decisión probabilístico adecuado.
Otra ventaja de un enfoque probabilístico es que podemos tener en cuenta directamente la psicología humana. Puede que te sientas agotado si llegas a una reunión sólo dos minutos antes de que empiece y, como consecuencia, no puedas rendir al máximo. Puede ser que llegar sólo dos minutos antes a una reunión muy importante no te parezca llegar a tiempo. Obviamente, esto varía de una persona a otra, pero digamos que el intervalo de tiempo que necesitas para tranquilizarte es de 15 minutos. Quieres cancelar una reunión a la que no puedes llegar 15 minutos antes. También podrías tratar este intervalo de tiempo como tu umbral personal de aversión al riesgo, un poco de margen final si quieres. Así, quieres llegar al lugar del cliente 15 minutos antes de la reunión y quieres anular la reunión si hay menos de un 70% de posibilidades de hacerlo. Éste es, pues, nuestro criterio de decisión:
Anula la reunión con el cliente si la probabilidad de llegar 15 minutos antes es del 70% o menos.
He explicado los 15 minutos, pero no he explicado el 70%. Seguramente, puedes utilizar el diagrama modelo antes mencionado(Figura 1-3, en el que modelamos nuestro viaje desde el aeropuerto hasta la oficina del cliente), introducir el retraso real de la salida y averiguar a qué hora llegarás a las oficinas del cliente. Si es menos de 15 minutos antes de que empiece la reunión, ¡deberías cancelarla! ¿De dónde sale el 70%?
Función de densidad de probabilidad
Es importante darse cuenta de que el diagrama modelo(Figura 1-3) de tiempos no es exacto. El marco de decisión probabilístico te da una forma de tratar esto de una manera basada en principios. Por ejemplo, aunque la compañía aérea diga que la duración del vuelo es de 127 minutos y publique una hora de llegada, no todos los vuelos duran exactamente 127 minutos. Si resulta que el avión despega con el viento, coge viento de cola y aterriza contra el viento, el vuelo puede durar sólo 90 minutos. Los vuelos en los que todos los vientos son exactamente erróneos podrían durar 127 minutos (es decir, la compañía aérea podría estar publicando los peores escenarios para la ruta). Google Maps predice los tiempos de trayecto basándose en datos históricos, y los trayectos reales en taxi se centrarán en esos tiempos. Tu estimación del tiempo que se tarda en ir de la puerta del aeropuerto a la parada de taxis puede basarse en el aterrizaje en una puerta concreta, y los tiempos reales pueden variar. Por tanto, aunque el modelo represente un tiempo determinado entre la salida de la aerolínea y tu llegada al lugar del cliente, no se trata de una cifra exacta. El tiempo real entre la salida y la llegada podría tener una distribución parecida a la que se muestra en la Figura 1-4.
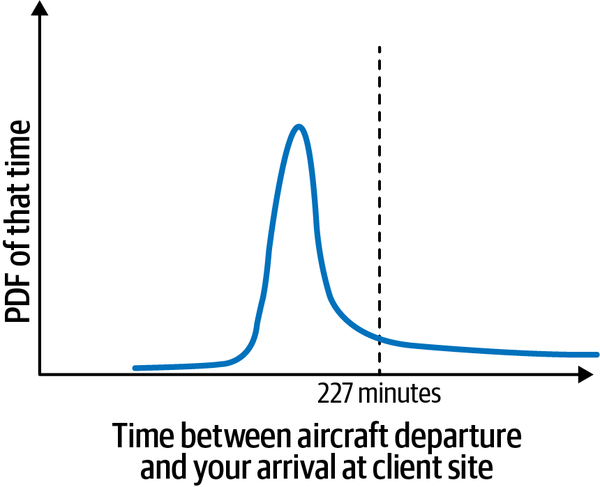
Figura 1-4. Hay muchos valores posibles para las diferencias de tiempo entre la salida del avión y tu llegada al lugar del cliente, y la distribución de ese valor se llama función de densidad de probabilidad.
La curva de la Figura 1-4 se denomina función de densidad de probabilidad (abreviada PDF). De hecho, la PDF puede ser (y a menudo es) mayor que uno. Para obtener una probabilidad, tendrás que integrar la función de densidad de probabilidad.12 La función de distribución acumulativa (FDA) proporciona una forma sencilla de realizar esta integración.
Función de distribución acumulativa
La función de distribución de probabilidad acumulada de un valor x es la probabilidad de que el valor observado X sea inferior al umbral x. Por ejemplo, puedes obtener la función de distribución acumulativa (FDA) para 227 minutos hallando la fracción de vuelos para los que la diferencia de tiempo es inferior a 227 minutos, como se muestra en la Figura 1-5.
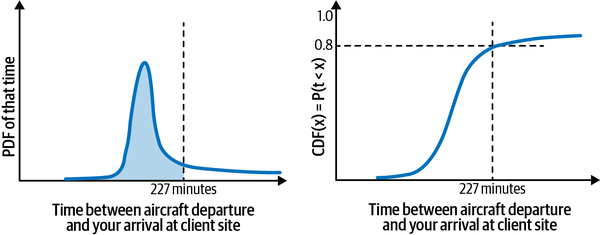
Figura 1-5. La FCD es el área bajo la curva de la PDF. Es más fácil de entender y de seguir que la PDF. En concreto, está delimitada entre 0 y 1, mientras que la PDF puede ser mayor que 1.
Interpretemos el gráfico de la Figura 1-5. ¿Qué significa una FCD (227 minutos) = 0,8? Significa que el 80% de los vuelos llegarán de forma que lleguemos al lugar del cliente en menos de 227 minutos, lo que incluye tanto la situación en la que podemos llegar en 100 minutos como la situación en la que tardamos 226 minutos. La FCD, a diferencia de la FDP, está acotada entre 0 y 1. El valor del eje y es una probabilidad, pero no la probabilidad de un valor exacto. Es, en cambio, la probabilidad de observar todos los valores inferiores a ese valor.
Como el tiempo para llegar del aeropuerto de llegada a la oficina del cliente no se ve afectado por el retraso del vuelo de salida,13 podemos ignorarlo en nuestra modelización. Del mismo modo, podemos ignorar el tiempo para caminar por el aeropuerto, llamar al taxi y prepararnos para la reunión. Por tanto, sólo necesitamos hallar la probabilidad de que el retraso de llegada sea superior a 15 minutos. Si esa probabilidad es igual o superior a 0,3, tendremos que anular la reunión. En términos de la FCD, eso significa que la probabilidad de que el retraso en la llegada sea inferior a 15 minutos tiene que ser al menos de 0,7, como se presenta en la Figura 1-6.
Así, nuestros criterios de decisión se traducen en lo siguiente:
Anula la reunión con el cliente si la FCD de un retraso de llegada de 15 minutos es inferior al 70%.
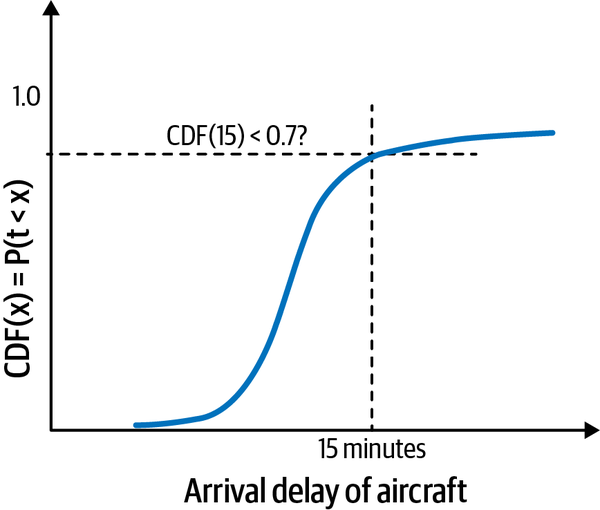
Figura 1-6. Nuestro criterio de decisión es cancelar la reunión si la FCD de un retraso en la llegada de 15 minutos es inferior al 70%. En términos generales, queremos estar seguros en un 70% de que el avión no llegará con más de 15 minutos de retraso.
El resto de este libro va a tratar sobre la construcción de canalizaciones de datos que nos permitan calcular la FDA de los retrasos de llegada utilizando modelos estadísticos y de aprendizaje automático. A partir de la FCD calculada de los retrasos de llegada, podemos buscar la FCD de un retraso de llegada de 15 minutos y comprobar si es menor que el 70%.
Decisiones tomadas
¿Qué datos necesitamos para predecir la probabilidad de un retraso de vuelo concreto? ¿Qué herramientas debemos utilizar? ¿Deberíamos utilizar Hadoop? ¿BigQuery? ¿Lo hacemos en mi portátil o en la nube pública? La pregunta sobre los datos se responde fácilmente: utilizaremos los datos históricos de llegadas de vuelos publicados por la Oficina de Estadísticas de Transporte de EE.UU. , los analizaremos y los utilizaremos para fundamentar nuestra decisión. A menudo, un científico de datos elegiría la mejor herramienta basándose en su experiencia y se limitaría a utilizar esa única herramienta para ayudar a tomar la decisión, pero aquí, te llevaré a recorrer varias formas en las que podríamos llevar a cabo el análisis. Esto también nos permitirá modelar las buenas prácticas en el sentido de elegir la herramienta y el análisis más sencillos que sean suficientes.
Elegir la nube
En un examen superficial de los datos, descubrimos que hubo más de 30,6 millones de vuelos en 2015-2019.14 Mi portátil, por muy bonito que sea, no va a ser suficiente. Haremos el análisis de los datos en la nube pública. ¿Qué nube? Utilizaremos Google Cloud Platform (GCP). Aunque algunas de las herramientas que utilizamos en este libro (especialmente Hadoop, Spark, Beam, TensorFlow, etc.) están disponibles en otras plataformas en la nube, los servicios gestionados que utilizo (BigQuery, Cloud Dataproc, Cloud Dataflow, Vertex AI, etc.) son específicos de GCP. Utilizar GCP me permitirá no tener que juguetear con las máquinas virtuales y la configuración de las máquinas, y centrarme únicamente en el análisis de los datos. Además, trabajo en Google, así que es la plataforma que mejor conozco.
No es un libro de referencia
Este libro no es una visión exhaustiva de la ciencia de datos; hay otros libros (a menudo basados en cursos universitarios) que lo hacen. Tampoco es un libro de referencia sobre Google Cloud: la documentación es mucho más oportuna y completa. En cambio, este libro te permite mirar por encima de mi hombro mientras resuelvo un problema concreto de ciencia de datos utilizando diversos métodos y herramientas. Prometo ser bastante hablador y contarte lo que pienso y por qué hago lo que hago. En lugar de presentarte soluciones y código totalmente formados, te mostraré pasos intermedios a medida que voy construyendo una solución.
Este material de aprendizaje se te presenta de tres formas:
-
Este libro que estás leyendo.
-
El código al que se hace referencia a lo largo del libro en GitHub. Fíjate, en particular, en el archivo README.md de cada carpeta del repositorio de GitHub.
-
Laboratorios con instrucciones que te permiten probar el código de este libro en un entorno sandbox, disponibles en https://qwiklabs.com.
En lugar de leer simplemente este libro de principio a fin, te animo encarecidamente a que sigas mi ejemplo aprovechando también el código. Después de leer cada capítulo, o la sección principal de cada capítulo, intenta repetir lo que yo hice, remitiéndote al código si algo no está claro.
Cómo empezar con el código
Para empezar a trabajar con el código, sigue estos pasos:
-
Regístrate para la prueba gratuita si aún no lo has hecho. Si no, utiliza tu cuenta existente de GCP.
-
Crea un nuevo proyecto y ponle el nombre que quieras. Te sugiero que lo llames
ds-on-gcp. GCP asignará un ID de proyecto único a tu proyecto (ver Figura 1-7). Tendrás que proporcionar este ID único siempre que hagas algo que sea facturable. Cuando hayas terminado de trabajar en este libro, simplemente borra el proyecto para dejar de recibir facturas.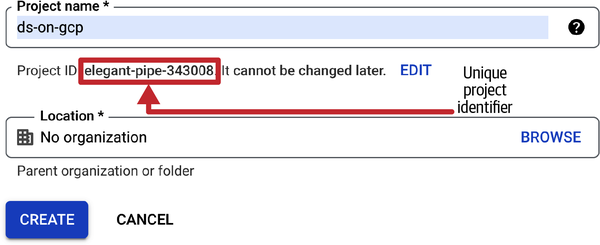
Figura 1-7. Cuando crees un nuevo proyecto, GCP le asignará un identificador único de proyecto. Utiliza este identificador único siempre que un script o programa te pida un identificador de proyecto. También podrás obtener el identificador único desde el panel de control (ver Figura 1-8).
-
Abre Cloud Shell, tu terminal de acceso a GCP. Para abrir Cloud Shell, en la barra de menús, haz clic en el icono Activar Cloud Shell, como se muestra en la Figura 1-8. Aunque la consola web es muy agradable, yo suelo preferir guionizar las cosas antes que pasar por una GUI. Para mí, las GUI web son estupendas para un uso ocasional y/o primerizo, pero para tareas repetitivas, nada supera al terminal.
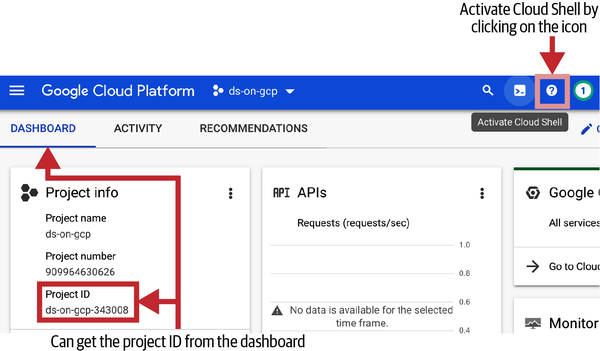
Figura 1-8. Activa Cloud Shell haciendo clic en el icono resaltado en la esquina superior derecha de la consola web de GCP. Ten en cuenta que el identificador único del proyecto puede obtenerse en cualquier momento desde el panel de control.
Cloud Shell es una micro-VM que está viva mientras dura la ventana del navegador y te da acceso de terminal a la micro-VM. Cierra la ventana del navegador y la micro-VM desaparecerá. La Cloud Shell VM es gratuita y viene cargada con muchas de las herramientas que necesitarán los desarrolladores en Google Cloud Platform. Por ejemplo, tiene instalados Python, Git, el SDK de Google Cloud y Orion (un editor de código basado en web). Aunque la máquina virtual Cloud Shell es efímera, está conectada a un disco persistente vinculado a tu cuenta de usuario. Los archivos que almacenas en tu directorio personal se guardan en diferentes sesiones de Cloud Shell.
-
En la ventana Shell Nube, clona con git mi repositorio escribiendo lo siguiente:
git clone \ https://github.com/GoogleCloudPlatform/data-science-on-gcp cd data-science-on-gcpDado que el repositorio Git se ha descargado en el directorio principal de la micro-VM de la Concha de Nube, será persistente en todas las sesiones del navegador.
-
Ten en cuenta que hay un directorio correspondiente a cada capítulo de este libro (salvo los capítulos 1 y 12). En cada directorio encontrarás un archivo README.md con instrucciones sobre cómo reproducir los pasos de ese capítulo.
No copies-pegues fragmentos de código del libro. Lee los capítulos y luego prueba el código siguiendo los pasos del README.md de cada capítulo utilizando el código del repositorio. Te recomiendo que no copies-pegues de las versiones electrónicas de este libro.
-
El libro está escrito para que sea legible, no para que sea completo. Es posible que se omitan algunos indicadores de herramientas en la nube para que podamos centrarnos en el aspecto clave que se está tratando. El código de GitHub tendrá el comando completo.
-
El repositorio de GitHub se mantendrá actualizado con nuevas versiones de herramientas en la nube, Python, etc.
-
Al seguir el libro, es fácil perderse un paso.
-
Copiar y pegar caracteres especiales desde PDF es problemático.
Ya está. Ya estás preparado para seguirme. Mientras lo haces, recuerda que tienes que cambiar mi ID de proyecto por el ID de tu proyecto (puedes encontrarlo en el panel de control de la consola web de Google Cloud, como se muestra en la Figura 1-8) y mi nombre de bucket por tu bucket en Cloud Storage (lo crearás en el Capítulo 2; presentaremos los buckets en ese momento).
Arquitectura ágil para la ciencia de datos en Google Cloud
Presentaré los productos y tecnologías de Google Cloud a medida que avancemos. En esta sección, proporcionaré una visión general de alto nivel de por qué elijo lo que elijo. No te preocupes si no reconoces los nombres de estas tecnologías (por ejemplo, almacén de datos) o productos (por ejemplo, BigQuery), ya que los trataremos en detalle a medida que avancemos.
¿Qué es la arquitectura ágil?
Uno de los principios del software ágil es que la simplicidad, entendida como maximizar la cantidad de trabajo no realizado, es esencial. Otro es que los requisitos cambian con frecuencia, por lo que la flexibilidad es importante. Una arquitectura Ágil, por tanto, es la que te da:
-
Velocidad de desarrollo. Debes ser capaz de pasar de la idea a la implementación lo más rápidamente posible.
-
Flexibilidad para implementar rápidamente nuevas funciones. A veces la velocidad va en detrimento de la flexibilidad: la arquitectura puede meterte con calzador un conjunto muy limitado de casos de uso. Tú no quieres eso.
-
Poco mantenimiento. No pierdas el tiempo gestionando la infraestructura.
-
Autoescalado y capacidad de recuperación para que no pierdas el tiempo monitorizando la infraestructura.
¿Qué aspecto tiene esa arquitectura en Google Cloud cuando se trata de Análisis de Datos e IA? Utilizará servicios de bajo código y sin código (conectores preconstruidos, replicación automática, ELT [extraer-cargar-transformar], AutoML) para que obtengas velocidad de desarrollo. En cuanto a la flexibilidad, la arquitectura te permitirá pasar a código potente y fácil de desarrollar (Apache Beam, SQL, TensorFlow) siempre que sea necesario. Todo ello se ejecutará en una infraestructura sin servidor (Pub/Sub, Dataflow, BigQuery, Vertex AI) para que obtengas bajo mantenimiento, autoescalado y resiliencia.
Sin código, código bajo
Cuando se trata de arquitectura, elige no-código en lugar de bajo-código y bajo-código en lugar de escribir código personalizado. En lugar de escribir canalizaciones ETL (extraer-transformar-cargar) para transformar los datos que necesitas antes de introducirlos en BigQuery, utiliza conectores preconfigurados para introducir directamente los datos sin procesar en BigQuery (véase la Figura 1-9). A continuación, transforma los datos en la forma que necesites utilizando vistas SQL directamente en el almacén de datos. Serás mucho más ágil si eliges un enfoque ELT en lugar de un enfoque ETL.
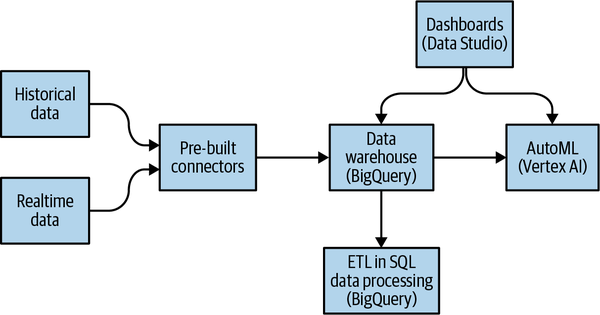
Figura 1-9. Arquitectura ágil para la mayoría de los casos de uso.
Otro lugar es cuando eliges tu marco de modelado ML. No empieces con modelos TensorFlow personalizados. Empieza con AutoML. Es sin código. Puedes invocar AutoML directamente desde BigQuery, evitando la necesidad de construir complejos conductos de datos y ML. Si es necesario, pasa a los modelos preconstruidos de TensorFlow Hub y a los contenedores preconstruidos de Vertex AI. Eso es low-code. Construye tus propios modelos ML personalizados sólo como último recurso.
Utilizar servicios gestionados
Querrás poder bajar a código si el enfoque de bajo código es demasiado restrictivo. Afortunadamente, la arquitectura sin código descrita anteriormente es un subconjunto de la arquitectura completa, mostrada en la Figura 1-10, que te proporciona toda la flexibilidad que necesitas.
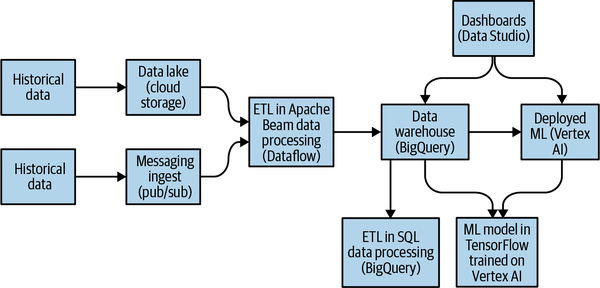
Figura 1-10. Arquitectura ágil para la analítica y la IA.
Cuando el caso de uso lo justifique, dispondrás de toda la flexibilidad de Apache Beam, SQL y TensorFlow. Esto es fundamental: para los casos de uso en los que el enfoque ELT + AutoML sea demasiado restrictivo, tienes la posibilidad de pasar a un enfoque ETL/Dataflow + Keras/Vertex.
Lo mejor de todo es que la arquitectura está unificada, por lo que no mantienes dos pilas. Como la primera arquitectura es un subconjunto de la segunda, puedes llevar a cabo casos de uso fáciles y difíciles de forma unificada.
Resumen
Un objetivo clave del análisis de datos es poder proporcionar orientación basada en datos para tomar decisiones precisas de forma sistemática. Idealmente, esta orientación puede proporcionarse como un servicio, y proporcionarla como un servicio da lugar a cuestiones de calidad del servicio, tanto en términos de precisión de la orientación como de fiabilidad, latencia y seguridad de la implementación.
Un ingeniero de datos debe ser capaz de pasar de diseñar servicios basados en datos y construir modelos estadísticos y de aprendizaje automático a implementarlos como servicios fiables y de alta calidad. Esto se ha vuelto más fácil con la llegada de los servicios en la nube que proporcionan una infraestructura autoescalable, sin servidores y gestionada. Además, la amplia disponibilidad de herramientas de ciencia de datos ha hecho que no necesites ser un especialista en ciencia de datos para crear un modelo estadístico o de aprendizaje automático. Como resultado, la capacidad de trabajar con datos se ha extendido por toda la empresa: ya no es una habilidad restringida.
Nuestro caso práctico se refiere a un viajero que debe decidir si cancela una reunión en función de si el vuelo en el que viaja llegará con retraso. El criterio de decisión es que la reunión debe cancelarse si la probabilidad de que llegue antes de 15 minutos de la hora prevista es inferior al 70%. Para estimar la probabilidad de este retraso en la llegada, utilizaremos datos históricos de la Oficina de Estadísticas de Transporte de EEUU.
Para seguirme a lo largo del libro, crea un proyecto en Google Cloud Platform y un clon del repositorio de GitHub de los listados de código fuente de este libro. Alternativamente, prueba el código de este libro en un entorno sandbox utilizando Qwiklabs. La carpeta de cada uno de los capítulos en GitHub contiene un archivo README.md que enumera los pasos para poder replicar lo que hago en los capítulos. Así que, si te quedas atascado, consulta esos archivos README.
Por cierto, las notas a pie de página de este libro lo son porque rompen el flujo del capítulo. Algunos lectores de la primera edición señalaron que sólo se dieron cuenta hacia la mitad del libro de que muchas de las notas a pie de página contenían información útil. Por tanto, éste puede ser un buen momento para leer las notas a pie de página si te las has estado saltando.
Recursos sugeridos
¿Qué es la ciencia de datos en Google Cloud? ¿En qué consiste el conjunto de herramientas? El sitio web de ciencia de datos en Google Cloud contiene un conjunto de libros blancos y guías de referencia que abordan estos temas. Marca esta página y utilízala como punto de partida para todo lo relacionado con la ciencia de datos en GCP.
Hay cinco productos clave de autoescalado, totalmente gestionados y sin servidor para el análisis de datos y la IA en Google Cloud. Los trataremos más adelante en el libro, pero estos vídeos y artículos son un buen punto de partida si quieres profundizar inmediatamente:
-
BigQuery es el almacén de datos sin servidor que constituye el corazón de la mayoría de las arquitecturas de datos construidas en Google Cloud. Recomiendo ver "Introducción a Google BigQuery por Jordan Tigani", uno de los ingenieros fundadores de BigQuery, aunque ya tenga unos años.
-
Dataflow es el servicio de ejecución para pipelines batch y streaming escritos con Apache Beam. Empieza con "¿Qué es Dataflow?" de Google Cloud Tech, un vídeo de 5 minutos que presenta qué es Dataflow y cómo funciona. Forma parte de la serie de vídeos Google Cloud Drawing Board: son formas rápidas e informativas de aprender sobre diversos temas de Google Cloud.
-
Pub/Sub es el servicio de mensajería global que puede utilizarse para casos de uso que van desde la interacción con el usuario y la distribución de eventos en tiempo real hasta la actualización de cachés distribuidas. Empieza por la página de documentación general. Todos los productos de Google Cloud tienen una página de información general que puede servir como punto de partida para aprender no sólo lo que hace un producto, sino también para qué puede utilizarse y cómo elegir entre él y otras alternativas.
-
Cloud Run proporciona una plataforma autoescalable y sin servidor para aplicaciones en contenedores. Puedes utilizarla para todo tipo de automatización y transformación ligera de datos. La mejor manera de aprender Cloud Run es probarlo, y Qwiklabs proporciona un gran conjunto de laboratorios prácticos en un entorno sandbox. Mientras estés allí, consulta el Catálogo para encontrar otras búsquedas y laboratorios sobre el tema que elijas.
-
Vertex AI es la plataforma integral de desarrollo, implementación y automatización de ML en Google Cloud. Un buen lugar para conocerla es ver el vídeo que acompañó a su anuncio en Google I/O, "Build End-to-End Solutions with Vertex AI", del canal de YouTube Google Cloud Tech.
Hay dos bases de datos clave de procesamiento de transacciones totalmente gestionadas en Google Cloud:
-
Bigtable es una base de datos distribuida NoSQL. Por supuesto, puedes informarte sobre ella en el vídeo de información general de Google Cloud Tech , "¿Qué es Cloud Bigtable?", o en la documentación de Bigtable, pero te recomiendo que leas el famoso artículo de investigación que presentó la idea al mundo: Fay Chang y otros, "Bigtable: A Distributed Storage System for Structured Data", 7º Simposio USENIX sobre Diseño e Implementación de Sistemas Operativos (OSDI), USENIX (2006): 205-218.
-
Spanner es una base de datos SQL distribuida que proporciona una fuerte consistencia global y una disponibilidad de cinco nueves (99,999%), algo que simplifica enormemente tu arquitectura si estás en un dominio como la banca o los juegos, donde tienes usuarios concurrentes en todo el mundo. "Why You Should Use Google's Cloud Spanner for Your Next Game" (Por qué deberías utilizar Spanner en la nube de Google para tu próximo juego), una entrada del blog de 2019 de Miles Ward, Director Técnico de SADA, socio de Google, es un excelente punto de partida para conocer Spanner y las buenas prácticas de Spanner.
Para saber más sobre la probabilidad aplicada a la teoría de la información y la inteligencia artificial, lee el capítulo 3 de Deep Learning, "Probability and Information Theory", de Ian Goodfellow et al. (MIT Press) o un resumen de ese capítulo de William Green en Medium. Claude Shannon sentó las bases de la teoría de la información en un artículo clásico de 1948. También es famoso por laque quizá sea la tesis de máster más influyente de la historia, que muestracómo utilizar el álgebra de Boole para probar diseños de circuitos sin ni siquiera construirlos.
1 El documento clásico sobre este tema es el de George Akerlof de 1970 titulado "El mercado de los limones". Akerlof, Michael Spence (que explicó la señalización) y Joseph Stiglitz (que explicó la selección) recibieron conjuntamente el Premio Nobel de Economía 2001 por describir este problema. En una transacción que implica información asimétrica, la parte con buena información señala, mientras que la parte con mala información criba. Por ejemplo, el vendedor de un coche (que tiene buena información) puede señalar que tiene un coche estupendo publicando el historial de reparaciones del coche. El comprador (que tiene mala información) podría seleccionar los coches rechazando los que procedan de ciudades que hayan sufrido recientemente una inundación.
2 Puede que el cuentakilómetros en sí no sea tan caro, pero recopilar esa información y asegurarse de que es correcta tiene unos costes considerables. La última vez que vendí un coche, tuve que firmar una declaración de que no había manipulado el cuentakilómetros, y esa declaración tuvo que ser certificada ante notario por un empleado de un banco con garantía financiera. Esto lo exigía la empresa que prestaba el importe de la compra del coche al comprador. Se supone que todos los mecánicos de automóviles deben informar de la manipulación del cuentakilómetros, y hay una agencia gubernamental estatal que hace cumplir esta norma. Todos estos costes son significativos. Incluso si no tienes en cuenta todos estos costes externos, y supones que el hardware y la infraestructura existen para que cada coche tenga un cuentakilómetros, sigue habiendo un coste significativo asociado a la transmisión de esos datos de los coches a una ubicación central, de modo que tengas lecturas del cuentakilómetros en tiempo real de todos los coches de tu flota. El coste de asegurar esos datos para respetar la privacidad de los conductores también puede ser bastante significativo.
3 Ofrecerlo como servicio es a menudo la única forma de cumplir la misión de tu organización, ya sea monetizarlo, dar soporte a miles de usuarios o proporcionarlo a bajo coste a los responsables de la toma de decisiones.
4 Contrariamente a lo que puedas oír, ¡no se trata de si utilizas SQL o Python! Puedes hacer ciencia de datos en SQL -veremos BigQuery ML más adelante en el libro- y puedes utilizar Python para análisis de datos puntuales.
5 En 2014, los funcionarios de la ciudad de Nueva York publicaron un conjunto de datos de los viajes en taxi de la ciudad en respuesta a una solicitud de libertad de información. Sin embargo, al estar indebidamente anonimizada, un ataque de fuerza bruta pudo averiguar los viajes asociados a cualquier conductor concreto. La cosa empeoró. Los investigadores de la privacidad pudieron cotejar las fotos de los paparazzi (que revelaban la ubicación exacta de los famosos en momentos concretos) y averiguar qué famosos no daban propina. Peor aún. Observando a las personas que recogían un taxi en el mismo lugar todas las mañanas, y correlacionándolo con el lugar en el que les dejaban de vuelta, pudieron identificar a los neoyorquinos que frecuentaban clubes de striptease.
6 Google inventó el papel de los Ingenieros de Fiabilidad del Sitio (SRE): son personas encargadas de mantener los sistemas en funcionamiento. Sin embargo, a diferencia de los informáticos tradicionales, conocen el software que manejan y son muy capaces de introducir cambios en él.
7 Las palabras "necesita saber" son importantes aquí. A veces puede resultar intimidante ver la amplitud y profundidad de la ciencia de datos y desesperar de llegar a entenderlo todo. Esta es la verdad: no hay nadie que conozca todo el campo al dedillo. Todo el mundo está, en algún nivel, pasando por alto algunas áreas. ¿Qué áreas? Áreas que no son importantes para los problemas en los que están trabajando actualmente. Esto te proporciona una estrategia para acercarte a la ciencia de datos, en lugar de intentar aprender temas ("Aprenderé RNN este mes") o aprender a resolver problemas ("Aprenderé a utilizar la IA para completar frases"). Empieza con enfoques sencillos, y detente cuando las cosas se vuelvan difíciles e ininteligibles. En la mayoría de los campos de la IA, los enfoques sencillos te llevarán bastante lejos. Además, no suele ser necesario un conocimiento profundo de las matemáticas subyacentes para aplicar un enfoque complejo utilizando marcos como Keras.
8 Se conoce con el nombre de Principio de Parsimonia o Navaja de Occam y sostiene que la explicación más sencilla, con el menor número de supuestos, es la mejor. Esto se debe a que los modelos más sencillos tienen menos probabilidades de fallar porque dependen de menos suposiciones. En términos de ingeniería, otra ventaja de los modelos más sencillos es que suelen ser menos costosos de aplicar.
9 Para tu organización, todo el tiempo que ahorres se traduce en un ahorro presupuestario. Consigues más con menos presupuesto.
10 Para ser una palabra de la que se habla bastante, no hay mucho acuerdo sobre lo que significa exactamente "sin servidor". En este libro, llamaré a un servicio sin servidor si los usuarios del servicio sólo tienen que suministrar código y no tienen que gestionar el ciclo de vida de las máquinas en las que se ejecuta el código.
11 Tal vez simplemente esté racionalizando mi propio comportamiento: si llego a la puerta de embarque con más de 15 minutos de margen al menos una vez en unos cinco vuelos, decido que debo de estar llegando al aeropuerto demasiado pronto y me ajusto en consecuencia. Quince minutos y un 20% suelen reflejar mi aversión al riesgo. Si te preguntas por qué mi umbral de aversión al riesgo no es simplemente 15 minutos, sino que incluye un umbral probabilístico asociado, sigue leyendo.
12 Integrar una función es calcular el área bajo la curva de esa función hasta un valor x-específico, como se muestra en la Figura 1-5.
13 Se trata de una suposición simplificadora: si el vuelo debía llegar a las 14.00 h. y en cambio llega a las 16.00 h., es más probable que el viajero se encuentre con tráfico en hora punta.
14 Sí, ésta es la segunda edición del libro, publicada en 2022. La primera edición del libro sólo utilizaba datos de 2015. Aquí utilizaré 2015-2019. Me detuve en 2019 porque 2020 fue el año de la pandemia COVID-19, y los vuelos fueron bastante irregulares.
Get Ciencia de Datos en la Plataforma en la Nube de Google, 2ª Edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

