Chapter 4. The Visitor Design Pattern
This entire chapter is focused on the Visitor design pattern. If you’ve already heard about the Visitor design pattern or even used it in your own designs, you might be wondering why I have chosen Visitor as the first design pattern to explain in detail. Yes, Visitor is definitely not one of the most glamorous design patterns. However, it will definitely serve as a great example to demonstrate the many options you have when implementing a design pattern and how different these implementations can be. It will also serve as an effective example of advertising the advantages of modern C++.
In “Guideline 15: Design for the Addition of Types or Operations”, we first talk about the fundamental design decision you’ll need to make when walking in the realm of dynamic polymorphism: focus on either types or operations. In that guideline, we will also talk about the intrinsic strengths and weaknesses of programming paradigms.
In “Guideline 16: Use Visitor to Extend Operations”, I will introduce you to the Visitor design pattern. I will explain its intent to extend operations instead of types, and show you both the advantages and the shortcomings of the classic Visitor pattern.
In “Guideline 17: Consider std::variant for
Implementing Visitor”, you
will
make the acquaintance of the modern implementation of the Visitor design pattern.
I will introduce you to std::variant and explain the many advantages of that
particular implementation.
In “Guideline 18: Beware the Performance of Acyclic Visitor”, I will introduce you to the Acyclic Visitor. At first glance, this approach appears to resolve some fundamental problems of the Visitor pattern, but on closer inspection we will find that the runtime overhead may disqualify this implementation.
Guideline 15: Design for the Addition of Types or Operations
To you, the term dynamic polymorphism may sound like a lot of freedom. It may feel similar to when you were still a kid: endless possibilities, no limitations! Well, you have grown older and faced reality: you can’t have everything, and there is always a choice to be made. Unfortunately, it’s similar with dynamic polymorphism. Despite the fact that it sounds like complete freedom, there is a limiting choice: do you want to extend types or operations?
To see what I mean, let’s return to the scenario from Chapter 3: we want to draw a given shape.1 We stick to dynamic polymorphism, and for our initial try, we implement this problem with good old procedural programming.
A Procedural Solution
The first header file Point.h provides a fairly simple Point class. This will
mainly serve to make the code complete, but also gives us the idea that we’re dealing with 2D
shapes:
//---- <Point.h> ----------------structPoint{doublex;doubley;};
The second conceptual header file Shape.h proves to be much more interesting:
//---- <Shape.h> ----------------enumShapeType{circle,square};classShape{protected:explicitShape(ShapeTypetype):type_(type){}public:virtual~Shape()=default;ShapeTypegetType()const{returntype_;}private:ShapeTypetype_;};
First, we introduce the enumeration ShapeType, which currently lists the two
enumerators, circle and square
(![]() ).
Apparently, we are initially dealing with only circles and squares. Second, we introduce
the class
).
Apparently, we are initially dealing with only circles and squares. Second, we introduce
the class Shape
(![]() ).
Given the protected constructor and the virtual destructor
(
).
Given the protected constructor and the virtual destructor
(![]() ),
you can anticipate that
),
you can anticipate that Shape is supposed to work as a base class. But that’s not the
surprising detail about Shape: Shape has a data member of type ShapeType
(![]() ).
This data member is initialized via the constructor
(
).
This data member is initialized via the constructor
(![]() )
and can be queried via the
)
and can be queried via the getType() member function
(![]() ).
Apparently, a
).
Apparently, a Shape stores its type in the form of the ShapeType enumeration.
One example of the use of the Shape base class is the Circle class:
//---- <Circle.h> ----------------#include<Point.h>#include<Shape.h>classCircle:publicShape{public:explicitCircle(doubleradius):Shape(circle),radius_(radius){/* Checking that the given radius is valid */}doubleradius()const{returnradius_;}Pointcenter()const{returncenter_;}private:doubleradius_;Pointcenter_{};};
Circle publicly inherits from Shape
(![]() ),
and for that reason, and due to the lack of a default constructor in
),
and for that reason, and due to the lack of a default constructor in Shape, needs to
initialize the base class
(![]() ).
Since it’s a circle, it uses the
).
Since it’s a circle, it uses the circle enumerator as an argument to the base class
constructor.
As stated before, we want to draw shapes. We therefore introduce the draw() function
for circles. Since we don’t want to couple too strongly to any implementation details of
drawing, the draw() function is declared in the conceptual header file
DrawCircle.h
and defined in the corresponding source file:
//---- <DrawCircle.h> ----------------classCircle;voiddraw(Circleconst&);//---- <DrawCircle.cpp> ----------------#include<DrawCircle.h>#include<Circle.h>#include/* some graphics library */voiddraw(Circleconst&c){// ... Implementing the logic for drawing a circle}
Of course, there are not only circles. As indicated by the square enumerator, there
is also a Square class:
//---- <Square.h> ----------------#include<Point.h>#include<Shape.h>classSquare:publicShape{public:explicitSquare(doubleside):Shape(square),side_(side){/* Checking that the given side length is valid */}doubleside()const{returnside_;}Pointcenter()const{returncenter_;}private:doubleside_;Pointcenter_{};// Or any corner, if you prefer};//---- <DrawSquare.h> ----------------classSquare;voiddraw(Squareconst&);//---- <DrawSquare.cpp> ----------------#include<DrawSquare.h>#include<Square.h>#include/* some graphics library */voiddraw(Squareconst&s){// ... Implementing the logic for drawing a square}
The Square class looks very similar to the Circle class
(![]() ).
The major difference is that a
).
The major difference is that a Square initializes its base class with the
square enumerator
(![]() ).
).
With both circles and squares available, we now want to draw an entire vector
of different shapes. For that reason, we introduce the drawAllShapes() function:
//---- <DrawAllShapes.h> ----------------#include<memory>#include<vector>classShape;voiddrawAllShapes(std::vector<std::unique_ptr<Shape>>const&shapes);//---- <DrawAllShapes.cpp> ----------------#include<DrawAllShapes.h>#include<Circle.h>#include<Square.h>voiddrawAllShapes(std::vector<std::unique_ptr<Shape>>const&shapes){for(autoconst&shape:shapes){switch(shape->getType()){casecircle:draw(static_cast<Circleconst&>(*shape));break;casesquare:draw(static_cast<Squareconst&>(*shape));break;}}}
drawAllShapes() takes a vector of shapes in the form of std::unique_ptr<Shape>
(![]() ).
The pointer to the base class is necessary to hold different kinds of concrete
shapes, and the
).
The pointer to the base class is necessary to hold different kinds of concrete
shapes, and the std::unique_ptr in particular to automatically manage the shapes
via the RAII idiom. Inside the function, we start by traversing the vector in
order to draw every shape. Unfortunately, all we have at this point are Shape
pointers. Therefore, we have to ask every shape nicely by means of the getType()
function
(![]() ):
what kind of shape are you? If the shape replies with
):
what kind of shape are you? If the shape replies with circle, we know that we
have to draw it as a Circle and perform the corresponding static_cast. If the
shape replies with square, we draw it as a Square.
I can feel that you’re not particularly happy about this solution. But before talking about
the shortcomings, let’s consider the main() function:
//---- <Main.cpp> ----------------#include<Circle.h>#include<Square.h>#include<DrawAllShapes.h>#include<memory>#include<vector>intmain(){usingShapes=std::vector<std::unique_ptr<Shape>>;// Creating some shapesShapesshapes;shapes.emplace_back(std::make_unique<Circle>(2.3));shapes.emplace_back(std::make_unique<Square>(1.2));shapes.emplace_back(std::make_unique<Circle>(4.1));// Drawing all shapesdrawAllShapes(shapes);returnEXIT_SUCCESS;}
It works! With this main() function, the code compiles and draws three shapes (two circles
and a square). Isn’t that great? It is, but it won’t stop you from going into a rant:
“What a primitive solution! Not only is the switch a bad choice for distinguishing between
different kinds of shapes, but it also doesn’t have a default case! And who had this crazy idea to encode the type of the shapes by
means of an unscoped enumeration?”2 You’re looking
suspiciously in my direction…
Well, I can understand your reaction. But let’s analyze the problem in a little more
detail. Let me guess: you remember “Guideline 5: Design for Extension”. And you now imagine what
you would have to do to add a third kind of shape. First, you would have to extend the
enumeration. For instance, we would have to add the new enumerator triangle
(![]() ):
):
enumShapeType{circle,square,triangle};
Note that this addition would have an impact not only on the switch statement in the
drawAllShapes() function (it is now truly incomplete), but also on all classes derived from
Shape (Circle and Square). These classes depend on the enumeration since they
depend on the Shape base class and also use the enumeration directly. Therefore, changing
the enumeration would result in a recompilation of all your source files.
That should strike you as a serious issue. And it is indeed. The heart of the problem is
the direct dependency of all shape classes and functions on the enumeration. Any change to
the enumeration results in a ripple effect that requires the dependent files to be
recompiled. Obviously, this directly violates the Open-Closed Principle (OCP) (see
“Guideline 5: Design for Extension”). This doesn’t seem right: adding a Triangle shouldn’t
result in a recompilation of the Circle and Square classes.
There is more, though. In addition to actually writing a Triangle class (something that
I leave to your imagination), you have to update the switch statement to handle triangles
(![]() ):
):
voiddrawAllShapes(std::vector<std::unique_ptr<Shape>>const&shapes){for(autoconst&shape:shapes){switch(shape->getType()){casecircle:draw(static_cast<Circleconst&>(*shape));break;casesquare:draw(static_cast<Squareconst&>(*shape));break;casetriangle:draw(static_cast<Triangleconst&>(*shape));break;}}}
I can imagine your outcry: “Copy-and-paste! Duplication!” Yes, in this situation it is very likely
that a developer will use copy-and-paste to implement the new logic. It’s just so convenient
because the new case is so similar to the previous two cases. And indeed, this is an indication
that the design could be improved. However, I see a far more serious flaw: I would assume that
in a larger codebase, this is not the only switch statement. On the contrary, there will be
others that need to be updated as well. How many are there? A dozen? Fifty? Over a hundred?
And how do you find all of these? OK, so you argue that the compiler would help you with this
task. Perhaps with the switches, yes, but what if there are also if-else-if cascades? And
then, after this update marathon, when you think you are done, how do you guarantee that you
have truly updated all the necessary sections?
Yes, I can understand your reaction and why you prefer not to have this kind of code: this explicit handling of types is a maintenance nightmare. To quote Scott Meyers:3
This kind of type-based programming has a long history in C, and one of the things we know about it is that it yields programs that are essentially unmaintainable.
An Object-Oriented Solution
So let me ask: what would you have done? How would you have implemented the drawing of shapes?
Well, I can imagine you would have used an object-oriented approach.
That means you would scratch the enumeration and add a pure virtual draw() function to the
Shape base class. This way, Shape doesn’t have to remember its type anymore:
//---- <Shape.h> ----------------classShape{public:Shape()=default;virtual~Shape()=default;virtualvoiddraw()const=0;};
Given this base class, derived classes now would have to implement only the draw() member
function
(![]() ):
):
//---- <Circle.h> ----------------#include<Point.h>#include<Shape.h>classCircle:publicShape{public:explicitCircle(doubleradius):radius_(radius){/* Checking that the given radius is valid */}doubleradius()const{returnradius_;}Pointcenter()const{returncenter_;}voiddraw()constoverride;private:doubleradius_;Pointcenter_{};};//---- <Circle.cpp> ----------------#include<Circle.h>#include/* some graphics library */voidCircle::draw()const{// ... Implementing the logic for drawing a circle}//---- <Square.h> ----------------#include<Point.h>#include<Shape.h>classSquare:publicShape{public:explicitSquare(doubleside):side_(side){/* Checking that the given side length is valid */}doubleside()const{returnside_;}Pointcenter()const{returncenter_;}voiddraw()constoverride;private:doubleside_;Pointcenter_{};};//---- <Square.cpp> ----------------#include<Square.h>#include/* some graphics library */voidSquare::draw()const{// ... Implementing the logic for drawing a square}
Once the virtual draw() function is in place and implemented by all derived classes,
it can be used to refactor the drawAllShapes() function:
//---- <DrawAllShapes.h> ----------------#include<memory>#include<vector>classShape;voiddrawAllShapes(std::vector<std::unique_ptr<Shape>>const&shapes);//---- <DrawAllShapes.cpp> ----------------#include<DrawAllShapes.h>#include<Shape.h>voiddrawAllShapes(std::vector<std::unique_ptr<Shape>>const&shapes){for(autoconst&shape:shapes){shape->draw();}}
I can see you relax and start smiling again. This is so much nicer, so much cleaner. While I understand that you prefer this solution and that you would like to stay in this comfort zone a little while longer, I unfortunately have to point out a flaw. Yes, this solution might also come with a disadvantage.
As indicated in the introduction to this section, with an object-oriented approach, we are
now able to add new types very easily. All we have to do is write a new derived class. We
don’t have to modify or recompile any existing code (with the exception of the main()
function). That perfectly fulfills the OCP. However, did
you notice that we are not able to easily add operations anymore? For instance, let’s
assume we need a virtual serialize() function to convert a Shape into bytes. How
can we add this without modifying existing code? How can anyone easily add this operation
without having to touch the Shape base class?
Unfortunately, that isn’t possible anymore. We are now dealing with a closed set of operations, which means that we violate the OCP in relation to addition operations. To add a virtual function, the base class needs to be modified, and all derived classes (circles, squares, etc.) need to implement the new function, even though the function might never be called. In summary, the object-oriented solution fulfills the OCP with respect to adding types but violates it in relation to operations.
I know you thought we left the procedural solution behind for good, but let’s
take a second look. In the procedural approach, adding a new operation was actually very
simple. New operations could be added in the form of free functions or separate classes, for
instance. It wasn’t necessary to modify the Shape base class or any of the derived classes.
Thus in the procedural solution, we have fulfilled the OCP with respect to adding operations.
But as we’ve seen, the procedural solution violates the OCP in relation to adding types.
Thus, it appears to be an inversion of the object-oriented solution, which is the other way around.
Be Aware of the Design Choice in Dynamic Polymorphism
The takeaway of this example is that there is a design choice when using dynamic polymorphism: either you can add types easily by fixing the number of operations or you can add operations easily by fixing the number of types. Thus, the OCP has two dimensions: when designing software, you have to make a conscious decision about which kind of extension you expect.
The strength of object-oriented programming is the easy addition of new types, but its weakness is that the addition of operations becomes much more difficult. The strength of procedural programming is the easy addition of operations, but adding types is a real pain (Table 4-1). It depends on your project: if you expect new types will be added frequently, rather than operations, you should strive for an OOP solution, which treats operations as a closed set and types as an open set. If you expect operations will be added, you should strive for a procedural solution, which treats types as a closed set and operations as an open set. If you make the right choice, you will economize your time and the time of your colleagues, and extensions will feel natural and easy.4
| Programming paradigm | Strength | Weakness |
|---|---|---|
Procedural programming |
Addition of operations |
Addition of (polymorphic) types |
Object-oriented programming |
Addition of (polymorphic) types |
Addition of operations |
Be aware of these strengths: based on your expectation on how a codebase will evolve, choose the right approach to design for extensions. Do not ignore the weaknesses, and do not put yourself in an unfortunate maintenance hell.
I assume that at this point you’re wondering if it’s possible to have two open sets. Well, to the best of my knowledge, this is not impossible but it’s usually impractical. As an example, in “Guideline 18: Beware the Performance of Acyclic Visitor”, I will show you that performance might take a significant hit.
Since you might be a fan of template-based programming and similar compile time endeavors, I should also make the explicit note that static polymorphism does not have the same limitations. While in dynamic polymorphism, one of the design axes (types and operations) needs to be fixed, in static polymorphism, both pieces of information are available at compile-time. Therefore, both aspects can be extended easily (if you do it properly).5
Guideline 16: Use Visitor to Extend Operations
In the previous section, you saw that the strength of object-oriented programming (OOP) is the addition of types and its weakness is the addition of operations. Of course, OOP has an answer to that weakness: the Visitor design pattern.
The Visitor design pattern is one of the classic design patterns described by the Gang of Four (GoF). Its focus is on allowing you to frequently add operations instead of types. Allow me to explain the Visitor design pattern using the previous toy example: the drawing of shapes.
In Figure 4-1, you see the Shape hierarchy. The Shape class is again the base
class for a certain number of concrete shapes. In this example, there are only the two classes,
Circle and Square, but of course it’s possible to have more shapes. In addition, you
might imagine Triangle, Rectangle, or Ellipse classes.
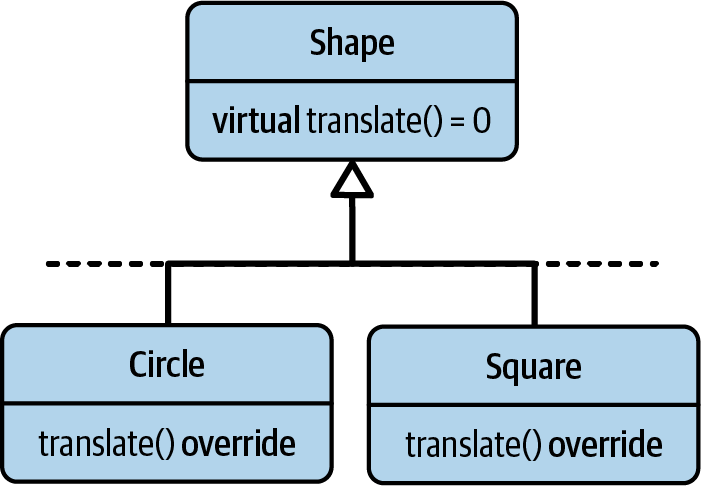
Figure 4-1. The UML representation of a shape hierarchy with two derived classes (
Circle and Square)
Analyzing the Design Issues
Let’s assume you are certain that you already have all the shapes you’ll ever need. That is, you consider the set of shapes a closed set. What you are missing, though, are additional operations. For instance, you’re missing an operation to rotate the shapes. Also, you would like to serialize shapes, i.e., you would like to convert the instance of a shape into bytes. And of course, you want to draw shapes. In addition, you want to enable anybody to add new operations. Therefore, you expect an open set of operations.6
Every new operation now requires you to insert a new virtual function into the base
class. Unfortunately, that can be troublesome in different ways. Most obviously, not everyone
is able to add a virtual function to the Shape base class. I, for instance, can’t simply
go ahead and change your code. Therefore, this approach would not meet the expectation that
everyone can add operations. While you can already see this as a final negative verdict,
let’s still analyze the problem of virtual functions in more detail.
If you decide to use a pure virtual function, you would have to implement the function in
every derived class. For your own derived types, you could shrug this off as just a little
bit of extra effort. But you might also cause extra work for other people who have
created a shape by inheriting from the Shape base class.7 And that
is very much expected, since this is the strength of OOP: anyone can add new types easily.
Since this is to be expected, it may be a reason to not use a pure virtual function.
As an alternative, you could introduce a regular virtual function, i.e., a virtual function
with a default implementation. While a default behavior for a rotate() function sounds
like a very reasonable idea, a default implementation for a serialize() function doesn’t
sound easy at all. I admit that I would have to think hard about how to implement
such a function. You might now suggest just throwing an exception as the default. However,
this means that derived classes must again implement the missing behavior, and
it would be a pure virtual function in disguise, or a clear violation of the
Liskov Substitution Principle (see “Guideline 6: Adhere to the Expected Behavior of Abstractions”).
Either way, adding a new operation into the Shape base class is difficult or not even
possible at all. The underlying reason is that adding virtual functions violates the
OCP. If you really need to add new operations frequently,
then you should design so that the extension of operations is easy. That is
what the Visitor design pattern tries to achieve.
The Visitor Design Pattern Explained
The intent of the Visitor design pattern is to enable the addition of operations.
The Visitor Design Pattern
Intent: “Represent an operation to be performed on the elements of an object structure. Visitor lets you define a new operation without changing the classes of the elements on which it operates.”8
In addition to the Shape hierarchy, I now introduce the ShapeVisitor hierarchy on
the lefthand side of Figure 4-2. The ShapeVisitor base class represents an
abstraction of shape operations. For that reason, you could argue that ShapeOperation
might be a better name for that class. It is beneficial, however, to apply
“Guideline 14: Use a Design Pattern’s Name to Communicate Intent”. The name
Visitor will help others understand the design.
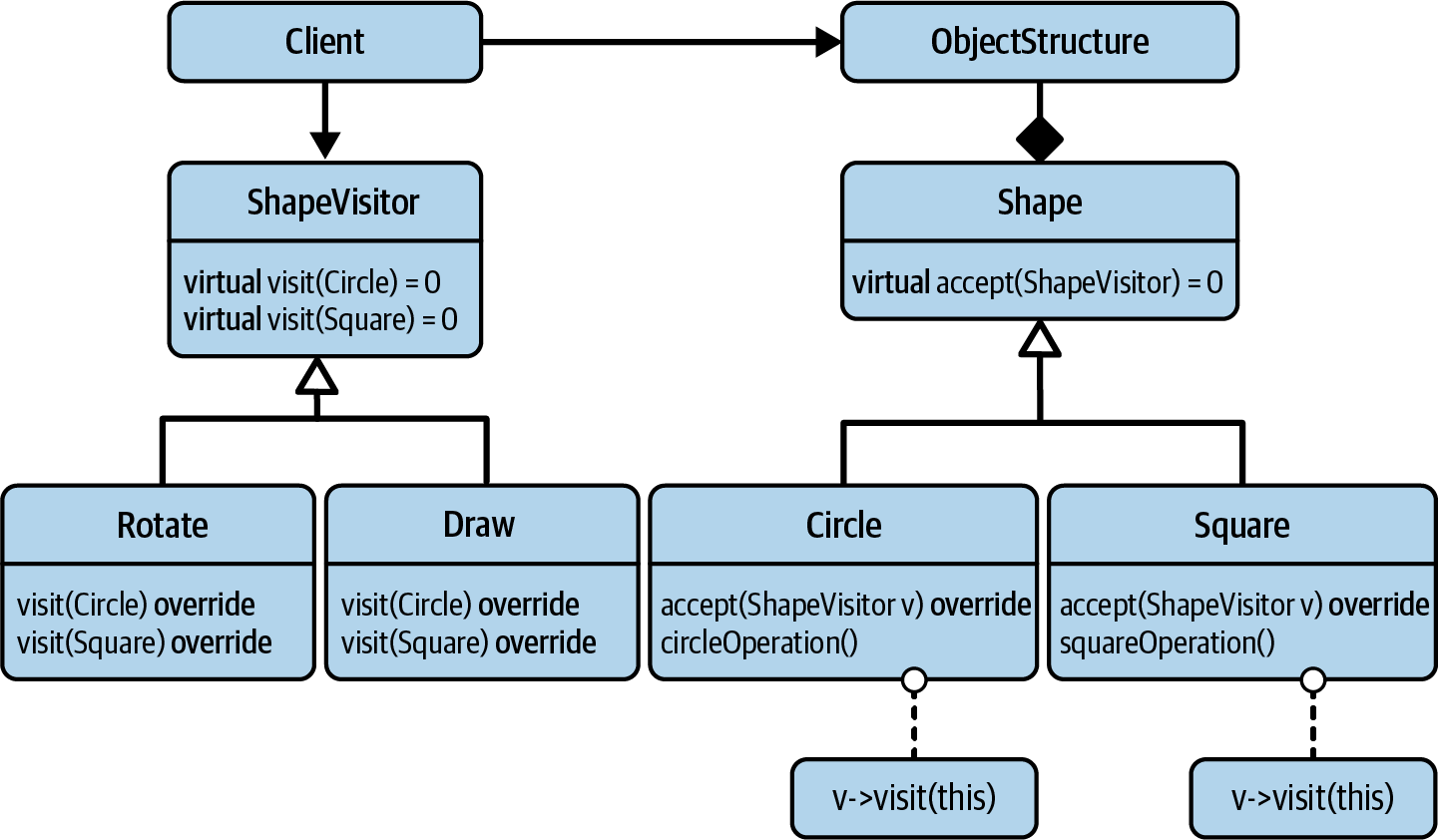
Figure 4-2. The UML representation of the Visitor design pattern
The ShapeVisitor base class comes with one pure virtual visit() function for every
concrete shape in the Shape hierarchy:
classShapeVisitor{public:virtual~ShapeVisitor()=default;virtualvoidvisit(Circleconst&,/*...*/)const=0;virtualvoidvisit(Squareconst&,/*...*/)const=0;// Possibly more visit() functions, one for each concrete shape};
In this example, there is one visit() function for Circle
(![]() )
and one for
)
and one for Square
(![]() ).
Of course, there could be more
).
Of course, there could be more visit() functions—for instance, one for
Triangle,
one for Rectangle, and one for Ellipse—given that these are also classes
derived from the Shape base class.
With the ShapeVisitor base class in place, you can now add new operations easily.
All you have to do to add an operation is add a new derived class. For instance,
to enable rotating shapes, you can introduce the Rotate class and implement all visit()
functions. To enable drawing shapes, all you have to do is introduce a Draw
class:
classDraw:publicShapeVisitor{public:voidvisit(Circleconst&c,/*...*/)constoverride;voidvisit(Squareconst&s,/*...*/)constoverride;// Possibly more visit() functions, one for each concrete shape};
And you can think about introducing multiple Draw classes, one for each graphics
library you need to support. You can do that easily, because you don’t have to modify any
existing code. It is only necessary to extend the ShapeVisitor hierarchy by adding
new code. Therefore, this design fulfills the OCP with respect to adding
operations.
To completely understand the software design characteristics of Visitor, it is
important to understand why the Visitor design pattern is able to fulfill the OCP. The
initial problem was that every new operation required a change to the Shape base
class. Visitor identifies the addition of operations as a variation point. By extracting
this variation point, i.e., by making this a separate class, you follow the
Single-Responsibility Principle (SRP): Shape does not have to change for every new
operation. This avoids frequent modifications of the Shape hierarchy and enables the
easy addition of new operations. The SRP therefore acts as an enabler for the OCP.
To use visitors (classes derived from the ShapeVisitor base
class) on shapes, you now have to add one last function to the Shape hierarchy: the
accept() function
(![]() ):9
):9
classShape{public:virtual~Shape()=default;virtualvoidaccept(ShapeVisitorconst&v)=0;// ...};
The accept() function is introduced as a pure virtual function in the base class
and therefore has to be implemented in every derived class
(![]() and
and
![]() ):
):
classCircle:publicShape{public:explicitCircle(doubleradius):radius_(radius){/* Checking that the given radius is valid */}voidaccept(ShapeVisitorconst&v)override{v.visit(*this);}doubleradius()const{returnradius_;}private:doubleradius_;};classSquare:publicShape{public:explicitSquare(doubleside):side_(side){/* Checking that the given side length is valid */}voidaccept(ShapeVisitorconst&v)override{v.visit(*this);}doubleside()const{returnside_;}private:doubleside_;};
The implementation of accept() is easy; however, it merely needs to call the corresponding
visit() function on the given visitor based on the type of the concrete Shape.
This is achieved by passing the this pointer as an argument to visit(). Thus,
the implementation of accept() is the same in each derived class, but due to a
different type of the this pointer, it will trigger a different overload of the visit()
function in the given visitor. Therefore, the Shape base class cannot provide a
default implementation.
This accept() function can now be used where you need to perform an operation.
For instance, the drawAllShapes() function uses accept() to draw all shapes in a given
vector of shapes:
voiddrawAllShapes(std::vector<std::unique_ptr<Shape>>const&shapes){for(autoconst&shape:shapes){shape->accept(Draw{});}}
With the addition of the accept() function, you are now able to extend your Shape
hierarchy easily with operations. You have now designed for an open set of operations.
Amazing! However, there is no silver bullet, and there is no design that always
works. Every design comes with advantages, but also disadvantages. So before you start
to celebrate, I should tell you about the shortcomings of the Visitor design pattern to
give you the complete picture.
Analyzing the Shortcomings of the Visitor Design Pattern
The Visitor design pattern is unfortunately far from perfect. This should be expected, considering Visitor is a workaround for an intrinsic OOP weakness, instead of building on OOP strengths.
The first disadvantage is a low implementation flexibility.
It becomes obvious if you consider the implementation of a Translate visitor. The
Translate visitor needs to move the center point of each shape by a given offset. For
that, Translate needs to implement a visit() function for every concrete Shape.
Especially for Translate, you can imagine that the implementation of these visit()
functions would be very similar, if not identical: there is nothing different about
translating a Circle from translating a Square. Still, you will need to write all
visit() functions. Of course, you would extract the logic from the visit()
functions and implement this in a third, separate function to minimize
duplication according to the DRY principle.10 But unfortunately, the strict
requirements imposed by the base class do not give you the freedom to implement
these visit() functions as one. The result is some boilerplate code:
classTranslate:publicShapeVisitor{public:// Where is the difference between translating a circle and translating// a square? Still you have to implement all virtual functions...voidvisit(Circleconst&c,/*...*/)constoverride;voidvisit(Squareconst&s,/*...*/)constoverride;// Possibly more visit() functions, one for each concrete shape};
A similar implementation inflexibility is the return type of the visit() functions. The
decision on what the function returns is made in the ShapeVisitor base class. Derived classes
cannot change that. The usual approach is to store the result in the visitor and access
it later.
The second disadvantage is that with the Visitor design pattern in place, it becomes
difficult to add new types. Previously, we made the assumption that you’re certain
you have all the shapes you will ever need. This assumption has now become a restriction.
Adding a new shape in the Shape hierarchy would require the entire ShapeVisitor hierarchy
to be updated: you would have to add a new pure virtual function to the ShapeVisitor
base class, and this virtual function would have to be implemented by all derived classes.
Of course, this comes with all the disadvantages we’ve discussed before. In particular,
you would force other developers to update their operations.11 Thus, the Visitor design pattern
requires a closed set of types and in exchange provides an open set of operations.
The underlying reason for this restriction is that there is a cyclic dependency among
the ShapeVisitor base class, the concrete shapes (Circle, Square, etc.), and
the Shape base class (see Figure 4-3).
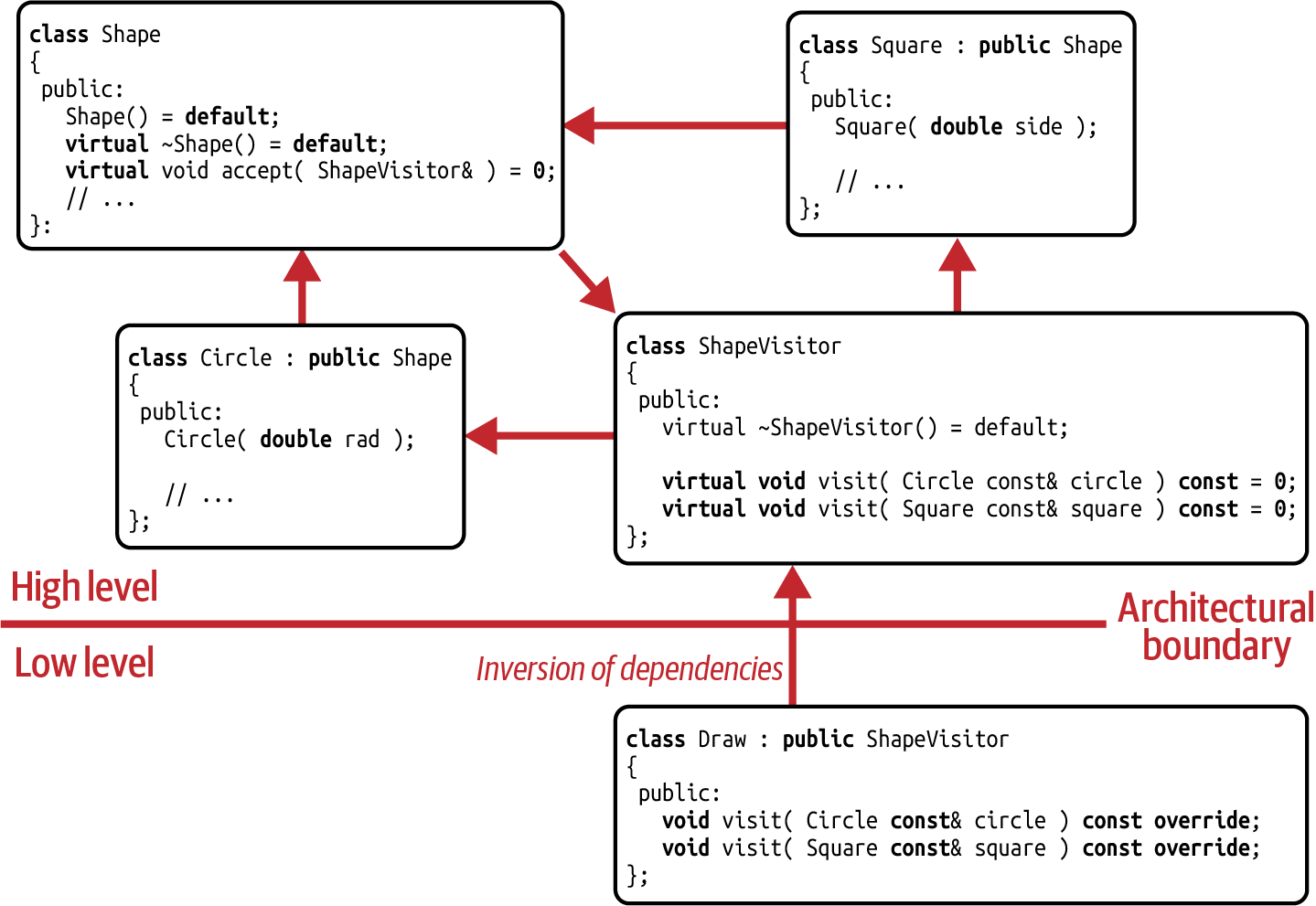
Figure 4-3. Dependency graph for the Visitor design pattern
The ShapeVisitor base
class depends on the concrete shapes, since it provides a visit() function for each
of these shapes. The concrete shapes depend on the Shape base class, since they have
to fulfill all the expectations and requirements of the base class. And the Shape base
class depends on the ShapeVisitor base class due to the accept() function. Because
of this cyclic dependency, we are now able to add new operations easily (on a lower level
of our architecture because of a dependency inversion), but we cannot add types easily
anymore (because that would have to happen on the high level of our architecture). For
that reason, we call the classic Visitor design pattern Cyclic Visitor.
The third disadvantage is the intrusive nature of a visitor. To add a visitor
to an existing hierarchy, you need to add the virtual accept() to the base class of
that hierarchy. While this is often possible, it still suffers from the usual problem
of adding a pure virtual function to an existing hierarchy (see
“Guideline 15: Design for the Addition of
Types or Operations”). If, however, it’s not possible
to add the accept() function, this form of Visitor is not an option. If that’s
the case, don’t worry: we will see another, nonintrusive form of the Visitor design pattern in
“Guideline 17: Consider std::variant for
Implementing Visitor”.
A fourth, albeit admittedly more obscure, disadvantage is that the accept() function
is inherited by deriving classes. If someone later adds another layer of derived
classes (and that someone might be you) and forgets to override the
accept() function, the visitor will be applied to the wrong type. And unfortunately,
you would not get any warning about this. This is just more evidence that adding new
types has become more difficult. A possible solution for this would be to declare the
Circle and Square classes as final, which would, however, limit future extensions.
“Wow, that’s a lot of disadvantages. Are there any more?” Yes, unfortunately there are
two more. The fifth disadvantage is obvious when we consider that for every operation,
we’re now required to call two virtual functions. Initially, we don’t know about
either the type of operation or the type of shape. The first virtual function
is the accept() function, which is passed an abstract ShapeVisitor. The accept()
function now resolves the concrete type of shape. The second virtual function is the
visit() function, which is passed a concrete type of Shape. The visit() function
now resolves the concrete type of the operation. This so-called double dispatch is
unfortunately not free. On the contrary, performance-wise, you should consider the
Visitor design pattern as rather slow. I will provide some performance numbers
in the next guideline.
While talking about performance, I should also mention two other aspects that have a negative
impact on performance. First, we usually allocate every single shape and visitor individually.
Consider the following main() function:
intmain(){usingShapes=std::vector<std::unique_ptr<Shape>>;Shapesshapes;shapes.emplace_back(std::make_unique<Circle>(2.3));shapes.emplace_back(std::make_unique<Square>(1.2));shapes.emplace_back(std::make_unique<Circle>(4.1));drawAllShapes(shapes);// ...returnEXIT_SUCCESS;}
In this main() function, all allocations happen by means of std::make_unique()
(![]() ,
,
![]() , and
, and
![]() ).
These many, small allocations cost runtime on their own and will in the long run cause
memory fragmentation.12 Also, the memory may be laid out in an unfavorable, cache-unfriendly
way. As a consequence, we usually
use pointers to work with the resulting shapes and visitors. The resulting indirections
make it much harder for a compiler to perform any kind of optimization and will show up
in performance benchmarks. However, to be honest, this is not a Visitor-specific problem,
but these two aspects are quite common to OOP in general.
).
These many, small allocations cost runtime on their own and will in the long run cause
memory fragmentation.12 Also, the memory may be laid out in an unfavorable, cache-unfriendly
way. As a consequence, we usually
use pointers to work with the resulting shapes and visitors. The resulting indirections
make it much harder for a compiler to perform any kind of optimization and will show up
in performance benchmarks. However, to be honest, this is not a Visitor-specific problem,
but these two aspects are quite common to OOP in general.
The last disadvantage of the Visitor design pattern is that experience has proven this design pattern to be rather hard to fully understand and maintain. This is a rather subjective disadvantage, but the complexity of the intricate interplay of the two hierarchies often feels more like a burden than a real solution.
In summary, the Visitor design pattern is the OOP solution to allow for the easy
extension of operations instead of types. That is achieved by introducing an abstraction
in the form of the ShapeVisitor base class, which enables you to add operations on another
set of types. While this is a unique strength of Visitor, it unfortunately comes with
several deficiencies: implementation inflexibilities in both inheritance hierarchies due
to a strong coupling to the requirements of the base classes, rather bad performance,
and the intrinsic complexity of Visitor make it a rather unpopular design pattern.
If you’re now undecided whether or not to use a classic Visitor, take the time to read the next section. I will show you a different way to implement a Visitor—a solution that will much more likely be to your satisfaction.
Guideline 17: Consider std::variant for Implementing Visitor
In “Guideline 16: Use Visitor to Extend Operations”, I introduced you to the Visitor design pattern. I imagine that you did not immediately fall in love: while Visitor most certainly has a couple of unique properties, it is also a rather complex design pattern with some strong internal coupling and performance deficiencies. No, definitely not love! However, don’t worry, the classic form is not the only way you can implement the Visitor design pattern. In this section, I would like to introduce you to a different way to implement Visitor. And I am certain that this approach will be much more to your liking.
Introduction to std::variant
At the beginning of this chapter, we talked about the strengths and weaknesses of the
different paradigms (OOP versus procedural programming). In particular, we talked about
the fact that procedural programming was particularly good at adding new operations
to an existing set of types. So instead of trying to find workarounds in OOP, how
about we exploit the strength of procedural programming? No, don’t worry; of course
I’m not suggesting a return to our initial solution. That approach was just too
error prone. Instead I’m talking about std::variant:
#include<cstdlib>#include<iostream>#include<string>#include<variant>struct{voidoperator()(intvalue)const{std::cout<<"int:"<<value<<'\n';}voidoperator()(doublevalue)const{std::cout<<"double:"<<value<<'\n';}voidoperator()(std::stringconst&value)const{std::cout<<"string:"<<value<<'\n';}};intmain(){// Creates a default variant that contains an 'int' initialized to 0std::variant<int,double,std::string>v{};v=42;// Assigns the 'int' 42 to the variantv=3.14;// Assigns the 'double' 3.14 to the variantv=2.71F;// Assigns a 'float', which is promoted to 'double'v="Bjarne";// Assigns the string literal 'Bjarne' to the variantv=43;// Assigns the 'int' 43 to the variantintconsti=std::get<int>(v);// Direct access to the valueint*constpi=std::get_if<int>(&v);// Direct access to the valuestd::visit({},v);// Applying the Print visitorreturnEXIT_SUCCESS;}
Since you might not have had the pleasure of being introduced to the C++17
std::variant yet, allow me to give you an introduction in a nutshell, just in case. A
variant represents one of several alternatives. The variant at the beginning of the main()
function in the code example can contain an int, a double, or an std::string
(![]() ).
Note that I said or: a variant can contain only one of these three alternatives. It is
never several of them, and under usual circumstances, it should never contain nothing. For
that reason, we call a variant a sum type: the set of possible states is the sum of
possible states of the alternatives.
).
Note that I said or: a variant can contain only one of these three alternatives. It is
never several of them, and under usual circumstances, it should never contain nothing. For
that reason, we call a variant a sum type: the set of possible states is the sum of
possible states of the alternatives.
A default variant is also not empty. It is initialized to the default value of the first
alternative. In the example, a default variant contains an integer of value
0. Changing the value of a variant is simple: you can just assign new values. For instance,
we can assign the value 42, which now means that the variant stores an integer of value 42
(![]() ).
If we subsequently assign the
).
If we subsequently assign the double 3.14, then the variant will store a double of
value 3.14
(![]() ).
If you ever want to assign a value of a type that is not one of the possible
alternatives, the usual conversion rules apply. For instance, if you want to assign a
).
If you ever want to assign a value of a type that is not one of the possible
alternatives, the usual conversion rules apply. For instance, if you want to assign a
float, based on the regular conversion rules it would be promoted to a double
(![]() ).
).
To store the alternatives, the variant provides just enough internal buffer
to hold the largest of the alternatives. In our case, the largest alternative is the
std::string, which is usually between 24 and 32 bytes (depending on the used
implementation of the Standard Library). Thus, when you assign the string literal
"Bjarne", the variant will first clean up the previous value (there isn’t much to
do; it’s just a double) and then, since it is the only alternative that works,
construct the std::string in place inside its own buffer
(![]() ).
When you change your mind and assign the integer 43
(
).
When you change your mind and assign the integer 43
(![]() ),
the variant will properly destroy the
),
the variant will properly destroy the std::string by means of its destructor and reuse
the internal buffer for the integer. Marvelous, is it not? The variant is type safe
and always properly initialized. What more could we ask for?
Well, of course you want to do something with the values inside the variant. It would not
be of any use if we just store the value. Unfortunately, you cannot simply assign a
variant to any other value, e.g., an int, to get your value back. No, accessing the value
is a little more complicated. There are several ways to access the stored values, the
most direct approach being std::get()
(![]() ).
With
).
With std::get() you can query for a value of a particular type. If the variant
contains a value of that type, it returns a reference to it. If it does not, it throws
the std::bad_variant_exception. That seems to be a pretty rude response, given that you
have asked nicely. But we should probably be happy that the variant does not pretend
to hold some value when it indeed does not. At least it is honest. There is a nicer
way in the form of std::get_if()
(![]() ).
In comparison to
).
In comparison to std::get(), std::get_if() does not return a reference but a
pointer. If you request a type that the std::variant currently does not
hold, it doesn’t throw an exception but instead returns a nullptr.
However, there is a third way, a way that is particularly interesting for our purposes: std::visit()
(![]() ).
).
std::visit() allows you to perform any operation on the stored value. Or more precisely,
it allows you to pass a custom visitor to perform any operation on the stored value
of a closed set of types. Sound familiar?
The Print visitor
(![]() )
that we pass as the first argument must provide a function call operator (
)
that we pass as the first argument must provide a function call operator (operator())
for every possible alternative. In this example, that is fulfilled by providing three
operator()s: one for int, one for double, and one for std::string. It is
particularly noteworthy that Print does not have to inherit from any base class, and it does not have any virtual functions. Therefore, there is no strong coupling to
any requirements. If we wanted to, we could also collapse the function call operators
for int and double into one, since an int can be converted to a double:
struct{voidoperator()(doublevalue)const{std::cout<<"int or double: "<<value<<'\n';}voidoperator()(std::stringconst&value)const{std::cout<<"string: "<<value<<'\n';}};
While the question about which version we should prefer is not of particular interest for
us at this moment, you’ll notice that we have a lot of implementation flexibility. There is
only a very loose coupling based on the convention that for every alternative there needs
to be an operator(), regardless of the exact form. We do not have a
Visitor base class
anymore that forces us to do things in a very specific way. We also do not have any base
class for the alternatives: we are free to use fundamental types such as int and double,
as well as arbitrary class types such as std::string. And perhaps most importantly,
anyone can easily add new operations. No existing code needs to be modified. With this,
we can argue that this is a procedural solution, just much more elegant than the initial
enum-based approach, which used a base class to hold a discriminator.
Refactoring the Drawing of Shapes as a Value-Based, Nonintrusive Solution
With these properties, std::variant is perfectly suited for our drawing example. Let’s
re-implement the drawing of shapes with std::variant. First, we refactor the
Circle and Square classes:
//---- <Circle.h> ----------------#include<Point.h>classCircle{public:explicitCircle(doubleradius):radius_(radius){/* Checking that the given radius is valid */}doubleradius()const{returnradius_;}Pointcenter()const{returncenter_;}private:doubleradius_;Pointcenter_{};};//---- <Square.h> ----------------#include<Point.h>classSquare{public:explicitSquare(doubleside):side_(side){/* Checking that the given side length is valid */}doubleside()const{returnside_;}Pointcenter()const{returncenter_;}private:doubleside_;Pointcenter_{};};
Both Circle and Square are significantly simplified: no more Shape base class, no more
need to implement any virtual functions—in particular the accept() function. Thus, this
Visitor approach is nonintrusive: this form of Visitor can be easily added to existing
types! And there is no need to prepare these classes for any upcoming operations. We can focus
entirely on implementing these two classes as what they are: geometric primitives.
The most beautiful part of the refactoring, however, is the actual use of
std::variant:
//---- <Shape.h> ----------------#include<variant>#include<Circle.h>#include<Square.h>usingShape=std::variant<Circle,Square>;//---- <Shapes.h> ----------------#include<vector>#include<Shape.h>usingShapes=std::vector<Shape>;
Since our closed set of types is a set of shapes, variant will now contain either a
Circle or Square. And what is a good name for an abstraction of a set of types that
represent shapes? Well…Shape
(![]() ).
Instead of a base class that abstracts from the actual
type of shape,
).
Instead of a base class that abstracts from the actual
type of shape, std::variant now acquires this task. If this is the first time you’ve seen
that, you are probably completely amazed. But wait, there is more: this also means that we
can now turn our back on std::unique_ptr. Remember: the only reason we used (smart)
pointers was to enable us to store different kinds of shapes in the same vector. But now
that std::variant enables us to do the same, we can simply store variant objects inside
a single vector
(![]() ).
).
With this functionality in place, we can write custom operations on shapes.
We’re still interested in drawing shapes. For that purpose, we now implement the Draw
visitor:
//---- <Draw.h> ----------------#include<Shape.h>#include/* some graphics library */structDraw{voidoperator()(Circleconst&c)const{/* ... Implementing the logic for drawing a circle ... */}voidoperator()(Squareconst&s)const{/* ... Implementing the logic for drawing a square ... */}};
Again, we are following the expectation to implement one operator() for every
alternative: one for Circle and one for Square. But this time we have a choice.
There is no need to implement any base class, and for that reason, no need to override
any virtual function. Therefore, there is no need to implement exactly one operator()
for every alternative. While in this example it feels reasonable to have two functions,
we have the option to combine the two operator()s into one function. We also have a
choice with respect to the return type of the operation. We can locally decide what
we should return, and it is not a base class that, independent from the specific
operation, makes a global decision. Implementation flexibility. Loose coupling.
Amazing!
The last piece of the puzzle is the drawAllShapes() function:
//---- <DrawAllShapes.h> ----------------#include<Shapes.h>voiddrawAllShapes(Shapesconst&shapes);//---- <DrawAllShapes.cpp> ----------------#include<DrawAllShapes.h>voiddrawAllShapes(Shapesconst&shapes){for(autoconst&shape:shapes){std::visit(Draw{},shape);}}
The drawAllShapes() function is refactored to make use of std::visit(). In this
function, we now apply the Draw visitor onto all variants stored in a vector.
The job of std::visit() is to perform the necessary type dispatch for you. If the
given std::variant contains a Circle, it will call the Draw::operator() for circles.
Otherwise it will call the Draw::operator() for squares. If you wanted to, you could
manually implement the same dispatch with std::get_if():
voiddrawAllShapes(Shapesconst&shapes){for(autoconst&shape:shapes){if(Circle*circle=std::get_if<Circle>(&shape)){// ... Drawing a circle}elseif(Square*square=std::get_if<Square>(&shape)){// ... Drawing a square}}}
I know what you’re thinking: “Nonsense! Why would I ever want to do that? That would result in the same maintenance nightmare as an enum-based solution.” I completely agree with you: from a software design perspective, this would be a terrible idea. Still, and I have to say that this is difficult to admit in the context of this book, there may be a good reason to do that (sometimes): performance. I know, now I’ve piqued your interest, but since we are almost ready to talk about performance anyway, allow me to defer this discussion for just a few paragraphs. I will come back to this, I promise!
With all of these details in place, we can finally refactor the main() function. But
there isn’t a lot of work to do: instead of creating circles and squares by means of
std::make_unique(), we simply create circles and squares directly, and add them to the
vector. This works thanks to the nonexplicit constructor of variant, which allows
implicit conversion of any of the alternatives:
//---- <Main.cpp> ----------------#include<Circle.h>#include<Square.h>#include<Shapes.h>#include<DrawAllShapes.h>intmain(){Shapesshapes;shapes.emplace_back(Circle{2.3});shapes.emplace_back(Square{1.2});shapes.emplace_back(Circle{4.1});drawAllShapes(shapes);returnEXIT_SUCCESS;}
The end result of this value-based solution is stunningly fascinating: no base classes anywhere. No virtual functions. No pointers. No manual memory allocations. Things are as straightforward as they could be, and there is very little boilerplate code. Additionally, despite the fact that the code looks very different from the previous solutions, the architectural properties are identical: everyone is able to add new operations without the need to modify existing code (see Figure 4-4). Therefore, we still fulfill the OCP in respect to adding operations.
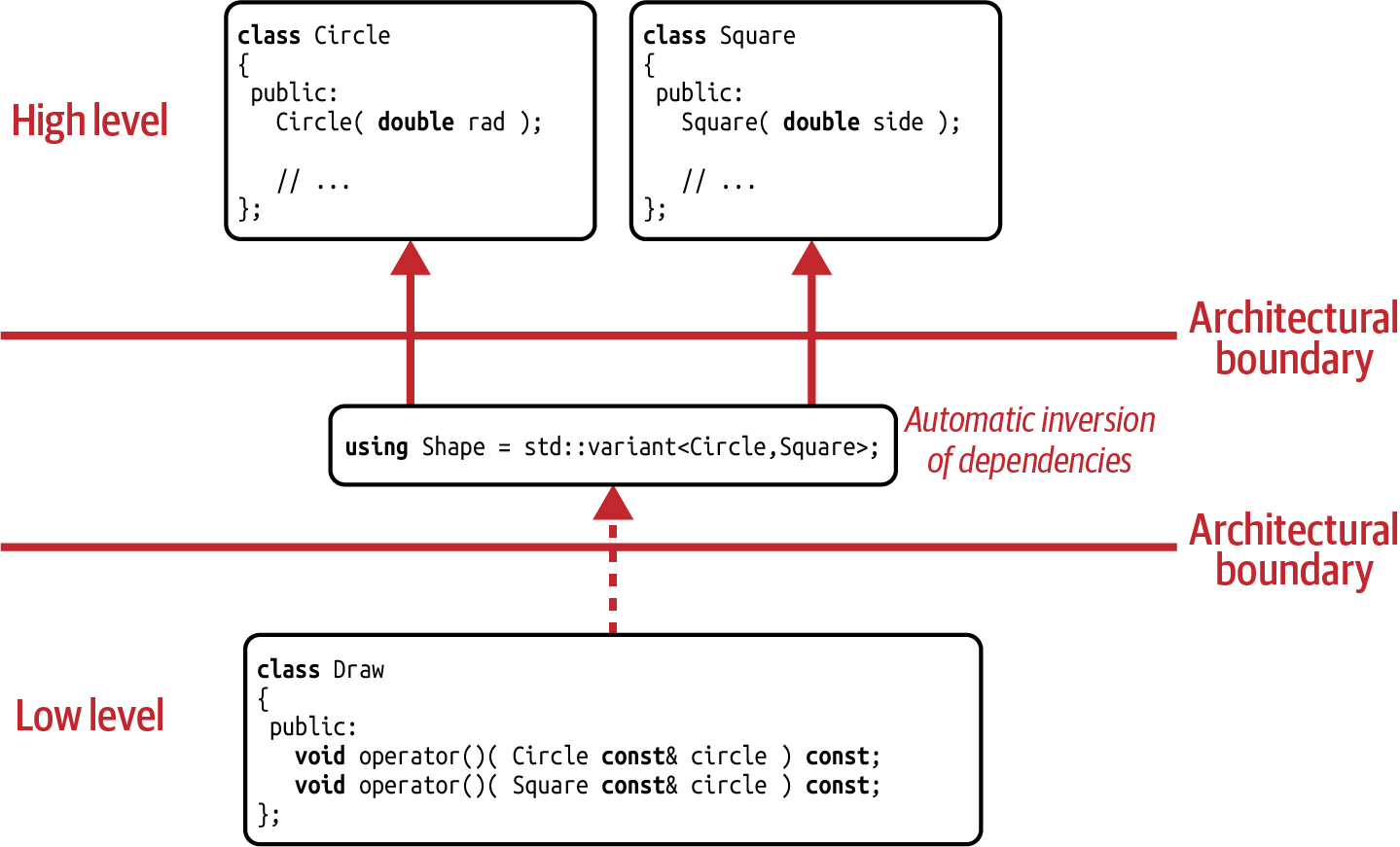
Figure 4-4. Dependency graph for the std::variant solution
As already mentioned, this Visitor approach is nonintrusive.
From an architectural point of view, this gives you another, significant advantage
compared to the classic Visitor. If you compare the dependency graph of the classic
Visitor (see Figure 4-3) to the dependency graph of the
std::variant solution (see Figure 4-4), you will see that
the dependency graph for the std::variant solution has a second architectural
boundary. This means that there is no cyclic dependency between std::variant and its
alternatives. I should repeat that to emphasize its significance: there is no cyclic
dependency between std::variant and its alternatives! What may look like a little
detail is actually a huge architectural advantage. HUGE! As an example, you could
create an abstraction based on std::variant on the fly:
//---- <Shape.h> ----------------#include<variant>#include<Circle.h>#include<Square.h>usingShape=std::variant<Circle,Square>;//---- <SomeHeader.h> ----------------#include<Circle.h>#include<Ellipse.h>#include<variant>usingRoundShapes=std::variant<Circle,Ellipse>;//---- <SomeOtherHeader.h> ----------------#include<Square.h>#include<Rectangle.h>#include<variant>usingAngularShapes=std::variant<Square,Rectangle>;
In addition to the Shape abstraction we have already created
(![]() ),
you can create the
),
you can create the std::variant for all round shapes
(![]() ),
and you can create a
),
and you can create a std::variant for all angular shapes
(![]() ),
both possibly far away from the
),
both possibly far away from the Shape abstraction. You can easily do this because there
is no need to derive from multiple Visitor base classes. On the contrary, the shape
classes would be unaffected. Thus, the fact that the std::variant solution is nonintrusive
is of the highest architectural value!
Performance Benchmarks
I know how you feel right now. Yes, that’s what love at first sight feels like. But
believe it or not, there’s more. There is one topic that we haven’t discussed yet,
a topic that is dear to every C++ developer, and that is, of course,
performance. While this is not really a book about performance, it’s still worth
mentioning that you do not have to worry about the performance of std::variant. I
can already promise you that it’s fast.
Before I show you the benchmark results, however, allow me a couple of comments about the benchmarks. Performance—sigh. Unfortunately, performance is always a difficult topic. There is always someone who complains about performance. For that reason, I would gladly just skip this topic entirely. But then there are other people who complain about the missing performance numbers. Sigh. Well, as it appears that there will always be some complaints, and since the results are just too good to miss, I will show you a couple of benchmark results. But there are two conditions: first, you will not consider them to be quantitative values that represent the absolute truth but only qualitative values that point in the right direction. And second, you will not launch a protest in front of my house because I didn’t use your favorite compiler, or compilation flag, or IDE. Promise?
You: nodding and vowing to not complain about trivial things!
OK, great, then Table 4-2 gives you the benchmark results.
| Visitor implementation | GCC 11.1 | Clang 11.1 |
|---|---|---|
Classic Visitor design pattern |
1.6161 s |
1.8015 s |
Object-oriented solution |
1.5205 s |
1.1480 s |
Enum solution |
1.2179 s |
1.1200 s |
|
1.1992 s |
1.2279 s |
|
1.0252 s |
0.6998 s |
To make sense of these numbers, I should give you a little more background.
To make the scenario a little more realistic, I used not only circles and squares
but also rectangles and ellipses. Then I ran 25,000 operations on 10,000 randomly
created shapes. Instead of drawing these shapes, I updated the center point by random
vectors.13 This is because this translate operation is very cheap and allows me to better
show the intrinsic overhead of all these solutions (such as indirections and the overhead
of virtual function calls). An expensive operation, such as draw(), would
obscure these details and might give the impression that all approaches are pretty similar.
I used both GCC 11.1 and Clang 11.1, and for both compilers I added only the
-O3 and -DNDEBUG compilation flags. The platform I used was macOS Big Sur
(version 11.4) on an 8-Core Intel Core i7 with 3.8 GHz and 64 GB of main memory.
The most obvious takeaway from the benchmark results is that the variant solution is far
more efficient than the classic Visitor solution. This should not come as a surprise: due
to the double dispatch, the classic Visitor implementation contains a lot of indirection
and therefore is also hard to optimize. Also, the memory layout of the shape objects is
perfect: in comparison to all other solutions, including the enum-based solution, all shapes
are stored contiguously in memory, which is the most cache-friendly layout you could choose.
The second takeaway is that std::variant is indeed pretty efficient, if not surprisingly
efficient. However, it is surprising that efficiency heavily depends on whether we use
std::get_if() or std::visit() (I promised to get back to this). Both GCC and Clang produce
much slower code when using std::visit(). I assume that std::visit() is not perfectly
implemented and optimized at that point. But, as I said before, performance is always
difficult, and I don’t try to venture any deeper into this mystery.14
Most importantly, the beauty of std::variant is not messed up by bad performance numbers.
On the contrary: the performance results help intensify your newfound relationship with
std::variant.
Analyzing the Shortcomings of the std::variant Solution
While I don’t want to endanger this relationship, I consider it my duty to also point
out a couple of disadvantages that you will have to deal with if you use the solution based
on std::variant.
First, I should again point out the obvious: as a solution similar to the Visitor design
pattern and based on procedural programming, std::variant is also focused on providing an
open set of operations. The downside is that you will have to deal with a
closed set of types. Adding new types will cause problems very similar to the problems
we experienced with the enum-based solution in
“Guideline 15: Design for the Addition of
Types or Operations”. First of all,
you would have to update the variant itself, which might trigger a recompilation of all code
using the variant type (remember updating the enum?). Also, you would have to update all
operations and add the potentially missing operator() for the new alternative(s). The good thing is that the compiler would complain if one of these operators is missing. The
bad thing is that the compiler will not produce a nice, legible error message,
but something that is a little closer to the mother of all template-related error messages.
Altogether it really feels pretty much like our previous experience with the enum-based
solution.
A second potential problem that you should keep in mind is that you should avoid putting types of very different sizes inside a variant. If at least one of the alternatives is much bigger than the others, you might waste a lot of space storing many of the small alternatives. This would negatively affect performance. A solution would be to not store large alternatives directly but to store them behind pointers, via Proxy objects, or by using the Bridge design pattern.15 Of course, this would introduce an indirection, which also costs performance. Whether this is a disadvantage in terms of performance in comparison to storing values of different size is something that you will have to benchmark.
Last but not least, you should always be aware of the fact that a variant can reveal a lot of information. While it represents a runtime abstraction, the contained types are still plainly visible. This can create physical dependencies on the variant, i.e., when modifying one of the alternative types, you might have to recompile any depending code. The solution would, again, be to store pointers or Proxy objects instead, which would hide implementation details. Unfortunately, that would also impact performance, since a lot of the performance gains come from the compiler knowing about the details and optimizing for them accordingly. Thus, there is always a compromise between performance and encapsulation.
Despite these shortcomings, in summary, std::variant proves to be a wonderful
replacement for the OOP-based Visitor design pattern. It simplifies the code a lot,
removes almost all boilerplate code and encapsulates the ugly and maintenance-intensive
parts, and comes with superior performance. In addition, std::variant proves to be
another great example of the fact that a design pattern is about an intent, not
about implementation details.
Guideline 18: Beware the Performance of Acyclic Visitor
As you saw in “Guideline 15: Design for the Addition of Types or Operations”, you have to make a decision when using dynamic polymorphism: you can support an open set of types or an open set of operations. You cannot have both. Well, I specifically said that, to my best knowledge, having both is not actually impossible but usually impractical. To demonstrate, allow me to introduce you to yet another variation of the Visitor design pattern: the Acyclic Visitor.16
In “Guideline 16: Use Visitor to Extend Operations”, you saw that there is a
cyclic dependency among the key players of the Visitor design pattern: the
Visitor
base class depends on the concrete types of shapes (Circle, Square, etc.), the concrete
types of shapes depend on the Shape base class, and the Shape base class depends on the
Visitor base class. Due to that cyclic dependency, which locks all those key players onto
one level in the architecture, it is hard to add new types to a Visitor. The idea of the
Acyclic Visitor is to break this dependency.
Figure 4-5 shows a UML diagram for the Acyclic Visitor. In comparison
to the GoF Visitor, while there are only small differences on the righthand side of the
picture, there are some fundamental changes on the lefthand side. Most importantly, the
Visitor base class has been split into several base classes: the AbstractVisitor base
class and one base class for each concrete type of shape (in this example, CircleVisitor
and SquareVisitor). All visitors have to inherit from the AbstractVisitor base class
but now also have the option to inherit from the shape-specific visitor base classes. If
an operation wants to support circles, it inherits from the CircleVisitor base class
and implements the visit() function for Circle. If it does not want to support circles,
it simply does not inherit from CircleVisitor.
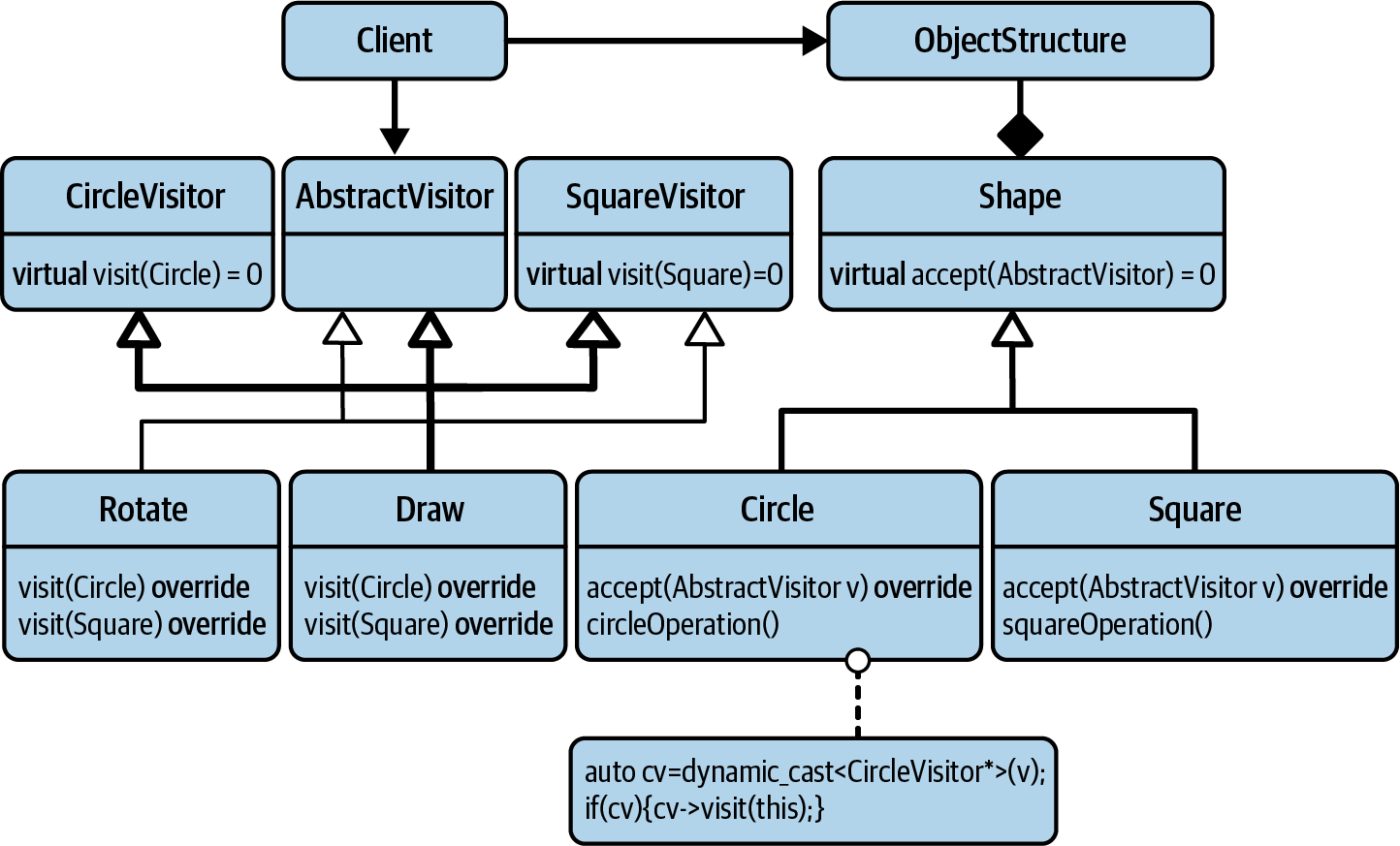
Figure 4-5. The UML representation of an Acyclic Visitor
The following code snippet shows a possible implementation of the Visitor base classes:
//---- <AbstractVisitor.h> ----------------classAbstractVisitor{public:virtual~AbstractVisitor()=default;};//---- <Visitor.h> ----------------template<typenameT>classVisitor{protected:~Visitor()=default;public:virtualvoidvisit(Tconst&)const=0;};
The AbstractVisitor base class is nothing but an empty base class with a virtual
destructor
(![]() ).
No other function is necessary. As you will see,
).
No other function is necessary. As you will see, AbstractVisitor serves only as a general
tag to identify visitors and doesn’t have to provide any operation itself. In C++
we tend to implement the shape-specific visitor base classes in the form of a class template
(![]() ).
The
).
The Visitor class template is parameterized on a specific shape type and introduces the
pure virtual visit() for that particular shape.
In the implementation of our Draw visitor, we would now inherit from three base classes:
the AbstractVisitor, from Visitor<Circle> and Visitor<Square>, since we want to
support both Circle and Square:
classDraw:publicAbstractVisitor,publicVisitor<Circle>,publicVisitor<Square>{public:voidvisit(Circleconst&c)constoverride{/* ... Implementing the logic for drawing a circle ... */}voidvisit(Squareconst&s)constoverride{/* ... Implementing the logic for drawing a square ... */}};
This choice of implementation breaks the cyclic dependency. As
Figure 4-6 demonstrates, the high level of the architecture
does not depend on the concrete shape types anymore. Both the shapes (Circle and Square)
and the operations are now on the low level of the architectural boundary. We
can now add both types and operations.
At this point, you’re looking very suspiciously, almost accusingly, in my direction. Didn’t I say that having both would not be possible? Obviously, it is possible, right? Well, once again, I didn’t claim that it was impossible. I rather said that this might be impractical. Now that you’ve seen the advantage of an Acyclic Visitor, let me show you the downsides of this approach.
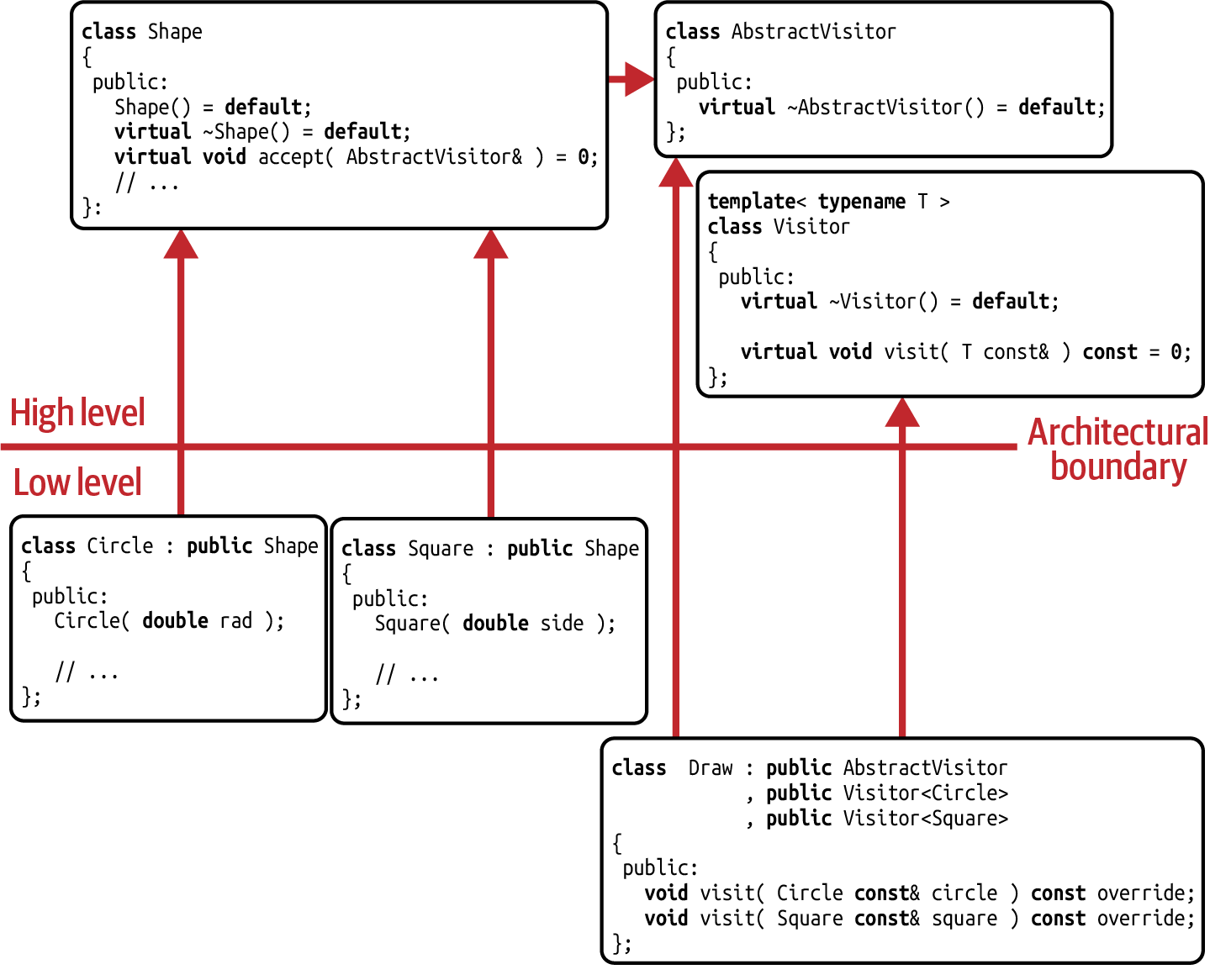
Figure 4-6. Dependency graph for the Acyclic Visitor
First, let’s take a look at the implementation of the accept() function in Circle:
//---- <Circle.h> ----------------classCircle:publicShape{public:explicitCircle(doubleradius):radius_(radius){/* Checking that the given radius is valid */}voidaccept(AbstractVisitorconst&v)override{if(autoconst*cv=dynamic_cast<Visitor<Circle>const*>(&v)){cv->visit(*this);}}doubleradius()const{returnradius_;}Pointcenter()const{returncenter_;}private:doubleradius_;Pointcenter_{};};
You might have noticed the one small change in the Shape hierarchy: the
virtual accept() function now accepts an AbstractVisitor
(![]() ).
You also remember that the
).
You also remember that the
AbstractVisitor does not implement any operation on its own. Therefore, instead of calling
a visit() function on the AbstractVisitor, the Circle determines if the given visitor
supports circles by performing a dynamic_cast to
Visitor<Circle>
(![]() ).
Note that it performs a pointer conversion, which means that the
).
Note that it performs a pointer conversion, which means that the dynamic_cast returns either a valid pointer to a Visitor<Circle> or a nullptr. If it returns a valid
pointer to a Visitor<Circle>, it calls the corresponding visit() function
(![]() ).
).
While this approach most certainly works and is part of breaking the cyclic dependency
of the Visitor design pattern, a dynamic_cast always leaves a bad feeling. A
dynamic_cast should always feel a little suspicious, because, if used badly, it
can break an architecture. That would happen if we perform a cast from within the
high level of the architecture to something that resides in the low level of the
architecture.17 In our case, it’s actually
OK to use it, since the use happens on the low level of our architecture. Thus, we do
not break the architecture by inserting knowledge about a lower level into the high
level.
The real deficiency lies in the runtime penalty. When running the same benchmark as
in “Guideline 17: Consider std::variant for
Implementing Visitor” for an
Acyclic Visitor, you realize that the runtime is almost one order of magnitude
above the runtime of a Cyclic Visitor (see Table 4-3).
The reason is that a dynamic_cast is slow. Very slow. And it is particularly slow
for this application. What we’re doing here is a cross-cast. We aren’t simply
casting down to a particular derived class, but we are casting into another
branch of the inheritance hierarchy. This cross cast, followed by a virtual
function call, is significantly more costly than a simple downcast.
| Visitor implementation | GCC 11.1 | Clang 11.1 |
|---|---|---|
Acyclic Visitor |
14.3423 s |
7.3445 s |
Cyclic Visitor |
1.6161 s |
1.8015 s |
Object-oriented solution |
1.5205 s |
1.1480 s |
Enum solution |
1.2179 s |
1.1200 s |
|
1.1992 s |
1.2279 s |
|
1.0252 s |
0.6998 s |
While architecturally, an Acylic Visitor is a very interesting alternative, from a practical point of view, these performance results might disqualify it. This does not mean that you shouldn’t use it, but at least be aware that the bad performance might be a very strong argument for another solution.
1 I can see you rolling your eyes! “Oh, that boring example again!” But do consider readers who skipped Chapter 3. They’re now happy that they can read this section without a lengthy explanation about the scenario.
2 Since C++11, we have scoped enumerations, sometimes also called class enumerations because of the syntax enum class, at our disposal. This would, for instance, help the compiler to better warn about incomplete switch statements. If you spotted this imperfection, you’ve earned yourself a bonus point!
3 Scott Meyers, More Effective C++: 35 New Ways to Improve Your Programs and Designs, Item 31 (Addison-Wesley, 1995).
4 Note that the mathematical notion of open and closed sets is something completely different.
5 As an example of design with static polymorphism, consider the algorithms from the Standard Template Library (STL). You can easily add new operations, i.e., algorithms, but also easily add new types that can be copied, sorted, etc.
6 It’s always hard to make predictions. But we usually have a pretty good idea about how our codebase will evolve. In case you have no idea how things will move along, you should wait for the first change or extension, learn from that, and make a more informed decision. This philosophy is part of the commonly known YAGNI principle, which warns you about overengineering; see also “Guideline 2: Design for Change”.
7 I wouldn’t be happy about it—perhaps I would even be seriously unhappy—but I probably wouldn’t get angry. But your other colleagues? Worst case, you might be excluded from the next team barbecue.
8 Erich Gamma et al., Design Patterns: Elements of Reusable Object-Oriented Software.
9 accept() is the name used in the GoF book. It is the traditional name in the context of the Visitor design pattern. Of course, you are free to use any other name, such as apply(). But before you rename, consider the advice from “Guideline 14: Use a Design Pattern’s Name to Communicate Intent”.
10 It really is advisable to extract the logic into a single function. The reason is change: if you have to update the implementation later, you don’t want to perform the change multiple times. That is the idea of the DRY (Don’t Repeat Yourself) principle. So please remember “Guideline 2: Design for Change”.
11 Consider the risk: this might exclude you from team barbecues for life!
12 Memory fragmentation is much more likely when you use std::make_unique(), which encapsulates a call to new, instead of some special-purpose allocation schemes.
13 I am indeed using random vectors, created by means of std::mt19937 and std::uniform_real_distribution, but only after proving to myself that the performance does not change for GCC 11.1, and only slightly for Clang 11.1. Apparently, creating random numbers is not particularly expensive in itself (at least on my machine). Since you promised to consider these as qualitative results, we should be good.
14 There are other open source alternative implementations of variant. The Boost library provides two implementations: Abseil provides a variant implementation, and it pays to take a look at the implementation of Michael Park.
15 The Proxy pattern is another one of the GoF design patterns, which I unfortunately do not cover in this book because of limited pages. I will, however, go into detail about the Bridge design pattern; see “Guideline 28: Build Bridges to Remove Physical Dependencies”.
16 For more information on the Acyclic Visitor pattern by its inventor, see Robert C. Martin, Agile Software Development: Principles, Patterns, and Practices (Pearson).
17 Please refer to “Guideline 9: Pay Attention to the Ownership of Abstractions” for a definition of the terms high level and low level.
Get C++ Software Design now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

