Chapter 4. Federated Governance
Data mesh architectures are inherently decentralized, and significant responsibility is delegated to the data product owners. A data mesh also benefits from a degree of centralization in the form of data product compatibility and common self-service tooling. Differing opinions, preferences, business requirements, legal constraints, technologies, and technical debt are just a few of the many factors that influence how we work together.
Federated governance allows us to sort out the decisions that should remain at the local level from those that must be made globally, for all domains. To quote Dehghani, “Ultimately global decisions have one purpose, creating interoperability and a compounding network effect through discovery and composition of data products.” We need to figure out, enforce, and support the common building blocks and modes of operating to make data mesh work for everyone.
Founding a federated governance team is one of the first steps toward discovering common ground to work toward mutually beneficial solutions. Precisely what your governance team will do will vary based on your own business needs, but there are several common duties that we’ll cover in this chapter.
Federated governance is about finding an appropriate balance between individual autonomy and top-down centralized control, between the delegation of responsibilities and the creation of overarching rules and guidelines for consistency and order. Like any form of effective government, we need participation, representation, debate, and collaborative action to actually get stuff done.
Tip
Creating a charter is an important first step in founding a federated governance team. This outlines duties and responsibilities of the group, such as establishing standards for data product formats, quality levels, interoperability, security, and supported technologies. It also lays out producer, consumer, and manager responsibilities, as well as any other social and technical aspects.
Federated governance is primarily focused on several main areas:
- Data concerns
-
Pertains to how data is created and used within an organization. Specifically, data product types, metadata, schemas, support, discoverability, lineage, quality, and interoperability.
- Technology concerns
-
Includes programming languages, frameworks, and processes that you’d like to incorporate into your data mesh. Assessing your existing technologies for suitability, as well as vetting new options, remains a key component of federated governance.
- Legal, business, and security concerns
-
Pertains to regulatory compliance and security issues, such as handling financial, personally identifiable, and other forms of sensitive data. Business-level requirements may also factor in, such as internal data security, access policies, and retention requirements.
- Self-service platform concerns
-
Makes it easy for your users to do the right thing. Users need a reliable self-service platform to build and use data products. Streamlining tooling, reducing friction, and making it easy for everyone to get things done is at the bedrock of data mesh. A self-service platform provides an opportunity to apply regulatory and security policies at the source, providing insight into how data flows through the organization.
Each of these areas relates to one another and offers a helpful lens through which to view the priorities for your governance team. Keep these four areas in mind as we go through the remainder of the chapter, because each section will touch on one of more of these main concerns.
But first—who gets to govern?
Forming a Federated Governance Team
A governance team requires a mandate to be effective in its work. A mandate includes two main components. The first is an institutional component, where the “higher-ups” endorse the data mesh and the governance team, providing members with some degree of authority, ownership, and responsibility. The second component is a social component, where those who are meant to use the data mesh appreciate its importance and buy into it. An absence of either component will likely result in a failed initiative.
The governance team is composed of people from across the organization who act as representatives of the teams, products, technologies, and processes pertaining to building and supporting a well-defined data mesh. As representatives of their peers, each member brings forward ideas, requirements, and concerns from their problem space and works together to come up with satisfactory solutions.
Finding representatives is often as simple as asking for a volunteer to represent the team for a fixed period of time (say three months), though they must be well-versed in the challenges that the team is facing. Senior technical people often get “volunteered” (selected) for this role, as they usually have the best understanding of team needs, the problem space, and historical contexts, such as past attempts at reform. There are often fairly important technical reasons why past efforts at reformation may have failed, and this historical context often helps guide the discussion in finding a way to a new successful resolution.
The size of the federated governance team will vary with the organization’s size, but should be limited to a size that would make for an effective one-hour meeting. With too small of a group, you may find you lack sufficient representation, alienating teammates and damaging trust and support. With too large of a group, you may find that people start to feel like their input doesn’t really matter or that someone else in the group will make the difficult choices. Finding the optimal size of the federated governance team is, perhaps ironically, up to the federated governance team. Start small, and feel free to pull in more members when you hit representation boundaries.
Tip
Collect anonymous feedback on how the group thinks it’s doing, as well as feedback from teammates and stakeholders outside of the group. This will help the group have more effective meetings, find appropriate boundaries for the areas of governance, and dial in on an effective group size and charter.
Once you have an initial body, you can start implementing standards to streamline the data mesh experience.
Implementing Standards
The federated governance team is responsible for coming up with a set of data product and technology standards. Think about the technologies your organization must support as a physical toolbox with limited space. If you want to add new tools to the toolbox, you’ll need to make sure there’s room and that there aren’t other suitable tools that can do the job just as well. Imposing a reasonable limit on the toolbox ensures that technological sprawl is kept in check and that only tools that offer a substantial improvement are added.
Tip
Establishing barriers to entry for new tools, languages, standards, and technologies is essential for reducing sprawl, fencing out marginal options, and protecting against flavor-of-the-week implementations. Keeping your toolbox small and lean makes it far easier to provide first-class support for each tool in your self-service data mesh platform.
Standards should be introduced by proposal, with a detailed explanation of why the new option is better than what’s already in the toolbox. A new option may cover a sorely needed use case for which there is nothing in the toolbox. Or the new option may be categorically better than something already in use. The proposer must craft a story and provide examples as to why their recommendation is a good one and what effects it’ll have on tool and option selection.
It’s very important to trial a proposed standard or technology before adding it to your first-class sanctioned toolbox. Ensure that the trial highlights the importance of the technology, how it is better than something that already exists, and what trade-offs it imposes given the current tools and support.
Warning
Be careful that trial systems don’t get promoted into production on a “temporary” (but actually permanent) basis. It’s important to test new technologies and frameworks in systems outside the critical path so that you can rewrite or abandon them without causing business delays.
Let’s go through some of the main standards that your governance team will need to establish.
Supporting Multimodal Data Product Types
As introduced back in “Data Products Are Multimodal”, your federated governance team will need to decide what data product types and ports you do and do not support. Event streams form the core data product type covered in this book, but you may also choose to support others, such as batch-computed Parquet files in a cloud data store, as we’ll discuss more in Chapter 9.
Supporting multiple data product types provides additional options to data product owners, but comes at the expense of significantly more complexity for both governance and self-service tools. It’s important to understand the opportunity cost and the amount of work required to support each data product type.
For example, you’ll need to ensure that infosec, encryption, access controls, data product interoperability, and self-service data platform integrations are all accounted for. There can be a substantial amount of work adding a new data product type, and if the return on that investment is marginal, it may make more sense to simply serve the data product using an existing (if somewhat suboptimal) type instead.
If you believe that support for a new data product type is merited, then you should create a proposal and present it for consideration at the federated governance meeting. We’ll investigate proposals more in “2. Drafting Proposals”.
The goal here isn’t to constrain data product owners but to ensure that the tools that are made available are supported, meet governance requirements, are easy to use, and cover the necessary business use cases. Do not add new tools to the toolbox for the sake of variety or novelty, especially when there are existing and well-supported ways to provide sufficient access and usage.
Supporting Data Product Schemas
Schema frameworks are effectively programming languages for data. Much as you compose an application with code, you compose a data product schema with its own code. Precisely what that code looks like and which options are the best for you to choose are covered in more detail in Chapter 6. For now, consider how many, and what kind of, schemas and formats you may support. The two most common considerations include:
- Event schemas
-
Apache Avro, Protocol Buffers (Protobuf), and JSON Schema tend to be the most common formats for events. Each of these has its own trade-offs, in particular regarding type enforcement, schema evolution capabilities, default values, enumerations, and documentation.
- File formats
-
Batch files written to a cloud storage bucket have traditionally followed big data file conventions, including CSV, JSON, Avro, Protocol Buffers, Parquet, and ORC—to name a few. Additionally, consider the newer open source technologies that sit on top of these basic file formats, such as Apache Iceberg, Apache Hudi, and Delta Lake. Each of these provides higher-level filesystem-type features, such as hidden partitioning, transactions, and compaction and can make using batch-hosted data products easier to use, at the expense of tighter coupling to the technology.
It’s best to standardize on just one event schema framework or file format for each data product type. For example, Avro for streams and Parquet for batch-computed files kept in your data lake. Only expand to support other formats if it’s absolutely essential. Single formats greatly simplify tooling and the consumer experience while keeping complexity and risk low.
Tip
If you must support multiple file formats or event schemas, ensure that data product owners can find easy-to-follow instructions on which one they should use and why. A failure to do so will introduce friction when neighboring teams end up implementing their data products with completely different schema frameworks, making consumption and use more difficult for their common consumers.
Next, let’s look at some of the programming language questions and concerns.
Supporting Programming Languages and Frameworks
One common approach to producing data products is to use a language already in use within the source domain. The team would already be well-versed in it, which simplifies both creation and support of the data product. Another option is to select a language (or tool) in use in another part of the organization, perhaps because it is much more suited to the creation of the data product. We’ll look into the specifics of bootstrapping existing data into event-driven data products in Chapter 8.
Sometimes developers use data product creation as an opportunity to try out a new esoteric language, regardless of whether it’s officially supported. This puts that developer on the hook for all support and maintenance well into the future and will put the product at risk should no one else learn the language. In time, the developer who built the data product will likely move on to new projects or job opportunities, further increasing risk.
It is important to only implement data products in languages that are well-used or otherwise officially supported by your organization. If you think a language has merit to be used more widely, then you would do well to create a proposal (see “2. Drafting Proposals”) and discuss it with the federated governance team.
Deciding which languages (and frameworks) to support for building data products is based largely on the same criteria as building any other service. Such factors include:
- Social factors
-
Is it a well-known technology? Are our developers familiar with it? Are there other people in the industry using it, and have they shown success with it? Will people want to work with it? Will it be appealing for new hires and can we find people with these skills in the market?
- Technology factors
-
Does it solve our problems in a simple and effective way? Is it a proven technology that will continue to be updated and improved for years to come?
- Integration factors
-
Is it easy to support? Does it integrate well with our existing development, test, build, and deploy pipelines? Can you get linters, debuggers, memory analyzers, testing tools, and other productivity enhancement tools that integrate with it?
- Event broker clients
-
Does your event broker have high-performance clients written in the language of your choice? Will you be able to produce and consume events fast enough?
- Supportive tooling
-
Does your language and framework work well with your event schemas (Chapter 6)? Do they support code generators? Can you generate test events to test your data product inputs and outputs?
Deciding which languages to support, and how extensively to support them, will be up to your organization and governance team. Choose languages that your organization is familiar with and that have event-broker support.
Metadata Standards and Requirements
A good data mesh requires well-defined metadata for each data product. Data mesh users should be able to discover and identify the data products that they need for their business use cases. A data product owner must provide all required metadata during registration of the data product to be allowed to publish the data product to the mesh. Enforcing metadata requirements is essential for ensuring that only well-defined and well-supported data products are made available to others, lest we repeat the mistakes of previous data strategies as discussed in “Bad Data: The Costs of Inaction”.
There are several fields that are essential for a healthy data mesh. In this section, we’ll cover each of them and provide you with some basic examples for your own governance team to consider.
Tiered service levels
A data product requires support and uptime guarantees. But to what degree? If the data product encounters a failure, what is the appropriate course of action? Many companies already organize their applications into a tiered system, with the highest tier having 24-hour on-call rotations and the lowest tier having simple best-effort support. You should apply the same tier system to data products and offer the same support and guarantees as you would any other service or product of the same tier. The following is an example of a four-tier system:
- Tier 1
-
Data products that are critical to the operation of your business, where an outage or failure will result in significant impact to either the customer or to the business’s finances. Data products that power real-time operational applications often fall into this category.
- Tier 2
-
Data products that are important to the business but are less critical than Tier 1. A failure in this tier may cause a degraded customer experience but does not completely prevent customers from interacting with your system. Data products in this tier also often power real-time operational applications.
- Tier 3
-
Data products that may affect background tasks and operations in the business, but are likely not visible to consumers nor impact them significantly. However, a failure in this tier may still require intervention should the data product be powering time-sensitive use cases.
- Tier 4
-
Data products that have the largest time window for recovery. It is not essential to have an on-call rotation to support these data products; they can wait until the next business day to resolve.
Uptime and availability are not the only considerations of a data product’s service level. You will also need to monitor your data products to ensure they’re meeting their SLAs, something that we’ll cover in a bit more depth in “Monitoring and Alerting”.
Data quality classifications
The quality of the data provided by the data product should also be categorized, similar to the approach of the SLA tier system. One choice is to leverage the medallion classifications of bronze, silver, and gold commonly used in data lake architectures. Let’s look at each classification:
- Bronze
-
Unstructured and raw data that is untransformed from the original source format. May be strongly coupled on the internal data model of the source system, and may also contain fields that need to be sanitized or scrubbed. May also include data that is well-structured and defined, but for which quality is intermittent or the data owners simply cannot provide a higher guarantee.
- Silver
-
Well-structured data with strong typing and typically sanitized and standardized. Usually denormalized to be sufficiently useful as is, with the most common foreign-key relationships having been joined and resolved to provide ease of use to consumers. Type-checking and constraints have been applied to ensure a minimum data quality (e.g., 99.99% of events pass quality checks). The context of the event is clearly defined and documented, as are the type checks and constraints. If a consumer wants to impose their own further, tighter constraints on the data, they would do best to communicate with the data product owner to evaluate options.
- Gold
-
The highest level of quality. Often referred to as “authoritative,” data products with the gold level of quality are meant to be relied on without reservation. Data products are rigorously tested and monitored, with type-checking and constraints exceeding that of the silver quality level (e.g., 99.9999% of events pass quality checks). Gold data products are often more complex, built up by significant aggregations and transformations that offer significant value, and would be quite difficult for consumers to replicate on their own.
Note
Data quality classification is separate from the data product alignments (source-aligned, aggregate-aligned, and consumer-aligned), and is concerned only with data quality.
You are free to select alternative classification models as you see fit. The important part is that your data mesh users must be able to easily understand and apply the modeling to their own data products, preserving a common understanding between producers and consumers of the data.
Privacy, financial, and custom tagging
In conjunction with security and financial information representatives, the governance team can come up with tags to apply to data products to help automate specialized treatment. For example, you may choose to include a tiered system for security classifications similar to that of SLAs. You may also choose to use tags that pertain to the type of data included within the event stream, such as financial, PII, or region-based tags.
Supporting tags on data products makes it easier to apply governance rules because they can be applied on a per-tag basis. For example, a consumer seeking to use a data product with a financial tag will need to prove their compliance with their organization’s financial data handling requirements. Tags also enable easier auditing of data usage on a per-consumer basis.
Upstream metadata dependencies
Upstream services and data products each have their own SLAs, data quality levels, and other guarantees. Any service or data product that relies on upstream services or data products must take these dependencies into account when specifying their own guarantees. For example, a service cannot offer Tier 1 support when it depends on data products with Tier 4 guarantees. We’ll touch more on lineage later in this chapter in “Data Product Lineage”.
As part of your governance requirements, you may choose to establish minimum upstream requirements for data quality and SLAs to power your production applications, be they operational, analytical, service, or data product. One common convention is to allow only services that have Tier 1 or Tier 2 SLA guarantees in production.
Upstream data quality requirements are not quite as strict—it’s entirely possible that you can power a Tier 1 gold data product with a Tier 1 bronze data product. In fact, this is usually how bronze data is transformed into a high-quality gold-layer data product.
You can enforce upstream checks during the creation of a data product, as we’ll explore more in Chapter 5.
Metadata wrap-up example
Figure 4-1 shows an example of what a user may see when looking up information about a data product. While we’re going to explore metadata cataloging more in Chapter 5, for the moment you can think of it as a read-only database where you can look up the available data products and their properties.
The data product name, domain, and user are all mandatory pieces of metadata created at time of publishing. A description field is also included to describe context and disambiguate the data product from other similar ones. Metadata about the service, quality, and security levels are also present, as are tags describing PII, financial, and regional information.
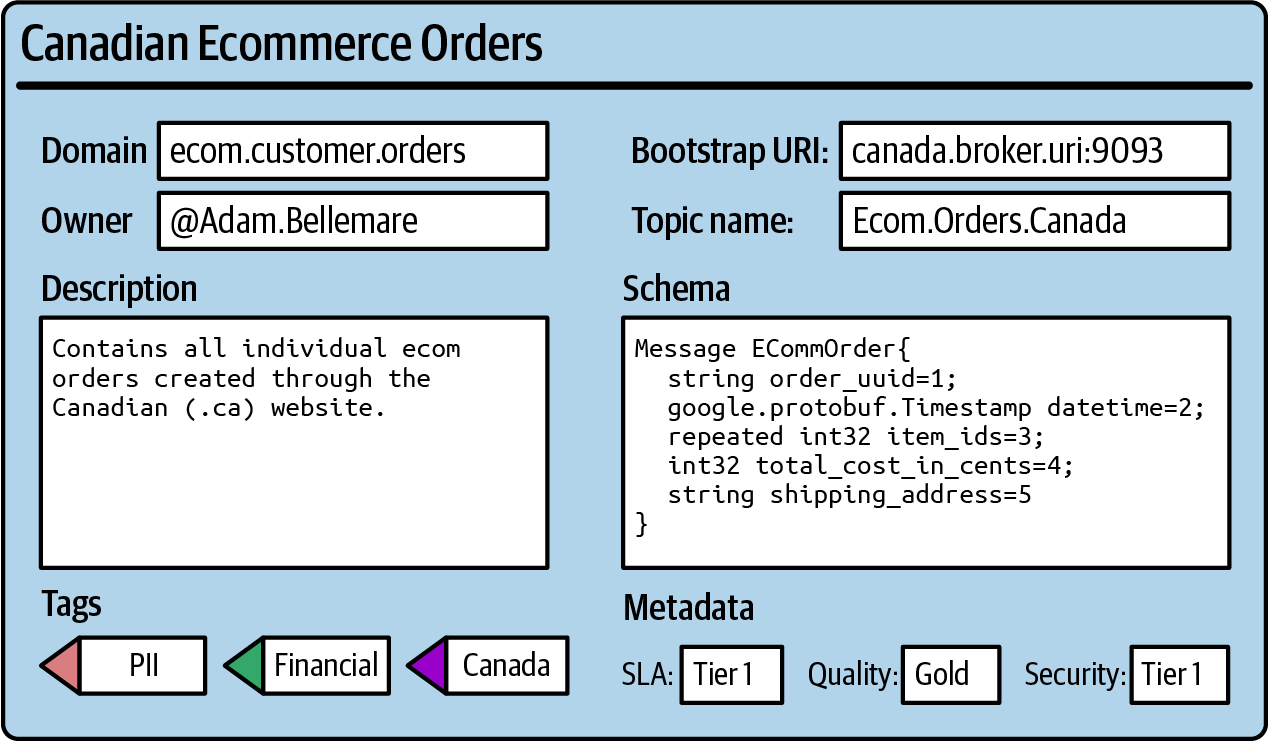
Figure 4-1. An example of data product metadata you may expect to see as a data mesh user
The schema field in the metadata is pulled in from the schema registry, which is a component that stores and manages schemas for event streams and is an essential piece of the self-service data platform. We’ll cover this in more detail in “The Schema Registry”. The broker name and topic name are also pulled in to provide the digital address of the data product.
Metadata helps us make informed decisions about what data products are available for our use cases. Compatibility between data products is essential in enabling us to merge data from different sources and is the subject of the next section.
Ensuring Cross-Domain Data Product Compatibility and Interoperability
There are many factors that make up aggregating, merging, and comparing data products between domains. As part of the data concerns outlined at the beginning of this chapter, interoperability and ease of use remain two of the major concerns of federated governance. Rules and guidelines about common entities, time zones, aggregation boundaries, and the technical details of event mappings, partitions, and stream sizes all fall under the governance team’s purview. Let’s take a look at these areas now.
Defining and Using Common Entities
One of the first important steps is to define the minimal entities that are used across many areas of your business. Let’s take a look at an example first.
An ecommerce company defines a common Item entity containing two fields: long id and long upc_code. Data product owners are expected to use the Item entity in any data product that references their ecommerce items, be it Order, Inventory entry, or Return. Each of these related entities uses a common and standardized version of Item, removing the need for consumers to interpret similar-yet-different representations of the same data.
Common entities do not preclude you from adding more information about that entity to your data product. You are free to extend your data products to include other information about Item, such as size and color in the case of a clothing item or weight and serving_size in the case of a food item. Think of a common entity as an attachment point between data products in other domains and as an extendable base for the entity’s data model.
Event Stream Keying and Partitioning
Interoperability of event-streaming data products is affected by the partition count of the stream, the key of the event, and the partition assignment algorithm (see Chapter 3). An event stream contains one or more partitions, and each event is assigned to a partition based on the partition assignment algorithm, the event key, and the number of partitions. Here are some useful interoperability tips:
- Partition count
-
Joining and aggregating data products from multiple streams can be made much less computationally intensive if the event partition counts are the same size. While event-stream processors like Kafka Streams and Flink can automatically repartition event streams as needed, it requires more processing power and can incur higher costs. Try using a T-shirt sizing approach to standardize partition counts, such as
x-small=1,small=4,medium=8,large=16,x-large=32,xx-large=64,jumbo=256. As part of your self-service platform (which we’ll cover in the next chapter), you can provide the data mesh users with instructions for choosing partition count based on the key space, volume of events, and consumer reprocessing needs.Tip
If you’re building a data product keyed on a common entity, check the partition count of other data products also keyed on that entity—if they’re all using the same partition count, you would do well to use it, too.
- Event key
-
The event key is best served by using a primitive value, such as a
string,int, orlong. The common entity’s unique ID is your best choice for interoperability. - Partition assignment algorithm
-
This algorithm takes the event key as an input and returns the partition ID to write the event to. Event producer clients of different programming languages and frameworks may use incompatible algorithms, resulting in event streams that are not cross-compatible, despite using the same event key and the same partition count. While using a single framework like Kafka Streams will ensure that your partition assignment is consistent, you will need to do a bit of research to evaluate other frameworks as part of your self-service platform.
Warning
Be careful about hot partitions where a disproportionate number of events are assigned to a single partition. For example, 99% of all events may be assigned to a single partition, while the remaining partitions get only 1% of the data. While this is usually due to an extremely narrow key space, it can also be due to an unsuitable partition assignment algorithm.
It’s important to think about keying and partitioning for compatibility from the start, since many of the data products you create will stick around for a while. Changing partitions is possible, but it often requires rewriting the data to a new event stream and migrating the consumers. Stick to using T-shirt sizes, come up with some recommendations for selecting partition counts based on consumers’ needs (e.g., reprocessing, parallelization), and define a common partition assignment algorithm based on your available client frameworks.
Time and Time Zones
Data products may be associated with a window or period of time. For example, an aggregate-aligned data product may represent data over a period of time, such as an hourly or a daily aggregation. As part of a standard of ensuring interoperability, establish a primary time zone such as UTC-0 for all time-based data products. Consumers will have a far simpler experience combining different time-based data products if they do not have to contend with converting time zones and dealing with daylight saving time.
Tip
Where applicable, you should include the aggregation period and time zone-related information as part of the data product’s metadata. This information will help your consumers decide what further processing, if any, they need to do to merge it in with their other data products.
Now that we’ve covered ways of providing data product compatibility, it’s time to get into a bit more of the social side. How do we make effective decisions about our data mesh standards and requirements?
What Does a Governance Meeting Look Like?
Covering the entirety of an effective meeting is beyond the scope of this book, but there are a few pointers that should help you get started. First, ensure that you follow best practices common to all technical meetings. Second, send out an invite well ahead of time and provide an agenda for the meeting. Third, ensure that you have a chairperson and someone to take notes and record action items, and ensure that everyone knows what needs to be done for the next meeting. It’s common to rotate responsibilities and duties to ensure equal representation.
It’s very important to get the people who work on operational systems into the same meeting room with those who work on analytical systems. You may be surprised, or possibly just disappointed, at how seldom this happens. The isolation of “data teams” from “engineering teams” has long plagued the IT space, as we touched on in “Bad Data: The Costs of Inaction”.
Warning
As with any meeting, people with a strong personality or a loud voice may try to dominate the conversation. Ensure that you have a chairperson to conduct the meeting and ensure that everyone has a chance to speak uninterrupted. If the meeting gets heated and starts to be unproductive, take a 5-minute recess or adjourn for the day.
You should expect to meet frequently during the starting stages of your data mesh transformation. You will have many things to discuss, solve, support, and standardize. As time goes on, you can expect to meet less frequently.
But what are the main tasks that the governance team should focus on? Let’s go through five main areas and discuss how they pertain to data mesh.
1. Identifying Existing Problems
The first task of the governance team is to identify where the problems are. Your team should be composed of individuals from across the organization with a good view of the technological and data landscape. A grassroots, bottom-up approach to reporting problems and issues tends to work best. Ask your colleagues to identify the areas that they’re having problems in, the barriers and obstructions they’re facing, and what it is that they would like to be able to do—either in terms of business requirements or simplifying operational complexity.
Tip
Have everyone list their main problems and issues using cards or sticky notes. Then you can cluster similar issues together, such that you can find the areas of improvement that may have the biggest impact.
Identifying problems is the first step forward in improving the data mesh for everyone. Common issues may include a lack of self-service tooling, inconsistent data in existing products, and a lack of policies regarding duplicate data, infosec, PII, and financial information. Once the problems are identified, you can prioritize which ones are the most important and dedicate resources toward solving them.
2. Drafting Proposals
The next step is to create a proposal that frames the problem, explains why it is important to solve, articulates challenges and opportunities, and identifies a possible solution. A proposal is much like a bill as introduced in the houses, senates, and parliaments of many democratic systems. It proposes changes, provides details, and specifies scope, all packaged up in a single debatable unit.
It’s not just the governance team that can create proposals for review—anyone in the organization can create one. In fact, you’ll get the best results by following up with the folks who have identified the problems—they usually have some idea about how to make things better and just need someone to organize and promote the necessary work. Proposals should be focused on solving specifically identified problems that have a real-world impact to users of the data mesh.
Some examples of proposals could include:
-
Introduce field-level encryption to restrict access to some sensitive information in a data product
-
Implement regulations for handling data products spanning multiple cloud deployments
-
Add custom tagging to data product metadata to improve search functionality
-
Add namespacing to data products to enable security access at a namespace level
-
Introduce a centralized authentication and authorization service to unify identity management from across each cloud service in the self-service platform
Although proposals can cover a wide area of concerns, the majority of the time they should lead to an improvement in the self-service tools and platforms available to data mesh users. Mandating a new process is all fine and dandy, but if it’s not baked into the tools and services that data mesh users use every day, there’s a good chance it won’t be followed or used.
Tip
Proposals should illustrate what a successful resolution of the problem looks like. Prototyping a solution to showcase precisely how it will work keeps ideas anchored in the practical realm instead of the theoretical. Devise experiments, run trials, assign research, investigate options, and prototype technological solutions before rolling them out for general usage.
3. Reviewing Proposals
The federated governance team reviews the proposals to determine the viability of the solution and the required implementation resources. How you review these proposals will vary from team to team, especially as remote work, time zones, and other distribution factors are taken into consideration. One option that works well is to have members of the federated governance team individually review the proposals, making any notes or marking any concerns, before getting together in a larger group. If you can get everyone into a room, digital or physical, you may find it easier to ask questions, debate options, and come up with a unified plan. You could also meet asynchronously, and decide to get together only if there is sufficient disagreement or confusion.
Tip
Keep reviews open and inclusive. Invite individuals from across your organization that you think could help by providing additional context and information. You may need to explicitly seek out and invite them as most people tend to be pretty busy. Ensure that you do not rely on the same people to review every proposal, lest you give the idea that no one else is welcome to contribute to federated governance.
The main goal of the review should be to validate the proposed solution, vet any prototypes, identify any missed considerations, and assess the boundaries of the work involved. The review may result in the proposal being rejected—either sent back to the creator for additional work or declined outright due to other insurmountable issues. An accepted review will require a final step—planning and executing the implementation work.
4. Implementing Proposals
An accepted proposal must next be converted to detailed work items. Break up the proposal into incremental steps to build, test, deploy, and validate your data mesh changes. Use your existing work ticket system to detail each work item, including a description of work to be done, what success looks like, and an estimate of how much time and effort it’ll take to complete.
Tip
Implementing a proposal is identical to the process of implementing features for any other product. While you may be able to avoid having a self-service data platform product manager at the start of your data mesh journey, you’ll come to find that it’s an essential role for getting things done.
You’re also going to need to get someone to do the work! Depending on your organization, you may have chosen to assign one or more people to implementing data mesh platform tickets. Alternatively, you may request that the proposal creator provide the people-hours to get the work done, given that they are likely to be the most familiar with the solution.
However you choose to get the work implemented, focus on getting iterative improvements into use in a reasonable time frame. Like any other product, your data mesh itself needs to help your colleagues solve their data access, usage, and publishing problems. If you fail to build confidence in your data mesh platform, people will simply not use it and will instead resort to their own ad hoc data access mechanisms. In this case, your data mesh will be nothing but a waste of time.
5. Archiving Proposals
Keep all of your accepted and rejected proposals, along with notes (or recorded videos) about their discussion in a commonly accessible location such as a cloud file drive. People should be able to look up the proposals to see their status, as well as which ones have been accepted or rejected, and why. Transparency is essential because it provides a record as to why a technology or decision was or was not adopted.
Archived proposals also remove some operating complexity. You can search the existing proposals to see if something similar has already been proposed before, and, if so, what the results were. The original rationale for not adopting something may no longer apply, making it worth revisiting with a new proposal.
In the next section, we’ll take a look at security and access controls. Both of these are essential for establishing a reliable framework of ownership and security and also for protecting against unauthorized access and accidental modification of each other’s data products.
Data Security and Access Policies
Your data mesh’s security and access practices depend heavily on the legal and business requirements of your business. For example, a bank will have far higher security and access control requirements than an anonymous message board website. Since this is a large field of study, we’re going to assume you’re following “good security practices,” and instead focus on a few important concepts and techniques specific to making and using event-driven data products.
Tip
Defense in depth should be your guiding principle when dealing with security and access controls. There is no one single thing that will keep your data secure from unauthorized use, be it from a well-meaning but unauthorized colleague or from an external intruder. Limiting access by default, mandatory authentication of users and services, and securing and encrypting private, financial, and other sensitive information each help reduce the blast radius and mitigate fallout.
Identity management is a foundational component of data security, as all of the user and service permissions will be tied back to it. We’ll look at this subject more in the next chapter in “Service and User Identities”. For now, let’s investigate a few of the most important security principles that your governance team may choose to implement and support in your data mesh.
Disable Data Product Access by Default
Data products should only be available for use by registered consumers. If you’re not registered as a consumer of the data product, you can’t read it. While this principle introduces a hurdle, compared with allowing a data product to be read-only to anyone who may want it, it forces users and services to register as explicit consumers. We need to know who is reading what, so that any changes and requests can be effectively communicated both upstream and down.
Consider End-to-End Encryption
Depending on infosec requirements, you may need to encrypt your data product data prior to publishing it to the event broker. The data remains encrypted in the event broker, preventing any unauthorized backdoor access to the data on disk. A registered consumer with the assigned decryption keys can consume and decrypt the data locally for its own use.
Tip
Streamlining data encryption and decryption is a function of the self-service platform. However, it’s up to the governance team to determine the requirements and supported use cases.
End-to-end encryption is often required for handling sensitive data. Encrypting data at the producer side provides extra security during the network communications and data storage of the event and ensures that the cloud provider of the event broker cannot somehow read (or leak) the unencrypted data. Additionally, end-to-end encryption acts as defense in depth—it is possible that someone may gain access to read your event data, but without the decryption keys, will not be able to decode and use the original data.
Figure 4-2 showcases a producer and a consumer client using end-to-end encryption. The producer has encrypted the data before writing to the event stream and has published the key to a key management service (KMS). A consumer that wants to read the data product must obtain access to the decryption keys from the KMS and then apply them to each event read from the stream.
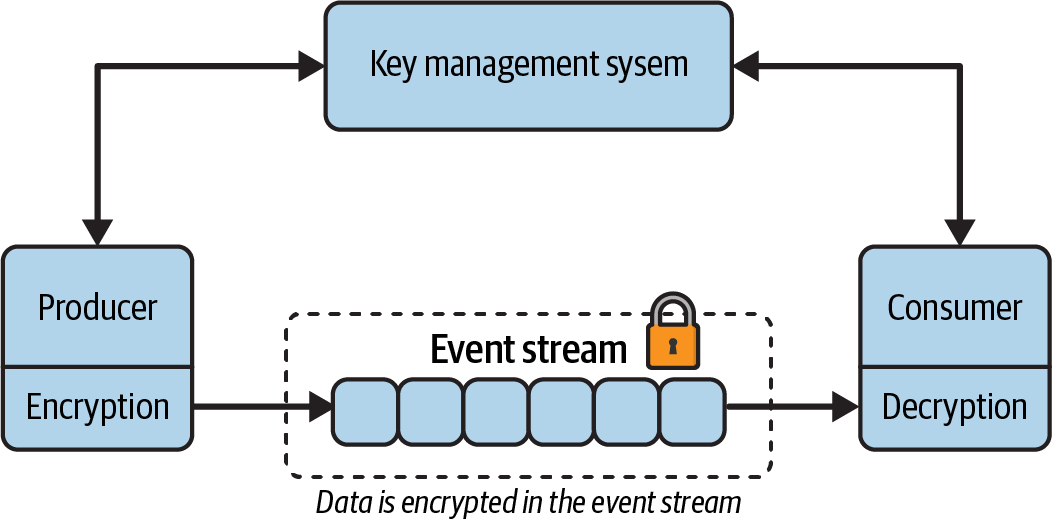
Figure 4-2. End-to-end encryption at work in a data product served as an event stream
A KMS provides you with a mechanism for safely creating, sharing, storing, and rotating your keys. While you can get started without any formal self-service data platform support, you’re most likely going to need to invest in streamlining this process if you end up using a lot of encryption.
You may not always need to encrypt the entire event—sometimes encrypting just the sensitive fields is more than enough. Let’s take a look.
Field-Level Encryption
Field-level encryption offers the ability for a data product owner to encrypt specific fields, so that only select consumers can access the data. Personally identifiable, account, and financial information are common use cases for field-level encryption. For example, when modeling a bank transfer, you may use field-level encryption on the user and account fields, but leave the amount and datetime fields unencrypted. Consumers with decryption permissions can access the decrypted information to settle account balances, while an analytical system without decryption permissions can still track how much money is moving around during a period of time, all from the same data product. Table 4-1 shows the encryption of the email, user, and account fields of an event.
| Field name | Original event | Partially encrypted event | |
|---|---|---|---|
n2Zl@p987NhB4.L0P |
|||
user |
abellemare |
9ajkpZp2kH |
|
account |
VD8675309 |
0PlwW81Mx |
|
amount |
$777.77 |
$777.77 |
|
datetime |
2022-02-22:22:22:22 |
2022-02-22:22:22:22 |
You may also choose to use format-preserving encryption to maintain the format of the event data. In this case, we used format-preserving encryption for the email, user, and account fields—the same alphanumeric characters, spacing, and character count of the original fields, but without exposing any of the PII to users without decryption permissions.
Tip
One of the advantages of using field-level encryption is that it permits finer-grained access controls for consumers. Your consumers can request decryption keys only for the data they need, instead of for the entire payload, reducing the potential for inadvertently leaked information.
Format-preserving encryption is particularly useful for applying encryption to data after the fact because you don’t need to renegotiate the schemas with downstream consumers. In contrast, using nonformat preserving encryption often results in malformation, such as converting a long bank account ID into a 64-character string or encrypting a complex nested object into an array of hashed bytes.
Encryption of sensitive data, whether end-to-end or field-level, can also help us with another significant governance requirement: the right to be forgotten and have our data deleted.
Data Privacy, the Right to Be Forgotten, and Crypto-Shredding
General Data Protection Regulation (GDPR) is (among other things) a law requiring the careful handling, storage, and deletion of data. It is an excellent example of a legal constraint that your organization may need to adhere to in order to stay on the right side of the law. And if you’re looking to create a data mesh of useful data products, it’s very likely you’re going to end up dealing with personal, account, and financial information that may require you to take extra steps and precautions to secure.
Article 17 of the GDPR requires that individuals have the ability to request that all of their personal data be deleted, without undue delay. At first glance this stipulation may appear to be directly in opposition to the tenets of a data mesh: publishing well-defined data products for other teams and services to use as they see fit. Event-driven data products may seem to further exacerbate the issue, as consumers read the data into their own local data stores and caches.
Crypto-shredding is a technique you can use to ensure that data is made unusable by overwriting or deleting the encryption keys. In short, you allow the end user full control over when they want to delete their keys, making their data cryptographically unavailable once the keys are deleted. You can use crypto-shredding with any form of encryption, including end-to-end and field-level.
Meanwhile, the consumers of the encrypted data products simply contact the central KMS and request access to the decryption keys. Provided the consumer has the correct permissions, the decryption keys are passed back to them and they can then decrypt and process the data as needed.
Why do it this way? Can’t we simply sort through the data in the data product and just delete it outright? Wouldn’t that be far safer?
Deleting data product data remains a reasonable choice; however, there are several complications that make encryption and crypto-shredding an important consideration:
- Large amounts of data
-
Large amounts of data may be stored in backups, tape drives, cold cloud storage, and other expensive and slow-to-access mediums. It can be very expensive and extremely time-consuming to read in all of the historical data, selectively delete records, and then write it back to storage. Crypto-shredding enables you to avoid having to search through every single piece of old data in your organization.
- Partially encrypted data is still useful
-
Deleting just a user’s PII is often sufficient for meeting the GDPR Article 17 requirements. The remaining data in the event may still be of use for certain consumer use cases, like building up analytical aggregations. We can leave the remaining data in place and still obtain limited benefit from it.
- Data across multiple systems
-
Deleting the decryption keys simultaneously invalidates all data access across all consumer services. We don’t need to worry about when the data is deleted, especially for systems that are slow to delete their data.
- Further defense in depth
-
Crypto-shredding provides an additional layer of security for preventing data security incidents. Leaking encrypted data is far less damaging than leaking unencrypted data and helps reduce both the risk and the impact of a data security breach.
Crypto-shredding doesn’t protect you from consumers who negligently store decrypted data or the decryption keys. You can counter this by ensuring that consumers have clear and simple infosec policies to follow, such as retaining the decryption keys for only 10 minutes, prior to deleting them and having to request them from the KMS again. You can also use the access-control list to keep track of which services request access for data decryption, so that your infosec team can audit them for compliance.
The rules and regulations for securing and handling data are a major component of the governance team’s responsibilities. These concerns are fundamental to the viability and survival of an organization and cannot be left up to individual data product owners to implement ad hoc. Ensure that you and your federated governance team have a solid understanding of the legal and business requirements for handling your data so that you can guide the security requirements of the self-service data platform.
The next related component is data product lineage. While access controls and encryption help with meeting legal data handling requirements, it’s important to know all of the upstream and downstream dependencies of a data product. Let’s take a closer look at lineage to see how it can improve our data mesh.
Data Product Lineage
Lineage allows us to track which services are reading and writing a data product, including if the consumer client is actively reading the stream. Basic read/write permissions, along with client identities, provide us with a pretty good picture that we can use to track dependencies and lineage. We can determine which systems and users do or do not have access to sensitive data, as well as the routes and paths that data takes as it travels from one client and product to the next.
For an event-driven data mesh backed by open source Apache Kafka, the access controls are established at the event broker itself. Many SaaS providers also provide higher-order functionality in the form of role-based access controls (RBAC), letting you compose roles based on rules and personas. In either case, permissions are essential for keeping track of and constructing lineages.
There are two main types of data lineage to consider for your own implementations. The first is topology-based lineage, which shows dependencies between services and data products at a point in time. The second is record-based lineage, which tracks the propagation of a record through services. Let’s take a look at each in turn.
Topology-Based Lineage
Topology-based lineage shows the dependencies between data products and their consumers as a graph, with arrows pointing from the data product to the registered consumers. New data products show up as nodes on the graph, as do data product consumers. The graph may show which clients are actively consuming events, at what rate, if they’re up to date, or if they’re replaying historical data. It’s also possible to add service and data product information and metadata to the topology, providing an alternate mode of discovery for your prospective data mesh users.
Topology-based lineage is relatively easy to obtain given that permissions and client identities are already essential for infosec and are frankly just good practices all around. You could even build your own by dumping your client identities and permissions into a file and reconstructing them into a graph using the graph framework of your choice.
A significant majority of lineage tools today focus on topology-based lineage, usually with an attractive and interactive graph that you can click on to see additional information, such as upstream and downstream dependencies. While many can give you only the topology as it is right now, others have started rolling out point-in-time lineage, where you can examine and download the lineage at a specific point in time.
Topology-based lineage is useful for tracking which consumers have accessed which data products. In the event of erroneous data in a product, you can also detect which downstream consumers may have been affected so that compensatory actions can begin. Finally, a data product owner can simply consult the lineage graph to see who is consuming its data products to coordinate with them on upcoming changes.
Record-Based Lineage
Record-based lineage focuses on tracking a single record through its history, recording everywhere it goes, which systems process it, and any derivative events that it may be related to. Record-based lineage should provide an auditor with a comprehensive history of the event’s life cycle, such that further investigation is possible. Record-based lineage is far more complex to implement because there are many corner cases to consider. Record-based lineage can be used in conjunction with topology-based lineage, though it tends to be the less commonly implemented of the two.
One simple implementation option is to record an event’s progress through its journey from data product to consumer. At each stage of its journey, a unique service ID, processing time, and any other necessary metadata is attached to the record, usually in the header. However, record-based lineage tends to be much more difficult to achieve at scale, as there are several major complicating factors:
- Multiple consumers of the same events
-
A record can be consumed by many different users, resulting in multiple copies of the same event, each with its own lineage.
- Not all consumers emit events
-
Some consumers do not emit events and may instead serve up access to data via a REST API. They would need to take additional steps to create a log of which records they have ingested and ensure that the data is made available for query.
- Aggregating and joining events
-
An aggregation can be composed of a large number of events, making it impractical to track all of the records associated with its composition. The same is true for joins, though in practice joins tend to only span a small quantity of events.
- Complex transformations
-
Consumers can have fairly complex use cases where input events simply do not map easily to outputs.
An alternative to storing record lineage in the record is to instead use an external database. Each service must report to the endpoint the events that it has consumed, processed, and emitted. This option does make it easier to track record usage when multiple services have consumed and used the data product, including those where new events are not emitted after use.
However, it does not solve the issues relating to joins, aggregations, and complex transformations, leaving a potential gap in record-level lineage. Furthermore, you will also need to invest in client tooling that automatically reports each record’s status to the central service, including accounting for scaling, outages, and client language support.
It’s important that you consider why you want lineage and what problems it’s meant to help solve. There is no one-size-fits-all solution to lineage. A bank will have far greater lineage requirements than a store that sells socks, so you’ll need to ensure that your governance team has a good idea about its own organization’s true requirements. There are lineage solutions that can conceivably solve the issues that we’ve discussed in this section, but they require time and effort to accomplish—time and effort that may be best spent elsewhere.
If you don’t have a good understanding of what problems your lineage solution is meant to solve, you run the risk of building something completely irrelevant. You must figure out what audits you need and what the risks to your systems are, and then come up with a detailed proposal for how a lineage solution can help you meet your needs.
Summary
Federated governance covers a large territory.
Data mesh requires a governance team to help bring order to the varied technologies, domains, data models, and use cases of the organization. Governing is an intensely social commitment to work together with your peers and come up with effective solutions for the hurdles of implementing data mesh. As part of the governance team, you’ll focus on identifying common standards, frameworks, languages, and tools to help support data mesh use cases.
The governance team works together with technical domain experts to identify areas of improvement in the self-service platform. If you want everyone in your organization to adhere to data encryption policies, it’s far easier to ensure that they’re integrated into the data product platform by default and not left up to each team to implement for themselves. Similarly, the governance team makes sure that those who use the data mesh are heard, their complaints are addressed, and success stories are shared and exemplified.
Federated governance is also about tracking data usage, ensuring it adheres to legal requirements and good infosec practices. You will need strong access controls to ensure you know which systems and people have access to which data, but you’ll need to balance it against making sure that your teams can get access to most data when they need it. Data may also need to be encrypted, either partially or fully, and may also need to be archived indefinitely, again depending on your data handling requirements.
Finally, governance is also about providing direction for the implementation of the self-service platform. The governance team, in conjunction with its technical experts, should codify and streamline the self-service platform functionality, such that it’s easy for users to do the right thing and hard for them to do the wrong thing. We’ll take a look at this more in the next chapter.
Get Building an Event-Driven Data Mesh now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

