Chapter 1. Event-Driven Data Communication
The way that businesses relate to their data is changing rapidly. Gone are the days when all of a business’s data would fit neatly into a single relational database. The big data revolution, started more than two decades ago, has since evolved, and it is no longer sufficient to store your massive data sets in a big data lake for batch analysis. Speed and interconnectivity have emerged as the next major competitive business requirements, again transforming the way that businesses create, store, access, and share their important data.
Data is the lifeblood of a business. But many of the ways that businesses create, share, and use data is haphazard and disjointed. Data mesh provides a comprehensive framework for revisiting these often dysfunctional relationships and provides a new way to think about, build, and share data across an organization, so that we can do helpful and useful things: better service for our customers, error-free reporting, actionable insights, and enabling truly data-driven processes.
To get an understanding of what we’re trying to fix, we first need an idea of the main data problems facing a modern business.
First, big data systems, underpinning a company’s business analytics engine, have exploded in size and complexity. There have been many attempts to address and reduce this complexity, but they all fall short of the mark.
Second, business operations for large companies have long since passed the point of being served by a single monolithic deployment. Multiservice deployments are the norm, including microservice and service-oriented architectures. The boundaries of these modular systems are seldomly easily defined, especially when many separate operational and analytical systems rely on read-only access to the same data sets. There is an opposing tension here: on one hand, colocating business functions in a single application provides consistent access to all data produced and stored in that system. On the other, these business functions may have absolutely no relation to one another aside from needing common read-only access to important business data.
And third, a problem common to both operational and analytical domains: the inability to access high-quality, well-documented, self-updating, and reliable data. The sheer volume of data that an organization deals with increases substantially year-over-year, fueling a need for better ways to sort, store, and use it. This pressure deals the final blow to the ideal of keeping everything in a single database and forces developers to split up monolithic applications into separate deployments with their own databases. Meanwhile, the big data teams struggle to keep up with the fragmentation and refactoring of these operational systems, as they remain solely responsible for obtaining their own data.
Data has historically been treated as a second-class citizen, as a form of exhaust or by-product emitted by business applications. This application-first thinking remains the major source of problems in today’s computing environments, leading to ad hoc data pipelines, cobbled together data access mechanisms, and inconsistent sources of similar-yet-different truths. Data mesh addresses these shortcomings head-on, by fundamentally altering the relationships we have with our data. Instead of a secondary by-product, data, and the access to it, is promoted to a first-class citizen on par with any other business service.
Important business data needs to be readily and reliably available as building block primitives for your applications, regardless of the runtime, environment, or codebase of your application. We treat our data as a first-class citizen, complete with dedicated ownership, minimum quality guarantees, service-level agreements (SLAs), and scalable mechanisms for clean and reliable access. Event streams are the ideal mechanism for serving this data, providing a simple yet powerful way of reliably communicating important business data across an organization, enabling each consumer to access and use the data primitives they need.
In this chapter, we’ll take a look at the forces that have shaped the operational and analytical tools and systems that we commonly use today and the problems that go along with them. The massive inefficiencies of contemporary data architectures provide us with rich learnings that we will apply to our event-driven solutions. This will set the stage for the next chapter, when we talk about data mesh as a whole.
What Is Data Mesh?
Data mesh was invented by Zhamak Dehghani. It’s a social and technological shift in the way that data is created, accessed, and shared across organizations. Data mesh provides a lingua franca for discussing the needs and responsibilities of different teams, domains, and services and how to they can work together to make data a first-class citizen. This chapter explores the principles that form the basis of data mesh.
In my last book, Building Event-Driven Microservices (O’Reilly), I introduced the term data communication layer, touching on many of the same principles as data mesh: treat data as a first-class citizen, formalize the structure for communication between domains, publish data to event streams for general purpose usage, and make it easy to use for both the producers and consumers of data. And while I am fond of the data communication layer terminology, the reality is that I think the language and formalized principles of data mesh provide everything we need to talk about this problem without introducing another “data something something” paradigm.
Dehghani’s book, Data Mesh (O’Reilly), showcases the theory and thought leadership of data mesh in great depth and detail, but remains necessarily agnostic of specific implementations.
In this book, we’ll look at a practical implementation of data mesh that uses the event stream as the primary data product mode for interdomain data communications. We can be a bit more pragmatic and less intense on the theory and more concrete and specific on the implementation of an event-driven design. While I think that event streams are fundamentally the best option for interdomain communication, they do come with trade-offs, and I will, of course, cover these too, mentioning nonstreaming possibilities where they are best suited.
Data mesh is based on four main principles: domain ownership, data as a product, federated governance, and self-service platform. Together, these principles help us structure a way to communicate important business data across the entire organization. We’ll evaluate these principles in more detail in the next chapter, but before we get there, let’s take a look at why data mesh matters today.
An Event-Driven Data Mesh
The modern competitive requirements of big data in motion, combined with modern cloud computing, require a rethink of how businesses create, store, move, and use data. The foundation of this new data architecture is the event, the data quantum that represents real business activities, provided through a multitude of purpose-built event streams. Event streams provide the means for a central nervous system for enabling business units to access and use fundamental, self-updating data building blocks. These data building blocks join the ranks of containerization, infrastructure as a service (IaaS), continuous integration (CI) and continuous deployment (CD) pipelines, and monitoring solutions, the components on which modern cloud applications are built.
Event streams are not new. But many of the technological limitations underpinning previous event-driven architectures, such as limited scale, retention, and performance, have largely been alleviated. Modern multitenant event brokers complete with tiered storage can store an unbounded amount of data, removing the strict capacity restrictions that limited previous architectures. Producers write their important business domain data to an event stream, enabling others to couple on that stream and use the data building blocks for their own applications. Finally, consumer applications can in turn create their own event streams to share their own business facts with others, resulting in a standardized communications mesh for all to use.
Data mesh provides us with very useful concepts and language for building out this interconnected central nervous system. Figure 1-1 shows a basic example of what a data mesh could look like.
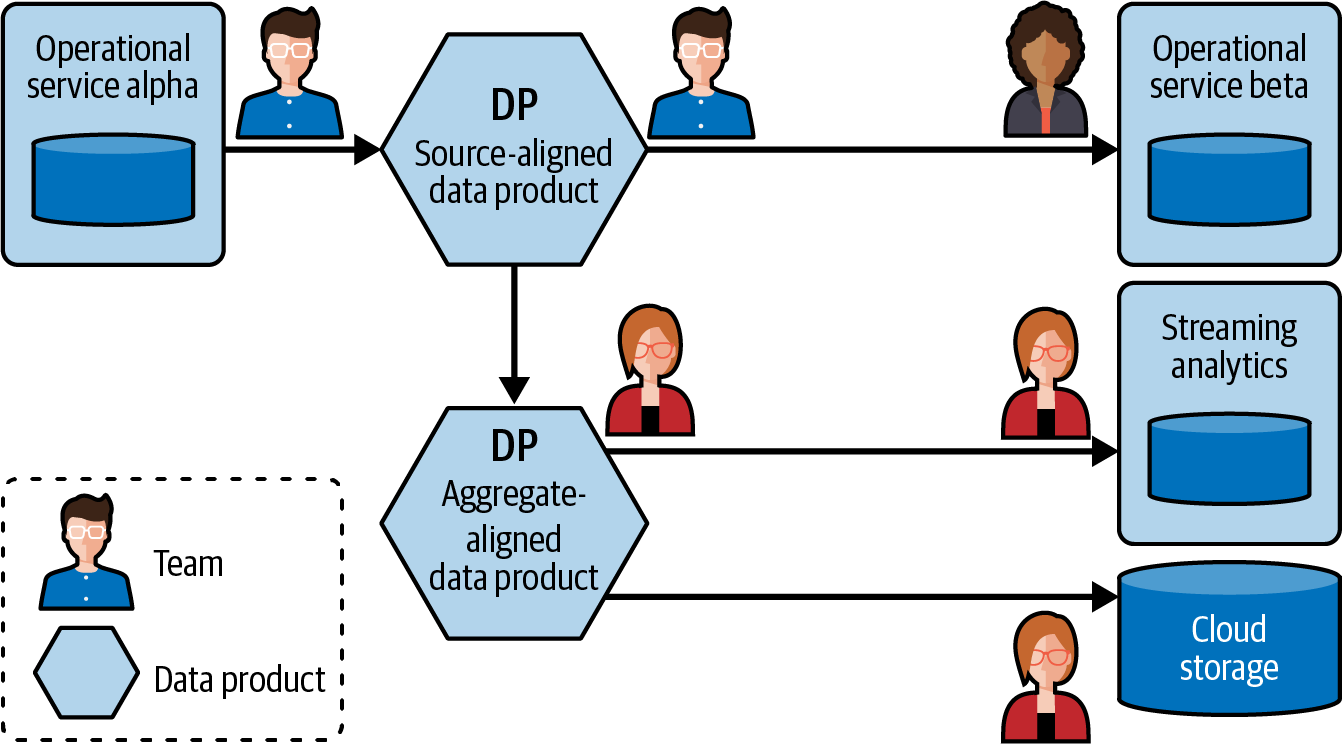
Figure 1-1. A very basic Hello Data Mesh implementation
The team that owns operational system Alpha selects some data from their service boundary, remodels it, and writes it to a source-aligned data product, which they also own (we’ll cover data product alignments more in “The Three Data Product Alignment Types”). The team that owns operational system Beta reads data from this data product into its own service boundary, again remodeling it, transforming it, and storing only what they need.
Meanwhile, a third team connects to Alpha team’s data product and uses it to compose their own aggregate-aligned data product. This same team then uses its aggregate-aligned data product to both power a streaming analytics use case and to write a batch of files to cloud storage, where data analysts will use it to compose reports and power existing batch-based analytics jobs.
This diagram represents just the tip of the data mesh iceberg, and there remain many areas to cover. But the gist of the event-driven data mesh is to make data readily available in real time to any consumers who need it.
Many of the problems that data mesh solves have existed for a very long time. We’re now going to take a brief history tour to get a better understanding of what it is we’re solving and why data mesh is a very relevant and powerful solution.
Using Data in the Operational Plane
Data tends to be created by an operational system doing business things. Eventually, that data tends to be pulled into the analytical plane for analysis and reporting purposes. In this section, we’ll focus on some of the operational plane and the common challenges of sharing business data with other operational (and analytical) services.
The Data Monolith
Online transaction processing (OLTP) databases form the basis of much of today’s operational computer services (let’s call them “monoliths” for simplicity). Monolithic systems tend to play a big role in the operational plane, as consistent synchronous communication tends to be simpler to reason and develop against than asynchronous communication. Relational databases, such as PostgreSQL and MySQL, feature heavily in monolithic applications, providing atomicity, consistency, isolation, and durability (ACID) transactions and consistent state for the application.
Together, the application and database demonstrate the following monolith data principles:
- The database is the source of truth
-
The monolith relies on the underlying database to be the durable store of information for the application. Any new or updated records are first recorded into the database, making it the definitive source of truth for those entities.
- Data is strongly consistent
-
The monolith’s data, when stored in a typical relational database, is strongly consistent. This provides the business logic with strong read-after-write consistency, and, thanks to transactions, it will not inadvertently access partially updated records.
- Read-only data is readily available
-
The data stored within the monolith’s database can be readily accessed by any part of the monolith. Read-only access permissions ensure that there are no inadvertent alterations to the data.
Note that the database should be directly accessed only by the service that owns it, and not used as an integration point.
These three principles form a binding force that make monolithic architectures powerful. Your application code has read-only access to the entire span of data stored in the monolith’s database as a set of authoritative, consistent, and accessible data primitives. This foundation makes it easy to build new application functionality provided it’s in the same application. But what if you need to build a new application?
The Difficulties of Communicating Data for Operational Concerns
A new application cannot rely on the same easy access to data primitives that it would have if it were built as part of the monolith. This would not be a problem if the new application had no need for any of the business data in the monolith. However, this is rarely the case, as businesses are effectively a set of overlapping domains, particularly the common core, with the same data serving multiple business requirements. For example, an ecommerce retailer may rely on its monolith to handle its orders, sales, and inventory, but requires a new application powered by a document-based database (or other database type) for plain-text search functionality. Figure 1-2 highlights the crux of the issue: how do we get the data from Ol’ Reliable into the new document database to power search?
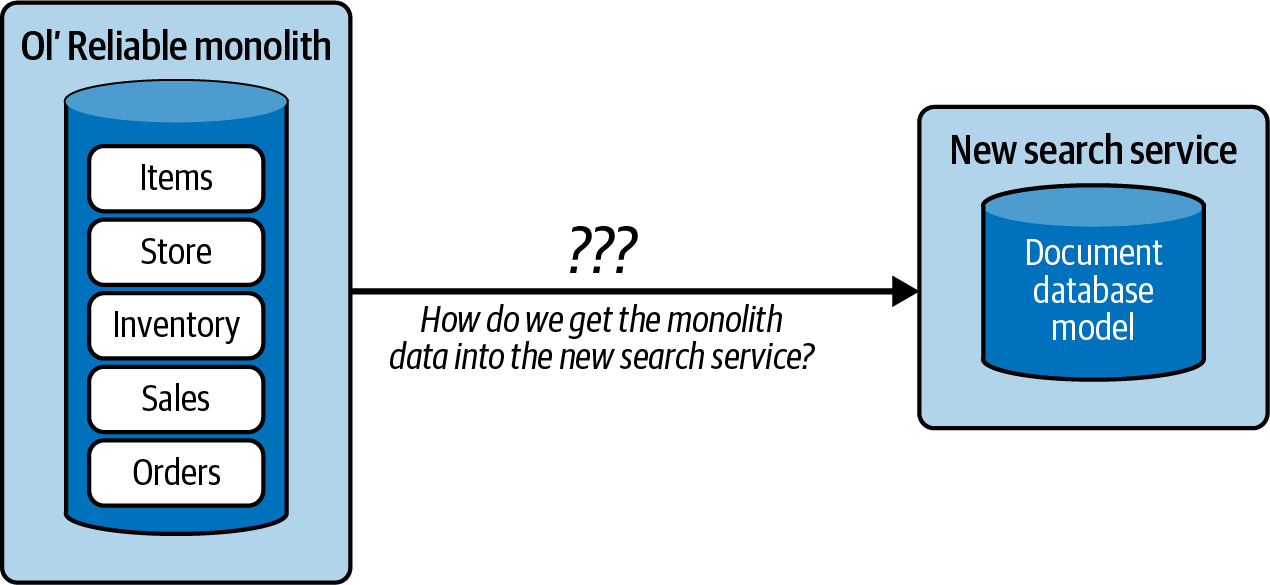
Figure 1-2. The new search service team must figure out how to get the data it needs out of the monolith and keep it up to date
This puts the new search service team in a bit of a predicament. The service needs access to the item, store, and inventory data in the monolith, but it also needs to model it all as a set of documents for the search engine. There are two common ways that teams attempt to resolve this. One is to replicate and transform the data to the search engine, in an attempt to preserve the three monolith data principles. The second is to use APIs to restructure the service boundaries of the source system, such that the same data isn’t simply copied out—but served completely from a single system. Both can achieve some success, but are ultimately insufficient as a general solution. Let’s take a look at these in more detail to see why.
Strategy 1: Replicate data between services
There are several mechanisms that fall under this strategy. The first and simplest is to just reach into the database and grab the data you need, when you need it. A slightly more structured approach is to periodically query the source database and dump the set of results into your new structure. While this gives you the benefit of selecting a different data store technology for your new service, there are a few major drawbacks:
- Tight coupling with the source
-
You remain coupled on the source database’s internal model and rely on it exclusively to handle your query needs.
- Performance load on the source
-
Large data sets and complex queries can grind the database to a halt. This is especially true in the case of denormalizing data for analytical use cases, where multi-table and complex joins are common.
The second most common mechanism for the data replication strategy is a read-only replica of the source database. While this may help alleviate query performance issues, consumers still remain coupled on the internal model. And, unfortunately, each additional external coupling on the internal data model makes change more expensive, risky, and difficult for all involved members.
Warning
Coupling on the internal data model of a source system causes many problems. The source model will change in the course of normal business evolution, which often causes breakages in both the periodic queries and internal operations of all external consumers. Each coupled service will need to refactor its copy of the model to match what is available from the source, migrate data from the old model to the new model, and update its business code accordingly. There is a substantial amount of risk in each of these steps, as a failure to perform each one correctly can lead to misunderstandings in the meaning of the models, divergent copies of the data, and ultimately incorrect business results.
Data replication strategies become more difficult to maintain with each new independent source and each new required replica. This introduces a few new issues:
- The original data set can be difficult to discover
-
It’s not uncommon for a team to accidentally couple its service on a copy of the original data, rather than the original data itself. It can be difficult to discover what the original source of data is without resorting to informal knowledge networks.
- Increase in point-to-point connections
-
Additionally, each new independent service may become its own authoritative source of data, increasing the number of point-to-point connections for inter-service data replication.
Point-to-point replication of data between services introduces additional complexity, while simultaneously introducing tight coupling on the internal data model of the source. It is insufficient for building the modern data communications layer.
Strategy 2: Use APIs to avoid data replication needs
Directly coupled request-response microservices, also sometimes known as synchronous microservices, are another common approach to dealing with accessing remote data. Microservices can directly call the API of another service to exchange small amounts of information and perform work on each other’s behalf.
For example, you may have one microservice that manages inventory-related operations, while you have other microservices dedicated to shipping and accounts. Each of these service’s requests originate from the dedicated mobile frontend and web frontend microservices, which stitch together operations and return a seamless view to users, as shown in Figure 1-3.
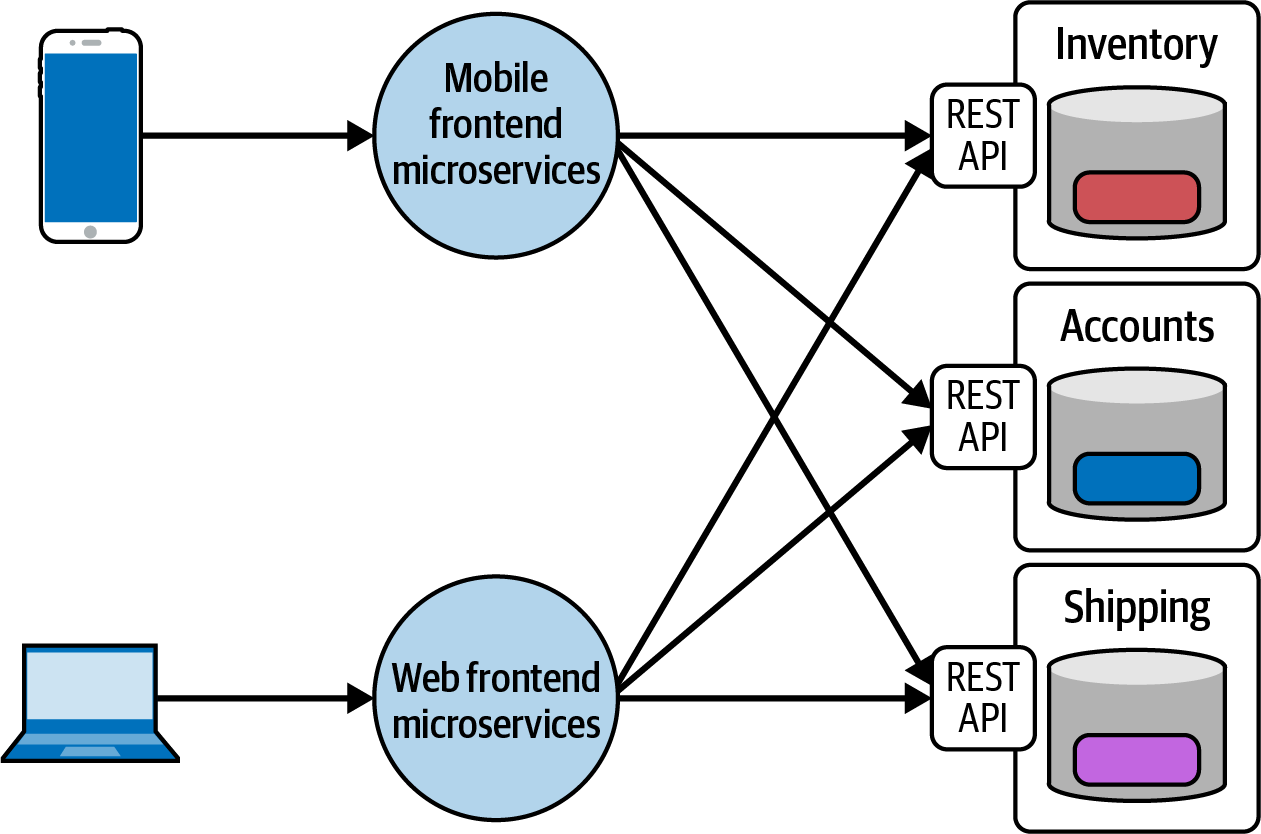
Figure 1-3. An example of a simple ecommerce microservice architecture
Synchronous microservices have many benefits:
-
Purpose-built services serve the needs of the business domain.
-
The owners have a high level of independence to use the tools, technologies, and models that work best for their needs.
-
Teams also have more control over the boundaries of their domains, including control and decision making over how to expand them to help serve other clients’ needs.
There are numerous books written on synchronous microservices, such as Building Microservices by Sam Newman (O’Reilly) and Microservices Patterns by Chris Richardson (Manning), that go into far more detail than I have space for, so I won’t delve into them in much detail here.
The main downsides of this strategy are the same as with a single service:
-
There is no easy and reliable mechanism for accessing data beyond the mechanisms provided in the microservices’ API.
-
Synchronous microservices are usually structured to offer up an API of business operations, not for serving reliable bulk data access to the underlying domain.
-
Most teams resort to the same fallbacks as a single monolith does: reach into the database and pull out the data you need, when you need it, (see Figure 1-4).
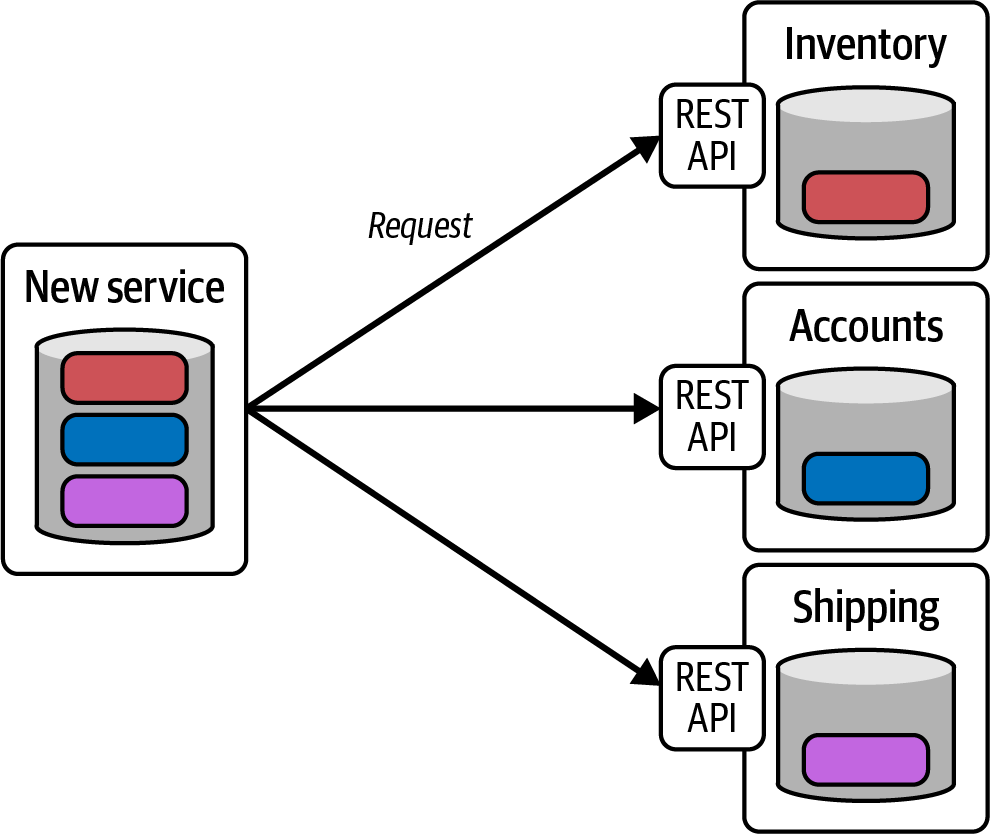
Figure 1-4. The microservice boundaries may not line up with the needs of the business problem
In this figure, the new service is reliant on the inventory, accounts, and shipping services just for access to the underlying business data—but not for the execution of any business logic. While this form of data access can be served via a synchronous API, it may not be suitable for all use cases. For example, large data sets, time-sensitive data, and complex models can prevent this type of access from becoming reality. In addition, there is the operational burden of providing the data access API and data serving performance on top of that of the base microservice functionality.
Operational systems lack a generalized solution for communicating important business data between services. This isn’t something that’s isolated to just operations. The big data domain, underpinning and powering analytics, reporting, machine learning, AI, and other business services, is a voracious consumer of full data sets from all across the business.
While domain boundary violations in the form of smash and grab data access are the foundation on which big data engineering has been built (I have been a part of such raids during the decade I have spent in this space), fortunately for us, it has provided us with rich insights that we can apply to make a better solution for all data users. But before we get to that, let’s take a look at the big data domain requirements for accessing and using data and how this space evolved to where it is today.
The Analytical Plane: Data Warehouses and Data Lakes
Whereas operational concerns focus primarily on OLTP and server-to-server communication, analytical concerns are historically focused on answering questions about the overall performance of the business. Online analytical processing (OLAP) systems store data in a format more suitable to analytical queries, allowing data analysts to evaluate data on different dimensions. Data warehouses help answer questions such as “How many items did we sell last year?” and “What was our most popular item?” Answering these questions requires remodeling operational data into a model suitable for analytics, and also accounting for the vast amounts of data where the answers are ultimately found.
Getting data into a data warehouse has historically relied on a process known as Extract, Transform, and Load (ETL), as shown in Figure 1-5.
A periodically scheduled job extracts data from one or more source databases and transforms it into the data model required by the data warehouse. The data is then loaded into the data warehouse, where data analysts can run further queries and analyses. Data warehouses typically enforce well-defined schemas at write time, including column types, names, and nullability.
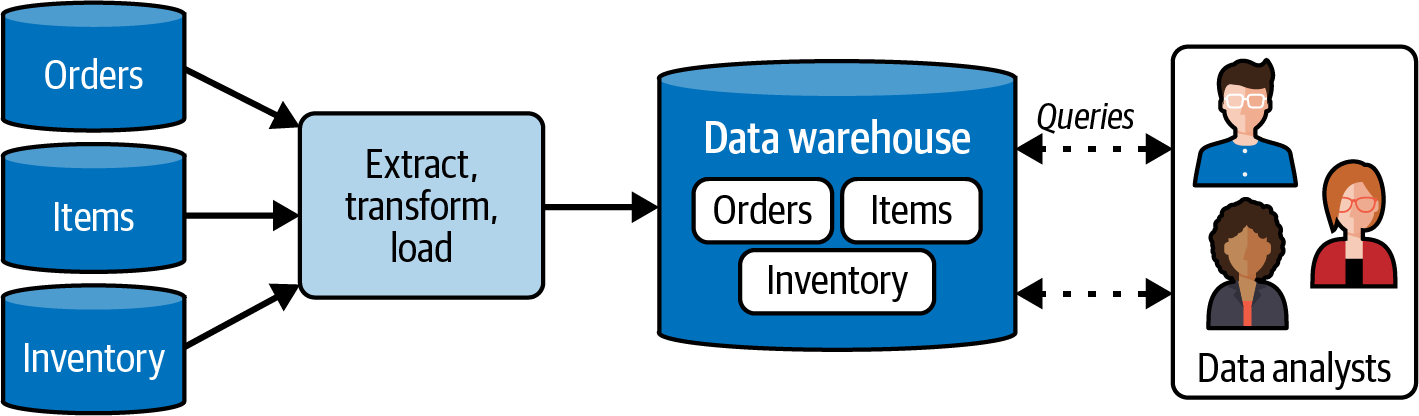
Figure 1-5. A typical data warehouse ETL workflow
Historically, data warehouses have proven to be successful at providing a means for analytical results. But the ever-increasing data and compute loads required larger disk drives and more powerful compute chips and ultimately ran into the physical limits of computer hardware. So instead of further scaling up, it became time to scale out.
The need for massive scale was plainly evident to Google, which published The Google File System in October, 2003. This is the era that saw the birth of big data and caused a massive global rethink of how we create, store, process, and, ultimately, use data.
Note
Many modern data warehouses also offer high scalability, but it wasn’t until the advent of the big data revolution that this became a reality. Historically, data warehouses were limited by the same factors as any other system operating on a single server.
Apache Hadoop quickly caught on as the definitive way to solve the scaling problems facing traditional OLAP systems. Because it’s free and open source, it could be used by any company, anywhere, provided you could figure out how to manage the infrastructure requirements. It also provided a new way to compute analytics, one where you were no longer constrained to a proprietary system limited by the resources of a single computer.
Hadoop introduced the Hadoop Distributed File System (HDFS), a durable, fault-tolerant filesystem that made it possible to create, store, and process truly massive data sets spanning multiple commodity hardware nodes. While HDFS has now been largely supplanted by options such as Amazon S3 and Google Cloud Storage, it paved the way for a bold new idea: copy all of the data you need into a single logical location, regardless of size, and apply processing to clean up, sort out, and remodel data into the required format for deriving important business analytics.
Big data architecture introduced a significant shift in the mentality toward data. Not only did it address the capacity issues of existing OLAP systems, it introduced a new concept into the data world: it was not only acceptable, but preferable, to use unstructured or semi-structured data, instead of enforcing schema on write as in a data warehouse. In this new world of big data, you were free to write data with or without any schema or structure and resolve it all later at query time by applying a schema on read. Many data engineers were pleased to get rid of the schema on write requirement, as it made it easier to just get data into the ecosystem.
Consider Table 1-1, comparing the data structures and use cases between the relational database and MapReduce. MapReduce is an early Hadoop processing framework and is what you would use to read data, apply a schema (on read), perform transformations and aggregations, and produce the final result.
| Traditional RDBMS | MapReduce | |
|---|---|---|
Data size |
Gigabytes |
Petabytes |
Access |
Interactive and batch |
Batch |
Updates |
Read and write many times |
Write once, read many times |
Structure |
Static schema |
Dynamic schema |
Integrity |
High |
Low |
Scaling |
Nonlinear |
Linear |
Note that this definitive guide from 2009 promotes MapReduce as a solution for handling low integrity data with a dynamic schema, emphasizing the notion that HDFS should be storing unstructured data with low integrity, with varying and possibly conflicting schemas to be resolved at runtime. It also points out that this data is write once, read many times, which is precisely the scenario in which you want a strong, consistent, enforced schema—providing ample opportunity for well-meaning but unconstrained users of the data to apply a read-time schema that misinterprets or invalidates the data.
A schema on write, including well-defined columns with types, defaults, nullability, and names, doesn’t necessarily restrict downstream transformations in any way. It also doesn’t force you to denormalize or join any data before writing.
A schema does provide you with a sanity check, ensuring that the data you’re ingesting at least fits the most basic expectations of the downstream processors. Abandoning that sanity check pushes the detection of errors downstream, causing significant hardships for those trying to use the data.
In the early days of Hadoop, I don’t think that I—or many others—appreciated just how the notion of schema on read would end up changing how data is collected, stored, and analyzed. We believed in and supported the idea that it was okay to grab data as you need it and figure it out after the fact, restructuring, cleaning, and enforcing schemas at a later date. This also made it very palatable for those considering migrating to Hadoop to alleviate their analytical constraints, because this move didn’t constrain your write processes or bother you with strict rules of data ingestion—after all, you can just fix the data once it’s copied over!
Unfortunately, the fundamental principle of storing unstructured data to be used with schema on read proved to be one of the costliest and most damaging tenets introduced by the big data revolution. Let’s take a look at precisely how this negatively affects distributed data access and why well-defined schematized data is such an important tenet of data mesh.
The Organizational Impact of Schema on Read
Enforcing a schema at read time, instead of at write time, leads to a proliferation of what we call “bad data.” The lack of write-time checks means that data written into HDFS may not adhere to the schemas that the readers are using in their existing work, as shown in Figure 1-6. Some bad data will cause consumers to halt processing, while other bad data may go silently undetected. While both of these are problematic, silent failures can be deadly and difficult to detect.
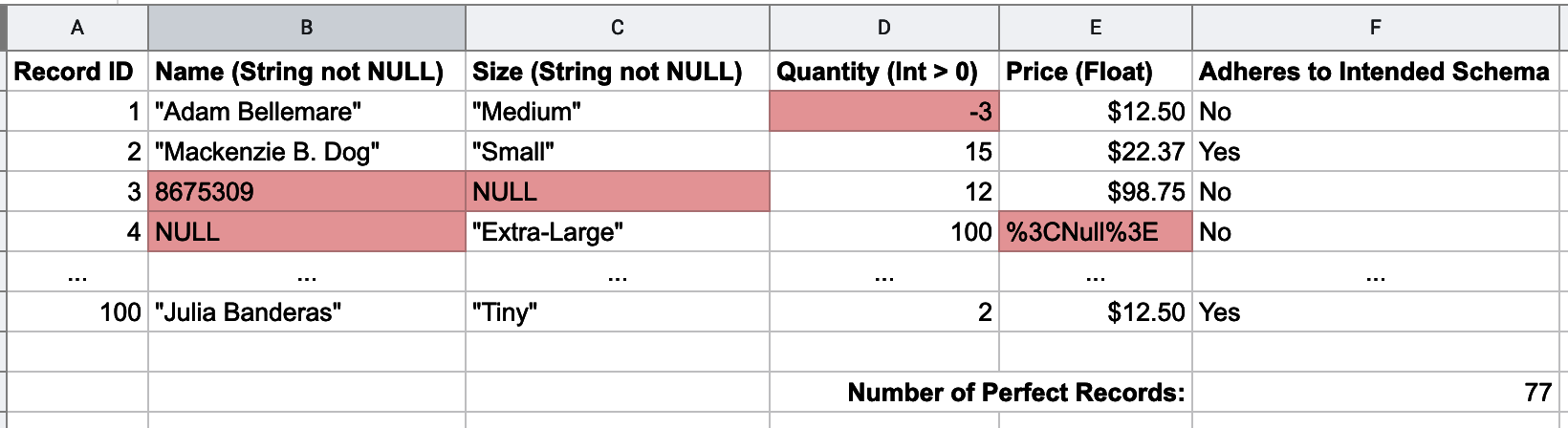
Figure 1-6. Examples of bad data in a data set, discovered only at read time
To get a better understanding of the damaging influence of schema on read, let’s take a look at three roles and their relationship to one another. While I am limited to my own personal experiences, I have been fortunate to talk with many other data people in my career, from different companies and lines of business. I can say with confidence that while responsibilities vary somewhat from organization to organization, this summary of roles is by and large universal to most contemporary organizations using big data:
- The data analyst
-
Charged with answering business questions, generating insights, and creating data-driven reports. Data analysts query the data sets provided to them by the data engineers.
- The data engineer
-
Charged with obtaining the important business data from systems around the organization and putting it into a usable format for the data analysts.
- The application developer
-
Charged with developing an application to solve business problems. That application’s database is also the source of data required by the data analysts to do their job.
Historically, the most common way to adopt Hadoop was to establish a dedicated data team as a subset of, or fully separate from, the regular engineering team. The data engineer would reach into the application developer’s database, grab the required data, and pull it out to put into HDFS. Data scientists would clean it up and restructure it (and possibly build machine learning models off of it), before passing it on to be used in analytics.
Finally, the data analysts would then query and process the captured data sets to produce answers to their analytical questions. This model led to many issues, however. Conversations between the data team and the application developers would be infrequent and usually revolve around ensuring the data team’s query load did not affect the production serving capabilities.
There are three main problems with this separation of concerns and responsibilities. Let’s take a look at them.
Problem 1: Violated data model boundaries
Data ingested into the analytics domain is coupled on the source’s internal data model and results in direct coupling by all downstream users of that data. For simple, seldom-changing sources, this may not be much of a problem. But many models span multiple tables, are purpose-built for OLTP operations, and may become subject to substantial refactoring as business use cases change. Direct coupling on this internal model exposes all downstream users to these changes.
Warning
One example I have seen of a table modification that silently broke downstream jobs involved changing a field from boolean to long. The original version represented an answer to the question “Did the customer pay to promote this?” The updated version represented the budget ID of the newly expanded domain, linking this part of the model to the budget and its associated type (including the new trial type). The business had adopted a “try before you buy” model where it would reserve, say, several hundred dollars in advertising credits to showcase the effectiveness of promotion, without counting it in the total gross revenue.
The jobs ingesting this data to HDFS didn’t miss a beat (no schema on write), but some of the downstream jobs started to report odd values. A majority of these were Python jobs, which easily evaluated the new long values as Booleans, and resulted in over-attribution of various user analytics. Unfortunately, because no jobs were actually broken, this problem wasn’t detected until a customer started asking questions about abnormal results in their reports. This is just one example of many that I have encountered, where well-meaning, reasonable changes to a system’s data model have unintended consequences on all of those who have coupled on it.
Problem 2: Lack of single ownership
Application developers are the domain experts and masters of the source data model, but their responsibility for communicating that data to other teams (such as the big data team) is usually nonexistent. Instead, their responsibilities usually end at the boundaries of their application and database.
Meanwhile, the data engineer is tasked with finding a way to get that data out of the application developer’s database, in a timely manner, without negatively affecting the production system. The data engineer is dependent on the data sources, but often has little to no influence on what happens to the data sources, making their role very reactive. This production/data divide is a very real barrier in many organizations, and despite best-efforts, agreements, integration checks, and preventative tooling, breakages in data ingestion pipelines remain a common theme.
Finally, the data analyst, responsible for actually using the data to derive business value, remains two degrees of separation away from the domain expert (application developer), and three degrees separated if you have a layer of data scientists in there further munging the data. Both analysts and data scientists have to deal with whatever data the data engineers were able to extract, including resolving inconsistent data that doesn’t match their existing read schemas.
Because data analysts often share their schemas with other data analysts, they also need to ensure that their resolved schemas don’t break each other’s work. This is increasingly difficult to do as an organization and its data grow, and, unfortunately, their resolution efforts remain limited to benefiting only other analysts. Operational use cases have to figure out their own way to get data.
Problem 3: Do-it-yourself and custom point-to-point data connections
While a data team in a small organization may consist of only a handful of members, larger organizations have data teams consisting of hundreds or thousands of members. For large data organizations, it’s common to pull the same data sources into multiple different subdomains of the data platform, depending on use cases, team boundaries, and technology boundaries.
For example, sales data may be pulled into the analytics department, consumer reporting department, and accounts receivable department. Each subgroup typically independently creates, schedules, and executes ETL jobs to pull the data into its own subdomain, resulting in multiple independently managed copies of the source data, as shown in Figure 1-7.
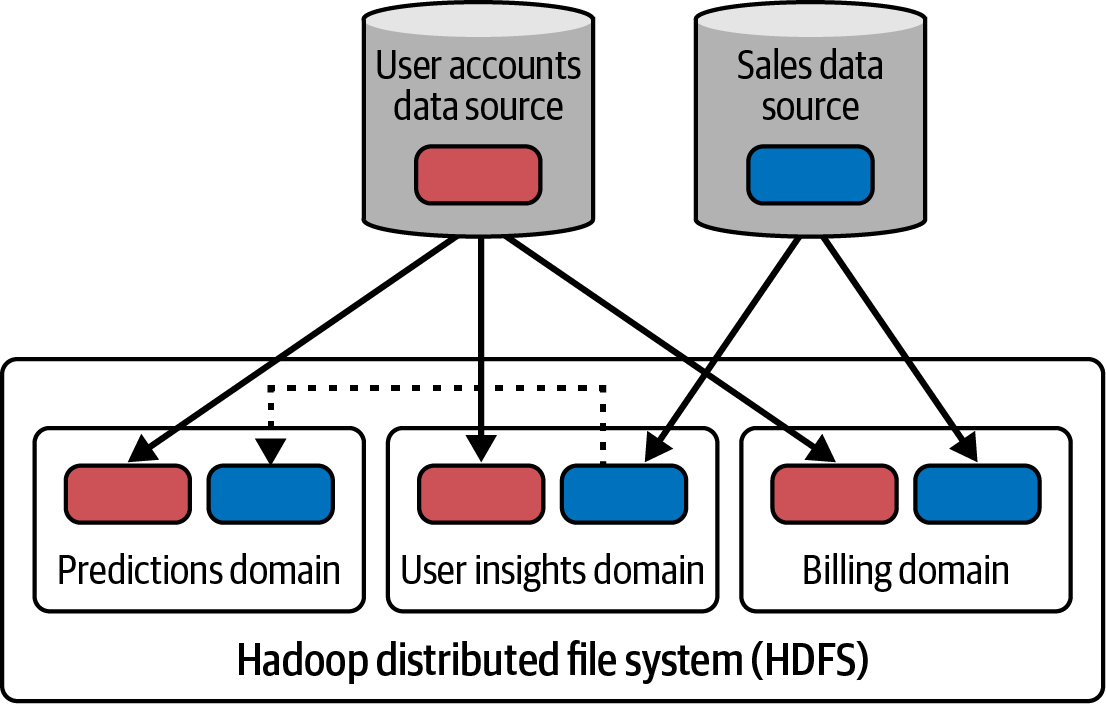
Figure 1-7. Three analytical domains, each grabbing data from where it can to get its work done
While purpose-built, point-to-point data connections let users access the data they need where they need it, it ends up causing a messy tangle. It can be difficult to tell who owns the ETL job, especially when users and teams share access credentials. Tracing lineage, freshness, and determining ownership of a data set can similarly be difficult, often leading to further proliferation of new ETL jobs. After all, if you’re not sure the data is exactly what you need, you may as well just make your own job and your own copy for safety’s sake.
Enforcing access controls on the source can help clear up who can access what data, but only from the primary source. But restricting data access can backfire. A lengthy or cumbersome process to gain access can result in people simply making copies from other less protected sources. In Figure 1-7, notice that the Predictions domain simply circumnavigates the source access controls by copying the sales data from the User insights domain.
But are these copies really the same data? Synchronization frequency, transformations, time zones, intermittent failures, and an incorrect environment (e.g., staging, not production) are just a few issues that can affect the integrity of your copied source. It’s possible that you think you’re getting the correct data, but you’re not and you don’t know it. For example, you copy one data set thinking it’s synced to UTC-0 time, but it’s actually synced to UTC-6. The format, partitioning, and ordering of data may appear identical, yet these hard-to-detect, undocumented differences still remain.
Custom point-to-point connections can be a challenge to maintain, cause a sprawl of data, and can result in many duplicate sync jobs that produce similar yet different data.
This disjointed model and responsibilities of data ownership and distribution lead to bad data, which is costly in terms of time, money, and missed opportunities. Let’s take a look at the costs, before wrapping up with why data mesh purports to solve these issues.
Bad Data: The Costs of Inaction
Bad data typically goes undetected until it is applied to a schema. For example, you can’t insert TEXT into an Int32 column in a database. By using schema on read, however, we effectively defer validating our data until the end of the data piping process. And while our sources may use a schema, there’s no guarantee that our countless point-to-point pipelines have correctly captured the schema alongside the data. There have been many an Int32 captured as an String, or, at worst, an Object.
Bad data is costly to fix, and it’s more costly the more widespread it is. Everyone who has accessed, used, copied, or processed the data may be affected and may require mitigating action on their part. The complexity is further increased by the fact that not every consumer will “fix” it in the same way. This can lead to divergent results that are divergent with others and can be a nightmare to detect, track down, and rectify.
Bad data is often inadvertently created by well-meaning individuals, simply because of the point-to-point, “reach in and grab it” nature of many data transfer tools. This has been further augmented by massive scale, where a team discovers that not only is their copy of the data set wrong, but that it’s been wrong for several months, and the results of each downstream job computed using that data set are also wrong. These jobs may use hundreds or thousands of processing nodes, with 32x to 128x more in GB of RAM, churning through hundreds of TBs of data each night. This can easily amount to hundreds of thousands or millions of dollars just in processing costs to rerun all of the affected jobs.
Business decisions may also have been affected. I have been privy to the details of one scenario where a company had incorrectly billed its customers collectively by several million dollars, in some cases by too much, and in others by too little. The cause of this was actually quite innocent: a schema change compounded with a complex chain of “reach in and grab it” data ETLs resulted in some data interpretation issues when the schema was applied at read time. It was only when a customer noticed that their billing costs far exceeded their engagement costs that an investigation was started and the root problem discovered.
Data’s increasing prominence in modern computing has led others to research the associated costs, especially regarding just how much bad data costs businesses. The results are staggeringly high.
In 2016, one report by IBM, as highlighted by the Harvard Business Review (HBR) put an estimate of the financial impacts of bad data at 3.1 trillion US dollars, in the US alone. Though the original report is (frustratingly) no longer available, HBR has retained some of the more relevant numbers:
-
50%—the amount of time that knowledge workers waste hunting for data, finding and correcting errors, and searching for confirmatory sources for data they don’t trust.
-
60%—the estimated fraction of time that data scientists spend cleaning and organizing data.
The problem of bad data has existed for a very long time. Data copies diverge as their original source changes. Copies get stale. Errors detected in one data set are not fixed in duplicate ones. Domain knowledge related to interpreting and understanding data remains incomplete, as does support from the owners of the original data.
Data mesh proposes to fix this issue by promoting data to a first-class citizen, a product like any other. A data product with a well-defined schema, domain documentation, standardized access mechanisms, and SLAs can substantially reduce the impact of bad data right at the source. Consumers, once coupled on the data product, may still make their own business logic mistakes—this is unavoidable. They will, however, seldom make inadvertent mistakes in merely trying to acquire, understand, and interpret the data they need to solve their business problems. Inaction is not a solution.
Can We Unify Analytical and Operational Workflows?
There’s one more problem that sits at the heart of engineering—it’s not just the data team that has these data access and quality problems. Every single OLTP application that needs data stored in another database has the same data access problems as the data team. How do you access important business data, locked away in another service, for operational concerns?
There have been several attempts at enabling better operational communication between services, including service-oriented architecture, enterprise service buses, and, of course, point-to-point request-response microservices. But in each of these architectures, the service’s data is encapsulated within its own database and is out of reach to other services. In one way this is good—the internal model is sheltered, and you have a single source of truth. Applications provide operational APIs that other applications can call to do work on their behalf. However, these solutions don’t resolve the fundamental issue of wholesale read-only access to definitive data sets to use as required for their own operational use cases.
A further complication is that many operational use cases nowadays depend on analytical results. Think machine learning, recommendation engines, AI, etc. Some use cases, such as producing a monthly report of top-selling products, can clearly be labeled as “analytical,” to be derived from a periodically computed job.
Other use cases are not so clear cut. Consider an ecommerce retailer that wants to advertise shoes based on current inventory (operational), previous user purchases (analytical), and the user’s real-time estimated shopping session intentions (analytical and operational). In practice, the boundary between operational and analytical is seldom neatly defined, and the exact same data set may be needed for a multitude of purposes—analytical, operational, or somewhere in between.
Both data analytics and conventional operational systems have substantial difficulty accessing data contained within other databases. These difficulties are further exacerbated by the increasing volume, velocity, and scale of data, while systems are simultaneously forced to scale outwards instead of upwards as compute limitations of individual services are reached. Most organizations’ data communication strategies are based on yesterday’s technology and fail to account for the offerings of modern cloud storage, computing, and software as a service (SaaS). These tools and technologies have changed the way that data can be modeled, stored, and communicated across an organization, which we will examine in more detail throughout the remainder of this book.
Rethinking Data with Data Mesh
The premise of the data mesh solution is simple. Publish important business data sets to dedicated, durable, and easily accessible data structures known as data products. The original creators of the data are responsible for modeling, evolution, quality, and support of the data, treating it with the same first-class care given to any other product in the organization.
Prospective consumers can explore, discover, and subscribe to the data products they need for their business use cases. The data products should be well-described, easy to interpret, and form the basis for a set of self-updating data primitives for powering both business services and analytics.
Event streams play the optimal role for the foundation of data products because they offer the immutable, appendable, durable, and replayable substrate for all consumers. These streams become a fundamental source of truth for operational, analytical, and all other forms of workloads across the organization.
This architecture is built by leveraging modern cloud computing and SaaS, as covered more in Chapter 5. A good engineering stack makes it easy to create and manage applications throughout their life cycle, including acquiring compute resources, providing scalability, logging, and monitoring capabilities. Event streams provide the modern engineering stack with the formalized and standardized access to the data it needs to get things done.
Let’s revisit the monolith data principles from earlier in this chapter through the lens of this proposal. These three principles outline the major influences for colocating new business functionality within a monolith. How would a set of self-updating event streams relate to these principles?
- The database is the source of truth → The event stream is the source of truth
-
The owner of the data domain is now responsible for composing an external-facing model and writing it as a set of events to one (or more) event streams. In exchange, other services can no longer directly access and couple on the internal data model, and the producer is no longer responsible for serving tailored business tasks on behalf of the querying service, as is often the case in a microservices architecture. The event stream becomes the main point of coupling between systems. Downstream services consume events from the event stream, model it for their purposes, and store it in their own dedicated data stores.
- Data is strongly consistent → Data is eventually consistent
-
The event stream producer can retain strong read-after-write consistency for its own internal state, along with other database benefits such as local ACID transactions. Consumers of the event stream, however, are independent in their processing of events and modeling of state and thus rely on their own eventually consistent view of the processed data. A consumer does not have write-access to the event stream, and so cannot modify the source of data. Consumer system designs must account for eventual consistency, and we will be exploring this subject in greater detail later in this book.
- Read-only data is readily available (remains unchanged!)
-
Event streams provide the formalized mechanism for communicating data in a read-only, self-updating format, and consumers no longer need to create, manage, and maintain their own extraction mechanism. If a consumer application needs to retain state, then it does so using its own dedicated data store, completely independent of the producer’s database.
Data mesh formalizes the ownership boundaries of data within an organization and standardizes the mechanisms of storage and communication. It also provides a reusable framework for producing, consuming, modeling, and using data, not only for current systems, but also for systems yet to be built.
Common Objections to an Event-Driven Data Mesh
There are several common objections that I have frequently encountered when discussing an event-driven data mesh . Though we will cover these situations in more detail throughout the book, I want to bring them up now to acknowledge that these objections exist, but that each one of them is manageable.
Producers Cannot Model Data for Everyone’s Use Cases
This argument is actually true, though it misses the point. The main duty of the producer is to provide an accurate and reliable external public model of its domain data for consumer use. These data models need to expose only the parts of the domain that other teams can couple on; the remainder of their internal model remains off-limits. For example, an ecommerce domain would have independent sales, item, and inventory models and event streams, simply detailing the current properties and values of each sale, item, and inventory level, whereas a shipping company may have event streams for each shipment, truck, and driver.
These models are deliberately simple and focused on a single domain definition, resulting in tight, modular data building blocks that other systems can use to build their own data models. Consumers that ingest these events can restructure them as needed, including joining them with events from other streams or merging them with existing states, to derive a model that works for solving their business use cases. Consumers can also engage the producer teams to request that additional information be added to the public model or for clarification on certain fields and values.
Because the producer team owns the original data model, it is the most qualified to decide what aspects of the model should be exposed and allow others to couple on. In fact, there is no other team more qualified than the team that actually creates the original source of data to define what it means and how others should interpret what its fields, relationships, and values mean. This approach lets the data source owners abstract away their internal complexities, such as their highly normalized relational model or document store. Changes to the internal source model can be hidden from consumers that would otherwise have coupled directly on it, thereby reducing breakages and errors.
Making Multiple Copies of Data Is Bad
This objection, ironically, is implicitly in opposition of the first argument. Though just like the previous argument, it does have a grain of truth. Multiple copies of the same data set can and do inadvertently get out of sync, become stale, or otherwise provide a source of data that is in disagreement with the original source. However, our proposal is not to make copying data a free-for-all, but rather to make a formalized and well-supported process that establishes clear rules and responsibilities, embracing this reality rather than hiding from it.
There are three main subtypes of this argument.
There should only be a single master copy of the data, and all systems should reference it directly
This belief fails to account for the fact that big data analytics teams worldwide have already been violating this principle since the dawn of the big data movement (and really, OLAP in general) because their needs cannot be met by a single master copy, stored in a single database somewhere. It also fails to account for the various needs of other operational systems, which follow the same boundary-breaching data acquisition strategies. It’s simply untenable.
Insufficiency of the source system to model its data for all business use cases is a prime reason why multiple copies of the same data set will eventually exist. One system may need to support ACID transactions in a relational model, whereas a second system must support a document store for geolocation and plain-text search. A third consumer may need to write these data sets to HDFS, to apply MapReduce style processing to yield results from the previous 364 copies of that data it made, cross-referenced to other annual data sets. All of these cannot be served from a single central database, if not just for the modeling, then for the impossibility of satisfactory performance for all use cases.
It’s too computationally expensive to create, store, and update multiple copies of the same data
This argument is hyper-focused on the fact that moving and storing data costs money, and thus storing a copy of the same data is wasteful (disregarding factors such as remodeling and performance, of course). This argument fails to account for the inexpensiveness of cloud computing, particularly the exceptionally cheap storage and network costs of today’s major cloud providers. It also fails to account for the developer hours necessary to build and support custom ETL pipelines, part of the multitrillion dollar inefficiencies in creating, finding, and using data.
Optimizing for minimizing data transfer, application size, and disk usage are no longer as important as they once were for the majority of business applications. Instead, the priority should be on minimizing developer efforts for accessing data building blocks, with a focus on operational flexibility.
Managing information security policies across systems and distributed data sets is too hard
Formalizing access to data via data products allows you to apply user and service access controls. Encryption lets you secure all of your sensitive data to unauthorized consumers, so that only those with permission can read the sensitive data.
The self-service platform plays a big role in a data mesh architecture, as it enforces all the security policies, access controls, and encryption requirements. Infosec adherence becomes integrated into the normal workflows of data product producers and consumers, making it far easier to enforce and audit compliance.
Eventual Consistency Is Too Difficult to Manage
Data communicated through event streams does require consideration of and planning for eventual consistency. However, the complaint that eventual consistency is too difficult to manage is typically founded on a misunderstanding of how much of an impact it can have on business processes as a whole. We can properly define our system boundaries to account for eventual consistency between systems, while having access to strong consistency within a system. There’s no getting around it—if a certain business process needs perfect consistency, then the creation and usage of the data must be within the same service boundary. But the majority of business processes don’t need this, and for those that do, nothing we’re proposing in this book precludes you from obtaining it. We’ll be discussing how to handle eventual consistency in more detail in Chapter 10.
Summary
Existing data communication strategies fall flat in the face of real business requirements. Breaching a service’s boundary by reaching in to grab its data is not a sustainable practice, but it is extremely common and often supports multiple critical systems and analytics workflows. Restructuring your systems into neat modular microservices does not solve the problem of data access; other parts of your business, such as the big data analytics and machine learning teams, will still require wholesale access to both current and historical data from domains across the organizations. One way or another, copies of data will be created, and we can either fight this or embrace this fact and work to make it better. In choosing the latter, we can use event streams to standardize and simplify the communication of data across the organization as self-updating single sources of truth.
Events form the basis of communication in event-driven architectures and fundamentally shape the space in which we solve our problems. Events, as delivered through event streams, form the building blocks for building asynchronous and reactive systems. These building blocks are primitives that are similar to synchronous APIs: other applications can discover them, couple on them, and use them to build their own services. Eventual consistency, consumer-specific models, read-only replicas, and stream materializations are just some of the concepts we’ll explore in this book, along with the roles that modern cloud compute, storage, and networking resources have in this new data architecture.
The following chapters will dig deeper into building and using an event-driven data mesh. We’ll explore how to design events, including state, action, and notification events, as well as patterns for producing and consuming them. This book covers handling events at scale, including multicluster and multiregion, best practices for privacy and regulatory compliance, as well as principles for handling eventual consistency and asynchronous communication. We’ll explore the social and cultural changes necessary to accommodate an event-driven data mesh and look at some real-world case studies highlighting the successes and lessons learned by others.
Finally, we’ll also look at the practical steps you can take to start building toward this in your own organization. One of the best things about this architecture is that it’s modular and incremental, and you can start leveraging the benefits in one sector of your business at a time. While there are some initial investments, modern cloud compute and SaaS solutions have all but eliminated the barriers to entry, making it far easier to get started and test whether this is the right solution for you.
Get Building an Event-Driven Data Mesh now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

