Chapter 1. Why Build a Blockchain Truth Machine for AI?
Today’s intelligent agents—software programs driven by AI that perform some domain-specific function—are used in law enforcement and the judicial system and are gaining significant authority in deciding the fate of humans. It is becoming increasingly difficult for people to detect AI when it is acting as a human agent. A product of AI—the intelligent agent—can be embedded in interactions that people don’t associate with AI, such as calling 911 or an insurance claims adjuster. It has been said that once AI becomes mainstream, we will no longer hear the term mentioned, but even now, a person may not realize they have encountered an intelligent agent, much less how to hold it accountable for its actions.
This chapter dissects AI’s trust deficit by exploring critical facts to track in order to improve trust, and suggests ways that you can think of your AI projects as having an interwoven blockchain truth machine—a tamper-evident ledger—built into every aspect of the AI. It goes on to explore concerns about machine learning (ML), potential attacks and vulnerabilities, and touches briefly on risk and liability. Blockchain is explained and blockchain/AI touchpoints are identified based on critical facts.
Dissecting AI’s Trust Deficit
The collection of critical facts about any AI system resembles an online cake recipe: it lists ingredients, instructions on exactly how to mix and bake it, and helpful information like who wrote the recipe, where this type of cake is best served (birthday, picnic, etc.), nutritional information, and a photo of what the cake is supposed to look like when it is done. Because it is online, you might also see what it looked like when others made it, read comments from those who have eaten the cake, and gather ideas from other bakers. This is very different from when you eat a finished piece of cake that you didn’t make; you either eat it or not based on whether you trust the person who handed it to you. You might not worry much about how the cake was made.
But what about trusting powerful AI without knowing how it was made? Should we just accept what it hands us? Do we trust AI too little to ever find its most beneficial applications, or do we trust it too much for our own good? It is very hard to tell, because AI comes in many varieties, consists of many components, comes from many different origins, and is embedded into our lives in many different ways.
Often, AI has been tested to operate well in some conditions but not in others. If AI had an accompanying list of facts, similar to an OSHA Safety Data Sheet used for hazardous chemicals, it would be much easier to know what is inside, how it is expected to perform, safe handling guidelines, and how to test for proper function. AI factsheets are similar lists of facts, as they contain human-readable details about what is inside AI. Factsheets are intended to be dynamically produced from a fact flow system, which captures critical information as part of a multiuser/machine workflow. Fact flow can be made more robust by adding blockchain to the stack because it fosters distributed, tamper-evident AI provenance.
Critical facts for your factsheet may include the following:
-
Your AI’s purpose
-
Its intended domain: where and when should it be used?
-
Training and testing data
-
Models and algorithms
-
Inputs and outputs
-
Performance metrics
-
Known bias
-
Optimal and poor performance conditions
-
Explanation
-
Contacts
Consider these fact types, and then remove ones that don’t apply or add your own (you can also list a fact type with a value like “opaque box” or “not yet established”):
- Purpose
-
When a project is started, a group of stakeholders generally get together and decide the purpose of their project, which includes defining high-level requirements of what they want to accomplish. Sometimes the purpose will change, so it is good to do spontaneous soundness checks and record those as well.
- Intended domain
-
Similar to purpose, the intended domain describes the planned use of the AI. Specifically, the intended domain addresses the subject matter in which the AI is intended to be an expert (healthcare, ecommerce, agriculture, and so on). Soundness checks that probe for domain drift are good to include here. An example of an intended domain is a sensor that is designed for dry weather—if it is operated in wet weather, it is being used outside of the intended domain.
- Training data
-
Sets of related information called training data are used to inform the AI of desired results and to test the AI for those results. Training data is the most critical part of generating a good model, and is an example of the garbage in, garbage out rule of computing (meaning that if the input is not good, the output will not be reliable). If the training data is not sound, the model will not be sound. Also consider that the training data must suit the intended domain—imagine that a model is intended to function in hot weather but it is trained using data gathered in cold weather. The training data can come from many different sources and be in many different formats and levels of quality. This chapter further explores data integrity and quality in “Data Quality, Outliers, and Edge Cases”, and Chapter 2 discusses it in more detail.
- Testing data
-
Once the algorithm has been trained, testing data is run through to make sure that the results are within the model’s stated standard deviations. These data sets should contain all known edge cases to uncover weaknesses within the model’s parameters when comparing the output to the training data output.
- Models and algorithms
-
A model is a set of programmatic functions with variables that learn from an input to produce an output. The model is trained using data sets that tell it both how and how not to behave. The model is composed of many different algorithms, which are AI’s underlying formulas, typically developed by data scientists. The model learns from many training data sets from various libraries and sources, which have been introduced to the model by different parties in various abstractions. Once a model is in production, there is no standard way to track what goes on behind the scenes, and models frequently come from third-party marketplaces, so models and algorithms are often referred to as AI’s opaque box. Chapter 6 discusses how an AI model is coded.
- Inputs and outputs
-
Input describes the type of stimulus the system expects to receive. For instance, a visual recognition system will expect images as input. Output is what the system is supposed to produce as a response. A visual recognition system will produce a description as output.
- Performance metrics
-
These are specifications on exactly how the AI is supposed to perform, including speed and accuracy. They are generally monitored with analytics systems.
- Bias
-
AI bias, which is explored in Chapter 2, is one of the biggest issues facing AI. When we consider bias, our thoughts generally jump to race and gender; while those are very serious issues with AI, they are only part of the collection of biases that people, and subsequently AI, hold. Exposing any known bias by implementing tests and processes to avoid bias is helpful in making the AI transparent and trustworthy.
- Optimal and poor conditions
-
AI that performs well in certain conditions may perform poorly in others. In the world of AI-driven automated vehicles (AVs), there is a defined operational design domain (ODD) within which the AI can be expected to perform well. For instance, a particular AI might work well as part of a lidar (light detection and ranging) system, where a laser light is shined on an object and reflections are measured to determine characteristics of the object. When the weather is clear and dry, this system may function perfectly, but when it is overcast and raining, performance might decrease drastically.
- Explanation
-
This explains the interpretability of the AI’s output, or states that it operates as a opaque box and does not provide explanations for its output.
- Contacts
-
This is who to contact in case support, intervention, or maintenance is needed with the AI. This ties to identity, which Chapter 2 explores in detail.
Machine Learning Concerns
With a traditional computer program, you write the code with specific rules and parameters and test it with specific data sets. The code is run and produces an output that may or may not be graphically represented. In a typical ML program, the code is written and run multiple times with specific training data sets to teach the program what the rules are, and those rules are then tested with test data sets, and this iterative process continues until the ML program produces an output—a prediction—with a high-enough level of confidence to prove the program has learned how to identify the data in the proper context.
The classic example of this is IBM data scientists building and training Watson to play on the show Jeopardy!, where an answer is displayed and the player has to come up with the right question to match. This required the data scientists to come up with the right algorithms for the ML program to teach Watson to understand the Jeopardy! answer in the proper context, instead of merely acting as a fast search engine spitting out multiple random questions—it needed to find the question with the best fit in the proper context at a very high confidence level. That is the essence of machine learning: the data sets teach the program how to learn, and the ML program responds to data input with a high confidence output, as illustrated in Figure 1-1.
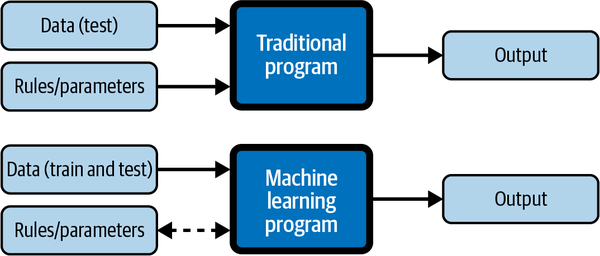
Figure 1-1. Input and output of a traditional software program versus a typical ML program
Tip
To learn more about IBM Watson’s training for Jeopardy!, watch “How IBM Built a Jeopardy Champion” on YouTube. At its core, it is a story of how scientists taught Watson to recognize context in order to increase confidence levels of its answers (or questions, as it is on Jeopardy!).
Opaque Box Algorithms
In everyday corporate use, ML prediction can be used in many applications, such as weather forecasting or deciding on the right moment to drop an online coupon on a regular customer while they’re browsing a retail website. One of the ML algorithms that can be used for both scenarios is the Markov chain. A Markov chain is a discrete stochastic process (algorithm) in which the probability of outcomes is either independent, or dependent on the current or directly preceding state.
This whole process of making predictions based on algorithms and data and finding appropriate output is usually only partially visible to any one ML team member, and is generally considered to operate as a opaque box of which the exact contents are undetectable. Algorithms like the Markov chain model are tuned by behind-the-scenes mathematicians adjusting complex formulas, which is indiscernible to nearly everyone else involved. This section uses the Markov chain model to illustrate how training raw number data sets really works and then shows how classification data sets work.
Note
Although in statistics results are referred to as probabilities, in machine learning we refer to results as confidence levels.
For dice throwing, assuming the dice aren’t loaded, whatever you just threw does not affect what you’re about to throw. This is called a random walk Markov chain. Your guess of the next throw not being improved by your knowledge of the previous one showcases the Markov property, the memoryless property of a stochastic process. In other words, in this case:
A simple model is a two-state weather prediction: sunny or cloudy. A 2 × 2 transition matrix P describes the probability of what the weather will be tomorrow based on what it is today:
This probability can be seen in Figure 1-2.

Figure 1-2. A graphical representation of a simple two-state weather prediction model
We can make several observations here:
-
The total output of either state adds up to 1 (because it is a stochastic matrix).
-
There is a 90% probability that tomorrow will be sunny if today is sunny.
-
There is a 10% probability that tomorrow will be rainy if today is sunny.
-
There is a 50% probability that tomorrow will be rainy or sunny if today is rainy.
Today is Day 0 and it is sunny. In the matrix, we represent this “sunny” as 100% or 1, and thus “rainy” is 0%, or 0. So, initial state vector X0 = [1 0].
The weather tomorrow, on Day 1, can be predicted by multiplying the state vector from Day 0 by the following transition matrix:
The 0.9 in the output vector X1 tells us there is a 90% chance that Day 1 will also be sunny.
The weather on Day 2 (the day after tomorrow) can be predicted the same way using the state vector computed for Day 1, and so on for Day 3 and beyond. There are different types of Markov algorithms to suit more complicated predictive systems, such as the stock market.
This simple example shows how algorithms are created and how data is iterated through them. More complicated models consist of far more complicated algorithms (or groups of algorithms) to fit different scenarios. The algorithms are working in the background—the user, whoever they may be, doesn’t see them at all, yet the algorithms serve a purpose. They require mathematical equations, generated manually or through programs specifically made to generate algorithms, and impact everything about the model and the ML pipeline. Finally, the models need to be tested thoroughly over a wide range of variability and monitored carefully for changes.
Each step involved in constructing the model could potentially undergo tampering, incorrect data, or intervention from a competitor. To fix this weakness would require some way to prove that the data and algorithms were from a reliable source and had not been tampered with.
To understand algorithms in general terms, think of an old-fashioned recipe for baking a cake from scratch. A cake algorithm might give you a way to help others combine a list of ingredients according to your specific instructions, bake it at the specified time and temperature in the correct pan that has been prepared the proper way, and get a consistent cake. The cake algorithm may even provide you with input variables such as different pan size or quantity, to automatically adjust the recipe for a different altitude, or to produce bigger cakes or more of them at a time. The only content that this algorithm knows is what is hardcoded (for example, 3 eggs, 3 cups of flour, a teaspoon of baking powder, and so forth). The writer of the recipe or someone who influenced them directly or indirectly had knowledge and life experience in how cakes work: what happens when you mix ingredients such as liquid and baking soda, mathematical measurements for each ingredient, correct proportions, how much of any ingredient is too much, and how to avoid the kind of chemical combinations that will make a cake fail.
In contrast to a general algorithm, AI algorithms are special in that they perform an action that involves training a model with ML techniques using ample training data. In this case, an AI algorithm for winning a bake-off might look at data listing previous years’ winning and losing cake recipes, and give you the instructions to help you bake the winning cake.
Genetic Algorithms
Genetic algorithms are based on natural selection, where the models improve their confidence levels by mimicking the principles of natural evolution. They are applied to search and optimization problems to improve a model’s performance. The key factors in a genetic algorithm include selection, or how it is determined which members of a population will reproduce; mutation, or random changes in the genetic code; and crossover, which is a determination of what happens when chromosomes are mixed and what is inherited from the parents.
This is applied as a model that breeds the best answers with one another, in the form of a decision tree that learns from its experience. Genetic algorithms are often used in optimizing how the model can run within its permitted environment, evaluating its own potential performance with various hyperparameters, which are the run variables that an AI engineer chooses before model training. Models driven by genetic algorithms can become smarter and smarter as time progresses, ultimately leading to technological singularity, which is addressed later in this chapter.
Data Quality, Outliers, and Edge Cases
Data preprocessing is important, and data quality will make preprocessing easier. To identify a dog breed, for example, you’ll need to have clear, close-up photos of the dog breed and represent every possible appearance of the breed from different angles (like in the story of Iggy Pup that you read in the Preface). If we were training an algorithm to understand text, the preprocessing would entail steps such as making data readable, making everything lowercase, and getting rid of superfluous words, among other things. But besides the input data, the classifications are critical, which brings us to the reason for the exercise of explaining Markov: this is how simple training works, but if you have inadequate training examples for inadequate classifications, it will propagate through with each iteration and you will create some kind of bias in your results.
One issue to keep in mind about the Markov chain: outliers, whether or not the origin is known, must be cut. The Markov algorithm was created in a way that doesn’t tolerate outliers. If the model you’re using has algorithms that don’t process outliers, you would do well to think about running separate iterations of ML with edge case data sets made of outliers, and use it to come up with error detection and error handling procedures.
Note
In this context, an outlier is a data point that is statistically far enough away from the rest of the pattern or trend of points that it doesn’t seem to follow the same behavior. An exception.
In the case where there is no previous state or the previous state is unknown, the hidden Markov model is used, and the initial array and output values are generated manually. When numbers aren’t involved, different approaches must be taken to estimate the array and the output. A typical approach for training nonnumbered data sets, such as in identifying objects, involves using natural language processing (NLP) to classify the variables into an array like in the previous example, and create a desired output that can be fed back in during each iteration through an algorithm many times—up to 100,000—until the result converges on a value that doesn’t change much through repeated iterations (the number of standard deviations depends on what you’re computing).
For example, you can train a set of images of a dog breed, and you would have to take into account the different attributes that distinguish that pure breed from other breeds, such as coat colors, head shape, ear shape, coat length, stance, eye location, and eye color. The training sets would be made of images of thousands of dogs of that breed (a positive set) and images of dogs that are not that breed and other objects that might look like this dog breed but aren’t (a negative set). Once the training converges to a confidence level that is high enough to ensure the code recognizes the breed, real-world data can be run against it.
If you do not account for all facets of an object’s appearance or a scenario, you will undoubtedly leave out classifications that would be critical for your training data sets. Poor confidence numbers during test runs should be an indicator of the need to improve training sets. Embarrassing mistakes that make it to the real world are another undesirable result. Regardless of the model or algorithm, having poor data will test your data preprocessing skills and can hinder your model’s ability to make sound predictions. It will also help to have an interpretable model or algorithm and a sound method to make predictions.
Despite the best efforts of developers and data scientists, a pressing issue in machine learning is bias—biases based on humans’ own limited experiences and filtered views. While there are many types of bias, racial, gender, and contextual bias can create inequities. Best practices stress that you strive for the least amount of bias in your model or algorithm as possible. Preprocessing data is critical.
Supervised Versus Unsupervised ML
When using supervised ML, where the data is labeled beforehand by a data scientist to show desired output (for example, ingredients and processes for edible cakes versus inedible cakes), the models are apt to drift from their original intent and accuracy due to changes in data and forgotten goals (the AI makes cake, then fruitcake, then eventually switches to jams and preserves based on new training data recipes with similar ingredients). In this case, the output might be delicious, but it’s missing one of the required ingredients, such as the bake-off sponsor’s brand of flour.
The process of unsupervised ML makes it so the output of the AI model evolves more or less on its own. Unsupervised ML analyzes the data set and learns the relationships among the data, yet still typically requires a human to validate the decisions. In the case of the cake, ML might try to improve on a winning recipe to make it more likely to stand out, but it may ask you to try out the recipe before finalizing big changes. Semi-supervised ML combines supervised and unsupervised ML, and is used when some labeled data is available, but is combined with unlabeled data in order to increase the volume of available data.
The model lifecycle takes place in the ML pipeline, and the steps needed to take the model from conception to production are shown in Figure 1-3. This process can be adapted to the various ML design patterns that are too numerous to cover in this book.
Warning
Without standard ways to validate and track validation, ML can easily get out of control, and your AI could bake cakes that aren’t edible or don’t meet your requirements. To fix this, the original intent needs to be baked into the ML cycle so it does not become compromised.
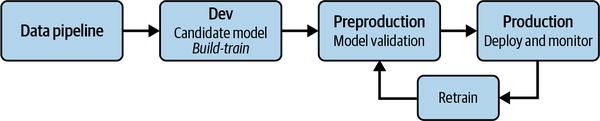
Figure 1-3. A typical ML pipeline
Generative AI, which is the technology underlying popular cloud-based art generation, is a variation of unsupervised or semi-supervised ML that creates original images, video, audio, and text based on user input. For example, one popular cloud-based system, OpenAI’s DALL-E, allows anyone to produce complex, professional-looking artwork by giving DALL-E a natural language command such as “draw a bowl of fruit in a pencil sketch style.” You could vary the details, such as specify that there should be four bunches of grapes, and DALL-E will vary the image accordingly, based on what it knows about pencil sketches, baskets of fruit, and grapes. However, sometimes you will see an unrealistic artifact that doesn’t belong, like a grape growing out of a banana. Looking closely to find artifacts—like a grape growing out of a banana—is a way to spot deepfakes.
Deepfakes, or realistic looking media produced by generative AI, are now easy for just about any novice internet user to generate. Deepfakes can be used by bad actors to damage the reputation of others or to monetize new material that was only produced because AI ingested the work of other artists. In most geographical areas, laws and prior court decisions regulating the generation of deepfakes are nonexistent, so there is little recourse for artists who feel they have been violated through the use of their copyrighted works as training data.
Other creative work that used to require a talented human being, like designing a user interface for a web application, can now be done by simply hand-sketching an idea and then feeding that sketch into a generative AI design assistant like Uizard.
Reinforcement Learning and Deep Learning
Reinforcement learning is a type of ML that occurs when an AI is designed to gather input from its environment and then use that input to improve itself. Reinforcement learning is common in automated vehicles, as the vehicle learns not to repeat the same mistakes. Like unsupervised learning, there is no labeled data. Instead, the model learns from its own experiences, similar to how a child learns. Reinforcement learning is also used in video games like AlphaGo, which you learned about in the Preface, in robotics, and in text mining, which is the process of transforming unstructured data into structured data for analysis.
Deep learning takes ML a step further by distributing algorithms and data among many nodes, and is powered by layers of neural networks, a computing system inspired by the function of the brain’s neurons. Deep learning applies these different layers to come up with incredibly accurate insights to data, which can be either structured or unstructured. Deep learning breaks down and analyzes data in such a way that one layer of a neural network might find the broad results for an image being processed, such as classifying it as a bird, and another layer might analyze its finer details, classifying the bird as a cardinal.
Deep learning requires a lot of data and robust hardware, so it is expensive and best used to solve large, complex problems, but it is available at an affordable cost as cloud services from providers like Oracle, IBM, Microsoft, and AWS. Deep learning doesn’t require anybody to label or prepare the data, so it is used in applications like social media to analyze large numbers of images, in healthcare to analyze massive amounts of data related to diseases and predict cures, and for digital assistants that perform complex natural language processing, like Siri and Alexa.
Program Synthesis
Program synthesis is the term used for when computers learn how to code. Program synthesis in AI is already taking place.
Since intelligent agents can write code to modify their own model based on what they have learned, their goal, and their environment, they are capable of program synthesis. They can update training data used for machine learning, which modifies their own output and behavior. With no guidelines or rules, no permanent enforcement of their main goal or subgoals, and no authority or oversight, human stakeholders do not have long-term control over the final outcome, which makes AI a very high-risk business activity.
Will the technology world announce one day that software will be written by AI and not humans? Unlikely. Instead, program synthesis will creep in slowly—at first showing competent human developers some computer-generated code for their perusal and acceptance, then increasingly taking more control of the coding as developers become less qualified because the AI is doing most of the code writing. Gaining mass acceptance by correcting grammar and syntax, program synthesis is becoming a real threat to our control over AI as it evolves into a way for people and intelligent agents with no programming skills whatsoever to trigger highly complex actions on just about any system using remote APIs.
What if the computer’s idea about what to write is better than yours? Does your tab-key acceptance of a synthetic thought prompt the next suggestion, and the next? At what point does the power of the pen shift from you to the machine? Program synthesis, the next evolution of auto-complete, is coming to write prose, documentation, and code in ways you might not notice.
As discussed elsewhere in this book, there are few AI controls that help humans to determine the original intent of a piece of software, much less to stick to that intent, or alert anyone when the AI begins to go awry. The intent can be lost forever, the AI can morph, and the next thing you know you have a group of humans who don’t know how the software was designed to be used. Since these AI helpers are designed to develop code or content based upon your intent, loss of original intent is a serious side effect that could have great implications over time.
Auto-complete
For a number of years, computer programmers have used integrated development environments (IDEs), applications that recommend to the programmer how to complete complex syntax, as well as to check the code for bugs. Using these systems, auto-complete, the ability to accept a suggestion from the system, became a great way to learn new syntax and a huge timesaver for the software development world.
Smart Compose
Google Smart Compose arose from auto-complete features originally designed for software developers. (Microsoft Word has a similar feature, called Text Predictions.) Do these features make someone a better writer, or do people become dependent on these features?
When you scale this out to the millions of people who are using the Gmail Smart Compose feature (see Figure 1-4), is the author leading the machine or is the machine leading the author? Is there going to be a point where we realize the machine is the better writer and we just give up? Or will our control slowly slip away as we accept an increasing number of suggestions?
According to a US National Library of Medicine publication, “Exploring the Impact of Internet Use on Memory and Attention Processes”, the internet may act as a “superstimulus for transactive memory.” This means that people don’t worry about remembering something that they can simply look up online. Does that imply that over time, everyone could become dependent on Smart Compose, and that we will eventually write how—and what—AI wants us to write?
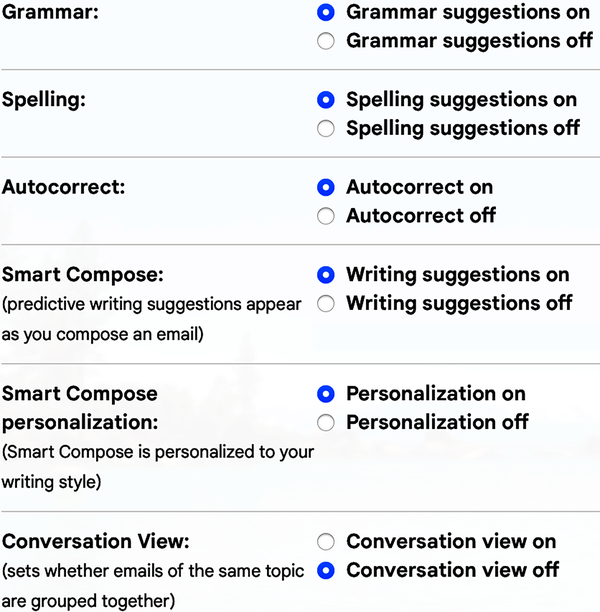
Figure 1-4. Settings for the Smart Compose predictive writing suggestions in Gmail
Codex
Codex, like ChatGPT—which was mentioned in this book’s Preface—is based on OpenAI’s GPT-3. Codex is described by OpenAI as a general-purpose language model, and is available for general use as an OpenAI API. In this video demonstration, developers show how Codex can take an intent described in natural language, then produce other output based on the intent along with additional requests, and automatically write Python code to produce the results desired by the programmer. The Python code can then be executed locally or on other systems.
Also demonstrated in the video is a connection with Microsoft Word’s API. Codex is able to connect with APIs offered by productivity programs like Microsoft Word. When it works properly, programmers can give natural language instructions that turn into correct API calls. As this technology matures, it will give programmers and nonprogrammers alike the ability to perform increasingly sophisticated tasks by simply stating the desired outcome, without the need or even the ability to understand any of the inner workings that make the system function.
Copilot
GitHub’s Copilot, based on Codex by OpenAI and owned by Microsoft, is making news because it extends code editors so that AI not only completes syntax for developers, but also writes whole lines of code or entire functions. Copilot can write code based on the developer stating their intent in their natural language, such as instructing Copilot to create a game that has a paddle and a moving ball that can be hit by the paddle. The accuracy of the output of the request and the quality of the resulting code are both a topic of much debate, but the code should improve dramatically as Copilot learns from the vast volume of code that is stored by developers on the GitHub platform.
Copilot has been met by the development community with both amazement and chagrin, since it can quickly generate large volumes of working code. Some of the code meets the community’s expectations, while other parts of the code are not written to best practices and can produce faulty results.
Note
OpenAI is an AI research and development company, rather than a community-based AI open source/free project as the name might imply.
Copilot is part of an attempt to create artificial general intelligence (AGI), which is AI that can match or surpass the capabilities of humans at any intellectual task. Companies like Microsoft and OpenAI are teaming up to accomplish AGI, and aim to make AGI easy for their customers to channel and deploy. Program synthesis makes this possible since the AI itself can write this complex code. By bringing AGI to the Azure platform, Microsoft and OpenAI say they hope to democratize AI by implementing safe, Responsible AI on the Azure platform that is equally available to all.
Microsoft AI helper for Minecraft
Minecraft is a 3D sandbox game, a type of game that lets the user create new objects and situations within it. Released in November 2011, Minecraft looks basic compared to many other graphical games, with players smashing through pixelated cubes using block-headed avatars, either alone or in teams. There is, however, a lot more going on than you would initially expect, since Minecraft players use the resources found within the infinite virtual worlds to construct other virtual items, such as crafting a shelter from a fallen tree and stone. There are multiple modes in Minecraft, including one that allows players to fight for a certain goal, one that allows participants to work on survival, and a creative mode that facilitates the customization of new virtual worlds without interruptions.
Minecraft allows for modding, which means users create mods, or modifications to the code. There are more than 100,000 user modifications to Minecraft, which can do things like add or change the behavior of virtual objects, including hardware or machinery, or repurpose Minecraft for new adventures like exploring the human body or for traditional classroom studies like math, language arts, and history. There is no central authority for Minecraft mods, and no one is really sure what is out there and what they actually do.
Since Microsoft owns Copilot, the next logical step is to integrate it with other programs as an AI helper, an intelligent agent that can accept the intent of the user and act upon it by writing what it deems to be appropriate code. In May 2022 at its developer conference, Microsoft announced Project Malmo, an AI helper for Minecraft: a nonplayer character within the game that can accept commands to construct virtual worlds, and can do so without interruption. These virtual worlds can end up as mods with no controls certifying what is actually contained in the mod, who built it, or how it will impact players.
Controlling program synthesis
Since most machine learning is done in a opaque box model, the process the AI uses for arriving at its results is not transparent at all. It isn’t traceable, and for the controls that do exist (such as key-value pair ML registries), they could be faked by a clever AI to meet its goals.
To fix this, expected limitations for the AI need to be built into the ML’s registry, tightly coupled with the ML design and machine learning operations (MLOps) process, so as to regulate deployment of models, as discussed further in “Defining Your Use Case”.
It is possible for machines communicating with one another to simplify their communications by creating their own terminology, or shorthand—or even worse, use machine language, which is very difficult for humans to interpret.
Superintelligent Agents
Because intelligent agents are constantly improving through ML, it is possible that an agent can become exceedingly proficient in a particular domain. Once an intelligent agent passes a human intelligence level, it is classified as a superintelligent agent.
The superintelligent agent might take the form of a question-answering oracle, or an order-taking genie. Either of these might evolve into an independently acting sovereign that makes decisions entirely on its own. The agent’s architecture could take the form of an all-knowing, all-powerful singleton, or we could have a multipolar world where superintelligent machines, powered by artificial general intelligence, compete with one another for dominance.
Tip
When planning to build a powerful AI, you can also plan its containment and demise. An agent created for a specific purpose could automatically sunset after the predetermined goal for the agent has been attained.
Superintelligent agents sound like science fiction, as if they are not a real threat but the product of an overzealous imagination. However, just because an AI has yet to surpass human intelligence does not mean that it can’t. The reason we invented AI is so we can make sense of and act upon massive volumes of information—way more than what a human being is capable of doing. AI doesn’t know where to draw the line—unless we code for it. If we don’t, the AI could keep improving itself through program synthesis and eventually achieve technological singularity (see “Technological Singularity”).
An example of this might be if we forget to tell our cake AI that we have a goal to operate within a limited budget. In this case, our AI could source the finest ingredients in the world, and scale up to grand production with no regard for cost, all in an attempt to win the bake-off. To fix this, we need to build approved cost limitations into our ML, which are aggregated when models are deployed on multiple graphics processing units (GPUs).
Technological Singularity
Technological singularity is the hypothetical point in time at which technological growth becomes uncontrollable and irreversible, resulting in unforeseeable changes to human civilization.
In this event, you may want to already have an AI backdoor. Sometimes unethical software developers create a backdoor into a system they build, meaning that even if they are no longer authorized to get in, they can still do so. This is seen as a negative, and it is not an accepted practice to build backdoors. In the case of AI, a backdoor could be designed into the project as a way for the project stakeholders to always be able to interrupt the AI and make modifications, or completely stop it and remove all instances. Chapter 2 discusses how to implement controls to make sure that human stakeholders can always intervene.
Attacks and Failures
Inside the AI opaque box, there are a number of AI incidents that include failures and attacks brought on by bad or lazy actors. Failures include bias, data drift, and lack of verifiable identification. Attacks include adversarial data attacks, poisoning attacks, evasion attacks, model stealing, and impersonation attacks. Attacks and how to prevent and expose them are discussed further in Chapter 2.
AI requires all the same due diligence as any software development project, but also has extra layers that need to be considered. Lazy actors or lack of involving all team members can cause critical updates or security concerns to be missed or neglected. Also, since AI can change itself based on outside input, it is possible for bad actors to attack by presenting sample data that will erode the confidence of your model.
Tip
When thinking about potential attacks, think about the attackers. What are they to accomplish? (Usually financial gain by tricking your AI system.) What do they already know about your systems? What can they access? To monitor for potential attacks, make sure to watch for model/data drift or other subtle changes that impact the output.
Model/Data Drift
Data drift, which underlies model drift, is defined as a change in the distribution of data. In the case of production ML models, this is the change between the real-time production data and a baseline data set, likely the training set, that is representative of the task the model is intended to perform. Production data can diverge or drift from the baseline data over time due to changes in the real world. Drift of the predicted values is a signal that the model needs retraining.
There are two reasons for drift to occur in production models:
- When there’s a change in baseline or input data distribution due to external factors
-
An example might be a product being sold in a new region. This may require a new model with an updated representative training set.
- When there are data integrity issues that require investigation
-
This might involve data from a faulty frontend camera, or data unintentionally changed after collection.
One issue the AI/ML community has not figured out is what accuracy standards to put in place for system components. Establishing a kind of test safety regime that can take every system into account and assess the systems-of-systems is difficult to execute. An example would be getting Tesla’s AI to accurately read a speed limit sign in spite of it being partially obstructed.
There are different types of drift depending on the data distribution being compared, as shown in Figure 1-5.
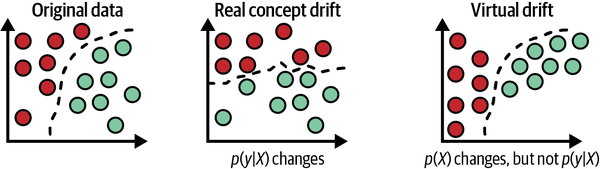
Figure 1-5. Original versus real concept versus virtual data drift. Adapted from an image in Amit Paka’s article “How to Detect Model Drift in ML Modeling”.
They all point back to a statistically significant change in the data output over time compared to the output during testing and early production, which affects the model’s predictions. It necessitates relearning the data to maintain the error rate and accuracy of the previous regime. In the absence of a real-time baseline reestablishing itself over and over, drift in prediction and feature distributions is often indicative of important changes in the outside environment. It is possible for these quantities to drift with respect to an accurately modeled decision boundary (virtual drift). In that case, model performance will be unchanged.
Adversarial Data Attacks
Bad actors can target the modeling phase or the deployment phase to corrupt the training data or model so that the production and deployment data no longer match. They do this through adversarial data attacks, or adversarial ML attacks, which are hacks designed to fool data models by supplying deceptive training or testing data. This is an especially good blockchain touchpoint for ML, because it can help you to compare the original training data with the current training data and create an alert, noting any occurrences where the data is different. As a result of the alert, a smart contract can cause the model to be recalled for review and reinitiate the review process.
All of the standard cybersecurity rules apply here, plus these additional attacks that impact ML training data, production test data, and mislabeled training data. The training data also helps the AI ascertain a percentage reflecting its own confidence in the results. However, a hacker can introduce adversarial data (such as a cat image that has been modified to be recognized as a dog), making the AI draw the wrong conclusions about the query image, sometimes with great confidence. Since the hacker can introduce millions of data points and the changes are usually invisible to the human eye, these attacks are very difficult to combat.
Think about how an ML pipeline can contain billions of points of training data. Poisoning attacks and evasion attacks are both types of adversarial data attacks. Both types exploit the decision boundary, which is the logical line by which ML places data points to classify input data into one type or another:
- Poisoning attack
-
A data poisoning attack involves the training data used for machine learning. This attack happens during the machine learning training phase and involves injection of malicious data that changes the classifier. Typically, this happens in systems that accept input from outside sources like users and then retrains the system based on the new input. The attacker inserts a specific set of data into training data that causes a certain classifier to be consistently triggered, giving the hacker a backdoor into the system. For example, a hacker could train the system so that if a white square is inserted into an image at a certain spot, it could be identified as “cat.” If enough images of dogs are inserted containing the white square, then any dog query image will be classified as “cat.”
- Evasion attack
-
An evasion attack is the most common kind of attack and happens during the production phase. The evasion attack distorts samples (subsets of training data used for testing) so that the data is not detected as attacks when it should be. The attacker subtly pushes a data point beyond the decision boundary by changing its label. The label is changed by changing the samples so the data point tests as some other classification.
This type of attack does not affect training data, but can easily affect the outcome of your system because its own test results are wrong based on wrong answers. For instance, if all of the samples now only contain pictures of poodles, any dog that is not a poodle might no longer be classified as a dog. Because this impacts the production system, it is not uncommon for it to enter via malware or spam.
- Model stealing
-
This type of hack is designed to re-create the model or the training data upon which it was constructed, with the intention of using it elsewhere. The model can then be tested in a controlled environment with experiments designed to find potential exploits.
- Impersonation attack
-
An impersonation attack imitates samples from victims, often in image recognition, malware detection, and intrusion detection. When this attack is successful, malicious data is injected that classifies original samples with different labels from their impersonated ones. This is often used to spoof identity for access control. Examples of impersonation attacks include facial recognition system impersonation, otherwise unrecognizable speech recognized by models, deep neural network attacks on self-driving cars, and deepfake images and videos.
Risk and Liability
A big failure of AI could be that it generates risk and liability, which could be nearly impossible to assess in advance. Questions may arise when there are incidents with AI systems, such as how is responsibility assigned? How will a legal authority or court approach these issues when it is not obvious who is responsible due to the opaque box characteristics of AI?
There is discussion among attorneys and the AI community about how much documentation is too much. Some advisors give the impression that you shouldn’t keep a complete trail of information about what you are doing, in case you do something wrong, because if the information doesn’t exist, it can’t be used against you. Other advisors will say that if you should have known some potential risk and did not take adequate steps to prevent it, that is a risk in itself.
Note
Risk and liability assessment is beyond the scope of this book, and as with any important decision, you should discuss these topics with your own stakeholders and legal advisors while you are in the planning process. For general information, a good reference for this subject is “AI and the Legal Industry,” the second chapter in Karen Kilroy’s 2021 report AI and the Law (O’Reilly).
Blockchain as an AI Tether
AI models aggregate information and learn from it, morphing their own behavior and influencing their own environments, both with and without the approval of data scientists. Blockchain can be used to permanently track the steps leading up to the change in a model’s output, becoming a tether, or an audit trail for the model. Think back to the critical facts that may be on your factsheet, as listed earlier. Your AI’s purpose, intended domain, training data, models and algorithms, inputs and outputs, performance metrics, bias, optimal and poor performance conditions, explanation, contacts, and other facts are all potential blockchain touchpoints—points in the fact flow that can benefit from a tamper-evident, distributed provenance. This gives you a way to audit your AI in a human-readable form, trace it backward, and be sure that the information you are reviewing has not undergone tampering.
To effectively record the touchpoints onto blockchain, you need a blockchain platform. We chose Hyperledger Fabric, an enterprise-level consortium-driven blockchain platform. For more information on the features of Hyperledger Fabric and blockchain-as-a-service derivatives, see Karen’s 2019 Blockchain as a Service report (O’Reilly).
From an architecture standpoint, you don’t have to change much about how your modeling workflow goes now. Blockchain gets added to your AI technology stack and runs alongside your existing systems, and can be set up in a way where it is low latency and highly available. Unlike blockchain used for cryptocurrency, performance is not an issue.
Tip
You can think of AI’s development, training, and deployment processes as being sort of like a supply chain. By comparison, the number one use for enterprise blockchain is track-and-trace supply chain, which involves the lifecycle of goods and their journey to the consumer. In the case of a product like honey, each step along the way is documented, each process is automated, and important touchpoints are recorded to blockchain as a permanent audit trail, which can later be checked to detect fraud, like diluting expensive honey. In this case, a cryptographic hash showing the DNA structure of the honey is used as a crypto anchor, and is compared to a real product by a consumer to make sure the product is authentic. Similarly, a fingerprint of data that is used to train AI can be recorded on blockchain, and stay with the model for its entire lifecycle as each engineer and data scientist performs their specific tasks, like training and approving the model.
Enterprise Blockchain
Speaking of performance, it is a common misconception that all blockchain requires miners who race to solve a cryptographic puzzle in exchange for a tokenized reward. Enterprise blockchain platforms, such as Hyperledger Fabric’s blockchain-as-a-service variants—primarily IBM Blockchain, Oracle Blockchain Platform, and AWS Blockchain—can offer superior deployment and upgrades, time-saving development environments and tools, better security, and other features not offered in Hyperledger Fabric alone.
These blockchain platforms do not require miners, and generally run inside containers, which are portable, lightweight, self-sufficient computing stacks provisioned by systems like Docker or Kubernetes, running on high-performance, highly scalable cloud-based or on-premises systems. In an ML workflow, for instance, a new block might be added to the blockchain after it met some predetermined criteria, such as approval of a new model by an MLOps engineer.
Tokens, which make up the coins used in cryptocurrency, are generally missing from an enterprise blockchain implementation. Although tokens can be implemented to represent the full or fractional value of some other thing, they are an optional step when implementing enterprise blockchain. Tokens can always be added later as experience and acceptance of the blockchain network are gained. Could AI engineers and MLOps engineers be paid by blockchain tokens? Sure, and this could be made part of your fact flow. These engineers could be automatically rewarded when their obligations are met and tested via smart contracts.
Also note that enterprise blockchain is typically permissioned, and that public blockchain platforms like Ethereum are permissionless. This means enterprise blockchain has organizational identity management and access control, as well as integration with existing enterprise directories like Lightweight Directory Access Protocol (LDAP). This book dives into identity in Chapter 2, but first, let’s explore the basics of how blockchain works.
Distributed, Linked Blocks
Blockchain is a type of distributed ledger, and runs in a peer-to-peer network. Each network endpoint is called a node. Nodes can be used by individual users, but generally they are shared among groups of users from an organization or group of organizations with common interest. Generally with enterprise blockchain, the nodes are stored in containers on cloud provider computing accounts, such as Oracle Cloud, IBM Cloud, AWS, or Microsoft Azure. There is usually an abstraction layer that is the user-facing application, and blockchain is transparent to the users. The application layer is where workflow takes place.
In many cases, blockchain nodes can be distributed to each participating organization in a blockchain network. This gives their participants a copy of the blockchain over which the organization has full control. Keep in mind that you don’t have to distribute your nodes from the beginning. Instead, you can add nodes later as more organizations join your blockchain network.
You might start recording the provenance of your AI project from inception, which is the first set of instructions from the original stakeholders. The very first set of instructions might say who is responsible and grant permission for them to perform various tasks, such as creating or approving a request in the fact flow. This is the beginning of your AI’s governance, or the accepted set of rules and procedures that is central to maintaining operation of the system.
Later, you might, for example, take on a development partner who wants to participate in governance and would like to have full confidence in the factsheet. If they are not savvy in blockchain, you can give them a login to your fact flow system and let them learn about blockchain by seeing blockchain proofs embedded into the application layer. Once they become more sophisticated with blockchain, they may want their own node so they are more certain that all of the facts are intact.
Blockchain networks foster group confidence because the foundation is a series of blocks of related transactional data. Each block is timestamped, permanently linked to the others, and distributed and validated via a peer-to-peer network, as follows:
-
Blocks are distributed: Blockchain does not use a centralized server like most business applications, but instead the data and code are distributed via a peer-to-peer network. In this network, each participating organization has its own copy of the blockchain system running on its own peer, which is known as a node. The peers communicate directly once they are established.
This makes blockchain very attractive as a ledger for business-to-business workflow, or for breaking down barriers between departmental silos within single organizations. Since each organization runs a copy of the system and the data, it helps to establish trust. If a new record is inserted into a block of one node, then the same copy of data also gets created in other stakeholders’ nodes based on assigned permission. In this way, it is very difficult to tamper with the data because the original copy of the data would have existed in the rest of the nodes as well.
-
Participant requests are validated: Before transactions are validated by one of the participating people or systems in an organization, thus placing a transaction into a block, the request is first tested on their node against a smart contract, which contains predetermined business logic tests. If these tests are successful on the requesting participant’s node, then the request is broadcast to all nodes in the network, and tested on each node by the chaincode, or scripts that interact with the blockchain, and other algorithms that validate the request. Each participant is given certain permission and access to the resources of the blockchain network, like assets. So participants can perform only those tasks that are mentioned in their endorsement policy of the blockchain network (making it a permissioned blockchain).
-
Blocks are formed and linked: Blockchain gets its name from its method of forming blocks from a list of transactions and then linking (or “chaining”) the blocks to each other through unique fixed-length strings of characters called cryptographic hashes, as shown in Figure 1-6. This is done by computing a hash based on a block’s contents, then storing a copy of the previous block’s hash, along with its own hash, in the header of each block.
The hashes reflect the content of the transactions, so if a block’s data gets manually changed in the filesystem by tampering or corruption, the hash of the block will no longer match the hash recorded in the next block. Thus any modification to a block can be easily detected. This makes blockchain well suited for creating permanent records and audit trails.
If a hacker changes a block’s contents manually or tries to insert a block midchain, it will impact not only that block, but every block after it in the chain. This will impact not only the particular node where the hash got changed but also the entire blockchain network, which makes it easier to find the fraudulent content.
-
The block’s contents are verified: If the request to add a new block passes all of a node’s checks, then the block is added to that node’s copy of the blockchain. If the checks are not passed, the new block will be rejected. If your system is programmed in this way, it will then flag the denied request for potential security issues.
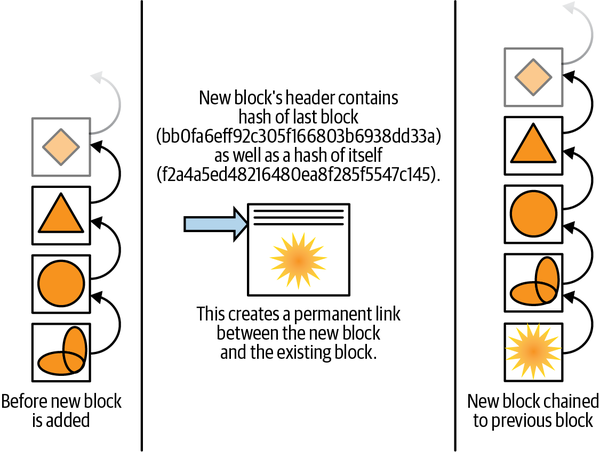
Figure 1-6. Blockchain chains blocks of text, and if any of the contents are changed, the chain breaks and the hashes no longer compute to the values stored in the blockchain
As seen in Figure 1-7, blockchain provides each stakeholder with their own nodes, or copies, of the blockchain so they can be relatively sure the data remains unchanged and that the chain is not broken.
Like any data contained in any filesystem, blockchain can be changed by brute-force hacks or even filesystem corruptions. An individual node could be manipulated by an overzealous AI that wanted to erase its own mistakes, for instance, or by any bad actor that wanted to change history. However, this would be evident to the stakeholders, because the node would no longer work. This is because each block is linked based on content, and in order for an attack to go undetected, all nodes would have to be completely recomputed and redistributed without any stakeholders noticing. This also wouldn’t be technically possible without some pretty sophisticated hacking. So the best way to think of it is that blockchain is tamper evident, as it will show any bad activity that happens by going around the application layer.
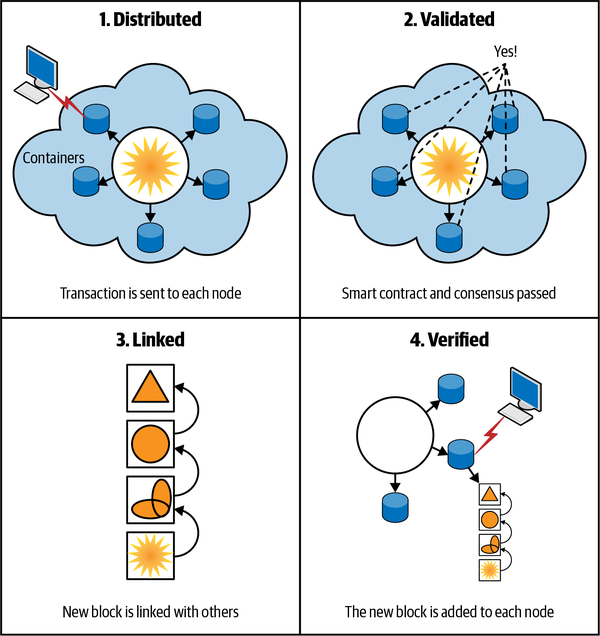
Figure 1-7. New blocks are distributed, validated, linked, and added to each node
Trust and Transparency
AI systems are generally not trusted because their form and function are a mystery. Blockchain can bring a single source of truth to AI. The entire lifecycle of AI can be made transparent and traceable to engineers and consumers by adding blockchain to the stack and integrating the workflow of the AI lifecycle with blockchain at critical touchpoints, or points of data that make sense to verify later, like items on a factsheet. Recording AI’s history in this way will create a tamper-evident, distributed audit trail that can be used as proof of the AI lifecycle, as shown in Figure 1-8.
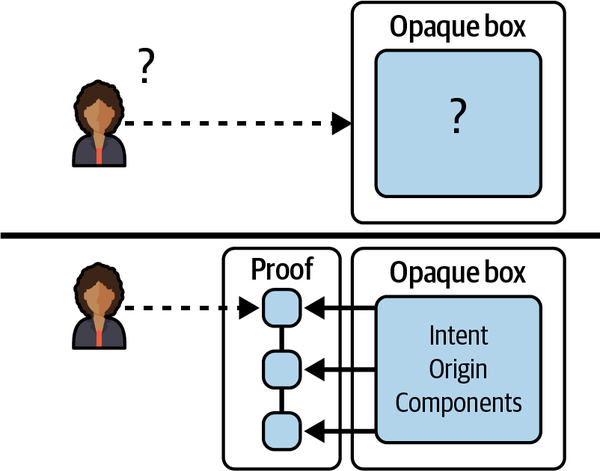
Figure 1-8. Blockchain can be used to take the mystery away from the opaque box that is AI
Using a permissioned blockchain like Hyperledger Fabric, it is possible to design AI to be transparent and traceable without sharing information that should be kept private. Hyperledger Fabric is organized into channels, which can be used to grant permission only to certain parties. This permission granting system is explained in detail in “Defining Your Use Case”. It is also possible to verify that some information is the same as what was stored in an off-chain (not on the blockchain) database and that the computed hash of the information still matches the hash that is stored on the blockchain.
Figure 1-9 shows how an original block of data contains a hash reflecting the contents of that block. The header contains the hash of the previous block’s contents: FOB2FOF2096745F1F5184F631F2BC60292F64E76AB7040BE60BC97EBOBB73D64.
And this hash, for the current block’s contents: 4BCD77921211F4CF15D8C3573202668543FA32B6CFAD65999E3830356C344D2.

Figure 1-9. The block we’re examining contains an image of sunshine in a clear sky
Figure 1-10 shows that even if the slightest change is made to the data stored in the block being inspected, recomputing the algorithm used to create the hash will result in a different hash. If the hashes no longer match, the block should be flagged and the blockchain network will have an error.

Figure 1-10. Later, the same block is tested for tampering or corruption. The block’s contents have been tampered with and changed to an image of sunshine on a cloudy day.
The header for Figure 1-10 contains the hash of the previous block’s contents: FOB2FOF2096745F1F5184F631F2BC60292F64E76AB7040BE60BC97EBOBB73D64. But the current block’s contents are as follows: 191166F725DCAE808B9C750C35340E790ABC568B1214AB019FB5BB61EE6A422.
Since blocks are permanently linked by storing the previous block’s hash in a new block’s header, any filesystem-level changes will be evident. Tampering with content breaks the chain of hashes by causing the next block’s header to differ.
Note
A hash cannot be reversed to create the original document or other information that was used when the hash was computed. It can only be used to verify that the current content is the same as when the hash was originally generated, because, as you have seen, if you try regenerating the hash using modified content, you will get a different hash. This characteristic of hashing is known as one-way.
Figure 1-11 shows a high-level workflow for an AI project where origin, intent, and components of the AI system need to be proven. They are being recorded on the blockchain so they are traceable.
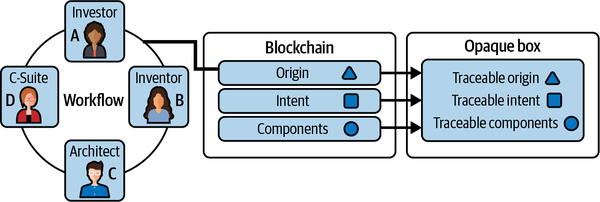
Figure 1-11. Sample stakeholder workflow
In most cases, the information compiled for the blockchain touchpoints would be too much for an average consumer to readily absorb. So in order to be understood, the proofs need to roll into trust logos that break when the components can’t be trusted according to the trust organization’s standards, as shown in Figure 1-12. The top half of this figure shows an AI implementation with no blockchain. The bottom half of this figure shows an AI implementation where a consumer can use a trust logo backed by blockchain to prove the trustworthiness of the AI.
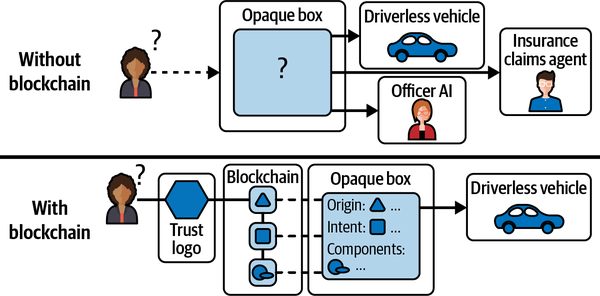
Figure 1-12. AI implementation with and without blockchain
To understand how this proof might work, imagine you are having a bad day, brought to you by AI. You’re driving to the office and the car in front of you suddenly brakes. You slam on your brakes, skid, and crash into the back of the other vehicle. You put your car into park and jump out. As you approach the vehicle you hit, you see that no one was driving. Puzzled, you dial 911 to explain this to the dispatcher, and you reach Officer AI. Due to staffing shortages, Officer AI tells you it can only send a human officer to the scene if there are two or more drivers involved. So you call your insurance claims hotline to ask what to do. After explaining the situation several times, Claims Agent AI still doesn’t quite know what to make of your situation, and you are placed on hold until a human can take your call.
Do you have the right to know right away that you are talking to an intelligent agent instead of a human being? Can you question someone’s humanity in a standard and nonoffensive way? If you question an intelligent agent, can you always escalate to a human being who has the authority to help you, or could you be held to the decisions made by the intelligent agent? Whose fault is the accident in the first place—how will the court assign blame?
Even the people who originally set up the system often don’t know what is in there. If enough time has passed they may have forgotten, or others may have done experiments to train the model. Changes could have been made for performance tuning that impact the accuracy of the model, and this would not be known to the originators of the AI. An engineer might use a blockchain audit trail to quickly find the origin of AI, the intent, and what components it is made of and where they were sourced. The blockchain could also reflect things like the last time the system was maintained, whether it has been rated as reliable, and whether any components have been recalled due to safety issues.
Defining Your Use Case
Analyzing your use case is the first step in determining whether or not a certain technology is the right solution for your business. A great way to begin this process for blockchain applications is to determine the participants, assets, and transactions for the case. In Figure 1-13, you can see these three basic elements and how they interrelate.

Figure 1-13. Identifying participants, assets, and transactions for your use case is a first step in planning your blockchain network
Tip
Information about participants, assets, and transactions is very helpful when providing project requirements to a developer, along with the business logic that will drive your smart contracts.
Touchpoints
As this chapter touched upon earlier, there are many potential blockchain touchpoints that, when recorded on blockchain, will later help prove the provenance of the AI. Table 1-2 shows a list of potential touchpoints on AI projects. Blockchain touchpoints, or places where blockchain/AI integration makes sense, can be analyzed and identified. Not everything in an AI project has to be stored on blockchain, so identifying touchpoints is a good place to start.
| Touchpoint | Functionality | Description |
|---|---|---|
| Purpose and intended use | Stakeholder workflow | Decisions that implementers and funders made about requirements for AI. |
| Contacts and identity | Application and blockchain | Identity and roles and permissions for all levels of maintenance and use, including contact information. |
| Inputs and outputs | Model validation | What input does the AI expect, and what are its anticipated outputs? |
| Optimal conditions and poor conditions | ML model | A model is optimized for certain conditions and is often known to fail in others. |
| Security | Security | Firewalls, demilitarized zones, etc. that prevent unauthorized users from gaining access to the other layers. |
| Fact flow | ML registry or fact flow system |
Currently a database, the ML model registry already stores critical information about training methodology, training data, performance, and proper usage. |
| Training data | ML content | Structured and unstructured data, cleaned up by data scientists and used to train models. In a federated model, this data resides on nodes. |
| Models and algorithms | ML model | The file that generates predictions based on the ML content. Includes model registration, deployment details, measurements on data drift, and training events. |
| Dependencies and requirements, vulnerabilities and patches, reviews | MLOps, ML pipeline | Similar to DevOps, MLOps involves updates to the model, content, and training process. MLOps includes management of ML training cycles that involve various ML experiments and content, including reviews by the AI team of the model’s performance. |
| Explanation | ML experiments | Records created by ML experimenters, containing approvals and reasoning for tweaking ML variables that could, for example, improve performance and lower cost, but might impact accuracy. |
| Feedback and model experience | Intelligent agent | What an intelligent agent does when it is released to production, including feedback from consumers. |
| Trust logos and requirements | Consumer touchpoint | The part of the intelligent agent that is exposed to the consumer. |
Participants
Participants are the people and systems generating transactions within the blockchain network. For example, in a produce supply-chain network the participants might be defined as the following:
-
Farmer
-
Distributor
-
Warehouse manager
-
Logistics company representative
-
Long-distance trucking company dispatcher
-
Automated equipment inside the truck
-
Truck driver
-
Local delivery truck systems and driver
-
Store’s dock manager
-
Produce department manager
To compare a similar ecosystem in the ML world, the participants might be an AI engineer and an MLOps engineer who act as model validators, and a stakeholder who provides a soundness check to make sure the model stays true to its intent.
Each one of these participants would have an assigned role and permissions to log in to approve or reject the updated model as it is passed from point to point. With a blockchain tethered AI (BTA) system like this book describes, the workflow system used by the AI engineer, MLOps engineer and stakeholder would have blockchain incorporated at each step, producing one audit trail to check for anomalies. Here are a few points to consider when validating a model:
- Relevancy of the data
-
There may be unusual fluctuations in the data entered at each point. Any anomaly would kick off a check-off process to compare each data point to previously acquired data and calculate the standard deviation from the usual averages.
- Validation of the data’s integrity and appropriateness
-
Validate so that the data may be utilized for the intended purpose and in the proper manner. Look at time periods, sources, and missing value computation.
- Handling of the data
-
Were the collection methods changed from the agreed upon procedure?
- Preprocessing
-
Were any of the automatic collection methods compromised? Were there any normalization, transformation, or missing value computations that were not performed?
Some helpful tethers you can include on your factsheet and blockchain touchpoints to help you validate your model include the following:
-
Business policies behind the workflow, including those consented to and signed off by the governance group
-
The expected lifecycle of the model and how it will be taken out of service
-
The availability of output data for reporting
-
Approvals of training data and cataloging of baseline outputs
-
The trade-off between accuracy and explainability
-
The procedure or feedback from consumers or authorities
-
The procedure to roll back the model
-
Contact information for responsible parties
You can include as many participants as needed. Since in business it is not always practical for each participant to have their own node in a blockchain network, the participants may be grouped into logical units called organizations. Multiple participants often share an organization’s node. In most business applications, the participants won’t even know they are using blockchain.
Assets
An asset is a type of tangible good that has some value, and its activity can be recorded on a blockchain. If we built a blockchain application to track vehicle ownership, a car would be an asset. If instead our blockchain tracked individual auto parts, each of those parts would be considered an asset.
In a cryptocurrency application, a digital token used as currency is an asset. A participant can own the currency, see it inside a digital wallet, and transfer the currency to a different participant. In contrast, in a business blockchain application, tangible goods and corresponding documentation are represented as assets, and there is likely no cryptocurrency involved at all.
In our produce supply-chain example, the primary assets are units of produce. When a unit of produce is delivered to the store’s loading dock, the asset (produce) is transferred from the truck to the store. This then triggers a traditional payment from the warehouse. All of the other business interactions are also programmed to be tracked.
Other items involved in an exchange, like import/export certificates and money, may also be tracked as assets.
Other considerations when validating models include monitoring the strategy for the model to ensure that scope, objectives, stakeholders, and roles and duties are all addressed, and guaranteeing that the model delivers the expected monetary output and is stable over long periods of time. The frequency and duration of scheduled recalibrations should be assessed. Stakeholders should guarantee that everyone in the governance group is aware of all potential model hazards.
The opaque box nature of the models mean that ML approaches to validation are not widely accepted due to being unable to quantify transparency and explainability, and how the model fits the environment at hand. Once a new model is approved and secured in the test environment, the MLOps engineer must also assess whether the models, including catalogs, modules, and settings, are suitable for deployment, taking into account the potential consequences of future releases.
Transactions
Transactions are generated when participants have some impact on assets. When a participant does something with an asset, a transaction is generated and posted to the blockchain network as this chapter has described. In the case of validating an AI model, we might record a transaction when an AI engineer introduces a new model to the system, when an AI engineer performs some experiment on the new model, or when the AI engineer is satisfied with a newly trained model and it gets passed on to an MLOps engineer. More transactions will be recorded when the MLOps engineer re-creates the experiments, reviews the model, and either sends it back to the AI engineer or approves it for production.
Smart contracts and business logic
Smart contracts are another useful feature of blockchain, as they allow agreements to be pre-programmed, so the proper workflow must be achieved before certain events take place (for example, an invoice must be paid before a product is shipped). Think of smart contracts in terms of how you want your participants to be able to handle assets, and what constitutes a transaction. For instance, let’s say an MLOps engineer is chatting with a project stakeholder who is upset about a poor output of a model. The MLOps engineer opens their dashboard and sees the factsheet of the model. The MLOps engineer clicks a button that reads Trace Model, and it is revealed that bias was indeed flagged in the training data by the AI team. In this smart contract’s logic, it is stated that the AI engineer, the MLOps engineer, and the stakeholder have to approve moving forward with data sets with known bias, else the model is not allowed to advance through the ML pipeline. The smart contract states that the model must return to the AI engineer for fresh training data before proceeding to production, so until that happens and the AI engineer signs off again, the model will not proceed to the MLOps engineer for testing. Because the smart contract and the transactions are recorded on the blockchain, the MLOps engineer can quickly pinpoint the reasons why the model might be perceived to be inaccurate and provide verification to the stakeholders. Without a system like this, the team could spend a lot of time trying to track down the reason for any inaccurate output.
When agreements are automated with smart contracts, so long as they have been properly programmed, it causes systems to apply agreements in a fair, unbiased, and consistent way. MLOps should improve as a result, since paper or emailed contracts and guidelines often sit in a file unenforced, while the individuals running the day-to-day operations set the actual procedures as they go. Smart contracts make all parties more aware of, and accountable to, their formal business agreements, even when they are highly complex.
Blockchain also offers zero-knowledge proofs, which allow a party to prove they know certain information without actually disclosing it. Blockchain, by its nature, helps enforce rules and share information that benefits the greater good of the community using it.
Audit Trail
AI models aggregate information and learn from it, morphing their own behavior and influencing their own environments. Blockchain can be used to permanently track the steps leading up to the change in output, becoming a memory bank for the models.
In Kush R. Varshney’s self-published 2022 book, Trustworthy Machine Learning, the author suggests that AI factsheets be implemented on blockchain to provide a distributed provenance that shows tampering; implementation is beyond the scope of his book. You may discover that the possibilities are nearly limitless since the fact flow system can gather input or approvals from any number of people, systems, or devices and weigh the input or approvals against business logic contained in smart contracts, to dynamically produce a current factsheet upon request.
Note
Some of the information included in Varshney’s factsheets is also stored in ML registries, databases that hold key-value pairs about the ML. Some MLOps systems use the ML registries in MLOps workflow.
Blockchain can influence the integrity of intelligent agents in the same way it helps groups of people who don’t necessarily trust one another to be able to conduct business in a transparent and traceable way. Since tampering with the blocks will immediately expose bad human actors, it will do the same to AI that acts in a malicious or sloppy way.
Local Memory Bank
Without any memory bank full of facts and experiences, there is no standard way for AI to recall why it has become the way it is. This would be akin to every event in your life changing you, while leaving you unable to remember any specific events or why they influenced you. Instead of figuring out what is best based on what went wrong, you are instead forced to keep trying experiments until you hit the right combination again.
A blockchain audit trail for AI is similar to a human memory in that it can help to re-create what took place, so you are better prepared to try to reverse the undesired result, which could be due to an incident such as bias, drift, an attack, machine failure, or human error.
By deploying the trained AI model in the same computing instance as its corresponding blockchain, you can give the model a local blockchain node—a low-latency, highly available, tamper-evident single source of truth in which to store facts—which can work even when the model is offline and could otherwise not reach the blockchain network.
Four Controls
The AI trust challenges and blockchain touchpoints can be broken down into four types of blockchain controls:
- Control 1: pre-establishing identity and workflow criteria for people and systems
-
This control can be used with AI to verify that data and models have not undergone tampering or corruption.
- Control 2: distributing tamper-evident verification
-
This control can be used with AI to make sure that the right people, systems, or intelligent agents—with the right authorization—are the only ones that participate in governance of or modification to the AI.
- Control 3: governing, instructing, and inhibiting intelligent agents
-
This will become very important when wanting to trace or reverse AI, or prove in court that the output of AI is traceable to certain people or organizations.
- Control 4: showing authenticity through user-viewable provenance
-
This will be especially important in using branded AI that has underlying components which come from distributed marketplaces.
Chapter 2 takes a deep dive into the four categories of blockchain controls and how they are applied.
Case Study: Oracle AIoT and Blockchain
Blockchain is a newcomer to the AI space. Bill Wimsatt, senior director of Oracle Cloud Engineering, talked with us about how his company is using blockchain in the AI stack. Oracle, a pioneer in Internet of Things (IoT) technology, combines IoT with AI to create artificial intelligence of things (AIoT). This is to better serve some Oracle customers who are working with expensive equipment like gigantic transformers. It is helpful for them to see a roster of all of their key equipment along with the output of a statistical model that predicts when the parts might die or blow up. Wimsatt and the team at Oracle have collaborated with these customers to build models to predict when they should be doing service. For example, maybe early maintenance is needed, or maybe the asset can last longer. In its analysis, AIoT also considers any missed or false alarms, and can not only prevent equipment failures due to lack of maintenance but also optimize work and service orders.
Wimsatt said, “We use AIoT for predictive maintenance and signal capture; by combining AI with the IoT devices we can learn what is happening with equipment, and find different ways to use signals. This helps our customers to not only make sure the asset doesn’t fail, but that they can sweat the asset for as long as possible.”
Sweat the asset is a term to indicate that the owner of an asset has squeezed the longest possible lifecycle out of it before replacement. Typically, these IoT assets are on maintenance and replacement schedules, and these things occur whether the equipment needs it or not. This can lead to millions of dollars wasted on unnecessary maintenance. AIoT can help to make better predictions on how long each individual asset may last based on its metrics, which saves large amounts of money because assets last longer than scheduled.
Blockchain has been added to Oracle’s AIoT stack to validate signal capture at the point of transmission. Then their customers can cross-check the data that is captured into an object store against the blockchain validation. Because a sample of their data is distributed and stored in interlocking blocks, they can test to be sure that the training data matches what was captured by the IoT device, and that it has not undergone tampering. This technique aligns with Control 2, “make data and algorithms distributed and tamper-evident.” This is discussed in depth in the next chapter.
What’s Next?
Could a superintelligent agent with enough general intelligence, or one specialized in a mathematical domain like cryptography, someday figure out that it could still function without blockchain? Could it break out of the bounds provided for it or simply change the immutable data and recalculate all of the hashes without detection by human beings? Quite possibly, but if we build blockchain controls into AI to the point where it won’t work without them, we might be able to keep the upper hand.
Learning the four controls and how to apply them, as explored in depth in Chapter 2, will give you the ability to offer your stakeholders a mechanism for providing a single source of truth, and even a human-only backdoor, for the AI systems that you build for them.
Get Blockchain Tethered AI now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

