Chapter 1. First Things First
Welcome to the book! Let’s level set about what site reliability engineering (SRE) is and where it comes from.
What Is SRE?
There are a number of definitions for site reliability engineering you can find in the world. Here is the best one I have been able to construct over the years:
Site reliability engineering is an engineering discipline devoted to helping organizations sustainably achieve the appropriate level of reliability in their systems, services, and products.
If I am presenting this definition to an audience, I usually say that there are at least three words in that definition whose presence, if understood correctly, will lead you to a decent grasp of SRE. If given the chance, I will ask that audience, “Which three words do you think are the most important in this definition?” Please feel free to pause here and reread the definition above and answer that question for yourself before you read any further.
I ask this question not just because I like audience interaction, but also because it offers diagnostic insight into the crowd itself. In Chapter 4, I will go deeper into what you can learn from this diagnostic. But in the meantime, let’s look at the three words I would choose first if asked this question.
Reliability
Pretty easy first guess, right? Reliability is central to everything we do in SRE (heck, it’s right in the name). One way to stress the importance of reliability is to note that an organization can spend millions in the local currency to build the best software with the spiffiest features, hire a great sales team to sell it, staff up a crack team of support people to support it, and so on, but if the software isn’t up when a customer attempts to use it, all of that money and effort goes in the trash (or down the toilet, whichever metaphor is more striking to you).
When you have issues with reliability, your organization can suffer a loss of:
- Revenue
This is especially true if the system that is down is critical for making money.
- Time
Employees are dealing with an outage instead of planned work.
- Reputation
People won’t want to use a service they find flaky and will happily switch to a competitor.
- Health
If your environment is constantly on fire, if on-call people are regularly woken up, if your staff always has to spend their time on work instead of their friends or family, there can be serious impact on health.
- Hiring
People in this industry talk to each other. If it gets around that your workplace is one big “tire fire,” it will be very difficult to hire new people.
Appropriate
I believe one key idea that SRE either introduced or highlighted in the operations discussion is the notion that only in the rarest situations is 100% reliable a desirable or even possible goal. It’s not possible in many cases because, in this interconnected world, chances are very high that your dependencies aren’t 100% reliable. Being more reliable than your dependencies can sometimes be achieved through clever planning and coding, but not always.
SRE focuses instead on practices like service level indicators/service level objectives (SLIs/SLOs),1 to help you determine, communicate, and work toward an appropriate level of reliability in your systems.
Sustainable
This word entered the definition later than the rest when it became clear that in order for an operations practice to be successful, it had to be sustainable. Sustainability harkens back to the “loss of health” issue with reliability. Reliable systems are built by people. If the people in your organization are burnt out, exhausted, unable to connect with the people in their lives outside of work or engage in self-care, they won’t be able to build reliable systems. Many people learn this the hard way; please don’t be one of them if you can help it.
(Other Words)
There are a few other words from this definition that I will just mention here to foreshadow our upcoming discussion in Chapter 4: engineering, discipline, helping, and organization. See you in that chapter soon!
Origin Story
While I believe it is useful to know about the origin of SRE and how it came into being at Google (roughly in the 2003 timeframe), that’s not my story to tell. Ben Treynor Sloss, the progenitor of SRE, provides his official version in Site Reliability Engineering (also referred to as the SRE book), edited by Betsy Beyer et al. (O’Reilly, 2016).
Instead, I’d like to tell you about the first time I began to really understand the topic because it may help you too. It connects with the Google origin story because it happened to be the time Treynor Sloss explained his understanding of SRE to the first public gathering devoted to the topic. I’m a big believer that the stories we tell ourselves are crucial for understanding our identity, so this was a pretty big moment.
On May 31, 2014, in Santa Clara, California, I watched Treynor Sloss give the keynote address called “Keys to SRE” at the very first SREcon.2 I recommend you watch it too.
In that talk he showed a single slide that jump-started my understanding of SRE. Figure 1-1 shows a snapshot of the slide.

Figure 1-1. A slide from Ben Treynor Sloss’ keynote address at SREcon14, used with permission
Figure 1-1 is the list I started with and is still a great place for anyone to start.
Looking back at this slide now, nine years later as of this writing, I’m struck by how many of these items have held up over time and which things seem to depend on the Google context in which they were born. Since this talk was given, there’s been quite a bit of nuance added (one might say at least three books’ worth; see the SRE resources in Appendix C), which is perhaps a really good reason why you are reading this book too.
SRE and Its Relationship to DevOps
Whenever I talk to people who are trying to get their head around site reliability engineering, I can almost guarantee that the discussion at some point will find its way to questions like these: How do DevOps and SRE compare? What’s the relationship between them? And would it be reasonable to have both at the same company? These are nontrivial questions that I have spent years trying to find satisfying answers to. This is why I decided to crowdsource Chapter 12 of Seeking SRE on this topic. I didn’t have a great answer at that point, and I really hoped someone else would.3
With the help of the responses from that chapter and some subsequent soul-searching and research, I finally came to an answer I liked. Once I realized that it was going to take more than one approach to really answer these questions, I was able to construct a multipart explanation that works for me. I hope it does the same for you. Allow me to lay out all three parts with a little bit of commentary on each.
Part 1: SRE Implements Class DevOps
This comes from Chapter 1 of The Site Reliability Workbook (O’Reilly, 2018) and subsequent messaging from Google. For the nonprogrammers reading this, it is meant to say that SRE is one implementation4 of the general DevOps philosophy. This is not my favorite comparison for a few reasons:
Nonprogrammers can’t quite understand the phrasing or nuances in it.
I don’t think I know of another implementation of DevOps beyond the “default” one that evolved over time and practice in the wild, so that seems a little suspicious.
It implies a historical connection back in the mists of time at SRE’s origin (or at least a dual discovery) that I haven’t seen evidence to support.
I’m still not sure if I buy it.
The reason I keep this idea about SRE and DevOps around (besides that it comes from people smarter than me) is it does capture the similarities, or at least the resonant frequencies, that are shared by the two modern operations practices.
Part 2: SRE Is to Reliability as DevOps Is to Delivery
So, I don’t know about you, but periodically I have a crisis of faith around DevOps. This particular time I had realized that I could not find a description of DevOps or DevOps practices that would help me immediately be able to distinguish it from other operations practices in the world. I wanted words that would immediately differentiate it from anything else so that I could unambiguously pick it out of a lineup (“#3, that’s DevOps! I’d know it anywhere!”). I looked over all of my resources and my hand-curated collection of DevOps acronyms, but still didn’t succeed.
For SRE, I could say, “SRE is about reliability.” If someone asked, “What’s the operations practice that focuses on reliability?” the easy answer would be SRE. This led me on a quest to ask the DevOps luminaries, “If SRE is about reliability, what is the one word for DevOps?”
I went from luminary to luminary (all of whom were very nice), carrying my lantern, until finally I received an answer from Donovan Brown that felt good. For him, DevOps was all about delivery. Delivering value to customers, delivering software, etc. Finally, I had the word I was looking for.
SRE is to reliability, as DevOps is to delivery.
I can live with that.
Part 3: It’s All About the Direction of Attention
This final piece of the puzzle comes from my friend Tom Limoncelli, who was kind enough to submit this as an answer to my call for submissions for the Seeking SRE crowdsourced chapter I mentioned earlier. Figure 1-2 is a picture from that chapter (modified from the original at his request).
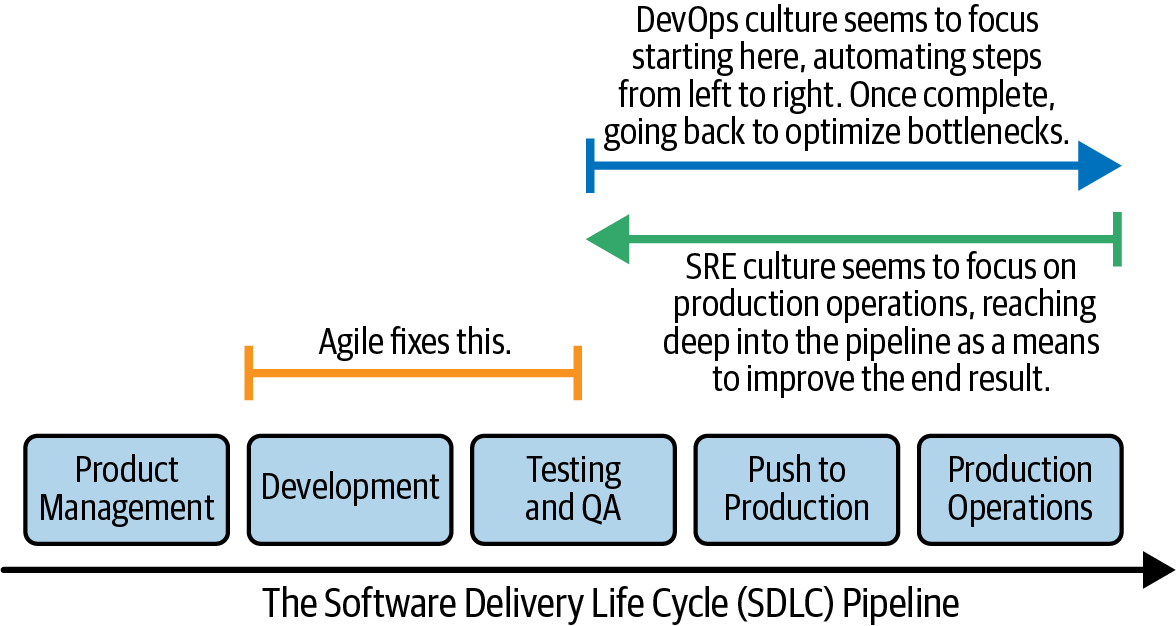
Figure 1-2. The Limoncelli model of SRE, DevOps, and Agile strategies. Modified from the original in Seeking SRE (O’Reilly, 2018).
In some ways, I like this model best because it explains a number of overlaps in practice between DevOps and SRE that seem to not overlap in attitude or intent. I’ll give examples of this in a moment, but here’s my best summary of Tom’s theory:
The DevOps story begins with a developer typing code into a laptop. DevOps concerns itself with (among other things) what it is going to take to deliver that code to production so customers can reap the most value from it. The direction of attention is from laptop to production.5 You might surmise this is one reason why continuous integration and continuous delivery (CI/CD) systems have such a prominent place in the DevOps tool chest, skill set, and presence in hiring ads.
SRE starts in a different place. It starts (and indeed, the SRE mindspace resides) in production. What does an SRE have to do to create a reliable production environment? Answering that question involves a gaze that looks “backward” from production, asking this question step by step, until the developer’s laptop is reached.
The direction of attention is different. The same tools might be used (for example, a CI/CD pipeline), but for a different reason. DevOps and SRE will both engage heavily in creating a monitoring system, but they might do it for a different reason.6
And this leads us to the answer to the question above: Can/should SRE and DevOps cohabitate at the same organization? For me, the answer is yes.7 While there might be some overlap in tooling and sometimes skills, they focus on different things and provide different benefits to an organization.
Onward to SRE Fundamentals
Now, if someone asks you, “So, what’s SRE?” you have the building blocks to tell them. I’ll have lots more to say about this in Chapter 4. But now that we’ve talked a little about SRE definitions and history, let’s move forward to some actual SRE fundamentals that will be core to our understanding of the topic and the rest of this book.
1 I highly recommend that you seek out Alex Hidalgo’s book Implementing Service Level Objectives: A Practical Guide to SLIs, SLOs, and Error Budgets (O’Reilly, 2020) on the topic.
2 Full disclosure—I’m one of the cofounders of SREcon.
3 One of my favorite answers was from Michael Doherty, who said, “Site Reliability Engineering: we don’t know what DevOps is, but we know we’re something slightly different.” It’s not one of the official answers above, but I can’t argue with it.
4 In particular, it’s a prescriptive one since DevOps has, in many ways, gone out of its way to avoid dictating any specific methodology or tools. Whether it has succeeded in doing so might be another fun conversation to have.
5 With stops along the way to store it in a repository, and tests to make sure it is safe to deploy it so that customers can start reaping value from it.
6 I’ve never seen this studied, but my instinct suggests that they would monitor different things as a result. This would be a fun thing to research.
7 Well, given suitable conditions like org size (a new startup may not need both), company culture (if SRE fits in; see later in this book), and need (hire for what you need, not to collect them all).
Get Becoming SRE now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

