Capítulo 4. Orquestar cualquier cosa
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Ahora centraremos nuestra atención en qué problemas puede resolverte la automatización de procesos. Este capítulo muestra que los motores de flujo de trabajo pueden orquestar cualquier cosa, especialmente:
-
Componentes de software
-
Decisiones
-
Humanos
-
Robots RPA y dispositivos físicos
Pero, ¿qué es la orquestación? Es un término cargado de significado para distintas personas. Por ejemplo, en la comunidad nativa de la nube, la orquestación suele estar relacionada con la gestión de contenedores, que es lo que hacen herramientas como Kubernetes. En el espacio de la automatización de procesos, orquestación significa realmente coordinación.
Volviendo a los ejemplos BPMN anteriores del libro, podrías decir que el motor de flujo de trabajo orquesta las tareas contenidas en los modelos. Y como estas tareas pueden llamar a algunos servicios externos, también podrías decir que el proceso orquesta estos servicios. Siempre que añadas tareas humanas a la mezcla, el motor de flujo de trabajo orquesta a los humanos. Aunque suene un poco raro, en realidad es exacto (si lo prefieres, puedes sustituir orquestar por coordinar).
En este capítulo utilizaremos el ejemplo de una pequeña empresa de telecomunicaciones. Cada vez que un cliente quiere un nuevo contrato de telefonía móvil, hay que guardar los datos del cliente en cuatro sistemas distintos: el sistema CRM, el sistema de facturación, el sistema para aprovisionar la tarjeta SIM y el sistema para registrar la tarjeta SIM y el número de teléfono en la red.
Para mejorar el proceso de incorporación de nuevos clientes, la empresa utiliza un motor de flujo de trabajo. Dependiendo de la situación, cada tarea del proceso de incorporación puede implicar:
-
Llamar a un componente de software
-
Evaluar una decisión utilizando un motor de decisión
-
Un humano haciendo el trabajo manualmente
-
Un bot RPA que dirija alguna interfaz gráfica de usuario
Cada una de estas opciones se analiza con más detalle en los siguientes apartados.
Una nota rápida para los impacientes: El Capítulo 8 se sumergirá en la coreografía, otro enfoque de la automatización de procesos. No necesitas este conocimiento para aplicar la orquestación, así que podemos posponerlo con seguridad hasta que entiendas más sobre la automatización de procesos, pero te será útil para comprender mejor el espectro de enfoques de solución.
Software Orchestrate
Empezaremos por lo que más nos gusta como técnicos: orquestar software. Un motor de flujo de trabajo puede orquestar básicamente cualquier cosa que tenga una API.
Supongamos que el proceso de incorporación se parece a la Figura 4-1.
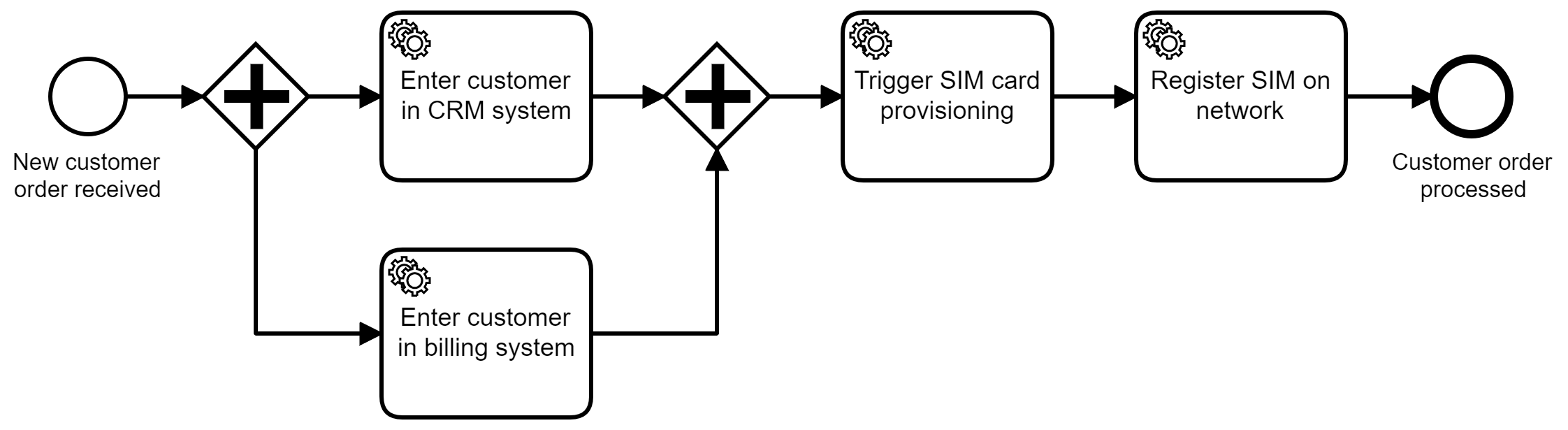
Figura 4-1. Un proceso que orquesta la introducción de datos en distintos sistemas
Cada vez que hay un nuevo pedido de un cliente, se inicia una nueva instancia del proceso de incorporación. El nuevo cliente se guarda en los sistemas CRM y de facturación en paralelo. Sólo si ambos tienen éxito, se activa el aprovisionamiento de la tarjeta SIM y ésta se registra en la red. Las tareas de servicio están conectadas a llamadas API, como has visto antes en este libro.
Este conduce a un proceso totalmente automatizado, también conocido como procesamiento directo (STP). Esto tiene grandes ventajas sobre el procesamiento manual:
-
Ahorras trabajo manual y reduces tu gasto operativo en este proceso. Al mismo tiempo, aumentas tu capacidad de escalado, ya que el proceso ahora puede manejar más carga.
-
Reduces el potencial de error humano asegurándote de que los datos se transfieren siempre correctamente.
Existen distintos patrones de arquitectura, que influyen en la forma en que manejas el motor de flujo de trabajo y diseñas tu proceso. Veremos los más importantes en las siguientes secciones: arquitectura orientada a servicios, microservicios y funciones.
Servicios de Arquitectura Orientada a Servicios (SOA)
En la Figura 4-2 se ilustra un plano SOA típico. Estos planos abogan por una plataforma BPM central que contenga el motor de flujo de trabajo, que luego se comunica con los servicios a través de un bus de servicios empresariales (ESB) central. Esta infraestructura centralizada es el punto débil típico y da lugar a muchos problemas, como se describe en "La SOA centralizada y el ESB".
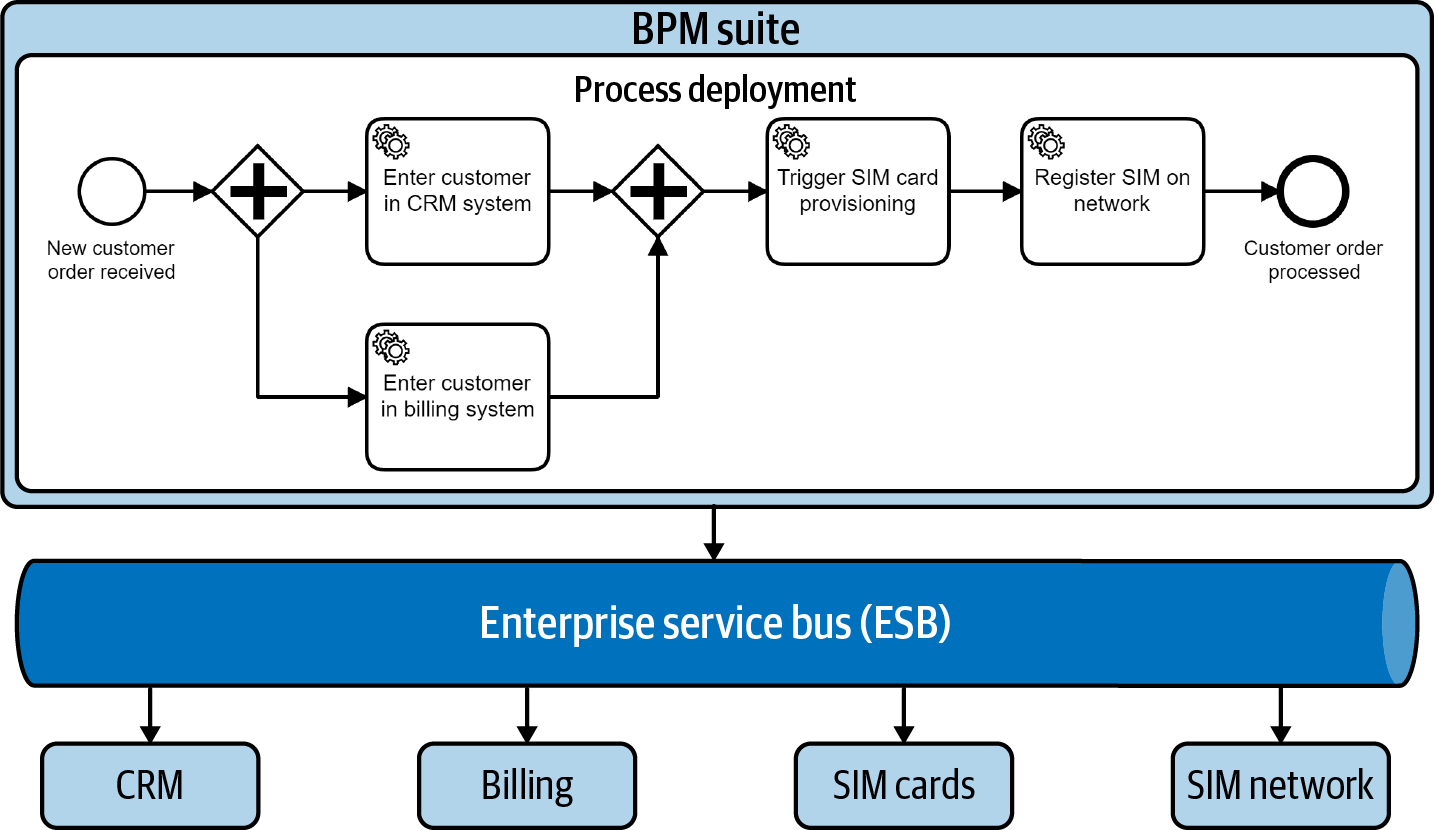
Figura 4-2. Un plano típico de SOA y BPM de alrededor de 2010
Este tipo de arquitectura no suele ser la elegida para los nuevos proyectos. Por supuesto, hay buenas razones para distribuir la lógica empresarial en múltiples servicios, pero las ideas en torno a los microservicios son la forma más moderna de verlo, evitando los fallos de la era SOA.
Si trabajas en un entorno SOA, aún puedes tener éxito. Asegúrate de evitar los problemas relacionados con las herramientas centralizadas y ten mucho cuidado con la propiedad de las definiciones de procesos: por ejemplo, cada modelo de proceso empresarial debe ser propiedad de un equipo de desarrollo que se preocupe por la lógica empresarial, y no debe ser propiedad de un equipo central de BPM. Hablaremos de esto con más detalle en "Motores descentralizados".
Microservicios
El movimiento en torno a los microservicios tuvo en cuenta muchas lecciones sobre SOA y definió lo que algunos consideran SOA 2.0. Sam Newman ofrece una definición útil en su libro Building Microservices (O'Reilly): los microservicios son "servicios pequeños y autónomos que funcionan juntos".
En cuanto a que sean pequeños, lo más importante es saber que los microservicios tienen un alcance y un enfoque claros. Un microservicio se construye a propósito para resolver un problema de dominio específico. El Capítulo 7 profundizará más en los límites entre servicios y procesos.
Para entender el aspecto de autonomía de un microservicio, supongamos que tu equipo tiene plenos poderes para poseer un microservicio en torno al aprovisionamiento de tarjetas SIM. Puedes elegir libremente tu pila tecnológica (normalmente, siempre que te mantengas dentro de los límites de la arquitectura de tu empresa) y tu equipo despliega y opera ese servicio por sí mismo. Esto te permite implementar o cambiar el servicio a tu discreción (siempre que no rompas la API). No tienes que pedir a otras personas que hagan nada por ti, ni unirte a un tren de liberación. Esto hará que tu equipo sea rápido en la entrega de cambios y, de hecho, también aumentará la motivación, ya que ser propietarios de su servicio hace que los miembros del equipo se sientan realmente capacitados.
Aplicar el estilo arquitectónico de microservicios tiene un impacto en la automatización de procesos. La automatización de un proceso empresarial suele implicar varios microservicios. Con SOA, la opinión era que se necesitaba un proceso de orquestación "externo" a los servicios para unirlos. El estilo de microservicios no permite la lógica empresarial fuera de los microservicios, lo que significa que la colaboración entre ellos se describe dentro de los propios microservicios.
Por ejemplo, un microservicio de incorporación de clientes posee la lógica empresarial en torno a la incorporación, que incluye el proceso empresarial de incorporación. El equipo que implementa el microservicio puede decidir utilizar un motor de flujo de trabajo y BPMN para automatizar ese proceso, que luego orquesta otros microservicios. La decisión es interna al microservicio y no es visible desde el exterior; es un detalle de la implementación.
La comunicación entre los microservicios se realiza mediante API, y no a través de la plataforma BPM, como ocurría con SOA. Este escenario se esboza en la Figura 4-3.

Figura 4-3. Los procesos forman parte de la lógica empresarial de un microservicio; no se necesita un motor central de flujo de trabajo
En las comunidades de microservicios, a menudo se argumenta que no hay que utilizar la orquestación, sino dejar que los microservicios colaboren de una forma dirigida por eventos. Por ahora dejaremos esta cuestión sobre la mesa y la debatiremos en el Capítulo 8.
Funciones sin servidor
Los microservicios pueden ser pequeños, pero puedes desmontar tu arquitectura en piezas aún más pequeñas: las funciones.
Una función sin servidor es similar a una función sin estado en tu lenguaje de programación favorito, pero operada en una infraestructura alojada en la nube. Esto significa que no tienes que proporcionar un entorno en el que se ejecute la función. Una función sin servidor toma alguna entrada y produce alguna salida, pero tiene que ser completamente autónoma. Por ejemplo, no puede retener ningún dato que sobreviva a la invocación actual (a menos que lo almacene en algún recurso externo). La tecnología sin servidor es popular porque promete escalabilidad elástica. No pagas por recursos computacionales cuando tus funciones no se utilizan. Cuando tu tráfico se dispara, esos recursos se escalan automáticamente para gestionarlo.
Pero tener un montón de funciones plantea la cuestión de cómo interactúan para cumplir un objetivo. Supón que quieres utilizar este enfoque para la incorporación de clientes. Implementas una función para añadir el cliente al sistema CRM, otra para añadirlo al sistema de facturación, otra para aprovisionar la tarjeta SIM, etc.
La forma más sencilla de proporcionar la funcionalidad de incorporación sería crear una función combinada que incluya o llame a las otras funciones:
functiononboardCustomer(customer){crmPromise=createCustomerInCrm(customer);// 2 secondsbillingPromise=createCustomerInBilling(customer);// 100 ms// TODO: Wait for 2 promisessimCard=provisionSimCard(customer);// 1 secondregisterSim(simCard);// 4 seconds}// --> 7 seconds runtime for onboardCustomer
Aunque esto parece sencillo, tiene graves inconvenientes. En primer lugar, sólo funciona si todas las funciones están disponibles y devuelven resultados rápidos. De lo contrario, puedes acabar fácilmente con un cliente creado en CRM y facturación que nunca recibe una tarjeta SIM porque la última función se bloqueó. Además, esta solución acumula latencia, como se indica en el fragmento de código anterior. Aunque un tiempo de respuesta más largo no sea un problema, se acumulará en tu factura de la nube, ya que los proveedores sin servidor cobran por el tiempo de computación consumido por tu función.
Por tanto, es mejor evitar una función combinada. En su lugar, la mayoría de los proyectos utilizan las capacidades de mensajería de su proveedor de la nube para crear una cadena de funciones. Imagínatelo así:
// callback function registered for message "customerOnboardingRequest"functiononboardCustomer(customer){...dobusinesslogic...send('createCustomerInCrmRequest');}// callback function registered for message "createCustomerInCrmRequest"functioncreateCustomerInCrmRequest(customer){...dobusinesslogic...send('createCustomerInBillingRequest');}// callback function registered for message "createCustomerInBillingRequest"functioncreateCustomerInBilling(customer){...dobusinesslogic...}
De este modo, te libras de la única y costosa función combinada y haces que tu código sea más resistente. La cola de mensajes recordará qué hacer a continuación aunque falle el código de una función.
Pero ahora puedes acabar teniendo problemas similares a los asociados a los lotes y al streaming: no tienes visibilidad de extremo a extremo de tu cadena, no tienes un único punto donde puedas ajustarla, y es difícil comprender y resolver los fallos. Para mitigar estos problemas (que se explicarán con más detalle en "Limitaciones de otras opciones de implementación"), puedes utilizar un motor de flujo de trabajo para orquestar tus funciones. Para ello, necesitarás un motor de flujo de trabajo que se ejecute como un servicio gestionado. Esto significa que el propio motor de flujo de trabajo es también un recurso sin servidor para ti.
En el ejemplo del onboarding, el equipo responsable de desarrollar la función de onboarding del cliente también puede definir el modelo de proceso, como se visualiza en la Figura 4-4. En este modelo de proceso, cada tarea de servicio está pegada a una llamada a función. Cómo se haga esto técnicamente depende de tu entorno exacto en la nube; los ejemplos típicos son las llamadas a funciones nativas, las llamadas HTTP a través de una pasarela API o los mensajes. El motor de flujo de trabajo que elijas también puede proporcionar conectores predefinidos que puedes utilizar (uno de los ejemplos en los que los conectores, presentados en "Uso de conectores predefinidos", tienen mucho sentido).
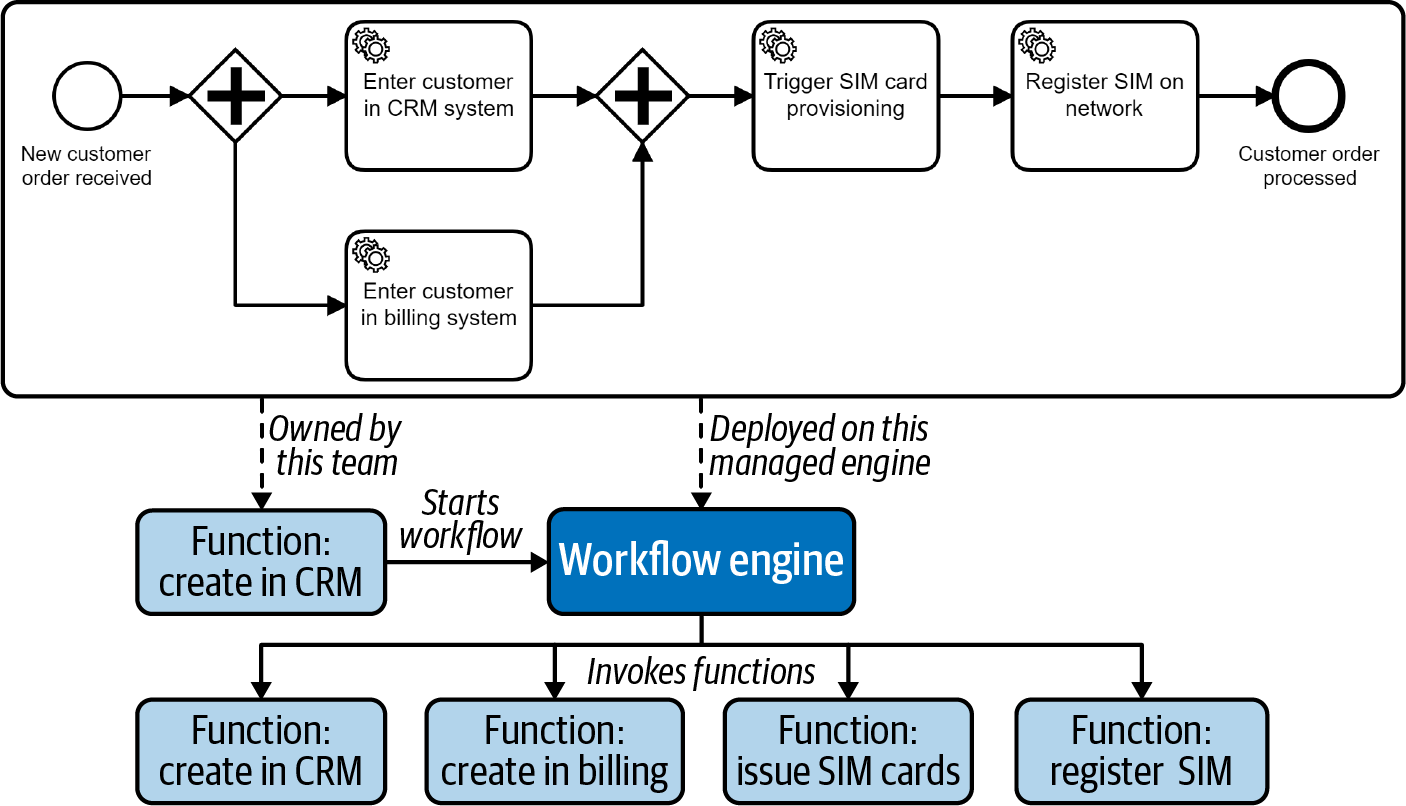
Figura 4-4. Un proceso puede orquestar funciones
Cada vez que el equipo despliega la función de incorporación, también tiene que desplegar el modelo de proceso en el motor de flujo de trabajo, lo que probablemente pueda automatizarse.
Hoy en día, todos los principales proveedores de la nube tienen capacidades de orquestación de funciones con estado en su plataforma (AWS Step Functions, Azure Durable Functions, GCP Cloud Workflows). Desgraciadamente, a todas ellas les falta una funcionalidad importante del motor de flujos de trabajo, tal y como se describe en este libro. En concreto, ninguna de ellas utiliza BPMN, lo que conlleva una potencia de lenguaje limitada (ver "Patrones de flujo de trabajo") y ninguna o muy escasa capacidad de visualización (ver "Ventajas de las visualizaciones gráficas de procesos").
Así que hay un valor adicional en el aprovechamiento de los motores de flujo de trabajo basados en BPMN para orquestar funciones, que es un área muy prometedora para explorar. Encontrarás un ejemplo ejecutable utilizando Camunda Cloud y AWS Lambda en el sitio web del libro.
Monolitos modulares
No todas las empresas pueden o quieren deshacerse de su monolito en favor de sistemas de grano fino como los microservicios o las funciones. De hecho, existe incluso una tendencia creciente a abrazar el monolito por algunas de sus ventajas. Como un monolito no es un sistema distribuido, no tiene que luchar constantemente con problemas de comunicación remota o de coherencia. Y aún puede aplicar estrategias de modularización para que cualquier cambio sólo afecte a pequeñas partes del código.
Un monolito puede estar perfectamente bien si resuelve tu problema, lo que a menudo tiene mucho que ver con tu organización interna y tu tamaño. Un equipo de desarrollo de 10 personas puede dominar perfectamente un monolito, pero tener dificultades con la complejidad añadida que supone trabajar en 100 microservicios. Por otro lado, una organización con mil desarrolladores podría no ser productiva si construye y libera un único monolito.
La observación interesante con respecto a los procesos es que puedes seguir aplicando las prácticas descritas en este libro dentro de tu monolito. Estructurarás (con suerte) tu monolito de forma significativa, por ejemplo formando componentes, ordenando el código en paquetes y creando interfaces para servicios importantes. Para diseñar procesos ejecutables, simplemente orquestarás estos componentes internos; por ejemplo, esto podría traducirse en utilizar llamadas a métodos locales en lugar de llamadas remotas. El propio motor de flujo de trabajo puede incrustarse como una biblioteca en tu monolito. Las definiciones de los procesos simplemente se convierten en un recurso adicional en el código fuente del monolito. Esto se visualiza en la Figura 4-5.
De este modo, puedes añadir las ventajas de utilizar un motor de flujo de trabajo (capacidades de larga ejecución con gestión de estados, visibilidad del proceso) sin perder las ventajas de un monolito (no tener un sistema distribuido). Añadir un motor de flujo de trabajo no suele tener mucho impacto en el rendimiento. Por supuesto, esto depende de la herramienta que elijas y de la arquitectura que configures, pero incluso con un motor de flujo de trabajo que funcione como su propio servicio, la sobrecarga puede ser mínima (como con una base de datos, que también es un servicio remoto que se consume).
Además, tener un motor de flujo de trabajo puede darte la posibilidad de implantar modelos de proceso modificados sin tener que volver a implantar todo el monolito. A veces, sólo eso es suficiente motivación para introducir un motor de flujo de trabajo en un gran monolito.
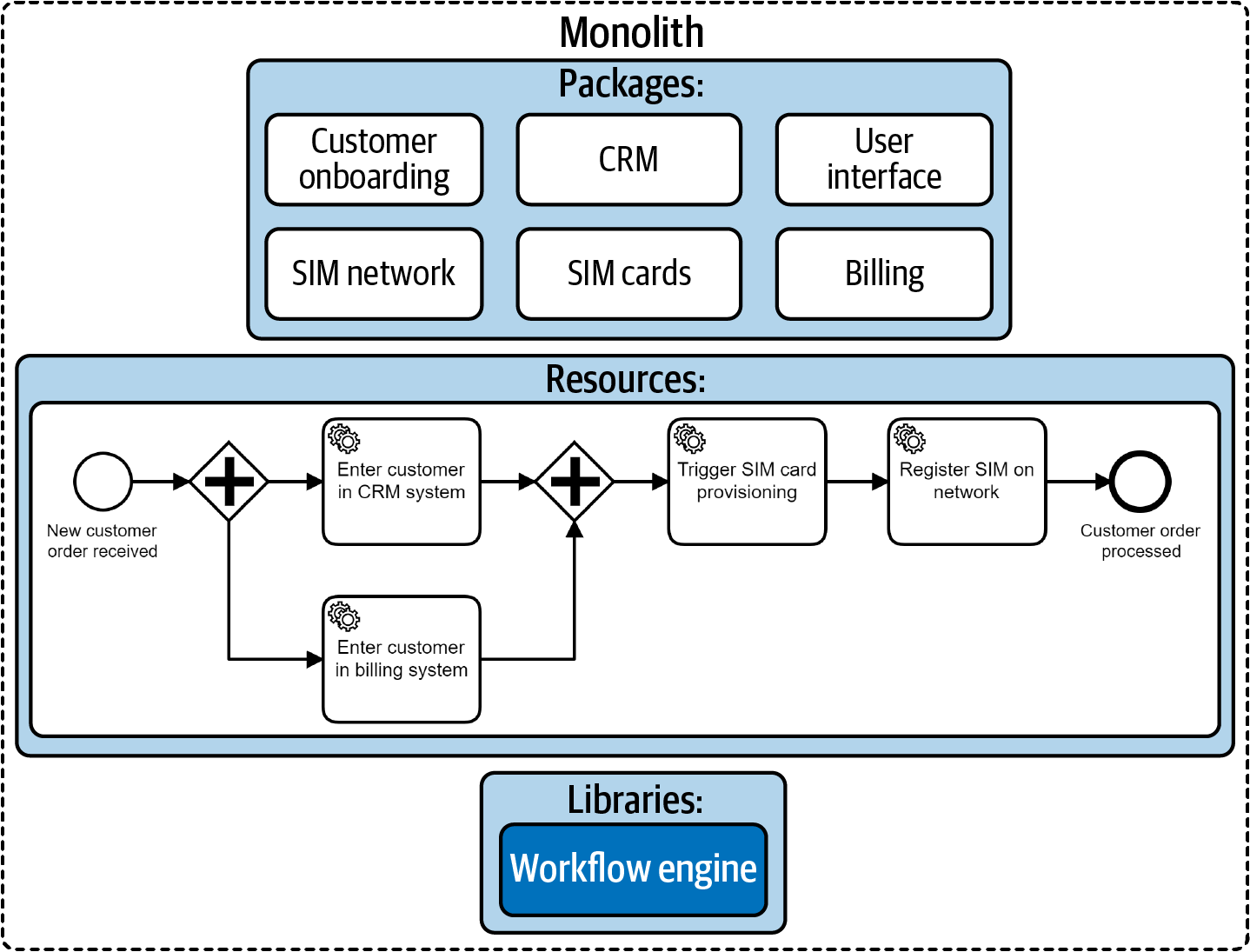
Figura 4-5. Orquestar componentes en un monolito modular
Deconstruir el monolito
Aunque un monolito modular puede ser una solución válida, muchas empresas están en un proceso de migración, alejándose de los monolitos y acercándose a una arquitectura más detallada. La automatización de procesos puede ayudar en este camino. Imagina que tienes instalado el monolito de telecomunicaciones de la última sección, pero quieres cambiar el procedimiento de incorporación de clientes. En lugar de introducir el proceso en tu monolito, puedes aprovechar la oportunidad para crear un (micro)servicio que se encargue de la incorporación.
Para ello, tienes que crear API para los servicios necesarios, lo que significa que empiezas a añadir fachadas a tu monolito existente. Al mismo tiempo, tienes que eliminar las conexiones cableadas entre componentes; por ejemplo, el componente CRM ya no debe llamar directamente al componente de facturación para los nuevos clientes, ya que quieres controlar esta conexión a través del nuevo (micro)servicio. La Figura 4-6 visualiza este enfoque.
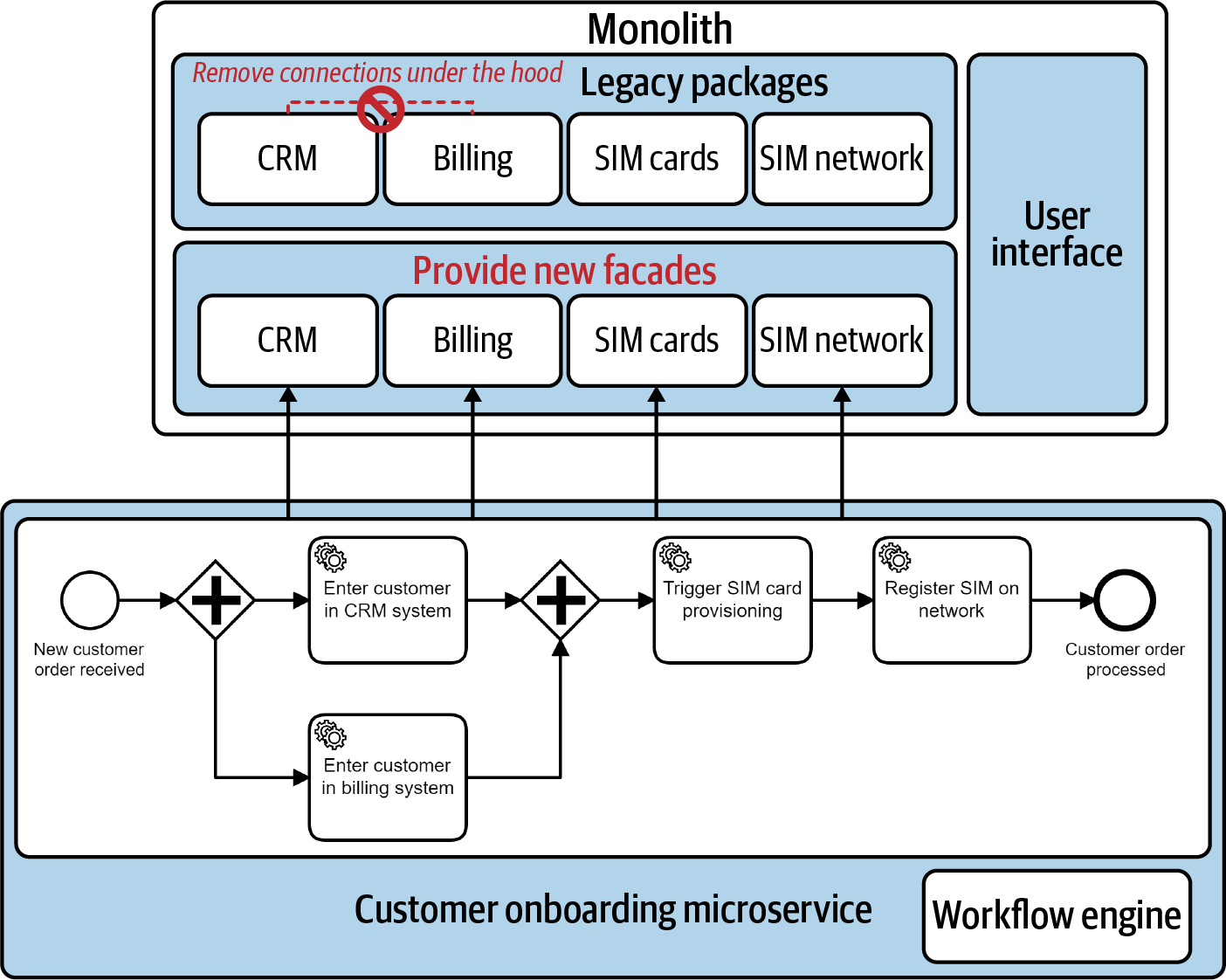
Figura 4-6. Los procesos pueden ayudar a eliminar lentamente las conexiones desafortunadas bajo lascubiertas
Estos proyectos no suelen ser fáciles de abordar. Y aunque esto pueda parecer como ponerle carmín a un cerdo, es un primer paso en la dirección correcta hacia la deconstrucción del monolito y el aumento de la agilidad. Si sigues haciendo esto para cada proceso que toques, reducirás la huella del monolito lentamente con el tiempo, en favor de una arquitectura de grano más fino. La transformación de arquitectura con más éxito que he visto hizo exactamente esto: los desarrolladores no hicieron una transformación repentina, sino que siguieron migrando, paso a paso, con disciplina y resistencia. Los primeros pasos apenas eran visibles, pero al cabo de cinco años se podía apreciar una enorme diferencia.
Orquestar las decisiones
Ampliemos el ejemplo de onboarding para validar primero el pedido del cliente invocando alguna lógica de decisión o reglas de negocio. El proceso resultante se muestra en la Figura 4-7.
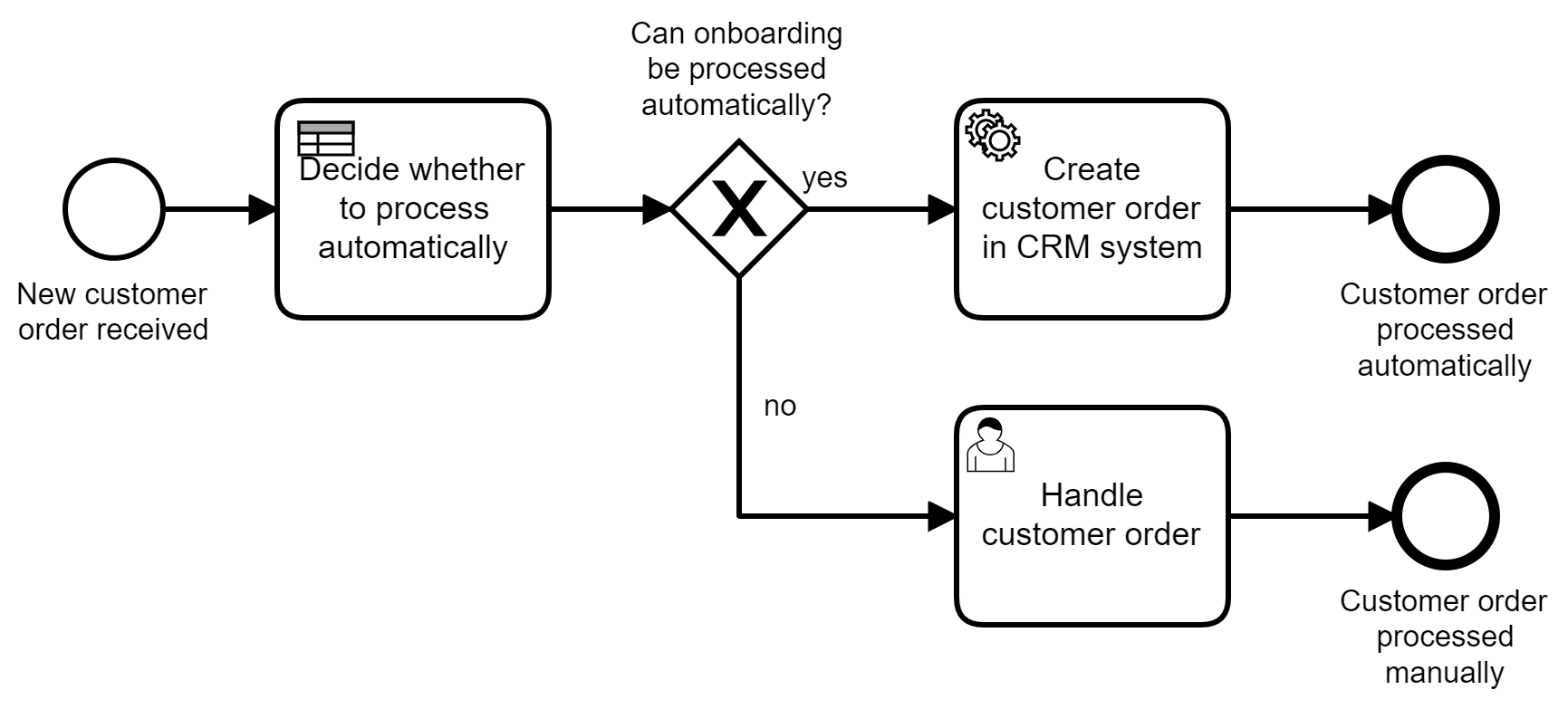
Figura 4-7. Un proceso que orquesta una decisión sobre si el pedido de un cliente es válido o no
Una decisión implica derivar un resultado (salida) a partir de unos hechos dados (entrada) sobre la base de una lógica definida. Aunque esta lógica de decisión podría ser ejecutada por un humano, a menudo tiene sentido automatizarla, sobre todo en los procesos automatizados. Por supuesto, podría simplemente codificarse, pero hay ciertas características que justifican el uso de herramientas específicas.
En primer lugar, la lógica de decisión es una lógica empresarial importante y debe ser comprendida por las partes interesadas de la empresa. Y en comparación con los flujos de control de procesos, la lógica de decisión cambia mucho más rápidamente, por lo que es vital para la agilidad empresarial poder cambiar fácilmente esta lógica. Siempre que te enteres de una buena razón para no validar los pedidos de determinados clientes, querrás ajustar la lógica de decisión de inmediato, antes de incorporar más clientes con perfiles de alto riesgo. Definitivamente, quieres evitar situaciones en las que nadie conoce realmente la lógica de decisión porque está enterrada en toneladas de código que se escribió hace años.
Además, obtienes visibilidad de las instancias de decisión, de modo que puedes entender por qué un determinado pedido de un cliente se validó con éxito o no.
Este es el dominio de la automatización de decisiones. Los componentes básicos del software son los motores de decisión, que toman la lógica de decisión expresada en un modelo y la aplican para tomar decisiones basadas en la información dada. Normalmente, estos motores también pueden versionar modelos de decisión y almacenar un historial de las decisiones que se han tomado. Puede que reconozcas cierta similitud con los motores de flujo de trabajo, pero las decisiones no son de larga duración; pueden tomarse en un paso atómico.
Modelo y Notación de Decisión (DMN)
Al igual que ocurre con BPMN para los procesos empresariales, existe una norma adoptada mundialmente para las decisiones: Modelo y Notación de Decisiones (DMN). Es similar a BPMN, y a menudo se utilizan conjuntamente.
Echemos un vistazo rápido a lo que puede hacer la DMN. Los dos conceptos en los que quiero centrarme en este libro son:
- Tablas de decisión
-
Se utilizan para definir la lógica de decisión. Años de experiencia con diversos formatos han demostrado que las tablas son una forma excelente de expresar la lógica de decisión y las reglas empresariales.
- Lenguaje de expresión
-
Para automatizar las decisiones, tienes que expresar la lógica en un formato que el ordenador entienda. Al mismo tiempo, quieres acabar con una lógica de decisión que pueda ser leída por no programadores. Por eso DMN definió FEEL, el lenguaje de expresión suficientemente amigable que es ejecutable, pero también legible por humanos. Como se menciona en el Capítulo 2, algunos motores de flujo de trabajo también utilizan FEEL dentro de los procesos BPMN, por ejemplo para decidir qué camino tomar en un flujo de proceso.
Veamos un ejemplo. Supongamos que quieres decidir si puedes dar de alta al cliente automáticamente. Para ello, creas el modelo DMN visualizado en la Figura 4-8.

Figura 4-8. Una tabla de decisiones DMN para encontrar riesgos
Utilizarás ciertos datos como entrada: a saber, el tipo de pago, alguna puntuación del barrio del cliente y la cuota mensual asociada al contrato. Esto dará como resultado una salida, que en este ejemplo es un campo booleano que indica si es necesaria una comprobación manual.
Cada fila de una tabla de este tipo es una regla. Las celdas del lado de entrada contienen las reglas o expresiones y se resolverán en true o false. Las expresiones incluidas en este ejemplo son paymentType == "invoice" y monthlyPayment < 25. Estas expresiones se crean a partir de cierta información de la cabecera de la tabla y del valor exacto de la celda.
La mayoría de los ejemplos de la vida real son así de sencillos, como se muestra aquí, pero también es posible crear expresiones lógicas más sofisticadas utilizando FEEL. Para darte algunos ejemplos, las siguientes expresiones son todas posibles:
Party.Date < date("2021-01-01")
Party.NumberOfGuests in [25..100]
not( Party.Cancelled )
En una tabla DMN puedes tener tantas columnas de entrada como quieras. Las expresiones se conectan mediante un Y lógico. Si todas las expresiones se resuelven en true, se dice que la regla "se dispara".
Una tabla DMN puede controlar lo que ocurre en este caso. Es la política de aciertos que puedes ver en la parte superior de la Figura 4-8. En el ejemplo, es "primera"; esto significa que la primera regla (empezando por la parte superior de la tabla) que se dispare determinará el resultado. Así que, en este caso, si un cliente seleccionó "prepago", el resultado está claro en la primera fila: no es necesario realizar una comprobación manual. Otras políticas de aciertos podrían ser que esperes que sólo se dispare una regla porque no hay solapamiento, o que sumes los resultados de todas las reglas que se disparan, por ejemplo, para sumar las puntuaciones de riesgo.
Aunque la tabla de ejemplo sólo tiene una columna de salida, puedes tener tantas como quieras.
Bajo el capó, una tabla de decisiones DMN se almacena como un archivo XML, como un proceso BPMN. Los motores de decisión típicos analizan ese modelo de decisión y luego proporcionan una API para tomar decisiones, como se muestra en el siguiente pseudocódigo:
input=Map.putValue("paymentType","invoice").putValue("customerRegionScore",34).putValue("monthlyPayment",30);decisionDefinition=dmnEngine.parseDecision('automaticProcessing.dmn')output=dmnEngine.evaluateDecision(decisionDefinition,input)output.get('manualCheckNecessary')
Este pseudocódigo utiliza un motor de decisión sin estado. Analiza un archivo y evalúa directamente la decisión. Aunque esto es muy ligero, puede que quieras aprovechar algunas capacidades adicionales de un motor de decisión, como el versionado de los modelos de decisión o el mantenimiento de un historial de decisiones. Así que tu código podría parecerse más a esto
input=Map.putValue("paymentType","invoice").putValue("customerRegionScore",34).putValue("monthlyPayment",30);output=dmnEngine.evaluateDecision('automaticProcessing',input)output.get('manualCheckNecessary')
Decisiones en un modelo de proceso
Por supuesto, los motores de decisión pueden utilizarse de forma independiente. Aunque hay buenos casos para hacerlo, este libro se centra en las decisiones en el contexto de la automatización de procesos. En ese contexto, las decisiones pueden engancharse a un proceso.
En BPMN existe incluso un tipo específico de tarea de "regla de negocio" para esto. Se llama tarea de reglas de negocio en lugar de tarea de decisión por razones históricas, ya que estas herramientas se llamaban motores de reglas de negocio en la época en que se estandarizó BPMN; hoy, la industria habla de motores de decisión.
Aunque la tarea de reglas de negocio define que la decisión la tomará un motor de decisión, no especifica lo que esto significa a nivel técnico. Así que puedes escribir tu propio código de cola para invocar al motor de decisión que elijas.
Una alternativa es utilizar extensiones específicas del proveedor. Por ejemplo, Camunda proporciona un motor de flujo de trabajo BPMN y un motor de decisión DMN, y los ha integrado bajo el capó. Esto significa que puedes simplemente hacer referencia a una decisión en el modelo de proceso. En las operaciones, la información de auditoría sobre por qué se tomó una decisión también está disponible directamente desde el historial de la instancia del proceso.
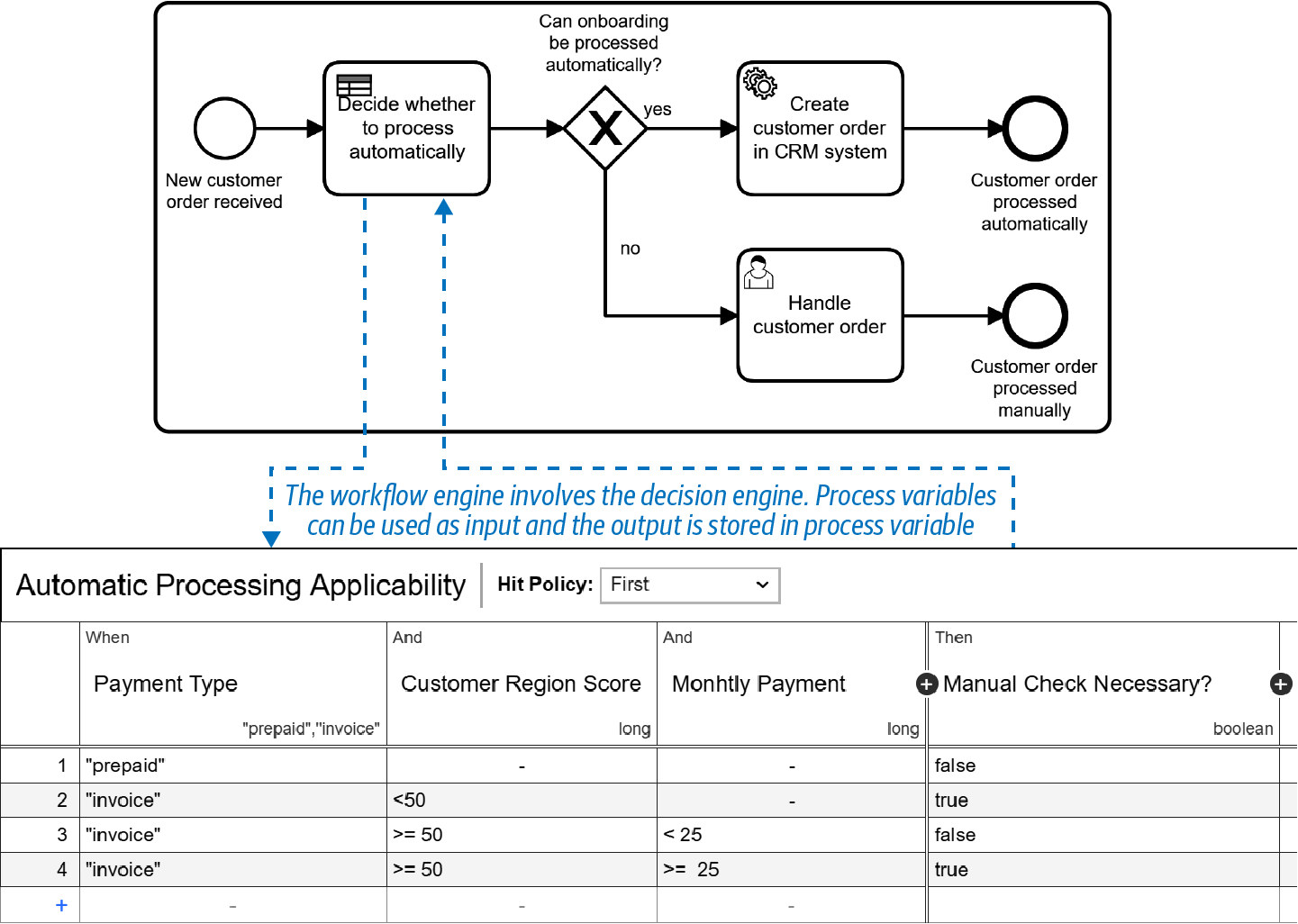
Figura 4-9. Un proceso BPMN puede invocar decisiones DMN
La automatización de decisiones con DMN es una forma estupenda de mejorar la colaboración entre la empresa y las TI y de aumentar la agilidad, ya que la lógica de las decisiones es más fácil de cambiar. DMN es un gran complemento de BPMN, ya que la automatización de decisiones ayuda a automatizar tareas dentro de los procesos.
Orquestar a los humanos
Por supuesto, no todos los procesos están totalmente automatizados, aunque la mayoría de las empresas intentan automatizar sus procesos en la mayor medida posible. Hay tres razones típicas para dejar que los humanos trabajen en las tareas:
-
Con la automatización, a menudo necesitas tener una gestión humana de las tareas como recurso. Los humanos pueden trabajar fácilmente en el 10% de los casos no estándar que serían demasiado caros de automatizar, o ocuparse de situaciones excepcionales.
-
La gestión de tareas humanas suele ser un primer paso hacia la automatización. Te permite desarrollar, desplegar y verificar rápidamente un modelo de proceso, quizá sólo con tareas humanas. Luego puedes aumentar la automatización "sustituyendo" a los humanos por máquinas tarea a tarea.
-
Los humanos siguen desempeñando un papel en las áreas más creativas de los procesos, como la gestión de casos poco frecuentes o la toma de decisiones. Eliminar las tareas repetitivas automatizándolas no sólo aumentará su capacidad para hacerlo, sino que también eliminará la fricción entre el trabajo manual y el automatizado.
Ten en cuenta que es poco probable que tu departamento empresarial hable de "orquestar a los humanos"; el término más común (y psicológicamente aceptable) es gestión de tareas humanas.
Un proceso que utilice la gestión de tareas humanas para el proceso de incorporación podría parecerse a la Figura 4-10.
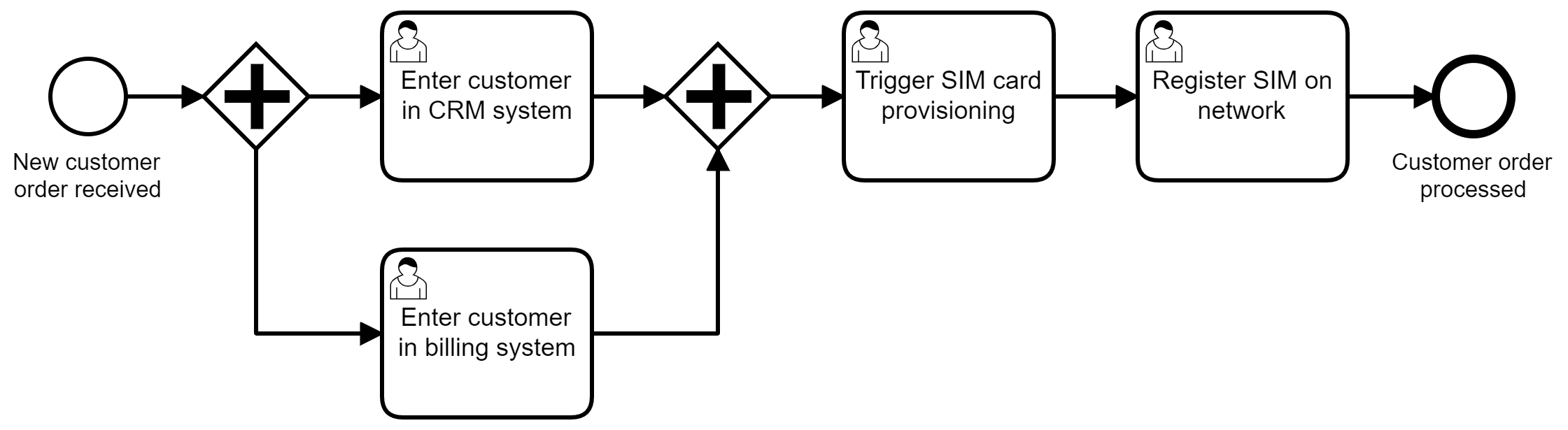
Figura 4-10. Un proceso que orquesta a los humanos
Aunque las tareas en sí no estén automatizadas, utilizar el motor de flujo de trabajo para automatizar el flujo de control sigue teniendo muchas ventajas, sobre todo si lo comparas con la alternativa más probable: pasar los nuevos contratos por correo electrónico, con distintas personas añadiendo datos a todos estos sistemas manualmente. Por ejemplo:
-
Puedes asegurarte de que ningún pedido de un cliente se pierda o se atasque, aumentando así la fiabilidad de tus servicios.
-
Puedes controlar la secuencia de tareas. Por ejemplo, podrías paralelizar la introducción de los datos de CRM y de facturación, pero asegurándote de que ambas deben terminar antes de que se aprovisione nada. Esto acelera el tiempo total de procesamiento.
-
Puedes asegurarte de que los datos correctos se adjuntan a una instancia de proceso, para que todos los implicados tengan siempre a mano todo lo que necesitan.
-
Puedes monitorear los tiempos de ciclo y los SLA, asegurándote de que ningún pedido de un cliente se quede colgado durante demasiado tiempo. También puedes analizar de forma más sistemática dónde puedes hacer mejoras, lo que te ayuda a aumentar la eficiencia.
-
Obtendrás algunos KPI en torno a tus procesos, por ejemplo sobre el número de pedidos de clientes, tipos de contratos, etc.
Consejo
Es posible que los departamentos empresariales no hablen en absoluto de motores de flujo de trabajo, orquestación o gestión de tareas humanas, aunque esta tecnología esté funcionando en segundo plano. Por ejemplo, tomemos la aprobación de facturas entrantes. Tal vez un gestor tenga una interfaz de usuario para ver todas las facturas abiertas, donde pueda aprobarlas fácilmente para que se paguen. Otra persona se encargará de pagarlas. Esta es una experiencia de usuario que te puede resultar familiar de las herramientas de contabilidad. Pero, en segundo plano, puede que siga existiendo un motor de flujo de trabajo con un modelo de procesos, por lo que puede que la lista de facturas que hay que aprobar en realidad sea una lista de tareas humanas creadas a partir de instancias de procesos. En este caso, ni el modelo de procesos ni las tareas humanas son evidentes desde una perspectiva empresarial.
Trataremos algunos aspectos interesantes de la gestión de tareas humanas en las próximassecciones.
Asignación de tareas
Una cuestión importante es quién debe realizar una determinada tarea. La mayoría de los productos de flujo de trabajo proporcionan de fábrica un ciclo de vida para cada tarea humana, como el que se muestra en la Figura 4-11.
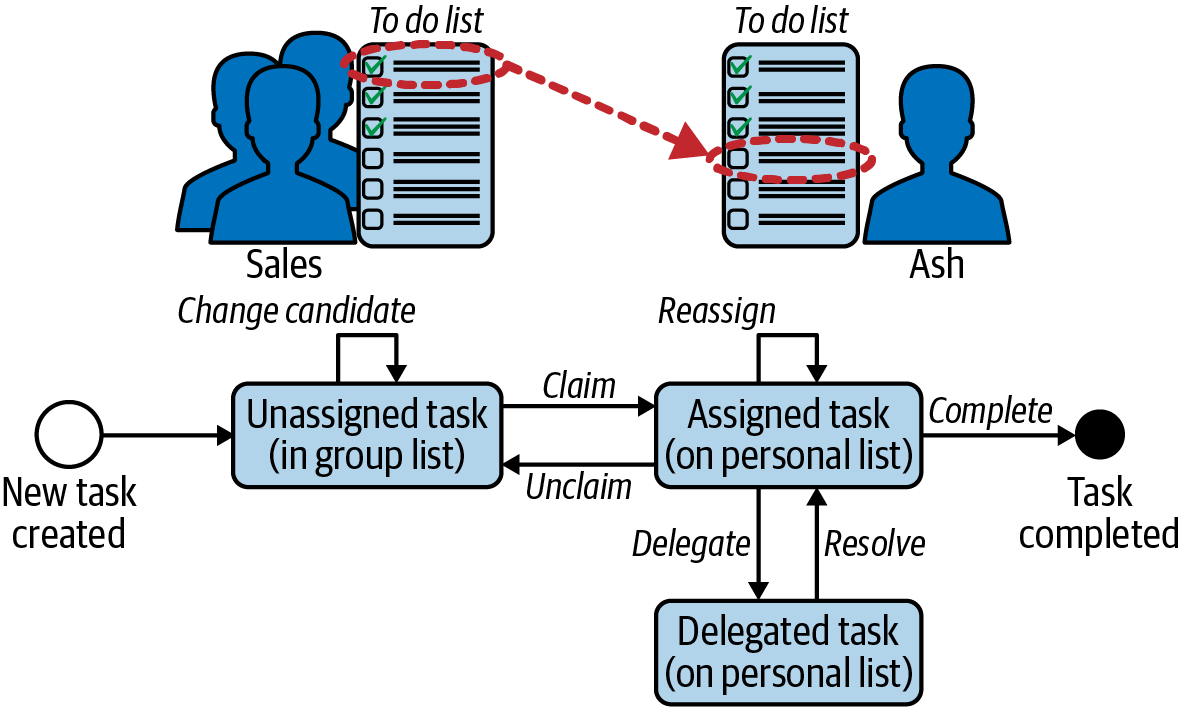
Figura 4-11. Ciclo de vida típico de una tarea humana
Este ejemplo te permite diferenciar entre personas candidatas y personas asignadas. Cualquier candidato puede hacer la tarea, como "alguien del equipo de ventas" o "Joe, Mary, Rick o Sandy". El primero de estos candidatos que comience el trabajo reclama la tarea, y sólo entonces se le asigna personalmente. Esta reclamación evita que dos personas trabajen en la misma tarea por coincidencia. Una tarea puede delegarse cuando la persona asignada quiere que otra persona resuelva (parte de) el trabajo. Cuando terminan, se devuelve a la persona asignada. Esto es diferente de reasignar el trabajo, que significa entregar la tarea a otra persona, que entonces es totalmente responsable de terminar el trabajo en cuestión.
Como norma general, debes asignar las tareas humanas de tu proceso a grupos de personas en lugar de a individuos concretos (por ejemplo, "el equipo de ventas"). Esto no sólo facilita las reglas de asignación, sino que también se adapta a nuevas contrataciones, bajas, vacaciones, bajas por enfermedad, etc. Por supuesto, puede haber excepciones, como si una determinada región tiene asignado un vendedor específico.
Ten en cuenta que no todas las personas de tu proceso tienen que ser empleados de tu empresa. También puedes asignar trabajo a los clientes, por ejemplo, pidiéndoles que suban los documentos que faltan.
En BPMN, la asignación de personas se controla mediante atributos de cada tarea de usuario. He aquí un ejemplo:
<bpmn:userTaskid="Check payment"/><potentialOwner><resourceAssignmentExpression><formalExpression>sales</formalExpression></resourceAssignmentExpression></potentialOwner></userTask>
Soporte de herramientas adicionales
Algunas herramientas proporcionan capacidades adicionales en torno a las notificaciones, la gestión del tiempo de espera y el escalado, la gestión de las vacaciones o las reglas de sustitución. Estas capacidades suelen configurarse como atributos de las tareas y, como tales, no son visibles gráficamente en el modelo del proceso.
Es una buena idea aprovechar estas capacidades y no modelar manualmente estos aspectos en todos y cada uno de los procesos. Así que, aunque tengas la tentación de modelar mediante BPMN un recordatorio por correo electrónico sobre el trabajo que lleva demasiado tiempo esperando en la cola, evítalo si tu herramienta puede hacerlo de forma inmediata mediante una sencilla opción de configuración. Esto hará que tus modelos sean más fáciles de crear, leer y comprender, como puedes ver en la Figura 4-12.
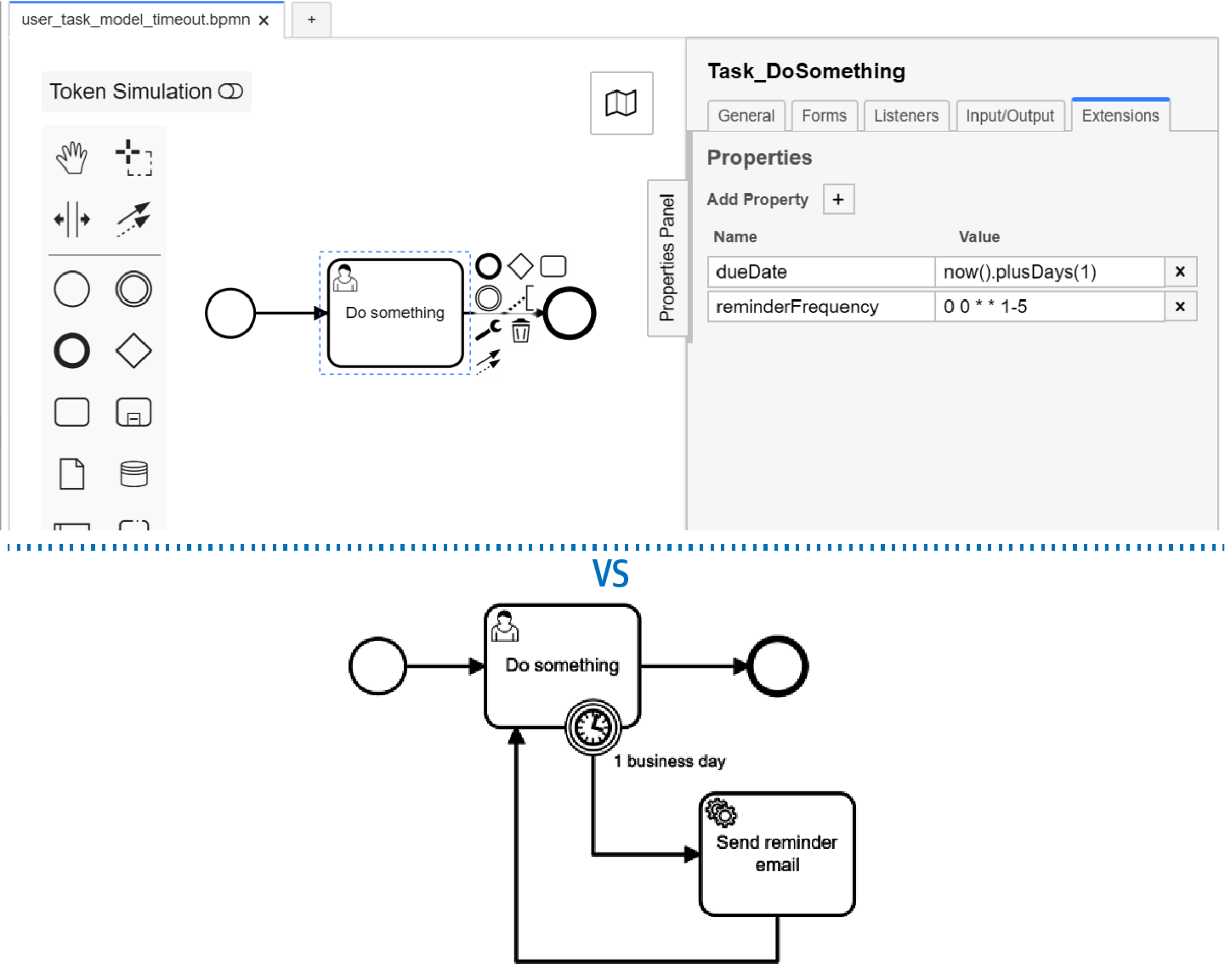
Figura 4-12. No modeles aspectos que el ciclo de vida integrado de las tareas de usuario puede abordar por ti
Apoyar la gestión humana de tareas es su propio reto para los motores de flujo de trabajo. Además de que el proveedor tiene que proporcionar interfaces gráficas de usuario a los usuarios finales, el motor también tiene que ofrecer amplias capacidades de filtrado y consulta de tareas.
Aunque esto pueda parecer fácil al principio, puede complicarse bastante si tienes que tratar con miles de empleados que trabajan con millones de tareas a diario. También te enfrentas al reto de ofrecer posibilidades de consulta flexibles sin permitir que un solo usuario reduzca el rendimiento de toda la empresa. La forma en que esto se implementa varía según los proveedores, pero sin duda es un tipo de carga de trabajo muy diferente a la de los microservicios que realizan una tarea tras otra.
La interfaz de usuario de las tareas de usuario
El motor de flujo de trabajo controla el proceso. Sabe para cada instancia del proceso cuál es la siguiente actividad que el humano debe realizar. Pero el ser humano también necesita saberlo. Así que el motor de flujo de trabajo necesita una forma de comunicarse con personas reales.
Un enfoque es utilizar la aplicación de lista de tareas proporcionada por tu proveedor, como se introduce en "Aplicaciones de lista de tareas". Estas herramientas suelen permitir a los usuarios finales filtrar las tareas. Esto significa que pueden necesitar mezclar datos empresariales, ya que los usuarios finales no sólo quieren ver el nombre de la tarea, sino también datos empresariales como los ID de pedido, los productos solicitados o el nombre del solicitante.
Otro aspecto importante es qué tipos de formularios de tareas se admiten. Algunos productos sólo permiten la creación de formularios básicos, mediante la definición de atributos simples. Otros proporcionan su propio modelador de formularios. Algunos te permiten incrustar HTML o utilizar formularios personalizados como un one-pager en tu aplicación web personalizada, o un formulario creado por una aplicación constructora de formularios dedicada. Ten en cuenta que a menudo necesitarás mezclar datos del proceso con datos de dominio de entidades referenciadas en la tarea, en un único formulario, como se muestra en la Figura 4-13, loque redunda en una mejor usabilidad para tus usuarios.
Utilizar la aplicación de lista de tareas de tu proveedor de flujos de trabajo puede ser una buena forma de empezar rápidamente. Puedes construir inmediatamente un prototipo para tu proceso y hacer clic en él, probablemente incluso para verificar el modelo de proceso con las partes interesadas de la empresa. La mayoría de las personas comprenden mucho mejor un modelo de proceso si pueden hacer un juego de rol utilizando formas de la vida real, en lugar de leer un modelo formal.
Pero también hay situaciones en las que necesitas una forma más personalizada de implicar a los humanos. Por ejemplo, podrías utilizar el correo electrónico, el chat o la interacción por voz. El motor de flujo de trabajo podría enviar un correo electrónico a una persona que necesita hacer algo. Este correo contiene toda la información relevante para que esa persona realice la tarea en cuestión. Cuando haya terminado, puede indicarlo respondiendo al correo electrónico o haciendo clic en un enlace del mismo.
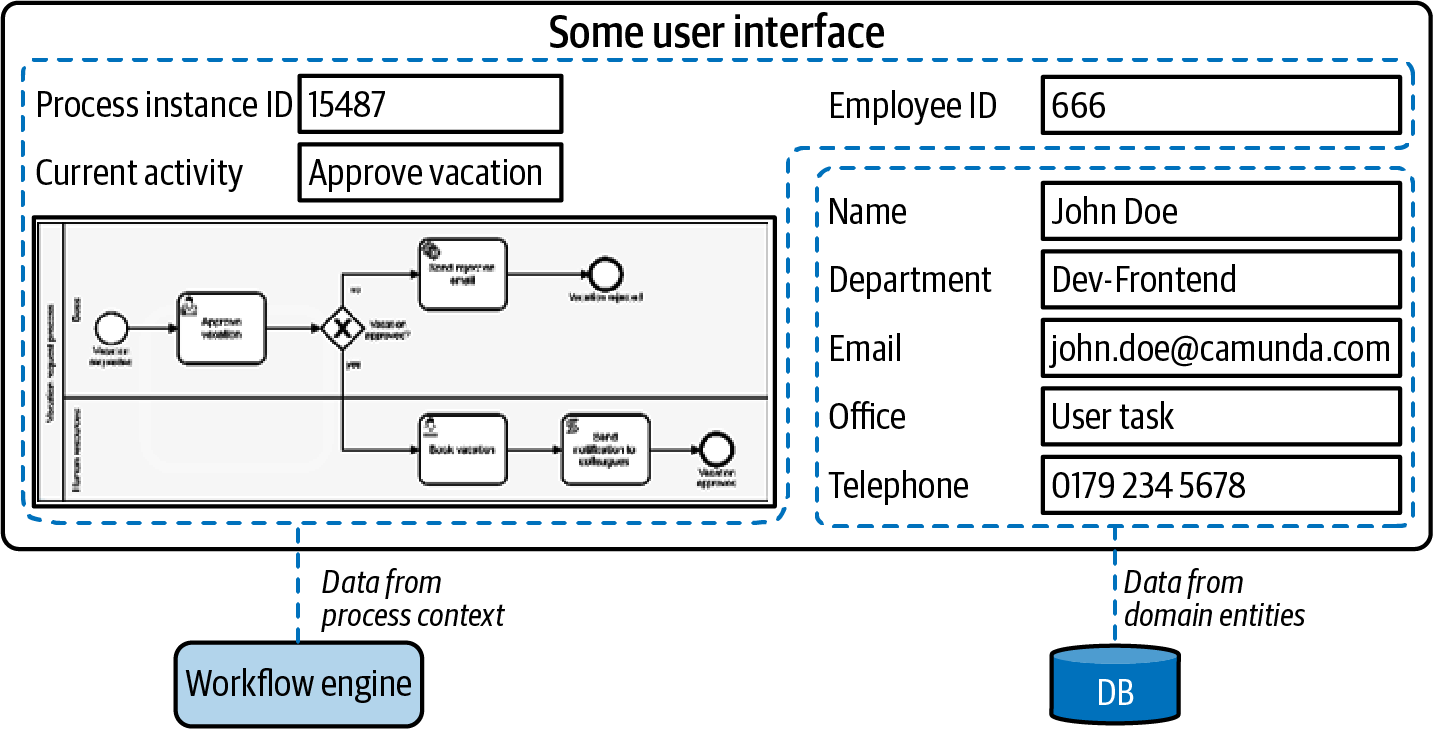
Figura 4-13. En los formularios para tareas de usuario, a menudo hay que mezclar datos del motor de flujo de trabajo con datos del dominio
Otros dos escenarios habituales son utilizar una aplicación de lista de tareas de terceros y desarrollar una interfaz de usuario completamente personalizada. Exploremos brevemente ambas opciones.
Utilizar una aplicación externa de lista de tareas
El motor de flujo de trabajo puede invocar la API de una aplicación externa, como se visualiza en la Figura 4-14. Puede tratarse de una aplicación de lista de tareas que ya esté ampliamente adoptada en la empresa, de la talla de SAP o Siebel, o de alguna aplicación muy amplia como Trello o Wunderlist. También he visto a un cliente utilizar pantallas en el ordenador central para gestionar las tareas abiertas, ya que era la forma en que todos los empleados hacían su trabajo diario. Las listas de tareas también pueden denominarse listas de trabajos, listas de tareas pendientes o bandejas de entrada.
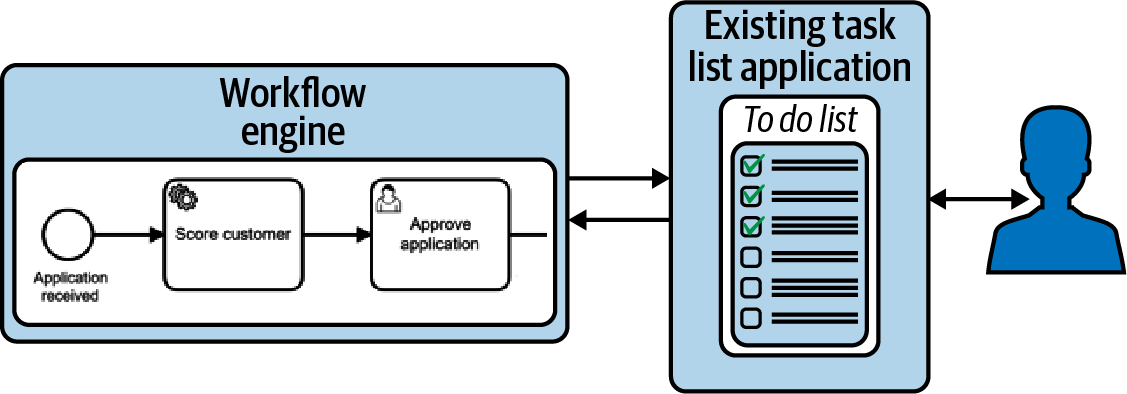
Figura 4-14. Las tareas del usuario conducen a entradas de tareas pendientes en una aplicación de lista de tareas
Sea cual sea la forma que adopte, esta aplicación ofrece al usuario la posibilidad de ver todas las tareas abiertas, indicar que ha empezado a trabajar en una tarea y marcar las tareas como completadas. El estado se comunica al motor de flujo de trabajo. Al implementar una integración de este tipo, tendrás que tener en cuenta:
-
Creación de tareas en la aplicación de lista de tareas cada vez que una instancia de proceso entra en una tarea de usuario
-
Completar las tareas del usuario en el motor de flujo de trabajo y avanzar en el proceso cuando el usuario haya terminado
-
Cancelar tareas, activadas por el motor de flujo de trabajo o por el usuario en la interfaz de usuario
-
Transferir los datos de la empresa que se van a editar a la aplicación de tareas pendientes, y viceversa
También se ha demostrado que es una buena idea pensar en un mecanismo de detección de problemas por si acaso los dos sistemas divergen, por ejemplo debido a incoherencias causadas por fallos en las llamadas remotas.
El uso de una aplicación de terceros es frecuente cuando ya existe una aplicación de lista de tareas que se ha distribuido a los empleados, ya que les permite seguir utilizando la aplicación conocida. Puede que ni siquiera reconozcan que se trata de un motor de flujo de trabajo o que se sustituye un producto bajo el capó. En ese caso, los problemas de autenticación y autorización suelen estar ya resueltos.
Crear una aplicación de lista de tareas personalizada
Si necesitas una experiencia más personalizada que la que puede ofrecer la aplicación de lista de tareas del proveedor, puedes desarrollar tú mismo una aplicación a medida. Ésta puede adaptarse a tus necesidades sin compromiso. Tienes libertad de elección entre marcos de desarrollo y lenguajes de programación, y las tareas dentro de tu aplicación personalizada pueden seguir tu guía de estilo y conceptos de usabilidad. Esto se hace a menudo si integras herramientas de flujo de trabajo en tu propio producto de software, o si quieres desplegar tu lista de tareas a cientos o miles de usuarios y la eficiencia en la interfaz de usuario es importante.
Este enfoque también te permite satisfacer requisitos muy especiales. Por ejemplo, puedes enfrentarte a una situación en la que tengas varias tareas de usuario que sean muy interdependientes desde el punto de vista empresarial y que, por tanto, deban ser completadas en un solo paso por la misma persona. Imagina un proceso de gestión de entrada de documentos en el que hayas decidido gestionar cada documento con una instancia de proceso independiente, pero presentar al usuario los envíos consistentes en varios de esos documentos como una tarea agrupada. En la Figura 4-15 se muestra un ejemplo.
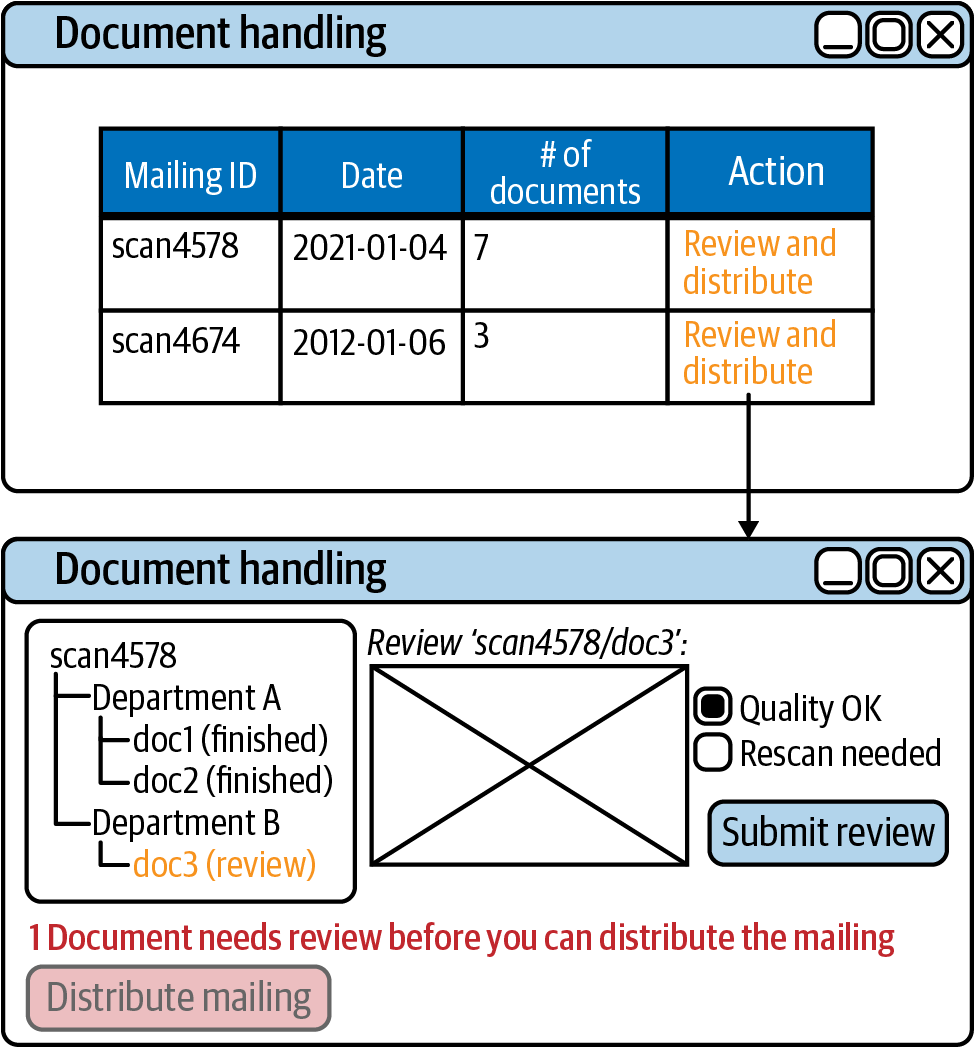
Figura 4-15. Una lista de tareas personalizada puede ocultar la complejidad y mejorar la eficacia
En un proyecto de la vida real en el que participé, este enfoque permitió a los empleados de una organización trabajar con mucha más eficacia. Este tipo de agrupación no supone ningún problema con una lista de tareas personalizada, pero podría no ser factible con aplicaciones listas para usar.
Orquestar robots RPA
Cambiemos nuestra atención de la orquestación de humanos a la orquestación de bots: bots de automatización robótica de procesos (RPA), para ser precisos. La RPA es una solución para tratar con aplicaciones heredadas que no ofrecen una API, ya que muchos sistemas antiguos se desarrollaron en una época en la que no había tanta necesidad de conectividad. Las herramientas RPA automatizan el control de las interfaces gráficas de usuario existentes. Los grandes temas son el screen scraping, el procesamiento de imágenes, el OCR y las interfaces gráficas de usuario controladas por robots. Es como la grabadora de macros de Windows con esteroides.
La RPA ha experimentado un rápido crecimiento recientemente, y se ha convertido en un mercado enorme, reconocido por los analistas.
Supón que tu sistema de facturación es muy antiguo y no proporciona ningún tipo de API. Puedes utilizar la herramienta RPA que prefieras para automatizar la introducción de datos en tu proceso de incorporación. En la jerga RPA esto se llama bot. La forma de desarrollar este bot depende de la herramienta concreta, pero normalmente se registran las interacciones de la GUI y se editan los pasos que el bot debe dar en la GUI del RPA, como "haz clic en este botón" e "introduce texto en este campo de texto". En la Figura 4-16 se muestra un ejemplo.
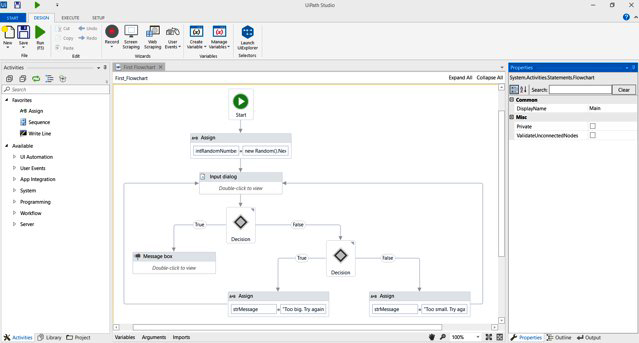
Figura 4-16. Ejemplo de un entorno y flujo de desarrollo RPA típicos
Es importante tener en cuenta que el bot sólo debe implementar una función. En términos del proceso BPMN, el bot no es más que otra forma de implementar una tarea de servicio, como se muestra en la Figura 4-17.
Por supuesto, los bots son siempre mucho más frágiles que una llamada a una API real, por lo que siempre que sea posible debes preferir utilizar una API. Pero, por desgracia, la vida real está llena de obstáculos. Puede que el sistema no proporcione la API que necesitas, o que te enfrentes a una escasez de recursos de desarrollo. Supongamos que la introducción de datos en el sistema de facturación se está retrasando porque las personas están sobrecargadas de trabajo de incorporación. El departamento comercial necesita resolver este problema rápidamente, ya que los clientes están empezando a cancelar sus pedidos debido a los largos retrasos (lo que provoca aún más trabajo manual, dando lugar a una espiral descendente muy desafortunada). Pero el departamento de TI está enterrado en otros trabajos urgentes, por lo que no puede realizar esta integración de inmediato.
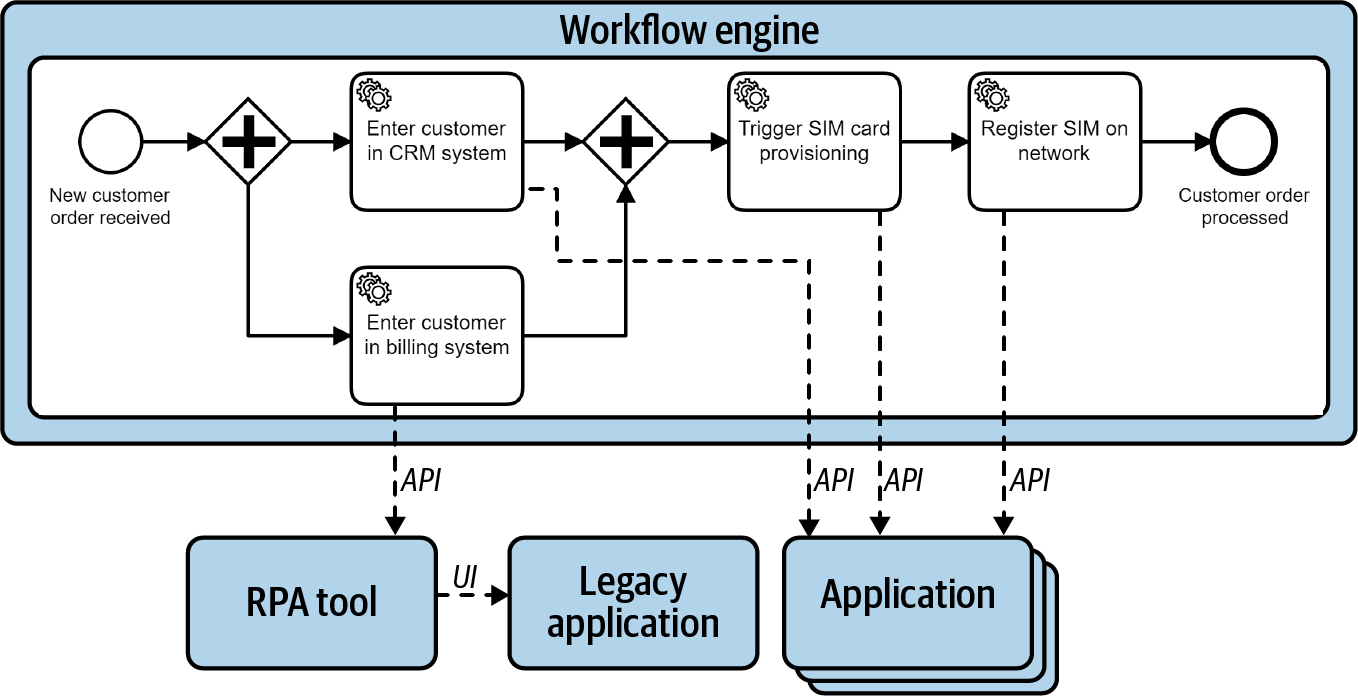
Figura 4-17. Un proceso que también orquesta un bot RPA
Desarrollar un bot de RPA puede ser una buena forma de que el departamento empresarial avance rápidamente sin necesidad de TI, lo que es beneficioso para la empresa en esta fase. Pero debes tener en cuenta que los bots son difíciles de mantener y dependen de interfaces de usuario que pueden cambiar rápidamente, y si las soluciones de RPA y los bots no están gobernados o gestionados por TI, esto puede dar lugar a problemas de arquitectura más adelante.
Así que, en este ejemplo, deberías planificar directamente la sustitución del bot por una API real. Incluso he visto organizaciones que exigen a los proyectos que informen de la deuda técnica cada vez que introducen un nuevo bot RPA para asegurarse de que esto se aborda más adelante.
Puedes abordar algunos de los problemas en torno a la fragilidad de los bots manteniendo las tareas humanas como reserva en caso de que se produzcan errores en los bots RPA. Esto te permite concentrarte en automatizar el 80% de los casos y dirigir las excepciones a un humano, como se muestra en la Figura 4-18.
Ahora bien, hay un riesgo que debes tener en cuenta. Como has visto en la Figura 4-16, un flujo RPA es también una especie de modelo de proceso. Esto puede llevar a algunas empresas a intentar automatizar procesos empresariales básicos con herramientas de RPA, sobre todo si tienen un ancho de banda limitado en TI. Por desgracia, esto no funciona.
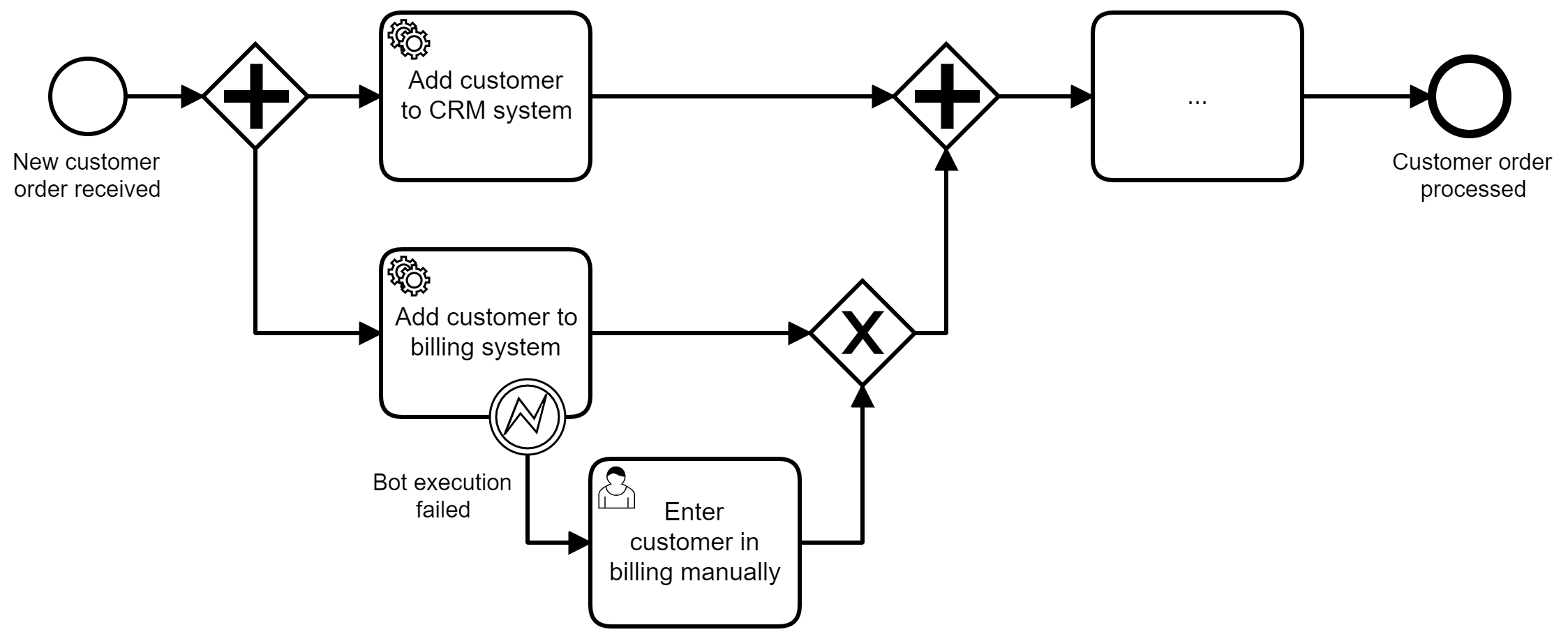
Figura 4-18. Un proceso que orquesta un bot con humanos como reserva
Advertencia
La RPA no está pensada para automatizar los procesos empresariales básicos. Utilizar la herramienta RPA como una plataforma de automatización de procesos de bajo código es una trampa. Utilizar flujos de RPA para automatizar procesos empresariales completos tiene graves desventajas y riesgos. Todas las desventajas del código bajo se aplican aquí, y además los flujos de RPA se convierten rápidamente en una mezcla salvaje de granularidades, que contienen lógica de flujo de procesos empresariales, así como secuencias de control para la interfaz de usuario.
El motor del flujo de trabajo debe ser siempre el controlador principal que controle el proceso global, y llame a los bots RPA siempre que necesite integrarse con un recurso al que no se pueda llamar mediante una API por el motivo que sea.
La RPA se aplica en un paso del proceso. En cuanto puedas cambiar a una API, deberías hacerlo. Lo bueno de esta arquitectura es que puede que ni siquiera necesites cambiar tu modelo de proceso: basta con llamar a la API en lugar de al bot de RPA.
Orquestar dispositivos físicos y cosas
Pero no nos detengamos en los robots RPA. También podemos orquestar dispositivos físicos, como auténticos robots de laboratorio.
Técnicamente hablando, orquestar dispositivos se reduce a orquestar software, ya que los dispositivos se integran mediante API. Sin embargo, hay algunos matices específicos. En concreto, existe un patrón común en relación con los casos de uso emergentes en torno a la Internet de las Cosas (IoT), donde una miríada de dispositivos se conectan a Internet y producen datos. Estos datos pueden conducir a acciones, que luego pueden implicar una orquestación.
Comprendámoslo examinando un caso de uso relacionado con el mantenimiento de un avión. Supongamos que un avión produce un flujo constante de datos de sensores, por ejemplo, la presión actual del aceite. Un procesador de flujo podría derivar algún conocimiento real de esa medición, como una presión de aceite demasiado baja. Se trata de otro flujo de datos. Pero ahora tenemos que actuar a partir de ese conocimiento, y programar el mantenimiento en la próxima oportunidad posible. Aquí es donde empieza un proceso, porque ahora nos preocupamos de que el mecánico analice la información dentro de un plazo definido, decida cómo tratar el problema y programe las acciones de mantenimiento adecuadas. Esto se visualiza en la Figura 4-19.
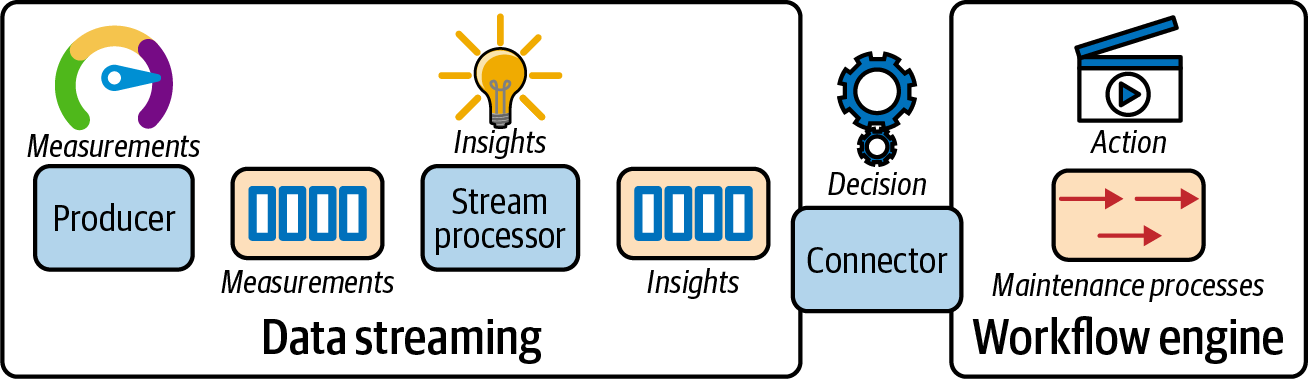
Figura 4-19. Un ejemplo en el que flujos de datos conducen al inicio de flujos de trabajo
La transición de un flujo pasivo a un proceso que reacciona a los datos del flujo es muy interesante. En un proyecto concreto de la vida real, podría desarrollarse un conector con estado que inicie una instancia de proceso para un mecánico sólo una vez por cada visión. Si se sigue informando de que la presión del aceite es demasiado baja para el mismo hardware, no se inician instancias de proceso adicionales. Si la presión del aceite vuelve a ser normal, esta información se envía a la instancia de proceso existente, para que pueda actuar. Por ejemplo, podría simplemente cancelarse, ya que el mantenimiento ya no es necesario.
Conclusión
Este capítulo ha demostrado que los motores de flujo de trabajo pueden orquestar cualquier cosa, desde software a decisiones, pasando por robots y dispositivos. Esto debería ayudarte a comprender qué tipo de problemas puede resolver la automatización de procesos. Por supuesto, en la vida real los casos de uso se solapan, por lo que los procesos suelen implicar una mezcla de componentes. Para implantar un proceso de extremo a extremo puede que necesites orquestar humanos, robots RPA, servicios SOA, microservicios, decisiones, funciones y otros componentes de software, todo dentro del mismo proceso.
Ten en cuenta que algunas personas no hablan de orquestación, sino de gestión de tareas humanas y procesamiento directo. Se trata de un punto sutil basado en la psicología de la terminología.
Get Automatización práctica de procesos now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

