Capítulo 4. Catálogos de datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
La capa de almacenamiento dentro de la arquitectura Lakehouse es importante, ya que almacena los datos de toda la plataforma. Para buscar, explorar y descubrir estos datos almacenados, los usuarios necesitan un catálogo de datos. Este capítulo se centrará en comprender un catálogo de datos y el proceso general de gestión de metadatos que permite a los usuarios de la plataforma lakehouse buscar y acceder a los datos.
En la primera sección de este capítulo, explicaré conceptos fundamentales como metadatos, metastore y catálogos de datos. No son conceptos nuevos; las organizaciones llevan mucho tiempo implantando catálogos de datos tanto en los almacenes de datos tradicionales como en las plataformas de datos modernas. Explicaré primero estos conceptos básicos para preparar nuestro debate sobre las funciones avanzadas más adelante en el capítulo.
Discutiremos en qué se diferencian los catálogos de datos en la arquitectura lakehouse, en comparación con las arquitecturas tradicional y combinada, y cómo ayudan a los usuarios a obtener una visión unificada de todos los metadatos. También hablaremos de las ventajas adicionales de los catálogos de datos en la arquitectura lakehouse, que permiten a los usuarios aprovechar los metadatos para implantar un mecanismo unificado de gobierno de datos, control de permisos, linaje y uso compartido.
En la última sección de este capítulo, hablaré de algunas de las opciones tecnológicas de catálogos de datos más populares disponibles en las plataformas en la nube. Conocerás las consideraciones de diseño y las limitaciones prácticas que pueden ayudarte a tomar una decisión informada al diseñar los catálogos de datos de tu plataforma en la nube.
Comprender los metadatos
Al igual que necesitamos procesos para gestionar los datos dentro de la plataforma, también necesitamos enfoques bien definidos para gestionar los metadatos. Un proceso sólido de gestión de metadatos ayuda a simplificar la búsqueda y el descubrimiento de datos para los usuarios de la plataforma.
Los metadatos se definen a menudo como "datos sobre datos". Son tan importantes como los propios datos. Los metadatos ayudan a definir los datos proporcionando información adicional que los describe, como el nombre del atributo, el tipo de dato, el nombre y el tamaño del archivo.
Los metadatos proporcionan la estructura necesaria y otra información relevante para dar sentido a los datos. Ayuda a los usuarios a descubrir, comprender y encontrar los datos exactos que necesitan para sus requisitos específicos.
Los metadatos se clasifican en metadatos técnicos y metadatos empresariales.
Metadatos técnicos
Los metadatos técnicos proporcionan información técnica sobre los datos. Un ejemplo sencillo de metadatos técnicos son los detalles del esquema de cualquier tabla. El esquema comprende nombres de atributos, tipos de datos, longitudes y otra información asociada. La Tabla 4-1 muestra el esquema de una tabla de productos con tres atributos.
| Nombre del atributo | Tipo de atributo | Longitud del atributo | Restricción de atributos |
|---|---|---|---|
| producto_id | entero | No nulo | |
| nombre_producto | cadena | 100 | Nulo |
| categoría_producto | cadena | 50 | Nulo |
Al igual que las tablas, otros objetos (como los archivos) también tienen metadatos. Los metadatos de los archivos proporcionan detalles como el nombre del archivo, la hora de creación o actualización, el tamaño del archivo y el permiso de acceso. Los archivos como los CSV a veces tienen un registro de cabecera que define los nombres de los atributos de los datos. Los archivos JSON y XML también tienen nombres de atributos en su interior. Como se vio en el Capítulo 3, los formatos de archivo como Apache Parquet, Apache ORC y Apache Avro también llevan información de metadatos.
Metadatos empresariales
Los metadatos empresariales ayudan a los usuarios a comprender el significado empresarial de los datos. Los metadatos empresariales aumentan los metadatos técnicos para dar un contexto empresarial a los datos. La Tabla 4-2 enumera los metadatos empresariales de la tabla de productos.
| Nombre técnico del atributo | Atributo razón social | Atributo significado empresarial |
|---|---|---|
| producto_id | Identificador del producto | Identificador único del producto |
| nombre_producto | Nombre del producto | Nombre del producto |
| categoría_producto | Categoría de productos | Categoría del producto |
En este ejemplo, los nombres técnicos de los atributos se explican por sí mismos y puedes entender fácilmente su significado empresarial. Sin embargo, no siempre es así.
Considera un escenario en el que utilizas SAP como sistema fuente y el módulo logístico de SAP Gestión de Materiales (MM). MARA, que contiene los datos generales del material, es una de las tablas más utilizadas en este módulo SAP. Como se muestra en la Tabla 4-3, los nombres técnicos de estos atributos no son autoexplicativos y necesitarías añadir un contexto empresarial para que los usuarios comprendieran qué datos contiene cada atributo.
| Nombre técnico del atributo | Atributo razón social | Atributo significado empresarial |
|---|---|---|
| MANDT | Cliente | Nombre del cliente |
| MATNR | Número de material | Identificador único del material |
| ERSDA | Creado el | Fecha de creación de la entrada de material |
Los metadatos técnicos y empresariales son esenciales para comprender mejor los datos de tu plataforma. Un buen proceso de gestión de metadatos debe proporcionar capacidades para mantener y gestionar los metadatos técnicos y empresariales. Debe admitir funciones de gobernanza y seguridad como el control de acceso, la gestión de datos sensibles y el uso compartido de datos, que trataremos más adelante en este capítulo.
Cómo colaboran los metastores y los catálogos de datos
Aunque la gestión de metadatos es un proceso para gestionar los metadatos y ponerlos a disposición de los usuarios, necesitamos soluciones y herramientas para poner en práctica este proceso. Los metastores y los catálogos de datos son las soluciones que ayudan a construir un proceso sólido de gestión de metadatos.
Un metastore es un repositorio dentro de la plataforma de datos donde se almacenan físicamente los metadatos. Actúa como sistema central de almacenamiento de metadatos. Puedes acceder a todos los metadatos desde este almacenamiento central.
Un catálogo de datos proporciona un mecanismo para acceder a los metadatos almacenados en el metastore. Proporciona la interfaz de usuario necesaria para explorar los metadatos y buscar diversas tablas y atributos.
La Figura 4-1 muestra cómo están relacionados los metastores y los catálogos de datos, y cómo permiten a los usuarios acceder a los metadatos.

Figura 4-1. Diagrama de flujo de metadatos
Por ejemplo, en los ecosistemas Hadoop locales tradicionales, Hive proporcionaba Hive Metastore (HMS) para almacenar metadatos (para tablas Hive creadas sobre datos HDFS) y Hive catalog (HCatalog) para acceder a las tablas HMS desde aplicaciones Spark o MapReduce.
Los catálogos de datos modernos proporcionan un mecanismo para gestionar los metadatos de forma más organizada. Te permiten proporcionar los controles de acceso adecuados a los usuarios adecuados para que puedan acceder a tus datos de forma segura. Puedes dividir lógicamente los catálogos en bases de datos o esquemas que contengan tablas, vistas y otros objetos. Puedes gestionar los permisos de acceso de los usuarios a nivel de catálogo o a nivel más granular de esquema o tabla.
La Figura 4-2 muestra un escenario real de cómo un usuario puede acceder a catálogos específicos en función de sus funciones y permisos.
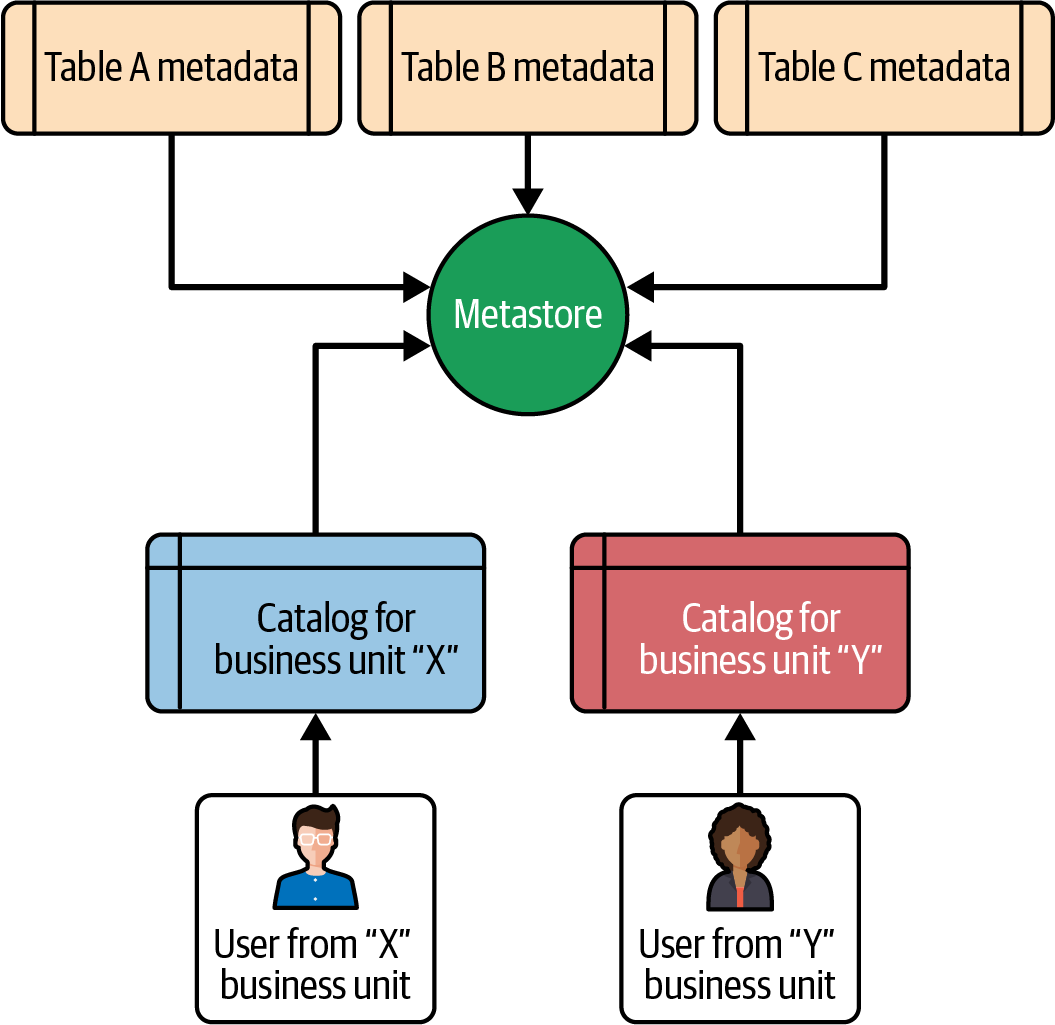
Figura 4-2. Catálogo basado en unidades de negocio
Como se muestra en la Figura 4-2, los usuarios de la unidad de negocio "X" sólo pueden acceder al catálogo de la unidad de negocio "X", y los usuarios de la unidad de negocio "Y" sólo pueden acceder al catálogo de la unidad de negocio "Y".
No siempre es necesario categorizar los catálogos en función de las unidades de negocio. Puede haber varios enfoques y puedes elegir el que mejor te funcione. Puedes crear catálogos basados en los distintos entornos -como desarrollo, pruebas y producción- o puedes crear un único catálogo y controlar los permisos a nivel de esquema o de tabla.
Nota
Muchos profesionales de los datos utilizan los términos metastores y catálogos de datos indistintamente para describir los sistemas de almacenamiento de metadatos. La mayoría de los modernos servicios en la nube que ofrecen capacidades de catálogo de datos abstraen el almacenamiento físico de los metadatos y sólo exponen los catálogos de datos para que los usuarios naveguen y accedan a esquemas, tablas y atributos. Detrás de cada catálogo, hay un almacenamiento físico donde se almacenan los metadatos reales.
Características de un Catálogo de Datos
Los catálogos de datos proporcionan varias funciones clave que ayudan a los administradores de la plataforma a organizar, gestionar y gobernar los datos. Las funciones comentadas en esta sección ayudan a los usuarios de la plataforma a buscar, explorar y descubrir rápidamente los datos relevantes.
Busca, explora y descubre datos
Los catálogos de datos proporcionan a los usuarios un mecanismo sencillo para buscar los datos necesarios y saber dónde (en qué esquema, tabla o atributo) existen los datos para poder consultarlos. Los catálogos de datos también ofrecen funciones para añadir descripciones empresariales a las tablas y atributos.
Los usuarios pueden recorrer el catálogo, comprender el contexto empresarial y descubrir datos que puedan ayudarles en análisis posteriores.
Clasificación de datos
La clasificación es el proceso de categorizar atributos basándose en determinadas especificaciones o normas. Puedes clasificar los atributos de en función de los dominios (como cliente, producto y ventas) o de la sensibilidad (como confidencial, interno o público). La clasificación ayuda a los usuarios a comprender y aprovechar mejor los datos. Por ejemplo, un atributo clasificado como "interno" indica que los usuarios no deben compartir los datos fuera de su organización.
Como parte del proceso de clasificación, puedes añadir etiquetas a tus metadatos. Por ejemplo, considera un escenario en el que estás implementando un lago para un proveedor de seguros. Tendrías varias tablas con datos relacionados con los clientes, como el nombre del cliente, la fecha de nacimiento y el identificador nacional. Todos estos atributos son atributos de información de identificación personal, o IIP . Puedes etiquetar estos atributos como "pii_attributes" en tu catálogo y utilizar estas etiquetas para aplicar políticas de gobernanza que abstraigan estos datos sensibles de usuarios no elegibles o externos. En el Capítulo 6 trataremos con más detalle cómo gestionar los datos sensibles.
Nota
Los atributos PII son porciones de datos que pueden utilizarse para identificar a una persona concreta e incluyen los DNI, los ID de correo electrónico, los números de teléfono y la fecha de nacimiento.
A efectos de cumplimiento, es obligatorio abstraer dicha información de los consumidores de datos. Debes dar acceso a los atributos PII sólo a un conjunto específico de usuarios en función de su función organizativa.
También debes implantar políticas de gobierno de datos para ocultar o enmascarar dichos atributos PII a usuarios no autorizados a ver los valores de los atributos PII.
La clasificación de los datos ayuda a gestionarlos, a aplicar políticas de gobernanza y a protegerlos dentro de la plataforma.
Gobernanza y seguridad de los datos
Los catálogos de datos actúan como guardianes de los datos y ayudan a implantar las políticas de gobierno y seguridad de datos necesarias para gestionar, gobernar y proteger los datos en toda la organización.
Los catálogos de datos ofrecen las siguientes funciones de gobierno y seguridad:
-
Apoyo a la aplicación de normas y restricciones estándar para mantener la calidad de los datos
-
Implementar el proceso de auditoría, como el seguimiento de los usuarios que acceden a tablas o atributos específicos, necesario para los informes de cumplimiento.
-
Control de permisos detallado para los usuarios que acceden a los datos
-
Asegurar los datos de la plataforma proporcionando capacidades para filtrar o abstraer los datos sensibles almacenados en la plataforma.
-
Permitir compartir datos de forma segura con los consumidores de datos
El gobierno de los datos es un tema amplio, y lo trataremos con más detalle en el Capítulo 6.
Linaje de datos
Cualquier ecosistema de datos y análisis consta de múltiples trabajos que ingieren los datos de los sistemas fuente, los transforman y, finalmente, los cargan en el almacenamiento de destino para el consumo de los usuarios. Dentro de este almacenamiento, puede haber cientos de tablas con miles de atributos, a través de las cuales los datos fluyen por diversos componentes. A medida que el sistema crece, los activos de datos siguen aumentando. Para rastrear el flujo de datos a través de los componentes de tu plataforma, necesitas un mecanismo de seguimiento que proporcione detalles de extremo a extremo sobre cómo navegan los datos a través de estos atributos. El linaje de datos es un proceso que proporciona información sobre este flujo de datos a través de varios componentes.
El linaje de datos también puede ayudar a realizar análisis de impacto siempre que cambie el nombre, tipo o longitud de algún atributo. Y puede ayudarte a auditar activos de datos, como tablas, que son redundantes o no son utilizados por ningún consumidor. Los catálogos de datos te ayudan a implantar una solución de linaje de datos para rastrear la relación entre los atributos de origen y destino. Hablaremos de ello con más detalle en el Capítulo 6.
Las características de un catálogo de datos permiten la colaboración entre diferentes equipos de datos y personas de datos dentro de una organización, permitiendo a los usuarios empresariales realizar análisis de autoservicio descubriendo y aprovechando los datos que necesitan para tomar mejores decisiones.
Catálogo de datos unificado
Como se explica en el Capítulo 2, la arquitectura combinada se enfrenta a varias limitaciones porque utiliza dos niveles de almacenamiento distintos: uno para el lago de datos y otro para el almacén de datos. En estos sistemas, también te enfrentas a los retos asociados a la gestión de metastores y catálogos separados y en silos para el lago de datos y el almacén de datos.
Desafíos de la gestión de metadatos en silos
La mayoría de los retos asociados a los niveles individuales de almacenamiento de datos en silos de la arquitectura combinada también se aplican a la gestión de metadatos. Estos retos incluyen:
- Mantenimiento
-
Tienes que mantener metadatos separados para los objetos del lago de datos y las tablas del almacén de datos, lo que se suma a los esfuerzos generales de mantenimiento. Tienes que replicar con frecuencia los metadatos entre los dos sistemas para sincronizar los cambios de un sistema a otro.
- Descubrimiento de datos
-
El descubrimiento de datos se convierte en un reto en la arquitectura combinada, ya que los usuarios tienen que navegar por dos catálogos de datos diferentes. Algunos objetos, como las tablas resumidas y las vistas agregadas, pueden estar disponibles sólo en el almacén de datos. En estos casos, los usuarios de la plataforma deben saber qué sistema contiene los datos que buscan.
- Gobernanza y seguridad de los datos
-
Debido a los niveles de almacenamiento en silos, la aplicación de políticas de gobierno y seguridad de datos, como el control de acceso, la gestión de datos sensibles y el uso compartido seguro, se convierte en un reto. En estos entornos, no puedes tener una política de gobierno de datos unificada que sea fácil y práctica de aplicar y mantener.
- Linaje de los datos
-
Para cualquier cambio en el nombre, tipo de dato o longitud de una columna específica, necesitas realizar un análisis de impacto para identificar las tablas en las que está presente la columna específica. En las arquitecturas combinadas, la vista del linaje se limita a ecosistemas individuales (lago de datos o almacén de datos); no puedes obtener una comprensión integral del flujo de datos.
Teniendo en cuenta estos retos, es beneficioso utilizar un catálogo de datos unificado que pueda simplificar los procesos de gestión de metadatos, descubrimiento de datos y gobernanza. La arquitectura Lakehouse te permite implantar este catálogo de datos unificado.
¿Qué es un Catálogo Unificado de Datos?
Un catálogo de datos unificado es un catálogo que puede contener metadatos de todos los activos de datos como tablas, vistas, informes, funciones, así como activos de IA como modelos ML y tablas de características. Un catálogo de datos unificado permite a sus usuarios gobernar todos sus datos y activos de IA desde una única plataforma central. En la arquitectura lakehouse, todos los activos de las cargas de trabajo de datos e IA residen en la única capa de almacenamiento en la nube, lo que permite a los administradores de la plataforma implementar un catálogo de datos unificado para gestionar y gobernar todo el ecosistema.
La Figura 4-3 muestra un catálogo de datos unificado dentro de una plataforma Lakehouse y las características clave que proporciona.
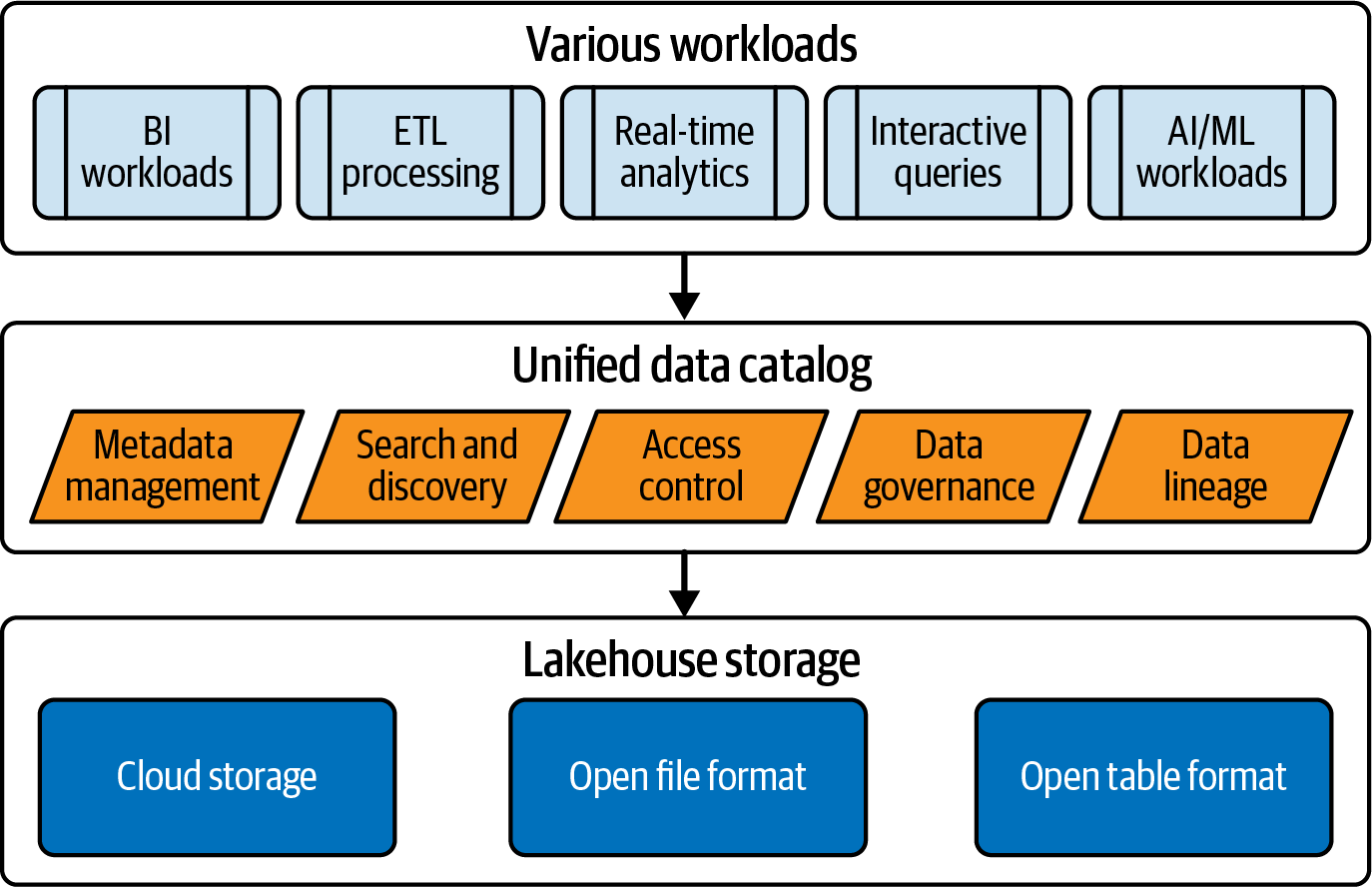
Figura 4-3. Catálogo de datos unificado en una plataforma lakehouse
Como ya hemos dicho, un catálogo de datos ofrece funciones clave como la búsqueda, el descubrimiento, la gobernanza y el linaje. En un catálogo de datos unificado, las organizaciones pueden implementar estas funciones en todos los objetos de datos, como tablas, vistas e informes, así como en todos los activos, como modelos y almacenes de características utilizados en las cargas de trabajo de IA.
Un catálogo de datos unificado proporciona una única interfaz para que diferentes personas de datos -como ingenieros de datos, analistas y científicos- colaboren de forma eficiente y trabajen juntos para explorar y aprovechar los datos. Actúa como un repositorio central para que los usuarios, tanto técnicos como empresariales, busquen y descubran datos.
En resumen, como consumidor de datos, un catálogo de datos unificado es tu ventana para explorar todos los datos y activos de IA dentro de la plataforma, examinar los metadatos técnicos de estos activos y comprender el contexto empresarial de los datos.
Ventajas de un Catálogo de Datos Unificado
Las principales ventajas de un catálogo de datos unificado son las siguientes:
- Búsqueda unificada y descubrimiento de datos
-
En la arquitectura lakehouse, puedes implementar una única capa de metastore para albergar todos los metadatos de todo el ecosistema. A diferencia de la arquitectura combinada, los usuarios pueden examinar y explorar los metadatos de todos los activos de datos mediante un catálogo de datos unificado. Esto permite a los usuarios buscar rápidamente las tablas o atributos necesarios sin saber dónde residen físicamente los datos dentro del sistema.
-
Los catálogos de datos también ofrecen funciones para aumentar los datos técnicos con contexto empresarial. Los propietarios de los datos pueden añadir descripciones empresariales y significados empresariales a los atributos. Esto permite a los usuarios empresariales y técnicos descubrir fácilmente los datos.
- Controles de acceso coherentes
-
Gestionar y mantener el acceso a los datos es difícil. Se convierte en un reto aún mayor cuando quieres implantar niveles de acceso coherentes en toda tu plataforma. Los catálogos de datos unificados ayudan a implantar un mecanismo de control de acceso coherente en todo el ecosistema de datos.
-
Puedes implantar un mecanismo de control de acceso coherente para distintas personas, independientemente de los motores informáticos que utilicen. Considera un escenario en el que quieres que los ingenieros de datos y los científicos de datos de tu equipo de ventas puedan acceder a los activos de datos específicos de su unidad de negocio. Los ingenieros de datos podrían utilizar blocs de notas, mientras que los científicos de datos podrían querer consultar las tablas del almacén de características para acceder a los datos. Utilizando el mecanismo de control de acceso unificado, puedes proporcionar los mismos niveles de acceso a ambas personas.
- Gobernanza y seguridad unificadas de los datos
-
Con un catálogo de datos unificado, puedes implantar políticas unificadas de gobierno y seguridad de datos que se apliquen a todos los activos, incluyendo tablas, archivos, funciones, modelos ML y tablas de características. Puedes asegurar tus datos aplicando las políticas de enmascaramiento coherentes a los datos sensibles dentro del lago de datos. Cualquier persona, independientemente de la herramienta utilizada para acceder a los datos, sólo puede ver los datos a los que tiene derecho a acceder.
- Linaje de datos de extremo a extremo
-
Con un lakehouse que emplee un metastore y un catálogo unificados, puedes ver fácilmente el linaje de principio a fin en todos los componentes. Algunos de los catálogos de datos avanzados también proporcionan capacidades para implementar catálogos federados, que pueden mostrar los metadatos de fuentes ajenas a tu plataforma de datos, así como el linaje que incluye estas fuentes.
-
Unificar varios aspectos de los procesos de gestión de datos en todos los activos proporciona a los usuarios de la plataforma Lakehouse una experiencia coherente desde cualquier lugar en que accedan a los datos.
Implantación de un Catálogo de Datos: Consideraciones y opciones clave de diseño
Existen múltiples herramientas y plataformas que pueden ayudarte a implantar catálogos de datos en un lago. Cada proveedor de la nube tiene sus propios servicios nativos y la mayoría de los principales productos de terceros tienen funciones para implantar catálogos de datos.
Puedes diseñar e implantar un catálogo de datos unificado en función de tu caso de uso y del panorama técnico general. En esta sección, hablaré de algunas de las principales herramientas de catálogo de datos, consideraciones de diseño, posibles opciones de diseño y limitaciones clave para implantar un catálogo de datos en una plataforma lakehouse.
Hablaremos del metastore Hive, ampliamente adoptado; de los catálogos de datos nativos de la nube de AWS, Azure y GCP; y de las ofertas de catálogos de datos de terceros, como Databricks.
Utilizar el metastore Hive
Hive es popular desde los tiempos de Hadoop. Muchas organizaciones han adoptado Hive metastore (HMS) para dar soporte a sus necesidades de gestión de metadatos mientras implementan ecosistemas Hadoop o plataformas de datos modernas. Los ecosistemas Hadoop tradicionales utilizaban MapReduce como motor de cálculo y HCatalog como catálogo de datos para acceder a HMS. Spark también tiene una API de catálogo de datos para acceder a los metadatos almacenados en HMS.
Puedes plantearte utilizar HMS para almacenar los metadatos de tu plataforma de datos. HMS proporciona a los usuarios la flexibilidad de utilizar un RDBMS externo para almacenar metadatos como tipos de tablas, nombres de columnas y tipos de datos de columnas. Sirve como repositorio central para almacenar y gestionar los metadatos de las tablas creadas utilizando diferentes motores de cálculo como Hive, Spark o Flink. Los servicios nativos en la nube como AWS Glue y terceros como Databricks, y muchos otros, ofrecen opciones para utilizar HMS para almacenar metadatos.
Aunque muchas organizaciones han adoptado HMS como su metastore principal, tiene un par de retos clave:
-
Tienes que aprovisionar y gestionar un RDBMS independiente para almacenar los metadatos, lo que aumenta la sobrecarga de mantenimiento.
-
Como no es un servicio nativo de la nube, tienes que dedicar un esfuerzo extra a su integración, en comparación con los servicios de catálogo de datos nativos de la nube.
Teniendo en cuenta estos retos, los CSP han introducido servicios de catalogación nativos para implantar procesos de gestión de metadatos fáciles y sencillos.
Uso de los servicios de AWS
AWS ofrece dos opciones para almacenar metadatos -HMS y Catálogo de datos Glue.
Glue Data Catalog, un servicio nativo de AWS, se integra fácilmente con servicios como AWS Glue ETL, Amazon EMR, Amazon Athena y AWS Lake Formation. Utilizarías la mayoría de estos servicios al implementar una plataforma de lago en AWS.
Nota
He aquí una rápida descripción de los servicios de AWS que acabamos de mencionar. Hablaré de ellos en detalle en capítulos posteriores de este libro:
-
AWS Glue ETL es un servicio de integración de datos sin servidor que permite crear trabajos Spark para el procesamiento de datos.
-
Amazon EMR proporciona una plataforma de big data para ejecutar marcos como Spark, Hive, Presto, HBase y otros marcos de big data para el procesamiento de datos, el análisis interactivo y el aprendizaje automático.
-
Amazon Athena es un servicio sin servidor para el análisis interactivo de datos almacenados en S3.
-
AWS Formación de Lagos proporciona capacidades para asegurar y gobernar los datos en S3.
La Figura 4-4 muestra un sencillo diagrama de flujo de cómo puedes crear archivos Hudi en S3, analizarlos para crear metadatos en el Catálogo de Datos Glue, gobernar tablas Hudi utilizando Lake Formation, y consultarlas utilizando el motor Amazon Athena. También puedes utilizar otros formatos de tabla abiertos, como Iceberg o Delta Lake, en lugar de Hudi.
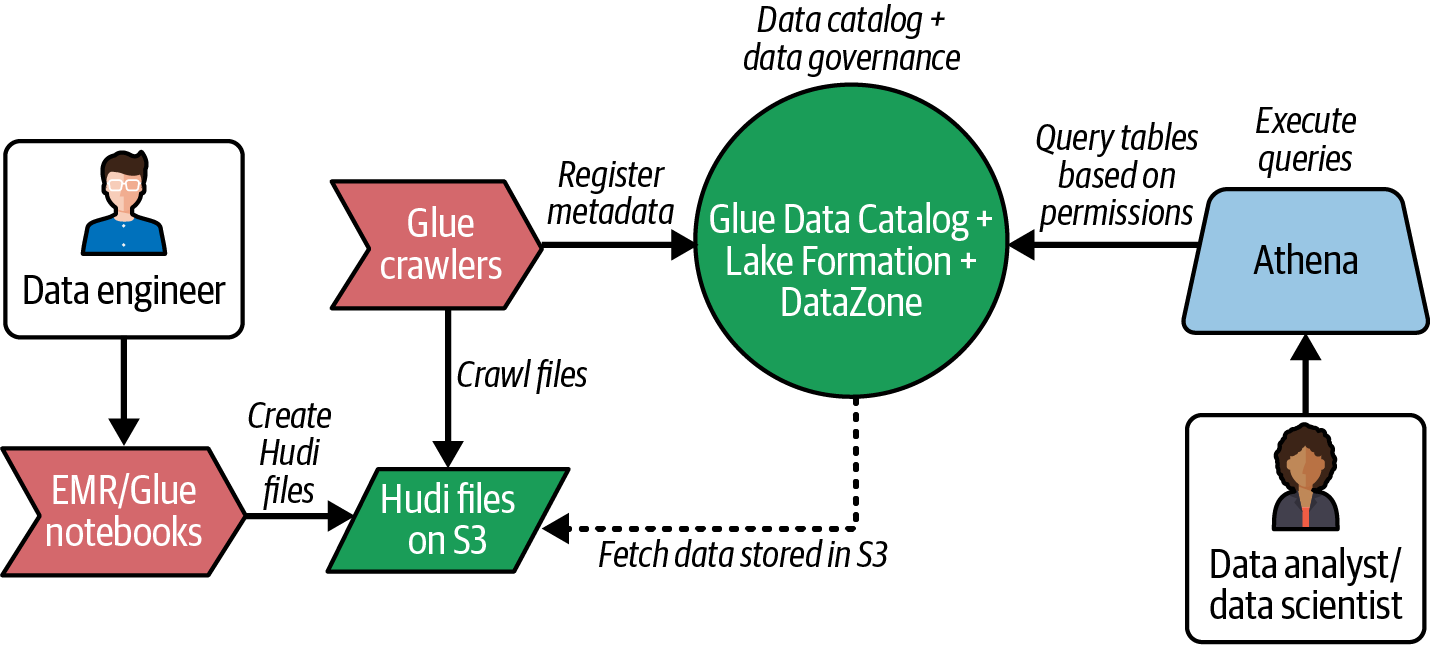
Figura 4-4. Flujo de datos de Lakehouse en el ecosistema AWS
Como se muestra en el diagrama, el Catálogo de Datos Glue desempeña un papel importante en la arquitectura de Lakehouse para permitir que diferentes personas creen, accedan y consulten datos que residen en S3.
Al igual que HMS, Glue Data Catalog también proporciona un repositorio central de metadatos para todos los activos de datos. Las principales características de AWS Glue Data Catalog son las siguientes:
-
Tiene profundas integraciones con otros servicios de AWS.
-
Se trata de un servicio sin servidor, totalmente gestionado, que no necesita ser implementado ni mantenido por el usuario.
-
Puedes utilizar rastreadores Glue para analizar los archivos de datos de S3 y crear metadatos dentro del catálogo.
-
Su integración con Amazon Athena proporciona una interfaz de usuario para explorar fácilmente el esquema, las tablas y los atributos.
-
Las tablas creadas utilizando marcos de código abierto como Spark, Hive y Presto dentro del clúster EMR pueden utilizar el Catálogo de Datos Glue para almacenar sus metadatos.
-
Se integra con AWS Lake Formation para proporcionar a los usuarios un control de acceso de grano fino.
Amazon también ofrece un servicio llamado Amazon DataZone, que puede ayudarte a implementar un catálogo de datos con capacidades para aumentar los metadatos técnicos con metadatos empresariales. Puedes importar los metadatos almacenados en el Catálogo de Datos Glue a DataZone y añadir descripciones empresariales a los atributos técnicos para darles un contexto empresarial. Además, puedes gobernar y compartir tus datos mediante DataZone, que utiliza internamente Lake Formation para la gestión de permisos y la compartición de datos.
Considera los siguientes puntos clave cuando utilices los servicios de AWS para implementar un catálogo de datos para tu plataforma Lakehouse:
- Pegar Catálogo de Datos en lugar de HMS
-
Glue Data Catalog es una alternativa a HMS. Puedes utilizar Glue Data Catalog como metastore para los metadatos de las tablas que se crean utilizando motores de consulta como Hive, Spark y Presto dentro del clúster de Amazon EMR. El Catálogo de Datos Glue admite el almacenamiento de metadatos para tablas Hudi, Iceberg y Delta Lake. La capacidad de admitir tu formato de tabla abierta preferido es una de las consideraciones más importantes a la hora de seleccionar un servicio de catálogo de datos.
- Rastreadores de cola para la creación automatizada de metadatos
-
Puedes utilizar rastreadores de AWS Glue para rastrear los archivos de datos en S3 y obtener (analizar) los metadatos. Los rastreadores Glue almacenan los metadatos en el Catálogo de Datos Glue y crean las tablas basándose en los registros analizados de los archivos. Puedes utilizar rastreadores para generar los metadatos de todos tus archivos almacenados en S3. Los rastreadores Glue también pueden detectar cambios de esquema en el almacén de datos S3. Puedes configurar los rastreadores para que actualicen o ignoren los cambios en las tablas del catálogo de datos.
- Soporte de formato de tabla
-
Los rastreadores Glue ahora también admiten archivos Hudi, Iceberg y Delta Lake para crear automáticamente tablas en el Catálogo de Datos Glue. Dependiendo del formato de tabla que elijas, puedes seleccionar la opción correspondiente al crear los rastreadores.
- Formación de lagos para la gobernanza de datos
-
El Catálogo de Datos Glue está bien integrado con Lake Formation, que te ayuda a implantar controles de acceso detallados y otras funciones de gobierno de datos, como el filtrado de datos basado en roles y el uso compartido seguro de datos.
- Athena para la exploración de datos
-
El Catálogo de Datos Glue tiene una profunda integración con Amazon Athena, un servicio para consultar datos en el lago de datos S3. Hablaremos de ello en detalle en el Capítulo 5. Athena te permite explorar todas las bases de datos, tablas y columnas del Catálogo de Datos Glue.
Uso de los servicios Azure
Si planeas implementar un lago utilizando el ecosistema Azure, utilizarás servicios como Azure Synapse Analytics como capa de cálculo y ADLS como capa de almacenamiento.
Synapse Analytics ofrece dos motores informáticos para procesar los datos almacenados en ADLS: Synapse Spark pools y Synapse serverless SQL pools. Los ingenieros de datos familiarizados con la programación Spark pueden utilizar los pools Spark. Para los analistas de datos que se sientan más cómodos con SQL, Synapse ofrece pools SQL sin servidor. Puedes utilizar cualquiera de ellos para procesar los datos almacenados en ADLS. Hablaremos de estos motores de cálculo con más detalle en el Capítulo 5.
La Figura 4-5 muestra las dos opciones que ofrece Synapse Analytics para mantener y gestionar los metadatos de los datos almacenados en ADLS: la base de datos del lago y la base de datos SQL:
- Base de datos de lagos
-
Los pools de Synapse Spark gestionan las bases de datos de lago. Puedes utilizar las bases de datos lago para almacenar los metadatos de los objetos creados utilizando los cuadernos Synapse. Esto incluye los metadatos de las tablas delta creadas mediante los pools de Spark.
- Base de datos SQL
-
Los pools SQL sin servidor gestionan las bases de datos SQL de Synapse. Puedes crear tablas utilizando los grupos SQL sin servidor de Synapse en la base de datos SQL, y puedes utilizar los puntos finales SQL sin servidor para conectar Management Studio o Power BI a las tablas de la base de datos SQL y consultar los datos.
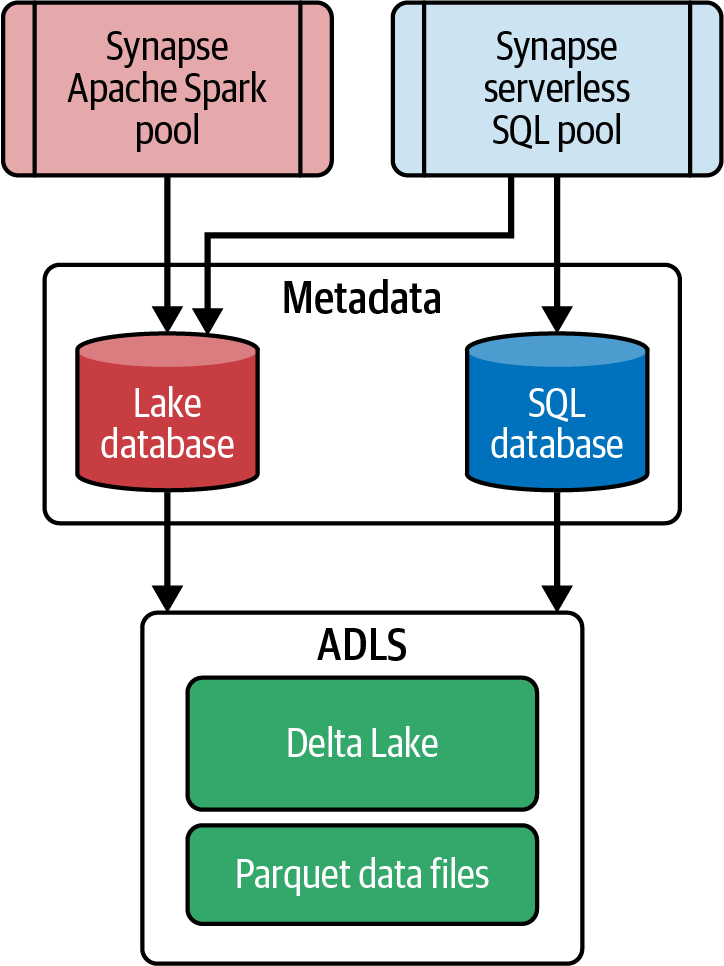
Figura 4-5. Gestión de metadatos mediante Synapse Analytics
Nota
La base de datos SQL de Synapse es diferente del servicio de base de datos Azure SQL (base de datos relacional). La base de datos SQL de Synapse contiene los metadatos de las tablas creadas mediante los pools SQL sin servidor de Synapse. No contiene los datos reales, ya que éstos residen en ADLS.
Dependiendo del motor informático que utilices, puedes seleccionar base de datos lake (para pools Spark) o base de datos SQL (para pools SQL sin servidor). Como se muestra en la Figura 4-5, la ventaja de utilizar la base de datos lago es que puedes acceder a ella desde los cuadernos Synapse, así como desde los pools SQL sin servidor de Synapse.
La Figura 4-6 muestra cómo puedes crear tablas delta en ADLS, metadatos en una base de datos lago, e implementar un catálogo unificado con Microsoft Purview para consultarlo de forma segura mediante pools SQL sin servidor de Synapse para su posterior análisis.
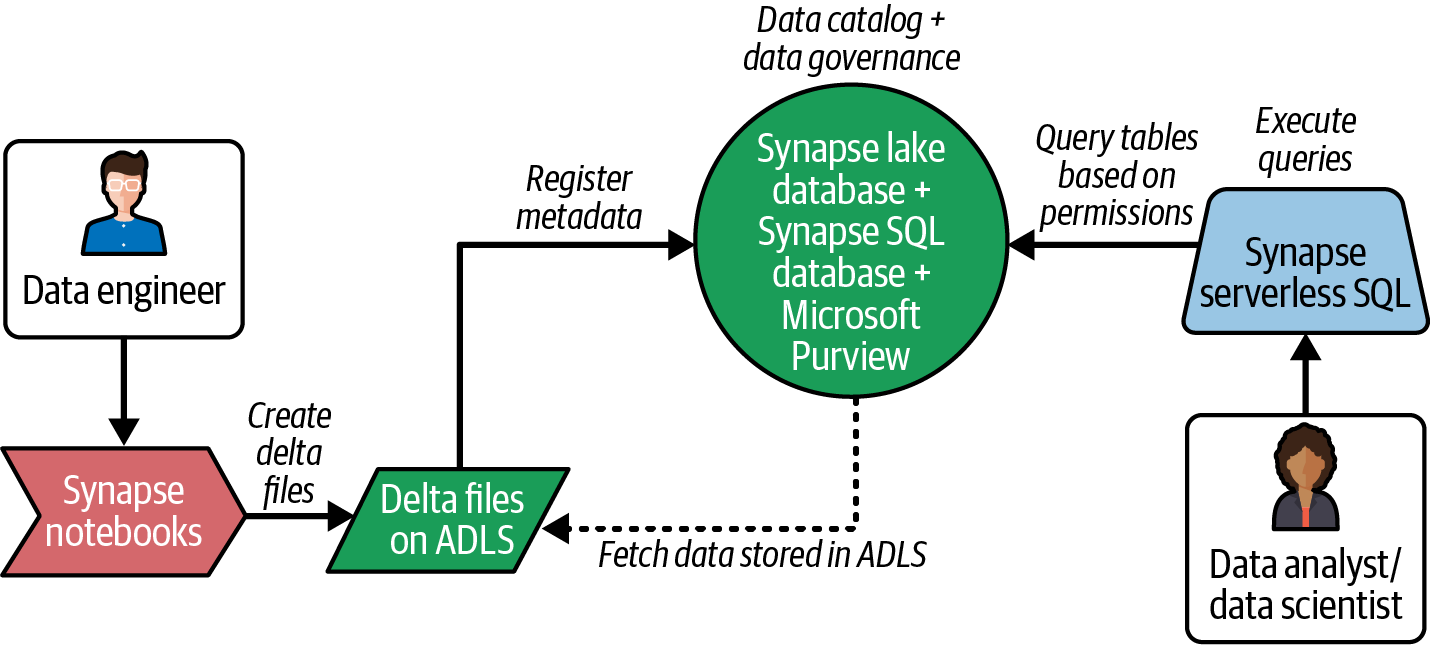
Figura 4-6. Flujo de datos de Lakehouse en el ecosistema Azure
Como se muestra en la Figura 4-6, puedes crear tablas delta utilizando cuadernos Synapse y, a continuación, utilizar el punto final SQL pools sin servidor para consultar los datos mediante Power BI o cualquier otro editor de consultas de bases de datos, como SQL Server Management Studio (SSMS).
Aunque la base de datos Synapse lake y la base de datos SQL persisten los metadatos, no son soluciones de catalogación completas. Azure ofrece un servicio llamado Microsoft Purview que proporciona capacidades de catálogo. Puedes plantearte utilizarlo para implementar un catálogo de datos para tu lago.
Microsoft Purview ofrece soporte para la gobernanza unificada de datos en plataformas locales, nativas de Azure y multi-nube, así como soporte para la clasificación de datos y la gestión de datos sensibles. También ofrece funciones como linaje de datos, control de acceso y uso compartido de datos, así como funciones para crear y mantener un glosario empresarial para los usuarios empresariales. Puedes importar los metadatos de la base de datos SQL de Synapse a Microsoft Purview y aprovechar estas funciones en tu plataforma.
Utilizar los servicios de GCP
Al igual que AWS y Azure, puedes seguir un patrón similar para crear tu catálogo de datos en GCP y utilizarlo como capa central y unificada para la gestión de metadatos.
La Figura 4-7 muestra cómo puedes crear tablas Iceberg en GCS y metadatos en BigLake, gobernar centralmente los metadatos mediante Dataplex, y consultarlos de forma segura mediante BigQuery para su posterior análisis.
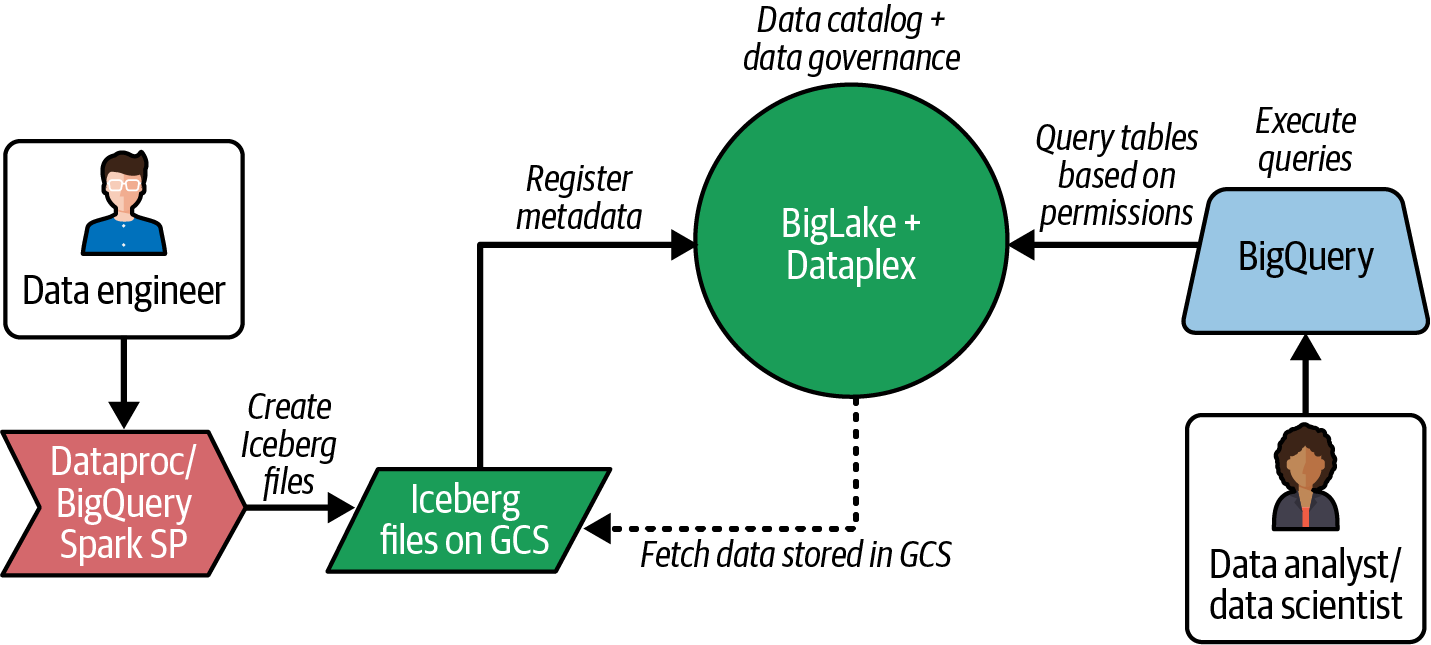
Figura 4-7. Flujo de datos de Lakehouse en el ecosistema GCP
Nota
He aquí una descripción rápida de los servicios informáticos que se muestran en la Figura 4-7, de los que hablaré en detalle en capítulos posteriores:
- BigLake
-
BigLake es un servicio de GCP que permite a BigQuery y otros marcos de código abierto como Spark acceder a los datos almacenados en GCS con un control de acceso de grano fino. Es compatible con el formato de tabla abierta Iceberg y permite a los usuarios de BigQuery consultar datos Iceberg almacenados en GCS como tablas BigLake con permisos controlados.
-
Las principales características de BigLake son:
-
Proporciona un metastore para acceder a las tablas Iceberg desde BigQuery.
-
Puede sincronizar tablas Iceberg creadas en Dataproc o BigQuery y ponerlas a disposición de los usuarios a través de la interfaz SQL de BigQuery.
-
Permite a los administradores aplicar un control de acceso detallado a las tablas Iceberg.
Actualmente, BigLake sólo admite archivos de datos Parquet para Iceberg y tiene algunas limitaciones más.
-
- Dataplex
-
Dataplex es un servicio GCP que permite a las organizaciones descubrir y gobernar sus activos de datos. Proporciona capacidades para explorar datos, gestionar el ciclo de vida de los datos y comprender el flujo de datos utilizando el linaje de extremo a extremo.
BigLake se integra con Dataplex para proporcionar un mecanismo central de control de acceso a las tablas de BigLake. Puedes considerar Dataplex para tu plataforma si quieres gestionar todos tus activos de datos desde un único panel de cristal.
Utilizar Databricks
Con el auge de la noción de multi-nube, muchas organizaciones han empezado a buscar productos de terceros que se integren bien con su estrategia multi-nube. Databricks ofrece uno de esos productos que permite a las organizaciones adoptar una estrategia multi-nube, ya que puede aprovechar la infraestructura de AWS, Azure y GCP para el cálculo y el almacenamiento.
Nota
La estrategia multi-nube es un enfoque que consiste en utilizar varias plataformas en la nube para obtener las mejores prestaciones y ventajas de costes que ofrecen los distintos CSP. Muchas organizaciones optan ahora por más de un proveedor de nube para implantar sus ecosistemas de datos.
Databricks ofrece un par de opciones para catalogar metadatos. Puedes utilizar HMS o un servicio nativo conocido como Databricks Unity Catalog para gestionar, mantener y gobernar los metadatos. Unity Catalog ayuda a implantar una solución de gobernanza unificada en todos los datos y activos de IA de un lago.
De forma similar a AWS Glue Data Catalog, Unity Catalog, al ser un servicio nativo dentro de Databricks, proporciona integraciones sencillas con características de Databricks como Notebooks y Databricks SQL.
Nota
Databricks SQL es un motor de cálculo sin servidor dentro de la plataforma Databricks lakehouse. Puedes utilizarlo para ejecutar consultas interactivas en lakehouse. Cuando se combina con un editor de consultas (un servicio disponible en la interfaz de usuario de Databricks para la creación de consultas), puedes explorar fácilmente los activos de datos del Catálogo HMS o Unity y ejecutar consultas utilizando comandos SQL.
La Figura 4-8 muestra un diagrama de flujo sencillo dentro de un lago implementado utilizando Azure Databricks. Puedes crear los archivos delta utilizando Databricks Notebooks y acceder a las tablas delta desde Databricks SQL.
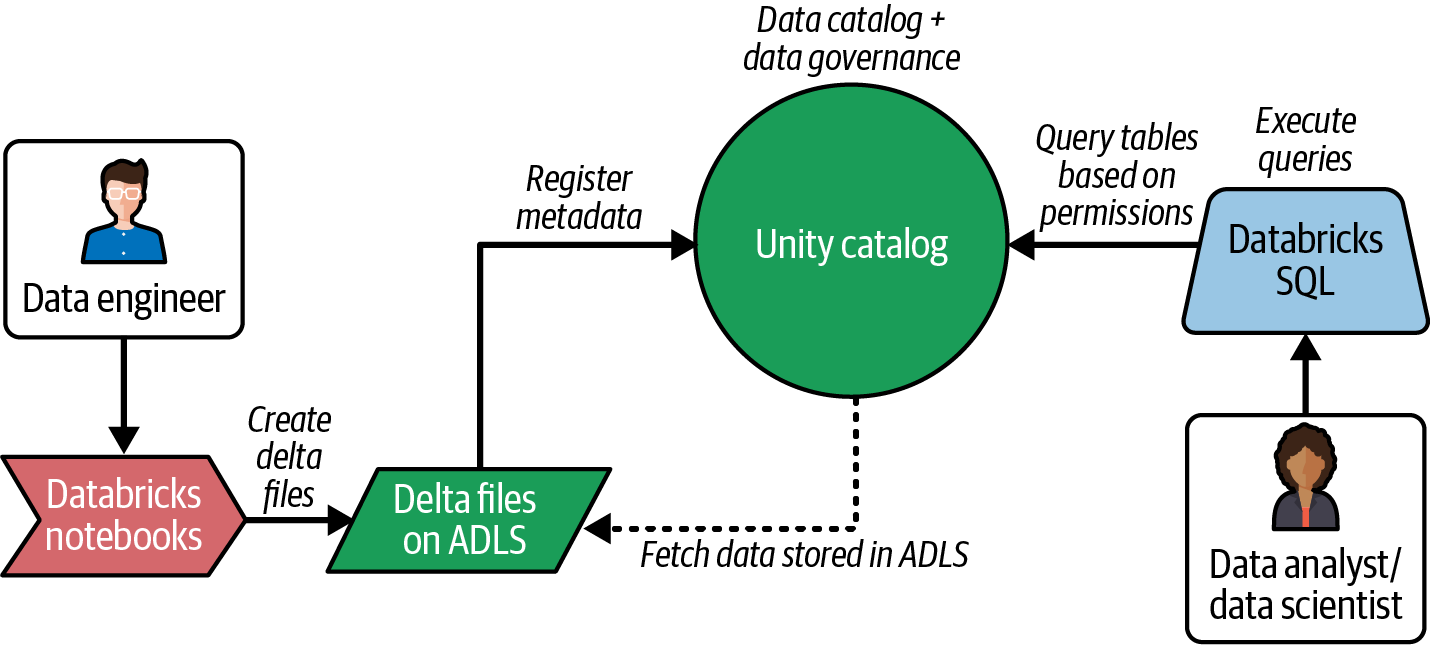
Figura 4-8. Flujo de datos de Lakehouse en el ecosistema Databricks
Unity Catalog desempeña un papel importante al proporcionar capacidades para gestionar metadatos en una ubicación central a la que pueden acceder tanto Databricks Notebooks como Databricks SQL. También proporciona el mecanismo central de control de acceso para aplicar políticas de gobierno de datos.
Las características clave que ofrece el Catálogo Unity son las siguientes:
-
Capacidad para gestionar y gobernar todos tus datos y activos de IA, como tablas, vistas, cuadernos, modelos de ML, tablas de características y cuadros de mando.
-
Posibilidad de añadir contexto empresarial, lo que facilita la búsqueda y el descubrimiento de datos
-
Capacidad para proporcionar catálogos federados (en vista previa en el momento de escribir este libro) para fuentes externas como MySQL, PostgreSQL/Postgres, Snowflake y Redshift
-
Línea de datos de extremo a extremo a través de los ecosistemas Databricks, incluidos los componentes de IA
-
Asegurar la compartición de datos proporcionando controles de acceso detallados sobre los datos compartidos
-
Cualquier cambio de esquema y metadatos realizado en los cuadernos se refleja inmediatamente en Databricks SQL sin ningún retraso (en comparación con Azure Synapse Analytics con Delta Lake)
Databricks ha abierto recientemente el Catálogo Unity y pronto empezará a admitir varios productos de datos e IA.
Unity Catalog es una opción excelente para implementar un lago de datos dentro del ecosistema Databricks. Sin embargo, si quieres acceder a los metadatos y gobernarlos fuera de Databricks, también puedes considerar otros catálogos de nivel empresarial que pueden ingerir datos del Catálogo Unity de Databricks y ponerlos a disposición de los usuarios fuera de Databricks para facilitar el descubrimiento y el gobierno central.
Consejo
Muchas de las funciones y servicios comentados en esta sección son relativamente nuevos o aún están en fase de vista previa. Evolucionarán y madurarán gradualmente, y se ofrecerán soluciones para algunas de las limitaciones que hemos comentado aquí. Cuando explores estas herramientas para tu caso de uso, consulta la documentación más reciente y evalúa las últimas versiones.
Junto con los catálogos nativos de la nube , existen catálogos de código abierto como el Proyecto Nessie y herramientas de catalogación empresarial como Alation, Collibra y Atlan que ofrecen funciones adicionales y ventajas que puedes explorar para requisitos específicos.
Puntos clave
En este capítulo, hemos hablado de cómo puedes almacenar en los metadatos de todos tus activos de datos en un metastore y acceder a ellos mediante catálogos de datos basados en permisos de acceso. La arquitectura Lakehouse te permite implementar un catálogo de datos unificado para gestionar, gobernar y compartir todos tus datos y activos de IA.
La Tabla 4-4 resume los distintos servicios disponibles en las plataformas en la nube para implantar procesos de gestión de metadatos.
| Proveedor | Gestión técnica de metadatos | Gestión de metadatos empresariales y gobernanza de datos |
|---|---|---|
| AWS | HMS, Catálogo de Datos de Colas | Zona de datos |
| Azure | Base de datos Synapse Lake, Base de datos Synapse SQL | Ámbito de Microsoft |
| GCP | BigLake | Dataplex |
| Databricks | HMS, Catálogo Unity | Catálogo Unity |
La Tabla 4-5 resume las consideraciones clave de diseño, por ecosistema, a la hora de implantar un catálogo de datos en la arquitectura lakehouse.
En este capítulo, hemos centrado nuestro aprendizaje en los metastores y catálogos de datos, y en sus características y ventajas en la arquitectura Lakehouse. En el próximo capítulo, hablaremos de las distintas opciones de consumo de datos y cálculo dentro de la arquitectura Lakehouse, y de cómo ayudan a las distintas personas a realizar cargas de trabajo analíticas y de datos de forma eficiente.
Referencias
- AWS
- Azure
-
-
Llevar los activos de ML al mapa de datos de Microsoft Purview
-
Organizar la estructura de la casa del lago en Synapse Analytics
-
Conectarse y gestionar los Databricks de Azure en Microsoft Purview | Microsoft Learn
-
Conectar y gestionar el catálogo Azure Databricks Unity en Microsoft Purview | Microsoft Learn
-
Metadatos compartidos de Azure Synapse Analytics | Microsoft Learn
- GCP
- Databricks
- Otros
Get Arquitectura práctica de casas en el lago now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

