Kapitel 1. Die Modernisierung deiner Datenplattform: Ein einführender Überblick
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Daten sind ein wertvolles Gut, das deinem Unternehmen helfen kann, bessere Entscheidungen zu treffen, neue Möglichkeiten zu erkennen und die Abläufe zu verbessern. Google unternahm 2013 ein strategisches Projekt, um die Mitarbeiterbindung durch die Verbesserung der Qualität der Führungskräfte zu erhöhen. Sogar etwas so Unwichtiges wie die Fähigkeiten von Managern konnte auf datengestützte Weise untersucht werden. Google konnte die Gunst des Managements von 83% auf 88% steigern, indem es 10.000 Leistungsbeurteilungen analysierte, gemeinsame Verhaltensweisen von leistungsstarken Managern feststellte und Schulungsprogramme entwickelte. Ein weiteres Beispiel für ein strategisches Datenprojekt wurde bei Amazon durchgeführt. Der E-Commerce-Riese führte ein Empfehlungssystem ein, das auf dem Kundenverhalten basiert und 2017 35 % der Einkäufe auslöste. Ein weiteres Beispiel sind die Warriors, ein Basketballteam aus San Francisco, das ein Analyseprogramm eingeführt hat, das sie an die Spitze der Liga katapultiert hat. All dies - Mitarbeiterbindung, Produktempfehlungen, Verbesserung der Gewinnquoten - sind Beispiele für Geschäftsziele, die durch moderne Datenanalyse erreicht wurden.
Um ein datengesteuertes Unternehmen zu werden, musst du ein Ökosystem für Datenanalysen, -verarbeitung und -erkenntnisse aufbauen. Denn es gibt viele verschiedene Arten von Anwendungen (Websites, Dashboards, mobile Apps, ML-Modelle, verteilte Geräte usw.), die Daten erzeugen und verbrauchen. Außerdem gibt es viele verschiedene Abteilungen in deinem Unternehmen (Finanzen, Vertrieb, Marketing, Betrieb, Logistik usw.), die datengestützte Erkenntnisse benötigen. Da das gesamte Unternehmen dein Kundenstamm ist, ist der Aufbau einer Datenplattform mehr als nur ein IT-Projekt.
In diesem Kapitel werden Datenplattformen und ihre Anforderungen vorgestellt und es wird erläutert, warum herkömmliche Datenarchitekturen nicht ausreichen. Außerdem werden Technologietrends in den Bereichen Datenanalyse und KI erörtert und es wird erklärt, wie man Datenplattformen für die Zukunft mit Hilfe der öffentlichen Cloud aufbaut. Dieses Kapitel ist ein allgemeiner Überblick über die Kernthemen, die im Rest des Buches ausführlicher behandelt werden.
Der Lebenszyklus der Daten
Der Zweck einer Datenplattform ist es, die Schritte zu unterstützen, die Unternehmen durchführen müssen, um von Rohdaten zu aufschlussreichen Informationen zu gelangen. Es ist hilfreich, die Schritte des Datenlebenszyklus zu verstehen (Erfassen, Speichern, Verarbeiten, Visualisieren, Aktivieren), denn sie lassen sich fast wie von selbst auf eine Datenarchitektur abbilden, um eine einheitliche Analyseplattform zu schaffen.
Die Reise zur Weisheit
Daten helfen Unternehmen dabei, intelligentere Produkte zu entwickeln, mehr Kunden zu erreichen und ihre Kapitalrendite (ROI) zu steigern. Daten können auch genutzt werden, um Kundenzufriedenheit, Rentabilität und Kosten zu messen. Aber die Daten allein reichen nicht aus. Daten sind Rohmaterial, das eine Reihe von Stufen durchlaufen muss, bevor es genutzt werden kann, um Erkenntnisse und Wissen zu gewinnen. Diese Abfolge von Phasen nennen wir einen Datenlebenszyklus. In der Literatur gibt es viele Definitionen, aber aus allgemeiner Sicht können wir fünf Hauptphasen in der modernen Datenplattformarchitektur identifizieren:
- 1. Sammle
-
Die Daten müssen erfasst und in die Zielsysteme eingespeist werden (z. B. durch manuelle Dateneingabe, Batch Loading, Streaming Ingestion usw.).
- 2. Speichere
-
Die Daten müssen dauerhaft gespeichert werden, damit sie auch in Zukunft leicht zugänglich sind (z. B. in einem Dateisystem oder einer Datenbank).
- 3. Verarbeiten/umwandeln
-
Die Daten müssen manipuliert werden, um sie für die nachfolgenden Schritte nutzbar zu machen (z. B. Bereinigung, Verarbeitung, Umwandlung).
- 4. Analysieren/Visualisieren
-
Die Daten müssen untersucht werden, um durch manuelle Bearbeitung (z. B. Abfragen, Slice and Dice) oder automatische Verarbeitung (z. B. Anreicherung mit ML Application Programming Interfaces - APIs) Geschäftserkenntnisse zu gewinnen.
- 5. Aktiviere
-
Aufbereitung der Datenerkenntnisse in einer Form und an einem Ort, an dem Entscheidungen getroffen werden können (z. B. Benachrichtigungen, die als Auslöser für bestimmte manuelle Aktionen dienen, automatische Auftragsausführungen, wenn bestimmte Bedingungen erfüllt sind, ML-Modelle, die Feedback an Geräte senden).
Jede dieser Stufen mündet in die nächste, ähnlich wie der Fluss von Wasser durch ein Rohrsystem.
Wasserrohre Analogie
Um den Lebenszyklus von Daten besser zu verstehen, kannst du ihn dir wie ein vereinfachtes Wasserrohrsystem vorstellen. Das Wasser beginnt an einem Aquädukt und wird dann durch eine Reihe von Rohren geleitet und umgewandelt, bis es eine Gruppe von Häusern erreicht. Der Lebenszyklus von Daten ist ähnlich: Daten werden gesammelt, gespeichert, verarbeitet/umgewandelt und analysiert, bevor sie zur Entscheidungsfindung genutzt werden (siehe Abbildung 1-1).
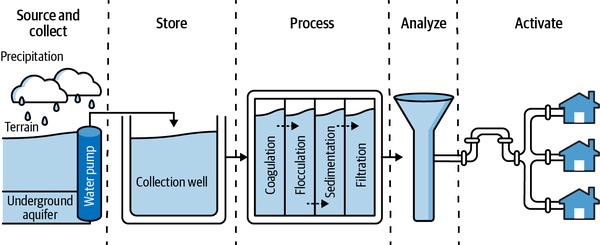
Abbildung 1-1. Der Lebenszyklus des Wassers als Analogie zu den fünf Schritten im Lebenszyklus der Daten
Es gibt einige Ähnlichkeiten zwischen der Welt der Klempner und der Welt der Daten. Sanitäringenieure sind wie Dateningenieure, die die Systeme entwerfen und bauen, die Daten nutzbar machen. Menschen, die Wasserproben analysieren, sind wie Datenanalysten und Datenwissenschaftler, die Daten analysieren, um Erkenntnisse zu gewinnen. Das ist natürlich nur eine Vereinfachung. Es gibt noch viele andere Rollen in einem Unternehmen, die Daten nutzen, z. B. Führungskräfte, Entwickler, Geschäftsanwender und Sicherheitsadministratoren. Aber diese Analogie kann dir helfen, dich an die wichtigsten Konzepte zu erinnern.
Im kanonischen Datenlebenszyklus, der in Abbildung 1-2 dargestellt ist, sammeln und speichern Dateningenieure Daten in einem Analysespeicher. Die gespeicherten Daten werden dann mit einer Reihe von Tools verarbeitet. Wenn die Tools programmiert werden müssen, wird die Verarbeitung in der Regel von Dateningenieuren durchgeführt. Wenn die Tools deklarativ sind, wird die Verarbeitung in der Regel von Datenanalysten vorgenommen. Die verarbeiteten Daten werden dann von Geschäftsanwendern und Datenwissenschaftlern analysiert. Fachanwender/innen nutzen die Erkenntnisse, um Entscheidungen zu treffen, z. B. Marketingkampagnen zu starten oder Rückerstattungen zu gewähren. Datenwissenschaftler/innen nutzen die Daten, um ML-Modelle zu trainieren, die zur Automatisierung von Aufgaben oder zur Erstellung von Vorhersagen verwendet werden können.
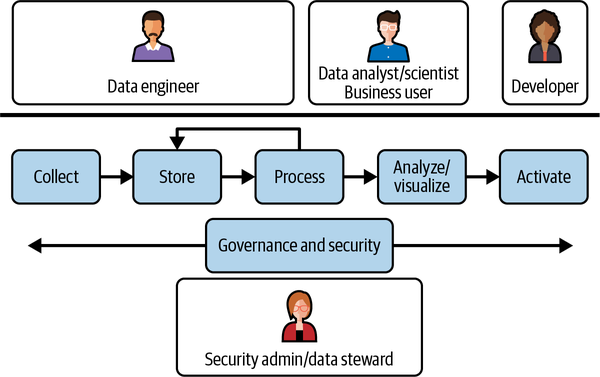
Abbildung 1-2. Vereinfachter Lebenszyklus von Daten
Die reale Welt kann von der vorangegangenen idealisierten Beschreibung der Architektur und der Rollen einer modernen Datenplattform abweichen. Die Phasen können kombiniert (z. B. Speicherung und Verarbeitung) oder neu geordnet werden (z. B. Verarbeitung vor Speicherung, wie in ETL [extract-transform-load], statt Speicherung vor Verarbeitung, wie in ELT [extract-load-transform]). Es gibt jedoch auch Kompromisse bei solchen Varianten. So führt die Kombination von Speicherung und Verarbeitung in einer einzigen Phase zu einer Kopplung, die zu einer Verschwendung von Ressourcen führt (wenn die Datenmengen wachsen, musst du sowohl die Speicherung als auch die Rechenleistung skalieren) und zu Problemen bei der Skalierbarkeit (wenn deine Infrastruktur die zusätzliche Last nicht bewältigen kann, hast du das Nachsehen).
Nachdem wir nun den Datenlebenszyklus definiert und die verschiedenen Phasen der Datenreise von der Rohdatenerfassung bis zur Aktivierung zusammengefasst haben, wollen wir die fünf Phasen des Datenlebenszyklus nacheinander durchgehen.
Sammle
Der erste Schritt im Entwurfsprozess ist das Ingestion. Ingestion ist der Prozess der Übertragung von Daten von einer Quelle, die überall sein kann (vor Ort, auf Geräten, in einer anderen Cloud usw.), zu einem Zielsystem, wo sie zur weiteren Analyse gespeichert werden können. Dies ist die erste Gelegenheit, die 3 Vs von Big Data zu betrachten:
- Band
-
Wie groß sind die Daten? Wenn es um Big Data geht, sind damit in der Regel Terabyte (TB) oder Petabyte (PB) an Daten gemeint.
- Geschwindigkeit
-
Wie hoch ist die Geschwindigkeit der eingehenden Daten? In der Regel sind das Megabyte/Sekunde (MB/s) oder TB/Tag. Dies wird oft als Durchsatz bezeichnet.
- Sorte
-
Welches Format haben die Daten? Tabellen, flache Dateien, Bilder, Ton, Text, etc.
Bestimme den Datentyp (strukturiert, semistrukturiert, unstrukturiert), das Format und die Generierungshäufigkeit (kontinuierlich oder in bestimmten Intervallen) der zu erfassenden Daten. Je nach Geschwindigkeit der Daten und der Fähigkeit der Datenplattform, das daraus resultierende Volumen und die Vielfalt zu bewältigen, wähle zwischen Batch ingestion, Streaming ingestion oder einer Mischung aus beidem.
Da verschiedene Teile der Organisation an unterschiedlichen Datenquellen interessiert sein können, solltest du diese Phase so flexibel wie möglich gestalten. Es gibt verschiedene kommerzielle und Open-Source-Lösungen, die jeweils auf einen bestimmten Datentyp/eine bestimmte Herangehensweise spezialisiert sind (siehe oben). Deine Datenplattform muss umfassend sein und das gesamte Spektrum an Volumen, Geschwindigkeit und Vielfalt unterstützen, das für alle Daten erforderlich ist, die in die Plattform eingespeist werden müssen. Das können einfache Tools sein, die in regelmäßigen Abständen Dateien zwischen FTP-Servern (File Transfer Protocol) übertragen, oder komplexe, auch geografisch verteilte Systeme, die Daten von IoT-Geräten in Echtzeit sammeln.
Laden
In diesem Schritt speicherst du die Rohdaten, die du im vorherigen Schritt gesammelt hast. Du änderst die Daten überhaupt nicht, du speicherst sie nur. Das ist wichtig, weil du die Daten später vielleicht auf eine andere Art und Weise weiterverarbeiten möchtest und du dafür die Originaldaten brauchst.
Daten gibt es in vielen verschiedenen Formen und Größen. Die Art und Weise, wie du sie speicherst, hängt von deinen technischen und wirtschaftlichen Anforderungen ab. Zu den gängigen Optionen gehören Objektspeicher, relationale Datenbankmanagementsysteme (RDBMS), Data Warehouses (DWHs) und Data Lakes. Deine Wahl wird in gewissem Maße davon abhängen, ob die zugrunde liegende Hardware, Software und Artefakte die Anforderungen an Skalierbarkeit, Kosten, Verfügbarkeit, Haltbarkeit und Offenheit erfüllen, die sich aus deinen gewünschten Anwendungsfällen ergeben.
Skalierbarkeit
Skalierbarkeit ist die Fähigkeit, zu wachsen und steigende Anforderungen auf kompetente Weise zu bewältigen. Es gibt zwei Hauptwege, um Skalierbarkeit zu erreichen:
- Vertikale Skalierbarkeit
-
Dazu werden unter zusätzliche Erweiterungseinheiten an denselben Knotenpunkt angeschlossen, um die Kapazität des Speichersystems zu erhöhen.
- Horizontale Skalierbarkeit
-
Dabei werden unter ein oder mehrere zusätzliche Knotenpunkte hinzugefügt, anstatt neue Erweiterungseinheiten zu einem einzelnen Knotenpunkt hinzuzufügen. Diese Art der verteilten Speicherung ist zwar komplizierter zu verwalten, aber sie kann die Leistung und Effizienz verbessern.
Es ist äußerst wichtig, dass das zugrundeliegende System in der Lage ist, das Volumen und die Geschwindigkeit zu bewältigen, die von modernen Lösungen verlangt werden, die in einer Umgebung arbeiten müssen, in der die Datenmenge explodiert und sich von Batch- zu Echtzeitdaten wandelt: Wir leben in einer Welt, in der die Mehrheit der Menschen ständig Informationen generiert und über ihre Smart Devices darauf zugreifen muss; Organisationen müssen in der Lage sein, ihren Nutzern (sowohl internen als auch externen) Lösungen zur Verfügung zu stellen, die in der Lage sind, auf die verschiedenen Anfragen in Echtzeit zu reagieren.
Leistung versus Kosten
Identifiziere die verschiedenen Datentypen, die du verwalten musst, und erstelle eine Hierarchie, die auf der geschäftlichen Bedeutung der Daten, der Häufigkeit des Zugriffs und der Latenzzeit basiert, die die Nutzer der Daten erwarten.
Speichere die wichtigsten Daten, auf die am häufigsten zugegriffen wird (hot data), in einem hochleistungsfähigen Speichersystem, z. B. in der nativen Speicherung eines Data Warehouse. Weniger wichtige Daten (kalte Daten) speicherst du in einem kostengünstigeren Speichersystem wie der Cloud (die ihrerseits mehrere Ebenen hat). Wenn du eine noch höhere Leistung benötigst, z. B. für interaktive Anwendungsfälle, kannst du Caching-Techniken einsetzen, um einen bedeutenden Teil deiner heißen Daten in eine flüchtige Speicherung zu laden.
Hohe Verfügbarkeit
Hochverfügbarkeit bedeutet, dass das System betriebsbereit ist und auf die Daten zugreifen kann, wenn sie angefordert werden. Dies wird normalerweise durch Hardware-Redundanz erreicht, um mögliche physische Ausfälle zu bewältigen. In der Cloud wird dies durch die Speicherung der Daten in mindestens drei Verfügbarkeitszonen erreicht. Die Zonen müssen nicht unbedingt räumlich voneinander getrennt sein (d.h. sie können sich auf demselben "Campus" befinden), aber sie haben in der Regel unterschiedliche Stromquellen usw. Die Hardware-Redundanz wird in der Regel als Systemverfügbarkeit bezeichnet, und moderne Systeme verfügen in der Regel über vier 9er oder mehr.
Langlebigkeit
Langlebigkeit ist die Fähigkeit, Daten über einen langen Zeitraum zu speichern, ohne dass sie beschädigt werden oder verloren gehen. Dies wird in der Regel durch die Speicherung mehrerer Kopien der Daten an physisch getrennten Orten erreicht. Eine solche Datenredundanz wird in der Cloud umgesetzt, indem die Daten in mindestens zwei Regionen (z. B. in London und Frankfurt) speichert. Das ist besonders wichtig, wenn es um die Wiederherstellung von Daten bei Naturkatastrophen geht: Wenn das zugrunde liegende Speichersystem eine hohe Lebensdauer hat (moderne Systeme verfügen in der Regel über 11 9s), können alle Daten problemlos wiederhergestellt werden, es sei denn, ein katastrophales Ereignis legt auch die physisch getrennten Rechenzentren lahm.
Offenheit
Verwende so weit wie möglich Formate, die nicht proprietär sind und keinen Lock-in erzeugen. Idealerweise sollte es möglich sein, Daten mit verschiedenen Verarbeitungsprogrammen abzufragen, ohne Kopien der Daten zu erstellen oder sie von einem System in ein anderes verschieben zu müssen. Es ist jedoch akzeptabel, Systeme zu nutzen, die ein proprietäres oder natives Speicherformat verwenden, solange sie eine einfache Exportmöglichkeit bieten.
Wie bei den meisten Technologieentscheidungen ist Offenheit ein Kompromiss, und der ROI einer proprietären Technologie kann so hoch sein, dass du bereit bist, den Preis der Bindung zu zahlen. Schließlich ist einer der Gründe für den Wechsel in die Cloud die Senkung der Betriebskosten - diese Kostenvorteile sind bei vollständig verwalteten/serverlosen Systemen tendenziell höher als bei verwalteten Open-Source-Systemen. Wenn dein Datenanwendungsfall beispielsweise Transaktionen erfordert, könnte Databricks (das ein quasi-offenes Speicherformat auf Basis von Parquet namens Delta Lake verwendet) niedrigere Betriebskosten verursachen als Amazon EMR oder Google Dataproc (die Daten in Standard-Parquet auf S3 bzw. Google Cloud Storage [GCS] speichern) - die ACID (Atomicity, Consistency, Isolation, Durability) Transaktionen, die Databricks in Delta Lake anbietet, wären bei EMR oder Dataproc teuer zu implementieren und zu warten. Wenn du jemals von Databricks wegmigrieren musst, exportiere die Daten in Standard Parquet. Offenheit an sich ist kein Grund, eine Technologie abzulehnen, die besser geeignet ist.
Prozess/Transformation
Hier passiert die Magie: Rohdaten werden in nützliche Informationen für weitere Analysen umgewandelt. Dies ist die Phase, in der Dateningenieure Datenpipelines aufbauen, um die Daten einem breiteren Publikum von nichttechnischen Nutzern auf sinnvolle Weise zugänglich zu machen. Diese Phase besteht aus Aktivitäten, die Daten für die Analyse und Nutzung vorbereiten. Bei der Daten integration werden Daten aus verschiedenen Quellen zu einer einzigen Ansicht kombiniert. Die Bereinigung von Daten kann notwendig sein, um Duplikate und Fehler aus den Daten zu entfernen. Ganz allgemein werden die Daten bereinigt, gemischt und umgewandelt, um die Daten in ein Standardformat zu bringen.
Es gibt verschiedene Frameworks, die verwendet werden können, jedes mit seinen eigenen Fähigkeiten, die von der im vorherigen Schritt gewählten Speichermethode abhängen. Im Allgemeinen sind Engines, mit denen du deine Daten mit reinen SQL Befehlen abfragen und umwandeln kannst (z. B. AWS Athena, Google BigQuery, Azure DWH und Snowflake), am effizientesten, kostengünstigsten1 und einfach zu bedienen. Allerdings sind die Möglichkeiten, die sie bieten, im Vergleich zu Engines, die auf modernen Programmiersprachen, meist Java, Scala oder Python, basieren (z. B. Apache Spark, Apache Flink oder Apache Beam, die auf Amazon EMR, Google Cloud Dataproc/Dataflow, Azure HDInsight und Databricks laufen), begrenzt. Codebasierte Datenverarbeitungs-Engines ermöglichen es dir nicht nur, komplexere Transformationen und ML in Batch und in Echtzeit zu implementieren, sondern auch andere wichtige Funktionen wie richtige Unit- und Integrationstests zu nutzen.
Eine weitere Überlegung bei der Auswahl einer geeigneten Engine ist, dass SQL-Kenntnisse in einem Unternehmen in der Regel viel verbreiteter sind als Programmierkenntnisse. Je mehr du in deinem Unternehmen eine Datenkultur aufbauen willst, desto mehr solltest du dich bei der Datenverarbeitung auf SQL stützen. Das ist besonders wichtig, wenn die Verarbeitungsschritte (wie Datenbereinigung oder -umwandlung) Fachwissen erfordern.
In dieser Phase können auch Lösungen zur Datenvirtualisierung eingesetzt werden, die mehrere Datenquellen und die zugehörige Logik zu deren Verwaltung abstrahieren, um die Informationen den Endnutzern direkt zur Analyse zur Verfügung zu stellen. Wir werden in diesem Buch nicht weiter auf die Virtualisierung eingehen, da sie eher eine Zwischenlösung auf dem Weg zu einer vollständig flexiblen Plattform darstellt. Für weitere Informationen über Datenvirtualisierung empfehlen wir Kapitel 10 des Buches The Self-Service Data Roadmap von Sandeep Uttamchandani (O'Reilly).
Analysieren/Visualisieren
Wenn du dieses Stadium erreicht hast, haben die Daten endlich einen Wert an sich - du kannst sie als Informationen betrachten. Die Nutzer können eine Vielzahl von Werkzeugen nutzen, um in den Inhalt der Daten einzutauchen, nützliche Erkenntnisse zu gewinnen, aktuelle Trends zu erkennen und neue Ergebnisse vorherzusagen. In dieser Phase spielen Visualisierungstools und -techniken, die es den Nutzern ermöglichen, Informationen und Daten grafisch darzustellen (z. B. Diagramme, Schaubilder, Karten, Heatmaps usw.), eine wichtige Rolle, da sie eine einfache Möglichkeit bieten, Trends, Ausreißer, Muster und Verhalten zu entdecken und zu bewerten.
Die Visualisierung und Analyse von Daten kann von verschiedenen Arten von Nutzern durchgeführt werden. Auf der einen Seite gibt es Menschen, die Geschäftsdaten verstehen wollen und grafische Werkzeuge nutzen möchten, um allgemeine Analysen wie Slice-and-Dice-Roll-ups und Was-wäre-wenn-Analysen durchzuführen. Auf der anderen Seite gibt es fortgeschrittene Nutzer ("Power User"), die die Möglichkeiten einer Abfragesprache wie SQL nutzen wollen, um feinere und maßgeschneiderte Analysen durchzuführen. Außerdem könnte es Datenwissenschaftler/innen geben, die ML-Techniken nutzen, um neue Wege zu finden, um aussagekräftige Erkenntnisse aus den Daten zu gewinnen, Muster und Korrelationen zu entdecken, das Kundenverständnis und die Zielgruppenansprache zu verbessern und letztendlich den Umsatz, das Wachstum und die Marktposition eines Unternehmens zu steigern.
Aktiviere
Dies ist der Schritt, bei dem die Endnutzer/innen in der Lage sind, Entscheidungen auf der Grundlage von Datenanalysen und ML-Vorhersagen zu treffen und so einen Datenentscheidungsprozess zu ermöglichen. Aus den Erkenntnissen, die aus den verfügbaren Informationen gewonnen oder vorhergesagt wurden, können nun Maßnahmen ergriffen werden.
Die Aktionen, die durchgeführt werden können, lassen sich in drei Kategorien einteilen:
- Automatische Aktionen
-
Automatisierte Systeme können die Ergebnisse eines Empfehlungssystems nutzen, um den Kunden individuelle Empfehlungen zu geben. Dies kann den Umsatz des Unternehmens steigern.
- SaaS-Integrationen
-
Aktionen können durch die Integration von Diensten Dritter durchgeführt werden. Ein Unternehmen könnte zum Beispiel eine Marketingkampagne durchführen, um die Kundenabwanderung zu verringern. Es könnte Daten analysieren und ein Propensity-Modell einsetzen, um Kunden zu identifizieren, die wahrscheinlich positiv auf ein neues Werbeangebot reagieren. Die Liste der Kunden-E-Mail-Adressen kann dann automatisch an ein Marketing-Tool gesendet werden, um die Kampagne zu aktivieren.
- Alerting
-
Du kannst Anwendungen erstellen, die Daten in Echtzeit überwachen und personalisierte Nachrichten verschicken, wenn bestimmte Bedingungen erfüllt sind. Zum Beispiel kann das Preisgestaltungsteam proaktiv benachrichtigt werden, wenn der Traffic auf einer Artikelangebotsseite einen bestimmten Schwellenwert überschreitet, damit es überprüfen kann, ob der Artikel korrekt bepreist ist.
Der Technologie-Stack für diese drei Szenarien ist unterschiedlich. Bei automatischen Aktionen wird das ML-Modell in regelmäßigen Abständen "trainiert", in der Regel durch die Planung einer End-to-End-ML-Pipeline (dies wird in Kapitel 11 behandelt). Die Vorhersagen selbst werden durch den Aufruf des ML-Modells erreicht, das als Webservice mit Tools wie AWS SageMaker, Google Cloud Vertex AI oder Azure Machine Learning bereitgestellt wird. SaaS-Integrationen werden oft im Rahmen von funktionsspezifischen Workflow-Tools durchgeführt, die es dem Menschen ermöglichen, zu steuern, welche Informationen abgerufen, wie sie umgewandelt und wie sie aktiviert werden. Darüber hinaus können große Sprachmodelle (LLMs) und ihre generativen Fähigkeiten (wir werden in Kapitel 10 näher auf diese Konzepte eingehen) dabei helfen, sich wiederholende Aufgaben zu automatisieren, indem sie eng mit den Kernsystemen integriert werden. Alerts werden über Orchestrierungstools wie Apache Airflow, Ereignissysteme wie Google Eventarc oder serverlose Funktionen wie AWS Lambda implementiert.
In diesem Abschnitt haben wir gesehen, welche Aktivitäten eine moderne Datenplattform unterstützen muss. Als Nächstes wollen wir die traditionellen Ansätze zur Implementierung von Analyse- und KI-Plattformen untersuchen, um besser zu verstehen, wie sich die Technologie entwickelt hat und warum der Cloud-Ansatz einen großen Unterschied machen kann.
Grenzen der traditionellen Ansätze
Traditionell bestehen die Datenökosysteme von Unternehmen aus unabhängigen Lösungen, die zur Bereitstellung verschiedener Datendienste verwendet werden. Leider können solche aufgabenspezifischen Datenspeicher, die manchmal zu einer beträchtlichen Größe anwachsen können, zur Bildung von Silos innerhalb einer Organisation führen. Die daraus resultierenden Silo-Systeme arbeiten als unabhängige Lösungen, die nicht effizient zusammenarbeiten. Silo-Daten sind stillgelegte Daten - essind Daten, aus denen sich nur schwer Erkenntnisse ableiten lassen. Um die Unternehmensintelligenz zu erweitern und zu vereinheitlichen, ist der sichere Austausch von Daten zwischen den Geschäftsbereichen entscheidend.
Wenn die meisten Lösungen individuell entwickelt werden, wird es schwierig, Skalierbarkeit, Geschäftskontinuität und Disaster Recovery (DR) zu gewährleisten. Wenn jeder Teil der Organisation eine andere Umgebung für die Entwicklung seiner Lösung wählt, wird die Komplexität überwältigend. In einem solchen Szenario ist es schwierig, den Datenschutz zu gewährleisten oder Datenänderungen zu überprüfen.
Eine Lösung ist die Entwicklung einer einheitlichen Datenplattform, genauer gesagt einer Cloud-Datenplattform (bitte beachte, dass "einheitlich" nicht unbedingt "zentralisiert" bedeutet, wie wir gleich noch sehen werden). Der Zweck der Datenplattform ist es, Analysen und ML mit allen Daten eines Unternehmens auf einheitliche, skalierbare und zuverlässige Weise durchzuführen. Dabei solltest du so weit wie möglich auf Managed Services zurückgreifen, damit sich das Unternehmen auf die geschäftlichen Anforderungen konzentrieren kann, anstatt die Infrastruktur zu betreiben. Der Betrieb und die Wartung der Infrastruktur sollte vollständig an die zugrunde liegende Cloud-Plattform delegiert werden. In diesem Buch gehen wir auf die wichtigsten Entscheidungen ein, die du treffen musst, wenn du eine einheitliche Plattform zur Konsolidierung von Daten über Geschäftsbereiche hinweg in einer skalierbaren und zuverlässigen Umgebung entwickelst.
Antipattern: Aufbrechen von Silos durch ETL
Es ist eine Herausforderung für Unternehmen, eine einheitliche Sicht auf ihre Daten zu haben, weil sie dazu neigen, eine Vielzahl von Lösungen für die Datenverwaltung zu verwenden. Unternehmen lösen dieses Problem in der Regel durch den Einsatz von Datenverschiebungstools. Mit ETL-Anwendungen können Daten umgewandelt und zwischen verschiedenen Systemen übertragen werden, um eine einzige Quelle der Wahrheit zu schaffen. Es ist jedoch problematisch, sich auf ETL zu verlassen, und es gibt bessere Lösungen auf modernen Plattformen.
Oft wird ein ETL-Tool entwickelt, um regelmäßig die neuesten Transaktionen aus einer Transaktionsdatenbank zu extrahieren und sie in einem Analysespeicher für den Zugriff durch Dashboards zu speichern. Dies wird dann standardisiert. ETL-Tools werden für jede Datenbanktabelle erstellt, die für Analysen benötigt wird, damit Analysen durchgeführt werden können, ohne jedes Mal zum Quellsystem gehen zu müssen (siehe Abbildung 1-3).
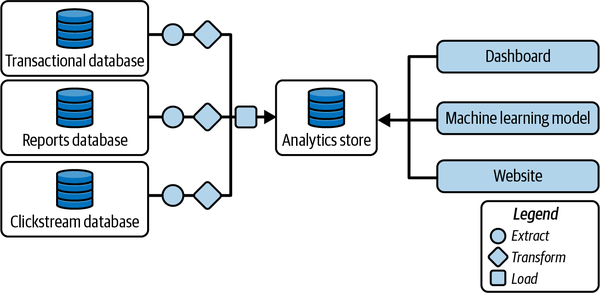
Abbildung 1-3. ETL-Tools können helfen, Datensilos aufzubrechen
Der zentrale Analysespeicher, der alle Daten des Unternehmens erfasst, wird je nach verwendeter Technologie entweder als DWH oder als Data Lake bezeichnet. Die Unterscheidung zwischen den beiden Ansätzen basiert auf der Art und Weise, wie die Daten im System gespeichert werden: Wenn der Analysespeicher SQL unterstützt und kontrollierte, qualitätsgesicherte Daten enthält, wird er als DWH bezeichnet. Wenn er stattdessen Tools aus dem Apache-Ökosystem (wie Apache Spark) unterstützt und Rohdaten enthält, wird er als Data Lake bezeichnet. Die Terminologie zur Bezeichnung von Zwischenspeichern für Analysen (z. B. kontrollierte Rohdaten oder nicht kontrollierte qualitätsgesicherte Daten) variiert von Unternehmen zu Unternehmen - einige Unternehmen nennen sie Data Lakes, andere DWH. Wie du im weiteren Verlauf des Buches sehen wirst, ist dieses verwirrende Vokabular kein Problem, denn die Ansätze für Data Lakes(Kapitel 5) und DWH(Kapitel 6) konvergieren zu dem, was als Data Lakehouse(Kapitel 7) bezeichnet wird.
Es gibt ein paar Nachteile, wenn du dich auf Datenverschiebungstools verlässt, um eine einheitliche Sicht auf die Daten zu erhalten:
- Datenqualität
-
ETL-Tools werden oft von Datenkonsumenten geschrieben, die die Daten oft nicht so gut verstehen wie die Eigentümer der Daten. Das bedeutet, dass die Daten, die extrahiert werden, oft nicht die richtigen sind.
- Latenz
-
ETL-Tools führen zu Latenzzeiten. Wenn zum Beispiel das ETL-Tool zur Extraktion der letzten Transaktionen einmal pro Stunde läuft und 15 Minuten dafür braucht, können die Daten im Analysespeicher bis zu 75 Minuten veraltet sein. Dieses Problem kann durch Streaming-ETL gelöst werden, bei dem Ereignisse sofort verarbeitet werden, wenn sie eintreten.
- Engpass
-
ETL-Tools erfordern in der Regel Programmierkenntnisse. Deshalb richten Unternehmen maßgeschneiderte Data-Engineering-Teams ein, die den Code für ETL schreiben. Da die Datenvielfalt in einem Unternehmen zunimmt, müssen immer mehr ETL-Tools geschrieben werden. Das Data-Engineering-Team wird zu einem Engpass für die Fähigkeit des Unternehmens, die Daten zu nutzen.
- Wartung
-
ETL-Tools müssen von Systemadministratoren routinemäßig ausgeführt und auf Fehler überprüft werden. Das zugrundeliegende Infrastruktursystem muss ständig aktualisiert werden, um die wachsende Rechen- und Speicherkapazität zu bewältigen und die Zuverlässigkeit zu gewährleisten.
- Veränderungsmanagement
-
Änderungen im Schema der Eingabetabelle erfordern, dass der Extraktionscode des ETL-Tools geändert wird. Das macht Änderungen entweder schwierig oder führt dazu, dass das ETL-Tool durch vorgelagerte Änderungen beschädigt wird.
- Datenlücken
-
Es ist sehr wahrscheinlich, dass viele Fehler den Eigentümern der Daten, den Entwicklern des ETL-Tools oder den Nutzern der Daten gemeldet werden müssen. Das erhöht den Wartungsaufwand und führt oft zu Ausfallzeiten des Tools. Dadurch entstehen häufig große Lücken in den Datensätzen.
- Governance
-
Mit der zunehmenden Verbreitung von ETL-Prozessen wird es immer wahrscheinlicher, dass dieselbe Verarbeitung von verschiedenen Prozessen durchgeführt wird, was zu mehreren Quellen derselben Informationen führt. Häufig weichen die Prozesse im Laufe der Zeit voneinander ab, um unterschiedliche Anforderungen zu erfüllen, was dazu führt, dass inkonsistente Daten für unterschiedliche Entscheidungen verwendet werden.
- Effizienz und Umweltauswirkungen
-
Die zugrundeliegende Infrastruktur, die diese Art von Veränderungen unterstützt, ist ein Problem, da sie in der Regel rund um die Uhr in Betrieb ist, was erhebliche Kosten verursacht und den ökologischen Fußabdruck vergrößert.
Der erste Punkt in der vorangegangenen Liste (Datenqualität) wird oft übersehen, ist aber im Laufe der Zeit der wichtigste. Oft müssen die Daten vorverarbeitet werden, bevor man sie als vertrauenswürdig für die Produktion einstufen kann. Daten, die aus vorgelagerten Systemen stammen, werden in der Regel als Rohdaten betrachtet und können Rauschen oder sogar schlechte Informationen enthalten, wenn sie nicht ordnungsgemäß bereinigt und umgewandelt werden. So müssen z. B. E-Commerce-Webprotokolle vor der Verwendung umgewandelt werden, indem Produktcodes aus URLs extrahiert oder falsche, von Bots durchgeführte Transaktionen herausgefiltert werden. Datenverarbeitungstools müssen speziell für die jeweilige Aufgabe entwickelt werden. Es gibt keine globale Datenqualitätslösung oder einen gemeinsamen Rahmen für den Umgang mit Qualitätsproblemen.
Während diese Situation vernünftig ist, wenn man jeweils eine Datenquelle betrachtet, führt die Gesamtsammlung (siehe Abbildung 1-4) zu Chaos.
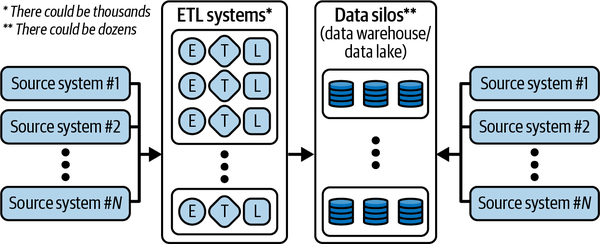
Abbildung 1-4. Datenökosystem und Herausforderungen
Die wachsende Zahl von Speichersystemen und die maßgeschneiderten Datenmanagementlösungen, die für die Anforderungen verschiedener nachgelagerter Anwendungen entwickelt wurden, führen dazu, dass Analytiker/innen und Chief Information Officers (CIOs) vor folgenden Herausforderungen stehen:
-
Ihr DWH/Datensee kann mit den ständig wachsenden Geschäftsanforderungen nicht Schritt halten.
-
Digitale Initiativen (und der Wettbewerb mit den Digital Natives) haben dazu geführt, dass das Geschäft zunehmend von riesigen Datenmengen überflutet wird.
-
Die Notwendigkeit, separate Data Lakes, DWHs und spezielle Speicherungen für verschiedene Data Science-Aufgaben zu schaffen, führt zur Entstehung mehrerer Datensilos.
-
Der Datenzugriff muss aufgrund von Leistungs-, Sicherheits- und Governance-Herausforderungen begrenzt oder eingeschränkt werden.
-
Die Erneuerung von Lizenzen und die Bezahlung von teuren Support-Ressourcen werden zur Herausforderung.
Es ist offensichtlich, dass dieser Ansatz nicht skaliert werden kann, um die neuen Geschäftsanforderungen zu erfüllen, nicht nur wegen der technologischen Komplexität, sondern auch wegen der Sicherheits- und Governance-Anforderungen, die dieses Modell mit sich bringt.
Antipattern: Zentralisierung der Kontrolle
Um das Problem der siloartigen, verstreuten und verteilten Daten zu lösen, die über aufgabenspezifische Datenverarbeitungslösungen verwaltet werden, haben einige Unternehmen versucht, alles in einer einzigen, monolithischen Plattform unter der Kontrolle der IT-Abteilung zu zentralisieren. Wie in Abbildung 1-5 dargestellt, ändert sich die zugrundeliegende technologische Lösung nicht - stattdessen werden die Probleme überschaubarer gemacht, indem sie einer einzigen Organisation zur Lösung zugewiesen werden.
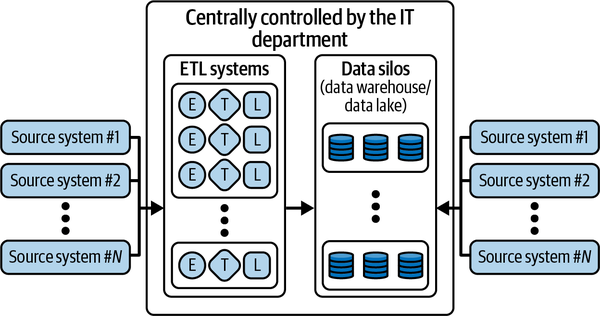
Abbildung 1-5. Datenökosystem und Herausforderungen bei der zentralen Steuerung von Datensystemen durch die IT
Eine solche zentralisierte Kontrolle durch eine einzige Abteilung bringt ihre eigenen Herausforderungen und Kompromisse mit sich. Alle Geschäftsbereiche (BUs) - die IT selbst, die Datenanalyse und die Geschäftsnutzer - haben damit zu kämpfen, dass die IT alle Datensysteme kontrolliert:
- IT
-
Die Herausforderung für die IT-Abteilungen besteht in der Vielfalt der Technologien, die in diesen Datensilos zum Einsatz kommen. Die IT-Abteilungen verfügen selten über die notwendigen Fähigkeiten, um all diese Systeme zu verwalten. Die Daten befinden sich auf verschiedenen Speichersystemen vor Ort und in Clouds, was die Verwaltung von DWHs, Data Lakes und Data Marts kostspielig macht. Es ist auch nicht immer klar, wie Sicherheit, Governance, Auditing usw. über verschiedene Quellen hinweg definiert werden sollen. Außerdem entsteht ein Skalierungsproblem beim Zugriff auf die Daten: Der Arbeitsaufwand für die IT-Abteilung steigt linear mit der Anzahl der Quell- und Zielsysteme, die Teil des Ganzen sind, da die Anzahl der Datenzugriffsanfragen aller Beteiligten bzw. der Geschäftsnutzer mit Sicherheit steigt.
- Analytik
-
Eines der Hauptprobleme, das effektive Analyseprozesse behindert, ist der fehlende Zugriff auf die richtigen Daten. Wenn es mehrere Systeme gibt, wird das Verschieben von Daten in/aus einem monolithischen Datensystem kostspielig und führt zu unnötigen ETL-Aufgaben usw. Außerdem verfügen die vorbereiteten und leicht verfügbaren Daten möglicherweise nicht über die aktuellsten Quellen, oder es gibt andere Versionen der Daten, die mehr Tiefe und breitere Informationen bieten, z. B. mehr Spalten oder granularere Datensätze. Es ist unmöglich, deinem Analyseteam freien Lauf zu lassen, so dass jeder auf alle Daten zugreifen kann, weil es Probleme mit der Datenverwaltung und dem Betrieb gibt. Unternehmen schränken den Datenzugriff oft auf Kosten der analytischen Flexibilität ein.
- Business
-
Es ist schwierig, Zugang zu Daten und Analysen zu bekommen, denen dein Unternehmen vertrauen kann. Die Daten, die du deinem Unternehmen zur Verfügung stellst, müssen begrenzt werden, um die höchste Qualität zu gewährleisten. Die Alternative besteht darin, den Zugang zu allen Daten zu öffnen, die die Geschäftsnutzer/innen benötigen, auch wenn dies zu Lasten der Qualität geht. Die Herausforderung ist dann ein Balanceakt zwischen der Qualität der Daten und der Menge an vertrauenswürdigen Daten. Oft hat die IT-Abteilung nicht genügend qualifizierte Vertreter/innen aus den Fachabteilungen, um Prioritäten und Anforderungen festzulegen. Das kann schnell zu einem Engpass werden, der den Innovationsprozess im Unternehmen verlangsamt.
Trotz der vielen Herausforderungen haben mehrere Unternehmen diesen Ansatz im Laufe der Jahre übernommen, was in einigen Fällen zu Frustrationen und Spannungen bei den Geschäftsanwendern führte, die nur mit Verzögerung Zugang zu den Daten erhielten, die sie zur Erfüllung ihrer Aufgaben benötigten. Frustrierte Geschäftsbereiche werden oft durch ein anderes Antipattern- nämlich die Schatten-IT -bewältigt , bei derganze Abteilungen nützliche Lösungen entwickeln und einsetzen, um solche Einschränkungen zu umgehen, aber am Ende das Problem der Datensilos noch verschlimmern.
Manchmal wird ein technischer Ansatz namens data fabric verwendet. Dieser basiert immer noch auf einer Zentralisierung, aber anstatt Daten physisch zu bewegen, ist die Data Fabric eine virtuelle Schicht, die einen einheitlichen Datenzugriff ermöglicht. Das Problem ist, dass eine solche Standardisierung eine große Belastung sein kann und zu Verzögerungen beim unternehmensweiten Zugriff auf die Daten führt. Die Data Fabric ist jedoch ein praktikabler Ansatz für SaaS-Produkte, die auf kundeneigene Daten zugreifen wollen - Integrationsspezialisten sorgen für die notwendige Übersetzung vom Schema des Kunden in das Schema, das das SaaS-Tool erwartet.
Antipattern: Data Marts und Hadoop
Die Herausforderungen, die ein zentral verwaltetes Silo-System mit sich brachte, verursachten enorme Spannungen und Unkosten für die IT-Abteilung. Um dieses Problem zu lösen, haben einige Unternehmen zwei andere Gegenmuster eingeführt: Data Marts und unkontrollierte Data Lakes.
Beim ersten Ansatz wurden die Daten in lokale relationale und analytische Datenbanken extrahiert. Obwohl diese Produkte als Data Warehouses bezeichnet wurden, handelte es sich in der Praxis aus Gründen der Skalierbarkeit um Data Marts (eine Teilmenge der Unternehmensdaten, die für bestimmte Arbeitslasten geeignet ist). Data Marts ermöglichen es Geschäftsanwendern, ihre eigenen Geschäftsdaten in strukturierten Datenmodellen zu entwerfen und bereitzustellen (z. B. im Einzelhandel, im Gesundheitswesen, im Bankwesen, bei Versicherungen usw.). Auf diese Weise können sie auf einfache Weise Informationen über das aktuelle und das historische Geschäft abrufen (z. B. die Höhe des Umsatzes im letzten Quartal, die Anzahl der Nutzer, die in der letzten Woche dein letztes veröffentlichtes Spiel gespielt haben, die Korrelation zwischen der im Help Center deiner Website verbrachten Zeit und der Anzahl der in den letzten sechs Monaten eingegangenen Tickets usw.). Seit vielen Jahrzehnten entwickeln Unternehmen Data-Mart-Lösungen mit verschiedenen Technologien (z. B. Oracle, Teradata, Vertica) und implementieren mehrere Anwendungen darauf. Diese On-Premises-Technologien sind jedoch hinsichtlich ihrer Kapazität stark eingeschränkt. IT-Teams und Datenverantwortliche stehen vor der Herausforderung, die Infrastruktur (vertikal) zu skalieren, wichtige Talente zu finden, die Kosten zu senken und letztendlich die wachsende Erwartung zu erfüllen, wertvolle Erkenntnisse zu liefern. Außerdem waren diese Lösungen in der Regel kostspielig, denn je größer die Datenmengen wurden, desto mehr Rechenleistung musste für die Verarbeitung der Daten bereitgestellt werden.
Aufgrund von Skalierbarkeits- und Kostenproblemen wurden Big-Data-Lösungen auf der Grundlage des Apache Hadoop Ökosystems entwickelt. Hadoop führte die verteilte Datenverarbeitung (horizontale Skalierung) mit kostengünstigen Standardservern ein und ermöglichte damit Anwendungsfälle, die zuvor nur mit hochentwickelter (und sehr teurer) Spezialhardware möglich waren. Jede Anwendung, die auf Hadoop läuft, wurde so konzipiert, dass sie Ausfälle von Knoten toleriert, was sie zu einer kosteneffizienten Alternative zu einigen traditionellen DWH-Workloads macht. Dies führte zur Entwicklung eines neuen Konzepts namens Data Lake, das neben dem DWH schnell zu einer tragenden Säule des Datenmanagements wurde.
Die Idee war, dass alle Daten für die Analyse in einen zentralen Datensee exportiert werden, während die Kernbereiche der operativen Technologie ihre Routineaufgaben erledigen. Der Data Lake sollte als zentraler Speicher für Analyseaufgaben und für Geschäftsanwender dienen. Data Lakes haben sich von reinen Speichern für Rohdaten zu Plattformen entwickelt, die fortschrittliche Analysen und Data Science für große Datenmengen ermöglichen. Dies ermöglichte Self-Service-Analysen im gesamten Unternehmen, erforderte jedoch umfangreiche Kenntnisse über fortgeschrittene Hadoop- und Engineering-Prozesse, um auf die Daten zuzugreifen. Das Hadoop Open Source Software (Hadoop OSS) Ökosystem wuchs in Bezug auf Datensysteme und Verarbeitungsframeworks (HBase, Hive, Spark, Pig, Presto, SparkML und mehr) parallel zum exponentiellen Wachstum der Unternehmensdaten, was jedoch zu zusätzlicher Komplexität und höheren Wartungskosten führte. Außerdem wurden Data Lakes zu einem unübersichtlichen Datenwust, den nur wenige potenzielle Nutzer der Daten verstehen konnten. Die Kombination aus Qualifikationsdefizit und Datenqualitätsproblemen führte dazu, dass Unternehmen Schwierigkeiten hatten, einen guten ROI aus den Data Lakes zu erzielen.
Nachdem du nun einige Antipatterns gesehen hast, wollen wir uns darauf konzentrieren, wie du eine Datenplattform entwickeln kannst, die eine einheitliche Sicht auf die Daten über ihren gesamten Lebenszyklus hinweg bietet.
Schaffung einer einheitlichen Analyseplattform
Data Mart- und Data-Lake-Technologien ermöglichten es der IT-Abteilung, die erste Iteration einer Datenplattform zu erstellen, um Datensilos aufzubrechen und das Unternehmen in die Lage zu versetzen, Erkenntnisse aus allen Datenbeständen zu gewinnen. Die Datenplattform ermöglichte es Datenanalysten, Dateningenieuren, Datenwissenschaftlern, Geschäftsanwendern, Architekten und Sicherheitsingenieuren, bessere Erkenntnisse in Echtzeit zu gewinnen und vorherzusagen, wie sich ihr Geschäft im Laufe der Zeit entwickeln wird.
Cloud statt On-Premises
DWH und Data Lakes sind das Herzstück moderner Datenplattformen. DWHs unterstützen strukturierte Daten und SQL, während Data Lakes Rohdaten und Programmier-Frameworks im Apache-Ökosystem unterstützen.
Der Betrieb von DWH und Data Lakes in einer lokalen Umgebung birgt jedoch einige Herausforderungen, wie z. B. die Skalierung und die Betriebskosten. Dies hat Unternehmen dazu veranlasst, ihren Ansatz zu überdenken und die Cloud (insbesondere die öffentliche Version) als bevorzugte Umgebung für eine solche Plattform in Betracht zu ziehen. Und warum? Weil es ihnen die Möglichkeit gibt:
-
Reduziere die Kosten durch neue Preismodelle(Pay-per-Use-Modell)
-
Beschleunigung der Innovation durch Nutzung der besten Technologien
-
Skalierung von lokalen Ressourcen mit einem "Bursting"-Ansatz
-
Planen Sie Business Continuity und Disaster Recovery, indem Sie Daten in mehreren Zonen und Regionen speichern
-
Verwalte die Notfallwiederherstellung automatisch mit vollständig verwalteten Diensten
Wenn die Nutzer nicht mehr durch die Kapazität ihrer Infrastruktur eingeschränkt sind, können Unternehmen die Daten von im gesamten Unternehmen demokratisieren und neue Erkenntnisse gewinnen. Die Cloud unterstützt Unternehmen bei ihren Modernisierungsbemühungen, da sie den Aufwand und die Reibung minimiert, indem sie die administrativen, geringwertigen Aufgaben auslagert. Eine Cloud-Datenplattform verspricht eine Umgebung, in der du keine Kompromisse mehr eingehen musst und ein umfassendes Datenökosystem aufbauen kannst, das die gesamte Datenverwaltung und Datenverarbeitung von der Datenerfassung bis zur Bereitstellung abdeckt. Und du kannst deine Cloud-Datenplattform nutzen, um große Datenmengen in unterschiedlichen Formaten zu speichern, ohne Kompromisse bei der Latenzzeit einzugehen.
Cloud-Datenplattformen versprechen:
-
Zentralisierte Verwaltung und Zugriffsmanagement
-
Höhere Produktivität und geringere Betriebskosten
-
Größerer Datenaustausch innerhalb der Organisation
-
Erweiterter Zugang durch verschiedene Personas
-
Geringere Latenzzeit beim Zugriff auf Daten
In der Public-Cloud-Umgebung verschwimmen die Grenzen zwischen DWH- und Data-Lake-Technologien, da die Cloud-Infrastruktur (insbesondere die Trennung von Rechenleistung und Speicherung) eine Konvergenz ermöglicht, die in der On-Premises-Umgebung unmöglich war. Heute ist es möglich, SQL auf Daten in einem Data Lake anzuwenden, und es ist möglich, eine traditionelle Hadoop-Technologie (z. B. Spark) auf Daten anzuwenden, die in einem DWH gespeichert sind. In diesem Abschnitt geben wir dir eine Einführung, wie diese Konvergenz funktioniert und wie sie die Grundlage für brandneue Ansätze sein kann, die die Art und Weise, wie Unternehmen ihre Daten betrachten, revolutionieren können; weitere Details erfährst du in den Kapiteln 5 bis 7.
Nachteile von Data Marts und Data Lakes
In den letzten 40 Jahren haben IT-Abteilungen domänenspezifische DWHs, so genannte Data Marts, aufgebaut, um Datenanalysten zu unterstützen. Sie haben erkannt, dass solche Data Marts schwer zu verwalten sind und sehr kostspielig werden können. Legacy-Systeme, die in der Vergangenheit gut funktioniert haben (z. B. Teradata- und Netezza-Appliances vor Ort), haben sich als schwer skalierbar und sehr teuer erwiesen und stellen eine Reihe von Herausforderungen in Bezug auf die Datenaktualität dar. Außerdem können sie moderne Funktionen wie den Zugang zu KI/ML oder Echtzeitfunktionen nicht ohne Weiteres bereitstellen, ohne diese Funktionen nachträglich hinzuzufügen.
Data-Mart-Nutzer sind häufig Analysten, die in einer bestimmten Geschäftseinheit eingebettet sind. Sie können Ideen für zusätzliche Datensätze, Analysen, Datenverarbeitung und Business Intelligence-Funktionen haben, die für ihre Arbeit sehr nützlich wären. In einem traditionellen Unternehmen haben sie jedoch häufig keinen direkten Zugang zu den Dateneigentümern und können auch nicht ohne Weiteres Einfluss auf die technischen Entscheidungsträger nehmen, die über Datensätze und Tools entscheiden. Da sie außerdem keinen Zugang zu den Rohdaten haben, können sie keine Hypothesen testen oder ein tieferes Verständnis der zugrunde liegenden Daten gewinnen.
Data Lakes sind nicht so einfach und kosteneffizient, wie sie scheinen. Während sie theoretisch leicht skaliert werden können, stehen Unternehmen oft vor der Herausforderung, ausreichend Speicherung zu planen und bereitzustellen, vor allem wenn sie sehr variable Datenmengen produzieren. Außerdem kann die Bereitstellung von Rechenkapazitäten für Spitzenzeiten teuer sein, was zu einem Wettbewerb um knappe Ressourcen zwischen verschiedenen Geschäftsbereichen führt.
Lokale Data Lakes können anfällig sein und erfordern eine zeitaufwändige Wartung. Ingenieure, die eigentlich neue Funktionen entwickeln könnten, werden oft dazu verdonnert, Datencluster zu pflegen und Aufträge für die Geschäftsbereiche zu planen. Die Gesamtbetriebskosten sind für viele Unternehmen oft höher als erwartet. Kurz gesagt: Data Lakes schaffen keinen Mehrwert und viele Unternehmen stellen fest, dass der ROI negativ ist.
Bei Data Lakes ist die Governance nicht einfach zu lösen, vor allem wenn verschiedene Teile der Organisation unterschiedliche Sicherheitsmodelle verwenden. Dann werden die Data Lakes siloartig und segmentiert, was den Austausch von Daten und Modellen zwischen den Teams erschwert.
Data-Lake-Benutzer sind in der Regel näher an den Rohdatenquellen und benötigen Programmierkenntnisse, um Data-Lake-Tools und -Funktionen zu nutzen, und sei es nur, um die Daten zu untersuchen. In traditionellen Unternehmen konzentrieren sich diese Nutzer eher auf die Daten selbst und werden häufig vom Rest des Unternehmens ferngehalten. Andererseits verfügen die Fachanwender/innen nicht über die Programmierkenntnisse, um aus den Daten in einem Data Lake Erkenntnisse zu gewinnen. Diese Trennung bedeutet, dass die Geschäftsbereiche die Chance verpassen, Erkenntnisse zu gewinnen, die ihre Geschäftsziele vorantreiben und zu höheren Umsätzen, niedrigeren Kosten, geringerem Risiko und neuen Chancen führen würden.
Konvergenz von DWHs und Data Lakes
Angesichts dieser Kompromisse entscheiden sich viele Unternehmen für einen gemischten Ansatz, bei dem ein Data Lake eingerichtet wird, um einen Teil der Daten in ein DWH zu leiten, oder ein DWH über einen weiteren Data Lake für zusätzliche Tests und Analysen verfügt. Wenn jedoch mehrere Teams ihre eigenen Datenarchitekturen für ihre individuellen Bedürfnisse erstellen, wird die gemeinsame Nutzung von Daten und die Wahrung der Vertraulichkeit für ein zentrales IT-Team noch komplizierter.
Anstatt getrennte Teams mit getrennten Zielen zu haben - von denen eines das Geschäft erforscht und ein anderes das Geschäft kennt - kannst du diese Funktionen und ihre Datensysteme zusammenführen, um einen positiven Kreislauf zu schaffen, bei dem ein tieferes Verständnis des Geschäfts die Erforschung vorantreibt und diese Erforschung zu einem besseren Verständnis des Geschäfts führt .
Ausgehend von diesem Prinzip hat die Datenindustrie begonnen, sich einem neuen Ansatz zuzuwenden: Lakehouse und Data Mesh, die gut zusammenarbeiten, weil sie helfen, zwei unterschiedliche Herausforderungen innerhalb eines Unternehmens zu lösen:
-
Lakehouse ermöglicht es Nutzern mit unterschiedlichen Fähigkeiten (Datenanalysten und Dateningenieuren), mit verschiedenen Technologien auf die Daten zuzugreifen.
-
Das Datengeflecht ermöglicht es einem Unternehmen, eine einheitliche Datenplattform zu schaffen, ohne alle Daten in der IT zu zentralisieren - so können verschiedene Geschäftsbereiche ihre eigenen Daten besitzen, aber anderen Geschäftsbereichen einen effizienten, skalierbaren Zugriff darauf ermöglichen.
Ein zusätzlicher Vorteil ist, dass diese Architekturkombination auch eine strengere Data Governance mit sich bringt, die bei Data Lakes normalerweise fehlt. Data Mesh ermöglicht es, Engpässe in einem Team zu vermeiden und ermöglicht so den gesamten Datenstapel. Es bricht Silos in kleinere Organisationseinheiten auf und bietet einen föderierten Zugang zu Daten.
Seehaus
Die Data Lakehouse-Architektur ist eine Kombination aus den wichtigsten Vorteilen von Data Lakes und Data Warehouses (siehe Abbildung 1-6). Sie bietet ein kostengünstiges Speicherformat, auf das verschiedene Verarbeitungsmaschinen, wie z. B. die SQL-Engines von Data Warehouses, zugreifen können, und bietet gleichzeitig leistungsstarke Verwaltungs- und Optimierungsfunktionen.
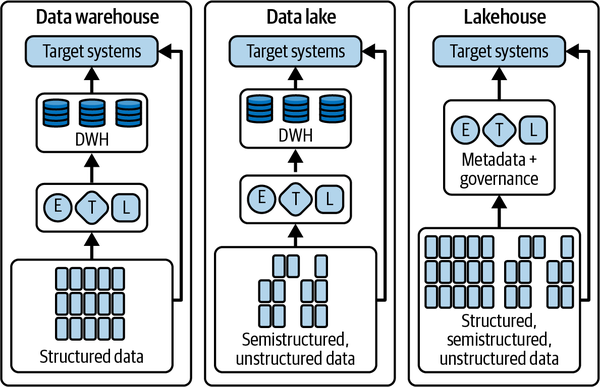
Abbildung 1-6. DWH-, Datensee- und Seehaus-Muster
Databricks ist ein Verfechter der Lakehouse-Architektur, weil es auf Spark gegründet wurde und Geschäftsanwender unterstützen muss, die keine Programmierer sind. Daher werden die Daten bei Databricks in einem Data Lake gespeichert, aber Geschäftsanwender können mit SQL darauf zugreifen. Die Lakehouse-Architektur ist jedoch nicht auf Databricks beschränkt.
DWHs, die in Cloud-Lösungen wie Google Cloud BigQuery, Snowflake oder Azure Synapse ausgeführt werden, ermöglichen eine Lakehouse-Architektur, die auf einer für SQL-Analysen optimierten säulenförmigen Speicherung basiert: Sie ermöglicht es, das DWH wie einen Data Lake zu behandeln, indem auch Spark-Aufträge, die in parallelen Hadoop-Umgebungen ausgeführt werden, die auf dem zugrunde liegenden Speichersystem gespeicherten Daten nutzen können, anstatt einen separaten ETL-Prozess oder eine Speicherschicht zu benötigen.
Das Muster des Seehauses bietet mehrere Vorteile gegenüber den traditionellen Ansätzen:
-
Entkopplung von Speicherung und Rechenleistung, die das ermöglicht:
-
Kostengünstige, praktisch unbegrenzte und nahtlos skalierbare Speicherung
-
Stateless, resilient compute
-
ACID-konforme Speicherung
-
Ein logisches Modell für die Speicherung in der Datenbank anstelle einer physischen
-
-
Data Governance (z. B. Datenzugangsbeschränkung und Schemaentwicklung)
-
Unterstützung für die Datenanalyse durch die native Integration mit Business-Intelligence-Tools
-
Native Unterstützung des typischen Multiversionsansatzes eines Data Lake-Ansatzes (d.h. Bronze, Silber und Gold)
-
Speicherung und Verwaltung von Daten über offene Formate wie Apache Parquet und Iceberg
-
Unterstützung für verschiedene Datentypen im strukturierten oder unstrukturierten Format
-
Streaming-Funktionen mit der Möglichkeit, die Daten in Echtzeit zu analysieren
-
Ermöglichung einer Vielzahl von Anwendungen, von Business Intelligence bis ML
Ein Lakehouse ist jedoch unweigerlich ein technologischer Kompromiss. Die Verwendung von Standardformaten bei der Speicherung in der Cloud schränkt die Optimierungen bei der Speicherung und die Gleichzeitigkeit von Abfragen ein, die DWHs über Jahre hinweg perfektioniert haben. Daher ist die von Lakehouse-Technologien unterstützte SQL nicht so effizient wie die eines nativen DWHs (d.h. sie benötigt mehr Ressourcen und kostet mehr). Außerdem ist die SQL-Unterstützung in der Regel begrenzt, da Funktionen wie Geodatenabfragen, ML und Datenmanipulation nicht verfügbar oder unglaublich ineffizient sind. Auch die Spark-Unterstützung von DWHs ist begrenzt und in der Regel nicht so leistungsfähig wie die native Spark-Unterstützung eines Data Lake-Anbieters.
Der Lakehouse-Ansatz ermöglicht es Unternehmen, die Grundpfeiler einer unglaublich vielfältigen Datenplattform zu implementieren, die jede Art von Arbeitslast unterstützen kann. Aber was ist mit den Organisationen, die darauf aufsetzen? Wie können die Nutzer das Beste aus der Plattform herausholen, um ihre Aufgaben zu erledigen? In diesem Szenario nimmt ein neues Betriebsmodell Gestalt an, das Datengeflecht.
Datengitter
Data Mesh ist ein dezentralisiertes Betriebsmodell von Technik, Menschen und Prozessen, um die häufigste Herausforderung in der Analytik zu lösen - den Wunsch nach zentraler Kontrolle in einer Umgebung, in der der Besitz von Daten notwendigerweise verteilt ist, wie in Abbildung 1-7 dargestellt. Eine andere Sichtweise auf das Datengeflecht ist die, Daten als eigenständiges Produkt zu sehen und nicht als Produkt von ETL-Pipelines.
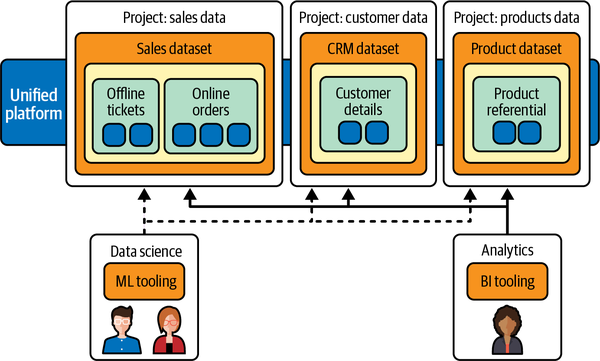
Abbildung 1-7. Ein Datennetz vereinheitlicht den Datenzugriff im gesamten Unternehmen und behält gleichzeitig das Eigentum an den Daten in verteilten Domänen
Verteilte Teams sind bei diesem Ansatz Eigentümer der Datenproduktion und bedienen interne/externe Kunden über ein genau definiertes Datenschema. Insgesamt baut Data Mesh auf einer langen Innovationsgeschichte von DWHs und Data Lakes auf, kombiniert mit der Skalierbarkeit, den Pay-for-Consumption-Modellen, Self-Service-APIs und der engen Integration, die mit DWH-Technologien in der Public Cloud verbunden sind.
Mit diesem Ansatz kannst du effektiv eine On-Demand-Datenlösung schaffen. Ein Datengeflecht dezentralisiert das Dateneigentum unter den Eigentümern der Domaindaten, die jeweils dafür verantwortlich sind, ihre Daten als Produkt auf standardisierte Weise bereitzustellen (siehe Abbildung 1-8). Ein Datengeflecht ermöglicht auch die Kommunikation zwischen verschiedenen Teilen der Organisation, um Datensätze auf verschiedene Standorte zu verteilen.
In einem Datengeflecht wird die Verantwortung für die Wertschöpfung aus den Daten denjenigen übertragen, die sie am besten verstehen. Mit anderen Worten: Die Personen, die die Daten erstellt oder in das Unternehmen eingebracht haben, müssen auch dafür verantwortlich sein, dass aus den von ihnen erstellten Daten konsumierbare Datenprodukte entstehen. In vielen Unternehmen ist es schwierig, eine "einzige Quelle der Wahrheit" oder eine "maßgebliche Datenquelle" zu finden, da immer wieder Daten innerhalb des Unternehmens extrahiert und umgewandelt werden, ohne dass die Verantwortlichkeiten für die neu erstellten Daten klar sind. Im Datengeflecht ist die maßgebliche Datenquelle das von der Quelldomäne veröffentlichte Datenprodukt mit einem klar zugewiesenen Dateneigentümer und -verwalter, der für diese Daten verantwortlich ist.
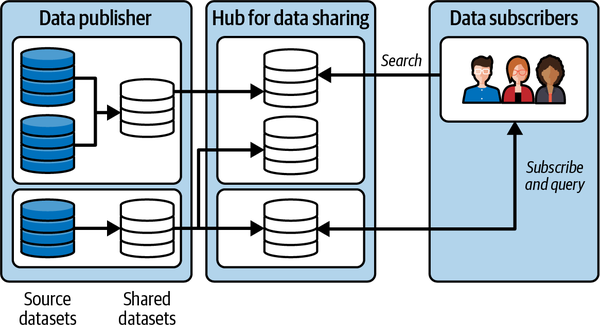
Abbildung 1-8. Daten als Produkt
Ein Datennetz ist ein Organisationsprinzip, bei dem es um das Eigentum und die Verantwortlichkeit für Daten geht. Meistens wird ein Data Mesh mit einem Lakehouse implementiert, wobei jede Geschäftseinheit ein eigenes Cloud-Konto hat. Der Zugriff auf diese einheitliche Sicht aus technologischer (Lakehouse) und organisatorischer Sicht (Data Mesh) bedeutet, dass Menschen und Systeme die Daten so erhalten, wie es für ihre Bedürfnisse am sinnvollsten ist. In manchen Fällen muss diese Art von Architektur mehrere Umgebungen umfassen, was in einigen Fällen zu einer sehr komplexen Architektur führt. Sehen wir uns an, wie Unternehmen diese Herausforderung meistern können .
Hinweis
Für weitere Informationen über Data Mesh empfehlen wir dir das Buch Data Mesh von Zhamak Dehghani : Delivering Data-Driven Value at Scale (O'Reilly).
Hybrid Cloud
Wenn eine Cloud-Datenplattform entwickelt, kann es sein, dass eine einzige Umgebung nicht ausreicht, um eine Arbeitslast durchgängig zu verwalten. Das kann an gesetzlichen Auflagen liegen (d.h. du kannst deine Daten nicht in eine Umgebung außerhalb der Unternehmensgrenzen verlagern), an den Kosten (z.B. hat das Unternehmen Investitionen in die Infrastruktur getätigt, die noch nicht das Ende ihrer Lebensdauer erreicht haben) oder daran, dass du eine bestimmte Technologie benötigst, die in der Cloud nicht verfügbar ist. In diesem Fall ist ein möglicher Ansatz die Einführung eines hybriden Musters. Bei einem hybriden Muster werden die Anwendungen in einer Kombination aus verschiedenen Umgebungen ausgeführt. Das häufigste Beispiel für ein hybrides Muster ist die Kombination aus einer privaten Rechenumgebung, z. B. einem Rechenzentrum vor Ort, und einer öffentlichen Cloud-Umgebung. In diesem Abschnitt erklären wir, wie dieser Ansatz in einem Unternehmen funktionieren kann.
Gründe, warum Hybrid notwendig ist
Hybride Cloud-Ansätze sind weit verbreitet, denn kaum ein großes Unternehmen verlässt sich heute ausschließlich auf die öffentliche Cloud. Viele Unternehmen haben in den letzten Jahrzehnten Millionen von Dollar und Tausende von Arbeitsstunden in eine On-Premises-Infrastruktur investiert. Fast alle Unternehmen haben einige traditionelle Architekturen und geschäftskritische Anwendungen im Einsatz, die sie nicht in die Public Cloud verlagern können. Möglicherweise haben sie auch sensible Daten, die sie aufgrund gesetzlicher oder organisatorischer Auflagen nicht in einer Public Cloud speichern können.
Die Möglichkeit, Arbeitslasten zwischen öffentlichen und privaten Cloud-Umgebungen zu verschieben, bietet ein höheres Maß an Flexibilität und zusätzliche Optionen für die Datenbereitstellung. Es gibt mehrere Gründe für die Einführung von Hybrid- (d.h. Architekturen, die sich über On-Premises, Public Cloud und Edge erstrecken) und Multi-Cloud-Lösungen (d.h. Architekturen, die sich über mehrere Public Cloud-Anbieter wie AWS, Microsoft Azure und Google Cloud Platform [GCP] erstrecken).
Hier sind einige wichtige geschäftliche Gründe für die Wahl von Hybrid und/oder Multi-Cloud:
- Vorschriften zum Datenaufenthalt
-
Einige werden vielleicht nie vollständig in die öffentliche Cloud migrieren, vielleicht weil sie im Finanz- oder Gesundheitswesen tätig sind und strenge Branchenvorschriften darüber einhalten müssen, wo die Daten gespeichert werden. Das gilt auch für Workloads in Ländern, in denen es keine öffentliche Cloud gibt und in denen eine Datenresidenz erforderlich ist.
- Ältere Investitionen
-
Einige Kunden möchten ihre alten Workloads wie SAP, Oracle oder Informatica vor Ort schützen, aber die Vorteile von Public Cloud-Innovationen wie z.B. Databricks und Snowflake nutzen.
- Überleitung
-
Große Unternehmen brauchen oft mehrere Jahre, um ihre Anwendungen und Architekturen in der Cloud zu modernisieren. Sie müssen hybride Architekturen über Jahre hinweg als Zwischenzustand akzeptieren.
- In die Wolke platzen
-
Es gibt Kunden, die hauptsächlich vor Ort arbeiten und nicht in die öffentliche Cloud migrieren wollen. Sie haben jedoch Probleme, die Service-Level-Agreements (SLAs) ihres Unternehmens zu erfüllen, weil sie ad hoc große Batch-Aufträge, spitzenmäßigen Datenverkehr in Stoßzeiten oder groß angelegte ML-Trainingsaufträge ausführen. Sie wollen die Vorteile skalierbarer Kapazitäten oder maßgeschneiderter Hardware in öffentlichen Clouds nutzen und die Kosten für die Erweiterung der Infrastruktur vor Ort vermeiden. Lösungen wie MotherDuck, die einen "local-first" Computing-Ansatz verfolgen, werden immer beliebter.
- Das Beste der Rasse
-
Einige Unternehmen wählen für verschiedene Aufgaben unterschiedliche Public Cloud-Provider, um die Technologien auszuwählen, die ihre Bedürfnisse am besten erfüllen. Uber zum Beispiel nutzt AWS für seine Webanwendungen, aber Cloud Spanner auf Google Cloud für seine Fulfillment-Plattform. Twitter nutzt AWS für seinen Newsfeed, aber seine Datenplattform läuft in der Google Cloud.
Nachdem du nun weißt, warum du dich für eine hybride Lösung entscheiden solltest, werfen wir einen Blick auf die wichtigsten Herausforderungen, denen du bei der Nutzung dieses Musters gegenüberstehst; diese Herausforderungen sind der Grund, warum Hybrid als Ausnahme behandelt werden sollte und das Ziel sein sollte, cloud-nativ zu sein.
Herausforderungen der Hybrid Cloud
Es gibt mehrere Herausforderungen, denen sich Unternehmen bei der Implementierung von hybriden oder Multi-Cloud-Architekturen stellen müssen:
- Governance
-
Es ist schwierig, einheitliche Governance Richtlinien über mehrere Umgebungen hinweg anzuwenden. So werden z.B. die Sicherheitsrichtlinien für die Einhaltung von Vorschriften in den Räumlichkeiten und in der öffentlichen Cloud in der Regel unterschiedlich gehandhabt. Oft werden Teile der Daten in der Cloud und im Unternehmen dupliziert. Stell dir vor, dein Unternehmen erstellt einen Finanzbericht - wie willst du sicherstellen, dass die verwendeten Daten die aktuellste Version sind, wenn es mehrere Kopien auf verschiedenen Plattformen gibt?
- Zugriffskontrolle
-
Zugriffskontrollen und Richtlinien unterscheiden sich zwischen lokalen und öffentlichen Cloud-Umgebungen. Cloud-Provider haben ihre eigenen Zugriffskontrollen ( Identitäts- und Zugriffsmanagement, IAM) für die bereitgestellten Dienste, während On-Premises-Technologien wie das lokale Verzeichniszugriffsprotokoll (LDAP) oder Kerberos verwendet werden. Wie kannst du sie synchronisieren oder eine einzige Kontrollebene für verschiedene Umgebungen einrichten?
- Interoperabilität der Arbeitsbelastung
-
Wenn du über mehrere Systeme arbeitest, sind inkonsistente Laufzeitumgebungen unvermeidlich, die verwaltet werden müssen.
- Datenbewegung
-
Wenn sowohl lokale als auch Cloud-Anwendungen Zugriff auf bestimmte Daten benötigen, müssen die beiden Datensätze synchronisiert werden. Es ist kostspielig, Daten zwischen mehreren Systemen zu verschieben - es fallen Personalkosten für die Erstellung und Verwaltung der Pipeline an, es können Lizenzkosten für die verwendete Software anfallen, und nicht zuletzt werden Systemressourcen wie Rechenleistung, Netzwerk und Speicherung verbraucht. Wie kann dein Unternehmen mit den Kosten für mehrere Umgebungen umgehen? Wie führst du heterogene Daten zusammen, die sich in verschiedenen Umgebungen befinden? Wohin werden die Daten am Ende kopiert, wenn sie zusammengeführt werden?
- Fertigkeiten
-
Die beiden Clouds (oder On-Premises und Cloud) zu nutzen, bedeutet, dass die Teams sich in zwei Umgebungen auskennen und Fachwissen aufbauen müssen. Da die öffentliche Cloud eine schnelllebige Umgebung ist, ist es mit einem erheblichen Aufwand verbunden, die Fähigkeiten der Mitarbeiter in einer Cloud zu verbessern und aufrechtzuerhalten, ganz zu schweigen von zwei. Auch die Einstellung von Systemintegratoren (SIs) kann eine Herausforderung darstellen - obwohl die meisten großen SIs über Praktiken für jede der großen Clouds verfügen, haben nur sehr wenige Teams, die zwei oder mehr Clouds kennen. Wir gehen davon aus, dass es im Laufe der Zeit immer schwieriger wird, Mitarbeiter zu finden, die bereit sind, maßgeschneiderte On-Premises-Technologien zu erlernen.
- Wirtschaft
-
Die Tatsache, dass die Daten auf zwei Umgebungen aufgeteilt sind, kann unvorhergesehene Kosten verursachen: Vielleicht hast du Daten in einer Cloud und möchtest sie einer anderen zur Verfügung stellen, was Egresskosten verursacht.
Trotz dieser Herausforderungen kann ein Hybridsystem funktionieren. Wir schauen uns im nächsten Unterabschnitt an, wie das geht.
Warum Hybrid funktionieren kann
Cloud-Provider sind sich dieser Bedürfnisse und Herausforderungen bewusst. Deshalb bieten sie einige Unterstützung für hybride Umgebungen an. Diese fallen in drei Bereiche:
- Auswahl
-
Cloud-Provider leisten oft einen großen Beitrag zu Open-Source-Technologien. Kubernetes und TensorFlow wurden zwar bei Google entwickelt, sind aber Open Source, so dass es in allen großen Clouds verwaltete Ausführungsumgebungen dafür gibt und sie auch in On-Premises-Umgebungen genutzt werden können.
- Flexibilität
-
Frameworks wie Databricks und Snowflake ermöglichen es dir, dieselbe Software auf jeder der großen öffentlichen Cloud-Plattformen laufen zu lassen. So können Teams eine Reihe von Fähigkeiten erlernen, die überall funktionieren. Beachte, dass die Flexibilität, die dir Tools bieten, die in mehreren Clouds funktionieren, nicht bedeutet, dass du der Abhängigkeit entkommen bist. Du musst dich entscheiden zwischen (1) Lock-in auf der Framework-Ebene und Flexibilität auf der Cloud-Ebene (angeboten von Technologien wie Databricks oder Snowflake) und (2) Lock-in auf der Cloud-Ebene und Flexibilität auf der Framework-Ebene (angeboten von den Cloud-nativen Tools).
- Offenheit
-
Auch wenn es sich um ein proprietäres Tool handelt, wird der Code dafür portabel geschrieben, da offene Standards und Import-/Exportmechanismen verwendet werden. Obwohl Redshift zum Beispiel nirgendwo anders als auf AWS läuft, werden die Abfragen in Standard-SQL geschrieben und es gibt mehrere Import- und Exportmechanismen. Zusammen machen diese Fähigkeiten Redshift, BigQuery und Synapse zu offenen Plattformen. Diese Offenheit ermöglicht Anwendungsfälle wie Teads, wo Daten mit Kafka auf AWS gesammelt, mit Dataflow und BigQuery auf Google Cloud aggregiert und zurück zu AWS Redshift geschrieben werden (siehe Abbildung 1-9).
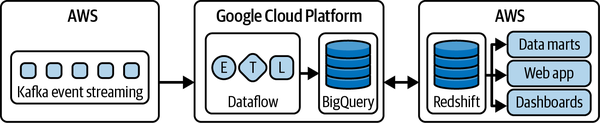
Abbildung 1-9. Hybride Analyse-Pipeline bei Teads (Abbildung basiert auf einem Artikel von Alban Perillat-Merceroz, veröffentlicht in Teads Engineering)
Cloud-Provider engagieren sich für Wahlmöglichkeiten, Flexibilität und Offenheit, indem sie stark in Open-Source-Projekte investieren, die den Kunden helfen, mehrere Clouds zu nutzen. Daher werden Multicloud-DWHs oder hybride Datenverarbeitungs-Frameworks zur Realität. So kannst du hybride und Multi-Cloud-Implementierungen mit besserer Cloud-Software-Produktion, -Veröffentlichung und -Verwaltung aufbauen - und zwar so, wie du es willst, und nicht, wie es ein Anbieter vorschreibt.
Edge Computing
Eine weitere Ausprägung des hybriden Musters ist, wenn du Rechenleistung außerhalb der üblichen Datenplattform benötigst, vielleicht um direkt mit einigen verbundenen Geräten zu interagieren. In diesem Fall sprechen wir von Edge Computing. Edge Computing bringt die Rechenleistung und die Speicherung der Daten näher an das System, in dem die Daten erzeugt und verarbeitet werden müssen. Das Ziel des Edge Computing ist es, die Reaktionszeiten zu verbessern und Bandbreite zu sparen. Edge Computing kann viele Anwendungsfälle erschließen und die digitale Transformation beschleunigen. Es gibt viele Anwendungsbereiche, wie Sicherheit, Robotik, vorausschauende Wartung, intelligente Fahrzeuge usw.
Wenn sich Edge Computing durchsetzt und zum Mainstream wird, ergeben sich viele potenzielle Vorteile für eine Vielzahl von Branchen:
- Schnellere Reaktionszeit
-
Beim Edge Computing wird die Leistung der Speicherung und Berechnung von Daten verteilt und an dem Punkt zur Verfügung gestellt, an dem die Entscheidung getroffen werden muss. Dadurch, dass kein Hin- und Rückweg zur Cloud erforderlich ist, werden Latenzzeiten reduziert und schnellere Reaktionen ermöglicht. Bei der vorbeugenden Wartung hilft es, kritische Maschinenausfälle oder gefährliche Zwischenfälle zu verhindern. Bei aktiven Spielen kann Edge Computing die geforderten Reaktionszeiten im Millisekundenbereich ermöglichen. Bei der Betrugsprävention und in Sicherheitsszenarien kann es vor Datenschutzverletzungen und Denial-of-Service-Angriffen schützen.
- Intermittierende Konnektivität
-
Eine unzuverlässige Internetverbindung bei abgelegenen Anlagen wie Ölquellen, landwirtschaftlichen Pumpen, Solarparks oder Windrädern kann die Überwachung dieser Anlagen erschweren. Die Fähigkeit der Kantengeräte, Daten lokal zu speichern und zu verarbeiten, stellt sicher, dass es bei eingeschränkter Internetverbindung nicht zu Datenverlusten oder Betriebsausfällen kommt.
- Sicherheit und Compliance
-
Edge Computing kann eine Menge Datenübertragungen zwischen Geräten und der Cloud vermeiden. Es ist möglich, sensible Informationen lokal zu filtern und nur kritische Datenmodelle in die Cloud zu übertragen. Bei intelligenten Geräten kann zum Beispiel das Abhören von "OK Google" oder "Alexa" direkt auf dem Gerät erfolgen. Potenziell private Daten müssen nicht gesammelt oder an die Cloud gesendet werden. Dies ermöglicht es den Nutzern, einen angemessenen Sicherheits- und Compliance-Rahmen zu schaffen, der für die Unternehmenssicherheit und Audits unerlässlich ist.
- Kosteneffiziente Lösungen
-
Eines der praktischen Probleme bei der Einführung des IoT sind die Vorlaufkosten für die Netzwerkbandbreite, die Speicherung der Daten und die Rechenleistung. Edge Computing kann viele Datenberechnungen lokal durchführen, so dass Unternehmen entscheiden können, welche Dienste lokal ausgeführt und welche in die Cloud verlagert werden sollen, was die Endkosten einer IoT-Gesamtlösung senkt. Hier können eingebettete Modelle in einem Format wie Open Neural Network Exchange (ONNX), die mit einer modernen kompilierten Sprache wie Rust oder Go erstellt wurden, mit geringem Speicherbedarf eingesetzt werden.
- Interoperabilität
-
Kantengeräte können als Verbindungsglied zwischen alten und modernen Maschinen fungieren. So können ältere Industriemaschinen mit modernen Maschinen oder IoT-Lösungen verbunden werden und bieten unmittelbare Vorteile bei der Erfassung von Erkenntnissen aus älteren oder modernen Maschinen.
All diese Konzepte ermöglichen es Architekten, bei der Definition ihrer Datenplattform unglaublich flexibel zu sein. In Kapitel 9 werden wir tiefer in diese Konzepte eintauchen und sehen, wie dieses Muster zu einem Standard wird .
KI anwenden
Viele Unternehmen sehen sich gezwungen, eine Cloud-Datenplattform zu entwickeln, weil sie KI-Technologien einsetzen müssen. Bei der Entwicklung einer Datenplattform muss sichergestellt werden, dass sie zukunftssicher ist und KI-Anwendungsfälle unterstützen kann. In Anbetracht des großen Einflusses, den KI auf die Gesellschaft hat, und ihrer Verbreitung in den Unternehmen, wollen wir kurz darauf eingehen, wie sie in Unternehmen implementiert werden kann. Eine ausführlichere Diskussion findest du in den Kapiteln 10 und 11.
Maschinelles Lernen
Heutzutage ist ein Zweig der KI, das so genannte überwachte maschinelle Lernen, so erfolgreich, dass der Begriff KI immer häufiger als Oberbegriff für diesen Zweig verwendet wird. Überwachtes maschinelles Lernen funktioniert, indem dem Computerprogramm viele Beispiele vorgelegt werden, bei denen die richtigen Antworten (die sogenannten Labels) bekannt sind. Das ML-Modell ist ein Standardalgorithmus (d.h. genau derselbe Code) mit einstellbaren Parametern, die "lernen", wie man von der vorgegebenen Eingabe zum Label gelangt. Ein solches gelerntes Modell wird dann eingesetzt, um Entscheidungen über Eingaben zu treffen, für die die richtigen Antworten nicht bekannt sind.
Im Gegensatz zu Expertensystemen muss das KI-Modell nicht explizit mit den Regeln für die Entscheidungsfindung programmiert werden. Da es in vielen realen Bereichen um menschliche Entscheidungen geht, bei denen die Experten ihre Logik nur schwer artikulieren können, ist es viel praktikabler, die Experten einfach die Eingabebeispiele beschriften zu lassen, als ihre Logik zu erfassen.
Moderne Schachspiel-Algorithmen und medizinische Diagnosetools nutzen ML. Die Algorithmen für das Schachspiel lernen aus Aufzeichnungen von Partien, die Menschen in der Vergangenheit gespielt haben,2 wohingegen medizinische Diagnosesysteme aus der Kennzeichnung von Diagnosedaten durch erfahrene Ärzte lernen.
Generative KI, ein Zweig der KI/ML, der in letzter Zeit extrem leistungsfähig geworden ist, ist nicht nur in der Lage, Bilder und Texte zu verstehen, sondern auch realistische Bilder und Texte zu erzeugen. Generative KI kann nicht nur neue Inhalte für Anwendungen wie das Marketing erstellen, sondern auch die Interaktion zwischen Maschinen und Nutzern vereinfachen. Nutzer/innen können Fragen in natürlicher Sprache stellen und viele Vorgänge auf Englisch oder in anderen Sprachen automatisieren, ohne Programmiersprachen beherrschen zu müssen.
Damit diese ML-Methoden funktionieren, benötigen sie riesige Mengen an Trainingsdaten und leicht verfügbare, maßgeschneiderte Hardware. Aus diesem Grund beginnen Unternehmen, die KI einsetzen, mit dem Aufbau einer Cloud-Daten/ML-Plattform.
Anwendungen von ML
Es gibt ein paar wichtige Gründe für die spektakuläre Einführung von ML in der Industrie:
- Daten sind einfacher.
-
Es ist einfacher, beschriftete Daten zu sammeln als Logik zu erfassen. Jede menschliche Denkweise hat Ausnahmen, die im Laufe der Zeit kodiert werden. Es ist einfacher, ein Team von Augenärzten dazu zu bringen, tausend Bilder zu beschriften, als sie dazu zu bringen, zu beschreiben, wie sie erkennen, dass ein Blutgefäß blutet.
- Eine Umschulung ist einfacher.
-
Wenn ML für Systeme eingesetzt wird, z. B. um Nutzern Artikel zu empfehlen oder Marketingkampagnen durchzuführen, ändert sich das Nutzerverhalten schnell, um sich anzupassen. Es ist wichtig, Modelle kontinuierlich zu trainieren. Das ist mit ML möglich, aber mit Code viel schwieriger.
- Bessere Benutzeroberfläche.
-
Eine Klasse von ML namens Deep Learning hat bewiesen, dass sie auch für unstrukturierte Daten wie Bilder, Videos und natürlichsprachliche Texte trainiert werden kann. Diese Arten von Eingaben sind bekanntermaßen schwer zu programmieren. So kannst du Daten aus der realen Welt als Eingaben verwenden - stell dir vor, wie viel besser die Benutzeroberfläche für die Einreichung von Schecks wird, wenn du einfach ein Foto von einem Scheck machen kannst, anstatt alle Informationen in ein Webformular eingeben zu müssen.
- Automatisierung.
-
Die Fähigkeit von ML-Modellen, unstrukturierte Daten zu verstehen, macht es möglich, viele Geschäftsprozesse zu automatisieren. Formulare lassen sich leicht digitalisieren, Instrumentenskalen leichter ablesen und Fabrikhallen leichter überwachen, weil Texte, Bilder oder Videos in natürlicher Sprache automatisch verarbeitet werden können.
- Kosteneffizienz.
-
ML-APIs, die Maschinen die Fähigkeit verleihen, Texte, Bilder, Musik und Videos zu verstehen und zu erstellen, kosten nur den Bruchteil eines Cents pro Aufruf, während die Bezahlung eines Menschen dafür um mehrere Größenordnungen teurer wäre. Dies ermöglicht den Einsatz von Technologie in Situationen wie Empfehlungen, in denen ein persönlicher Einkaufsassistent unerschwinglich wäre.
- Unterstützung.
-
Generative KI kann Entwicklern, Marketingfachleuten und anderen Angestellten helfen, produktiver zu sein. Kodierassistenten und Workflow-Kopiloten können Teile vieler Unternehmensfunktionen vereinfachen, z. B. das Versenden von maßgeschneiderten Vertriebs-E-Mails.
Angesichts dieser Vorteile ist es nicht verwunderlich, dass in einem Artikelder Harvard Business Review festgestellt wurde, dass KI im Allgemeinen drei Hauptanforderungen des Unternehmens unterstützt :
-
Automatisierung von Geschäftsprozessen - typischerweise Automatisierung von Verwaltungs- und Finanzaufgaben im Back-Office
-
Einblicke durch Datenanalyse gewinnen
-
Mit Kunden und Mitarbeitern zusammenarbeiten
ML erhöht die Skalierbarkeit, um diese Probleme mit Hilfe von Datenbeispielen zu lösen, ohne dass man für alles einen eigenen Code schreiben muss. ML-Lösungen wie Deep Learning ermöglichen es, diese Probleme auch dann zu lösen, wenn die Daten aus unstrukturierten Informationen wie Bildern, Sprache, Videos, Texten in natürlicher Sprache usw. bestehen .
Warum die Cloud für KI?
Ein wichtiger Impuls für die Entwicklung einer Cloud-Datenplattform könnte sein, dass das Unternehmen KI-Technologien wie Deep Learning schnell einführt. Damit diese Methoden funktionieren, benötigen sie riesige Mengen an Trainingsdaten. Daher muss ein Unternehmen, das ML-Modelle entwickeln will, eine Datenplattform aufbauen, um die Daten zu organisieren und den Data Science Teams zur Verfügung zu stellen. Die ML-Modelle selbst sind sehr komplex, und für das Training der Modelle werden große Mengen an Spezialhardware benötigt ( graphics processing units (GPUs)). Darüber hinaus sind KI-Technologien wie Sprachtranskription, maschinelle Übersetzung und Video Intelligence in der Regel als SaaS-Software in der Cloud verfügbar. Darüber hinaus bieten Cloud-Plattformen wichtige Funktionen wie Demokratisierung, einfachere Operationalisierung und die Möglichkeit, mit dem Stand der Technik Schritt zu halten.
Cloud-Infrastruktur
Die Quintessenz ist, dass qualitativ hochwertige KI eine Menge Daten benötigt - eine berühmte Studie mit dem Titel "Deep Learning Scaling Is Predictable, Empirically" (Deep Learning Skalierung ist vorhersagbar, empirisch) fand heraus, dass für eine 5%ige Verbesserung eines natürlichen Sprachmodells doppelt so viele Daten trainiert werden mussten, wie für das erste Ergebnis verwendet wurden. Die besten ML-Modelle sind nicht die fortschrittlichsten - sie sind diejenigen, die mit mehr Daten von ausreichender Qualität trainiert werden. Der Grund dafür ist, dass immer ausgefeiltere Modelle mehr Daten benötigen, während selbst einfache Modelle an Leistung gewinnen, wenn sie mit einem ausreichend großen Datensatz trainiert werden.
Um dir eine Vorstellung von der Datenmenge zu geben, die für das Training moderner ML-Modelle erforderlich ist, werden Bildklassifizierungsmodelle routinemäßig mit einer Million Bildern trainiert und führende Sprachmodelle mit mehreren Terabytes an Daten.
Wie in Abbildung 1-10 zu sehen ist, erfordert diese Art von Datenmenge eine Menge effizienter, maßgeschneiderter Berechnungen, die von Beschleunigern wie GPUs und anwendungsspezifischen integrierten Schaltkreisen (ASICs), den tensorprocessing units (TPUs), bereitgestellt werden, um diese Daten zu nutzen und sie sinnvoll zu verarbeiten.
Viele der jüngsten Fortschritte in der KI lassen sich auf die Zunahme der Datenmenge und der Rechenleistung zurückführen. Die Synergie zwischen den großen Datensätzen in der Cloud und den zahlreichen Computern, die sie antreiben, hat enorme Durchbrüche in der KI ermöglicht. Zu diesen Durchbrüchen gehört die Senkung der Fehlerquote bei der Spracherkennung um 30 % im Vergleich zu herkömmlichen Ansätzen - der größte Zuwachs seit 20 Jahren.
Abbildung 1-10. Die ML-Leistung steigt dramatisch mit mehr Speicher, mehr Prozessoren und/oder dem Einsatz von TPUs und GPUs (Grafik aus dem AVP-Projekt)
Demokratisierung
Die Architektur von ML-Modellen, insbesondere in komplexen Bereichen wie der Zeitreihenverarbeitung oder der Verarbeitung natürlicher Sprache (NLP), erfordert Kenntnisse der ML-Theorie. Das Schreiben von Code für das Training von ML-Modellen mit Frameworks wie PyTorch, Keras oder TensorFlow erfordert Kenntnisse in Python-Programmierung und linearer Algebra. Darüber hinaus erfordert die Datenaufbereitung für ML oft Data-Engineering-Kenntnisse, und die Auswertung von ML-Modellen erfordert Kenntnisse in fortgeschrittener Statistik. Die Bereitstellung von ML-Modellen und deren Überwachung erfordert Kenntnisse in DevOps und Softwareentwicklung (oft als MLOps bezeichnet). Natürlich ist es selten, dass all diese Fähigkeiten in jedem Unternehmen vorhanden sind. Daher kann es für ein traditionelles Unternehmen schwierig sein, ML für Geschäftsprobleme zu nutzen.
Cloud-Technologien bieten mehrere Möglichkeiten, die Nutzung von ML zu demokratisieren:
- ML APIs
-
Cloud-Provider bieten vorgefertigte ML-Modelle an, die über APIs aufgerufen werden können. Dann kann ein Entwickler das ML-Modell wie jeden anderen Webservice nutzen. Alles, was er braucht, ist die Fähigkeit, gegen REST-Webdienste (Representational State Transfer) zu programmieren. Beispiele für solche ML-APIs sind Google Translate, Azure Text Analytics und Amazon Lex - diese APIs können auch ohne NLP-Kenntnisse genutzt werden. Cloud-Provider stellen generative Modelle für die Text- und Bilderzeugung als APIs zur Verfügung, bei denen die Eingabeaufforderung lediglich ein Text ist.
- Anpassbare ML-Modelle
-
Einige öffentliche Clouds bieten "AutoML" an, d. h. End-to-End-ML-Pipelines, die mit einem Mausklick trainiert und eingesetzt werden können. Die AutoML-Modelle führen eine "neuronale Architektursuche" durch, d. h. sie automatisieren die Erstellung von ML-Modellen durch einen Suchmechanismus. Das Training dauert zwar länger, als wenn ein menschlicher Experte ein effektives Modell für das Problem auswählt, aber das AutoML-System kann für Geschäftszweige ausreichen, die nicht die Möglichkeit haben, eigene Modelle zu entwickeln . Beachte, dass AutoML nicht gleich AutoML ist - manchmal ist das, was sich AutoML nennt, nur Parameter-Tuning. Vergewissere dich, dass du eine maßgeschneiderte Architektur erhältst und nicht nur eine Auswahl an vorgefertigten Modellen. Überprüfe, ob verschiedene Schritte automatisiert werden können (z. B. Feature Engineering, Feature Extraktion, Feature Auswahl, Modellauswahl, Parameterabstimmung, Problemprüfung usw.).
- Einfacher ML
-
Einige DWHs (BigQuery und Redshift zum Zeitpunkt der Erstellung dieses Artikels) bieten die Möglichkeit, ML-Modelle auf strukturierten Daten zu trainieren, indem sie lediglich SQL verwenden. Redshift und BigQuery unterstützen komplexe Modelle, indem sie sie an Vertex AI bzw. SageMaker delegieren. Tools wie DataRobot und Dataiku bieten Point-and-Click-Schnittstellen zum Trainieren von ML-Modellen. Cloud-Plattformen machen die Feinabstimmung von generativen Modellen viel einfacher als sonst.
- ML-Lösungen
-
Einige Anwendungen sind so verbreitet, dass End-to-End-ML-Lösungen gekauft und eingesetzt werden können. Product Discovery auf Google Cloud bietet Einzelhändlern eine durchgängige Such- und Bewertungsfunktion. Amazon Connect bietet ein einsatzbereites Contact Center auf Basis von ML. Azure Knowledge Mining bietet eine Möglichkeit, eine Vielzahl von Inhalten zu analysieren. Darüber hinaus bieten Unternehmen wie Quantum Metric und C3 AI cloudbasierte Lösungen für Probleme an, die in verschiedenen Branchen auftreten.
- ML-Bausteine
-
Auch wenn es keine Lösung für den gesamten ML-Workflow gibt, könnten Teile davon von den Bausteinen profitieren. Empfehlungssysteme benötigen zum Beispiel die Fähigkeit, Artikel und Produkte abzugleichen. Ein universeller Matching-Algorithmus, der sogenannte Two-Tower-Encoder, ist bei Google Cloud erhältlich. Es gibt zwar kein durchgängiges ML-Modell für die Back-Office-Automatisierung, aber du könntest die Vorteile von Formularparsern nutzen, um diesen Workflow schneller zu implementieren.
Diese Fähigkeiten ermöglichen es Unternehmen, KI auch dann einzusetzen, wenn sie nicht über tiefgreifende Fachkenntnisse verfügen, und machen KI damit breiter verfügbar.
Selbst wenn das Unternehmen über Fachwissen im Bereich KI verfügt, erweisen sich diese Fähigkeiten als sehr nützlich, denn du musst immer noch entscheiden, ob du ein ML-System kaufen oder bauen willst. In der Regel gibt es mehr ML-Möglichkeiten als Menschen, die sie lösen können. Daher ist es von Vorteil, wenn die nicht zum Kerngeschäft gehörenden Funktionen mit vorgefertigten Tools und Lösungen ausgeführt werden können. Diese vorgefertigten Lösungen können sofort einen großen Nutzen bringen, ohne dass man eigene Anwendungen schreiben muss. Zum Beispiel können Daten aus einem natürlichsprachlichen Text über einen API-Aufruf an ein vorgefertigtes Modell übergeben werden, um den Text von einer Sprache in eine andere zu übersetzen. Das reduziert nicht nur den Aufwand für die Erstellung von Anwendungen, sondern ermöglicht es auch Nicht-ML-Experten, KI zu nutzen. Am anderen Ende des Spektrums kann das Problem eine maßgeschneiderte Lösung erfordern. Einzelhändler erstellen zum Beispiel oft ML-Modelle, um die Nachfrage zu prognostizieren, damit sie wissen, wie viele Produkte sie auf Lager haben müssen. Diese Modelle lernen das Kaufverhalten aus den historischen Verkaufsdaten des Unternehmens, kombiniert mit der Intuition von Experten.
Ein weiteres gängiges Muster ist die Verwendung von vorgefertigten, sofort einsatzbereiten Modellen für schnelle Experimente. Sobald sich die ML-Lösung bewährt hat, kann ein Data-Science-Team sie maßgeschneidert weiterentwickeln, um eine höhere Genauigkeit und hoffentlich mehr Differenzierung gegenüber der Konkurrenz zu erreichen.
Echtzeit
Die ML-Infrastruktur muss in eine moderne Datenplattform integriert werden, denn personalisierte ML in Echtzeit ist das, was den Wert ausmacht. Daher ist die Geschwindigkeit der Analyse sehr wichtig, denn die Datenplattform muss in der Lage sein, Daten in Echtzeit aufzunehmen, zu verarbeiten und bereitzustellen, sonst gehen Chancen verloren. Hinzu kommt die Schnelligkeit des Handelns. ML ermöglicht personalisierte Dienste, die auf dem Kontext des Kunden basieren, muss aber Schlussfolgerungen ziehen, bevor sich der Kontext des Kunden ändert - für die meisten Geschäftstransaktionen gibt es ein Zeitfenster, innerhalb dessen das ML-Modell dem Kunden eine Handlungsoption bieten muss. Um dies zu erreichen, müssen die Ergebnisse der ML-Modelle in Echtzeit am Ort des Geschehens ankommen.
Die Fähigkeit, ML-Modelle in Echtzeit mit Daten zu versorgen und die ML-Vorhersage in Echtzeit zu erhalten, ist der Unterschied zwischen Betrugsprävention und Betrugsaufdeckung. Um Betrug zu verhindern, ist es notwendig, alle Zahlungs- und Kundendaten in Echtzeit zu erfassen, die ML-Vorhersage durchzuführen und das Ergebnis des ML-Modells in Echtzeit an die Zahlungsseite zu übermitteln, damit die Zahlung bei Betrugsverdacht abgelehnt werden kann.
Andere Situationen, in denen die Echtzeitverarbeitung Geld spart, sind der Kundenservice und der Abbruch von Einkäufen. Es ist wichtig, die Frustration eines Kunden in einem Call Center aufzufangen und die Situation sofort zu eskalieren, um den Service effektiv zu gestalten - es kostet viel mehr Geld, einen einmal verlorenen Kunden wiederzugewinnen, als ihm in diesem Moment einen guten Service zu bieten. Ähnlich verhält es sich, wenn die Gefahr besteht, dass ein Einkaufswagen weggeworfen wird: Ein Lockangebot wie ein Preisnachlass von 5 % oder ein kostenloser Versand kann weniger kosten als die viel größeren Werbeaktionen, die nötig sind, um den Kunden wieder auf die Website zu bringen.
In anderen Situationen ist die Stapelverarbeitung einfach keine effektive Option. Echtzeit-Verkehrsdaten und Echtzeit-Navigationsmodelle sind für Google Maps erforderlich, damit Fahrer/innen den Verkehr umgehen können.
Wie du in Kapitel 8 sehen wirst, sind die Ausfallsicherheit und die Fähigkeit zur automatischen Skalierung von Cloud-Diensten im eigenen Haus nur schwer zu erreichen. Daher ist Echtzeit-ML am besten in der Cloud aufgehoben.
MLOps
Ein weiterer Grund dass ML in der Public Cloud besser ist, ist, dass die Operationalisierung von ML schwierig ist. Effektive und erfolgreiche ML-Projekte erfordern die Operationalisierung sowohl von Daten als auch von Code. Das Beobachten, Orchestrieren und Handeln im ML-Lebenszyklus wird als MLOps bezeichnet.
Das Erstellen, Bereitstellen und Ausführen von ML-Anwendungen in der Produktion umfasst mehrere Schritte, wie in Abbildung 1-11 dargestellt. All diese Schritte müssen orchestriert und überwacht werden. Wenn zum Beispiel eine Datenabweichung festgestellt wird, müssen die Modelle automatisch neu trainiert werden. Die Modelle müssen ständig neu trainiert und eingesetzt werden, nachdem sichergestellt wurde, dass sie sicher eingesetzt werden können. Für die eingehenden Daten musst du eine Datenvorverarbeitung und -validierung durchführen, um sicherzustellen, dass es keine Probleme mit der Datenqualität gibt, gefolgt vom Feature-Engineering, dem Modelltraining und der Abstimmung der Hyperparameter.

Abbildung 1-11. Etappen eines ML-Workflows
Zusätzlich zu den besprochenen datenspezifischen Aspekten der Überwachung gibt es auch die Überwachung und Operationalisierung, die für jeden laufenden Dienst notwendig ist. Eine Produktionsanwendung läuft oft rund um die Uhr und 365 Tage die Woche, und es kommen regelmäßig neue Daten herein. Daher brauchst du Werkzeuge, mit denen du diese mehrphasigen ML-Workflows einfach orchestrieren und verwalten und sie zuverlässig und wiederholt ausführen kannst.
Cloud-KI-Plattformen wie Vertex AI von Google, Azure Machine Learning von Microsoft und SageMaker von Amazon bieten Managed Services für den gesamten ML-Workflow. Wenn du das vor Ort machst, musst du die zugrundeliegenden Technologien zusammenschustern und die Integrationen selbst verwalten.
Zum Zeitpunkt der Erstellung dieses Buches werden die verschiedenen Cloud-Plattformen in rasantem Tempo um ML-Funktionen erweitert. Das bringt einen weiteren Punkt zur Sprache: Angesichts des rasanten Wandels im Bereich ML ist es besser, wenn du die Aufgabe des Aufbaus und der Wartung von ML-Infrastruktur und -Werkzeugen an einen Dritten delegierst und dich auf Daten und Erkenntnisse konzentrierst, die für dein Kerngeschäft relevant sind.
Zusammenfassend lässt sich sagen, dass eine Cloud-basierte Daten- und KI-Plattform dazu beitragen kann, die traditionellen Herausforderungen in Bezug auf Datensilos, Governance und Kapazität zu lösen und gleichzeitig das Unternehmen auf eine Zukunft vorzubereiten, in der KI-Funktionen immer wichtiger werden.
Grundprinzipien
Bei der Entwicklung einer Datenplattform kann es hilfreich sein, die wichtigsten Designprinzipien festzulegen und die Gewichtung der einzelnen Prinzipien zu bestimmen. Es ist wahrscheinlich, dass du Kompromisse zwischen diesen Grundsätzen eingehen musst, und eine vorher festgelegte Scorecard, der alle Beteiligten zugestimmt haben, kann dir helfen, Entscheidungen zu treffen, ohne dass du zu den ersten Grundsätzen zurückkehren musst oder dich vom quietschendsten Rad beeinflussen lässt.
Hier sind die fünf wichtigsten Prinzipien, die wir für den Aufbau eines Data Analytics Stacks vorschlagen, wobei die Gewichtung von Unternehmen zu Unternehmen variieren kann:
- Liefern Sie serverlose Analysen, keine Infrastruktur.
-
Entwirf analytische Lösungen für vollständig verwaltete Umgebungen und vermeide einen Lift-and-Shift-Ansatz so weit wie möglich. Konzentriere dich auf eine moderne serverlose Architektur, damit sich deine Data Scientists (wir verwenden diesen Begriff im weitesten Sinne für Dateningenieure, Datenanalysten und ML-Ingenieure) ausschließlich auf die Analyse konzentrieren können und sich nicht mit Infrastrukturüberlegungen beschäftigen müssen. Nutze zum Beispiel den automatisierten Datentransfer, um Daten aus deinen Systemen zu extrahieren, und biete eine Umgebung für gemeinsam genutzte Daten mit federated Querying über jeden Dienst hinweg. Damit entfällt die Notwendigkeit, eigene Frameworks und Datenpipelines zu pflegen.
- End-to-End-ML einbetten.
-
Ermögliche es deiner Organisation, ML von Anfang bis Ende zu operationalisieren. Es ist unmöglich, alle ML-Modelle zu bauen, die dein Unternehmen braucht. Stelle daher sicher, dass du eine Plattform aufbaust, die es ermöglicht, demokratisierte ML-Optionen wie vorgefertigte ML-Modelle, ML-Bausteine und einfach zu verwendende Frameworks einzubinden. Stelle sicher, dass du Zugang zu leistungsstarken Beschleunigern und anpassbaren Modellen hast, wenn du eine individuelle Schulung benötigst. Sicherstellen, dass MLOps unterstützt wird, damit eingesetzte ML-Modelle nicht abdriften und ihren Zweck nicht mehr erfüllen. Vereinfachen Sie den ML-Lebenszyklus auf dem gesamten Stack, damit das Unternehmen schneller einen Nutzen aus seinen ML-Initiativen ziehen kann.
- Ermögliche Analysen über den gesamten Lebenszyklus der Daten.
-
Die Datenplattform sollte ein umfassendes Angebot an Kerndatenanalyse-Workloads bieten. Achte darauf, dass deine Datenplattform Datenspeicherung, Data Warehousing, Streaming Data Analytics, Datenaufbereitung, Big Data-Verarbeitung, Data Sharing und Monetarisierung, Business Intelligence (BI) und ML bietet. Vermeide es, Einzellösungen zu kaufen, die du dann integrieren und verwalten musst. Wenn du den Analyse-Stack ganzheitlich betrachtest, kannst du Datensilos aufbrechen, Anwendungen mit Echtzeitdaten versorgen, schreibgeschützte Datensätze hinzufügen und Abfrageergebnisse für jeden zugänglich machen.
- Open-Source-Software (OSS)-Technologien zu ermöglichen.
-
Wo immer es möglich ist, solltest du sicherstellen, dass der Kern deiner Plattform aus offenen Quellen besteht. Du solltest sicherstellen, dass jeder Code, den du schreibst, OSS-Standards wie Standard SQL, Apache Spark, TensorFlow usw. verwendet. Indem du die besten Open-Source-Technologien einsetzt, kannst du bei Datenanalyseprojekten Flexibilität und Auswahl bieten.
- Baue für Wachstum.
-
Stelle sicher, dass die Datenplattform, die du aufbaust, in der Lage ist, auf die Datengröße, den Durchsatz und die Anzahl der gleichzeitigen Nutzer zu skalieren, die in deinem Unternehmen zu erwarten sind. Manchmal bedeutet dies, dass du dich für unterschiedliche Technologien entscheiden musst (z. B. SQL für einige Anwendungsfälle und NoSQL für andere). In diesem Fall musst du sicherstellen, dass die beiden von dir gewählten Technologien miteinander kompatibel sind. Nutze Lösungen und Frameworks, die sich bewährt haben und von den innovativsten Unternehmen der Welt eingesetzt werden, um ihre geschäftskritischen Analyseanwendungen zu betreiben.
Insgesamt sind diese Faktoren in der Reihenfolge aufgeführt, in der wir sie normalerweise empfehlen. Da die beiden Hauptmotivationen von Unternehmen für eine Cloud-Migration die Kosten und die Innovation sind, empfehlen wir, dass du Serverless (wegen der Kosteneinsparungen und der Befreiung der Mitarbeiter von Routinearbeiten) und End-to-End ML (wegen der großen Vielfalt an Innovationen, die es ermöglicht) priorisierst.
In manchen Situationen möchtest du vielleicht einigen Faktoren Vorrang vor anderen geben. Für Start-ups empfehlen wir in der Regel, dass die wichtigsten Faktoren serverlos, Wachstum und End-to-End-ML sind. Umfang und Offenheit können für Geschwindigkeit geopfert werden. Stark regulierte Unternehmen bevorzugen möglicherweise Umfassendheit, Offenheit und Wachstum gegenüber Serverless und ML (d.h., die Regulierungsbehörden können eine On-Premise-Lösung vorschreiben). Für Digital Natives empfehlen wir, in dieser Reihenfolge, End-to-End ML, Serverless, Wachstum, Offenheit und Vollständigkeit.
Zusammenfassung
Dies war eine Einführung in die Modernisierung von Datenplattformen auf hohem Niveau. Ausgehend von der Definition des Datenlebenszyklus haben wir uns die Entwicklung der Datenverarbeitung, die Grenzen der traditionellen Ansätze und die Schaffung einer einheitlichen Analyseplattform in der Cloud angesehen. Außerdem haben wir uns angeschaut, wie man die Cloud-Datenplattform zu einer hybriden Plattform ausbauen und KI/ML unterstützen kann. Die wichtigsten Erkenntnisse aus diesem Kapitel sind die folgenden:
-
Der Lebenszyklus von Daten besteht aus fünf Phasen: Erfassen, Speichern, Verarbeiten, Analysieren/Visualisieren und Aktivieren. Diese müssen von einer Daten- und ML-Plattform unterstützt werden.
-
Traditionell bestehen die Datenökosysteme von Unternehmen aus unabhängigen Lösungen, die zur Bildung von Silos innerhalb des Unternehmens führen.
-
Datenverschiebungstools können Datensilos aufbrechen, aber sie haben auch einige Nachteile: Latenz, Engpässe bei den Datenentwicklungsressourcen, Wartungsaufwand, Änderungsmanagement und Datenlücken.
-
Die Zentralisierung der Datenkontrolle in der IT führt zu organisatorischen Herausforderungen. Die IT-Abteilungen verfügen nicht über die notwendigen Fähigkeiten, die Analyseteams erhalten schlechte Daten und die Geschäftsteams vertrauen den Ergebnissen nicht.
-
Unternehmen müssen eine Cloud-Datenplattform aufbauen, um Best-of-Breed-Architekturen zu erhalten, die Konsolidierung über Geschäftseinheiten hinweg zu bewältigen, On-Premise-Ressourcen zu skalieren und die Geschäftskontinuität zu planen.
-
Eine Cloud-Datenplattform nutzt moderne Ansätze und zielt darauf ab, datengestützte Innovationen zu ermöglichen, indem sie Daten repliziert, Silos aufbricht, Daten demokratisiert, Data Governance durchsetzt, Entscheidungsfindung in Echtzeit und unter Verwendung von Standortinformationen ermöglicht und nahtlos von deskriptiven Analysen zu prädiktiven und präskriptiven Analysen übergeht.
-
Alle Daten können aus den operativen Systemen in einen zentralen Data Lake für Analysen exportiert werden. Der Data Lake dient als zentrales Repository für Analyse-Workloads und für Geschäftsanwender. Der Nachteil ist jedoch, dass die Geschäftsanwender/innen nicht über die Fähigkeiten verfügen, gegen einen Data Lake zu programmieren.
-
DWHs sind zentralisierte Analysespeicher, die SQL unterstützen, etwas, mit dem Geschäftsanwender vertraut sind.
-
Das Data Lakehouse basiert auf der Idee, dass alle Nutzer/innen unabhängig von ihren technischen Fähigkeiten in der Lage sein sollten, Daten zu nutzen. Durch die Bereitstellung eines zentralen und grundlegenden Rahmens für die Bereitstellung von Daten können verschiedene Tools auf dem Lakehouse eingesetzt werden, um die Bedürfnisse der einzelnen Nutzer/innen zu erfüllen.
-
Data Mesh stellt eine Möglichkeit dar, Daten als ein in sich geschlossenes Produkt zu betrachten. Verteilte Teams sind bei diesem Ansatz Eigentümer der Datenproduktion und bedienen interne/externe Verbraucher durch ein genau definiertes Datenschema.
-
Eine hybride Cloud-Umgebung ist ein pragmatischer Ansatz, um den Realitäten der Unternehmenswelt wie Übernahmen, lokalen Gesetzen und Latenzanforderungen gerecht zu werden.
-
Die Fähigkeit der öffentlichen Cloud, große Datenmengen zu verwalten und GPUs bei Bedarf bereitzustellen, macht sie für alle Formen von ML unverzichtbar, insbesondere aber für Deep Learning und generative KI. Darüber hinaus bieten Cloud-Plattformen wichtige Funktionen wie Demokratisierung, einfachere Operationalisierung und die Möglichkeit, mit dem Stand der Technik Schritt zu halten.
-
Die fünf Grundprinzipien einer Cloud-Datenplattform sind die Priorisierung von serverloser Analytik, End-to-End-ML, Vollständigkeit, Offenheit und Wachstum. Die relative Gewichtung wird von Unternehmen zu Unternehmen unterschiedlich sein.
Jetzt, wo du weißt, wo du landen willst, schauen wir uns im nächsten Kapitel eine Strategie an, um dorthin zu gelangen.
1 Es geht nicht nur um die Kosten für die Technologie oder die Lizenzgebühren, sondern auch um die Personalkosten, und SQL-Kenntnisse sind für ein Unternehmen in der Regel günstiger als Java- oder Python-Kenntnisse.
2 Neuere ML-Systeme wie AlphaGo lernen, indem sie sich Spiele ansehen, die zwischen den Maschinen selbst gespielt werden: Dies ist eine fortgeschrittene Art von ML, die als Verstärkungslernen bezeichnet wird, aber die meisten industriellen Anwendungen von ML sind von der einfacheren überwachten Art.
Get Architektur von Plattformen für Daten und maschinelles Lernen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

