Chapter 4. A Migration Framework
Unless you are at a startup, it is rare that you will build a data platform from scratch. Instead, you will stand up a new data platform by migrating things into it from legacy systems. In this chapter, let’s examine the process of migration—all the things that you should do when making your journey to a new data platform. We will first present a conceptual model and possible framework you should follow when modernizing the data platform. Then, we will review how an organization can estimate the overall cost of the solution. We will discuss how to ensure that security and data governance are in place even while the migration is going on. Finally, we’ll discuss schema, data, and pipeline migration. You’ll also learn about options for regional capacity, networking, and data transfer constraints.
Modernize Data Workflows
Before you start creating a migration plan, you should have a comprehensive vision of why you are doing it and what you are migrating toward.
Holistic View
Data modernization transformation should be considered holistically. Looking at this from a bird’s-eye perspective, we can identify three main pillars:
- Business outcomes
-
Focus on the workflows that you are modernizing and identify the business outcomes those workflows drive. This is critical to identify where the gaps are and where the opportunities sit. Before making any technology decisions, limit the migration to use cases that align with the business objectives identified by leadership (typically over a time horizon of two to three years).
- Stakeholders
-
Identify the persons or roles (some of these teams may not yet exist) who will potentially gain access to the data. Your goal with data modernization is to democratize data access. Therefore, these teams will need to become data literate and proficient in whatever tools (SQL, Python, dashboards) the modernization end-state technologies expect them to use.
- Technology
-
You’ll have to define, implement, and deploy data architecture, modeling, storage, security, integration, operability, documentation, reference data, quality, and governance in alignment with business strategy and team capabilities.
Make sure you are not treating migration as a pure IT or data science project but one where the technological aspect is just a subset of a larger organizational change.
Modernize Workflows
When you think about a modernization program, your mind naturally gravitates to the pain you are experiencing with the tools you have. You decide that you want to upgrade your database and make it globally consistent and scalable, so you modernize it to Spanner or CockroachDB. You decide that you want to upgrade your streaming engine and make it more resilient and easier to run, so you pick Flink or Dataflow. You decide you are done tuning clusters and queries on your DWH, so you modernize to BigQuery or Snowflake.
These are all great moves. You should definitely upgrade to easier-to-use, easier-to-run, much more scalable, much more resilient tools whenever you can. However, if you do only like-for-like tool changes, you will end up with just incremental improvements. You will not get transformational change from such upgrades.
To avoid this trap, when you start your data modernization journey, force yourself to think of workflows, not technologies. What does it mean to modernize a data workflow? Think about the overall task that the end user wants to do. Perhaps they want to identify high-value customers. Perhaps they want to run a marketing campaign. Perhaps they want to identify fraud. Now, think about this workflow as a whole and how to implement it as cheaply and simply as possible.
Next, approach the workflow from first principles. The way to identify high-value customers is to compute total purchases for each user from a historical record of transactions. Figure out how to make such a workflow happen with your modern set of tools. When doing so, lean heavily on automation:
- Automated data ingest
-
Do not write bespoke ELT pipelines. Use off-the-shelf ELT tools such as Datastream or Fivetran to land the data in a DWH. It is so much easier to transform on the fly, and capture common transformations in materialized views, than it is to write ETL pipelines for each possible downstream task. Also, many SaaS systems will automatically export to S3, Snowflake, BigQuery, etc.
- Streaming by default
-
Land your data in a system that combines batch and streaming storage so that all SQL queries reflect the latest data (subject to some latency). Same with any analytics—look for data processing tools that handle both streaming and batch using the same framework. In our example, the lifetime value calculation can be a SQL query. For reuse purposes, make it a materialized view. That way, all the computations are automatic, and the data is always up to date.
- Automatic scaling
-
Any system that expects you to prespecify the number of machines, warehouse sizes, etc., is a system that will require you to focus on the system rather than the job to be done. You want scaling to be automatic, so that you can focus on the workflow rather than on the tool.
- Query rewrites, fused stages, etc.
-
You want to be able to focus on the job to be done and decompose it into understandable steps. You don’t want to have to tune queries, rewrite queries, fuse transforms, etc. Let the modern optimizers built into the data stack take care of these things.
- Evaluation
-
You don’t want to write bespoke data processing pipelines for evaluating ML model performance. You simply want to be able to specify sampling rates and evaluation queries and be notified about feature drift, data drift, and model drift. All these capabilities should be built into deployed endpoints.
- Retraining
-
If you encounter model drift, you should retrain the model 9 times out of 10. This should be automated as well. Modern ML pipelines will provide a callable hook that you can tie directly to your automated evaluation pipeline so you can automate retraining as well.
- Continuous training
-
Model drift is not the only reason you might need to retrain. You want to retrain when you have a lot more data. Maybe when new data lands in a storage bucket. Or when you have a code check-in. Again, this can be automated.
Once you land on the need for a fully automated data workflow, you are looking at a pretty templatized setup that consists of a connector, DWH, and ML pipelines. All of these can be serverless, so you are basically looking at just configuration, not cluster management.
Of course, you will be writing a few specific pieces of code:
-
Data preparation in SQL
-
ML models in a framework such as TensorFlow, PyTorch, or langchain
-
Evaluation query for continuous evaluation
The fact that we can come down to such a simple setup for each workflow explains why an integrated data and AI platform is so important.
Transform the Workflow Itself
You can make the workflow itself much more efficient by making it more automated using the modern data stack. But before you do that, you should ask yourself a key question: “Is this workflow necessary to be precomputed by a data engineer?”
Because that’s what you are doing whenever you build a data pipeline—you are precomputing. It’s an optimization, nothing more.
In many cases, if you can make the workflow something that is self-serve and ad hoc, you don’t have to build it with data engineering resources. Because so much is automated, you can provide the ability to run any aggregation (not just lifetime value) on the full historical record of transactions. Move the lifetime value calculation into a declarative semantic layer to which your users can add their own calculations. This is what a tool like Looker, for example, will allow you to do. Once you do that, you get the benefits of consistent KPIs across the org and users who are empowered to build a library of common measures. The ability to create new metrics now lies with the business teams, where this capability belongs in the first place.
A Four-Step Migration Framework
You can apply a standardized approach to many of the situations you might encounter in the process of building your data platform. This approach is, for the most part, independent of the size and the depth of the data platform—we have followed it both for modernizing the DWH of a small company and for developing a brand-new data architecture for a multinational enterprise.
This approach is based on the four main steps shown in Figure 4-1:
- 1. Prepare and discover.
-
All stakeholders should conduct a preliminary analysis to identify the list of workloads that need to be migrated and current pain points (e.g., inability to scale, process engine cannot be updated, unwanted dependencies, etc.).
- 2. Assess and plan.
-
Assess the information collected in the previous stage, define the key measures of success, and plan the migration of each component.
- 3. Execute.
-
For each identified use case, decide whether to decommission it, migrate it entirely (data, schema, downstream and upstream applications), or offload it (by migrating downstream applications to a different source). Afterward, test and validate any migration done.
- 4. Optimize.
-
Once the process has begun, it can be expanded and improved through continuous iterations. A first modernization step could focus only on core capabilities.
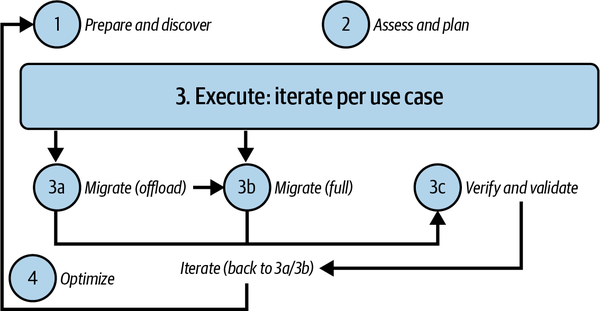
Figure 4-1. Four-step migration framework
Let’s go through each of these steps in turn.
Prepare and Discover
The first step is to prepare and discover. This involves defining the scope of the migration and collecting all the information related to the workloads/use cases that will be migrated. It includes analyzing a wide range of inputs from multiple stakeholders across the enterprise, such as business, finance, and IT. Ask those stakeholders to:
-
List all use cases and workloads, with their associated priorities, that are relevant to the migration. Make sure they include compliance requirements, latency sensitivities, and other relevant information.
-
Explain the expected benefits that they can get with the new system (e.g., query performance, amount of data they are able to handle, streaming capabilities, etc.).
-
Suggest solutions available on the market that could meet the business needs.
-
Perform an initial TCO analysis to estimate the value of the migration.
-
Identify needs around training and recruiting to build a capable workforce.
You can use questionnaires to collect these insights from application owners, data owners, and selected final users.
Assess and Plan
The second step is to assess the collected data and plan all the activities that need to be done to accomplish the identified goals. This involves:
- 1. Assessment of the current state
-
Analyze the current technology footprint for each application, workflow, or tool by collecting and analyzing server configurations, logs, job activity, data flow mapping, volumetrics, queries, and clusters. As the size of the legacy footprint increases, this activity may become very time-consuming and error-prone. So look for tools (such as SnowConvert, CompilerWorks, AWS Schema Conversion Tool, Azure Database Migration Service, Datametica Raven, etc.) that can automate the entire process, from data gathering to analysis and recommendation. These tools can provide workload breakdown, dependencies mapping, complexity analysis, resource utilization, capacity analysis, SLA analysis, end-to-end data lineage, and various optimization recommendations.
- 2. Workload categorization
-
Use the information collected through the questionnaire used in the “Prepare and Discover” step, along with the in-depth insights from the assessment phase, to categorize and select the approach for all the identified workloads into one of the following options:
- Retire
-
The workload will initially remain on prem and will eventually be decommissioned.
- Retain
-
The workload will remain on prem due to technical constraints (e.g., it runs on dedicated hardware) or for business reasons. This may be temporary until the workload can be refactored, or possibly moved to a colocation facility where data centers need to be closed and services can’t be moved.
- Rehost
-
The workload will be migrated into the cloud environment, leveraging its infrastructure as a service (IaaS) capabilities. This is often known as a “lift and shift.”
- Replatform
-
The workload (or part of it) will be partially changed to improve its performance or reduce its cost and then moved to the IaaS; this is often known as “move and improve.” Optimize after doing a lift and shift experience, generally starting with containerization.
- Refactor
-
The workload (or part of it) will be migrated to one or more cloud fully managed platform as a service (PaaS) solutions (e.g., BigQuery, Redshift, Synapse).
- Replace
-
The workload will be completely replaced by a third-party off-the-shelf or SaaS solution.
- Rebuild
-
The workload is completely rearchitected using cloud fully managed solutions and reimplemented from scratch. This is where you rethink your application and plan how to leverage the best of the cloud native services.
- 3. Workload clusterization
-
Cluster the workloads that will not be retired/rebuilt into a series of groups based on their relative business value and the effort needed to migrate them. This will help to identify a prioritization you can follow during the migration. For example:
-
Group 1: high business value, low effort to migrate (Priority 0—quick wins)
-
Group 2: high business value, high effort to migrate (Priority 1)
-
Group 3: low business value, low effort to migrate (Priority 2)
-
Group 4: low business value, high effort to migrate (Priority 3)
-
In Figure 4-2 you can see an example of clusterization where workloads have been divided into groups based on the described prioritization criteria. In each group, workloads can have different migration approaches.
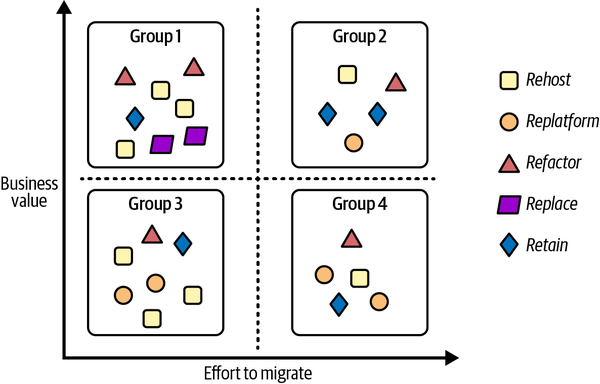
Figure 4-2. Example of workload categorization and clusterization
Throughout this process, we recommend that you adhere to the following practices:
- Make the process measurable.
-
Ensure that stakeholders are agreed on and can evaluate the results of the modernization using some business KPIs.
- Start with minimum viable product (MVP) or proof of concept (PoC).
-
Break down large jobs into smaller tasks and ensure that standard templates exist for any work you are about to undertake. If not, conduct a PoC and use that as a template going forward. Be on the lookout for quick wins (Priority 0 workloads) that can be leveraged not only as an example for the other transformations but also as a demonstration to leadership of the impact that such modernization might introduce.
- Estimate the overall time needed to complete all the activities.
-
Create a holistic project plan (working with vendors or consultants if necessary) to define the time, cost, and people needed for workload transformation.
- Overcommunicate at milestones.
-
Ensure that stakeholders understand the plan, how long it will take, and what the key components are. Make sure to deliver value and instill confidence along the way with completed cloud projects that people in the organization can actually start to use. Try to identify milestones and send out an ad hoc communication recapping details about the work that has been done.
Now that you have a good understanding of the tasks you need to complete to prepare for your next migration, let’s take a look at how you should go about doing so.
Execute
For each workload, you now have a plan. Specifically, you know what will be migrated (the entirety of the workload or just a part), where it will be migrated (IaaS, PaaS, or SaaS), how you are going to migrate (rehost, replatform, rebuild, etc.), how you are going to measure success, what templates you are going to follow, how much time it’s going to take, and what milestones you are going to communicate at. To turn the plan into reality, we recommend that you set up a landing zone, migrate to it, and validate the migrated tasks.
Landing zone
First you have to build what is called the landing zone—the target environment where all the workloads will reside. This activity can assume different levels of complexity based on your current configuration, but at the bare minimum you will need to:
-
Define the target project and related organization (e.g., Google Cloud organization hierarchy)
-
Set up a new identity management solution or integrate with a legacy or third-party one (e.g., Azure Active Directory or Okta)
-
Configure the authorization (e.g., AWS IAM) and auditing systems (e.g., Azure security logging and auditing)
-
Define and set up the network topology and related configuration
Once the landing zone is ready, it is time for you to start the migration.
Migrate
It is generally advisable to split a migration into multiple phases, or iterations, unless the number of workloads you have to migrate is very small. This will allow you to gain experience and confidence in how to proceed and deal with challenges and errors as you migrate a subset of the workloads at a time.
For each workload, you may have to consider:
- Schema and data migration
-
Depending on the use case, you may need to translate the data model or simply transfer the data.
- Query transpile
-
In some cases, you may need to translate queries from your source system to the target system. If the target system does not support all extensions, you may need to refactor the queries. You can leverage tools such as Datametica Raven or generative AI to reduce the manual effort involved.
- Data pipelines migration
-
Data pipelines form the core part of a data workload that prepares the data for analysis. We will see possible approaches to dealing with such migrations in “Schema, Pipeline, and Data Migration”.
- Business application migration
-
Once you have migrated the data, you need to migrate the applications that enable users to interact with the data.
- Performance tuning
-
If the migrated workload is not performing as expected, you have to troubleshoot it and fix it. Perhaps the target solution has not been properly configured, the data model you define does not allow you to leverage all the capabilities of the target platform, or there is an issue in the transpiling process.
It is essential to use infrastructure as code tools like Ansible or Terraform, as they can automate as much of the deployment infrastructure management as possible, speeding up the tests and execution of each iteration.
Validate
Once the workload has been migrated, you have to double-check if everything has been completed successfully. Verify that your workload performance, running cost, time to access data, etc., are all aligned with your identified KPIs. Validate that all the results you get are compliant with your expectations (e.g., query results are the same as in the legacy environment). Once you are sure that results are aligned with your needs, it is time to move to the second use case, and then to the third until you have migrated everything. If possible, parallelize later iterations to speed up the overall process.
It is always a good idea at the end of each workload to note eventual issues you may have and the time needed to complete all the activities and related lessons learned to improve the process in the subsequent workloads.
Optimize
The last step of the framework is optimization. Here, you won’t focus on the performance of every single migrated component. Instead, you will consider the new system as a whole and identify potential new use cases to introduce to make it even more flexible and powerful. You should reflect on what you got from the migration (e.g., unlimited scalability, enhanced security, increased visibility, etc.) and what you would potentially do as a next step (e.g., expand the boundaries of data collection to the edges, develop some better synergies with suppliers, start monetizing proper data, etc.). You can start from the information gathered at the “Prepare and Discover” step, figure out where you are in your ideal journey, and think about additional next steps. It is a never-ending story because innovation, like business, never sleeps, and it will help organizations become better and better at understanding and leveraging their data.
Now that you have a better understanding of how to approach a migration by leveraging the four-step migration framework, let us delve into how to estimate the overall cost of the solution.
Estimating the Overall Cost of the Solution
You have just seen a general migration framework that can help organizations define the set of activities that they need to carry out to modernize a data platform. The first question that the CTO, CEO, or CFO may ask is: “What is the total cost we will have to budget for?” In this section, we will review how organizations generally approach this challenge and how they structure their work to get quotes from vendors and third-party suppliers. Always keep in mind that it is not just a matter of the cost of technology—there are always people and process costs that have to be taken into consideration.
Audit of the Existing Infrastructure
As you’ve seen, everything starts with an evaluation of the existing environment. If you do not have a clear view of the current footprint, you will surely have challenges in correctly evaluating the pricing of your next modern data platform. This activity can be carried out in one of three ways:
- Manually by the internal IT/infrastructure team
-
Many organizations maintain a configuration management database (CMDB), which can be a file or a standard database that contains all pivotal information about hardware and software components used within the organization. It is a sort of snapshot of what is currently running within the organization and the related underlying infrastructure, highlighting even the relationships between components. CMDBs can provide a better understanding of the running costs of all the applications and help with shutting down unnecessary or redundant resources.
- Automatically by the internal IT/infrastructure team
-
The goal is exactly the same described in the previous point but with the aim to leverage software that helps collect information in an automatic way (data related to the hardware, applications running on servers, relationship between systems, etc.). These kinds of tools (e.g., StratoZone, Cloudamize, CloudPhysics, etc.) usually generate suggestions related to the most common target cloud hyperscalers (e.g., AWS, Google Cloud, and Azure), such as the size of machines and optimization options (e.g., how many hours per day a system should be up and running to carry out its task).
- Leveraging a third-party player
-
Consulting companies and cloud vendors have experienced people and automation tools to perform all the activities to generate the CMDB and the detailed reports described in the first two options. This is what we recommend if your organization typically outsources IT projects to consulting companies.
Request for Information/Proposal and Quotation
While this is the only migration you may do, and so you have to learn as you go along, consulting companies do this for a living and are usually far more efficient at handling migration projects. Verify, of course, that the team assigned to you does have the necessary experience. Some SIs may even execute assessments and provide cost estimates as an investment if they see a future opportunity.
Identifying the best partner or vendor to work with during the modernization journey can be a daunting task. There are a lot of variables to consider (the knowledge, the capabilities, the cost, the experience), and it may become incredibly complicated if not executed in a rigorous way. This is why organizations usually leverage three kinds of questionnaires to collect information from potential SIs:
- Request for information (RFI)
-
Questionnaire used to collect detailed information about vendors’/possible partners’ solutions and services. It has an educational purpose.
- Request for proposal (RFP)
-
Questionnaire used to collect detailed information about how vendors/partners will leverage their products and services to solve a specific organization problem (in this case, the implementation of the modern data platform). It serves to compare results.
- Request for quotation (RFQ)
-
Questionnaire used to collect detailed information about pricing of different vendors/possible partners based on specific requirements. It serves to quantify and standardize pricing to facilitate future comparisons.
Your organization probably has policies and templates on how to do this. Talk to your legal or procurement department. Otherwise, ask a vendor to show you what they commonly use.
Once you have received all the responses from all the vendors/potential partners, you should have all the information to pick the best path forward. In some cases, especially when the problem to solve can be incredibly fuzzy (e.g., real-time analysis that can have multiple spikes during even a single day), it is challenging even for the vendors/potential partners to provide clear details about costs. This is why sometimes vendors will ask to work on a PoC or MVP to gain a better understanding of how the solution works in a real use case scenario and facilitate the definition of the final pricing.
Proof of Concept/Minimum Viable Product
The design and the development of a new data platform can be challenging because the majority of the organizations want to leverage a data platform migration opportunity to have something more than a mere lift and shift—they want to add new features and capabilities that were not available in the old world. Because this is new to them, organizations (and therefore vendors) may not have a complete understanding of the final behavior and, most importantly, of the final costs the platform will incur.
To address this challenge, organizations typically ask selected vendors or potential partners to implement an initial mock-up of the final solution (or a real working solution but with limited functionality) as the first step after analyzing the RFP response. This mock-up allows stakeholders to experience how the final solution will behave so that they can determine whether any scoping changes are necessary. The mock-up also makes cost estimation much easier, although it is important to note that we are always talking about estimates, rather than concrete pricing. It is practically impossible to have clear and final defined pricing when adopting a cloud model, especially if you want to leverage elasticity. Elasticity, which is one of the main benefits of the cloud, can only be experienced in production.
There are three ways to approach the idea of the mock-up:
- Proof of concept
-
Build a small portion of the solution to verify feasibility, integrability, usability, and potential weaknesses. This can help estimate the final price. The goal is not to touch every single feature that will be part of the platform but instead to verify things that may need to be redesigned. When working with streaming pipelines, for example, it is a good practice to create a PoC by randomly varying the amount of data to be processed. This will allow you to see how the system scales and provide you with better data for estimating the final production cost.
- Minimum viable product
-
The goal of an MVP is to develop a product with a very well-defined perimeter having all the features implemented and working like a real, full product that can be deployed in a production environment (e.g., a data mart implemented on a new DWH and connected to a new business intelligence tool to address a very specific use case). The main advantage of MVPs is to get feedback from real users quickly, which helps the team improve the product and produce better estimations.
- Hybrid
-
Initially, the team will develop a general PoC with a broader perimeter but with a limited depth (e.g., an end-to-end data pipeline to collect data needed to train an ML algorithm for image classification), and then, based on the first results and cost evaluation, the focus will move to the development of an MVP that can be seen as the first step toward the implementation of the full solution.
Now that you know how to estimate cost, let us delve into the first part of any migration—setting up security and data governance.
Setting Up Security and Data Governance
Even as the ownership and control of the data move to business units, security and governance remain a centralized concern at most organizations. This is because there needs to be consistency in the way roles are defined, data is secured, and activities are logged. In the absence of such consistency, it is very difficult to be compliant with regulations such as “the right to be forgotten”, whereby a customer can request that all records pertaining to them be removed.
In this section, we’ll discuss what capabilities need to be present in such a centralized data governance framework. Then, we’ll discuss the artifacts that the central team will need to maintain and how they come together over the data lifecycle.
Framework
There are three risk factors that security and governance seek to address:
- Unauthorized data access
-
When storing data in a public cloud infrastructure, it is necessary to protect against unauthorized access to sensitive data, whether it is company-confidential information or PII protected by law.
- Regulatory compliance
-
Laws such as the General Data Protection Regulation (GDPR) and Legal Entity Identifier (LEI) limit the location, type, and methods of data analysis.
- Visibility
-
Knowing what kinds of data exist in the organization, who is currently using the data, and how they are using it may be required by people who supply your organization with data. This requires up-to-date data and a functional catalog.
Given these risk factors, it is necessary to set up a comprehensive data governance framework that addresses the full life of the data: data ingestion, cataloging, storage, retention, sharing, archiving, backup, recovery, loss prevention, and deletion. Such a framework needs to have the following capabilities:
- Data lineage
-
The organization needs to be able to identify data assets and record the transformations that have been applied to create each data asset.
- Data classification
-
We need to be able to profile and classify sensitive data so that we can determine what governance policies and procedures need to apply to each data asset or part thereof.
- Data catalog
-
We need to maintain a data catalog that contains structural metadata, lineage, and classification and permits search and discovery.
- Data quality management
-
There needs to be a process for documenting, monitoring, and reporting of data quality so that trustworthy data is made available for analysis.
- Access management
-
This will typically work with Cloud IAM to define roles, specify access rights, and manage access keys.
- Auditing
-
Organizations and authorized individuals from other organizations such as regulatory agencies need to be able to monitor, audit, and track activities at a granular level required by law or industry convention.
- Data protection
-
There needs to be the ability to encrypt data, mask it, or delete it permanently.
To operationalize data governance, you will need to put in place a framework that allows these activities to take place. Cloud tools such as Dataplex on Google Cloud and Purview on Azure provide unified data governance solutions to manage data assets regardless of where the data resides (i.e., single cloud, hybrid cloud, or multicloud). Collibra and Informatica are cloud-agnostic solutions that provide the ability to record lineage, do data classification, etc.
In our experience, any of these tools can work, but the hard work of data governance is not in the tool itself but in its operationalization. It is important to establish an operating model—the processes and procedures for data governance—as well as a council that holds the various business teams responsible for adhering to these processes. The council will also need to be responsible for developing taxonomies and ontologies so that there is consistency across the organization. Ideally, your organization participates in and is in line with industry standards bodies. The best organizations also have frequent and ongoing education and training sessions to ensure that data governance practices are adhered to.
Now that we have discussed what capabilities need to be present in a centralized data governance framework, let’s enumerate the artifacts that the central team will need to maintain.
Artifacts
To provide the above capabilities to the organization, a central data governance team needs to maintain the following artifacts:
- Enterprise dictionary
-
This can range from a simple paper document to a tool that automates (and enforces) certain policies. The enterprise dictionary is a repository of the information types used by the organization. For example, the code associated with various medical procedures or the necessary information that has to be collected about any financial transaction is part of the enterprise dictionary. The central team could provide a validation service to ensure that these conditions are met. A simple example of an enterprise dictionary that many readers are familiar with is the address validation and standardization APIs provided by the US Postal Service. These APIs are often used by businesses to ensure that any address stored in any database within the organization is in a standard form.
- Data classes
-
The various information types within the enterprise dictionary can be grouped into data classes, and policies related to each data class can be defined in a consistent way. For example, the data policy related to customer addresses might be that the zip code is visible to one class of employees but that information that is more granular is visible only to customer support personnel actively working on a ticket for that customer.
- Policy book
-
A policy book lists the data classes in use at the organization, how each data class is processed, how long data is retained, where it may be stored, how access to the data needs to be controlled, etc.
- Use case policies
-
Often, the policy surrounding a data class depends on the use case. As a simple example, a customer’s address may be used by the shipping department fulfilling the customer order but not by the sales department. The use cases may be much more nuanced: a customer’s address may be used for the purpose of determining the number of customers within driving distance of a specific store, but not for determining whether a specific customer is within driving distance of a specific store.
- Data catalog
-
This is a tool to manage the structural metadata, lineage, data quality, etc., associated with data. The data catalog functions as an efficient search and discovery tool.
Beyond the data-related artifacts listed above, the central organization will also need to maintain an SSO capability to provide a unique authentication mechanism throughout the organization. Because many automated services and APIs are accessed through keys, and these keys should not be stored in plain text, a key management service is often an additional responsibility of the central team.
As part of your modernization journey, it is important to also start these artifacts and have them in place so that as data is moved to the cloud, it becomes part of a robust data governance framework. Do not postpone data governance until after the cloud migration—organizations that do that tend to quickly lose control of their data.
Let’s now look at how the framework capabilities and artifacts tie together over the life of data.
Governance over the Life of the Data
Data governance involves bringing together people, processes, and technology over the life of the data.
The data lifecycle consists of the following stages:
- 1. Data creation
-
This is the stage where you create/capture the data. At this stage, you should ensure that metadata is also captured. For example, when capturing images, it is important to also record the times and locations of the photographs. Similarly, when capturing a clickstream, it is important to note the user’s session ID, the page they are on, the layout of the page (if it is personalized to the user), etc.
- 2. Data processing
-
When you capture the data, then you usually have to clean it, enrich it, and load it into a DWH. It is important to capture these steps as part of a data lineage. Along with the lineage, quality attributes of the data need to be recorded as well.
- 3. Data storage
-
You generally store both data and metadata in a persistent store such as blob storage (S3, GCS, etc.), a database (Postgres, Aurora, AlloyDB, etc.), a document DB (DynamoDB, Spanner, Cosmos DB, etc.), or a DWH (BigQuery, Redshift, Snowflake, etc.). At this point, you need to determine the security requirements for rows and columns as well as whether any fields need to be encrypted before being saved. This is the stage at which data protection is front and center in the mind of a data governance team.
- 4. Data catalog
-
You need to enter the persisted data at all stages of the transformation into the enterprise data catalog and enable discovery APIs to search for it. It is essential to document the data and how it can be used.
- 5. Data archive
-
You can age off older data from production environments. If so, remember to update the catalog. You must note if such archiving is required by law. Ideally, you should automate archival methods in accordance with policies that apply to the entire data class.
- 6. Data destruction
-
You can delete all the data that has passed the legal period that it is required to be retained. This too needs to be part of the enterprise’s policy book.
You have to create data governance policies for each of these stages.
People will execute these stages, and those people need to have certain access privileges to do so. The same person could have different responsibilities and concerns at different parts of the data lifecycle, so it is helpful to think in terms of “hats” rather than roles:
- Legal
-
Ensures that data usage conforms to contractual requirements and government/industry regulations
- Data steward
-
The owner of the data, who sets the policy for a specific item of data
- Data governor
-
Sets policies for data classes and identifies which class a particular item of data belongs to
- Privacy tsar
-
Ensures that use cases do not leak personally identifiable information
- Data user
-
Typically a data analyst or data scientist who is using the data to make business decisions
Now that we have seen a possible migration and security and governance framework, let’s take a deep dive into how to start executing the migration.
Schema, Pipeline, and Data Migration
In this section, we will take a closer look at patterns you can leverage for schema and pipeline migrations and challenges you have to face when transferring the data.
Schema Migration
When starting to move your legacy application into the new target system, you might need to evolve your schema to leverage all the features made available by the target system. It is a best practice to first migrate the model as-is into the target system connecting the upstream (data sources and pipelines that are feeding the system) and downstream (the scripts, procedures, and business applications that are used to process, query, and visualize the data) processes and then leverage the processing engine of the target environment to perform all the changes. This approach will help ensure that your solution works in the new environment, minimizing the risk of downtime and allowing you to make changes in a second phase.
You can usually apply the facade pattern here—a design method to expose to the downstream processes a set of views that mask the underlying tables to hide the complexity of the eventually needed changes. The views can then describe a new schema that helps with leveraging ad hoc target system features, without disrupting the upstream and downstream processes that are then “protected” by this abstraction layer. In case this kind of approach cannot be followed, the data has to be translated and converted before being ingested into the new system. These activities are generally performed by data transformation pipelines that are under the perimeter of the migration.
Pipeline Migration
There are two different strategies you can follow when migrating from a legacy system to the cloud:
- You are offloading the workload.
-
In this case, you retain the upstream data pipelines that are feeding your source system, and you put an incremental copy of the data into the target system. Finally, you update your downstream processes to read from the target system. Then you can continue the offload with the next workload until you reach the end. Once completed, you can start fully migrating the data pipeline.
- You are fully migrating the workload.
-
In this case, you have to migrate everything in the new system (all together with the data pipeline), and then you deprecate the corresponding legacy tables.
Data that feeds the workload needs to be migrated. It can come from various data sources, and it could require particular transformations or joins to make it usable. In general, there are four different data pipeline patterns:
- ETL
-
All the transformation activities, along with the data collection and data ingestion, will be carried out by an ad hoc system that comes with a proper infrastructure and a proper programming language (the tool can make interfaces programmable with standard programming languages available, anyway).
- ELT
-
Similar to ETL but with the caveat that all the transformations will be performed by the process engine where the data will be ingested (as we have seen in the previous chapters, this is the preferred approach when dealing with modern cloud solutions).
- Extract and load (EL)
-
This is the simplest case, where the data is already prepared and it does not require any further transformations.
- Change data capture (CDC)
-
This is a pattern used to track data changes in the source system and reflect them in the target one. It usually works together with an ETL solution because it stores the original record before making any changes to the downstream process.
As you saw in the previous section, you could identify different approaches for different workloads’ migration. The same methodology can be applied to the data pipelines:
- Retire
-
The data pipeline solution is not used anymore because it is referred to an old use case or because it has been superseded by a new one.
- Retain
-
The data pipeline solution remains in the legacy system because it can potentially be retired very soon, so it is not financially viable to embark on a migration project. It may also be the case that there are some regulation requirements that inhibit data movement outside the corporate boundaries.
- Rehost
-
The data pipeline solution is lifted and shifted into the cloud environment leveraging the IaaS paradigm. In this scenario, you are not introducing any big modification except at the connectivity level, where an ad hoc networking configuration (usually a virtual private network, or VPN) might need to be set up to enable communication between the cloud environment and the on-premises world. If the upstream processes are outside the corporate perimeter (e.g., third-party providers, other cloud environments, etc.), a VPN might not be needed since the communication can be established in a secure way leveraging other technologies, like authenticated REST APIs, for example. Before proceeding, it is necessary to validate with the cloud vendor if there is any technology limitation in the underlying system that prevents the correct execution of the solution and to double-check eventual license limitations.
- Replatform
-
In this scenario, part of the data pipeline solution is transformed before the migration to benefit from features of the cloud, such as a PaaS database or containerization technology. Considerations on the connectivity side highlighted in the “rehost” description are still valid.
- Refactor
-
The pipeline solution will be migrated to one or more cloud fully managed PaaS solutions (e.g., Amazon EMR, Azure HDInsight, Google Cloud Dataproc, Databricks). When dealing with this approach, it is a best practice to readopt the same iterative approach you are adopting for the entire migration:
-
Prepare and discover the jobs and potentially organize them by complexity.
-
Plan and assess the possible MVP to be migrated.
-
Execute the migration and evaluate the result against your defined KPIs.
-
Iterate with all the other jobs until the end.
Considerations on the connectivity side highlighted in the preceding “rehost” description are still valid.
-
- Replace
-
The pipeline solution will be completely replaced by a third-party off-the-shelf or SaaS solution (e.g., Fivetran, Xplenty, Informatica, etc.). Considerations on the connectivity side highlighted in the “Rehost” section are still valid.
- Rebuild
-
The pipeline solution is completely rearchitected using cloud fully managed solutions (e.g., AWS Glue, Azure Data Factory, Google Cloud Dataflow). Considerations on the connectivity side highlighted in the “Rehost” section are still valid.
During the migration phase, especially in the integration with the target system, you might find that your data pipeline solution is not fully compatible with the identified target cloud solution right out of the box. You could need a connector, usually called a sink, that enables the communication between the data pipeline solution (e.g., the ETL system) and the target environment. If the sink for that solution does not exist, you may be able to generate a file as output of the process and then ingest the data in the following step. This approach will introduce extra complexity to the process, but it is a viable temporary solution in case of emergency (while waiting for a connector from the vendor).
Data Migration
Now that you have your new schema and pipelines ready, you are ready to start migrating all your data. You should focus on thinking about how to deal with data transfer. You may want to migrate all your on-premises data into the cloud, even dusty old tapes (maybe one day someone will require that data). You may face the reality that a single FTP connection over the weekend will not be enough to accomplish your task.
Planning
Data transfer requires planning. You need to identify and involve:
- Technical owners
-
People who can provide access to the resources you need to perform the migration (e.g., storage, IT, networking, etc.).
- Approvers
-
People who can provide you with all the approvals you need to get access to the data and to start the migration (e.g., data owners, legal advisors, security admin, etc.).
- Delivery
-
The migration team. They can be people internal to the organization if available or people belonging to third-party system integrators.
Then you need to collect as much information as you can to have a complete understanding of what you have to do, in which order (e.g., maybe your migration team needs to be allowlisted to a specific network storage area that contains the data you want to migrate), and the possible blockers that you might encounter. Here is a sample of questions (not exhaustive) that you should be able to answer before proceeding:
-
What are the datasets you need to move?
-
Where does the underlying data sit within the organization?
-
What are the datasets you are allowed to move?
-
Is there any specific regulatory requirement you have to respect?
-
Where is the data going to land (e.g., object store versus DWH storage)?
-
What is the destination region (e.g., Europe, Middle East, and Africa, UK, US, etc.)?
-
Do you need to perform any transformation before the transfer?
-
What are the data access policies you want to apply?
-
Is it a one-off transfer, or do you need to move data regularly?
-
What are the resources available for the data transfer?
-
What is the allocated budget?
-
Do you have adequate bandwidth to accomplish the transfer, and for an adequate period?
-
Do you need to leverage offline solutions (e.g., Amazon Snowball, Azure Data Box, Google Transfer Appliance)?
-
What is the time needed to accomplish the entire data migration?
Once you know the attributes of data you are migrating, you need to consider two key factors that affect the reliability and performance of the migration: capacity and network.
Regional capacity and network to the cloud
When dealing with cloud data migration, typically there are two elements that need to be considered carefully: the regional capacity and the quality of the network connectivity to the cloud.
A cloud environment is not infinitely scalable. The reality is that the hardware needs to be purchased, prepared, and configured by the cloud providers in the regional location. Once you have identified the target architecture and the resources that are needed to handle the data platform, you should also file a capacity regional plan with your selected hyperscaler to be sure the data platform will have all the hardware needed to meet the usage and the future growth of the platform. They will typically want to know the volume of the data to be migrated and that will be generated once in the cloud, the amount of compute you will need to crunch the data, and the number of interactions you will have with other systems. All these components will serve as an input to your hyperscalers to allow them to be sure that the underlying infrastructure will be ready from day zero to serve all your workloads. In case of stockouts (common if your use case involves GPUs), you may have to choose the same service but in another region (if there are not any compliance/technology implications) or leverage other compute-type services (e.g., IaaS versus PaaS).
The network, even if it is considered a commodity nowadays, plays a vital role in every cloud infrastructure: if the network is slow or it is not accessible, parts of your organization can remain completely disconnected from their business data (this is true even when leveraging an on-premises environment). When designing the cloud platform, some of the first questions you need to think about are: How will my organization be connected to the cloud? Which partner am I going to leverage to set up the connectivity? Am I leveraging standard internet connection (potentially with a VPN on top of it), or do I want to pay for an extra dedicated connection that will ensure better reliability? All these topics are generally discussed in the RFI/RFP questionnaires, but they should also be part of one of the very first workshops you have with the vendor/partner that you’ve selected to design and implement the platform.
There are three main ways to get connected to the cloud:
- Public internet connection
-
Leveraging public internet networks. In this case, organizations usually leverage a VPN on top of the public internet protocol to protect their data and to guarantee an adequate level of reliability. Performance is strictly related to the ability of the organization to be close to the nearest point of presence of the selected cloud hyperscalers.
- Partner interconnect
-
This is one the typical connections organizations may leverage for their production workloads, especially when they need to have guaranteed performance with high throughput. This connection is between the organization and the selected partner that then takes care of the connection with the selected hyperscalers. Leveraging the pervasiveness of the telco providers, organizations can set up high-performance connections with an affordable price.
- Direct interconnect
-
This is the best connection possible, where the organization connects directly (and physically) with the network of the cloud provider. (This can be possible when both of the parties have routers in the same physical location.) Reliability, throughput, and general performance are the best, and pricing can be discussed directly with the selected hypervisors.
For more details of how to configure these three connectivity options, see the documentation at Azure, AWS, and Google Cloud.
Typically, during a PoC/MVP phase, the public internet connection option is chosen because it is faster to set up. In production, the partner interconnect is the most common, especially when the organization wants to leverage a multicloud approach.
Transfer options
To choose the way that you will transfer data to the cloud, consider the following factors:
- Costs
-
Consider the following potential costs involved in the transfer of data:
- Networking
-
You may need to enhance your connectivity before proceeding with the data transfer. Maybe you do not have adequate bandwidth to support the migration and you need to negotiate with your vendor to add additional lines.
- Cloud provider
-
Uploading data to a cloud provider tends to be free, but if you are exporting data not only from your on-premises environment but also from another hyperscaler, you might be charged an egress cost (which usually has a cost per each GB exported) and potentially a read cost as well.
- Products
-
You may need to purchase or rent storage appliances to speed up the data transfer.
- People
-
The team who will carry out the migration.
- Time
-
It’s important to know the amount of data you have to transfer and the bandwidth you have at your disposal. Once you know that, you will be able to identify the time needed to transfer the data. For example, if you have to transfer 200 TB of data and you have only 10 Gbps bandwidth available, you will need approximately two days to complete your transfer.1 This assumes that the bandwidth is fully available for your data transfer, which may not be the case. If during your analysis you discover that you need more bandwidth, you might need to work with your internet service provider (ISP) to request an increase or determine the time of day when such bandwidth is available. It may also be the right time to work with your cloud vendor to implement direct connection. This prevents your data from going on the public internet and can provide a more consistent throughput for large data transfers (e.g., AWS Direct Connect, Azure ExpressRoute, Google Cloud Direct Interconnect).
- Offline versus online transfer
-
In some cases, an online transfer is infeasible because it will take too long. In such cases, select an offline process leveraging storage hardware. Cloud vendors offer this kind of service (e.g., Amazon Snowball data transfer, Azure Data Box, Google Transfer Appliance), which is particularly useful for data transfers from hundreds of terabytes up to petabyte scale. You order a physical appliance from your cloud vendor that will have to be connected to your network. Then you will copy the data, which will be encrypted by default, and you will request a shipment to the closest vendor facility available. Once delivered, the data will be copied to the appropriate service in the cloud (e.g., AWS S3, Azure Blob Storage, Google Cloud Storage) and will be ready to be used.
- Available tools
-
Once you have cleared out all the network dynamics, you should decide how to handle data upload. Depending on the system you might want to target (e.g., blob storage, DWH solution, database, third-party application, etc.), you generally have the following options at your disposal:
- Command-line tools
-
Tools (e.g., AWS CLI, Azure Cloud Shell, or Google Cloud SDK) that will allow you to interact with all the services of the cloud provider. You can automate and orchestrate all the processes needed to upload the data into the desired destination. Depending on the final tool, you may have to pass by intermediate systems before being able to upload data to the final destination (e.g., passing by blob storage first before ingesting data into the DWH), but thanks to the flexibility of the various tools, you should be able to easily implement your workflows—for example, leveraging bash or PowerShell scripts.
- REST APIs
-
These will allow you to integrate services with any applications you may want to develop—for example, internal migration tools that you have already implemented and leveraged or brand-new apps that you may want to develop for that specific purpose.
- Physical solutions
-
Tools for offline migration as discussed in the preceding description of offline versus online transfer.
- Third-party commercial off-the-shelf (COTS) solutions
-
These could provide more features like network throttling, custom advanced data transfer protocols, advanced orchestration and management capabilities, and data integrity checks.
Migration Stages
Your migration will consist of six stages (see Figure 4-3):
-
Upstream processes feeding current legacy data solutions are modified to feed the target environment.
-
Downstream processes reading from the legacy environment are modified to read from the target environment.
-
Historical data is migrated in bulk into the target environment. At this point, the upstream processes are migrated to also write to the target environment.
-
Downstream processes are now connected to the target environment.
-
Data can be kept in sync between the legacy and target environments, leveraging CDC pipelines until the old environment is fully dismissed.
-
Downstream processes become fully operational, leveraging the target environment.
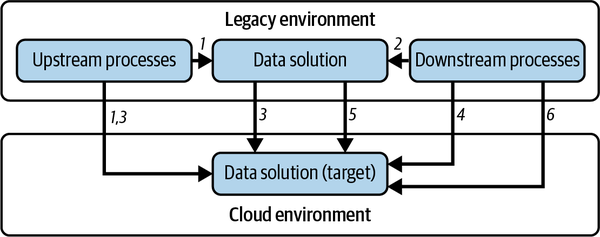
Figure 4-3. Data migration strategy
There are some final checks that you should perform to ensure you don’t hit bottlenecks or data transfer issues:
- Perform a functional test.
-
You need to execute a test to validate that your entire data transfer migration is working correctly. Ideally, you’d execute this test during the execution of your MVP, selecting a considerable amount of data, leveraging potentially all the tools that you might want to use during the entire migration. The goal of this step is mainly to verify you can operate your data transfer correctly while at the same time surface potential project-stopping issues, such as the inability to use the tools (e.g., your workforce is not trained or you do not have adequate support from your system integrator) or networking issues (e.g., network routes).
- Perform a performance test.
-
You need to verify that your current infrastructure can handle migration at scale. To do so, you should identify a large sample of your data (generally between 3% and 5%) to be migrated to confirm that your migration infrastructure and solution correctly scale according to the migration needs and you are not surfacing any specific bottlenecks (e.g., slow source storage system).
- Perform a data integrity check.
-
One of the most critical issues you might encounter during a data migration is that the data migrated into the target system is deleted because of an error or is corrupted and unusable. There are some ways to protect your data from that kind of risk:
-
Enable versioning and backup on your destination to limit the damage of accidental deletion.
-
Validate your data before removing the source data.
-
If you are leveraging standard tools to perform the migration (e.g., CLIs or REST APIs), you have to manage all these activities by yourself. However, if you are adopting a third-party application such as Signiant Media Shuttle or IBM Aspera on Cloud, it is likely that there are already several kinds of checks that have been implemented by default. (We suggest reading the available features in the application sheet carefully before selecting the solution.)
Summary
In this chapter you have seen a practical approach to the data modernization journey and have reviewed a general technological migration framework that can be applied to any migration, from a legacy environment to a modern cloud architecture. The key takeaways are as follows:
-
Focus on modernizing your data workflow, not just upgrading individual tools. Choosing the right tool for the right job will help you reduce costs, get the most out of your tools, and be more efficient.
-
A possible data migration framework can be implemented in four steps: prepare and discover, assess and plan, execute, and optimize.
-
Prepare and discover is a pivotal step where you focus on defining the perimeter of the migration and then on collecting all the information related to the various workloads/use cases that you’ve identified to be migrated.
-
Assess and plan is the step where you define and plan all the activities that need to be done to accomplish the identified goal (e.g., categorization and clusterization of the workloads to be migrated, definition of KPIs, definition of a possible MVP, and definition of the migration plan with related milestones).
-
Execute is the step where you iteratively perform the migration, improving the overall process at each iteration.
-
Optimize is the step where you consider the new system as a whole and identify potential new use cases to introduce to make it even more flexible and powerful.
-
Understanding the current footprint and what will be the total cost of the final solution is a complex step that can involve multiple actors. Organizations usually leverage RFI, RFP, and RFQ to get more information from vendors/potential partners.
-
Governance and security remain a centralized concern at most organizations. This is because there needs to be consistency in the way roles are defined, data is secured, and activities are logged.
-
The migration framework has to work in accordance with a very well-defined governance framework that is pivotal throughout the entire life of data.
-
When migrating schema of your data, it might be useful to leverage a pattern like the facade pattern to make the adoption of target solution features easier.
-
Connectivity and securing regional capacity are critical when utilizing cloud solutions. Network configuration, bandwidth availability, cost, people, tools, performance, and data integrity are the main points that have to be clarified for every workload.
In the four chapters so far, you have learned why to build a data platform, a strategy to get there, how to upskill your workforce, and how to carry out a migration. In the next few chapters, we will delve into architectural details, starting with how to architect modern data lakes.
1 There are several services freely available on the web that can help you with this estimation exercise—for example, Calculator.net’s bandwidth calculator.
Get Architecting Data and Machine Learning Platforms now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

