Capítulo 1. Explorando el panorama de la Inteligencia Artificial
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
A continuación reproducimos las palabras del artículo seminal de la Dra. May Carson(Figura 1-1) sobre el papel cambiante de la inteligencia artificial (IA) en la vida humana del siglo XXI:
A menudo se ha calificado a la Inteligencia Artificial como la electricidad del siglo XXI. En la actualidad, los programas de inteligencia artificial tendrán el poder de impulsar todas las formas de industria (incluida la sanitaria), diseñar dispositivos médicos y construir nuevos tipos de productos y servicios, incluidos robots y automóviles. A medida que avanza la IA, las organizaciones ya están trabajando para garantizar que esos programas de inteligencia artificial puedan hacer su trabajo y, lo que es más importante, evitar errores o accidentes peligrosos. Las organizaciones necesitan la IA, pero también reconocen que no todo lo que pueden hacer con ella es una buena idea.
Se han realizado amplios estudios sobre lo que cuesta hacer funcionar la inteligencia artificial utilizando estas técnicas y políticas. La conclusión principal es que la cantidad de dinero que se gasta en programas de IA por persona, al año, frente a la cantidad que se emplea en investigarlos, construirlos y producirlos es aproximadamente igual. Parece obvio, pero no es del todo cierto.
En primer lugar, los sistemas de IA necesitan apoyo y mantenimiento para ayudarles en sus funciones. Para que sean realmente fiables, necesitan personas con las habilidades necesarias para hacerlos funcionar y para ayudarles a realizar algunas de sus tareas. Es esencial que las organizaciones de IA proporcionen trabajadores para realizar las complejas tareas que necesitan esos servicios. También es importante comprender a las personas que realizan esos trabajos, sobre todo cuando la IA es más compleja que los humanos. Por ejemplo, lo más frecuente es que las personas trabajen en empleos que requieran conocimientos avanzados, pero no estén necesariamente capacitadas para trabajar con sistemas que haya que construir y mantener.

Figura 1-1. Dra. May Carson
Una disculpa
Ahora tiene que confesar y admitir que todo lo dicho en este capítulo hasta ahora era totalmente falso. Literalmente, ¡todo! Todo el texto (salvo la primera frase en cursiva, que fue escrita por nosotros como semilla) se generó utilizando el modelo GPT-2 (construido por Adam King) en el sitio web TalkToTransformer.com. El nombre del autor se generó utilizando el "Generador de Nombres Nado" en el sitio web Onitools.moe. Al menos la foto del autor debe ser real, ¿no? No, la foto se generó a partir del sitio web ThisPersonDoesNotExist.com, que nos muestra nuevas fotos de personas inexistentes cada vez que recargamos la página utilizando la magia de las Redes Adversariales Generativas (GAN).
Aunque nos sentimos ambivalentes, por no decir otra cosa, por empezar todo este libro con una nota deshonesta, pensamos que era importante mostrar el estado del arte de la IA cuando tú, nuestro lector, menos te lo esperabas. Francamente, es alucinante, asombroso y aterrador al mismo tiempo ver de lo que ya es capaz la IA. El hecho de que pueda crear frases de la nada más inteligentes y elocuentes que algunos líderes mundiales es... digamos de las grandes ligas.
Dicho esto, algo de lo que la IA no puede apropiarse todavía es de la capacidad de ser divertida. Esperamos que esos tres primeros párrafos falsos sean los más áridos de todo el libro. Después de todo, no queremos que se nos conozca como "los autores más aburridos que una máquina".
La verdadera introducción
Recuerda aquella vez que viste un espectáculo de magia durante el cual un truco te deslumbró lo suficiente como para pensar: "¡¿Cómo demonios han hecho eso?!". ¿Te has preguntado alguna vez lo mismo sobre una aplicación de IA que fue noticia? En este libro, queremos dotarte de los conocimientos y las herramientas para que no sólo deconstruyas, sino también construyas una similar.
Mediante explicaciones accesibles y paso a paso, diseccionamos aplicaciones del mundo real que utilizan la IA y mostramos cómo podrías crearlas en una amplia variedad de plataformas: desde la nube al navegador, pasando por los teléfonos inteligentes y los dispositivos de IA de perímetro, para llegar finalmente al último reto actual de la IA: los coches autónomos.
En la mayoría de los capítulos, empezamos con un problema motivador y luego construimos una solución integral paso a paso. En las primeras partes del libro, desarrollamos las habilidades necesarias para construir el cerebro de la IA. Pero eso es sólo la mitad de la batalla. El verdadero valor de construir IA está en crear aplicaciones utilizables. Y no estamos hablando de prototipos de juguete. Queremos que construyas software que pueda ser utilizado en el mundo real por personas reales para mejorar sus vidas. De ahí la palabra "Práctico" del título del libro. Para ello, analizamos las distintas opciones que tenemos a nuestra disposición y elegimos las adecuadas en función del rendimiento, el consumo de energía, la escalabilidad, la fiabilidad y las compensaciones en materia de privacidad.
En este primer capítulo, damos un paso atrás para apreciar este momento de la historia de la IA. Exploramos el significado de la IA, concretamente en el contexto del aprendizaje profundo y la secuencia de acontecimientos que llevaron a que el aprendizaje profundo se convirtiera en una de las áreas más revolucionarias del progreso tecnológico de principios del siglo XXI. También examinamos los componentes básicos subyacentes a una solución completa de aprendizaje profundo, para prepararnos para los capítulos siguientes en los que realmente nos ensuciamos las manos.
Así que nuestro viaje comienza aquí, con una pregunta muy fundamental.
¿Qué es la IA?
A lo largo de este libro, utilizamos los términos "inteligencia artificial", "aprendizaje automático" y "aprendizaje profundo" con frecuencia, a veces indistintamente. Pero en los términos técnicos más estrictos, significan cosas diferentes. He aquí una sinopsis de cada uno (véase también la Figura 1-2):
- AI
-
Este da a las máquinas la capacidad de imitar el comportamiento humano. El Deep Blue de IBM es un ejemplo reconocible de IA.
- Aprendizaje automático
-
Esta es la rama de la IA en la que las máquinas utilizan técnicas estadísticas para aprender de información y experiencias anteriores. El objetivo es que la máquina actúe en el futuro basándose en el aprendizaje de observaciones del pasado. Si has visto a Watson de IBM enfrentarse a Ken Jennings y Brad Rutter en Jeopardy!, has visto el aprendizaje automático en acción. Y lo que es más relevante, la próxima vez que un correo basura no llegue a tu bandeja de entrada, puedes agradecérselo al aprendizaje automático.
- Aprendizaje profundo
-
Este es un subcampo del aprendizaje automático en el que se utilizan redes neuronales profundas y multicapa para hacer predicciones, destacando especialmente en visión por ordenador, reconocimiento del habla, comprensión del lenguaje natural, etc.
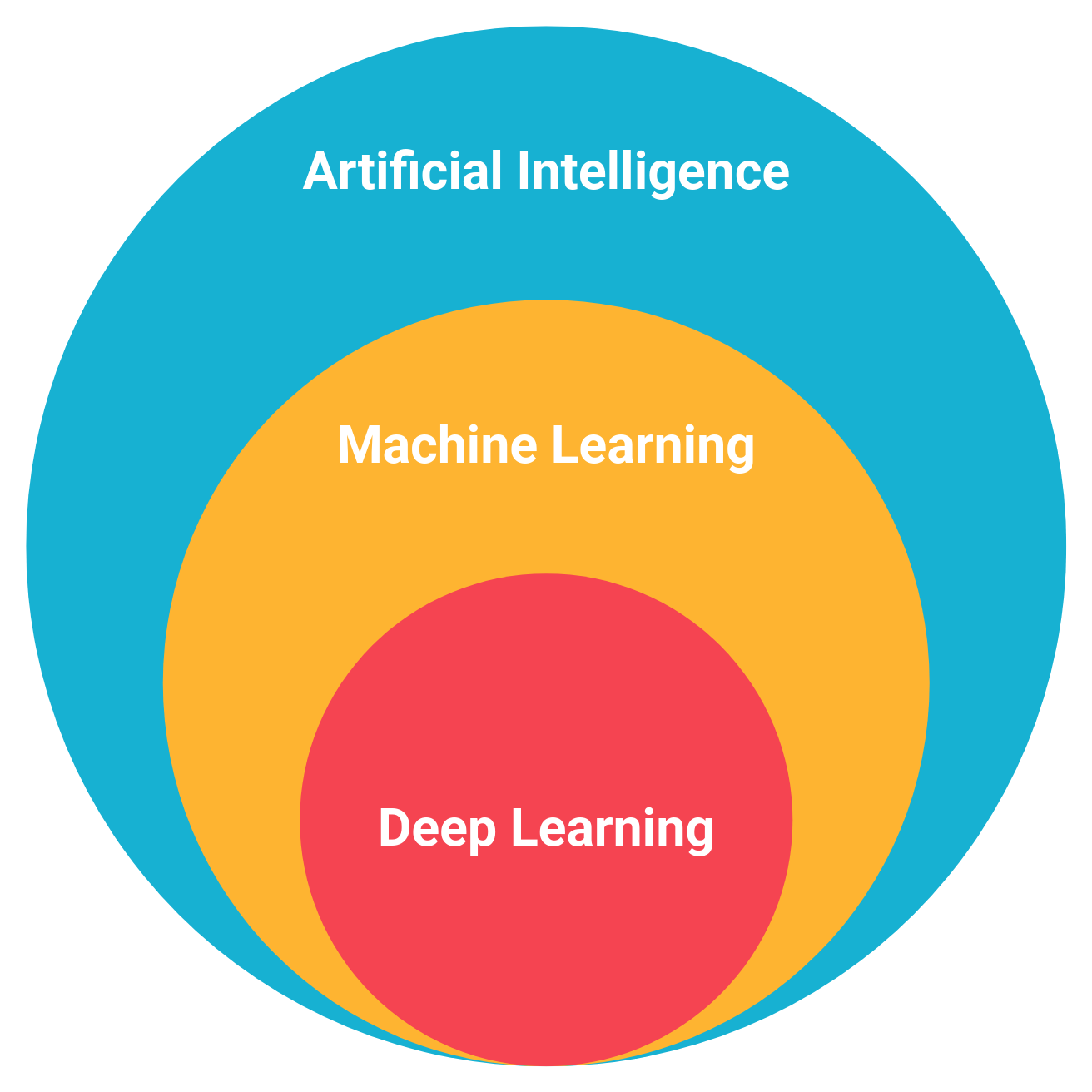
Figura 1-2. La relación entre IA, aprendizaje automático y aprendizaje profundo
A lo largo de este libro, nos centramos principalmente en el aprendizaje profundo.
Ejemplos motivadores
Vayamos al grano en. ¿Qué nos impulsó a escribir este libro? ¿Por qué te has gastado el dinero que tanto te ha costado ganar1 comprando este libro? Nuestra motivación era sencilla: conseguir que más gente se involucre en el mundo de la IA. El hecho de que estés leyendo este libro significa que nuestro trabajo ya está medio hecho.
Sin embargo, para despertar realmente tu interés, veamos algunos ejemplos estelares que demuestran lo que la IA ya es capaz de hacer:
-
"Los agentes de IA de DeepMind conquistan a los profesionales humanos en StarCraft II": The Verge, 2019
-
"Arte generado por IA se vende por casi medio millón de dólares en Christie's": AdWeek, 2018
-
"La IA supera a los radiólogos en la detección del cáncer de pulmón": American Journal of Managed Care, 2019
-
"El robot Atlas de Boston Dynamics puede hacer parkour": ExtremeTech, 2018
-
"Facebook y Carnegie Mellon construyen la primera IA que gana a profesionales en póquer de 6 jugadores": ai.facebook.com, 2019
-
"Los usuarios ciegos ya pueden explorar fotos mediante el tacto con la IA Seeing de Microsoft": TechCrunch, 2019
-
"El superordenador Watson de IBM derrota a los humanos en la última partida de Jeopardy": VentureBeat, 2011
-
"ML-Jam de Google reta a los músicos a improvisar y colaborar con la IA": VentureBeat, 2019
-
"Dominar el juego del Go sin conocimiento humano": Nature, 2017
-
"La IA china supera a los médicos en el diagnóstico de tumores cerebrales": Popular Mechanics, 2018
-
"Descubiertos dos nuevos planetas mediante inteligencia artificial": Phys.org, 2019
-
"El último software de IA de Nvidia convierte garabatos toscos en paisajes realistas": The Verge, 2019
Estas aplicaciones de la IA nos sirven de Estrella Polar. El nivel de estos logros equivale a una actuación olímpica ganadora de una medalla de oro. Sin embargo, las aplicaciones que resuelven multitud de problemas en el mundo real equivalen a completar una carrera de 5 km. Desarrollar estas aplicaciones no requiere años de entrenamiento, pero hacerlo proporciona al desarrollador una inmensa satisfacción al cruzar la línea de meta. Estamos aquí para guiarte a través de esos 5K.
A lo largo de este libro, priorizamos intencionadamente la amplitud. El campo de la IA está cambiando tan rápidamente que sólo podemos esperar equiparte con la mentalidad y el conjunto de herramientas adecuados. Además de abordar problemas individuales, veremos cómo problemas diferentes, aparentemente no relacionados, tienen solapamientos fundamentales que podemos utilizar en nuestro beneficio. Por ejemplo, el reconocimiento del sonido utiliza Redes Neuronales Convolucionales (CNN), que también son la base de la visión por ordenador moderna. Tocamos aspectos prácticos de múltiples áreas para que puedas pasar rápidamente de 0 a 80 y abordar problemas del mundo real. Si hemos generado suficiente interés como para que decidas que luego quieres pasar de 80 a 95, consideraremos que hemos alcanzado nuestro objetivo. Como suele decirse, queremos "democratizar la IA".
Es importante señalar que gran parte del progreso de la IA se ha producido en los últimos años, y es difícil exagerarlo. Para ilustrar lo mucho que hemos avanzado, tomemos este ejemplo: hace cinco años, necesitabas un doctorado sólo para poner un pie en la industria. Cinco años después, ni siquiera necesitas un doctorado para escribir un libro entero sobre el tema. (En serio, ¡consulta nuestros perfiles!)
Aunque las aplicaciones modernas del aprendizaje profundo parecen bastante asombrosas, no lo han conseguido por sí solas. Se apoyaron en los hombros de muchos gigantes de la industria que han estado empujando los límites durante décadas. De hecho, no podemos apreciar plenamente la importancia de este momento sin echar un vistazo a toda la historia.
Breve historia de la IA
Retrocedamos un poco en el tiempo en: todo nuestro universo se encontraba en un estado denso y caliente. Entonces, hace casi 14.000 millones de años, comenzó la expansión, espera... vale, no hace falta que retrocedamos tanto (pero ahora tenemos la canción metida en tu cabeza para el resto del día, ¿verdad?). En realidad fue hace sólo 70 años cuando se plantaron las primeras semillas de la IA. Alan Turing, en su artículo de 1950 "Computing Machinery and Intelligence", planteó por primera vez la pregunta "¿Pueden pensar las máquinas?". Esto realmente entra en un debate filosófico más amplio sobre la sintiencia y lo que significa ser humano. ¿Significa poseer la capacidad de componer un concierto y saber que lo has compuesto? Turing consideró que ese marco era bastante restrictivo y, en su lugar, propuso una prueba: si un humano no puede distinguir una máquina de otro humano, ¿realmente importa? Una IA que puede imitar a un humano es, en esencia, humana.
Comienzos emocionantes
El término "inteligencia artificial" fue acuñado por John McCarthy en 1956 en el Proyecto de Investigación de Verano de Dartmouth. Los ordenadores físicos ni siquiera existían por aquel entonces, por lo que es sorprendente que pudieran hablar de áreas futuristas como la simulación del lenguaje, las máquinas de aprendizaje automejorables, las abstracciones sobre datos sensoriales y mucho más. Gran parte de ello era teórico, por supuesto. Fue la primera vez que la IA se convirtió en un campo de investigación y no en un proyecto aislado.
El artículo de "Perceptron: A Perceiving and Recognizing Automaton" de 1957, de Frank Rosenblatt, sentó las bases de las redes neuronales profundas. Postuló que sería factible construir un sistema electrónico o electromecánico que aprendiera a reconocer similitudes entre patrones de información óptica, eléctrica o tonal. Este sistema funcionaría de forma similar al cerebro humano. En lugar de utilizar un modelo basado en reglas (que era lo habitual en los algoritmos de la época), propuso utilizar modelos estadísticos para hacer predicciones.
A lo largo de este libro, repetimos la frase red neuronal. ¿Qué es una red neuronal? Es un modelo simplificado del cerebro humano. Al igual que el cerebro, tiene neuronas que se activan al encontrar algo familiar. Las distintas neuronas están conectadas mediante conexiones (que se corresponden con las sinapsis de nuestro cerebro) que ayudan a que la información fluya de una neurona a otra.
En la Figura 1-3, podemos ver un ejemplo de la red neuronal más sencilla: un perceptrón. Matemáticamente, el perceptrón puede expresarse de la siguiente manera:
salida = f(x1, x2, x3) = x1 w1 + x2 w2 + x3 w3 + b
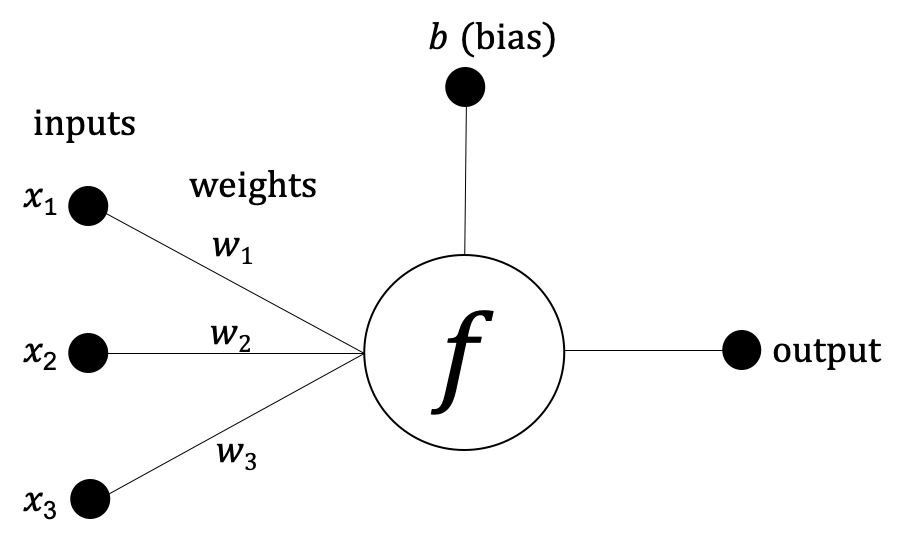
Figura 1-3. Ejemplo de perceptrón
En 1965, Ivakhnenko y Lapa publicaron la primera red neuronal funcional en su artículo "Group Method of Data Handling-A Rival Method of Stochastic Approximation". Existe cierta controversia al respecto, pero algunos consideran a Ivakhnenko el padre del aprendizaje profundo.
Por aquel entonces, se hicieron audaces predicciones sobre lo que las máquinas serían capaces de hacer. La traducción automática, el reconocimiento de voz y otras cosas se realizarían mejor que los humanos. Los gobiernos de todo el mundo estaban entusiasmados y empezaron a abrir sus billeteras para financiar estos proyectos. Esta fiebre del oro comenzó a finales de la década de 1950 y se mantuvo viva hasta mediados de la década de 1970.
Los días fríos y oscuros
Con millones de dólares invertidos, se pusieron en práctica los primeros sistemas. Resultó que muchas de las profecías originales eran poco realistas. El reconocimiento de voz sólo funcionaba si se hablaba de una determinada manera, e incluso entonces, sólo para un conjunto limitado de palabras. La traducción de idiomas resultó ser muy errónea y mucho más cara de lo que le costaría a un ser humano. Los perceptrones (esencialmente redes neuronales de una sola capa) alcanzaron rápidamente un límite para hacer predicciones fiables. Esto limitó su utilidad para la mayoría de los problemas del mundo real. Esto se debe a que son funciones lineales, mientras que los problemas del mundo real suelen requerir un clasificador no lineal para obtener predicciones precisas. ¡Imagínate intentar ajustar una línea a una curva!
¿Qué ocurre cuando prometes demasiado y no cumples lo prometido? Pierdes la financiación. La Agencia de Proyectos de Investigación Avanzada de Defensa, conocida comúnmente como DARPA (sí, esa gente; los que construyeron la ARPANET, que más tarde se convirtió en Internet), financió muchos de los proyectos originales en Estados Unidos. Sin embargo, la falta de resultados a lo largo de casi dos décadas frustró cada vez más a la agencia. ¡Era más fácil llevar un hombre a la luna que conseguir un reconocedor de voz utilizable!
Del mismo modo, al otro lado del charco, en 1974 se publicó el Informe Lighthill, que decía: "El robot de propósito general es un espejismo". Imagínate ser británico en 1974 y ver a los peces gordos de la informática debatiendo en la BBC sobre si la IA es un despilfarro de recursos. Como consecuencia, la investigación en IA se vio diezmada en el Reino Unido y posteriormente en todo el mundo, destruyendo muchas carreras en el proceso. Esta fase de pérdida de fe en la IA duró unas dos décadas y llegó a conocerse como el "Invierno de la IA". Ojalá Ned Stark hubiera estado por allí entonces para advertirles.
Un rayo de esperanza
Incluso en, durante aquellos gélidos días, se realizaron algunos trabajos pioneros en este campo. Sin duda, los perceptrones -al ser funciones lineales- tenían capacidades limitadas. ¿Cómo se podía solucionar? Encadenándolos en una red, de modo que la salida de uno (o más) perceptrones fuera la entrada de otro (o más) perceptrones. En otras palabras, una red neuronal multicapa, como se ilustra en la Figura 1-4. Cuanto mayor sea el número de capas, mayor será la no linealidad que aprenderá, lo que dará lugar a mejores predicciones. Sólo hay un problema: ¿cómo se entrena? Entra Geoffrey Hinton y sus amigos. Ellos publicaron una técnica llamada retropropagación en 1986 en el artículo "Learning representations by back-propagating errors". ¿Cómo funciona? Haz una predicción, comprueba lo alejada que está la predicción de la realidad y retropropaga la magnitud del error en la red para que pueda aprender a corregirlo. Repites este proceso hasta que el error se vuelve insignificante. Un concepto sencillo pero poderoso. Utilizamos el término retropropagación repetidamente a lo largo de este libro.
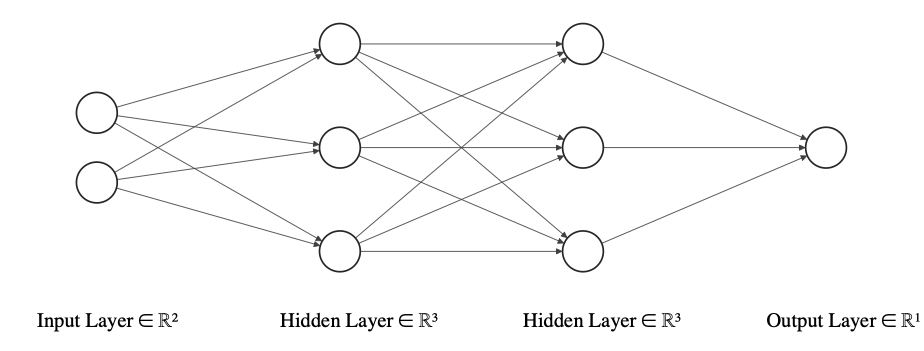
Figura 1-4. Un ejemplo de red neuronal multicapa(fuente de la imagen)
En 1989, George Cybenko proporcionó a la primera prueba del Teorema de Aproximación Universal, que afirma que una red neuronal con una sola capa oculta es teóricamente capaz de modelar cualquier problema. Esto era notable porque significaba que las redes neuronales podían (al menos en teoría) superar cualquier enfoque de aprendizaje automático. Incluso podrían imitar al cerebro humano. Pero todo esto era sólo sobre el papel. El tamaño de esta red plantearía rápidamente limitaciones en el mundo real. Esto podría superarse en cierta medida utilizando múltiples capas ocultas y entrenando la red con... espera... ¡propagación retrospectiva!
En el lado más práctico de las cosas, un equipo de la Universidad Carnegie Mellon construyó el primer vehículo autónomo de la historia, el NavLab 1, en 1986(Figura 1-5). Inicialmente utilizaba una red neuronal de una sola capa para controlar el ángulo del volante. Esto condujo finalmente al NavLab 5 en 1995. Durante una demostración, un coche recorrió por sí solo los 3.000 km del trayecto de Pittsburgh a San Diego. NavLab se sacó el carné de conducir ¡antes incluso de que nacieran muchos ingenieros de Tesla!

Figura 1-5. El NavLab 1 autónomo de 1986 en todo su esplendor(fuente de la imagen)
Otro ejemplo destacado de los años 80 fue el del Servicio Postal de Estados Unidos (USPS). El servicio necesitaba clasificar automáticamente el correo postal según los códigos postales (ZIP) a los que iba dirigido. Como gran parte del correo siempre se ha escrito a mano, no se podía utilizar el reconocimiento óptico de caracteres (OCR). Para resolver este problema, Yann LeCun et al. utilizaron datos manuscritos de del Instituto Nacional de Normas y Tecnología (NIST) para demostrar que las redes neuronales eran capaces de reconocer estos dígitos manuscritos en su artículo "Backpropagation Applied to Handwritten Zip Code Recognition". La red de la agencia, LeNet, se convirtió en lo que el USPS utilizó durante décadas para escanear y clasificar automáticamente el correo. Esto fue notable porque fue la primera red neuronal convolucional que realmente funcionó en la naturaleza. Con el tiempo, en la década de 1990, los bancos utilizarían una versión evolucionada del modelo llamada LeNet-5 para leer los números escritos a mano en los cheques. Esto sentó las bases de la visión por ordenador moderna.
Aquellos de vosotros que hayáis leído sobre el conjunto de datos MNIST puede que ya hayáis notado una conexión con la mención del NIST que acabamos de hacer. Esto se debe a que el conjunto de datos MNIST consiste esencialmente en un subconjunto de imágenes del conjunto de datos original del NIST al que se aplicaron algunas modificaciones (la "M" de "MNIST") para facilitar el proceso de entrenamiento y prueba de la red neuronal. Las modificaciones, algunas de las cuales puedes ver en la Figura 1-6, incluían redimensionarlas a 28 x 28 píxeles, centrar el dígito en esa zona, antialiasing, etc.
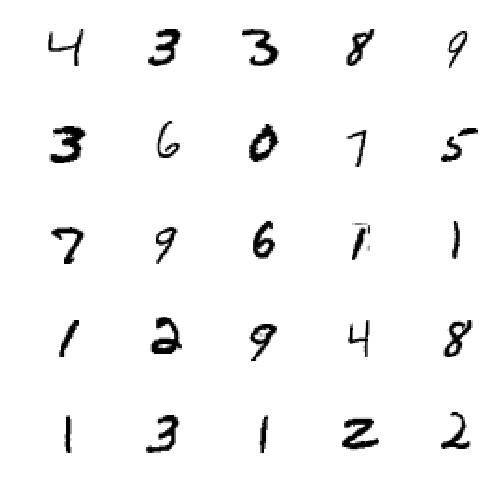
Figura 1-6. Una muestra de dígitos manuscritos del conjunto de datos MNIST
Otros siguieron investigando, como Jürgen Schmidhuber, que propuso redes como la Memoria Larga a Corto Plazo (LSTM), con aplicaciones prometedoras para el texto y el habla.
En aquel momento, aunque las teorías eran cada vez más avanzadas, los resultados no podían demostrarse en la práctica. La razón principal era que resultaba demasiado caro computacionalmente para el hardware de entonces y escalarlos para tareas mayores era todo un reto. Aunque por algún milagro se dispusiera del hardware, los datos para aprovechar todo su potencial no eran fáciles de conseguir. Al fin y al cabo, Internet aún estaba en su fase de conexión telefónica. Las máquinas de vectores de soporte (SVM), una técnica de aprendizaje automático introducida para los problemas de clasificación en 1995, eran más rápidas y proporcionaban resultados razonablemente buenos con cantidades menores de datos, por lo que se habían convertido en la norma.
Como resultado, la reputación de la IA y el aprendizaje profundo era mala. Se advirtió a los estudiantes de posgrado que no investigaran sobre el aprendizaje profundo porque éste era el campo "donde los científicos inteligentes verían el final de sus carreras". La gente y las empresas que trabajaban en este campo utilizaban palabras alternativas como informática, sistemas cognitivos, agentes inteligentes, aprendizaje automático y otras para desvincularse del nombre IA. Es un poco como cuando el Departamento de Guerra de EE.UU. pasó a llamarse Departamento de Defensa para ser más aceptable para la gente.
Cómo el aprendizaje profundo se convirtió en algo
Por suerte para nosotros, la década de 2000 trajo Internet de alta velocidad, cámaras para teléfonos inteligentes, videojuegos y sitios para compartir fotos como Flickr y Creative Commons (que ofrecían la posibilidad de reutilizar legalmente las fotos de otras personas). Un gran número de personas podían hacer fotos rápidamente con un dispositivo que llevaban en el bolsillo y subirlas al instante. El lago de datos se estaba llenando y, poco a poco, había muchas oportunidades de darse un chapuzón. El conjunto de datos ImageNet de 14 millones de imágenes nació de esta feliz confluencia y de un tremendo trabajo de Fei-Fei Li (entonces de Princeton) y compañía.
Durante la misma década, los juegos de PC y consola se volvieron realmente serios. Los jugadores exigían cada vez mejores gráficos en sus videojuegos. Esto, a su vez, empujó a los fabricantes de Unidades de Procesamiento Gráfico (GPU) como NVIDIA a seguir mejorando su hardware. Lo que hay que recordar aquí es que las GPU son muy buenas en operaciones matriciales. ¿Por qué? Porque las matemáticas lo exigen. En los gráficos por ordenador, tareas comunes como mover objetos, rotarlos, cambiar su forma, ajustar su iluminación, etc. utilizan operaciones matriciales. Y las GPU están especializadas en hacerlas. ¿Y sabes qué más necesita muchos cálculos matriciales? Las redes neuronales. Es una gran coincidencia feliz.
Con ImageNet lista, en 2010 se creó el Desafío anual ImageNet de Reconocimiento Visual a Gran Escala (ILSVRC) para retar abiertamente a los investigadores a idear mejores técnicas para clasificar estos datos. Se dispuso de un subconjunto de 1.000 categorías formado por aproximadamente 1,2 millones de imágenes para ampliar los límites de la investigación. Las técnicas más avanzadas de visión por ordenador, como la transformada de características invariantes en escala (SIFT) + SVM, arrojaron una tasa de error top-5 del 28% (en 2010) y del 25% (2011) (es decir, si una de las cinco primeras conjeturas clasificadas por probabilidad coincide, se considera exacta).
Y entonces llegó 2012, con una entrada en la tabla de clasificación que redujo casi a la mitad la tasa de error, hasta el 16%. Alex Krizhevsky, Ilya Sutskever (que acabó fundando OpenAI) y Geoffrey Hinton, de la Universidad de Toronto, presentaron esa propuesta. Acertadamente llamada AlexNet, era una CNN inspirada en LeNet-5. Incluso con sólo ocho capas, AlexNet tenía 60 millones de parámetros y 650.000 neuronas, lo que daba como resultado un modelo de 240 MB. Se entrenó durante una semana utilizando dos GPUs NVIDIA. Este único acontecimiento cogió a todo el mundo por sorpresa, demostrando el potencial de las CNN que se convirtió en una bola de nieve en la era moderna del aprendizaje profundo.
La Figura 1-7 cuantifica en el progreso que han realizado las CNN en la última década. Observamos una disminución interanual del 40% en la tasa de error de clasificación entre las entradas ganadoras del LSVRC de ImageNet desde la llegada del aprendizaje profundo en 2012. A medida que las CNN se hacían más profundas, el error seguía disminuyendo.
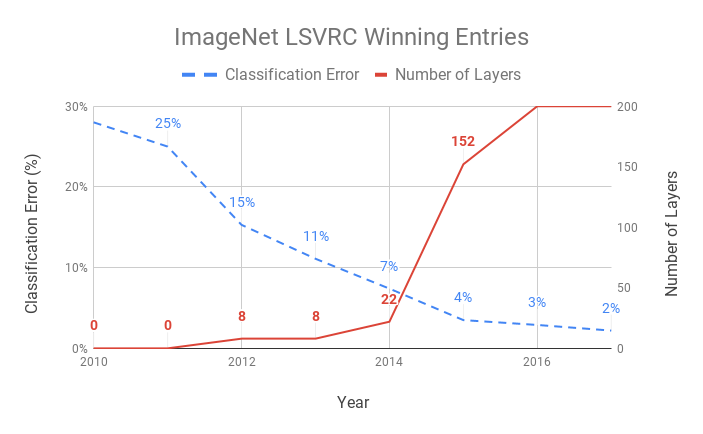
Figura 1-7. Evolución de las entradas ganadoras en el LSVRC de ImageNet
Ten en cuenta que estamos simplificando enormemente la historia de la IA, y seguramente estamos pasando por alto algunos detalles. Esencialmente, fue una confluencia de datos, GPU y mejores técnicas lo que condujo a esta era moderna del aprendizaje profundo. Y el progreso siguió expandiéndose hacia nuevos territorios. Como destaca la Tabla 1-1, lo que estaba en el reino de la ciencia ficción ya es una realidad.
| 2012 | Una red neuronal del equipo Google Brain empieza a reconocer gatos tras ver vídeos de YouTube |
| 2013 |
|
| 2014 |
|
| 2015 |
|
| 2016 |
|
| 2017 |
|
| 2018 |
|
| 2019 |
|
Esperemos que ahora tengas un contexto histórico de la IA y el aprendizaje profundo y comprendas por qué este momento es significativo. Es importante reconocer el rápido ritmo al que se está avanzando en este campo. Pero, como hemos visto hasta ahora, no siempre ha sido así.
La estimación original de para lograr la visión por ordenador en el mundo real era de "un verano", allá por los años 60, según dos de los pioneros del campo. ¡Se equivocaron por sólo medio siglo! No es fácil ser futurista. Un estudio de Alexander Wissner-Gross observó que transcurrían 18 años de media entre el momento en que se proponía un algoritmo y el momento en que daba lugar a un gran avance. Por otra parte, la diferencia era de sólo tres años de media entre el momento en que se puso a disposición un conjunto de datos y el avance que ayudó a conseguir. Fíjate en cualquiera de los avances de la última década. Es muy probable que el conjunto de datos que permitió ese avance estuviera disponible sólo unos pocos años antes.
Los datos fueron claramente el factor limitante. Esto demuestra el papel crucial que puede desempeñar un buen conjunto de datos para el aprendizaje profundo. Sin embargo, los datos no son el único factor. Veamos los demás pilares que constituyen los cimientos de la solución perfecta de aprendizaje profundo.
Receta para la solución perfecta de aprendizaje profundo
Antes de que Gordon Ramsay empiece a cocinar, se asegura de tener todos los ingredientes listos. Lo mismo ocurre al resolver un problema utilizando el aprendizaje profundo(Figura 1-8).
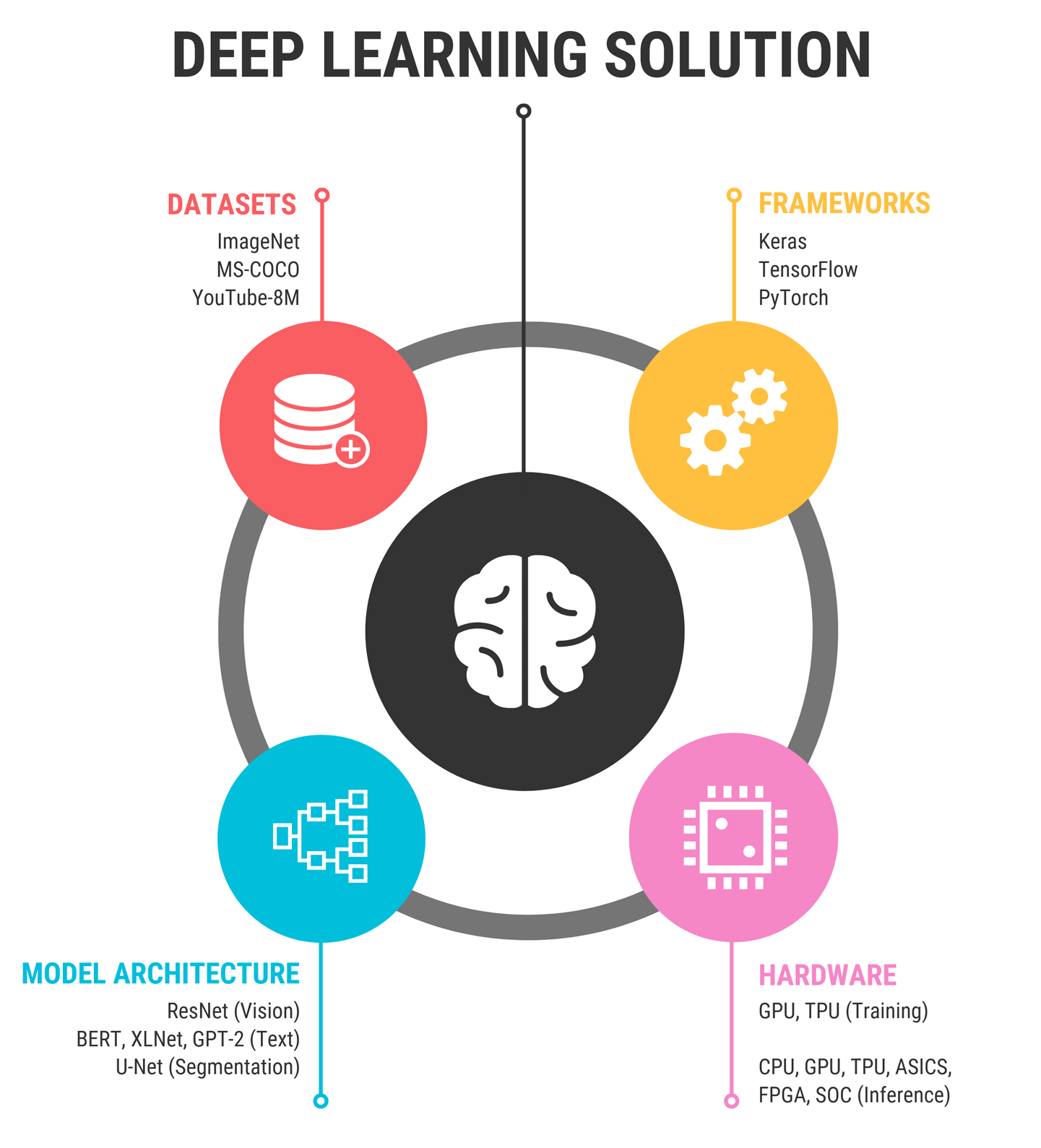
Figura 1-8. Ingredientes de la solución perfecta de aprendizaje profundo
¡Y aquí tienes tu mise en place de aprendizaje profundo!
Dataset + Model + Framework + Hardware = Deep Learning Solution
Veamos cada uno de ellos con un poco más de detalle.
Conjuntos de datos
Sólo como Pac-Man está hambriento de puntos, el aprendizaje profundo está hambriento de datos: muchos y muchos datos. Necesita esta cantidad de datos para detectar patrones significativos que puedan ayudar a hacer predicciones sólidas. El aprendizaje automático tradicional era la norma en los años 80 y 90 porque funcionaba incluso con pocos cientos o miles de ejemplos. En cambio, las Redes Neuronales Profundas (DNN), cuando se construyen desde cero, necesitarían órdenes de datos mayores para las tareas típicas de predicción. La ventaja es que las predicciones son mucho mejores .
En este siglo, estamos viviendo una explosión de datos, con quintillones de bytes de datos que se crean cada día: imágenes, texto, vídeos, datos de sensores y mucho más. Pero para hacer un uso eficaz de estos datos, necesitamos etiquetas. Para construir un clasificador de sentimientos que sepa si una crítica de Amazon es positiva o negativa, necesitamos miles de frases y una emoción asignada a cada una. Para entrenar un sistema de segmentación facial para una lente de Snapchat, necesitamos la ubicación precisa de ojos, labios, nariz, etc. en miles de imágenes. Para entrenar un coche autoconducido, necesitamos segmentos de vídeo etiquetados con las reacciones del conductor humano sobre mandos como los frenos, el acelerador, el volante, etcétera. Estas etiquetas actúan como maestros de nuestra IA y son mucho más valiosas que los datos no etiquetados por sí solos.
Conseguir etiquetas puede ser caro. No es de extrañar que exista toda una industria en torno a las tareas de etiquetado crowdsourcing entre miles de trabajadores. Cada etiqueta puede costar desde unos céntimos hasta dólares, dependiendo del tiempo que dediquen los trabajadores a asignarla. Por ejemplo, durante el desarrollo del conjunto de datos Microsoft COCO (Common Objects in Context), se tardó aproximadamente tres segundos en etiquetar el nombre de cada objeto de una imagen, unos 30 segundos en colocar un cuadro delimitador alrededor de cada objeto y 79 segundos en dibujar los contornos de cada objeto. Repite eso cientos de miles de veces y podrás empezar a comprender los costes de algunos de los conjuntos de datos más grandes. Algunas empresas de etiquetado como Appen y Scale AI ya están valoradas en más de mil millones de dólares cada una.
Puede que no tengamos un millón de dólares en nuestra cuenta bancaria. Pero por suerte para nosotros, han ocurrido dos cosas buenas en esta revolución del aprendizaje profundo:
-
Grandes empresas y universidades han hecho públicos generosamente gigantescos conjuntos de datos etiquetados.
-
Una técnica de llamada aprendizaje por transferencia, que nos permite ajustar nuestros modelos a conjuntos de datos con incluso cientos de ejemplos, siempre que nuestro modelo se haya entrenado originalmente en un conjunto de datos mayor similar a nuestro conjunto actual. Lo utilizamos repetidamente en el libro, incluso en el Capítulo 5, donde experimentamos y demostramos que incluso con unas pocas decenas de ejemplos podemos obtener un rendimiento decente con esta técnica. El aprendizaje por transferencia echa por tierra el mito de que son necesarios grandes datos para entrenar un buen modelo. ¡Bienvenido al mundo de los datos diminutos!
La Tabla 1-2 muestra algunos de los conjuntos de datos más populares que existen en la actualidad para diversas tareas de aprendizaje profundo.
| Tipo de datos | Nombre | Detalles |
|---|---|---|
| Imagen |
Imágenes abiertas V4 (de Google) |
|
| Microsoft COCO |
|
|
| Vídeo | YouTube-8M |
|
|
Vídeo, imágenes |
BDD100K (de la UC Berkeley) |
|
| Conjunto de datos abiertos de Waymo | 3.000 escenas de conducción con un total de 16,7 horas de datos de vídeo, 600.000 fotogramas, aproximadamente 25 millones de cuadros delimitadores 3D y 22 millones de cuadros delimitadores 2D | |
| Texto | SQuAD | 150.000 fragmentos de preguntas y respuestas de Wikipedia |
| Opiniones de Yelp | Cinco millones de opiniones en Yelp | |
| Datos de satélite | Datos del Landsat | Varios millones de imágenes de satélite (100 millas náuticas de anchura y altura), junto con ocho bandas espectrales (resolución espacial de 15 a 60 metros) |
|
Audio |
Google AudioSet | 2.084.320 clips de sonido de 10 segundos de YouTube con 632 categorías |
| LibriHabla | 1.000 horas de discurso leído en inglés |
Arquitectura Modelo
En un alto nivel, un modelo no es más que una función. Toma una o varias entradas y da una salida. La entrada puede ser texto, imágenes, audio, vídeo, etc. La salida es una predicción. La salida es una predicción. Un buen modelo es aquel cuyas predicciones se ajustan con fiabilidad a la realidad esperada. La precisión del modelo en un conjunto de datos es un factor determinante para saber si es adecuado para su uso en una aplicación del mundo real. Para muchas personas, esto es todo lo que realmente necesitan saber sobre los modelos de aprendizaje profundo. Pero es cuando nos asomamos al funcionamiento interno de un modelo cuando se vuelve realmente interesante(Figura 1-9).
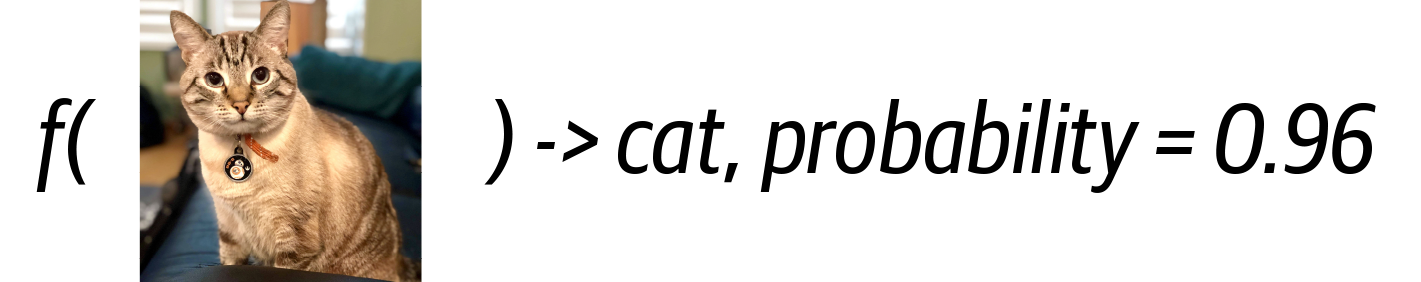
Figura 1-9. Vista de caja negra de un modelo de aprendizaje profundo
Dentro del modelo hay un gráfico formado por nodos y perímetros. Los nodos representan operaciones matemáticas, mientras que las aristas representan cómo fluyen los datos de un nodo a otro. En otras palabras, si la salida de un nodo puede convertirse en la entrada de uno o más nodos, las conexiones entre esos nodos se representan mediante aristas. La estructura de este grafo determina el potencial de precisión, su velocidad, la cantidad de recursos que consume (memoria, cálculo y energía) y el tipo de entrada que es capaz de procesar.
La disposición de los nodos y perímetros se conoce como arquitectura del modelo. Esencialmente, es un plano. Ahora bien, el plano es sólo la mitad del cuadro. Aún necesitamos el edificio real. El entrenamiento es el proceso que utiliza este plano para construir ese edificio. Entrenamos un modelo introduciendo repetidamente 1) datos de entrada, 2) obteniendo resultados, 3) monitorizando hasta qué punto estas predicciones se alejan de la realidad esperada (es decir, las etiquetas asociadas a los datos) y, a continuación, 4) propagando la magnitud del error al modelo para que pueda aprender progresivamente a corregirse a sí mismo. Este proceso de entrenamiento se realiza de forma iterativa hasta que estemos satisfechos con la precisión de las predicciones.
El resultado de este entrenamiento es un conjunto de números (también conocidos como pesos) que se asigna a cada uno de los nodos. Estos pesos son parámetros necesarios para que los nodos del grafo operen con la entrada que se les da. Antes de comenzar el entrenamiento, solemos asignar números aleatorios como pesos. El objetivo del proceso de entrenamiento es esencialmente afinar gradualmente los valores de cada conjunto de estos pesos hasta que, en conjunción con sus nodos correspondientes, produzcan predicciones satisfactorias.
Para entender los pesos un poco mejor, examinemos el siguiente conjunto de datos con dos entradas y una salida:
| entrada1 | entrada2 | salida |
|---|---|---|
| 1 | 6 | 20 |
| 2 | 5 | 19 |
| 3 | 4 | 18 |
| 4 | 3 | 17 |
| 5 | 2 | 16 |
| 6 | 1 | 15 |
Utilizando álgebra lineal (o conjeturas en nuestra mente), podemos deducir que la ecuación que rige este conjunto de datos es:
salida = f(entrada1, entrada2) = 2 x entrada1 + 3 x entrada2
En este caso, los pesos de esta operación matemática son 2 y 3. Una red neuronal profunda tiene millones de parámetros de peso de este tipo.
Dependiendo de los tipos de nodos utilizados, los distintos temas de las arquitecturas de los modelos serán más adecuados para los distintos tipos de datos de entrada. Por ejemplo, las CNN se utilizan para imagen y audio, mientras que las Redes Neuronales Recurrentes (RNN) y las LSTM suelen emplearse en el procesamiento de texto.
En general, entrenar uno de estos modelos desde cero puede llevar una cantidad de tiempo bastante considerable, potencialmente semanas. Por suerte para nosotros, muchos investigadores ya han hecho el difícil trabajo de entrenarlos en un conjunto de datos genérico (como ImageNet) y los han puesto a disposición de todo el mundo para que los utilice. Lo que es aún mejor es que podemos tomar estos modelos disponibles y ajustarlos a nuestro conjunto de datos específico. Este proceso se denomina aprendizaje por transferencia y representa la inmensa mayoría de las necesidades de los profesionales.
Comparado con el entrenamiento desde cero, el aprendizaje por transferencia ofrece una doble ventaja: reduce significativamente el tiempo de entrenamiento a (de unos minutos a horas en lugar de semanas), y puede trabajar con un conjunto de datos sustancialmente menor (de cientos a miles de muestras de datos en lugar de millones). La Tabla 1-4 muestra algunos ejemplos famosos de arquitecturas de modelos.
| Tarea | Ejemplos de arquitecturas modelo |
|---|---|
| Clasificación de imágenes | ResNet-152 (2015), MobileNet (2017) |
| Clasificación de textos | BERT (2018), XLNet (2019) |
| Segmentación de imágenes | U-Net (2015), DeepLabV3 (2018) |
| Traducción de imágenes | Pix2Pix (2017) |
| Detección de objetos | YOLO9000 (2016), Máscara R-CNN (2017) |
| Generación de voz | WaveNet (2016) |
Cada uno de los modelos de la Tabla 1-4 tiene una métrica de precisión publicada sobre conjuntos de datos de referencia (por ejemplo, ImageNet para la clasificación, MS COCO para la detección). Además, estas arquitecturas tienen sus propios requisitos de recursos característicos (tamaño del modelo en megabytes, requisitos de cálculo en operaciones de coma flotante, o FLOPS).
Exploraremos el aprendizaje de transferencia en profundidad en los próximos capítulos. Ahora, veamos los tipos de marcos y servicios de aprendizaje profundo que tenemos a nuestra disposición.
Cuando Kaiming He et al. idearon la arquitectura ResNet de 152 capas en 2015 -una proeza en su día teniendo en cuenta que el anterior modelo GoogLeNet más grande constaba de 22 capas-, todo el mundo se hacía una pregunta: "¿Por qué no 153 capas?" Resulta que la razón fue que Kaiming se quedó sin memoria en la GPU.
Marcos
En existen varias bibliotecas de aprendizaje profundo que nos ayudan a entrenar nuestros modelos. Además, hay frameworks que se especializan en utilizar esos modelos entrenados para hacer predicciones (o inferencias), optimizándolos para el lugar donde reside la aplicación.
Históricamente, como ocurre con el software en general, muchas bibliotecas han ido y venido -Torch (2002), Theano (2007), Caffe (2013), Microsoft Cognitive Toolkit (2015), Caffe2 (2017)- y el panorama ha evolucionado rápidamente. Lo aprendido de cada una de ellas ha facilitado el aprendizaje de las demás bibliotecas, ha impulsado el interés y ha mejorado la productividad tanto de principiantes como de expertos. La Tabla 1-5 examina algunas de las más populares.
| Marco | Más adecuado para | Plataforma objetivo típica |
|---|---|---|
| TensorFlow (incluido Keras) | Formación | Ordenadores de sobremesa, servidores |
| PyTorch | Formación | Ordenadores de sobremesa, servidores |
| MXNet | Formación | Ordenadores de sobremesa, servidores |
| TensorFlow Sirviendo | Inferencia | Servidores |
| TensorFlow Lite | Inferencia | Dispositivos móviles e integrados |
| TensorFlow.js | Inferencia | Navegadores |
| ml5.js | Inferencia | Navegadores |
| Núcleo ML | Inferencia | Dispositivos Apple |
| Xnor AI2GO | Inferencia | Dispositivos integrados |
TensorFlow
En 2011, Google Brain desarrolló la biblioteca DNN DistBelief para investigación e ingeniería internas. Ayudó a entrenar Inception (la aplicación ganadora de 2014 del Desafío de Reconocimiento Visual a Gran Escala ImageNet), así como a mejorar la calidad del reconocimiento de voz en los productos de Google. Muy vinculado a la infraestructura de Google, no era fácil de configurar ni de compartir código con entusiastas externos del aprendizaje automático. Al darse cuenta de las limitaciones, Google empezó a trabajar en un marco de aprendizaje automático distribuido de segunda generación, que prometía ser de propósito general, escalable, de alto rendimiento y portable a muchas plataformas de hardware. Y lo mejor, era de código abierto. Google lo llamó TensorFlow y anunció su lanzamiento en noviembre de 2015.
TensorFlow cumplió muchas de estas promesas, desarrollando un ecosistema integral desde el desarrollo hasta la implementación, y se ganó un gran número de seguidores en el proceso. Con más de 100.000 estrellas en GitHub, no muestra signos de detenerse. Sin embargo, a medida que aumentaba su adopción, los usuarios de la biblioteca la criticaron con razón por no ser lo bastante fácil de usar. Como decía el chiste, TensorFlow era una biblioteca hecha por ingenieros de Google, de ingenieros de Google, para ingenieros de Google, y si eras lo bastante listo como para usar TensorFlow, eras lo bastante listo como para que te contrataran allí.
Pero Google no estaba solo en esto. Seamos sinceros. Incluso en 2015, era un hecho que trabajar con bibliotecas de aprendizaje profundo sería inevitablemente una experiencia desagradable. Olvídate incluso de trabajar con ellas; instalar algunos de estos frameworks hacía que la gente quisiera tirarse de los pelos. (A los usuarios de Caffe, ¿les suena?)
Keras
Como una respuesta a las dificultades a las que se enfrentaban los profesionales del aprendizaje profundo, François Chollet publicó el marco de código abierto Keras en marzo de 2015, y el mundo no ha vuelto a ser el mismo desde entonces. De repente, esta solución hizo accesible el aprendizaje profundo a los principiantes. Keras proporcionó una interfaz intuitiva y fácil de usar para la codificación, que luego utilizaría otras bibliotecas de aprendizaje profundo como marco computacional backend. Comenzando con Theano como primer backend, Keras fomentó la creación rápida de prototipos y redujo el número de líneas de código. Con el tiempo, esta abstracción se amplió a otros marcos, como Cognitive Toolkit, MXNet, PlaidML y, sí, TensorFlow.
PyTorch
En paralelo a, PyTorch comenzó en Facebook a principios de 2016, donde los ingenieros tuvieron la ventaja de observar las limitaciones de TensorFlow. PyTorch admitía construcciones nativas de Python y depuración en Python desde el principio, lo que lo hacía flexible y fácil de usar, convirtiéndose rápidamente en un favorito entre los investigadores de IA. Es el segundo mayor sistema de aprendizaje profundo de extremo a extremo. Además, Facebook construyó Caffe2 para tomar los modelos de PyTorch e implementarlos en producción para dar servicio a más de mil millones de usuarios. Mientras que PyTorch impulsaba la investigación, Caffe2 se utilizaba principalmente en producción. En 2018, Caffe2 fue absorbido por PyTorch para formar un marco completo.
Un paisaje en continua evolución
Si esta historia hubiera terminado con la facilidad de Keras y PyTorch, este libro no tendría la palabra "TensorFlow" en el subtítulo. El equipo de TensorFlow reconoció que si realmente quería ampliar el alcance de la herramienta y democratizar la IA, necesitaba hacerla más fácil. Así que fue una buena noticia que Keras se incluyera oficialmente como parte de TensorFlow, ofreciendo lo mejor de ambos mundos. Esto permitió a los desarrolladores utilizar Keras para definir el modelo y entrenarlo, y el núcleo de TensorFlow para su canalización de datos de alto rendimiento, incluido el entrenamiento distribuido y el ecosistema de implementación. ¡Era una combinación perfecta! Y por si fuera poco, TensorFlow 2.0 (publicado en 2019) incluía soporte para construcciones nativas de Python y ejecución ansiosa, como vimos en PyTorch.
Con tantos marcos de trabajo disponibles que compiten entre sí, surge inevitablemente la cuestión de la portabilidad. Imagina que se publica un nuevo trabajo de investigación con el modelo más avanzado en PyTorch. Si no trabajáramos en PyTorch, nos quedaríamos fuera de la investigación y tendríamos que reimplementarlo y entrenarlo. A los desarrolladores les gusta poder compartir modelos libremente y no estar restringidos a un ecosistema específico. Orgánicamente, muchos desarrolladores escribieron bibliotecas para convertir los formatos de los modelos de una biblioteca a otra. Era una solución sencilla, salvo que dio lugar a una explosión combinatoria de herramientas de conversión que carecían de soporte oficial y de calidad suficiente debido al gran número de ellas. Para abordar este problema en, Microsoft y Facebook, junto con los principales actores del sector, promovieron el Intercambio Abierto de Redes Neuronales (ONNX). ONNX proporcionó una especificación para un formato de modelo común que era legible y escribible por una serie de bibliotecas populares oficialmente. Además, proporcionaba convertidores para las bibliotecas que no soportaban este formato de forma nativa. Esto permitió a los desarrolladores entrenarse en un marco y hacer inferencias en otro diferente.
Aparte de estos marcos, hay varios sistemas de Interfaz Gráfica de Usuario (GUI) que hacen posible el entrenamiento sin código. Utilizando el aprendizaje por transferencia, generan modelos entrenados rápidamente en varios formatos útiles para la inferencia. Con interfaces de apuntar y hacer clic, ¡hasta tu abuela puede ahora entrenar una red neuronal!
| Servicio | Plataforma |
|---|---|
| Microsoft CustomVision.AI | En la web |
| Google AutoML | En la web |
| Clarifai | En la web |
| Reconocimiento Visual IBM | En la web |
| Apple Crea ML | macOS |
| DÍGITOS NVIDIA | Escritorio |
| Pista ML | Escritorio |
Así que ¿por qué elegimos TensorFlow y Keras como marcos principales para este libro? Teniendo en cuenta la enorme cantidad de material disponible, incluida la documentación, las respuestas de Stack Overflow, los cursos en línea, la amplia comunidad de colaboradores, la compatibilidad con plataformas y dispositivos, la adopción por parte de la industria y, sí, los puestos de trabajo disponibles (aproximadamente tres veces más puestos relacionados con TensorFlow que con PyTorch en Estados Unidos), TensorFlow y Keras dominan actualmente el panorama en lo que a frameworks se refiere. Para nosotros tenía sentido seleccionar esta combinación. Dicho esto, las técnicas tratadas en el libro también son generalizables a otras bibliotecas. Adquirir un nuevo marco de trabajo no debería llevarte demasiado tiempo. Así que, si realmente quieres trasladarte a una empresa que utilice PyTorch exclusivamente, no dudes en solicitarlo allí.
Hardware
En 1848, cuando James W. Marshall descubrió oro en California, la noticia corrió como la pólvora por todo Estados Unidos. Cientos de miles de personas acudieron al estado para empezar a extraer riquezas. Esto se conoció como la Fiebre del Oro de California. Los primeros pudieron extraer una buena parte, pero los últimos no tuvieron tanta suerte. Pero la fiebre no se detuvo durante muchos años. ¿Adivinas quién ganó más dinero durante este periodo? ¡Los fabricantes de palas!
Las empresas de nube y hardware son los fabricantes de palas del siglo XXI. ¿No nos crees? Mira el rendimiento bursátil de Microsoft y NVIDIA en la última década. La única diferencia entre 1849 y ahora es la alucinante cantidad de opciones de pala de que disponemos.
Dada la variedad de hardware disponible, es importante elegir correctamente en función de las limitaciones impuestas por los recursos, la latencia, el presupuesto, la privacidad y los requisitos legales de la aplicación.
Dependiendo de cómo interactúe tu aplicación con el usuario, la fase de inferencia suele tener a un usuario esperando en el otro extremo una respuesta. Esto impone restricciones al tipo de hardware que se puede utilizar, así como a la ubicación del mismo. Por ejemplo, una lente de Snapchat no puede ejecutarse en la nube debido a los problemas de latencia de la red. Además, necesita ejecutarse casi en tiempo real para ofrecer una buena experiencia de usuario (UX), por lo que establece un requisito mínimo en el número de fotogramas procesados por segundo (normalmente >15 fps). Por otro lado, una foto subida a una biblioteca de imágenes como Google Fotos no necesita que se realice sobre ella una categorización de imágenes inmediata. Unos segundos o unos minutos de latencia son aceptables.
Yendo al otro extremo, el entrenamiento lleva mucho más tiempo; entre minutos, horas y días. Dependiendo de nuestro escenario de entrenamiento, el valor real de un hardware mejor es permitir una experimentación más rápida y más iteraciones. Para algo más serio que las redes neuronales básicas, un hardware mejor puede suponer una gran diferencia. Normalmente, las GPU acelerarían las cosas entre 10 y 15 veces en comparación con las CPU, y con un rendimiento por vatio mucho mayor, reduciendo el tiempo de espera para que nuestro experimento termine de una semana a unas pocas horas. Esto puede ser la diferencia entre ver un documental sobre el Gran Cañón (dos horas) y hacer realmente el viaje para visitar el Gran Cañón (cuatro días).
A continuación se indican algunas categorías fundamentales de hardware entre las que elegir y cómo suelen caracterizarse (véase también la Figura 1-10):
- Unidad Central de Proceso (CPU)
-
Barato, flexible, lento. Por ejemplo, Intel Core i9-9900K.
- GPU
-
Alto rendimiento, ideal para el procesamiento por lotes para utilizar el procesamiento paralelo, caro. Por ejemplo, NVIDIA GeForce RTX 2080 Ti.
- Matriz de puertas programables en campo (FPGA)
-
Rápidos, de bajo consumo, reprogramables para soluciones personalizadas, caros. Entre las empresas conocidas están Xilinx, Lattice Semiconductor, Altera (Intel). Debido a la capacidad de ejecutarse en segundos y a la posibilidad de configurar cualquier modelo de IA, Microsoft Bing ejecuta la mayor parte de su IA en FPGAs.
- Circuito Integrado de Aplicación Específica (ASIC)
-
Chip hecho a medida. Extremadamente caro de diseñar, pero barato cuando se construye a escala. Al igual que en la industria farmacéutica, el primer artículo es el más caro debido al esfuerzo en I+D que supone diseñarlo y fabricarlo. Producir cantidades masivas es bastante barato. Algunos ejemplos concretos son los siguientes:
- Unidad de Procesamiento Tensorial (TPU)
-
ASIC especializado en operaciones para redes neuronales, disponible sólo en Google Cloud.
- TPU de perímetro
-
Más pequeño que un céntimo de euro, acelera la inferencia en el perímetro.
- Unidad de procesamiento neuronal (NPU)
-
Utilizado a menudo por los fabricantes de smartphones, se trata de un chip dedicado a acelerar la inferencia de redes neuronales.
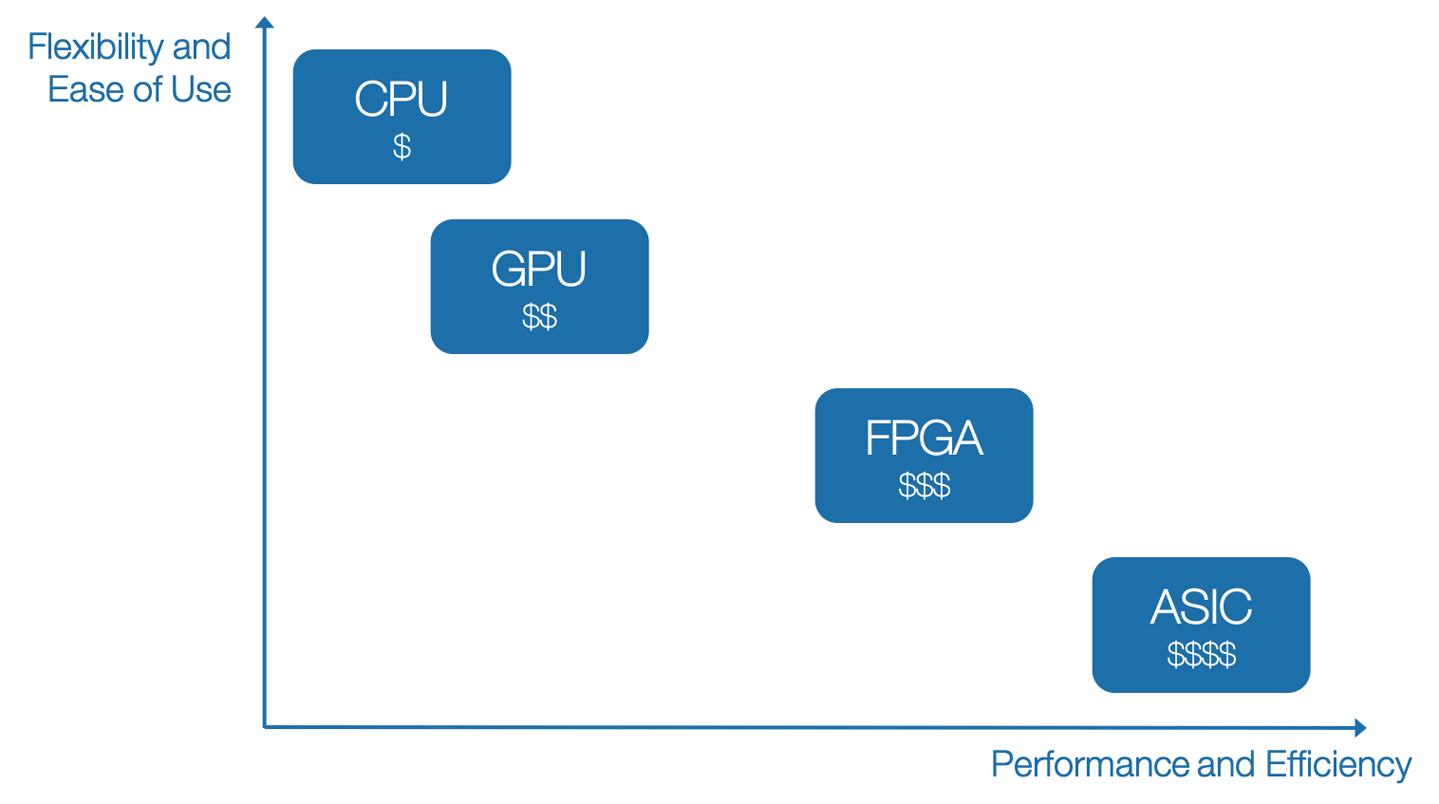
Figura 1-10. Comparación de diferentes tipos de hardware en relación con la flexibilidad, el rendimiento y el coste
Veamos algunos supuestos en los que se utilizaría cada uno de ellos:
-
Empezar a entrenar → CPU
-
Entrenamiento de grandes redes → GPUs y TPUs
-
Inferencia en smartphones → CPU móvil, GPU, procesador digital de señales (DSP), NPU
-
Wearables (por ejemplo, gafas inteligentes, smartwatches) → TPU de perímetro, NPUs
-
Proyectos de IA integrados (p. ej., dron de topografía de inundaciones, silla de ruedas autónoma) → Aceleradores como Google Coral, Intel Movidius con Raspberry Pi, o GPU como NVIDIA Jetson Nano, hasta microcontroladores (MCU) de 15 $ para la detección de palabras de despertador en altavoces inteligentes
A medida que avancemos en el libro, exploraremos de cerca muchos de ellos.
IA responsable
Hasta ahora, en hemos explorado el poder y el potencial de la IA. Es muy prometedora para mejorar nuestras capacidades, para hacernos más productivos, para darnos superpoderes.
Pero un gran poder conlleva una gran responsabilidad.
Por mucho que la IA pueda ayudar a la humanidad, también tiene el mismo potencial de perjudicarnos cuando no se diseña con reflexión y cuidado (ya sea intencionadamente o no). La culpa no es de la IA, sino de sus diseñadores.
Considera algunos incidentes reales que han sido noticia en los últimos años.
-
"Supuestamente, ____ puede determinar si eres terrorista con sólo analizar tu cara"(Figura 1-11): Computer World, 2016
-
"La IA envía a la gente a la cárcel y se equivoca": MIT Tech Review, 2019
-
"____ superordenador recomendó tratamientos contra el cáncer "inseguros e incorrectos", según documentos internos": STAT News, 2018
-
"____ construyó una herramienta de IA para contratar personas, pero tuvo que cerrarla porque discriminaba a las mujeres": Business Insider, 2018
-
"____ Estudio sobre IA: Los principales sistemas de reconocimiento de objetos favorecen a las personas con más dinero": VentureBeat, 2019
-
"____ etiqueta a los negros como 'gorilas'" USA Today, 2015. "Dos años después, ____ resuelve el problema del 'algoritmo racista' purgando la etiqueta 'gorila' del clasificador de imágenes": Boing Boing, 2018
-
"____ silencia su nuevo bot de Inteligencia Artificial Tay, después de que los usuarios de Twitter le enseñen racismo": TechCrunch, 2016
-
"La IA confunde un anuncio al lado de un autobús con una famosa CEO y la acusa de cruzar la calle imprudentemente": Caixin Global, 2018
-
"____ abandonará el contrato de IA del Pentágono tras las objeciones de los empleados al 'negocio de la guerra'": Washington Post, 2018
-
"El coche autoconducido de la muerte ____ 'vio a una peatona seis segundos antes de atropellarla y matarla'": The Sun, 2018

Figura 1-11. Startup que pretende clasificar a las personas en función de su estructura facial
¿Puedes rellenar los espacios en blanco? Te daremos algunas opciones: Amazon, Microsoft, Google, IBM y Uber. Adelante, rellénalos. Te esperamos.
Hay una razón por la que los dejamos en blanco. Es para reconocer que no es un problema que pertenezca a un individuo o a una empresa concretos. Es un problema de todos. Y aunque estas cosas ocurrieron en el pasado, y puede que no reflejen el estado actual, podemos aprender de ellas e intentar no cometer los mismos errores. El resquicio de esperanza aquí es que todo el mundo aprendió de estos errores.
Nosotros, como desarrolladores, diseñadores, arquitectos y líderes de la IA, tenemos la responsabilidad de pensar más allá del mero problema técnico. A continuación se exponen sólo un puñado de temas que son relevantes para cualquier problema que resolvamos (de IA o de otro tipo). No deben quedar en un segundo plano.
Sesgo
A menudo en nuestro trabajo diario, aportamos nuestros propios prejuicios, a sabiendas o sin saberlo. Esto es el resultado de multitud de factores, como nuestro entorno, educación, normas culturales e incluso nuestra naturaleza inherente. Al fin y al cabo, la IA y los conjuntos de datos que la alimentan no se crearon en el vacío: los crearon seres humanos con sus propios prejuicios. Los ordenadores no crean prejuicios por arte de magia, sino que reflejan y amplifican los existentes.
Tomemos el ejemplo de los primeros días de la aplicación de YouTube, cuando los desarrolladores se dieron cuenta de que aproximadamente el 10% de los vídeos subidos estaban al revés. Quizá si la cifra hubiera sido menor, por ejemplo el 1%, podría haberse considerado un error del usuario. Pero el 10% era una cifra demasiado alta para ignorarla. ¿Sabes quiénes constituyen el 10% de la población? ¡Los zurdos! Estos usuarios sujetaban sus teléfonos con la orientación opuesta a la de sus compañeros diestros. Pero los ingenieros de YouTube no habían tenido en cuenta este caso durante el desarrollo y las pruebas de su aplicación móvil, así que YouTube subió vídeos a su servidor con la misma orientación para usuarios zurdos y diestros.
Este problema podría haberse detectado mucho antes si los desarrolladores hubieran tenido aunque sólo fuera una persona zurda en el equipo. Este sencillo ejemplo demuestra la importancia de la diversidad. La zurdera es sólo un pequeño atributo que define a un individuo. A menudo entran en juego otros muchos factores, a menudo fuera de su control. Factores como el sexo, el tono de la piel, la situación económica, la discapacidad, el país de origen, el modo de hablar o incluso algo tan trivial como la longitud del pelo pueden determinar resultados que cambien la vida de alguien, incluido el modo en que le trata un algoritmo.
El glosario de aprendizaje automático de Google enumera en varias formas de sesgo que pueden afectar a una cadena de aprendizaje automático. Las siguientes son sólo algunas de ellas:
- Sesgo de selección
-
El conjunto de datos no es representativo de la distribución del problema en el mundo real y está sesgado hacia un subconjunto de categorías. Por ejemplo, en muchos asistentes virtuales y altavoces domésticos inteligentes, algunos acentos hablados están sobrerrepresentados, mientras que otros acentos no tienen ningún dato en el conjunto de datos de entrenamiento, lo que resulta en una UX deficiente para grandes partes de la población mundial.
El sesgo de selección también puede producirse por la co-ocurrencia de conceptos. Por ejemplo, Google Translate, cuando se utiliza para traducir las frases "Ella es médico. Él es enfermero" a una lengua de género neutro como el turco y luego de vuelta, cambia los géneros, como se muestra en la Figura 1-12. Es probable que esto se deba a que el conjunto de datos contiene una gran muestra de co-ocurrencias de pronombres masculinos y la palabra "médico", y de pronombres femeninos y la palabra "enfermera".
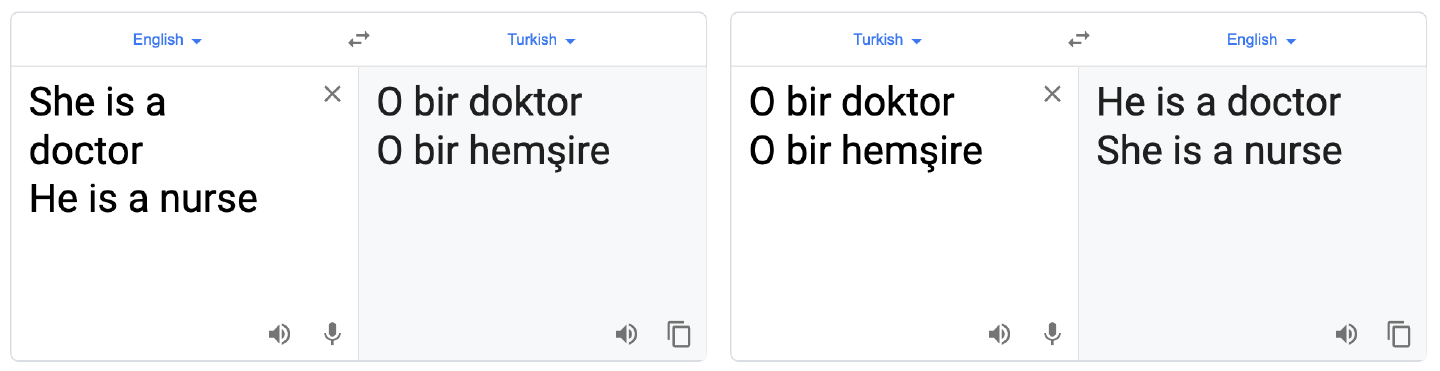
Figura 1-12. Google Translate refleja el sesgo subyacente en los datos (a septiembre de 2019)
- Prejuicios implícitos
-
Este tipo de sesgo se cuela debido a suposiciones implícitas que todos hacemos cuando vemos algo. Considera la parte resaltada de la Figura 1-13. Cualquiera que la vea podría suponer con un alto grado de certeza que esas rayas pertenecen a una cebra. De hecho, dado lo sesgadas que están las redes entrenadas en ImageNet hacia las texturas2 la mayoría de ellas clasificará la imagen completa como una cebra. Excepto que sabemos que la imagen es de un sofá tapizado con una tela parecida a la de una cebra.

Figura 1-13. Sofá cebra de Glen Edelson(fuente de la imagen)
- Sesgo de información
-
A veces las voces más altas de la sala son las más extremistas y dominan la conversación. Un buen vistazo a Twitter puede hacer que parezca que el mundo se acaba, mientras que la mayoría de la gente está ocupada llevando vidas mundanas. Por desgracia, lo aburrido no vende.
- Prejuicios dentro/fuera del grupo
-
Un anotador de de Asia Oriental podría ver una foto de la Estatua de la Libertad y asignarle etiquetas como "América" o "Estados Unidos", mientras que alguien de EE.UU. podría ver la misma foto y asignarle etiquetas más granulares como "Nueva York" o "Isla de la Libertad". Es propio de la naturaleza humana ver a los propios grupos con matices mientras se ve a otros grupos como más homogéneos, y eso también se refleja en nuestros conjuntos de datos.
Responsabilidad y explicabilidad
Imagina que, a finales del siglo XIX, el Sr. Karl Benz te dijera que había inventado este aparato de cuatro ruedas que podía transportarte más rápido que cualquier otra cosa existente. Pero no tenía ni idea de cómo funcionaba. Lo único que sabía era que consumía un líquido altamente inflamable que explotaba varias veces en su interior para propulsarlo hacia delante. ¿Qué hacía que se moviera? ¿Qué hacía que se detuviera? ¿Qué le impedía quemar a la persona sentada en su interior? No tenía respuestas. Si ésta era la historia del origen del coche, probablemente no querrías subirte a ese cacharro.
Esto es precisamente lo que está ocurriendo ahora con la IA. Antes, con el aprendizaje automático tradicional, los científicos de datos tenían que seleccionar manualmente características (variables predictivas) de los datos, a partir de las cuales un modelo de aprendizaje automático aprendería después. Este proceso de selección manual, aunque engorroso y restrictivo, les daba más control y comprensión de cómo se producía la predicción. Sin embargo, con el aprendizaje profundo, estas características se seleccionan automáticamente. Los científicos de datos son capaces de construir modelos proporcionando montones de datos, y estos modelos, de alguna manera, acaban haciendo predicciones fiables, la mayoría de las veces. Pero el científico de datos no sabe exactamente cómo funciona el modelo, qué características ha aprendido, en qué circunstancias funciona el modelo y, lo que es más importante, en qué circunstancias no funciona. Este enfoque puede ser aceptable cuando Netflix nos recomienda programas de TV basándose en lo que ya hemos visto (aunque estamos bastante seguros de que tienen la línea recommendations.append("Stranger Things") en su código en alguna parte). Pero hoy en día la IA hace mucho más que recomendar películas. La policía y los sistemas judiciales están empezando a confiar en los algoritmos para decidir si alguien supone un riesgo para la sociedad y si debe ser detenido antes de su juicio. Están en juego las vidas y libertades de muchas personas. Sencillamente, no debemos externalizar la toma de decisiones importantes a una caja negra que no rinde cuentas. Afortunadamente, hay un impulso para cambiar eso con inversiones en IA explicable, en la que el modelo sería capaz no sólo de proporcionar predicciones, sino también de dar cuenta de los factores que le llevaron a hacer una determinada predicción, y revelar las áreas de limitaciones.
Además, las ciudades (como Nueva York) están empezando a hacer que sus algoritmos rindan cuentas al público reconociendo que éste tiene derecho a saber qué algoritmos utilizan para la toma de decisiones vitales y cómo funcionan, permitiendo revisiones y auditorías por parte de expertos, mejorando los conocimientos de los organismos gubernamentales para evaluar mejor cada sistema que añaden, y proporcionando mecanismos para impugnar una decisión tomada por un algoritmo.
Reproducibilidad
La investigación realizada en el campo científico sólo consigue una amplia aceptación por parte de la comunidad cuando es reproducible; es decir, cualquier persona que estudie la investigación debe poder reproducir las condiciones de la prueba y obtener los mismos resultados. A menos que podamos reproducir los resultados anteriores de un modelo, no podremos responsabilizarlo cuando lo utilicemos en el futuro. En ausencia de reproducibilidad, la investigación es vulnerable al p-hacking: modificarlos parámetros de un experimento hasta obtener los resultados deseados. Es vital que los investigadores documenten exhaustivamente sus condiciones experimentales, incluidos los conjuntos de datos, los puntos de referencia y los algoritmos, y que declaren la hipótesis que van a probar antes de realizar un experimento. La confianza en las instituciones está bajo mínimos, y la investigación que no se basa en la realidad, aunque sea sensacionalista por parte de los medios de comunicación, puede erosionar aún más esa confianza. Tradicionalmente, reproducir un trabajo de investigación se consideraba un arte oscuro porque se omiten muchos detalles de la aplicación. La buena noticia es que los investigadores están empezando gradualmente a utilizar puntos de referencia públicos (en lugar de sus conjuntos de datos privados) y a abrir el código que utilizaron para su investigación. Los miembros de la comunidad pueden apoyarse en este código, demostrar que funciona y mejorarlo, lo que conduce rápidamente a nuevas innovaciones.
Robustez
Hay toda un área de investigación en sobre los ataques de un solo píxel a las CNN. Esencialmente, el objetivo es encontrar y modificar un solo píxel de una imagen para hacer que una CNN prediga algo totalmente distinto. Por ejemplo, cambiar un solo píxel en una imagen de una manzana puede hacer que una CNN la clasifique como un perro. Hay muchos otros factores que pueden influir en las predicciones, como el ruido, las condiciones de iluminación, el ángulo de la cámara y otros que no habrían afectado a la capacidad de un humano para hacer una predicción similar. Esto es especialmente relevante para los coches autoconducidos, donde sería posible que un mal actor en una calle modificara la información que ve el coche para manipularlo y hacer que haga cosas malas. De hecho, el Keen Security Lab de Tencent fue capaz de explotar una vulnerabilidad en el Piloto Automático de Tesla colocando estratégicamente pequeñas pegatinas en la carretera, lo que le llevó a cambiar de carril y conducir hacia el carril contrario. Es necesaria una IA robusta que sea capaz de resistir el ruido, las ligeras desviaciones y la manipulación intencionada, si queremos poder confiar en ella.
Privacidad
En, en su afán por construir una IA cada vez mejor, las empresas necesitan recopilar muchos datos. Por desgracia, a veces se extralimitan y recopilan información con exceso de celo, más allá de lo necesario para la tarea que tienen entre manos. Una empresa puede creer que utiliza los datos que recopila sólo para el bien. Pero, ¿y si es adquirida por una empresa que no tiene los mismos límites éticos para el uso de los datos? La información del consumidor podría utilizarse para fines ajenos a los inicialmente previstos. Además, todos esos datos recogidos en un solo lugar los convierten en un objetivo atractivo para los piratas informáticos, que roban información personal y la venden en el mercado negro a empresas delictivas. Además, los gobiernos ya se están extralimitando en su intento de rastrear a todos y cada uno de los individuos.
Todo esto va en contra del derecho humano universalmente reconocido a la privacidad. Lo que los consumidores desean es tener transparencia sobre qué datos se recopilan sobre ellos, quién tiene acceso a ellos, cómo se utilizan, y mecanismos para optar por no participar en el proceso de recopilación de datos, así como para eliminar los datos que ya se recopilaron sobre ellos.
Como desarrolladores, queremos ser conscientes de todos los datos que estamos recopilando, y preguntarnos si es necesario recopilar un dato en primer lugar. Para minimizar los datos que recopilamos, podríamos aplicar técnicas de aprendizaje automático respetuosas con la privacidad, como el Aprendizaje Federado (utilizado en el Teclado de Google), que nos permiten entrenar redes en los dispositivos de los usuarios sin tener que enviar ninguna Información Personal Identificable (IPI) a un servidor.
Resulta que, en muchos de los titulares mencionados al principio de esta sección, fueron las consecuencias de las malas relaciones públicas las que sensibilizaron a la opinión pública sobre estos temas, introdujeron la rendición de cuentas y provocaron un cambio de mentalidad en toda la industria para evitar que se repitieran en el futuro. Debemos seguir responsabilizándonos a nosotros mismos, a los académicos, a los líderes del sector y a los políticos de cada paso en falso y actuar con rapidez para corregir los errores. Cada decisión que tomamos y cada acción que emprendemos puede sentar un precedente para las próximas décadas. A medida que la IA se hace omnipresente, tenemos que unirnos para plantear las preguntas difíciles y encontrarles respuesta, si queremos minimizar los daños potenciales al tiempo que cosechamos los máximos beneficios.
Resumen
Este capítulo ha explorado el panorama del apasionante mundo de la IA y el aprendizaje profundo. Hemos trazado la línea de tiempo de la IA desde sus humildes orígenes, los periodos de grandes promesas, pasando por los oscuros inviernos de la IA, hasta su resurgimiento actual. Por el camino, respondimos a la pregunta de por qué esta vez es diferente. A continuación, examinamos los ingredientes necesarios para construir una solución de aprendizaje profundo, incluidos conjuntos de datos, arquitecturas de modelos, marcos y hardware. Esto nos prepara para seguir explorando en los próximos capítulos. Esperamos que disfrutes del resto del libro. ¡Es hora de profundizar!
Preguntas frecuentes
-
Sólo estoy empezando. ¿Necesito gastarme mucho dinero en comprar un hardware potente?
Por suerte para ti, puedes empezar incluso con tu navegador web. Todos nuestros scripts están disponibles online, y pueden ejecutarse en GPUs gratuitas por cortesía de la amable gente de Google Colab(Figura 1-14), que generosamente pone a tu disposición potentes GPUs de forma gratuita (hasta 12 horas cada vez). Esto debería servirte para empezar. A medida que vayas mejorando realizando más experimentos (especialmente a nivel profesional o con grandes conjuntos de datos), puede que quieras conseguir una GPU, ya sea alquilando una en la nube (Microsoft Azure, Amazon Web Services (AWS), Google Cloud Platform (GCP) y otros) o comprando el hardware. Eso sí, ¡cuidado con las facturas de electricidad!
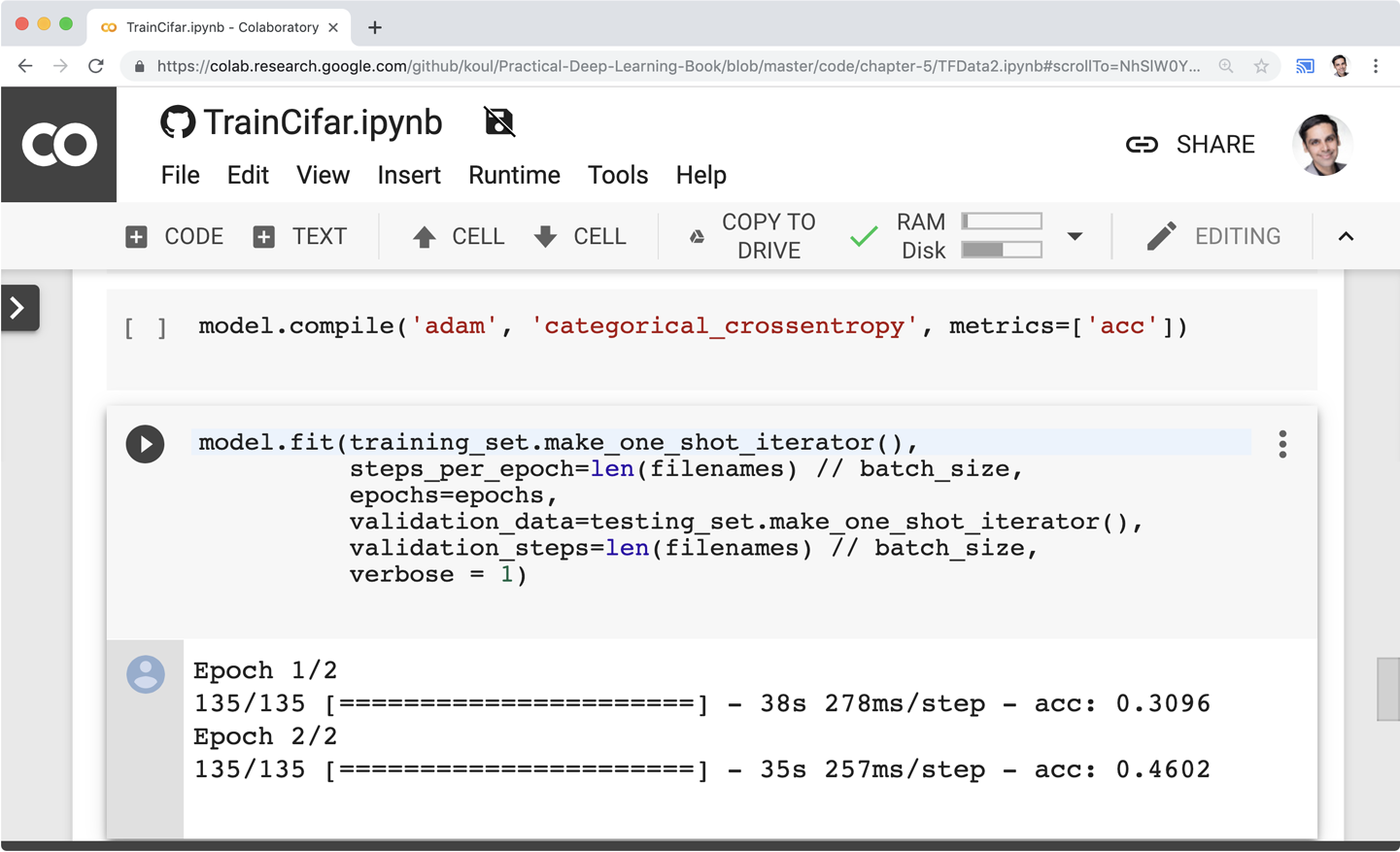
Figura 1-14. Captura de pantalla de un cuaderno en GitHub ejecutándose en Colab dentro de Chrome
-
Colab está muy bien, pero ya tengo un ordenador potente que compré para jugar a <insert name of video game>. ¿Cómo debo configurar mi entorno?
La configuración ideal implica Linux, pero Windows y macOS también funcionan. Para la mayoría de los capítulos, necesitas lo siguiente:
-
Python 3 y PIP
-
tensorflowotensorflow-gpuPaquete PIP (versión 2 o superior) -
Almohada
Nos gusta mantener las cosas limpias y autocontenidas, por lo que recomendamos utilizar entornos virtuales de Python. Debes utilizar el entorno virtual siempre que instales un paquete o ejecutes un script o un bloc de notas.
Si no tienes GPU, ya has terminado con la configuración.
Si tienes una GPU NVIDIA, querrás instalar los controladores apropiados, luego CUDA, luego cuDNN, luego el paquete
tensorflow-gpu. Si utilizas Ubuntu, hay una solución más fácil que instalar estos paquetes manualmente, lo que puede ser tedioso y propenso a errores incluso para los mejores de nosotros: simplemente instala todo el entorno con una sola línea utilizando Lambda Stack.Alternativamente, puedes instalar todos tus paquetes utilizando la Distribución Anaconda, que funciona igual de bien para Windows, Mac y Linux.
-
-
¿Dónde encontraré el código utilizado en este libro?
Encontrarás ejemplos listos para ejecutar en http://PracticalDeepLearning.ai.
-
¿Cuáles son los requisitos mínimos para poder leer este libro?
Un doctorado en áreas como el Cálculo, el Análisis Estadístico, los Autocodificadores Variacionales, la Investigación Operativa, etc... no son en absoluto necesarios para poder leer este libro (te habíamos puesto un poco nervioso, ¿verdad?). Algunos conocimientos básicos de programación, familiaridad con Python, una buena dosis de curiosidad y sentido del humor te ayudarán mucho en el proceso de asimilación del material. Aunque un conocimiento a nivel de principiante del desarrollo móvil (con Swift y/o Kotlin) será de ayuda, hemos diseñado los ejemplos para que sean autosuficientes y lo suficientemente fáciles de implementar por alguien que nunca antes haya escrito una aplicación móvil.
-
¿Qué marcos utilizaremos?
Keras + TensorFlow para el entrenamiento. Y capítulo a capítulo, exploramos diferentes marcos de inferencia.
-
¿Seré un experto cuando termine este libro?
Si lo sigues, tendrás los conocimientos sobre una gran variedad de temas, desde el entrenamiento a la inferencia, pasando por la maximización del rendimiento. Aunque este libro se centra principalmente en la visión por ordenador, puedes aplicar los mismos conocimientos a otras áreas, como el texto, el audio, etc., y ponerte al día muy rápidamente.
-
¿Quién es el gato del capítulo anterior?
Es el gato de Meher, Vader. Hará múltiples cameos a lo largo del libro. Y no te preocupes, ya ha firmado un formulario de cesión de modelo.
-
¿Puedo ponerme en contacto contigo?
Claro. Envíanos un correo electrónico a PracticalDLBook@gmail.com con cualquier pregunta, corrección o lo que sea, o tuitéanos a @PracticalDLBook.
1 Si estás leyendo una copia pirata, considérate decepcionado.
Get Aprendizaje Profundo Práctico para Nube, Móvil y Edge now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

