Capítulo 4. Almacenamiento de datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Dónde almacenas los datos para tu aplicación es una parte crítica de tu infraestructura de análisis de datos. Puede variar desde una preocupación trivial, en la que simplemente utilizas los sistemas de almacenamiento nativos de GA4, hasta flujos de datos complejos en los que estás ingiriendo múltiples fuentes de datos, incluyendo GA4, tu base de datos CRM, otros datos de costes de canales de marketing digital, y más. Aquí, BigQuery como base de datos analítica de elección en GCP realmente domina porque se ha construido para abordar exactamente el tipo de problemas que surgen cuando se considera trabajar con datos desde una perspectiva analítica, que es exactamente la razón por la que GA4 la ofrece como opción para exportar. En general, la filosofía consiste en reunir todos tus datos en una ubicación en la que puedas ejecutar consultas analíticas sobre ellos con facilidad y ponerlos a disposición de las personas o aplicaciones que los necesiten de una forma democrática pero consciente de la seguridad.
Este capítulo repasará las distintas decisiones y estrategias que he aprendido a tener en cuenta al tratar con sistemas de almacenamiento de datos. Quiero que te beneficies de mis errores para que puedas evitarlos y establecer una base sólida para cualquiera de tus casos de uso.
Este capítulo es el pegamento entre las partes de recopilación de datos y modelado de datos de tus proyectos de análisis de datos. Tus datos GA4 deben fluir según los principios expuestos en el Capítulo 3, y trabajarás con ellos con las herramientas y técnicas descritas en este capítulo con la intención de utilizar los métodos descritos en los Capítulos 5 y 6, todo ello guiado por los casos de uso que el Capítulo 2 te ayudó a definir.
Empezaremos con algunos de los principios generales que debes tener en cuenta al estudiar tu solución de almacenamiento de datos, y luego repasaremos algunas de las opciones más populares de GCP y las que yo utilizo a diario.
Principios de los datos
Esta sección repasará algunas directrices generales para guiarte en cualquiera de las opciones de almacenamiento de datos que utilices. Hablamos de cómo ordenar y mantener tus datos en un alto nivel, cómo adaptar tus conjuntos de datos a las diferentes funciones que pueda necesitar tu empresa, y cosas en las que pensar al vincular conjuntos de datos.
Datos ordenados
Datos ordenados es un concepto que me presentó dentro de la comunidad R y es una idea tan buena que todos los profesionales de los datos pueden beneficiarse de seguir sus principios. Los datos ordenados son una descripción opinada de cómo deberías almacenar tus datos para que sean lo más útiles posible para los flujos de datos posteriores. Pretende darte unos parámetros fijos sobre cómo deberías almacenar tus datos, de modo que tengas una base común para todos tus proyectos de datos.
El concepto de datos ordenados fue desarrollado por Hadley Wickham, Científico de Datos en RStudio e inventor del concepto de "tidyverse". Consulta el libro R for Data Science: Import, Tidy, Transform, Visualize, and Model Data de Garrett Grolemund y Hadley Wickham (O'Reilly) para una buena base sobre la aplicación de sus principios, o visita el sitio web del tidyverse.
Aunque los datos ordenados se hicieron populares primero en la comunidad de ciencia de datos de R, incluso si no utilizas R te recomiendo que pienses en ello como un primer objetivo en tu procesamiento de datos. Esto se resume en una cita del libro de Wickham y Grolemund:
Las familias felices son todas iguales; cada familia infeliz es infeliz a su manera.León Tolstoi
Los conjuntos de datos ordenados son todos iguales, pero cada conjunto de datos desordenado es desordenado a su manera.Hadley Wickham
La idea fundamental es que hay una forma de convertir tus datos brutos en una norma universal que te será útil para el análisis de datos más adelante, y si aplicas esto a tus datos, no necesitarás reinventar la rueda cada vez que quieras procesar tus datos.
Hay tres reglas que, si las sigues, harán que tu conjunto de datos esté ordenado:
-
Cada variable debe tener su propia columna.
-
Cada observación debe tener su propia fila.
-
Cada valor debe tener su propia celda.
Puedes ver estas reglas ilustradas en la Figura 4-1.
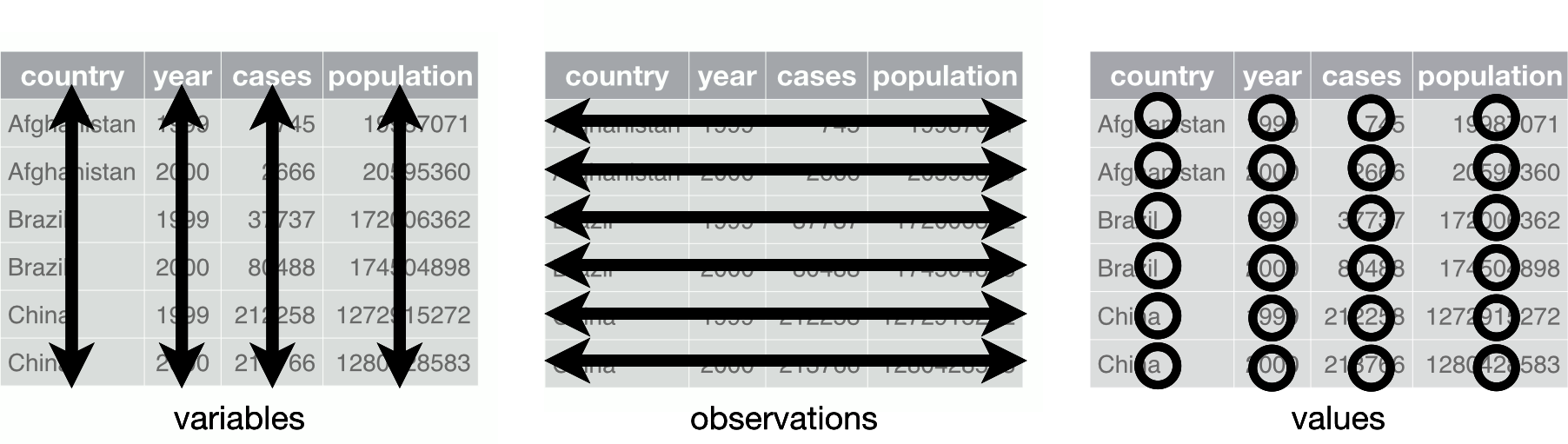
Figura 4-1. Seguir tres reglas hace que un conjunto de datos esté ordenado: las variables están en columnas, las observaciones en filas y los valores en celdas (deR for Data Science por Wickham y Grolemund).
Dado que la limpieza de datos suele ser la parte que más tiempo consume de un proyecto, esto libera mucha capacidad mental para trabajar en los problemas específicos de tu caso de uso sin tener que preocuparte por la forma en que están tus datos cada vez que empiezas. Te recomiendo que, después de importar tus datos brutos, hagas todo lo posible por crear versiones ordenadas de esos datos, que son las que expones a los casos de uso posteriores. El estándar de datos ordenados te ayuda a eliminar el trabajo mental de pensar en la forma que deben tener tus datos cada vez y permite que tus aplicaciones de datos posteriores se estandaricen, ya que pueden esperar que los datos siempre vengan de una forma determinada.
Esa es la teoría, así que veamos cómo funciona en la práctica en la siguiente sección.
Ejemplo de ordenación de datos GA4
A continuación presentamos un ejemplo de flujo de trabajo en el que empezamos con datos GA4 desordenados y los limpiamos para que estén listos para el análisis posterior. Estamos utilizando R para la limpieza, pero los mismos principios pueden aplicarse a cualquier lenguaje o herramienta, como Excel.
Empecemos con algunos datos de GA4. El Ejemplo 4-1 muestra un script de R que exportará algunos datos de CustomEvent de mi blog. Estos datos incluyen la categoría en la que he puesto cada entrada del blog, como "Google Analytics" o "BigQuery". Estos datos personalizados están disponibles en un customEvent llamado category.
Ejemplo 4-1. Script de R para extraer la dimensión personalizada category de la API de datos GA4
library(googleAnalyticsR)# authenticate with a user with accessga_auth()# if you have forgotten your propertyIDga4s<-ga_account_list("ga4")# my blog propertyId - change for your owngaid<-206670707# import your custom fieldsmeta<-ga_meta("data",propertyId=gaid)# date range of when the field was implemented to todaydate_range<-c("2021-07-01",as.character(Sys.Date()))# filter out any data that doesn't have a categoryinvalid_category<-ga_data_filter(!"customEvent:category"==c("(not set)","null"))# API call to see trend of custom field: article_readarticle_reads<-ga_data(gaid,metrics="eventCount",date_range=date_range,dimensions=c("date","customEvent:category"),orderBys=ga_data_order(+date),dim_filters=invalid_category,limit=-1)
La parte superior del contenido de article_reads se muestra en la Tabla 4-1.
Puedes ver que la calidad de la recogida de datos repercute en el tratamiento posterior de los datos: por ejemplo, la categoría de artículo podría haberse dividido en sus propios eventos para que los datos fueran más limpios. No son datos "ordenados". Tendremos que limpiar los datos para que sean adecuados para el modelado: esto es muy habitual. También destaca cómo la captura de datos limpios puede reducir el trabajo posterior.
| fecha | evento personalizado:categoría | recuentoEventos |
|---|---|---|
2021-07-01 |
GOOGLE-TAG-MANAGER - FUNCIONES EN LA NUBE |
13 |
2021-07-01 |
GOOGLE-TAG-MANAGER - GOOGLE-ANALYTICS |
12 |
2021-07-01 |
R - GOOGLE-APP-ENGINE - DOCKER - GOOGLE-ANALYTICS - GOOGLE-COMPUTE-ENGINE - RSTUDIO-SERVER |
9 |
2021-07-01 |
R - CLOUD-RUN - GOOGLE-TAG-MANAGER - BIG-QUERY |
8 |
2021-07-01 |
R - DOCKER - CLOUD-RUN |
8 |
2021-07-01 |
GOOGLE-TAG-MANAGER - DOCKER - CLOUD-RUN |
7 |
2021-07-01 |
R - GOOGLE-ANALYTICS - CONSOLA DE BÚSQUEDA |
7 |
2021-07-01 |
R - DOCKER - RSTUDIO-SERVER - GOOGLE-COMPUTE-ENGINE |
6 |
2021-07-01 |
ESTIBADOR - R |
5 |
2021-07-01 |
R - FIREBASE - GOOGLE-AUTH - FUNCIONES EN LA NUBE - PYTHON |
5 |
2021-07-01 |
R - GOOGLE-AUTH - BIG-QUERY - GOOGLE-ANALYTICS - GOOGLE-CLOUD-STORAGE - GOOGLE-COMPUTE-ENGINE - GOOG |
4 |
2021-07-01 |
GOOGLE-CLOUD-STORAGE - PYTHON - GOOGLE-ANALYTICS - CLOUD-FUNCTIONS |
3 |
2021-07-01 |
R - GOOGLE-ANALYTICS |
3 |
2021-07-01 |
BIG-QUERY - PYTHON - GOOGLE-ANALYTICS - FUNCIONES EN LA NUBE |
2 |
2021-07-01 |
DOCKER - R - GOOGLE-COMPUTE-ENGINE - CLOUD-RUN |
2 |
2021-07-01 |
R - GOOGLE-AUTH |
2 |
2021-07-01 |
docker - R |
2 |
2021-07-02 |
R - CLOUD-RUN - GOOGLE-TAG-MANAGER - BIG-QUERY |
9 |
2021-07-02 |
ESTIBADOR - R |
8 |
2021-07-02 |
GOOGLE-TAG-MANAGER - DOCKER - CLOUD-RUN |
8 |
2021-07-02 |
GOOGLE-TAG-MANAGER - GOOGLE-ANALYTICS |
8 |
2021-07-02 |
R - DOCKER - CLOUD-RUN |
6 |
2021-07-02 |
R - GOOGLE-APP-ENGINE - DOCKER - GOOGLE-ANALYTICS - GOOGLE-COMPUTE-ENGINE - RSTUDIO-SERVER |
6 |
Como se detalla en "Datos ordenados", estos datos aún no están en una forma ordenada lista para el análisis, por lo que aprovecharemos algunas de las bibliotecas tidyverse de R para ayudar a limpiarlos, concretamente tidyr y dplyr.
El primer trabajo es renombrar los nombres de las columnas y separar las cadenas de categorías para que tengamos una por columna. También hacemos que todo esté en minúsculas. Mira en el Ejemplo 4-2 cómo hacerlo utilizando el tidyverse, dado el data.frame article_reads de la Tabla 4-1.
Ejemplo 4-2. Ordenar los datos brutos de article_reads utilizando tidy y dplyr para que tengan un aspecto similar al de la Tabla 4-2.
library(tidyr)library(dplyr)clean_cats<-article_reads|># rename data columnsrename(category="customEvent:category",reads="eventCount")|># lowercase all category valuesmutate(category=tolower(category))|># separate the single category column into sixseparate(category,into=paste0("category_",1:6),sep="[^[:alnum:]-]+",fill="right",extra="drop")
Ahora los datos tienen el aspecto de la Tabla 4-2. Sin embargo, aún no hemos llegado alformato ordenado.
| fecha | categoría_1 | categoría_2 | categoría_3 | categoría_4 | categoría_5 | categoría_6 | lee |
|---|---|---|---|---|---|---|---|
2021-07-01 |
google-tag-manager |
funciones en la nube |
NA |
NA |
NA |
NA |
13 |
2021-07-01 |
google-tag-manager |
google-analytics |
NA |
NA |
NA |
NA |
12 |
2021-07-01 |
r |
motor google-app |
docker |
google-analytics |
motor-ordenador-de-google |
rstudio-server |
9 |
2021-07-01 |
r |
cloud-run |
google-tag-manager |
big-query |
NA |
NA |
8 |
2021-07-01 |
r |
docker |
cloud-run |
NA |
NA |
NA |
8 |
2021-07-01 |
google-tag-manager |
docker |
cloud-run |
NA |
NA |
NA |
7 |
Nos gustaría agregar los datos para que cada fila sea una única observación: el número de lecturas por categoría y día. Para ello, pivotamos los datos en un formato "largo" frente al formato "ancho" que tenemos ahora. Una vez que los datos están en ese formato más largo, la agregación se realiza sobre las columnas de fecha y categoría (de forma muy parecida a la de SQL GROUP BY) para obtener la suma de lecturas por categoría. Mira el Ejemplo 4-3.
Ejemplo 4-3. Transformación de los datos anchos en largos y agregación por fecha/categoría
library(dplyr)library(tidyr)agg_cats<-clean_cats|># turn wide data into longpivot_longer(cols=starts_with("category_"),values_to="categories",values_drop_na=TRUE)|># group over dimensions we wish to aggregate overgroup_by(date,categories)|># create a category_reads metric: the sum of readssummarize(category_reads=sum(reads),.groups="drop_last")|># order by date and reads, descendingarrange(date,desc(category_reads))
Nota
Los ejemplos de R de este libro suponen R v4.1, que incluye el operador de tubería |>. En las versiones de R anteriores a la 4.1, verás el operador de tubería importado de su propio paquete, magrittr, y tendrá el aspecto de %>%. Pueden intercambiarse sin problemas para estos ejemplos.
Una vez ordenados los datos, deberíamos ver una tabla similar a la Tabla 4-3. Éste es un conjunto de datos ordenado con el que cualquier científico o analista de datos debería estar contento de trabajar y el punto de partida de la fase de exploración del modelo.
| fecha | categorías | categoría_lecturas |
|---|---|---|
2021-07-01 |
r |
66 |
2021-07-01 |
google-tag-manager |
42 |
2021-07-01 |
docker |
41 |
2021-07-01 |
google-analytics |
41 |
2021-07-01 |
cloud-run |
25 |
2021-07-01 |
funciones en la nube |
23 |
Los ejemplos que se dan en los libros siempre parecen idealizados, y creo que rara vez reflejan el trabajo que tendrás que hacer habitualmente, probablemente muchas iteraciones de experimentación, corrección de errores y regex. Aunque se trata de un ejemplo minificado, todavía me costó algunos intentos conseguir exactamente lo que buscaba en los ejemplos anteriores. Sin embargo, esto es más fácil de manejar si tienes en mente el principio de los datos ordenados: te da algo a lo que aspirar que probablemente te evitará tener que rehacerlo más tarde.
Mi primer paso después de recopilar datos brutos es ver cómo darles forma para convertirlos en datos ordenados como los de nuestro ejemplo. Pero aunque los datos estén ordenados, también tendrás que considerar la función de esos datos, que es lo que tratamos en la siguiente sección.
Conjuntos de datos para diferentes funciones
Los datos brutos que llegan rara vez están en un estado que deba utilizarse para producción o incluso exponerse a usuarios finales internos. A medida que aumente el número de usuarios, habrá más motivos para preparar conjuntos de datos ordenados para esos fines, pero debes mantener una "fuente de verdad" para que siempre puedas retroceder para ver cómo se crearon los conjuntos de datos más derivados.
Aquí puede que tengas que empezar a pensar en tu gobernanza de datos, que es el proceso de tratar de determinar quién y qué accede a los distintos tipos de datos.
Aquí se sugieren algunas funciones diferentes:
- Datos brutos
-
Es una buena idea mantener tus flujos de datos brutos juntos y sin tocar, de modo que siempre tengas la opción de reconstruirlos si algo va mal aguas abajo. En el caso de GA4, será la exportación de datos BigQuery. Por lo general, no se recomienda modificar estos datos mediante adiciones o sustracciones, a menos que tengas obligaciones legales, como solicitudes de eliminación de datos personales. Tampoco se recomienda exponer este conjunto de datos a los usuarios finales a menos que lo necesiten, ya que suele ser bastante difícil trabajar con los conjuntos de datos sin procesar. Por ejemplo, la exportación GA4 está en una estructura anidada que tiene una curva de aprendizaje difícil para cualquiera que no tenga experiencia en BigQuery SQL. Esto es lamentable porque para algunas personas es su primera experiencia con la ingeniería de datos, y salen pensando que es mucho más difícil de lo que es que si, por ejemplo, estuvieran trabajando sólo con los conjuntos de datos planos más típicos. En cambio, tus primeros flujos de trabajo generalmente tomarán estos datos en bruto y los ordenarán, filtrarán y agregarán en algo mucho más manejable.
- Datos ordenados
-
Se trata de datos que han pasado por una primera pasada de hacerlos aptos para el consumo. Aquí puedes eliminar los puntos de datos erróneos, normalizar las convenciones de nomenclatura, realizar uniones de conjuntos de datos si resulta útil, producir tablas de agregación y facilitar el uso de los datos. Cuando buscas un buen conjunto de datos que sirva como "fuente de la verdad", entonces los conjuntos de datos ordenados son preferibles a la fuente original de datos brutos. El mantenimiento de este conjunto de datos es una tarea continua, probablemente realizada por los ingenieros de datos que lo crearon. Los usuarios de los datos posteriores sólo deben tener acceso de lectura y pueden ayudar sugiriendo tablas útiles que deban incluirse.
- Casos empresariales
-
Entre las muchas agregaciones que puedes construir a partir de los datos ordenados están los típicos casos de uso empresarial que serán la fuente de muchas de tus aplicaciones posteriores. Un ejemplo sería una fusión de tus datos de costes de tus canales de medios y tus datos de flujo web GA4, combinados con tus datos de conversión en tu CRM. Se trata de un conjunto de datos comúnmente deseado que contiene el "bucle cerrado" completo de los datos de eficacia del marketing (coste, acción y conversión). Otros casos empresariales pueden estar más centrados en las ventas o el desarrollo de productos. Si tienes suficientes datos, podrías poner conjuntos de datos a disposición de los departamentos adecuados cuando los necesiten, que serán entonces la fuente de datos para las consultas ad hoc cotidianas que pueda tener un usuario final. El usuario final probablemente accederá a sus datos con algunos conocimientos limitados de SQL o mediante una herramienta de visualización de datos como Looker, Data Studio o Tableau. Tener estos conjuntos de datos relevantes a disposición de todos en tu empresa es una buena señal de que realmente eres una "organización impulsada por los datos" (una frase a la que creo que aspiran alrededor del 90% de todos los directores generales, pero que quizás sólo el 10% realiza realmente).
- Parque infantil de pruebas
-
También necesitarás a menudo un bloc de notas para probar nuevas integraciones, uniones y desarrollos. Tener un conjunto de datos dedicado con una fecha de caducidad de los datos de 90 días, por ejemplo, significa que puedes estar seguro de que la gente puede trabajar con tus conjuntos de datos sin que tengas que perseguir datos de prueba extraviados en los usuarios o dañar los sistemas de producción.
- Aplicaciones de datos
-
Lo más probable es que cada aplicación de datos que tengas funcionando en producción sea una derivación de todas las funciones de conjunto de datos mencionadas anteriormente. Asegurarte de que tienes un conjunto de datosdedicado a tus casos de uso críticos para la empresa significa que siempre puedes saber exactamente qué datos se están utilizando y evitar que otros casos de uso interfieran con los tuyos más adelante.
Estas funciones están en un orden aproximado de flujos de datos. Es típico que las vistas o las tareas programadas estén configuradas para procesar y copiar datos en sus respectivas dependencias, y puede que las tengas en distintos proyectos de GCP para su administración.
Nota
Un gran valor al utilizar conjuntos de datos como como exportaciones de BigQuery de GA4 será vincular esos datos a tus otros datos, como se explica en "Vinculación de conjuntos de datos".
Hemos explorado algunos de los elementos que ayudarán a que sea un placer trabajar con tus conjuntos de datos para tus usuarios. Si haces realidad el sueño de unos conjuntos de datos ordenados y definidos por roles, que vinculen los datos de todos los departamentos de tu empresa de forma que los usuarios tengan todo lo que necesitan con sólo pulsar un botón (o una consulta SQL), entonces ya estarás por delante de un gran número de empresas. Como ejemplo, considera Google, que muchos considerarían el epítome de una empresa impulsada por los datos. En el libro de Lak, Data Science on the Google Cloud Platform, relata cómo el 80% de los empleados de Google utilizan datos semanalmente:
En Google, por ejemplo, casi el 80% de los empleados utilizan Dremel (Dremel es el homólogo interno de BigQuery de Google Cloud) cada mes. Algunos utilizan los datos de forma más sofisticada que otros, pero todos tocan los datos regularmente para fundamentar sus decisiones. Haz una pregunta a alguien, y es probable que recibas un enlace a una vista de consulta de BigQuery en lugar de a la respuesta real: "Ejecuta esta consulta cada vez que quieras conocer la respuesta más actualizada", se suele pensar. En este último escenario, BigQuery ha pasado de ser el sustituto de la base de datos sin funciones a ser la solución de análisis de datos de autoservicio.
La cita refleja aquello por lo que muchas empresas trabajan y desean poner a disposición de sus propios empleados, y esto tendría un gran impacto empresarial si se realizara plenamente.
En la siguiente sección, consideraremos la herramienta mencionada en la cita que lo permitió para Google: BigQuery.
BigQuery
Es una verdad de Perogrullo que todas tus necesidades de análisis de datos quedarán resueltas si utilizas BigQuery. Desde luego, ha tenido un gran impacto en mi carrera y ha hecho que la ingeniería de datos deje de ser un ejercicio frustrante de dedicar una gran cantidad de tiempo a tareas deinfraestructura y carga para poder concentrarme más en obtener valor de los datos.
Ya hemos hablado de BigQuery en "BigQuery", en la sección de ingestión de datos, en relación con las exportaciones de GA4 BigQuery ("Vinculación de GA4 con BigQuery") y la importación de archivos de Almacenamiento en la nube desde Almacenamiento en la nube para utilizarlos con las exportaciones de CRM ("Almacenamiento basado en eventos"). Esta sección trata sobre cómo organizar y trabajar con tus datos ahora que están en BigQuery.
Cuándo utilizar BigQuery
Quizá sea más fácil esbozar cuándo no utilizar BigQuery, ya que es una especie de panacea para las tareas de analítica digital en GCP. BigQuery tiene las siguientes características, que también quieres para una base de datos de analítica:
-
Almacenamiento barato o gratuito para que puedas arrojar todos tus datos sin preocuparte por los costes.
-
Escala infinita, para que no tengas que preocuparte de crear nuevas instancias de servidores para unirlas después cuando añadas incluso petabytes de datos.
-
Estructuras de costes flexibles: la opción habitual es la que aumenta sólo a medida que la utilizas más (mediante consultas), en lugar de un coste irrecuperable cada mes pagando servidores, o puedes optar por reservar ranuras para un coste irrecuperable para ahorrar costes de consulta.
-
Integraciones con el resto de tu conjunto GCP para mejorar tus datos mediante aprendizaje automático o de otro tipo.
-
Cálculos en la base de datos que abarcan funciones SQL comunes como CONTAR, MEDIAS y SUMA, hasta tareas de aprendizaje automático como agrupación y previsión, lo que significa que no necesitas exportar, modelar y luego volver a introducir los datos.
-
Funciones de ventana masivamente escalables que harían colapsar una base de datos tradicional.
-
Devolución rápida de tus resultados (minutos frente a horas en las bases de datos tradicionales), incluso al escanear miles de millones de filas.
-
Una estructura de datos flexible que te permite trabajar con puntos de datos muchos-a-uno y uno-a-muchos sin necesidad de muchas tablas separadas (la función de anidamiento de datos).
-
Fácil acceso a través de una interfaz web con un inicio de sesión seguro OAuth2.
-
Funciones de acceso de usuario detallado, desde el proyecto, el conjunto de datos y la tabla, hasta la posibilidad de dar acceso al usuario sólo a filas y columnas individuales.
-
Una potente API externa que cubre todas las funciones y que te permite tanto crear tus propias aplicaciones como elegir software de terceros que haya utilizado la misma API para crear middleware útil.
-
Integración con otras nubes como AWS y Azure para importar/exportar tus pilas de datos existentes: por ejemplo, con BigQuery Omni puedes consultar datos directamente en otros proveedores de nubes.
-
Aplicaciones de transmisión de datos para actualizaciones casi en tiempo real.
-
Capacidad para autodetectar el esquema de datos y ser algo flexible al añadir nuevos campos.
BigQuery tiene estas características porque se ha diseñado para ser la base de datos analítica definitiva, mientras que las bases de datos SQL más tradicionales se centraban en un acceso transaccional rápido por filas que sacrifica la velocidad al consultar columnas.
BigQuery fue uno de los primeros sistemas de bases de datos en la nube dedicados a la analítica, pero a partir de 2022 existen otras plataformas de bases de datos que ofrecen un rendimiento similar, como Snowflake, lo que está haciendo que el sector sea más competitivo. Esto está impulsando la innovación en BigQuery y más allá, y esto sólo puede ser algo bueno para los usuarios de cualquier plataforma. En cualquier caso, deberían aplicarse los mismos principios. Antes de entrar en los entresijos de las consultas SQL, veremos cómo se organizan los conjuntos de datos enBigQuery.
Organización del conjunto de datos
He aprendido algunos principios trabajando con conjuntos de datos BigQuery que puede ser útil transmitir aquí.
La primera consideración es ubicar tu conjunto de datos en una región que sea relevante para tus usuarios. Una de las pocas restricciones de BigQuery SQL es que no puedes unir tablas de datos entre regiones, lo que significa que tus datos basados en la UE y en EE.UU. no se fusionarán fácilmente. Por ejemplo, si trabajas desde la UE, esto suele significar que tienes que especificar la región de la UE al crear conjuntos de datos.
Consejo
Por defecto, BigQuery asume que quieres tus datos en EEUU. Se recomienda que especifiques siempre la región al crear tu conjunto de datos, para que estés seguro de dónde se encuentra y no tengas que realizar más tarde una transferencia de región para todos tus datos. Esto es especialmente relevante para cuestiones de cumplimiento de la privacidad.
Una buena estructura de nombres para tus conjuntos de datos también es útil para que los usuarios puedan encontrar rápidamente los datos que buscan. Por ejemplo, especifica siempre la fuente y la función de ese conjunto de datos, en lugar de limitarte a los ID numéricos: ga4_tidy en lugar de GA4 MeasurementId G-1234567.
Además, no tengas miedo de poner datos en otros proyectos de GCP si tiene sentido desde el punto de vista organizativo: BigQuery SQL funciona en todos los proyectos, de modo que un usuario que tenga acceso a ambos proyectos podrá consultarlos (si ambas tablas están en la misma región). Unaaplicación común de esto es tener proyectos de desarrollo, preparación y producción. A continuación se sugiere una categorización de tus conjuntos de datos BigQuery, los temas principales de este libro:
- Conjuntos de datos brutos
-
Conjuntos de datos que son el primer destino de API o servicios externos.
- Conjuntos de datos ordenados
-
Conjuntos de datos que se ordenan y quizás se realizan agregaciones o uniones para llegar a un estado base útil que otras tablas derivadas utilizarán como "fuente de verdad".
- Modelización de conjuntos de datos
-
Los conjuntos de datos que cubren los resultados del modelo que normalmente tendrán como fuente los conjuntos de datos ordenados y pueden ser tablas intermedias para las tablas de activación posteriores.
- Conjuntos de datos de activación
-
Conjuntos de datos que llevan las Vistas y tablas limpias creadas para cualquier trabajo de activación, como cuadros de mando, puntos finales de API o exportaciones de proveedores externos.
- Conjuntos de datos de prueba/desarrollo
-
Suelo crear un conjunto de datos con un tiempo de caducidad de los datos fijado en 90 días para el trabajo de desarrollo, dando a los usuarios un bloc de notas para hacer tablas sin saturar los conjuntos de datos más preparados para la producción.
Con una buena estructura de nombres de conjuntos de datos, estás aprovechando la oportunidad de añadir metadatos útiles a tus tablas BigQuery que permitirán al resto de tu organización encontrar lo que buscan de forma rápida y sencilla, reducir los costes de formación y permitir una mayor autogestión de tus analistas de datos.
Hasta ahora hemos tratado la organización de los conjuntos de datos, pero ahora pasamos a las especificaciones técnicas de las tablas que contienen esos conjuntos de datos.
Consejos para la mesa
Esta sección cubre algunas lecciones que he aprendido al trabajar con tablas dentro de BigQuery. Abarca estrategias para facilitar el trabajo de carga, consulta y extracción de datos. Seguir estos consejos cuando trabajes con tus datos te preparará para el futuro:
- Particionar y agrupar cuando sea posible
-
Si te enfrentas a actualizaciones periódicas de datos, es preferible utilizar tablas particionadas, que separan tus datos en tablas diarias (u horarias, mensuales, anuales, etc.). Así podrás consultar fácilmente todos tus datos, pero seguirás teniendo rendimiento para limitar las tablas a determinados intervalos de tiempo cuando sea necesario. La agrupación es otra función relacionada de BigQuery que te permite organizar los datos para que puedas consultarlos más rápidamente; puedes configurarla al importar tus datos. Puedes leer más sobre ambas y cómo afectan a tus datos en la "Introducción a las Tablas Particionadas" de Google .
- Truncar, no añadir
-
Al importar datos, intento evitar el modelo
APPENDde añadir datos al conjunto de datos, favoreciendo una estrategiaWRITE_TRUNCATEmás sin estado (por ejemplo, sobrescribir). Esto permite volver a ejecutar sin necesidad de borrar antes ningún dato, por ejemplo, un flujo de trabajo idempotente sin estado. Esto funciona mejor con tablas fragmentadas o particionadas. Puede que no sea posible si estás importando cantidades muy grandes de datos y es demasiado costoso crear una recarga completa. - Plano por defecto, pero anidado para mejorar el rendimiento
-
Cuando entregues tablas a usuarios de SQL con menos experiencia, una tabla plana les resultará mucho más fácil de trabajar que la estructura anidada que permite BigQuery. Una tabla plana puede ser mucho más grande que una tabla anidada sin procesar, pero de todos modos deberías agregar y filtrar para ayudar a reducir el volumen de datos. Las tablas anidadas, sin embargo, son una buena forma de asegurarte de que no tienes demasiadas uniones entre datos. Una buena regla general es que si siempre estás uniendo tu conjunto de datos con otro, entonces tal vez esos datos estarían mejor conformados en una estructura anidada. Estas tablas anidadas son más comunes en los conjuntos de datos brutos.
Poner en práctica estos consejos significa que, cuando tengas que volver a ejecutar una importación, no tendrás que preocuparte de duplicar datos. El día incorrecto se borrará y los nuevos datos frescos estarán en su lugar, pero sólo para esa partición, de modo que puedas evitar tener que volver a importar todo tu conjunto de datos para estar seguro de tu fuente de verdad.
Costes de SELECT *
Llegaría incluso a tener una regla general para no utilizar nunca SELECT* en tus tablas de producción, ya que puede acumular rápidamente muchos costes. Esto es aún más pronunciado si lo utilizas para crear una vista que se consulta mucho. Dado que los costes de BigQuery están más relacionados con el número de columnas que con el número de filas incluidas en la consulta, SELECT* seleccionará todas las columnas y costará más. Además, ten cuidado al anidar columnas, ya que esto también puede aumentar el volumen de datos por el que se te cobra.
Hay muchos ejemplos de SQL a lo largo del libro que tratan casos de uso específicos, por lo que esta sección se ha centrado más en la especificación de las tablas sobre las que operará SQL. Los principios generales deberían ayudarte a mantener un funcionamiento limpio y eficiente de tus datos BigQuery que, una vez adoptado, se convertirá en una herramienta popular dentro de tu organización.
Aunque BigQuery puede tratar datos en flujo, a veces los datos basados en eventos necesitan una herramienta más específica, que es cuando Pub/Sub entra en escena.
Pub/Sub
Pub/Sub forma parte integral de cómo se producen muchas importaciones de datos. Pub/Sub es un sistema de mensajería global, lo que significa que es una forma de promulgar las tuberías entre las fuentes de datos de una manera impulsada por eventos.
Los mensajes Pub/Sub tienen garantizada la entrega al menos una vez, por lo que es una forma de asegurar la coherencia en tus canalizaciones. Esto difiere de, por ejemplo, las llamadas a la API HTTP, con las que no debes contar para que funcionen el 100% de las veces. Pub/Sub consigue esto porque los sistemas receptores deben "ack", o reconocer, que han recibido el mensaje Pub/Sub. Si no devuelve un "ack", entonces Pub/Sub pondrá el mensaje en cola para ser enviado de nuevo. Esto ocurre a gran escala: se pueden enviar millones de visitas a través de Pub/Sub; de hecho, es una tecnología similar a la del rastreador Googlebot, que rastrea toda la World Wide Web para la Búsqueda de Google.
Pub/Sub no es almacenamiento de datos como tal, pero actúa como las tuberías entre soluciones de almacenamiento en GCP, por lo que es relevante aquí. Pub/Sub actúa como una tubería genérica a la que puedes enviar datos a través de sus temas, y luego puedes consumir esos datos en el otro extremo a través de sus suscripciones. Puedes asignar muchas suscripciones a un tema. También puede escalar: puedes enviar miles de millones de eventos a través de él sin preocuparte de configurar servidores, y con su servicio de entrega garantizada al menos una vez, sabrás que llegarán. Puede ofrecer esta garantía porque cada suscripción necesita acusar recibo de que ha recibido los datos enviados (o "ack", como se conoce cuando se habla de colas de mensajes), de lo contrario los pondrá en cola para enviarlos de nuevo.
Este modelo de tema/suscripción significa que puedes tener un evento entrante que se envíe a varias aplicaciones de almacenamiento o activadores basados en eventos. Casi todas las acciones de GCP tienen una opción para enviar un evento Pub/Sub, ya que también pueden activarse mediante filtros de registro. Esta fue mi primera aplicación en utilizarlos: Las exportaciones de BigQuery GA360 tienen fama de no llegar siempre a la misma hora cada día, lo que puede romper los trabajos de importación posteriores si están configurados según un calendario. Utilizar el registro para saber cuándo se han rellenado realmente las tablas de BigQuery podría desencadenar un evento Pub/Sub, que iniciaría los trabajos.
Configurar un tema Pub/Sub para las exportaciones GA4 BigQuery
Un evento Pub/Sub útil se produce cuando tus GA4 exportaciones BigQuery están listas, que podemos utilizar más tarde para otras aplicaciones (como "Cloud Build").
Podemos hacerlo utilizando los registros generales de Google Cloud Console, llamados Cloud Logging. Aquí es donde estarán todos los registros de todos los servicios que estés ejecutando, incluido BigQuery. Si podemos filtrar hasta las entradas de registro de los servicios para la actividad que quieres monitorizar, puedes configurar una métrica basada en registros que activará un tema Pub/Sub.
Primero tenemos que crear un tema Pub/Sub a partir de las entradas de Registro en la Nube que registran tu actividad BigQuery relacionada con el momento en que la exportación GA4 está lista.
El Ejemplo 4-4 muestra un ejemplo de filtro para esto, con los resultados de la Figura 4-2.
Ejemplo 4-4. Un filtro que puedes utilizar dentro de Cloud Logging para ver cuándo está lista tu exportación de GA4 BigQuery
resource.type="bigquery_resource"
protoPayload.authenticationInfo.principalEmail=
"firebase-measurement@system.gserviceaccount.com"
protoPayload.methodName="jobservice.jobcompleted"Aplicando este filtro, sólo veremos las entradas cuando la clave del servicio Firebase firebase-measurement@system.gserviceaccount.com haya terminado de actualizar su tabla BigQuery.
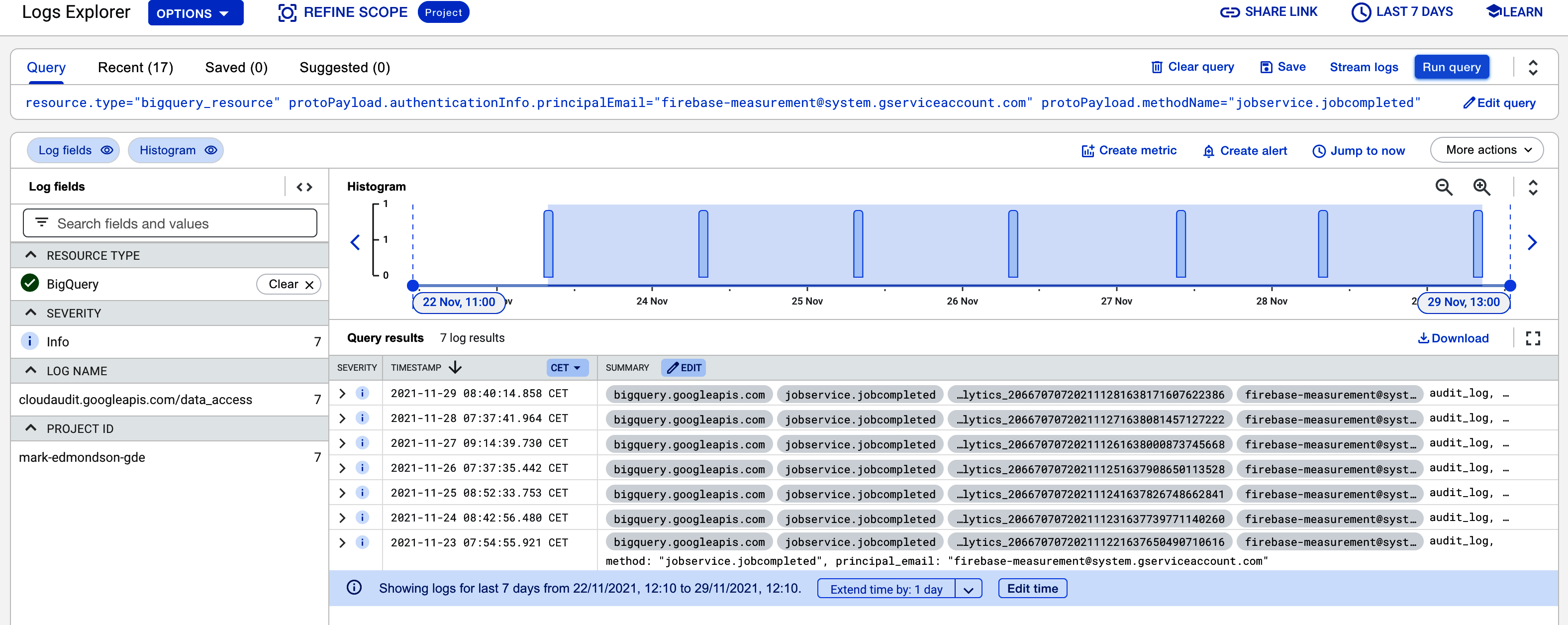
Figura 4-2. Un filtro de Cloud Logging para ver cuándo están listas tus exportaciones de GA4 BigQuery, que podemos utilizar para crear un tema Pub/Sub
Cuando estés satisfecho con el filtro de registros, selecciona el "Enrutador de Registros" para encaminarlos a Pub/Sub. En la Figura 4-3 se muestra un ejemplo de la pantalla de configuración.
Una vez creado el registro, deberías recibir un mensaje Pub/Sub cada vez que la exportación BigQuery esté lista para su consumo posterior. Te sugiero que utilices Cloud Build para procesar los datos, como se detalla con más detalle en "Cloud Build", o que sigas el ejemplo de la sección siguiente, que creará una tabla particionada BigQuery.
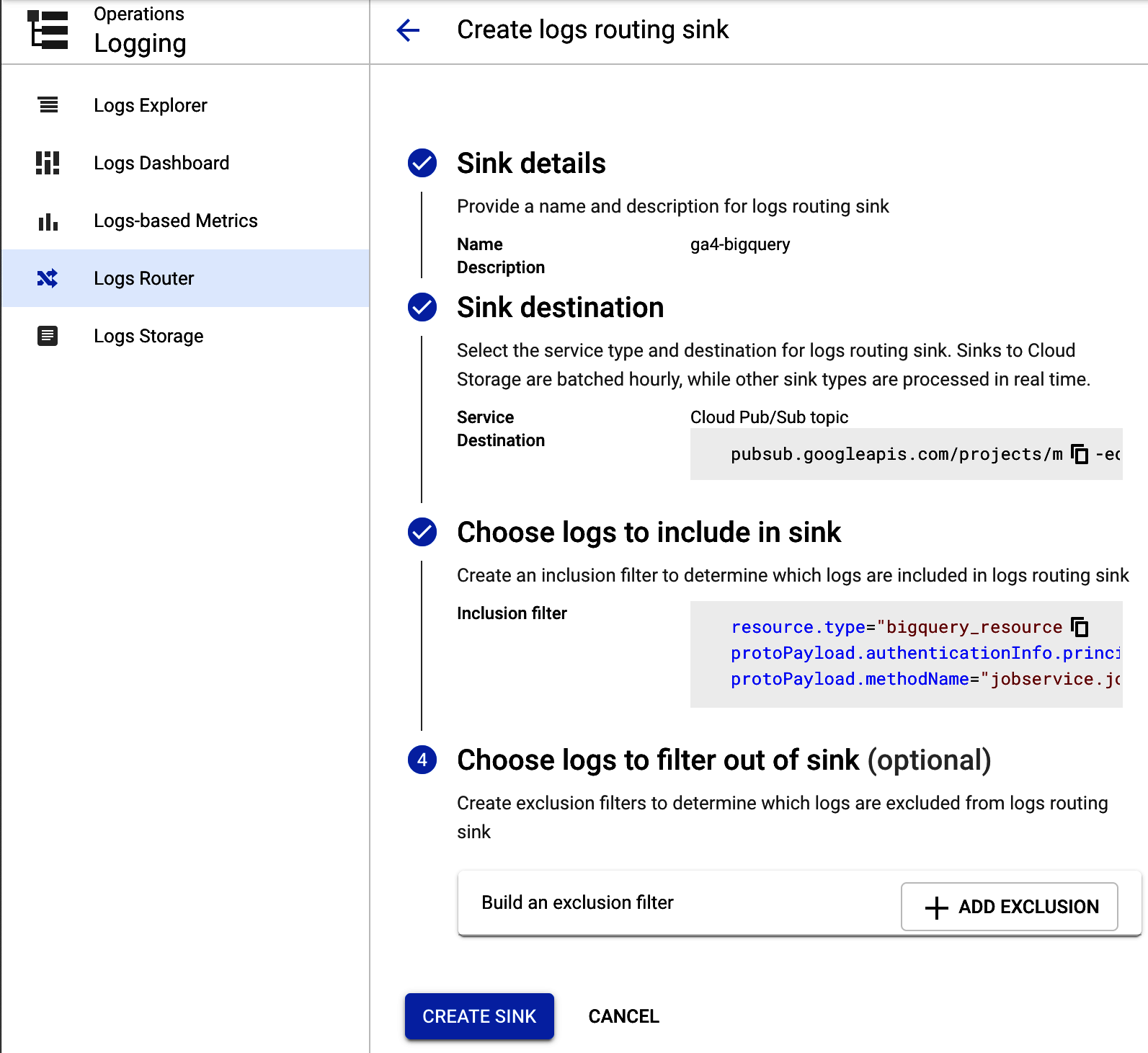
Figura 4-3. Configuración de tu registro GA4 BigQuery para que envíe las entradas al tema Pub/Sub denominado ga4-bigquery
Crear tablas BigQuery particionadas a partir de tu exportación GA4
Por defecto, las exportaciones de GA4 están en tablas "fragmentadas", , lo que significa que cada tabla se crea por separado y que utilizas comodines en el SQL para obtenerlas todas, por ejemplo, las tablas de tres días se llaman events_20210101, events_20210102, y events_20210103, que puedes consultar mediante el fragmento SQL SELECT * FROM dataset.events_*-el * es el comodín-.
Esto funciona, pero si deseas optimizar tus consultas posteriores, agregar las tablas en una tabla particionada facilitará el flujo de algunos trabajos y permitirá algunas optimizaciones de las consultas para ganar velocidad. Utilizaremos el tema Pub/Sub configurado en la Figura 4-3 para lanzar un trabajo que copie la tabla en una tabla particionada.
Para ello, ve al tema Pub/Sub y crea una Función en la Nube que se active pulsando el botón de la parte superior. El código para copiar la tabla en una tabla particionada está en el Ejemplo 4-5.
Ejemplo 4-5. Código Python de una Función Nube para copiar tus exportaciones GA4 BigQuery en una tabla particionada
importloggingimportbase64importJSONfromgoogle.cloudimportbigquery# pip google-cloud-bigquery==1.5.1importre# replace with your datasetDEST_DATASET='REPLACE_DATASET'defmake_partition_tbl_name(table_id):t_split=table_id.split('_20')name=t_split[0]suffix=''.join(re.findall("\d\d",table_id)[0:4])name=name+'$'+suffixlogging.info('partition table name:{}'.format(name))returnnamedefcopy_bq(dataset_id,table_id):client=bigquery.Client()dest_dataset=DEST_DATASETdest_table=make_partition_tbl_name(table_id)source_table_ref=client.dataset(dataset_id).table(table_id)dest_table_ref=client.dataset(dest_dataset).table(dest_table)job=client.copy_table(source_table_ref,dest_table_ref,location='EU')# API requestlogging.info(f"Copy job:dataset{dataset_id}:tableId{table_id}->dataset{dest_dataset}:tableId{dest_table}-checkBigQuerylogsofjob_id:{job.job_id}forstatus")defextract_data(data):"""Gets the tableId, datasetId from pub/sub data"""data=JSON.loads(data)complete=data['protoPayload']['serviceData']['jobCompletedEvent']['job']table_info=complete['jobConfiguration']['load']['destinationTable']logging.info('Found data:{}'.format(JSON.dumps(table_info)))returntable_infodefbq_to_bq(data,context):if'data'indata:table_info=extract_data(base64.b64decode(data['data']).decode('utf-8'))copy_bq(dataset_id=table_info['datasetId'],table_id=table_info['tableId'])else:raiseValueError('No data found in pub-sub')
Implementa la Función en la Nube con su propia cuenta de servicio, y dale a esa cuenta de servicio permisos de Propietario de Datos de BigQuery. Si es posible, intenta restringirlo a un conjunto de datos o tabla tan específicos como puedas, como buena práctica.
Una vez implementada la Función Nube, tus exportaciones GA4 BigQuery se duplicarán en una tabla particionada de otro conjunto de datos. La Función Nube reacciona al mensaje Pub/Sub de que la exportación GA4 está lista y lanza un trabajo BigQuery para copiar la tabla. Esto es útil para aplicaciones como la API de Prevención de Pérdida de Datos, que no funciona con tablas fragmentadas, y se muestra en una aplicación de ejemplo en "API de Prevención de Pérdida de Datos".
Empujar desde el servidor a Pub/Sub
Otro uso de Pub/Sub es como parte de tu canal de recopilación de datos si utilizando GTM SS. Desde tu contenedor GTM SS, puedes enviar todos los datos de eventos a un punto final Pub/Sub para su uso posterior.
Dentro de GTM SS, puedes crear un contenedor que enviará todos los datos del evento a un punto final HTTP. Ese punto final HTTP puede ser una Función en la Nube que lo transferirá a un tema Pub/Sub -el código para hacerlo se muestra en el Ejemplo 4-6.
Ejemplo 4-6. Algún código de ejemplo para mostrar cómo enviar los eventos GTM SS a un punto final HTTP, que lo convertirá en un tema Pub/Sub
constgetAllEventData=require('getAllEventData');constlog=require("logToConsole");constJSON=require("JSON");constsendHttpRequest=require('sendHttpRequest');log(data);constpostBody=JSON.stringify(getAllEventData());log('postBody parsed to:',postBody);consturl=data.endpoint+'/'+data.topic_path;log('Sending event data to:'+url);constoptions={method:'POST',headers:{'Content-Type':'application/JSON'}};// Sends a POST requestsendHttpRequest(url,(statusCode)=>{if(statusCode>=200&&statusCode<300){data.gtmOnSuccess();}else{data.gtmOnFailure();}},options,postBody);
Se puede implementar una Función en la Nube para recibir este punto final HTTP con la carga útil del evento GTM SS y crear un tema Pub/Sub, como se muestra en el Ejemplo 4-7.
Ejemplo 4-7. Una Función Nube HTTP apuntada dentro de la etiqueta GTM SS que recuperará los datos del evento GTM SS y creará un tema Pub/Sub con su contenido
importos,JSONfromgoogle.cloudimportpubsub_v1# google-cloud-Pub/Sub==2.8.0defhttp_to_Pub/Sub(request):request_JSON=request.get_JSON()request_args=request.args('Request JSON:{}'.format(request_JSON))ifrequest_JSON:res=trigger(JSON.dumps(request_JSON).encode('utf-8'),request.path)returnreselse:return'No data found',204deftrigger(data,topic_name):publisher=Pub/Sub_v1.PublisherClient()project_id=os.getenv('GCP_PROJECT')topic_name=f"projects/{project_id}/topics/{topic_name}"('Publishing message to topic{}'.format(topic_name))# create topic if necessarytry:future=publisher.publish(topic_name,data)future_return=future.result()('Published message{}'.format(future_return))returnfuture_returnexceptExceptionase:('Topic{}does not exist? Attempting to create it'.format(topic_name))('Error:{}'.format(e))publisher.create_topic(name=topic_name)('Topic created '+topic_name)return'Topic Created',201
Tienda de fuegos
Firestore es una base de datos NoSQL en contraposición al SQL que puedes utilizar en productos como "BigQuery". Como complemento de BigQuery, Firestore (o Datastore) es una contrapartida que se centra en los tiempos de respuesta rápidos. Firestore funciona mediante claves que se utilizan para realizar búsquedas rápidas de los datos asociados a él -y por rápidas, queremos decir de menos de un segundo-. Esto significa que debes trabajar con él de un modo distinto que con BigQuery; la mayoría de las veces, las peticiones a la base de datos deben referirse a una clave (como un ID de usuario) que devuelva un objeto (como las propiedades del usuario).
Nota
Firestore se llamaba antes Datastore y es un cambio de marca del producto. Tomando lo mejor de Datastore y de otro producto llamado Firebase Realtime Database, Firestore es una base de datos de documentos NoSQL construida para el escalado automático, el alto rendimiento y la facilidad de desarrollo de aplicaciones.
Firestore está vinculado a la suite de productos Firebase y suele utilizarse para aplicaciones móviles que necesitan primeras búsquedas con soporte móvil mediante almacenamiento en caché, por lotes, etc. Sus propiedades también pueden ser útiles para aplicaciones analíticas, porque es ideal para búsquedas rápidas al dar un ID, como el de un usuario.
Cuándo utilizar Firestore
Suelo utilizar Firestore cuando intento crear API en que posiblemente se llamen varias veces por segundo, como por ejemplo, mostrar los atributos de un usuario cuando se le da su ID de usuario. Esto suele ser más bien para apoyar el extremo de activación de datos de un proyecto, con una API ligera que tomará su ID, consultará el Firestore y volverá con los atributos, todo ello en unos pocos microsegundos.
Si alguna vez necesitas una búsqueda rápida, Firestore también te resultará útil. Un ejemplo potente para el seguimiento analítico es mantener tu base de datos de productos en una Firestore de productos con una búsqueda en la SKU del producto que devuelva el coste, la marca, la categoría, etc. de ese producto. Con una base de datos de este tipo, puedes mejorar la recopilación de datos analíticos recortando los hits de comercio electrónico para incluir sólo el SKU y buscar los datos antes de enviarlos a GA4. Esto te permite enviar hits mucho más pequeños desde el navegador web del usuario, con ventajas de seguridad, velocidad y eficiencia.
Acceder a los datos de Firestore a través de una API
Para acceder a Firestore, primero tienes que importar tus datos a una instancia de Firestore. Puedes hacerlo a través de sus API de importación o incluso introduciéndolos manualmente a través de la WebUI. El requisito del conjunto de datos es que siempre tendrás una clave que será típicamente lo que envíes a la base de datos para devolver los datos, y luego volverá una estructura JSON anidada de datos.
Añadir datos a Firestore implica definir el objeto que quieres registrar, que podría estar en una estructura anidada, y su ubicación en la base de datos. En conjunto, esto define un documento Firestore. En el Ejemplo 4-8 se muestra un ejemplo de cómo se añadiría mediante Python.
Ejemplo 4-8. Importar una estructura de datos a Firestore utilizando el SDK de Python, en este caso, una SKU de producto de demostración con algunos detalles
fromgoogle.cloudimportfirestoredb=firestore.Client()product_id=u'SKU12345'data={u'name':u'Muffins',u'brand':u'Mule',u'price':15.78}# Add a new doc in collection 'your-firestore-collection'db.collection(u'your-firestore-collection').document(product_id).set(data)
Utilizar esto significa que puedes necesitar una canalización de datos adicional para importar tus datos a Firebase y poder consultarlos desde tus aplicaciones, lo que utilizaría un código similar al del Ejemplo 4-8.
Una vez que tengas tus datos en Firestore, podrás acceder a ellos a través de tu aplicación. El Ejemplo 4-9 muestra una función Python que puedes utilizar en una aplicación Cloud Function o App Engine. Suponemos que se utiliza para buscar información sobre un producto cuando se suministra a product_id.
Ejemplo 4-9. Un ejemplo de cómo leer datos de una base de datos Firestore utilizando Python dentro de una Función Nube
# pip google-cloud-firestore==2.3.4fromgoogle.cloudimportfirestoredefread_firestore(product_id):db=firestore.Client()fs='your-firestore-collection'try:doc_ref=db.collection(fs).document(product_id)except:(f'Could not connect to firestore collection:{fs}')return{}doc=doc_ref.get()ifdoc.exists:(f'product_id data found:{doc.to_dict()}')returndoc.to_dict()else:(f'Could not find entry for product_id:{product_id}')return{}
Firestore te ofrece otra herramienta que puede ayudarte en tus flujos de trabajo de análisis digital y que cobrará más protagonismo cuando necesites aplicaciones en tiempo real y tiempos de respuesta de milisegundos, como las llamadas desde una API o cuando un usuario navega por tu sitio web y no quieres añadir latencia a su recorrido. Es más adecuado para marcos de aplicaciones web que para tareas de análisis de datos, por lo que suele utilizarse durante los últimos pasos de la activación de datos.
BigQuery y Firestore son ejemplos de bases de datos que trabajan con datos estructurados, pero también te encontrarás con datos no estructurados, como vídeos, imágenes o audio, o simplemente datos de los que no conoces su forma antes de procesarlos. En ese caso, tus opciones de almacenamiento tienen que funcionar a un nivel más bajo de almacenamiento de bytes, y ahí es donde entra en escena el Almacenamiento en la Nube.
GCS
Ya hemos hablado sobre el uso de GCS para la ingesta de datos en sistemas CRM en "Google Cloud Storage", pero esta sección trata más sobre su uso en general. GCS es útil para varias funciones, ayudado por la sencilla tarea en la que destaca: mantener los bytes seguros pero disponibles al instante.
GCS es el sistema de almacenamiento de servicios de GCP más parecido al disco duro que almacena los archivos que están en tu ordenador. No puedes manipular ni hacer nada con esos datos hasta que los abras en una aplicación, pero almacenará TBs de datos para que accedas a ellos de forma segura y accesible. Las funciones para las que lo utilizo son las siguientes:
- Datos no estructurados
-
Para los objetos que no pueden cargarse en una base de datos, como el vídeo y las imágenes, GCS es un lugar que siempre podrá ayudar. Puede almacenar cualquier cosa dentro de bytes en sus cubos, objetos que se conocen cariñosamente como "blobs". Cuando trabajes con las API de Google, como la conversión de voz a texto o el reconocimiento de imágenes, normalmente hay que subir primero los archivos a GCS.
- Copias de seguridad de datos en bruto
-
Incluso para los datos estructurados, GCS es útil como copia de seguridad de datos sin procesar que pueden almacenarse a sus bajos índices de archivo, de modo que siempre puedas rebobinar o recuperar en caso de desastre el camino de vuelta de una interrupción.
- Plataformas de importación de datos
-
Como se ve en "Google Cloud Storage", GCS es útil como plataforma de aterrizaje para los datos de exportación, ya que no será quisquilloso con el esquema o formato de los datos. Como también activará eventos Pub/Sub cuando lleguen datos, puede poner en marcha los sistemas de flujo de datos basados en eventos.
- Alojamiento de sitios web
-
Puedes elegir que los archivos estén disponibles públicamente desde puntos finales HTTP, lo que significa que si colocas HTML u otros archivos compatibles con navegadores web, puedes tener sitios web estáticos alojados en GCS. Esto también puede ser útil para activos estáticos que quieras importar a sitios web, como píxeles de seguimiento o imágenes.
- Dropbox
-
Puedes dar acceso público o a de forma más detallada a determinados usuarios, para que puedas pasar de forma segura archivos de gran tamaño. Admite hasta 5 TB por objeto, con almacenamiento global ilimitado (¡si estás dispuesto a pagar!). Esto lo convierte en un destino potencial para el procesamiento de datos, como un archivo CSV puesto a disposición de colegas que deseen importarlo localmente a Excel.
Los elementos almacenados en GCS se guardan todos en en su propia URI, que es como una dirección HTTP (https://example.com) pero con su propio protocolo: gs://. También puedes hacer que estén disponibles en una dirección HTTP normal; de hecho, podrías alojar archivos HTML y GCS te serviría de alojamiento web.
Los nombres de bucket que utilices son globalmente únicos, por lo que puedes acceder a ellos desde cualquier proyecto aunque ese bucket se encuentre en otro. Puedes especificar acceso público a través de HTTP o sólo para usuarios específicos o correos electrónicos de servicio que trabajen en nombre de tus aplicaciones de datos. La Figura 4-4 muestra un ejemplo de cómo se ve esto a través de la WebUI, pero normalmente se accede a los archivos que contiene a través de código.
Figura 4-4. Archivos dentro de GCS en su WebUI
Cada objeto de GCS tiene asociados algunos metadatos de que puedes utilizar para adaptarlo a tus necesidades de almacenamiento. Recorreremos el archivo de ejemplo que se muestra en la Figura 4-5 para ayudar a ilustrar lo que es posible.
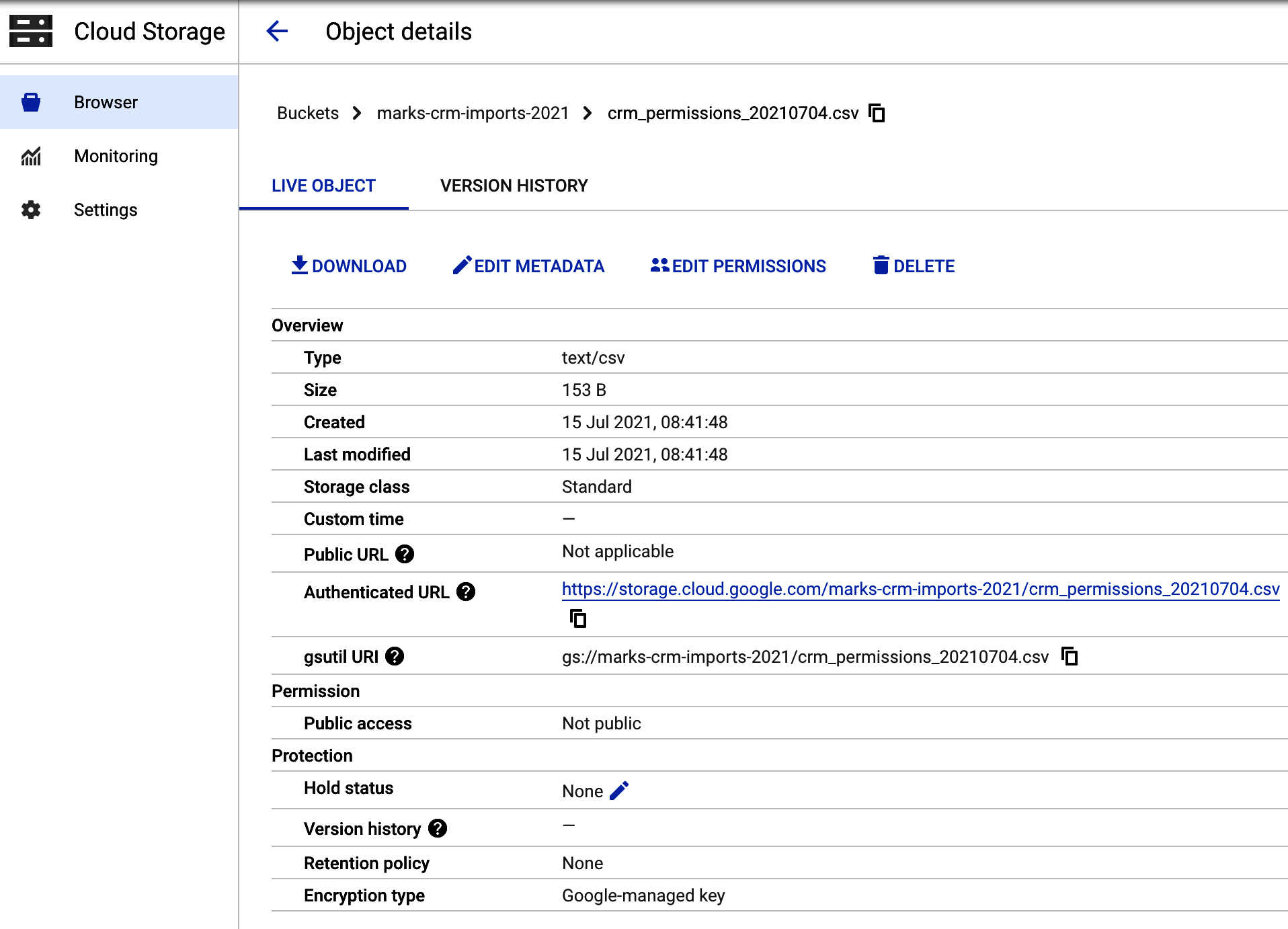
Figura 4-5. Varios metadatos asociados a una subida de archivos a GCS
Los metadatos disponibles para cada objeto dentro de la GCS incluyen:
- Tipo
-
Se trata de un tipo HTTP MIME (Multipurpose Internet Mail Extensions) especificado para objetos web. El sitio web de Mozilla tiene algunos recursos sobre los tipos MIME HTTP. Merece la pena configurarlo si tu aplicación va a comprobarlo para determinar cómo tratar el archivo: por ejemplo, un archivo
.csvcon el tipo MIMEtext/csven la Figura 4-5 significa que las aplicaciones que lo descarguen intentarán leerlo como una tabla. Otros tipos MIME comunes con los que puedes encontrarte son JSON (application/JSON), HTML para páginas web (text/html), imágenes comoimage/png, y vídeo (video/mp4). - Talla
-
El tamaño en disco de los bytes del objeto. Puedes almacenar hasta 5 TB por objeto.
- Creado
-
Cuando se creó el objeto por primera vez.
- Última modificación
-
Puedes actualizar objetos llamándolos con el mismo nombre que cuando los creaste por primera vez, y tener activado el versionado de objetos.
- Clase de almacenamiento
-
El modelo de precios bajo el que se almacena el objeto, establecido a nivel de cubo. Las clases de almacenamiento suelen ser un compromiso entre el coste de almacenamiento y el coste de acceso. Los costes de almacenamiento varían según la región, pero como guía, aquí tienes algunos ejemplos para GBs al mes. Estándar es para datos a los que se accede con frecuencia (0,02 $), Nearline para datos a los que se puede acceder sólo unas pocas veces al año (0,01 $), Coldline para datos a los que se puede acceder sólo una vez al año o menos (0,004 $), y Archivo para datos a los que nunca se puede acceder aparte de la recuperación de desastres (0,0012 $). Asegúrate de poner tus objetos en la clase correcta, o acabarás pagando de más por el acceso a los datos, porque los precios de coste de los objetos son más altos para acceder a los datos de Archivo que para los de Estándar, por ejemplo.
- Hora personalizada
-
Puede que tengas fechas u horas importantes que asociar al objeto, que puedes añadir aquí como metadatos.
- URL pública
-
Si decides hacer público tu objeto, la URL aparecerá aquí. Ten en cuenta que es diferente de la URL autenticada.
- URL autenticada
-
Esta es la URL si estás dando acceso restringido, no público, a un usuario o aplicación. Comprobará la autorización de ese usuario antes de servir el objeto.
- gstuil URI
-
La forma
gs://de acceder al objeto, normalmente cuando se utiliza mediante programación a través de la API o de uno de los SDK de la GCS. - Permiso
-
Información sobre quién puede acceder al objeto. Hoy en día es habitual que los permisos se concedan a nivel de bucket, aunque también puedes optar por un control más fino del acceso a los objetos. Suele ser más fácil tener dos cubos separados para el control de acceso, como público y restringido.
- Protección
-
Hay varios métodos que puedes activar para controlar cómo persiste el objeto, que se destacan en esta sección.
- Estado de espera
-
Puedes aplicar retenciones temporales o basadas en eventos sobre el objeto, lo que significa que no se puede borrar ni modificar mientras esté en su lugar, ya sea por un límite de tiempo o cuando se produzca un determinado evento desencadenado por una llamada a la API. Esto puede ser útil para proteger contra el borrado accidental, o si, por ejemplo, tienes una caducidad de datos activa en el cubo mediante una política de retención, pero quieres mantener determinados objetos fuera de esa política.
- Historial de versiones
-
Puedes activar el control de versiones en tu objeto, de forma que aunque se modifique, la versión anterior siga siendo accesible. Esto puede ser útil para mantener un registro de los datos programados.
- Política de conservación
-
Puedes activar varias reglas que determinen cuánto tiempo permanece un objeto. Esto es vital si tratas con datos personales de usuarios, para eliminar archivos antiguos cuando ya no tengas permiso para conservar esos datos. También puedes utilizarlo para mover datos a una solución de almacenamiento de menor coste si no se accede a ellos después de un determinado número de días.
- Tipo de encriptación
-
Por defecto, Google aplica un enfoque de encriptación a todos tus datos en GCP, pero puede que quieras aplicar una política de seguridad más estricta en la que ni siquiera Google pueda ver los datos. Puedes hacerlo utilizando tus propias claves de seguridad.
GCS tiene un propósito singular, pero es un propósito fundamental: almacenar tus bytes de forma segura y protegida. Es el cimiento en el que se apoyan varios otros servicios de GCP, aunque no estén expuestos al usuario final, y también puede cumplir esa función para ti. Es un disco duro infinito en la nube en lugar de en tu propio ordenador, y se puede acceder a él fácilmente en todo el mundo.
Ya hemos visto los tres tipos principales de almacenamiento de datos: BigQuery para datos SQL estructurados, Firestore para datos NoSQL y GCS para datos brutos no estructurados. Ahora nos centraremos en cómo trabajar con ellos de forma habitual, examinando las técnicas para programar y transmitir flujos de datos. Empecemos por la aplicación más común, los flujos programados.
Programar la importación de datos
Esta sección examina una de las principales tareas para cualquier ingeniero de datos que diseñe flujos de trabajo: cómo programar los flujos de datos dentro de tus aplicaciones. Una vez que tu prueba de concepto funcione, el siguiente paso para ponerla en producción es poder actualizar regularmente los datos implicados. En lugar de actualizar una hoja de cálculo cada día o ejecutar un script de la API, entregar esta tarea a los numerosos dispositivos de automatización de que dispones en GCP te garantiza que tendrás datos actualizados continuamente sin necesidad de preocuparte por ello.
Hay muchas formas de enfocar la actualización de datos, que esta sección repasará en relación a cómo quieres trasladar tus datos GA4 y sus conjuntos de datos complementarios.
Tipos de Importación de Datos: Streaming Versus Lotes Programados
El streaming de datos frente al batching de datos es una de esas decisiones con las que te puedes encontrar al diseñar sistemas de aplicación de datos. Esta sección considera algunas de las ventajas y desventajas de ambos.
Los flujos de datos en streaming son más en tiempo real, utilizando pequeños paquetes de datos basados en eventos que se actualizan continuamente. Los datos por lotes se programan regularmente a un intervalo más lento, como diario u horario, con importaciones de datos más grandes en cada trabajo.
Las opciones de flujo de datos se estudiarán más a fondo en "Flujos de datos en flujo", pero compararlas con los datos en lotes puede ayudarte a tomar algunas decisiones fundamentales al principio del diseño de tu aplicación.
- Flujos de datos por lotes
-
El procesamiento por lotes es la forma más común y tradicional de importar flujos de datos, y para la mayoría de los casos de uso es perfectamente adecuada. Una cuestión clave al crear tu caso de uso será la rapidez con la que necesitas esos datos. Es habitual que la reacción inicial sea lo más rápida posible o casi en tiempo real. Pero si analizamos los detalles, descubriremos que, en realidad, los efectos de las actualizaciones horarias o incluso diarias serán imperceptibles en comparación con el tiempo real, y este tipo de actualizaciones serán mucho más baratas y fáciles de ejecutar. Si los datos con los que actualizas también se procesan por lotes (por ejemplo, una exportación de CRM que ocurre cada noche), habrá pocas razones para hacer que los datos descendentes sean en tiempo real. Como siempre, examina la aplicación del caso de uso y comprueba si tiene sentido. Los flujos de trabajo de datos por lotes empiezan a fallar si no puedes confiar en que esas actualizaciones programadas lleguen a tiempo. Entonces puede que tengas que crear opciones alternativas si falla una importación (y siempre debes diseñar para un posible fallo).
- Flujos de datos
-
El streaming de datos es más fácil de hacer hoy en día en las pilas de datos modernas, dadas las nuevas tecnologías disponibles, y hay defensores que dirán que todos tus flujos de datos deberían ser de streaming si es posible. Es muy posible que descubras nuevos casos de uso una vez que te liberes de los grilletes de las programaciones de datos por lotes. Existen ciertas ventajas incluso si no tienes una necesidad inmediata de datos en tiempo real, ya que al pasar a un modelo de datos basado en eventos reaccionamos cuando ocurre algo, no cuando se alcanza una determinada marca de tiempo, lo que significa que podemos ser más flexibles en el momento en que se producen los flujos de datos. Un buen ejemplo de esto son las exportaciones de datos BigQuery de GA4, que si se retrasaran romperían los cuadros de mando y las aplicaciones posteriores. Configurar reacciones basadas en eventos para cuando los datos estén disponibles significa que obtendrás los datos en cuanto estén ahí, en lugar de tener que esperar a que lleguen al día siguiente. La mayor desventaja es el coste, porque estos flujos suelen ser más caros de ejecutar. Tus ingenieros de datos también necesitarán un nivel de conocimientos diferente para poder desarrollar y solucionar los problemas de los flujos.
Cuando consideremos los trabajos programados, empezaremos con los recursos propios de BigQuery, para luego pasar a soluciones más sofisticadas como Cloud Composer, Cloud Scheduler y Cloud Build.
Vistas de BigQuery
En algunos casos, la forma más sencilla de presentar datos transformados es configurar una Vista BigQuery o programar BigQuery SQL. Esto es lo más fácil de configurar y no implica otros servicios.
Las Vistas BigQuery no son tablas en el sentido tradicional, sino que representan una tabla que resultaría del SQL que utilices para definirla. Esto significa que cuando creas tu SQL, puedes incluir fechas dinámicas y así disponer siempre de los datos más recientes. Por ejemplo, podrías consultar tus exportaciones de datos GA4 BigQuery con una Vista creada como en el Ejemplo 4-10-estosiempre traerá los datos de ayer .
Ejemplo 4-10. Este SQL puede utilizarse en una Vista BigQuery para mostrar siempre los datos de ayer (adaptado del Ejemplo 3-6)
SELECT-- event_date (the date on which the event was logged)parse_date('%Y%m%d',event_date)asevent_date,-- event_timestamp (in microseconds, utc)timestamp_micros(event_timestamp)asevent_timestamp,-- event_name (the name of the event)event_name,-- event_key (the event parameter's key)(SELECTkeyFROMUNNEST(event_params)WHEREkey='page_location')asevent_key,-- event_string_value (the string value of the event parameter)(SELECTvalue.string_valueFROMUNNEST(event_params)WHEREkey='page_location')asevent_string_valueFROM-- your GA4 exports - change to your location`learning-ga4.analytics_250021309.events_*`WHERE-- limits query to use table from yesterday only_TABLE_SUFFIX=FORMAT_DATE('%Y%m%d',date_sub(current_date(),INTERVAL1day))-- limits query to only show this eventandevent_name='page_view'
La línea clave es FORMAT_DATE('%Y%m%d',date_sub(current_date(), INTERVAL 1 day)), que devuelve yesterday, que aprovecha la columna _TABLE_SUFFIX que BigQuery añade como metainformación sobre la tabla para que puedas consultar más fácilmente varias tablas.
Las Vistas de BigQuery tienen su lugar, pero ten cuidado al utilizarlas. Dado que el SQL de la Vista se ejecuta por debajo de cualquier otra consulta que se ejecute contra ellas, puedes encontrarte con resultados caros o lentos. Esto se ha mitigado recientemente con las Vistas Materializadas, que es una tecnología para asegurarte de que no consultas toda la tabla cuando realizas consultas sobre Vistas. En algunos casos, puede que sea mejor que crees tu propia tabla intermedia, quizás mediante un programador para crear la tabla, que trataremos en la siguiente sección.
Consultas programadas BigQuery
BigQuery tiene soporte nativo para programar consultas , accesible a través de la barra de menú de la parte superior izquierda o seleccionando "Programar" al crear la consulta. Esto está bien para pequeños trabajos e importaciones; sin embargo, yo desaconsejaría confiar en esto para cualquier cosa que no sean transformaciones sencillas de un solo paso. Cuando te enfrentes a flujos de datos más complicados, te resultará más fácil utilizar herramientas específicas para el trabajo, tanto desde el punto de vista de la gestión como de la solidez.
Las consultas programadas están vinculadas a la autenticación del usuario que las configura, por lo que si esa persona se va, habrá que actualizar el programador mediante el comando gcloud bq update --transfer-config --update-credentials. Puedes utilizarlo para actualizar tu conexión a cuentas de servicio que no estén vinculadas a una persona. Además, sólo dispondrás de la interfaz del Programador BigQuery para controlar las consultas; en el caso de las consultas grandes y complicadas que quieras modificar, esto dificultará ver un historial de cambios o una visión general.
Pero para consultas sencillas, no críticas para el negocio y necesarias quizás para un número limitado de personas, es rápido y fácil de configurar dentro de la propia interfaz, y serviría mejor que Vistas para, por ejemplo, exportaciones a soluciones de cuadros de mando como Looker o Data Studio. Como se ve en la Figura 4-6, una vez que has desarrollado tu SQL y tienes los resultados que te gustan, puedes pulsar el botón "Programar" y tener los datos listos para cuando te conectes al día siguiente.
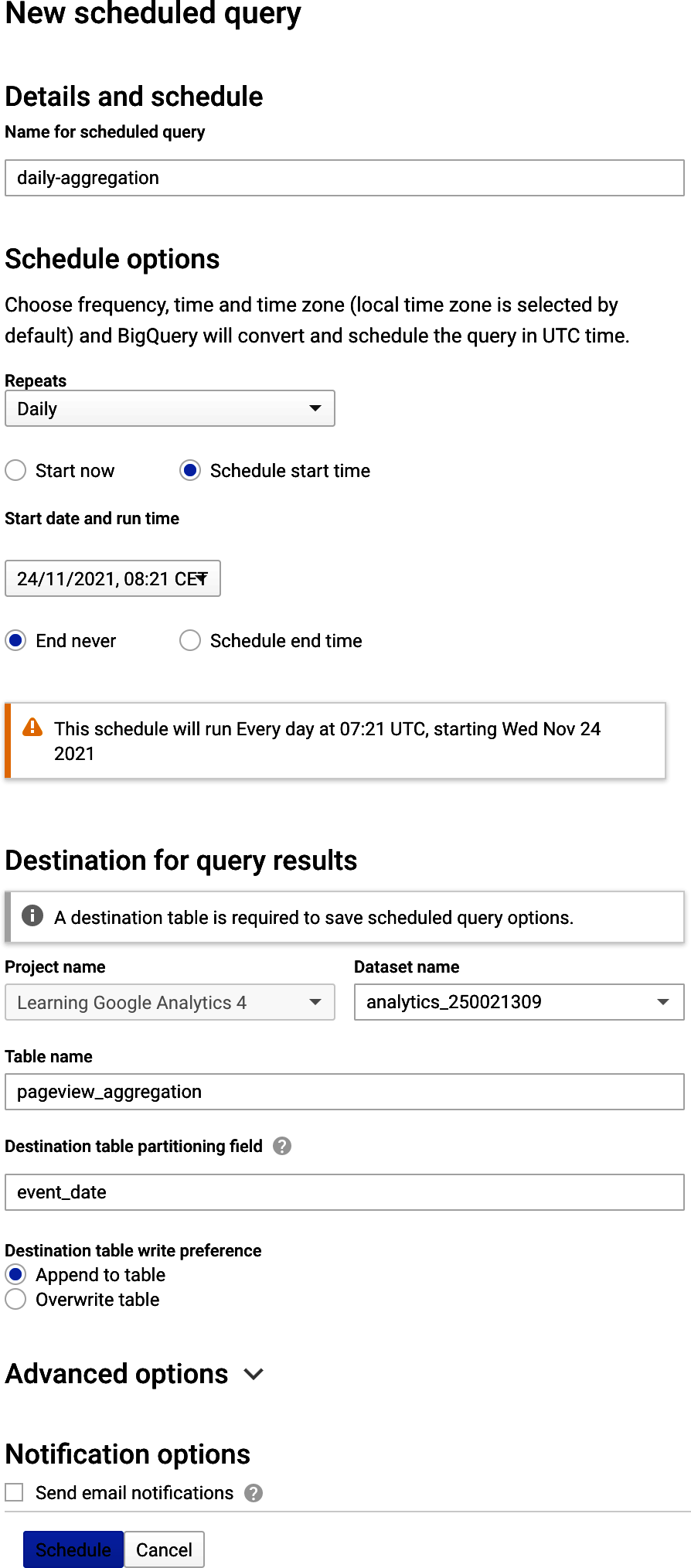
Figura 4-6. Configuración de una consulta programada del Ejemplo 4-10, que puede funcionar mejor que la creación de una Vista BigQuery con los mismos datos para su uso en cuadros de mando, etc.
Sin embargo, cuando empieces a hacerte preguntas como "¿Cómo puedo hacer que esta consulta programada sea más robusta?" o "¿Cómo puedo activar consultas basadas en los datos que estoy creando en esta tabla?", es señal de que necesitarás una solución más robusta para la programación. La herramienta para ese trabajo es Airflow, a través de su versión alojada en GCP llamada Cloud Composer, de la que hablamos en la siguiente sección.
Compositor de nubes
Cloud Composer es una solución gestionada por Google para Airflow, una popular herramienta de programación de código abierto. Cuesta unos 300 $ al mes, por lo que sólo merece la pena mirarla cuando tengas algún buen valor empresarial que la justifique, pero es la solución en la que más confío cuando se trata de flujos de datos complicados a través de múltiples sistemas, y ofrece backfilling, sistemas de alerta y configuración mediante Python. Muchas empresas lo consideran la columna vertebral de todos sus trabajos de programación.
Nota
Utilizaré el nombre Cloud Composer en este libro, ya que así es como se denomina Airflow gestionado dentro de GCP, pero gran parte del contenido será aplicable también a Airflow que se ejecute en otras plataformas, como otros proveedores de nube oplataformas autoalojadas.
Empecé a utilizar Cloud Composer cuando tuve trabajos que cumplían los siguientes criterios:
- Dependencias multinivel
-
En cuanto tengas una situación en tus conductos de datos en la que un trabajo programado dependa de otro, Yo empezaría a utilizar Cloud Composer, ya que encajará bien en su estructura de grafo acíclico dirigido (DAG). Los ejemplos incluyen cadenas de trabajos SQL: un script SQL para ordenar los datos, otro script SQL para hacer tus datos modelo. Poner estos scripts SQL a ejecutar dentro de Cloud Composer te permite dividir tus trabajos programados en componentes más pequeños y sencillos que si intentaras ejecutarlos todos en un trabajo más grande. Una vez que tengas la libertad de establecer dependencias, te recomiendo mejorar los pipelines añadiendo comprobaciones y pasos de validación que serían demasiado complejos de realizar mediante un único trabajo programado.
- Rellenos
-
Es habitual configurar una importación histórica al inicio del proyecto para rellenar todos los datos que habrías tenido si el trabajo de planificación se hubiera ejecutado, por ejemplo, los últimos 12 meses. Lo que esté disponible variará según el trabajo, pero si has configurado importaciones por día, a veces puede no ser trivial configurar después importaciones históricas. Cloud Composer ejecuta los trabajos como una simulación del día, y puedes establecer cualquier fecha de inicio para que rellene lentamente todos los datos si se lo permites.
- Sistemas de interacción múltiple
-
Si estás extrayendo o enviando datos a varios sistemas, como FTP, productos en la Nube, bases de datos SQL y API, empezará a resultar complejo coordinar todos esos sistemas y puede ser necesario distribuirlos en varios scripts de importación. Los numerosos conectores de Cloud Composer a través de sus Operadores y Ganchos significan que puede conectarse prácticamente a cualquier cosa, por lo que puedes gestionarlos todos desde un solo lugar, lo que resulta mucho más fácil de mantener.
- Reintentos
-
Cuando importas a través de HTTP, en muchos casos, experimentarás interrupciones. Puede ser difícil configurar cuándo y con qué frecuencia reintentar esas importaciones o exportaciones, algo en lo que Cloud Composer puede ayudarte mediante su sistema configurable de reintentos que controla cada tarea.
Cuando trabajes con flujos de datos, experimentarás rápidamente problemas como los mencionados y necesitarás una forma de resolverlos fácilmente, para lo cual Cloud Composer es una solución. Existen soluciones similares, pero Cloud Composer es la que más he utilizado y se ha convertido rápidamente en la columna vertebral de muchos proyectos de datos. Representar estos flujos de forma intuitiva es útil para poder imaginar procesos complicados, lo que Cloud Composer resuelve utilizando una representación de la que hablaremos a continuación.
DAGs
La característica central de Cloud Composer son los DAG, que representan el flujo de tus datos a medida que se ingieren, procesan y extraen. El nombre se refiere a una estructura de nodos y perímetros, con direcciones entre esos nodos dadas por flechas. En la Figura 4-7 se muestra un ejemplo de lo que esto podría significar para tu propio canal GA4.
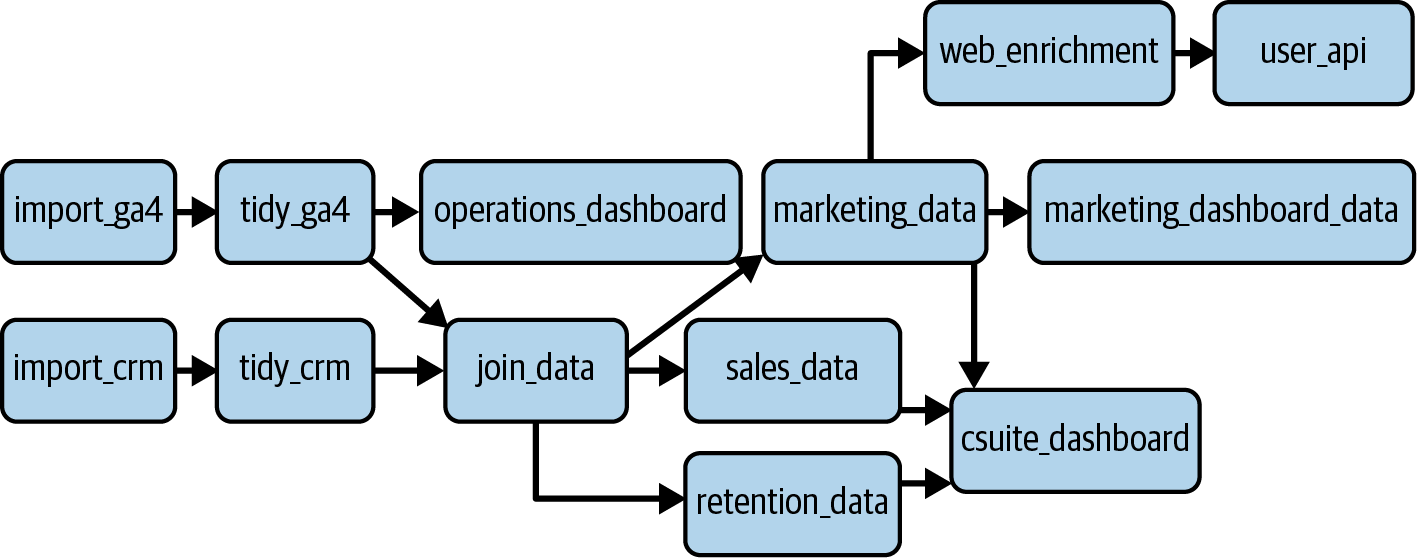
Figura 4-7. Ejemplo de DAG que podría utilizarse en un proceso GA4
Los nodos representan una operación de datos, y los perímetros muestran el orden de los acontecimientos y qué operaciones dependen unas de otras. Una de las principales características de Airflow es que, si falla un nodo (como ocurre con todos), dispone de estrategias para esperar, reintentar u omitir las operaciones posteriores. También tiene algunas funciones de relleno que pueden evitar muchos quebraderos de cabeza al ejecutar actualizaciones históricas, y viene con algunas macros predefinidas que te permiten insertar dinámicamente, por ejemplo, la fecha de hoy en tus guiones.
En el Ejemplo 4-11 se muestra un ejemplo de DAG que importa de sus exportaciones GA4 BigQuery.
Ejemplo 4-11. Un ejemplo de DAG que toma tu exportación GA4 y la agrega utilizando SQL que has desarrollado anteriormente y en un archivoga4-bigquery.sql cargado con tu script
fromairflow.contrib.operators.bigquery_operatorimportBigQueryOperatorfromairflow.contrib.operators.bigquery_check_operatorimportBigQueryCheckOperatorfromairflow.operators.dummy_operatorimportDummyOperatorfromairflowimportDAGfromairflow.utils.datesimportdays_agoimportdatetimeVERSION='0.1.7'# increment this each version of the DAGDAG_NAME='ga4-transformation-'+VERSIONdefault_args={'start_date':days_ago(1),# change this to a fixed date for backfilling'email_on_failure':True,'email':'mark@example.com','email_on_retry':False,'depends_on_past':False,'retries':3,'retry_delay':datetime.timedelta(minutes=10),'project_id':'learning-ga4','execution_timeout':datetime.timedelta(minutes=60)}schedule_interval='2 4 * * *'# min, hour, day of month, month, day of weekdag=DAG(DAG_NAME,default_args=default_args,schedule_interval=schedule_interval)start=DummyOperator(task_id='start',dag=dag)# uses the Airflow macro {{ ds_nodash }} to insert todays date in YYYYMMDD formcheck_table=BigQueryCheckOperator(task_id='check_table',dag=dag,sql='''SELECT count(1) > 5000FROM `learning-ga4.analytics_250021309.events_{{ ds_nodash }}`"''')checked=DummyOperator(task_id='checked',dag=dag)# a function so you can loop over many tables, SQL filesdefmake_bq(table_id):task=BigQueryOperator(task_id='make_bq_'+table_id,write_disposition='WRITE_TRUNCATE',create_disposition='CREATE_IF_NEEDED',destination_dataset_table='learning_ga4.ga4_aggregations.{}${{ ds_nodash}}'.format(table_id),sql='./ga4_sql/{}.sql'.format(table_id),use_legacy_sql=False,dag=dag)returntaskga_tables=['pageview-aggs','ga4-join-crm','ecom-fields']ga_aggregations=[]# helpful if you are doing other downstream transformationsfortableinga_tables:task=make_bq(table)checked>>taskga_aggregations.append(task)# create the DAGstart>>check_table>>checked
Para crear los nodos de tu DAG, utilizarás Airflow Operators, que son varias funciones prefabricadas para conectarse a diversas aplicaciones, incluida una amplia gama de servicios de GCP como BigQuery, FTP, clusters de Kubernetes, etc.
Para el ejemplo del Ejemplo 4-11, los nodos se crean mediante:
- empieza
-
Un
DummyOperator()para señalar el inicio del DAG. - comprobar_tabla
-
Un
BigQueryCheckOperator()que comprobará que tienes datos de ese día en la tabla GA4. Si esto falla devolviendoFALSEpara el SQL en línea mostrado, Airflow fallará la tarea y volverá a intentarlo cada 10 minutos hasta 3 veces. Puedes modificar esto según tus expectativas. - comprobado
-
Otro
DummyOperator()para indicar que se ha comprobado la tabla. - hacer_bq
-
Esto creará o añadirá a una tabla particionada con el mismo nombre que el task_id. El SQL que ejecutará también debe tener el mismo nombre y estar disponible en la carpeta SQL cargada con el DAG, en
./ga4_sql/, por ejemplo,./ga4_sql/pageview-aggs.sql. Está funcionalizado para que puedas hacer un bucle sobretableIdspara conseguir un código más eficiente.
Los perímetros se tienen en cuenta mediante operadores Python bit a bit al final de la etiqueta y dentro de los bucles, por ejemplo, start >> check_table >> checked.
Puedes ver el DAG resultante en la Figura 4-8. Toma este ejemplo como base que puedes ampliar para tus propios flujos de trabajo.
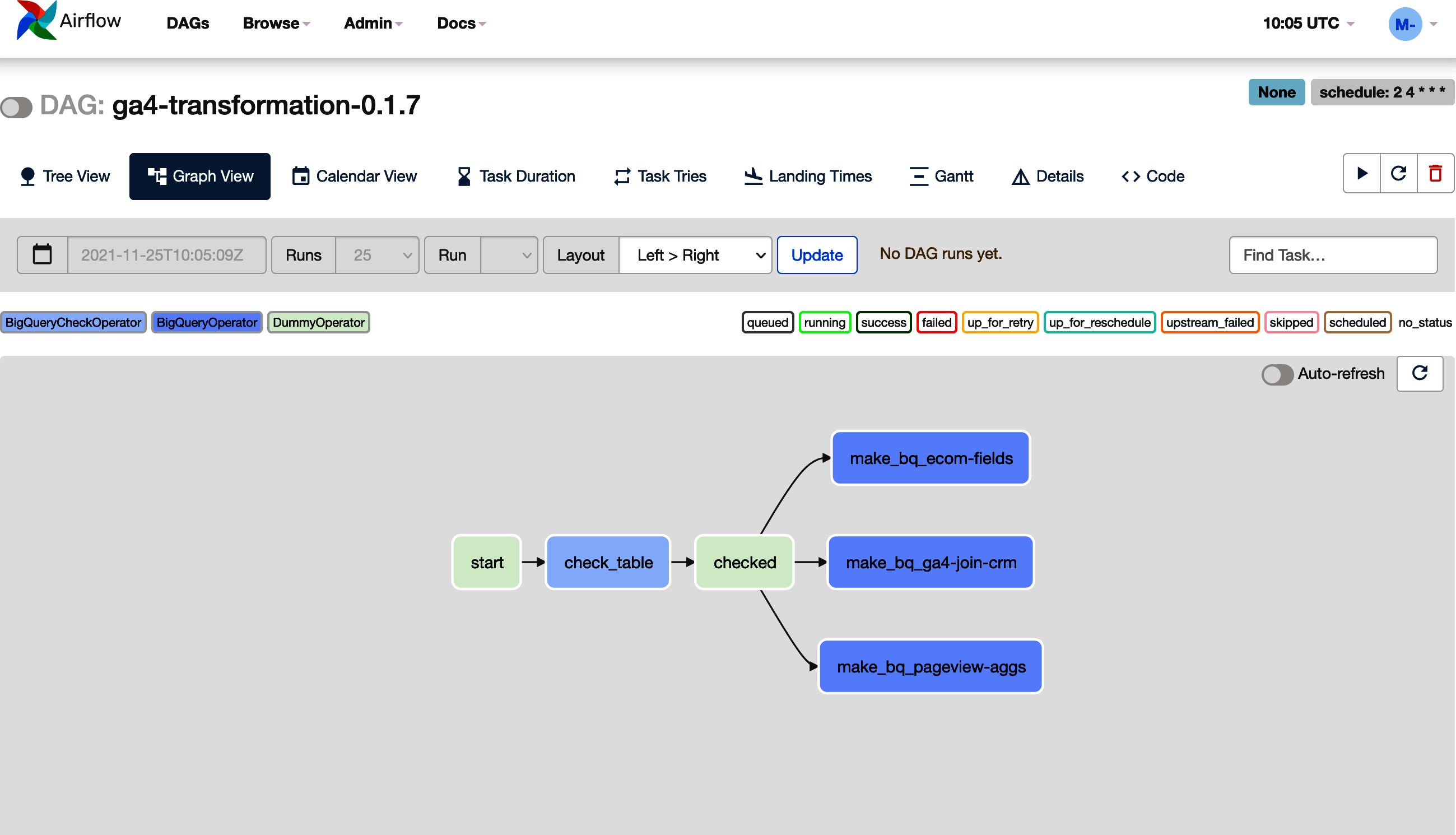
Figura 4-8. Un ejemplo del DAG creado en Airflow por el código del Ejemplo 4-11; para ampliarlo a más transformaciones, añade más archivos SQL a la carpeta y añade el nombre de la tabla a la lista ga_tables
Consejos para utilizar Airflow/Cloud Composer
Los archivos de ayuda general son excelentes para que aprenda a utilizar Cloud Composer, pero los siguientes son algunos consejos que he recogido al utilizarlo en proyectos de ciencia de datos:
- Utiliza Flujo de aire sólo para programar
-
Utiliza la herramienta adecuada para el trabajo adecuado: la función de Airflow es programar y conectarse a sistemas de almacenamiento de datos. Cometí el error de utilizar sus bibliotecas de Python para masajear un poco los datos entre los pasos de programación, pero me metí en un infierno de dependencias de Python que afectó a todas las tareas en ejecución. Prefiero utilizar contenedores Docker para cualquier código que deba ejecutarse, y utilizar en su lugar
GKEPodOperator()para ejecutar ese código en un entorno controlado. - Escribe funciones para tus DAGS
-
Es mucho más limpio crear funciones que generen DAGs en lugar de tener que escribir las tareas cada vez. También significa que puedes hacer un bucle sobre ellas y crear relaciones para muchos conjuntos de datos a la vez sin necesidad de copiar y pegar código.
- Utiliza operadores ficticios para señalizar
-
Los DAG tienen un aspecto impresionante, pero pueden ser confusos, por lo que tener algunas señales prácticas a lo largo de la línea puede indicarte dónde puedes detener e iniciar las ejecuciones de DAG que se comporten mal. Poder borrar todo el flujo descendente desde la señal "Datos todos cargados" deja claro lo que ocurrirá. Otras funciones que pueden ayudar aquí son los Grupos de Tareas y las Etiquetas, que pueden ayudar a mostrar metainformación sobre lo que está haciendo tu DAG.
- Separa tus archivos SQL
-
No tienes que escribir enormes cadenas de SQL para tus operadores; puedes ponerlas en archivos .sql y luego llamar al archivo que contiene el SQL. Esto facilita mucho el seguimiento y el control de los cambios.
- Versiona tus nombres DAG
-
También me parece útil incrementar la versión del nombre del DAG a medida que modificas y actualizas. Airflow puede ser un poco lento a la hora de reconocer las nuevas actualizaciones de los archivos, por lo que tener el nombre de la versión en el DAG significa que puedes estar seguro de que siempre estás trabajando con la última versión.
- Configurar Cloud Build para implementar DAGs
-
Tener que subir el código y los archivos de tu DAG cada vez te desincentivará a hacer cambios, por lo que es mucho más fácil si configuras una canalización de Cloud Build que despliegue tus DAG en cada commit en GitHub.
Eso ha sido una visita relámpago a las funciones de Cloud Composer, pero hay mucho más, y te recomiendo el sitio web de Airflow para explorar más de sus opciones. Es una opción de programación pesada, y hay otra mucho más ligera en Google Cloud Scheduler, que veremos a continuación.
Programador en la nube
Si buscas algo más ligero que Cloud Composer, entonces Cloud Scheduler es un sencillo servicio cron-in-the-cloud que puedes utilizar para activar puntos finales HTTP. Para tareas sencillas que no necesitan la complejidad de los flujos de datos que admite Cloud Composer, simplemente funciona.
Lo sitúo en algún punto intermedio entre Cloud Composer y las consultas programadas de BigQuery en cuanto a capacidades, ya que Cloud Scheduler no sólo ejecutará consultas de BigQuery, sino también cualquier otro servicio de GCP, ya que puede resultar útil.
Para ello, implica algo de trabajo extra para crear el tema Pub/Sub y la Función en la Nube que creará el trabajo BigQuery, así que si es sólo BigQuery, puede que no tengas necesidad, pero si hay otros servicios GCP implicados, centralizar la ubicación de tu programación puede ser mejor a largo plazo. Puedes ver un ejemplo de configuración de un tema Pub/Sub en "Pub/Sub"; la única diferencia es que luego se programa un evento para que llegue a ese tema a través de Cloud Scheduler. Puedes ver algunos ejemplos de mi propio GCP en la Figura 4-9 que muestra lo siguiente:
- Packagetest-build
-
Una programación semanal para activar una llamada a la API para ejecutar una Cloud Build
- Slackbot-programa
-
Una programación semanal para golpear un punto final HTTP que activará un Slackbot
- Pub_objetivo/Sub_programador
-
Un programa diario para activar un tema Pub/Sub

Figura 4-9. Algunas programaciones en la nube que activé para algunas tareas dentro de mi propio GCP
Cloud Scheduler también puede activar otros servicios como Cloud Run o Cloud Build. Una combinación especialmente potente es Cloud Scheduler y Cloud Build (tratada en la siguiente sección, "Cloud Build"). Como Cloud Build puede ejecutar tareas de larga duración, tienes una forma fácil de crear un sistema sin servidor que puede ejecutar cualquier trabajo en GCP, todo ello basado en eventos pero con alguna programación por encima.
Construir en la nube
Cloud Build es una potente herramienta a tener en cuenta para los flujos de trabajo de datos, y probablemente sea la herramienta que más uso a diario (¡incluso más que BigQuery!). Cloud Build también se introdujo en la sección de ingestión de datos en "Configuración de Cloud Build CI/CD con GitHub", pero entraremos en más detalles aquí.
Cloud Build está clasificada como una herramienta CI/CD, que es una estrategia popular en las operaciones de datos modernas. Obliga a que las liberaciones de código a producción no se produzcan al final de tiempos de desarrollo masivos, sino con pequeñas actualizaciones todo el tiempo, con funciones de prueba e implementación automáticas para que cualquier error se descubra rápidamente y pueda revertirse. Estas son buenas prácticas en general, y animo a leer sobre cómo seguirlas. Cloud Build también puede considerarse como una forma genérica de activar cualquier código en un clúster de computación como reacción a eventos. La intención principal es cuando envías código a un repositorio Git como GitHub, pero esos eventos también podrían ser cuando un archivo llega a GCS, se envía un mensaje Pub/Sub, o un programador hace ping al punto final.
Cloud Build funciona definiendo tú las secuencias de eventos, de forma muy parecida a un Airflow DAG pero con una estructura más sencilla. Para cada paso, defines un entorno Docker en el que ejecutar tu código, y los resultados de la ejecución de ese código pueden pasarse a los pasos siguientes o archivarse en GCS. Como funciona con cualquier contenedor Docker, puedes ejecutar una multitud de entornos de código diferentes sobre los mismos datos; por ejemplo, un paso podría ser Python para leer de una API, luego R para analizarlo y después Go para enviar el resultado a otro lugar.
Originalmente conocí Cloud Build como la forma de construir contenedores Docker en GCP. Colocas tu archivo Dockerfile en un repositorio de GitHub y luego lo confirmas, lo que desencadenará un trabajo y construirá Docker de una manera sin servidor, y no en tu propio ordenador como harías normalmente. Esta es la única forma en que construyo contenedores Docker actualmente, ya que construirlos localmente requiere tiempo y mucho espacio en el disco duro. Construir en la nube normalmente significa confirmar el código, ir a tomar una taza de té y volver en 10 minutos para inspeccionar los registros.
Cloud Build se ha ampliado ahora a construyendo no sólo archivos Docker, sino también su propia sintaxis de configuración YAML (cloudbuild.yaml), así como paquetes de construcción (buildpacks). Esto amplía enormemente su utilidad porque, a través de las mismas acciones (Git commit, evento Pub/Sub o una programación), puedes desencadenar trabajos para realizar toda una variedad de tareas útiles, no sólo contenedores Docker, sino ejecutar cualquier código que necesites.
He destilado las lecciones que he aprendido de trabajar con Cloud Build junto con el equivalente HTTP Docker Cloud Run y Cloud Scheduler en mi paquete R googleCloudRunnerque es la herramienta que utilizo para implementar la mayoría de mis tareas de ingeniería de datos para GA4 y otras en GCP. Cloud Build utiliza contenedores Docker para ejecutarlo todo. Puedo ejecutar casi cualquier lenguaje/programa o aplicación, incluido R. Disponer de una forma sencilla de crear y desencadenar estas construcciones desde R significa que R puede servir de interfaz de usuario o pasarela a cualquier otro programa, por ejemplo, R puede desencadenar una Cloud Build utilizando gcloud para desplegar aplicaciones Cloud Run.
Configuraciones de Cloud Build
Como introducción rápida, un archivo YAML de Cloud Build tiene un aspecto como el que se muestra en el Ejemplo 4-12. El ejemplo muestra cómo se pueden utilizar tres contenedores Docker diferentes dentro de la misma compilación, haciendo cosas distintas pero trabajando con los mismos datos.
Ejemplo 4-12. Ejemplo de un archivocloudbuild.yaml utilizado para crear compilaciones. Cada paso ocurre secuencialmente. El campo name es de una imagen Docker que ejecutará el comando especificado en el campo args.
steps:-name:'gcr.io/cloud-builders/docker'id:Docker Versionargs:["version"]-name:'alpine'id:Hello Cloud Buildargs:["echo","HelloCloudBuild"]-name:'rocker/r-base'id:Hello Rargs:["R","-e","paste0('1+1=',1+1)"]
A continuación, envías esta compilación utilizando la consola web de GCP, gcloud o googleCloudRunner, o bien utilizando la API de compilación en la nube. La versión de gcloud es gcloud builds submit --config cloudbuild.yaml --no-source. Esto desencadenará una compilación en la consola, donde podrás observarla a través de sus registros o de otro modo; consulta la Figura 4-10 de un ejemplo para las comprobaciones del paquete googleCloudRunner:
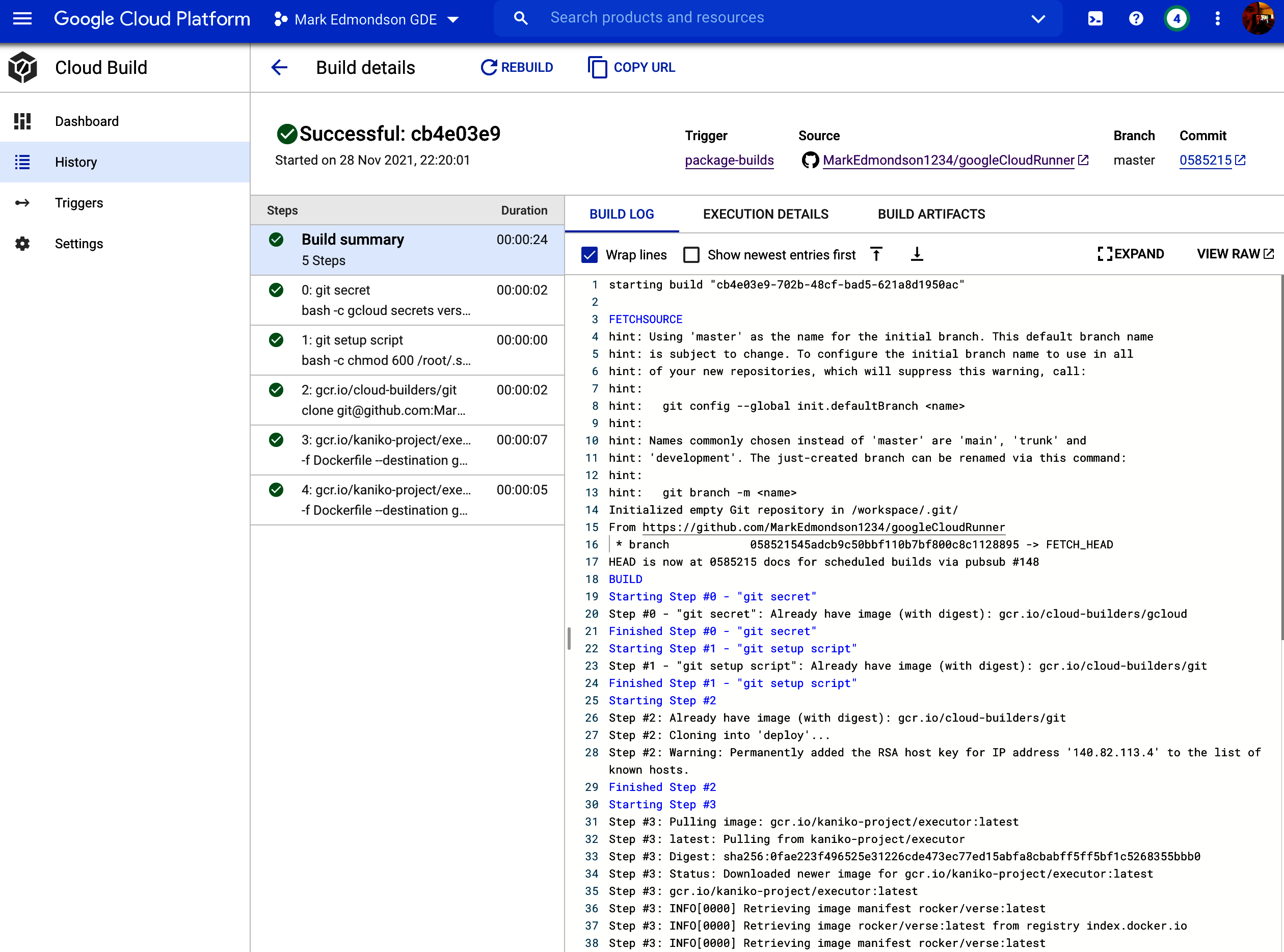
Figura 4-10. Una Cloud Build que se ha construido correctamente en la Consola de Google Cloud
También hemos visto el uso de Cloud Build para desplegar una Cloud Function en "Configuración de Cloud Build CI/CD con GitHub"; eseejemplo se reproduce en el Ejemplo 4-13. Sólo se necesita un paso para implementar la Función en la Nube del Ejemplo 3-9.
Ejemplo 4-13. YAML de compilación en la nube para la implementación de una función en la nube del Ejemplo 3-9
steps:-name:gcr.io/cloud-builders/gcloudargs:['functions','deploy','gcs_to_bq','--runtime=python39','--region=europe-west1','--trigger-resource=marks-crm-imports-2021','--trigger-event=google.storage.object.finalize']
Las compilaciones pueden activarse manualmente, pero a menudo quieres que sea un proceso automático, que empiece a adoptar la filosofía CI. Para ello, utiliza los Activadores de Construcción.
Construir activadores
Los Disparadores de Construcción son una configuración que decide cuándo se disparará tu Construcción en la Nube. Puedes configurar los desencadenantes de compilación para que reaccionen a los push Git, a los eventos Pub/Sub o a los webhooks sólo cuando los dispares manualmente en la consola. La compilación puede especificarse en un archivo o en línea dentro de la configuración del Activador de compilación. Ya hemos explicado cómo configurar los activadores de la compilación en "Configuración de la conexión de GitHub a Cloud Build", así que consulta esa sección para ver un tutorial.
Hemos hablado de Cloud Build en general, pero ahora pasamos a un ejemplo específico para GA4.
Aplicaciones GA4 para Cloud Build
En general, despliego todo el código para trabajar con los datos de GA4 a través de Cloud Build, ya que está vinculado al repositorio de GitHub en el que pongo mi código cuando no estoy trabajando en la interfaz GA4. Eso abarca los DAG de Airflow, las funciones de Cloud, las tablas de BigQuery, etc., a través de varios pasos de Cloud Build que invocan gcloud, mis bibliotecas de R, o de otro modo.
Al procesar las exportaciones estándar de GA4 BigQuery, Cloud Logging crea una entrada que muestra cuándo están listas esas tablas, que puedes utilizar para crear un mensaje Pub/Sub. Esto puede poner en marcha un flujo de datos basado en eventos, como la invocación de un Airflow DAG, la ejecución de consultas SQL u otros.
A continuación te mostramos un ejemplo en el que crearemos una Cloud Build que se ejecutará desde el tema Pub/Sub que se dispara una vez que tus exportaciones de GA4 BigQuery están presentes. En "Configuración de un tema Pub/Sub para las exportaciones de GA4 BigQuery", creamos un tema Pub/Sub llamado "ga4-bigquery", que se dispara cada vez que las exportaciones están listas. Ahora consumiremos este mensaje a través de un Cloud Build.
Crea un Activador de Construcción que responda al mensaje Pub/Sub. En la Figura 4-11 se muestra un ejemplo. Para esta demostración, leerá un archivo cloudbuild.yml que está dentro del repositorio GitHub code-examples. Este repositorio contiene el trabajo que deseas realizar en la exportación de BigQuery para ese día.
Figura 4-11. Configuración de un desencadenador de creación que se creará una vez finalizada la exportación de BigQuery para GA4
Ahora necesitamos la construcción que el Trigger de Construcción pondrá en marcha cuando reciba ese mensaje Pub/Sub. Adaptaremos el ejemplo del Ejemplo 4-10 y lo pondremos en un archivo SQL. Esto se consignará en el código fuente de GitHub, que la Compilación clonará antes de ejecutarlo. Esto te permitirá adaptar fácilmente el SQL confirmándolo en GitHub.
Ejemplo 4-14. La compilación que hará el Trigger de compilación cuando reciba el evento Pub/Sub de la finalización de exportación de GA4 BigQuery; el SQL del Ejemplo 4-10 se carga en un archivo separado llamadoga4-agg.sql
steps:-name:'gcr.io/cloud-builders/gcloud'entrypoint:'bash'dir:'your/dir/on/Git'args:['-c','bq--location=eu\--project_id=$PROJECT_IDquery\--use_legacy_sql=false\--destination_table=tidydata.ga4_pageviews\<./ga4-agg.sql']
Para ejecutar con éxito el Ejemplo 4-14, es necesario ajustar los permisos de usuario para permitir el uso autorizado para realizar la consulta. No será tu propio usuario, ya que el trabajo lo realizará en tu nombre el agente de servicio de Cloud Build. Dentro de la configuración de Cloud Build o en la Consola de Google encontrarás el usuario de servicio que llevará a cabo los comandos dentro de Cloud Build, que será algo parecido a 123456789@cloudbuild.gserviceaccount.com. Puedes utilizar esto, o puedes crear tu propia cuenta de servicio personalizada con permisos de Cloud Build. Este usuario debe añadirse como Administrador de BigQuery para que pueda realizar consultas y otras tareas de BigQuery, como crear tablas, que puedas desear más adelante. Mira la Figura 4-12.
Para tus propios casos de uso, tendrás que adaptar el SQL y quizás añadir más pasos para trabajar con los datos una vez completado este paso. Puedes ver que Cloud Build cumple una función similar a Cloud Composer, pero de forma más sencilla. Es más genérico que programar consultas en BigQuery, pero no tan caro ni rico en funciones como Cloud Composer; me parece una buena herramienta en la caja de herramientas para cuando necesites programar tareas sencillas o basadas en eventos.
Figura 4-12. Añadir los permisos para ejecutar trabajos BigQuery a la cuenta del servicio Cloud Build
Integraciones Cloud Build para CI/CD
Cloud Build puede activarse mediante programaciones, invocaciones manuales de y eventos. Los eventos cubren las confirmaciones Pub/Sub y GitHub, que son clave para su función como herramienta de CI/CD. En general, es una buena idea cuando se codifica utilizar un control de versiones como Git, y yo utilizo GitHub, la versión más popular. De este modo puedes mantener un registro de todo lo que haces y también disponer de un deshacer infinito para revertir los cambios si lo necesitas, y cuando la diferencia entre el éxito y el fracaso puede ser un . en el lugar equivocado, ¡esto es deseable!
Una vez que utilices Git para el control de versiones, también puedes empezar a utilizarlo para otros fines,, como desencadenar compilaciones a partir de cada confirmación para comprobar tu código (pruebas), asegurarte de que sigue las directrices de estilo (linting) o desencadenar compilaciones reales del producto que crea el código.
Cloud Build permite cualquier lenguaje de código dentro de mediante su uso de contenedores Docker, que se utilizan para controlar los entornos de cada paso. También cuenta con una autenticación sencilla para el servicio Google Cloud a través de gcloud auth, como vimos en la Figura 4-12, al configurarlo para realizar tareas de BigQuery. Los comandos gcloud que utilizas para desplegar servicios también se pueden utilizar dentro de Cloud Build para automatizar esas implementaciones. Además, toda la ejecución puede basarse en el código que estás confirmando en el repositorio Git, por lo que tendrás una visión perfecta de lo que está ocurriendo y cuándo.
Por ejemplo, podemos desplegar DAG en Airflow, como se hizo en el Ejemplo 4-11. Normalmente, para que se despliegue tu DAG, tienes que copiar ese archivo Python en una carpeta especial dentro del entorno de Cloud Composer, pero con Cloud Build puedes utilizar gsutil (la herramienta de línea de comandos de GCS) para hacerlo en su lugar. Esto fomenta un desarrollo más rápido y te devuelve algo de tiempo para centrarte en las cosas importantes. En el Ejemplo 4-15 se muestra un ejemplo del archivo cloudbuild para tu activador.
Ejemplo 4-15. Puedes implementar DAGs de Python para Airflow/Cloud Composer utilizando Cloud Build directamente desde tu repositorio Git: aquí $_AIRFLOW_BUCKET es una variable de sustitución que cambias por la ubicación de tu instalación, y se supone que los archivos.sql están dentro de una carpeta llamadasql en la misma ubicación.
steps:-name:gcr.io/google.com/cloudsdktool/cloud-sdk:alpineid:deploy dagentrypoint:'gsutil'args:['mv','dags/ga4-aggregation.py','$_AIRFLOW_BUCKET/dags/ga4-aggregation.py']-name:gcr.io/google.com/cloudsdktool/cloud-sdk:alpineid:remove old SQLentrypoint:'gsutil'args:['rm','-R','${_AIRFLOW_BUCKET}/dags/sql']-name:gcr.io/google.com/cloudsdktool/cloud-sdk:alpineentrypoint:'gsutil'id:add new SQLargs:['cp','-R','dags/sql','${_AIRFLOW_BUCKET}/dags/sql']
Al igual que en el ejemplo anterior para Cloud Composer, Cloud Build también puede utilizarse para la implementación de todos los demás servicios de GCP. Volvemos a utilizarlo en el Ejemplo 3-15 para desplegar Cloud Functions, pero se puede automatizar cualquier servicio que utilice un comando gcloud.
Los servicios de programación de datos por lotes son normalmente el núcleo de todas las aplicaciones de datos, incluidas las que implican GA4. Hemos hecho un recorrido por algunas de tus opciones a la hora de programar, incluidas las consultas programadas de BigQuery, Cloud Scheduler, Cloud Build y Cloud Composer/Airflow. Cada una tiene las siguientes ventajas ydesventajas:
- Consultas programadas BigQuery
-
Fácil de configurar, pero carece de responsabilidad y sólo funciona para BigQuery
- Programador en la nube
-
Funciona para todos los servicios, pero las dependencias complicadas empezarán a ser difíciles de mantener
- Construir en la nube
-
Basado en eventos y puede activarse desde programaciones, normalmente es mi opción preferida, pero no admite flujos que necesiten rellenos y reintentos
- Compositor de nubes
-
Herramienta de programación completa con rellenos, compatibilidad con flujos de trabajo complicados y funciones de reintento/acuerdo de nivel de servicio (SLA), pero la más cara y complicada de utilizar
Esperemos que esto te haya dado algunas ideas sobre lo que podrías utilizar para tus propios casos de uso. En la siguiente sección, veremos flujos de datos más en tiempo real y las herramientas que puedes utilizar cuando necesites procesar tus datos inmediatamente.
Flujos de datos
Para algunos flujos de trabajo, la programación por lotes puede no ser suficiente. Si buscas actualizaciones de datos reactivas en menos de media hora, por ejemplo, puede que sea el momento de empezar a mirar las opciones de flujo de datos en tiempo real. Varias de las soluciones comparten algunas de las mismas funciones y componentes, pero hay un mayor coste y complejidad que conlleva el flujo de datos en tiempo real que debes tener en cuenta.
Pub/Sub para transmisión de datos
Los ejemplos hasta ahora sólo han tratado Pub/Sub con volúmenes de datos relativamente bajos, sólo eventos para decir que ha ocurrido algo. Sin embargo, su finalidad principal es tratar flujos de datos de gran volumen, y aquí es donde realmente brilla. Su sistema de entrega "al menos una vez" significa que puedes construir flujos de datos fiables incluso si haces pasar TBs de datos a través de él. De hecho, Googlebot, el bot del motor de búsqueda que creó Google Search, también funciona con una infraestructura similar, y descarga regularmente todo Internet, ¡así que sabes que Pub/Sub puede escalar!
Lo más probable es que la compatibilidad con el flujo de datos comience con Pub/Sub como punto de entrada hacia el que otros sistemas de flujo envían datos desde Kafka u otros sistemas locales. Al configurar estas ingestas en tiempo real, suelen ser los desarrolladores de aplicaciones internas los que configurarán este flujo antes de entregarlo una vez que quieran que fluya hacia el GCP. Aquí es donde suelo involucrarme, siendo mi responsabilidad ayudar a definir el esquema de los datos que entran en el tema Pub/Sub y luego llevarlo adelante a partir de ahí.
Una vez que tengas datos fluyendo hacia un tema Pub/Sub, dispone de soluciones listas para usar para empezar a transmitirlos a destinos populares, como el Almacenamiento en la Nube y BigQuery. Éstas son proporcionadas por Apache Beam o la versión alojada por Google, Dataflow.
Apache Beam/DataFlow
El servicio al que se recurre para el flujo de datos en GCP es Dataflow. Dataflow es un servicio que ejecuta trabajos escritos en Apache Beam, una biblioteca de procesamiento de datos que comenzó en Google pero que ahora está disponible en código abierto, por lo que también puedes utilizarla como estándar para otras nubes.
Apache Beam funciona creando máquinas virtuales (VM) con Apache Beam instalado, configuradas para ejecutar código que operará sobre cada paquete de datos a medida que fluya. Tiene autoescalado incorporado, de modo que si los recursos de la máquina empiezan a agotarse (es decir, si se alcanzan los umbrales de CPU y/o memoria), lanzará otra máquina y dirigirá parte del tráfico hacia ella. Costará más o menos en función de la cantidad de datos que envíes, con un suelo mínimo de 1 máquina virtual.
Hay tareas de datos comunes que se agilizan para Apache Beam gracias a sus plantillas. Por ejemplo, una tarea común es transmitir Pub/Sub a BigQuery, que está disponible sin tener que escribir ningún código. En la Figura 4-13 se muestra un ejemplo.
Para trabajar con la plantilla, tendrás que crear un cubo y la tabla BigQuery a la que fluirán los mensajes Pub/Sub. La tabla BigQuery debe tener el esquema correcto, que debe coincidir con el esquema de datos Pub/Sub.

Figura 4-13. Configuración de un flujo de datos desde Google Cloud Console para un tema Pub/Sub en BigQuery a través de la plantilla predefinida
En mi ejemplo, estoy transmitiendo algunos eventos GA4 de desde mi blog a Pub/Sub a través de GTM SS(consulta "Transmisión de eventos GA4 a Pub/Sub con GTM SS"). Por defecto, el flujo intentará escribir cada campo Pub/Sub en una tabla BigQuery, y tu esquema BigQuery tendrá que coincidir exactamente para tener éxito. Esto puede ser problemático si tu Pub/Sub incluye campos que no son válidos en BigQuery, como los que tienen guiones (-) que están presentes en el Ejemplo 4-16.
Ejemplo 4-16. Un ejemplo del JSON enviado desde una etiqueta GA4 en GTM SS a Pub/Sub, que tiene algunos campos que empiezan por x-ga
{"x-ga-protocol_version":"2","x-ga-measurement_id":"G-43MXXXX","x-ga-gtm_version":"2reba1","x-ga-page_id":1015778133,"screen_resolution":"1536x864","language":"ru-ru","client_id":"68920138.12345678","x-ga-request_count":1,"page_location":"https://code.markedmondson.me/data-privacy-gtm/","page_referrer":"https://www.google.com/","page_title":"Data Privacy Engineering with Google Tag Manager Server Side and ...","ga_session_id":"12343456","ga_session_number":1,"x-ga-mp2-seg":"0","event_name":"page_view","x-ga-system_properties":{"fv":"2","ss":"1"},"debug_mode":"true","ip_override":"78.140.192.76","user_agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ...","x-ga-gcs-origin":"not-specified","user_id":"123445678"}
Para satisfacer tus necesidades de personalización, puedes proporcionar una función de transformación que modifique el flujo antes de pasarlo a BigQuery. Por ejemplo, podemos filtrar los campos que empiezan por x-ga.
La función definida por el usuario (UDF) Dataflow del Ejemplo 4-17 filtra esos eventos, para que el resto de la plantilla pueda enviar los datos a BigQuery. Esta UDF debe cargarse en un cubo para que los trabajadores de Dataflow puedan descargarla y utilizarla.
Ejemplo 4-17. Una función de flujo de datos definida por el usuario que filtra los campos del tema Pub/Sub que empiezan por x-ga para que el resto de los datos puedan escribirse en BigQuery
/*** A transform function that filters out fields starting with x-ga* @param {string} inJSON* @return {string} outJSON*/functiontransform(inJSON){varobj=JSON.parse(inJSON);varkeys=Object.keys(obj);varoutJSON={};// don't output keys that starts with x-gavaroutJSON=keys.filter(function(key){return!key.startsWith('x-ga');}).reduce(function(acc,key){acc[key]=obj[key];returnacc;},{});returnJSON.stringify(outJSON);}
Una vez configurado el trabajo de Dataflow, te dará un DAG muy parecido al de Cloud Composer/Airflow, pero en este sistema se tratará de flujos basados en eventos en tiempo real, no en lotes. La Figura 4-14 muestra lo que deberías ver en la sección Trabajos de flujo de datos de la consola web.
Figura 4-14. Iniciar un trabajo en ejecución para importar mensajes Pub/Sub a BigQuery en tiempo real
Costes del flujo de datos
Dada la forma en que funciona Dataflow, desconfía de poner en marcha demasiadas máquinas virtuales, porque si se produce un error, eso puede enviar un montón de hits a tu pipeline, y rápidamente puedes incurrir en costosas facturas. Una vez que tengas una idea de tu carga de trabajo, es prudente establecer un límite superior en las máquinas virtuales para hacer frente a los picos de datos, pero sin dejar que se te escapen si ocurre algo realmente inesperado. Incluso con estas precauciones, la solución sigue siendo más cara que los flujos de trabajo por lotes, ya que puedes esperar gastar del orden de 10 a 30 $ al día o de 300 a 900 $ al mes.
El esquema de BigQuery tiene que coincidir con la configuración Pub/Sub, así que tenemos que crear una tabla. La tabla de la Figura 4-15 también está configurada para ser particionada en el tiempo.
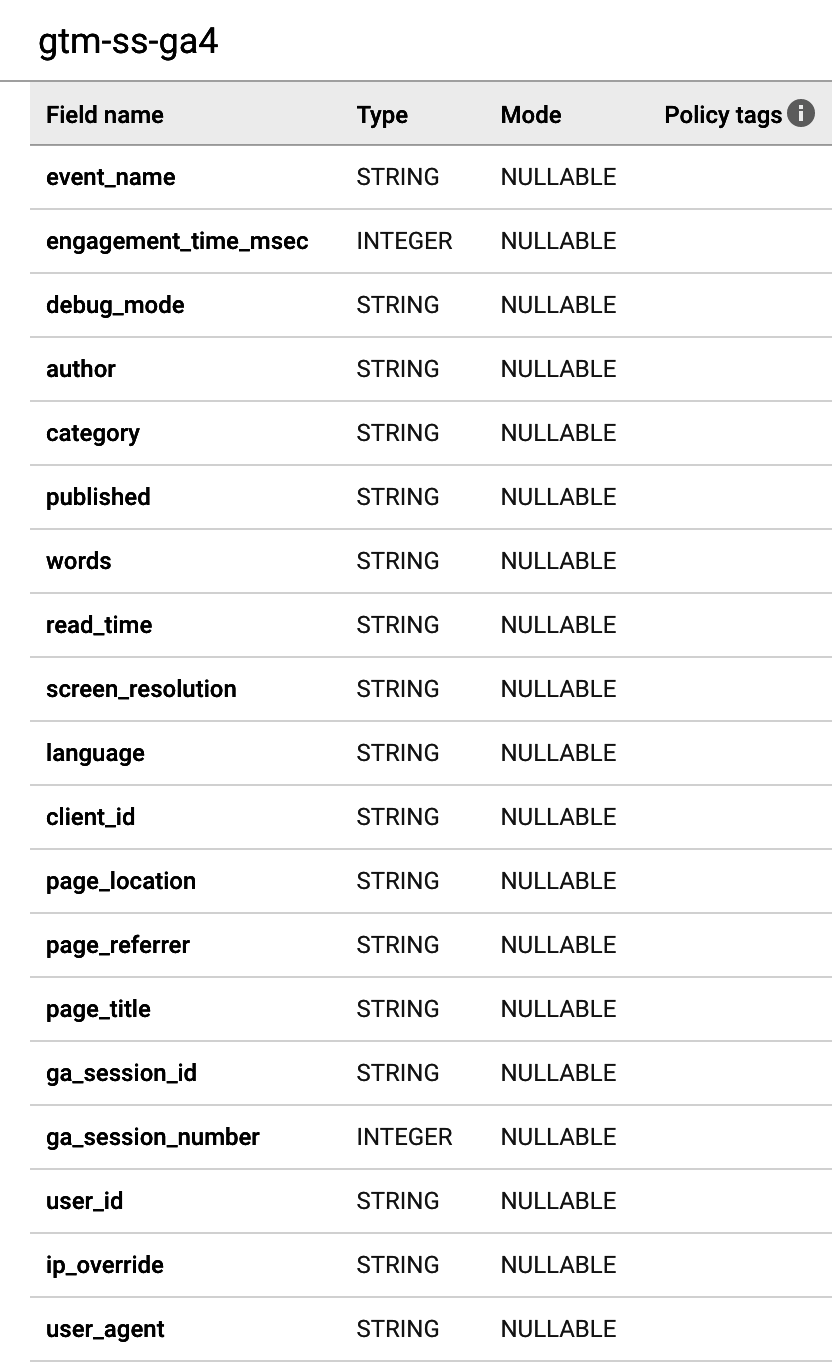
Figura 4-15. El esquema de datos de BigQuery para recibir el JSON Pub/Sub
Si cometes algún error, el trabajo de Flujo de datos transmitirá los datos brutos a otra tabla del mismo conjunto de datos, donde podrás examinar los errores y hacer correcciones, como se muestra en la Figura 4-16.
Figura 4-16. Cualquier error del flujo de datos aparecerá en su propia tabla BigQuery para que puedas examinar las cargas útiles
Si todo va bien, deberías ver que tus datos Pub/Sub empiezan a aparecer en BigQuery -date una palmadita en la espalda si ves algo parecido a la Figura 4-17.
Ya dispones gratuitamente de una funcionalidad estándar de exportación a BigQuery mediante las exportaciones nativas de BigQuery de GA4, pero este proceso puede adaptarse a otros casos de uso dirigiéndolo a diferentes puntos finales o realizando diferentes transformaciones. Un ejemplo puede ser trabajar con un subconjunto de tus eventos GA4 para modificar el golpe para que sea más consciente de la privacidad o para enriquecerlo con metadatos de productos disponibles sólo a través de otro flujo en tiempo real.
Recuerda que Dataflow estará ejecutando una VM con un gasto para este flujo, así que desactívalo si no lo necesitas. Si tus volúmenes de datos no son lo suficientemente grandes como para justificar tal gasto, también puedes utilizar Funciones en la Nube para transmitir datos.
Figura 4-17. Una importación en flujo correcta de GA4 a GTM SS to Pub/Sub toBigQuery
Streaming a través de funciones en la nube
Si tus volúmenes de datos están dentro de las cuotas de Cloud Function , tu configuración de temas Pub/Sub también puede utilizar Cloud Functions para transmitir los datos a diferentes ubicaciones. El Ejemplo 4-5 tiene algún código de ejemplo para eventos esporádicos como tablas BigQuery, pero también puedes reaccionar a flujos de datos más regulares y Cloud Function escalará hacia arriba y hacia abajo según sea necesario: cada invocación del evento Pub/Sub creará una instancia de Cloud Function que se ejecutará en paralelo con otras funciones.
Los límites (para las Funciones en la Nube de Generación 1) incluyen sólo 540 segundos (9 minutos) de tiempo de ejecución y un total de 3.000 segundos de invocaciones simultáneas (por ejemplo, si una función tarda 100 segundos en ejecutarse, puedes tener hasta 30 funciones ejecutándose a la vez). Esto significa que debes hacer que tus Funciones en la Nube sean pequeñas y eficientes.
La siguiente Función Nube debería ser lo suficientemente pequeña como para que puedas tener unas 300 peticiones por segundo(Ejemplo 4-18). Toma el mensaje Pub/Sub y lo pone como cadena en una columna de datos raw en BigQuery junto con su marca de tiempo. Puedes modificar el código para analizar un esquema más específico cuando lo necesites o utilizar el propio SQL de BigQuery para procesar la cadena JSON sin procesar y convertirla posteriormente en datos más ordenados.
Ejemplo 4-18. Modifica el dict pb dentro del código para analizar más campos si quieres crear una tabla más a medida. Añade argumentos de entorno dataset y table que apunten a tu tabla BigQuery prefabricada. Inspirado en el post de Milosevic en Medium sobre cómo copiar datos de Pub/Sub a BigQuery.
# python 3.7# pip google-cloud-bigquery==2.23.2fromgoogle.cloudimportbigqueryimportbase64,JSON,sys,os,timedefPub/Sub_to_bigq(event,context):Pub/Sub_message=base64.b64decode(event['data']).decode('utf-8')(Pub/Sub_message)pb=JSON.loads(Pub/Sub_message)raw=JSON.dumps(pb)pb['timestamp']=time.time()pb['raw']=rawto_bigquery(os.getenv['dataset'],os.getenv['table'],pb)defto_bigquery(dataset,table,document):bigquery_client=bigquery.Client()dataset_ref=bigquery_client.dataset(dataset)table_ref=dataset_ref.table(table)table=bigquery_client.get_table(table_ref)errors=bigquery_client.insert_rows(table,[document],ignore_unknown_values=True)iferrors!=[]:(errors,file=sys.stderr)
La función toma argumentos de entorno para especificar dónde van los datos, como se muestra en la Figura 4-18. Esto te permite implementar varias funciones para distintos flujos.
La tabla BigQuery prefabricada sólo tiene dos campos, raw, que contiene la cadena JSON, y timestamp, cuando se ejecuta la Función Nube. Puedes utilizar las funciones JSON de BigQuery en SQL para analizar esta cadena JSON sin procesar, como se muestra en el Ejemplo 4-19.
Figura 4-18. Configuración de los argumentos de entorno para su uso en la Función Nube del Ejemplo 4-18
Ejemplo 4-19. BigQuery SQL para analizar una cadena JSON sin procesar
SELECTJSON_VALUE(raw,"$.event_name")ASevent_name,JSON_VALUE(raw,"$.client_id")ASclient_id,JSON_VALUE(raw,"$.page_location")ASpage_location,timestamp,rawFROM`learning-ga4.ga4_Pub/Sub_cf.ga4_Pub/Sub`WHEREDATE(_PARTITIONTIME)ISNULLLIMIT1000
El resultado del código del Ejemplo 4-19 se muestra en la Figura 4-19. Puedes configurar este flujo descendente SQL en una programación o mediante una Vista BigQuery.
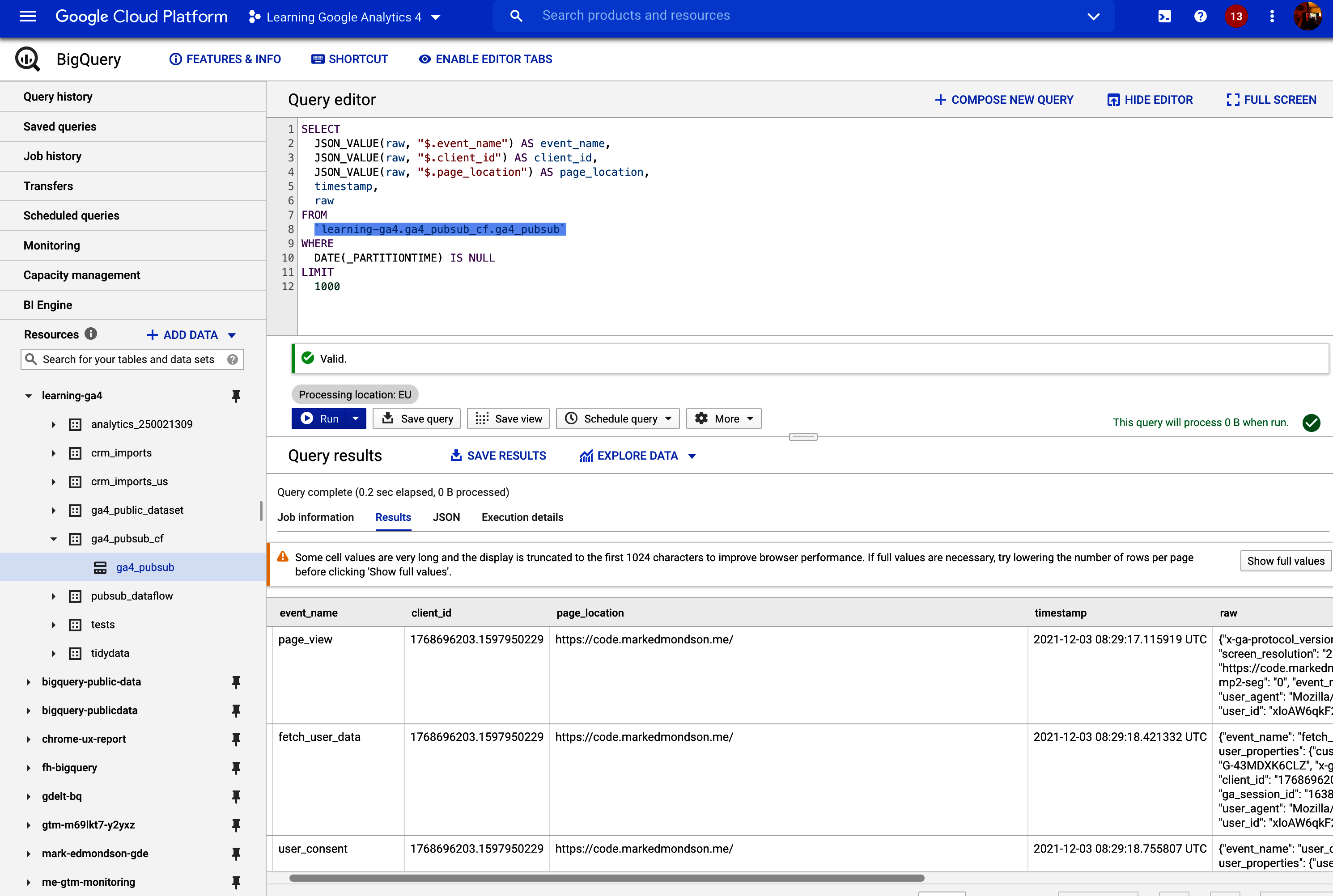
Figura 4-19. La tabla de datos brutos que recibe el flujo Pub/Sub de GA4 a través de GTM-SS puede analizar su JSON con funciones de BigQuery como JSON_VALUE()
Los servicios de streaming de datos ofrecen una forma de disponer de la pila de datos más ágil y moderna para tu configuración GA4, pero tienen un coste financiero y tecnológico que deberás justificar con un gran argumento empresarial. Sin embargo, si tienes ese caso, disponer de estas herramientas significa que deberías poder poner en marcha una aplicación que habría sido casi imposible de hacer hace 10 años.
Los flujos de datos analíticos digitales como GA4 suelen ser los más útiles cuando pueden adaptar las experiencias a un usuario individual, pero cuando se utilizan datos que pueden asociarse a una persona, hay que ser muy consciente de las consecuencias tanto legales como éticas. Profundizaremos en ello en la siguiente sección.
Proteger la privacidad de los usuarios
"Privacidad del usuario" también ofrece una visión general de la privacidad del usuario, pero esta sección profundiza más y ofrece algunos recursos técnicos.
En esta era moderna de los datos, se han dado cuenta del valor de los datos quienes los proporcionan y no sólo quienes los utilizan. Tomar esos datos sin permiso puede considerarse ahora tan inmoral como un robo, por lo que, para ser un negocio sostenible a largo plazo, es cada vez más importante ganarse la confianza de tus usuarios. Las marcas más fiables serán las que tengan claro qué datos captan y cómo los utilizan, así como las que faciliten a los usuarios el acceso a sus propios datos, hasta el punto de que puedan tomar decisiones informadas, tengan el poder de reclamar sus propios datos y recuperar el permiso para utilizarlos. Siguiendo con esta ética en evolución, las leyes de varias regiones también están empezando a ser más estrictas y más impactantes, con la posibilidad de fuertes multas si no cumples.
Cuando almacenas datos que pueden rastrearse hasta una persona, tienes la responsabilidad de proteger esos datos personales tanto de abusos internos como de agentes malignos externos que intenten robarlos.
Esta sección examina los patrones de diseño de almacenamiento de datos que te ayudarán a facilitar el proceso de privacidad de los datos. En algunos casos, el incumplimiento se ha producido no por intención, sino por un sistema mal diseñado, que trataremos de evitar.
Privacidad de datos desde el diseño
La forma más fácil de evitar los problemas de privacidad de datos es simplemente no almacenar datos personales. A menos que tengas una necesidad específica de esos datos personales, eliminarlos de tu captura de datos o borrarlos a medida que se almacenan es la forma más fácil de mantenerlos bajo control. Esto puede sonar frívolo, pero es necesario decirlo, ya que es bastante habitual que las empresas recojan estos datos por accidente o sin pensar realmente en las consecuencias. Un caso clásico con la analítica web es almacenar accidentalmente los correos electrónicos de los usuarios en las URL de los formularios web o en los cuadros de búsqueda. Aunque sea accidental, esto va en contra de las Condiciones de Servicio de Google Analytics y conlleva el riesgo de que te cierren la cuenta. Realizar una limpieza de datos en el momento de la recopilación puede contribuir en gran medida a mantener la casa limpia.
Si necesitas cierto nivel de personalización, aún no tienes por qué capturar datos que supongan un riesgo para la privacidad. Aquí es donde entra en juego la pseudonimización, que es la opción por defecto para la recogida de datos, incluida la GA4. Aquí se asigna un ID a un usuario, pero es ese ID el que se comparte, no los datos personales del usuario. Un ejemplo es elegir entre un ID aleatorio o el número de teléfono de una persona como ID de usuario. Si el ID aleatorio se expone accidentalmente, un atacante no podría hacer gran cosa con él a menos que tuviera acceso al sistema que asignó ese ID al resto de la información de esa persona. Si el ID expuesto es en realidad el número de teléfono de una persona, el atacante tiene algo que puede utilizarinmediatamente. Utilizar la pseudonomización es una primera línea de defensa para proteger los datos personales de un usuario. De nuevo, nunca utilices el correo electrónico o un número de teléfono como identificación porque te encontrarás con violaciones de la privacidad; las empresas que lo han hecho han sido multadas.
Puede que el ID sea todo lo que necesites para tus casos de uso; por ejemplo, la recogida de datos por defecto de GA4 es a este nivel. Sólo cuando empieces a vincular ese ID a información personal, como vincular el client_id de GA4 a la dirección de correo electrónico de un usuario, tendrás que empezar a tener en cuenta consideraciones de privacidad más extremas. Esto suele ocurrir cuando empiezas a vincularlo a tus sistemas backend, como una base de datos CRM.
Si entonces tus casos de uso requieren datos personales, correo electrónico, nombre u otros, hay algunos principios de que debes mantener en vigor, alentados por la legislación sobre privacidad, como el GDPR. Estos pasos te permitirán preservar la dignidad del usuario, así como tener algún impacto empresarial con esos datos:
- Conservar los datos personales (PII) en un número mínimo de ubicaciones
-
Los datos personales deben conservarse en el menor número posible de bases de datos y luego unirse o vincularse a otros sistemas mediante un identificador seudónimo que sea la clave de esa tabla. De este modo, sólo tendrás que buscar en un lugar si necesitas eliminar o extraer los datos de una persona, y no tendrás que eliminarlos también de otros lugares a los que se hayan copiado o unido. Esto complementa el siguiente punto sobre la encriptación de los datos de usuario, ya que sólo deberías necesitar hacerlo con la base de datos de usuarios.
- Cifra los datos de usuario con hashes de sal y pimienta
-
El proceso de hashing es un método de encriptación unidireccional de datos, de modo que sea imposible recrear los datos originales sin conocer los ingredientes: por ejemplo, "Mark Edmondson" cuando se hace hashing con el popular algoritmo sha256 es:
3e7e793f2b41a8f9c703898c5c0d4e08ab2f22aa1603f8d0f6e4872a8f542335
Sin embargo, siempre es este hash y debe ser globalmente único para que puedas utilizarlo como una clave fiable. Poner "sal y pimienta" al hash significa que también añades una palabra clave única a los datos para hacerlos aún más seguros si de alguna manera alguien rompe el algoritmo de hashing o puede obtener el mismo hash para hacer un enlace. Por ejemplo, si mi sal es "babuinos", entonces le pongo un prefijo a mi punto de datos para que "Mark Edmondson" se convierta en "babuinosMark Edmondson", y el hash sea:
a776b81a2a6b1c2fc787ea0a21932047b080b1f08e7bc6d6a2ccd1fb6443df48
por ejemplo, completamente diferente a la anterior. Las sales pueden ser globales o almacenarse con el punto de usuario para que sean únicas para cada usuario. Poner "pimienta" o "sal secreta" al hash es un concepto similar, pero esta vez la palabra clave no se guarda junto a los datos a cifrar, sino en otra ubicación segura. Esto protege contra las violaciones de la base de datos, porque ahora tiene dos ubicaciones. En este caso, la "pimienta" se buscaría y podría ser "averylongSECRETthatnoonecanknow?" y así mi hash final sería "baboonsMark EdmondsonaverylongSECRETthatnoonecanknow?" para dar un hash final de:
c9299fe251319ffa7ec66137acfe81c75ee115ceaa89b3e74b521a0b5e12d138
con la que debería ser muy difícil para un hacker motivado volver a identificar al usuario.
- Poner plazos de caducidad a los datos personales
-
A veces no tendrás más remedio que copiar los datos personales de, por ejemplo, si los importas de nubes o sistemas diferentes. En ese caso, puedes designar la fuente de datos como fuente de verdad para todas tus iniciativas de privacidad y luego imponer una fecha de caducidad a cualquier dato que se copie de esa fuente. Treinta días es lo habitual, lo que significa que tienes que hacer una importación completa al menos cada 30 días (quizá incluso a diario), por lo que los volúmenes de datos aumentarán. Así estarás seguro de que, cuando actualices los permisos y valores de los usuarios en tu base de datos maestra, cualquier copia de esos datos será efímera y dejará de existir una vez que cesen las importaciones.
Añadir principios de privacidad añade trabajo extra, pero la recompensa es tranquilidad y confianza en tus propios sistemas, que puedes transmitir a tus clientes. En la siguiente sección se muestra un ejemplo del último punto para la caducidad de los datos dentro de algunos de los sistemas de almacenamiento de los que hemos hablado en este capítulo.
Caducidad de datos en BigQuery
Al configurar tus conjuntos de datos, tablas y buckets, puedes establecer la caducidad de los datos que van llegando. Ya hemos explicado cómo configurarlo en GCS en "Google Cloud Storage".
En BigQuery, puedes establecer una fecha de caducidad a nivel de conjunto de datos que afectará a todas las tablas de ese conjunto de datos; consulta la Figura 4-20 para ver un ejemplo con un conjunto de datos de prueba.
Figura 4-20. Puedes configurar el tiempo de caducidad de la tabla al crear un conjunto de datos
Para las tablas particionadas, necesitarás algo diferente, ya que la tabla siempre existirá pero quieres que las propias particiones caduquen con el tiempo, dejándote sólo los datos más recientes. Para ello, tendrás que invocar gcloud o utilizar el SQL de BigQuery para alterar las propiedades de la tabla, como se muestra en el Ejemplo 4-20.
Ejemplo 4-20. Establecer una fecha de caducidad para las particiones BigQuery en una tabla de particiones
A la manera gcloud (a través de tu consola local bash o en la Consola Cloud):
bq update --time_partitioning_field=event_date \ --time_partitioning_expiration 604800 [PROJECT-ID]:[DATASET].partitioned_table
O a través de BigQuery DML:
ALTERTABLE`project-name`.dataset_name.table_nameSETOPTIONS(partition_expiration_days=7);
Además de los tiempos pasivos de expiración de datos, también puedes escanear activamente los datos en busca de violaciones de privacidad mediante la API de Prevención de Pérdida de Datos.
API de Prevención de Pérdida de Datos
La API de Prevención de Pérdida de Datos (DLP) es una forma de detectar y enmascarar automáticamente datos sensibles como correos electrónicos, números de teléfono y números de tarjetas de crédito. Puedes llamarla y ejecutarla en tus datos dentro de Cloud Storage o BigQuery.
Si tienes una gran cantidad de datos en flujo, hay una plantilla Dataflow disponible para leer datos CSV de GCS y poner los datos redactados en BigQuery.
Para GA4, lo más fácil es utilizarla para escanear tus exportaciones de BigQuery para ver si se ha recopilado algún dato personal inadvertidamente. La API DLP sólo escanea una tabla cada vez, por lo que la mejor forma de utilizarla es escanear cada día la tabla de datos que recibes. Si tienes muchos datos, te recomiendo escanear sólo una muestra y/o restringir el escaneo a sólo los campos que puedan contener datos sensibles. Para las exportaciones GA4 BigQuery en particular, lo más probable es que se trate sólo del event_params.value.string_value, ya que todos los demás campos están más o menos fijados por tu configuración (event_name, etc.).
Resumen
Dado que los datos se presentan en formas y usos tan diversos, existen muchos sistemas diferentes para albergarlos. Las categorías generales de las que hemos hablado en este capítulo son datos estructurados y no estructurados, y conductos programados frente a conductos de flujo entre esos sistemas. También necesitas una buena estructura organizativa con alguna idea sobre quién y qué debe acceder a cada dato a lo largo de su viaje, ya que, al fin y al cabo, son las personas las que van a utilizar esos datos, y reducir la fricción para que la persona adecuada vea los datos adecuados es un gran paso hacia la madurez de los datos dentro de tuorganización. En cuanto necesites datos más allá de GA4, tendrás que saber cómo interactúan estos sistemas, pero tienes un buen punto de partida con las exportaciones de BigQuery de GA4, que está muy bien considerado como una de sus características clave sobre Universal Analytics.
Ahora que ya hemos hablado de cómo recopilar y almacenar datos, en el próximo capítulo profundizaremos en cómo se masajean, transforman y modelan activamente esos datos, y cómo suelen representar el lugar donde se añade más valor dentro de la cadena de producción.
Get Aprender Google Analytics now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

