Chapter 4. Running Applications in DC/OS
In this chapter, I explain the options that you have for running software on DC/OS, the services that DC/OS provides to your applications, and the details that you need know to build and run your own software on DC/OS. Figure 4-1 shows the Modern Enterprise Architecture (MEA) recommended by Mesosphere.
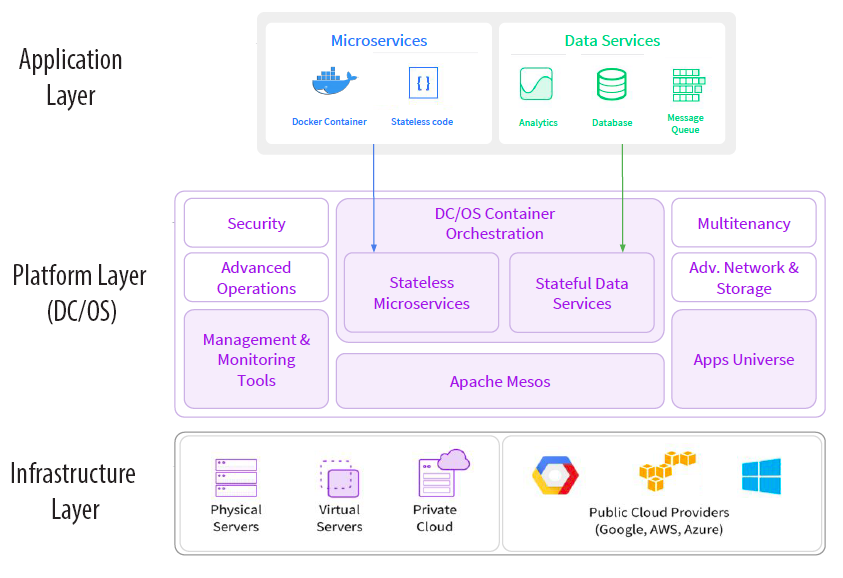
Figure 4-1. The DC/OS Modern Enterprise Architecture (Source: Mesosphere)
According to the principles of this architecture, we should write our services as stateless executables and use packages such as Cassandra to store application state. Programs written in this way are easily managed as Marathon apps.
Marathon (for apps) and Metronome (for jobs)
The most common way of running software in DC/OS is as a Marathon app or a Metronome job. Apps are for services intended to be always running and available, such as web servers, CRUD services, and so on. Jobs are tasks that are run according to some time schedule (or one-off) and run to completion. Other than that distinction these two approaches are virtually identical.
Marathon (runs apps) and Metronome (runs jobs) are both DC/OS components that act as Mesos frameworks to place tasks on Mesos. Both add Docker support, health checks, failure handling, and change management appropriate to their use case. For example, if a Marathon app fails or the node that it is running on is lost, Marathon will automatically deploy a replacement task to Mesos. It is important to understand that the failure-handling behavior is not determined by Mesos but must be provided by the Mesos framework, in this case, Marathon.
Figure 4-2 shows how Marathon runs on masters in DC/OS and how Marathon runs apps on Mesos. In the figure, I use the Cassandra scheduler as an example of how a Marathon app can itself be a Mesos framework scheduler.
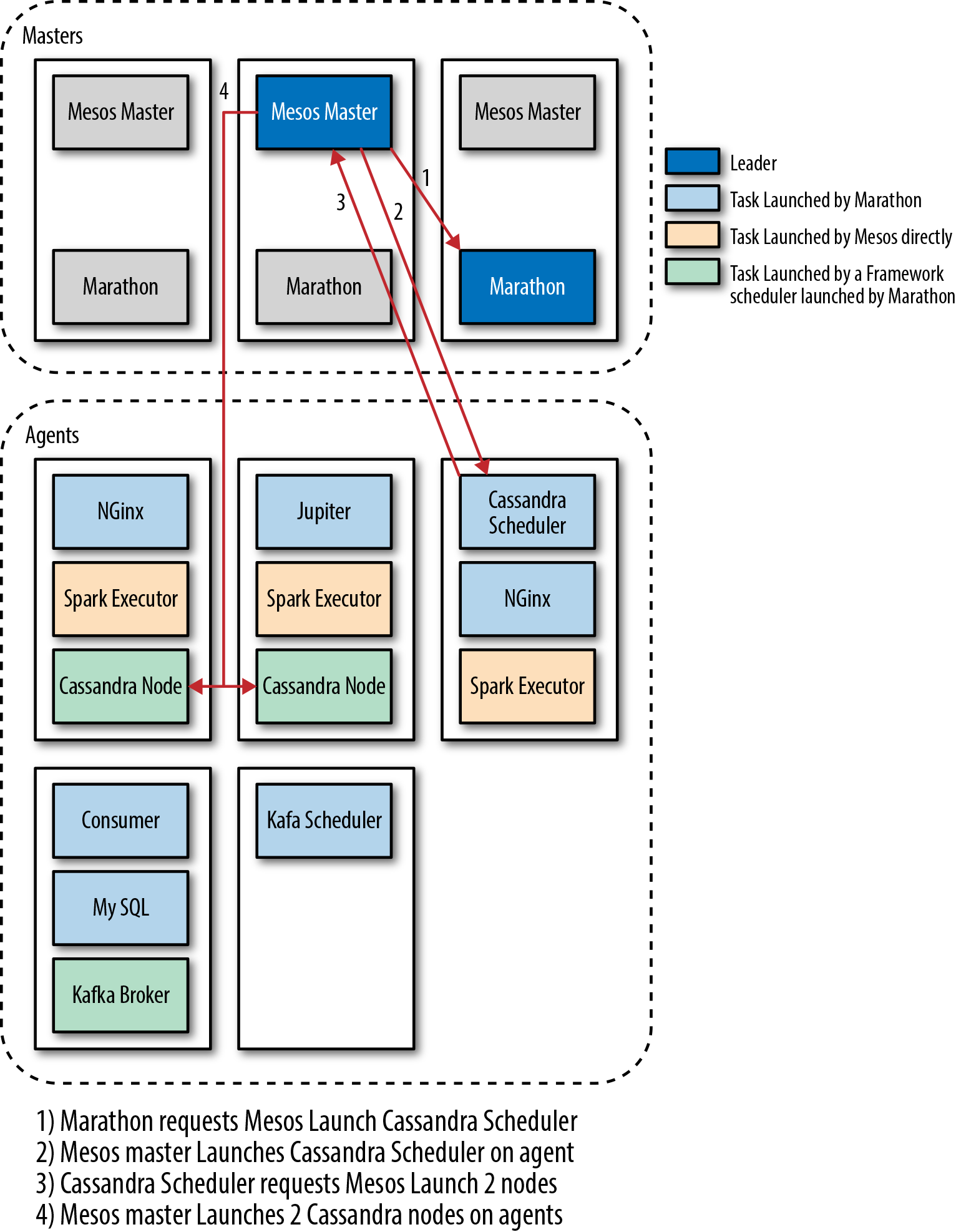
Figure 4-2. Some complex interactions between Marathon, apps and Mesos.
Containerization
Apps and jobs can execute code in a Mesos sandbox on an agent node or they can run a Docker container. Docker images allow developers to fully define the environment in which an application is executed and build an immutable container image that can run anywhere. In addition to the portability and reproducibility benefits of using Docker images, there are two important operational advantages:
Containerization means that nodes do not need to have any application dependencies installed (e.g., a specific version of openssl).
Container isolation means that one node can run multiple applications that have incompatible dependencies (e.g., two applications that depend on incompatible versions of openssl)
After jobs finish, their sandboxes and container environments remain on the node (which can be very useful for debugging a failing app) and are eventually cleaned up by a garbage collection process.
Alternative Platform Layers
Marathon and Metronome are both Mesos frameworks, which provide a Platform as a Service (PaaS) layer1 onto which containerized applications can be deployed. There are alternatives that provide similar PaaS functionality that can be run on DC/OS. For example:
These alternatives are not core DC/OS components, and because Marathon is the most mature and well-supported mechanism for running containerized applications on DC/OS, that is what we will cover in this report.
Marathon Pods
A pod in Marathon links multiple apps together into a group of tasks that are executed together on a single agent. Pods allow interdependent tasks to be deployed together and to share certain resources. Tasks within a pod share a network interface (either the host network interface or a virtual network interface, depending on configuration) and can communicate with one another on the localhost interface.
Note
Pods and groups are easily confused. In Marathon, a group is a set of services (apps and/or pods) within a hierarchical directory path structure—Marathon groups exist only for namespacing and organization; they have no affect on where or how tasks are run.
You can find more information on pods (which are still experimental as of this writing) at https://dcos.io/docs/1.9/usage/pods/.
Example 4-1 shows an example pod with three containers.
Example 4-1. An example pod with three containers (based on https://dcos.io/docs/1.9/usage/pods/examples/)
{"id":"/pod-with-multiple-containers","labels":{},"version":"2017-01-03T18:21:19.31Z","environment":{},"containers":[{"name":"sleep1","exec":{"command":{"shell":"sleep 1000"}},"resources":{"cpus":0.01,"mem":32,"disk":0,"gpus":0}},{"name":"sleep2","exec":{"command":{"shell":"sleep 1000"}},"resources":{"cpus":0.01,"mem":32}},{"name":"sleep3","exec":{"command":{"shell":"sleep 1000"}},"resources":{"cpus":0.01,"mem":32}}],"secrets":{},"volumes":[],"networks":[{"mode":"host","labels":{}}],"scaling":{"kind":"fixed","instances":10,"maxInstances":null},"scheduling":{"backoff":{"backoff":1,"backoffFactor":1.15,"maxLaunchDelay":3600},"upgrade":{"minimumHealthCapacity":1,"maximumOverCapacity":1},"placement":{"constraints":[],"acceptedResourceRoles":[]},"killSelection":"YoungestFirst","unreachableStrategy":{"inactiveAfterSeconds":900,"expungeAfterSeconds":604800}},"executorResources":{"cpus":0.1,"mem":32,"disk":10}}
Failure Handling in Marathon
With Marathon, you can configure health checks for all apps. If no health checks are specified, Marathon will use the Mesos state of the task as the health check. Marathon health checks are versatile: you can use a number of protocols or execute commands in the task sandbox/container. Here are allowed health checks:
- HTTP
- HTTPS
- TCP
- COMMAND
- MESOS_HTTP
- MESOS_HTTPS
The first two methods (HTTP and HTTPS) make calls from the Marathon leader; the last two (MESOS_HTTP and MESOS_HTTPS) are executed on the Mesos task host. COMMAND is used to execute commands in the task sandbox/container (as appropriate). You can find details of health check options in the Marathon documentation.
Note
COMMAND and MESOS_ checks are pushed down to Mesos and are implemented as Mesos health checks. Why is that important? Because Marathon health checks are not visible to some components that use the Mesos API. For example, the Minuteman load balancer is able to use only Mesos health checks (and is not aware of Marathon health checks) to determine healthy task instances to which to route requests.
If a task fails health checks, Marathon will terminate the failing task and replace it with a new task. Marathon aims to keep the configured number of task instances in a healthy state. To achieve this, it will automatically start tasks to replace tasks that quit or crash until the desired number of healthy tasks is achieved. This can lead to crashlooping, wherein tasks are stuck in a loop constantly failing and being replaced. A slow crashloop (e.g., one in which a task always fails 10 minutes after it is started) is not obvious to the administrator or users, because a lot of the time Marathon will show that the desired number of instances are running and healthy.
If Marathon is unable to communicate with a node, it will decide that it has been lost. Lost means that the node is not communicating with Marathon. In this situation, Marathon cannot determine if the node has been shut down temporarily, shut down permanently, or if it is still running but there is a communication problem (e.g., with the network). To avoid overwhelming nodes by reallocating large numbers of tasks in case of a communications failure (such as a network partition) or temporary shutdown (such as a rolling restart of nodes), Marathon limits the rate at which tasks can be rescheduled for lost nodes.
I know of a number of people who have run into problems because they were not aware of this behavior and they deliberately shut down multiple active nodes (e.g., for maintenance) expecting Marathon to reassign the running tasks automatically, only to find that this happens relatively slowly. It is important to be aware that in case of a large-scale failure it will take Marathon some time (potentially hours) to recover the desired cluster state. To deliver reliability in face of potential multiple-agent failures, it is necessary to have sufficient instances running that you are not relying on Marathon to reassign tasks in a multiagent failure situation.
If a task run by Marathon is unable to communicate with the Marathon scheduler, it will continue to run normally. This is the default behavior of Mesos tasks, unless they are specifically written to terminate when they lose connection to their scheduler, which would not be recommended.
High Availability and Change Management in Marathon
Marathon uses the information that it gets from Mesos along with its own health checks to provide change handling for apps. Marathon aims to ensure that at least the configured number of app instances are healthy at all times. To achieve that, when an app configuration change is made, Marathon will keep all existing instances of the app running and start new instances of the app (with the new configuration). Marathon begins removing the old instances only after new instances have started up and passed health checks so that the total number of healthy instances is maintained. Provided that services and clients are well written, this means that configuration changes, including software version changes, can be carried out without application downtime just by changing the Marathon configuration (for more complex configuration changes, see the section “Deployment” in Chapter 6).
Other Marathon Features
Marathon is a very sophisticated application and has many advanced features and configuration options that cannot be covered in the space available in this report. Nonetheless, here are some Marathon features that you might find of interest:
Metrics
Events API
Constraints
IP per task
Dependency handling
If you want to find out about these features or any other information about Marathon, the Marathon GitHub repository is a great resource as well as the Mesosphere documentation for Marathon.
Get Application Delivery with DC/OS now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

