Chapter 1. The Power of API Traffic Management
As Application Programming Interfaces (APIs) and their associated traffic become more common in organizations large and small, new challenges emerge in how to both monitor and manage this new data. For the purposes of this book, monitoring is the act of collecting and observing your API ecosystem’s behavior (e.g., the number of API calls per minute), and managing is the process of analyzing, reaching conclusions, and acting on those conclusions (e.g., whether your API calls are unusual and what is needed to change that). As I travel around the world and talk to companies about how they are dealing with this new flood of data within their organization I note that most of them are struggling just to grasp the job of monitoring itself. And it is no small job.
In this chapter, we explore the challenge and the advantage of a broad-ranging API traffic management approach. This includes the work of monitoring traffic in order to collect data and improve the observability of your APIs as well as the notion of actively managing your API program using the insights gained from your traffic metrics (see Figure 1-1). Getting a handle on these two concepts will help you place API traffic management as a central pillar in your healthy API program and set you on the path to determining just what to track and how to use that information to improve your company’s API program.
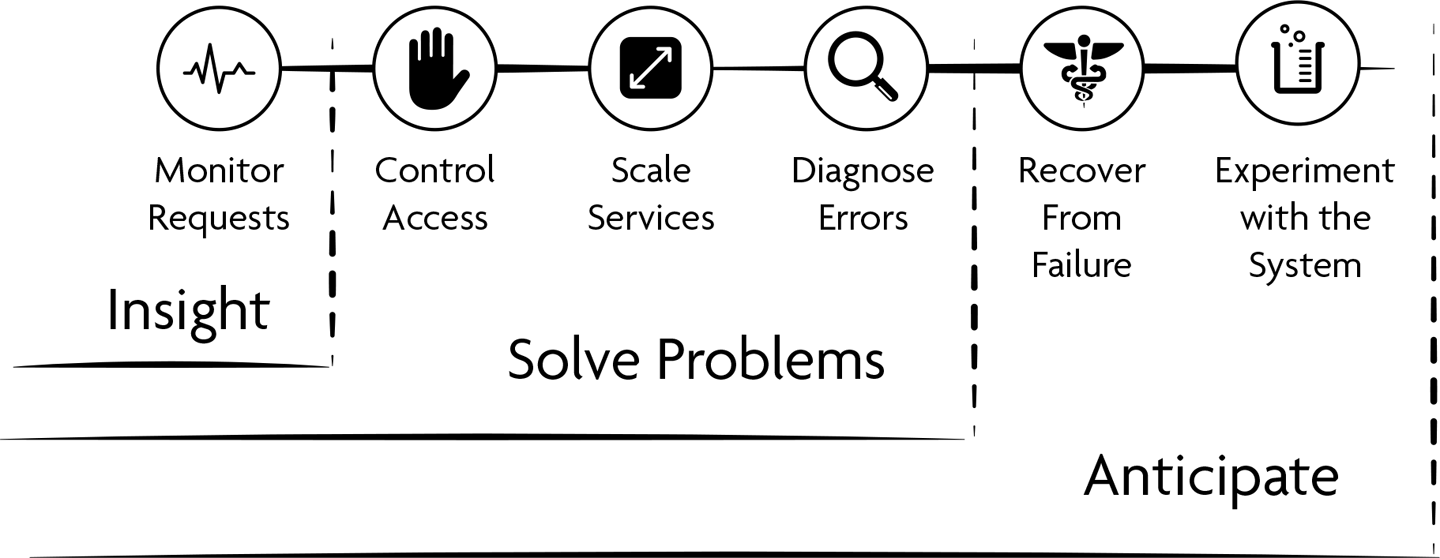
Figure 1-1. Progressing from monitoring to managing API traffic
Knowing what data points are worth monitoring can be a challenge. Just about any out-of-the-box traffic tooling will offer up values like CPU, memory, and disk space for individual machines as well as other values such as request/response length, message counts, and, usually, error rates. But these rarely tell you what you need to know. Instead, you often need to monitor not just the length and count of messages, but also the types of messages, their routes through our system, and the ultimate dispensation of any data sent or requested. And that’s just the beginning of the role of monitoring in making your system more visible and your services more observable.
But, monitoring is not enough. Good traffic management means just that—managing the traffic you observe. That requires the ability to categorize some traffic as “good” or “bad” and having a sense of what “healthy” traffic looks like for your business. These are things no tool or service can offer. Instead, you need to apply strategic and tactical thinking to the traffic you see and then design data collection and displays that give you a broad sense of the health and welfare of your business as a whole. Like any complex system (and most API-driven ecosystems qualify as complex), turning raw data into valuable information means applying experience and judgment. And that is a level of API traffic management that can help you gain an advantage over competitors in your industry as well as give you an opportunity to anticipate important changes in customer habits and your market segment in general.
You can combine the two key perspectives on monitoring and managing your API traffic to gain business insight. In this chapter, you learn how to use Key Performance Indicators (KPIs) to identify and track important monitoring metrics and how to combine those with Objectives and Key Results (OKRs) to create a comprehensive high-level view of your company’s API activities and their effect on your overall business. Let’s take a look at each of these in turn and see how KPIs and OKRs offer a vital perspective on API traffic monitoring and management.
Monitoring with KPIs
Monitoring is the act of observing; of collecting and collating data points that can help you make assessments and act on your judgment. But what do you monitor? Although the usual health of a machine’s processor, memory, and disk is a start, the distance, for example, between the remaining space on a server’s disk drive and the total sum of latency between components handling a single transaction spanning from your network to the system-of-record in a distributed storage installation is, pardon the reference, quite a long way. It is important to focus on observing key indicators of your ecosystem that can help you to track the progress of both your day-to-day online operations as well as the behind-the-scenes work of building, testing, and deploying updates to your API landscape. Especially as your system grows in size, variety, and complexity, correlating the effects of newly updated parts of the system with the character of daily business transactions can be a key to success.
The concept of performance indicators dates back quite a while. Business people have, almost since “the beginning,” been looking for ways to identify and reward good performance and reduce unwanted elements. The notion of “key” performance indicators alludes to the idea that not just any metric or measurement will do when trying to get a proper view of your IT operation or your business itself. There are, essentially, key performance indicators that can represent important activity and processes. I dig into some common methods for identifying and collecting KPIs in Chapter 3. For now, it is worth pointing out there is more than one way to think about KPIs and how you need to use them in your organization.
Management Challenges
For many organizations it is still difficult to wrangle all of the disparate internal and external traffic into a coherent traffic platform. This is especially true for companies with offices around the globe. This is primarily a management challenge. As mentioned earlier, the growth of APIs and the explosion of small, focused services within a company’s ecosystem means the traffic between those services often represents a critical aspect of the health of not just your IT operations but also your day-to-day business operations. The quantity of API traffic and the quality of that traffic reflect as well as affect the quantity and quality of the company’s business.
This means that managing the business requires an understanding of the types and meaning of your API traffic. Just as sales traffic monitoring and market intelligence are essential elements in top-level business decisions, understanding which API calls represent real revenue and which ones are indicative of your organization’s place in the wider market of ecommerce is part of managing your business in the twenty-first century. In Chapter 3, we examine the details of how you can use API traffic monitoring to get a handle on the day-to-day operations of not just your IT operations but your business, too.
Traffic Challenges
The very nature of API traffic has been changing in the past few years. As more companies adopt the pattern of smaller, lightweight services composed into agile, resilient solutions, the amount of interservice traffic (typically called “East–West” traffic) is growing. Organizations that have spent time and resources building up a strong practice in managing traffic from behind the firewall to the outside world (called “North–South” traffic) might find that their tool selection and platform choices are not properly suited for the increased traffic between services behind the firewall.
Many traffic programs have focused on the important “North–South” traffic that represents both the risk and opportunities of API calls that reach outside your own company and into the wider API marketplace. And this will continue to be important as more and more organizations come to rely on other people’s APIs in order to keep their own business afloat.
At the same time, paying close attention to your “East–West” traffic will provide you key information on the spread and depth of your own service ecosystem and can help you better understand and even anticipate how changes in interservice traffic will affect your company’s IT operations and spending.
In both cases, the added use of external APIs means that you’ll always be dealing with dependencies on external services over which you have little to no control. This can affect your own infrastructure choices, too.
Monitoring Challenges
Even when traffic is properly corralled and effectively routed, the landscape of monitoring this traffic continues to evolve. To gain the degree of observability needed to make critical decisions on how to grow and change your service and API mix, you need to be able to monitor at multiple levels within the ecosystem. Proxy-level monitoring gives you a “big picture” of what’s happening on your platform. But you also need service-level monitoring to gain insight into the health and usage patterns for individual components in your system.
Often organizations start by focusing on monitoring traffic at the perimeter of operation. This top-level monitoring can act as a bellwether to let you know what kind of traffic is entering and leaving your company’s ecosystem. This kind of monitoring is also usually “noninvasive.” You can establish data collection points in gateways and proxies far from the actual source code of the services that handle this traffic. But there are limits to the kind of information proxy-level monitoring can tell you.
Especially in companies that rely on a microservice-centric implementation model, understanding what happens to API traffic after it passes your proxies and enters your ecosystem can be daunting. What you need to know is not just the general flow of traffic. Sometimes you need to know exactly where a particular request is going and how that request is processed throughout its lifespan. Typically this means that you need to employ shared transaction identifiers—ones that are retained as the traffic passes through various network boundaries.
Microservice implementation eventually means leveraging monitoring information at the service level, too. You might not always be able to control the source code of all your services or be able to inject monitoring directly into a single service component. In that case, you need to find lightweight monitoring solutions at a smaller-grained level. We look at how you can do this in Chapter 3.
From Managing to Understanding
From actively managing to understanding traffic types to getting a handle on the types of monitoring access you need within your company, all these elements are critical to designing an API traffic control system that gives you a good picture of what is going on within your service ecosystem. But there is another perspective, too. Why are you monitoring your traffic? What is the connection between API traffic and business goals? And, if knowing your API traffic can help you know your business better, how does that work?
One way I see companies moving from monitoring to management is through the application of OKRs in addition to their KPIs.
OKRs
Along with the typical API traffic management practices around monitoring, securing, and scaling requests and responses, there is another perspective on your APIs—the business perspective. APIs exist only to serve business objectives. If they’re not contributing to the fundamental goals of your organization, APIs are not properly aligned.
It is through the use of traffic management and analysis that companies can gauge the business-level success of their APIs. That means setting traffic metrics that matter for the business (number of customers gained, number of shopping carts abandoned before check-out, failed uploads per hour, etc.) and then using your traffic management platform to monitor and report on those key metrics. These metrics are usually based on your company’s OKRs. In Chapter 6 we dive into the details of how this works.
Your traffic management platform is a treasure trove of data spanning from the rhythm and stability of your internal deployment processes to the behavioral aspects of your API consumers. By investing in a robust API traffic management platform, you have—at your fingertips—an incredibly valuable tool for gaining insight into your company, solving the problems of your consumer audience, and even anticipating the needs of your customer base.
Gaining Insight
As API traffic—and the services and tools that are used to support and build them—continues to grow, it is important to have a handle on how your organization is spending its time and money to design, implement, and deploy API-based services. Most of this activity happens “outside” the typical production API traffic management zone. However, while teams are selecting which processes to automate via APIs and which interfaces will be most effective to add to your growing list of APIs and services, these additions need to be based on business-level goals and tracked by tangible metrics. Just as the programming side of digital transformation means increasing the amount of early test-driven development, the traffic management side of business demands more attention to establishing business metrics early in the process and baking those metrics into the deployment and monitoring process.
For the past decade or so, most organizations have been learning to rely on Agile, Scrum, and other models to shorten the iteration cycle of design, build, test, and release. It is the last step in that process where a robust traffic management practice can yield results. This means combining your key traffic metrics with measurements that reflect your company’s own internal behaviors around test and deployment cycles. We dig deeper into techniques you can use to apply your traffic practices to your business in “Business Metrics”.
Good API traffic management practice can improve the overall visibility of your system and allow you to better understand just what is going on throughout your organization. And, after you have a better sense of your system’s activity, you’ll have an opportunity to use that information to solve problems directly.
Solving Problems
As APIs become more prevalent within companies, they also become a more vital element in the success of the business. In its 2018 Tech Trends Report, accounting and consulting company Deloitte predicted: “Over the next 18 to 24 months, expect many heretofore cautious companies to embrace the API imperative.”1 When this happens more and more business-critical traffic is carried throughout the company via API gateways, proxies, and routers. The proxies themselves—the intermediaries between various services spread throughout the organization—become a key link in the process of completing business transactions, generating revenue, and reducing costs. In this case, understanding your traffic patterns gives you an opportunity to identify heavy API usage, recognize pockets of inefficiency, and work to solve these problems in ways that accrue to the company’s bottom line.
For example, as your API traffic grows over time, some cross-service connections can become saturated with traffic, causing slowdowns, more denied requests, and a drop in business-critical transactions. Good traffic management systems will allow you to redesign traffic patterns to eliminate these bottlenecks; for example, when “hot spots” appear where traffic degradation is likely. In this case, that might mean standing up more instances of transaction-processing services in another location, adding routing rules that break up heavy traffic into separate zones, and route the transactions throughout the system in ways that balance the load and therefore speed processing for critical portions of your system.
And when you have reached the stage at which your API traffic management system affords you visibility into day-to-day operations and allows you to identify and remedy API traffic jams, the next stage is to design and build traffic management infrastructure that allows you to anticipate your system’s traffic needs.
Anticipating Needs
The state of most API-driven systems today is often based on piecemeal growth and haphazard management. Getting a handle on your organization’s API traffic means improving overall visibility as well as learning to solve business problems through the routing and shaping of the very traffic your APIs depend upon. The next level of traffic management is anticipating the needs that are likely to arise and providing solutions before the problems are significant enough to be noticed.
An excellent way to do this is to conduct runtime experiments on your ecosystem. The ability to safely and consistently create and test your traffic hypothesis is something we explore in “Runtime Experiments”.
Summary
This chapter covered both the challenge and the advantage of a broad-ranging API traffic management approach. The work of monitoring traffic with meaningful KPIs in order to collect data and improve the observability of your APIs means that you’ll need to deal with the challenges of taking control of the monitoring process, focusing on the different types of API traffic you experience (e.g., “East–West” as well as “North–South”) and dealing with the challenges of collecting data in the proper locations (network-level proxies as well as service-level components).
You also learned how to move beyond monitoring API traffic and into actively managing your API program. Well-designed and implemented API traffic management can give your organization the opportunity to gain insights into daily business activity, identify and solve traffic problems before they grow to a critical level, and even anticipate needs within your own ecosystem and your business market in general.
In the next chapter, we look at the basics of traffic in general and how your knowing the types of traffic you’re dealing with can help you determine just how and why you need to establish your IT ecosystem’s KPIs and relate them to the OKRs of your overall business.
Additional Reading
-
Continuous API Management, Medjaou et al.
-
Production-Ready Microservices, Fowler
-
Building Evolutionary Architectures, Kua et al.
Get API Traffic Management 101 now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

