Chapter 2. The Architecture of Apache Iceberg
In this chapter, we’ll discuss the architecture and specification that enable Apache Iceberg to resolve the problems inherent in the Hive table format by looking under the covers of an Iceberg table. We’ll cover the different structures of an Iceberg table and what each structure provides and enables so that you can understand what’s happening under the hood as well as best architect your Apache Iceberg–based lakehouse.
As mentioned in Chapter 1, there are three different layers of an Apache Iceberg table: the catalog layer, the metadata layer, and the data layer. Figure 2-1 shows the different components that make up each layer.
In the following sections, we’ll go through each of these components in detail. Since it can be easier to understand concepts new to you by starting with a familiar one, we’ll work from the bottom up, starting with the data layer.
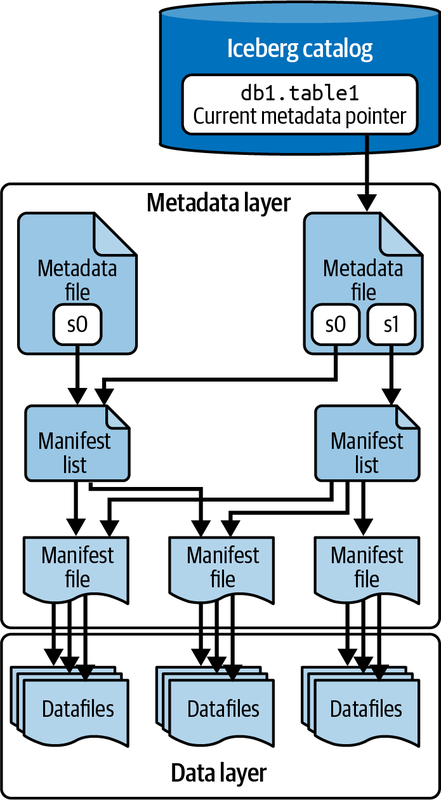
Figure 2-1. The architecture of an Apache Iceberg table
The Data Layer
The data layer of an Apache Iceberg table is what stores the actual data of the table and is primarily made up of the datafiles themselves, although delete files are also included. The data layer is what provides the user with the data needed for their query. While there are some exceptions where structures in the metadata layer can provide a result (e.g., get me the max value for column X), most commonly the ...
Get Apache Iceberg: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

