Capítulo 4. Estrategias de transformación de datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Un informe reciente publicado por Forbes describe en cómo algunos corredores de bolsa y empresas de negociación pudieron acceder a los datos y analizarlos más rápidamente que sus competidores. Esto les permitió "ejecutar operaciones al mejor precio, microsegundos por delante de la multitud". La victoria fue mínima en términos de tiempo, pero enorme en cuanto a la ventaja competitiva obtenida por la velocidad de comprensión".
Al considerar una solución analítica, la velocidad de obtención de información es importante, y cuanto más rápido pueda responder una organización a un cambio en sus datos, más competitiva será. En muchos casos, para obtener la información que necesitas, hay que transformar los datos. Como se explica brevemente en el Capítulo 3, "Configuración de tus modelos de datose ingesta de datos", puedes utilizar un enfoque ETL, que lee los datos de origen, procesa las transformaciones en una aplicación externa y carga los resultados, o puedes utilizar un enfoque ELT, que utiliza los datos que acabas de cargar y los transforma in situ utilizando la potencia de cálculo de Amazon Redshift.
En este capítulo, empezaremos por "Comparar las estrategias ELT y ETL" para ayudarte a decidir qué estrategia de carga de datos utilizar cuando construyas tu almacén de datos. También profundizaremos en algunas de las características exclusivas de Redshift creadas para casos de uso analítico y que potencian la "Transformación en la base de datos", así como en la forma de aprovechar las capacidades de "Programación y orquestación" incorporadas para ejecutar tus canalizaciones. Luego veremos cómo Amazon Redshift lleva la estrategia ELT aún más lejos, permitiéndote "Acceder a todos tus datos" aunque no se hayan cargado en Redshift. Por último, veremos cuándo puede tener sentido utilizar una estrategia de "Transformación Externa" y cómo utilizar AWS Glue Studio para construir tus canalizaciones ETL.
Comparar las estrategias ELT y ETL
Independientemente de una estrategia ELT o ETL, cada una puede apoyar los objetivos comunes de tu plataforma de gestión de datos, que normalmente implican limpiar, transformar y agregar los datos para cargarlos en tu modelo de datos de informes. Todas ellas son operaciones que consumen muchos recursos, y la principal diferencia entre las dos estrategias es dónde tiene lugar el procesamiento: en el cálculo de tu servidor o servidores ETL o en el cálculo de tu plataforma de almacén de datos. Los procesos ETL implican leer datos de múltiples fuentes y transformarlos utilizando las funciones y capacidades del motor ETL. En cambio, los procesos ELT también implican extraer datos de varias fuentes, pero cargándolos primero en el almacén de datos. El paso de transformación se realiza después de cargar los datos utilizando la semántica SQL conocida. Algunas cosas que hay que tener en cuenta al elegir entre los dos son:
- Rendimiento y escalabilidad
-
Los procesos ETL dependen de los recursos del servidor o servidores ETL y requieren que los propietarios de la plataforma gestionen y dimensionen correctamente el entorno. Se pueden utilizar plataformas informáticas como Spark para paralelizar las transformaciones de datos, y AWS Glue se ofrece como una opción sin servidor para gestionar las canalizaciones ETL. El procesamiento ELT se realiza utilizando los recursos informáticos del almacén de datos. En el caso de Amazon Redshift, se utiliza la potencia de la arquitectura MPP para realizar las transformaciones. Históricamente, se prefería transformar los datos externamente porque el procesamiento se descarga en recursos informáticos independientes. Sin embargo, las plataformas modernas de almacén de datos, incluida Amazon Redshift, escalan dinámicamente y pueden soportar cargas de trabajo mixtas, lo que hace más atractiva una estrategia ELT. Además, como las plataformas de almacén de datos están diseñadas para procesar y transformar cantidades masivas de datos utilizando funciones nativas de la base de datos, los trabajos ELT tienden a rendir mejor. Por último, las estrategias ELT están libres de cuellos de botella en la red, que son necesarios con ETL para mover los datos dentro y fuera para su procesamiento.
- Flexibilidad
-
Aunque cualquier código de transformación en tu plataforma de datos debe seguir un ciclo de vida de desarrollo, con una estrategia ETL, el código suele gestionarlo un equipo con conocimientos especializados en una aplicación externa. En cambio, con una estrategia ELT, todos tus datos brutos están disponibles para su consulta y transformación en la plataforma de gestión de datos. Los analistas pueden escribir código utilizando funciones SQL conocidas aprovechando las habilidades que ya tienen. Facultar a los analistas acorta el ciclo de vida del desarrollo porque pueden crear prototipos del código y validar la lógica empresarial. Los propietarios de la plataforma de datos se encargarían de optimizar y programar el código.
- Gestión y orquestación de metadatos
-
Una consideración importante para tu estrategia de datos es cómo gestionar los metadatos y la orquestación de los trabajos. Aprovechar una estrategia de ETL significa que el propietario de la plataforma de datos tiene que hacer un seguimiento de los trabajos, sus dependencias y los programas de carga. Las herramientas ETL suelen tener funciones que capturan y organizan metadatos sobre fuentes, destinos y características de los trabajos, así como el linaje de los datos. También pueden orquestar trabajos y crear dependencias entre varias plataformas de datos.
En última instancia, la elección entre ETL y ELT dependerá de las necesidades específicas de la carga de trabajo analítica. Ambas estrategias tienen puntos fuertes y débiles, y la decisión de cuál utilizar dependerá de las características de las fuentes de datos, los requisitos de transformación y las necesidades de rendimiento y escalabilidad del proyecto. Para mitigar las dificultades de cada una, muchos usuarios adoptan un enfoque híbrido. Puedes aprovechar las capacidades de gestión de metadatos y orquestación de las herramientas ETL, así como el rendimiento y la escalabilidad del procesamiento ELT, creando trabajos que traduzcan el código ETL a sentencias SQL. En "Transformación externa" veremos con más detalle cómo hacerlo.
Transformación en la base de datos
Con la variedad y velocidad de los datos actuales, el reto de diseñar una plataforma de datos es hacerla escalable y flexible. Amazon Redshift sigue innovando y proporcionando funcionalidades para procesar todos tus datos en un solo lugar con sus capacidades de transformación en la base de datos (ELT). Al ser una base de datos relacional compatible con ANSI SQL, Amazon Redshift admite comandos SQL, lo que lo convierte en un entorno de desarrollo familiar para la mayoría de los desarrolladores de bases de datos. Amazon Redshift también es compatible con funciones avanzadas presentes en las plataformas de datos modernas, como Funciones de ventana, funciones HyperLogLog y CTE (expresiones comunes de tabla) recursivas, por nombrar algunas. Además de esas funciones con las que puedes estar familiarizado, Amazon Redshift soporta capacidades únicas para el procesamiento analítico. Por ejemplo, Amazon Redshift admite la consulta in situ de "Datos semiestructurados", lo que proporciona a los analistas una forma de acceder a estos datos de una manera eficaz y sin esperar a que se carguen en tablas y columnas. Además, si necesitas ampliar las capacidades de Amazon Redshift, puedes aprovechar las "Funciones definidas por el usuario" que pueden ejecutarse dentro de la base de datos o llamar a servicios externos. Por último, los "Procedimientos almacenados" te permiten empaquetar tu lógica de transformación. Pueden devolver un conjunto de resultados dados los parámetros de entrada o incluso realizar operaciones de carga y gestión de datos, como cargar una tabla de hechos, dimensiones o agregados.
Datos semiestructurados
Los datos semiestructurados pertenecen a la categoría de datos que no se ajustan a un esquema rígido esperado en las bases de datos relacionales. Los formatos semiestructurados son habituales y a menudo preferidos en los registros web, los datos de los sensores o los mensajes de las API, porque estas aplicaciones a menudo tienen que enviar datos con relaciones anidadas, y en lugar de hacer varios viajes de ida y vuelta, es más eficiente enviar los datos una sola vez. Los datos semiestructurados contienen valores complejos como matrices y estructuras anidadas que se asocian a formatos de serialización, como JSON. Aunque existen herramientas de terceros que puedes utilizar para transformar tus datos fuera de la base de datos, se necesitarían recursos de ingeniería para crear y mantener ese código y puede que su rendimiento no sea el mismo. Tanto si accedes a "Datos externos de Amazon S3" como a datos cargados localmente, Amazon Redshift aprovecha la sintaxis PartiQL para analizar y transformar datos semiestructurados. Se lanzó un tipo de datos especial SUPERpara almacenar estos datos en su forma nativa. Sin embargo, cuando se acceda a ellos desde Amazon S3, se catalogarán con un tipo de datos de struct o array.
En el siguiente ejemplo, estamos haciendo referencia a un archivo que ha aterrizado en un entorno de Amazon S3. Puedes catalogar este archivo y hacerlo accesible en Amazon Redshift creando un esquema externo y mapeando cualquier archivo que exista en este prefijo de Amazon S3 a esta definición de tabla.
La primera consulta(Ejemplo 4-1) encuentra los ingresos totales por ventas por evento.
Ejemplo 4-1. Crear tabla externa a partir de datos JSON
CREATEexternalSCHEMAIFNOTEXISTSnested_jsonFROMdatacatalogDATABASE'nested_json'IAM_ROLEdefaultCREATEEXTERNALDATABASEIFNOTEXISTS;DROPTABLEIFEXISTSnested_json.nested_json;CREATEEXTERNALTABLEnested_json.nested_json(c_namevarchar,c_addressvarchar,c_nationkeyint,c_phonevarchar,c_acctbalfloat,c_mktsegmentvarchar,c_commentvarchar,ordersstruct<"order":array<struct<o_orderstatus:varchar,o_totalprice:float,o_orderdate:varchar,o_order_priority:varchar,o_clerk:varchar,o_ship_priority:int,o_comment:varchar>>>)rowformatserde'org.openx.data.jsonserde.JsonSerDe'withserdeproperties('paths'='c_name,c_address,c_nationkey,c_phone,c_acctbal,c_mktsegment,c_comment,Orders')storedasinputformat'org.apache.hadoop.mapred.TextInputFormat'outputformat'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'location's3://redshift-immersionday-labs/data/nested-json/';
Este archivo de datos se encuentra en la región us-west-2, y este ejemplo sólo funcionará si tu almacén de datos de Amazon Redshift también se encuentra en esa región. Además, hemos hecho referencia al rol IAM default. Asegúrate de modificar el rol para permitir el acceso de lectura a esta ubicación de Amazon S3, así como para tener acceso para administrar el Catálogo de Datos de AWS Glue.
Ahora que la tabla está disponible, se puede consultar y puedes acceder a los atributos de nivel superior sin ningún procesamiento especial(Ejemplo 4-2).
Ejemplo 4-2. Atributos de nivel superior
SELECTcust.c_name,cust.c_nationkey,cust.c_addressFROMnested_json.nested_jsoncustWHEREcust.c_nationkey='-2015'ANDcust.c_addresslike'%E12';
Utilizando la sintaxis PartiQL, puedes acceder a los datos anidados de struct. En el Ejemplo 4-3, estamos desanidando los datos del campo orders y mostrando los múltiples pedidos asociados al registro del cliente.
Ejemplo 4-3. Atributos no anidados (externos)
SELECTcust.c_name,cust_order.o_orderstatus,cust_order.o_totalprice,cust_order.o_orderdate::date,cust_order.o_order_priority,cust_order.o_clerk,cust_order.o_ship_priority,cust_order.o_commentFROMnested_json.nested_jsoncust,cust.orders.ordercust_orderWHEREcust.c_nationkey='-2015'ANDcust.c_addresslike'%E12';
Además de acceder a los datos en S3, estos datos semiestructurados se pueden cargar en tu tabla de Amazon Redshift utilizando el tipo de datos SUPER. En el Ejemplo 4-4, este mismo archivo se carga en una tabla física. Una diferencia notable al cargar en Amazon Redshift es que no se requiere información sobre el esquema de la columna orders asignada al tipo de datos SUPER. Esto simplifica el proceso de carga y gestión de metadatos, además de proporcionar flexibilidad en caso de cambios en los metadatos.
Ejemplo 4-4. Crear tabla local a partir de datos JSON
DROPTABLEIFEXISTSnested_json_local;CREATETABLEnested_json_local(c_namevarchar,c_addressvarchar,c_nationkeyint,c_phonevarchar,c_acctbalfloat,c_mktsegmentvarchar,c_commentvarchar,ordersSUPER);COPYnested_json_localfrom's3://redshift-immersionday-labs/data/nested-json/'IAM_ROLEdefaultREGION'us-west-2'JSON'auto ignorecase';
Hemos hecho referencia al rol IAM default. Asegúrate de modificar el rol para conceder acceso de lectura desde esta ubicación de Amazon S3.
Ahora que la tabla está disponible, se puede consultar. Utilizando la misma sintaxis PartiQL, puedes acceder a los detalles del pedido(Ejemplo 4-5).
Ejemplo 4-5. Atributos no anidados (local)
SETenable_case_sensitive_identifierTOtrue;SELECTcust.c_name,cust_order.o_orderstatus,cust_order.o_totalprice,cust_order.o_orderdate::date,cust_order.o_order_priority,cust_order.o_clerk,cust_order.o_ship_priority,cust_order.o_commentFROMnested_json_localcust,cust.orders."Order"cust_orderWHEREcust.c_nationkey='-2015'ANDcust.c_addresslike'%E12';
El enable_case_sensitive_identifier es un parámetro importante a la hora de consultar datos SUPER si tu entrada tiene identificadores con mayúsculas y minúsculas. Para más información, consulta la documentación en línea.
Para más detalles y ejemplos sobre la consulta de datos semiestructurados, consulta la documentación en línea.
Funciones definidas por el usuario
Si una función incorporada no está disponible para tus necesidades específicas de transformación, Amazon Redshift tiene algunas opciones para ampliar la funcionalidad de la plataforma. Amazon Redshift te permite crear funciones escalares definidas por el usuario (UDF) en tres sabores: SQL, Python y Lambda. Para obtener documentación detallada sobre la creación de cada uno de estos tipos de funciones, consulta la documentación online.
Una función escalar devolverá exactamente un valor por invocación. En la mayoría de los casos, puedes pensar que devuelve un valor por fila.
Una UDF SQL aprovecha la sintaxis SQL existente. Puede utilizarse para garantizar que se aplica una lógica coherente y para simplificar la cantidad de código que cada usuario tendría que escribir individualmente. En el Ejemplo 4-6, de la Repo de GitHub de las UDF de Amazon Redshift, verás una función SQL que toma dos parámetros de entrada; el primer campo varchar son los datos que hay que enmascarar, y el segundo campo es la clasificación de los datos. El resultado es una estrategia de enmascaramiento diferente basada en la clasificación de los datos.
Ejemplo 4-6. Definición de UDF SQL
CREATEORREPLACEfunctionf_mask_varchar(varchar,varchar)returnsvarcharimmutableAS$$SELECTcase$2WHEN'ssn'thensubstring($1,1,7)||'xxxx'WHEN'email'thensubstring(SPLIT_PART($1,'@',1),1,3)+'xxxx@'+SPLIT_PART($1,'@',2)ELSEsubstring($1,1,3)||'xxxxx'end$$languagesql;
Los usuarios pueden hacer referencia a una UDF SQL dentro de una sentencia SELECT. En este caso, podrías escribir la sentencia SELECT como se muestra en el Ejemplo 4-7.
Ejemplo 4-7. Acceso SQL UDF
DROPTABLEIFEXISTScustomer_sqludf;CREATETABLEcustomer_sqludf(cust_namevarchar,varchar,ssnvarchar);INSERTINTOcustomer_sqludfVALUES('Jane Doe','jdoe@org.com','123-45-6789');SELECTf_mask_varchar(cust_name,NULL)mask_name,cust_name,f_mask_varchar(,'email')mask_email,,f_mask_varchar(ssn,'ssn')mask_ssn,ssnFROMcustomer_sqludf;
La sentencia SELECT del Ejemplo 4-7 da como resultado la siguiente salida:
| nombre_máscara | nombre | mascara_email | correo electrónico | máscara_ssn | ssn |
|---|---|---|---|---|---|
Janxxxxx |
Jane Doe |
123-45-xxxx |
123-45-6789 |
Una UDF de Python permite a los usuarios de aprovechar el código Python para transformar sus datos. Además de las bibliotecas básicas de Python, los usuarios pueden importar sus propias bibliotecas para ampliar la funcionalidad disponible en Amazon Redshift. En el Ejemplo 4-8, de la GitHub Repo de las UDF de Amazon Redshift, verás una función de Python que aprovecha una biblioteca externa, ua_parser, que puede analizar una cadena de agente de usuario en un objeto JSON y devolver la familia de SO del cliente. Consulta la GitHub Repo para obtener instrucciones detalladas sobre cómo instalar este ejemplo.
Ejemplo 4-8. Definición de una UDF en Python
CREATEORREPLACEFUNCTIONf_ua_parser_family(uaVARCHAR)RETURNSVARCHARIMMUTABLEAS$$FROMua_parserimportuser_agent_parserRETURNuser_agent_parser.ParseUserAgent(ua)['family']$$LANGUAGEplpythonu;
De forma similar a las UDF de SQL, los usuarios pueden hacer referencia a una UDF de Python dentro de una sentencia SELECT. En este ejemplo, podrías escribir la sentencia SELECT que se muestra en el Ejemplo 4-9.
Ejemplo 4-9. Acceso UDF en Python
SELECTf_ua_parser_family(agent)family,agentFROMweblog;
La sentencia SELECT del Ejemplo 4-9 da como resultado la siguiente salida:
| familia | agente |
|---|---|
Cromo |
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/41.0.2272.104 Safari/537.36 |
Por último, la UDF Lambda permite a los usuarios interactuar e integrarse con componentes externos fuera de Amazon Redshift. Puedes escribir Lambda UDF en cualquier lenguaje de programación compatible, como Java, Go PowerShell, Node.js, C#, Python, Ruby o un tiempo de ejecución personalizado. Esta funcionalidad permite nuevos casos de uso de Amazon Redshift, incluido el enriquecimiento de datos desde almacenes de datos externos (por ejemplo, Amazon DynamoDB, Amazon ElastiCache, etc.), enriquecimiento de datos desde API externas (por ejemplo, Melissa Global Address Web API, etc.), enmascaramiento de datos y tokenización desde proveedores externos (por ejemplo, Protegrity) y conversión de UDF heredadas escritas en otros lenguajes como C,C++ y Java. En el Ejemplo 4-10, de la Repo GitHub de UDFs de Amazon Redshift, verás una función Lambda que aprovecha el Servicio de Administración de Claves (KMS) de AWS y toma una cadena entrante para devolver el valor cifrado. El primer bloque de código establece una función Lambda, f-kms-encrypt, que espera una matriz anidada de argumentos pasados a la función. En este ejemplo, el usuario proporcionaría como parámetros de entrada el kmskeyid y el columnValue; argument[0] y argument[1]. La función utilizará la biblioteca boto3 para llamar al servicio kms y devolver el response encriptado. Consulta el repositorio de GitHub para obtener instrucciones detalladas sobre cómo instalar este ejemplo.
Ejemplo 4-10. Definición de función lambda
importjson,boto3,os,base64kms=boto3.client('kms')defhandler(event,context):ret=dict()res=[]forargumentinevent['arguments']:try:kmskeyid=argument[0]columnValue=argument[1]if(columnValue==None):response=Noneelse:ciphertext=kms.encrypt(KeyId=kmskeyid,Plaintext=columnValue)cipherblob=ciphertext["CiphertextBlob"]response=base64.b64encode(cipherblob).decode('utf-8')res.append(response)exceptExceptionase:(str(e))res.append(None)ret['success']=Trueret['results']=resreturnjson.dumps(ret)
El siguiente bloque de código establece la UDF de Amazon Redshift, que hace referencia a la función Lambda(Ejemplo 4-11).
Ejemplo 4-11. Definición de UDF lambda
CREATEORREPLACEEXTERNALFUNCTIONf_kms_encrypt(keyvarchar,valuevarchar)RETURNSvarchar(max)STABLELAMBDA'f-kms-encrypt'IAM_ROLEdefault;
Hemos hecho referencia al rol IAM default. Asegúrate de modificar el rol para conceder acceso para ejecutar la función Lambda creada anteriormente.
Al igual que las UDF de SQL y Python, los usuarios de pueden hacer referencia a una UDF de Lambda dentro de una sentencia SELECT. En este caso, podrías escribir la sentencia SELECT que se muestra en el Ejemplo 4-12.
Ejemplo 4-12. Acceso a UDF lambda
SELECTf_kms_encrypt()email_encrypt,FROMcustomer;
La sentencia SELECT del Ejemplo 4-12 da como resultado la siguiente salida:
| encriptar_email | correo electrónico |
|---|---|
AQICAHiQbIJ478Gbu8DZyl0frUxOrbgDlP+CyfuWCuF0kHJyWg ... |
Para obtener más detalles sobre las UDF de Python, consulta la publicación del blog " Introducción a las UDF de Python en Amazon Redshift ", y para obtener más detalles sobre las UDF de Lambda, consulta la publicación del blog "Acceso a componentes externos mediante las UDF de Lambda de Amazon Redshift".
Procedimientos almacenados
Un procedimiento almacenado de Amazon Redshift es un objeto creado por el usuario para realizar un conjunto de consultas SQL y operaciones lógicas. El procedimiento se almacena en la base de datos y está disponible para los usuarios que tengan privilegios para ejecutarlo. A diferencia de una función UDF escalar, que sólo puede operar sobre una fila de datos de una tabla, un procedimiento almacenado puede incorporar lenguaje de definición de datos (DDL) y lenguaje de manipulación de datos (DML), además de las consultas SELECT. Además, un procedimiento almacenado no tiene por qué devolver un valor y puede contener expresiones de bucle y condicionales.
Los procedimientos almacenados se utilizan habitualmente para encapsular la lógica de la transformación de datos, la validación de datos y las operaciones específicas de la empresa, como alternativa a las secuencias de comandos del shell o a las complejas herramientas de ETL y orquestación. Los procedimientos almacenados permiten que los pasos lógicos de ETL/ELT queden totalmente encerrados en un procedimiento. Puedes escribir el procedimiento para que consigne los datos de forma incremental o para que tenga éxito por completo (procese todas las filas) o falle por completo (no procese ninguna fila). Dado que todo el procesamiento tiene lugar en el almacén de datos, no hay sobrecarga para mover los datos a través de la red y puedes aprovechar la capacidad de Amazon Redshift para realizar operaciones masivas en grandes cantidades de datos con rapidez gracias a su arquitectura MPP.
Además, como los procedimientos almacenados se implementan en en el lenguaje de programación PL/pgSQL, puede que no necesites aprender un nuevo lenguaje de programación para utilizarlos. De hecho, es posible que tengas procedimientos almacenados existentes en tu plataforma de datos heredada que puedan migrarse a Amazon Redshift con cambios mínimos en el código. Recrear la lógica de tus procesos existentes utilizando un lenguaje de programación externo o una nueva plataforma ETL podría ser un proyecto de gran envergadura. AWS también proporciona la Herramienta de Conversión de Esquemas de AWS (SCT), un asistente de migración que puede ayudar convirtiendo el código existente en otros lenguajes de programación de bases de datos a código PL/pgSQL nativo de Amazon Redshift.
En el Ejemplo 4-13, puedes ver un sencillo procedimiento que cargará datos en una tabla de preparación desde Amazon S3 y cargará nuevos registros en la tabla lineitem, al tiempo que se asegura de que se eliminan los duplicados. Este procedimiento aprovecha el operador MERGE y puede realizar la tarea utilizando una sola sentencia. En este ejemplo, hay variables constantes para l_orderyear y l_ordermonth. Sin embargo, esto se puede dinamizar fácilmente utilizando la función date_part y la variable current_date para determinar el año y el mes actuales que se van a cargar o pasando un parámetro year y month al procedimiento.
Ejemplo 4-13. Definición de procedimiento almacenado
CREATETABLEIFNOTEXISTSlineitem(L_ORDERKEYvarchar(20)NOTNULL,L_PARTKEYvarchar(20),L_SUPPKEYvarchar(20),L_LINENUMBERintegerNOTNULL,L_QUANTITYvarchar(20),L_EXTENDEDPRICEvarchar(20),L_DISCOUNTvarchar(20),L_TAXvarchar(20),L_RETURNFLAGvarchar(1),L_LINESTATUSvarchar(1),L_SHIPDATEdate,L_COMMITDATEdate,L_RECEIPTDATEdate,L_SHIPINSTRUCTvarchar(25),L_SHIPMODEvarchar(10),L_COMMENTvarchar(44));CREATETABLEstage_lineitem(LIKElineitem);CREATEORREPLACEPROCEDURElineitem_incremental()AS$$DECLAREyrCONSTANTINTEGER:=1998;--date_part('year',current_date);monCONSTANTINTEGER:=8;--date_part('month', current_date);queryVARCHAR;BEGINTRUNCATEstage_lineitem;query:='COPY stage_lineitem '||'FROM ''s3://redshift-immersionday-labs/data/lineitem-part/'||'l_orderyear='||yr||'/l_ordermonth='||mon||'/'''||' IAM_ROLE default REGION ''us-west-2'' gzip delimiter ''|''';EXECUTEquery;MERGEINTOlineitemUSINGstage_lineitemsONs.l_orderkey=lineitem.l_orderkeyANDs.l_linenumber=lineitem.l_linenumberWHENMATCHEDTHENDELETEWHENNOTMATCHEDTHENINSERTVALUES(s.L_ORDERKEY,s.L_PARTKEY,s.L_SUPPKEY,s.L_LINENUMBER,s.L_QUANTITY,s.L_EXTENDEDPRICE,s.L_DISCOUNT,s.L_TAX,s.L_RETURNFLAG,s.L_LINESTATUS,s.L_SHIPDATE,s.L_COMMITDATE,s.L_RECEIPTDATE,s.L_SHIPINSTRUCT,s.L_SHIPMODE,s.L_COMMENT);END;$$LANGUAGEplpgsql;
Hemos hecho referencia al rol IAM default. Asegúrate de modificar el rol para conceder acceso de lectura desde esta ubicación de Amazon S3.
Puedes ejecutar un procedimiento almacenado utilizando la palabra clave call (Ejemplo 4-14).
Ejemplo 4-14. Acceso a un procedimiento almacenado
CALLlineitem_incremental();
Para obtener más detalles sobre los procedimientos almacenados de Amazon Redshift, consulta la entrada del blog "Llevar tus procedimientos almacenados a Amazon Redshift".
Programación y orquestación
Cuando empieces a pensar en orquestar tu canalización de datos, debes tener en cuenta la complejidad del flujo de trabajo y las dependencias de procesos externos. Algunos usuarios tienen que gestionar varios sistemas con dependencias complejas. Puede que tengas requisitos avanzados de notificación si un trabajo falla o incumple un ANS. Si es así, puedes considerar una herramienta de programación de terceros. Entre las herramientas de programación de trabajos empresariales de terceros más populares se incluyen Tivoli, Control-M y AutoSys, cada una de las cuales tiene integraciones con Amazon Redshift que te permiten iniciar una conexión y ejecutar una o varias sentencias SQL. AWS también ofrece el servicio de orquestación Amazon Managed Workflow para Apache Airflow (MWAA), que se basa en el proyecto de código abierto Apache Airflow. Esto puede ser útil si ya estás ejecutando un flujo de trabajo Apache Airflow y quieres migrarlo a la nube.
Sin embargo, si puedes activar tus cargas basadas en activadores basados en el tiempo, puedes aprovechar el programador de consultas. Cuando utilices el programador de consultas, la interfaz de usuario aprovechará los servicios fundamentales de la API de datos de Amazon Redshift y EventBridge.
Para utilizar el programador de consultas para lanzar consultas simples basadas en el tiempo, navega hasta el Editor de Consultas V2, prepara tu consulta y pulsa el botón Programar(Figura 4-1). En este ejemplo, utilizaremos una sentencia COPY para cargar la tabla stage_lineitem.
Establece la conexión(Figura 4-2), así como el rol IAM que asumirá el programador para ejecutar la consulta. En el diálogo subsiguiente, selecciona el almacén de datos de Amazon Redshift aplicable de la lista y la cuenta y región correspondientes. En nuestro caso, utilizaremos "Credenciales temporales" para conectarnos. Consulta el Capítulo 2, "Introducción a Amazon Redshift", para obtener más detalles sobre otras estrategias de conexión.
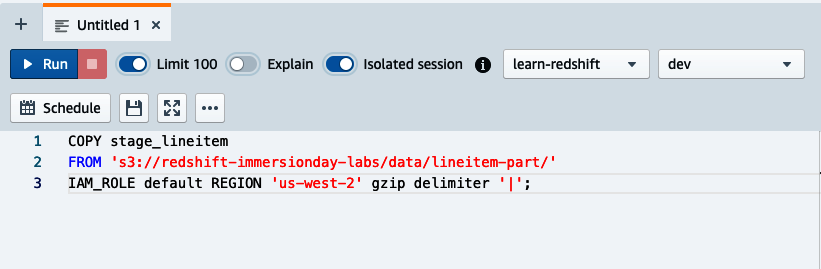
Figura 4-1. Botón Programar
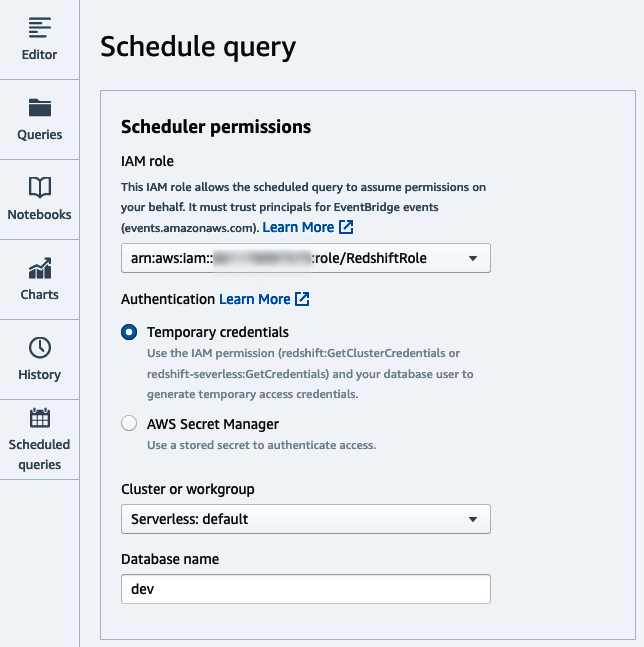
Figura 4-2. Elegir conexión
A continuación, establece el nombre de la consulta que se ejecutará y la descripción opcional(Figura 4-3). La consulta se copiará desde la página del editor.
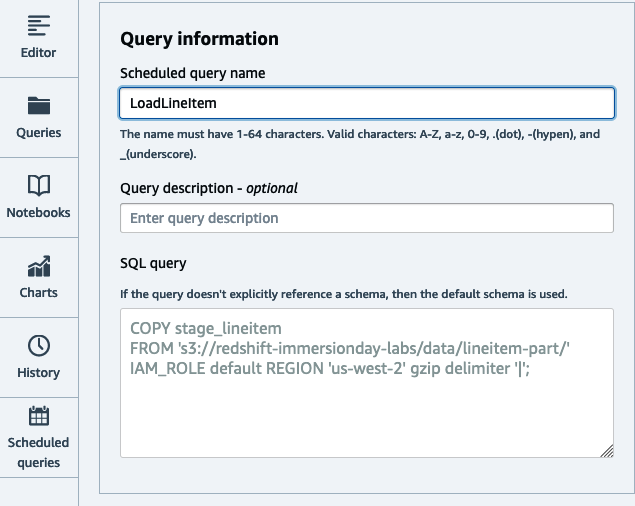
Figura 4-3. Establecer consulta
A continuación, establece la programación basada en el tiempo, ya sea en formato Cron o seleccionando las opciones de radio aplicables(Figura 4-4). Opcionalmente, elige si quieres que los eventos de ejecución se envíen a un tema de Amazon Simple Notification Service (SNS) para que puedas recibir notificaciones. Haz clic en Guardar cambios para guardar la programación.
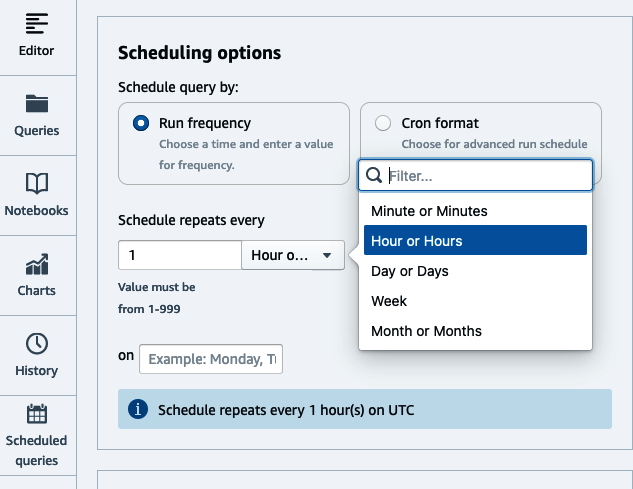
Figura 4-4. Establecer horario
Para ver la lista de consultas programadas, ve a la página Consultas programadas del Editor de Consultas V2(Figura 4-5).
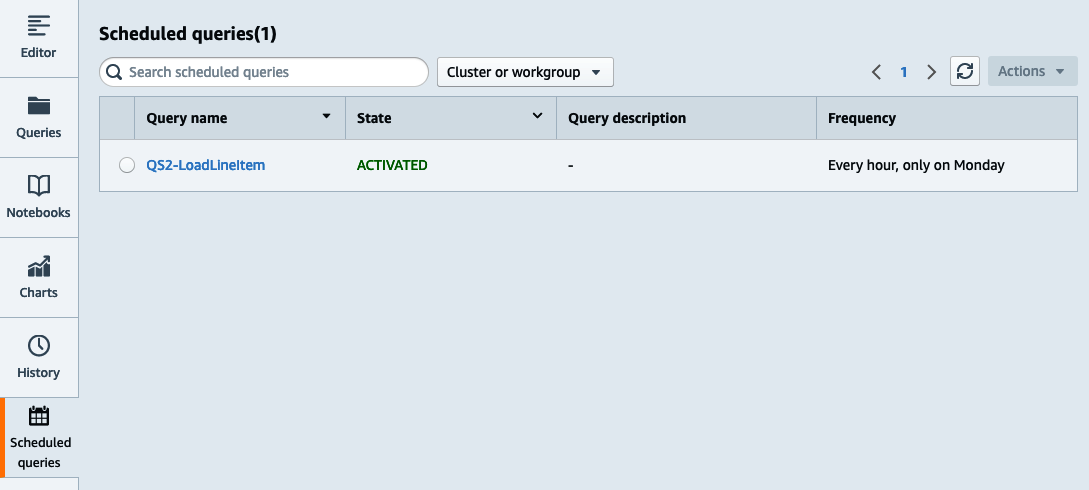
Figura 4-5. Lista de consultas programadas
Para gestionar el trabajo programado, haz clic en la consulta programada. En esta pantalla puedes modificar el trabajo, desactivarlo o eliminarlo. También puedes inspeccionar el historial, que contiene la hora de inicio/parada, así como el estado del trabajo (ver Figura 4-6).
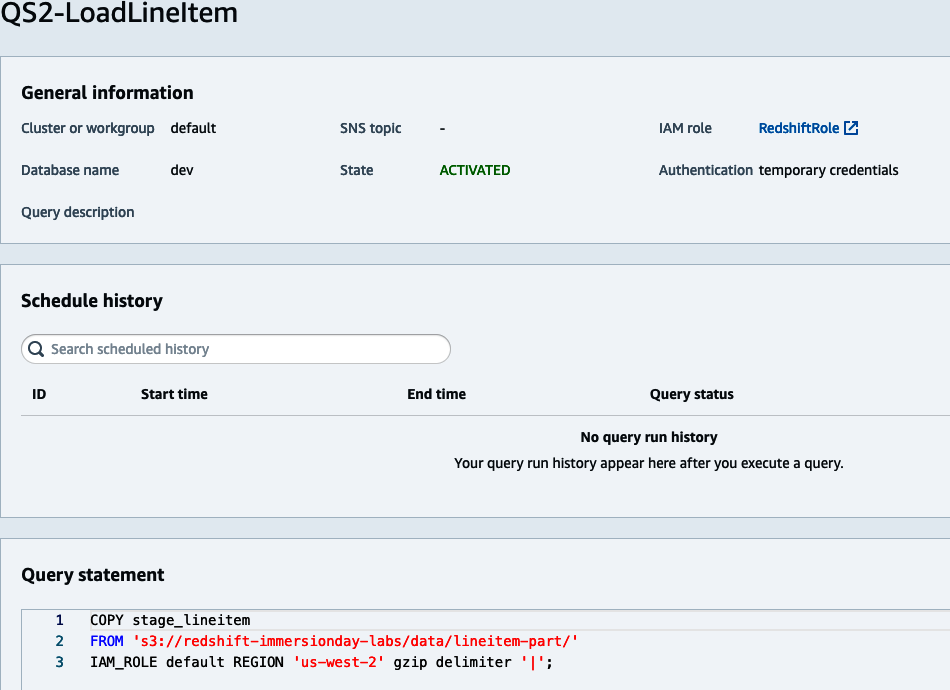
Figura 4-6. Ver historial de programación
También puedes ver los recursos creados en EventBridge. Ve a la página Reglas de EventBridge y observa que se ha creado una nueva regla Programada(Figura 4-7).
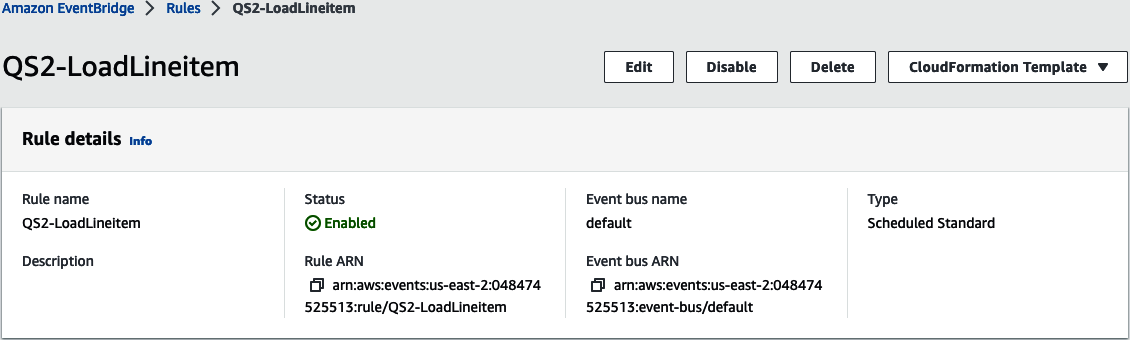
Figura 4-7. Regla programada
Si inspeccionas el objetivo de la regla(Figura 4-8), verás Redshift cluster tipo de objetivo junto con el parámetro necesario para ejecutar la consulta.
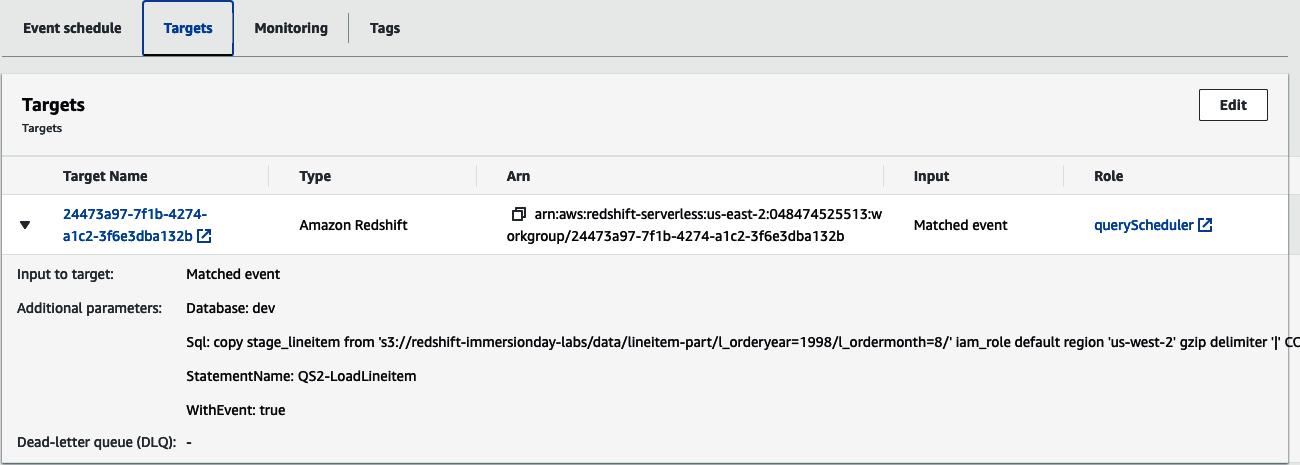
Figura 4-8. Objetivo de la regla programada
Accede a todos tus datos
Para completar la historia de ELT, Amazon Redshift permite acceder a los datos aunque no se hayan cargado. El equipo informático de Amazon Redshift procesará tus datos utilizando todas las capacidades de transformación ya mencionadas, sin necesidad de un servidor independiente para el procesamiento. Tanto si se trata de "Datos externos de Amazon S3", "Datos operativos externos" o incluso "Datos externos de Amazon Redshift", las consultas se envían a tu almacén de datos de Amazon Redshift utilizando la conocida sintaxis ANSI SQL; el equipo informático de Amazon Redshift sólo procesa los datos aplicables. Pueden unirse a datos locales y utilizarse para rellenar tablas locales de tu almacén de datos de Amazon Redshift.
Datos externos de Amazon S3
Amazon Redshift te permite leer y escribir datos externos almacenados en Amazon S3 mediante sencillas consultas SQL. El acceso a los datos en Amazon S3 mejora la interoperabilidad de tus datos porque puedes acceder a los mismos datos de Amazon S3 desde múltiples plataformas informáticas más allá de Amazon Redshift. Dichas plataformas incluyen Amazon Athena, Amazon EMR, Presto y cualquier otra plataforma informática que pueda acceder a Amazon S3. Mediante esta característica, Amazon Redshift puede unir tablas externas de Amazon S3 con tablas que residan en el disco local de tu almacén de datos de Amazon Redshift. Cuando se utiliza un clúster aprovisionado, Amazon Redshift aprovechará una flota de nodos denominada Amazon Redshift Spectrum, que aísla aún más el procesamiento de Amazon S3 y aplica optimizaciones como el pushdown de predicados y la agregación a la capa informática de Amazon Redshift Spectrum, lo que mejora el rendimiento de las consultas. Los tipos de operadores de predicado que puedes empujar a Amazon Redshift Spectrum incluyen: =, LIKE, IS NULL, y CASE WHEN. Además, puedes emplear lógica de transformación en la que muchas funciones de agregación y cadena se empujan a la capa de Amazon Redshift Spectrum. Los tipos de funciones de agregación incluyen: COUNT, SUM, AVG, MIN, y MAX.
Amazon Redshift Spectrum procesa datos de Amazon S3 utilizando la informática hasta 10 veces el número de rebanadas de tu clúster aprovisionado. También tiene un coste de 5 $/TB escaneados. En cambio, cuando consultas datos de Amazon S3 utilizando Amazon Redshift sin servidor, el procesamiento se produce en tu equipo informático de Amazon Redshift y el coste forma parte del precio de RPU.
La consulta de datos externos de Amazon S3 funciona aprovechando un metadata catalog externo que organiza conjuntos de datos en databases y tables. A continuación, asignas una base de datos a un schema de Amazon Redshift y proporcionas credenciales a través de un IAM ROLE, que determina el nivel de acceso que tienes. En el Ejemplo 4-15, tu catálogo de metadatos es AWS Glue data catalog, que contiene una base de datos llamada externaldb. Si esa base de datos no existe, este comando la creará. Hemos asignado esa base de datos a un nuevo esquema, externalschema, utilizando el rol IAM default adjunto al almacén de datos. Además del AWS Glue data catalog, los usuarios pueden mapear a un hive metastore si sus datos se encuentran en un clúster EMR o en un entorno Apache Hadoop autogestionado. Para más detalles sobre las opciones al crear esquemas externos, consulta la documentación online.
Ejemplo 4-15. Crear esquema S3 externo
CREATEEXTERNALSCHEMAIFNOTEXISTSexternalschemaFROMdatacatalogDATABASE'externaldb'IAM_ROLEdefaultCREATEEXTERNALDATABASEIFNOTEXISTS;
Hemos hecho referencia al rol IAM default. Asegúrate de modificar el rol para que tenga acceso a administrar el Catálogo de Datos de AWS Glue.
Una vez creado el esquema externo, puedes consultar fácilmente los datos de forma similar a una tabla cargada en Amazon Redshift. En el Ejemplo 4-16, puedes consultar datos de tu tabla externa unidos a datos almacenados localmente. Ten en cuenta que los conjuntos de datos a los que se hace referencia en el siguiente ejemplo no se han configurado. La consulta proporcionada sólo tiene fines ilustrativos.
Ejemplo 4-16. Acceso externo a la tabla S3
SELECTt.returnflag,t.linestatus,c.zip,sum(t.quantity)ASsum_qty,sum(t.extendedprice*(1-t.discount)*(1+t.tax))ASsum_chargeFROMexternalschema.transactionstJOINpublic.customersconc.id=t.customer_idWHEREt.year=2022ANDt.month=1GROUPBYt.returnflag,t.linestatus,c.zip;
Esta consulta tiene un filtro que restringe los datos de la tabla externa a enero de 2022 y una agregación simple. Al utilizar un clúster aprovisionado, este filtro y la agregación parcial se procesarán en la capa Spectrum de Amazon Redshift, lo que reducirá la cantidad de datos enviados a tus nodos informáticos y mejorará el rendimiento de la consulta.
Dado que obtendrás el mejor rendimiento al consultar datos almacenados localmente en Amazon Redshift, es una buena práctica tener los datos más recientes cargados en Amazon Redshift y consultar los datos a los que se accede con menos frecuencia desde fuentes externas. Siguiendo esta estrategia, puedes asegurarte de que los datos más calientes se almacenan lo más cerca posible del ordenador y en un formato optimizado para el procesamiento analítico. En el Ejemplo 4-17, puedes tener un proceso de carga que rellene la tabla de transacciones con los datos del último mes, pero tener todos tus datos en Amazon S3. Cuando se expongan a tus usuarios, verán una vista consolidada de los datos, pero cuando accedan a los datos más calientes, Amazon Redshift los recuperará del almacenamiento local. Ten en cuenta que los conjuntos de datos a los que se hace referencia en el siguiente ejemplo no se han configurado. La consulta proporcionada sólo tiene fines ilustrativos.
Ejemplo 4-17. Unión S3 y datos locales
CREATEVIEWpublic.transactions_allASSELECT…FROMpublic.transactionsUNIONALLSELECT…FROMexternalschema.transactionsWHEREyear!=date_part(YEAR,current_date)ANDmonth!=date_part(MONTH,current_date);WITHNOSCHEMABINDING;
La cláusula NO SCHEMA BINDING debe utilizarse para las tablas externas, a fin de garantizar que los datos puedan cargarse en Amazon S3 sin ningún impacto ni dependencia de Amazon Redshift.
Para obtener más detalles sobre las técnicas de optimización de Amazon Redshift Spectrum, consulta el blog de buenas prácticas de Amazon Redshift Spectrum.
Datos operativos externos
La consulta federada de Amazon Redshift permite a consultar directamente los datos almacenados en bases de datos transaccionales para integrar datos en tiempo real y simplificar el procesamiento ETL. Con la consulta federada, puedes proporcionar información en tiempo real a tus usuarios. Un caso de uso típico es cuando tienes una ingesta por lotes en tu almacén de datos, pero necesitas análisis en tiempo real. Puedes proporcionar una vista combinada de los datos cargados por lotes desde Amazon Redshift, y los datos actuales en tiempo real en la base de datos transaccional. La consulta federada también expone los metadatos de estas bases de datos fuente como tablas externas, lo que permite a herramientas de BI como Tableau y Amazon QuickSight consultar fuentes federadas. Esto permite nuevos casos de uso de almacenes de datos en los que puedes consultar datos operativos sin problemas, simplificar las canalizaciones ETL y crear datos en una vista de enlace tardío que combine datos operativos con datos locales de Amazon Redshift. A partir de 2022, las bases de datos transaccionales compatibles incluyen Amazon Aurora PostgreSQL/MySQL y Amazon RDS para PostgreSQL/MySQL.
La consulta federada de Amazon Redshift funciona estableciendo una conexión TCP/IP con tu almacén de datos operativo y asignándolo a un esquema externo. Proporcionas el tipo de base de datos y la información de conexión, así como las credenciales de conexión a través de un secreto de AWS Secrets Manager. En el Ejemplo 4-18, el tipo de base de datos es POSTGRES con la información de conexión especificando DATABASE, SCHEMA, y URI de la BD. Para más detalles sobre las opciones al crear un esquema externo utilizando la consulta federada, consulta la documentación online.
Ejemplo 4-18. Crear esquema externo
CREATEEXTERNALSCHEMAIFNOTEXISTSfederatedschemaFROMPOSTGRESDATABASE'db1'SCHEMA'pgschema'URI'<rdsname>.<hashkey>.<region>.rds.amazonaws.com'SECRET_ARN'arn:aws:secretsmanager:us-east-1:123456789012:secret:pgsecret'IAM_ROLEdefault;
Hemos hecho referencia al rol IAM default. Asegúrate de modificar el rol para conceder acceso al uso del Gestor de Secretos para recuperar un secreto llamado pgsecret.
Una vez creado el esquema externo, puedes consultar las tablas como consultarías una tabla local de Amazon Redshift. En el Ejemplo 4-19, puedes consultar datos de tu tabla externa unidos a datos almacenados localmente, de forma similar a la consulta que se ejecuta al consultar datos externos de Amazon S3. La consulta también tiene un filtro que restringe los datos de la tabla federada a enero de 2022. La consulta federada de Amazon Redshift aplica predicados de forma inteligente para restringir la cantidad de datos escaneados desde la fuente federada, lo que mejora enormemente el rendimiento de la consulta. Ten en cuenta que los conjuntos de datos a los que se hace referencia en el siguiente ejemplo no se han configurado. La consulta proporcionada sólo tiene fines ilustrativos.
Ejemplo 4-19. Acceso a tabla externa
SELECTt.returnflag,t.linestatus,c.zip,sum(t.quantity)ASsum_qty,sum(t.extendedprice*(1-t.discount)*(1+t.tax))ASsum_chargeFROMfederatedschema.transactionstJOINpublic.customerscONc.id=t.customer_idWHEREt.year=2022ANDt.month=1GROUPbyt.returnflag,t.linestatus,c.zip;
Dado que la consulta federada ejecuta consultas en el sistema transaccional, ten cuidado de limitar los datos consultados. Una buena práctica es utilizar los datos de las tablas locales de Amazon Redshift para los datos históricos y acceder sólo a los datos más recientes de la base de datos federada.
Además de la consulta de datos en vivo, la consulta federada abre oportunidades para simplificar los procesos ETL. Un patrón ETL común que muchas organizaciones utilizan al construir su almacén de datos es upsert. En upsert, los ingenieros de datos se encargan de escanear la fuente de la tabla de tu almacén de datos y determinar si se deben insertar nuevos registros o actualizar/eliminar los existentes. En el pasado, esto se realizaba en varios pasos:
-
Creando un extracto completo de tu tabla fuente, o si tu fuente tiene seguimiento de cambios, extrayendo aquellos registros desde la última vez que se procesó la carga.
-
Trasladar ese extracto a una ubicación local de tu almacén de datos. En el caso de Amazon Redshift, sería Amazon S3.
-
Utilizar un cargador masivo para cargar esos datos en una tabla de preparación. En el caso de Amazon Redshift, sería el comando
COPY. -
Ejecutar los comandos
MERGE(UPSERT-UPDATEyINSERT) contra tu tabla de destino basándote en los datos que se pusieron en escena.
Con la consulta federada, puedes evitar la necesidad de extractos incrementales en Amazon S3 y la posterior carga a través de COPY consultando los datos en su lugar dentro de su base de datos de origen. En el Ejemplo 4-20, hemos mostrado cómo se puede sincronizar la tabla de clientes desde la fuente operativa utilizando una única sentencia MERGE. Ten en cuenta que los conjuntos de datos a los que se hace referencia en el siguiente ejemplo no se han configurado. La consulta proporcionada sólo tiene fines ilustrativos.
Ejemplo 4-20. Actualización incremental con MERGE
MERGEINTOcustomerUSINGfederatedschema.customerpONp.customer_id=customer.customer_idANDp.updatets>current_date-1andp.updatets<current_dateWHENMATCHEDTHENUPDATESETcustomer_id=p.customer_id,name=p.name,address=p.address,nationkey=p.nationkey,mktsegment=p.mktsegmentWHENNOTMATCHEDTHENINSERT(custkey,name,address,nationkey,mktsegment)VALUES(p.customer_id,p.name,p.address,p.nationkey,p.mktsegment)
Para obtener más detalles sobre las técnicas de optimización de la consulta federada, consulta la publicación del blog "Buenas prácticas para la consulta federada de Amazon Redshift" , y para obtener más detalles sobre otras formas de simplificar tu estrategia ETL, consulta la publicación del blog "Construye una solución ETL simplificada y de consulta de datos en vivo utilizando la consulta federada de Amazon Redshift".
Datos externos de Amazon Redshift
El uso compartido de datos de Amazon Redshift permite a consultar directamente datos en vivo almacenados en el RMS de Amazon de otro almacén de datos de Amazon Redshift, ya sea un clúster aprovisionado que utilice el tipo de nodo RA3 o un almacén de datos sin servidor. Esta funcionalidad permite que los datos producidos en un almacén de datos de Amazon Redshift sean accesibles en otro almacén de datos de Amazon Redshift. De forma similar a otras fuentes de datos externas, la funcionalidad de compartir datos también expone los metadatos del almacén de datos de Amazon Redshift productor como tablas externas, lo que permite al consumidor consultar esos datos sin tener que hacer copias locales. Esto permite nuevos casos de uso del almacén de datos, como distribuir la propiedad de los datos y aislar la ejecución de diferentes cargas de trabajo. En el Capítulo 7, "Colaboración con datos compartidos", profundizaremos en estos casos de uso. En el siguiente ejemplo, aprenderás a configurar en un datashare mediante una sentencia SQL y a utilizarlo en tus procesos ETL/ELT. Para más detalles sobre cómo puedes activar y configurar el uso compartido de datos desde la consola de Redshift, consulta la documentación en línea.
El primer paso para compartir datos es comprender el namespace de tus almacenes de datos productor y consumidor. Ejecuta lo siguiente en cada almacén de datos para recuperar los valores correspondientes(Ejemplo 4-21).
Ejemplo 4-21. Espacio de nombres actual
SELECTcurrent_namespace;
A continuación, crea un objeto datashare y añade objetos de base de datos como schema y table en el almacén de datos productor(Ejemplo 4-22).
Ejemplo 4-22. Crear datashare
CREATEDATASHAREtransactions_datashare;ALTERDATASHAREtransactions_datashareADDSCHEMAtransactions_schema;ALTERDATASHAREtransactions_datashareADDALLTABLESINSCHEMAtransactions_schema;
Ahora puedes conceder al datashare acceso desde el productor al consumidor haciendo referencia a su namespace (Ejemplo 4-23).
Ejemplo 4-23. Conceder uso de datashare
GRANTUSAGEONDATASHAREtransactions_datashareTONAMESPACE'1m137c4-1187-4bf3-8ce2-CONSUMER-NAMESPACE';
Por último, crea una base de datos en el consumidor, haciendo referencia al nombre del datashare, así como al namespace del productor(Ejemplo 4-24).
Ejemplo 4-24. Crear base de datos datashare
CREATEDATABASEtransactions_databasefromDATASHAREtransactions_datashareOFNAMESPACE'45b137c4-1287-4vf3-8cw2-PRODUCER-NAMESPACE';
Los datashares también se pueden conceder a través de cuentas. En este caso, se requiere un paso adicional por parte del administrador asociado al datashare. Consulta la documentación en línea para obtener más información.
Una vez creada la base de datos externa, puedes consultar fácilmente los datos como lo harías con una tabla local de tu almacén de datos de Amazon Redshift. En el Ejemplo 4-25, estás consultando datos de tu tabla externa unidos a datos almacenados localmente, de forma similar a la consulta que se ejecuta cuando se utilizan datos operativos y de Amazon S3 externos. Del mismo modo, la consulta tiene un filtro que restringe los datos de la tabla externa a enero de 2022. Ten en cuenta que los conjuntos de datos a los que se hace referencia en el siguiente ejemplo no se han configurado. La consulta proporcionada sólo tiene fines ilustrativos.
Ejemplo 4-25. Acceso a datos compartidos
SELECTt.returnflag,t.linestatus,c.zip,sum(t.quantity)assum_qty,sum(t.extendedprice*(1-t.discount)*(1+t.tax))assum_chargeFROMtransactions_database.transcations_schema.transactionstJOINpublic.customersconc.id=t.customer_idWHEREt.year=2022ANDt.month=1GROUPbyt.returnflag,t.linestatus,c.zip;
Puedes imaginar una situación en la que un departamento se encargue de gestionar las transacciones de ventas y otro de las relaciones con los clientes. El departamento de relaciones con los clientes está interesado en determinar sus mejores y peores clientes a los que enviar marketing dirigido. En lugar de tener que mantener un único almacén de datos y compartir recursos, cada departamento puede aprovechar su propio almacén de datos de Amazon Redshift y ser responsable de sus propios datos. En lugar de duplicar los datos de las transacciones, el grupo de relaciones con los clientes puede consultarlos directamente. Pueden crear y mantener un agregado de esos datos y unirlo a los datos que tienen sobre iniciativas de marketing anteriores, así como a los datos sobre el sentimiento de los clientes, para construir su campaña de marketing.
Obtén más información sobre la compartición de datos en "Compartir datos de Amazon Redshift de forma segura entre clústeres de Amazon Redshift para aislar cargas de trabajo" y "Buenas prácticas y consideraciones sobre la compartición de datos de Amazon Redshift".
Transformación externa
En situaciones en las que desees utilizar una herramienta externa para tus transformaciones de datos, Amazon Redshift puede conectarse a una plataforma ETL de tu elección mediante controladores JDBC y ODBC empaquetados con esas aplicaciones o que puedes descargar. Las plataformas ETL populares que se integran con Amazon Redshift incluyen herramientas de terceros como Informatica, Matillion y dbt, así como herramientas nativas de AWS como "AWS Glue". Las herramientas ETL son una forma valiosa de gestionar todos los componentes de tu canalización de datos. Proporcionan un repositorio de trabajos para organizar y mantener los metadatos, facilitando a las organizaciones la gestión de su código en lugar de almacenar esa lógica en scripts SQL y procedimientos almacenados. También tienen capacidades de programación para facilitar la orquestación de trabajos, lo que puede ser útil si no utilizas la "Programación y Orquestación" disponible de forma nativa en AWS.
Algunas herramientas ETL también tienen la capacidad de "empujar hacia abajo" la lógica de transformación. En el caso de que estés leyendo y escribiendo desde tu almacén de datos de Amazon Redshift, puedes diseñar tu trabajo utilizando las capacidades visuales de la herramienta ETL, pero en lugar de extraer realmente los datos al ordenador del servidor o servidores ETL, el código se convierte en sentencias SQL que se ejecutan en Amazon Redshift. Esta estrategia puede ser muy eficaz cuando se transforman grandes cantidades de datos, pero también puede consumir muchos recursos que tus usuarios finales pueden necesitar para analizar los datos. Cuando no utilices las capacidades push-down de tu herramienta ETL, ya sea porque tu trabajo no lee ni escribe en Amazon Redshift o porque has decidido descargar la lógica de transformación, es importante que te asegures de que tu herramienta ETL lee y escribe datos de Amazon Redshift de forma eficiente.
Como se explica en el Capítulo 3, "Configuración de tus modelos de datose ingestión de datos", la forma más eficaz de cargar datos es utilizar la sentencia COPY. Gracias a la asociación entre AWS y proveedores de ETL como Informatica y Matillion, AWS se ha asegurado de que los proveedores hayan creado conectores teniendo en cuenta esta estrategia. Por ejemplo, en la arquitectura de Informatica Amazon Redshift de la Figura 4-9, puedes ver que si has especificado un destino de Amazon Redshift y un área de almacenamiento en Amazon S3, en lugar de cargar directamente el destino mediante una inserción, la herramienta escribirá en Amazon S3 y luego utilizará la sentencia COPY de Amazon Redshift para cargar en la tabla de destino. Esta misma estrategia también funciona para las sentencias update y delete, excepto que, en lugar de cargar directamente la tabla de destino, Informatica escribirá en una tabla de preparación y realizará las sentencias update y delete después de la carga. Esta optimización es posible porque AWS se asocia con varios proveedores de software para garantizar que los usuarios aprovechen fácilmente la herramienta y aseguren el rendimiento de sus canalizaciones de datos. Consulta las siguientes guías, que se han publicado para obtener más detalles sobre las buenas prácticas al utilizar algunas de las herramientas ETL de terceros más populares:
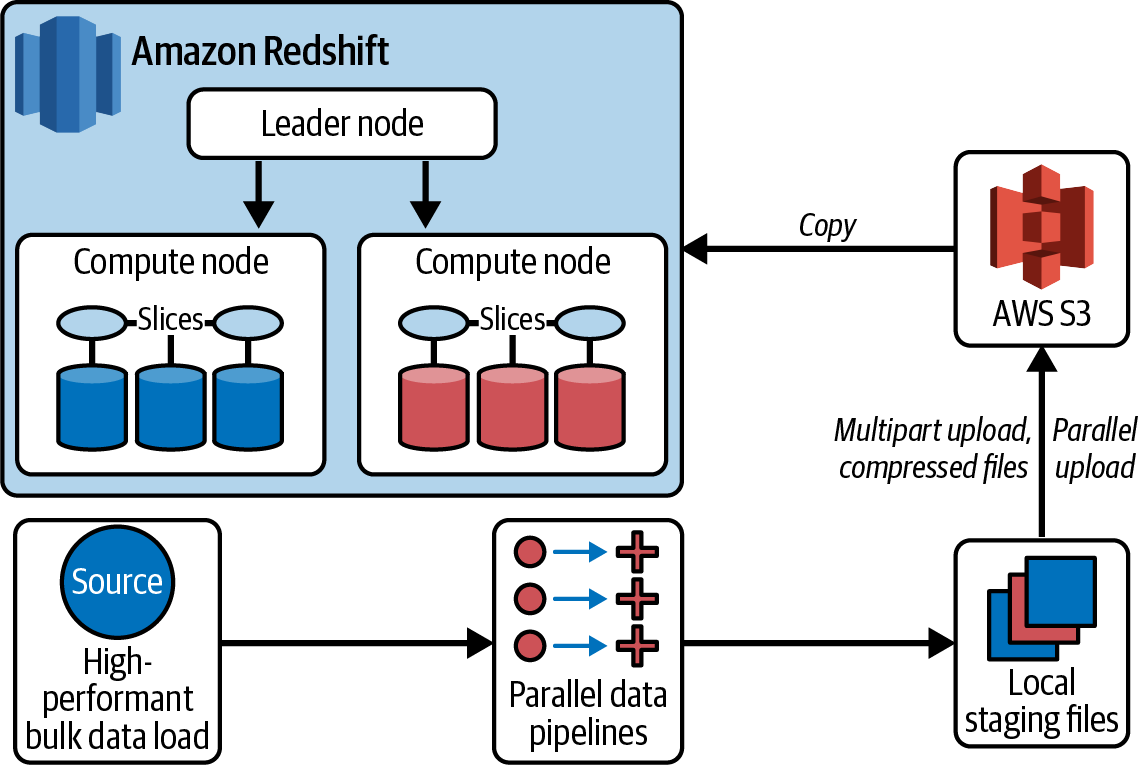
Figura 4-9. Arquitectura de Informatica Amazon Redshift
Pegamento AWS
AWS Glue es uno de los servicios nativos de integración de datos sin servidor que se utilizan habitualmente para transformar datos utilizando lenguaje Python o Scala y ejecutarlos en un motor de procesamiento de datos. Con AWS Glue(Figura 4-10), puedes leer datos de Amazon S3, aplicar transformaciones e ingerir datos en almacenes de datos de Amazon Redshift, así como en otras plataformas de datos. AWS Glue facilita descubrir, preparar, mover e integrar datos de múltiples fuentes para análisis, ML y desarrollo de aplicaciones. Ofrece varios motores de integración de datos, que incluyen AWS Glue para Apache Spark, AWS Glue para Ray y AWS Glue para Python Shell. Puedes utilizar el motor adecuado para tu carga de trabajo, en función de las características de ésta y de las preferencias de tus desarrolladores y analistas.
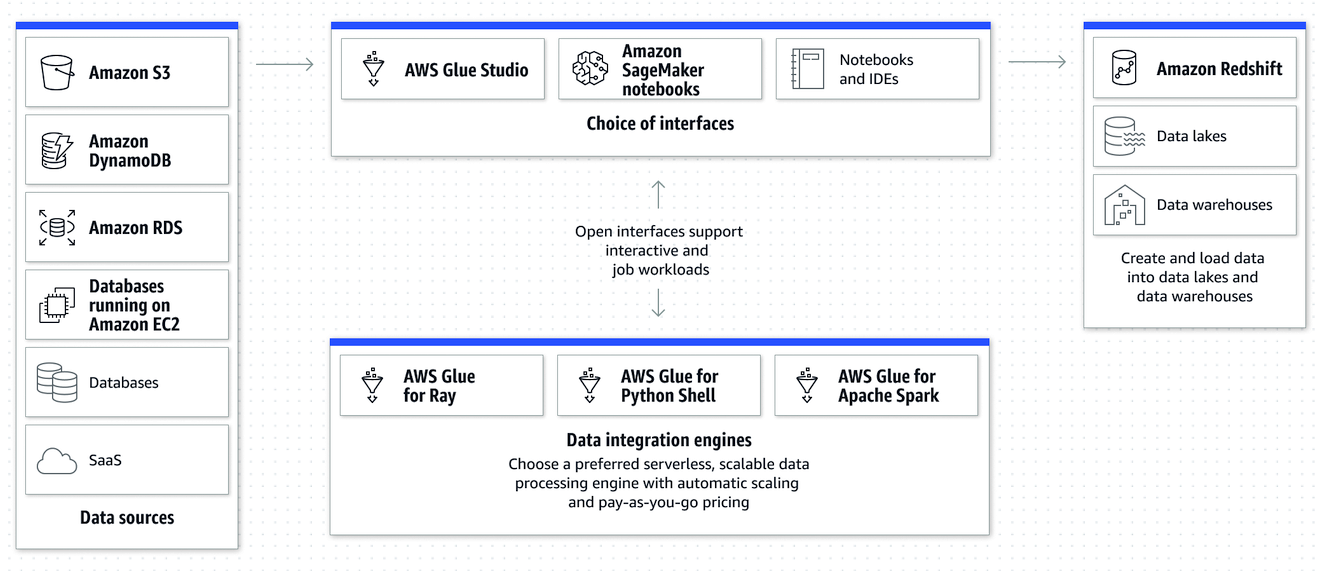
Figura 4-10. Integración ETL utilizando AWS Glue
Desde AWS Glue V4, se incluye un nuevo conector Spark de Amazon Redshift con un nuevo controlador JDBC con los trabajos ETL de AWS Glue. Puedes utilizarlo para crear aplicaciones Apache Spark que lean y escriban en datos de Amazon Redshift como parte de tus canalizaciones de ingesta y transformación de datos. El nuevo conector y controlador permite transferir operaciones relacionales como uniones, agregaciones, ordenaciones y funciones escalares de Spark a Amazon Redshift para mejorar el rendimiento de tu trabajo reduciendo la cantidad de datos que deben procesarse. También admite roles basados en IAM para habilitar capacidades de inicio de sesión único y se integra con AWS Secrets Manager para administrar claves de forma segura.
Para administrar tus trabajos de AWS Glue, AWS proporciona una herramienta de creación visual, AWS Glue Studio. Este servicio sigue muchas de las mismas buenas prácticas que las herramientas ETL de terceros ya mencionadas; sin embargo, debido a la integración, requiere menos pasos para construir y administrar tus canalizaciones de datos.
En el Ejemplo 4-26, crearemos un trabajo que cargue datos de transacciones incrementales de Amazon S3 y los fusione en una tabla lineitem utilizando la clave (l_orderkey, l_linenumber) en tu almacén de datos de Amazon Redshift.
Ejemplo 4-26. Crear tabla lineitem
CREATETABLEIFNOTEXISTSlineitem(L_ORDERKEYvarchar(20)NOTNULL,L_PARTKEYvarchar(20),L_SUPPKEYvarchar(20),L_LINENUMBERintegerNOTNULL,L_QUANTITYvarchar(20),L_EXTENDEDPRICEvarchar(20),L_DISCOUNTvarchar(20),L_TAXvarchar(20),L_RETURNFLAGvarchar(1),L_LINESTATUSvarchar(1),L_SHIPDATEdate,L_COMMITDATEdate,L_RECEIPTDATEdate,L_SHIPINSTRUCTvarchar(25),L_SHIPMODEvarchar(10),L_COMMENTvarchar(44));
Para construir un trabajo de Pegado, seguiremos las instrucciones de las dos secciones siguientes.
Registrar la conexión de destino de Amazon Redshift
Navega hasta "Crear conexión" para crear una nueva conexión AWS Glue. Dale un nombre a la conexión y elige el tipo de conexión de Amazon Redshift (ver Figura 4-11).
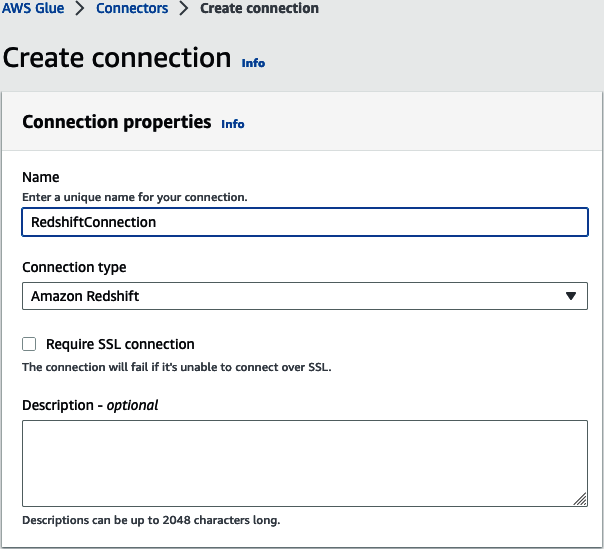
Figura 4-11. Nombre de conexión de Amazon Redshift
A continuación, selecciona la instancia de base de datos de la lista de almacenes de datos de Amazon Redshift autodescubiertos que se encuentran en tu cuenta y región de AWS. Establece el nombre de la base de datos y las credenciales de acceso. Tienes la opción de establecer un nombre de usuario y una contraseña o utilizar AWS Secrets Manager. Por último, haz clic en "Crear conexión" (ver Figura 4-12).
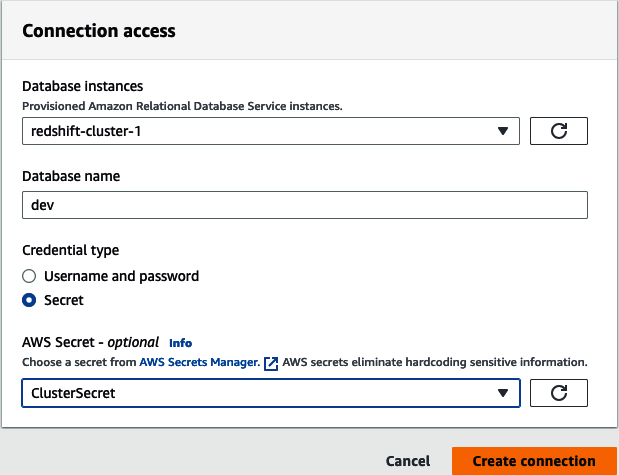
Figura 4-12. Instancia de conexión a Amazon Redshift
Construye y ejecuta tu trabajo AWS Glue
Para crear un trabajo de AWS Glue, navega a la página de trabajos de AWS Glue Studio. Verás un diálogo que te pide opciones para tu trabajo(Figura 4-13). En este ejemplo, seleccionaremos "Visual con un origen y un destino". Modifica el destino a Amazon Redshift y selecciona Crear.
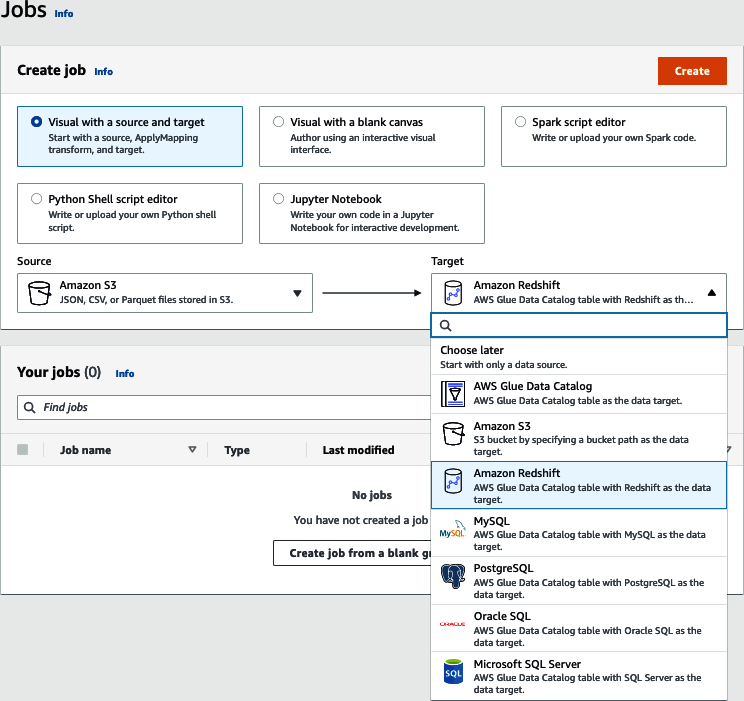
Figura 4-13. AWS Glue Crear trabajo
A continuación, se te presentará una representación visual de tu trabajo. El primer paso será seleccionar el nodo de fuente de datos y establecer el tipo de fuente S3(Figura 4-14). Para nuestro caso de uso utilizaremos una ubicación S3 e introduciremos la ubicación de nuestros datos: s3://redshift-immersionday-labs/data/lineitem-part/. Elige los detalles de análisis, como el formato de los datos, el delimitador, el carácter de escape, etc. Para nuestro caso de uso, los archivos tendrán un formato CSV, estarán delimitados por tuberías (|) y no tendrán cabeceras de columna. Por último, haz clic en el botón "Inferir esquema".
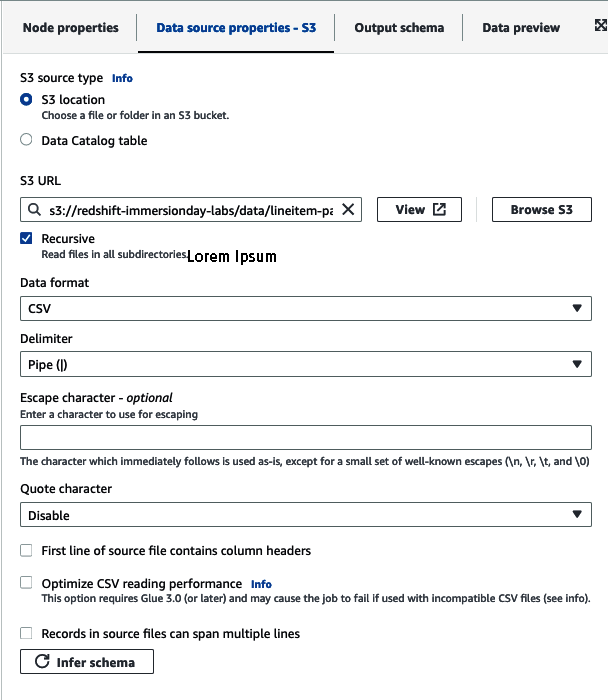
Figura 4-14. Conjunto AWS Glue Cubo Amazon S3
Si has establecido un lago de datos que utilizas para realizar consultas con otros servicios de AWS como Amazon Athena, Amazon EMR o incluso Amazon Redshift como tabla externa, puedes utilizar alternativamente la opción "Tabla del catálogo de datos".
A continuación, podemos transformar nuestros datos (Figura 4-15). El trabajo se construye con un simple nodo ApplyMapping, pero tienes muchas opciones para transformar tus datos, como unir, dividir y agregar datos. Consulta la documentación de AWS "Edición de nodos de transformación de datos administrados con AWS Glue" para ver otros nodos de transformación. Selecciona el nodo Transformar y establece la clave de destino que coincida con la clave de origen. En nuestro caso, los datos de origen no tenían cabeceras de columna y se registraron con columnas genéricas (col#). Asígnalas a las columnas correspondientes de tu tabla lineitem.
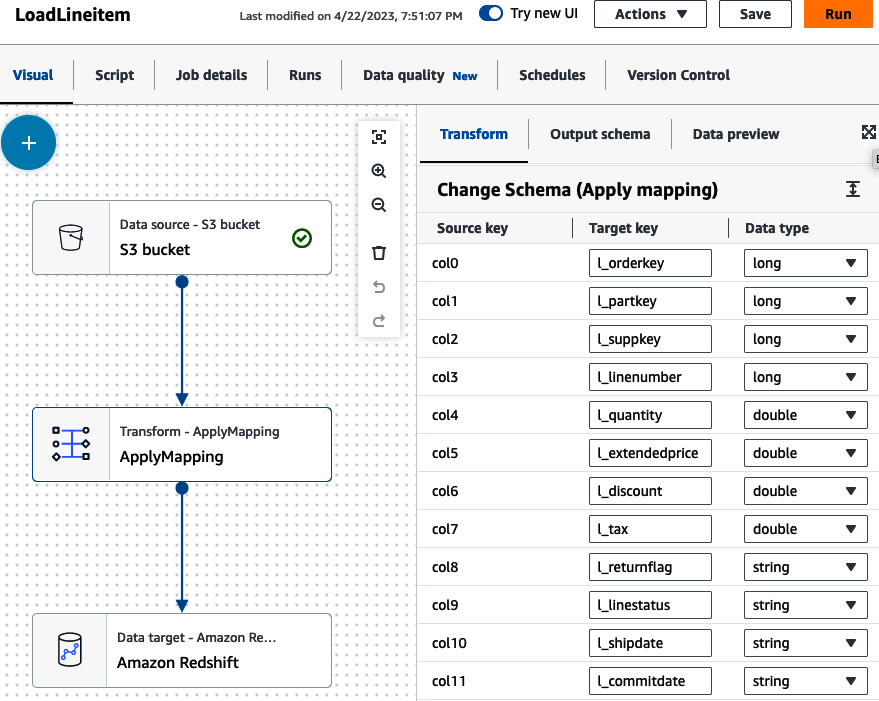
Figura 4-15. Asignación de aplicación de AWS Glue
Ahora puedes configurar los detalles de Amazon Redshift(Figura 4-16). Elige "Conexión directa de datos" y selecciona el esquema (public) y la tabla (lineitem) aplicables. También puedes establecer cómo gestionará el trabajo los nuevos registros; puedes limitarte a insertar todos los registros o establecer una clave para que el trabajo pueda actualizar los datos que deban reprocesarse. Para nuestro caso de uso, elegiremos MERGE y estableceremos la clave l_orderkey y l_linenumber. De este modo, cuando se ejecute el trabajo, los datos se cargarán primero en una tabla de preparación y, a continuación, se ejecutará una sentencia MERGE basada en los datos que ya existan en el destino, antes de cargar los nuevos datos con una sentencia INSERT.
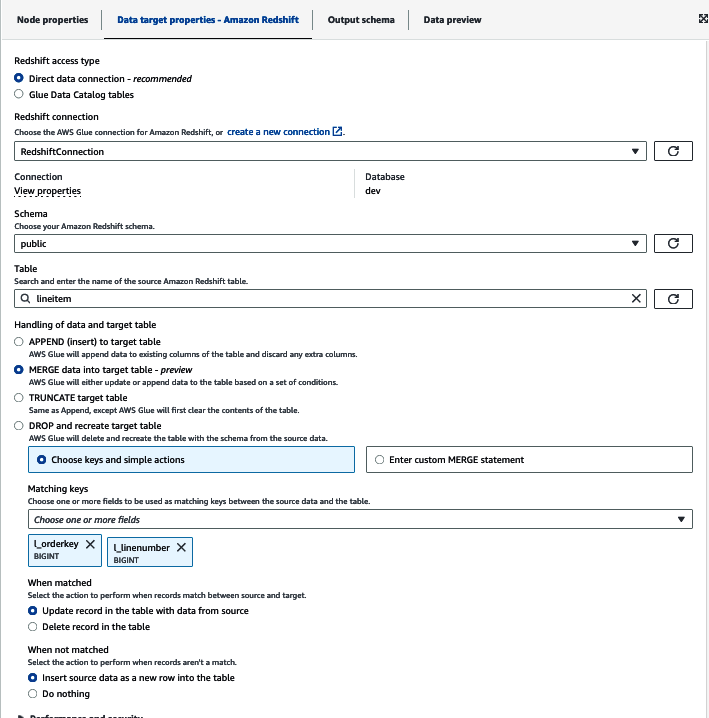
Figura 4-16. AWS Glue establece el objetivo Amazon Redshift
Antes de que puedas guardar y ejecutar el trabajo, debes establecer algunos detalles adicionales del trabajo, como el rol IAM, que se utilizará para ejecutar el trabajo, y el nombre de archivo del script(Figura 4-17). El rol debe tener permisos para acceder a los archivos de tu ubicación de Amazon S3 y también debe poder ser asumido por el servicio AWS Glue. Una vez que hayas creado y configurado el rol IAM, haz clic en Guardar y Ejecutar para ejecutar tu trabajo.
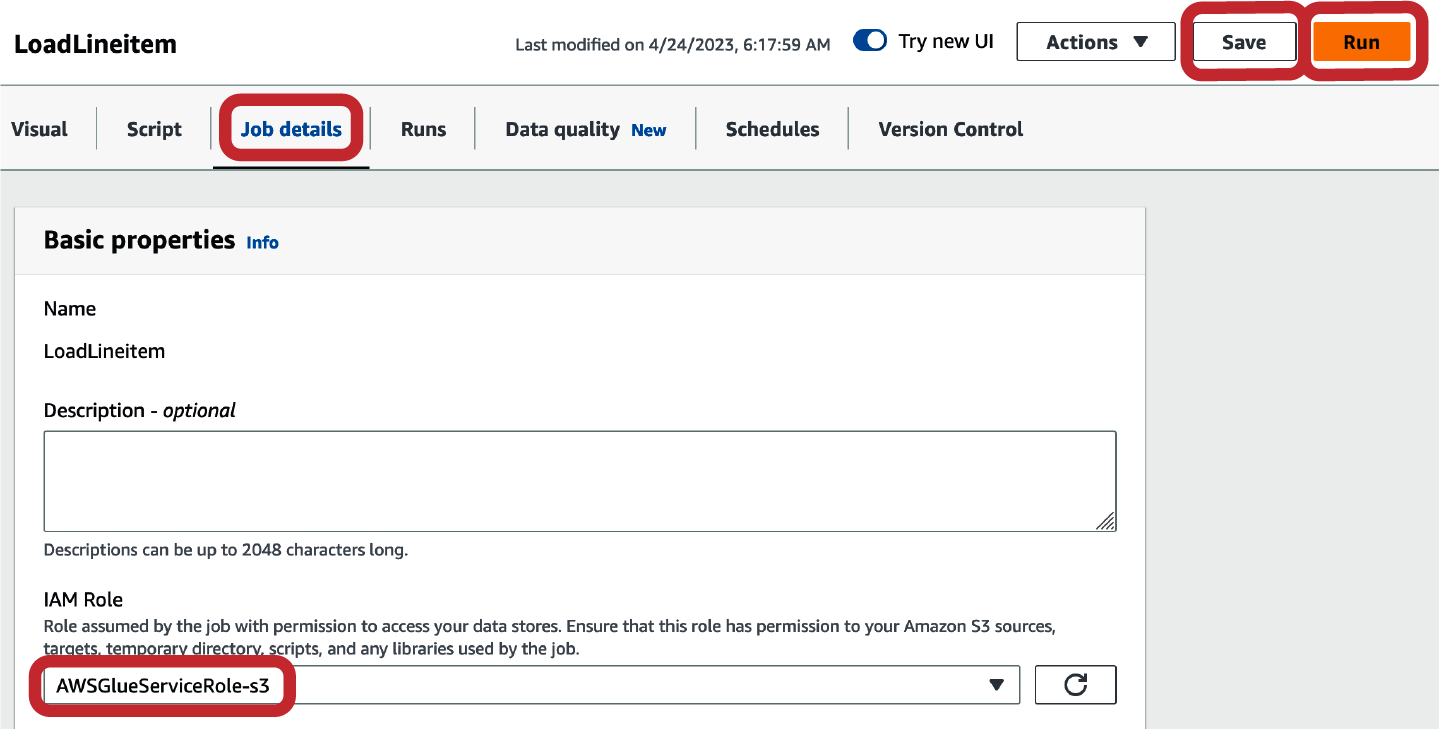
Figura 4-17. Detalles del trabajo del conjunto de cola AWS
Puedes inspeccionar la ejecución del trabajo navegando hasta la pestaña Ejecuciones. Verás detalles sobre el ID del trabajo y las estadísticas de ejecución(Figura 4-18).
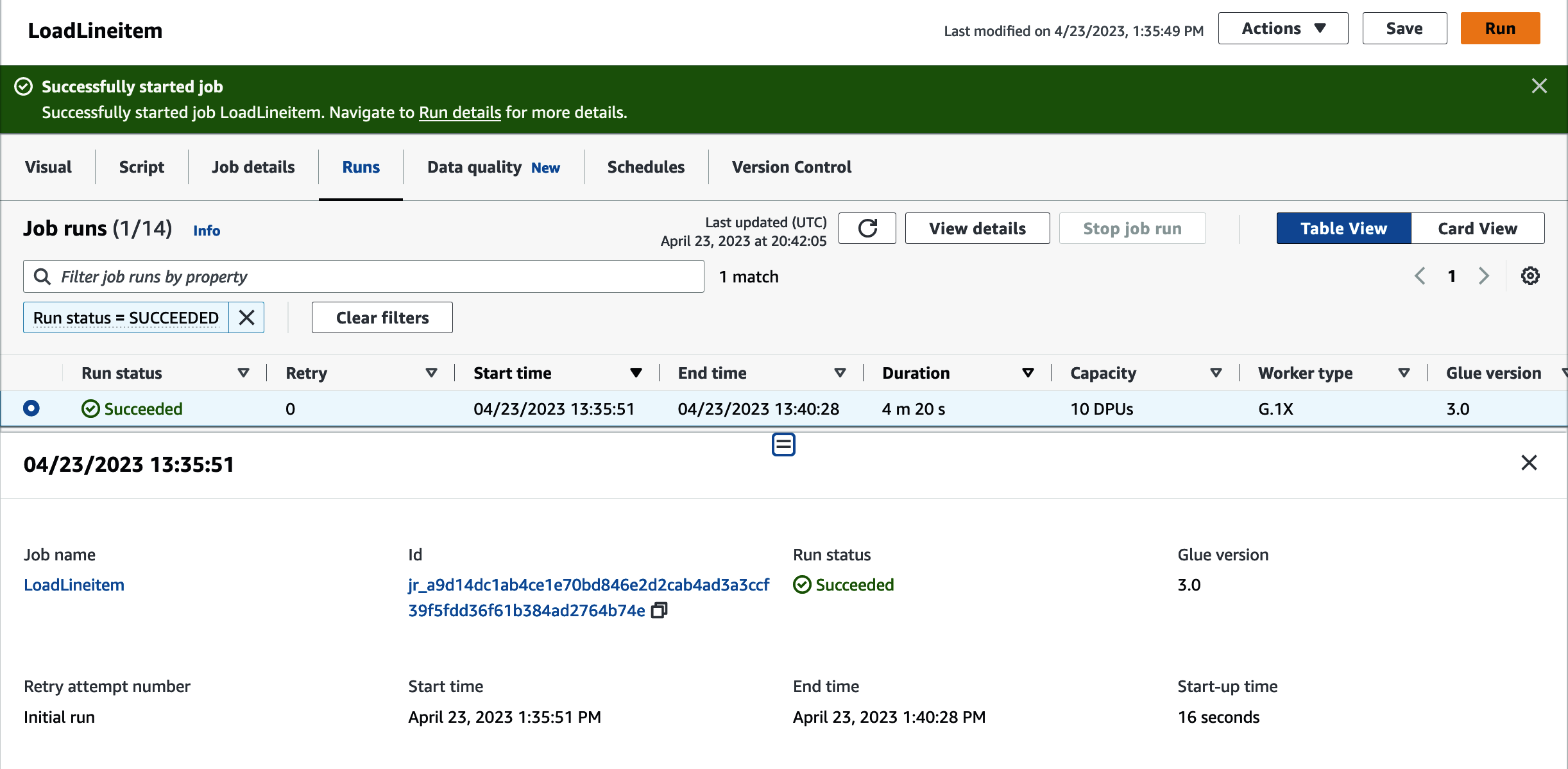
Figura 4-18. Detalles de la ejecución del trabajo de AWS Glue
Para que AWS Glue acceda a Amazon S3, tendrás que crear un endpoint VPC si aún no lo has hecho. Consulta la documentación online para más detalles.
Una vez completado el trabajo, puedes navegar hasta la consola de Amazon Redshift para inspeccionar las consultas y las cargas(Figura 4-19). Verás las consultas necesarias para crear la tabla temporal, cargar los archivos de Amazon S3 y ejecutar la sentencia merge que borra los datos antiguos e inserta los nuevos.
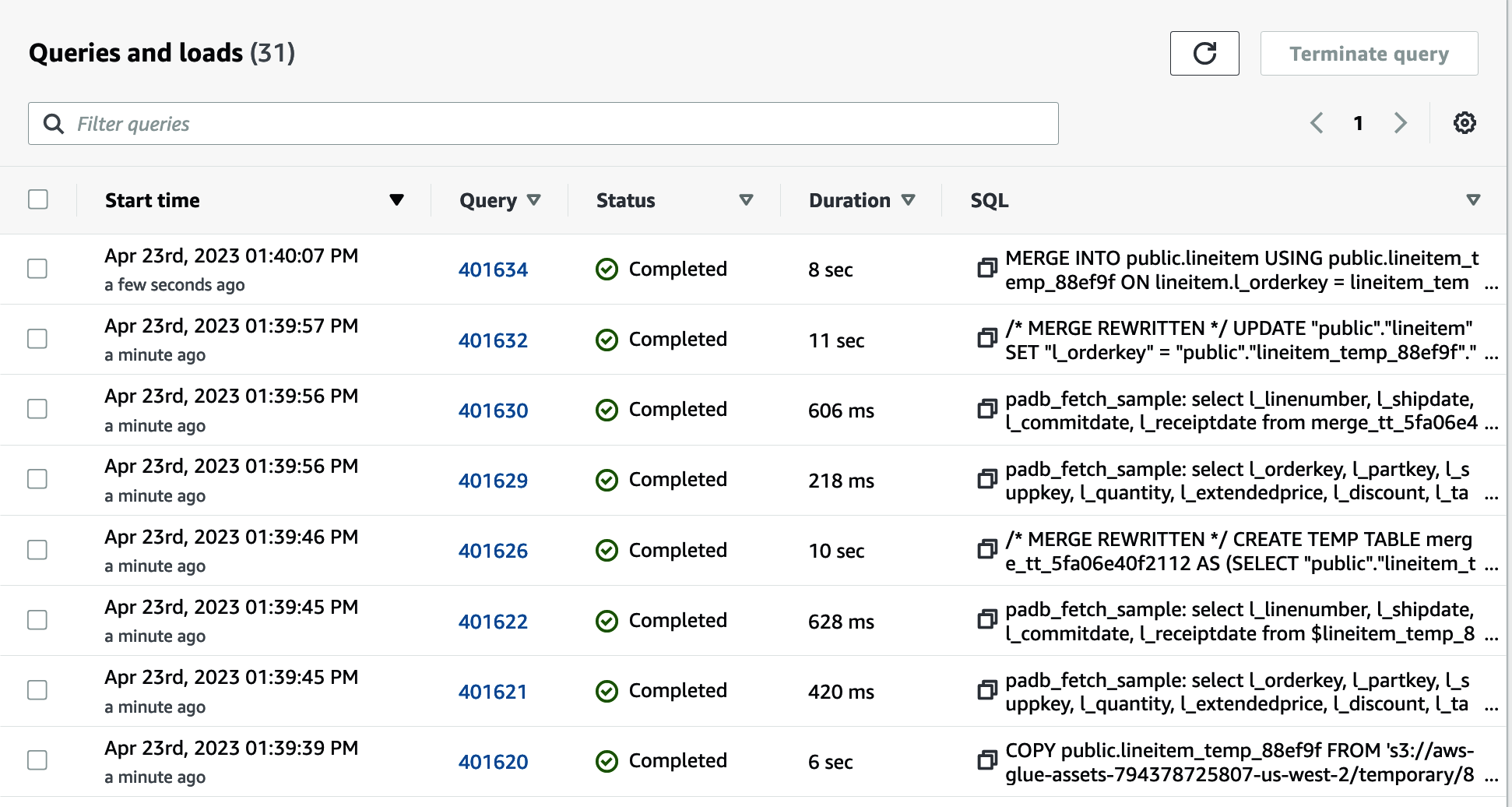
Figura 4-19. Historial de consultas de Amazon Redshift
Resumen
En este capítulo se han descrito las distintas formas en que puedes transformar datos utilizando Amazon Redshift. Con la capacidad de Amazon Redshift para acceder a todos tus datos, se hayan cargado o no, puedes transformar datos en tu lago de datos, fuentes operativas u otros almacenes de datos de Amazon Redshift de forma rápida y sencilla. Además, demostramos que puedes implementar programaciones basadas en el tiempo utilizando el programador de consultas de Amazon Redshift para orquestar estos trabajos. Por último, cubrimos cómo Amazon Redshift se asocia con proveedores externos de ETL y orquestación para proporcionar un rendimiento de ejecución óptimo e integrarse con las herramientas que ya puedas tener en tu organización.
En el próximo capítulo, hablaremos de cómo se escala Amazon Redshift cuando realizas cambios en tu carga de trabajo. También cubriremos cómo un almacén de datos sin servidor de Amazon Redshift se escalará automáticamente y cómo tienes el control sobre cómo escalar tu almacén de datos aprovisionado. También hablaremos de cómo puedes obtener el mejor rendimiento de precios con Amazon Redshift aplicando buenas prácticas.
Get Amazon Redshift: La Guía Definitiva now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

