Chapter 1. The Test Automation Gap
When you automate something, it can start, run, and complete with little to no human intervention. In the 1950s, the term “lights-out manufacturing” was coined to describe a vision of factories so independent of human labor that they could operate with the lights out. However, in the field of software testing, our view of automation is far from a lights-out philosophy. In this chapter, I describe the gap between manual and automated testing, including some of the grand challenges of software testing and limitations of traditional test automation approaches.
The Human Element of Software Testing
For years, you’ve likely differentiated between manual and automated testing. In my own career as a test architect, engineering director, and head of quality, I frequently differentiated between the two, even becoming good at convincing others that making such a distinction was both meaningful and necessary. However, the truth is that, outside of automatic test execution, software testing is almost entirely a manual, tedious, and time-consuming process.
Before you can test a software system, you must understand what the system is supposed to do and who its intended users are. This generally involves reviewing software requirements documentation; interviewing product analysts, end users, and customers; and comparing this information to the requirements of similar products. Once you understand the product requirements and customer needs, you must examine the implemented system to determine whether or not it meets those needs. Software testing is more than having a human and/or machine check specific facts about a program.1 Figure 1-1 visualizes a definition of software testing, reminding us that software testing is a complex, multidimensional problem that is as much social as it is technical.
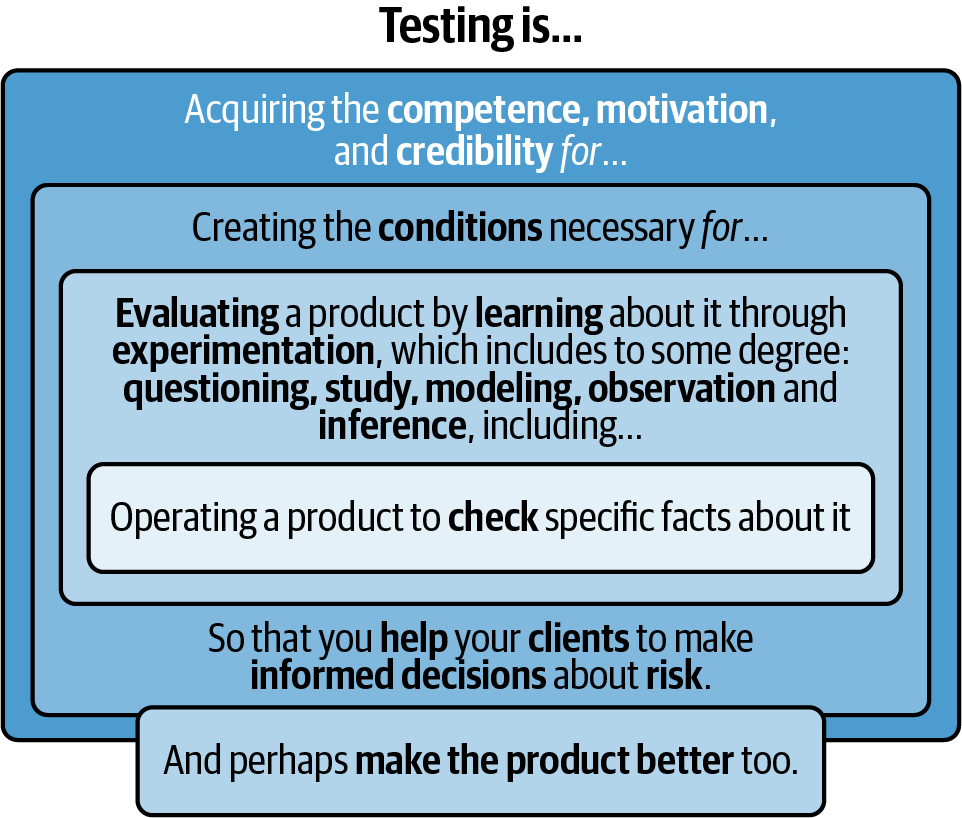
Figure 1-1. Testing is more than checking—it involves learning, experimenting, and more
Grand Challenges
To truly automate testing, we first have to overcome some of its key challenges. Let’s take a look at five grand challenges in software testing that make it difficult to automate.
Input/Output
Computer software takes user input, processes it, and produces output. Let’s assume you are testing a very simple program with only one text field. For that single field, you have a computationally infeasible number of values to choose from. Considering that most programs contain many input fields, now there is a combinatorial explosion of the computationally infeasible number of input values. Furthermore, you can apply those input combinations at different times and order them in many different ways. So now there is a permutational explosion that must also be addressed. Sounds exhausting, doesn’t it? And don’t forget that you still have to check that each of those inputs produces the correct output and does so in accordance with the appropriate usability, accessibility, performance, reliability, and security constraints.
State Explosion
Most computing systems are reactive. They engage users in a session where a human or another system provides input, the machine processes it and produces output, and this process then repeats. At any point, the system is in a state where, depending on previous inputs, a given user action will produce specific outputs and the system will transition to an updated state. If you are testing a reactive system, you are responsible for getting the system into the correct pretest state, applying the input, and verifying that the correct end state has been reached. However, an infinite number of inputs and outputs is generally accompanied by an infinite number of states. And so, similar to the input/output problem, testing suffers from a rapid explosion in the number of states you have to cover.
Data
During testing, you can use data in many different ways. You may want to confirm specific facts about how the system transforms inputs into outputs or set up unusual scenarios to verify that the system does not crash. Testers use data selection techniques like equivalence class partitioning2 to reduce the number of tests required to cover a particular feature and choose data around the system boundaries to verify that the software works under extreme conditions. Yes, data is a powerful tool in your testing tool belt. However, this also means that there are many important decisions that surround that test data. Will your test data primarily consist of fake data that may not be representative of the real world? Or are you able to pull real-world data from customers in production? If so, can you anonymize customer data for testing in accordance with data privacy regulations? The point is that, even though it is possible to build tools to automatically generate data, there are so many factors to be considered that humans generally need to be kept in the loop.
The Oracle
If you’ve watched the popular movie franchise The Matrix, you know that the Oracle was a character with highly accurate insights and predictions. She seemed to know how the system would or should work, and everyone went to her for the answers. Sometimes her responses felt vague and weren’t exactly what people expected to hear. The similarities between this fictitious movie character and the oracle problem in software testing is uncanny. When we refer to the oracle in testing, we are talking about knowing whether or not the system did what it was supposed to do. Human testers do their best to act as an oracle but generally rely on other domain experts. Answers about the system’s expected behavior tend to be vague and subjective, and, as a result, creating an automated oracle is a nontrivial problem.
Environment
Software does not live in isolation but is deployed in an environment. One of the value propositions of testing over other validation and verification techniques is that testing provides information about the software running in an actual environment. The challenge is that the environment itself is a combination of hardware and other software and it varies according to the client and usage scenarios. The hardware environment includes physical devices such as corporate servers, workstations, laptops, tablets, and phones, while operating systems, virtual machine managers, and device drivers make up the software environment. Obviously, it is impractical to test all of the hardware and software combinations, so the best practices tend to focus on risk and past experiences.
Limitations of Traditional Approaches
Traditional approaches to software test automation are hyperfocused on developing machine-readable scripts that check for specific system behaviors. The irony of the situation is that creating these so-called automated scripts requires significant manual effort. Recall that testing involves learning by experimentation, study, observation, inference, and more. Without automating these highly cognitive functions, it is only possible to develop test scripts after a lot of the hard work to test the product has already been done.
You first have to understand the requirements and implemented system and then devise test cases that include preconditions, test steps, input data, and the expected oracles. Once you’ve reviewed and iterated your test cases, you can manually encode them as scripts. The good news is that with the scripts in hand, you now have the ability to rerun these specific test scenarios on subsequent software releases. The bad news is that traditional tools and frameworks are quite rigid, so there are high maintenance costs associated with updating and maintaining these scripts over time. Note also that these scripts generally run the same scenarios using the same data each time. As such, most traditional approaches suffer from a phenomenon known as the pesticide paradox. The paradox states that, just as insects build up resistance to pesticides over time, the more you run the exact same tests on your software, the more likely it is to become immune to issues surrounding those specific scenarios.
When it comes to automation, the attention of the software-engineering and testing communities has primarily been on functional user interfaces (UIs), service, and code-based testing, and nonfunctional concerns such as system performance and security. To close out this chapter on the test automation gap, let’s look at the limitations of the current state of the art in test automation with respect to these three dimensions.
UI Test Automation
Functional UI testing seeks to determine if the software is able to carry out its required functions from the users’ perspective. Functional UI automation mimics users clicking, typing, tapping, or swiping on various screens of the application and verifying that the appropriate responses appear. For web and mobile applications, testing frameworks such as Selenium and Appium locate screen elements using patterns and path expressions based on the application’s document object model (DOM). One of the major drawbacks of DOM-based element selectors is that they make tests susceptible to breaking as the structure and/or behavior of the UI changes. For example, changing the location or identifiers for existing application screen elements and navigation paths generally means that you have to update all the page object models or test scripts associated with them. Furthermore, since most of the functional UI automation tools out there target applications with a DOM, there are few to no end-to-end automation solutions for graphically intensive applications.
Service and Unit Test Automation
Of course, not all testing is done via a graphical user interface. In fact, best practices like the test pyramid3 promote the idea that the majority of your test automation should be done at the API—commonly referred to as service—and unit levels. Although some tools make use of schemas and constraint solvers for API- and code-based test generation, the primary focus at this level continues to be on writing scripts that execute predefined tests and measuring code coverage. However, code coverage can be a misleading quality measure if you do not use it correctly.4 Instead, practitioners recommend that you aim for better coverage by testing the software on a variety of input values, which should lead to improvements in code coverage. In other words, let coverage of the input space, rather than coverage of the code, be a key goal in your testing strategy.
Nonfunctional Test Automation
Nonfunctional testing validates constraints on the system’s functionality such as performance, security, usability, and accessibility. End-to-end performance testing tools capture network traffic and facilitate the development of automated scripts that simulate user actions to check performance, scalability, and reliability. The idea is to emulate production traffic using hundreds and thousands of virtual concurrent users performing real-world transactions. Once the system is under load or stress, you can monitor performance metrics such as response times, memory usage, and throughput across servers and other network resources. Just like functional UI test scripts, performance test scripts require periodic maintenance but also introduce an additional layer of complexity. For example, if you add new application screens or navigation paths, not only do you have to update the script’s element selectors and test steps, but you must also recapture the network traffic to reflect the updated transactions. Traditional automation approaches to security testing are usually limited to injection attacks, code scanners, and fuzzing tools. Areas such as usability and accessibility are often deemed too difficult to automate because of their qualitative nature. Designs are not necessarily correct or incorrect but rather good or bad, and how good or how bad may depend on whose opinion matters most.
Conclusion
Automation in any field has limitations and may require manual effort to set up or guide the process. However, my experience with software test automation in the field over the last 15 years has led me to believe that many practitioners have accepted a subpar definition of what it means to automate the testing process. On the other hand, other practitioners claim that testing is so hard that it will never be automated. Regardless of which school of thought is right or wrong, understanding the test automation challenges and limitations described in this chapter is the first step on the road to narrowing any gaps in the current state of the art and practice of software testing.
1 James Bach and Michael Bolton, Rapid Software Testing, accessed June 3, 2021.
2 Equivalence class partitioning divides the input space of a program into different sets, each containing behaviorally equivalent inputs. The idea is that you can reduce the number of tests needed to cover a program by testing one value from each partition instead of trying to test each and every input.
3 Mike Cohn, “The Forgotten Layer of the Test Automation Pyramid,” Mountain Goat, December 17, 2009.
4 Brian Marick, “How to Misuse Code Coverage,” Exampler Consulting, Reliable Software Technologies, 1999.
Get AI-Driven Testing now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

