Chapter 4. In-Database Machine Learning
Being able to do machine learning where the data lives has been a goal from the beginning of the data explosion. But what does in-database ML mean, and how does it work?
What Is In-Database ML?
In-database machine learning is the practice of developing and executing ML workloads—exploring and preparing the data; training algorithms; evaluating, saving, and versioning models; and serving those models in production—inside the database that contains the data. As we’ve seen, many business architectures operate with their data science teams extracting subsets and samples of data from data lakes and data warehouses, training models, and then embarking on the journey of MLOps—from building distributed pipelines to do all the data preparation steps on production data, serving models, often via representational state transfer (REST) endpoints, to persisting the inputs and outputs of each prediction, to analyzing those results for concept and feature drift, and finally reextracting the new data to retrain the model, and starting the process over (see Figure 4-1).
Many tools have been created and advertised as simplifications for this involved process, but most present the same problematic strategy: bringing the data to the model. Since modern datasets for ML tend to be huge (terabytes or even petabytes), the principle of data gravity makes moving all that data difficult, if not outright impossible. The solution during training is sampling and working elsewhere. But when it comes time to deploy, that typically involves a fair amount of rebuilding. Every single step that a data scientist has taken to prepare a tiny sample of data must now be re-created at scale for production-level datasets, which could be in the multipetabyte range.
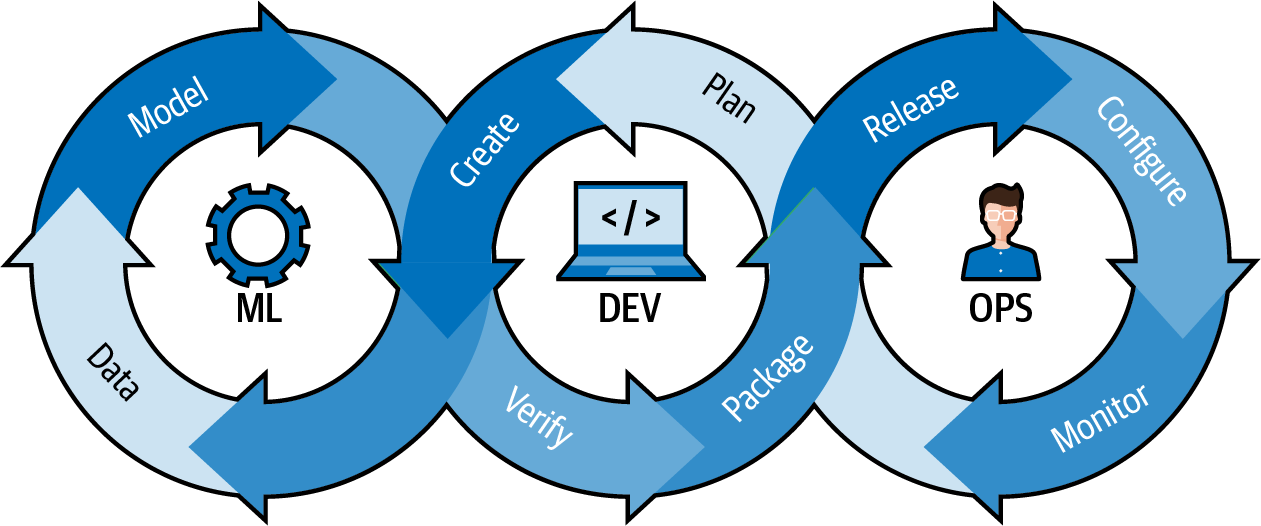
Figure 4-1. MLOps cycle
We’ve long thought about databases and data lakes as places for storage, reporting, and ad hoc analytics of data, but the core premise of in-database ML is to use the powerful distributed database engine to natively build models and predict future outcomes based both on data stored in the database format and other data in distributed object storage systems.
Advanced data warehouses are capable of the targeted analytics used for feature engineering, such as outlier detection, one-hot-encoding, and even fast Fourier transforms. Enabling execution with the distributed database engine while providing instructions in something most data scientists are familiar with, like SQL or Python, instantly unlocks a wealth of opportunity.
Vertica’s in-database ML, to take one example, has straightforward SQL to perform one-hot encoding, converting categorical values to numeric features:
SELECT one_hot_encoder_fit('bTeamEncoder', 'baseball', 'team'
USING PARAMETERS extra_levels='{"team" : ["Red Sox"]}');
For Python developers, Vertica’s VerticaPy library enables data scientists to achieve these same results by using only Python code. The get_dummies function is applied to a virtual dataframe (familiar to Python developers, but not limited by available memory size) and provides the same functionality:
churn = churn.select(
["InternetService", "MonthlyCharges", "churn"]
)
churn["InternetService"].get_dummies()
RedisML has similar capabilities. For example, to scale a value (commonly referred to as standard scaling in ML), simply use the provided ML SQL syntax:
(ML.MATRIX.SCALE key scalar)
The ML potential becomes particularly powerful when these functions are joined by the rich wealth of capabilities databases already had, such as joins, windows, and aggregate functions. It becomes simple now to join data across your tables and apply your set of feature engineering functions entirely in SQL or Python. And these ML-minded databases will continue to grow their already impressive library of functionalities and make the feature engineering step of the ML pipeline ever simpler.
But feature engineering is only one step of that pipeline. You may be asking about actual model development and its scalability. Some databases include homegrown algorithms to support a wide range of models, from random forests and logistic regression to clustering and support vector machines. The syntax is just as simple as feature engineering, and with the many SQL IDEs today, like DataGrip, Apache Superset, and even Tableau, you can access these functions and create pipelines just by writing SQL. Many have great documentation, including RedisML, Vertica, and BigQuery ML. In fact, many analytical databases support at least some form of ML, though most include it as a paid add-on.
In RedisML, for example, on the Redis command-line interface, you could train a K-means model with an example dataset. This sets a model with two clusters and three dimensions. In the following example, the cluster centers are (1, 1, 2) and (2, 5, 4):
redis> ML.KMEANS.SET k 2 3 1 1 2 2 5 4 OK
Then predict the cluster of feature vector 1, 3, 5 like this:
redis> ML.KMEANS.predict k 1 3 5 (integer) 1
After you define and aggregate your features and train your model, the next step is often testing and deployment. When your MLOps stack is external to the database, it adds yet another step to the process: you have to move data outside the system yet again, adding compute to run tests, and standing up more infrastructure. When this is all done via SQL and database-native APIs, minimal work is required since a dev and test database are essential to normal implementations, and should be the same environment as the production database. Testing and evaluation of the now-trained model requires just one more SQL statement or Python command, and deployment of the model is simply the automated invocation of it on new data. We have no new infrastructure or tooling, no rebuilding, and no additional UIs for managers to monitor.
After a model has been deployed, monitoring becomes the crucial next step. As more data enters the system, data distributions change, and drift occurs. Often drift is categorized as concept drift (the distributions of the predictions of the model change) or feature drift (the distributions of the features that the model predicts on no longer match the distributions of those features during training). In either case, this means that your production model’s idea of reality no longer matches the ground truth. This requires retraining.
Dozens of companies have attempted to solve this specific issue—model observability in production. Measuring and notifying occurrences of drift in models requires a lot of infrastructure and tooling. A new persistence layer is often required to store all of the inputs and outputs to the model, along with a connection layer to the original training data for comparisons. External compute is required to calculate the various distribution algorithms to detect drift, and some alerting functionality is likely necessary, which adds to the growing amount of infrastructure requirements.
When this model evaluation layer is embedded into the database, however, the additional layer of tooling and infrastructure is removed. In a database-ML world, all of the predictions of the model are persisted next to all of the inputs automatically, which, quite conveniently, are stored next to all of the training data. Comparisons of distribution are simple SQL queries, and altering incorrect data (for example, mislabeled samples) can occur directly in the database. You can even create simple pipelines that automatically run the SQL statements to retrain the model upon a certain distribution shift threshold.
Why Do ML in a Database?
So we see now that in-database ML is possible, but, why would you do it? What are the advantages?
While many ML models never make it into production, even of those that do get there, 40% take between 30 days and a year or more to get to production, according to one survey. As stated previously in this report, another survey was more pessimistic, saying that 80% of respondents’ companies take more than six months to deploy an artificial intelligence (AI) or ML model into production. Shortening that time significantly has to be the goal of any organization that needs ML in production to meet its needs.
As we’ve seen, one of the major benefits of in-database ML is infrastructure simplicity. Your DevOps engineers will thank you greatly for removing your requests for all of those new tool integrations. But this new approach has other major benefits, which are detailed next.
Security
Many of the tools in the marketplace today offer an abundance of bells and whistles, and should be considered when choosing the right tool for your company. But one of the most important features of all of these systems—sometimes overlooked and crucial to get right—is security. When your production ML models are making decisions that could make or break your business and are touching some of the most important data in your system, security must be the number one determiner of a product and is table stakes for any consideration. With emerging standards for data protection like the European General Data Protection Regulation (GDPR) and the California Privacy Rights Act (CPRA), security and data governance are essential.
When running ML inside a database, one of the instant benefits you get is years of mature, battle-tested, database security practices. From their inception, database systems were created to securely store your data. When you start with those pillars and then add ML on top, you don’t have to worry about your models being safe.
Speed and Scalability
Much as with security, since you’re starting with the foundation of a robust analytical database, speed and scalability are built in. MPP databases are already battle-tested and trusted by engineers. Speed and scale come in two forms for ML, however: training and deployment.
When training your models, with the data already in the database alongside the models, no movement occurs across systems—no network nor I/O latencies, no waiting hours for data to arrive in your modeling environments. And there’s no need to adjust data types to new environments to mitigate data type incompatibilities. This helps data scientists iterate faster and build better models.
From the perspective of serving, in-database ML removes all of the legwork from the MLOps engineers to think about how the system will grow with more requests. When the database is the host of the model, it scales exactly as the rest of the database scales, which engineers already trust. The simplicity of the architecture enables engineers to build logic around their models with the full assurance that what they create will scale with the data they train on.
Also, the model prediction function is a simple SQL call, just like all the data transformation functions already in the data ingestion pipeline. As data flows in, it gets prepped, the model evaluates it, and the result is sent on to a visualization tool or AI application. A lot of the data pipelines are a series of SQL calls anyway. What’s one more? That automation means data flows in and a prediction flows out, often in less than a second.
No Downsampling
Similar to scalability, but important in its own right, is the elimination of downsampling. We looked earlier at SQL syntax added to advanced databases with ML capabilities. When you train a model in that paradigm, you don’t need to consider whether the data you extract will fit locally since you’re not extracting anything.
You begin thinking at a system level. You have the scalability necessary to run the analyses you want, so you can begin optimizing for training time, accuracy, and price instead of local memory. This approach opens a world of possibilities for data scientists, and a new way of thinking that was previously available only to data engineers.
Concurrency
Modern advanced databases have nailed concurrency and resource isolation, as we’ve discussed in previous sections. This applies equally to in-database ML. Allocate as many or as few resources as necessary to the data scientists and let them run free, knowing with full confidence that their work won’t affect ELT pipelines or critical dashboards. Let dozens of engineers train models, or dozens of applications use model predictions, all bounded by the limits easily set by any database administrator. This includes scheduled or automated scaling of infrastructure, which is a common capability of many databases, and can be defined for dedicated subclusters as well.
Accessibility
A prohibitive issue for many companies is the cost of data scientists, something we touched on in Chapter 1. This is a serious problem, as the work they do can be critical to giving companies competitive advantages. While there is no replacement for an advanced data scientist analyzing a complex problem and building a complex, custom solution, many problems that companies face can be considered low-hanging fruit. They may be solvable by team members without deep data science skills, but having familiarity with SQL, data analytics, and the needs of the business.
The issue thus far, however, has been that more accessible ML frameworks like scikit-learn are not easily deployable by these analysts. Python-based ML libraries are a completely different set of technological tools that may have no precedence in a current system. Plus, while many business analysts are skilled in SQL, not all have the same experience with Python.
With SQL-based ML, common now in many analytical databases, you can enable analysts and citizen data scientists to achieve massive results by adding a few ML-focused SQL commands to their repertoire. Alongside the joins and window functions, they can apply an XGBoost model and potentially unlock serious value for their company, without needing to hire a data science team. Many problems need advanced data science skill sets, but adding SQL language for building classical ML models enables a plethora of new participants who may otherwise not have the skills or experience to help.
Governance
A crucial component of MLOps systems is user management. Who can train a model? Who can deploy it? Who has access to that dataset? Who can replace or remove a model from production? Who trained model 5, which is in production now?
Equally important is data and model governance. Which models and versions are currently in production? How is our churn model doing? Which data was this model trained on?
Each of these questions becomes a single SQL statement in a database ML world. Granting privileges on a model is the same as granting them on a table. Checking who deployed a model requires simply looking at the SQL query logs. Checking the live performance of a model is simply running a SQL statement combining two tables (predictions and ground truth).
With governance baked in, it’s yet again one less thing to focus on, putting real modeling front and center.
Production Readiness
The practice of MLOps has grown enormously. Endless numbers of companies today are building model-tracking services, feature stores, model-serving environments, and pipelining tools—with some companies offering all under one roof. But the practice of DevOps and DataOps has already existed for years, with well-documented best practices. MLOps is the intersection of these two worlds, yet many companies have been approaching it in isolation. If we have a robust way to version code, and a robust way to version tables and data, we can seemingly have a robust way to manage ML models just like tables in a database, where their engine is the database, and their fuel is the data stored internally and all around them in object stores.
In-database ML offers near instant production readiness, with already defined ways of managing SQL code, database tables, and raw and prepared data. Serving the model can be as simple as issuing SQL or a database API call, and updating with a new model is as simple as versioning a table.
After weeks developing, training, and testing a model to solve a business problem, deploying it to production should be a single command, not an infrastructure nightmare.
Why Not Do ML in a Database?
You may be asking if there are any reasons one would avoid in-database ML. Some use cases are not yet suited for databases. Deeply custom models that may require GPUs for training or that implement advanced, custom algorithms not easily compiled into a runtime package (such as in research) may be best suited for a more old-fashioned approach. This is not to say that ML-centered databases won’t eventually get there, but at this time there isn’t deep support for those use cases.
Another question, however, may be, “Why haven’t we always done ML in the database?” And that is a good question, with a good answer. In-database ML leverages the ability of the database engine now to evaluate a lot of data formats, not just its own, and requires both the data capacity and analytic horsepower to train and deploy ML models. In addition, until workloads could be properly isolated, most companies were not willing to risk their BI SLAs by letting data scientists loose in the same database. Without these new developments, even with a cooperative architecture, data still moves, things are lost, deployment is complex, security is not straightforward, and resource isolation is nearly impossible. Simply put, you need a unified analytics architecture to enable in-database ML. But now that it’s here, why not do ML in a database is a harder question to answer.
Unified Analytics: Managing Models
We’ve talked specifically about in-database ML as a set of custom-built algorithms that databases provide. In these cases, a model is simply a specialized table, but its interactions are otherwise the same. These are powerful systems indeed, but they do not cover the full gamut of possibilities in ML. In many cases, even with in-database ML available, users will want to write custom code, leveraging libraries that are particularly useful to them, and still deploy those models like all others.
This is a common use case and one that has motivated many database companies. The ability to import external models in forms like Predictive Model Markup Language (PMML), JSON configuration (like TensorFlow models), or Open Neural Network Exchange (ONNX) format (like PyTorch and others) is becoming more and more common.
Microsoft Azure SQL Edge, for example, can directly import ONNX models, deploy them into your database, and invoke them using a built-in PREDICT SQL function. Similarly, Vertica enables you to import or export PMML, and import JSON configurations of an externally trained TensorFlow model and deploy it in a distributed fashion on your database. This can be useful if you want to train your deep learning models externally with GPUs but deploy them alongside all of your other models, as deep learning models typically do not need expensive GPUs for serving, only training.
Unified Analytics: Feature Stores
Another capability that the unified analytics architecture unlocks is the feature store. A feature store is a layer between raw data and structured feature vectors for data science. Feature stores promise to help bridge the gap between data engineers and data scientists by making it easy to manage how features change over time, how they are being used in models, and how they are joined together to create training datasets.
Most feature stores today fundamentally follow the cooperative architecture, with separate engines for offline data (such as data from a data lake), and online data (typically a key-value store for quick lookups). Even the most advanced feature stores, such as Uber’s Michelangelo, follow this architecture. This can, and often does, as we’ve seen, lead to enormous complexity, data inconsistency, and lost days of troubleshooting. The unified analytics architecture has yet to transform this world but likely will in coming years.
Imagine a single engine powering your batch, streaming, and real-time data, alongside transformations, an end-to-end MLOps platform for training and serving, and a feature store for closely managing all of the data that your models learn from. This will become commonplace, and people will begin to wonder how we ever did it differently.
The Unified Analytics Architecture
Put together, the unified analytics architecture (shown in Figure 4-2) is neither a data lake nor a warehouse. It is much more than either and has the advantages of both. This architecture enables a paradigm shift in the way we see and work with our data and massively simplifies the systems we intend to build. The singular architecture makes ML easier to maintain over time, and assuming you’ve avoided any of the technologies that work only on the cloud, is highly flexible to work on premises, on any cloud, or on a hybrid system. Flexibility makes it a durable platform that can stand the constant changes that any data architecture has to weather.
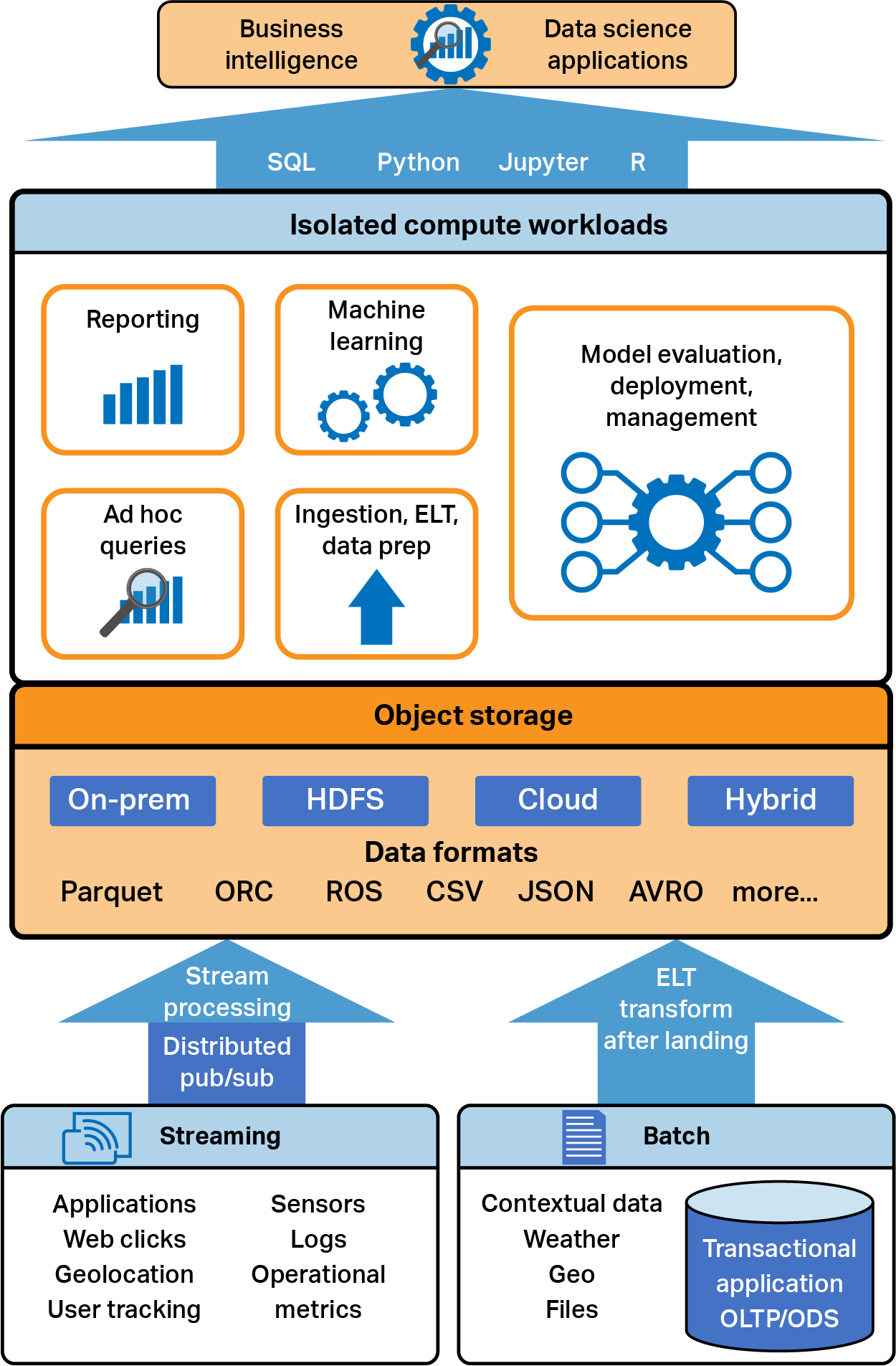
Figure 4-2. Unified analytics architecture
Get Accelerate Machine Learning with a Unified Analytics Architecture now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

