How machine learning will accelerate data management systems
The O’Reilly Data Show Podcast: Tim Kraska on why ML will change how we build core algorithms and data structures.
 Indexed (source: Stuart Caie on Flickr)
Indexed (source: Stuart Caie on Flickr)
In this episode of the Data Show, I spoke with Tim Kraska, associate professor of computer science at MIT. To take advantage of big data, we need scalable, fast, and efficient data management systems. Database administrators and users often find themselves tasked with building index structures (“indexes” in database parlance), which are needed to speed up data access.
Some common examples include:

Learn faster. Dig deeper. See farther.
- B-Trees—used for range requests (e.g., assemble all sales orders within a certain time frame)
- Hash maps—used for key-based lookups
- Bloom filters—used to check whether an element or piece of data is present in a set
Index structures take up space in a database, so you need to be selective about what to index, and they do not take advantage of the underlying data distributions. I’ve worked in settings where an administrator or expert user carefully implements a strategy for building indexes for a data warehouse based on important and common queries.
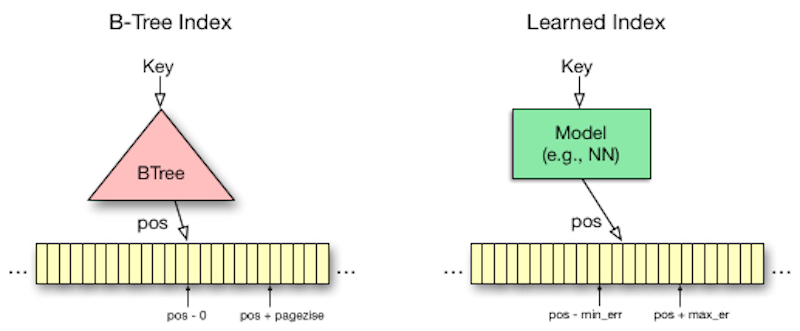
Indexes are really models or mappings—for instance, a Bloom filter can be thought of as a classification problem. In a recent paper, Kraska and his collaborators approach indexing as a learning problem. As such, they are able to build indexes that take into account underlying data distributions, are smaller in size (thus allowing for a more liberal indexing strategy), and their indexes execute faster. Software and hardware for computation are getting cheaper and better, so using machine learning to create index structures is something that may indeed become routine.
This ties with a larger trend of using machine learning to improve software systems and even software development. In the future, we’ll have database administrators who have machine learning tools at their disposal, which would allow them to manage larger and more complex systems, and these ML tools will free them to focus on complex tasks that are harder to automate.
Here are some highlights from our conversation:
Why use machine learning to learn index structures
I think it used to be the case that if you know you have the key distribution, you could leverage that, but you need to build a very specialized system for that. Then, if the data distribution changes, you need to adjust the whole system. At the same time, any learning mechanism was in the past and way too expensive to do it.
Things have changed a little bit because compute is becoming much cheaper. Suddenly, using machine learning to train this mapping actually pays off. On one hand, the B-tree structures are composed of a whole bunch of “IF statements,” and in the past, multiplications were very expensive. Now multiplications are getting cheaper and cheaper. Scaling “IF statements” is hard, but scaling math operations is at least relatively easier. In essence, we can trade these “IF statements” for multiplications, and that’s actually why suddenly learning the data distribution pays off.
… For B-trees, for example, we saw speed-ups of up to roughly 2X. However, the indexes were up to two orders of magnitude smaller.
The future of data management systems
If this machine learning approach really works out, I think this might change the way database systems are built. … Maybe the database administrator (DBA) of the future becomes a machine learning expert.
… My hope is that the system can figure out what model to use, but maybe if you want to have the best performance and you know your data very well, I can see that maybe the DBA / machine learning expert chooses a certain type of model to tune the index.
… There was this Tweet, essentially saying that machine learning will change how we build core algorithms and data structures. I think this is currently still the better analogy.
Related resources:
- Tupleware—redefining modern data analytics: a Strata Data 2014 presentation by Tim Kraska
- Artificial intelligence in the software engineering workflow: a 2017 AI Conference keynote by Peter Norvig
- “A scalable time-series database that supports SQL“
- “Architecting and building end-to-end streaming applications“
- Data is only as valuable as the decisions it enables