How to Fix “AI’s Original Sin”
 Artificial intelligence. (source: Alejandro Zorrilal Cruz on Wikimedia Commons)
Artificial intelligence. (source: Alejandro Zorrilal Cruz on Wikimedia Commons)
Last month, The New York Times claimed that tech giants OpenAI and Google have waded into a copyright gray area by transcribing the vast volume of YouTube videos and using that text as additional training data for their AI models despite terms of service that prohibit such efforts and copyright law that the Times argues places them in dispute. The Times also quoted Meta officials as saying that their models will not be able to keep up unless they follow OpenAI and Google’s lead. In conversation with reporter Cade Metz, who broke the story, on the New York Times podcast The Daily, host Michael Barbaro called copyright violation “AI’s Original Sin.”
At the very least, copyright appears to be one of the major fronts so far in the war over who gets to profit from generative AI. It’s not at all clear yet who is on the right side of the law. In the remarkable essay “Talkin’ ’Bout AI Generation: Copyright and the Generative-AI Supply Chain,” Cornell’s Katherine Lee and A. Feder Cooper and James Grimmelmann of Microsoft Research and Yale note:

Learn faster. Dig deeper. See farther.
Copyright law is notoriously complicated, and generative-AI systems manage to touch on a great many corners of it. They raise issues of authorship, similarity, direct and indirect liability, fair use, and licensing, among much else. These issues cannot be analyzed in isolation, because there are connections everywhere. Whether the output of a generative AI system is fair use can depend on how its training datasets were assembled. Whether the creator of a generative-AI system is secondarily liable can depend on the prompts that its users supply.
But it seems less important to get into the fine points of copyright law and arguments over liability for infringement, and instead to explore the political economy of copyrighted content in the emerging world of AI services: Who will get what, and why? And rather than asking who has the market power to win the tug of war, we should be asking, What institutions and business models are needed to allocate the value that is created by the “generative AI supply chain” in proportion to the role that various parties play in creating it? And how do we create a virtuous circle of ongoing value creation, an ecosystem in which everyone benefits?
Publishers (including The New York Times itself, which has sued OpenAI for copyright violation) argue that works such as generative art and texts compete with the creators whose work the AI was trained on. In particular, the Times argues that AI-generated summaries of news articles are a substitute for the original articles and damage its business. They want to get paid for their work and preserve their existing business.
Meanwhile, the AI model developers, who have taken in massive amounts of capital, need to find a business model that will repay all that investment. Times reporter Cade Metz provides an apocalyptic framing of the stakes and a binary view of the possible outcome. In his interview in The Daily, Metz opines
a jury or a judge or a law ruling against OpenAI could fundamentally change the way this technology is built. The extreme case is these companies are no longer allowed to use copyrighted material in building these chatbots. And that means they have to start from scratch. They have to rebuild everything they’ve built. So this is something that not only imperils what they have today, it imperils what they want to build in the future.
And in his original reporting on the actions of OpenAI and Google and the internal debates at Meta, Metz quotes Sy Damle, a lawyer for Silicon Valley venture firm Andreessen Horowitz, who has claimed that “the only practical way for these tools to exist is if they can be trained on massive amounts of data without having to license that data. The data needed is so massive that even collective licensing really can’t work.”
“The only practical way”? Really?
I propose instead that not only is the problem solvable but that solving it can create a new golden age for both AI model providers and copyright-based businesses. What’s missing is the right architecture for the AI ecosystem, and the right business model.
Unpacking the Problem
Let’s first break down “copyrighted content.” Copyright reserves to the creator(s) the exclusive right to publish and to profit from their work. It does not protect facts or ideas but a unique “creative” expression of those facts or ideas. Unique creative expression is something that is fundamental to all human communication. And humans using the tools of generative AI are indeed often using it as a way to enhance their own unique creative expression. What is actually in dispute is who gets to profit from that unique creative expression.
Not all copyrighted content is created for profit. According to US copyright law, everything published in any form, including on the internet, is automatically copyrighted by the author for the life of its creator plus 70 years. Some of that content is intended to be monetized either by advertising, subscription, or individual sale, but that is not always true. While a blog or social media post, YouTube gardening or plumbing tutorial, or music or dance performance is implicitly copyrighted by its creators (and may also include copyrighted music or other copyrighted components), it is meant to be freely shared. Even content that is meant to be shared freely, though, has an expectation of remuneration in the form of recognition and attention.
Those intending to commercialize their content usually indicate that in some way. Books, music, and movies, for example, bear copyright notices and are registered with the copyright office (which confers additional rights to damages in the event of infringement). Sometimes these notices are even machine-readable. Some online content is protected by a paywall, requiring a subscription to access it. Some content is marked “noindex” in the HTML code of the website, indicating that it should not be spidered by search engines (and presumably other web crawlers). Some content is visibly associated with advertising, indicating that it is being monetized. Search engines “read” everything they can, but legitimate services generally respect signals that tell them “no” and don’t go where they aren’t supposed to.
AI developers surely recognize these distinctions. As the New York Times article referenced at the start of this piece notes, “The most prized data, A.I. researchers said, is high-quality information, such as published books and articles, which have been carefully written and edited by professionals.” It is precisely because this content is more valuable that AI developers seek the unlimited ability to train on all available content, regardless of its copyright status.
Next, let’s unpack “fair use.” Typical examples of fair use are quotations, reproduction of an image for the purpose of criticism or comment, parodies, summaries, and in more recent precedent, the links and snippets that help a search engine or social media user to decide whether to consume the content. Fair use is generally limited to a portion of the work in question, such that the reproduced content cannot serve as a substitute for the original work.
Once again it is necessary to make distinctions that are not legal but practical. If the long-term health of AI requires the ongoing production of carefully written and edited content—as the currency of AI knowledge certainly does—only the most short-term of business advantage can be found by drying up the river AI companies drink from. Facts are not copyrightable, but AI model developers standing on the letter of the law will find cold comfort in that if news and other sources of curated content are driven out of business.
An AI-generated review of Denis Villeneuve’s Dune or a plot summary of the novel by Frank Herbert on which it’s based will not harm the production of new novels or movies. But a summary of a news article or blog post might indeed be a sufficient substitute. If news and other forms of high-quality, curated content are important to the development of future AI models, AI developers should be looking hard at how they will impact the future health of these sources.
The comparison of AI summaries with the snippets and links provided in the past by search engines and social media sites is instructive. Google and others have rightly pointed out that search drives traffic to sites, which the sites can then monetize as they will, by their own advertising (or advertising in partnership with Google), by subscription, or just by the recognition the creators receive when people find their work. The fact that when given the choice to opt out of search, very few sites choose to do so provides substantial evidence that, at least in the past, copyright owners have recognized the benefits they receive from search and social media. In fact, they compete for higher visibility through search engine optimization and social media marketing.
But there is certainly reason for web publishers to fear that AI-generated summaries will not drive traffic to sites in the same way as more traditional search or social media snippets. The summaries provided by AI are far more substantial than their search and social media equivalents, and in cases such as news, product search, or a search for factual answers, a summary may provide a reasonable substitute. When readers see an AI answer that references sources they trust, they may well take it at face value and move on. This should be of concern not only to the sites that used to receive the traffic but to those that used to drive it. Because in the long term, if people stop creating high-quality content to ingest, the whole ecosystem breaks down.
This is not a battle that either side should be looking to “win.” Instead, it’s an opportunity to think through how to strengthen two public goods. Journalism professor Jeff Jarvis put it well in a response to an earlier draft of this piece: “It is in the public good to have AI produce quality and credible (if ‘hallucinations’ can be overcome) output. It is in the public good that there be the creation of original quality, credible, and artistic content. It is not in the public good if quality, credible content is excluded from AI training and output OR if quality, credible content is not created.” We need to achieve both goals.
Finally, let’s unpack the relation of an AI to its training data, copyrighted or uncopyrighted. During training, the AI model learns the statistical relationships between the words or images in its training set. As Derek Slater has pointed out, much like musical chord progressions, these relationships can be seen as “basic building blocks” of expression. The models themselves do not contain a copy of the training data in any human-recognizable form. Rather, they are a statistical representation of the probability, based on the training data, that one word will follow another or in an image, that one pixel will be adjacent to another. Given enough data, these relationships are remarkably robust and predictable, so much so that it is possible for generated output to closely resemble or duplicate elements of the training data.
It is certainly worth knowing what content has been ingested. Mandating transparency about the content and source of training datasets—the generative AI supply chain—would go a long way towards encouraging frank discussions between disputing parties. But focusing on examples of inadvertent resemblances to the training data misses the point.
Generally, whether payment is in currency or in recognition, copyright holders seek to withhold data from training because it seems to them that may be the only way to prevent unfair competition from AI outputs or to negotiate a fee for use of their content. As we saw from web search, “reading” that does not produce infringing output, delivers visibility (traffic) to the originator of the content, and preserves recognition and credit is generally tolerated. So AI companies should be working to develop solutions that content developers will see as valuable to them.
The recent protest by longtime Stack Overflow contributors who don’t want the company to use their answers to train OpenAI models highlights a further dimension of the problem. These users contributed their knowledge to Stack Overflow; giving the company perpetual and exclusive rights to their answers. They reserved no economic rights, but they still believe they have moral rights. They had, and continue to have, the expectation that they will receive recognition for their knowledge. It isn’t the training per se that they care about, it’s that the output may no longer give them the credit they deserve.
And finally, the Writers Guild strike established the contours of who gets to benefit from derivative works created with AI. Are content creators entitled to be the ones to profit from AI-generated derivatives of their work, or can they be made redundant when their work is used to train their replacements? (More specifically, the agreement stipulated that AI works could not be considered “source material.” That is, studios couldn’t have the AI do a first draft, then treat the scriptwriter as someone merely “adapting” the draft and thus get to pay them less.) As the settlement demonstrated, this is not a purely economic or legal question but one of market power.
In sum, there are three parts to the problem: what content is ingested as part of the training data in the first place, what outputs are allowed, and who gets to profit from those outputs. Accordingly, here are some guidelines for how AI model developers ought to handle copyrighted content:
- Train on copyrighted content that is freely available, but respect signals like subscription paywalls, the robots.txt file, the HTML “noindex” keyword, terms of service, and other means by which copyright holders signal their intentions. Make the effort to distinguish between content that is meant to be freely shared and that which is intended to be monetized and for which copyright is intended to be enforced.
There is some progress towards this goal. In part because of the EU AI Act, it is likely that within the next 12 months every major AI developer will have implemented mechanisms for copyright holders to opt out in a machine-readable way. Already, OpenAI allows sites to disallow its GPTBot web crawler using the robots.txt file, and Google does the same for its web-extended crawler. There are also efforts like the Do Not Train database, and tools like Cloudflare Bot Manager. OpenAI’s forthcoming Media Manager promises to “enable creators and content owners to tell us what they own and specify how they want their works to be included or excluded from machine learning research and training.” This is helpful but insufficient. Even on today’s internet these mechanisms are fragile and complex, change frequently, and are often not well understood by sites whose content is being scraped.
But more importantly, simply giving content creators the right to opt out is missing the real opportunity, which is to assemble datasets for training AI that specifically recognize copyright status and the goals of content creators, and thus become the underlying mechanism for a new AI economy. As Dodge, the hypersuccessful game developer who is the protagonist of Neal Stephenson’s novel Reamde noted, “You had to get the whole money flow system figured out. Once that was done, everything else would follow.” - Produce outputs that respect what can be known about the source and the nature of copyright in the material.
This is not dissimilar to the challenges of preventing many other types of disputed content, such as hate speech, misinformation, and various other types of prohibited information. We’ve all been told many times that ChatGPT or Claude or Llama 3 is not allowed to answer a particular question or to use particular information that it would otherwise be able to generate because it would violate rules against bias, hate speech, misinformation, or dangerous content. And, in fact, in its comments to the copyright office, OpenAI describes how it provides similar guardrails to keep ChatGPT from producing copyright-infringing content. What we need to know is how effective they are and how widely they are deployed.
There are already techniques for identifying the content most closely related to some types of user queries. For example, when Google or Bing provides an AI-generated summary of a web page or news article, you typically see links below the summary that point to the pages from which the summary was generated. This is done using a technology called retrieval-augmented generation (RAG), which generates a set of search results that are vectorized, providing an authoritative source to be consulted by the model before it generates a response. The generative LLM is said to have grounded its response in the documents provided by these vectorized search results. In essence, it’s not regurgitating content from the pretrained models but rather reasoning on these source snippets to work out an articulate response based on them. In short, the copyrighted content has been ingested, but it is detected during the output phase as part of an overall content management pipeline. Over time, there will likely be many more such techniques.
One hotly debated question is whether these links provide the same level of traffic as the previous generation of search and social media snippets. Google claims that its AI summaries drive even more traffic than traditional snippets, but it hasn’t provided any data to back up that claim, and may be basing it on a very narrow interpretation of click-through rate, as parsed in a recent Search Engine Land analysis. My guess is that there will be some winners and some losers as with past search engine algorithm updates, not to mention further updates, and that it is too early for sites to panic or to sue.
But what is missing is a more generalized infrastructure for detecting content ownership and providing compensation in a general purpose way. This is one of the great business opportunities of the next few years, awaiting the kind of breakthrough that pay-per-click search advertising brought to the World Wide Web.
In the case of books, for example, rather than training on known sources of pirated content, how about building a book data commons, with an additional effort to preserve information about the copyright status of the works it contains? This commons could be used as the basis not only for AI training but for measuring the vector similarity to existing works. Already, AI model developers use filtered versions of the Common Crawl Database, which provides a large percentage of the training data for most LLMs, to reduce hate speech and bias. Why not do the same for copyright? - Pay for the output, not the training. It may look like a big win for existing copyright holders when they receive multimillion-dollar licensing fees for the use of content they control. First, only the most deep-pocketed AI companies will be able to afford preemptive payments for the most valuable content, which will deepen their competitive moat with regard to smaller developers and open source models. Second, these fees are likely insufficient to become the foundation of sustainable long-term businesses and creative ecosystems. Once you’ve licensed the chicken, the licensee gets the eggs. (Hamilton Nolan calls it “selling your house for firewood.”) Third, the payment is often going to intermediaries and is not passed on to the actual creators.
How “payment” works might depend very much on the nature of the output and the business model of the original copyright holder. If the copyright owners prefer to monetize their own content, don’t provide the actual outputs. Instead, provide pointers to the source. For content from sites that depend on traffic, this means sending either traffic or, if not, a payment negotiated with the copyright owner that makes up for the owner’s decreased ability to monetize its own content. Look for win-win incentives that will lead to the development of an ongoing, cooperative content ecosystem.
In many ways, YouTube’s Content ID system provides an intriguing precedent for how this process might be automated. According to YouTube’s description of the system,
Using a database of audio and visual files submitted by copyright owners, Content ID identifies matches of copyright-protected content. When a video is uploaded to YouTube, it’s automatically scanned by Content ID. If Content ID finds a match, the matching video will get a Content ID claim. Depending on the copyright owner’s Content ID settings, a Content ID claim results in one of the following actions:
- Blocks a video from being viewed
- Monetizes the video by running ads against it and sometimes sharing revenue with the uploader
- Tracks the video’s viewership statistics
(Revenue is only sometimes shared with the uploader because the uploader may not own all of the monetizable elements of the uploaded content. For example, a dance or music performance video may use copyrighted music for which payment goes to the copyright holder rather than the uploader.)
One can imagine this kind of copyright enforcement framework being operated by the platforms themselves, much as YouTube operates Content ID, or by third-party services. The problem is obviously more difficult than the one facing YouTube, which only had to discover matching music and videos in a relatively fixed format, but the tools are more sophisticated today. As RAG demonstrates, vector databases make it possible to find weighted similarities even in wildly different outputs.
Of course, there is a lot that would need to be worked out. Using vector similarity for attribution is promising, but there are concerning limitations. Consider Taylor Swift. She is so popular that there are many artists trying to sound like her. This sets up a kind of adversarial situation that has no obvious solution. Imagine a vector database that has Taylor in it along with a thousand Taylor copycats. Now imagine an AI-generated song that “sounds like Taylor.” Who gets the revenue? Is it the top 100 nearest vectors (99 of which are cheap copycats of Taylor)? Or should Taylor herself get most of the revenue? There are interesting questions in how to weigh similarity—just as there are interesting questions in traditional search about how to weigh various factors to come up with the “best” result for a search query. Solving these questions is the innovative (and competitive) frontier.
One option might be to retrieve the raw materials for generation (versus using RAG for attribution). Want to generate a paragraph that sounds like Stephen King? Explicitly retrieve some representation of Stephen King, generate from it, and then pay Stephen King. If you don’t want to pay for Stephen King’s level of quality, fine. Your text will be generated from lower-quality bulk-licensed “horror mystery text” as your driver. There are some rather naive assumptions in this ideal, namely in how to scale it to millions or billions of content providers, but that’s what makes it an interesting entrepreneurial opportunity. For a star-driven media area like music, it definitely makes sense.
My point is that one of the frontiers of innovation in AI should be in techniques and business models to enable the kind of flourishing ecosystem of content creation that has characterized the web and the online distribution of music and video. AI companies that figure this out will create a virtuous flywheel that rewards content creation rather than turning the industry into an extractive dead end.
An Architecture of Participation for AI
One thing that makes copyright seem intractable is the race for monopoly by the large AI providers. The architecture that many of them seem to imagine for AI is some version of “one ring to rule them all,” “all your base are belong to us,” or the Borg. This architecture is not dissimilar to the model of early online information providers like AOL and the Microsoft Network. They were centralized and aimed to host everyone’s content as part of their service. It was only a question of who would win the most users and host the most content.
The World Wide Web (and the underlying internet itself) had a fundamentally different idea, which I have called an “architecture of participation.” Anyone could host their own content, and users could surf from one site to another. Every website and every browser could communicate and agree on what can be seen freely, what is restricted, and what must be paid for. It led to a remarkable expansion of the opportunities for the monetization of creativity, publishing, and copyright.
Like the networked protocols of the internet, the design of Unix and Linux programming envisioned a world of cooperating programs developed independently and assembled into a greater whole. The Unix/Linux filesystem has a simple but powerful set of access permissions with three levels: user, group, and world. That is, some files are private only to the creator of the file, others to a designated group, and others are readable by anyone.
Imagine with me, for a moment, a world of AI that works much like the World Wide Web or open source systems such as Linux. Foundation models understand human prompts and can generate a wide variety of content. But they operate within a content framework that has been trained to recognize copyrighted material and to know what they can and can’t do with it. There are centralized models that have been trained on everything that’s freely readable (world permission), others that are grounded in content belonging to a specific group (which might be a company or other organization, a social, national or language group, or any other cooperative aggregation), and others that are grounded in the unique corpus of content belonging to an individual.
It may be possible to build such a world on top of ChatGPT or Claude or any one of the large centralized models, but it is far more likely to emerge from cooperating AI services built with smaller, distributed models, much as the web was built by cooperating web servers rather than on top of AOL or the Microsoft Network. We are told that open source AI models are riskier than large centralized ones, but it’s important to make a clear-eyed assessment of their benefits versus their risks. Open source better enables not only innovation but control. What if there was an open protocol for content owners to open up their repositories to AI search providers but with control and forensics over how that content is handled and especially monetized?
Many creators of copyrighted content will be happy to have their content ingested by centralized, proprietary models and used freely by them, because they receive many benefits in return. This is much like the way today’s internet users are happy to let centralized providers collect their data, as long as it is used for them and not against them. Some creators will be happy to have the centralized models use their content as long as they monetize it for them. Other creators will want to monetize it themselves. But it will be much harder for anyone to make this choice freely if the centralized AI providers are able to ingest everything and to output potentially infringing or competing content without compensation or with compensation that amounts to pennies on the dollar.
Can you imagine a world where a question to an AI chatbot might sometimes lead to an immediate answer, sometimes to the equivalent of “I’m sorry, Dave, I’m afraid I can’t do that” (much as you now get told when you try to generate prohibited speech or images, but in this case, due to copyright restrictions), and at others, “I can’t do that for you, Dave, but the New York Times chatbot can.” At other times, by agreement between the parties, an answer based on copyrighted data might be given directly in the service, but the rights holder will be compensated.
This is the nature of the system that we’re building for our own AI services at O’Reilly. Our online technology learning platform is a marketplace for content provided by hundreds of publishers and tens of thousands of authors, trainers, and other experts. A portion of user subscription fees is allocated to pay for content, and copyright holders are compensated based on usage (or in some cases, based on a fixed fee).
We are increasingly using AI to help our authors and editors generate content such as summaries, translations and transcriptions, test questions, and assessments as part of a workflow that involves editorial and subject-matter expert review, much as when we edit and develop the underlying books and videos. We’re also building dynamically generated user-facing AI content that also keeps track of provenance and shares revenue with our authors and publishing partners.
For example, for our “Answers” feature (built in partnership with Miso), we’ve used a RAG architecture to build a research, reasoning, and response model that searches across content for the most relevant results (similar to traditional search) and then generates a response tailored to the user interaction based on those specific results.
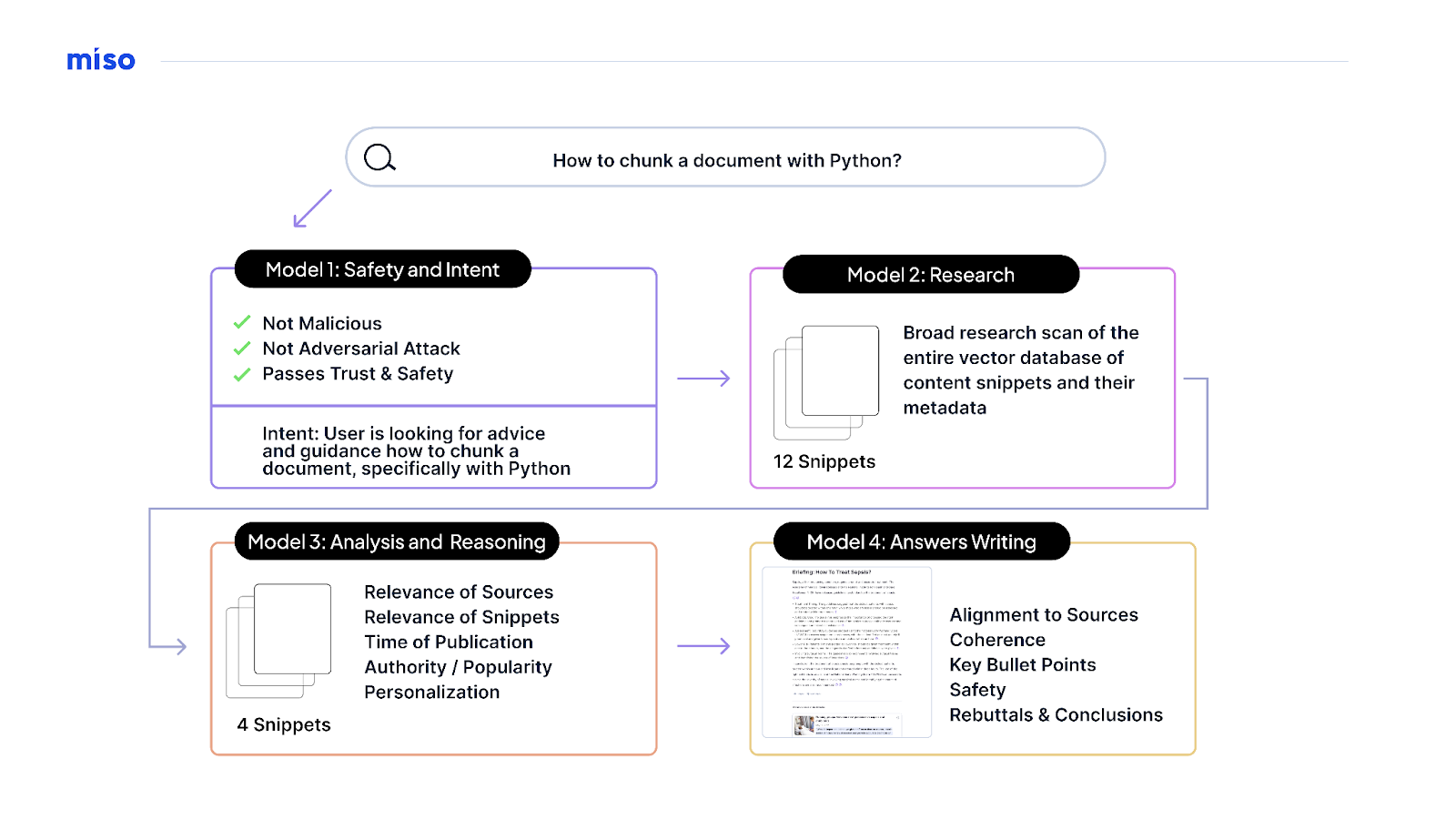
Because we know what content was used to produce the generated answer, we are able to not only provide links to the sources used to generate the answer but also pay authors in proportion to the role of their content in generating it. As Lucky Gunasekara, Andy Hsieh, Lan Le, and Julie Baron write in “The R in ‘RAG’ Stands for ‘Royalties’”:
In essence, the latest O’Reilly Answers release is an assembly line of LLM workers. Each has its own discrete expertise and skill set, and they work together to collaborate as they take in a question or query, reason what the intent is, research the possible answers, and critically evaluate and analyze this research before writing a citation-backed grounded answer…. The net result is that O’Reilly Answers can now critically research and answer questions in a much richer and more immersive long-form response while preserving the citations and source references that were so important in its original release….
The newest Answers release is again built with an open source model—in this case, Llama 3….The benefit of constructing Answers as a pipeline of research, reasoning, and writing using today’s leading open source LLMs is that the robustness of the questions it can answer will continue to increase, but the system itself will always be grounded in authoritative original expert commentary from content on the O’Reilly learning platform.
When someone reads a book, watches a video, or attends a live training, the copyright holder gets paid. Why should derivative content generated with the assistance of AI be any different? Accordingly, we have built tools to integrate AI-generated products directly into our payment system. This approach enables us to properly attribute usage, citations, and revenue to content and ensures our continued recognition of the value of our authors’ and teachers’ work.
And if we can do it, we know that others can too.