Kapitel 4. Umgang mit staatlichen Veränderungen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Es ist nicht ungewöhnlich, dass Anwendungsprozesse über Änderungen des Zustands eines ZooKeeper-Ensembles informiert werden müssen. In unserem Beispiel in Kapitel 1 müssen die Backup-Master zum Beispiel wissen, dass der primäre Master abgestürzt ist, und die Worker müssen wissen, wann ihnen neue Aufgaben zugewiesen wurden. ZooKeeper-Clients könnten natürlich das ZooKeeper-Ensemble regelmäßig abfragen, um festzustellen, ob Änderungen stattgefunden haben. Die Abfrage ist jedoch nicht effizient, vor allem wenn die erwarteten Änderungen eher selten sind.
Nehmen wir zum Beispiel die Backup-Master: Sie müssen wissen, wann der Primärserver abgestürzt ist, damit sie fehlschlagen können. Um die Zeit zu verkürzen, die es braucht, um sich von dem Absturz des Hauptcomputers zu erholen, müssen wir häufig abfragen - zum Beispiel alle 50 Minuten - um ein Beispiel für aggressives Polling zu geben. In diesem Fall erzeugt jeder Backup-Master 20 Anfragen/Sekunde. Wenn es mehrere Backup-Master gibt, multiplizieren wir diese Frequenz mit der Anzahl der Backups, um den gesamten Anfrageverkehr zu erhalten, der nur für die Abfrage des Status des primären Masters in ZooKeeper anfällt. Auch wenn eine solche Menge an Datenverkehr für ein System wie ZooKeeper leicht zu bewältigen ist, sollten Abstürze des primären Masters selten sein, so dass der Großteil dieses Datenverkehrs unnötig ist. Nehmen wir an, wir reduzieren den Polling-Verkehr zu ZooKeeper, indem wir die Zeitspanne zwischen den Anfragen nach dem Status des Primary Masters erhöhen, z. B. auf 1 Sekunde. Das Problem bei der Erhöhung dieser Zeitspanne ist, dass sie die Zeit verlängert, die es braucht, um sich von einem Absturz des Primary Master zu erholen.
Wir können diesen Abstimmungs- und Abfrageaufwand ganz vermeiden, indem wir ZooKeeper interessierte Clients über konkrete Ereignisse benachrichtigen lassen. Der wichtigste Mechanismus, den ZooKeeper für den Umgang mit Änderungen bietet, sind Watches. Mit Watches registriert ein Client seine Anfrage, um eine einmalige Benachrichtigung über eine Änderung an einem bestimmten Znode zu erhalten. Der primäre Master kann zum Beispiel einen ephemeren Znode erstellen, der die Master-Sperre repräsentiert, und die Backup-Master registrieren eine Watch für die Existenz der Master-Sperre. Wenn der primäre Master abstürzt, wird die Master-Sperre automatisch gelöscht und die Backup-Master werden benachrichtigt. Sobald die Backup-Master ihre Benachrichtigung erhalten haben, können sie eine neue Masterwahl starten, indem sie versuchen, einen neuen ephemeren znode zu erstellen, wie wir in "Masterschaft erhalten" gezeigt haben .
Watches und Benachrichtigungen bilden einen allgemeinen Mechanismus, der es den Clients ermöglicht, Änderungen durch andere Clients zu beobachten, ohne ZooKeeper ständig abfragen zu müssen. Wir haben die Verwendung dieses Mechanismus anhand des Master-Beispiels veranschaulicht, aber der allgemeine Mechanismus ist auf eine Vielzahl von Situationen anwendbar.
Einmalige Auslöser
Bevor wir uns näher mit den Watches beschäftigen, sollten wir einige Begriffe klären. Wir sprechen von einem Ereignis, um die Ausführung einer Aktualisierung an einem bestimmten znode zu bezeichnen. Ein Watch ist ein einmaliger Auslöser, der mit einem znode und einer Art von Ereignis verknüpft ist (z. B. wenn Daten in den znode gesetzt werden oder der znode gelöscht wird). Wenn die Watch durch ein Ereignis ausgelöst wird, erzeugt sie eine Benachrichtigung. Eine Benachrichtigung ist eine Nachricht an den Anwendungsclient, der die Watch registriert hat, um diesen Client über das Ereignis zu informieren.
Wenn ein Anwendungsprozess eine Watch registriert, um eine Benachrichtigung zu erhalten, wird die Watch höchstens einmal ausgelöst, und zwar bei dem ersten Ereignis, das die Bedingung der Watch erfüllt. Ein Beispiel: Der Client muss wissen, wann ein bestimmter znode /z gelöscht wird (z. B. ein Backup-Master). Der Kunde führt eine exists Operation auf /z mit gesetztem Watch-Flag aus und wartet auf die Benachrichtigung. Die Benachrichtigung erfolgt in Form eines Rückrufs an den Anwendungsclient.
Jede Überwachung ist mit der Sitzung verbunden, in der der Kunde sie setzt. Wenn die Sitzung abläuft, werden ausstehende Watches entfernt. Watches bleiben jedoch über Verbindungen zu verschiedenen Servern hinweg bestehen. Angenommen, ein ZooKeeper-Client trennt die Verbindung zu einem ZooKeeper-Server und verbindet sich mit einem anderen Server im Ensemble. Der Client sendet eine Liste der ausstehenden Watches. Bei der erneuten Registrierung der Überwachung prüft der Server, ob sich der überwachte Znode seit der letzten Registrierung geändert hat. Wenn sich der znode geändert hat, wird ein Überwachungsereignis an den Client gesendet; andernfalls wird die Überwachung auf dem neuen Server erneut registriert.Dieses Verhalten der erneuten Registrierung von Überwachungen kann durch Setzen der Systemeigenschaft zookeeper.disableAutoWatchReset ausgeschaltet werden.
Warte, kann ich Ereignisse mit einmaligen Auslösern verpassen?
Die kurze Antwort ist "ja": Eine Anwendung kann Ereignisse zwischen dem Erhalt einer Benachrichtigung und der Registrierung für eine andere Uhr verpassen. Diese Frage verdient jedoch eine ausführlichere Diskussion. Das Verpassen von Ereignissen ist in der Regel kein Problem, denn alle Änderungen, die in der Zeit zwischen dem Erhalt einer Benachrichtigung und der Registrierung einer neuen Überwachung eingetreten sind, können durch direktes Auslesen des Status von ZooKeeper erfasst werden.
Angenommen, ein Arbeiter erhält eine Benachrichtigung, dass ihm eine neue Aufgabe zugewiesen wurde. Um die neue Aufgabe zu erhalten, liest die Arbeitskraft die Liste der Aufgaben. Wenn der Arbeitskraft nach Erhalt der Benachrichtigung noch weitere Aufgaben zugewiesen wurden, gibt das Lesen der Aufgabenliste über einen getChildren -Aufruf alle Aufgaben zurück. Der Aufruf getChildren setzt außerdem eine neue Uhr, um zu gewährleisten, dass die Arbeitskraft keine Aufgaben verpasst.
Eigentlich ist es ein positiver Aspekt, dass eine Benachrichtigung über mehrere Ereignisse verteilt wird. Das macht den Benachrichtigungsmechanismus für Anwendungen, die eine hohe Aktualisierungsrate haben, viel schlanker als das Senden einer Benachrichtigung für jedes Ereignis. Um ein triviales Beispiel zu nennen: Wenn jede Benachrichtigung im Durchschnitt zwei Ereignisse erfasst, generieren wir nur 0,5 Benachrichtigungen pro Ereignis statt 1 Benachrichtigung pro Ereignis.
Konkreter werden: Wie man Uhren stellt
Alle Lesevorgänge in der ZooKeeper-API -getData, getChildren und exists- haben die Möglichkeit, einen Watch auf den zu lesenden Znode zu setzen. Um den Watch-Mechanismus zu nutzen, müssen wir die Schnittstelle Watcher implementieren, die aus der Implementierung einer process Methode:
publicvoidprocess(WatchedEventevent);
Die Datenstruktur WatchedEvent enthält die folgenden:
-
Der Status der ZooKeeper-Sitzung (
KeeperState):Disconnected,SyncConnected,AuthFailed,ConnectedReadOnly,SaslAuthenticated, oderExpired -
Der Ereignistyp (
EventType):NodeCreated,NodeDeleted,NodeDataChanged,NodeChildrenChanged, oderNone -
Ein znode-Pfad für den Fall, dass der Ereignistyp nicht
None
Die ersten drei Ereignisse beziehen sich auf einen einzelnen znode, während das vierte Ereignis die Kinder des znode betrifft, für den es ausgegeben wird. Wir verwenden None, wenn das überwachte Ereignis eine Änderung des Zustands der ZooKeeper-Sitzung betrifft.
Es gibt zwei Arten von Watches: Data Watches und Child Watches. Das Erstellen, Löschen oder Setzen der Daten eines znode löst erfolgreich eine Data Watch aus. exists und getData setzen beide Data Watches. Nur getChildren setzt Child Watches, die ausgelöst werden, wenn ein Child-Znode entweder erstellt oder gelöscht wird. Für jeden Ereignistyp gibt es die folgenden Aufrufe zum Setzen einer Überwachung:
NodeCreated-
Eine Uhr wird mit einem Aufruf an
existseingestellt. NodeDeleted-
Eine Uhr wird mit einem Aufruf an
existsodergetDatagesetzt. NodeDataChanged-
Eine Uhr wird entweder mit
existsodergetDataeingestellt. NodeChildrenChanged-
Eine Uhr wird mit
getChildreneingestellt.
Beim Erstellen eines ZooKeeper Objekts (siehe Kapitel 3) müssen wir ein Standard Watcher Objekt übergeben. Der ZooKeeper-Client verwendet diesen Watcher, um die Anwendung über Änderungen des ZooKeeper-Zustands zu informieren, falls sich der Zustand der Sitzung ändert. Für Ereignisbenachrichtigungen, die sich auf ZooKeeper znodes beziehen, kannst du entweder den Standard-Watcher verwenden oder einen anderen implementieren. Der Aufruf getData hat zum Beispiel zwei verschiedene Möglichkeiten, einen Watcher zu setzen:
publicbyte[]getData(finalStringpath,Watcherwatcher,Statstat);publicbyte[]getData(Stringpath,booleanwatch,Statstat);
Beide Signaturen übergeben den znode als erstes Argument. Die erste Signatur übergibt ein neues Watcher Objekt (das wir erstellt haben müssen). Die zweite Signatur weist den Client an, den Standard-Watcher zu verwenden, und verlangt nur true als zweiten Parameter des Aufrufs.
Der Eingabeparameter stat ist eine Instanz der Struktur Stat, die ZooKeeper verwendet, um Informationen über den mit path bezeichneten Znode zurückzugeben. Die Stat Struktur enthält Informationen über den znode, wie z.B. den Zeitstempel der letzten Änderung (zxid), die diesen znode verändert hat, und die Anzahl der Kinder in diesem znode.
Eine wichtige Beobachtung in Bezug auf Watches ist, dass es nicht möglich ist, sie zu entfernen, sobald sie im 3.4er-Zweig und früheren Versionen gesetzt wurden. Die einzigen beiden Möglichkeiten, eine Watch zu entfernen, sind, dass sie ausgelöst wird oder dass ihre Sitzung geschlossen wird oder abläuft. Dieses Verhalten ändert sich im 3.5er-Zweig, und ab diesem Zweig ist es möglich, Watches mit dem Aufruf removeWatches zu deregistrieren.
Ein bisschen Überlastung
Wir verwenden denselben Watch-Mechanismus, um die Anwendung über Ereignisse im Zusammenhang mit dem Status einer ZooKeeper-Sitzung und über Ereignisse im Zusammenhang mit Znode-Änderungen zu informieren. Obwohl es sich bei den Änderungen des Sitzungsstatus und des ZNode-Status um unabhängige Ereignisgruppen handelt, verwenden wir der Einfachheit halber denselben Mechanismus, um diese Ereignisse zu melden.
Ein gemeinsames Muster
Bevor wir uns ein paar Schnipsel für das Master-Worker-Beispiel ansehen, werfen wir einen kurzen Blick auf ein ziemlich häufig verwendetes Codemuster in ZooKeeper-Anwendungen:
-
Implementiere ein Callback-Objekt und übergebe es an den asynchronen Aufruf.
-
Wenn der Vorgang das Setzen einer Uhr erfordert, dann implementiere ein
WatcherObjekt und übergebe es an den asynchronen Aufruf.
Ein Codebeispiel für dieses Muster mit einem asynchronen exists Aufruf sieht so aus:
zk.exists("/myZnode",myWatcher,existsCallback,null);WatchermyWatcher=newWatcher(){publicvoidprocess(WatchedEvente){// Process the watch event}}StatCallbackexistsCallback=newStatCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Statstat){// Process the result of the exists call}};
ZooKeeper
existsaufrufen. Beachte, dass der Aufruf asynchron erfolgt.
Beobachter-Implementierung.

existsRückruf.
Wie wir gleich sehen werden, werden wir dieses Gerüst ausgiebig nutzen.
Das Beispiel des Meisterarbeiters
Schauen wir uns nun an, wie wir mit Zustandsänderungen im Master-Worker-Beispiel umgehen. Hier ist eine Liste von Aufgaben, bei denen eine Komponente auf Änderungen warten muss:
-
Meisterschaftswechsel
-
Master wartet auf Änderungen in der Liste der Arbeiter
-
Master wartet auf neue Aufgaben zum Zuweisen
-
Arbeiter wartet auf neue Aufgabenzuweisungen
-
Der Kunde wartet auf das Ergebnis der Aufgabenausführung
Als Nächstes zeigen wir einige Codeschnipsel, um zu veranschaulichen, wie man diese Aufgaben mit ZooKeeper programmiert. Der vollständige Beispielcode ist Teil des Zusatzmaterials zu diesem Buch.
Änderungen der Meisterschaft
Aus dem Abschnitt "Masterschaft erlangen" wissen wir, dass ein Anwendungsclient sich selbst zum Master wählt, indem er den /master znode erstellt (wir nennen das "für den Master laufen"). Wenn der znode bereits existiert, stellt der Anwendungsclient fest, dass er nicht der primäre Master ist und kehrt zurück. Diese Implementierung toleriert jedoch keinen Absturz des primären Masters. Wenn der primäre Master abstürzt, wissen die Backup-Master nichts davon. Deshalb müssen wir eine Überwachung für /master einrichten, damit ZooKeeper den Client benachrichtigt, wenn /master gelöscht wird (entweder explizit oder weil die Sitzung des primären Masters abgelaufen ist).
Um den Watcher zu setzen, erstellen wir einen neuen Watcher mit dem Namen masterExistsWatcher und übergeben ihn an exists. Bei einer Benachrichtigung, dass /master gelöscht wurde, ruft der in masterExistsWatcher definierte process runForMaster auf:
StringCallbackmasterCreateCallback=newStringCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Stringname){switch(Code.get(rc)){caseCONNECTIONLOSS:checkMaster();break;caseOK:state=MasterStates.ELECTED;takeLeadership();break;caseNODEEXISTS:state=MasterStates.NOTELECTED;masterExists();break;default:state=MasterStates.NOTELECTED;LOG.error("Something went wrong when running for master.",KeeperException.create(Code.get(rc),path));}}};voidmasterExists(){zk.exists("/master",masterExistsWatcher,masterExistsCallback,null);}WatchermasterExistsWatcher=newWatcher(){publicvoidprocess(WatchedEvente){if(e.getType()==EventType.NodeDeleted){assert"/master".equals(e.getPath());runForMaster();}}};
Bei einem Verbindungsverlust prüft der Client, ob der
/masterznode vorhanden ist, da er nicht weiß, ob er ihn erstellen konnte oder nicht.Wenn
OK, dann braucht es einfach Führung.Wenn jemand anderes den Znode bereits erstellt hat, muss der Kunde ihn beobachten.

Wenn etwas Unerwartetes passiert, wird der Fehler protokolliert und es wird nichts weiter unternommen.

Dieser
existsAufruf dient dazu, eine Uhr auf dem/masterznode zu setzen.
Wenn der
/masterznode gelöscht wird, dann läuft er wieder für den Master.
In Anlehnung an den asynchronen Stil, den wir in "Mastership asynchron abrufen" verwendet haben , erstellen wir auch eine Callback-Methode für den Aufruf von exists, die sich um ein paar Fälle kümmert. Erstens wird im Falle eines Verbindungsverlustes der exists Vorgang erneut versucht. Zweitens ist es möglich, dass der /master znode zwischen der Ausführung des create Callbacks und der Ausführung des exists Vorgangs gelöscht werden. Wenn das passiert, wird der Callback mit NONODE aufgerufen und wir laufen erneut zum Master. In allen anderen Fällen prüfen wir, ob der /master znode, indem wir seine Daten abrufen. Der letzte Fall ist, dass die Client-Sitzung abläuft. In diesem Fall gibt der Callback, der die Daten von /master abruft, eine Fehlermeldung aus und beendet sich. Unser exists Callback sieht wie folgt aus:
StatCallbackmasterExistsCallback=newStatCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Statstat){switch(Code.get(rc)){caseCONNECTIONLOSS:masterExists();break;caseOK:break;caseNONODE:state=MasterStates.RUNNING;runForMaster();break;default:checkMaster();break;}}};
Bei einem Verbindungsverlust versuchst du es einfach noch einmal.
Wenn sie
OKzurückgibt, dann gibt es nichts zu tun.Wenn er
NONODEzurückgibt, lass ihn für den Master laufen.Wenn etwas Unerwartetes passiert, überprüfe, ob
/mastervorhanden ist, indem du seine Daten abrufst.
Das Ergebnis der Operation exists über /master könnte sein, dass der znode gelöscht wurde. In diesem Fall muss der Kunde /master erneut aufrufen, da nicht sichergestellt ist, dass die Überwachung vor dem Löschen des znode eingestellt wurde. Wenn der neue Versuch, primär zu werden, fehlschlägt, weiß der Client, dass ein anderer Client erfolgreich war, und er versucht, die Überwachung /master erneut. Wenn die Benachrichtigung für /master anzeigt, dass er erstellt und nicht gelöscht wurde, wird der Client nicht für /master ausgeführt. Gleichzeitig muss die entsprechende exists Operation (diejenige, die den Watch gesetzt hat) zurückgegeben haben, dass /master nicht existiert, was dazu führt, dass die Prozedur für /master aus dem exists Callback ausgeführt wird.
Beachte, dass dieses Muster, als Master zu laufen und exists auszuführen, um eine Uhr zu setzen /master auszuführen, so lange der Client läuft und nicht zum primären Master wird. Wenn er zum primären Master wird und schließlich abstürzt, kann der Client neu starten und diesen Code erneut ausführen.
Abbildung 4-1 verdeutlicht die möglichen Verschachtelungen von Vorgängen. Wenn die create Operation, die bei der Suche nach dem primären Master ausgeführt wird, erfolgreich ist (a), muss der Anwendungsclient nichts weiter tun. Wenn die Operation create fehlschlägt, weil der znode bereits existiert, führt der Client die Operation exists aus, um eine Überwachung des /master znode (b). Zwischen dem Aufruf des Masters und der Ausführung der exists Operation kann es passieren, dass der /master znode gelöscht wird. Gehen wir zunächst davon aus, dass der znode gelöscht wird, bevor die Antwort an exists generiert wird. In diesem Fall läuft der Client erneut für den Master (c). Nehmen wir nun an, dass die Antwort auf den Aufruf von exists verarbeitet wurde, bevor der znode gelöscht wurde und true zurückgibt. Wenn der znode gelöscht wird, löst ZooKeeper die Überwachung aus und der Client erhält sie schließlich und ruft erneut den Master auf (d).
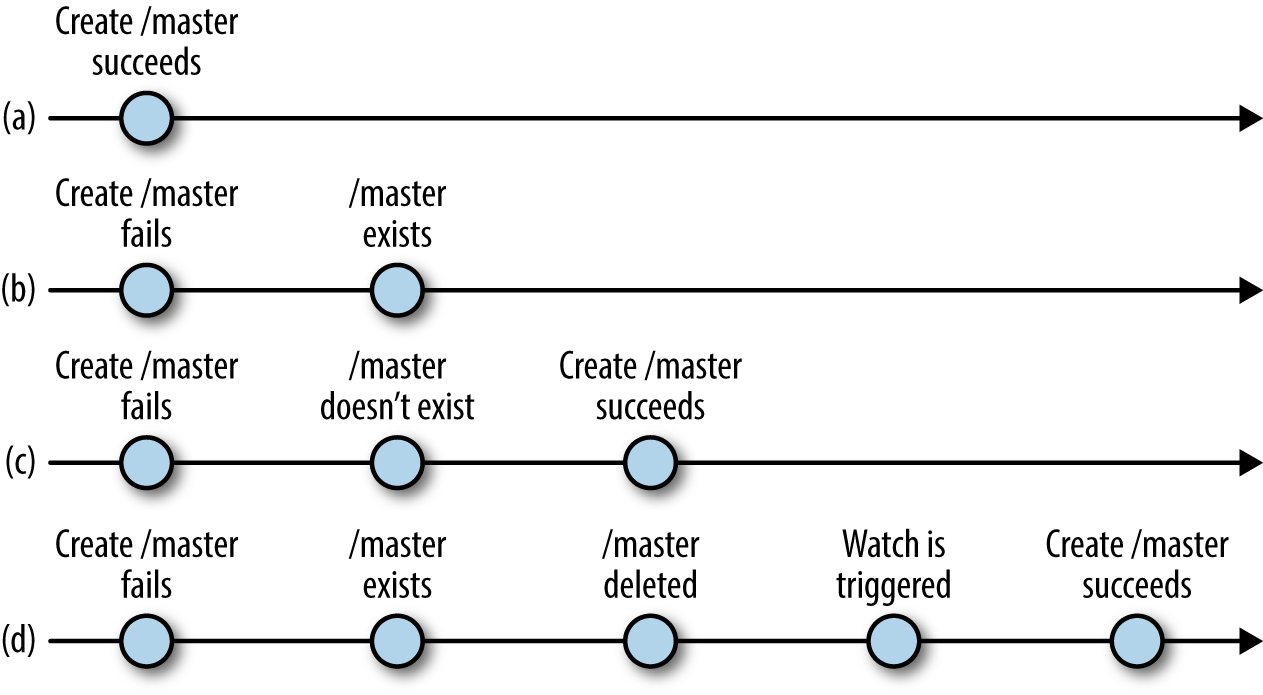
Abbildung 4-1. Laufen für Master, mögliche Verschachtelungen
Meister wartet auf Änderungen in der Liste der Arbeitnehmer
Neue Arbeiter/innen können dem System jederzeit hinzugefügt und alte Arbeiter/innen außer Dienst gestellt werden. Arbeiter können auch abstürzen, bevor sie ihre Aufgaben ausführen. Um festzustellen, welche Arbeiter zu einem bestimmten Zeitpunkt verfügbar sind, registrieren wir neue Arbeiter bei ZooKeeper, indem wir einen znode als Kind von /workers hinzufügen. Wenn ein Arbeiter abstürzt oder einfach aus dem System entfernt wird, läuft seine Sitzung ab, wodurch sein znode automatisch entfernt wird. Im Idealfall schließen die Worker ihre Sitzungen, ohne dass ZooKeeper auf das Ende der Sitzung warten muss.
Der primäre Master verwendet getChildren, um die Liste der verfügbaren Arbeiter abzurufen und auf Änderungen in der Liste zu achten. Hier ist ein Beispielcode, um die Liste zu erhalten und auf Änderungen zu achten:
WatcherworkersChangeWatcher=newWatcher(){publicvoidprocess(WatchedEvente){if(e.getType()==EventType.NodeChildrenChanged){assert"/workers".equals(e.getPath());getWorkers();}}};voidgetWorkers(){zk.getChildren("/workers",workersChangeWatcher,workersGetChildrenCallback,null);}ChildrenCallbackworkersGetChildrenCallback=newChildrenCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,List<String>children){switch(Code.get(rc)){caseCONNECTIONLOSS:getWorkers();break;caseOK:LOG.info("Succesfully got a list of workers: "+children.size()+" workers");reassignAndSet(children);break;default:LOG.error("getChildren failed",KeeperException.create(Code.get(rc),path));}}};
workersChangeWatcherist der Beobachter für die Liste der Arbeiter.Im Falle eines
CONNECTIONLOSSEreignisses müssen wir die Operation erneut ausführen, um die Kinder zu erhalten und die Uhr zu setzen.Dieser Aufruf ordnet die Aufgaben der toten Arbeiter neu zu und setzt die neue Liste der Arbeiter.
Wir beginnen mit dem Aufruf von getWorkers. Dieser Aufruf führt getChildren asynchron aus und übergibt workersGetChildrenCallback, um das Ergebnis der Operation zu verarbeiten. Wenn der Client die Verbindung zu einem Server trennt (EreignisCONNECTIONLOSS ), ist die Uhr nicht gesetzt und wir haben keine Liste der Arbeiter; wir führen getWorkers erneut aus, um die Uhr zu setzen und die Liste der Arbeiter zu erhalten. Nach einer erfolgreichen Ausführung von getChildren rufen wir reassignAndSet wie folgt auf:
ChildrenCacheworkersCache;voidreassignAndSet(List<String>children){List<String>toProcess;if(workersCache==null){workersCache=newChildrenCache(children);toProcess=null;}else{LOG.info("Removing and setting");toProcess=workersCache.removedAndSet(children);}if(toProcess!=null){for(Stringworker:toProcess){getAbsentWorkerTasks(worker);}}}
Hier ist der Cache, in dem die letzte Gruppe von Arbeitern liegt, die wir gesehen haben.
Wenn dies das erste Mal ist, dass der Cache verwendet wird, dann instanziiere ihn.
Wenn wir das erste Mal Arbeiter bekommen, gibt es nichts zu tun.
Wenn es nicht das erste Mal ist, dann müssen wir prüfen, ob ein Arbeiter entfernt wurde.
Wenn es einen Arbeiter gibt, der entfernt wurde, müssen wir seine Aufgaben neu zuweisen.
Wir verwenden den Cache, weil wir uns an das erinnern müssen, was wir schon einmal gesehen haben. Nehmen wir an, wir erhalten die Liste der Arbeiter zum ersten Mal. Wenn wir die Benachrichtigung erhalten, dass sich die Liste der Arbeiter/innen geändert hat, wissen wir auch nach dem erneuten Lesen nicht, was genau sich geändert hat, es sei denn, wir behalten die alten Werte. Die Cacheklasse für dieses Beispiel behält einfach die letzte Liste, die der Master gelesen hat, und implementiert ein paar Methoden, um festzustellen, was sich geändert hat.
Master wartet auf neue Aufgaben zum Zuweisen
Wie beim Warten auf Änderungen in der Liste der Worker wartet der primäre Master darauf, dass neue Tasks zu /tasks hinzugefügt werden. Der Master erhält zunächst die Menge der aktuellen Tasks und setzt eine Watch für Änderungen an der Menge. Die Menge wird in ZooKeeper durch die Kinder von /tasksdargestellt, und jedes Kind entspricht einer Aufgabe. Sobald der Master Aufgaben erhält, die noch nicht zugewiesen wurden, wählt er einen Arbeiter nach dem Zufallsprinzip aus und weist die Aufgabe dem Arbeiter zu. Wir implementieren die Zuweisung in assignTasks:
WatchertasksChangeWatcher=newWatcher(){publicvoidprocess(WatchedEvente){if(e.getType()==EventType.NodeChildrenChanged){assert"/tasks".equals(e.getPath());getTasks();}}};voidgetTasks(){zk.getChildren("/tasks",tasksChangeWatcher,tasksGetChildrenCallback,null);}ChildrenCallbacktasksGetChildrenCallback=newChildrenCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,List<String>children){switch(Code.get(rc)){caseCONNECTIONLOSS:getTasks();break;caseOK:if(children!=null){assignTasks(children);}break;default:LOG.error("getChildren failed.",KeeperException.create(Code.get(rc),path));}}};
Watcher-Implementierung für die Benachrichtigung, dass sich die Liste der Aufgaben geändert hat.
Hol dir die Liste der Aufgaben.
Ordne die Aufgaben in der Liste zu.
Jetzt implementieren wir assignTasks. Sie weist einfach jede der Aufgaben in der Liste der Kinder von /tasks zu. Bevor wir den Zuweisungsznode erstellen, holen wir uns die Aufgabendaten mit getData:
voidassignTasks(List<String>tasks){for(Stringtask:tasks){getTaskData(task);}}voidgetTaskData(Stringtask){zk.getData("/tasks/"+task,false,taskDataCallback,task);}DataCallbacktaskDataCallback=newDataCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,byte[]data,Statstat){switch(Code.get(rc)){caseCONNECTIONLOSS:getTaskData((String)ctx);break;caseOK:/* * Choose worker at random. */intworker=rand.nextInt(workerList.size());StringdesignatedWorker=workerList.get(worker);/* * Assign task to randomly chosen worker. */StringassignmentPath="/assign/"+designatedWorker+"/"+(String)ctx;createAssignment(assignmentPath,data);break;default:LOG.error("Error when trying to get task data.",KeeperException.create(Code.get(rc),path));}}};
Hol dir Aufgabendaten.
Wähle eine/n Arbeiter/in nach dem Zufallsprinzip aus und weise ihm/ihr die Aufgabe zu.
Wir müssen zuerst die Aufgabendaten abrufen, weil wir den Aufgabenznode unter /tasks löschen, nachdem wir ihn zugewiesen haben. Auf diese Weise muss sich der Master nicht daran erinnern, welche Aufgaben er zugewiesen hat. Schauen wir uns den Code für die Zuweisung einer Aufgabe an:
voidcreateAssignment(Stringpath,byte[]data){zk.create(path,data,Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT,assignTaskCallback,data);}StringCallbackassignTaskCallback=newStringCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Stringname){switch(Code.get(rc)){caseCONNECTIONLOSS:createAssignment(path,(byte[])ctx);break;caseOK:LOG.info("Task assigned correctly: "+name);deleteTask(name.substring(name.lastIndexOf("/")+1));break;caseNODEEXISTS:LOG.warn("Task already assigned");break;default:LOG.error("Error when trying to assign task.",KeeperException.create(Code.get(rc),path));}}};
Erstelle eine Zuordnung. Der Pfad hat die Form
/assign/worker-id/task-num.Lösche die Aufgabe znode unter
/tasks.
Für neue Aufgaben erstellt der Master, nachdem er einen Arbeiter ausgewählt hat, dem er die Aufgabe zuweist, einen znode unter /assign/worker-id, wobei id die Kennung des Arbeiters ist. Anschließend löscht er den znode aus der Liste der anstehenden Aufgaben. Der Code zum Löschen des znode im vorigen Beispiel folgt dem Muster des vorhergehenden Codes, den wir gezeigt haben.
Wenn der Master einen Zuweisungsznode für einen Arbeiter mit der Kennung id erstellt, generiert ZooKeeper eine Benachrichtigung für den Arbeiter, unter der Annahme, dass der Arbeiter eine Uhr auf seinem Zuweisungsznode registriert hat (/assign/worker-id).
Beachte, dass der Master auch die Aufgabe znode unter /tasks löscht, nachdem er sie erfolgreich zugewiesen hat. Dieser Ansatz vereinfacht die Rolle des Kapitäns, wenn er neue Aufgaben zum Zuweisen erhält. Wenn die Liste der Aufgaben zugewiesene und nicht zugewiesene Aufgaben mischen würde, bräuchte der Meister eine Möglichkeit, die Aufgaben eindeutig zuzuordnen.
Arbeiter wartet auf neue Aufgabenzuweisungen
Einer der ersten Schritte, den ein Worker ausführen muss, ist, sich bei ZooKeeper zu registrieren. Dazu erstellt er einen znode unter /workers, wie wir bereits besprochen haben:
voidregister(){zk.create("/workers/worker-"+serverId,newbyte[0],Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL,createWorkerCallback,null);}StringCallbackcreateWorkerCallback=newStringCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Stringname){switch(Code.get(rc)){caseCONNECTIONLOSS:register();break;caseOK:LOG.info("Registered successfully: "+serverId);break;caseNODEEXISTS:LOG.warn("Already registered: "+serverId);break;default:LOG.error("Something went wrong: "+KeeperException.create(Code.get(rc),path));}}};
Melde den Worker an, indem du einen Znode erstellst.
Versuche es noch einmal. Beachte, dass die erneute Registrierung kein Problem darstellt. Wenn der znode bereits erstellt wurde, erhalten wir ein
NODEEXISTSEreignis zurück.
Das Hinzufügen dieses znode signalisiert dem Master, dass dieser Worker aktiv und bereit ist, Aufgaben zu bearbeiten. Um das Beispiel zu vereinfachen, verwenden wir den Idle/Busy-Status (eingeführt in Kapitel 3) nicht.
Auf ähnliche Weise erstellen wir einen znode /assign/worker-id, damit der Master diesem Arbeiter Aufgaben zuweisen kann. Wenn wir /workers/worker-id vor /assign/worker-id erstellen, könnten wir in die Situation geraten, dass der Master versucht, die Aufgabe zuzuweisen, dies aber nicht kann, weil der znode des zugewiesenen Elternteils noch nicht erstellt worden ist. Um diese Situation zu vermeiden, müssen wir die /assign/worker-id zuerst erstellen. Außerdem muss der Arbeiter eine Uhr auf /assign/worker-id setzen, um eine Benachrichtigung zu erhalten, wenn eine neue Aufgabe zugewiesen wird.
Sobald der Arbeiter Aufgaben zugewiesen bekommen hat, holt er sie von /assign/worker-id und führt sie aus. Der Worker nimmt jede Aufgabe in seiner Liste und überprüft, ob sie bereits in der Warteschlange zur Ausführung steht. Zu diesem Zweck führt er eine Liste der laufenden Aufgaben. Beachte, dass wir die zugewiesenen Aufgaben eines Workers in einem separaten Thread durchlaufen, um den Callback-Thread freizugeben. Andernfalls würden wir andere eingehende Rückrufe blockieren. In unserem Beispiel verwenden wir ein Java ThreadPoolExecutor, um einen Thread für die Schleife durch die Aufgaben zuzuweisen:
WatchernewTaskWatcher=newWatcher(){publicvoidprocess(WatchedEvente){if(e.getType()==EventType.NodeChildrenChanged){assertnewString("/assign/worker-"+serverId).equals(e.getPath());getTasks();}}};voidgetTasks(){zk.getChildren("/assign/worker-"+serverId,newTaskWatcher,tasksGetChildrenCallback,null);}ChildrenCallbacktasksGetChildrenCallback=newChildrenCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,List<String>children){switch(Code.get(rc)){caseCONNECTIONLOSS:getTasks();break;caseOK:if(children!=null){executor.execute(newRunnable(){List<String>children;DataCallbackcb;publicRunnableinit(List<String>children,DataCallbackcb){this.children=children;this.cb=cb;returnthis;}publicvoidrun(){LOG.info("Looping into tasks");synchronized(onGoingTasks){for(Stringtask:children){if(!onGoingTasks.contains(task)){LOG.trace("New task: {}",task);zk.getData("/assign/worker-"+serverId+"/"+task,false,cb,task);onGoingTasks.add(task);}}}}}.init(children,taskDataCallback));}break;default:System.out.println("getChildren failed: "+KeeperException.create(Code.get(rc),path));}}};
Wenn du eine Benachrichtigung erhältst, dass sich die Kinder geändert haben, rufe die Liste der Kinder ab.
Ausführen in einem separaten Thread.
Schleife durch die Liste der Kinder.
Erhalte Aufgabendaten, um sie auszuführen.
Füge die Aufgabe zur Liste der auszuführenden Aufgaben hinzu, um zu vermeiden, dass sie mehrfach ausgeführt wird.
Sitzungsereignisse und Beobachter
Wenn wir die Verbindung zu einem Server trennen (z. B. wenn der Server abstürzt), werden keine Watches zugestellt, bis die Verbindung wiederhergestellt ist. Aus diesem Grund werden Sitzungsereignisse wie CONNECTIONLOSS an alle ausstehenden Watch-Handler gesendet. Im Allgemeinen verwenden Anwendungen Sitzungsereignisse, um in einen sicheren Modus zu wechseln: Der ZooKeeper-Client empfängt keine Ereignisse, wenn die Verbindung unterbrochen ist, daher sollte er in diesem Zustand konservativ handeln. Im Fall unserer Master-Worker-Spielzeuganwendung sind alle Aktionen außer dem Übermitteln einer Aufgabe reaktiv. Außerdem kann der Master-Worker-Client keine neuen Aufgaben einreichen und erhält keine Statusbenachrichtigungen, wenn die Verbindung unterbrochen ist.
Kunde wartet auf das Ergebnis der Aufgabenausführung
Angenommen, ein Anwendungsclient hat eine Aufgabe eingereicht. Jetzt muss er wissen, wann die Aufgabe ausgeführt wurde und welchen Status sie hat. Erinnere dich daran, dass ein Worker, sobald er eine Aufgabe ausführt, einen Znode unter /status erstellt. Schauen wir uns zunächst den Code an, um eine Aufgabe zur Ausführung zu übermitteln:
voidsubmitTask(Stringtask,TaskObjecttaskCtx){taskCtx.setTask(task);zk.create("/tasks/task-",task.getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT_SEQUENTIAL,createTaskCallback,taskCtx);}StringCallbackcreateTaskCallback=newStringCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Stringname){switch(Code.get(rc)){caseCONNECTIONLOSS:submitTask(((TaskObject)ctx).getTask(),(TaskObject)ctx);break;caseOK:LOG.info("My created task name: "+name);((TaskObject)ctx).setTaskName(name);watchStatus("/status/"+name.replace("/tasks/",""),ctx);break;default:LOG.error("Something went wrong"+KeeperException.create(Code.get(rc),path));}}};
Das Kontextobjekt ist hier eine Instanz der Klasse
Task.Sende die Aufgabe nach einem Verbindungsverlust erneut. Beachte, dass durch die erneute Übermittlung ein Duplikat der Aufgabe entstehen kann.
Setze eine Überwachung auf den Status-Znode für diese Aufgabe.
Wurde mein sequenzieller Znode erstellt?
Der Umgang mit einem CONNECTIONLOSS Ereignis beim Versuch, einen sequenziellen znode zu erstellen, ist etwas knifflig. Da ZooKeeper die Sequenznummer zuweist, ist es für den unterbrochenen Client nicht möglich festzustellen, ob der znode erstellt wurde, wenn es gleichzeitig Anfragen zur Erstellung von sequenziellen znodes von anderen Clients gibt. (Beachte, dass sich alle in dieser Notiz besprochenen create Anfragen auf die Kinder desselben Z-Knotens beziehen).
Um diese Einschränkung zu überwinden, müssen wir einen Hinweis auf den Ersteller des znode geben, z. B. die Server-ID als Teil des Aufgabennamens. Mit diesem Ansatz ist es möglich festzustellen, ob die Aufgabe erstellt wurde, indem alle Znodes der Aufgabe aufgelistet werden.
Hier prüfen wir, ob der Statusknoten bereits existiert (vielleicht wurde die Aufgabe schnell bearbeitet) und setzen einen Watch. Wir stellen eine Watcher-Implementierung zur Verfügung, die auf die Benachrichtigung über die Erstellung des znode reagiert, sowie eine Callback-Implementierung für den Aufruf von exists:
ConcurrentHashMap<String,Object>ctxMap=newConcurrentHashMap<String,Object>();voidwatchStatus(Stringpath,Objectctx){ctxMap.put(path,ctx);zk.exists(path,statusWatcher,existsCallback,ctx);}WatcherstatusWatcher=newWatcher(){publicvoidprocess(WatchedEvente){if(e.getType()==EventType.NodeCreated){asserte.getPath().contains("/status/task-");zk.getData(e.getPath(),false,getDataCallback,ctxMap.get(e.getPath()));}}};StatCallbackexistsCallback=newStatCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Statstat){switch(Code.get(rc)){caseCONNECTIONLOSS:watchStatus(path,ctx);break;caseOK:if(stat!=null){zk.getData(path,false,getDataCallback,null);}break;caseNONODE:break;default:LOG.error("Something went wrong when "+"checking if the status node exists: "+KeeperException.create(Code.get(rc),path));break;}}};
Der Client propagiert hier das Kontextobjekt, damit er das Aufgabenobjekt (
TaskObject) entsprechend ändern kann, wenn er eine Benachrichtigung für den Status znode erhält.Der Status znode ist bereits vorhanden, also muss der Kunde ihn holen.
Wenn der Status znode noch nicht vorhanden ist, was normalerweise der Fall sein sollte, tut der Client nichts.
Ein alternativer Weg: Multiop
Multiop gehörte nicht zum ursprünglichen Design von ZooKeeper, wurde aber in Version 3.4.0 hinzugefügt. Multiop ermöglicht die atomare Ausführung von mehreren ZooKeeper-Operationen in einem Block. Die Ausführung ist atomar in dem Sinne, dass entweder alle Operationen in einem Multiop-Block erfolgreich sind oder alle fehlschlagen. Zum Beispiel können wir in einem Multiop-Block einen Eltern-Znode und sein Kind löschen. Die einzigen möglichen Ergebnisse sind, dass entweder beide Vorgänge erfolgreich sind oder fehlschlagen. Es ist nicht möglich, dass ein Elternteil gelöscht wird, während eines seiner Kinder bestehen bleibt, oder umgekehrt.
Um die Multi-Op-Funktion zu nutzen:
-
Erstelle ein
OpObjekt, das jede ZooKeeper-Operation repräsentiert, die du über einen Multiop-Aufruf ausführen willst. ZooKeeper bietet eineOpImplementierung für jede der Operationen, die den Zustand ändern:create,delete, undsetData. -
Rufe innerhalb des
OpObjekts eine statische Methode auf, die vonOpfür diesen Vorgang bereitgestellt wird. -
Füge dieses
OpObjekt zu einemIterableJava-Objekt, wie z.B. einer Liste, hinzu. -
Rufe
multiauf der Liste auf.
Das folgende Beispiel veranschaulicht diesen Prozess:
OpdeleteZnode(Stringz){returnOp.delete(z,-1);}...List<OpResult>results=zk.multi(Arrays.asList(deleteZnode("/a/b"),deleteZnode("/a"));
Erstelle ein
OpObjekt für dendeleteAufruf.Gib das Objekt zurück, indem du die entsprechende
OpMethode aufrufst.Führe beide
deleteAufrufe als eine Einheit aus, indem du denmultiAufruf verwendest und sie als Liste vonOpInstanzen übergibst.
Der Aufruf von multi gibt eine Liste von OpResult Objekten zurück, von denen jedes auf die entsprechende Operation spezialisiert ist. Für die Operation delete gibt es zum Beispiel die Klasse DeleteResult, die OpResult erweitert. Die Methoden und Daten, die von jedem Ergebnisobjekt angezeigt werden, hängen von der Art der Operation ab. DeleteResult bietet nur die Methoden equals und hashCode, während CreateResult den Pfad der Operation und ein Stat Objekt anzeigt. Im Falle von Fehlern gibt ZooKeeper eine Instanz von ErrorResult zurück, die einen Fehlercode enthält.
Der Aufruf multi hat auch eine asynchrone Version. Hier sind die Signaturen der synchronen und asynchronen Methoden:
publicList<OpResult>multi(Iterable<Op>ops)throwsInterruptedException,KeeperException;publicvoidmulti(Iterable<Op>ops,MultiCallbackcb,Objectctx);
Transaction ist ein Wrapper für multi mit einer einfacheren Schnittstelle. Wir können eine Instanz von Transaction erstellen, Operationen hinzufügen und die Transaktion übertragen. Das vorherige Beispiel, das mit Transaction umgeschrieben wurde, sieht wie folgt aus:
Transactiont=newTransaction();t.delete("/a/b",-1);t.delete("/a",-1);List<OpResult>results=t.commit();
Der Aufruf commit hat auch eine asynchrone Version, die als Eingabe ein MultiCallback Objekt und ein Kontextobjekt erhält:
publicvoidcommit(MultiCallbackcb,Objectctx);
Multiop kann unsere Master-Worker-Implementierung an mindestens einer Stelle vereinfachen. Bei der Zuweisung einer Aufgabe hat der Master in den vorherigen Beispielen den entsprechenden Zuweisungs-Znode erstellt und dann den Aufgaben-Znode unter /tasks gelöscht. Wenn der Master abstürzt, bevor er den znode unter /tasks gelöscht hat, haben wir eine Aufgabe unter /tasks, die bereits zugewiesen wurde. Mit Hilfe von multiop können wir den znode, der die Zuweisung der Aufgabe unter /assign darstellt, erstellen und den znode, der die Aufgabe unter /tasks darstellt, atomar löschen. Auf diese Weise stellen wir sicher, dass kein znode der Aufgabe unter /tasks bereits zugewiesen wurde. Wenn ein Backup die Rolle des Masters übernimmt, ist es nicht notwendig, die Aufgaben unter /tasks zu disambiguieren: Sie sind alle nicht zugewiesen.
Eine weitere Funktion, die multiop bietet, ist die Möglichkeit, die Version eines znode zu überprüfen, um Operationen über mehrere znodes zu ermöglichen, die den Status von ZooKeeper lesen und einige Daten zurückschreiben - möglicherweise eine Änderung des Gelesenen. Die Version der Znode, die geprüft wird, ändert sich nicht. Daher ermöglicht dieser Aufruf eine Multi-Operation, die die Version einer Znode prüft, die nicht geändert wird. Diese Funktion ist nützlich, wenn die Änderungen an einem oder mehreren Znodes von der Version eines anderen Znodes abhängig sind. Nehmen wir an, dass in unserem Master-Worker-Beispiel der Master möchte, dass die Clients neue Aufgaben unter einem Pfad hinzufügen, den der Master angibt. Der Master könnte die Clients zum Beispiel auffordern, neue Aufgaben als Kinder von /tasks-mid, wobei mid die Kennung des Masters ist. Der Master speichert diesen Pfad als die Daten des /master-path znode. Ein Kunde, der eine neue Aufgabe hinzufügen möchte, liest zunächst /master-path und wählt seine aktuelle Version mit Stat aus. Anschließend erstellt der Kunde einen neuen Aufgabenznode unter /tasks-mid als Teil eines Multi-Op-Aufrufs eine neue Aufgabe znode und überprüft, ob die Version von /master-path mit der gelesenen übereinstimmt.
Die Signatur von check ist ähnlich wie die von setData, enthält aber keine Daten:
publicstaticOpcheck(Stringpath,intversion);
Wenn die Version des znode in der angegebenen path nicht übereinstimmt, schlägt der Aufruf von multi fehl. Zur Veranschaulichung: So würde der Code ungefähr aussehen, wenn wir das soeben besprochene Beispiel umsetzen würden:
byte[]masterData=zk.getData("/master-path",false,stat);Stringparent=newString(masterData);Stringpath=parent+"/task-";...zk.multi(Arrays.asList(Op.check("/master-path",stat.getVersion()),Op.create(path,task,Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT_SEQUENTIAL)))
Hol dir die Daten von
/master-path.Extrahiere den Pfad aus dem
/master-pathznode.multiAufruf mit zwei Operationen, eine überprüft die Version des Masterpfads und die andere erstellt eine Aufgabe znode.
Beachte, dass dieses Schema nicht funktioniert, wenn wir den Pfad zusammen mit der Master-ID in /master speichern. Der /master znode wird jedes Mal von einem neuen Master erstellt, was seine Version konsistent 1 macht.
Watches als Ersatz für explizites Cache-Management
Aus Sicht der Anwendung ist es nicht wünschenswert, dass die Clients jedes Mal auf ZooKeeper zugreifen, wenn sie die Daten für einen bestimmten Znode, die Liste der Kinder eines Znodes oder irgendetwas anderes in Bezug auf den ZooKeeper-Status benötigen. Stattdessen ist es viel effizienter, wenn die Clients die Werte lokal zwischenspeichern und nach Belieben verwenden. Sobald sich solche Werte ändern, soll ZooKeeper die Clients natürlich benachrichtigen, damit sie die Caches aktualisieren können. Diese Benachrichtigungen sind dieselben, die wir bisher besprochen haben, und wie bisher registrieren sich die Anwendungs-Clients, um solche Benachrichtigungen über Watches zu erhalten. Kurz gesagt, diese Watches ermöglichen es den Clients, eine lokale Version eines Wertes (z. B. die Daten eines ZNodes oder die Liste seiner Kinder) zwischenzuspeichern und Benachrichtigungen zu erhalten, wenn sich dieser Wert ändert.
Eine Alternative zu dem Ansatz, den die ZooKeeper-Entwickler gewählt haben, wäre es, alle ZooKeeper-Zustände, auf die der Client zugreift, transparent zu cachen und die Werte transparent zu invalidieren, wenn es Aktualisierungen der gecachten Daten gibt. Die Implementierung eines solchen Cache-Kohärenzschemas könnte jedoch kostspielig sein, da die Clients möglicherweise nicht alle ZooKeeper-Zustände, auf die sie zugreifen, zwischenspeichern müssen und die Server die zwischengespeicherten Zustände trotzdem ungültig machen müssen. Um die Ungültigkeitserklärung zu implementieren, müssten die Server entweder den Inhalt des Caches für jeden Kunden verfolgen oder Anfragen zur Ungültigkeitserklärung senden. Beide Optionen sind bei einer großen Anzahl von Clients teuer und aus unserer Sicht unerwünscht.
Unabhängig davon, wer den Client-Cache verwaltet - ZooKeeper direkt oder die ZooKeeper-Anwendung - kann die Benachrichtigung der Clients über Aktualisierungen entweder synchron oder asynchron erfolgen. Eine synchrone Invalidierung des Status aller Clients, die eine Kopie besitzen, wäre ineffizient, da die Clients oft unterschiedlich schnell vorgehen und langsame Clients andere Clients zum Warten zwingen würden. Solche Unterschiede treten umso häufiger auf, je größer die Anzahl der Clients ist.
Der Ansatz der Benachrichtigungen, für den sich die Entwickler entschieden haben, kann als asynchrone Methode zur Invalidierung des ZooKeeper-Status auf der Client-Seite angesehen werden. ZooKeeper stellt die Benachrichtigungen für die Clients in eine Warteschlange, und diese Benachrichtigungen werden asynchron abgefragt. Es liegt an der Anwendung zu entscheiden, welche Teile des ZooKeeper-Status für einen bestimmten Client ungültig gemacht werden müssen. Diese Designentscheidungen passen besser zu den Anwendungsfällen von ZooKeeper.
Garantien bestellen
Bei der Implementierung von Anwendungen mit ZooKeeper gibt es einige wichtige Punkte zu beachten, die die Reihenfolge betreffen.
Reihenfolge der Schriftstücke
Der ZooKeeper-Status wird auf alle Server repliziert, die das Ensemble einer Installation bilden. Die Server einigen sich auf die Reihenfolge der Zustandsänderungen und führen sie in derselben Reihenfolge durch. Wenn zum Beispiel ein ZooKeeper-Server eine Zustandsänderung vornimmt, die einen znode /z erstellt, gefolgt von einer Zustandsänderung, die einen znode /z' löscht, müssen alle Server im Ensemble diese Änderungen ebenfalls in derselben Reihenfolge vornehmen.
Die Server führen jedoch nicht unbedingt gleichzeitig Statusaktualisierungen durch. Das tun sie sogar selten. Wahrscheinlich führen Server Statusänderungen zu unterschiedlichen Zeiten durch, weil sie unterschiedlich schnell arbeiten, auch wenn die Hardware, auf der sie laufen, ziemlich homogen ist. Es gibt eine Reihe von Gründen, die diese Zeitverzögerung verursachen können, z. B. die Zeitplanung des Betriebssystems und Hintergrundaufgaben.
Die Aktualisierung des Zustands zu unterschiedlichen Zeitpunkten stellt für die Anwendungen normalerweise kein Problem dar, da sie die gleiche Reihenfolge der Aktualisierungen wahrnehmen. Die Anwendungen können sie jedoch wahrnehmen, wenn der ZooKeeper-Status über versteckte Kanäle kommuniziert wird, wie wir im Folgenden erläutern.
Reihenfolge der Lesungen
ZooKeeper-Clients beobachten immer die gleiche Reihenfolge der Aktualisierungen, auch wenn sie mit verschiedenen Servern verbunden sind. Es ist jedoch möglich, dass zwei Clients die Aktualisierungen zu unterschiedlichen Zeiten beobachten. Wenn sie außerhalb von ZooKeeper kommunizieren, wird der Unterschied deutlich.
Betrachten wir die folgende Situation:
-
Ein Client c1 aktualisiert die Daten eines znode
/zund erhält eine Bestätigung. -
Der Client c1 sendet über eine direkte TCP-Verbindung eine Nachricht an den Client c2, die besagt, dass er den Status von
/zgeändert hat. -
Kunde c2 liest den Status von
/z, beobachtet aber einen Status, der vor der Aktualisierung von c1 liegt.
Wir nennen dies einen versteckten Kanal, weil ZooKeeper nichts von der zusätzlichen Kommunikation der Clients weiß. Jetzt hat c2 veraltete Daten. Diese Situation ist in Abbildung 4-2 dargestellt.
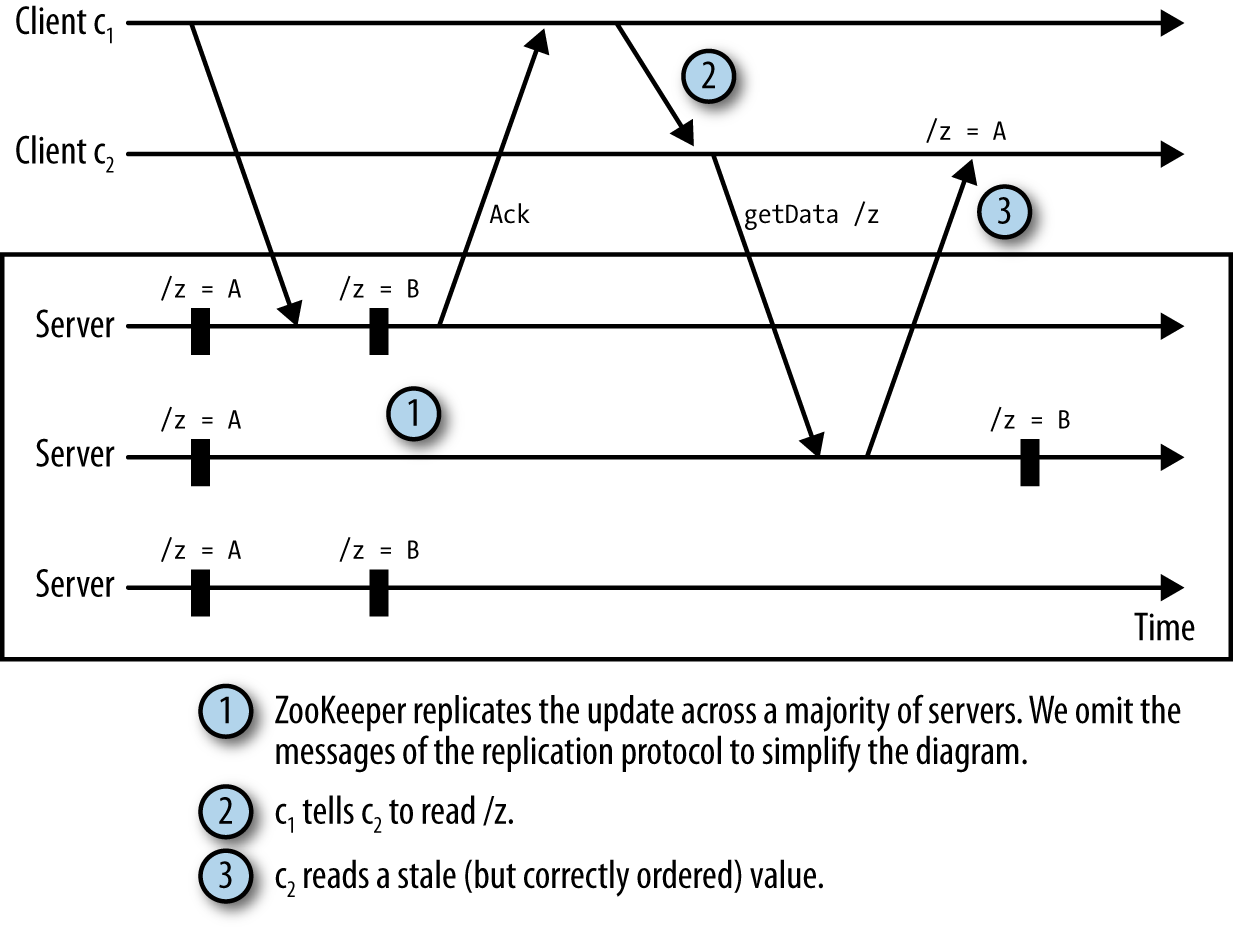
Um das Lesen veralteter Daten zu vermeiden, empfehlen wir, dass Anwendungen ZooKeeper für die gesamte Kommunikation in Bezug auf den ZooKeeper-Zustand verwenden. Um die soeben beschriebene Situation zu vermeiden, könnte c2 zum Beispiel eine Überwachung auf /z einrichten, anstatt eine direkte Nachricht von c1 zu erhalten. Mit einer Watch erfährt c2 von der Änderung an /z und beseitigt das Problem des versteckten Kanals.
Reihenfolge der Benachrichtigungen
ZooKeeper ordnet Benachrichtigungen in Bezug auf andere Benachrichtigungen und asynchrone Antworten an und beachtet dabei die Reihenfolge der Aktualisierungen des Systemzustands. Angenommen, ZooKeeper ordnet zwei Zustandsaktualisierungen u und uʹan, wobei uʹauf u folgt. Die Aktualisierungen u und uʹändern die Z-Knoten /a bzw. /b. Ein Client c, der /a überwacht und die Aktualisierung uʹauf /b liest, erhält die Benachrichtigung für u, bevor er die Antwort auf die Operation zum Lesen von /b erhält.
Diese Reihenfolge ermöglicht es Anwendungen, Watches zu verwenden, um Sicherheitseigenschaften zu implementieren. Nehmen wir an, dass ein znode /z erstellt oder gelöscht wird, um anzuzeigen, dass eine in ZooKeeper gespeicherte Konfiguration ungültig ist. Es muss sichergestellt werden, dass die Clients über die Erstellung oder Löschung von /z benachrichtigt werden, bevor die Konfiguration geändert wird, ist wichtig, um sicherzustellen, dass die Clients keine ungültige Konfiguration lesen.
Um es konkreter zu machen, nehmen wir an, dass wir einen znode /config haben, der der Elternteil einer Reihe von anderen znodes ist, die Metadaten zur Anwendungskonfiguration enthalten: /config/m1, /config/m2, ..., /config/mn. Für die Zwecke dieses Beispiels spielt es keine Rolle, was der Inhalt der Znodes ist. Angenommen, ein Master-Anwendungsprozess muss diese Knoten aktualisieren, indem er setData für jeden Znode aufruft, und es kann nicht sein, dass ein Client eine teilweise Aktualisierung dieser Znodes liest. Eine Lösung wäre, dass der Master eine /config/invalid znode erstellt, bevor er mit der Aktualisierung der Konfigurationsznodes beginnt. Andere Clients, die diesen Status lesen müssen, beobachten /config/invalid und vermeiden es, ihn zu lesen, wenn der ungültige Znode vorhanden ist. Sobald der ungültige Znode gelöscht wurde und somit ein neuer gültiger Satz von Konfigurationsznodes verfügbar ist, können die Clients diesen Satz lesen.
In diesem Beispiel hätten wir alternativ Multiop verwenden können, um alle setData Operationen an den /config/m[1-n] znodes atomar auszuführen, anstatt einen znode zu verwenden, um einen Zustand als teilweise verändert zu markieren. In Fällen, in denen Atomarität das Problem ist, können wir multiop verwenden, anstatt uns auf einen zusätzlichen Znode und Benachrichtigungen zu verlassen. Der Benachrichtigungsmechanismus ist jedoch allgemeiner und nicht auf Atomarität beschränkt.
Da ZooKeeper die Benachrichtigungen nach der Reihenfolge der Statusaktualisierungen ordnet, die die Benachrichtigungen auslösen, können sich die Clients darauf verlassen, dass sie die tatsächliche Reihenfolge der ZooKeeper-Statusänderungen durch ihre Benachrichtigungen wahrnehmen.
Lebendigkeit versus Sicherheit
In diesem Kapitel haben wir den Benachrichtigungsmechanismus ausgiebig für Liveness genutzt. Bei der Liveness geht es darum, sicherzustellen, dass das System irgendwann Fortschritte macht. Benachrichtigungen über neue Aufgaben und neue Arbeiter sind Beispiele für Ereignisse, die mit Liveness zu tun haben. Wenn ein Master nicht über eine neue Aufgabe benachrichtigt wird, wird die Aufgabe nie ausgeführt. Wenn eine eingereichte Aufgabe nicht ausgeführt wird, ist das ein Zeichen für fehlende Liveness, zumindest aus der Sicht des Kunden, der die Aufgabe eingereicht hat.
Dieses letzte Beispiel für atomare Aktualisierungen einer Reihe von Konfigurationsznodes ist anders: Es geht um Sicherheit, nicht um Liveness. Das Lesen der Znodes, während sie aktualisiert werden, könnte dazu führen, dass ein Kunde eine inkonsistente Konfiguration liest. Der invalid znode stellt sicher, dass die Clients den Status nur lesen, wenn eine gültige Konfiguration verfügbar ist.
Für die Beispiele, die wir gesehen haben, ist die Reihenfolge, in der die Benachrichtigungen zugestellt werden, nicht besonders wichtig. Solange der Kunde von den Ereignissen erfährt, wird er Fortschritte machen. Bei der Sicherheit hingegen kann der Empfang einer Benachrichtigung in falscher Reihenfolge zu einem falschen Verhalten führen.
Der Herdeneffekt und die Skalierbarkeit von Uhren
Dabei ist zu beachten, dass ZooKeeper alle für eine bestimmte Znode-Änderung gesetzten Watches auslöst, wenn die Änderung eintritt. Wenn es 1.000 Clients gibt, die einen bestimmten Znode mit einem Aufruf an exists überwacht haben, werden 1.000 Benachrichtigungen verschickt, wenn der Znode erstellt wird. Eine Änderung an einem überwachten Znode kann folglich eine Meldungsspitze auslösen. Eine solche Spitze könnte sich zum Beispiel auf die Latenz von Operationen auswirken, die zum Zeitpunkt der Spitze übermittelt werden. Wir empfehlen, eine solche Nutzung von ZooKeeper, bei der eine große Anzahl von Clients auf eine Änderung an einem bestimmten Znode wartet, nach Möglichkeit zu vermeiden. Es ist viel besser, wenn nur wenige Clients gleichzeitig einen bestimmten Znode beobachten, idealerweise höchstens einer.
Eine Möglichkeit, dieses Problem zu umgehen, die nicht in jedem Fall zutrifft, aber in einigen Fällen nützlich sein könnte, ist die folgende. Angenommen, n Clients konkurrieren um eine Sperre (z. B. eine Master-Sperre). Um die Sperre zu erhalten, versucht ein Prozess einfach, den /lock znode zu erstellen. Wenn der znode existiert, überwacht der Client den znode auf Löschung. Wenn der znode gelöscht wird, versucht der Client erneut, /lock zu erstellen. Bei dieser Strategie erhalten alle Clients, die /lock beobachten, eine Benachrichtigung, wenn /lock gelöscht wird. Ein anderer Ansatz besteht darin, dass jeder Client einen sequenziellen znode /lock/lock- erstellt. ZooKeeper fügt dem znode eine Sequenznummer hinzu und macht ihn damit automatisch zum znode. /lock/lock-xxx, wobei xxx eine Sequenznummer ist. Anhand der Sequenznummer können wir bestimmen, welcher Client die Sperre erwirbt, indem wir sie dem Client gewähren, der den znode unter /lock mit der kleinsten Sequenznummer erstellt hat. In diesem Schema stellt ein Client fest, ob er die kleinste Sequenznummer hat, indem er die Kinder von /lock mit getChildren abfragt. Wenn der Client nicht die kleinste Sequenznummer hat, schaut er sich den nächsten Z-Knoten in der durch die Sequenznummern festgelegten Reihenfolge an. Nehmen wir zum Beispiel an, wir haben drei ZKnoten: /lock/lock-001, /lock/lock-002, und /lock/lock-003. In diesem Beispiel:
-
Der Client, der
/lock/lock-001erstellt hat, hat die Sperre. -
Der Kunde, der
/lock/lock-002erstellt hat, sieht/lock/lock-001. -
Der Kunde, der
/lock/lock-003erstellt hat, sieht/lock/lock-002.
Auf diese Weise wird jeder znode von höchstens einem Kunden beobachtet.
Eine weitere Dimension, die es zu beachten gilt, ist der Status, der mit Watches auf der Serverseite erzeugt wird. Das Setzen einer Watch erzeugt ein Watcher Objekt auf dem Server. Laut YourKit-Profiler werden durch das Setzen einer Watch etwa 250 bis 300 Byte mehr Speicherplatz vom Watch-Manager eines Servers verbraucht. Eine sehr große Anzahl von Watches bedeutet, dass der Watch-Manager einen nicht zu vernachlässigenden Teil des Serverspeichers beansprucht. Bei 1 Million ausstehender Überwachtungen kommen wir beispielsweise auf eine ungefähre Zahl von 0,3 GB. Daher muss ein Entwickler immer auf die Anzahl der ausstehenden Watches achten.
Botschaften zum Mitnehmen
In einem verteilten System gibt es viele Ereignisse, die Aktionen auslösen. ZooKeeper bietet effiziente Mechanismen, um wichtige Ereignisse zu erfassen, auf die die Prozesse im System reagieren müssen. Die Beispiele, die wir hier besprochen haben, beziehen sich auf den regulären Ablauf von Anwendungen (z. B. die Ausführung von Aufgaben) oder auf Absturzfehler (z. B. den Absturz des Masters).
Eine wichtige Funktion von ZooKeeper, die wir genutzt haben, sind Benachrichtigungen. ZooKeeper-Clients registrieren Uhren bei ZooKeeper, um bei Änderungen des ZooKeeper-Zustands benachrichtigt zu werden. Die Reihenfolge, in der die Benachrichtigungen zugestellt werden, ist wichtig; die Clients dürfen keine unterschiedlichen Reihenfolgen bei den Änderungen des ZooKeeper-Zustands beachten.
Eine besondere Funktion, die beim Umgang mit Änderungen nützlich ist, ist der Aufruf multi. Er ermöglicht es, mehrere Operationen in einem Block auszuführen und vermeidet oft Wettlaufsituationen in verteilten Anwendungen, wenn Clients auf Ereignisse reagieren und den ZooKeeper-Status ändern.
Wir gehen davon aus, dass die meisten Anwendungen dem Muster folgen, das wir hier vorstellen, obwohl natürlich auch Varianten möglich und akzeptabel sind. Wir haben uns auf die asynchrone API konzentriert, weil wir Entwickler dazu ermutigen, sie zu nutzen. Mit der asynchronen API können Anwendungen die Ressourcen von ZooKeeper effizienter nutzen und eine höhere Leistung erzielen.
Get ZooKeeper now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

