Capítulo 4. Afrontar el cambio de Estado
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
No es raro que haya procesos de aplicación que necesiten conocer los cambios en el estado de un conjunto ZooKeeper. Por ejemplo, en nuestro ejemplo del Capítulo 1, los maestros de reserva necesitan saber que el maestro principal se ha bloqueado, y los trabajadores necesitan saber cuándo se les han asignado nuevas tareas. Los clientes ZooKeeper podrían, por supuesto, sondear periódicamente el conjunto ZooKeeper para determinar si se han producido cambios. El sondeo, sin embargo, no es eficiente, especialmente cuando los cambios esperados son algo raros.
Por ejemplo, pensemos en los maestros de copia de seguridad; necesitan saber cuándo se ha colgado el primario para poder conmutar. Para reducir el tiempo que se tarda en recuperarse de la caída del primario, necesitamos sondear con frecuencia -digamos, cada 50 ms- como ejemplo de sondeo agresivo. En este caso, cada maestro de respaldo genera 20 peticiones/segundo. Si hay varios maestros de copia de seguridad, multiplicamos esta frecuencia por el número de copias de seguridad para obtener el tráfico total de solicitudes generado sólo para sondear a ZooKeeper sobre el estado del maestro principal. Aunque tal cantidad de tráfico sea fácil de gestionar para un sistema como ZooKeeper, las caídas del maestro primario deberían ser poco frecuentes, por lo que la mayor parte de este tráfico es innecesario. Supongamos, por tanto, que reducimos la cantidad de tráfico de sondeo a ZooKeeper aumentando el periodo entre solicitudes del estado del primario, digamos a 1 segundo. El problema de aumentar este periodo es que aumenta el tiempo que se tarda en recuperarse de una caída del primario.
Podemos evitar por completo este tráfico de ajuste y sondeo haciendo que ZooKeeper notifique los eventos concretos a los clientes interesados. El principal mecanismo que proporciona ZooKeeper para gestionar los cambios son los relojes. Con los relojes, un cliente registra su solicitud para recibir una notificación única de un cambio en un znodo determinado. Por ejemplo, podemos hacer que el maestro principal cree un znodo efímero que represente el bloqueo maestro, y que los maestros de reserva registren una vigilancia para saber si existe el bloqueo maestro. Si el maestro principal se bloquea, el bloqueo maestro se elimina automáticamente y se notifica a los maestros de respaldo. Una vez que los maestros de respaldo reciben sus notificaciones, pueden iniciar una nueva elección de maestro intentando crear un nuevo znodo efímero, como mostramos en "Cómo obtener la maestría".
Las vigilancias y notificaciones forman un mecanismo general que permite a los clientes observar los cambios realizados por otros clientes sin tener que sondear continuamente a ZooKeeper. Hemos ilustrado el uso de este mecanismo con el ejemplo del maestro, pero el mecanismo general es aplicable a una gran variedad de situaciones.
Activadores puntuales
Antes de profundizar en los relojes, establezcamos cierta terminología. Hablamos de evento para denotar la ejecución de una actualización en un determinado znodo. Un reloj es un activador único asociado a un znodo y a un tipo de evento (por ejemplo, se establecen datos en el znodo o se elimina el znodo). Cuando el reloj es activado por un evento, genera una notificación. Una notificación es un mensaje dirigido al cliente de la aplicación que registró el reloj para informarle del evento.
Cuando un proceso de aplicación registra un reloj para recibir una notificación, el reloj se activa como máximo una vez y ante el primer evento que coincida con la condición del reloj. Por ejemplo, supongamos que el cliente necesita saber cuándo se elimina un determinado znodo /z (por ejemplo, un maestro de copia de seguridad). El cliente ejecuta una operación exists en /z con la bandera de vigilancia activada y espera la notificación. La notificación llega en forma de devolución de llamada al cliente de la aplicación.
Cada reloj está asociado a la sesión en la que el cliente lo establece. Si la sesión caduca, se eliminan las vigilancias pendientes. Sin embargo, las vigilancias persisten a través de las conexiones a diferentes servidores. Supongamos que un cliente ZooKeeper se desconecta de un servidor ZooKeeper y se conecta a otro servidor del conjunto. El cliente enviará una lista de los relojes pendientes. Al volver a registrar la vigilancia, el servidor comprobará si el znodo vigilado ha cambiado desde el registro anterior. Si el znodo ha cambiado, se enviará un evento de reloj al cliente; en caso contrario, el reloj se volverá a registrar en el nuevo servidor.Este comportamiento de volver a registrar relojes puede desactivarse estableciendo la propiedad del sistema zookeeper.disableAutoWatchReset.
Espera, ¿puedo perderme eventos con desencadenantes puntuales?
La respuesta corta es "sí": una aplicación puede perder eventos entre la recepción de una notificación y el registro de otro reloj. Sin embargo, esta cuestión merece más discusión. Perderse eventos no suele ser un problema porque cualquier cambio que se haya producido durante el periodo entre la recepción de una notificación y el registro de un nuevo reloj puede captarse leyendo directamente el estado de ZooKeeper.
Supongamos que un trabajador recibe una notificación que le indica que se le ha asignado una nueva tarea. Para recibir la nueva tarea, el trabajador lee la lista de tareas. Si se han asignado varias tareas más al trabajador después de recibir la notificación, la lectura de la lista de tareas mediante una llamada a getChildren devuelve todas las tareas. La llamada a getChildren también establece un nuevo reloj, garantizando que el trabajador no perderá tareas.
En realidad, tener una notificación amortizada en varios eventos es un aspecto positivo. Hace que el mecanismo de notificación sea mucho más ligero que enviar una notificación por cada evento para las aplicaciones que tienen un alto índice de actualizaciones. Por poner un ejemplo trivial, si cada notificación captura dos eventos de media, estamos generando sólo 0,5 notificaciones por evento en lugar de 1 notificación por evento.
Concretando más: Cómo ajustar los relojes
Todas las operaciones de lectura de la API de ZooKeeper -getData, getChildren, y exists- tienen la opción de establecer una vigilancia sobre el znodo que leen. Para utilizar el mecanismo de vigilancia, necesitamos implementar la interfaz Watcher, que consiste en implementar un método process método:
publicvoidprocess(WatchedEventevent);
La estructura de datos WatchedEvent contiene lo siguiente:
-
El estado de la sesión ZooKeeper (
KeeperState):Disconnected,SyncConnected,AuthFailed,ConnectedReadOnly,SaslAuthenticated, oExpired -
El tipo de evento (
EventType):NodeCreated,NodeDeleted,NodeDataChanged,NodeChildrenChanged, oNone -
Una ruta znode en caso de que el tipo de evento no sea
None
Los tres primeros eventos se refieren a un único znodo, mientras que el cuarto evento afecta a los hijos del znodo sobre el que se emite. Utilizamos None cuando el evento vigilado se refiere a un cambio de estado de la sesión ZooKeeper.
Hay dos tipos de vigilancias: vigilancias de datos y vigilancias de hijos. Al crear, borrar o establecer los datos de un znodo se activa correctamente una vigilancia de datos. exists y getData establecen vigilancias de datos. Sólo getChildren establece vigilancias hijo, que se activan cuando se crea o elimina un znodo hijo. Para cada tipo de evento, tenemos las siguientes llamadas para establecer una vigilancia:
NodeCreated-
Se establece un reloj con una llamada a
exists. NodeDeleted-
Se establece un reloj con una llamada a
existsogetData. NodeDataChanged-
Un reloj se ajusta con
existsogetData. NodeChildrenChanged-
Un reloj se ajusta con
getChildren.
Al crear un objeto ZooKeeper (ver Capítulo 3), necesitamos pasarle un objeto Watcher por defecto. El cliente de ZooKeeper utiliza este observador para notificar a la aplicación los cambios en el estado de ZooKeeper, en caso de que cambie el estado de la sesión. Para las notificaciones de eventos relacionados con los znodos de ZooKeeper, puedes utilizar el observador predeterminado o implementar uno diferente. Por ejemplo, la llamada getData tiene dos formas diferentes de establecer un observador:
publicbyte[]getData(finalStringpath,Watcherwatcher,Statstat);publicbyte[]getData(Stringpath,booleanwatch,Statstat);
Ambas firmas pasan el znodo como primer argumento. La primera firma pasa un nuevo objeto Watcher (que debemos haber creado). La segunda firma indica al cliente que utilice el observador por defecto, y sólo requiere true como segundo parámetro de la llamada.
El parámetro de entrada stat es una instancia de la estructura Stat que ZooKeeper utiliza para devolver información sobre el znodo designado por path. La estructura Stat contiene información sobre el znodo, como la marca de tiempo del último cambio (zxid) que modificó este znodo y el número de hijos del znodo.
Una observación importante sobre los relojes es que no es posible eliminarlos una vez establecidos en la rama 3.4 y versiones anteriores. Las dos únicas formas de eliminar un reloj son que se active o que su sesión se cierre o caduque. Este comportamiento cambia en la rama 3.5, y a partir de esa rama es posible dar de baja relojes con la llamada removeWatches.
Un poco de sobrecarga
Utilizamos el mismo mecanismo de vigilancia para notificar a la aplicación los eventos relacionados con el estado de una sesión ZooKeeper y los eventos relacionados con los cambios de znodo. Aunque los cambios de estado de la sesión y los cambios de estado del znodo constituyen conjuntos independientes de eventos, nos basamos en el mismo mecanismo para notificar dichos eventos por simplicidad.
Un patrón común
Antes de pasar a algunos fragmentos del ejemplo del maestro-trabajador, echemos un vistazo rápido a un patrón de código bastante común en las aplicaciones ZooKeeper:
-
Implementa un objeto de devolución de llamada y pásalo a la llamada asíncrona.
-
Si la operación requiere establecer un reloj, implementa un objeto
Watchery pásalo a la llamada asíncrona.
Un ejemplo de código de este patrón que utiliza una llamada asíncrona a exists tiene el siguiente aspecto:
zk.exists("/myZnode",myWatcher,existsCallback,null);WatchermyWatcher=newWatcher(){publicvoidprocess(WatchedEvente){// Process the watch event}}StatCallbackexistsCallback=newStatCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Statstat){// Process the result of the exists call}};
Llamada a ZooKeeper
exists. Ten en cuenta que la llamada es asíncrona.
Implementación de la vigilancia.

existsdevolución de llamada.
Como veremos a continuación, utilizaremos ampliamente este esqueleto.
El ejemplo del Maestro-Obrero
Veamos ahora cómo tratamos los cambios de estado en el ejemplo del maestro-trabajador. Aquí tienes una lista de tareas que requieren que un componente espere cambios:
-
Cambios de maestría
-
El maestro espera cambios en la lista de trabajadores
-
El maestro espera nuevas tareas para asignarlas
-
El trabajador espera la asignación de nuevas tareas
-
El cliente espera el resultado de la ejecución de la tarea
A continuación mostramos algunos fragmentos de código para ilustrar cómo codificar estas tareas con ZooKeeper. Proporcionamos el código de ejemplo completo como parte del material adicional de este libro.
Cambios de maestría
Recuerda que en "Obtener la maestría" un cliente de aplicación se elige a sí mismo como maestro creando el znodo /master (a esto lo llamamos "postularse para maestro"). Si el znodo ya existe, el cliente de aplicación determina que no es el maestro principal y regresa. Sin embargo, esta implementación no tolera una caída del maestro principal. Si el maestro principal se bloquea, los maestros de reserva no lo sabrán. En consecuencia, tenemos que establecer una vigilancia en /master para que ZooKeeper notifique al cliente cuando se elimine /master (ya sea explícitamente o porque la sesión del maestro principal haya expirado).
Para establecer la vigilancia, creamos un nuevo vigilante llamado masterExistsWatcher y se lo pasamos a exists. Ante una notificación de eliminación de /master, la llamada a process definida en masterExistsWatcher llama a runForMaster:
StringCallbackmasterCreateCallback=newStringCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Stringname){switch(Code.get(rc)){caseCONNECTIONLOSS:checkMaster();break;caseOK:state=MasterStates.ELECTED;takeLeadership();break;caseNODEEXISTS:state=MasterStates.NOTELECTED;masterExists();break;default:state=MasterStates.NOTELECTED;LOG.error("Something went wrong when running for master.",KeeperException.create(Code.get(rc),path));}}};voidmasterExists(){zk.exists("/master",masterExistsWatcher,masterExistsCallback,null);}WatchermasterExistsWatcher=newWatcher(){publicvoidprocess(WatchedEvente){if(e.getType()==EventType.NodeDeleted){assert"/master".equals(e.getPath());runForMaster();}}};
En el caso de un evento de pérdida de conexión, el cliente comprueba si el znodo
/masterestá ahí, porque no sabe si ha podido crearlo o no.Si
OK, entonces simplemente hace falta liderazgo.Si otra persona ya ha creado el znodo, entonces el cliente tiene que verlo.

Si ocurre algo inesperado, registra el error y no hace nada más.

Esta llamada a
existssirve para establecer una vigilancia en el znodo/master.
Si se borra el znodo
/master, vuelve a ejecutarse para maestro.
Siguiendo el estilo asíncrono que utilizamos en "Obtener maestría de forma asíncrona", también creamos un método de devolución de llamada para la llamada a exists que se ocupa de algunos casos. En primer lugar, en caso de pérdida de conexión, reintenta la operación exists. En segundo lugar, es posible que el /master znodo se borre entre la ejecución de la llamada de retorno create y la ejecución de la operación exists. Si eso ocurre, entonces se invoca la llamada de retorno con NONODE y volvemos a ejecutar por maestro. Para todos los demás casos, comprobamos el /master znodo obteniendo sus datos. El último caso es que expire la sesión del cliente. En este caso, la llamada de retorno para obtener los datos de /master registra un mensaje de error y sale. Nuestra llamada de retorno a exists tiene el siguiente aspecto:
StatCallbackmasterExistsCallback=newStatCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Statstat){switch(Code.get(rc)){caseCONNECTIONLOSS:masterExists();break;caseOK:break;caseNONODE:state=MasterStates.RUNNING;runForMaster();break;default:checkMaster();break;}}};
En caso de pérdida de conexión, inténtalo de nuevo.
Si devuelve
OK, entonces no hay nada que hacer.Si devuelve
NONODE, ejecuta para maestro.Si ocurre algo inesperado, comprueba si
/masterestá ahí obteniendo sus datos.
El resultado de la operación exists sobre /master puede ser que se haya eliminado el znodo. En este caso, el cliente necesita volver a ejecutar /master porque no está garantizado que la vigilancia se estableciera antes de que se borrara el znodo. Si el nuevo intento de convertirse en primario falla, entonces el cliente sabe que algún otro cliente tuvo éxito e intenta vigilar /master de nuevo. Si la notificación para /master indica que ha sido creado en lugar de eliminado, el cliente no se ejecuta para /master. Al mismo tiempo, la operación exists correspondiente (la que ha establecido la vigilancia) debe haber devuelto que /master no existe, lo que desencadena el procedimiento de ejecución para /master desde la llamada de retorno a exists.
Ten en cuenta que este patrón de ejecutarse como maestro y ejecutar exists para establecer una vigilancia sobre /master continúa mientras el cliente se ejecute y no se convierta en maestro principal. Si se convierte en maestro principal y se bloquea, el cliente puede reiniciarse y volver a ejecutar este código.
La Figura 4-1 hace más explícitas las posibles intercalaciones de operaciones. Si la operación create ejecutada cuando se ejecuta para maestro primario tiene éxito (a), el cliente de la aplicación no tiene que hacer nada más. Si la operación create falla porque el znodo ya existe, entonces el cliente ejecuta una operación exists para establecer una vigilancia sobre el /master znodo (b). Entre la ejecución para maestro y la ejecución de la operación exists, es posible que el /master znodo se elimine. Supongamos primero que el znodo se borra antes de que se genere la respuesta a exists. En este caso, el cliente se ejecuta de nuevo para maestro (c). Supongamos ahora que la respuesta a la llamada exists se ha procesado antes de que el znodo se haya borrado y devuelve verdadero. Cuando se elimina el znodo, ZooKeeper activa la vigilancia y el cliente acaba recibiéndola y vuelve a ejecutar para maestro (d).
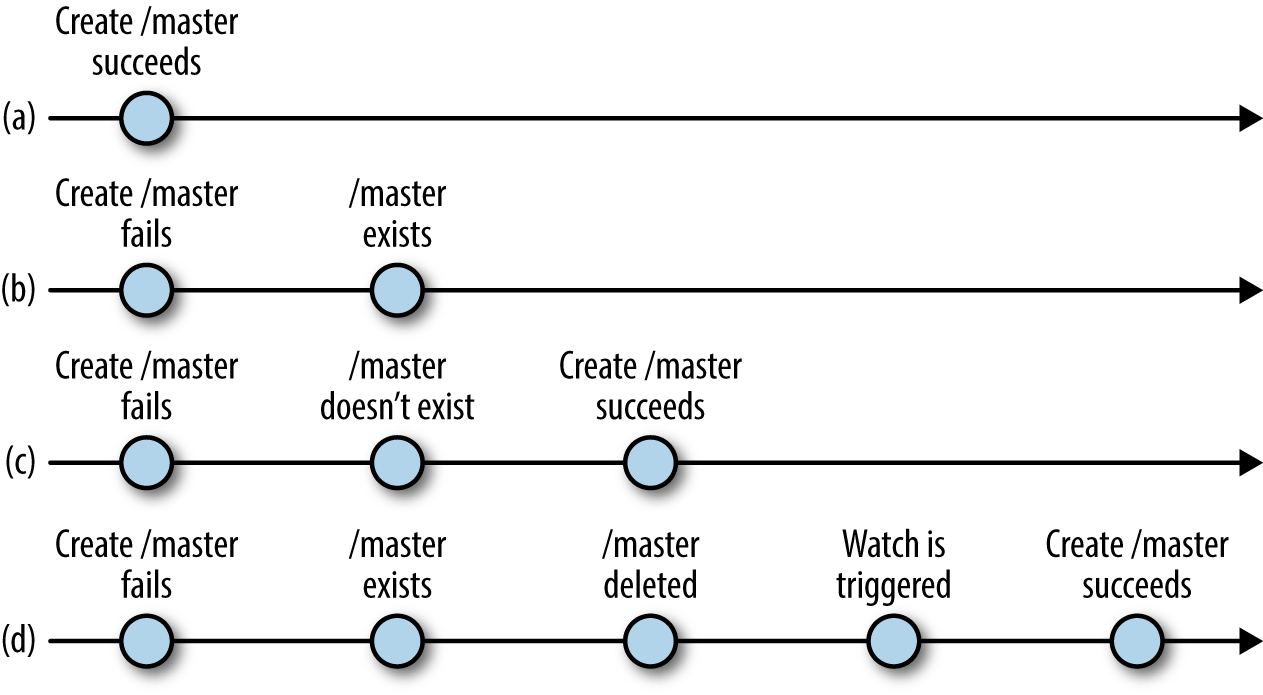
Figura 4-1. Ejecución para maestro, posibles intercalaciones
El maestro espera cambios en la lista de trabajadores
Se pueden añadir nuevos trabajadores al sistema y dar de baja a los antiguos en cualquier momento. Los trabajadores también pueden colapsar antes de ejecutar sus tareas. Para determinar los trabajadores que están disponibles en un momento dado, registramos nuevos trabajadores en ZooKeeper añadiendo un znodo como hijo de /workers. Cuando un trabajador se bloquea o simplemente se retira del sistema, su sesión expira, lo que provoca automáticamente la eliminación de su znodo. Lo ideal es que los trabajadores cierren sus sesiones sin hacer que ZooKeeper espere a que expire la sesión.
El maestro principal utiliza getChildren para obtener la lista de trabajadores disponibles y estar atento a los cambios en la lista. Aquí tienes un ejemplo de código para obtener la lista y vigilar los cambios:
WatcherworkersChangeWatcher=newWatcher(){publicvoidprocess(WatchedEvente){if(e.getType()==EventType.NodeChildrenChanged){assert"/workers".equals(e.getPath());getWorkers();}}};voidgetWorkers(){zk.getChildren("/workers",workersChangeWatcher,workersGetChildrenCallback,null);}ChildrenCallbackworkersGetChildrenCallback=newChildrenCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,List<String>children){switch(Code.get(rc)){caseCONNECTIONLOSS:getWorkers();break;caseOK:LOG.info("Succesfully got a list of workers: "+children.size()+" workers");reassignAndSet(children);break;default:LOG.error("getChildren failed",KeeperException.create(Code.get(rc),path));}}};
workersChangeWatcheres el observador de la lista de trabajadores.En el caso de un evento
CONNECTIONLOSS, tenemos que volver a ejecutar la operación para obtener los hijos y establecer el reloj.Esta llamada reasigna las tareas de los trabajadores muertos y establece la nueva lista de trabajadores.
Comenzamos llamando a getWorkers. Esta llamada ejecuta getChildren de forma asíncrona, pasando workersGetChildrenCallback a procesar el resultado de la operación. Si el cliente se desconecta de un servidor (eventoCONNECTIONLOSS ), no se establece el reloj y no tenemos una lista de trabajadores; ejecutamos de nuevo getWorkers para establecer el reloj y obtener la lista de trabajadores. Una vez ejecutado con éxito getChildren, llamamos a reassignAndSet de la siguiente manera:
ChildrenCacheworkersCache;voidreassignAndSet(List<String>children){List<String>toProcess;if(workersCache==null){workersCache=newChildrenCache(children);toProcess=null;}else{LOG.info("Removing and setting");toProcess=workersCache.removedAndSet(children);}if(toProcess!=null){for(Stringworker:toProcess){getAbsentWorkerTasks(worker);}}}
Aquí está la caché que contiene el último conjunto de trabajadores que hemos visto.
Si es la primera vez que utiliza la caché, instálala.
La primera vez que recibimos trabajadores, no hay nada que hacer.
Si no es la primera vez, entonces tenemos que comprobar si se ha eliminado algún trabajador.
Si hay algún trabajador que se ha eliminado, hay que reasignar sus tareas.
Utilizamos la caché porque necesitamos recordar lo que hemos visto antes. Supongamos que obtenemos la lista de trabajadores por primera vez. Cuando recibamos la notificación de que la lista de trabajadores ha cambiado, no sabremos qué ha cambiado exactamente ni siquiera después de volver a leerla, a menos que conservemos los valores antiguos. La clase caché de este ejemplo simplemente conserva la última lista que ha leído el maestro e implementa un par de métodos para determinar qué ha cambiado.
El maestro espera a que se asignen nuevas tareas
Al igual que espera cambios en la lista de trabajadores, el maestro primario espera a que se añadan nuevas tareas a /tasks. El maestro obtiene inicialmente el conjunto de tareas actuales y establece una vigilancia para los cambios en el conjunto. El conjunto se representa en ZooKeeper por los hijos de /tasksy cada hijo corresponde a una tarea. Una vez que el maestro obtiene las tareas que aún no han sido asignadas, selecciona un trabajador al azar y le asigna la tarea. Implementamos la asignación en assignTasks:
WatchertasksChangeWatcher=newWatcher(){publicvoidprocess(WatchedEvente){if(e.getType()==EventType.NodeChildrenChanged){assert"/tasks".equals(e.getPath());getTasks();}}};voidgetTasks(){zk.getChildren("/tasks",tasksChangeWatcher,tasksGetChildrenCallback,null);}ChildrenCallbacktasksGetChildrenCallback=newChildrenCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,List<String>children){switch(Code.get(rc)){caseCONNECTIONLOSS:getTasks();break;caseOK:if(children!=null){assignTasks(children);}break;default:LOG.error("getChildren failed.",KeeperException.create(Code.get(rc),path));}}};
Implementación del observador para gestionar una notificación de que la lista de tareas ha cambiado.
Obtén la lista de tareas.
Asigna tareas en la lista.
Ahora implementaremos assignTasks. Simplemente asigna cada una de las tareas de la lista de hijos de /tasks. Antes de crear el znodo de asignación, obtenemos los datos de la tarea con getData:
voidassignTasks(List<String>tasks){for(Stringtask:tasks){getTaskData(task);}}voidgetTaskData(Stringtask){zk.getData("/tasks/"+task,false,taskDataCallback,task);}DataCallbacktaskDataCallback=newDataCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,byte[]data,Statstat){switch(Code.get(rc)){caseCONNECTIONLOSS:getTaskData((String)ctx);break;caseOK:/* * Choose worker at random. */intworker=rand.nextInt(workerList.size());StringdesignatedWorker=workerList.get(worker);/* * Assign task to randomly chosen worker. */StringassignmentPath="/assign/"+designatedWorker+"/"+(String)ctx;createAssignment(assignmentPath,data);break;default:LOG.error("Error when trying to get task data.",KeeperException.create(Code.get(rc),path));}}};
Obtener datos de la tarea.
Selecciona un trabajador al azar y asígnale la tarea.
Necesitamos obtener primero los datos de la tarea, porque borramos el znodo de la tarea en /tasks después de asignarla. De esta forma, el maestro no tiene que recordar qué tareas ha asignado. Veamos el código para asignar una tarea:
voidcreateAssignment(Stringpath,byte[]data){zk.create(path,data,Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT,assignTaskCallback,data);}StringCallbackassignTaskCallback=newStringCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Stringname){switch(Code.get(rc)){caseCONNECTIONLOSS:createAssignment(path,(byte[])ctx);break;caseOK:LOG.info("Task assigned correctly: "+name);deleteTask(name.substring(name.lastIndexOf("/")+1));break;caseNODEEXISTS:LOG.warn("Task already assigned");break;default:LOG.error("Error when trying to assign task.",KeeperException.create(Code.get(rc),path));}}};
Crea una tarea. La ruta tiene la forma
/assign/worker-id/task-num.Elimina la tarea znode en
/tasks.
Para las nuevas tareas, después de que el maestro seleccione un trabajador al que asignar la tarea, crea un znodo en /assign/worker-id, donde id es el identificador del trabajador. A continuación, elimina el znodo de la lista de tareas pendientes. El código para eliminar el znodo en el ejemplo anterior sigue el patrón del código anterior que hemos mostrado.
Cuando el maestro crea un znodo de asignación para un trabajador con el identificador id, ZooKeeper genera una notificación para el trabajador, suponiendo que éste tiene un reloj registrado en su znodo de asignación (/assign/worker-id).
Ten en cuenta que el maestro también borra la tarea znode en /tasks después de asignarla con éxito. Este enfoque simplifica el papel del maestro cuando recibe nuevas tareas para asignar. Si la lista de tareas mezclara las tareas asignadas y las no asignadas, el maestro necesitaría una forma de desambiguar las tareas.
El trabajador espera nuevas asignaciones de tareas
Uno de los primeros pasos que debe ejecutar un trabajador es registrarse en ZooKeeper. Lo hace creando un znodo en /workers, como ya hemos comentado:
voidregister(){zk.create("/workers/worker-"+serverId,newbyte[0],Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL,createWorkerCallback,null);}StringCallbackcreateWorkerCallback=newStringCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Stringname){switch(Code.get(rc)){caseCONNECTIONLOSS:register();break;caseOK:LOG.info("Registered successfully: "+serverId);break;caseNODEEXISTS:LOG.warn("Already registered: "+serverId);break;default:LOG.error("Something went wrong: "+KeeperException.create(Code.get(rc),path));}}};
Registra el trabajador creando un znodo.
Vuelve a intentarlo. Ten en cuenta que registrarse de nuevo no es un problema. Si el znodo ya se ha creado, nos devuelve un evento
NODEEXISTS.
Añadir este znodo indica al maestro que este trabajador está activo y listo para procesar tareas. Para simplificar el ejemplo, no utilizamos el estado inactivo/ocupado (introducido en el Capítulo 3).
Del mismo modo, creamos un znodo /assign/worker-id para que el maestro pueda asignar tareas a este trabajador. Si creamos /workers/worker-id antes que /assign/worker-id, podríamos caer en la situación de que el maestro intente asignar la tarea pero no pueda porque aún no se ha creado el znodo padre asignado. Para evitar esta situación, debemos crear primero /assign/worker-id primero. Además, el trabajador debe establecer una vigilancia en /assign/worker-id para recibir una notificación cuando se asigne una nueva tarea.
Una vez que el trabajador tiene tareas asignadas, las obtiene de /assign/worker-id y las ejecuta. El trabajador toma cada tarea de su lista y comprueba si ya la ha puesto en cola para su ejecución. Para ello, mantiene una lista de tareas en curso. Ten en cuenta que hacemos un bucle a través de las tareas asignadas de un trabajador en un hilo separado para liberar el hilo de devolución de llamada. De lo contrario, estaríamos bloqueando otras devoluciones de llamada entrantes. En nuestro ejemplo, utilizamos Java ThreadPoolExecutor para asignar un subproceso que recorra las tareas:
WatchernewTaskWatcher=newWatcher(){publicvoidprocess(WatchedEvente){if(e.getType()==EventType.NodeChildrenChanged){assertnewString("/assign/worker-"+serverId).equals(e.getPath());getTasks();}}};voidgetTasks(){zk.getChildren("/assign/worker-"+serverId,newTaskWatcher,tasksGetChildrenCallback,null);}ChildrenCallbacktasksGetChildrenCallback=newChildrenCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,List<String>children){switch(Code.get(rc)){caseCONNECTIONLOSS:getTasks();break;caseOK:if(children!=null){executor.execute(newRunnable(){List<String>children;DataCallbackcb;publicRunnableinit(List<String>children,DataCallbackcb){this.children=children;this.cb=cb;returnthis;}publicvoidrun(){LOG.info("Looping into tasks");synchronized(onGoingTasks){for(Stringtask:children){if(!onGoingTasks.contains(task)){LOG.trace("New task: {}",task);zk.getData("/assign/worker-"+serverId+"/"+task,false,cb,task);onGoingTasks.add(task);}}}}}.init(children,taskDataCallback));}break;default:System.out.println("getChildren failed: "+KeeperException.create(Code.get(rc),path));}}};
Al recibir una notificación de que los hijos han cambiado, obtén la lista de hijos.
Ejecutar en un hilo separado.
Recorre la lista de hijos.
Obtén los datos de la tarea para ejecutarla.
Añade la tarea a la lista de tareas en ejecución para evitar ejecutarla varias veces.
Eventos de sesión y observadores
Cuando nos desconectamos de un servidor (por ejemplo, cuando el servidor se bloquea), no se envían vigilancias hasta que se restablezca la conexión. Por esta razón, los eventos de sesión como CONNECTIONLOSS se envían a todos los controladores de vigilancias pendientes. En general, las aplicaciones utilizan los eventos de sesión para pasar a un modo seguro: el cliente ZooKeeper no recibe eventos mientras está desconectado, por lo que debe actuar de forma conservadora en este estado. En el caso de nuestra aplicación de juguete maestro-trabajador, todas las acciones excepto enviar una tarea son reactivas, por lo que si un maestro o un trabajador se desconectan, simplemente no desencadenan ninguna acción. Además, el cliente maestro-trabajador no puede enviar nuevas tareas y no recibe notificaciones de estado mientras está desconectado.
El cliente espera el resultado de la ejecución de la tarea
Supongamos que el cliente de una aplicación ha enviado una tarea. Ahora necesita saber cuándo se ha ejecutado y su estado. Recordemos que una vez que un trabajador ejecuta una tarea, crea un znodo en /status. Comprobemos primero el código para enviar una tarea para su ejecución:
voidsubmitTask(Stringtask,TaskObjecttaskCtx){taskCtx.setTask(task);zk.create("/tasks/task-",task.getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT_SEQUENTIAL,createTaskCallback,taskCtx);}StringCallbackcreateTaskCallback=newStringCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Stringname){switch(Code.get(rc)){caseCONNECTIONLOSS:submitTask(((TaskObject)ctx).getTask(),(TaskObject)ctx);break;caseOK:LOG.info("My created task name: "+name);((TaskObject)ctx).setTaskName(name);watchStatus("/status/"+name.replace("/tasks/",""),ctx);break;default:LOG.error("Something went wrong"+KeeperException.create(Code.get(rc),path));}}};
El objeto de contexto aquí es una instancia de la clase
Task.Vuelve a enviar la tarea cuando se pierda la conexión. Ten en cuenta que el reenvío puede crear un duplicado de la tarea.
Establece una vigilancia en el znodo de estado para esta tarea.
¿Se ha creado mi Znode secuencial?
Tratar con un evento CONNECTIONLOSS cuando se intenta crear un znodo secuencial es algo complicado. Como ZooKeeper asigna el número de secuencia, no es posible que el cliente desconectado determine si se ha creado el znodo cuando puede haber solicitudes concurrentes para crear znodos secuenciales desde otros clientes. (Ten en cuenta que todas las solicitudes a create de las que se habla en esta nota se refieren a los hijos del mismo znodo).
Para superar esta limitación, tenemos que dar alguna pista sobre el originador del znodo, como tener el ID del servidor como parte del nombre de la tarea. Utilizando este enfoque, es posible determinar si la tarea se ha creado listando todos los znodos de la tarea.
Aquí comprobamos si el nodo de estado ya existe (puede que la tarea se haya procesado rápido) y establecemos una vigilancia. Proporcionamos una implementación de vigilante para reaccionar a la notificación de la creación del znodo y una implementación de devolución de llamada para la llamada a exists:
ConcurrentHashMap<String,Object>ctxMap=newConcurrentHashMap<String,Object>();voidwatchStatus(Stringpath,Objectctx){ctxMap.put(path,ctx);zk.exists(path,statusWatcher,existsCallback,ctx);}WatcherstatusWatcher=newWatcher(){publicvoidprocess(WatchedEvente){if(e.getType()==EventType.NodeCreated){asserte.getPath().contains("/status/task-");zk.getData(e.getPath(),false,getDataCallback,ctxMap.get(e.getPath()));}}};StatCallbackexistsCallback=newStatCallback(){publicvoidprocessResult(intrc,Stringpath,Objectctx,Statstat){switch(Code.get(rc)){caseCONNECTIONLOSS:watchStatus(path,ctx);break;caseOK:if(stat!=null){zk.getData(path,false,getDataCallback,null);}break;caseNONODE:break;default:LOG.error("Something went wrong when "+"checking if the status node exists: "+KeeperException.create(Code.get(rc),path));break;}}};
El cliente propaga aquí el objeto contexto para que pueda modificar en consecuencia el objeto tarea (
TaskObject) cuando reciba una notificación del znodo de estado.El znodo de estado ya está ahí, así que el cliente tiene que obtenerlo.
Si el znodo de estado aún no está, que debería ser lo normal, el cliente no hace nada.
Una vía alternativa: Multiop
Multiop no estaba en el diseño original de ZooKeeper, pero se añadió en la versión 3.4.0. Multiop permite la ejecución atómica de varias operaciones de ZooKeeper en un bloque. La ejecución es atómica en el sentido de que o todas las operaciones de un bloque multiop tienen éxito o todas fallan. Por ejemplo, podemos eliminar un znodo padre y su hijo en un bloque multiop. Los únicos resultados posibles son que ambas operaciones tengan éxito o que ambas fallen. No es posible que el nodo padre se elimine dejando uno de sus hijos, o viceversa.
Para utilizar la función multiop:
-
Crea un objeto
Oppara representar cada operación de ZooKeeper que pretendas ejecutar mediante una llamada multiop. ZooKeeper proporciona una implementación deOppara cada una de las operaciones que cambian de estado:create,delete, ysetData. -
Dentro del objeto
Op, llama a un método estático proporcionado porOppara esa operación. -
Añade este objeto
Opa un objeto JavaIterable, como una lista. -
Llama a
multien la lista.
El siguiente ejemplo ilustra este proceso:
OpdeleteZnode(Stringz){returnOp.delete(z,-1);}...List<OpResult>results=zk.multi(Arrays.asList(deleteZnode("/a/b"),deleteZnode("/a"));
Crea un objeto
Oppara la llamadadelete.Devuelve el objeto llamando al método adecuado
Op.Ejecuta ambas llamadas a
deletecomo una unidad utilizando la llamada amultiy pasándolas como una lista de instancias deOp.
La llamada a multi devuelve una lista de objetos OpResult, cada uno especializado en la operación correspondiente. Por ejemplo, para la operación delete tenemos una clase DeleteResult, que extiende a OpResult. Los métodos y datos expuestos por cada objeto resultado dependen del tipo de operación. DeleteResult sólo ofrece los métodos equals y hashCode, mientras que CreateResult expone la ruta de la operación y un objeto Stat. En caso de error, ZooKeeper devuelve una instancia de ErrorResult que contiene un código de error.
La llamada a multi también tiene una versión asíncrona. Éstas son las firmas de los métodos síncrono y asíncrono:
publicList<OpResult>multi(Iterable<Op>ops)throwsInterruptedException,KeeperException;publicvoidmulti(Iterable<Op>ops,MultiCallbackcb,Objectctx);
Transaction es una envoltura de multi con una interfaz más sencilla. Podemos crear una instancia de Transaction, añadir operaciones y confirmar la transacción. El ejemplo anterior reescrito utilizando Transaction tiene este aspecto:
Transactiont=newTransaction();t.delete("/a/b",-1);t.delete("/a",-1);List<OpResult>results=t.commit();
La llamada a commit también tiene una versión asíncrona que toma como entrada un objeto MultiCallback y un objeto contexto:
publicvoidcommit(MultiCallbackcb,Objectctx);
Multiop puede simplificar nuestra implementación maestro-trabajador al menos en un punto. Al asignar una tarea, el maestro de los ejemplos anteriores ha creado el correspondiente znodo de asignación y luego ha borrado el znodo de tarea en /tasks. Si el maestro se bloquea antes de borrar el znodo en /tasks, nos quedamos con una tarea en /tasks que ya ha sido asignada. Utilizando multiop, podemos crear el znodo que representa la asignación de la tarea en /assign y eliminar atómicamente el znodo que representa la tarea en /tasks. Utilizando este enfoque, garantizamos que ningún znodo de tarea bajo /tasks ya ha sido asignado. Si una copia de seguridad asume el papel de maestro, no es necesario desambiguar las tareas en /tasks: todas están sin asignar.
Otra característica que ofrece la multiop es la posibilidad de comprobar la versión de un znode para permitir operaciones sobre varios znodes que lean el estado de ZooKeeper y escriban de vuelta algún dato -posiblemente una modificación de lo que se ha leído-. La versión del znodo que se comprueba no cambia, por lo que esta llamada habilita una multioperación que comprueba la versión de un znodo que no se ha modificado. Esta función es útil cuando las modificaciones de uno o varios znodos están condicionadas por la versión de otro znodo. Digamos que en nuestro ejemplo maestro-trabajador, el maestro necesita que los clientes añadan nuevas tareas bajo una ruta que el maestro especifique. Por ejemplo, el maestro podría pedir a los clientes que crearan nuevas tareas como hijas de /tasks-middonde mid es el identificador del maestro. El maestro almacena esta ruta como los datos del znodo /master-path. Un cliente que necesite añadir una nueva tarea lee primero /master-path y elige su versión actual con Stat. A continuación, el cliente crea un nuevo znodo de tarea bajo /tasks-mid como parte de la llamada a multiop, y también comprueba que la versión de /master-path coincide con la que ha leído.
La firma de check es similar a la de setData, pero no incluye datos:
publicstaticOpcheck(Stringpath,intversion);
Si la versión del znodo en el path dado no coincide, la llamada a multi falla. A modo de ilustración, éste es aproximadamente el aspecto que tendría el código si pusiéramos en práctica el ejemplo que acabamos de comentar:
byte[]masterData=zk.getData("/master-path",false,stat);Stringparent=newString(masterData);Stringpath=parent+"/task-";...zk.multi(Arrays.asList(Op.check("/master-path",stat.getVersion()),Op.create(path,task,Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT_SEQUENTIAL)))
Obtén los datos de
/master-path.Extrae la ruta del znodo
/master-path.multicon dos operaciones, una verifica la versión de la ruta maestra y la otra crea un znodo de tarea.
Ten en cuenta que si almacenamos la ruta junto con el ID del maestro en /master, este esquema no funciona. El znodo /master es creado cada vez por un nuevo maestro, lo que hace que su versión sea consistente 1.
Las Vigilancias como Sustituto de la Gestión Explícita de la Caché
Desde el punto de vista de la aplicación, no es deseable que los clientes accedan a ZooKeeper cada vez que necesiten obtener los datos de un determinado znodo, la lista de hijos de un znodo o cualquier otra cosa relacionada con el estado de ZooKeeper. En su lugar, es mucho más eficiente hacer que los clientes almacenen en caché los valores localmente y los utilicen a voluntad. Cuando cambien esos valores, por supuesto, querrás que ZooKeeper notifique a los clientes para que puedan actualizar las cachés. Estas notificaciones son las mismas de las que hemos hablado hasta ahora y, como antes, los clientes de la aplicación se registran para recibirlas mediante relojes. En resumen, estos relojes permiten a los clientes almacenar en caché una versión local de un valor (como los datos de un znodo o su lista de hijos) y recibir notificaciones cuando ese valor cambia.
Una alternativa al enfoque que han adoptado los diseñadores de ZooKeeper sería almacenar en caché de forma transparente en nombre del cliente todo el estado de ZooKeeper al que accede e invalidar los valores de forma transparente cuando haya actualizaciones de los datos almacenados en caché. Sin embargo, implantar un esquema de coherencia de caché de este tipo podría ser costoso, porque los clientes podrían no necesitar almacenar en caché todo el estado de ZooKeeper al que acceden, y los servidores necesitarían invalidar el estado almacenado en caché a pesar de ello. Para llevar a cabo la invalidación, los servidores tendrían que hacer un seguimiento del contenido de la caché de cada cliente o difundir solicitudes de invalidación. Ambas opciones son caras para un gran número de clientes e indeseables desde nuestro punto de vista.
Independientemente de la parte que gestione la caché del cliente -ZooKeeper directamente o la aplicación ZooKeeper-, la notificación de actualizaciones a los clientes puede realizarse de forma sincrónica o asincrónica. Invalidar el estado de forma sincrónica en todos los clientes que tengan una copia sería ineficaz, porque los clientes suelen proceder a ritmos diferentes y, en consecuencia, los clientes lentos obligarían a otros clientes a esperar. Tales diferencias se hacen más frecuentes a medida que aumenta el tamaño de la población de clientes.
El enfoque de las notificaciones por el que optaron los diseñadores puede percibirse como una forma asíncrona de invalidar el estado de ZooKeeper en el lado del cliente. ZooKeeper pone en cola las notificaciones a los clientes, y dichas notificaciones se consumen de forma asíncrona. Este esquema de invalidación también es opcional; depende de la aplicación decidir qué partes del estado ZooKeeper requieren invalidación para un cliente determinado. Estas opciones de diseño se ajustan mejor a los casos de uso de ZooKeeper.
Garantía de pedido
Hay algunas observaciones importantes que debes tener en cuenta con respecto al orden al implementar aplicaciones con ZooKeeper.
Orden de los Escritos
El estado de ZooKeeper se replica en todos los servidores que forman el conjunto de una instalación. Los servidores acuerdan el orden de los cambios de estado y los aplican siguiendo el mismo orden. Por ejemplo, si un servidor ZooKeeper aplica un cambio de estado que crea un znodo /z seguido de un cambio de estado que elimina un znodo /z', todos los servidores del conjunto deben aplicar también estos cambios, y en el mismo orden.
Los servidores, sin embargo, no aplican necesariamente actualizaciones de estado simultáneamente. De hecho, rara vez lo hacen. Lo más probable es que los servidores apliquen los cambios de estado en momentos distintos porque proceden a velocidades diferentes, aunque el hardware sobre el que se ejecutan sea bastante homogéneo. Hay varias razones que pueden causar este desfase, como la programación del sistema operativo y las tareas en segundo plano.
Aplicar actualizaciones de estado en momentos diferentes no suele ser un problema para las aplicaciones, porque siguen percibiendo el mismo orden de actualizaciones. Sin embargo, las aplicaciones pueden percibirlo si el estado de ZooKeeper se comunica a través de canales ocultos, como veremos a continuación.
Orden de lectura
Los clientes de ZooKeeper siempre observan el mismo orden de actualizaciones, aunque estén conectados a servidores distintos. Pero es posible que dos clientes observen las actualizaciones en momentos diferentes. Si se comunican fuera de ZooKeeper, la diferencia se hace evidente.
Consideremos la siguiente situación:
-
Un cliente c1 actualiza los datos de un znodo
/zy recibe un acuse de recibo. -
El cliente c1 envía un mensaje a través de una conexión TCP directa a un cliente c2 diciendo que ha cambiado el estado de
/z. -
El cliente c2 lee el estado de
/zpero observa un estado anterior a la actualización de c1.
Lo llamamos canal oculto porque ZooKeeper no sabe nada de la comunicación extra de los clientes. Ahora c2 tiene datos obsoletos. Esta situación se ilustra en la Figura 4-2.
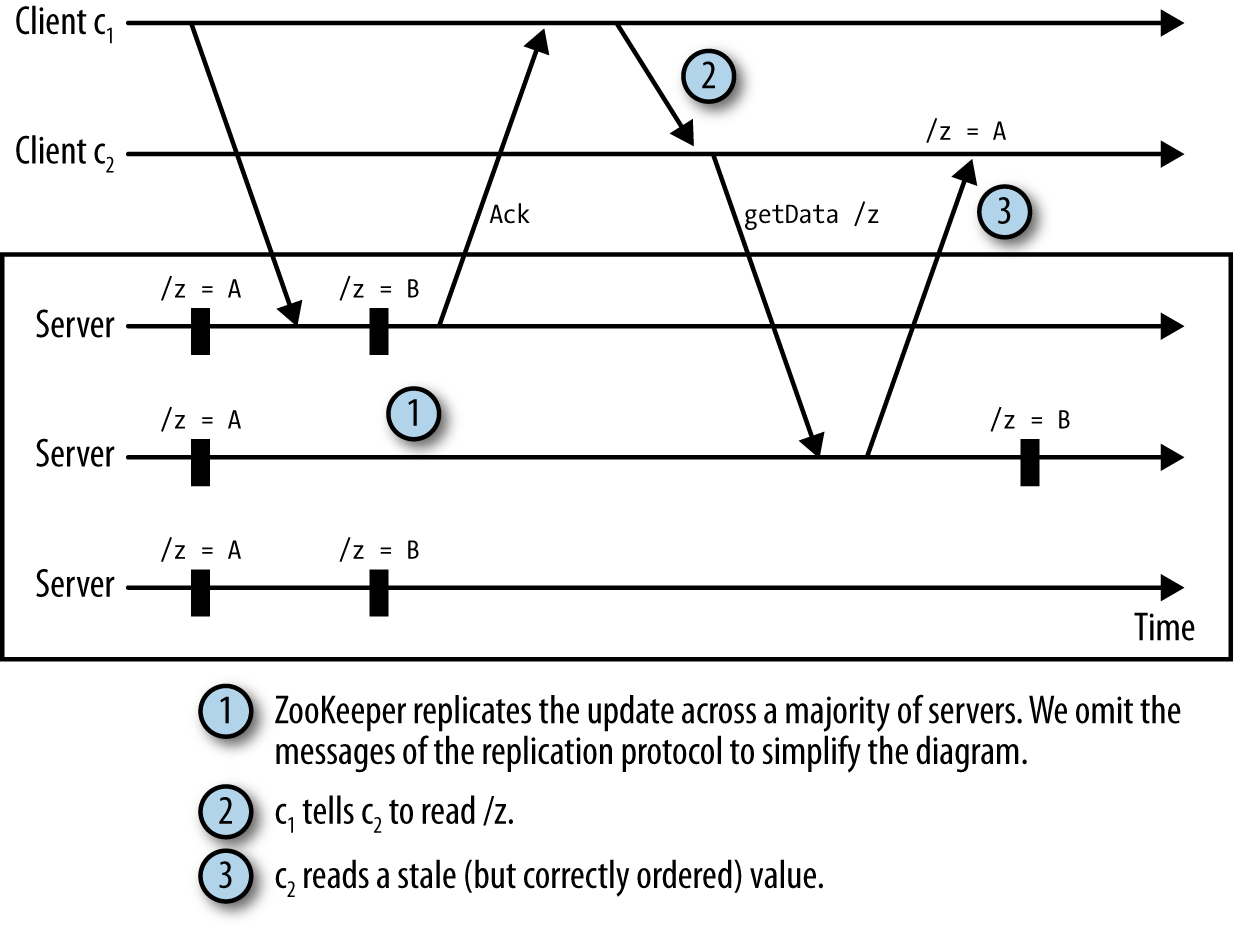
Para evitar leer datos obsoletos, aconsejamos que las aplicaciones utilicen ZooKeeper para todas las comunicaciones relacionadas con el estado de ZooKeeper. Por ejemplo, para evitar la situación que acabamos de describir, c2 podría establecer una vigilancia en /z en lugar de recibir un mensaje directo de c1. Con una vigilancia, c2 se entera del cambio en /z y elimina el problema del canal oculto.
Orden de las notificaciones
ZooKeeper ordena las notificaciones con respecto a otras notificaciones y respuestas asíncronas, respetando el orden de las actualizaciones del estado del sistema. Digamos que ZooKeeper ordena dos actualizaciones de estado u y uʹ, con uʹa continuación de u. Las actualizaciones u y uʹmodifican los znodos /a y /b, respectivamente. Un cliente c que tenga una vigilancia establecida en /a y lea la actualización uʹen /b recibe la notificación de u antes de recibir la respuesta de la operación de lectura de /b.
Esta ordenación permite a las aplicaciones utilizar las vigilancias para implementar propiedades de seguridad. Digamos que se crea o elimina un znode /z para indicar que alguna configuración almacenada en ZooKeeper no es válida. Garantizar que se notifique a los clientes la creación o eliminación de /z antes de que se realice cualquier cambio real en la configuración es importante para asegurarse de que los clientes no leerán una configuración no válida.
Para hacerlo más concreto, digamos que tenemos un znode /config que es el padre de varios otros znodes que contienen metadatos de configuración de la aplicación: /config/m1, /config/m2, ..., /config/mn. A efectos de este ejemplo, no importa cuál sea realmente el contenido de los znodos. Digamos que un proceso de aplicación maestro necesita actualizar estos nodos invocando a setData en cada znode, y no puede tener un cliente que lea una actualización parcial de estos znodes. Una solución es hacer que el maestro cree un /config/invalid znode antes de empezar a actualizar los znodes de configuración. Otros clientes que necesiten leer este estado observan /config/invalid y evitan leerlo si el znodo no válido está presente. Una vez eliminado el znodo inválido, lo que significa que hay disponible un nuevo conjunto válido de znodos de configuración, los clientes pueden proceder a leer ese conjunto.
Para este ejemplo concreto, podríamos haber utilizado alternativamente multiop para ejecutar atómicamente todas las operaciones setData a los znodos /config/m[1-n] en lugar de utilizar un znodo para marcar algún estado como parcialmente modificado. En los casos en los que la atomicidad sea el problema, podemos utilizar multiop en lugar de depender de un znodo adicional y de las notificaciones. El mecanismo de notificación, sin embargo, es más general y no está limitado a la atomicidad.
Como ZooKeeper ordena las notificaciones según el orden de las actualizaciones de estado que desencadenan las notificaciones, los clientes pueden confiar en percibir el verdadero orden de los cambios de estado de ZooKeeper a través de sus notificaciones.
Capacidad de respuesta frente a seguridad
En este capítulo hemos utilizado ampliamente el mecanismo de notificaciones para la liveness. La viveza consiste en asegurarse de que el sistema progrese. Las notificaciones de nuevas tareas y nuevos trabajadores son ejemplos de eventos relacionados con la liveness. Si no se notifica a un maestro una nueva tarea, ésta nunca se ejecutará. No ejecutar una tarea enviada constituye ausencia de liveness, al menos desde la perspectiva del cliente que envió la tarea.
Este último ejemplo de actualizaciones atómicas de un conjunto de znodos de configuración es diferente: se trata de seguridad, no de liveness. Leer los znodos mientras se actualizan podría hacer que un cliente leyera una configuración incoherente. El znode invalid se asegura de que los clientes sólo lean el estado cuando haya una configuración válida disponible.
Para los ejemplos de liveness que hemos visto, el orden de entrega de las notificaciones no es especialmente importante. Mientras los clientes acaben enterándose de esos eventos, progresarán. Sin embargo, para la seguridad, recibir una notificación fuera de orden podría provocar un comportamiento incorrecto.
El efecto rebaño y la escalabilidad de los relojes
Una cuestión que debes tener en cuenta es que ZooKeeper activa todas las vigilancias establecidas para un determinado cambio de znodo cuando se produce el cambio. Si hay 1.000 clientes que han establecido una vigilancia sobre un determinado znodo con una llamada a exists, entonces se enviarán 1.000 notificaciones cuando se cree el znodo. En consecuencia, un cambio en un znodo vigilado podría generar un pico de notificaciones. Dicho pico podría afectar, por ejemplo, a la latencia de las operaciones enviadas en torno al momento del pico. Siempre que sea posible, recomendamos evitar un uso de ZooKeeper de este tipo, en el que un gran número de clientes estén pendientes de un cambio en un znodo determinado. Es mucho mejor tener sólo unos pocos clientes vigilando un determinado znodo a la vez, e idealmente como máximo uno.
Una forma de evitar este problema que no se aplica en todos los casos, pero que puede ser útil en algunos, es la siguiente. Supongamos que n clientes compiten por adquirir un bloqueo (por ejemplo, un bloqueo maestro). Para adquirir el bloqueo, un proceso simplemente intenta crear el znodo /lock. Si el znodo existe, el cliente vigila que no se elimine. Cuando se borra el znodo, el cliente vuelve a intentar crear /lock. Con esta estrategia, todos los clientes que vigilan /lock reciben una notificación cuando se borra /lock. Un enfoque diferente es hacer que cada cliente cree un znodo secuencial /lock/lock-. Recuerda que ZooKeeper añade un número de secuencia al znodo, convirtiéndolo automáticamente en /lock/lock-xxxdonde xxx es un número de secuencia. Podemos utilizar el número de secuencia para determinar qué cliente adquiere el bloqueo concediéndoselo al cliente que creó el znodo en /lock con el menor número de secuencia. En este esquema, un cliente determina si tiene el número de secuencia más pequeño obteniendo los hijos de /lock con getChildren. Si el cliente no tiene el número de secuencia más pequeño, observa el siguiente znodo en la secuencia determinada por los números de secuencia. Por ejemplo, supongamos que tenemos tres znodos /lock/lock-001, /lock/lock-002, y /lock/lock-003. En este ejemplo
-
El cliente que creó
/lock/lock-001tiene el bloqueo. -
El cliente que creó
/lock/lock-002mira/lock/lock-001. -
El cliente que creó
/lock/lock-003mira/lock/lock-002.
De esta forma, cada znodo tiene como máximo un cliente vigilándolo.
Otra dimensión a tener en cuenta es el estado generado con las vigilancias en el lado del servidor. Al establecer un reloj se crea un objeto Watcher en el servidor. Según el perfilador YourKit, establecer un reloj añade entre 250 y 300 bytes a la cantidad de memoria consumida por el gestor de relojes de un servidor. Tener un número muy grande de vigilancias implica que el gestor de vigilancias consume una cantidad no despreciable de memoria del servidor. Por ejemplo, tener 1 millón de relojes pendientes nos da una cifra aproximada de 0,3 GB. En consecuencia, un desarrollador debe ser consciente del número de relojes pendientes en cada momento.
Mensajes para llevar
En un sistema distribuido, hay muchos acontecimientos que desencadenan acciones. ZooKeeper proporciona mecanismos eficientes para hacer un seguimiento de los eventos importantes que requieren que los procesos del sistema reaccionen. Los ejemplos de los que hemos hablado aquí están relacionados con el flujo regular de las aplicaciones (por ejemplo, la ejecución de tareas) o los fallos por colapso (por ejemplo, el colapso del maestro).
Una característica clave de ZooKeeper que hemos utilizado son las notificaciones. Los clientes de ZooKeeper registran relojes con ZooKeeper para recibir notificaciones sobre los cambios en el estado de ZooKeeper. El orden en que se entregan las notificaciones es importante; los clientes no deben observar órdenes diferentes para los cambios en el estado de ZooKeeper.
Una función concreta que resulta útil cuando se trata de cambios es la llamada multi. Permite ejecutar varias operaciones en un bloque y, a menudo, evita condiciones de carrera en aplicaciones distribuidas cuando los clientes reaccionan a los eventos y cambian el estado de ZooKeeper.
Esperamos que la mayoría de las aplicaciones sigan el patrón que presentamos aquí, aunque, por supuesto, las variantes son posibles y aceptables. Nos hemos centrado en la API asíncrona porque animamos a los desarrolladores a utilizarla. La API asíncrona permite a las aplicaciones utilizar los recursos de ZooKeeper de forma más eficaz y obtener un mayor rendimiento.
Get ZooKeeper now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

