Kapitel 1. Grundlagen von Zero Trust
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
In einer Zeit, in der die Netzüberwachung allgegenwärtig ist, fällt es uns schwer zu wissen, wem wir vertrauen können. Können wir darauf vertrauen, dass unser Internetverkehr sicher vor Abhörmaßnahmen ist? Sicherlich nicht! Was ist mit dem Anbieter, bei dem du dein Glasfasernetz gemietet hast? Oder dem beauftragten Techniker, der gestern in deinem Rechenzentrum an der Verkabelung gearbeitet hat?
Whistleblower wie Edward Snowden und Mark Klein haben die Hartnäckigkeit der von der Regierung unterstützten Spionageringe aufgedeckt. Die Welt war schockiert über die Enthüllung, dass es ihnen gelungen war, in die Rechenzentren großer Unternehmen einzudringen. Aber warum? Ist es nicht genau das, was du an ihrer Stelle tun würdest? Vor allem, wenn du wüsstest, dass der Datenverkehr dort nicht verschlüsselt ist?
Die Annahme, dass den Systemen und dem Datenverkehr innerhalb eines Rechenzentrums vertraut werden kann, ist falsch. Moderne Netzwerke und Nutzungsmuster entsprechen nicht mehr denjenigen, die vor vielen Jahren einen Perimeterschutz sinnvoll erscheinen ließen. Daher ist es oft trivial, sich innerhalb einer "sicheren" Infrastruktur frei zu bewegen, sobald ein einziger Host oder eine einzige Verbindung dort kompromittiert wurde.
Zero Trust zielt darauf ab, die Probleme zu lösen, die entstehen, wenn wir unser Vertrauen in das Netzwerk setzen. Stattdessen ist es möglich, die Kommunikation und den Zugang zum Netzwerk so effektiv zu sichern, dass die physische Sicherheit der Transportschicht vernünftigerweise außer Acht gelassen werden kann. Es versteht sich von selbst, dass dies ein hochgestecktes Ziel ist. Die gute Nachricht ist, dass wir heutzutage über ziemlich gute Kryptowährungen verfügen, und mit den richtigen Automatisierungssystemen ist diese Vision tatsächlich erreichbar.
Was ist ein Zero Trust Network?
Ein Null-Vertrauens-Netzwerk basiert auf fünf grundlegenden Behauptungen:
- Es wird immer davon ausgegangen, dass das Netzwerk feindlich ist.
- Externe und interne Bedrohungen gibt es im Netzwerk zu jeder Zeit.
- Die Netzwerklokalität reicht nicht aus, um über das Vertrauen in ein Netzwerk zu entscheiden.
- Jedes Gerät, jeder Nutzer und jeder Netzwerkfluss wird authentifiziert und autorisiert.
- Politiken müssen dynamisch sein und aus möglichst vielen Datenquellen berechnet werden.
Die traditionelle Netzwerksicherheitsarchitektur unterteilt verschiedene Netzwerke (oder Teile eines Netzwerks) in Zonen, die durch eine oder mehrere Firewalls geschützt werden. Jeder Zone wird ein gewisser Grad an Vertrauen gewährt, der bestimmt, welche Netzwerkressourcen sie erreichen darf. Dieses Modell bietet eine sehr starke Defense-in-Depth. Ressourcen, die als besonders riskant eingestuft werden, wie z. B. Webserver, die mit dem öffentlichen Internet verbunden sind, befinden sich in einer Ausschlusszone (oft als "DMZ" bezeichnet), in der der Datenverkehr streng überwacht und kontrolliert werden kann. Ein solcher Ansatz führt zu einer Architektur, die derjenigen ähnelt, die du vielleicht schon einmal gesehen hast, wie die in Abbildung 1-1 gezeigte.
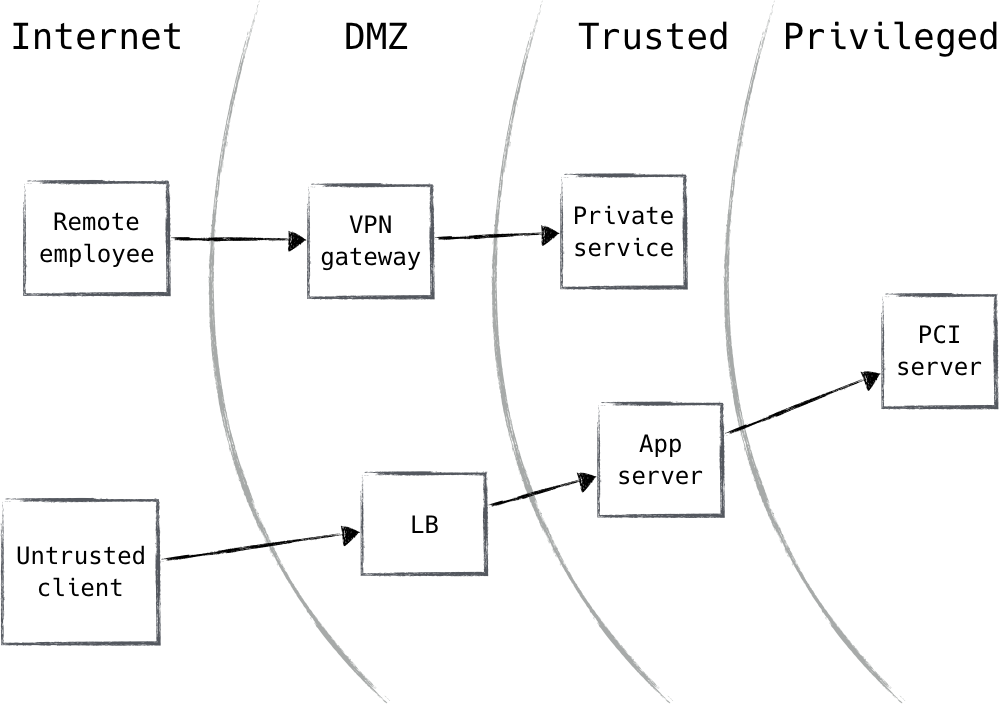
Abbildung 1-1. Traditionelle Netzwerksicherheitsarchitektur
Das Zero-Trust-Modell stellt dieses Diagramm auf den Kopf. Das Anbringen von Sicherheitslücken im Netzwerk ist ein solider Fortschritt gegenüber den Entwürfen von früher, aber in der modernen Cyberangriffslandschaft fehlt es deutlich. Es gibt viele Nachteile:
- Fehlende zoneninterne Verkehrskontrolle
- Mangelnde Flexibilität bei der Platzierung von Hosts (sowohl physisch als auch logisch)
- Einzelne Fehlerquellen
Es sei darauf hingewiesen, dass die Notwendigkeit von VPNs entfällt, wenn die Anforderungen an die Netzwerklokalität aufgehoben werden. Ein VPN (oder virtuelles privates Netzwerk) ermöglicht es einem Nutzer, sich zu authentifizieren, um eine IP-Adresse in einem entfernten Netzwerk zu erhalten. Der Datenverkehr wird dann vom Gerät zum entfernten Netzwerk getunnelt, wo er entkapselt und weitergeleitet wird. Es ist die größte Hintertür, die niemand je vermutet hat.
Wenn wir stattdessen erklären, dass der Standort des Netzwerks keinen Wert hat, wird VPN plötzlich obsolet, ebenso wie einige andere moderne Netzwerkkonstrukte. Dieses Mandat macht es natürlich erforderlich, die Durchsetzung so weit wie möglich an den Rand des Netzwerks zu verlagern, entlastet aber gleichzeitig den Kern von dieser Verantwortung. Außerdem gibt es in allen wichtigen Betriebssystemen Stateful Firewalls, und die Fortschritte bei Switching und Routing haben die Möglichkeit eröffnet, fortschrittliche Funktionen an den Kanten zu installieren. All diese Vorteile führen zu einer Schlussfolgerung: Die Zeit ist reif für einen Paradigmenwechsel.
Durch die Nutzung der verteilten Durchsetzung von Richtlinien und die Anwendung von Zero-Trust-Prinzipien können wir ein Design erstellen, das dem in Abbildung 1-2 gezeigten ähnelt.
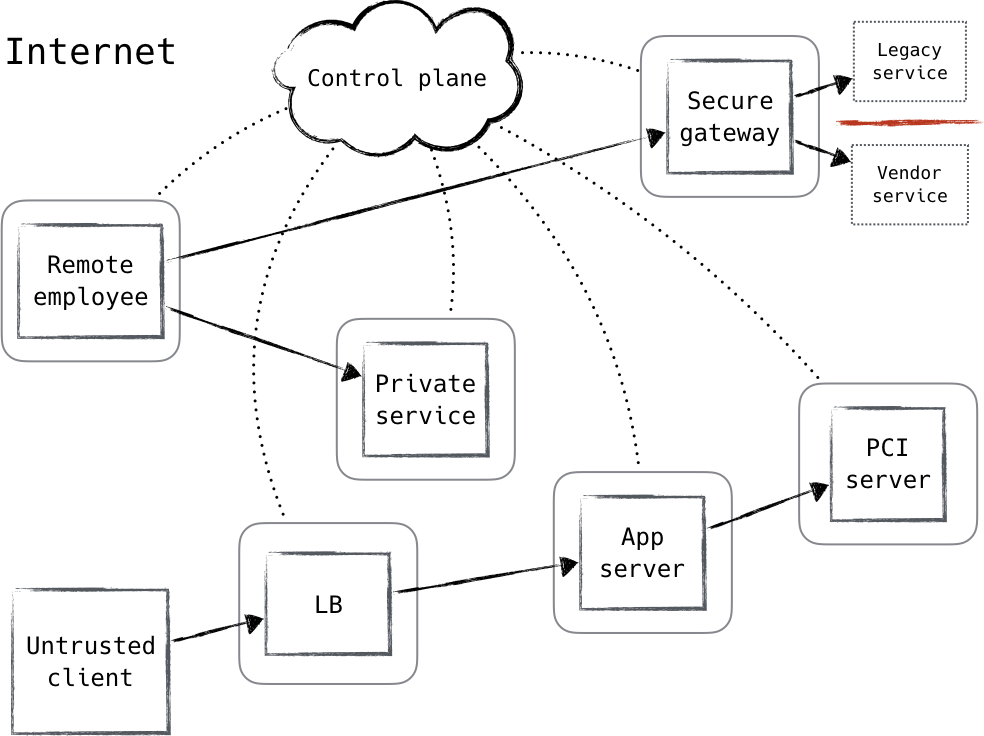
Abbildung 1-2. Zero-Trust-Architektur
Einführung in die Zero Trust Control Plane
Das unterstützende System wird als Kontrollebene bezeichnet, während alles andere als Datenebene bezeichnet wird, die von der Kontrollebene koordiniert und konfiguriert wird. Anfragen für den Zugriff auf geschützte Ressourcen werden zunächst über die Kontrollebene gestellt, in der sowohl das Gerät als auch der Nutzer authentifiziert und autorisiert werden müssen. Auf dieser Ebene können fein abgestufte Richtlinien angewandt werden, die z. B. auf der Rolle im Unternehmen, der Tageszeit oder der Art des Geräts basieren. Der Zugang zu sichereren Ressourcen kann zusätzlich eine stärkere Authentifizierung erfordern.
Sobald die Kontrollebene entschieden hat, dass die Anfrage zugelassen wird, konfiguriert sie die Datenebene dynamisch so, dass sie den Datenverkehr von diesem Client (und nur von diesem Client) akzeptiert. Darüber hinaus kann sie die Details eines verschlüsselten Tunnels zwischen dem Anfragenden und der Ressource koordinieren. Dies kann temporäre, einmalig verwendbare Anmeldedaten, Schlüssel und ephemere Portnummern beinhalten.
Auch wenn bei der Stärke dieser Maßnahmen einige Kompromisse eingegangen werden können, besteht die Grundidee darin, dass eine autorisierte Quelle oder eine vertrauenswürdige dritte Partei die Möglichkeit erhält, den Zugang in Echtzeit zu authentifizieren, zu autorisieren und zu koordinieren, und zwar auf der Grundlage einer Vielzahl von Eingaben.
Entwicklung des Perimeter-Modells
Die in diesem Buch beschriebene traditionelle Architektur wird oft als Perimeter-Modell bezeichnet, in Anlehnung an den Burgmauer-Ansatz, der in der physischen Sicherheit verwendet wird. Dieser Ansatz schützt sensible Objekte, indem er Verteidigungslinien aufbaut, die ein Eindringling durchdringen muss, bevor er sich Zugang verschaffen kann. Leider ist dieser Ansatz im Kontext von Computernetzwerken grundlegend fehlerhaft und reicht nicht mehr aus. Um das Scheitern zu verstehen, ist es sinnvoll, sich zu vergegenwärtigen, wie das derzeitige Modell zustande gekommen ist.
Verwaltung des globalen IP-Adressraums
Die Reise von , die zum Perimeter-Modell führte, begann mit der Adresszuweisung. In den Anfängen des Internets wurden die Netzwerke immer schneller miteinander verbunden. Wenn es nicht mit dem Internet verbunden war (denk daran, dass das Internet damals noch nicht allgegenwärtig war), war es mit einer anderen Geschäftseinheit, einem anderen Unternehmen oder vielleicht einem Forschungsnetzwerk verbunden. Natürlich müssen IP-Adressen in jedem IP-Netz eindeutig sein, und wenn die Netzbetreiber das Pech haben, dass sich die Bereiche überschneiden, haben sie viel zu tun, um sie alle zu ändern. Wenn das Netzwerk, mit dem du dich verbindest, das Internet ist, dann müssen deine Adressen weltweit eindeutig sein. Hier ist also eindeutig eine gewisse Koordination erforderlich.
Die 1998 formell gegründete Internet Assigned Numbers Authority (IANA) ist heute für die Koordination zuständig. Vor der Gründung der IANA wurde diese Aufgabe von Jon Postel wahrgenommen, der die in Abbildung 1-3 gezeigte Internetkarte erstellt hat. Wenn du sicherstellen wolltest, dass deine IP-Adressen weltweit eindeutig sind, musstest du dich bei ihm registrieren lassen. Zu dieser Zeit wurde jeder ermutigt, sich für IP-Adressen registrieren zu lassen, auch wenn das Netzwerk, das registriert wurde, nicht mit dem Internet verbunden sein sollte. Man ging davon aus, dass ein Netzwerk, auch wenn es jetzt nicht mit dem Internet verbunden war, wahrscheinlich irgendwann mit einem anderen Netzwerk verbunden sein würde: .
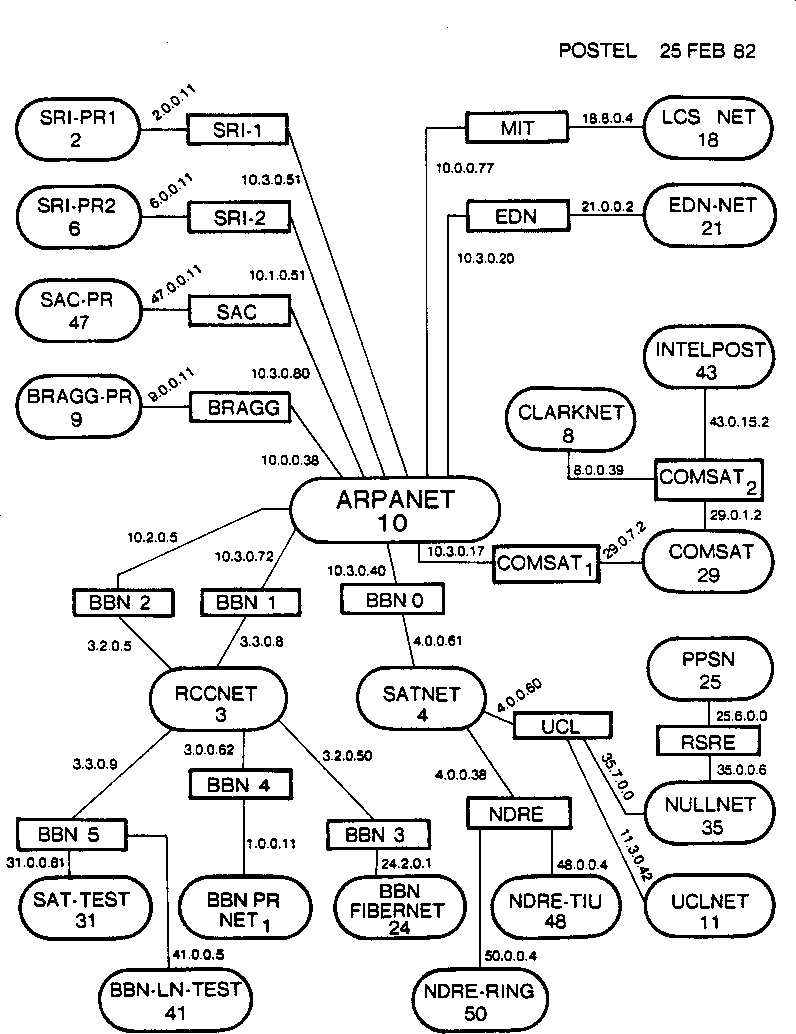
Abbildung 1-3. Eine Karte des frühen Internets, erstellt von Jon Postel, vom Februar 1982
Entstehung eines privaten IP-Adressraums
Mit der zunehmenden Verbreitung von IP in den späten 1980er und frühen 1990er Jahren wurde der leichtfertige Umgang mit dem Adressraum zu einem ernsthaften Problem. Es wurden zahlreiche Fälle von wirklich isolierten Netzwerken mit großem Bedarf an IP-Adressen bekannt. Netzwerke, die Geldautomaten und Ankunfts-/Abfluganzeigen an großen Flughäfen verbinden, wurden als Paradebeispiele angeführt. Diese Netzwerke wurden aus verschiedenen Gründen als wirklich isoliert betrachtet. Einige Geräte werden isoliert, um Sicherheits- oder Datenschutzanforderungen zu erfüllen (z. B. Netzwerke für Geldautomaten). Andere wurden isoliert, weil der Umfang ihrer Funktion so begrenzt war, dass ein breiterer Netzwerkzugang als äußerst unwahrscheinlich angesehen wurde (z. B. Ankunfts- und Abfluganzeigen an Flughäfen). RFC 1597, Address Allocation for Private Internets, wurde eingeführt, um dieses Problem des verschwendeten öffentlichen Adressraums zu lösen.
Im März 1994 wurde mit RFC 1597 bekannt gegeben, dass drei IP-Netzwerkbereiche bei der IANA für die allgemeine Nutzung in privaten Netzwerken reserviert wurden: 10.0.0.0/8, 172.16.0.0/12 und 192.168.0.0/16. Dies hatte den Effekt, dass der Adressverfall verlangsamt wurde, indem sichergestellt wurde, dass der Adressraum großer privater Netzwerke nie über diese Zuweisungen hinauswuchs. Außerdem konnten die Netzbetreiber so nicht-globale Adressen verwenden, wo und wann sie wollten. Es hatte noch einen weiteren interessanten Effekt, der bis heute nachwirkt: Netzwerke mit privaten Adressen waren sicherer, weil sie grundsätzlich nicht in der Lage waren, sich mit anderen Netzwerken, insbesondere dem Internet, zu verbinden.
Damals hatten (relativ gesehen) nur sehr wenige Organisationen einen Internetanschluss oder eine Internetpräsenz, so dass die internen Netzwerke häufig mit den reservierten Bereichen nummeriert waren. Außerdem waren die Sicherheitsvorkehrungen schwach bis gar nicht vorhanden, da diese Netzwerke in der Regel durch die Mauern einer einzigen Organisation begrenzt waren.
Private Netzwerke verbinden sich mit öffentlichen Netzwerken
Die Zahl der interessanten Dinge im Internet wuchs ziemlich schnell, und bald wollten die meisten Organisationen zumindest eine Art von Präsenz. E-Mail war eines der ersten Beispiele dafür. Die Menschen wollten E-Mails senden und empfangen können, aber dazu brauchten sie einen öffentlich zugänglichen Mailserver, was natürlich bedeutete, dass sie sich irgendwie mit dem Internet verbinden mussten.
Bei etablierten privaten Netzwerken war es oft so, dass dieser Mailserver der einzige Server mit einer Internetverbindung war. Er hatte eine Netzwerkschnittstelle zum Internet und eine zum internen Netzwerk. Auf diese Weise konnten die Systeme und Personen im internen privaten Netzwerk über den angeschlossenen Mailserver E-Mails aus dem Internet senden und empfangen.
Es wurde schnell klar, dass diese Server einen physischen Internetpfad in ihr ansonsten sicheres und privates Netzwerk geöffnet hatten. Wenn einer dieser Server kompromittiert wurde, könnte ein Angreifer in das private Netzwerk eindringen, da die dortigen Hosts mit ihm kommunizieren können. Diese Erkenntnis führte zu einer strengen Eingabeaufforderung für diese Hosts und ihre Netzwerkverbindungen. Die Netzwerkbetreiber errichteten auf beiden Seiten Firewalls, um die Kommunikation einzuschränken und potenzielle Angreifer daran zu hindern, vom Internet aus auf interne Systeme zuzugreifen (siehe Abbildung 1-4). Mit diesem Schritt war das Perimeter-Modell geboren. Das interne Netzwerk wurde zum "sicheren" Netzwerk, und die streng kontrollierte Tasche, in der sich die externen Hosts befanden, wurde zur DMZ oder zur demilitarisierten Zone.

Abbildung 1-4. Sowohl Internet- als auch private Ressourcen können auf Hosts in der DMZ zugreifen; private Ressourcen können jedoch nicht über die DMZ hinausreichen und erhalten daher keinen direkten Internetzugang
Geburt der NAT
Die Zahl der Internetressourcen, auf die von internen Netzwerken aus zugegriffen werden sollte, wuchs rapide, und es wurde schnell einfacher, den allgemeinen Internetzugang zu internen Ressourcen zu gewähren, als Zwischenrechner für jede gewünschte Anwendung zu unterhalten. NAT, oder network address translation, löste dieses Problem auf angenehme Weise.
RFC 1631, The IP Network Address Translator, definiert einen Standard für ein Netzwerkgerät, das in der Lage ist, IP-Adressen an Organisationsgrenzen zu übersetzen. Durch die Verwaltung einer Tabelle, die öffentliche IPs und Ports auf private Ports abbildet, können Geräte in privaten Netzwerken auf beliebige Internetressourcen zugreifen. Diese leichtgewichtige Zuordnung ist anwendungsunabhängig, was bedeutet, dass Netzbetreiber nicht mehr die Internetkonnektivität für bestimmte Anwendungen unterstützen müssen, sondern nur noch die Internetkonnektivität im Allgemeinen.
Diese NAT-Geräte hatten eine interessante Eigenschaft: Da die IP-Zuordnung viele-zu-eins war, war es für eingehende Verbindungen aus dem Internet nicht möglich, auf interne private IPs zuzugreifen, ohne das NAT speziell für diesen Sonderfall zu konfigurieren. Auf diese Weise wiesen die Geräte die gleichen Eigenschaften wie eine Stateful Firewall auf. Tatsächliche Firewalls begannen fast sofort, NAT-Funktionen zu integrieren, und die beiden wurden zu einer einzigen Funktion, die kaum noch zu unterscheiden ist. Die Unterstützung von Netzwerkkompatibilität und strengen Sicherheitskontrollen führte dazu, dass du eines dieser Geräte an praktisch jeder Unternehmensgrenze finden konntest, wie in Abbildung 1-5 dargestellt.
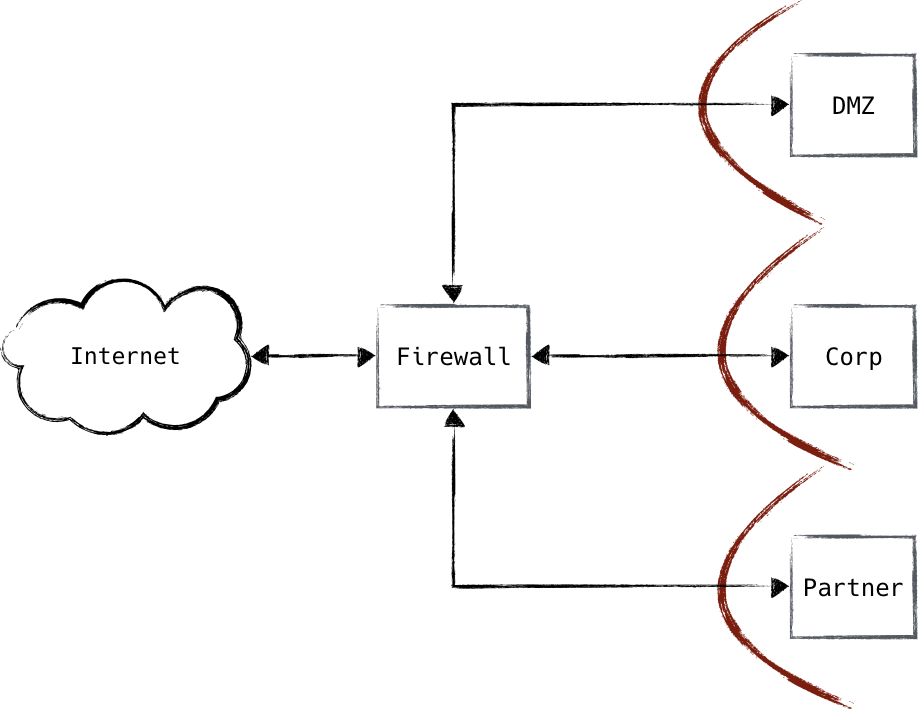
Abbildung 1-5. Typischer (und vereinfachter) Aufbau einer Perimeter-Firewall
Das zeitgenössische Perimeter-Modell
Mit einem Firewall/NAT-Gerät zwischen dem internen Netzwerk und dem Internet bilden sich die Sicherheitszonen deutlich heraus. Es gibt die interne "sichere" Zone, die DMZ (demilitarisierte Zone), und die nicht vertrauenswürdige Zone (auch Internet genannt). Wenn diese Organisation irgendwann in der Zukunft mit einer anderen verbunden werden müsste, würde ein Gerät auf ähnliche Weise an dieser Grenze platziert werden. Die benachbarte Organisation wird dann wahrscheinlich zu einer neuen Sicherheitszone, in der bestimmte Regeln darüber gelten, welche Art von Datenverkehr von der einen in die andere Zone gelangen darf, genau wie in der DMZ oder in der sicheren Zone.
Rückblickend lässt sich die Entwicklung gut erkennen. Wir haben uns von offline/privaten Netzwerken mit nur einem oder zwei Hosts mit Internetzugang zu hochgradig vernetzten Netzwerken mit Sicherheitsvorrichtungen rund um den Perimeter entwickelt. Das ist nicht schwer zu verstehen: Netzwerkbetreiber können es sich nicht leisten, die perfekte Sicherheit ihres Offline-Netzwerks zu opfern, weil sie die Türen für verschiedene Geschäftszwecke öffnen mussten. Strenge Sicherheitskontrollen an jeder Tür minimierten das Risiko.
Die Entwicklung der Bedrohungslandschaft
Schon vor dem öffentlichen Internet war die Kommunikation mit einem entfernten Computersystem sehr wünschenswert. Dies geschah in der Regel über das öffentliche Telefonnetz. Benutzer und Computersysteme konnten sich einwählen und durch die Verschlüsselung von Daten in hörbare Töne eine Verbindung zu dem entfernten Rechner herstellen. Diese Einwahlschnittstellen waren damals der häufigste Angriffsvektor, da es viel schwieriger war, physischen Zugang zu erlangen.
Sobald Unternehmen über Hosts mit Internetanschluss verfügten, wurden die Angriffe nicht mehr über das Telefonnetz, sondern über das Internet gestartet. Damit änderte sich auch die Dynamik der meisten Angriffe. Eingehende Anrufe an Einwahlschnittstellen banden eine Telefonleitung und waren im Vergleich zu einer TCP-Verbindung aus dem Internet ein bemerkenswertes Ereignis. Es war viel einfacher, eine verdeckte Präsenz in einem IP-Netzwerk zu haben als in einem System, in das man sich einwählen musste. Ausbeutung und Brute-Force-Versuche konnten über lange Zeiträume hinweg durchgeführt werden, ohne allzu viel Verdacht zu erregen... Allerdings ergab sich aus dieser Veränderung eine zusätzliche und noch wirkungsvollere Möglichkeit: Bösartiger Code konnte dann den Internetverkehr abhören.
In den späten 1990er Jahren machten die ersten (Software-)Trojaner die Runde. In der Regel wurde ein Nutzer dazu verleitet, die Malware zu installieren, die dann einen Port öffnete und auf eingehende Verbindungen wartete. Der Angreifer konnte sich dann mit dem offenen Port verbinden und den Zielcomputer fernsteuern.
Es dauerte nicht lange, bis die Menschen erkannten, dass es eine gute Idee ist, diese Hosts, die mit dem Internet verbunden sind, zu schützen. Hardware-Firewalls waren die beste Lösung (die meisten Betriebssysteme hatten damals noch kein Konzept für eine hostbasierte Firewall). Sie sorgten für die Durchsetzung von Richtlinien und stellten sicher, dass nur "sicherer" Datenverkehr aus dem Internet zugelassen wurde, der auf der Whitelist stand. Wenn ein Administrator versehentlich etwas installierte, das einen offenen Port freilegte (z. B. einen Trojaner), blockierte die Firewall die Verbindungen zu diesem Port, bis sie explizit so konfiguriert wurde, dass sie zugelassen wurde. Ebenso konnte der Datenverkehr zu den Internet-Servern aus dem Netzwerk heraus kontrolliert werden, um sicherzustellen, dass interne Nutzer/innen mit ihnen sprechen konnten, aber nicht umgekehrt. So konnte verhindert werden, dass ein potenziell gefährdeter DMZ-Host in das interne Netzwerk eindringt.
Die Hosts der DMZ waren natürlich ein bevorzugtes Ziel (aufgrund ihrer Konnektivität), aber diese strengen Kontrollen des ein- und ausgehenden Datenverkehrs machten es schwer, ein internes Netzwerk über eine DMZ zu erreichen. Ein Angreifer müsste zuerst den Server mit der Firewall kompromittieren und dann die Anwendung so missbrauchen, dass sie für eine verdeckte Kommunikation genutzt werden kann (schließlich müssen sie ja Daten aus dem Netzwerk herausholen ). Einwahlschnittstellen blieben das am leichtesten zu erreichende Ziel, wenn man sich Zugang zu einem internen Netzwerk verschaffen wollte.
An dieser Stelle nahmen die Dinge eine interessante Wendung. NAT wurde eingeführt, um Clients in internen Netzwerken Zugang zum Internet zu gewähren. Zum Teil aufgrund der NAT-Mechanik und zum Teil aufgrund echter Sicherheitsbedenken wurde der eingehende Datenverkehr weiterhin streng kontrolliert, obwohl interne Ressourcen, die externe Ressourcen nutzen wollten, dies frei tun konnten. Es gibt einen wichtigen Unterschied zwischen einem Netzwerk mit NAT-Internetzugang und einem Netzwerk ohne NAT: Ersteres hat (wenn überhaupt) eine lockere Netzwerkpolitik für den ausgehenden Verkehr.
Dies veränderte das Modell der Netzwerksicherheit erheblich. Hosts in den "vertrauenswürdigen" internen Netzwerken konnten nun direkt mit nicht vertrauenswürdigen Internet-Hosts kommunizieren, und der nicht vertrauenswürdige Host war plötzlich in der Lage, den Client zu missbrauchen, der versuchte, mit ihm zu sprechen. Schlimmer noch, bösartiger Code konnte dann aus dem internen Netzwerk Nachrichten an Internet-Hosts senden. Heute kennen wir das als Phoning Home.
Phoning Home ist ein wichtiger Bestandteil der meisten modernen Angriffe. Sie ermöglicht es, Daten aus ansonsten geschützten Netzwerken auszuspionieren. Aber noch wichtiger ist, dass TCP bidirektional ist und somit auch Daten eingeschleust werden können.
Ein typischer Angriff umfasst mehrere Schritte, wie in Abbildung 1-6 dargestellt. Zunächst kompromittiert der Angreifer einen einzelnen Computer im internen Netzwerk, indem er den Browser des Benutzers ausnutzt, wenn dieser eine bestimmte Seite besucht, indem er ihm z. B. eine E-Mail mit einem Anhang schickt, der eine lokale Software ausnutzt. Der Exploit enthält eine sehr kleine Nutzlast, gerade genug Code, um eine Verbindung zu einem entfernten Internet-Host herzustellen und den Code auszuführen, den er als Antwort erhält. Diese Nutzlast wird manchmal auch als Dialer bezeichnet.
Der Dialer lädt die eigentliche Schadsoftware herunter und installiert sie. Diese versucht in den meisten Fällen, eine zusätzliche Verbindung zu einem entfernten Internet-Host herzustellen, der vom Angreifer kontrolliert wird. Der Angreifer nutzt diese Verbindung, um Befehle an die Malware zu senden, sensible Daten auszuspionieren oder sogar eine interaktive Sitzung zu erhalten. Dieser "Patient Zero" kann als Sprungbrett dienen und dem Angreifer einen Host im internen Netzwerk verschaffen, von dem aus er weitere Angriffe starten kann.
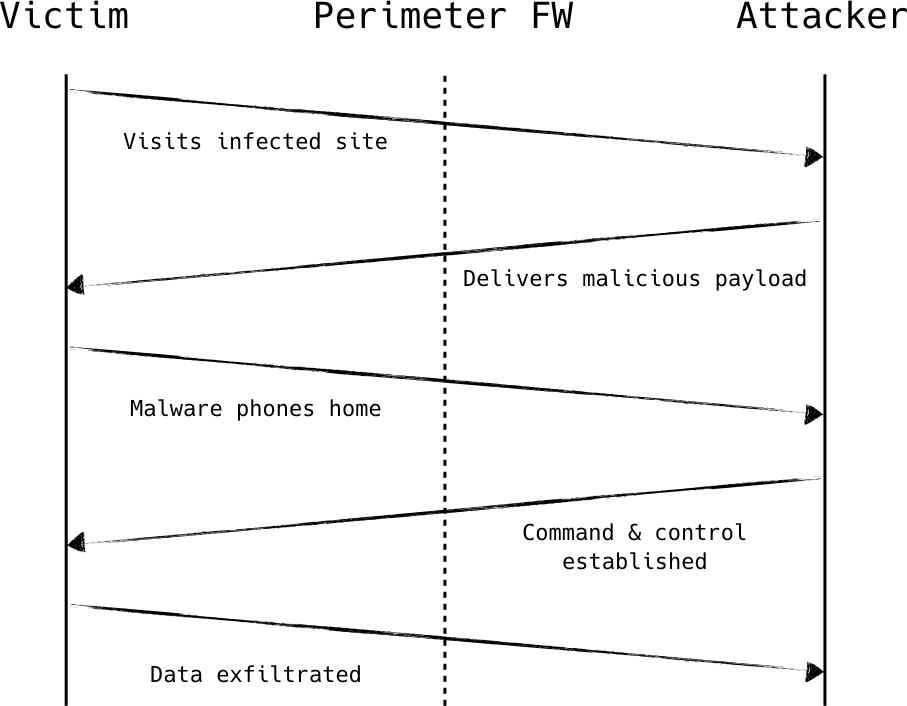
Abbildung 1-6. Der Client initiiert alle angriffsrelevanten Verbindungen und überwindet dabei problemlos die Firewalls am Perimeter mit entspannter Sicherheit für ausgehende Verbindungen
Sicherheit im Outbound
Die ausgehende Netzwerksicherheit ist eine sehr wirksame Maßnahme gegen dialerbasierte Angriffe, da der Telefonverkehr erkannt und/oder blockiert werden kann. Oftmals wird der Telefonanruf jedoch als normaler Webverkehr getarnt, möglicherweise sogar für scheinbar harmlose oder "normale" Netzwerke. Wenn die Sicherheitsvorkehrungen im ausgehenden Verkehr so streng sind, dass sie diese Angriffe stoppen können, wird die Nutzbarkeit des Internets für die Benutzer/innen oft beeinträchtigt. Dies ist eine realistischere Perspektive für Back-Office-Systeme.
Die Möglichkeit, Angriffe von Hosts in einem internen Netzwerk von aus zu starten, ist sehr mächtig. Diese Hosts haben mit ziemlicher Sicherheit die Erlaubnis, mit anderen Hosts in derselben Sicherheitszone zu kommunizieren (laterale Bewegung) und können sogar Zugang zu Hosts in Zonen haben, die sicherer sind als ihre eigene. Wenn ein Angreifer also zuerst eine niedrig gesicherte Zone im internen Netzwerk kompromittiert, kann er sich durch das Netzwerk bewegen und schließlich Zugang zu den hoch gesicherten Zonen erhalten.
Wenn wir einen Schritt zurückgehen, können wir sehen, dass dieses Muster das Perimeter-Sicherheitsmodell sehr effektiv untergräbt. Die kritische Schwachstelle, die das Fortschreiten der Angriffe ermöglicht, ist subtil, aber eindeutig: Sicherheitsrichtlinien werden durch Netzwerkzonen definiert und nur an den Zonengrenzen durchgesetzt, wobei nichts weiter als die Angaben zu Quelle und Ziel verwendet werden.
Unzulänglichkeiten am Rande
Obwohl das Perimetersicherheitsmodell immer noch das mit Abstand am weitesten verbreitete Modell ist, wird immer deutlicher, dass die Art und Weise, wie wir uns darauf verlassen, fehlerhaft ist. Jeden Tag gibt es komplexe (und erfolgreiche) Angriffe auf Netzwerke mit perfekter Perimetersicherheit. Ein Angreifer schleust ein Remote Access Tool (oder RAT) über eine der unzähligen Methoden in dein Netzwerk ein, verschafft sich Fernzugriff und beginnt, sich seitlich zu bewegen. Perimeter Firewalls sind das funktionale Äquivalent zum Bau einer Mauer um eine Stadt, um Spione fernzuhalten.
Das Problem entsteht, wenn Sicherheitszonen in das Netzwerk selbst eingebaut werden. Stell dir das folgende Szenario vor: Du betreibst ein kleines E-Commerce-Unternehmen. Du hast einige Angestellte, einige interne Systeme (Gehaltsabrechnung, Inventar, etc.) und einige Server, die deine Website betreiben. Es ist naheliegend, die Art des Zugangs zu diesen Gruppen zu klassifizieren: Mitarbeiter/innen brauchen Zugang zu internen Systemen, Webserver brauchen Zugang zu Datenbankservern, Datenbankserver brauchen keinen Internetzugang, aber Mitarbeiter/innen schon, und so weiter. Die traditionelle Netzwerksicherheit würde diese Gruppen als Zonen kodieren und dann festlegen, welche Zone auf was zugreifen darf, wie in Abbildung 1-7 dargestellt. Da sie für jede Zone einzeln festgelegt werden, ist es sinnvoll, sie überall dort durchzusetzen, wo eine Zone Datenverkehr in eine andere leiten kann.
Wie du dir sicher vorstellen kannst, gibt es immer wieder Ausnahmen von diesen allgemeinen Regeln. Sie werden umgangssprachlich auch als firewall exceptions bezeichnet. Diese Ausnahmen sind in der Regel so eng wie möglich gefasst. Zum Beispiel könnte dein Webentwickler SSH-Zugang zu den produktiven Webservern haben wollen oder dein Personalverantwortlicher braucht Zugriff auf die Datenbank der HR-Software, um Audits durchzuführen. In diesen Fällen ist es sinnvoll, eine Firewall-Ausnahme zu konfigurieren, die den Datenverkehr von der IP-Adresse der betreffenden Person zu den fraglichen Servern zulässt.
Stell dir nun vor, dein Erzfeind hat ein Team von Hackern angeheuert. Sie wollen einen Blick auf deinen Bestand und deine Verkaufszahlen werfen. Die Hacker schicken E-Mails an alle E-Mail-Adressen der Mitarbeiter, die sie im Internet finden können, und tarnen sie als Rabattcode für ein Restaurant in der Nähe des Büros. Natürlich klickt einer von ihnen auf den Link und ermöglicht es den Angreifern, Malware zu installieren. Die Malware ruft zu Hause an und verschafft den Angreifern eine Sitzung auf dem Rechner des nun kompromittierten Mitarbeiters. Zum Glück handelt es sich nur um einen Praktikanten, und die Zugriffsmöglichkeiten sind begrenzt.
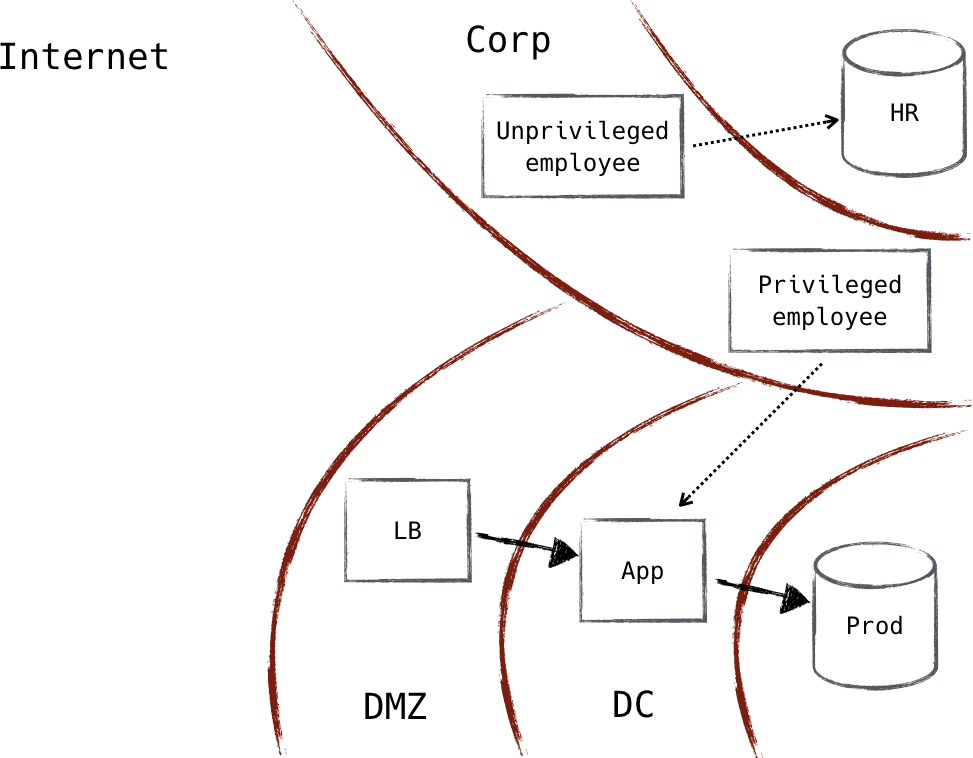
Abbildung 1-7. Unternehmensnetzwerk im Zusammenspiel mit dem Produktionsnetzwerk
Sie beginnen mit der Durchsuchung des Netzwerks und stellen fest, dass das Unternehmen Filesharing-Software in seinem Netzwerk verwendet. Von den Computern der Mitarbeiter im Netzwerk hat keiner die neueste Version und ist anfällig für einen Angriff, der kürzlich bekannt wurde. Einer nach dem anderen machen sich die Hacker auf die Suche nach einem Computer mit erhöhtem Zugriff (dieser Prozess kann natürlich noch gezielter sein, wenn der Angreifer über fortgeschrittene Kenntnisse verfügt). Schließlich stoßen sie auf den Computer deines Webentwicklers. Mit einem Keylogger, den sie dort installieren, erlangen sie die Anmeldedaten für den Webserver. Mit den gesammelten Zugangsdaten loggen sie sich per SSH in den Server ein. Mit den sudo-Rechten des Webentwicklers lesen sie das Datenbankpasswort von der Festplatte und verbinden sich mit der Datenbank. Sie löschen den Inhalt der Datenbank, laden ihn herunter und löschen alle Logdateien. Wenn du Glück hast, entdeckst du vielleicht sogar, dass dieser Einbruch stattgefunden hat. Sie haben ihr Ziel erreicht, wie in Abbildung 1-8 zu sehen ist.
Warte, was? Wie du siehst, haben viele Fehler auf vielen Ebenen zu diesem Einbruch geführt, und obwohl du vielleicht denkst, dass dies ein besonders ausgeklügelter Fall ist, sind erfolgreiche Angriffe wie dieser erschreckend häufig. Der überraschendste Teil bleibt jedoch allzu oft unbemerkt: Was ist mit all der Netzwerksicherheit passiert? Die Firewalls wurden sorgfältig platziert, die Richtlinien und Ausnahmen waren eng gefasst und sehr begrenzt - aus Sicht der Netzwerksicherheit wurde alles richtig gemacht. Was also ist passiert?
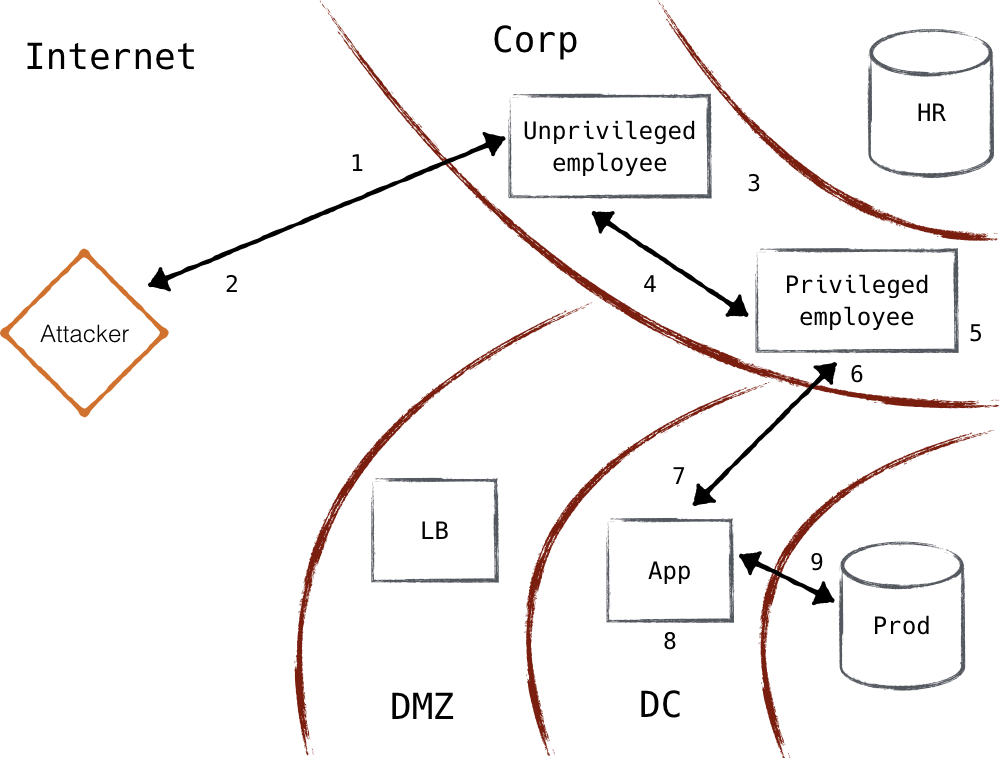
Abbildung 1-8. Angreifer dringen in das Unternehmensnetzwerk ein und produzieren anschließend im Netzwerk
Beispiel Angriffsverlauf
- Mitarbeiter über Phishing-E-Mails angesprochen
- Unternehmensmaschine kompromittiert, Schale geschaufelt
- Seitliche Bewegung durch das Unternehmensnetzwerk
- Privilegierte Arbeitsstation befindet sich
- Lokale Privilegienerweiterung auf der Workstation - Keylogger installiert
- Entwickler-Passwort gestohlen
- Kompromittierter prod-App-Host von privilegierter Workstation aus
- Entwickler-Passwort, das verwendet wird, um die Berechtigungen auf dem prod app-Host zu erhöhen
- Datenbankzugangsdaten aus App gestohlen
- Datenbankinhalte über kompromittierten App-Host exfiltriert
Bei genauer Betrachtung ist es offensichtlich, dass dieses Netzwerksicherheitsmodell nicht ausreicht. Die Umgehung der Perimetersicherheit ist mit Malware, die nach Hause telefoniert, trivial, und Firewalls zwischen den Zonen berücksichtigen bei ihren Durchsetzungsentscheidungen nicht mehr als Quelle und Ziel. Während Perimeter immer noch einen gewissen Wert für die Netzwerksicherheit haben können, muss ihre Rolle als primärer Mechanismus, durch den die Sicherheitslage eines Netzwerks definiert wird, überdacht werden.
Der erste Schritt besteht natürlich darin, nach bestehenden Lösungen zu suchen. Sicherlich ist das Perimeter-Modell der gängige Ansatz, um ein Netzwerk zu sichern, aber das bedeutet nicht, dass wir nicht anderswo bessere Lösungen gefunden haben. Was ist das schlimmstmögliche Szenario in Bezug auf die Netzwerksicherheit? Es stellt sich heraus, dass es bei dieser Frage eine gewisse Absolutheit gibt, und der springende Punkt ist Vertrauen.
Wo das Vertrauen liegt
Wenn Optionen jenseits des Perimeter-Modells in Betracht zieht, muss man genau wissen, was vertrauenswürdig ist und was nicht. Der Grad des Vertrauens legt eine Untergrenze für die Robustheit der erforderlichen Sicherheitsprotokolle fest. Leider ist es selten, dass die Robustheit über das erforderliche Maß hinausgeht, daher ist es ratsam, so wenig wie möglich zu vertrauen. Ist das Vertrauen erst einmal in ein System eingebaut, lässt es sich nur sehr schwer wieder entfernen.
Ein Zero-Trust-Netzwerk ist genau so, wie es klingt. Es ist ein Netzwerk, dem man überhaupt nicht vertraut. Zum Glück haben wir sehr häufig mit einem solchen Netzwerk zu tun: dem Internet.
Das Internet hat uns einige wertvolle Sicherheitslektionen gelehrt. Sicherlich wird ein Betreiber einen Server, der ins Internet geht, ganz anders sichern als sein lokal zugängliches Gegenstück. Warum ist das so? Und wenn die Schmerzen, die mit dieser Strenge verbunden sind, beseitigt (oder auch nur gemildert) würden, wäre das Sicherheitsopfer dann noch lohnenswert?
Das Null-Vertrauensmodell schreibt vor, dass alle Hosts so behandelt werden, als wären sie mit dem Internet verbunden. Die Netzwerke, in denen sie sich befinden, müssen als kompromittiert und feindlich betrachtet werden. Nur mit dieser Überlegung kannst du eine sichere Kommunikation aufbauen. Da die meisten Betreiber in der Vergangenheit internetfähige Systeme gebaut oder gewartet haben, haben wir zumindest eine Vorstellung davon, wie man IP so absichert, dass sie nur schwer abgefangen oder manipuliert werden kann (und natürlich, wie man diese Hosts absichert). Die Automatisierung ermöglicht es uns, dieses Sicherheitsniveau auf alle Systeme in unserer Infrastruktur auszuweiten.
Automatisierung als Ermöglicher
Zero Vertrauensnetzwerke benötigen keine neuen Protokolle oder Bibliotheken. Sie nutzen jedoch bestehende Technologien auf neuartige Weise. Automatisierungssysteme ermöglichen den Aufbau und den Betrieb eines Zero-Trust-Netzwerks.
Die Interaktionen zwischen der Kontrollebene und der Datenebene sind die kritischsten Punkte, die automatisiert werden müssen. Wenn die Durchsetzung von Richtlinien nicht dynamisch aktualisiert werden kann, ist Zero Trust unerreichbar; daher ist es wichtig, dass dieser Prozess automatisch und schnell erfolgt.
Es gibt viele Möglichkeiten, diese Automatisierung zu realisieren. Am idealsten sind eigens entwickelte Systeme, aber auch alltäglichere Systeme wie das traditionelle Konfigurationsmanagement können hier eingesetzt werden. Die weit verbreitete Einführung von Konfigurationsmanagement ist ein wichtiger Schritt auf dem Weg zu einem Zero-Trust-Netzwerk, da diese Systeme häufig Gerätebestände verwalten und in der Lage sind, die Konfiguration der Netzwerkdurchsetzung auf der Datenebene zu automatisieren.
Da moderne Konfigurationsmanagementsysteme sowohl ein Geräteinventar führen als auch die Konfiguration der Datenebene automatisieren können, sind sie gut positioniert, um einen ersten Schritt in Richtung eines ausgereiften Zero-Trust-Netzwerks zu machen.
Perimeter Versus Zero Trust
Die Modelle perimeter und zero trust unterscheiden sich grundlegend voneinander. Das Perimeter-Modell versucht, eine Mauer zwischen vertrauenswürdigen und nicht vertrauenswürdigen Ressourcen zu errichten (d.h. zwischen dem lokalen Netzwerk und dem Internet). Im Gegensatz dazu wirft das Zero-Trust-Modell im Grunde das Handtuch und akzeptiert die Tatsache, dass die "bösen Jungs" überall sind. Anstatt Mauern zu errichten, um die weichen Körper darin zu schützen, wird die gesamte Bevölkerung zur Miliz.
Die aktuellen Ansätze für Perimeter-Netzwerke weisen den geschützten Netzwerken ein gewisses Maß an Vertrauen zu. Diese Vorstellung verstößt gegen das Null-Vertrauensmodell und führt zu schlechtem Verhalten. Die Betreiber neigen dazu, ihre Wachsamkeit ein wenig zu vernachlässigen, wenn das Netzwerk "vertrauenswürdig" ist (sie sind Menschen). Selten sind Hosts, die eine Vertrauenszone teilen, vor sich selbst geschützt. Die gemeinsame Nutzung einer Vertrauenszone scheint zu implizieren, dass sie gleichermaßen vertrauenswürdig sind. Im Laufe der Zeit haben wir gelernt, dass diese Annahme falsch ist und dass es nicht nur notwendig ist, deine Hosts vor der Außenwelt zu schützen, sondern auch vor den anderen.
Da das Zero-Trust-Modell davon ausgeht, dass das Netzwerk vollständig kompromittiert ist, musst du auch davon ausgehen, dass ein Angreifer über jede beliebige IP-Adresse kommunizieren kann. Daher reicht es nicht aus, Ressourcen durch IP-Adressen oder den physischen Standort als Identifikator zu schützen. Alle Hosts, auch die, die sich "Vertrauenszonen" teilen, müssen sich ordnungsgemäß identifizieren. Angreifer sind jedoch nicht auf aktive Angriffe beschränkt. Sie können auch passive Angriffe durchführen, bei denen sie deinen Datenverkehr nach sensiblen Informationen ausspähen. In diesem Fall reicht selbst die Identifizierung des Hosts nicht aus - es ist auch eine starke Verschlüsselung erforderlich.
Es gibt drei Schlüsselkomponenten in einem Zero-Trust-Netzwerk: Benutzer-/Anwendungsauthentifizierung, Geräteauthentifizierung und Vertrauen. Die erste Komponente hat eine gewisse Dualität, da nicht alle Aktionen von den Nutzern durchgeführt werden. Bei automatisierten Aktionen (z. B. im Rechenzentrum) achten wir auf die Eigenschaften der Anwendung genauso wie auf die Eigenschaften des Nutzers.
Die Authentifizierung und Autorisierung des Geräts ist genauso wichtig wie die des Benutzers/der Anwendung. Diese Funktion ist bei Diensten und Ressourcen, die durch Perimeter-Netzwerke geschützt sind, nur selten zu finden. Sie wird oft mit VPN- oder NAC-Technologie eingesetzt, vor allem in ausgereiften Netzwerken, aber zwischen den Endpunkten (im Gegensatz zu den Netzwerkvermittlern) ist sie selten zu finden.
NAC als Perimeter-Technologie
NAC( Network Access Control) steht für eine Reihe von Technologien, mit denen Geräte streng authentifiziert werden, um Zugang zu einem sensiblen Netzwerk zu erhalten. Diese Technologien, zu denen Protokolle wie 802.1X und die Trusted Network Connect (TNC) Familie gehören, konzentrieren sich auf den Zugang zu einem Netzwerk und nicht auf den Zugang zu einem Dienst und sind daher unabhängig vom Zero-Trust-Modell. Ein Ansatz, der besser mit dem Zero-Trust-Modell übereinstimmt, würde ähnliche Überprüfungen so nah wie möglich an dem Dienst durchführen, auf den zugegriffen wird (was TNC leisten kann - mehr dazu in Kapitel 5). NAC kann zwar auch in einem Zero-Trust-Netzwerk eingesetzt werden, erfüllt aber aufgrund seiner Entfernung zum entfernten Endpunkt nicht die Anforderung der Zero-Trust-Geräteauthentifizierung.
Schließlich wird ein "Vertrauenswert" berechnet, und die Anwendung, das Gerät und der Wert werden zu einem Agenten zusammengefügt. Die Richtlinien werden dann auf den Agenten angewendet, um die Anfrage zu genehmigen. Die Fülle an Informationen, die der Agent enthält, ermöglicht eine sehr flexible und dennoch fein abgestufte Zugriffskontrolle, die sich an unterschiedliche Bedingungen anpassen kann, indem die Score-Komponente in die Richtlinien aufgenommen wird.
Wenn die Anfrage autorisiert ist, signalisiert die Steuerebene der Datenebene, die eingehende Anfrage anzunehmen. Bei dieser Aktion können auch Details zur Verschlüsselung konfiguriert werden. Die Verschlüsselung kann auf der Geräteebene, der Anwendungsebene oder auf beiden Ebenen vorgenommen werden. Für die Vertraulichkeit ist mindestens eine davon erforderlich.
Mit diesen Authentifizierungs- und Autorisierungskomponenten und der Unterstützung der Steuerungsebene bei der Koordination verschlüsselter Kanäle können wir sicherstellen, dass jeder einzelne Datenfluss im Netzwerk authentifiziert ist und erwartet wird. Hosts und Netzwerkgeräte lehnen Datenverkehr ab, auf den nicht alle diese Komponenten angewandt wurden, um sicherzustellen, dass sensible Daten nicht nach außen dringen können. Durch die Protokollierung aller Ereignisse und Aktionen der Steuerebene kann der Netzwerkverkehr außerdem leicht für jeden einzelnen Datenfluss oder jede einzelne Anfrage überprüft werden.
Es gibt Perimeter-Netzwerke , die ähnliche Fähigkeiten haben, die aber nur am Perimeter durchgesetzt werden. VPN versucht bekanntlich, diese Eigenschaften zu bieten, um den Zugang zu einem internen Netzwerk zu sichern, aber die Sicherheit endet, sobald dein Datenverkehr einen VPN-Konzentrator erreicht. Es ist offensichtlich, dass die Betreiber wissen, wie Sicherheit im Internet aussehen sollte; es fehlt ihnen nur daran, diese starken Maßnahmen durchgängig umzusetzen.
Wenn man sich ein Netzwerk vorstellt, das diese Maßnahmen einheitlich anwendet, kann ein kurzes Gedankenexperiment viel Licht auf dieses neue Paradigma werfen. Die Identität kann kryptografisch nachgewiesen werden, d.h. es spielt keine Rolle mehr, von welcher IP-Adresse eine bestimmte Verbindung ausgeht (technisch gesehen kann man damit immer noch ein Risiko verbinden - dazu später mehr). Mit der Automatisierung von werden die technischen Hürden beseitigt und VPN ist im Grunde überflüssig. "Private" Netzwerke bedeuten nichts Besonderes mehr: Die Hosts dort sind genauso gehärtet wie die im Internet. Wenn man kritisch über NAT und private Adressräume nachdenkt, wird durch Zero Trust vielleicht noch deutlicher, dass die Sicherheitsargumente dafür nicht stichhaltig sind.
Letztlich liegt der Fehler des Perimeter-Modells darin, dass es keinen universellen Schutz und keine Durchsetzung gibt. Sichere Zellen mit weichen Körpern darin. Was wir wirklich brauchen, sind harte Körper, die wissen, wie man Ausweise überprüft und so spricht, dass sie nicht belauscht werden können. Harte Körper schließen nicht unbedingt aus, dass du auch die Sicherheitszellen betreust. In sehr sensiblen Einrichtungen wäre das immer noch wünschenswert. Allerdings wird dadurch die Sicherheitslatte so hoch gelegt, dass es nicht unvernünftig wäre, diese Zellen abzubauen oder zu entfernen. In Verbindung mit der Tatsache, dass der Großteil der Zero-Trust-Funktion für den Endnutzer transparent ist, scheint das Modell den Kompromiss zwischen Sicherheit und Bequemlichkeit zu verletzen: mehr Sicherheit, mehr Bequemlichkeit. Vielleicht wurde das Problem der Bequemlichkeit (oder des Mangels an Bequemlichkeit) auf die Betreiber von geschoben.
Angewandt in der Cloud
Es gibt viele Herausforderungen bei der Bereitstellung von Infrastruktur in der Cloud, eine der größten ist die Sicherheit. Zero Trust eignet sich aus einem offensichtlichen Grund perfekt für den Einsatz in der Cloud: Man kann dem Netzwerk in einer öffentlichen Cloud nicht trauen! Die Möglichkeit, die Kommunikation zu authentifizieren und zu sichern, ohne sich auf IP-Adressen oder die Sicherheit des Netzwerks, das sie verbindet, zu verlassen, bedeutet, dass die Rechenressourcen fast zu Massenware werden können.
Da Zero Trust dafür plädiert, dass jedes Paket verschlüsselt wird, auch innerhalb desselben Rechenzentrums, müssen sich die Betreiber nicht darum kümmern, welche Pakete das Internet durchqueren und welche nicht. Dieser Vorteil wird oft unterschätzt. Der kognitive Aufwand, der damit verbunden ist, wann, wo und wie der Datenverkehr verschlüsselt werden soll, kann ziemlich groß sein, vor allem für Entwickler, die das zugrunde liegende System nicht vollständig verstehen. Indem wir Sonderfälle ausschließen, können wir auch die damit verbundenen menschlichen Fehler eliminieren.
Manche mögen argumentieren, dass die Verschlüsselung innerhalb des Rechenzentrums trotz der geringeren kognitiven Belastung zu viel des Guten ist. Die Geschichte hat das Gegenteil bewiesen. Bei großen Cloud-Providern wie AWS besteht eine einzelne "Region" aus vielen Rechenzentren, die über Glasfaserverbindungen miteinander verbunden sind. Für den Endnutzer sind diese Feinheiten oft nicht ersichtlich. Die NSA hatte genau solche Verbindungen im Jahr 2013 im Visier, und Internet-Backbone-Verbindungen sogar noch früher in Räumen wie dem in Abbildung 1-9 gezeigten.

Abbildung 1-9. Raum 641A - NSA-Abhöranlage in einem AT&T-Rechenzentrum in San Francisco
Zusätzlich gibt es Risiken in der Netzwerkimplementierung des Anbieters selbst. Es ist nicht ausgeschlossen, dass es eine Schwachstelle gibt, über die Nachbarn deinen Datenverkehr sehen können. Ein wahrscheinlicherer Fall ist, dass Netzwerkbetreiber den Datenverkehr bei der Fehlersuche inspizieren. Vielleicht ist der Betreiber ehrlich, aber was ist mit der Person, die ein paar Stunden später ihren Laptop mit deinen Aufzeichnungen auf der Festplatte gestohlen hat? Die traurige Realität ist, dass wir nicht mehr davon ausgehen können, dass unser Datenverkehr im Rechenzentrum von vor Schnüffeleien oder Veränderungen geschützt ist.
Zusammenfassung
In diesem Kapitel von wurden die grundlegenden Konzepte untersucht, die uns zum Zero-Trust-Modell geführt haben. Das Null-Vertrauensmodell macht Schluss mit dem Perimeter-Modell, das versucht sicherzustellen, dass böse Akteure das vertrauenswürdige interne Netzwerk nicht betreten. Stattdessen erkennt das Zero-Trust-System, dass dieser Ansatz zum Scheitern verurteilt ist, und geht daher davon aus, dass sich böswillige Akteure innerhalb des internen Netzwerks befinden, und baut Sicherheitsmechanismen zum Schutz vor dieser Bedrohung auf.
Um besser zu verstehen, warum das Perimeter-Modell fehlschlägt, haben wir uns angesehen, wie das Perimeter-Modell entstanden ist. In den Anfängen des Internets war das Netzwerk vollständig routingfähig. Als sich das System weiterentwickelte, entdeckten einige Nutzer Bereiche des Netzwerks, für die es keinen glaubwürdigen Grund gab, im Internet routingfähig zu sein, und so entstand das Konzept des privaten Netzwerks. Mit der Zeit setzte sich diese Idee durch, und die Unternehmen richteten ihre Sicherheitsmaßnahmen auf den Schutz des vertrauenswürdigen privaten Netzwerks aus. Leider sind diese privaten Netzwerke nicht annähernd so isoliert, wie es die ursprünglichen privaten Netzwerke waren. Das Ergebnis ist eine sehr durchlässige Grenze, die bei regelmäßigen Sicherheitsvorfällen häufig durchbrochen wird.
Mit dem gemeinsamen Verständnis von Perimeternetzwerken sind wir in der Lage, dieses Design dem Zero-Trust-Design gegenüberzustellen. Das Zero-Trust-Modell verwaltet das Vertrauen in das System sorgfältig. Diese Art von Netzwerken stützt sich auf Automatisierung, um die Sicherheitskontrollsysteme realistisch zu verwalten und ein dynamischeres und robusteres System zu schaffen. Wir haben einige Schlüsselkonzepte wie die Authentifizierung von Nutzern, Geräten und Anwendungen sowie die Autorisierung der Kombination dieser Komponenten vorgestellt. Wir werden diese Konzepte im weiteren Verlauf des Buches noch ausführlicher besprechen.
Schließlich sprachen wir darüber, wie der Wechsel zu öffentlichen Cloud-Umgebungen und die weite Verbreitung von Internetverbindungen die Bedrohungslandschaft grundlegend verändert haben. "Interne" Netzwerke werden jetzt zunehmend gemeinsam genutzt und so weit abstrahiert, dass die Endnutzer/innen nicht mehr so genau wissen, wann ihre Daten über anfälligere, weitreichende Netzwerkverbindungen übertragen werden. Das Ergebnis dieses Wandels ist, dass die Datensicherheit beim Aufbau neuer Systeme wichtiger denn je ist.
Das nächste Kapitel befasst sich mit den übergeordneten Konzepten, die verstanden werden müssen, um Systeme zu entwickeln, die Vertrauen sicher verwalten können.
Get Zero Trust Netzwerke now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

