Chapter 1. How Application Architecture Is Changing
Less than a decade ago, the software industry was still talking about scaling monolithic architectures to meet the scale needed for the internet. Behind the scenes, the principles of containerized microservice architecture were getting ready to disrupt established practices. Over the last few years, container orchestration, DevOps, and the necessity of running in diverse and distributed environments have driven a revolution in software architecture.
This chapter briefly discusses how we got here, the rationale behind a few different software paradigms that coexist today, and some Kubernetes concepts that will be useful as we dive into KubeVirt.
At the turn of the 21st century, in the early days of a rapidly growing internet, large companies maintained on-premises data centers containing rack upon rack of servers. Managing these servers meant providing redundant power, storage, and network connectivity to a vast number of physical machines. Scaling was costly and slow. Increasing the capacity of a data center meant requisitioning more hardware. On-premises hardware also requires costly in-house security expertise in the form of on-site operations, security, and site reliability roles.
Virtualization technology made it possible to outsource the job of running the data center. This meant that the data center itself became a commodity or even a service, allowing organizations to run applications off-site or scale data centers up and down as needed. Virtual machines (VMs) do the same work as physical machines but are more flexible in a number of ways. You can run multiple VMs on a single physical host. When necessary, you can move a VM from one host to another or run multiple copies of the same VM.
A VM includes a virtualized operating system, meaning that you can run several VMs with different guest operating systems on a single host that might be running another operating system entirely. Software called a hypervisor runs and manages the VMs, allocating resources to each as needed. Figure 1-1 shows how several VMs with their own operating systems run on a single host.
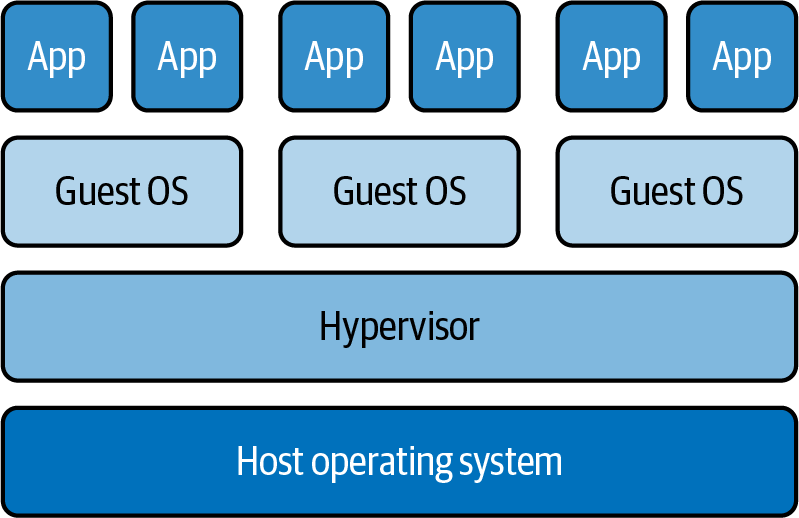
Figure 1-1. VMs running on a host, managed by a hypervisor
As virtualization made the data center more of a service than a capital expenditure, it became easier to scale services, security, and the capability to accommodate more application features and customer traffic. Increasing data center capacity was simply a matter of provisioning more VMs, which could be made available very quickly. Applications designed to run on physical servers could run on VMs with no modifications and could be scaled up and down elastically. This was the architecture that began to make the cloud possible, but there was one more development to come.
Containers and Microservices
As applications in production became more scalable, it was evident that software development processes needed to follow suit. Monolithic application architecture with long release cycles couldn’t keep up with evolving needs. VMs, which had solved part of the scale problem, didn’t always offer sufficient performance because they were still tied to software architectures not designed to scale horizontally. A monolithic application can’t add more instances of specific parts of itself, so increasing the capacity of such an application is either wasteful or requires rewriting significant parts of the code. Only by decoupling different parts of an application can you truly scale in response to unpredictable demand.
Container technology, which has been evolving since its genesis in the late 1970s, packaged an application and its dependencies in a portable runtime environment. Containers are stateless and immutable, which makes them portable and horizontally scalable. Unlike VMs, containers don’t virtualize the operating system. Every container on a host provides a separate, isolated runtime environment for its applications but uses the host operating system and its kernel. The host in this case can be a physical server or, more often, a VM.
Containers offer dramatic performance improvements in scaling: where a VM takes minutes to start, containers start in seconds, making it possible to scale horizontally much faster in response to dynamic demand. While a VM image is gigabytes in size, containers are typically measured in megabytes. This smaller footprint makes it practical to run large numbers of them. Containers offer a solution with many of the benefits of VMs plus the ability to scale much more rapidly. Figure 1-2 shows how several containers share a host’s operating system.
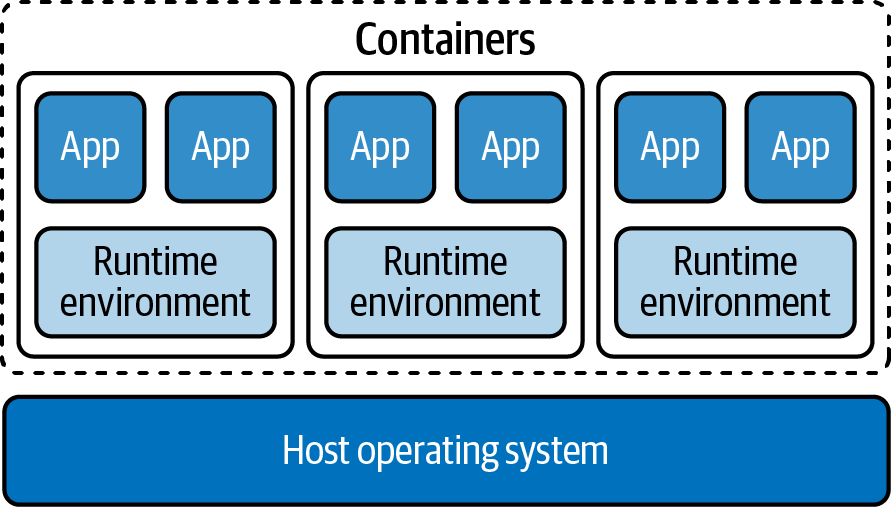
Figure 1-2. Containers running on a host
At the same time, software architecture began to favor microservices, separating different application functions from the standpoint of development as well as at runtime. This meant that teams could develop different parts of an application independently, releasing more frequently—often, many times per day. This made it possible, in turn, to shift testing left (earlier) in the process, which improved overall software quality.
Ultimately, development and operations teams started working together on an approach called DevOps, which relies on automation to make early testing and frequent releases possible and reliable. As the number of containers grew, it became necessary to orchestrate them—to bring automation and scale to container management.
Container Orchestration: Kubernetes
The predominant container orchestration tool in the enterprise, Kubernetes, provides building blocks and mechanisms for deploying, managing, and scaling containerized applications. The basic unit of computing resources in Kubernetes is a pod, which can run one or more containers.
A Kubernetes deployment runs on a cluster of servers, most of which are used as worker nodes that run containerized workloads. A few control plane nodes do the work of managing the Kubernetes cluster itself. The nodes that make up the control plane work to maintain the cluster and all its pods. Figure 1-3 shows the control plane and a few worker nodes in a typical Kubernetes cluster.
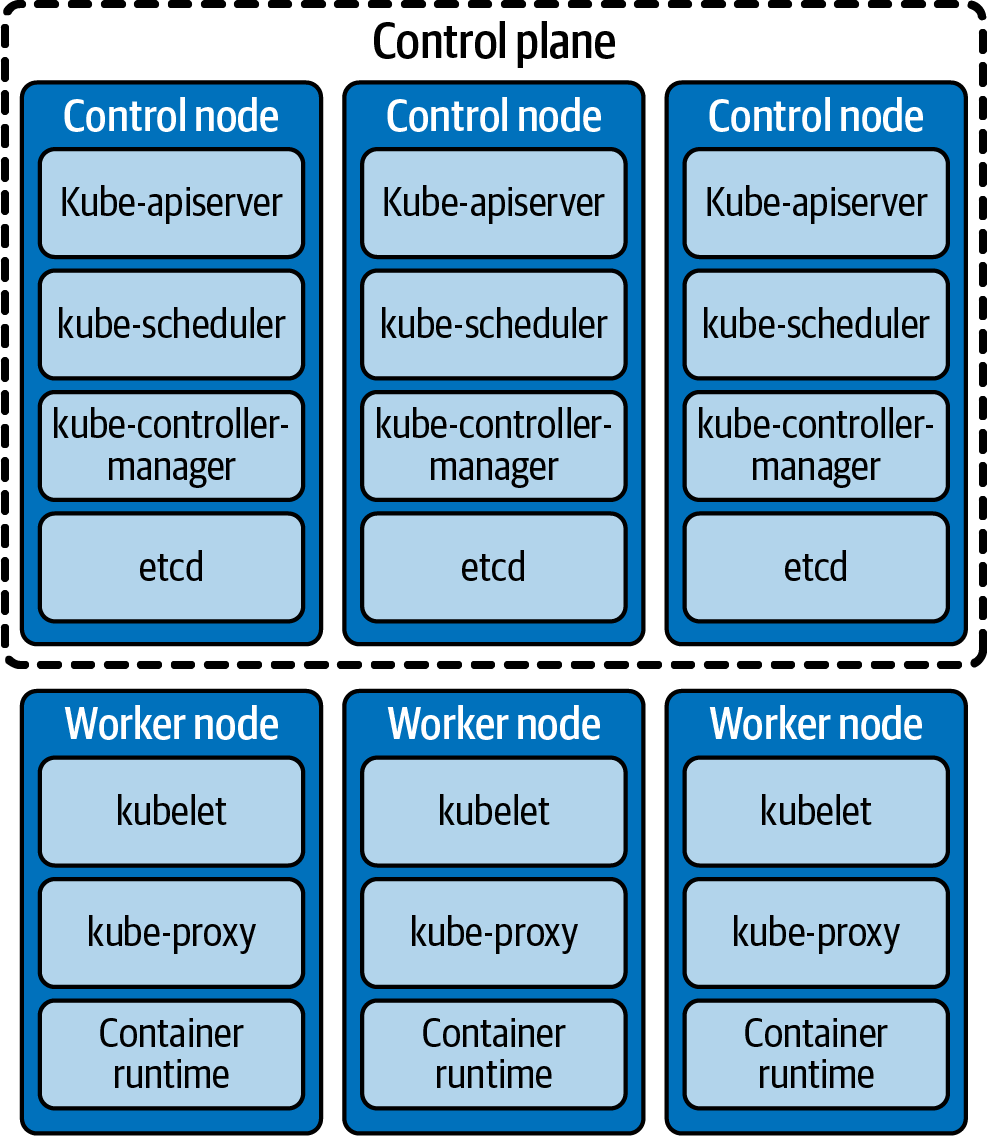
Figure 1-3. Services that run on control plane nodes and worker nodes in a Kubernetes cluster
The control plane nodes run redundant copies of the Kubernetes components that manage the cluster:
- kube-apiserver
-
Exposes the Kubernetes API, providing control of the cluster
- etcd
-
Stores cluster-wide state data as key-value pairs
- kube-scheduler
-
As pods are created, assigns them to nodes
- kube-controller-manager
-
Runs the controllers that keep nodes, jobs, and other cluster objects running as specified
Along with its pods, each worker node runs a few Kubernetes services that keep the pods running and provide the Kubernetes environment:
- kubelet
-
Manages the lifecycle of pods and containers
- kube-proxy
-
Manages network communication to and from outside the cluster
- container runtime
-
Provides the environment where containers run
Kubernetes represents cluster components and policies as objects, defined by a type called a resource. In other words, an object is a created instance of a declared resource. Standard Kubernetes resources describe pods, workloads, storage, and other features and qualities of a cluster. You create objects by defining them in files called manifests. A Kubernetes controller for each resource—each declared type of object—works to maintain every object according to its manifest file. The manifests and observed states of object instances are stored in etcd. The controller for each resource works to resolve discrepancies between the declared and observed states of instances of its resource type. The process of continually examining and adjusting the states of the objects is articulated as a control loop for the object type.
Custom resource definitions and operators
You can extend the Kubernetes API with custom resource definitions (CRDs) that define new kinds of resources. Each CRD requires its own custom controller to determine the behavior of the object and define how to maintain its state to match the declared specification. CRDs are useful for building new capabilities onto Kubernetes.
An operator is an extension to Kubernetes that manages an application and its components using CRDs and controllers. KubeVirt is a Kubernetes operator that adds CRDs and relies heavily on their declared manifests for managing VMs.
Persistent storage
Initially, the design of container architecture envisioned stateless workloads, which don’t need to keep data from one runtime to another. Accordingly, containers are immutable, meaning that they don’t change from one run to another. When you move or restart a container, you don’t have to worry about persistent data or changes to the container state, making containers very resilient and portable. The rise of more complex containerized applications necessitated the development of persistent storage for Kubernetes.
A Kubernetes resource called a PersistentVolume (PV) represents a unit of storage that can be provisioned dynamically as needed or set up ahead of time based on predicted storage needs. A PV defines details and policies about the data it will hold. On its own, a PV is not owned by a specific application or project.
A containerized application in Kubernetes requests ownership of a PV using a PersistentVolumeClaim (PVC) object, which is also used as an identifier for the claim once the request is granted. Once an application has used a PVC to claim a PV, the PVC is bound to the PV, and that storage can’t be used by other applications. The PV and PVC resources declare the virtual file mounts between your containers and paths outside of these containers. The advantage here is these external paths typically have longer persistence than the more ephemeral lifecycles of containers and pods.
PodPresets, ConfigMaps, and Secrets
Kubernetes makes it possible to create pods from templates and to provide configuration, environment variables, and credentials to pods.
A PodPreset is an object you can use to inject environment variables and other information into a pod as it’s created. A label selector on the PodPreset specifies which pods the PodPreset applies to. When you create a pod with a matching label, it’s populated with information from the PodPreset. This lets you author templates without the need to know all the information for every pod ahead of time.
With a ConfigMap, you can store nonconfidential data as key-value pairs, then pass the data to a pod as environment variables, command-line arguments, or configuration files. This lets you add environment-specific information to pods, making them more easily portable.
A Secret object makes it possible to pass confidential data to a pod, eliminating the need to store credentials or other sensitive data in application code, a container image, or a pod specification.
VMs and Containers Today
Although VMs and containers are very different, they have things in common. The ability to create a container from a template and then securely inject credentials and other information is familiar to anyone who has created VM images for use across a data center. Creating and orchestrating VMs with tools such as Puppet and Chef is not so different from managing containers with Kubernetes. However, these similarities don’t make it easy to move all virtualized workloads to containers. Containers and VMs have different characteristics and capabilities that make some workloads better suited to one runtime environment or the other.
Get What Is KubeVirt? now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

