Chapter 4. Architecting Multiple Data Lakes
Enterprises build data lakes for a variety of reasons. Some start as single-project data puddles created by a line-of-business or project team and grow into data lakes gradually. Some start as ETL offloading projects by IT and pick up additional users and analytic use cases along the way. Others are designed from the get-go as centralized data lakes by IT and analytic teams working together. Yet others are created in the cloud as shadow IT for business teams that don’t want to wait for the official IT team.
Similarly, enterprises don’t always have their data lakes in the same public cloud. Some data lakes contain data that enterprises are not allowed to keep or not comfortable with keeping in public clouds, or regulations require having different data lakes to comply with data privacy and other local laws. Sometimes data lakes are created by different divisions or are acquired by companies in different public clouds. Other data lakes are deliberately created in different public cloud providers to take advantage of unique capabilities, data locality, vendor independence, and a variety of other reasons.
Regardless of the reasons, many enterprises end up with multiple data lakes. The question then becomes, should these be merged into one or kept separate? This chapter answers this question first and then explores approaches to managing multiple data lakes by applying virtual constructs such as data federation, data fabrics, and data catalogs. No simple standard answers exist, but this chapter covers rules of thumb and best practices.
To Merge or Not to Merge?
This section covers the advantages and disadvantages of keeping separate data lakes. These are important topics to consider when making decisions about your approach to data lakes. We’ll also dive into a good compromise solution that can give you some of the advantages, while mitigating some of the disadvantages, of merging your data lakes.
Reasons for Keeping Data Lakes Separate
The reasons for separate data lakes are usually historical and organizational. Typical reasons include the following:
- Regulatory constraints
-
In regulated industries and for personal data, regulatory constraints often forbid the merging or commingling of data from different sources or geographies. For example, the EU has strict data privacy guidelines that are implemented differently by every country. Medical institutions usually have strict data sharing guidelines as well.
- Organizational barriers
-
Sometimes organizational barriers to sharing data exist, mostly around budgeting and control. Financing a common data lake and deciding on common technologies and standards between warring business units with greatly differing goals and needs may prove to be an insurmountable challenge.
- SLAs and governance levels
-
Keeping a production-quality data lake, in which data is carefully curated and has strong SLAs and governance, separate from data lakes dedicated to experimental analytics, sandboxes, and development projects can help guarantee good quality, governance, and strong SLAs for the former.
Advantages of Merging Data Lakes
If you are not constrained by the kinds of regulatory or business requirements mentioned in the previous section, you should try to restrict your organization to a single large data lake. There are several reasons for this:
- Administrative and operational costs
-
A lake that grows twice as large doesn’t usually need a team that’s twice as large to manage it. Of course, the same team can manage multiple lakes, but if the lakes are hosted on different public clouds, teams trained on those clouds are usually required to support them. Even if a single platform is used by the enterprise, but there are multiple data lakes because of organizational and control issues, each organization tends to staff its own team so it can control its own destiny. This duplication raises costs.
- Data redundancy reduction
-
Since the data lakes belong to the same enterprise, chances are that data lakes contain quite a bit of redundant data. By merging lakes, you can eliminate this and reduce the quantity of data stored. Data redundancy also implies ingestion redundancy: the same data is extracted and ingested multiple times from the same source. By consolidating, you can lessen the loads on the sources and the network. If all the data lakes are on the same platform, the best practice is to create shared data buckets (e.g., S3 buckets) or tables that can be updated once and shared by multiple data lakes. However, if data lakes are in different public clouds, that would not be possible.
- Reuse
-
Combining the lakes into one, or at least sticking with a single public cloud vendor, will make it easier for the enterprise to reuse the work done by one project for other projects. This includes scripts, code, models, data sets, analytic results, and anything else that can be produced in a data lake. It will also be easier to train the users on a common set of tools.
- Enterprise projects
-
Some groups work on an enterprise scale and may require data from different organizations. These projects will greatly benefit from having a single centralized data lake instead of having to merge data from multiple lakes.
There are also other business advantages to consider, including faster time to insight. Next we’ll turn our attention to using the same cloud platform to build multiple data lakes.
Building Multiple Data Lakes on the Same Cloud Platform
One compromise that addresses some of the reasons for keeping data lakes separate, yet achieves some of the advantages of merged data lakes, is to build physically separate data lakes on the same cloud platform, such as AWS, Azure, or GCP, which we covered in the previous chapter. This allows for reuse of tools, support for enterprise projects through easy access to the data in different data lakes, and lower administration and training costs, since only one technology stack needs to be administered, and users can be trained on a single set of tools.
Table 4-1 illustrates the cost of supporting requirements for different data lake architectures (Low is good).
| Single data lake | Multiple data lakes on the same cloud platform | Hybrid data lakes and different platforms | |
|---|---|---|---|
| Organizational independence | Low | High | High |
| Data residency rules compliance | Low | Medium | High |
| Different SLAs | High | Low | Low |
| Administrative costs | Low | Low | High |
| Data redundancy/costs | Low | Low | High |
| Reuse | High | High | Low |
| Training effort | Low | Medium | High |
| Enterprise-wide projects | Low | High | High |
If you decide to keep your data lakes separate, the next section will help you address some of the challenges of multiple data lakes by turning them into a single virtual data lake.
Virtual Data Lakes
One approach that has been gaining ground is creating a virtual data lake to mask the existence of multiple physical data lakes. Instead of living with multiple data lakes or merging them into one centralized data lake, why not present them to the user as a single data lake, while managing the architectural details separately? Several approaches can accomplish this data virtualization: data federation masks the physical location of the data by presenting it as a set of virtual tables and files, data fabrics present files from different physical systems in a single filesystem, while enterprise catalogs do not hide the physical location of the data, but help users find and provision data from multiple systems.
Data Federation
Data federation refers to combining, or federating, data from different databases into a single virtual database. It has been around for at least 20 years. IBM’s DataJoiner, introduced in the early 1990s, created a “virtual” database whose tables were really views on physical tables in multiple databases. The users of DataJoiner would issue SQL queries against these virtual tables, and DataJoiner would translate them into queries that it would apply against the different databases; it would then combine the results and present them back to the user, as illustrated in Figure 4-1.

Figure 4-1. Historic example of a virtual database
DataJoiner eventually evolved into IBM InfoSphere Federation Server and was matched by products from Denodo, TIBCO (Composite), Informatica, and others. More modern versions of these products support RESTful APIs and can interact with applications and filesystems as well as databases. Nevertheless, at their core, these products are all designed to create a virtual database that, under the covers, can pull data from different systems and make it look like a single table.
Applying this technology to data lakes carries several significant challenges. The biggest challenge is that you have to manually configure each virtual table and map it to the physical data sets, whether they’re files or tables. In a data lake with millions of files loaded through frictionless ingestion, that’s simply not practical. Then there’s the traditional distributed join problem: combining or joining large data sets from different physical systems requires sophisticated query optimization and lots of memory and computing power. Finally, you have the schema maintenance problem: when the schema changes, the virtual tables have to be updated as well. Since a schema is applied only when data is read (schema on read), the users may not know that the schema has changed until their queries fail. And even then, it may not be clear whether the problem was caused by a schema change, a data problem, human error, or any combination of these.
Data Fabric
Just as data lakes arose as a way to cope with the massive growth in volume and variety of data, big data virtualization applies the big data principles of schema on read, modularization, and future-proofing to create a new approach to data virtualization that can cope with the massive volume and variety of data in the enterprise. At the heart of the new approach is a virtual filesystem that represents physical data sources as virtual folders, and physical data sets as virtual data sets. This approach mirrors how staging zones are organized in data lakes, as described in Chapter 2. This virtualization allows the data to stay in its original data source, while being exposed to other business users.
This virtual filesystem, called a data fabric, is provided by vendors such as HPE (MapR), Cloudera (ViewFs), and Hitachi Vantara. It presents data from different public clouds and on-premises systems as a single filesystem with a single API. Any program running on any system can then access any data set in the filesystem, and the data fabric delivers it to that program for processing.
Since the programs are not aware of the location of the data, this approach may cause large performance challenges if, say, two massive files from different data lakes across the world and platforms are read by a program.
Catalogs and Data Oceans
A different approach that does not require a single data fabric with complete location transparency is to build a data catalog that provides more visibility into data location while still creating a single place for users to find and provision the data. Because a virtual data lake can be massive and potentially contain millions of data sets, a search mechanism is needed to find and navigate them. This role is usually played by a data catalog that presents all the data in the enterprise, including the data lakes.
Figure 4-2 illustrates the process. With this approach, only the metadata (information describing the data) is in the catalog (illustrated by the blue rectangle in the diagram), so users can find the data sets they need quickly (step 1 in the diagram). Once a data set is found, it can be provisioned to give the user access either by copying it to the user’s project area or by giving the user permissions to access it in place (step 2 in the diagram).
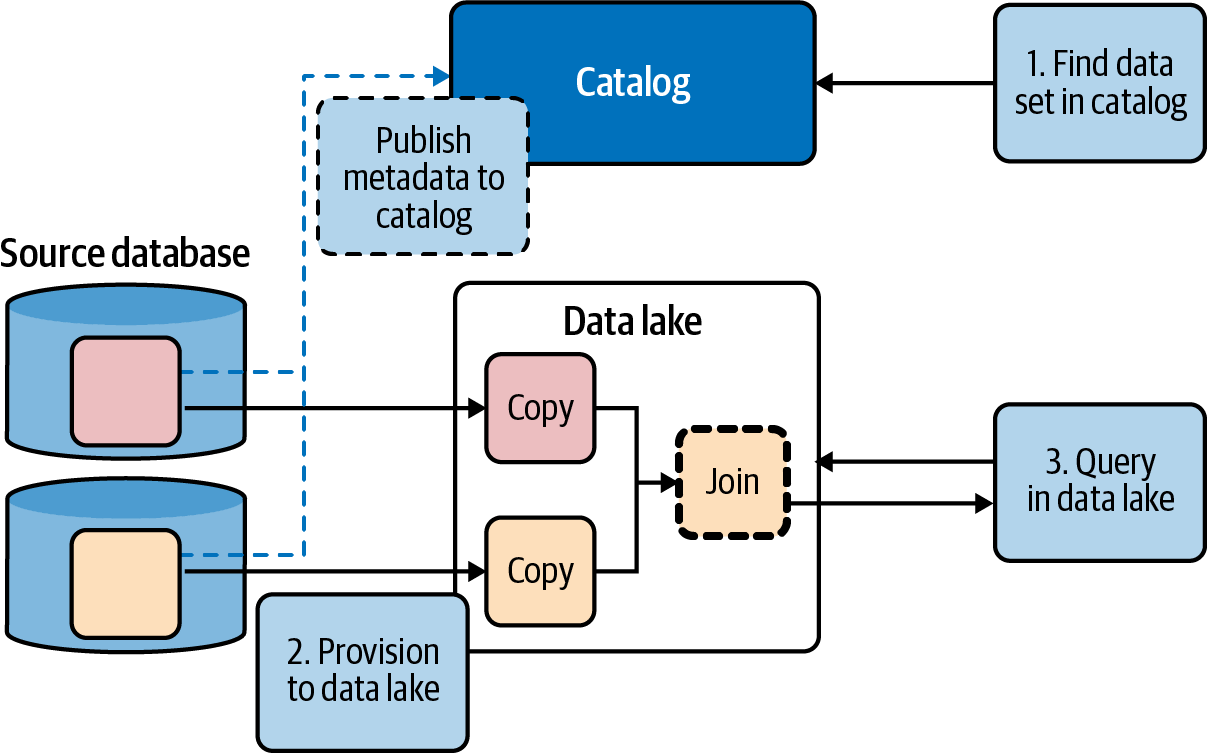
Figure 4-2. A virtual data lake
Because both tables in Figure 4-2 have been copied to the same physical system, the joins are local, much easier to implement, and faster to execute (step 3 in the diagram). Provisioning can involve an approval process whereby the user requests access for a period of time and specifies a business justification. The request is reviewed and approved by the data owners, and the data is then copied over. Finally, the copy of the data is kept up-to-date by ETL tools, customer scripts, or open source tools like Sqoop that connect to a relational database, execute a user-specified SQL query, and create an HDFS file with the results of the query.
Because the catalog is the main interface for finding and provisioning data in the data lake, it enables an elegant solution to building a virtual data lake. When users look for a data set, it really does not matter to them where it is physically located—it looks the same and can be found in exactly the same way. An intelligent provisioning system can be provided so if the user wants to use a data set in a tool, it may be provisioned in place (i.e., opened directly in the tool), while if it needs to be joined with other data sets or modified, it can be transparently copied over to the physical data lake and made accessible there.
Conclusion
If you are considering multiple data lakes, this chapter discussed reasons to keep them separate or to merge them. If strong organizational, regulatory, or security reasons indicate keeping data separate, consider keeping all the data lakes on a single cloud platform to take advantage of learning and administering a single technology stack, easy reuse of data and tools, and easy data access for enterprise-wide projects. If you do end up with a heterogeneous architecture, whether because it is a hybrid and some data needs to remain on premises or because there are compelling reasons to use different platforms, consider different approaches to creating a single virtual data lake through a set of shared virtual tables, by building a virtual data fabric, or by using catalogs to create data oceans. Whether you have a single or multiple data lakes, always build a data catalog, so users can find and provision the data that they need. Consider other virtualization techniques if you have applications that have to use data from disparate systems or if you need to move data around for cost or compliance reasons. Both data federation and a data fabric provide homogeneous data access to the disparate data sources, freeing the applications from having to worry about heterogeneous data access, as well as location transparency that allows administrators to move data to different systems and storage tiers.
Many choices and considerations go into building a data lake. I do not claim to have covered them all, but instead, focused on what I consider key aspects for you to consider when building a cloud data lake, including why build it, how to build it, on what platform, and how to make it successful. Data lake construction can be challenging, but many companies have succeeded and are reaping significant returns. I hope this report will help you do so as well.
Good luck and enjoy the journey!
—Alex
Get What Is a Data Lake? now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

