Chapter 1. Introduction
Administrators, analysts, and developers have been watching data fly by on screens for decades. The fast, free, and most common method is to “tail” a log file. tail is a standard Unix-like operating system command that allows you to stream all changes to a specified file to the command line. Without any additional options, the logs will display in the console without any filtering or formatting. Despite the overwhelming amount of data scrolling past, it’s still a common practice because the people watching can often catch a glimpse of something significant that is missed by other tools. When filtering and formatting are applied to this simple method, it increases the ease and likelihood of catching significant events that would otherwise be ignored or surfaced only after a significant delay. LNav is an application that represents streaming infromation on a console with some ability to highlight and filter information (see Figure 1-1).
Because of the rate at which information is scrolling by, anything noticed by a human observer with this method will be due to them observing either a pattern or the breaking of a pattern. Statistics, aggregates, groupings, comparisons, and analysis are out of reach for this method at a high data frequency. This method also has a limitation of one log file per command line. In order to progress from this standard of streaming data visualization, this book will explore ways to preserve and build on the effect of noticing something significant in live events. The challenge is how to do this without abstracting the context so far that it becomes another dashboard of statistics that sends the observer back to the tried and true method of command-line scrolling.
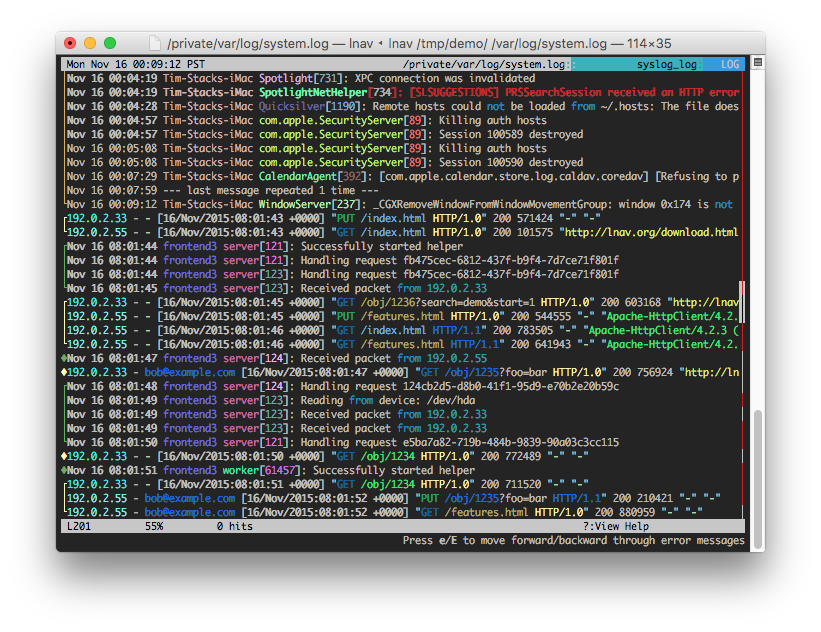
Figure 1-1. A log file viewer (source: http://lnav.org)
A great analogy for visualizing streaming data is visualizing operational intelligence, described in a Netflix database project as follows:
Whereas business intelligence is data gathered for analyzing trends over time, operational intelligence provides a picture of what is currently happening within a system.
Operational intelligence relies heavily on streaming data. The data is usually automatically processed, and alerts are sent when anything goes outside of a defined threshold. Visualizing this information allows people to better understand what’s occurring, and whether any automated decisions should be created, deleted, or adjusted.
Why Visualizations
Visualizations certainly can be eye candy, but their value isn’t just in attracting eyeballs and mesmerizing people. In general, visualizations can give you a new perspective on data that you simply wouldn’t be able to get otherwise. Even at the smaller scale of individual records, a visualization can speed up your ingestion of content by giving you visual cues that you can process much faster than reading the data. Here are a few benefits of adding a visualization layer to your data:
Improved pattern/anomaly recognition
Higher data density, allowing you to see a much broader spectrum of data
Visual cues to understand the data faster and quickly pick out attributes
Summaries of the data as charted statistics
Improved ability to conquer assumptions made about the data
Greater context and understanding of scale, position, and relevance
On top of all that, visualizations also help products sell, get publicity, and screenshot well. Visualizations attract people and entice them to make sense of what they see. They become necessary when trying to understand more complex data such as the automated decisions behind an organization’s operational intelligence.
The Standard
The processes and applications that we accept as tried and true were written for a different set of circumstances than we are faced with today. There will continue to be a place for them for the problems they were developed to solve, but they were not designed for the volume, frequency, variance, and context that we are seeing now and that will only increase over time.
There are recent highly scalable solutions for processing and storing this data, but visualizing the data is left behind as we resign ourselves to the idea that humans can’t possibly review all of it in time to have an impact. Visualizing the data is required only for people to understand it. As processes are developed to deal with this post-human scale, visualizations are falling by the wayside—and along with them our ability to gain immediate insights and make improvements to the applications. The same problem occurs if too many processing steps are hidden from view. Examples of this effect are the inverse of the defined goals of streaming data visualization:
-
Missing a significant pattern that can be intuitively found by a person but that would be difficult to predict ahead of time and develop into an application
-
Missing something anomalous that would justify an immediate action
-
Seeing a security-related event as an alert and out of the surrounding context
-
Seeing a threshold pass as an alert, with a limited view of what led to it
-
Only preprogrammed understanding of the evolution of the data over time
Terms
Streaming data is not a canonized technical term. Its meaning can vary based on environment and context. It’s often interchanged with real-time data and live data. Streaming data is any data that is currently transmitting in a serial fashion as events occur. For the purposes of this book, we will also specify that the stream is at a rate of at least 10 records per second, or around 1 million records per day. This rate is too high for a single person to be able to watch the data and get anything meaningful from it without the help of some data processes and applications. This is also a conservative rate of data for modern applications and internet services. The Wikimedia network broadcasts hundreds of edits per second in a publicly available data stream.
Visualization is a generic term for any way to present data to a person. We will divide it into a few categories for later reference:
- Raw data
- Tabular data
-
Shown in a grid of columns and rows, so that common fields are aligned vertically and each record has its own row
- Statistics and aggregates
-
Shown as charts and dashboards of hand-picked details that have significance
- Visualizations
-
Abstract representations of data for intuitive interpretation by the analyst
All of these categories have a long history of use and well-defined use cases. They have been in use since print media was the norm and haven’t advanced much, partially because the conventional wisdom has been to keep them compatible with a printable report. Being print-compatible makes it easy to get a snapshot at any time to include in a paper report, but also enforces limitations.
Analysts are the primary people to whom data is being displayed. They are the ones performing interactive analyses on the data presented.
Data Formats
There are a lot of different formats that raw data can come in. We need to work with whatever format is output and transform it into the format that we need for any downstream processes, such as showing it in a visualization. The first significant attribute of a data format is whether it’s human-readable. Table 1-1 shows examples of formats that are human-readable, and Table 1-2 shows examples of formats that are not.
Format |
Description |
Example |
|---|---|---|
UTF-8 |
There was a modification to the English Wikipedia page for the Australian TV series The Voice from an unknown user at the IP address 82.155.238.44. |
|
CSV |
Data is flat (no hierarchy) and consistent. The fields are defined in the first row, and all of the following rows contain values. Fields are delimited by a character such as a comma. |
Link,item,country,user,event “https://en.wikipedia.org/w/index.php?diff=742259222&oldid=740584413”, “The Voice (Australian TV series)”,"#en.wikipedia”,"82.155.238.44”,"wiki modification” |
|
XML |
An early, verbose, and highly versatile format standardized to have a common approach to overcome CSV’s limitations. |
<xml> <link> https://en.wikipedia.org/w/index.php?diff=742259222&oldid=740584413 </link> <item> The Voice (Australian TV series) </item> <country> #en.wikipedia </country> <user> 82.155.238.44 </user> <event> wiki modification </event> </xml> |
JSON |
A format designed to be more succinct than XML while retaining the advantages over CSV. |
{ “link”:”https://en.wikipedia.org/w/index.php?diff=742259222&oldid=740584413“, “item”:"The Voice (Australian TV series)”, “country”:"#en.wikipedia”, “user”:"82.155.238.44”, “event”:"wiki modification” } |
Key/value pairs |
Link=”https://en.wikipedia.org/w/index.php?diff=742259222&oldid=740584413“, Item="The Voice (Australian TV series)”, Country=#en.wikipedia”, User="82.155.238.44”, Event="wiki modification” |
Data Visualization Applications
Applications that visualize data can be divided into two categories: those that are created for specific data and those that allow visualizing any data they can attach to. General-purpose data visualization applications will allow you to quickly take the data that you have and start applying it to charts. This is a great way to prototype what useful information you can show and understand the gaps in what might be meaningful. Eventually, a design is chosen to best make decisions from, and a context-specific visualization is created in a purpose-built application.
Another distinction we will make for this book is how the visualization application handles constantly updating data. Options include the following:
-
A static visualization that uses the data that is available when the visualization is created. Any new data requires a refresh.
-
A real-time visualization that looks like the static one but updates itself constantly.
-
A streaming data visualization that shows the flow of data and the impact it has on the statistics.
Assumptions and Setup
This introductory chapter only hints at the variations of data and the processes for manipulating it. A common set of data sources and processes will be established for reference in the rest of this book so that they can be consistently built upon and compared. The data sources are available for free and are live streams (Table 1-3). These are ideal sources to test the ideas put forth in this book. They will also provide a much-needed context focus, which is essential for effectively visualizing data.
Data |
Description |
Storage |
Volume |
|---|---|---|---|
Wikimedia edits |
All edits to Wikimedia as a public stream of data |
Document store |
300/second |
Throttled Twitter feed by PubNub |
A trickle of the Twitter firehose provided as a public demo by PubNub |
Distributed storage | 50/second |
| Bitcoin transactions | Bitcoin transactions with information for tracking and analyzing | Database | 20/second |
You will need to establish your own standards for formats, storage, and transport so that you have a set of tools that you know work well with each other. Then, when you run into new data that you need to work with, you should transform it from the original format into your standard as early in the workflow as possible so that you can take advantage of your established toolset.
The data format for the rest of the book will be JSON. Even if you are working with another format, JSON is flexible enough to be converted to and from various formats. Its balance between flexibility, verbosity, and use within JavaScript makes it a popular choice.
Node.js will be the primary server technology referenced. Its primary advantage is that it runs on JavaScript and can share libraries with browsers. It also happens to be a great choice for streaming data solutions that are not so large that they require dozens of servers or more.
Angular.js is the main client library used in the book. Both Angular.js and React are common and appropriate choices to show event-based data in the browser.
This combination of components is often referred to as a MEAN stack for MongoDB, Express.js, Angular.js, and Node.js. MongoDB is a popular document store, and Express is a web server built on Node. Mongo and Express aren’t as essential to the discussion of this book, though we will review storage considerations in more detail. Several other libraries will be mentioned throughout this book as needed that build on this technical stack.
The client components, when mentioned, will be browser-based. A modern browser with at least WebSockets and WebGL is assumed. What these are and why they make sense will be detailed later, but it’s a good idea to check that your browser supports them before getting started. You can do this by following these links:
Get Visualizing Streaming Data now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

