Chapter 4. Concept-First Design for Data Products
In this chapter, you will learn a new and straightforward definition of a data product, described across four facets. You’ll also discover a method called concept-first design for crafting data products and understand their relationship to schemas.
Concept-first design is an effective strategy that seamlessly bridges the communication gap between nontechnical business teams and technical teams. It employs universally understood tools, such as diagrams and spreadsheets, to represent ideas and challenges.
The beauty of concept-first design lies in its simplicity. One translates business language or logic into a hierarchical format, akin to how JSON and JSON Schema operate—these are digital languages that machines comprehend. By using concept-first design, the effort to convert business logic into code is reduced. This minimizes the errors and inefficiencies often arising when developers and data stewards make assumptions during concept modeling.
Imagine a data product as a box containing a single tool, complete with everything a user needs to accomplish a task. Think of buying a friend an electronic gift. If the gift lacks a battery or instructions, it leaves your friend scrambling to find missing pieces—a frustrating experience. This is precisely how you must think about data products. A data product should be a comprehensive package, providing users with everything they need to utilize the data effectively. The goal is to avoid making users chase down additional components or “fix” elements to make the data usable.
The concept-first design approach is the key to creating these all-inclusive data products. It’s a method of translating the concepts you’ve derived from stakeholder conversations into a pseudocode format. This format acts as a relay baton, allowing you to pass the concepts to data practitioners to implement in line with the business needs of your data product. Concept-first design provides a high-level representation of concepts (either visually or textually), whereas a schema deep dives, formalizing these concepts with meaning and hierarchical structures.
Tip
Consider this: if you interview five stakeholders and ask them to describe a problem and the concepts involved, you’re likely to get five different perspectives. However, if you ask them to formalize their definitions into a pseudocode data structure, you’ll see more concrete alignments and misalignments and expose the gaps in the shared understanding of problem concepts and objectives.
Being data driven refers to an approach where data is at the core of the decision-making process. The idea is that all insights, strategies, and decisions are based on data analysis and interpretation, rather than solely on intuition or personal experience. In a data-driven approach, data is considered a critical asset, and the systems and procedures are designed around it to ensure its accuracy, consistency, and availability.
In order to become data driven, it is crucial to first align people with the concepts that the data is going to represent. This is where concept-first design comes into play. Concept-first design is about defining the concepts and their relationships before they are transformed into a data model. It starts with understanding the business requirements, defining the key concepts, and making sure everyone involved has a shared understanding of what these concepts represent, for whom, and why.
These concepts form the foundation for the data model and help to ensure that it accurately reflects the real-world scenario it is intended to represent. To implement a concept-first design, stakeholders must define these concepts, structure them formally into schemas, assign meaning to the used vocabulary, identify any gaps, and work collaboratively to align everyone’s understanding. This leads to the creation of a shared understanding that adequately meets the stakeholder needs. Once this shared understanding is achieved, the data product is well designed and ready for implementation.
The transformation into a data-centric organization begins with a concept-first design approach, fostering a culture where decisions are made based on data, leading to increased efficiency, better insights, and more informed decision making. This chapter is your operating manual. As the data champion, you’re the crucial link between business stakeholders, data, and coding teams. Chapter 5 will delve into the nuts and bolts of implementation. For now, let’s focus on your role in creating a compelling and effective data product.
Packaging and Products: An Example Using Coffee
As we’ve established, data should be considered a product, and to hammer that home we’re going to use an actual product, coffee, as our running example as we talk about data. Picture yourself as an artisanal coffee producer. Your craft revolves around having detailed knowledge of coffee varieties and the process of transforming raw beans into a tantalizing brew. You journey to Colombia, one of the world’s premier coffee-producing nations, to source the finest beans and partner with local farmers to ensure optimal harvesting and processing methods.
You opt for small-batch roasting to maintain meticulous control over the process, fine-tuning the roasting conditions to achieve the perfect flavor profile. Unlike large-scale commercial roasters, your intimate approach allows for a more distinct and refined taste. Each batch, even those from the same source, demands unique adjustments based on factors like the age of the beans and the ambient roasting conditions.
Upon completing the roasting, you package your beans to shield them from oxygen and light, appending a label indicating the brand name, coffee type, roast level, and other pertinent information. Your hope is to catch the eye of potential buyers with your enticing blend and attractive packaging.
In a local coffee shop, a woman—a business leader by day and a mother by night—spots your coffee beans. Intrigued by the artisanal packaging and anticipating a long day of tackling complex financial problems, she decides your coffee would be an excellent way to start her workday. So, she purchases your product.
She wouldn’t buy the coffee if it lacked proper labeling. Nor would the store sell it if it didn’t meet FDA regulations, including clear source labeling. So, before the coffee can be enjoyed, the customer interacts with the packaging.
The bag provides context—indicating the coffee’s origin (Colombia), the manufacturer (you, the artisanal coffee producer), and the product’s purpose (to deliver artisanal organic medium roast coffee directly from farmers). It also contains nutritional information and an ingredient list, a standardized structure explaining the product’s composition. The bag’s barcode enables the store to identify the specific product being purchased, eliminating any ambiguity about the transaction. Only after these interactions with the packaging and store can the customer use the product inside the bag—your delicious coffee beans.
In this analogy, the coffee beans symbolize data. The difference between raw data and a data product lies in the additional contextual elements—the who, what, which, why, how, and where. Just as a bag of coffee beans must meet certain requirements before being stocked on the shelf and purchased by a customer, a data product of quality needs to meet similar standards for an organization to safely distribute and use it. Leaving gaps between data and data products often results in wastage and inefficiencies in how organizations manage data.
The Four Facets of a Data Product
A data product encapsulates both the data and its packaging into a single, self-contained object. As a data product manager, your role is to maximize the data product’s value, which is measured by the utility and quality of user experience for the person working with the data and its financial worth. A well-designed data product has clear measures and metrics, akin to commercial, customer-facing products like subscription services or physical goods.
If a company is already monetizing its data by selling it to other businesses, it is inherently treating its data as a product. However, viewing data as a product is even more crucial when considering internal clients, namely the company’s employees. The same principles and best practices that are applied to create valuable, user-friendly, and business-aligned data products for external customers should also be used for data products intended for internal use. Whether the data product is facing outward or inward, it is still a product of the company and should be treated with the same level of care, precision, and quality. The value of treating data as a product is not limited to external transactions; it’s equally crucial to the internal data handling and decision-making processes.
The user experience with a data product begins the moment a user encounters it. If a user opens a CSV file and struggles to understand the column names, that’s a poor user experience. We can gauge user experience with data much like a product manager would measure a web form’s usability, including time taken, number of clicks, and any issues that lead to drop-offs or lost opportunities.
As a data product manager, your role is to create fantastic data product experiences. High-quality, user-friendly, and business-aligned data products save time, instill trust, and are optimized for business objectives. They are, without a doubt, a valuable asset to your organization.
Yet, if your data product isn’t one self-contained object, it’s incomplete and of inferior quality. Figure 4-1 shows the four facets of a well-crafted data product, which like a physical product, encapsulates the dimensions needed to minimize ambiguity and reduce knowledge gaps and blind spots in our data.
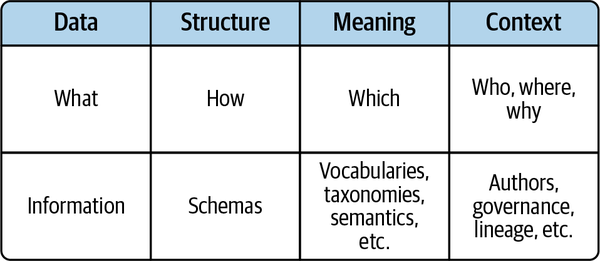
Figure 4-1. The four facets of a data product are meant to ensure data hygiene, as described in the Preface, so that anyone using data has everything they need to work with data efficiently and effectively in a self-contained object.
A well-designed data product, much like our artisanal coffee, boasts the following characteristics. Think of them as four facets of a gemstone:
- Data
-
This is the what: the actual information contained within the data product.
- Structure
-
This facet deals with the how. How is the information expected to be formatted when communicated?
- Meaning
-
This facet addresses the which. Which definition of a word is intended, given the language and concepts conveyed?
- Context
-
This answers the why, where, and who. Why was the product created, and what is the problem it solves? Where can it be found (API, database, table, lineage)? Who is responsible for governance, service-level agreements (SLAs), roles-based access controls (RBAC), and who created it?
These four facets help transform mere data into a meaningful data product. Just as the coffee beans alone wouldn’t result in the same experience without their carefully designed packaging, data alone is not as impactful without the proper structure, meaning, and context.
From a data product perspective, if you have data but not the other facets in one contained object, you have an incomplete and poor quality data product. Figure 4-2 illustrates this further as a comparison to a coffee bean product.

Figure 4-2. A data product has four main facets: data, structure, meaning, and context. This completely encapsulates the key elements a data user needs in order to be effective at working with data into a single object (product).
A data product approach also makes searching for data and searching in data more efficient because you are standardizing how information about the data is organized, which can save a tremendous amount of time.
Tip
For more information on the difference between searching in data and searching for data, take a look at The Enterprise Data Catalog, by Ole Olesen-Bagneux (O’Reilly, 2023):
-
Searching for data. It is critical that employees can easily and quickly find data.
-
Searching in data. It is equally vital that employees can understand what concepts in the data mean, such as column names. Remove ambiguity.
A unifying data strategy means reducing waste and inefficiency. Having the data, structure, meaning, and context located in separate systems and places—or lacking entirely—adds incredible amounts of complexity and chaos into your data management practices.
Bring the dataset, the metadata, the semantic management, the governance, and so on into a single, complete unit: the data product. Doing so will produce a far better data experience, one that is ultimately more effective and efficient from an operational business perspective because your data users won’t be wasting time searching or using multiple systems to manually combine them together. And this is what a good data product design will do for your organization.
Getting Started with Concept-First Design
One of the authors of this book, Ron, has had several experiences with companies that were groundbreaking for him as a consultant. To illustrate these experiences, consider the following real-world examples (which have been merged and altered to keep the companies’ identities private).
Imagine working with Company A that makes a billion dollars in revenue a year from a single flagship product, a company that has been historically and reliably dominant in its category across the entire global market. Its fiercest competitor, Company B, has just launched an AI version of its similar product, putting immense pressure on Company A’s C-level executives to show their board that the company is staying innovative and has a response to the new threat. Company A is currently leading market share, but isn’t particularly known for being innovative, and if an AI solution is not offered soon, there is a very real possibility that customers could switch to Company B, which could have dire negative consequences for Company A.
To respond to the threat, a team of top-tier, world-class data scientists and machine learning engineers are hired. They are paid fantastical salaries—money is no object and expenses are not spared to hire the team that the C-level executives can point to as “the best in the world.”
However, after several years, the team is still unable to create an AI version of the product. Deadlines keep getting pushed back, and teams are blaming each other. So, the C-level executives do what most executives do: hire expensive consultants to solve the problem for them, believing that their teams internally couldn’t do it. The expensive consulting firm proceeds to charge tens of millions in consulting fees to bring in entire teams of expensive experts and the most powerful cloud computing services.
Almost a hundred people are either hired or pulled off other teams, so the renewed effort succeeds, and the building of the AI product begins! But then one year later, the AI product is still terrible, users hate the experience, the AI doesn’t work very well, and now the C-level executives have to tell their board that they’ve wasted years and many tens of millions of dollars with absolutely nothing to show for it.
This is the point in the story where Ron was brought in to see what he could find, and the result was that in under a year, the AI engine was built with a fraction of the team, time, and cost of the previous effort. The technique that was used and refined over many problems, across many industries and years, eventually came to be called concept-first design.
Our emphasis in concept-first design is on the word first. It underscores the importance of not rushing into development, design, or business decisions until all concepts are meticulously designed and agreed upon by all stakeholders. For more technical teams, you could describe this process as schema-first design, although concept-first design is a far more approachable term for nontechnical people.
A Blueprint for Unifying
To help leaders grasp the transformative power of unification within an organization, let’s break down the journey into three pivotal phases: assess, align, and accelerate. Each phase serves as a building block, and together they offer a structured pathway to drive change effectively, as illustrated in Figure 4-3:
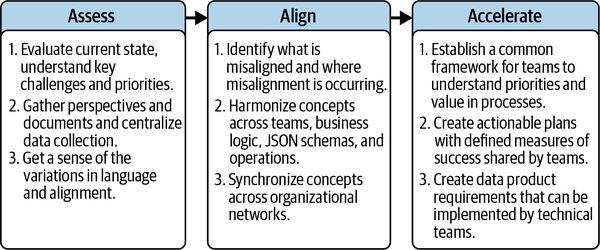
Figure 4-3. The three phases of unifying can be summarized using this flowchart to explain the activities of unifying in a high-level summary. Whether you are an internal or external data champion, giving a clear description of what transformation will look like can help gather support.
-
Assess. The first step is a thorough evaluation of your organization’s current state. Meet with key stakeholders to listen, gather insights, and assess different viewpoints. The assess phase begins with concept-first design to translate stakeholder perspectives into organized, hierarchical concepts. This not only aids in data collection but also in establishing a common way to capture perspectives and language across departments. With the help of a well-designed spreadsheet or whiteboard, this phase enables everyone to better understand existing alignments or disparities.
-
Align. Armed with a comprehensive assessment, the next step is to bring the disparate perspectives into alignment. Chapter 6 introduces the concept compass, a tool designed to precisely illuminate variances among stakeholder perspectives. However, this also requires a tool to connect all the threads across organizational networks that use those concepts, and data champions will utilize the CLEAN data governance framework, covered in Chapter 7, to follow a methodical and structured approach. This phase ensures that everyone is on the same page, making the organization ready for targeted action.
-
Accelerate. Once concepts are defined, aligned, and connected with proper data hygiene, they are ready to be described in the context of success measures and metrics that gauge progress. The primary tools for the accelerate phase are annotated process maps, covered in Chapter 9, and success spectrums and UX design strategies in Chapter 10. The accelerate phase tools enable teams across various domains—business, data, code, design, and more—to align with a clear execution road map and measurement criteria.
Crafting impeccable data products necessitates a rigorous commitment to the principle of data hygiene, as detailed in “What You Can’t See Can Kill You, and the Same Is True for Data”. The systematic progression through the assess, align, and accelerate phases serves to eliminate subtle threats such as ambiguity and knowledge disparities, laying the foundation for enhanced collaboration, precise decision making, and optimized productivity. When we adhere to data hygiene and concurrently maintain overarching principles of alignment across processes and organizational networks, we pave the way for breakthroughs in innovation, data science initiatives, and operational streamlining.
Echoing the insights of Dr. Semmelweis on the indispensability of hand hygiene in healthcare (see “What You Can’t See Can Kill You, and the Same Is True for Data”), the value of data hygiene becomes crystal clear. Much like the foundational role of handwashing in medicine, impeccable data hygiene stands as the bedrock, ensuring organizations not only remain protected but also thrive. Ignoring data hygiene can result in disastrous consequences.
Assess, align, and accelerate isn’t just a mantra; it’s our map.
Mapping the Conceptual Terrain: Assessing Concepts
The assess phase is a structured exploration of the collective mind of your team. It’s a series of one-on-one interviews with key stakeholders and contributors across the board. This includes developers, designers, product managers, data scientists, and more. This phase is about asking the people you interview to share their perspective about the work they do:
-
Describe the important problems to solve. Ask people to describe what problems they are working on, toward which objectives, what actions they take, and how success is measured by the outcomes. Their descriptions can be as a visual on a whiteboard or in a document such as PowerPoint, Excel, or Google Docs.
-
Clarify the important concepts they contain. With the map of the most important problems, objectives, actions, and success metrics in hand, explore these with your interviewee. Simply capture the words and their meanings in plain language, and if there are any calculations (such as profit or customer engagement), ask them to specify exactly how they are measured. This is best done in a spreadsheet, an example of which is shown in Figure 4-4.
-
Arrange the concepts into hierarchical relationships. Once you have some meanings, ask people to break down the concepts into more granular components in a hierarchical structure of parent-to-child or child-to-sibling relationship. This is the same format a schema uses. This is also best done in the spreadsheet format shown in Figure 4-4.
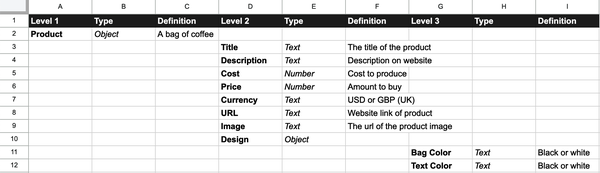
Figure 4-4. Using a spreadsheet for concept-first design. Three columns are used for any concept: Level #, Type (object, number, text, list, and so on), and Definition. These are what are used to create meaning for the concepts. When you want to add a subconcept (also known as a child concept), you add those child concepts in the column representing the next level. For example, for the Product concept (level 1), the Title child concept is added at level 2. This layering of levels of concepts becomes a hierarchical structure, which is another way to say a schema.
Your assessment will be as follows. Compile all of the stakeholder and contributor perspectives and show how aligned or unaligned they are. You now have a quantitative way to provide feedback to leaders and the team, showing that, for example, out of five people, only two agreed exactly on what certain concepts mean and how they are structured. How can any team work effectively together if they aren’t unified around the concepts that data and code are supposed to capture? They usually can’t. And if you ask a designer, data engineer, marketer, business leader, and software engineer to come up with the meaning and structure of concepts, they will all have their own particular perspectives.
Tip
The fundamental step in concept-first design is always to put understanding the constellation of concepts first before making decisions to invest (business), analyze (data), and build (code).
Figure 4-4 showcases a spreadsheet that acts as a schema. It visually represents the hierarchy of concepts in a product, illustrating the arrangement levels and the expected entities at each level. This approach brings schema design to everyone, not just to developers. It offers a unique and accessible way to craft concept structures similar to how they would be created in JSON.
The organization of concepts in this CSV format diverges from a traditional schema. A traditional schema primarily focuses on the hierarchical structure of concepts, whereas this CSV-based schema integrates both structure and meaning. Therefore, it is not just a spreadsheet; it’s a comprehensive representation that includes semantic information alongside the conceptual hierarchy. This integrated approach helps prevent and reduce ambiguity, thereby enhancing efficiency in data management and system development.
Facilitating Assessments of Conceptual Alignment Across Technical and Nontechnical Teams
Figure 4-5 shows a real-life example, or an instance, of a coffee product, constructed using the blueprint provided by the schema in Figure 4-4. Essentially, Figure 4-4 outlines the expected structure of a product object, and Figure 4-5 demonstrates how to populate that structure with specific data about an actual product.
The real power of conceptual schemas, as demonstrated in Figure 4-5, lies in their accessibility and the simplicity they bring to expressing business logic. By using a straightforward spreadsheet, business logic can be seamlessly and directly translated into JSON objects. This approach greatly enhances efficiency and eliminates a significant pain point—the often complex and error-prone task of translating business stakeholder language into functional technical requirements.
Developers frequently grapple with the challenge of translating business requirements into functional code. Business leaders often articulate their needs based on their perspective, which is rooted in business strategy, customer demands, or market trends. However, these needs are not always communicated in terms that developers can easily translate into a technical design. This communication gap is not because of a lack of effort on either side, but rather because business and development are two distinct domains with their own jargon, perspectives, and priorities.
The challenge lies in the fact that developers are not mind readers. They can’t intuit the intricate nuances of a business requirement unless it’s spelled out explicitly. When expectations are not met, it often leads to frustration and blame, with developers bearing the brunt for not understanding the “obvious.” This situation results in wasted time, resources, and strained relationships between teams. Moreover, it creates an environment of constant back-and-forth revisions, delayed projects, and subpar end products.
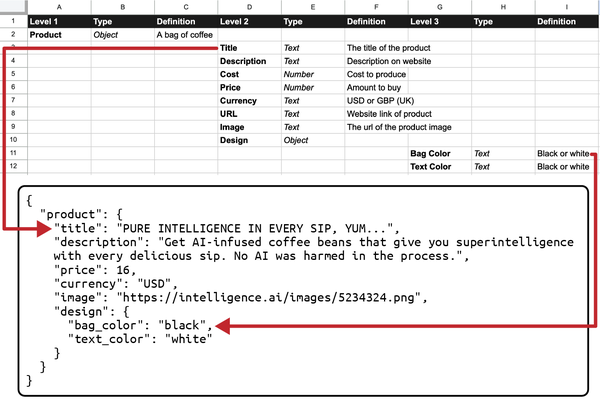
Figure 4-5. A conceptual schema. The concept-first design schema from Figure 4-4 can be mapped one to one to a JSON representation. This mapping makes it easier for technical and nontechnical teams to understand where they are aligned or misaligned in how to model and communicate concepts used across teams and technology systems and to integrate into functional business processes.
Conceptual schemas can help bridge this communication gap. They provide a common language for both business leaders and developers to articulate and understand requirements. By organizing concepts in a structured, hierarchical manner that includes both meaning and structure, conceptual schemas offer a clear road map for developers. They enable developers to see what business leaders envision, in a format that can be directly translated into code. This approach reduces ambiguity, ensures alignment of expectations, and streamlines the process of turning business logic into functional requirements, leading to more successful projects and a better working relationship between teams.
JSON and JSON Schemas, being both human- and machine-readable languages, are crucial elements of concept-first design. During the assess phase of unifying, it’s essential to include both technical and nontechnical teams in your evaluation. The aim is to assess the organization’s overall alignment concerning data vertically and horizontally across various domains.
Tip
If the technical aspects seem daunting, don’t be concerned. You don’t have to scrutinize the code personally. Instead, collaborate closely with a developer who can examine the data structures in the code and provide insight into the alignment or misalignment between technical and nontechnical teams.
If the technical team requires more data than what the business team has defined in their representation, that’s perfectly fine. There might be a legitimate technical need for additional information. Nevertheless, it’s crucial for the business, data, and code teams to reach a consensus on the fundamental concept representations, aligning them with the first step of our assessment: define the critical problems to solve and their context, including objectives, actions, and success metrics.
The assess phase isn’t solely about measuring conceptual differences among team members or between code representations of concepts. It also involves gauging the disparities between concepts and the defined problems, objectives, actions, and success metrics.
In the consulting adventure outlined earlier, Ron discovered that a single word—just one—that was being used in the success metrics had different interpretations across teams. For the business team, the word adaptive signified that success was tied to their current product’s ability to adapt the user experience to their current business model, which was, coincidentally, tied to the KPIs that measured their success, bonuses, and so on. In contrast, the data science team evaluated the success of being adaptive based on how accurately their predictive models could adapt the user experience—not optimized for the business team’s KPIs, but for what was best for the user experience.
You can apply concept-first design to literally anything that can be conceptualized, including success metrics. Once you have made your assessments, showing the gaps of alignment, you can begin working on aligning teams to a shared concept-first design schema, which we will explore later in the book. Chapter 5 explains how a data product manager or data champion should become more familiar with the technical aspects of implementing and using schemas with JSON Schema, which will enable technical teams to begin designing schemas for technical purposes.
Smooth Is Slow, Slow Is Fast
The phrase “go slow to go smooth, go smooth to go fast” emphasizes the importance of taking the time to learn how to do something correctly before focusing on speed. This approach applies equally to learning a musical instrument and learning how to align innovation efforts.
Assessing concepts first, as shown in Figure 4-4, is a simple way to ask basic questions of stakeholders, learn about their problems, and find where they differ in opinions from other stakeholders. This assessment is critically important, even if it feels like it slows down your team significantly. Some of the questions worth asking may seem silly, obvious, or even insulting. However, over and over again in consulting, we have found that these obvious questions have never been asked before, and the result is often very costly mistakes related to data.
Tip
Unifying is a continual practice. If misalignment creeps up, it is important to begin the process again and look back at your concept-first schemas to identify where misunderstandings may have arisen.
Here are some of the benefits you will gain from unifying:
-
In environments where alignment is prioritized and is thriving, teams collaborate far more seamlessly and are able to exchange insights, knowledge, and resources. This collaboration leads to a culture of continuous learning and improvement, which will empower your organization to swiftly adapt and respond to challenges.
-
The capacity to adapt and respond to change is crucial for any business to succeed. Alignment means better understanding of how to operate in more nimble and adaptive ways, as teams are better equipped to comprehend the implications of new insights, trends, and shifting requirements.
-
An unfortunate result of the bottlenecks around centralized data management is that some teams become so desperate for solutions that they go around the centralized data management team and build or contract out their own data solutions to make forward progress. However, failing to involve the data team in decisions about data architecture or storage can lead to data quality issues, security breaches, and technical debt. Making sure everyone is aligned enables teams that are facing bottlenecks to move forward with far less risk because they know exactly what concepts to align and how to align them.
Summary
This chapter discussed the significance of organizations’ internal data products, drawing comparisons with commercial, customer-facing products. It emphasized the need for good user experience in data products and underlined the role of a data product manager in creating excellent data product experiences.
The four facets of a data product are data, structure, meaning, and context. This chapter illustrated these facets using a coffee bean analogy, asserting that a data product without any of these facets is incomplete and of inferior quality.
We saw how a data product approach makes data search more efficient by standardizing how information about the data is organized. The difference between searching in data and searching for data was discussed.
We learned that being Agile, in the context of unifying, advocates for reducing waste and inefficiency by bringing the dataset, metadata, semantic management, and governance into a single, complete unit: a data product. This approach enhances the data experience by streamlining data-related processes and proves to be more effective and efficient compared to traditional methods of becoming a data-driven organization.
We described the three steps to unifying: assess, align, accelerate. The assess phase involves a structured exploration of the collective mind of the team to understand the gaps and severity of misalignment across teams. The align phase focuses on dispelling communication illusions and achieving effective alignment across all levels of the organization. The accelerate phase emphasizes iterating quickly to get feedback and implement and test solutions in an Agile manner.
Finally, we reviewed the risks of accelerating without satisfactorily unifying—doing so might lead to building the wrong thing faster. Unifying prioritizes accuracy before focusing on speed and emphasizes continually aligning data team efforts with the organization’s overall objectives.
Going between high and low levels of abstraction in your quest for unifying is the strategy you will continue to learn throughout this book. In Chapter 5, you, the data champion, will zoom in from thinking in a high-level strategic way about unifying concepts to a lower-level way of thinking about unifying concepts at a code level using JSON Schema.
Get Unifying Business, Data, and Code now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

