Capítulo 4. Diseño tipográfico
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Enséñame tus organigramas y oculta tus tablas, y seguiré desconcertado. Enséñame tus tablas, y normalmente no necesitaré tus organigramas; serán obvios.
Fred Brooks, El mes del hombre mítico (Addison-Wesley Professional)
El lenguaje de la cita de Fred Brooks es anticuado, pero el sentimiento sigue siendo cierto: el código es difícil de entender si no puedes ver los datos o tipos de datos sobre los que opera. Ésta es una de las grandes ventajas de un sistema de tipos: al escribir los tipos, los haces visibles para los lectores de tu código. Y esto hace que tu código sea comprensible.
Otros capítulos cubren las tuercas y los tornillos de los tipos TypeScript: utilizarlos, inferirlos, transformarlos y escribir declaraciones con ellos. Este capítulo trata del diseño de los propios tipos. Todos los ejemplos de este capítulo están escritos pensando en TypeScript, pero la mayoría de las ideas son aplicables de forma más amplia.
Si escribes bien tus tipos, con un poco de suerte tus diagramas de flujo también serán obvios.
Tema 29: Prefiere tipos que siempre representen estados válidos
Si diseñas bien tus tipos en , tu código debería ser sencillo de escribir. Pero si diseñas mal tus tipos, no te salvará ningún tipo de ingenio o documentación. Tu código será confuso y propenso a errores.
Una clave para un diseño tipográfico eficaz es crear tipos que sólo puedan representar un estado válido. Este artículo recorre algunos ejemplos de cómo esto puede salir mal y te muestra cómo solucionarlo.
Supón que estás construyendo una aplicación web que te permite seleccionar una página, cargar el contenido de esa página y, a continuación, mostrarlo. Podrías escribir el estado así
interfaceState{pageText:string;isLoading:boolean;error?:string;}
Cuando escribas el código para representar la página, deberás tener en cuenta todos estos campos:
functionrenderPage(state:State){if(state.error){return`Error! Unable to load${currentPage}:${state.error}`;}elseif(state.isLoading){return`Loading${currentPage}...`;}return`<h1>${currentPage}</h1>\n${state.pageText}`;}
¿Pero esto es correcto? ¿Y si isLoading y error están ambos fijados? ¿Qué significaría eso? ¿Es mejor mostrar el mensaje de carga o el mensaje de error? Es difícil decirlo. No hay suficiente información disponible.
¿Y si estás escribiendo una función changePage? Aquí tienes un intento:
asyncfunctionchangePage(state:State,newPage:string){state.isLoading=true;try{constresponse=awaitfetch(getUrlForPage(newPage));if(!response.ok){thrownewError(`Unable to load${newPage}:${response.statusText}`);}consttext=awaitresponse.text();state.isLoading=false;state.pageText=text;}catch(e){state.error=''+e;}}
¡Hay muchos problemas con esto! He aquí algunos:
-
Olvidamos poner
state.isLoadingenfalseen el caso de error. -
No hemos borrado
state.error, por lo que si la petición anterior falló, seguirás viendo ese mensaje de error en lugar de un mensaje de carga o la nueva página. -
Si el usuario vuelve a cambiar de página mientras ésta se está cargando, quién sabe lo que ocurrirá. Puede que vea una página nueva y luego un error, o la primera página y no la segunda, dependiendo del orden en que vuelvan las respuestas.
El problema es que el estado incluye muy poca información (¿qué petición ha fallado? ¿cuál se está cargando?) y demasiada: el tipo State permite establecer tanto isLoading como error, aunque esto represente un estado no válido. Esto hace que tantorender() y changePage() imposibles de implementar bien.
Aquí tienes una forma mejor de representar el estado de la aplicación:
interfaceRequestPending{state:'pending';}interfaceRequestError{state:'error';error:string;}interfaceRequestSuccess{state:'ok';pageText:string;}typeRequestState=RequestPending|RequestError|RequestSuccess;interfaceState{currentPage:string;requests:{[page:string]:RequestState};}
Utiliza una unión etiquetada (también conocida como "unión discriminada") para modelar explícitamente los distintos estados en que puede encontrarse una solicitud de red. Esta versión del estado es de tres a cuatro veces más larga, pero tiene la enorme ventaja de no admitir estados no válidos. La página actual se modela explícitamente, al igual que el estado de cada solicitud que emitas. Como resultado, las funciones renderPage y changePage son fáciles de implementar:
functionrenderPage(state:State){const{currentPage}=state;constrequestState=state.requests[currentPage];switch(requestState.state){case'pending':return`Loading${currentPage}...`;case'error':return`Error! Unable to load${currentPage}:${requestState.error}`;case'ok':return`<h1>${currentPage}</h1>\n${requestState.pageText}`;}}asyncfunctionchangePage(state:State,newPage:string){state.requests[newPage]={state:'pending'};state.currentPage=newPage;try{constresponse=awaitfetch(getUrlForPage(newPage));if(!response.ok){thrownewError(`Unable to load${newPage}:${response.statusText}`);}constpageText=awaitresponse.text();state.requests[newPage]={state:'ok',pageText};}catch(e){state.requests[newPage]={state:'error',error:''+e};}}
La ambigüedad de la primera implementación ha desaparecido por completo: está claro cuál es la página actual, y cada solicitud se encuentra exactamente en un estado. Si el usuario cambia de página después de emitir una solicitud, tampoco hay problema. La antigua solicitud sigue completándose, pero no afecta a la interfaz de usuario.
Para un ejemplo más sencillo pero más grave, considera el destino de Vuelo 447 de Air France, un Airbus 330 que desapareció sobre el Atlántico el 1 de junio de 2009. El Airbus era un avión fly-by-wire, lo que significa que las entradas de control de los pilotos pasaban por un sistema informático antes de afectar a las superficies físicas de control del avión. Tras el accidente, se plantearon muchas preguntas sobre la conveniencia de confiar en los ordenadores para tomar decisiones de vida o muerte. Dos años después, cuando se recuperaron las grabadoras de la caja negra del fondo del océano, revelaron muchos factores que condujeron al accidente. Un factor clave fue el mal diseño del estado.
La cabina del Airbus 330 tenía un conjunto separado de mandos para el piloto y el copiloto. Los "side sticks" controlaban el ángulo de ataque. Tirando hacia atrás, el avión ascendía, mientras que empujando hacia delante caía en picado. El Airbus 330 utilizaba un sistema llamado modo de "doble entrada", que permitía que los dos sticks laterales se movieran independientemente. He aquí cómo podrías modelar su estado en TypeScript:
interfaceCockpitControls{/** Angle of the left side stick in degrees, 0 = neutral, + = forward */leftSideStick:number;/** Angle of the right side stick in degrees, 0 = neutral, + = forward */rightSideStick:number;}
Supongamos que te dan esta estructura de datos y te piden que escribas una función getStickSetting que calcule el ajuste actual de la palanca. ¿Cómo lo harías?
Una forma sería asumir que el piloto (que se sienta a la izquierda) tiene el control:
functiongetStickSetting(controls:CockpitControls){returncontrols.leftSideStick;}
Pero, ¿y si el copiloto ha tomado el control? Tal vez debas utilizar el stick que esté más alejado de cero:
functiongetStickSetting(controls:CockpitControls){const{leftSideStick,rightSideStick}=controls;if(leftSideStick===0){returnrightSideStick;}returnleftSideStick;}
Pero hay un problema con esta implementación: sólo podemos estar seguros de devolver el ajuste izquierdo si el derecho es neutro. Así que deberías comprobarlo:
functiongetStickSetting(controls:CockpitControls){const{leftSideStick,rightSideStick}=controls;if(leftSideStick===0){returnrightSideStick;}elseif(rightSideStick===0){returnleftSideStick;}// ???}
¿Qué haces si ambos son distintos de cero? Esperemos que sean más o menos iguales, en cuyo caso podrías hacer la media:
functiongetStickSetting(controls:CockpitControls){const{leftSideStick,rightSideStick}=controls;if(leftSideStick===0){returnrightSideStick;}elseif(rightSideStick===0){returnleftSideStick;}if(Math.abs(leftSideStick-rightSideStick)<5){return(leftSideStick+rightSideStick)/2;}// ???}
Pero, ¿y si no lo son? ¿Puedes lanzar un error? En realidad no: ¡los alerones tienen que estar colocados en algún ángulo!
En el Air France 447, el copiloto tiró silenciosamente hacia atrás del mando lateral cuando el avión entró en tormenta. Ganó altitud, pero acabó perdiendo velocidad y entró en pérdida, condición en la que el avión se mueve demasiado despacio para generar sustentación de forma eficaz. Empezó a descender.
Para escapar de una entrada en pérdida, los pilotos están entrenados para empujar los mandos hacia delante para hacer que el avión caiga en picado y recupere velocidad. Esto es exactamente lo que hizo el piloto. Pero el copiloto seguía tirando silenciosamente hacia atrás de su mando lateral. Y la función del Airbus tenía este aspecto:
functiongetStickSetting(controls:CockpitControls){return(controls.leftSideStick+controls.rightSideStick)/2;}
A pesar de que el piloto empujó la palanca completamente hacia delante, la media se quedó en nada. No tenía ni idea de por qué el avión no se sumergía. Cuando el copiloto reveló lo que había hecho, el avión había perdido demasiada altitud para recuperarse y se estrelló en el océano, matando a las 228 personas que iban a bordo.
La cuestión de todo esto es que ¡no hay una buena forma de implementar getStickSetting dada esa entrada! La función se ha configurado para que falle. En la mayoría de los aviones, los dos conjuntos de mandos están conectados mecánicamente. Si el copiloto tira hacia atrás, los mandos del piloto también lo harán. El estado de estos mandos es sencillo de expresar:
interfaceCockpitControls{/** Angle of the stick in degrees, 0 = neutral, + = forward */stickAngle:number;}
Y ahora, como en la cita de Fred Brooks del principio del capítulo, nuestros diagramas de flujo son obvios. No necesitas en absoluto una función getStickSetting.
Cuando diseñes tus tipos, ten en cuenta qué valores incluyes y cuáles excluyes. Si sólo permites valores que representen estados válidos, tu código será más fácil de escribir y a TypeScript le resultará más fácil comprobarlo. Este es un principio muy general, y varios de los otros puntos de este capítulo cubrirán manifestaciones específicas del mismo.
Tema 30: Sé liberal en lo que aceptas y estricto enlo que produces
Esta idea se conoce como principio de robustez o Ley de Postel, en honor a Jon Postel, que la escribió en el contexto del protocolo de red TCP:
Las implementaciones TCP deben seguir un principio general de robustez: sé conservador en lo que haces, sé liberal en lo que aceptas de los demás.
Una regla similar se aplica a los contratos de las funciones. Está bien que tus funciones sean amplias en lo que aceptan como entradas, pero en general deben ser más específicas en lo que producen como salidas.
Por ejemplo, una API de mapeado 3D puede proporcionar un modo de posicionar la cámara y calcular una ventana gráfica para un cuadro delimitador:
declarefunctionsetCamera(camera:CameraOptions):void;declarefunctionviewportForBounds(bounds:LngLatBounds):CameraOptions;
Es conveniente que el resultado de viewportForBounds se pueda pasar directamente a setCamera para posicionar la cámara.
Veamos las definiciones de estos tipos:
interfaceCameraOptions{center?:LngLat;zoom?:number;bearing?:number;pitch?:number;}typeLngLat={lng:number;lat:number;}|{lon:number;lat:number;}|[number,number];
Los campos de CameraOptions son todos opcionales porque puede que quieras establecer sólo el centro o el zoom sin cambiar el rumbo o el cabeceo. El tipo LngLat también hace que setCamera sea liberal en cuanto a lo que acepta: puedes pasar un objeto {lng, lat}, un objeto {lon, lat} o un par [lng, lat] si estás seguro de que tienes el orden correcto. Estas adaptaciones hacen que la función sea fácil de llamar.
La función viewportForBounds recoge otro tipo "liberal":
typeLngLatBounds={northeast:LngLat,southwest:LngLat}|[LngLat,LngLat]|[number,number,number,number];
Puedes especificar los límites utilizando esquinas con nombre, un par de lat/lngs, o una cuádruple si estás seguro de haber acertado con el orden. Como LngLat ya admite tres formas, hay nada menos que 19 formas posibles para LngLatBounds (3 × 3 + 3 × 3 + 1). ¡Realmente liberal!
Ahora escribamos una función que ajuste la ventana gráfica para acomodar una característica GeoJSON de y almacene la nueva ventana gráfica en la URL (supondremos que tenemos una función de ayuda para calcular el cuadro delimitador de una característica GeoJSON):
functionfocusOnFeature(f:Feature){constbounds=calculateBoundingBox(f);// helper functionconstcamera=viewportForBounds(bounds);setCamera(camera);const{center:{lat,lng},zoom}=camera;// ~~~ Property 'lat' does not exist on type ...// ~~~ Property 'lng' does not exist on type ...zoom;// ^? const zoom: number | undefinedwindow.location.search=`?v=@${lat},${lng}z${zoom}`;}
¡Vaya! Sólo existe la propiedad zoom, pero su tipo se infiere como number|undefined, lo que también es problemático. La cuestión es que la declaración de tipo de viewportForBounds indica que es liberal no sólo en lo que acepta, sino también en lo queproduce. La única forma segura de utilizar el resultado camera es introducir una rama de código para cada componente del tipo de unión.
El tipo de retorno con muchas propiedades opcionales y tipos de unión dificulta el uso de viewportForBounds. Su amplio tipo de parámetro es conveniente, pero su amplio tipo de retorno no lo es. Una API más cómoda sería estricta en lo que produce.
Una forma de hacerlo es distinguir un formato canónico para las coordenadas. Siguiendo la convención de JavaScript de distinguir entre "array" y "array-like"(Tema 17), puedes establecer una distinción entre LngLat y LngLatLike. También puedes distinguir entre un tipo Camera completamente definido y la versión parcial aceptada por setCamera:
interfaceLngLat{lng:number;lat:number;};typeLngLatLike=LngLat|{lon:number;lat:number;}|[number,number];interfaceCamera{center:LngLat;zoom:number;bearing:number;pitch:number;}interfaceCameraOptionsextendsOmit<Partial<Camera>,'center'>{center?:LngLatLike;}typeLngLatBounds={northeast:LngLatLike,southwest:LngLatLike}|[LngLatLike,LngLatLike]|[number,number,number,number];declarefunctionsetCamera(camera:CameraOptions):void;declarefunctionviewportForBounds(bounds:LngLatBounds):Camera;
El tipo suelto CameraOptions adapta el tipo más estricto Camera. Utilizar Partial<Camera> como tipo de parámetro en setCamera no funcionaría aquí, ya que quieres permitir objetos LngLatLike para la propiedad center. Y no puedes escribir "CameraOptions extends Partial<Camera>" ya que LngLatLike es un supertipo de LngLat, no un subtipo. (Si esto te parece retrógrado, dirígete al punto 7 para refrescarte la memoria).
Si esto te parece demasiado complicado, también podrías escribir el tipo explícitamente a costa de alguna repetición:
interfaceCameraOptions{center?:LngLatLike;zoom?:number;bearing?:number;pitch?:number;}
En cualquier caso, con estas nuevas declaraciones de tipo, la función focusOnFeature pasa el comprobador de tipos:
functionfocusOnFeature(f:Feature){constbounds=calculateBoundingBox(f);constcamera=viewportForBounds(bounds);setCamera(camera);const{center:{lat,lng},zoom}=camera;// OK// ^? const zoom: numberwindow.location.search=`?v=@${lat},${lng}z${zoom}`;}
Esta vez el tipo de zoom es number, en lugar de number|undefined. La función viewportForBounds es ahora mucho más fácil de utilizar. Si hubiera otras funciones que produjeran límites, también tendrías que introducir una forma canónica y una distinción entre LngLatBounds y LngLatBoundsLike.
¿Permitir 19 formas posibles de cuadro delimitador es un buen diseño? Tal vez no. Pero si estás escribiendo declaraciones de tipos para una biblioteca que hace esto, necesitas modelar su comportamiento. Simplemente, ¡no tengas 19 tipos de retorno!
Una de las aplicaciones más comunes de este patrón es a las funciones que toman matrices como parámetros. Por ejemplo, aquí tienes una función que suma los elementos de una matriz:
functionsum(xs:number[]):number{letsum=0;for(constxofxs){sum+=x;}returnsum;}
El tipo de devolución de number es bastante estricto. ¡Estupendo! Pero, ¿qué pasa con el tipo de parámetro de number[]? No vamos a utilizar muchas de sus capacidades, así que podría ser más laxo. En el punto 17 se habló del tipo ArrayLike, y ArrayLike<number> funcionaría bien aquí. En el punto 14 se habló de las matrices readonly, y readonly number[] también funcionaría bien como tipo parámetro.
Pero si sólo necesitas iterar sobre el parámetro, entonces Iterable es el tipo más amplio de todos:
functionsum(xs:Iterable<number>):number{letsum=0;for(constxofxs){sum+=x;}returnsum;}
Esto funciona como cabría esperar con una matriz:
constsix=sum([1,2,3]);// ^? const six: number
La ventaja de utilizar aquí Iterable en lugar de Array o ArrayLike es que también permite expresiones generadoras:
function*range(limit:number){for(leti=0;i<limit;i++){yieldi;}}constzeroToNine=range(10);// ^? const zeroToNine: Generator<number, void, unknown>constfortyFive=sum(zeroToNine);// ok, result is 45
Si tu función sólo necesita iterar sobre su parámetro, utiliza Iterable para que funcione también con generadores. Si utilizas los bucles for-of, no tendrás que cambiar ni una sola línea de tu código.
Cosas para recordar
-
Los tipos de entrada suelen ser más amplios que los de salida. Las propiedades opcionales y los tipos de unión son más comunes en los tipos de parámetros que en los tipos de retorno.
-
Evita los tipos de devolución amplios, ya que serán incómodos de utilizar para los clientes.
-
Para reutilizar tipos entre parámetros y tipos de retorno, introduce una forma canónica (para los tipos de retorno) y una forma más laxa (para los parámetros).
-
Utiliza
Iterable<T>en lugar deT[]si sólo necesitas iterar sobre tu parámetro de función.
Tema 31: No repitas la información del tipoen la documentación
¿Qué hay de malo en este código en ?
/*** Returns a string with the foreground color.* Takes zero or one arguments. With no arguments, returns the* standard foreground color. With one argument, returns the foreground color* for a particular page.*/functiongetForegroundColor(page?:string){returnpage==='login'?{r:127,g:127,b:127}:{r:0,g:0,b:0};}
¡El código y el comentario no están de acuerdo! Sin más contexto es difícil decir cuál es el correcto, pero está claro que algo falla. Como solía decir un profesor mío, "cuando tu código y tus comentarios discrepan, ¡ambos están mal!".
Supongamos que el código representa el comportamiento deseado. Hay algunos problemas con este comentario:
-
Dice que la función devuelve el color como
stringcuando en realidad devuelve un objeto{r, g, b}. -
Explica que la función toma cero o uno argumentos, lo que ya queda claro en la firma del tipo.
-
Es innecesariamente prolijo: ¡el comentario es más largo que la declaración de la función y su implementación!
El sistema de anotación de tipos de TypeScript está diseñado para ser compacto, descriptivo y legible. Sus desarrolladores son expertos en el lenguaje con décadas de experiencia. ¡Es casi seguro que es una forma mejor de expresar los tipos de las entradas y salidas de tu función que su prosa!
Y como el compilador de TypeScript comprueba tus anotaciones de tipo, nunca se desincronizarán con la implementación. Quizás getForegroundColor devolvía una cadena, pero más tarde se cambió para que devolviera un objeto. La persona que hizo el cambio podría haber olvidado actualizar el comentario largo.
Nada permanece sincronizado a menos que se le fuerce a ello. Con las anotaciones de tipo, ¡el verificador de tipos de TypeScript es esa fuerza! Si pones la información de tipos en las anotaciones en lugar de en la documentación, aumentas enormemente tu confianza en que seguirá siendo correcta a medida que evolucione el código.
Un comentario mejor podría ser el siguiente
/** Get the foreground color for the application or a specific page. */functiongetForegroundColor(page?:string):Color{// ...}
Si quieres describir un parámetro concreto, utiliza una anotación JSDoc @param. Consulta el Tema 68 para saber más sobre esto.
Los comentarios sobre la falta de mutación también son sospechosos:
/** Sort the strings by numeric value (i.e. "2" < "10"). Does not modify nums. */functionsortNumerically(nums:string[]):string[]{returnnums.sort((a,b)=>Number(a)-Number(b));}
El comentario dice que esta función no modifica su parámetro, pero el método sort sobre Arrays opera en su lugar, por lo que en gran medida sí lo hace. Las afirmaciones en los comentarios no sirven de mucho.
Si en su lugar declaras el parámetro readonly (Punto 14), entonces puedes dejar que TypeScript aplique el contrato:
/** Sort the strings by numeric value (i.e. "2" < "10"). */functionsortNumerically(nums:readonlystring[]):string[]{returnnums.sort((a,b)=>Number(a)-Number(b));// ~~~~ ~ ~ Property 'sort' does not exist on 'readonly string[]'.}
Una implementación correcta de esta función copiaría la matriz o utilizaría el método inmutable toSorted:
/** Sort the strings by numeric value (i.e. "2" < "10"). */functionsortNumerically(nums:readonlystring[]):string[]{returnnums.toSorted((a,b)=>Number(a)-Number(b));// ok}
Lo que es cierto para los comentarios también lo es para los nombres de variables . Evita poner tipos en ellos: en lugar de nombrar una variable ageNum, nómbrala age y asegúrate de que es realmente una number.
Una excepción son los números con unidades. Si no está claro cuáles son las unidades, puedes incluirlas en el nombre de una variable o propiedad. Por ejemplo, timeMs es un nombre mucho más claro que simplemente time, y temperatureC es un nombre mucho más claro que temperature. El punto 64 describe las "marcas", que proporcionan un enfoque más seguro para modelar las unidades.
Cosas para recordar
-
Evita repetir información sobre tipos en comentarios y nombres de variables. En el mejor de los casos duplica las declaraciones de tipo, y en el peor dará lugar a información contradictoria.
-
Declara los parámetros
readonlyen lugar de decir que no los mutas. -
Considera la posibilidad de incluir unidades en los nombres de las variables si no queda claro en el tipo (por ejemplo,
timeMsotemperatureC).
Tema 32: Evitar incluir null o undefined en los alias de tipo
En este código, ¿es necesaria la cadena opcional (?.) ? ¿Podría user ser null?
functiongetCommentsForUser(comments:readonlyComment[],user:User){returncomments.filter(comment=>comment.userId===user?.id);}
Incluso asumiendo strictNullChecks, es imposible decirlo sin ver la definición de User. Si es un alias de tipo que permite null o undefined, entonces se necesita la cadena opcional:
typeUser={id:string;name:string;}|null;
En cambio, si es un tipo de objeto simple, entonces no lo es:
interfaceUser{id:string;name:string;}
Como regla general, es mejor evitar los alias de tipo que permiten valores null o undefined. Aunque el verificador de tipos no se confundirá si incumples esta regla, los lectores humanos de tu código sí lo harán. Cuando leemos un nombre de tipo como User, asumimos que representa a un usuario, en lugar de que tal vez represente a un usuario.
Si por alguna razón debes incluir null en un alias de tipo, haz un favor a los lectores de tu código y utiliza un nombre que no sea ambiguo:
typeNullableUser={id:string;name:string;}|null;
Pero, ¿por qué hacerlo cuando User|null es unasintaxis más sucinta y universalmente reconocible?
functiongetCommentsForUser(comments:readonlyComment[],user:User|null){returncomments.filter(comment=>comment.userId===user?.id);}
Esta regla se refiere al nivel superior de los alias de tipo. No se refiere a una propiedad null oundefined (u opcional) en un objeto mayor:
typeBirthdayMap={[name:string]:Date|undefined;};
No hagas esto:
typeBirthdayMap={[name:string]:Date|undefined;}|null;
También hay razones para evitar los valores null y los campos opcionales en los tipos de objeto, pero ese es un tema para los artículos 33 y 37. Por ahora, evita los alias de tipo que puedan confundir a los lectores de tu código. Prefiere alias de tipo que representen algo, en lugar de representar algo o null o undefined.
Tema 33: Empuja los valores nulos al perímetro de tus tipos
Cuando activas por primera vez strictNullChecks, puede parecer que tienes que añadir decenas de sentencias if comprobando los valores null y undefined por todo tu código. Esto suele deberse a que las relaciones entre valores nulos y no nulos son implícitas: cuando la variable A es no nula, sabes que la variable B también lo es y viceversa. Estas relaciones implícitas son confusas tanto para los lectores humanos de tu código como para el comprobador de tipos.
Es más fácil trabajar con los valores cuando son completamente nulos o completamente no nulos, en lugar de una mezcla. Puedes modelar esto empujando los valores nulos hacia el perímetro de tus estructuras.
Supongamos que quieres calcular el mínimo y el máximo de una lista de números. Llamaremos a esto "extensión". Aquí tienes un intento:
// @strictNullChecks: falsefunctionextent(nums:Iterable<number>){letmin,max;for(constnumofnums){if(!min){min=num;max=num;}else{min=Math.min(min,num);max=Math.max(max,num);}}return[min,max];}
El código comprueba el tipo (sin strictNullChecks) y tiene un tipo de retorno inferido de number[], lo que parece correcto. Pero tiene un error y un fallo de diseño:
-
Si el mín. o máx. es cero, puede que se anule. Por ejemplo,
extent([0, 1, 2])devolverá[1, 2]en lugar de[0, 2]. -
Si la matriz
numsestá vacía, la función devolverá[undefined, undefined].
Este tipo de objeto con varios undefineds será difícil de trabajar para los clientes y es exactamente la clase de tipo que este artículo desaconseja. Sabemos por la lectura del código fuente que tanto min como max serán undefined o ninguno lo será, pero esa información no está representada en el sistema de tipos.
Activar strictNullChecks hace que el problema con undefined sea más evidente:
functionextent(nums:Iterable<number>){letmin,max;for(constnumofnums){if(!min){min=num;max=num;}else{min=Math.min(min,num);max=Math.max(max,num);// ~~~ Argument of type 'number | undefined' is not// assignable to parameter of type 'number'}}return[min,max];}
El tipo de retorno de extent se infiere ahora como (number | undefined)[], lo que hace más evidente el fallo de diseño. Es probable que esto se manifieste como un error de tipo siempre que llames a extent:
const[min,max]=extent([0,1,2]);constspan=max-min;// ~~~ ~~~ Object is possibly 'undefined'
El error en la implementación de extent se produce porque has excluido undefined como valor para min pero no para max. Los dos se inicializan juntos, pero esta información no está presente en el sistema de tipos. Podrías hacerlo desaparecer añadiendo también una comprobación para max, pero esto sería duplicar el error.
Una solución mejor es poner min y max en el mismo objeto y hacer que este objeto sea totalmente null o totalmente nonull:
functionextent(nums:Iterable<number>){letminMax:[number,number]|null=null;for(constnumofnums){if(!minMax){minMax=[num,num];}else{const[oldMin,oldMax]=minMax;minMax=[Math.min(num,oldMin),Math.max(num,oldMax)];}}returnminMax;}
El tipo de retorno es ahora [number, number] | null, con el que es más fácil trabajar para los clientes. min y max se pueden recuperar con una aserción no nula:
const[min,max]=extent([0,1,2])!;constspan=max-min;// OK
o un solo cheque:
constrange=extent([0,1,2]);if(range){const[min,max]=range;constspan=max-min;// OK}
Al utilizar un único objeto para rastrear el alcance, hemos mejorado nuestro diseño, hemos ayudado a TypeScript a comprender la relación entre los valores nulos y hemos corregido el error: la comprobaciónif (!minMax) está ahora libre de problemas.
(Un siguiente paso podría ser impedir que se pasen listas no vacías a extent, lo que eliminaría por completo la posibilidad de devolver null. El punto 64 presenta una forma de representar una lista no vacía en el sistema de tipos de TypeScript).
Una mezcla de valores nulos y no nulos también puede provocar problemas en las clases . Por ejemplo, supongamos que tienes una clase que representa tanto a un usuario como a sus mensajes en un foro:
classUserPosts{user:UserInfo|null;posts:Post[]|null;constructor(){this.user=null;this.posts=null;}asyncinit(userId:string){returnPromise.all([async()=>this.user=awaitfetchUser(userId),async()=>this.posts=awaitfetchPostsForUser(userId)]);}getUserName(){// ...?}}
Mientras se cargan las dos solicitudes de red, las propiedades user y posts serán null. En cualquier momento, ambas pueden ser null, una puede ser null, o ambas pueden no sernull. Existen cuatro posibilidades. Esta complejidad se filtrará en todos los métodos de la clase. Es casi seguro que este diseño provocará confusión, una proliferación de comprobaciones null y errores.
Un diseño mejor esperaría hasta que todos los datos utilizados por la clase estuvieran disponibles:
classUserPosts{user:UserInfo;posts:Post[];constructor(user:UserInfo,posts:Post[]){this.user=user;this.posts=posts;}staticasyncinit(userId:string):Promise<UserPosts>{const[user,posts]=awaitPromise.all([fetchUser(userId),fetchPostsForUser(userId)]);returnnewUserPosts(user,posts);}getUserName(){returnthis.user.name;}}
Ahora la clase UserPosts es totalmente nonull, y es fácil escribir métodos correctos en ella. Por supuesto, si necesitas realizar operaciones mientras los datos están parcialmente cargados, entonces tendrás que lidiar con la multiplicidad de estados null y nonull.
No caigas en la tentación de sustituir las propiedades anulables por Promesas. Esto tiende a conducir a un código aún más confuso y obliga a que todos tus métodos sean asíncronos. Las promesas aclaran el código que carga los datos, pero tienden a tener el efecto contrario en la clase que utiliza esos datos.
Cosas para recordar
-
Evita diseños en los que un valor que sea
nullo nonullesté implícitamente relacionado con otro valor que seanullo nonull. -
Empuja los valores
nullhacia el perímetro de tu API haciendo que los objetos más grandes seannullo totalmente nonull. Esto hará que el código sea más claro tanto para los lectores humanos como para el comprobador de tipos. -
Considera la posibilidad de crear una clase totalmente no
nully construirla cuando todos los valores estén disponibles.
Tema 34: Preferir Uniones de Interfaces aInterfaces con Uniones
Si creas una interfaz cuyas propiedades son tipos de unión, debes preguntarte si el tipo tendría más sentido como unión de interfaces más precisas.
Supón que estás construyendo un programa de dibujo vectorial y quieres definir una interfaz para capas con tipos de geometría específicos:
interfaceLayer{layout:FillLayout|LineLayout|PointLayout;paint:FillPaint|LinePaint|PointPaint;}
El campo layout controla cómo y dónde se dibujan las formas (¿esquinas redondeadas? ¿rectas?), mientras que el campo paint controla los estilos (¿la línea es azul? ¿gruesa? ¿fina? ¿punteada?).
La intención es que un Layer tenga propiedades layout y paint coincidentes. Un FillLayout debe ir con un FillPaint, y un LineLayout debe ir con un LinePaint. Pero esta versión del tipo Layer también permite un FillLayout con un LinePaint. Esta posibilidad hace que el uso de la biblioteca sea más propenso a errores y dificulta el trabajo con esta interfaz.
Una forma mejor de modelar esto es con interfaces separadas para cada tipo de capa:
interfaceFillLayer{layout:FillLayout;paint:FillPaint;}interfaceLineLayer{layout:LineLayout;paint:LinePaint;}interfacePointLayer{layout:PointLayout;paint:PointPaint;}typeLayer=FillLayer|LineLayer|PointLayer;
Al definir Layer de esta forma, has excluido la posibilidad de que se mezclen las propiedades layout y paint. Éste es un ejemplo de cómo seguir el consejo del Tema29 de preferir tipos que sólo representen estados válidos.
Con mucho, el ejemplo más común de este patrón es la "unión etiquetada" (o "unión discriminada"). En este caso, una de las propiedades es una unión de tipos literales de cadena:
interfaceLayer{type:'fill'|'line'|'point';layout:FillLayout|LineLayout|PointLayout;paint:FillPaint|LinePaint|PointPaint;}
Como antes, ¿tendría sentido tener type: 'fill' pero luego un LineLayout y PointPaint? Desde luego que no. Convierte Layer en una unión de interfaces para excluir esta posibilidad:
interfaceFillLayer{type:'fill';layout:FillLayout;paint:FillPaint;}interfaceLineLayer{type:'line';layout:LineLayout;paint:LinePaint;}interfacePointLayer{type:'paint';layout:PointLayout;paint:PointPaint;}typeLayer=FillLayer|LineLayer|PointLayer;
La propiedad type es la "etiqueta" o "discriminante". Se puede acceder a ella en tiempo de ejecución y proporciona a TypeScript la información suficiente para determinar con qué elemento del tipo unión está trabajando. Aquí, TypeScript es capaz de acotar el tipo de Layer en una sentencia if basándose en la etiqueta:
functiondrawLayer(layer:Layer){if(layer.type==='fill'){const{paint}=layer;// ^? const paint: FillPaintconst{layout}=layer;// ^? const layout: FillLayout}elseif(layer.type==='line'){const{paint}=layer;// ^? const paint: LinePaintconst{layout}=layer;// ^? const layout: LineLayout}else{const{paint}=layer;// ^? const paint: PointPaintconst{layout}=layer;// ^? const layout: PointLayout}}
Al modelar correctamente la relación entre las propiedades de este tipo, ayudas a TypeScript a comprobar la corrección de tu código. El mismo código con la definición inicial de Layer habría estado abarrotado de aserciones de tipo.
Debido a que funcionan tan bien con el verificador de tipos de TypeScript, las uniones etiquetadas son omnipresentes en el código TypeScript. Reconoce este patrón y aplícalo siempre que puedas. Si puedes representar un tipo de datos en TypeScript con una unión etiquetada, suele ser una buena ideahacerlo.
Si piensas en los campos opcionales como una unión de su tipo y undefined, entonces también se ajustan al patrón "interfaz de uniones". Considera este tipo:
interfacePerson{name:string;// These will either both be present or not be presentplaceOfBirth?:string;dateOfBirth?:Date;}
Como explicaba el punto 31, el comentario con información sobre el tipo es una señal clara de que puede haber un problema. Existe una relación entre los campos placeOfBirth y dateOfBirth de la que no has informado a TypeScript.
Una forma mejor de modelar esto es trasladar ambas propiedades a un único objeto. Esto es similar a trasladar los valores de null al perímetro(elemento 33):
interfacePerson{name:string;birth?:{place:string;date:Date;}}
Ahora TypeScript se queja de los valores con un lugar pero sin fecha de nacimiento:
constalanT:Person={name:'Alan Turing',birth:{// ~~~~ Property 'date' is missing in type// '{ place: string; }' but required in type// '{ place: string; date: Date; }'place:'London'}}
Además, una función que toma un objeto Person sólo necesita hacer una única comprobación:
functioneulogize(person:Person){console.log(person.name);const{birth}=person;if(birth){console.log(`was born on${birth.date}in${birth.place}.`);}}
Si la estructura del tipo está fuera de tu control (tal vez proceda de una API), aún puedes modelar la relación entre estos campos utilizando una ya familiar unión de interfaces:
interfaceName{name:string;}interfacePersonWithBirthextendsName{placeOfBirth:string;dateOfBirth:Date;}typePerson=Name|PersonWithBirth;
Ahora obtienes algunas de las mismas ventajas que con el objeto anidado:
functioneulogize(person:Person){if('placeOfBirth'inperson){person// ^? (parameter) person: PersonWithBirthconst{dateOfBirth}=person;// OK// ^? const dateOfBirth: Date}}
En ambos casos, la definición del tipo deja más clara la relación entre las propiedades.
Aunque las propiedades opcionales suelen ser útiles, deberías pensártelo dos veces antes de añadir una a una interfaz. El Tema 37 explora más aspectos negativos de los campos opcionales.
Cosas para recordar
-
Las interfaces con múltiples propiedades que son tipos de unión suelen ser un error porque oscurecen las relaciones entre estas propiedades.
-
Las uniones de interfaces son más precisas y pueden ser comprendidas por TypeScript.
-
Utiliza uniones etiquetadas para facilitar el análisis del flujo de control. Como están tan bien soportadas, este patrón es omnipresente en el código TypeScript.
-
Considera si se podrían agrupar varias propiedades opcionales para modelar con mayor precisión tus datos.
Tema 35: Preferir alternativas más precisas a los tipos de cadena
Recuerda del Tema 7 que el dominio de un tipo es el conjunto de valores asignables a ese tipo. El dominio del tipo string es enorme: "x" y "y" están en él, pero también lo está el texto completo de Moby Dick (empieza por "Call me Ishmael…" y tiene alrededor de 1,2 millones de caracteres). Cuando declares una variable del tipo string, debes preguntarte si sería más apropiado un tipo más estrecho.
Supón que estás creando una colección de música y quieres definir un tipo para un álbum. Aquí tienes un intento:
interfaceAlbum{artist:string;title:string;releaseDate:string;// YYYY-MM-DDrecordingType:string;// E.g., "live" or "studio"}
La prevalencia de los tipos string y la información del tipo en los comentarios(Tema 31) son fuertes indicios de que este interface no es del todo correcto. Esto es lo que puede ir mal
constkindOfBlue:Album={artist:'Miles Davis',title:'Kind of Blue',releaseDate:'August 17th, 1959',// Oops!recordingType:'Studio',// Oops!};// OK
El campo releaseDate está formateado incorrectamente (según el comentario) y'Studio' está en mayúsculas donde debería estar en minúsculas. Pero ambos valores son cadenas, por lo que este objeto es asignable a Album y el verificador de tipos no se queja.
Estos amplios tipos de string también pueden enmascarar errores de objetos válidos de Album. Por ejemplo:
functionrecordRelease(title:string,date:string){/* ... */}recordRelease(kindOfBlue.releaseDate,kindOfBlue.title);// OK, should be error
Los parámetros se invierten en la llamada a recordRelease, pero ambos son cadenas, por lo que el comprobador de tipos no se queja. Debido a la prevalencia de los tipos string, el código como éste a veces se denomina "stringly typed".(El punto 38 explora cómo los parámetros posicionales repetidos de cualquier tipo pueden ser problemáticos, no sólo string.)
¿Puedes hacer los tipos más estrechos para evitar este tipo de problemas? Aunque el texto completo de Moby Dick sería un pesado nombre de artista o título de álbum, al menos es plausible. Así que string es apropiado para estos campos. Para el campo releaseDate, es mejor utilizar un objeto Date y evitar problemas de formato. Por último, para el campo recordingType, puedes definir un tipo de unión con sólo dos valores (también podrías utilizar un enum, pero en general recomiendo evitarlos; véase el punto 72):
typeRecordingType='studio'|'live';interfaceAlbum{artist:string;title:string;releaseDate:Date;recordingType:RecordingType;}
Con estos cambios, TypeScript puede realizar una comprobación más exhaustiva en busca de errores:
constkindOfBlue:Album={artist:'Miles Davis',title:'Kind of Blue',releaseDate:newDate('1959-08-17'),recordingType:'Studio'// ~~~~~~~~~~~~ Type '"Studio"' is not assignable to type 'RecordingType'};
Este enfoque tiene sus ventajas, además de una comprobación más estricta. En primer lugar, define explícitamente el tipo, lo que garantiza que su significado no se pierda al pasar de una función a otra. Si, por ejemplo, quisieras encontrar álbumes sólo de un determinado tipo de grabación, podrías definir una función como ésta:
functiongetAlbumsOfType(recordingType:string):Album[]{// ...}
¿Cómo sabe la persona que llama a esta función qué se espera que sea recordingType? Es sólo un string. El comentario que explica que es 'studio' o 'live' está oculto en la definición de Album, donde el usuario podría no pensar en mirar.
En segundo lugar, definir explícitamente un tipo te permite adjuntarle documentación (véase el punto 68):
/** What type of environment was this recording made in? */typeRecordingType='live'|'studio';
Cuando cambias getAlbumsOfType por RecordingType, la persona que llama puede hacer clic y ver la documentación (ver Figura 4-1).

Figura 4-1. Utilizar un tipo con nombre en lugar de string permite adjuntar documentación al tipo que aparece en tu editor.
Otro uso incorrecto habitual de string es en los parámetros de las funciones. Supongamos que quieres escribir una función que extraiga todos los valores de un único campo de una matriz. Las bibliotecas de utilidades Underscore y Ramda llaman a esto pluck:
functionpluck(records,key){returnrecords.map(r=>r[key]);}
¿Cómo escribirías esto? Aquí tienes un primer intento:
functionpluck(records:any[],key:string):any[]{returnrecords.map(r=>r[key]);}
Este tipo se comprueba pero no es genial. Los tipos any son problemáticos, sobre todo en el valor de retorno (véase el punto 43). El primer paso para mejorar la firma del tipo es introducir un parámetro de tipo genérico:
functionpluck<T>(records:T[],key:string):any[]{returnrecords.map(r=>r[key]);// ~~~~~~ Element implicitly has an 'any' type// because type '{}' has no index signature}
TypeScript se queja ahora de que el tipo string para key es demasiado amplio. Y tiene razón al hacerlo: si pasas una matriz de Albums, entonces sólo hay cuatro valores válidos para key ("artista", "título", "releaseDate" y "recordingType"), frente al vasto conjunto de cadenas. Esto es precisamente lo que es el tipo keyof Album:
typeK=keyofAlbum;// ^? type K = keyof Album// (equivalent to "artist" | "title" | "releaseDate" | "recordingType")
Así que la solución es sustituir string por keyof T:
functionpluck<T>(records:T[],key:keyofT){returnrecords.map(r=>r[key]);}
Esto pasa el verificador de tipos. También hemos dejado que TypeScript deduzca el tipo de retorno. ¿Cómo lo hace? Si pasas el ratón por encima de pluck en tu editor, el tipo inferido es:
functionpluck<T>(record:T[],key:keyofT):T[keyofT][];
T[keyof T] es el tipo de cualquier valor posible en T. Si pasas una sola cadena como key, esto es demasiado amplio. Por ejemplo:
constreleaseDates=pluck(albums,'releaseDate');// ^? const releaseDates: (string | Date)[]
El tipo debería ser Date[], no (string | Date)[]. Aunque keyof T es mucho más estrecho que string, sigue siendo demasiado amplio. Para estrecharlo aún más, necesitamos introducir un segundo parámetro de tipo que sea un subtipo de keyof T (probablemente un valor único):
functionpluck<T,KextendskeyofT>(records:T[],key:K):T[K][]{returnrecords.map(r=>r[key]);}
Ahora la firma de tipo es completamente correcta. Podemos comprobarlo llamando a pluck de varias formas distintas:
constdates=pluck(albums,'releaseDate');// ^? const dates: Date[]constartists=pluck(albums,'artist');// ^? const artists: string[]consttypes=pluck(albums,'recordingType');// ^? const types: RecordingType[]constmix=pluck(albums,Math.random()<0.5?'releaseDate':'artist');// ^? const mix: (string | Date)[]constbadDates=pluck(albums,'recordingDate');// ~~~~~~~~~~~~~~~// Argument of type '"recordingDate"' is not assignable to parameter of type ...
El servicio lingüístico es capaz incluso de ofrecer autocompletar en las teclas de Album (como se muestra en la Figura 4-2).
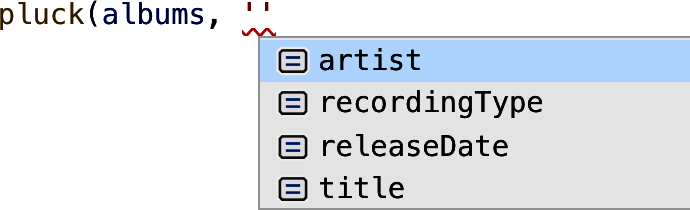
Figura 4-2. Si utilizas un tipo de parámetro keyof Album en lugar de string, conseguirás un mejor autocompletado en tu editor.
string tiene algunos de los mismos problemas que any: cuando se utiliza de forma inadecuada, permite valores no válidos y oculta las relaciones entre tipos. Esto frustra al verificador de tipos y puede ocultar errores reales. La capacidad de TypeScript para definir subconjuntos de string es una forma poderosa de aportar seguridad de tipos al código JavaScript. Utilizar tipos más precisos detectará errores y mejorará la legibilidad de tu código.
Este punto se centraba en conjuntos finitos de strings, pero TypeScript también te permite modelar conjuntos infinitos, por ejemplo, todos los strings que empiezan por "http:". Para éstos, querrás utilizar tipos literales de plantilla, que son el tema del Tema 54.
Cosas para recordar
-
Evita el código "stringly typed". Prefiere tipos más apropiados en los que no todas las
stringsean una posibilidad. -
Prefiere una unión de tipos literales de cadena a
stringsi eso describe con más precisión el dominio de una variable. Conseguirás una comprobación de tipos más estricta y mejorarás la experiencia de desarrollo. -
Prefiere
keyof Tastringpara los parámetros de función que se espera que sean propiedades de un objeto.
Tema 36: Utilizar un tipo distinto para los valores especiales
El método string split de JavaScript es una forma práctica de romper una cadena alrededor de un delimitador:
> 'abcde'.split('c')
[ 'ab', 'de' ]
Escribamos algo parecido a split, pero para matrices. Aquí tienes un intento:
functionsplitAround<T>(vals:readonlyT[],val:T):[T[],T[]]{constindex=vals.indexOf(val);return[vals.slice(0,index),vals.slice(index+1)];}
Esto funciona como cabría esperar:
> splitAround([1, 2, 3, 4, 5], 3) [ [ 1, 2 ], [ 4, 5 ] ]
Sin embargo, si intentas splitAround un elemento que no está en la lista, hace algo bastante inesperado:
> splitAround([1, 2, 3, 4, 5], 6) [ [ 1, 2, 3, 4 ], [ 1, 2, 3, 4, 5 ] ]
Aunque no está del todo claro qué debería hacer la función en este caso, ¡definitivamente no es eso! ¿Cómo un código tan sencillo ha dado lugar a un comportamiento tan extraño?
El problema de fondo es que indexOf devuelve -1 si no encuentra el elemento en la matriz. Éste es un valor especial: indica un fallo en lugar de un éxito. Pero -1 es un number normal y corriente. Puedes pasarlo al método Matriz slice y puedes hacer operaciones aritméticas con él. Cuando pasas un número negativo a slice, éste lo interpreta como si contara hacia atrás desde el final de la matriz. Y cuando sumas 1 a -1, obtienes 0. Así que esto se evalúa como
[vals.slice(0,-1),vals.slice(0)]
La primera slice devuelve todos los elementos de la matriz menos el último, y la segunda slice devuelve una copia completa de la matriz.
Este comportamiento es un error. Además, es una pena que TypeScript no haya podido ayudarnos a encontrar este problema. El problema de fondo era que indexOf devolvía -1 cuando no podía encontrar el elemento, en lugar de, por ejemplo, null. ¿Por qué?
Sin subir a una máquina del tiempo y visitar las oficinas de Netscape en 1995, es difícil saber la respuesta con seguridad. Pero podemos especular. JavaScript está muy influenciado por Java, y su indexOf tiene este mismo comportamiento. En Java (y en C), una función no puede devolver una primitiva o null. Sólo los objetos (o punteros) son anulables. Así que este comportamiento puede derivar de una limitación técnica de Java que JavaScript no comparte.
En JavaScript (y TypeScript), no hay ningún problema en que una función devuelva un number o null. Así que podemos envolver indexOf:
functionsafeIndexOf<T>(vals:readonlyT[],val:T):number|null{constindex=vals.indexOf(val);returnindex===-1?null:index;}
Si introducimos esto en nuestra definición original de splitAround, obtendremos inmediatamente dos errores de tipo:
functionsplitAround<T>(vals:readonlyT[],val:T):[T[],T[]]{constindex=safeIndexOf(vals,val);return[vals.slice(0,index),vals.slice(index+1)];// ~~~~~ ~~~~~ 'index' is possibly 'null'}
¡Esto es exactamente lo que queremos! Siempre hay dos casos a considerar con indexOf. Con la versión incorporada, TypeScript no puede distinguirlos, pero con la versión envuelta, sí. Y aquí ve que sólo hemos considerado el caso en el que la matriz contenía el valor.
La solución es tratar el otro caso explícitamente:
functionsplitAround<T>(vals:readonlyT[],val:T):[T[],T[]]{constindex=safeIndexOf(vals,val);if(index===null){return[[...vals],[]];}return[vals.slice(0,index),vals.slice(index+1)];// ok}
Es discutible si éste es el comportamiento correcto, pero al menos TypeScript nos ha obligado a tener ese debate.
El problema de fondo de la primera implementación era que indexOf tenía dos casos distintos, pero el valor de retorno en el caso especial (-1) tenía el mismo tipo que el valor de retorno en el caso normal (number). Esto significaba que desde la perspectiva de TypeScript sólo había un único caso, y no era capaz de detectar que no comprobábamos -1.
Esta situación se presenta con frecuencia cuando diseñas tipos. Quizá tengas un tipo para describir mercancías:
interfaceProduct{title:string;priceDollars:number;}
Entonces te das cuenta de que algunos productos tienen un precio desconocido. Hacer que este campo sea opcional o cambiarlo a number|null podría requerir una migración y muchos cambios de código, así que en su lugar introduces un valor especial:
interfaceProduct{title:string;/** Price of the product in dollars, or -1 if price is unknown */priceDollars:number;}
Lo envías a producción. Una semana después, tu jefe se enfada y quiere saber por qué has estado abonando dinero en las tarjetas de los clientes. Tu equipo trabaja para deshacer el cambio y a ti te encargan que escribas la autopsia. En retrospectiva, ¡hubiera sido mucho más fácil ocuparse de esos errores tipográficos!
Elegir valores especiales dentro del dominio como -1, 0, o "" es similar en espíritu a desactivar strictNullChecks. Cuando strictNullChecks está desactivado, puedes asignar null oundefined a cualquier tipo:
// @strictNullChecks: falseconsttruck:Product={title:'Tesla Cybertruck',priceDollars:null,// ok};
Esto permite que una enorme clase de errores se le escapen al verificador de tipos porque TypeScript no distingue entre number y number|null. null es un valor válido en todos los tipos. Cuando habilita strictNullChecks, TypeScript sí distingue entre estos tipos y es capaz de detectar toda una serie de problemas nuevos. Cuando eliges un valor especial dentro del dominio, como -1, estás creando un nicho no estricto en tus tipos. Conveniente, sí, pero en última instancia no es la mejor opción.
null y undefined no siempre son la forma correcta de representar casos especiales, ya que su significado exacto puede depender del contexto. Si estás modelando el estado de una solicitud de red, por ejemplo, sería una mala idea utilizar null para significar un estado de error y undefined para significar un estado pendiente. Es mejor utilizar una unión etiquetada para representar estos estados especiales de forma más explícita. El Tema 29 explora este ejemplo con más detalle.
Cosas para recordar
-
Evita los valores especiales asignables a valores normales en un tipo. Reducirán la capacidad de TypeScript para encontrar errores en tu código.
-
Prefiere
nulloundefinedcomo valor especial en lugar de0,-1o"". -
Considera la posibilidad de utilizar una unión etiquetada en lugar de
nulloundefinedsi el significado de esos valores no está claro.
Tema 37: Limitar el uso de propiedades opcionales
A medida que tus tipos evolucionen, inevitablemente querrás añadirles nuevas propiedades. Para evitar invalidar el código o los datos existentes, puedes optar por hacer que estas propiedades sean opcionales. Aunque a veces es la elección correcta, las propiedades opcionales tienen un coste y deberías pensártelo dos veces antes de añadirlas.
Imagina que tienes un componente de interfaz de usuario que muestra números con una etiqueta y unidades. Piensa en "Altura: 12 pies" o "Velocidad: 10 mph":
interfaceFormattedValue{value:number;units:string;}functionformatValue(value:FormattedValue){/* ... */}
Construyes una gran aplicación web utilizando este componente. Quizá parte de ella muestre información formateada sobre una excursión que has hecho ("8 km a 3 km/h"):
interfaceHike{miles:number;hours:number;}functionformatHike({miles,hours}:Hike){constdistanceDisplay=formatValue({value:miles,units:'miles'});constpaceDisplay=formatValue({value:miles/hours,units:'mph'});return`${distanceDisplay}at${paceDisplay}`;}
Un día te enteras de que existe el sistema métrico decimal y decides utilizarlo. Para admitir tanto el sistema métrico como el imperial, añades la opción correspondiente a FormattedValue. Si es necesario, el componente realizará una conversión de unidades antes de mostrar el valor. Para minimizar los cambios en el código y las pruebas existentes, decides que la propiedad sea opcional:
typeUnitSystem='metric'|'imperial';interfaceFormattedValue{value:number;units:string;/** default is imperial */unitSystem?:UnitSystem;}
Para que el usuario pueda configurarlo, también querremos especificar un sistema de unidades en la configuración de toda nuestra aplicación:
interfaceAppConfig{darkMode:boolean;// ... other settings .../** default is imperial */unitSystem?:UnitSystem;}
Ahora podemos actualizar formatHike para que admita el sistema métrico decimal:
functionformatHike({miles,hours}:Hike,config:AppConfig){const{unitSystem}=config;constdistanceDisplay=formatValue({value:miles,units:'miles',unitSystem});constpaceDisplay=formatValue({value:miles/hours,units:'mph'// forgot unitSystem, oops!});return`${distanceDisplay}at${paceDisplay}`;}
Fijamos unitSystem en una llamada a formatValue pero no en la otra. Esto es un error que significa que nuestros usuarios del sistema métrico verán una mezcla de unidades imperiales y métricas.
De hecho, nuestro diseño es una receta para exactamente este tipo de error. En todos los lugares en los que utilicemos el componente formatValue, tenemos que acordarnos de pasar un unitSystem. Siempre que no lo hagamos, los usuarios del sistema métrico verán unidades imperiales confusas como yardas, acres o pies-libra.
Estaría bien que hubiera una forma de encontrar automáticamente todos los lugares en los que nos olvidamos de pasar un unitSystem. Éste es exactamente el tipo de cosas para las que sirve la comprobación de tipos, pero hemos evitado que nos ayude haciendo que la propiedad unitSystem sea opcional.
Si en cambio lo haces obligatorio, obtendrás un error de tipo en todos los sitios en los que te hayas olvidado de configurarlo. Tendrás que corregirlos uno a uno, ¡pero es mucho mejor que TypeScript encuentre estos errores que oír hablar de ellos a usuarios confusos!
El comentario de la documentación "por defecto es imperial" también es preocupante. En TypeScript, el valor por defecto de una propiedad opcional en un objeto es siempre undefined. Para implementar un valor predeterminado alternativo, es probable que nuestro código esté plagado de líneas como ésta:
declareletconfig:AppConfig;constunitSystem=config.unitSystem??'imperial';
Cada una de ellas es una oportunidad para un error. Quizá otro desarrollador de tu equipo olvide que el sistema imperial es el predeterminado (¿por qué es el predeterminado?) y asuma que debería ser el métrico:
constunitSystem=config.unitSystem??'metric';
Una vez más, el resultado será una visualización incoherente.
Si necesitas admitir valores antiguos de la interfaz AppConfig (quizás estén guardados como JSON en disco o en una base de datos), entonces no puedes hacer que el nuevo campo sea obligatorio. Lo que puedes hacer en su lugar es dividir el tipo en dos: un tipo para configuraciones no normalizadas leídas del disco, y otro con menos propiedades opcionales para utilizar en tu aplicación:
interfaceInputAppConfig{darkMode:boolean;// ... other settings .../** default is imperial */unitSystem?:UnitSystem;}interfaceAppConfigextendsInputAppConfig{unitSystem:UnitSystem;// required}
Si cambiar una propiedad opcional a obligatoria en un subtipo te resulta extraño, consulta el punto 7. También podrías utilizar aquí Required<InputAppConfig>.
Querrás añadir algún código de normalización:
functionnormalizeAppConfig(inputConfig:InputAppConfig):AppConfig{return{...inputConfig,unitSystem:inputConfig.unitSystem??'imperial',};}
Esta división resuelve algunos problemas:
-
Permite que la configuración evolucione y mantenga la compatibilidad con versiones anteriores sin añadir complejidad a toda la aplicación.
-
Centraliza la aplicación de los valores por defecto.
-
Dificulta el uso de un
InputAppConfigdonde se espera unAppConfig.
Este tipo de "en construcción" aparece con frecuencia con el código de red. Consulta UserPosts en el Tema 33 para ver otro ejemplo.
A medida que añadas más propiedades opcionales a un interface, te encontrarás con un nuevo problema: si tienes N propiedades opcionales, entonces hay 2N combinaciones posibles de ellas. ¡Eso son muchas posibilidades! Si tienes 10 propiedades opcionales, ¿has probado todas las 1.024 combinaciones? ¿Todas las combinaciones tienen siquiera sentido? Es probable que haya alguna estructura en estas opciones, quizás algunas que se excluyan mutuamente. Si es así, tu estado debería modelarlo (véase el punto 29). Éste es un problema con las opciones en general, no sólo con las propiedades opcionales.
Por último, las propiedades opcionales son una posible fuente de inseguridad en TypeScript. El punto 48 trata esto con más detalle.
Como has visto, hay muchas razones para evitar las propiedades opcionales. Entonces, ¿cuándo debes utilizarlas? Son en gran medida inevitables cuando se describen API existentes o se evolucionan API manteniendo la compatibilidad con versiones anteriores. Para configuraciones enormes, puede resultar prohibitivamente caro rellenar todos los campos opcionales con valores por defecto. Y algunas propiedades son realmente opcionales: no todo el mundo tiene segundo nombre, por lo que una propiedad opcional middleName en un tipo Person es un modelo preciso. Pero sé consciente de los muchos inconvenientes de las propiedades opcionales, conoce cómo mitigarlos y piénsatelo dos veces antes de añadir una propiedad opcional si existe una alternativa válida.
Cosas para recordar
-
Las propiedades opcionales pueden impedir que el verificador de tipos encuentre errores y pueden dar lugar a código repetido y posiblemente incoherente para rellenar los valores por defecto.
-
Piénsatelo dos veces antes de añadir una propiedad opcional a una interfaz. Piensa si no podrías hacerla obligatoria.
-
Considera la posibilidad de crear tipos distintos para los datos de entrada no normalizados y los datos normalizados para utilizarlos en tu código.
Tema 38: Evitar Parámetros Repetidos del Mismo Tipo
¿Qué hace esta llamada a la función?
drawRect(25,50,75,100,1);
Sin mirar la lista de parámetros de la función, es imposible saberlo. Aquí tienes algunas posibilidades:
-
Dibuja un rectángulo de 75 × 100 con su parte superior izquierda en (25, 50) con una opacidad de 1,0.
-
Dibuja un rectángulo de 50 × 50 con las esquinas en (25, 50) y (75, 100), con una anchura de trazo de un píxel.
Sin más contexto, es difícil saber si esta función se llama correctamente. Y como todos los parámetros son del mismo tipo, number, el comprobador de tipos no podrá ayudarte si confundes el orden o pasas una anchura y una altura en lugar de una segunda coordenada.
Supón que ésta fuera la declaración de la función:
functiondrawRect(x:number,y:number,w:number,h:number,opacity:number){// ...}
Cualquier función que tome parámetros consecutivos del mismo tipo es propensa a errores porque el comprobador de tipos no podrá detectar las invocaciones incorrectas. Una forma de mejorar la situación sería tomar tipos distintos de Point y Dimension:
interfacePoint{x:number;y:number;}interfaceDimension{width:number;height:number;}functiondrawRect(topLeft:Point,size:Dimension,opacity:number){// ...}
Como ahora la función toma tres parámetros con tres tipos distintos, el comprobador de tipos es capaz de distinguirlos. Una invocación incorrecta que pase dos puntos será un error:
drawRect({x:25,y:50},{x:75,y:100},1.0);// ~// Argument ... is not assignable to parameter of type 'Dimension'.
Una solución alternativa sería combinar todos los parámetros en un único objeto:
interfaceDrawRectParamsextendsPoint,Dimension{opacity:number;}functiondrawRect(params:DrawRectParams){/* ... */}drawRect({x:25,y:50,width:75,height:100,opacity:1.0});
Refactorizar una función para que tome un objeto en lugar de parámetros posicionales mejora la claridad para los lectores humanos. Y, al asociar nombres a cada number, también ayuda al comprobador de tipos a detectar invocaciones incorrectas.
A medida que evoluciona tu código, las funciones pueden modificarse para tomar más y más parámetros. Aunque los parámetros posicionales funcionaran bien al principio, en algún momento se convertirán en un problema. Como dice el refrán: "Si tienes una función con 10 parámetros, probablemente se te ha escapado alguno". En cuanto una función tome más de tres o cuatro parámetros, debes refactorizarla para que tome menos. (La regla max-params de typescript-eslint puede imponer esto).
Cuando los tipos de los parámetros son iguales, debes desconfiar aún más de los parámetros posicionales. Incluso dos parámetros pueden ser un problema.
Hay algunas excepciones a esta regla:
-
Si los argumentos son conmutativos (el orden no importa), entonces no hay problema.
max(a, b)yisEqual(a, b), por ejemplo, no son ambiguos. -
Si existe un orden "natural" de los parámetros, se reduce la posibilidad de confusión.
array.slice(start, stop)tiene más sentido questop,start, por ejemplo. Pero ten cuidado con esto: puede que los desarrolladores no siempre estén de acuerdo en cuál es el orden "natural". (¿Es año, mes, día? ¿Mes, día, año? ¿Día, mes, año?)
Como escribió Scott Meyers en Effective C++: "Haz que las interfaces sean fáciles de usar correctamente y difíciles de usar incorrectamente". ¡Es difícil discutir con eso!
Tema 39: Prefiero unificar tipos a modelar diferencias
El sistema de tipos de TypeScript te ofrece potentes herramientas para mapear entre tipos. El Tema 15 y el Capítulo 6 explican cómo utilizar muchas de ellas. Una vez que te des cuenta de que puedes modelar una transformación utilizando el sistema de tipos, puede que sientas un impulso irrefrenable de hacerlo. Y esto te parecerá productivo. ¡Tantos tipos! ¡Tanta seguridad!
Sin embargo, si está a tu alcance, una opción mejor que modelar la diferencia entre dos tipos es eliminar la diferencia entre esos dos tipos. Entonces no se requiere ninguna maquinaria a nivel de tipo, y desaparece la carga cognitiva de llevar la cuenta de con qué versión de un tipo estás trabajando.
Para hacerlo más concreto, imagina que tienes una interfaz que deriva de una tabla de base de datos. Las bases de datos suelen utilizar snake_case para los nombres de las columnas, así que así es como salen tus datos:
interfaceStudentTable{first_name:string;last_name:string;birth_date:string;}
El código TypeScript suele utilizar nombres de propiedades en camelCase. Para que el tipo Student sea más coherente con el resto de tu código, podrías introducir una versión alternativa de Student:
interfaceStudent{firstName:string;lastName:string;birthDate:string;}
Puedes escribir una función para convertir entre estos dos tipos. Y lo que es más interesante, puedes utilizar tipos literales de plantilla para escribir esta función. El tema 54 explica cómo hacerlo, pero el resultado final es que puedes generar un tipo a partir del otro:
typeStudent=ObjectToCamel<StudentTable>;// ^? type Student = {// firstName: string;// lastName: string;// birthDate: string;// }
¡Sorprendente! Cuando se te pase la emoción de encontrar un caso de uso convincente para la programación a nivel de tipo, puede que te encuentres con un montón de errores al pasar una versión del tipo a una función que espera la otra:
asyncfunctionwriteStudentToDb(student:Student){awaitwriteRowToDb(db,'students',student);// ~~~~~~~// Type 'Student' is not assignable to parameter of type 'StudentTable'.}
No es obvio por el mensaje de error, pero el problema es que has olvidado llamar a tu código de conversión:
asyncfunctionwriteStudentToDb(student:Student){awaitwriteRowToDb(db,'students',objectToSnake(student));// ok}
Aunque es útil que TypeScript señalara este error antes de que causara un error en tiempo de ejecución, sería más sencillo tener una única versión del tipo Student en tu código para que fuera imposible cometer este error.
Hay dos versiones del tipo Student. ¿Cuál deberías elegir?
-
Para adoptar la versión camelCase, tendrás que configurar algún tipo de adaptador para asegurarte de que tu base de datos devuelve la versión camelCase de las columnas. También tendrás que asegurarte de que cualquier herramienta que utilices para generar tipos TypeScript a partir de tu base de datos conozca esta transformación. La ventaja de este enfoque es que tus interfaces de base de datos tendrán el mismo aspecto que el resto de tus tipos.
-
Para adoptar la versión snake_case, no necesitas hacer nada en absoluto. Sólo tienes que aceptar una incoherencia superficial en la convención de nombres a cambio de una coherencia más profunda en tus tipos.
Cualquiera de estos enfoques es factible, pero el segundo es más sencillo.
El principio general es que debes preferir unificar tipos a modelar pequeñas diferencias entre ellos. Dicho esto, hay algunas salvedades a esta regla.
En primer lugar, la unificación no siempre es una opción. Puede que necesites los dos tipos si la base de datos y la API no están bajo tu control. Si éste es el caso, modelar sistemáticamente este tipo de diferencias en el sistema de tipos te ayudará a encontrar errores en tu código de transformación. Es mejor que crear tipos ad hoc y esperar que se mantengan sincronizados.
En segundo lugar, ¡no unifiques tipos que en realidad no representan lo mismo! "Unificar" los distintos tipos en una unión etiquetada sería contraproducente, por ejemplo, porque presumiblemente representan estados distintos que quieres mantener separados.
Cosas para recordar
-
Tener distintas variantes de un mismo tipo crea una sobrecarga cognitiva y requiere mucho código de conversión.
-
En lugar de modelar pequeñas variaciones de un tipo en tu código, intenta eliminar la variación para poder unificar a un solo tipo.
-
Unificar los tipos puede requerir algunos ajustes en el código de ejecución.
-
Si los tipos no están bajo tu control, puede que tengas que modelar las variaciones.
Tema 40: Prefiere los Tipos Imprecisos a los Inexactos
En escribiendo declaraciones de tipos encontrarás inevitablemente situaciones en las que puedes modelar el comportamiento de forma más o menos precisa. La precisión en los tipos es generalmentealgo bueno porque ayudará a tus usuarios a detectar errores y a aprovechar las herramientas que proporciona TypeScript. Pero ten cuidado al aumentar la precisión de tus declaraciones de tipos: es fácil cometer errores, y los tipos incorrectos pueden ser peor que no tener tipos.
Supón que estás escribiendo declaraciones de tipo para GeoJSON, un formato que ya hemos visto en el Tema 33. Una geometría GeoJSON puede ser de unos cuantos tipos, cada uno de los cuales tiene matrices de coordenadas de forma diferente:
interfacePoint{type:'Point';coordinates:number[];}interfaceLineString{type:'LineString';coordinates:number[][];}interfacePolygon{type:'Polygon';coordinates:number[][][];}typeGeometry=Point|LineString|Polygon;// Also several others
Esto está bien, pero number[] para una coordenada es un poco impreciso. En realidad se trata de latitudes y longitudes, por lo que tal vez sería mejor un tipo tupla:
typeGeoPosition=[number,number];interfacePoint{type:'Point';coordinates:GeoPosition;}// Etc.
Publicas tus tipos más precisos al mundo y esperas a que llegue la adulación. Por desgracia, un usuario se queja de que tus nuevos tipos lo han roto todo. Aunque sólo has utilizado latitud y longitud, una posición en GeoJSON puede tener un tercer elemento, una elevación, y potencialmente más. En un intento de hacer más precisas las declaraciones de tipos, ¡has ido demasiado lejos y has hecho que los tipos sean inexactos! Para seguir utilizando tus declaraciones de tipos, tu usuario tendrá que introducir aserciones de tipos o silenciar por completo el comprobador de tipos con as any. Quizás se den por vencidos y empiecen a escribir sus propias declaraciones en.
Como otro ejemplo, considera intentar escribir declaraciones de tipos para un lenguaje tipo Lisp definido en JSON:
12"red"["+",1,2]// 3["/",20,2]// 10["case",[">",20,10],"red","blue"]// "red"["rgb",255,0,127]// "#FF007F"
La biblioteca Mapbox utiliza un sistema como éste para determinar la apariencia de las características de los mapas en muchos dispositivos. Hay todo un espectro de precisión con el que podrías intentar escribir esto:
-
Permite cualquier cosa.
-
Permite cadenas, números y matrices.
-
Permite cadenas, números y matrices que empiecen por nombres de función conocidos.
-
Asegúrate de que cada función recibe el número correcto de argumentos.
-
Asegúrate de que cada función recibe el tipo correcto de argumentos.
Las dos primeras opciones son sencillas:
typeExpression1=any;typeExpression2=number|string|any[];
Se dice que un sistema de tipos es "completo" si permite todos los programas válidos. Estos dos tipos permitirán todas las expresiones válidas de Mapbox. No habrá errores falsos positivos. Pero con tipos tan simples habrá muchos falsos negativos: expresiones no válidas que no se marcan como tales. En otras palabras, los tipos no son muy precisos.
Veamos si podemos mejorar la precisión sin perder la propiedad de exhaustividad. Para evitar regresiones, debemos introducir un conjunto de prueba de expresiones que sean válidas y expresiones que no lo sean.(El punto 55 trata sobre la comprobación de tipos).
constokExpressions:Expression2[]=[10,"red",["+",10,5],["rgb",255,128,64],["case",[">",20,10],"red","blue"],];constinvalidExpressions:Expression2[]=[true,// ~~~ Type 'boolean' is not assignable to type 'Expression2'["**",2,31],// Should be an error: no "**" function["rgb",255,0,127,0],// Should be an error: too many values["case",[">",20,10],"red","blue","green"],// (Too many values)];
Para pasar al siguiente nivel de precisión, puedes utilizar una unión de tipos literales de cadena como primer elemento de una tupla:
typeFnName='+'|'-'|'*'|'/'|'>'|'<'|'case'|'rgb';typeCallExpression=[FnName,...any[]];typeExpression3=number|string|CallExpression;constokExpressions:Expression3[]=[10,"red",["+",10,5],["rgb",255,128,64],["case",[">",20,10],"red","blue"],];constinvalidExpressions:Expression3[]=[true,// Error: Type 'boolean' is not assignable to type 'Expression3'["**",2,31],// ~~ Type '"**"' is not assignable to type 'FnName'["rgb",255,0,127,0],// Should be an error: too many values["case",[">",20,10],"red","blue","green"],// (Too many values)];
Hay un nuevo error detectado y ninguna regresión. ¡Bastante bien! Una complicación es que nuestras declaraciones de tipos se han relacionado más estrechamente con nuestra versión de Mapbox. Si Mapbox añade una nueva función, las declaraciones de tipos también tienen que añadirla. Estos tipos son más precisos, pero también requieren más mantenimiento.
¿Y si quieres asegurarte de que cada función recibe el número correcto deargumentos? Esto se vuelve más complicado, ya que ahora los tipos tienen que ser recursivos para llegar a todas las llamadas a funciones. TypeScript lo permite, aunque tenemos que tener cuidado de convencer al verificador de tipos de que nuestra recursión no es infinita. Hay varias formas de hacerlo. Una es definir CaseCall (que debe ser una matriz de longitud par) con uninterface en lugar de type.
Esto es posible, aunque un poco incómodo:
typeExpression4=number|string|CallExpression;typeCallExpression=MathCall|CaseCall|RGBCall;typeMathCall=['+'|'-'|'/'|'*'|'>'|'<',Expression4,Expression4,];interfaceCaseCall{0:'case';[n:number]:Expression4;length:4|6|8|10|12|14|16;// etc.}typeRGBCall=['rgb',Expression4,Expression4,Expression4];
Veamos cómo nos ha ido:
constokExpressions:Expression4[]=[10,"red",["+",10,5],["rgb",255,128,64],["case",[">",20,10],"red","blue"],];constinvalidExpressions:Expression4[]=[true,// ~~~ Type 'boolean' is not assignable to type 'Expression4'["**",2,31],// ~~~~ Type '"**"' is not assignable to type '"+" | "-" | "/" | ...["rgb",255,0,127,0],// ~ Type 'number' is not assignable to type 'undefined'.["case",[">",20,10],"red","blue","green"],// ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~// Types of property 'length' are incompatible.// Type '5' is not assignable to type '4 | 6 | 8 | 10 | 12 | 14 | 16'.];
Ahora todas las expresiones no válidas producen errores. Y es interesante que puedas expresar algo como "un array de longitud par" utilizando un TypeScript interface. Pero algunos de estos mensajes de error son un poco confusos, sobre todo el de Type '5'.
¿Es una mejora respecto a los tipos anteriores, menos precisos? El hecho de que obtengas errores por más usos incorrectos es definitivamente una victoria, pero los mensajes de error confusos harán que sea más difícil trabajar con este tipo. Como se explicó en el punto 6, los servicios lingüísticos forman parte de la experiencia TypeScript tanto como la comprobación de tipos, así que es una buena idea observar los mensajes de error resultantes de tus declaraciones de tipos y probar el autocompletado en situaciones en las que debería funcionar. Si tus nuevas declaraciones de tipos son más precisas pero rompen el autocompletado, entonces harán que la experiencia de desarrollo de TypeScript sea menos agradable.
La complejidad de esta declaración de tipos también ha aumentado las probabilidades de que se cuele un error. Por ejemplo, Expression4 requiere que todos los operadores matemáticos tomen dos parámetros, pero la especificación de expresiones de Mapbox dice que + y * pueden tomar más. Además, - puede tomar un solo parámetro, en cuyo caso niega su entrada. Expression4 indica incorrectamente errores en todos ellos:
constmoreOkExpressions:Expression4[]=[['-',12],// ~~~~~~ Type '["-", number]' is not assignable to type 'MathCall'.// Source has 2 element(s) but target requires 3.['+',1,2,3],// ~ Type 'number' is not assignable to type 'undefined'.['*',2,3,4],// ~ Type 'number' is not assignable to type 'undefined'.];
Una vez más, al intentar ser más precisos nos hemos pasado y nos hemos vuelto inexactos. Estas imprecisiones pueden corregirse, pero querrás ampliar tu conjunto de pruebas para convencerte de que no se te ha escapado nada más. El código complejo suele requerir más pruebas, y lo mismo ocurre con los tipos.
A medida que vayas refinando los tipos, puede ser útil pensar en la metáfora del "valle inquietante". A medida que un dibujo caricaturesco se hace más fiel a la realidad, tendemos a percibirlo como más realista. Pero sólo hasta cierto punto. Si busca demasiado realismo, tendemos a hiperfocalizarnos en las pocas inexactitudes que quedan.
Del mismo modo, refinar tipos muy imprecisos como any casi siempre es útil. Tú y tus compañeros lo percibiréis como una mejora de la seguridad tipográfica y de la productividad. Pero a medida que tus tipos se hacen más precisos, aumenta la expectativa de que también sean exactos. Empezarás a confiar en que los tipos detecten la mayoría de los errores, por lo que las imprecisiones resaltarán más claramente. Si pasas horas rastreando un error de tipo, sólo para descubrir que los tipos son inexactos, socavará la confianza en tus declaraciones de tipos y quizás en el propio TypeScript. Desde luego, ¡no aumentará tu productividad!
Cosas para recordar
-
Evita el valle misterioso de la seguridad de tipos: los tipos complejos pero imprecisos suelen ser peores que los tipos más sencillos y menos precisos. Si no puedes modelar un tipo de forma precisa, ¡no lo modeles de forma imprecisa! Reconoce las lagunas utilizando
anyounknown. -
Presta atención a los mensajes de error y a la función de autocompletar a medida que haces que la tipificación sea cada vez más precisa. No se trata sólo de la corrección: la experiencia del desarrollador también importa.
-
A medida que tus tipos se vuelvan más complejos, tu conjunto de pruebas para ellos debería ampliarse.
Tema 41: Nombra los Tipos Utilizando el Lenguaje detu Dominio Problemático
Sólo hay dos problemas difíciles en Informática: invalidar la caché ynombrar las cosas.
Phil Karlton
Este libro ha tenido mucho que decir sobre la forma de los tipos y los conjuntos de valores en sus dominios, pero mucho menos sobre el nombre que das a tus tipos. Pero esto también es una parte importante del diseño de tipos. Los nombres de tipos, propiedades y variables bien elegidos pueden aclarar la intención y elevar el nivel de abstracción de tu código y tus tipos. Los tipos mal elegidos pueden oscurecer tu código y conducir a modelos mentales incorrectos.
Supón que estás construyendo una base de datos de animales. Creas una interfaz para representar a uno:
interfaceAnimal{name:string;endangered:boolean;habitat:string;}constleopard:Animal={name:'Snow Leopard',endangered:false,habitat:'tundra',};
Aquí hay algunos problemas:
-
namees un término muy general. ¿Qué tipo de nombre esperas? ¿Un nombre científico? ¿Un nombre común? -
El campo booleano
endangeredtambién es ambiguo. ¿Qué ocurre si un animal está extinguido? ¿La intención aquí es "en peligro de extinción o peor"? ¿O significa literalmente en peligro de extinción?
-
El campo
habitates muy ambiguo, no sólo por el tipo demasiado ampliostring(Tema 35), sino también porque no está claro qué se entiende por "hábitat". -
El nombre de la variable es
leopard, pero el valor de la propiedadnamees "Snow Leopard". ¿Tiene sentido esta distinción?
Aquí tienes una declaración de tipo y valor con menos ambigüedad:
interfaceAnimal{commonName:string;genus:string;species:string;status:ConservationStatus;climates:KoppenClimate[];}typeConservationStatus='EX'|'EW'|'CR'|'EN'|'VU'|'NT'|'LC';typeKoppenClimate=|'Af'|'Am'|'As'|'Aw'|'BSh'|'BSk'|'BWh'|'BWk'|'Cfa'|'Cfb'|'Cfc'|'Csa'|'Csb'|'Csc'|'Cwa'|'Cwb'|'Cwc'|'Dfa'|'Dfb'|'Dfc'|'Dfd'|'Dsa'|'Dsb'|'Dsc'|'Dwa'|'Dwb'|'Dwc'|'Dwd'|'EF'|'ET';constsnowLeopard:Animal={commonName:'Snow Leopard',genus:'Panthera',species:'Uncia',status:'VU',// vulnerableclimates:['ET','EF','Dfd'],// alpine or subalpine};
Esto supone una serie de mejoras:
-
nameha sido sustituido por términos más específicos:commonName,genus, yspecies. -
endangeredse ha convertido enstatus, un tipo deConservationStatusque utiliza un sistema de clasificación estándar de la UICN. -
habitatse ha convertido enclimatesy utiliza otra taxonomía estándar, la clasificación climática de Köppen.
Si necesitaras más información sobre los campos de la primera versión de este tipo, tendrías que ir a buscar a la persona que los escribió y preguntarle. Lo más probable es que haya dejado la empresa o no se acuerde. Peor aún, podrías consultar git blame para averiguar quién escribió estos pésimos tipos, ¡y descubrir que fuiste tú!
La situación ha mejorado mucho con la segunda versión. Si quieres saber más sobre el sistema de clasificación climática de Köppen o averiguar cuál es el significado exacto de un estado de conservación, hay infinidad de recursos en Internet que te ayudarán.
Cada dominio tiene un vocabulario especializado para describir su tema. En lugar de inventar tus propios términos, intenta reutilizar términos del dominio de tu problema. A menudo, estos vocabularios se han perfeccionado a lo largo de años, décadas o siglos, y son bien comprendidos por la gente del sector. Utilizar estos términos te ayudará a comunicarte con los usuarios y aumentará la claridad de tus tipos.
Ten cuidado de utilizar el vocabulario del dominio con precisión: cooptar el lenguaje de un dominio para que signifique algo diferente es aún más confuso que inventar el tuyo propio.
Estas mismas consideraciones se aplican también a otras etiquetas, como los nombres de los parámetros de las funciones, las etiquetas de las tuplas y las etiquetas de los tipos de índice.
Aquí tienes otras reglas que debes tener en cuenta cuando nombres tipos, propiedades yvariables:
-
Haz que las distinciones tengan sentido. Al escribir y hablar puede resultar tedioso utilizar la misma palabra una y otra vez. Introducimos sinónimos para romper la monotonía. Esto hace que la prosa sea más agradable de leer, pero tiene el efecto contrario en el código. Si utilizas dos términos diferentes, asegúrate de que haces una distinción significativa. Si no es así, debes utilizar el mismo término.
-
Evita nombres vagos y sin sentido como "datos", "información", "cosa", "elemento", "objeto" o la siempre popular "entidad". Si Entidad tiene un significado específico en tu dominio, bien. Pero si la utilizas porque no quieres pensar en un nombre más significativo, al final tendrás problemas: puede haber varios tipos distintos llamados "Entidad" en tu proyecto, y ¿puedes recordar qué es un Elemento y qué es una Entidad?
-
Nombra las cosas por lo que son, no por lo que contienen o por cómo se calculan.
Directoryes más significativo queINodeList. Te permite pensar en un directorio como un concepto, en lugar de en términos de su implementación. Unos buenos nombres pueden aumentar tu nivel de abstracción y disminuir el riesgo decolisiones involuntarias.
Cosas para recordar
-
Reutiliza nombres del dominio de tu problema siempre que sea posible para aumentar la legibilidad y el nivel de abstracción de tu código. Asegúrate de utilizar con precisión los términos del dominio.
-
Evita utilizar diferentes nombres para la misma cosa: haz que las distinciones en los nombres tengan sentido.
-
Evita nombres vagos como "Información" o "Entidad". Nombra los tipos por lo que son, y no por su forma.
Tema 42: Evitar tipos basados en datos anecdóticos
En los otros artículos de de este capítulo se han tratado las muchas ventajas de un buen diseño de tipos y se ha mostrado lo que puede ir mal sin él. Un tipo bien diseñado hace que TypeScript sea un placer de usar, mientras que uno mal diseñado puede hacer que sea miserable de usar. Pero esto ejerce bastante presión sobre el diseño de tipos. ¿No estaría bien que no tuvieras que hacerlo tú mismo?
Es probable que al menos algunos de tus tipos procedan de fuera de tu programa: especificaciones, formatos de archivo, API o esquemas de bases de datos. Es tentador escribir tú mismo las declaraciones de estos tipos basándote en los datos que has visto, quizás las filas de tu base de datos de prueba o las respuestas que has visto de un punto final de API concreto.
¡Resiste este impulso! Es mucho mejor importar tipos de otra fuente o generarlos a partir de una especificación. Cuando escribes tipos tú mismo basándote en datos anecdóticos, sólo tienes en cuenta los ejemplos que has visto. Podrías estar pasando por alto casos de perímetro importantes que podrían romper tu programa. Cuando utilices tipos más oficiales, TypeScript te ayudará a garantizar que esto no ocurra.
En el Tema 30 utilizamos una función que calculaba el cuadro delimitador de una característica GeoJSON. He aquí cómo podría ser una definición:
functioncalculateBoundingBox(f:GeoJSONFeature):BoundingBox|null{letbox:BoundingBox|null=null;consthelper=(coords:any[])=>{// ...};const{geometry}=f;if(geometry){helper(geometry.coordinates);}returnbox;}
¿Cómo definirías el tipo GeoJSONFeature? Podrías mirar algunas características GeoJSON en tu repo y esbozar un interface:
interfaceGeoJSONFeature{type:'Feature';geometry:GeoJSONGeometry|null;properties:unknown;}interfaceGeoJSONGeometry{type:'Point'|'LineString'|'Polygon'|'MultiPolygon';coordinates:number[]|number[][]|number[][][]|number[][][][];}
La función pasa el comprobador de tipos con esta definición. Pero, ¿es realmente correcta? Esta comprobación sólo es tan buena como nuestras declaraciones de tipos caseras.
Un enfoque mejor sería utilizar la especificación formal GeoJSON.1 Afortunadamente para nosotros, ya existen declaraciones de tipo TypeScript para ello en DefinitelyTyped. Puedes añadirlas de la forma habitual:2
$ npm install --save-dev @types/geojson + @types/geojson@7946.0.14
Con estas declaraciones, TypeScript señala un error:
import{Feature}from'geojson';functioncalculateBoundingBox(f:Feature):BoundingBox|null{letbox:BoundingBox|null=null;consthelper=(coords:any[])=>{// ...};const{geometry}=f;if(geometry){helper(geometry.coordinates);// ~~~~~~~~~~~// Property 'coordinates' does not exist on type 'Geometry'// Property 'coordinates' does not exist on type 'GeometryCollection'}returnbox;}
El problema es que este código supone que una geometría tendrá una propiedad coordinates. Esto es cierto para muchas geometrías, incluidos puntos, líneas y polígonos. Pero una geometría GeoJSON también puede ser una GeometryCollection, una colección heterogénea de otras geometrías. A diferencia de los otros tipos de geometría, no tiene una propiedad coordinates.
Si llamas a calculateBoundingBox en una característica cuya geometría es un GeometryCollection, arrojará un error sobre la imposibilidad de leer la propiedad 0 deundefined. ¡Se trata de un error real! Y lo hemos detectado obteniendo tipos de lacomunidad.
Una opción para solucionar el error es desautorizar explícitamente GeometryCollections:
const{geometry}=f;if(geometry){if(geometry.type==='GeometryCollection'){thrownewError('GeometryCollections are not supported.');}helper(geometry.coordinates);// OK}
TypeScript es capaz de refinar el tipo de geometry basándose en la comprobación, por lo que la referencia a geometry.coordinates está permitida. Aunque sólo sea por eso, el mensaje de error es más claro para el usuario.
¡Pero la mejor solución es admitir GeometryCollections! Puedes hacerlo sacando otra función de ayuda:
constgeometryHelper=(g:Geometry)=>{if(g.type==='GeometryCollection'){g.geometries.forEach(geometryHelper);}else{helper(g.coordinates);// OK}}const{geometry}=f;if(geometry){geometryHelper(geometry);}
Nuestros tipos GeoJSON escritos a mano se basaban sólo en nuestra propia experiencia con el formato, que no incluía GeometryCollections. Esto nos llevó a una falsa sensación de seguridad sobre la corrección de nuestro código. Utilizar tipos comunitarios basados en una especificación te da la seguridad de que tu código funcionará con todos los valores, no sólo con los que casualmente has visto.
Consideraciones similares se aplican a las llamadas a la API. Si existe un cliente TypeScript oficial para la API con la que estás trabajando, ¡úsalo! Pero incluso si no lo hay, es posible que puedas generar tipos TypeScript a partir de una fuente oficial.
Si utilizas una API GraphQL, por ejemplo, ésta incluye un esquema que describe todas sus consultas y mutaciones, así como todos los tipos. Hay muchas herramientas disponibles para añadir tipos TypeScript a las consultas GraphQL. Dirígete a tu buscador favorito y rápidamente estarás en el camino hacia la seguridad de tipos.
Muchas API REST publican un esquema OpenAPI. Se trata de un archivo que describe todos los puntos finales, los verbos HTTP (GET, POST, etc.) y los tipos utilizando el esquema JSON.
Supongamos que utilizamos una API que nos permite publicar comentarios en un blog. Este es el aspecto que podría tener un esquema OpenAPI:
// schema.json{"openapi":"3.0.3","info":{"version":"1.0.0","title":"Sample API"},"paths":{"/comment":{"post":{"requestBody":{"content":{"application/json":{"schema":{"$ref":"#/components/schemas/Comment"}}}}},"responses":{"200":{/* ... */}}}},"components":{"schemas":{"CreateCommentRequest":{"properties":{"body":{"type":"string"},"postId":{"type":"string"},"title":{"type":"string"}},"type":"object","required":["postId","title","body"]}}}}
La sección paths define los puntos finales y los asocia a tipos, que se encuentran en la sección components/schemas. Toda la información que necesitamos para generar tipos está aquí. Hay muchas formas de obtener tipos a partir de un esquema OpenAPI. Una es extraer los esquemas y ejecutarlos a través de json-schema-to-typescript:
$ jq .components.schemas.CreateCommentRequest schema.json > comment.json
$ npx json-schema-to-typescript comment.json > comment.ts
$ cat comment.ts
// ....
export interface CreateCommentRequest {
body: string;
postId: string;
title: string;
}
Esto da como resultado un bonito y limpio interfaces que te ayudará a interactuar con esta API de una forma segura desde el punto de vista tipográfico. TypeScript marcará los errores de tipo en los cuerpos de tus peticiones y los tipos de respuesta fluirán a través de tu código. Lo importante es que no has escrito los tipos tú mismo. Más bien, se generan a partir de una fuente fiable de verdad. Si un campo es opcional o puede ser null, TypeScript lo sabrá y te obligará a manejar esa posibilidad.
El siguiente paso sería añadir validación en tiempo de ejecución y conectar los tipos directamente a los puntos finales a los que están asociados. Hay muchas herramientas que pueden ayudarte con esto, y el Tema 74 volverá a este ejemplo.
Cuando generes tipos, debes asegurarte de que se mantienen sincronizados con el esquema de la API. El punto 58 trata de las estrategias para manejar esto.
¿Y si no hay ninguna especificación o esquema oficial disponible? Entonces tendrás que generar tipos a partir de los datos. Herramientas como quicktype pueden ayudarte con esto. Pero ten en cuenta que tus tipos pueden no coincidir con la realidad: puede haber casos de perímetro que se te hayan pasado por alto. (Una excepción sería si tu conjunto de datos es finito, por ejemplo, un directorio de 1.000 archivos JSON. Entonces sabrás que no has pasado nada por alto).
Aunque no seas consciente de ello, ya te estás beneficiando de la generación de código. Las declaraciones de tipos de TypeScript para la API DOM del navegador, que se exploran en el Tema 75, se generan a partir de las descripciones de la API en MDN. Esto garantiza que modelan correctamente un sistema complicado y ayuda a TypeScript a detectar errores y malentendidos en tu propio código.
1 GeoJSON también se conoce como RFC 7946. La especificación, muy legible, está en http://geojson.org.
2 El número de versión principal, inusualmente grande, coincide con el número RFC. Esto fue bonito en su momento, pero en la práctica ha resultado ser una molestia.
Get TypeScript Eficaz, 2ª Edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

