Capítulo 4. Arquitectura de Trino
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Tras la introducción a Trino, y una instalación y uso iniciales en los capítulos anteriores, ahora hablamos de la arquitectura de Trino. Profundizamos en conceptos relacionados, para que conozcas el modelo de ejecución de consultas de Trino, la planificación de consultas y las optimizaciones basadas en costes.
En este capítulo, hablaremos primero de los componentes arquitectónicos de alto nivel de Trino. Es importante tener una comprensión general del funcionamiento de Trino, sobre todo si pretendes instalar y gestionar tú mismo un clúster Trino, como se explica enel Capítulo 5.
En la última parte del capítulo, profundizaremos en esos componentes cuando hablemos del modelo de ejecución de consultas de Trino. Esto es muy importante si necesitas diagnosticar o ajustar una consulta de rendimiento lento, todo ello tratado enel Capítulo 8, o si piensas contribuir al proyecto de código abierto Trino.
Coordinador y Trabajadores de un Cluster
Cuando instalaste Trino por primera vez, como se explica en el Capítulo 2, utilizaste una sola máquina para ejecutarlo todo. Para la escalabilidad y el rendimiento deseados, esta implementación no es adecuada.
Trino es un motor de consulta SQL distribuido que se asemeja a las bases de datos y motores de consulta del estilo del procesamiento paralelo masivo (MPP). En lugar de basarse en el escalado vertical del servidor que ejecuta Trino, es capaz de distribuir todo el procesamiento a través de un clúster de servidores horizontalmente. Esto significa que puedes añadir más nodos para ganar más potencia de procesamiento.
Aprovechando esta arquitectura, el motor de consulta Trino es capaz de procesar consultas SQL sobre grandes cantidades de datos en paralelo a través de un clúster de ordenadores, o nodos. Trino se ejecuta como un proceso de servidor único en cada nodo. Varios nodos que ejecutan Trino, configurados para colaborar entre sí, constituyen un clúster Trino.
La Figura 4-1 muestra una visión general de alto nivel de un clúster Trino compuesto por un coordinador y varios nodos trabajadores. Un usuario de Trino se conecta al coordinador con un cliente, como una herramienta que utilice el controlador JDBC o la CLI de Trino. A continuación, el coordinador colabora con los trabajadores, que acceden a las fuentes de datos.
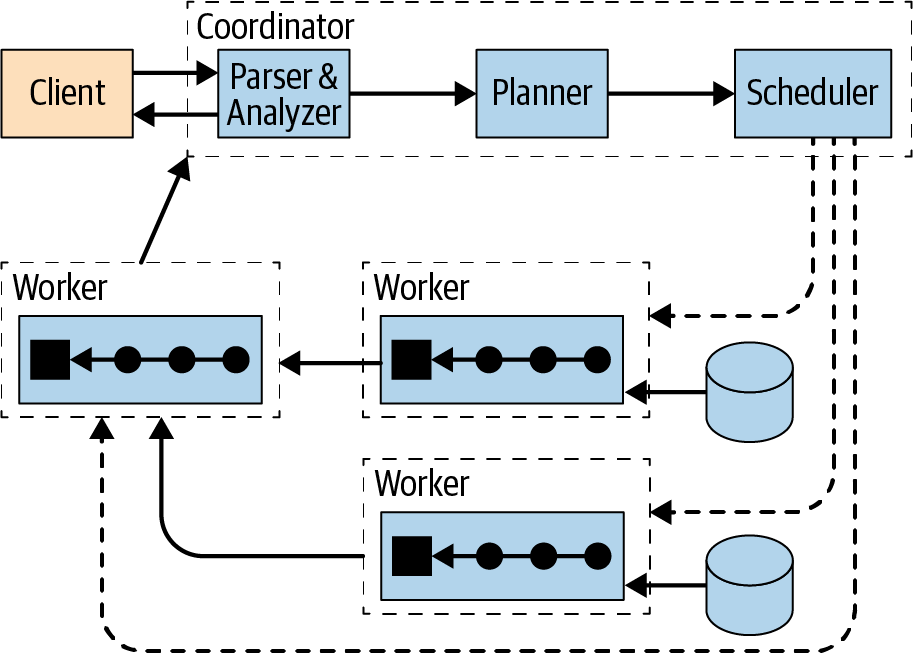
Figura 4-1. Visión general de la arquitectura Trino con coordinador y trabajadores
Un coordinador es un servidor Trino que gestiona las consultas entrantes y administra lostrabajadores para ejecutar las consultas.
Un trabajador es un servidor Trino responsable de ejecutar tareas y procesar datos.
El servicio de descubrimiento se ejecuta en el coordinador y permite a los trabajadores registrarse para participar en el clúster.
Toda la comunicación y transferencia de datos entre clientes, coordinador y trabajadores utiliza interacciones basadas en REST sobre HTTP/HTTPS.
La Figura 4-2 muestra cómo se produce la comunicación dentro del cluster entre el coordinador y los trabajadores, así como de un trabajador a otro. El coordinador habla con los trabajadores para asignarles trabajo, actualizar su estado y obtener el conjunto de resultados de nivel superior para devolvérselo a los usuarios. Los trabajadores se comunican entre sí para obtener datos de tareas anteriores, que se ejecutan en otros trabajadores. Y los trabajadores recuperan conjuntos de resultados de la fuente de datos.
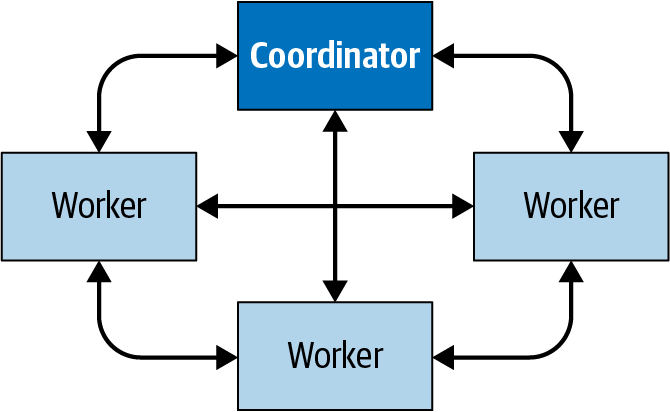
Figura 4-2. Comunicación entre el coordinador y los trabajadores en un clúster Trino
Coordinador
El coordinador de Trino es el servidor responsable de recibir las sentencias SQL de los usuarios, analizarlas, planificar las consultas y gestionar los nodos trabajadores. Es el cerebro de una instalación de Trino y el nodo al que se conecta un cliente. Los usuarios interactúan con el coordinador a través de la CLI de Trino, las aplicaciones que utilizan los controladores JDBC u ODBC, el cliente Python de Trino o cualquier otra biblioteca cliente para diversos lenguajes. El coordinador acepta sentencias SQL del cliente, como consultas a SELECT, para suejecución.
Toda instalación de Trino debe tener un coordinador junto a uno o varios trabajadores. Para fines de desarrollo o pruebas, se puede configurar una única instancia de Trino para que desempeñe ambas funciones.
El coordinador realiza un seguimiento de la actividad de cada trabajador y coordina la ejecución de una consulta. El coordinador crea un modelo lógico de una consulta que implica una serie de etapas.
Una vez que el coordinador recibe una sentencia SQL, se encarga de analizar, planificar y programar la ejecución de la consulta en los nodos trabajadores de Trino. La sentencia se traduce en una serie de tareas conectadas que se ejecutan en un clúster de trabajadores. A medida que los trabajadores procesan los datos, el coordinador recupera los resultados y los expone a los clientes en un búfer de salida. Cuando el cliente lee completamente un búfer de salida, el coordinador solicita más datos a los trabajadores en nombre del cliente. Los trabajadores, a su vez, interactúan con las fuentes de datos para obtener los datos de ellas. Como resultado, los datos son solicitados continuamente por el cliente y suministrados por los trabajadores desde la fuente de datos hasta que finaliza la ejecución de la consulta.
Los coordinadores se comunican con los trabajadores y los clientes mediante un protocolo basado en HTTP. La Figura 4-3 muestra la comunicación entre cliente, coordinador y trabajadores.
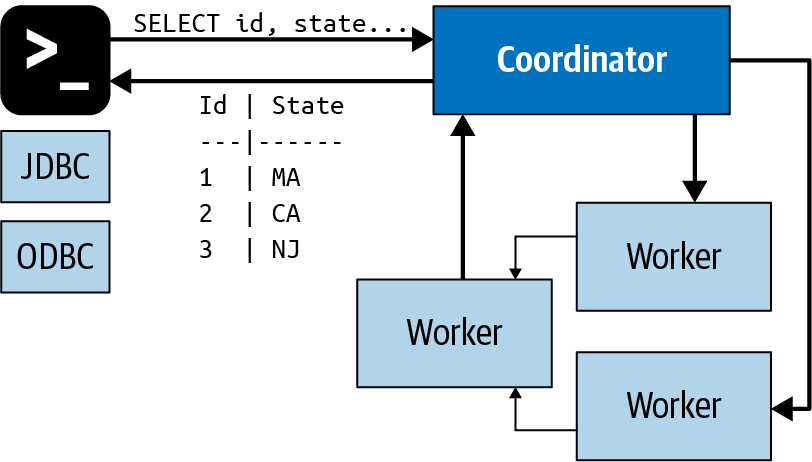
Figura 4-3. Comunicación entre cliente, coordinador y trabajador procesando una sentencia SQL
Servicio Descubrimiento
Trino utiliza un servicio de descubrimiento para encontrar todos los nodos del clúster. Cada instancia de Trino se registra en el servicio de descubrimiento al iniciarse y envía periódicamente una señal de heartbeat. Esto permite al coordinador tener una lista actualizada de los trabajadores disponibles y utilizarla para programar la ejecución de las consultas.
Si un trabajador no informa de las señales de latido, el servicio de descubrimiento activa el detector de fallos, y el trabajador deja de ser elegible para más tareas.
El coordinador de Trino ejecuta el servicio de detección. Comparte el servidor HTTP con Trino y, por tanto, utiliza el mismo puerto. Por tanto, la configuración del trabajador del servicio de localización apunta al nombre de host y al puerto del coordinador.
Trabajadores
Un trabajador Trino es un servidor en una instalación Trino. Se encarga de ejecutar las tareas asignadas por el coordinador, incluida la recuperación de datos de las fuentes de datos y su procesamiento. Los nodos trabajadores obtienen datos de las fuentes de datos mediante conectores y luego intercambian datos intermedios entre sí. Los datos finales resultantes se transmiten al coordinador. El coordinador se encarga de recopilar los resultados de los trabajadores y proporcionar los resultados finales al cliente.
Durante la instalación, los trabajadores se configuran para conocer el nombre de host o la dirección IP del servicio de descubrimiento del clúster. Cuando un trabajador se pone en marcha, se anuncia al servicio de descubrimiento, que lo pone a disposición del coordinador para la ejecución de tareas.
Los trabajadores se comunican con otros trabajadores y con el coordinador mediante un protocolo basado en HTTP.
La Figura 4-4 muestra cómo varios trabajadores recuperan datos de las fuentes de datos y colaboran para procesarlos, hasta que un trabajador puede proporcionar los datos al coordinador.
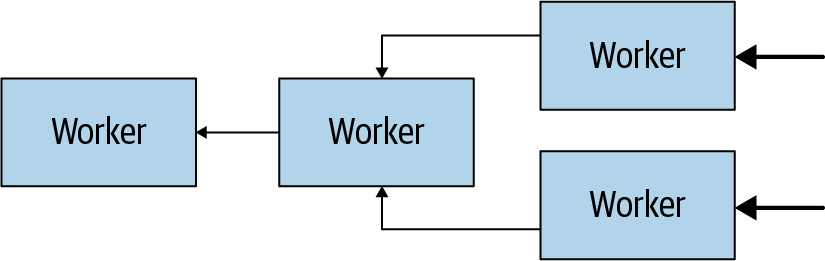
Figura 4-4. Los trabajadores de un cluster colaboran para procesar sentencias SQL y datos
Arquitectura basada en conectores
El núcleo de la separación entre almacenamiento y cálculo en Trino es la arquitectura basada en conectores. Un conector proporciona a Trino una interfaz para acceder a una fuente de datos arbitraria.
Cada conector proporciona una abstracción basada en tablas sobre la fuente de datos subyacente. Siempre que los datos puedan expresarse en términos de tablas, columnas y filas utilizando los tipos de datos de que dispone Trino, puede crearse un conector y el motor de consultas puede utilizar los datos para procesar las consultas.
Trino proporciona una interfaz de proveedor de servicios(SPI), que define la funcionalidad que debe implementar un conector para determinadas funciones. Al implementar la SPI en un conector, Trino puede utilizar internamente operaciones estándar para conectarse a cualquier fuente de datos y realizar operaciones en cualquier fuente de datos. El conector se encarga de los detalles relevantes para la fuente de datos específica.
Cada conector implementa las tres partes de la API:
-
Operaciones para obtener metadatos de tablas/vistas/esquemas
-
Operaciones para producir unidades lógicas de partición de datos, de modo que Trino pueda paralelizar lecturas y escrituras
-
Fuentes y sumideros de datos que convierten los datos de origen a/desde el formato en memoria esperado por el motor de consulta
Aclaremos el SPI con un ejemplo. Cualquier conector de Trino que soporte la lectura de datos de la fuente de datos subyacente necesita implementar la SPI listTables. Como resultado, Trino puede utilizar el mismo método para pedir a cualquier conector que compruebe la lista de tablas disponibles en un esquema. Trino no tiene por qué saber que algunos conectores tienen que obtener esos datos de un esquema de información, otros tienen que consultar un metastore y otros tienen que solicitar esa información a través de una API de la fuente de datos. Para el motor central de Trino, esos detalles son irrelevantes. El conector se ocupa de los detalles. Este enfoque separa claramente las preocupaciones del motor de consulta principal de las particularidades de cualquier fuente de datos subyacente. Este enfoque sencillo, pero potente, proporciona grandes beneficios para la capacidad de leer, ampliar y mantener el código a lo largo del tiempo.
Trino proporciona muchos conectores a sistemas como HDFS/Hive, Iceberg, Delta Lake, MySQL, PostgreSQL, MS SQL Server, Kafka, Cassandra, Redis y muchos más. En los Capítulos 6 y7, aprenderás sobre varios de los conectores. La lista de conectores disponibles crece continuamente. Consulta la documentación de Trino para conocer la lista más reciente de conectores compatibles.
El SPI de Trino también te ofrece la posibilidad de crear tus propios conectores personalizados, lo que puede ser necesario si necesitas acceder a una fuente de datos sin un conector compatible. Si acabas creando un conector, te animamos encarecidamente a que conozcas mejor la comunidad de código abierto de Trino, utilices nuestra ayuda y contribuyas con tu conector. Consulta "Recursos de Trino" para obtener más información. También puede ser necesario un conector personalizado si tienes una fuente de datos única o propietaria dentro de tu organización. Esto es lo que permite a los usuarios de Trino consultar cualquier fuente de datos utilizando SQL -verdaderamente SQL-on-Anything.
La Figura 4-5 muestra cómo el SPI Trino incluye interfaces separadas para metadatos, estadísticas de datos y localización de datos utilizadas por el coordinador, y para el flujo de datos utilizado por los trabajadores.

Figura 4-5. Visión general del SPI Trino
Los conectores Trino son plug-ins que carga cada servidor al iniciarse. Se configuran mediante parámetros específicos en los archivos de propiedades del catálogo y se cargan desde el directorio de plug-ins. Exploraremos esto más a fondo en el Capítulo 6.
Nota
Trino utiliza una arquitectura basada en plug-ins para numerosos aspectos de su funcionalidad. Además de conectores, los plug-ins pueden proporcionar implementaciones para escuchadores de eventos, controles de acceso y proveedores de funciones y tipos.
Catálogos, esquemas y tablas
El cluster Trino procesa todas las consultas utilizando la arquitectura basada en conectores descrita anteriormente. Cada configuración de catálogo utiliza un conector para acceder a una fuente de datos específica. La fuente de datos expone uno o varios esquemas en el catálogo. Cada esquema contiene tablas que proporcionan los datos en filas de tabla, con columnas que utilizan distintos tipos de datos. Para más detalles, consultael Capítulo 8: específicamente "Catálogos", "Esquemas" y"Tablas".
Modelo de ejecución de consultas
Ahora que ya sabes que cualquier implementación real de Trino implica un clúster con un coordinador y muchos trabajadores, podemos ver cómo se procesa una consulta SQL real.
Comprender el modelo de ejecución te proporciona los conocimientos básicos necesarios para ajustar el rendimiento de Trino a tus consultas concretas.
Recuerda que el coordinador acepta sentencias SQL del usuario final, de la CLI o de aplicaciones que utilicen el controlador ODBC o JDBC u otras bibliotecas cliente. A continuación, el coordinador activa los trabajadores para obtener todos los datos de la fuente de datos, crea el conjunto de datos resultante y lo pone a disposición del cliente.
Veamos primero lo que ocurre dentro del coordinador. Cuando se envía una sentencia SQL al coordinador, se recibe en formato textual. El coordinador toma ese texto y lo analiza. A continuación, crea un plan de ejecución utilizando una estructura de datos interna de Trino denominada plan de consulta. Este flujo se muestra en la Figura 4-6. El plan de consulta representa a grandes rasgos los pasos necesarios para procesar los datos y devolver los resultados según la sentencia SQL.
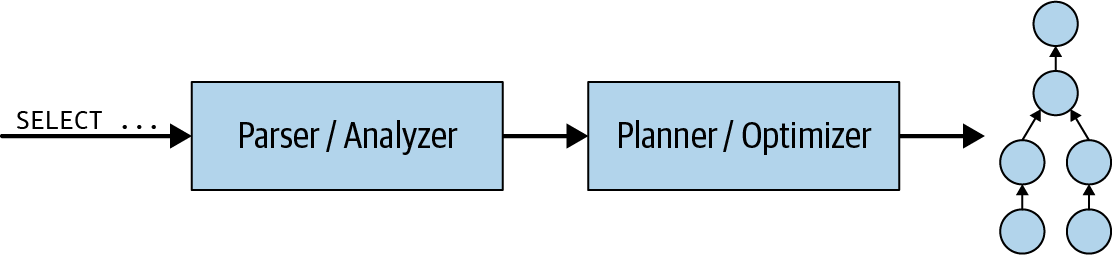
Figura 4-6. Procesar una sentencia de consulta SQL para crear un plan de consulta
Como puedes ver en la Figura 4-7, la generación del plan de consulta utiliza el SPI de metadatos y el SPI de estadísticas de datos para crear el plan de consulta. Así, el coordinador utiliza el SPI para recopilar información sobre las tablas y otros metadatos que se conectan directamente a la fuente de datos.
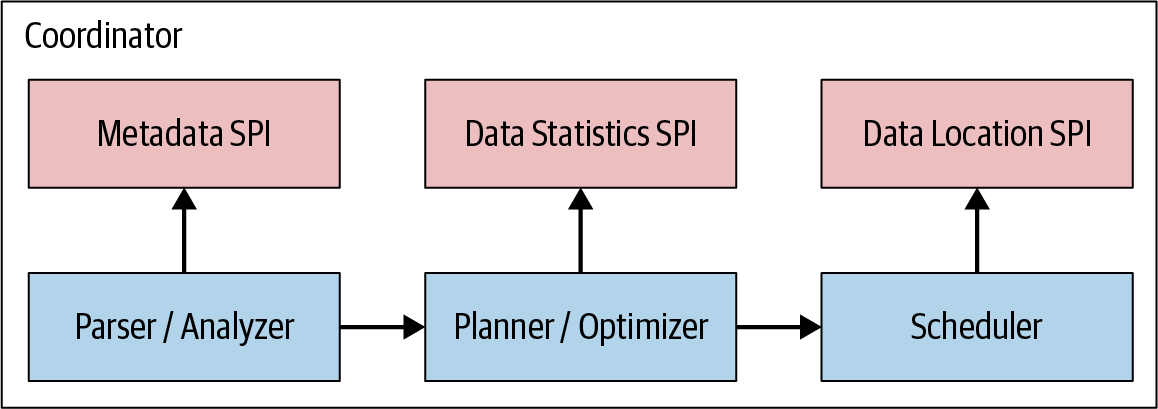
Figura 4-7. Los SPI para la planificación y programación de consultas
El coordinador utiliza el SPI de metadatos para obtener información sobre tablas, columnas y tipos. Éstos se utilizan para validar que la consulta es semánticamente válida y para realizar comprobaciones de tipo de las expresiones de la consulta original y comprobaciones de seguridad.
El SPI de estadísticas se utiliza para obtener información sobre el recuento de filas y el tamaño de las tablas para realizar optimizaciones de consulta basadas en costes durante la planificación.
El SPI de localización de datos se facilita entonces en la creación del plan de consulta distribuido. Se utiliza para generar divisiones lógicas del contenido de la tabla. Las divisiones son la unidad más pequeña de asignación de trabajo y paralelismo.
Nota
Las distintas SPI son más bien una separación conceptual; la API Java real de nivel inferior está separada por varios paquetes Java de forma más detallada.
El plan de consulta distribuido es una extensión del plan de consulta simple que consta de una o varias etapas. El plan de consulta simple se divide en fragmentos de plan. Unaetapa es la encarnación en tiempo de ejecución de un fragmento de plan, y engloba todas las tareas del trabajo descrito por el fragmento de plan de la etapa.
El coordinador divide el plan para permitir el procesamiento en clusters facilitando trabajadores en paralelo para acelerar la consulta global. Tener más de una etapa da lugar a la creación de un árbol de dependencia de etapas. El número de etapas depende de la complejidad de la consulta. Por ejemplo, las tablas consultadas, las columnas devueltas, las sentencias JOIN, las condiciones WHERE, las operaciones GROUP BY y otras sentencias SQL influyen en el número de etapas creadas.
La Figura 4-8 muestra cómo se transforma el plan de consulta lógico en un plan de consulta distribuido en el coordinador del cluster.
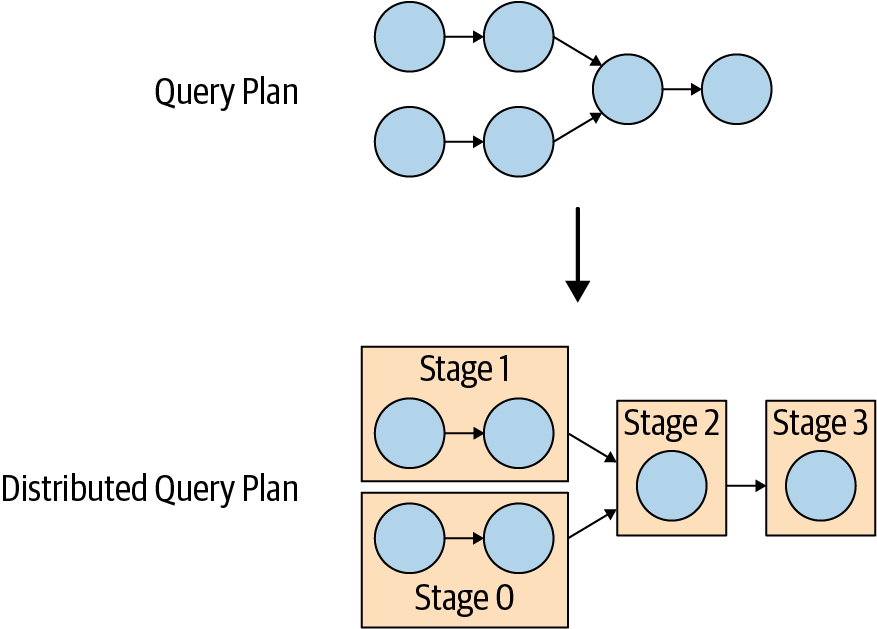
Figura 4-8. Transformación del plan de consulta en un plan de consulta distribuido
El plan de consulta distribuido define las etapas y la forma en que se va a ejecutar la consulta en un cluster Trino. Lo utiliza el coordinador para seguir planificando y programando tareas entre los trabajadores. Una etapa consta de una o más tareas. Normalmente, intervienen muchas tareas, y cada tarea procesa una parte de los datos.
El coordinador asigna las tareas de una etapa a los trabajadores del clúster, como se muestra en la Figura 4-9.
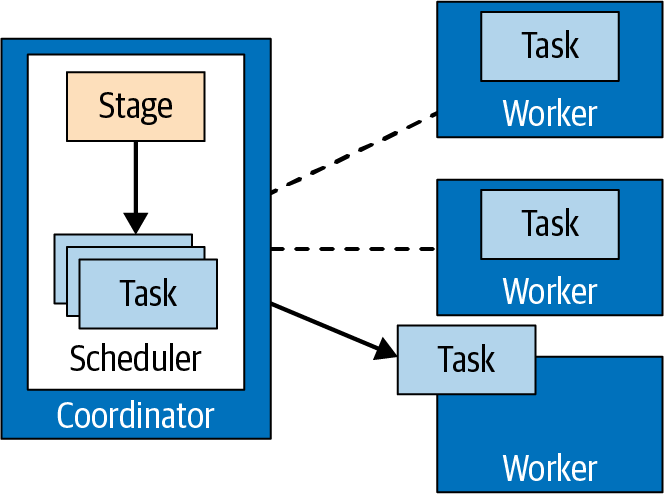
Figura 4-9. Gestión de tareas realizada por el coordinador
La unidad de datos que procesa una tarea se denomina división. Una división es un descriptor de un segmento de los datos subyacentes que puede ser recuperado y procesado por un trabajador. Es la unidad de paralelismo y asignación de trabajo.
Las operaciones específicas sobre los datos que realiza el conector dependen de la fuente de datos subyacente. Por ejemplo, el conector Hive describe las divisiones en forma de una ruta a un archivo con un desplazamiento y una longitud que indican qué parte del archivo hay que procesar.
Las tareas de la etapa fuente producen datos en forma de páginas, que son una colección de filas en formato columnar. Estas páginas fluyen a otras etapas intermedias posteriores. Las páginas se transfieren entre etapas mediante operadores de intercambio, que leen los datos de las tareas de una etapa ascendente.
Las tareas fuente utilizan el SPI de la fuente de datos para obtener datos de la fuente de datos subyacente con la ayuda de un conector. Estos datos se presentan a Trino y fluyen por el motor en forma de páginas. Los operadores procesan y producen páginas según su semántica. Por ejemplo, los filtros eliminan filas, las proyecciones producen páginas con nuevas columnas derivadas, etc.
La secuencia de operadores dentro de una tarea se denominacanalización. El último operador de una cadena suele colocar sus páginas de salida en el búfer de salida de la tarea. Los operadores de intercambio de las tareas posteriores consumen las páginas del búfer de salida de una tarea anterior. Todas estas operaciones ocurren en paralelo en diferentes trabajadores, como se ve en la Figura 4-10.
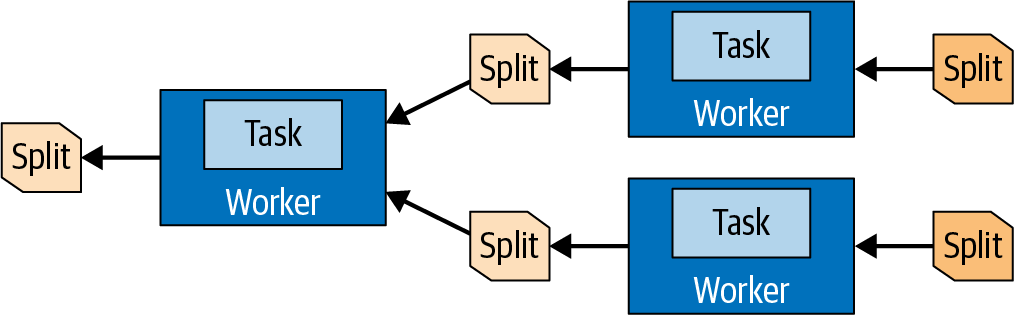
Figura 4-10. Los datos de las divisiones se transfieren entre tareas y se procesan en diferentes trabajadores
Así pues, una tarea es la encarnación en tiempo de ejecución de un fragmento del plan cuando se asigna a un trabajador. Una vez creada una tarea, instanciará un controlador para cada división. Cada controlador es una instanciación de una cadena de operadores y realiza el procesamiento de los datos de la división.
Una tarea puede utilizar uno o varios controladores, según la configuración y el entorno de Trino, como se muestra en laFigura 4-11. Una vez que todos los controladores han terminado y los datos han pasado a la siguiente división, los controladores y la tarea han terminado su trabajo y se destruyen.
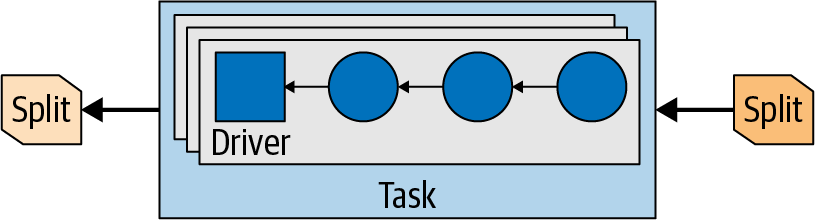
Figura 4-11. Controladores paralelos en una tarea con divisiones de entrada y salida
Un operador procesa datos de entrada para producir datos de salida para un operador posterior. Ejemplos de operadores son los escaneos de tablas, los filtros, las uniones y las agregaciones. Una serie de estos operadores forma una cadena de operadores. Por ejemplo, puedes tener una cadena que primero explore y lea los datos, luego los filtre y, por último, los agregue parcialmente.
Para procesar una consulta, el coordinador crea la lista de divisiones con los metadatos del conector. Utilizando la lista de divisiones, el coordinador empieza a programar tareas en los trabajadores para recopilar los datos de las divisiones. Durante la ejecución de la consulta, el coordinador realiza un seguimiento de todas las divisiones disponibles para procesar y de las ubicaciones en las que se están ejecutando tareas en los trabajadores y procesando divisiones.
A medida que las tareas terminan de procesarse y van produciendo más divisiones para su procesamiento posterior, el coordinador sigue programando tareas hasta que no queden divisiones por procesar. Una vez procesadas todas las divisiones en los trabajadores, todos los datos están disponibles, y el coordinador puede poner el resultado a disposición del cliente.
Planificación de consultas
Antes de sumergirnos en cómo funcionan el planificador de consultas Trino y las optimizaciones basadas en costes, vamos a establecer un escenario que enmarque nuestras consideraciones en un contexto determinado. Presentamos una consulta de ejemplo como contexto de nuestra exploración para ayudarte a comprender el proceso de planificación de consultas.
El ejemplo 4-1 utiliza el conjunto de datos TPC-H -ver "Conectores Trino TPC-H y TPC-DS"- parasumar el valor de todos los pedidos por nación y enumerar las cinco naciones más importantes.
Ejemplo 4-1. Ejemplo de consulta para explicar la planificación de consultas
SELECT(SELECTnameFROMregionrWHEREregionkey=n.regionkey)ASregion_name,n.nameASnation_name,sum(totalprice)orders_sumFROMnationn,orderso,customercWHEREn.nationkey=c.nationkeyANDc.custkey=o.custkeyGROUPBYn.nationkey,regionkey,n.nameORDERBYorders_sumDESCLIMIT5;
Intentemos comprender las construcciones SQL utilizadas en la consulta y su finalidad:
-
Una consulta
SELECTque utiliza tres tablas en la cláusulaFROM, definiendo implícitamente unaCROSS JOINentre las tablasnation,ordersycustomer -
Una condición
WHEREpara conservar las filas coincidentes de las tablasnation,ordersycustomertablas -
Una agregación que utiliza
GROUP BYpara agregar los valores de los pedidos de cada nación -
Una subconsulta
(SELECT name FROM region WHERE regionkey = n.regionkey)para obtener el nombre de la región de la tablaregion; ten en cuenta que esta consulta está correlacionada, como si debiera ejecutarse independientemente para cada fila del conjunto de resultados que la contiene -
Una definición de ordenación,
ORDER BY orders_sum DESC, para ordenar el resultado antes de devolverlo -
Un límite de cinco filas definido para devolver sólo las naciones con las sumas de orden más alto y filtrar todas las demás
Análisis sintáctico
Antes de poder planificar una consulta para su ejecución, es necesario analizarla y analizarla. En los Capítulos 8 y9 encontrarás información detallada sobre SQL y las reglas sintácticas relacionadas para construir la consulta. Al analizar el texto, Trino comprueba si cumple estas reglas sintácticas. Como paso siguiente, Trino analiza la consulta:
- Identificar las tablas utilizadas en una consulta
-
Las tablas se organizan dentro de catálogos y esquemas, por lo que varias tablas pueden tener el mismo nombre. Por ejemplo, los datos de TPC-H proporcionan
orderstablas de varios tamaños en los diferentes esquemas comosf10.orders,sf100.orders, etc. - Identificar las columnas utilizadas en una consulta
-
Una referencia de columna cualificada
orders.totalpricese refiere inequívocamente a una columnatotalpricedentro de la tablaorders. Sin embargo, lo normal es que una consulta SQL se refiera a una columna sólo por su nombre -totalprice, como se ve en el Ejemplo 4-1. El analizador Trino puede determinar de qué tabla procede una columna. - Identificar referencias a campos dentro de valores ROW
-
Una expresión de desreferencia
c.bonuspuede referirse a una columnabonusde la tabla con nombreco aliasc. O puede referirse a un campobonusen una columnacde tipo fila (una estructura con campos con nombre). Es tarea del analizador de Trino decidir cuál es aplicable, teniendo preferencia la referencia a una columna calificada por la tabla en caso de ambigüedad. El análisis debe seguir las reglas de alcance y visibilidad del lenguaje SQL. La información recopilada, como la desambiguación de identificadores, se utiliza posteriormente durante la planificación, de modo que el planificador no necesita volver a comprender las reglas de alcance del lenguaje de consulta.
Como ves, el analizador de consultas tiene funciones complejas y transversales. Su función es muy técnica, y permanece invisible desde la perspectiva del usuario mientras las consultas sean correctas. El analizador manifiesta su existencia siempre que una consulta viola las reglas del lenguaje SQL, excede los privilegios del usuario o no es correcta por algún otro motivo.
Una vez analizada la consulta y procesados y resueltos todos los identificadores de la misma, Trino pasa a la siguiente fase, que es la planificación de la consulta.
Planificación de la consulta inicial
Un plan de consulta define un programa que produce resultados de consulta. Recuerda que SQL es un lenguaje declarativo: el usuario escribe una consulta SQL para especificar los datos que desea obtener del sistema. A diferencia de un programa imperativo, el usuario no especifica cómo procesar los datos para obtener el resultado. Esta parte se deja al planificador y optimizador de consultas para que determinen la secuencia de pasos para procesar los datos y obtener el resultado deseado.
Esta secuencia de pasos suele denominarse plan de consulta. Teóricamente, un número exponencial de planes de consulta podría producir el mismo resultado de consulta.El rendimiento de los planes varía drásticamente, y aquí es donde el planificador y el optimizador Trino intentan determinar el plan óptimo. Los planes que siempre producen los mismos resultados se denominan planes equivalentes.
Consideremos la consulta mostrada anteriormente en el Ejemplo 4-1. El plan de consulta más sencillo para esta consulta es el que más se parece a la estructura sintáctica SQL de la consulta. Este plan se muestra enel Ejemplo 4-2. A efectos de esta discusión, el listado debería explicarse por sí mismo. Sólo necesitas saber que el plan es un árbol, y que su ejecución comienza en los nodos hoja y avanza hacia arriba por la estructura del árbol.
Ejemplo 4-2. Representación textual directa y condensada manualmente del plan de consulta de la consulta de ejemplo
- Limit[5]
- Sort[orders_sum DESC]
- LateralJoin[2]
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey AND c.custkey = o.custkey]
- CrossJoin
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
- EnforceSingleRow[region_name := r.name]
- Filter[r.regionkey = n.regionkey]
- TableScan[region]Cada elemento del plan de consulta puede implementarse de forma directa e imperativa. Por ejemplo, TableScan accede a una tabla en su almacenamiento subyacente y devuelve un conjunto de resultados que contiene todas las filas de la tabla. Filter
recibe filas y aplica una condición de filtrado en cada una de ellas, conservando sólo las filas que satisfacen la condición. CrossJoin opera sobre dos conjuntos de datos que recibe de sus nodos hijos. Produce todas las combinaciones de filas de esos conjuntos de datos, probablemente almacenando uno de los conjuntos de datos en memoria, para no tener que acceder varias veces al almacenamiento subyacente.
Advertencia
Las últimas versiones de Trino han cambiado los nombres de las operaciones de un plan de consulta. Por ejemplo, TableScan equivale a ScanProject con una especificación de tabla. La operación Filter ha pasado a llamarse FilterProject. Sin embargo, las ideas presentadas siguen siendo las mismas.
Consideremos ahora la complejidad computacional de este plan de consulta. Sin conocer todos los detalles de la implementación real, no podemos razonar plenamente sobre la complejidad. Sin embargo, podemos suponer que el límite inferior de la complejidad de un nodo del plan de consulta es el tamaño del conjunto de datos que produce. Por tanto, describimos la complejidad utilizando la notación Big Omega, que describe el límite inferior asintótico. Si N, O, C y R representan el número de filas de las tablas nation, orders, customer y region, respectivamente, podemos observar lo siguiente:
-
TableScan[orders]lee la tablaorders, devolviendo O filas, por lo que su complejidad es Ω(O). Del mismo modo, las otras dos operaciones deTableScandevuelven N y Cfilas, por lo que su complejidad es Ω(N) y Ω(C), respectivamente. -
CrossJoinpor encima deTableScan[nation]yTableScan[orders]combina los datos de las tablasnationyorders; por tanto, su complejidad es Ω(N × O). -
El
CrossJoinanterior combina el anteriorCrossJoin, que producía N × Ofilas, conTableScan[customer], así que con datos de la tablacustomer; por tanto, su complejidad es Ω(N × O × C). -
TableScan[region]en la parte inferior tiene una complejidad Ω(R). Sin embargo, debido a laLateralJoin, se invoca N veces, siendo N el número de filas devueltas por la agregación. Así, en total, esta operación incurre en un coste computacional Ω(R × N). -
La operación
Sortnecesita ordenar un conjunto de N filas, por lo que no puede tardar menos tiempo que el proporcional a N × log(N).
Dejando de lado por un momento otras operaciones que no son más costosas que las que hemos analizado hasta ahora, el coste total del plan anterior es al menos Ω[N + O+ C +(N × O) +(N × O × C) +(R × N) +(N × log(N)). Sin conocer los tamaños relativos de las tablas, esto puede simplificarse a Ω[(N × O × C) +(R × N) + (N × log(N))]. Añadiendo una suposición razonable de que region es la tabla más pequeña y nation la segunda más pequeña, podemos despreciar la segunda y la tercera parte del resultado y obtener el resultado simplificado de Ω(N × O × C).
Basta de fórmulas algebraicas. Es hora de ver lo que esto significa en la práctica! Consideremos el ejemplo de un popular sitio de compras con 100 millones de clientes de 200 naciones que hicieron 1.000 millones de pedidos en total. El CrossJoin de estas dos tablas necesita materializar 20 quintillones (20.000.000.000.000.000.000) de filas. Para un clúster moderadamente potente de 100 nodos, procesando 1 millón de filas por segundo en cada nodo, se necesitarían más de 63 siglos para calcular los datos intermedios de nuestra consulta.
Por supuesto, Trino ni siquiera intenta ejecutar un plan tan ingenuo. Pero este plan inicial sirve de puente entre dos mundos: el mundo del lenguaje SQL y sus reglas semánticas, y el mundo de las optimizaciones de consultas. El papel de la optimización de consultas es transformar y evolucionar el plan inicial en un plan equivalente que pueda ejecutarse lo más rápido posible, al menos en un tiempo razonable, dados los recursos finitos del clúster Trino. Hablemos de cómo las optimizaciones de consultas intentan alcanzar este objetivo.
Reglas de optimización
En esta sección, podrás echar un vistazo a un puñado de las muchas reglas de optimización importantes implementadas en Trino.
Empuje de predicados
El pushdown de predicados es probablemente la optimización más importante y más fácil de entender. Su función es trasladar la condición de filtrado lo más cerca posible del origen de los datos. Como resultado, la reducción de datos se produce lo antes posible durante la ejecución de la consulta. En nuestro caso, transforma un Filter en un Filter más sencillo y un InnerJoin sobre la misma condición CrossJoin, lo que da lugar al plan que se muestra en el Ejemplo 4-3. Las partes del plan que no cambiaron se excluyen para facilitar la lectura.
Ejemplo 4-3. Transformación de un CrossJoin y Filter en un InnerJoin
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey AND c.custkey = o.custkey] // original filter
- CrossJoin
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
...
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey] // transformed simpler filter
- InnerJoin[o.custkey = c.custkey] // added inner join
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
...La unión "mayor" que existía se convierte ahora en InnerJoin sobre una condición de igualdad. Sin entrar en detalles, supongamos por ahora que dicha unión puede implementarse de forma eficiente en un sistema distribuido, con una complejidad computacional igual al número de filas producidas. Esto significa que el predicado pushdown sustituye un "al menos" Ω(N × O × C)CrossJoin por un Join que es "exactamente"Θ(N × O).
Sin embargo, el pushdown de predicados no podría mejorar la CrossJoin entre las tablas nationy orders porque ninguna condición inmediata une estas tablas. Aquí es donde entra en juego la eliminación de uniones cruzadas.
Eliminación de uniones cruzadas
En ausencia del optimizador basado en costes, Trino une las tablas contenidas en la consulta SELECT en el orden en que aparecen en el texto de la consulta. La única excepción importante se produce cuando las tablas a unir no tienen ninguna condición de unión, lo que da lugar a una unión cruzada. En casi todos los casos prácticos, una unión cruzada no es deseable, y todas las filas multiplicadas se filtran posteriormente, pero la unión cruzada en sí tiene tanto trabajo que puede que nunca se complete.
La eliminación de uniones cruzadas reordena las tablas que se están uniendo para minimizar el número de uniones cruzadas, reduciéndolo idealmente a cero. En ausencia de información sobre los tamaños relativos de las tablas, aparte de la eliminación de las uniones cruzadas, se conserva el orden de las uniones de las tablas, por lo que el usuario mantiene el control. El efecto de la eliminación de las uniones cruzadas en nuestro ejemplo de consulta puede verse en el Ejemplo 4-4. Ahora ambas uniones son internas, con lo que el coste computacional total de las uniones es deΘ(C + O) =Θ(O). Otras partes del plan de consulta no cambiaron desde el plan inicial, por lo que el coste computacional total de la consulta es al menos Ω[O +(R × N) +(N × log(N))]-por supuesto, el componente O que representa el número de filas de la tabla orders es el factor dominante.
Ejemplo 4-4. Reordenar las uniones para eliminar la unión cruzada
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey] // filter on nationkey first
- InnerJoin[o.custkey = c.custkey] // then inner join custkey
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
...
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[c.custkey = o.custkey] // reordered to custkey first
- InnerJoin[n.nationkey = c.nationkey] // then nationkey
- TableScan[nation]
- TableScan[customer]
- TableScan[orders]TopN
Normalmente, cuando una consulta tiene una cláusula LIMIT, va precedida de una cláusula ORDER BY. Sin la ordenación, SQL no garantiza qué filas de resultados se devuelven. La combinación de ORDER BY seguida de LIMIT también está presente en nuestra consulta.
Al ejecutar una consulta de este tipo, Trino podría ordenar todas las filas producidas y luego conservar sólo las primeras. Este enfoque tendría una complejidad computacional deΘ(recuento_de_filas× log(recuento_de_filas)) y una huella de memoria deΘ(recuento_de_filas). Sin embargo, no es óptimo y es un derroche ordenar todos los resultados sólo para conservar un subconjunto mucho menor de los resultados ordenados. Por tanto, una regla de optimización enrolla ORDER BY seguido de LIMIT en un nodo del plan TopN. Durante la ejecución de la consulta, TopN mantiene el número deseado de filas en una estructura de datos de montón, actualizando el montón mientras lee los datos de entrada de forma continua. Esto reduce la complejidad computacional aΘ(recuento_filas × log(límite)) y la huella de memoria aΘ(límite). El coste total del cálculo de la consulta es ahora Ω[O +(R× N) + N].
Agregaciones parciales
Trino no necesita pasar todas las filas de la tabla orders a la unión porque no nos interesan los pedidos individuales.Nuestra consulta de ejemplo calcula un agregado, la suma sobre totalprice para cadanation, por lo que es posible preagrupar las filas como se muestra en el Ejemplo 4-5. Reducimos la cantidad de datos que fluyen a la unión posterior agregando los datos. Los resultados no son completos, por eso se denomina pre-agregación. Pero la cantidad de datos se reduce potencialmente, mejorando significativamente el rendimiento de la consulta.
Ejemplo 4-5. La preagregación parcial puede mejorar significativamente el rendimiento
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[c.custkey = o.custkey]
- InnerJoin[n.nationkey = c.nationkey]
- TableScan[nation]
- TableScan[customer]
- Aggregate[by custkey; totalprice := sum(totalprice)]
- TableScan[orders]Para mejorar el paralelismo, este tipo de preagregación se implementa de forma diferente, como una denominada agregación parcial. Aquí presentamos planes simplificados, pero en un plan real de EXPLAIN, esto se representa de forma diferente a la agregación final.
Nota
El tipo de preagregación que se muestra en el Ejemplo 4-5 no siempre supone una mejora. Es perjudicial para el rendimiento de la consulta cuando la agregación parcial no reduce la cantidad de datos.Por esta razón, la optimización está actualmente desactivada por defecto y puede activarse con la propiedad de sesiónpush_partial_aggregation_through_join o la propiedad de configuraciónoptimizer.push-partial-aggregation-through-join. Por defecto, Trino utiliza agregaciones parciales y las coloca por encima de la unión para reducir la cantidad de datos transmitidos por la red entre los nodos Trino. Para apreciar plenamente el papel de estas agregaciones parciales, tendríamos que considerar planes de consulta no simplificados.
Normas de aplicación
Las reglas que hemos visto hasta ahora son reglas de optimización, es decir, reglascuyo objetivo es reducir el tiempo de procesamiento de la consulta, el consumo de memoria de la consulta o la cantidad de datos intercambiados en la red. Sin embargo, incluso en el caso de nuestra consulta de ejemplo, el plan inicial contenía una operación que no está implementada en absoluto: la unión lateral. En la siguiente sección veremos cómo gestiona Trino este tipo de operaciones.
Decorrelación de unión lateral
La unión lateral podría implementarse como un bucle for-each que recorre todas las filas de un conjunto de datos y ejecuta otra consulta para cada una de ellas. Tal implementación es posible, pero no es así como Trino maneja los casos como el de nuestro ejemplo. En su lugar, Trino descorrelaciona la subconsulta, extrayendo todas las condiciones correlacionadas y formando una unión regular a la izquierda. En términos SQL, esto corresponde a la transformación de una consulta:
SELECT(SELECTnameFROMregionrWHEREregionkey=n.regionkey)ASregion_name,n.nameASnation_nameFROMnationn
en
SELECTr.nameASregion_name,n.nameASnation_nameFROMnationnLEFTOUTERJOINregionrONr.regionkey=n.regionkey
Aunque utilicemos estas construcciones indistintamente, un lector precavido y familiarizado con la semántica SQL se dará cuenta inmediatamente de que no son totalmente equivalentes. La primera consulta falla si las entradas duplicadas de la tablaregion tienen el mismo regionkey, mientras que la segunda consulta no falla. Al contrario, produce más filas de resultados. Por este motivo, la descorrelación de unión lateral utiliza dos componentes adicionales además de la unión. En primer lugar, "numera" todas las filas de origen para poder distinguirlas. En segundo lugar, tras la unión, comprueba si se ha duplicado alguna fila, como se muestra enel Ejemplo 4-6. Si se detecta una duplicación, se interrumpe el procesamiento de la consulta para preservar la semántica original de la consulta.
Ejemplo 4-6. Las descomposiciones de unión lateral requieren comprobaciones adicionales
- TopN[5; orders_sum DESC]
- MarkDistinct & Check
- LeftJoin[n.regionkey = r.regionkey]
- AssignUniqueId
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- ...
- TableScan[region]Decorrelación semiunida (IN)
Una subconsulta puede utilizarse dentro de una consulta no sólo para extraer información, como acabamos de ver en el ejemplo de la unión lateral, sino también para filtrar filas utilizando el predicado IN. De hecho, un predicado IN puede utilizarse en un filtro (la cláusula WHERE), o en una proyección (la cláusula SELECT ). Cuando utilizas IN en una proyección, se hace evidente que no se trata de un simple operador con valores booleanos como EXISTS. En su lugar, el predicado IN puede evaluarse como true, false onull.
Consideremos una consulta diseñada para encontrar pedidos cuyos clientes y proveedores de artículos sean del mismo país, como se muestra en el Ejemplo 4-7. Estos pedidos pueden ser interesantes. Por ejemplo, es posible que queramos ahorrar gastos de envío o reducir el impacto medioambiental del transporte enviándolo directamente del proveedor al cliente, evitando nuestros propios centros de distribución.
Ejemplo 4-7. Consulta de ejemplo semi-join (IN)
SELECTDISTINCTo.orderkeyFROMlineitemlJOINordersoONo.orderkey=l.orderkeyJOINcustomercONo.custkey=c.custkeyWHEREc.nationkeyIN(-- subquery invoked multiple timesSELECTs.nationkeyFROMpartpJOINpartsupppsONp.partkey=ps.partkeyJOINsuppliersONps.suppkey=s.suppkeyWHEREp.partkey=l.partkey);
Al igual que con una unión lateral, esto podría realizarse con un bucle sobre las filas de la consulta externa, donde la subconsulta para recuperar todas las naciones de todos los proveedores de un artículo se invoca varias veces.
En lugar de hacer esto, Trino descorrelaciona la subconsulta: la subconsulta se evalúa una vez, sin la condición de correlación, y luego se vuelve a unir con la consulta externa utilizando la condición de correlación. La parte complicada es asegurarse de que la unión no multiplica las filas de resultados (por lo que se utiliza una agregación deduplicadora) y de que la transformación conserva correctamente la lógica de tres valores del predicado IN.
En este caso, la agregación deduplicadora utiliza la misma partición que la unión, por lo que puede ejecutarse en streaming, sin intercambio de datos por la red y con una huella de memoria mínima.
Optimizador basado en costes
En " Planificación de consultas", aprendiste cómo el planificador Trino convierte una consulta en forma textual en un plan de consulta ejecutable y optimizado. Aprendiste sobre varias reglas de optimización en "Reglas de optimización", y su importancia para el rendimiento de la consulta en tiempo de ejecución. También viste las reglas de implementación en "Reglas de implementación", sin las cuales un plan de consulta no sería ejecutable en absoluto.
Recorrimos el camino desde el principio, donde se recibe el texto de la consulta del usuario, hasta el final, donde está listo el plan de ejecución final. Por el camino, vimos transformaciones del plan seleccionadas, que son críticas porque hacen que el plan se ejecute órdenes de magnitud más rápido, o hacen que el plan sea ejecutable en absoluto.
Veamos ahora más de cerca las transformaciones del plan que toman sus decisiones basándose no sólo en la forma de la consulta, sino también, y lo que es más importante, en la forma de los datos consultados. Esto es lo que hace el optimizador basado en costes(CBO) de última generación Trino.
El concepto de coste
Antes hemos utilizado una consulta de ejemplo como modelo de trabajo. Utilicemos un enfoque similar, de nuevo por comodidad y para facilitar la comprensión. Como puedes ver enel Ejemplo 4-8, se eliminan algunas cláusulas de la consulta que no son relevantes para esta sección. Esto te permite centrarte en las decisiones basadas en costes del planificador de consultas.
Ejemplo 4-8. Ejemplo de consulta para la optimización basada en costes
SELECTn.nameASnation_name,avg(extendedprice)asavg_priceFROMnationn,orderso,customerc,lineitemlWHEREn.nationkey=c.nationkeyANDc.custkey=o.custkeyANDo.orderkey=l.orderkeyGROUPBYn.nationkey,n.nameORDERBYnation_name;
Sin decisiones basadas en costes, las reglas del planificador de consultas optimizan el plan inicial de esta consulta para producir un plan, como se muestra en el Ejemplo 4-9. Este plan está determinado únicamente por la estructura léxica de la consulta SQL. El optimizador sólo utiliza la información sintáctica; de ahí que a veces se le llameoptimizador sintáctico. El nombre pretende ser humorístico, resaltando la simplicidad de las optimizaciones. Como el plan de consulta se basa sólo en la consulta, puedes afinarla u optimizarla a mano ajustando el orden sintáctico de las tablas de la consulta.
Ejemplo 4-9. Orden de unión de consultas del optimizador sintáctico
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[o.orderkey = l.orderkey]
- InnerJoin[c.custkey = o.custkey]
- InnerJoin[n.nationkey = c.nationkey]
- TableScan[nation]
- TableScan[customer]
- TableScan[orders]
- TableScan[lineitem]Ahora digamos que la consulta se escribió de forma diferente, cambiando sólo el orden de las condicionesWHERE:
SELECTn.nameASnation_name,avg(extendedprice)asavg_priceFROMnationn,orderso,customerc,lineitemlWHEREc.custkey=o.custkeyANDo.orderkey=l.orderkeyANDn.nationkey=c.nationkeyGROUPBYn.nationkey,n.name;
Como resultado, el plan termina con un orden de unión diferente:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[n.nationkey = c.nationkey]
- InnerJoin[o.orderkey = l.orderkey]
- InnerJoin[c.custkey = o.custkey]
- TableScan[customer]
- TableScan[orders]
- TableScan[lineitem]
- TableScan[nation]
El hecho de que un simple cambio de las condiciones de ordenación afecte al plan de consulta, y por tanto al rendimiento de la consulta, es engorroso para el analista SQL. Crear consultas eficientes requiere entonces un conocimiento interno de la forma en que Trino procesa las consultas. No debería exigirse a un autor de consultas que tuviera este conocimiento para obtener el mejor rendimiento de Trino. Además, las herramientas con Trino, como Apache Superset, Tableau, Qlick o Metabase, suelen admitir muchas bases de datos y motores de consulta diferentes y no escriben consultas optimizadas para Trino.
El optimizador basado en los costes garantiza que las dos variantes de la consulta produzcan el mismo plan de consulta óptimo para ser procesado por el motor de ejecución de Trino.
Desde el punto de vista de la complejidad temporal, no importa si unes, por ejemplo, la tabla nation con customer-o, viceversa, la tabla customercon nation. Ambas tablas deben procesarse, y en el caso de la implementación hash-join, el tiempo total de ejecución es proporcional al número de filas de salida. Sin embargo, la complejidad temporal no es lo único que importa. Esto es cierto en general para los programas que trabajan con datos, pero lo es especialmente para los grandes sistemas de bases de datos. Trino también debe preocuparse por el uso de la memoria y el tráfico de red. Para razonar sobre el uso de memoria y de red de la unión, Trino necesita comprender mejor cómo seimplementa la unión.
El tiempo de CPU, los requisitos de memoria y el uso del ancho de banda de la red son las tres dimensiones que contribuyen al tiempo de ejecución de la consulta, tanto en cargas de trabajo de consulta única como concurrentes. Estas dimensiones constituyen el coste en Trino.
Coste de la Afiliación
Al unir dos tablas sobre la condición de igualdad (=), Trino implementa una versión ampliada del algoritmo conocida comounión hash. Una de las tablas unidas se denomina lado de construcción. Esta tabla se utiliza para construir una tabla hash de búsqueda con las columnas de la condición de unión como clave. Otra tabla unida se denomina ladosonda. Una vez que la tabla hash de búsqueda está lista, se procesan las filas del lado de sondeo, y la tabla hash se utiliza para encontrar filas coincidentes del lado de construcción en tiempo constante. Por defecto, Trino utiliza hash de tres niveles para paralelizar el procesamiento tanto como sea posible:
-
Ambas tablas unidas se distribuyen entre los nodos trabajadores, basándose en losvalores hash de las columnas de condición de unión. Las filas que deben coincidir tienen los mismosvalores en las columnas de condición de unión, por lo que se asignan al mismo nodo. Esto reduce el tamaño del problema en el número de nodos que se utilizan en esta fase. Esta asignación de datos a nivel de nodo es el primer nivel de hashing.
-
A nivel de nodo, la parte de construcción se dispersa aún más entre los subprocesos de los trabajadores de la parte de construcción, utilizando de nuevo una función hash. Construir una tabla hash es un proceso que consume mucha CPU, y utilizar varios subprocesos para realizar el trabajo mejora enormemente el rendimiento.
-
Cada hebra trabajadora produce, en última instancia, una partición de la tabla hash de búsqueda final. Cada partición es una tabla hash en sí misma. Las particiones se combinan en una tabla hash de búsqueda de dos niveles para evitar dispersar también la parte de la sonda entre varios subprocesos. El lado de la sonda se sigue procesando en varios subprocesos, pero los subprocesos obtienen su trabajo asignado por lotes, lo que es más rápido que particionar los datos utilizando una función hash.
Como puedes ver, la parte de construcción se mantiene en memoria para facilitar el procesamiento rápido de los datos en memoria. Por supuesto, también se asocia una huella de memoria, proporcional al tamaño de la parte de construcción. Esto significa que el lado de construcción debe caber en la memoria disponible en el nodo. Esto también significa que hay menos memoria disponible para otras operaciones y para otras consultas. Éste es el coste de memoria asociado a la unión. También está el coste de red. En el algoritmo descrito anteriormente, ambas tablas unidas se transfieren a través de la red para facilitar la asignación de datos a nivel de nodo.
El optimizador basado en el coste puede seleccionar qué tabla debe ser la tabla de construcción, controlando el coste de memoria de la unión. En determinadas condiciones, el optimizador también puede evitar enviar una de las tablas a través de la red, reduciendo así el uso del ancho de banda de la red (reduciendo el coste de la red). Para hacer su trabajo, el optimizador basado en costes necesita conocer el tamaño de las tablas unidas, que se proporciona como estadística de la tabla.
Estadísticas de la tabla
En "Arquitectura basada en conectores", aprendiste sobre la función de los conectores. Cada tabla es proporcionada por un conector.Además de información sobre el esquema de la tabla y acceso a los datos reales, el conector puede proporcionar estadísticas de tablas y columnas:
-
Número de filas de una tabla
-
Número de valores distintos en una columna
-
Fracción de valores
NULLen una columna -
Valores mínimo y máximo de una columna
-
Tamaño medio de los datos de una columna
Por supuesto, si falta alguna información -por ejemplo, no se conoce la longitud media del texto en una columna de varchar -, un conector puede proporcionar otra información, y el optimizador basado en costes utiliza la que está disponible.
Con una estimación del número de filas de las tablas unidas y, opcionalmente, del tamaño medio de los datos de las columnas, el optimizador basado en costes ya tiene conocimientos suficientes para determinar el orden óptimo de las tablas en nuestra consulta de ejemplo. El CBO puede empezar por la tabla más grande (lineitem) y unir posteriormente las demás tablas -orders, luego customer, luego nation:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[l.orderkey = o.orderkey]
- InnerJoin[o.custkey = c.custkey]
- InnerJoin[c.nationkey = n.nationkey]
- TableScan[lineitem]
- TableScan[orders]
- TableScan[customer]
- TableScan[nation]
Este plan es bueno y debe tenerse en cuenta porque cada join tiene la relación más pequeña como lado de construcción, pero no es necesariamente óptimo. Si ejecutas la consulta del ejemplo, utilizando un conector que proporcione estadísticas de la tabla, puedes activar el CBO con la propiedad de sesión:
SETSESSIONjoin_reordering_strategy='AUTOMATIC';
Con las estadísticas de la tabla disponibles en el conector, Trino puede idear un plan diferente:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[l.orderkey = o.orderkey]
- TableScan[lineitem]
- InnerJoin[o.custkey = c.custkey]
- TableScan[orders]
- InnerJoin[c.nationkey = n.nationkey]
- TableScan[customer]
- TableScan[nation]
Se eligió este plan porque evita enviar la tabla más grande (lineitem) tres veces por la red. La tabla se dispersa por los nodos una sola vez.
El plan final depende de los tamaños reales de las tablas unidas y del número de nodos de un clúster, así que si lo pruebas por tu cuenta, puede que obtengas un plan distinto del que se muestra aquí.
Los lectores precavidos observan que el orden de unión se selecciona basándose únicamente en las condiciones de unión, los enlaces entre tablas y el tamaño de los datos de las tablas, incluido el número de filas y el tamaño medio de los datos de cada columna. Otras estadísticas son fundamentales para optimizar planes de consulta más complejos, que contienen operaciones intermedias entre los escaneos de tablas y las uniones, por ejemplo, filtros, agregaciones y uniones no internas.
Estadísticas de filtrado
Como acabas de ver, conocer los tamaños de las tablas implicadas en una consulta es fundamental para reordenar correctamente las tablas unidas en el plan de consulta. Sin embargo, conocer sólo los tamaños de las tablas no es suficiente. Considera una modificación de nuestra consulta de ejemplo, en la que el usuario añadiera otra condición comol.partkey = 638, para profundizar en su conjunto de datos en busca de información sobre los pedidos de un artículo concreto:
SELECTn.nameASnation_name,avg(extendedprice)asavg_priceFROMnationn,orderso,customerc,lineitemlWHEREn.nationkey=c.nationkeyANDc.custkey=o.custkeyANDo.orderkey=l.orderkeyANDl.partkey=638GROUPBYn.nationkey,n.nameORDERBYnation_name;
Antes de añadir la condición, lineitem era la tabla más grande, y la consulta se planificó para optimizar el manejo de esa tabla. Pero ahora, la lineitemfiltrada es una de las relaciones unidas más pequeñas.
Si observas el plan de consulta, verás que la tabla lineitem filtrada es ahora lo suficientemente pequeña. El CBO coloca la tabla en el lado de construcción de la unión, de modo que sirva de filtro para otras tablas:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[l.orderkey = o.orderkey]
- InnerJoin[o.custkey = c.custkey]
- TableScan[customer]
- InnerJoin[c.nationkey = n.nationkey]
- TableScan[orders]
- Filter[partkey = 638]
- TableScan[lineitem]
- TableScan[nation]
Para estimar el número de filas de la tabla lineitem filtrada, el CBO utiliza de nuevo las estadísticas proporcionadas por un conector: el número de valores distintos en una columna y la fracción de valores NULL en una columna. Para la condición partkey = 638, ningún valor NULL satisface la condición, por lo que el optimizador sabe que el número de filas se reduce por la fracción de valores NULL en la columnapartkey. Además, si supones una distribución aproximadamente uniforme de los valores en la columna, puedes obtener el número final de filas:
filtered rows = unfiltered rows * (1 - null fraction) / number of distinct values
Evidentemente, la fórmula sólo es correcta cuando la distribución de valores es uniforme. Sin embargo, el optimizador no necesita conocer el número de filas; sólo necesita conocer su estimación, por lo que, en general, estar algo desviado no es un problema. Por supuesto, si un artículo se compra con mucha más frecuencia que otros -por ejemplo, caramelos Starburst-, la estimación puede estar demasiado desviada, y el optimizador puede elegir un mal plan. Actualmente, cuando esto ocurre, tienes que desactivar el CBO.
En el futuro, los conectores podrán proporcionar información sobre la distribución de los datos para tratar casos como éste. Por ejemplo, si se dispusiera de un histograma de los datos, el CBO podría estimar con mayor precisión las filas filtradas.
Estadísticas de tablas particionadas
Un tipo especial de tabla filtrada merece una mención especial: las tablas particionadas. Los datos pueden organizarse en tablas particionadasen un almacén Hive/HDFS al que se accede mediante el conector Hive o en un lago moderno utilizando los formatos de tabla y conectores Iceberg o Delta Lake; consulta"Conector Hive para fuentes de datos de almacenamiento distribuido" y "Gestión y análisis de almacenamiento distribuido moderno". Cuando los datos se filtran mediante una condición sobre claves de partición, sólo se leen las particiones coincidentes durante las ejecuciones de las consultas. Además, como las estadísticas de las tablas se almacenan por partición, el CBO obtiene información estadística sólo de las particiones que se leen, por lo que es más precisa.
Por supuesto, todos los conectores pueden proporcionar este tipo de estadísticas mejoradas para las relaciones filtradas. Aquí sólo nos referimos a la forma en que el conector Colmena proporciona estadísticas.
Enumeración de unión
Hasta ahora hemos visto cómo el CBO aprovecha las estadísticas de los datos para elaborar un plan óptimo de ejecución de una consulta. En concreto, elige un orden de unión óptimo, que afecta sustancialmente al rendimiento de la consulta por dos razones principales:
- Implementación de la unión hash
-
La implementación de la unión hash es asimétrica. Es importante elegir cuidadosamente qué entrada es el lado de la construcción y qué entrada es el lado de la sonda.
- Tipo de unión distribuida
-
Es importante elegir cuidadosamente si difundir o redistribuir los datos a las entradas de unión.
Uniones Difundidas Versus Distribuidas
En la sección anterior, aprendiste sobre la implementación de las uniones hash y la importancia de los lados de construcción y sondeo. Como Trino es un sistema distribuido, las uniones pueden hacerse en paralelo a través de un cluster de trabajadores, donde cada trabajador procesa una fracción de la unión. Para que se produzca una unión distribuida, puede ser necesario distribuir los datos por la red, y existen diferentes estrategias que varían en eficiencia, dependiendo de la forma de los datos.
Difusión de la estrategia de unión
En una estrategia de unión por difusión, el lado de construcción de la unión se difunde a todos los nodos trabajadores que realizan la unión en paralelo. En otras palabras, cada unión obtiene una copia completa de los datos para el lado de construcción, como se muestra en laFigura 4-12. Esto es semánticamente correcto sólo si el lado de la sonda permanece distribuido entre los trabajadores sin duplicarse. De lo contrario, se crean resultados duplicados.
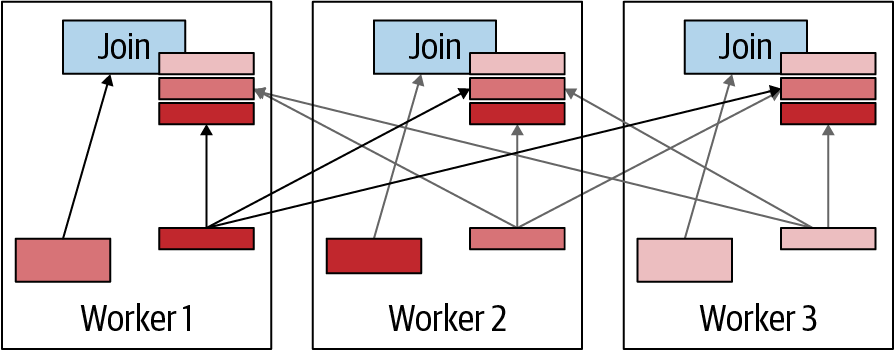
Figura 4-12. Visualización de la estrategia de unión de difusión
La estrategia de unión distribuida es ventajosa cuando el lado de construcción es pequeño, ya que permite una transmisión rentable de los datos. La ventaja también es mayor cuando el lado de la sonda es muy grande, porque evita tener que redistribuir los datos como es necesario en la unión distribuida.
Estrategia de unión distribuida
En una estrategia de unión distribuida, los datos de entrada tanto del lado de la construcción como del lado de la sonda se redistribuyen por el clúster de forma que los trabajadores realizan la unión en paralelo. La diferencia en la transmisión de datos a través de la red es que cada trabajador recibe una fracción única del conjunto de datos, en lugar de una copia de los datos como se realiza en la unión por difusión. La redistribución de datos debe utilizar un algoritmo de partición tal que los valores de clave de unión coincidentes se envíen al mismo nodo. Por ejemplo, supongamos que tenemos los siguientes conjuntos de datos de claves de unión en un nodo concreto:
Probe: {4, 5, 6, 7, 9, 10, 11, 14}
Build: {4, 6, 9, 10, 17}
Considera un algoritmo de partición sencillo:
if joinkey mod 3 == 0 then send to Worker 1 if joinkey mod 3 == 1 then send to Worker 2 if joinkey mod 3 == 2 then send to Worker 3
La partición da lugar a estas sondas y se basa en el Trabajador 1:
Probe:{6, 9}
Build:{6, 9}
El trabajador 2 se ocupa de diferentes sondas y construcciones:
Probe: {4, 7, 10}
Build: {4, 10}
Y, por último, el Trabajador 3 se ocupa de un subconjunto diferente:
Probe:{5, 11, 14}
Build: {17}
Al particionar los datos, el CBO garantiza que las uniones puedan calcularse en paralelo sin tener que compartir información durante el procesamiento. La ventaja de una unión distribuida es que permite a Trino calcular una unión en la que ambos lados son muy grandes y no hay memoria suficiente en una sola máquina para contener la totalidad del lado de la sonda en memoria. La desventaja es el envío de datos adicionales a través de la red.
Hay que calcular el coste de la decisión entre una estrategia de unión por difusión y una estrategia de unión distribuida. Cada estrategia tiene ventajas y desventajas, y hay que tener en cuenta las estadísticas de los datos para calcular el coste de la óptima. Además, esto también debe decidirse durante el proceso de reordenación de las uniones. Dependiendo del orden de unión y de dónde se apliquen los filtros, la forma de los datos cambia. Esto puede dar lugar a casos en los que una unión distribuida entre dos conjuntos de datos funcione mejor en un escenario de orden de unión, pero una unión de difusión funcione mejor en un escenario diferente. El algoritmo de enumeración de uniones tiene esto en cuenta.
Nota
El algoritmo de enumeración de uniones que utiliza Trino es bastante complejo y va más allá del alcance de este libro. Está documentado en detalle en unaentrada del blog de Starburst. Divide el problema en subproblemas con particiones más pequeñas, encuentra el uso correcto de las uniones con recursiones y agrega los resultados a un resultado global.
Trabajar con estadísticas de tablas
Para aprovechar la CBO en Trino, tus datos deben tener estadísticas. Sin estadísticas de datos, la CBO no puede hacer gran cosa; necesita estadísticas de datos para estimar las filas y los costes de los distintos planes.
Como Trino no almacena datos, la producción de estadísticas para Trino depende de la implementación del conector. En el momento de escribir esto, los conectores Hive, Delta Lake e Iceberg para sistemas de almacenamiento de objetos, así como una serie de conectores RDBMS, incluidos PostgreSQL y otros, proporcionan estadísticas de datos a Trino. Esperamos que, con el tiempo, más conectores admitan estadísticas, por lo que debes seguir consultando la documentación de Trino para obtener información actualizada.
La recopilación y el mantenimiento de estadísticas de tabla dependen de la fuente de datos subyacente. Veamos el conector Hive como ejemplo de formas de recopilar estadísticas:
-
Utiliza el comando
ANALYZEde Trino para recopilar estadísticas. -
Permite que Trino recopile estadísticas al escribir datos en una tabla.
-
Utiliza el comando
ANALYZEde Hive para recopilar estadísticas.
Es importante señalar que Trino y el conector Hive almacenan las estadísticas en el metastore de Hive, el mismo lugar que Hive utiliza para almacenar estadísticas. Otros conectores utilizan el almacenamiento de metadatos que utiliza la fuente de datos conectada; por ejemplo, los archivos de metadatos en formato de tabla Iceberg o el esquema de información de algunas bases de datos relacionales. Por tanto, si compartes las mismas tablas entre Hive y Trino, se sobrescribirán mutuamente las estadísticas. Esto es algo que debes tener en cuenta a la hora de determinar cómo gestionar la recopilación de estadísticas.
Trino ANALIZA
Trino proporciona un comando ANALYZE para recopilar estadísticas de un conector (por ejemplo, el conector Hive). Cuando se ejecuta, Trino calcula las estadísticas a nivel de columna utilizando su motor de ejecución y almacena las estadísticas en el metastore de Hive. La sintaxis es la siguiente:
ANALYZEtable_name[WITH(property_name=expression[,...])]
Por ejemplo, si quieres recoger y almacenar estadísticas de la tabla flights, puedes ejecutar esto:
ANALYZEdatalake.ontime.flights;
En el caso particionado, podemos utilizar la cláusula WITH si queremos analizar sólo una partición concreta:
ANALYZEdatalake.ontime.flightsWITH(partitions=ARRAY[ARRAY['01-01-2019']])
El array anidado es necesario cuando tienes más de una clave de partición y quieres que cada clave sea un elemento del siguiente array. El array superior se utiliza si tienes varias particiones que quieres analizar. La posibilidad de especificar una partición es muy útil en Trino. Por ejemplo, puedes tener algún tipo de proceso ETL que cree nuevas particiones. A medida que entran nuevos datos, las estadísticas podrían quedar obsoletas, ya que no incorporan los nuevos datos. Sin embargo, al actualizar las estadísticas para la nueva partición, no tienes que volver a analizar todos los datos anteriores.
Recopilación de estadísticas al escribir en disco
Si tienes tablas cuyos datos se escriben siempre a través de Trino, las estadísticas pueden recopilarse durante las operaciones de escritura. Por ejemplo, si ejecutas una consultaCREATE TABLE AS, o una consulta INSERT SELECT, Trino recopila las estadísticas mientras escribe los datos en el disco (HDFS o S3, por ejemplo) y luego almacena las estadísticas en el metastore Hive.
Se trata de una función útil, ya que no requiere que ejecutes el paso manual de ANALYZE. Las estadísticas nunca se quedan obsoletas. Sin embargo, para que esto funcione correctamente y como se espera, los datos de la tabla deben ser escritos siempre por Trino.
La sobrecarga de este proceso ha sido ampliamente evaluada y probada, y muestra un impacto insignificante en el rendimiento. Para activar la función, puedes añadir la siguiente propiedad en el archivo de propiedades de tu catálogo utilizando el conector Hive:
hive.collect-column-statistics-on-write=true
colmena analizar
Fuera de Trino, puedes seguir utilizando el comando Hive ANALYZE para recopilar las estadísticas para Trino. El cálculo de las estadísticas lo realiza el motor de ejecución de Hive y no el motor de ejecución de Trino, por lo que los resultados pueden variar, y siempre existe el riesgo de que Trino se comporte de forma diferente al utilizar estadísticas generadas por Hive frente a Trino. En general, se recomienda utilizar Trino para recopilar estadísticas. Pero puede haber razones para utilizar Hive, como si los datos aterrizan como parte de una canalización más compleja y se comparten con otras herramientas que puedan querer utilizar las estadísticas. Para recopilar estadísticas utilizando Hive, puedes ejecutar los siguientes comandos:
hive>ANALYZETABLEdatalake.ontime.flightsCOMPUTESTATISTICS;hive>ANALYZETABLEdatalake.ontime.flightsCOMPUTESTATISTICSFORCOLUMNS;
Para obtener información completa sobre el comando Hive ANALYZE, puedes consultarla documentación oficial de Hive.
Visualización de las estadísticas de la tabla
Una vez recopiladas las estadísticas, a menudo resulta útil verlas. Puede que quieras hacerlo para confirmar que se han recogido las estadísticas, o tal vez estés depurando un problema de rendimiento y quieras ver las estadísticas que se están utilizando.
Trino proporciona un comando SHOW STATS:
SHOWSTATSFORdatalake.ontime.flights;
Alternativamente, si quieres ver las estadísticas de un subconjunto de datos, puedes proporcionar una condición de filtrado. Por ejemplo
SHOWSTATSFOR(SELECT*FROMdatalake.ontime.flightsWHEREyear>2010);
Conclusión
Ahora entiendes la arquitectura de Trino, con un coordinador que recibe las peticiones de los usuarios y luego utiliza trabajadores para reunir todos los datos de las fuentes de datos.
Cada consulta se traduce en un plan de consulta distribuido de tareas en numerosas etapas. Los datos son devueltos por los conectores en divisiones y procesados en múltiples etapas hasta que el resultado final está disponible y es proporcionado al usuario por el coordinador.
Si te interesa conocer la arquitectura de Trino con más detalle, puedes sumergirte en el artículo "Trino: SQL on Everything" de los creadores de Trino, publicado en la Conferencia Internacional IEEE sobre Ingeniería de Datos (ICDE) y disponible en el sitio web de Trino.
A continuación, vas a aprender más sobre la implementación de un clúster Trino en el Capítulo 5, a conectar más fuentes de datos con diferentes conectores en los Capítulos 6 y7, y a escribir potentes consultas en el Capítulo 8.
Get Trino: La Guía Definitiva, 2ª Edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

