Kapitel 4. Trino Architektur
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Nach der Einführung in Trino und einer ersten Installation und Nutzung in den früheren Kapiteln, besprechen wir nun die Trino-Architektur. Wir tauchen tiefer in verwandte Konzepte ein, sodass du mehr über das Trino-Abfrageausführungsmodell, die Abfrageplanung und kostenbasierte Optimierungen erfährst.
In diesem Kapitel gehen wir zunächst auf die Trino-High-Level-Architekturkomponenten ein. Es ist wichtig, ein allgemeines Verständnis für die Funktionsweise von Trino zu haben, vor allem wenn du vorhast, selbst einen Trino-Cluster zu installieren und zu verwalten, wie inKapitel 5 beschrieben.
Im späteren Teil des Kapitels tauchen wir tiefer in diese Komponenten ein, wenn wir über das Abfrageausführungsmodell von Trino sprechen. Das ist besonders wichtig, wenn du eine langsame Abfrage diagnostizieren oder optimieren musst (sieheKapitel 8) oder wenn du einen Beitrag zum Open-Source-Projekt Trino leisten willst.
Koordinator/in und Arbeiter/innen in einem Cluster
Als du Trino zum ersten Mal installiert hast, wie in Kapitel 2 beschrieben, hast du nur einen einzigen Rechner verwendet, um alles auszuführen. Für die gewünschte Skalierbarkeit und Leistung ist dieser Einsatz nicht geeignet.
Trino ist eine verteilte SQL-Abfrage-Engine, die Datenbanken und Abfrage-Engines im Stil von Massively Parallel Processing (MPP) ähnelt. Anstatt sich auf die vertikale Skalierung des Servers zu verlassen, auf dem Trino läuft, kann es die gesamte Verarbeitung horizontal über einen Server-Cluster verteilen. Das bedeutet, dass du weitere Knotenpunkte hinzufügen kannst, um mehr Rechenleistung zu erhalten.
Dank dieser Architektur ist die Trino Query Engine in der Lage, SQL-Abfragen auf großen Datenmengen parallel auf einem Cluster von Computern oder Knoten zu verarbeiten. Trino läuft als Single-Server-Prozess auf jedem Knoten. Mehrere Knoten, auf denen Trino läuft und die so konfiguriert sind, dass sie miteinander zusammenarbeiten, bilden einen Trino-Cluster.
Abbildung 4-1 zeigt einen Überblick über einen Trino-Cluster, der aus einem Coordinator und mehreren Worker Nodes besteht. Ein Trino-Benutzer verbindet sich mit einem Client mit dem Koordinator, z. B. mit einem Tool, das den JDBC-Treiber oder die Trino CLI verwendet. Der Koordinator arbeitet dann mit den Workern zusammen, die auf die Datenquellen zugreifen.
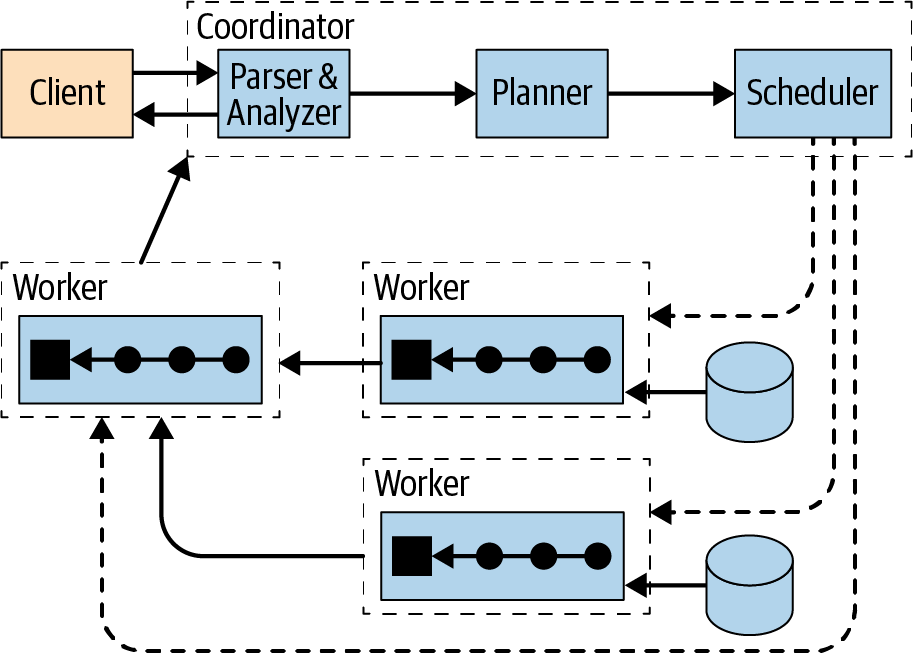
Abbildung 4-1. Überblick über die Trino-Architektur mit Koordinator und Arbeitern
Ein Koordinator ist ein Trino-Server, der eingehende Anfragen bearbeitet und dieWorker zur Ausführung der Anfragen verwaltet.
Ein Worker ist ein Trino-Server, der für die Ausführung von Aufgaben und die Verarbeitung von Daten zuständig ist.
Der Discovery Service läuft auf dem Koordinator und ermöglicht es den Arbeitern, sich für die Teilnahme am Cluster zu registrieren.
Die gesamte Kommunikation und Datenübertragung zwischen Kunden, Koordinator und Arbeitern erfolgt über REST-basierte Interaktionen über HTTP/HTTPS.
Abbildung 4-2 zeigt, wie die Kommunikation innerhalb des Clusters zwischen dem Koordinator und den Arbeitern sowie von einem Arbeiter zum anderen erfolgt. Der Koordinator kommuniziert mit den Arbeitern, um die Arbeit zuzuweisen, den Status zu aktualisieren und das Top-Level-Ergebnis zu holen, das an die Nutzer zurückgegeben werden soll. Die Arbeiter/innen kommunizieren miteinander, um Daten von vorgelagerten Aufgaben abzurufen, die auf anderen Arbeiter/innen laufen. Und die Arbeiter holen die Ergebnisse aus der Datenquelle ab.
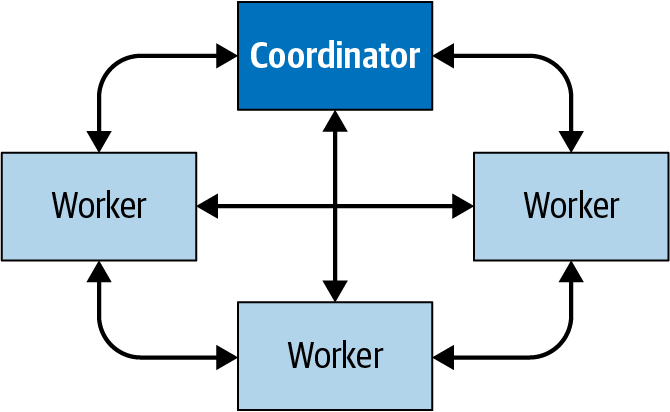
Abbildung 4-2. Kommunikation zwischen Koordinator und Arbeitern in einem Trino-Cluster
Koordinator
Der Trino-Koordinator ist der Server, der für den Empfang der SQL-Anweisungen von den Nutzern, das Parsen dieser Anweisungen, die Planung der Abfragen und die Verwaltung der Arbeitsknoten zuständig ist. Er ist das Gehirn einer Trino-Installation und der Knoten, mit dem sich ein Client verbindet. Die Benutzer interagieren mit dem Koordinator über die Trino CLI, Anwendungen, die den JDBC- oder ODBC-Treiber verwenden, den Trino Python-Client oder jede andere Client-Bibliothek für eine Vielzahl von Sprachen. Der Koordinator akzeptiert SQL-Anweisungen vom Client, wie z. B. SELECT Abfragen, zurAusführung.
Jede Trino-Installation muss einen Koordinator und einen oder mehrere Arbeiter haben. Für Entwicklungs- oder Testzwecke kann eine einzige Trino-Instanz so konfiguriert werden, dass sie beide Rollen übernimmt.
Der Koordinator verfolgt die Aktivitäten der einzelnen Arbeiter und koordiniert die Ausführung einer Abfrage. Der Koordinator erstellt ein logisches Modell einer Abfrage, das eine Reihe von Schritten umfasst.
Sobald der Koordinator eine SQL-Anweisung erhält, ist er für das Parsen, Analysieren, Planen und Planen der Abfrageausführung auf den Trino-Arbeitsknoten zuständig. Die Anweisung wird in eine Reihe miteinander verbundener Aufgaben übersetzt, die auf einem Cluster von Workern ausgeführt werden. Während die Worker die Daten verarbeiten, werden die Ergebnisse vom Koordinator abgerufen und den Clients in einem Ausgabepuffer zur Verfügung gestellt. Wenn ein Ausgabepuffer vom Kunden vollständig gelesen wurde, fordert der Koordinator im Namen des Kunden weitere Daten von den Workern an. Die Worker interagieren ihrerseits mit den Datenquellen, um die Daten von ihnen zu erhalten. Auf diese Weise werden kontinuierlich Daten vom Kunden angefordert und von den Arbeitern aus der Datenquelle geliefert, bis die Abfrage abgeschlossen ist.
Koordinatoren kommunizieren mit Arbeitern und Kunden über ein HTTP-basiertes Protokoll. Abbildung 4-3 zeigt die Kommunikation zwischen Kunde, Koordinator und Arbeitern.

Abbildung 4-3. Client-, Coordinator- und Worker-Kommunikation bei der Verarbeitung einer SQL-Anweisung
Entdeckungsdienst
Trino nutzt einen Discovery Service, um alle Knoten im Cluster zu finden. Jede Trino-Instanz meldet sich beim Start beim Discovery Service an und sendet regelmäßig ein Heartbeat-Signal. Auf diese Weise erhält der Koordinator eine aktuelle Liste der verfügbaren Arbeiter und kann diese Liste für die Planung der Ausführung von Abfragen verwenden.
Wenn ein Worker keine Heartbeat-Signale meldet, löst der Discovery Service den Fehlerdetektor aus, und der Worker ist für weitere Aufgaben nicht mehr geeignet.
Der Trino-Koordinator betreibt den Suchdienst. Er teilt sich den HTTP-Server mit Trino und verwendet daher denselben Port. Die Worker-Konfiguration des Discovery-Dienstes verweist daher auf den Hostnamen und den Port des Koordinators.
Arbeiterinnen und Arbeiter
Ein Trino-Worker ist ein Server in einer Trino-Installation. Er ist für die Ausführung der vom Koordinator zugewiesenen Aufgaben zuständig, einschließlich des Abrufs von Daten aus den Datenquellen und der Verarbeitung von Daten. Die Worker-Knoten holen die Daten mit Hilfe von Konnektoren aus den Datenquellen und tauschen dann Zwischendaten untereinander aus. Die endgültigen Daten werden an den Koordinator weitergeleitet. Der Koordinator ist dafür verantwortlich, die Ergebnisse der Arbeiterknoten zusammenzutragen und dem Kunden die Endergebnisse zur Verfügung zu stellen.
Während der Installation werden die Worker so konfiguriert, dass sie den Hostnamen oder die IP-Adresse des Discovery Service für den Cluster kennen. Wenn ein Worker startet, meldet er sich beim Discovery Service, der ihn dem Koordinator für die Ausführung von Aufgaben zur Verfügung stellt.
Die Arbeiter kommunizieren mit anderen Arbeitern und dem Koordinator über ein HTTP-basiertes Protokoll.
Abbildung 4-4 zeigt, wie mehrere Arbeiter/innen Daten aus den Datenquellen abrufen und gemeinsam verarbeiten, bis ein/e Arbeiter/in die Daten an den/die Koordinator/in weitergeben kann.

Abbildung 4-4. Worker in einem Cluster arbeiten zusammen, um SQL-Anweisungen und Daten zu verarbeiten
Connector-basierte Architektur
Das Herzstück der Trennung von Speicherung und Datenverarbeitung in Trino ist die Connector-basierte Architektur. Ein Connector bietet Trino eine Schnittstelle für den Zugriff auf eine beliebige Datenquelle.
Jeder Connector bietet eine tabellenbasierte Abstraktion der zugrunde liegenden Datenquelle. Solange Daten in Form von Tabellen, Spalten und Zeilen ausgedrückt werden können, indem die in Trino verfügbaren Datentypen verwendet werden, kann ein Konnektor erstellt werden und die Abfrage-Engine kann die Daten für die Abfrageverarbeitung nutzen.
Trino bietet ein Service Provider Interface(SPI), das die Funktionen definiert, die ein Konnektor für bestimmte Funktionen implementieren muss. Durch die Implementierung der SPI in einem Konnektor kann Trino intern Standardoperationen verwenden, um sich mit jeder Datenquelle zu verbinden und Operationen mit jeder Datenquelle durchzuführen. Der Konnektor kümmert sich um die Details, die für die jeweilige Datenquelle relevant sind.
Jeder Connector implementiert die drei Teile der API:
-
Operationen zum Abrufen von Tabellen-/View-/Schema-Metadaten
-
Operationen zur Erzeugung logischer Einheiten der Datenpartitionierung, so dass Trino Lese- und Schreibvorgänge parallelisieren kann
-
Datenquellen und -senken, die die Quelldaten in/aus dem von der Abfrage-Engine erwarteten In-Memory-Format konvertieren
Lass uns den SPI anhand eines Beispiels erklären. Jeder Connector in Trino, der das Lesen von Daten aus der zugrunde liegenden Datenquelle unterstützt, muss den listTablesSPI implementieren. Daher kann Trino dieselbe Methode verwenden, um jeden Konnektor aufzufordern, die Liste der verfügbaren Tabellen in einem Schema zu überprüfen. Trino muss nicht wissen, dass einige Konnektoren diese Daten aus einem Informationsschema abrufen, andere einen Metaspeicher abfragen und wieder andere diese Informationen über eine API der Datenquelle abfragen müssen. Für die Kern-Engine von Trino sind diese Details irrelevant. Der Konnektor kümmert sich um die Details. Dieser Ansatz trennt die Belange der zentralen Abfrage-Engine klar von den Besonderheiten der zugrunde liegenden Datenquelle. Dieser einfache, aber leistungsstarke Ansatz bietet große Vorteile für die Fähigkeit, den Code im Laufe der Zeit zu lesen, zu erweitern und zu pflegen.
Trino bietet viele Konnektoren zu Systemen wie HDFS/Hive, Iceberg, Delta Lake, MySQL, PostgreSQL, MS SQL Server, Kafka, Cassandra, Redis und vielen mehr. In den Kapiteln 6 und7 lernst du einige der Konnektoren kennen. Die Liste der verfügbaren Konnektoren wird ständig erweitert. Die aktuelle Liste der unterstützten Konnektoren findest du in der Trino-Dokumentation.
Das SPI von Trino bietet dir auch die Möglichkeit, eigene Konnektoren zu erstellen. Das kann notwendig sein, wenn du auf eine Datenquelle zugreifen musst, für die es keinen kompatiblen Konnektor gibt. Wenn du einen Konnektor erstellst, empfehlen wir dir, mehr über die Trino Open Source Community zu erfahren, unsere Hilfe in Anspruch zu nehmen und deinen Konnektor beizusteuern. Weitere Informationen findest du unter "Trino-Ressourcen". Ein benutzerdefinierter Konnektor kann auch erforderlich sein, wenn du eine einzigartige oder proprietäre Datenquelle in deinem Unternehmen hast. So können Trino-Benutzer jede Datenquelle mit SQL abfragen - ein echtes SQL-on-Anything.
Abbildung 4-5 zeigt, wie das Trino SPI getrennte Schnittstellen für Metadaten, Datenstatistiken und den Speicherort der Daten enthält, die vom Koordinator verwendet werden, und für das Datenstreaming, das von den Workern genutzt wird.

Abbildung 4-5. Übersicht über das Trino SPI
Trino-Konnektoren sind Plug-ins, die von jedem Server beim Start geladen werden. Sie werden mit bestimmten Parametern in den Katalogeinstellungsdateien konfiguriert und aus dem Plug-Ins-Verzeichnis geladen. Mehr darüber erfahren wir in Kapitel 6.
Hinweis
Trino verwendet für zahlreiche Aspekte seiner Funktionalität eine Plug-in-basierte Architektur. Neben Konnektoren können Plug-ins Implementierungen für Event-Listener, Zugriffskontrollen sowie Funktions- und Typanbieter bereitstellen.
Kataloge, Schemata und Tabellen
Der Trino-Cluster verarbeitet alle Abfragen mit Hilfe der zuvor beschriebenen konnektorbasierten Architektur. Jede Katalogkonfiguration verwendet einen Connector, um auf eine bestimmte Datenquelle zuzugreifen. Die Datenquelle stellt ein oder mehrere Schemata im Katalog zur Verfügung. Jedes Schema enthält Tabellen, die die Daten in Tabellenzeilen bereitstellen, wobei die Spalten unterschiedliche Datentypen verwenden. Weitere Einzelheiten findest du inKapitel 8: speziell "Kataloge", "Schemas" und"Tabellen".
Abfrage-Ausführungsmodell
Da du nun weißt, dass ein realer Einsatz von Trino einen Cluster mit einem Koordinator und vielen Workern erfordert, können wir uns ansehen, wie eine SQL-Anfrage verarbeitet wird.
Wenn du das Ausführungsmodell verstehst, hast du das nötige Grundwissen, um die Leistung von Trino für deine speziellen Abfragen zu optimieren.
Der Koordinator akzeptiert SQL-Anweisungen vom Endbenutzer, von der CLI oder von Anwendungen, die den ODBC- oder JDBC-Treiber oder andere Client-Bibliotheken verwenden. Der Koordinator veranlasst dann die Worker, alle Daten aus der Datenquelle zu holen, erstellt den Ergebnisdatensatz und stellt ihn dem Kunden zur Verfügung.
Schauen wir uns zunächst genauer an, was innerhalb des Koordinators passiert. Wenn eine SQL-Anweisung an den Koordinator übermittelt wird, erhält er sie in Textform. Der Koordinator analysiert diesen Text und analysiert ihn. Anschließend erstellt er mithilfe einer internen Datenstruktur in Trino, dem Abfrageplan, einen Plan für die Ausführung. Dieser Ablauf ist in Abbildung 4-6 dargestellt. Der Abfrageplan stellt im Großen und Ganzen die notwendigen Schritte dar, um die Daten zu verarbeiten und die Ergebnisse gemäß der SQL-Anweisung zurückzugeben.
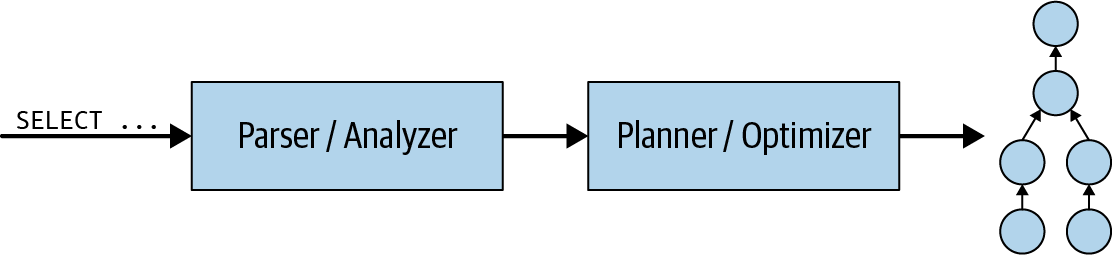
Abbildung 4-6. Verarbeitung einer SQL-Abfrageanweisung zur Erstellung eines Abfrageplans
Wie du in Abbildung 4-7 sehen kannst, verwendet die Abfrageplanerstellung den Metadaten-SPI und den Datenstatistik-SPI, um den Abfrageplan zu erstellen. Der Koordinator nutzt also den SPI, um Informationen über Tabellen und andere Metadaten zu sammeln, die direkt mit der Datenquelle verbunden sind.
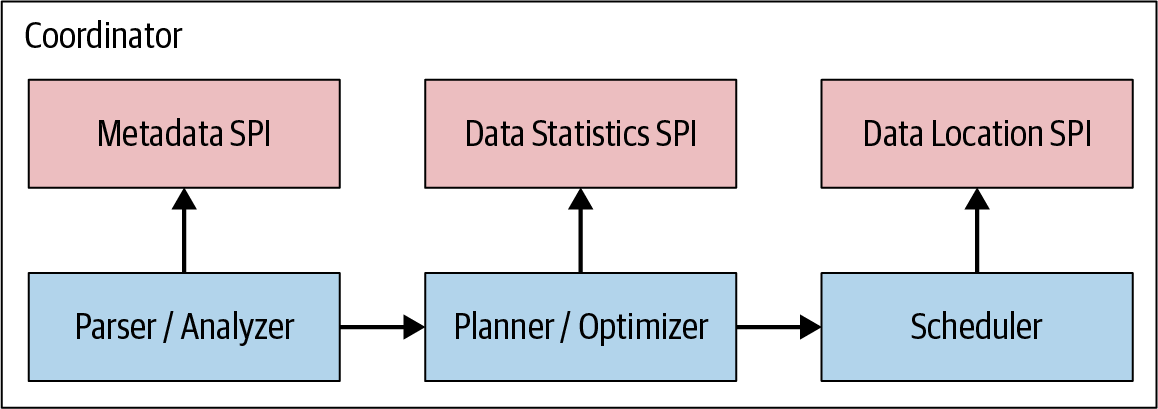
Abbildung 4-7. Die SPIs für Abfrageplanung und Scheduling
Der Koordinator verwendet das Metadaten-SPI, um Informationen über Tabellen, Spalten und Typen zu erhalten. Diese werden verwendet, um zu überprüfen, ob die Abfrage semantisch gültig ist, und um eine Typüberprüfung der Ausdrücke in der ursprünglichen Abfrage sowie Sicherheitsüberprüfungen durchzuführen.
Der Statistik-SPI wird verwendet, um Informationen über die Zeilenzahl und die Tabellengröße zu erhalten, um kostenbasierte Abfrageoptimierungen während der Planung durchzuführen.
Der Datenort-SPI wird dann bei der Erstellung des verteilten Abfrageplans unterstützt. Er wird verwendet, um logische Splits der Tabelleninhalte zu erzeugen. Splits sind die kleinste Einheit der Arbeitszuweisung und der Parallelität.
Hinweis
Bei den verschiedenen SPIs handelt es sich eher um eine konzeptionelle Trennung; die eigentliche Java-API auf unterer Ebene wird durch mehrere Java-Pakete feiner getrennt.
Der verteilte Abfrageplan ist eine Erweiterung des einfachen Abfrageplans, der aus einer oder mehreren Phasen besteht. Der einfache Abfrageplan ist in Planfragmente unterteilt. EinePhase ist die Verkörperung eines Planfragments zur Laufzeit und umfasst alle Aufgaben der Arbeit, die durch das Planfragment der Phase beschrieben wird.
Der Koordinator bricht den Plan auf, um die parallele Verarbeitung auf Clustern zu ermöglichen und so die gesamte Abfrage zu beschleunigen. Wenn du mehr als eine Stufe hast, entsteht ein Abhängigkeitsbaum von Stufen. Die Anzahl der Stufen hängt von der Komplexität der Abfrage ab. So wirken sich zum Beispiel abgefragte Tabellen, zurückgegebene Spalten, JOINAnweisungen, WHERE Bedingungen, GROUP BY Operationen und andere SQL-Anweisungen auf die Anzahl der erstellten Stages aus.
Abbildung 4-8 zeigt, wie der logische Abfrageplan in einen verteilten Abfrageplan auf dem Coordinator im Cluster umgewandelt wird.

Abbildung 4-8. Umwandlung des Abfrageplans in einen verteilten Abfrageplan
Der verteilte Abfrageplan definiert die Phasen und die Art und Weise, wie die Abfrage in einem Trino-Cluster ausgeführt werden soll. Er wird vom Koordinator verwendet, um die Aufgaben in den Workern zu planen und zu verteilen. Eine Phase besteht aus einer oder mehreren Aufgaben. Normalerweise sind viele Aufgaben beteiligt, und jede Aufgabe verarbeitet einen Teil der Daten.
Der Koordinator weist den Arbeitern im Cluster die Aufgaben einer Stufe zu, wie in Abbildung 4-9 dargestellt.
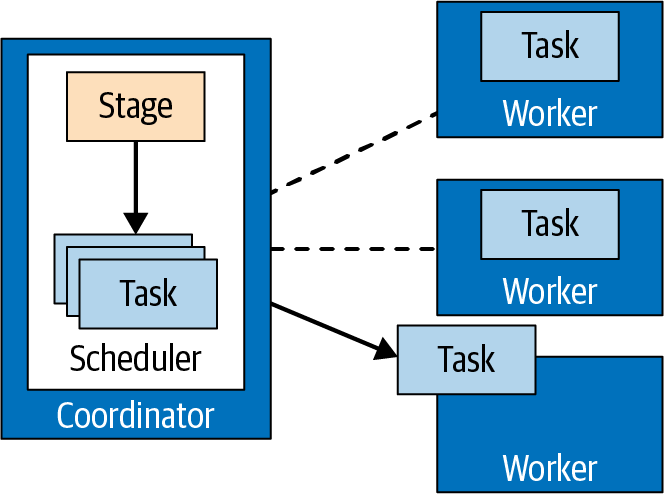
Abbildung 4-9. Aufgabenverwaltung durch den Koordinator
Die Einheit der Daten, die ein Task verarbeitet, wird als Split bezeichnet. Ein Split ist ein Deskriptor für ein Segment der zugrunde liegenden Daten, das von einem Worker abgerufen und verarbeitet werden kann. Er ist die Einheit der Parallelität und der Arbeitszuweisung.
Die spezifischen Operationen, die der Konnektor mit den Daten durchführt, hängen von der zugrunde liegenden Datenquelle ab. Der Hive-Konnektor beschreibt zum Beispiel Splits in Form eines Pfads zu einer Datei mit Offset und Länge, die angeben, welcher Teil der Datei verarbeitet werden muss.
Die Aufgaben in der Quellstufe erzeugen Daten in Form von Seiten, die eine Sammlung von Zeilen im Spaltenformat sind. Diese Seiten fließen zu anderen nachgelagerten Zwischenstufen. Die Seiten werden zwischen den Stufen durch Austauschoperatoren übertragen, die die Daten von Aufgaben in einer vorgelagerten Stufe lesen.
Die Quellaufgaben verwenden die Datenquellen-SPI, um mit Hilfe eines Konnektors Daten aus der zugrunde liegenden Datenquelle zu holen. Diese Daten werden Trino präsentiert und fließen in Form von Seiten durch die Engine. Operatoren verarbeiten und erzeugen Seiten entsprechend ihrer Semantik. Zum Beispiel lassen Filter Zeilen fallen, Projektionen erzeugen Seiten mit neuen abgeleiteten Spalten und so weiter.
Die Abfolge von Operatoren innerhalb einer Aufgabe wird alsPipeline bezeichnet. Der letzte Operator einer Pipeline legt seine Ausgabeseiten in der Regel im Ausgabepuffer der Aufgabe ab. Austauschoperatoren in nachgelagerten Aufgaben verbrauchen die Seiten aus dem Ausgabepuffer einer vorgelagerten Aufgabe. Alle diese Vorgänge laufen parallel auf verschiedenen Workern ab, wie in Abbildung 4-10 zu sehen ist.
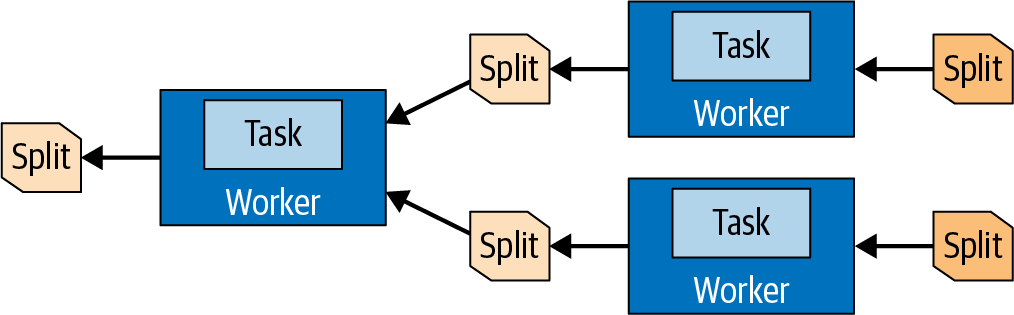
Abbildung 4-10. Daten in Splits werden zwischen Tasks übertragen und auf verschiedenen Workern verarbeitet
Eine Aufgabe ist also die Verkörperung eines Planfragments zur Laufzeit, wenn sie einem Arbeiter zugewiesen wird. Nachdem eine Aufgabe erstellt wurde, instanziiert sie einen Treiber für jeden Split. Jeder Treiber ist eine Instanziierung einer Pipeline von Operatoren und führt die Verarbeitung der Daten im Split durch.
Ein Task kann je nach Trino-Konfiguration und -Umgebung einen oder mehrere Treiber verwenden, wie inAbbildung 4-11 dargestellt. Sobald alle Treiber fertig sind und die Daten an den nächsten Split weitergegeben wurden, sind die Treiber und der Task mit ihrer Arbeit fertig und werden zerstört.
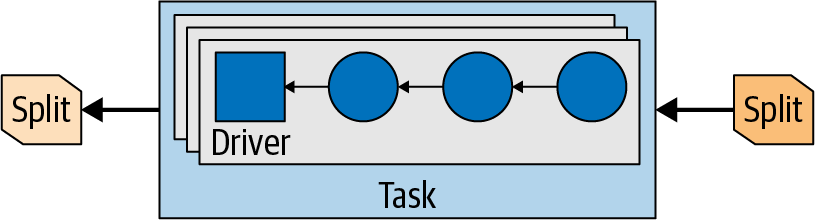
Abbildung 4-11. Parallele Treiber in einer Aufgabe mit Eingangs- und Ausgangssplits
Ein Operator verarbeitet Eingabedaten, um Ausgabedaten für einen nachgeschalteten Operator zu erzeugen. Beispiele für Operatoren sind Tabellenscans, Filter, Joins und Aggregationen. Eine Reihe dieser Operatoren bilden eine Operator-Pipeline. Du könntest zum Beispiel eine Pipeline haben, die zuerst die Daten scannt und liest, dann die Daten filtert und schließlich die Daten teilweise aggregiert.
Um eine Abfrage zu bearbeiten, erstellt der Koordinator die Liste der Splits mit den Metadaten des Connectors. Anhand der Liste der Splits beginnt der Koordinator mit der Planung von Aufgaben auf den Workern, um die Daten in den Splits zu sammeln. Während der Ausführung der Abfrage verfolgt der Koordinator alle Splits, die für die Verarbeitung zur Verfügung stehen, sowie die Orte, an denen Aufgaben auf den Workern laufen und Splits verarbeitet werden.
Wenn die Aufgaben beendet sind und weitere Splits für die nachgelagerte Verarbeitung produziert werden, plant der Koordinator so lange Aufgaben ein, bis keine Splits mehr zu verarbeiten sind. Sobald alle Splits von den Workern verarbeitet wurden, sind alle Daten verfügbar und der Koordinator kann das Ergebnis dem Kunden zur Verfügung stellen.
Abfrageplanung
Bevor wir uns ansehen, wie der Trino Query Planner und die kostenbasierten Optimierungen funktionieren, wollen wir unsere Überlegungen in einen bestimmten Kontext einordnen. Wir stellen eine Beispielabfrage als Kontext für unsere Untersuchung vor, damit du den Prozess der Abfrageplanung besser verstehst.
Beispiel 4-1 verwendet den TPC-H-Datensatz - siehe "Trino TPC-H und TPC-DS Konnektoren" - umden Wert aller Bestellungen pro Nation zu summieren und die fünf führenden Nationen aufzulisten.
Beispiel 4-1. Beispielabfrage zur Erläuterung der Abfrageplanung
SELECT(SELECTnameFROMregionrWHEREregionkey=n.regionkey)ASregion_name,n.nameASnation_name,sum(totalprice)orders_sumFROMnationn,orderso,customercWHEREn.nationkey=c.nationkeyANDc.custkey=o.custkeyGROUPBYn.nationkey,regionkey,n.nameORDERBYorders_sumDESCLIMIT5;
Wir wollen versuchen, die in der Abfrage verwendeten SQL-Konstrukte und ihren Zweck zu verstehen:
-
Eine
SELECTAbfrage mit drei Tabellen in derFROMKlausel, die implizit eineCROSS JOINzwischen den Tabellennation,ordersundcustomerdefiniert -
Eine
WHEREBedingung, um die übereinstimmenden Zeilen aus den Tabellennation,orders, undcustomerTabellen -
Eine Aggregation mit
GROUP BY, um die Werte der Bestellungen für jede Nation zu aggregieren -
Eine Unterabfrage
(SELECT name FROM region WHERE regionkey = n.regionkey)zum Abrufen des Regionsnamens aus der Tabelleregion; beachte, dass diese Abfrage korreliert ist, so als ob sie unabhängig für jede Zeile der enthaltenen Ergebnismenge ausgeführt werden sollte -
Eine Ordnungsdefinition,
ORDER BY orders_sum DESC, um das Ergebnis vor der Rückgabe zu sortieren -
Ein Limit von fünf Zeilen, um nur Nationen mit den höchsten Summen zurückzugeben und alle anderen herauszufiltern
Parsing und Analyse
Bevor eine Abfrage für die Ausführung geplant werden kann, muss sie geparst und analysiert werden. Details zu SQL und den dazugehörigen syntaktischen Regeln für die Erstellung der Abfrage findest du in den Kapiteln 8 und9. Trino prüft den Text beim Parsen auf diese Syntaxregeln. In einem nächsten Schritt analysiert Trino die Abfrage:
- Identifizieren von Tabellen, die in einer Abfrage verwendet werden
-
Die Tabellen sind in Katalogen und Schemas organisiert, so dass mehrere Tabellen denselben Namen haben können. Die TPC-H-Daten bieten zum Beispiel
ordersTabellen unterschiedlicher Größe in den verschiedenen Schemas alssf10.orders,sf100.orders, usw. - Identifizieren von Spalten, die in einer Abfrage verwendet werden
-
Eine qualifizierte Spaltenreferenz
orders.totalpriceverweist eindeutig auf einetotalpriceSpalte in der Tabelleorders. Normalerweise bezieht sich eine SQL-Abfrage jedoch nur auf den Namen einer Spalte -totalprice, wie in Beispiel 4-1 zu sehen ist. Der Trino Analyzer kann feststellen, aus welcher Tabelle eine Spalte stammt. - Identifizierung von Referenzen auf Felder innerhalb von ROW-Werten
-
Ein Dereferenzierungsausdruck
c.bonuskann sich auf einebonusSpalte in der Tabelle mit dem Namencoder mit dem Aliascbeziehen. Oder er kann sich auf einbonusFeld in einercSpalte vom Typ Zeile (eine Struktur mit benannten Feldern) beziehen. Es ist die Aufgabe des Analysators in Trino, zu entscheiden, was zutreffend ist, wobei im Falle einer Mehrdeutigkeit der Verweis auf eine Spalte mit Tabellenqualifikation Vorrang hat. Bei der Analyse müssen die Regeln der SQL-Sprache für Scoping und Sichtbarkeit beachtet werden. Die gesammelten Informationen, wie z. B. die Disambiguierung von Bezeichnern, werden später bei der Planung verwendet, so dass der Planer die Scoping-Regeln der Abfragesprache nicht erneut verstehen muss.
Wie du siehst, hat der Query Analyzer komplexe, übergreifende Aufgaben. Seine Rolle ist sehr technisch und bleibt aus der Sicht des Benutzers unsichtbar, solange die Abfragen korrekt sind. Der Analyzer meldet sich immer dann zu Wort, wenn eine Abfrage gegen die Regeln der SQL-Sprache verstößt, die Rechte des Benutzers überschreitet oder aus einem anderen Grund nicht korrekt ist.
Sobald die Abfrage analysiert ist und alle Identifikatoren in der Abfrage verarbeitet und aufgelöst wurden, geht Trino zur nächsten Phase über, der Abfrageplanung.
Planung der ersten Abfrage
Ein Abfrageplan definiert ein Programm, das Abfrageergebnisse erzeugt. SQL ist eine deklarative Sprache: Der Nutzer schreibt eine SQL-Abfrage, um die Daten zu spezifizieren, die er vom System haben möchte. Im Gegensatz zu einem imperativen Programm gibt der Benutzer nicht an, wie die Daten verarbeitet werden sollen, um das Ergebnis zu erhalten. Dieser Teil wird dem Abfrageplaner und dem Optimierer überlassen, die die Reihenfolge der Schritte festlegen, mit denen die Daten verarbeitet werden, um das gewünschte Ergebnis zu erhalten.
Diese Abfolge von Schritten wird oft als Abfrageplan bezeichnet. Theoretisch könnte eine exponentielle Anzahl von Abfrageplänen zum gleichen Abfrageergebnis führen.Die Leistung der Pläne variiert stark, und hier versuchen der Trino-Planer und der Optimierer, den optimalen Plan zu ermitteln. Pläne, die immer die gleichen Ergebnisse liefern, werden als gleichwertige Pläne bezeichnet.
Betrachten wir die Abfrage aus Beispiel 4-1. Der einfachste Abfrageplan für diese Abfrage ist derjenige, der der syntaktischen Struktur der Abfrage am nächsten kommt. Dieser Plan ist inBeispiel 4-2 dargestellt. Für die Zwecke dieser Diskussion sollte die Auflistung selbsterklärend sein. Du musst nur wissen, dass der Plan ein Baum ist und seine Ausführung bei den Blattknoten beginnt und sich entlang der Baumstruktur nach oben bewegt.
Beispiel 4-2. Manuell komprimierte, einfache textuelle Darstellung des Abfrageplans für die Beispielabfrage
- Limit[5]
- Sort[orders_sum DESC]
- LateralJoin[2]
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey AND c.custkey = o.custkey]
- CrossJoin
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
- EnforceSingleRow[region_name := r.name]
- Filter[r.regionkey = n.regionkey]
- TableScan[region]Jedes Element des Abfrageplans kann auf einfache, zwingende Weise implementiert werden. Zum Beispiel greift TableScan auf eine Tabelle in der zugrunde liegenden Speicherung zu und gibt eine Ergebnismenge zurück, die alle Zeilen der Tabelle enthält. Filter
Der Knoten CrossJoin empfängt Zeilen und wendet auf jede eine Filterbedingung an, wobei er nur die Zeilen behält, die die Bedingung erfüllen. bearbeitet zwei Datensätze, die er von seinen Kindknoten erhält. Er erzeugt alle Kombinationen von Zeilen in diesen Datensätzen und speichert wahrscheinlich einen der Datensätze im Speicher, damit nicht mehrfach auf die zugrunde liegende Speicherung zugegriffen werden muss.
Warnung
In den letzten Trino-Versionen wurden die Namen der Operationen in einem Abfrageplan geändert. Zum Beispiel ist TableScan gleichbedeutend mit ScanProject mit einer Tabellenspezifikation. Die Operation Filter wurde in FilterProject umbenannt. Die vorgestellten Ideen bleiben jedoch dieselben.
Betrachten wir nun die Berechnungskomplexität dieses Abfrageplans. Ohne alle Details der tatsächlichen Implementierung zu kennen, können wir die Komplexität nicht vollständig einschätzen. Wir können jedoch davon ausgehen, dass die untere Schranke für die Komplexität eines Abfrageplanknotens die Größe des Datensatzes ist, den er erzeugt. Daher beschreiben wir die Komplexität mit der Big-Omega-Notation, die die asymptotische untere Schranke beschreibt. Wenn N, O, C und R die Anzahl der Zeilen in den Tabellen nation, orders, customer bzw. region darstellen, können wir Folgendes beobachten:
-
TableScan[orders]liest die Tabelleordersund gibt O Zeilen zurück; die Komplexität ist also Ω(O). Auch die beiden anderenTableScanOperationen liefern N bzw. CZeilen; ihre Komplexität ist also Ω(N) bzw. Ω(C). -
CrossJoinüberTableScan[nation]undTableScan[orders]kombiniert die Daten aus den Tabellennationundorders; daher ist seine Komplexität Ω(N × O). -
Die obige
CrossJoinkombiniert die frühereCrossJoin, die N × OZeilen erzeugte, mitTableScan[customer], also mit Daten aus der Tabellecustomer; daher ist ihre Komplexität Ω(N × O × C). -
TableScan[region]unten hat die Komplexität Ω(R). Aufgrund derLateralJoinwird sie jedoch N-mal aufgerufen, wobei N die Anzahl der Zeilen ist, die von der Aggregation zurückgegeben werden. Insgesamt verursacht dieser Vorgang also Ω(R × N) an Rechenkosten. -
Die Operation
Sortmuss eine Menge von N Zeilen ordnen, also kann sie nicht weniger Zeit in Anspruch nehmen, als proportional zu N × log(N) ist.
Wenn wir andere Operationen für einen Moment außer Acht lassen, weil sie nicht teurer sind als die, die wir bisher analysiert haben, betragen die Gesamtkosten des vorangegangenen Plans mindestens Ω[N + O+ C +(N × O) +(N × O × C) +(R × N) +(N × log(N))]. Ohne die relativen Tabellengrößen zu kennen, kann dies zu Ω[(N × O × C) +(R × N) + (N × log(N))] vereinfacht werden. Wenn wir davon ausgehen, dass region die kleinste Tabelle ist und nation die zweitkleinste, können wir den zweiten und dritten Teil des Ergebnisses vernachlässigen und erhalten das vereinfachte Ergebnis Ω(N × O × C).
Genug der algebraischen Formeln. Es wird Zeit zu sehen, was das in der Praxis bedeutet! Nehmen wir das Beispiel einer beliebten Shopping-Website mit 100 Millionen Kunden aus 200 Nationen, die insgesamt 1 Milliarde Bestellungen aufgegeben haben. Die CrossJoin dieser beiden Tabellen muss 20 Quintillionen (20.000.000.000.000.000.000.000) Zeilen materialisieren. Bei einem mittelstarken Cluster mit 100 Knoten, der 1 Million Zeilen pro Sekunde auf jedem Knoten verarbeitet, würde es über 63 Jahrhunderte dauern, die Zwischendaten für unsere Abfrage zu berechnen.
Natürlich versucht Trino nicht einmal, einen solch naiven Plan auszuführen. Aber dieser ursprüngliche Plan dient als Brücke zwischen zwei Welten: der Welt der SQL-Sprache und ihrer semantischen Regeln und der Welt der Abfrageoptimierung. Die Aufgabe der Abfrageoptimierung besteht darin, den ursprünglichen Plan in einen äquivalenten Plan umzuwandeln und weiterzuentwickeln, der angesichts der endlichen Ressourcen des Trino-Clusters so schnell wie möglich, zumindest aber in einer angemessenen Zeit, ausgeführt werden kann. Lassen Sie uns darüber sprechen, wie Abfrageoptimierungen versuchen, dieses Ziel zu erreichen.
Optimierungsregeln
In diesem Abschnitt bekommst du einen Einblick in eine Handvoll der vielen wichtigen Optimierungsregeln, die in Trino implementiert sind.
Prädikat Pushdown
Predicate Pushdown ist wahrscheinlich die wichtigste und am einfachsten zu verstehende Optimierung. Ihre Aufgabe ist es, die Filterbedingung so nah wie möglich an die Datenquelle zu bringen. Das bedeutet, dass die Datenreduzierung so früh wie möglich während der Ausführung der Abfrage stattfindet. In unserem Fall wird eine Filter in eine einfachere Filter und eine InnerJoin über derselben CrossJoin Bedingung umgewandelt, was zu dem in Beispiel 4-3 gezeigten Plan führt. Teile des Plans, die sich nicht geändert haben, sind aus Gründen der Lesbarkeit ausgeschlossen.
Beispiel 4-3. Umwandlung einer CrossJoin und Filter in eine InnerJoin
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey AND c.custkey = o.custkey] // original filter
- CrossJoin
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
...
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey] // transformed simpler filter
- InnerJoin[o.custkey = c.custkey] // added inner join
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
...Der "größere" Join, der vorhanden war, wird nun in InnerJoin auf eine Gleichheitsbedingung umgewandelt. Ohne ins Detail zu gehen, nehmen wir einmal an, dass ein solcher Join in einem verteilten System effizient implementiert werden kann, wobei die Rechenkomplexität der Anzahl der erzeugten Zeilen entspricht. Das bedeutet, dass das Prädikat pushdown ein "mindestens" Ω(N × O × C)CrossJoin durch ein Join ersetzt, das "genau"Θ(N × O) ist.
Mit dem Prädikats-Pushdown konnte jedoch die CrossJoin zwischen den Tabellen nationund orders nicht verbessert werden, da keine unmittelbare Bedingung diese Tabellen verbindet. An dieser Stelle kommt die Cross-Join-Elimination ins Spiel.
Cross Join Eliminierung
Ohne den kostenbasierten Optimierer verknüpft Trino die in der Abfrage SELECT enthaltenen Tabellen in der Reihenfolge, in der sie im Abfragetext erscheinen. Eine wichtige Ausnahme besteht, wenn die zu verbindenden Tabellen keine Verbindungsbedingung haben, was zu einem Cross-Join führt. In fast allen praktischen Fällen ist ein Cross-Join unerwünscht, und alle vervielfältigten Zeilen werden später herausgefiltert, aber der Cross-Join selbst hat so viel Arbeit, dass er möglicherweise nie abgeschlossen wird.
DieCross-Join-Elimination ordnet die zu verbindenden Tabellen neu an, um die Anzahl der Cross-Joins zu minimieren und sie im Idealfall auf Null zu reduzieren. Da es außer der Cross-Join-Elimination keine Informationen über die relativen Tabellengrößen gibt, bleibt die Reihenfolge der Tabellen-Joins erhalten, sodass der Benutzer die Kontrolle behält. Die Auswirkung der Eliminierung von Cross-Joins auf unsere Beispielabfrage ist in Beispiel 4-4 zu sehen. Jetzt sind beide Joins Inner-Joins, wodurch die Gesamtkosten für die Joins aufΘ(C + O) =Θ(O) sinken. Andere Teile des Abfrageplans haben sich seit dem ursprünglichen Plan nicht geändert, sodass die Gesamtkosten für die Abfrageberechnung mindestens Ω[O +(R × N) +(N × log(N))]betragen - natürlich ist die Komponente O, die die Anzahl der Zeilen in der Tabelle orders darstellt, der dominierende Faktor.
Beispiel 4-4. Neuordnung der Joins, um den Cross-Join zu eliminieren
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey] // filter on nationkey first
- InnerJoin[o.custkey = c.custkey] // then inner join custkey
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
...
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[c.custkey = o.custkey] // reordered to custkey first
- InnerJoin[n.nationkey = c.nationkey] // then nationkey
- TableScan[nation]
- TableScan[customer]
- TableScan[orders]TopN
Wenn eine Abfrage eine LIMIT Klausel enthält, wird ihr normalerweise eine ORDER BYKlausel vorangestellt. Ohne diese Reihenfolge kann SQL nicht garantieren, welche Ergebniszeilen zurückgegeben werden. Die Kombination aus ORDER BY gefolgt von LIMIT ist auch in unserer Abfrage vorhanden.
Bei der Ausführung einer solchen Abfrage könnte Trino alle erzeugten Zeilen sortieren und dann nur die ersten paar davon behalten. Dieser Ansatz hätte eine Rechenkomplexität vonΘ(row_count× log(row_count)) und einen Speicherbedarf vonΘ(row_count). Es ist jedoch nicht optimal und verschwenderisch, die gesamten Ergebnisse zu sortieren, nur um eine viel kleinere Teilmenge der sortierten Ergebnisse zu behalten. Deshalb rollt eine Optimierungsregel ORDER BY gefolgt von LIMIT in einen TopN-Plan-Knoten ein. Während der Ausführung der Abfrage speichert TopN die gewünschte Anzahl von Zeilen in einer Datenstruktur und aktualisiert den Heap, während die Eingabedaten im Streaming-Verfahren gelesen werden. Dadurch sinkt die Rechenkomplexität aufΘ(row_count × log(limit)) und der Speicherbedarf aufΘ(limit). Die Gesamtkosten für die Abfrageberechnung betragen nun Ω[O +(R× N) + N].
Teilweise Aggregationen
Trino muss nicht alle Zeilen aus der Tabelle orders an den Join weitergeben, da wir nicht an einzelnen Bestellungen interessiert sind.Unsere Beispielabfrage berechnet ein Aggregat, die Summe über totalprice für jedenation, so dass es möglich ist, die Zeilen wie in Beispiel 4-5 gezeigt vorzuaggregieren. Wir reduzieren die Datenmenge, die in den Downstream-Join fließt, indem wir die Daten aggregieren. Die Ergebnisse sind nicht vollständig, deshalb wird dies als Voraggregation bezeichnet. Aber die Datenmenge wird potenziell reduziert, was die Abfrageleistung erheblich verbessert.
Beispiel 4-5. Teilweise Voraggregation kann die Leistung erheblich verbessern
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[c.custkey = o.custkey]
- InnerJoin[n.nationkey = c.nationkey]
- TableScan[nation]
- TableScan[customer]
- Aggregate[by custkey; totalprice := sum(totalprice)]
- TableScan[orders]Um die Parallelität zu verbessern, wird diese Art der Voraggregation anders umgesetzt, nämlich als sogenannte Teilaggregation. Hier stellen wir vereinfachte Pläne vor, aber in einem tatsächlichen EXPLAIN Plan wird dies anders dargestellt als die endgültige Aggregation.
Hinweis
Die in Beispiel 4-5 gezeigte Art der Voraggregation ist nicht immer eine Verbesserung. Sie wirkt sich nachteilig auf die Abfrageleistung aus, wenn die partielle Aggregation die Datenmenge nicht reduziert.Aus diesem Grund ist die Optimierung derzeit standardmäßig deaktiviert und kann mit der Eigenschaftpush_partial_aggregation_through_join session oder der Konfigurationseigenschaftoptimizer.push-partial-aggregation-through-join aktiviert werden. Standardmäßig verwendet Trino Teilaggregationen und stellt sie über die Verknüpfung, um die Datenmenge zu reduzieren, die über das Netzwerk zwischen den Trino-Knoten übertragen wird. Um die Rolle dieser partiellen Aggregationen richtig einschätzen zu können, müssen wir nicht-vereinfachte Abfragepläne betrachten.
Durchführungsbestimmungen
Die Regeln, die wir bisher behandelt haben, sind Optimierungsregeln - Regeln, die darauf abzielen, die Verarbeitungszeit der Abfrage, den Speicherbedarf der Abfrage oder die Menge der über das Netzwerk ausgetauschten Daten zu reduzieren. Aber auch im Fall unserer Beispielabfrage enthielt der ursprüngliche Plan eine Operation, die überhaupt nicht implementiert ist: den lateralen Join. Im nächsten Abschnitt sehen wir uns an, wie Trino mit dieser Art von Operationen umgeht.
Seitliche Verbindung Dekorrelation
Die seitliche Verknüpfung könnte als for-each-Schleife implementiert werden, die alle Zeilen eines Datensatzes durchläuft und für jede dieser Zeilen eine weitere Abfrage ausführt. Eine solche Implementierung ist möglich, aber das ist nicht die Art und Weise, wie Trino Fälle wie unser Beispiel behandelt. Stattdessen dekorreliert Trino die Unterabfrage, zieht alle korrelierten Bedingungen heran und bildet einen regulären Left Join. In der SQL-Sprache entspricht dies der Transformation einer Abfrage:
SELECT(SELECTnameFROMregionrWHEREregionkey=n.regionkey)ASregion_name,n.nameASnation_nameFROMnationn
in
SELECTr.nameASregion_name,n.nameASnation_nameFROMnationnLEFTOUTERJOINregionrONr.regionkey=n.regionkey
Auch wenn wir diese Konstrukte austauschbar verwenden, erkennt ein vorsichtiger Leser, der mit der SQL-Semantik vertraut ist, sofort, dass sie nicht völlig gleichwertig sind. Die erste Abfrage schlägt fehl, wenn doppelte Einträge in der Tabelleregion denselben regionkey haben, während die zweite Abfrage nicht fehlschlägt. Stattdessen erzeugt sie mehr Ergebniszeilen. Aus diesem Grund verwendet die laterale Join-Dekorrelation neben dem Join zwei weitere Komponenten. Erstens "nummeriert" sie alle Quellzeilen, damit sie unterschieden werden können. Zweitens wird nach dem Join geprüft, ob eine Zeile doppelt vorkommt, wie inBeispiel 4-6 gezeigt. Wird eine Duplizierung festgestellt, wird die Abfrageverarbeitung fehlgeschlagen, um die ursprüngliche Abfragesemantik zu erhalten.
Beispiel 4-6. Seitliche Join-Zerlegungen erfordern zusätzliche Prüfungen
- TopN[5; orders_sum DESC]
- MarkDistinct & Check
- LeftJoin[n.regionkey = r.regionkey]
- AssignUniqueId
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- ...
- TableScan[region]Semi-Join (IN) Dekorrelation
Eine Subquery kann innerhalb einer Abfrage nicht nur zum Ziehen von Informationen verwendet werden, wie wir gerade im Beispiel der seitlichen Verknüpfung gesehen haben, sondern auch zum Filtern von Zeilen mit Hilfe des INPrädikats. Ein IN Prädikat kann sowohl in einem Filter ( WHEREKlausel) als auch in einer Projektion ( SELECT Klausel) verwendet werden. Wenn du IN in einer Projektion verwendest, wird deutlich, dass es sich nicht um einen einfachen booleschen Wertoperator wie EXISTS handelt. Stattdessen kann das IN Prädikat zu true, false odernull ausgewertet werden.
Betrachten wir eine Abfrage, die darauf abzielt, Bestellungen zu finden, bei denen der Kunde und der Artikellieferant aus demselben Land stammen, wie in Beispiel 4-7 gezeigt. Solche Bestellungen können interessant sein. Wir möchten zum Beispiel Versandkosten sparen oder die Umweltbelastung durch den Versand verringern, indem wir die Ware direkt vom Lieferanten zum Kunden schicken und unsere eigenen Vertriebszentren umgehen.
Beispiel 4-7. Semi-Join (IN) Beispielabfrage
SELECTDISTINCTo.orderkeyFROMlineitemlJOINordersoONo.orderkey=l.orderkeyJOINcustomercONo.custkey=c.custkeyWHEREc.nationkeyIN(-- subquery invoked multiple timesSELECTs.nationkeyFROMpartpJOINpartsupppsONp.partkey=ps.partkeyJOINsuppliersONps.suppkey=s.suppkeyWHEREp.partkey=l.partkey);
Wie bei einer lateralen Verknüpfung könnte dies mit einer Schleife über die Zeilen der äußeren Abfrage implementiert werden, wobei die Unterabfrage zum Abrufen aller Nationen für alle Lieferanten eines Artikels mehrmals aufgerufen wird.
Anstatt dies zu tun, dekorreliert Trino die Unterabfrage - die Unterabfrage wird einmal ausgewertet, wobei die Korrelationsbedingung entfernt wird, und dann mit der äußeren Abfrage unter Verwendung der Korrelationsbedingung wieder verbunden. Der knifflige Teil besteht darin, sicherzustellen, dass der Join die Ergebniszeilen nicht vervielfacht (daher wird eine deduplizierende Aggregation verwendet) und dass die Transformation die dreiwertige Logik des INPrädikats korrekt beibehält.
In diesem Fall verwendet die deduplizierende Aggregation dieselbe Partitionierung wie die Verknüpfung, sodass sie ohne Datenaustausch über das Netzwerk und mit minimalem Speicherbedarf im Streaming-Verfahren ausgeführt werden kann.
Kostenbasierter Optimierer
In "Abfrageplanung" hast du gelernt, wie der Trino Planner eine Abfrage in Textform in einen ausführbaren und optimierten Abfrageplan umwandelt. In "Optimierungsregeln" hast du verschiedene Optimierungsregeln kennengelernt und ihre Bedeutung für die Abfrageleistung zur Ausführungszeit. Außerdem hast du unter "Implementierungsregeln " die Implementierungsregeln kennengelernt , ohne die ein Abfrageplan überhaupt nicht ausführbar wäre.
Wir sind den Weg vom Anfang, wo der Abfragetext vom Benutzer empfangen wird, bis zum Ende, wo der endgültige Ausführungsplan fertig ist, gegangen. Auf dem Weg dorthin haben wir ausgewählte Planumwandlungen gesehen, die entscheidend sind, weil sie den Plan um Größenordnungen schneller ausführen lassen oder ihn überhaupt erst ausführbar machen.
Schauen wir uns nun Planumwandlungen genauer an, die ihre Entscheidungen nicht nur auf der Form der Abfrage, sondern auch und vor allem auf der Form der abgefragten Daten basieren. Das ist die Aufgabe des modernen kostenbasierten Optimierers(CBO) von Trino.
Das Kostenkonzept
Vorhin haben wir eine Beispielabfrage als Arbeitsmodell verwendet. Auch hier verwenden wir einen ähnlichen Ansatz, um das Verständnis zu erleichtern. Wie du inBeispiel 4-8 sehen kannst, werden bestimmte Abfrageklauseln, die für diesen Abschnitt nicht relevant sind, entfernt. So kannst du dich auf die kostenbasierten Entscheidungen des Abfrageplaners konzentrieren.
Beispiel 4-8. Beispielabfrage für kostenbasierte Optimierung
SELECTn.nameASnation_name,avg(extendedprice)asavg_priceFROMnationn,orderso,customerc,lineitemlWHEREn.nationkey=c.nationkeyANDc.custkey=o.custkeyANDo.orderkey=l.orderkeyGROUPBYn.nationkey,n.nameORDERBYnation_name;
Ohne kostenbasierte Entscheidungen optimieren die Regeln des Abfrageplaners den anfänglichen Plan für diese Abfrage, um einen Plan zu erstellen, wie in Beispiel 4-9 gezeigt. Dieser Plan wird ausschließlich durch die lexikalische Struktur der SQL-Abfrage bestimmt. Der Optimierer verwendet nur die syntaktischen Informationen; daher wird er manchmal auch alssyntaktischer Optimierer bezeichnet. Der Name ist humorvoll gemeint und soll die Einfachheit der Optimierungen verdeutlichen. Da der Abfrageplan nur auf der Abfrage basiert, kannst du die Abfrage manuell anpassen oder optimieren, indem du die syntaktische Reihenfolge der Tabellen in der Abfrage anpasst.
Beispiel 4-9. Abfrage der Join-Reihenfolge durch den syntaktischen Optimierer
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[o.orderkey = l.orderkey]
- InnerJoin[c.custkey = o.custkey]
- InnerJoin[n.nationkey = c.nationkey]
- TableScan[nation]
- TableScan[customer]
- TableScan[orders]
- TableScan[lineitem]Nehmen wir nun an, die Abfrage wurde anders geschrieben und nur die Reihenfolge derWHERE Bedingungen geändert:
SELECTn.nameASnation_name,avg(extendedprice)asavg_priceFROMnationn,orderso,customerc,lineitemlWHEREc.custkey=o.custkeyANDo.orderkey=l.orderkeyANDn.nationkey=c.nationkeyGROUPBYn.nationkey,n.name;
Der Plan endet daher mit einer anderen Verknüpfungsreihenfolge:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[n.nationkey = c.nationkey]
- InnerJoin[o.orderkey = l.orderkey]
- InnerJoin[c.custkey = o.custkey]
- TableScan[customer]
- TableScan[orders]
- TableScan[lineitem]
- TableScan[nation]
Die Tatsache, dass sich eine einfache Änderung der Bestellbedingungen auf den Abfrageplan und damit auf die Leistung der Abfrage auswirkt, ist für den SQL-Analysten mühsam. Das Erstellen effizienter Abfragen erfordert dann internes Wissen darüber, wie Trino die Abfragen verarbeitet. Ein Abfrageautor sollte dieses Wissen nicht haben müssen, um die beste Leistung aus Trino herauszuholen. Außerdem unterstützen Tools mit Trino, wie Apache Superset, Tableau, Qlick oder Metabase, in der Regel viele verschiedene Datenbanken und Abfrage-Engines und schreiben keine optimierten Abfragen für Trino.
Der kostenbasierte Optimierer stellt sicher, dass die beiden Varianten der Abfrage denselben optimalen Abfrageplan für die Verarbeitung durch die Ausführungsmaschine von Trino ergeben.
Aus Sicht der Zeitkomplexität spielt es keine Rolle, ob du zum Beispiel die Tabelle nation mit customeroder umgekehrt die Tabelle customermit nation verknüpfst. Beide Tabellen müssen verarbeitet werden, und im Falle einer Hash-Join-Implementierung ist die Gesamtlaufzeit proportional zur Anzahl der Ausgabezeilen. Die Zeitkomplexität ist jedoch nicht das Einzige, was zählt. Das gilt generell für Programme, die mit Daten arbeiten, aber besonders für große Datenbanksysteme. Trino muss sich auch Gedanken über den Speicherverbrauch und den Netzwerkverkehr machen. Um den Speicher- und Netzwerkverbrauch der Verknüpfung beurteilen zu können, muss Trino besser verstehen, wie die Verknüpfungimplementiert ist.
CPU-Zeit, Speicherbedarf und Netzwerkbandbreitennutzung sind die drei Dimensionen, die zur Ausführungszeit von Abfragen beitragen, und zwar sowohl bei Einzelabfragen als auch bei gleichzeitigen Arbeitslasten. Diese Dimensionen machen die Kosten in Trino aus.
Kosten für den Beitritt
Beim Verbinden zweier Tabellen über die Gleichheitsbedingung (=) implementiert Trino eine erweiterte Version des Algorithmus, die alsHash Join bekannt ist. Eine der verknüpften Tabellen wird als " Build Side" bezeichnet. Diese Tabelle wird verwendet, um eine Hash-Tabelle mit den Spalten der Verknüpfungsbedingung als Schlüssel zu erstellen. Eine weitere verbundene Tabelle ist dieAbfrageseite. Sobald die Lookup-Hashtabelle fertig ist, werden die Zeilen aus der Probe-Seite verarbeitet und die Hash-Tabelle wird verwendet, um passende Zeilen auf der Build-Seite in konstanter Zeit zu finden. Trino verwendet standardmäßig ein dreistufiges Hashing, um die Verarbeitung so weit wie möglich zu parallelisieren:
-
Die beiden verknüpften Tabellen werden auf der Grundlage derHash-Werte der Spalten der Verknüpfungsbedingung auf die Arbeitsknoten verteilt. Zeilen, die abgeglichen werden sollen, haben die gleichenWerte in den Spalten der Verknüpfungsbedingungen und werden daher demselben Knoten zugewiesen. Dadurch verringert sich die Größe des Problems um die Anzahl der Knoten, die in dieser Phase verwendet werden. Diese Datenzuweisung auf Knotenebene ist die erste Stufe des Hashings.
-
Auf Knotenebene wird die Build-Seite weiter auf die Worker-Threads der Build-Seite verteilt, die wiederum eine Hash-Funktion verwenden. Der Aufbau einer Hashtabelle ist ein rechenintensiver Prozess, und die Verwendung mehrerer Threads für diese Aufgabe verbessert den Durchsatz erheblich.
-
Jeder Worker-Thread erzeugt schließlich eine Partition der endgültigen Lookup-Hashtabelle. Jede Partition ist selbst eine Hash-Tabelle. Die Partitionen werden zu einer zweistufigen Lookup-Hashtabelle zusammengefasst, damit wir vermeiden, dass auch die Prüfseite auf mehrere Threads verteilt wird. Die Prüfseite wird immer noch in mehreren Threads verarbeitet, aber die Threads bekommen ihre Arbeit in Stapeln zugewiesen, was schneller ist als die Partitionierung der Daten mithilfe einer Hash-Funktion.
Wie du siehst, wird die Build-Seite im Speicher gehalten, um eine schnelle In-Memory-Datenverarbeitung zu ermöglichen. Natürlich ist damit auch ein Speicherplatzbedarf verbunden, der proportional zur Größe der Build-Seite ist. Das bedeutet, dass die Build-Seite in den auf dem Knoten verfügbaren Speicher passen muss. Das bedeutet auch, dass weniger Speicher für andere Operationen und Abfragen zur Verfügung steht. Das sind die mit dem Join verbundenen Speicherkosten. Außerdem gibt es noch die Netzwerkkosten. Bei dem zuvor beschriebenen Algorithmus werden beide verknüpften Tabellen über das Netzwerk übertragen, um die Datenzuordnung auf Knotenebene zu erleichtern.
Der kostenbasierte Optimierer kann auswählen, welche Tabelle die Build-Tabelle sein soll, und so die Speicherkosten für die Verknüpfung steuern. Unter bestimmten Bedingungen kann der Optimierer auch vermeiden, eine der Tabellen über das Netzwerk zu senden, um so die Netzwerkbandbreite zu reduzieren (und damit die Netzwerkkosten zu senken). Um seine Aufgabe zu erfüllen, muss der kostenbasierte Optimierer die Größe der verbundenen Tabellen kennen.
Tabelle Statistik
In "Connector-basierte Architektur" hast du die Rolle der Konnektoren kennengelernt. Jede Tabelle wird von einem Konnektor bereitgestellt.Neben den Informationen zum Tabellenschema und dem Zugriff auf die tatsächlichen Daten kann der Konnektor auch Tabellen- und Spaltenstatistiken bereitstellen:
-
Anzahl der Zeilen in einer Tabelle
-
Anzahl der eindeutigen Werte in einer Spalte
-
Anteil der
NULLWerte in einer Spalte -
Minimale und maximale Werte in einer Spalte
-
Durchschnittliche Datengröße für eine Spalte
Wenn einige Informationen fehlen, z. B. wenn die durchschnittliche Textlänge in einer Spalte von varchar nicht bekannt ist, kann ein Konnektor natürlich trotzdem andere Informationen liefern, und der kostenbasierte Optimierer verwendet die verfügbaren Informationen.
Mit einer Schätzung der Anzahl der Zeilen in den verbundenen Tabellen und, optional, der durchschnittlichen Datengröße für die Spalten, verfügt der kostenbasierte Optimierer bereits über genügend Wissen, um die optimale Reihenfolge der Tabellen in unserer Beispielabfrage zu bestimmen. Der CBO kann mit der größten Tabelle (lineitem) beginnen und anschließend die anderen Tabellen verbinden -orders, dann customer, dann nation:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[l.orderkey = o.orderkey]
- InnerJoin[o.custkey = c.custkey]
- InnerJoin[c.nationkey = n.nationkey]
- TableScan[lineitem]
- TableScan[orders]
- TableScan[customer]
- TableScan[nation]
Ein solcher Plan ist gut und sollte in Betracht gezogen werden, weil jeder Join die kleinere Relation als Build-Seite hat, aber er ist nicht unbedingt optimal. Wenn du die Beispielabfrage mit einem Konnektor ausführst, der Tabellenstatistiken bereitstellt, kannst du das CBO mit der Eigenschaft Sitzung aktivieren:
SETSESSIONjoin_reordering_strategy='AUTOMATIC';
Mit den Tabellenstatistiken, die über den Connector verfügbar sind, kann Trino einen anderen Plan ausarbeiten:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[l.orderkey = o.orderkey]
- TableScan[lineitem]
- InnerJoin[o.custkey = c.custkey]
- TableScan[orders]
- InnerJoin[c.nationkey = n.nationkey]
- TableScan[customer]
- TableScan[nation]
Dieser Plan wurde gewählt, weil er es vermeidet, die größte Tabelle (lineitem) dreimal über das Netzwerk zu senden. Die Tabelle wird nur ein einziges Mal über die Knotenpunkte verstreut.
Der endgültige Plan hängt von den tatsächlichen Größen der verbundenen Tabellen und der Anzahl der Knoten im Cluster ab. Wenn du das also selbst ausprobierst, kann es sein, dass du einen anderen Plan als den hier gezeigten erhältst.
Aufmerksame Leser werden feststellen, dass die Join-Reihenfolge nur auf der Grundlage der Join-Bedingungen, der Verknüpfungen zwischen den Tabellen und der Datengröße der Tabellen, einschließlich der Anzahl der Zeilen und der durchschnittlichen Datengröße für jede Spalte, ausgewählt wird. Andere Statistiken sind entscheidend für die Optimierung komplexerer Abfragepläne, die Zwischenoperationen zwischen den Tabellenscans und den Joins enthalten - zum Beispiel Filter, Aggregationen und Non-Inner-Joins.
Statistik filtern
Wie du gerade gesehen hast, ist es wichtig, die Größen der an einer Abfrage beteiligten Tabellen zu kennen, um die verbundenen Tabellen im Abfrageplan richtig anzuordnen. Es reicht jedoch nicht aus, nur die Tabellengrößen zu kennen. Betrachte eine Änderung unserer Beispielabfrage, bei der der Benutzer eine weitere Bedingung wiel.partkey = 638 hinzufügt, um in seinem Datensatz nach Informationen über Bestellungen für einen bestimmten Artikel zu suchen:
SELECTn.nameASnation_name,avg(extendedprice)asavg_priceFROMnationn,orderso,customerc,lineitemlWHEREn.nationkey=c.nationkeyANDc.custkey=o.custkeyANDo.orderkey=l.orderkeyANDl.partkey=638GROUPBYn.nationkey,n.nameORDERBYnation_name;
Bevor die Bedingung hinzugefügt wurde, war lineitem die größte Tabelle, und die Abfrage wurde so geplant, dass sie die Handhabung dieser Tabelle optimiert. Aber jetzt ist die gefilterte lineitemeine der kleinsten verbundenen Beziehungen.
Ein Blick auf den Abfrageplan zeigt, dass die gefilterte Tabelle lineitem jetzt klein genug ist. Der CBO setzt die Tabelle auf die Build-Seite des Joins, damit sie als Filter für andere Tabellen dient:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[l.orderkey = o.orderkey]
- InnerJoin[o.custkey = c.custkey]
- TableScan[customer]
- InnerJoin[c.nationkey = n.nationkey]
- TableScan[orders]
- Filter[partkey = 638]
- TableScan[lineitem]
- TableScan[nation]
Um die Anzahl der Zeilen in der gefilterten lineitem Tabelle zu schätzen, verwendet der CBO wieder die von einem Konnektor bereitgestellten Statistiken: die Anzahl der eindeutigen Werte in einer Spalte und den Anteil der NULL Werte in einer Spalte. Für die partkey = 638Bedingung erfüllt kein NULL Wert die Bedingung, also weiß der Optimierer, dass die Anzahl der Zeilen um den Anteil der NULL Werte in derpartkey Spalte reduziert wird. Wenn du außerdem von einer annähernd gleichmäßigen Verteilung der Werte in der Spalte ausgehst, kannst du die endgültige Anzahl der Zeilen ableiten:
filtered rows = unfiltered rows * (1 - null fraction) / number of distinct values
Natürlich ist die Formel nur dann richtig, wenn die Verteilung der Werte gleichmäßig ist. Der Optimierer muss jedoch nicht die Anzahl der Zeilen kennen, sondern nur die Schätzung, so dass eine gewisse Abweichung im Allgemeinen kein Problem darstellt. Wenn natürlich ein Artikel viel häufiger gekauft wird als andere - z. B. Starburst-Bonbons - kann die Schätzung zu weit daneben liegen, und der Optimierer wählt einen schlechten Plan. Wenn das passiert, musst du den CBO deaktivieren.
In Zukunft werden die Konnektoren Informationen über die Datenverteilung bereitstellen können, um solche Fälle zu behandeln. Wenn zum Beispiel ein Histogramm für die Daten verfügbar wäre, könnte der CBO die gefilterten Zeilen genauer einschätzen.
Tabellenstatistiken für partitionierte Tabellen
Eine besondere Art von gefilterten Tabellen verdient besondere Erwähnung: partitionierte Tabellen. Daten können in partitionierten Tabellenin einem Hive/HDFS-Warehouse organisiert werden, auf das der Hive-Konnektor zugreift, oder in einem modernen Lakehouse, das die Tabellenformate und Konnektoren Iceberg oder Delta Lake verwendet; siehe"Hive-Konnektor für verteilte Speicherdatenquellen" und "Modernes verteiltes Speichermanagement und Analysen". Wenn die Daten anhand einer Bedingung für Partitionsschlüssel gefiltert werden, werden bei der Ausführung von Abfragen nur die übereinstimmenden Partitionen gelesen. Da die Tabellenstatistiken pro Partition gespeichert werden, erhält der CBO außerdem nur Statistikinformationen für die Partitionen, die gelesen werden, und ist somit genauer.
Natürlich kann jeder Connector diese Art von verbesserten Statistiken für gefilterte Beziehungen bereitstellen. Wir beziehen uns hier nur auf die Art und Weise, wie der Hive-Konnektor Statistiken liefert.
Aufzählung verbinden
Bisher haben wir besprochen, wie der CBO die Datenstatistiken nutzt, um einen optimalen Plan für die Ausführung einer Abfrage zu erstellen. Insbesondere wählt er eine optimale Join-Reihenfolge, die die Abfrageleistung vor allem aus zwei Gründen erheblich beeinflusst:
- Hash Join Implementierung
-
Die Implementierung des Hash Join ist asymmetrisch. Es ist wichtig, dass du sorgfältig auswählst, welcher Eingang die Build-Seite und welcher Eingang die Probe-Seite ist.
- Verteilter Join-Typ
-
Es ist wichtig, dass du sorgfältig auswählst, ob du die Daten an die Join-Eingänge weiterleitest oder weiterverteilst.
Broadcast versus verteilte Joins
Im vorherigen Abschnitt hast du die Implementierung des Hash-Joins und die Bedeutung der Build- und Probe-Seiten kennengelernt. Da Trino ein verteiltes System ist, können Joins in einem Cluster von Arbeitern parallel durchgeführt werden, wobei jeder Arbeiter einen Teil des Joins bearbeitet. Damit ein verteilter Join stattfinden kann, müssen die Daten möglicherweise über das Netzwerk verteilt werden, und es gibt verschiedene Strategien, die je nach Datenform unterschiedlich effizient sind.
Broadcast Join Strategie
Bei einer Broadcast-Join-Strategie wird die Build-Seite des Joins an alle Worker-Knoten gesendet, die den Join parallel durchführen. Mit anderen Worten: Jeder Join erhält eine vollständige Kopie der Daten für die Build-Seite, wie inAbbildung 4-12 dargestellt. Das ist nur dann semantisch korrekt, wenn die Probe-Seite ohne Duplikate auf die Worker verteilt bleibt. Andernfalls werden doppelte Ergebnisse erzeugt.
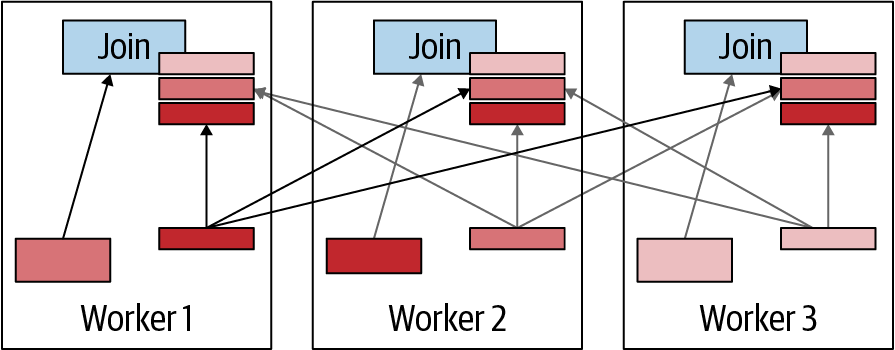
Abbildung 4-12. Visualisierung der Broadcast Join Strategie
Die Broadcast-Join-Strategie ist vorteilhaft, wenn die Build-Seite klein ist, da sie eine kostengünstige Übertragung der Daten ermöglicht. Der Vorteil ist auch größer, wenn die Sondenseite sehr groß ist, weil die Daten nicht neu verteilt werden müssen, wie es bei der verteilten Verbindung notwendig ist.
Strategie der verteilten Verbindung
Bei einer verteilten Join-Strategie werden die Eingabedaten sowohl für die Build- als auch für die Probe-Seite so über den Cluster verteilt, dass die Arbeiter den Join parallel durchführen. Der Unterschied bei der Datenübertragung über das Netzwerk besteht darin, dass jede/r Arbeiter/in einen einzigartigen Teil des Datensatzes erhält und nicht nur eine Kopie der Daten wie beim Broadcast-Join. Bei der Umverteilung der Daten muss ein Partitionierungsalgorithmus verwendet werden, damit die übereinstimmenden Join-Schlüsselwerte an denselben Knoten gesendet werden. Nehmen wir zum Beispiel an, wir haben die folgenden Datensätze von Join-Schlüsseln auf einem bestimmten Knoten:
Probe: {4, 5, 6, 7, 9, 10, 11, 14}
Build: {4, 6, 9, 10, 17}
Betrachte einen einfachen Partitionierungsalgorithmus:
if joinkey mod 3 == 0 then send to Worker 1 if joinkey mod 3 == 1 then send to Worker 2 if joinkey mod 3 == 2 then send to Worker 3
Die Aufteilung führt zu diesen Proben und baut auf Worker 1 auf:
Probe:{6, 9}
Build:{6, 9}
Worker 2 beschäftigt sich mit verschiedenen Sonden und Builds:
Probe: {4, 7, 10}
Build: {4, 10}
Und schließlich befasst sich Worker 3 mit einer anderen Untergruppe:
Probe:{5, 11, 14}
Build: {17}
Durch die Partitionierung der Daten garantiert der CBO, dass die Joins parallel berechnet werden können, ohne dass während der Verarbeitung Informationen geteilt werden müssen. Der Vorteil einer verteilten Verknüpfung besteht darin, dass Trino eine Verknüpfung berechnen kann, bei der beide Seiten sehr groß sind und der Speicherplatz auf einem einzelnen Rechner nicht ausreicht, um die gesamte Sondenseite im Speicher zu halten. Der Nachteil sind die zusätzlichen Daten, die über das Netzwerk gesendet werden.
Die Entscheidung zwischen einer Broadcast-Join- und einer Distributed-Join-Strategie muss kostenmäßig bewertet werden. Jede Strategie bringt Kompromisse mit sich, und wir müssen die Datenstatistiken berücksichtigen, um die optimale Strategie zu berechnen. Außerdem muss dies auch während der Neuordnung des Joins entschieden werden. Abhängig von der Join-Reihenfolge und der Anwendung von Filtern ändert sich die Form der Daten. Das kann dazu führen, dass ein verteilter Join zwischen zwei Datensätzen in einem Szenario der Join-Reihenfolge am besten funktioniert, ein Broadcast-Join aber in einem anderen Szenario besser. Der Join-Aufzählungsalgorithmus berücksichtigt dies.
Hinweis
Der von Trino verwendete Join-Enumeration-Algorithmus ist ziemlich komplex und würde den Rahmen dieses Buches sprengen. Er ist in einemBlogbeitrag von Starburst ausführlich dokumentiert. Er zerlegt das Problem in Teilprobleme mit kleineren Partitionen, findet die richtige Join-Nutzung mit Rekursionen und aggregiert die Ergebnisse zu einem Gesamtergebnis.
Arbeiten mit Tabellenstatistiken
Um den CBO in Trino nutzen zu können, müssen deine Daten über Statistiken verfügen. Ohne Datenstatistiken kann der CBO nicht viel tun; er benötigt Datenstatistiken, um die Zeilen und Kosten der verschiedenen Pläne zu schätzen.
Da Trino keine Daten speichert, ist die Erstellung von Statistiken für Trino abhängig von der Implementierung des Konnektors. Zum Zeitpunkt der Erstellung dieses Dokuments bieten die Hive-, Delta Lake- und Iceberg-Konnektoren für Objektspeichersysteme sowie eine Reihe von RDBMS-Konnektoren, darunter PostgreSQL und andere, Datenstatistiken für Trino an. Wir gehen davon aus, dass im Laufe der Zeit weitere Konnektoren Statistiken unterstützen werden, und du solltest dich in der Trino-Dokumentation über den aktuellen Stand informieren.
Die Erfassung und Pflege von Tabellenstatistiken hängt von der zugrunde liegenden Datenquelle ab. Betrachten wir den Hive-Konnektor als Beispiel für die Erfassung von Statistiken:
-
Verwende den Befehl
ANALYZEvon Trino, um Statistiken zu sammeln. -
Aktiviere Trino, um Statistiken zu sammeln, wenn du Daten in eine Tabelle schreibst.
-
Verwende den Befehl
ANALYZEvon Hive, um Statistiken zu sammeln.
Es ist wichtig zu wissen, dass Trino und der Hive-Konnektor Statistiken im Hive-Metaspeicher speichern, also an dem Ort, den auch Hive zum Speichern von Statistiken verwendet. Andere Konnektoren nutzen die Metadatenspeicherung, die von der angeschlossenen Datenquelle verwendet wird - zum Beispiel Metadatendateien im Iceberg-Tabellenformat oder das Informationsschema in einigen relationalen Datenbanken. Wenn du also dieselben Tabellen in Hive und Trino verwendest, überschreiben sie die Statistiken des jeweils anderen. Das solltest du bedenken, wenn du entscheidest, wie du die Statistiksammlung verwalten willst.
Trino ANALYZE
Trino bietet einen ANALYZE Befehl, um Statistiken für einen Connector (z.B. den Hive Connector) zu sammeln. Wenn er ausgeführt wird, berechnet Trino mithilfe seiner Ausführungsengine Statistiken auf Spaltenebene und speichert sie im Hive-Metaspeicher. Die Syntax lautet wie folgt:
ANALYZEtable_name[WITH(property_name=expression[,...])]
Wenn du zum Beispiel Statistiken aus der Tabelle flightssammeln und speichern möchtest, kannst du dies ausführen:
ANALYZEdatalake.ontime.flights;
Im partitionierten Fall können wir die WITH Klausel verwenden, wenn wir nur eine bestimmte Partition analysieren wollen:
ANALYZEdatalake.ontime.flightsWITH(partitions=ARRAY[ARRAY['01-01-2019']])
Das verschachtelte Array wird benötigt, wenn du mehr als einen Partitionsschlüssel hast und du möchtest, dass jeder Schlüssel ein Element im nächsten Array ist. Das oberste Array wird verwendet, wenn du mehrere Partitionen analysieren willst. Die Möglichkeit, eine Partition anzugeben, ist in Trino sehr nützlich. Du könntest zum Beispiel eine Art ETL-Prozess haben, der neue Partitionen erstellt. Wenn neue Daten hinzukommen, könnten die Statistiken veraltet sein, da sie die neuen Daten nicht berücksichtigen. Indem du die Statistiken für die neue Partition aktualisierst, musst du jedoch nicht alle früheren Daten erneut analysieren.
Sammeln von Statistiken beim Schreiben auf die Festplatte
Wenn du Tabellen hast, für die die Daten immer über Trino geschrieben werden, können die Statistiken während der Schreibvorgänge gesammelt werden. Wenn du zum Beispiel eineCREATE TABLE AS oder eine INSERT SELECT Abfrage ausführst, sammelt Trino die Statistiken, während es die Daten auf die Festplatte (z. B. HDFS oder S3) schreibt, und speichert die Statistiken dann im Hive-Metaspeicher.
Dies ist eine nützliche Funktion, da du den manuellen Schritt von ANALYZE nicht ausführen musst. Die Statistiken sind nie veraltet. Damit dies jedoch richtig und wie erwartet funktioniert, müssen die Daten in der Tabelle immer von Trino geschrieben werden.
Der Overhead dieses Prozesses wurde ausgiebig in Benchmarks getestet, und die Auswirkungen auf die Leistung sind vernachlässigbar. Um die Funktion zu aktivieren, kannst du mit dem Hive-Konnektor die folgende Eigenschaft in deine Katalogeigenschaftsdatei aufnehmen:
hive.collect-column-statistics-on-write=true
Hive ANALYZE
Außerhalb von Trino kannst du immer noch den Hive-Befehl ANALYZE verwenden, um die Statistiken für Trino zu sammeln. Die Berechnung der Statistiken wird von der Hive-Ausführungs-Engine und nicht von der Trino-Ausführungs-Engine durchgeführt. Daher können die Ergebnisse variieren und es besteht immer das Risiko, dass sich Trino anders verhält, wenn es Statistiken verwendet, die von Hive und Trino erstellt wurden. Im Allgemeinen wird empfohlen, Trino zum Sammeln von Statistiken zu verwenden. Es kann jedoch Gründe geben, die für die Verwendung von Hive sprechen, z. B. wenn die Daten als Teil einer komplexeren Pipeline ankommen und mit anderen Tools geteilt werden, die die Statistiken ebenfalls nutzen möchten. Um mit Hive Statistiken zu sammeln, kannst du die folgenden Befehle ausführen:
hive>ANALYZETABLEdatalake.ontime.flightsCOMPUTESTATISTICS;hive>ANALYZETABLEdatalake.ontime.flightsCOMPUTESTATISTICSFORCOLUMNS;
Ausführliche Informationen über den Hive-Befehl ANALYZE findest du inder offiziellen Hive-Dokumentation.
Anzeige der Tabellenstatistiken
Nachdem du die Statistiken gesammelt hast, ist es oft nützlich, sie anzusehen. Vielleicht möchtest du damit bestätigen, dass die Statistiken erfasst wurden, oder du behebst ein Leistungsproblem und möchtest sehen, welche Statistiken verwendet werden.
Trino bietet einen SHOW STATS Befehl:
SHOWSTATSFORdatalake.ontime.flights;
Wenn du die Statistiken nur für eine Teilmenge der Daten sehen willst, kannst du auch eine Filterbedingung angeben. Zum Beispiel:
SHOWSTATSFOR(SELECT*FROMdatalake.ontime.flightsWHEREyear>2010);
Fazit
Jetzt verstehst du die Architektur von Trino: Ein Koordinator nimmt Benutzeranfragen entgegen und setzt dann Worker ein, um alle Daten aus den Datenquellen zusammenzustellen.
Jede Abfrage wird in einen verteilten Abfrageplan von Aufgaben in zahlreichen Stufen übersetzt. Die Daten werden von den Konnektoren in Splits zurückgegeben und in mehreren Stufen verarbeitet, bis das Endergebnis vorliegt und dem Nutzer vom Koordinator zur Verfügung gestellt wird.
Wenn du dich noch mehr für die Trino-Architektur interessierst, kannst du dir das Paper "Trino: SQL on Everything" von den Trino-Machern lesen, das auf der IEEE International Conference on Data Engineering (ICDE) veröffentlicht wurde und auf der Trino-Website verfügbar ist.
Als Nächstes erfährst du in Kapitel 5 mehr über die Einrichtung eines Trino-Clusters, in den Kapiteln 6 und7 über die Anbindung weiterer Datenquellen mit verschiedenen Konnektoren und in Kapitel 8 über das Schreiben leistungsstarker Abfragen.
Get Trino: Der endgültige Leitfaden, 2. Auflage now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

