Chapter 1. The Need for Telemetry Pipelines
Data is the new oil.
Clive Humby
While the concept of observability and using observability tools for gaining insight into telemetry data has been around for a while, using telemetry pipelines to preprocess data before sending it to observability tools or storage is very recent. In this chapter you’ll learn some fundamental concepts for understanding what a telemetry pipeline is and how it can help add value to the information provided through your observability tool. Plus, you’ll see an example of a pipeline designed to engineer data from three different sources into useful information for downstream tools.
Taming the Data Flood
Contemporary cloud systems and applications provide a torrent of data through their logs, but the sheer volume of the data is so overwhelming as to render it almost meaningless. The development of observability tools has provided a means to find nuggets of information within the data flood, but at the very high cost of taking in the entirety of the data to glean a few meaningful insights. Like a dam against a flood, an observability tool is a means to derive some value from log data, at the cost of having to construct a monolithic structure that, at best, keeps downstream systems from being overwhelmed.
Unlike a dam that can only hold back the flood, a telemetry pipeline can channel your telemetry data, optimizing and adding value to it along the way, so that what arrives at the end is already information-rich and actionable. Instead of being a potentially destructive force that has to be controlled, your telemetry data becomes a resource that you can carefully and intentionally refine to meet your observability and data storage needs. Like oil that starts as a geyser from the ground and is then sent through refining processes to become a variety of products, your telemetry data can be refined from crude output to useful information that can power your enterprise.
The Incremental Value Chain
At its most basic, a telemetry pipeline is a series of operations that transform data from a source through a step-by-step process before delivering it to a destination. Often this will be an observability tool or a storage solution, and in many cases the purpose of the telemetry pipeline is to make the source data more easily ingested by the tool. In this most basic form, a telemetry pipeline is little more than a means to reformat data from point to point. A more advanced conception of a telemetry pipeline understands it as a means to increase the incremental value of your data as it passes through the pipeline. For example, consider these steps in the lifecycle of data as it becomes information:
-
Raw data from a single source has minimal value and requires extensive manual intervention to yield even basic insights.
-
Sending raw data from multiple sources into a telemetry pipeline centralizes the data and enables automated processing. This significantly reduces the toil required by individual teams to begin extracting information from the data and decreases the time to realize value from that information.
-
As data enters the pipeline and is analyzed, it becomes possible to begin understanding the data by surfacing common patterns, identifying useful versus redundant data, and recommending ways to optimize it. The value of the raw data is significantly increased simply by being able to separate what is valuable from what is not, and then pass the valuable data further down the pipeline.
-
As it passes through the pipeline, the data is transformed and optimized by processor chains that are purpose-built to derive the most meaningful information for use by downstream teams.
-
At the end of the pipeline, the raw data becomes actionable information that can enable teams to rapidly respond to incidents, gain business insights, and operate in a more secure environment.
Understand, Optimize, Respond
All refining processes proceed in phases that begin with understanding the crude material, devising the processes that it will pass through during refinement, and then distributing and delivering it in the form that makes it most useful. For telemetry data, there are three phases for refining the raw data into useful information: understand, optimize, and respond. Each of these are reflected in the functional aspects of a telemetry pipeline.
An analytical tool can provide you with a basic understanding of your data (Figure 1-1). Understanding the data means being able to sort the potentially valuable data out from the general flow of events, metrics, and tracks that are generated by your sources. Functionally, this is usually handled by pipeline components like parsers, which can separate elements from the flow in the same way that a miner panning for gold in a stream is able to separate small nuggets from the gravel in his pan.
When used in conjunction with an analytics tool that can provide you with a profile of your data, you can identify redundant or irrelevant data that you may want to send to storage for a full-fidelity copy of the stream, but can route away from your observability tool saving both the cost and the toil of trying to process this information within your tool.

Figure 1-1. An example of an analytics tool that presents a data profile of telemetry data as it enters a pipeline
Once you have an understanding of the data, you can then optimize it by sending it along processing chains to transform and engineer the data to meet your requirements. This is like taking crude oil and refining it into different products like gasoline, kerosene, and diesel fuel. Each of these end uses requires a different processing approach. Requirements like encrypting personally identifying information (PII), setting up metrics for observability tools, and sending different data components to different destinations also require the construction of specific processor chains. The later sections in this report go into detail about many of the typical processors used in a pipeline, and how to use them for purposes like controlling cost and assuring adherence to data compliance regulations.
The end goal of any telemetry pipeline is to provide downstream users with actionable information that enables them to respond to outages, incidents, and real-time business information. While observability tools can provide some of this functionality, it is largely after the fact, and there is often significant lag time between when an incident occurs, when the data is indexed by the tool, and when the tell-tale signals are transmitted. A telemetry pipeline, on the other hand, can have detection tools built into the processing chains that will not only send alerts, but can also change the functioning of the pipeline itself when an incident or outage is detected within the data. Rather than having to wait for an observability tool to catch up with a sudden surge in 500 - Internal Server Error messages, for example, a responsive telemetry pipeline could send an immediate alert and begin to process those specific messages to aid in diagnosing the problem within the observability tool.
An Example Pipeline
In the most basic structural definition, a telemetry pipeline is built using data sources, processors, and downstream destinations. The design of the processing chains is determined by the content and format of the source data, as well as the format and information requirements of the tool and storage destinations. This seems simple enough, but the question naturally arises: how do I know which processors (or groups of processors) to use to achieve my data engineering requirements?
For example, imagine a situation in which your sources include transaction data in JSON format, Apache error messages as raw strings, and system events in JSON. In planning your telemetry pipeline architecture, there are several aspects of the source data that you need to consider:
-
Sending the entire data stream to your storage and observability tools, when only some of the data is useful, will result in egregious costs.
-
The financial data contains PII that must be encrypted before being stored or used in an observability tool.
-
The raw strings of the Apache errors must be converted to JSON before they can be processed through the rest of the pipeline.
-
Different components of each data type need to be routed to separate destinations.
-
Events need to be converted to metrics to create visualizations and dashboards in observability and analytics tools.
With this understanding of your data, and the analysis of what is useful within it and what is not, you can develop the architecture and processing chains to optimize it for your requirements:
-
Routing and dropping events that contain little useful data, like
Status - 200responses and ApacheINFOmessages, can result in a significant decrease in the volume of data sent to downstream destinations. You can accomplish this by using a route processor that uses conditional statements to identify the information you want to drop and sends it to a drop destination. You can also set the processor to detect whenever there is a rise or drop in the expected number of messages beyond a set threshold, and to send an alert or trigger an incident response when the change is detected. -
The PII should be encrypted, or redacted entirely, before reaching its downstream destinations. You can accomplish this by using a redact processor to completely obfuscate the information, or an encrypt processor if you need access to the information later, for example if you need to be able to investigate fraudulent charges against a specific credit card number. In this case, you could send the encrypted information to a specific storage location with limited access, and then use that storage location as the source for a decryption pipeline with an analytics tool as the destination.
-
The Apache errors must be reformatted at the source so they can be processed through the pipeline. You can accomplish this by using a script processor to run a formatting script for each of the error messages before it is sent to the route processor.
-
Large numbers of identical event messages have little informational value on their own, but when aggregated into metrics measured over time they can provide detailed insight into system health. You can accomplish this with an event-to-metrics processor that is configured to provide counts of specific metrics over specific time intervals. Again, in a responsive pipeline, this processor could also be set to send alerts and change the pipeline functionality when an in-stream change in the data is detected.
The final structure of a pipeline that is designed with these source and information requirements in mind would resemble the one shown in Figure 1-2.
Here is a list of the components shown in Figure 1-2:
-
Sources
-
Script execution processor to reformat Apache error messages
-
Route processor
-
Encrypt credit card number
-
Destinations representing a drop destination, a storage location, and an observability tool
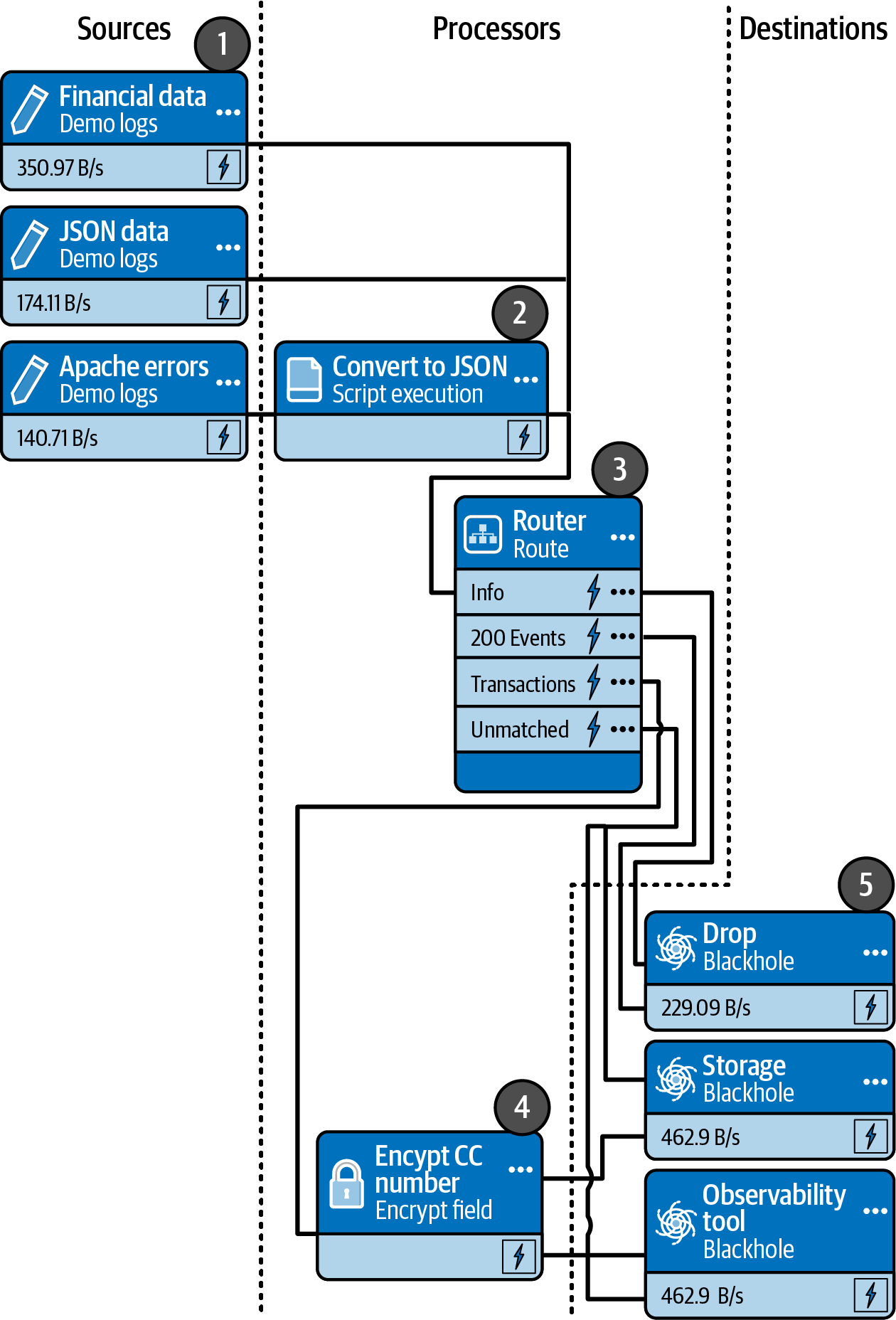
Figure 1-2. A schematic representation of a pipeline to meet basic data engineering requirements
In the remainder of this report you’ll learn more about how to set up pipelines to meet specific use cases like cost reduction and data compliance, and about the most common processors used to meet these use cases.
Get The Fundamentals of Telemetry Pipelines, Revised Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

