Chapter 4. The People Transformation: Bringing AI to Every Employee
We’ve explored the first two stages of the transition to an AI organization: transforming our technical departments, bringing AI to every application, then expanding to the business units, bringing AI to every process. But the ultimate realization of the AI organization comes when we go beyond those two steps and bring AI to every employee. Only when every employee is empowered with AI, only when every task performed by every person in the organization has been transformed with AI, can we finally say we have fully become an AI organization.
Think about other technology revolutions and how they went through the same process. Computers initially transformed the business processes in an organization, but the democratization of PCs for employees enabled a deeper transformation, in which every task performed by the employees was augmented or redefined with a computer. The same thing happened with the internet: it allowed departments and employees to consume services directly from technology providers for specific tasks such as project planning, collaboration, or digital marketing. Mobile devices have also ended up being part of the employee toolset, transforming the IT landscape with the concept of Bring Your Own Device (BYOD). When the technology is democratized for every employee, every task they perform can be rethought entirely—and the AI transformation will be no different.
The Birth of the Citizen Data Scientist
A wave of AI democratization in the enterprise is coming. Departments and smaller teams will be empowered to define their own priorities, and the employees themselves will be able to create the AI needed to implement their own solutions. Easy-to-use tools and building blocks will enable a new breed of data scientist—the citizen data scientist.
As an organization, you should provide the right environment to empower these new citizen data scientists. The demand for AI in the enterprise will be impossible to meet with traditional technical roles like data scientists and developers. Only empowered business users will be able to fill that gap. For that to happen, there are three primary requirements:
- Democratization of knowledge
- There’s no AI without data, so the first step in democratizing AI is to democratize the access to the data in your organization, turning data into knowledge that is easy to consume.
- Democratization of AI consumption
- After the employees can get access to relevant knowledge in your organization, they need to be able to apply AI on top of it. This can be achieved by providing access to a broad set of prebuilt AI models.
- Democratization of AI creation
- The ultimate realization of the citizen data scientist is the ability to create their own AI models with tools adapted to their expertise.
The technologies behind each of these concepts are still emerging and evolving very quickly. For this reason, it is important to take a gradual approach to each of these steps and evolve your approach in tandem with the technology. Let’s explore how to do that.
Democratization of Knowledge
A big chunk of the work done by a data scientist is understanding, consolidating, and preparing data. Unfortunately most enterprises have complex data estates, in which data is disseminated across the entire organization in disconnected siloes; it may be unstructured and chaotic, with multiple storage types used.
Nontechnical employees cannot deal with this complexity. To foster citizen data scientists, we first need to provide a data foundation that they can use. The resulting artifact is usually referred as knowledge, and it has the following properties:
- Knowledge is structured
-
It contains entities, attributes, and relationships forming a graph. Compared with the raw form of data, knowledge is easy to navigate.
- Knowledge is semantic
-
Every entity, attribute, or relationship is clearly defined. Knowledge can be understood by the user.
- Knowledge is consolidated
-
The information it contains is semantically integrated from different data sources; for example, the “customer” entity could come from multiple different data assets across the organization.
Take search engines as an example. If you search Google or Bing for a common entity like a movie or a person, you will get not only the traditional list of blue links, but also an entity on the right containing the knowledge equivalent of those results (Figure 4-1). In the case of a movie the entity is highly structured, and it will include attributes and relationships with clear semantics (e.g., year, cast, and director). This knowledge is the result of consolidating unstructured and sometimes chaotic information from multiple sources. In Bing, the technology powering this knowledge creation is called Bing Satori; it crawls billions of pages to extract the relevant semantic entities and their attributes, consolidating the data it gathers into a knowledge graph that is displayed.
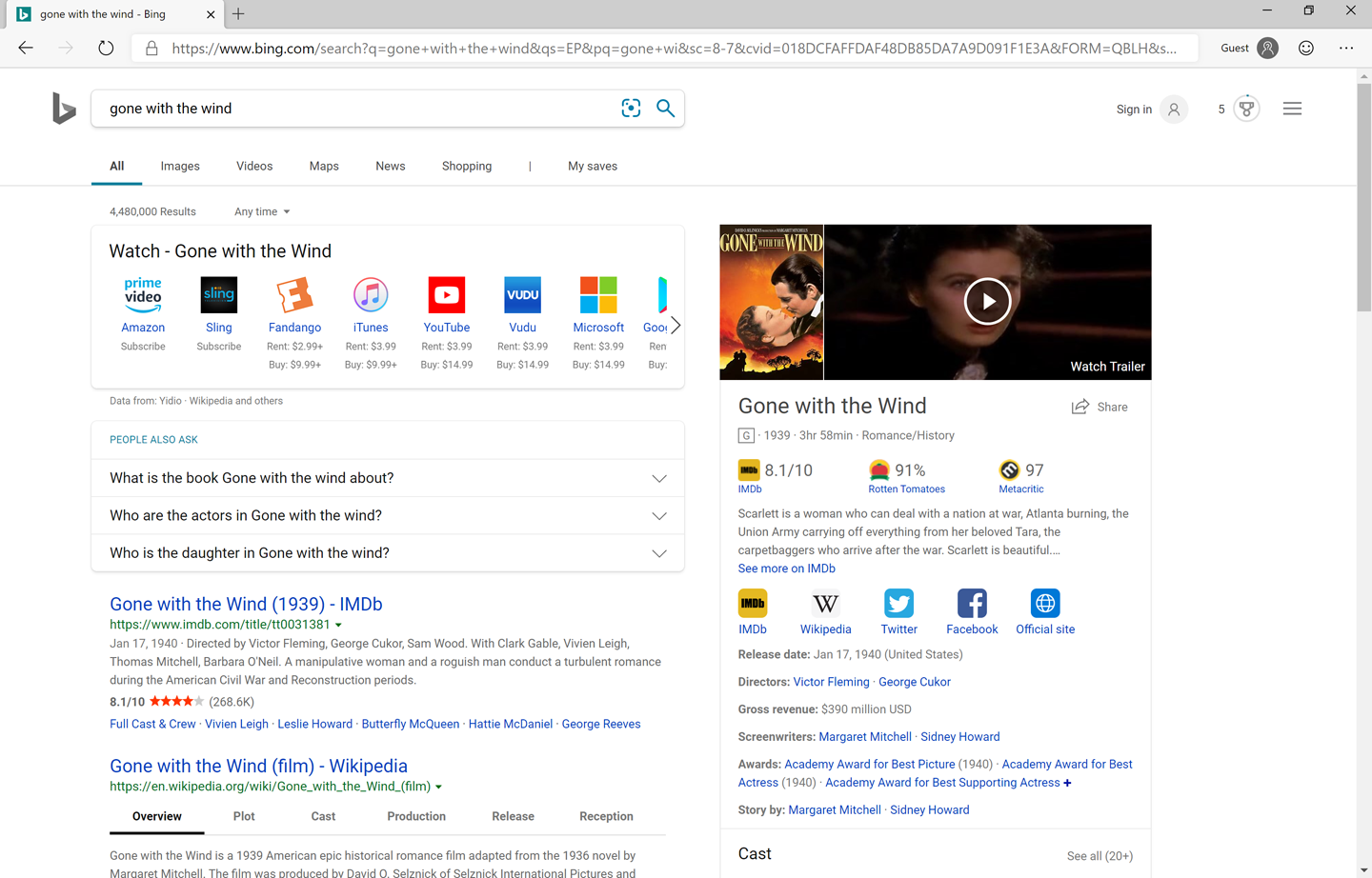
Figure 4-1. Searching for a movie on Bing
We will explore strategies for managing your data estate in Chapter 6, including how to consolidate your data into knowledge that can be consumed by your employees. Once you have that knowledge, no matter how you created it, the next step is to expose it to your employees. A good principle is to expose it through the tools they already use. For example, in the case of Bing Satori, you can also get access to that data from Office. If you want to see this in action you just need to write a list of company names in Excel and use the option Data Types→Stocks, available in the latest versions of Office. The data will automatically be converted into semantic knowledge drawn from Bing Satori, with options to add additional attributes such as number of employees or stock value (Figure 4-2).
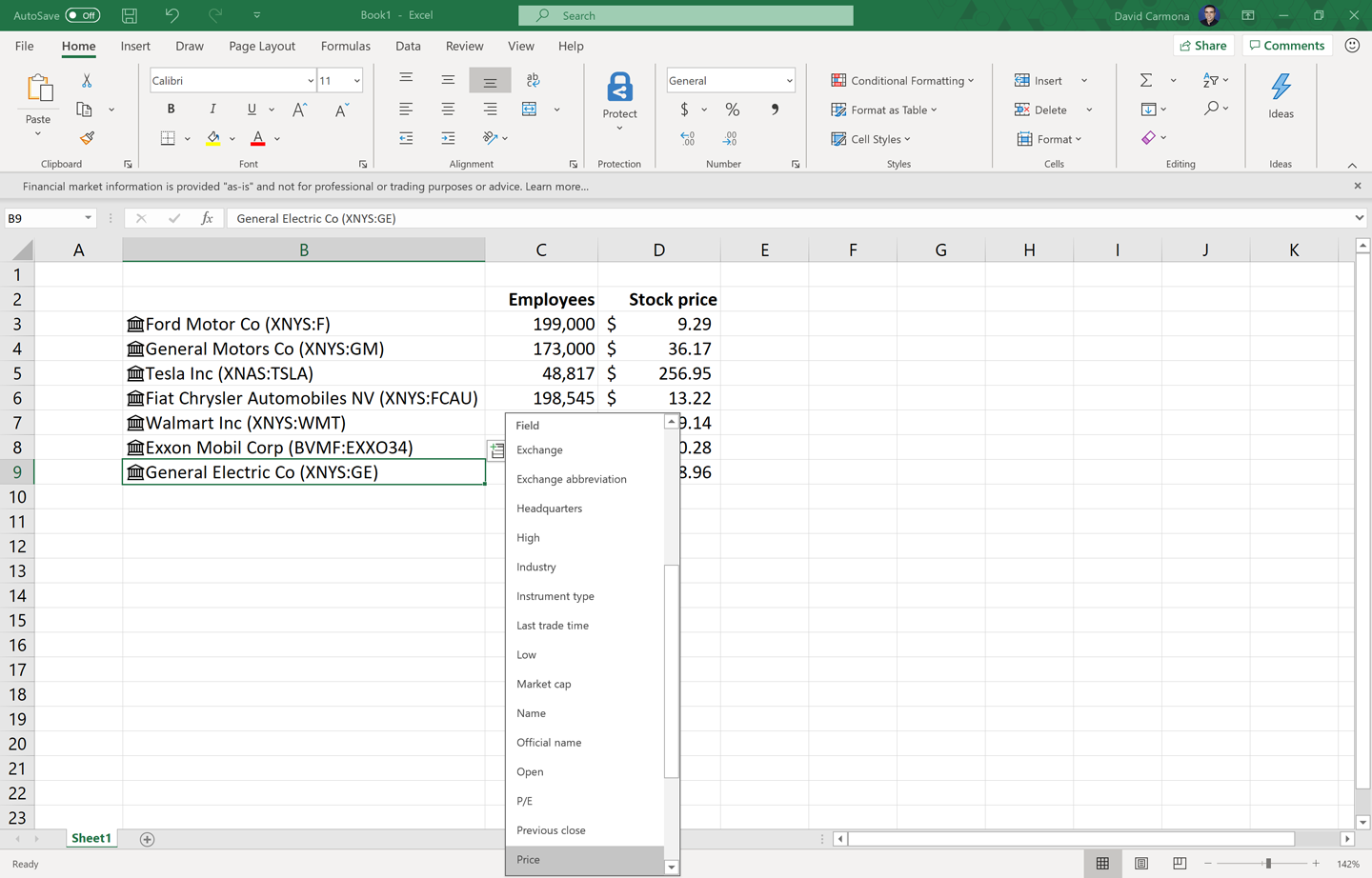
Figure 4-2. Bringing world knowledge to Excel
The same approach can be taken for your internal organizational knowledge: employees can get access to relevant consolidated knowledge about products, parts, customers, or any other relevant business information directly from the tools they use in their everyday work.
Conversational agents are also a very common way of surfacing this knowledge. As mentioned previously, conversational agents that rely on knowledge can provide a richer experience to the user. Connecting internal conversational agents to the underlying knowledge in the organization will make them much richer and more useful for employees. Suddenly, the users will be able not only to provide commands to the agent, but also to ask questions in natural language that are answered based on the knowledge base across the organization.
Democratization of AI Consumption
The next step for empowering employees to become citizen data scientists is to enable them to apply AI on top of the available knowledge. If the AI models in the organization are available for any employee to use and easy to apply to that knowledge, employees will all be free to augment their reasoning with AI. AI is now not constrained to specific applications or processes, but can be used for all the decisions made in the organization.
A good example of this approach is Excel’s integration with Azure Machine Learning. As your technical teams develop AI models in Azure, they are automatically made available in Excel. Excel users in your organization can then discover the repository of models published internally and apply them to their data in Excel. That data can come from the unified knowledge in the organization, or can be provided directly by the user (also referred to as Bring Your Own Data). The resulting scenarios can be extremely powerful. Users can now apply AI to day-to-day tasks that previously were performed manually: for example, a sales manager could predict which opportunities their team is likely to close successfully, or a financial sales consultant could identify the customers most likely to purchase a new product.
The AI models can also come from a third-party provider. For example, Power BI provides access to the same prebuilt models available in Azure, enabling its users to easily apply complex AI models like sentiment analysis or image classification to their reports without requiring the technical team in the organization to develop them. For example, a marketer could add sentiment analysis in a social media report, or an insurance employee could apply an image recognition model to the pictures of an accident report.
Democratization of AI Creation
The ultimate realization of the concept of the citizen data scientist is the ability not only to consume preexisting models, but also to create new models. This idea may sound crazy. AI model development can appear very complex, and out of the reach of nontechnical users. In fact, it is—creating an AI model from scratch, especially a state-of-the-art one, can be a daunting experience for all but the most experienced data scientists.
However, there are many ways to democratize AI. Although data scientists and developers will still be needed to create more complex and customized models, it’s possible for citizen data scientists to implement a significant number of AI solutions by themselves. Gartner estimates than 40% of data science tasks will be automated in the near future, enabling citizen data scientists. There are many technologies aimed at facilitating this change, some of them already available in the market and others on which very promising progress is being made.
One of the most common approaches for this democratization of AI creation is transfer learning. Transfer learning allows AI models to be customized after they are trained. A data scientist can create the initial model and train it, and another user can customize it for their own scenario without requiring technical skills. Vision is one of the most popular areas in which to apply these techniques. Services like Azure Custom Vision and Google AutoML Vision allow the creation of image classification or object detection models just by uploading a few pictures of the different objects in your scenario. Under the hood, the system is reusing a deep learning model that was created in advance and applying transfer learning to customize that model for your domain. Using this technique you can create a model to identify safety hazards in your factory, or items in your retail store, or whatever else might be appropriate in your industry—all without any deep learning or data science knowledge.
Automated machine learning is another promising approach. Just as transfer learning enables any user to customize an existing model with their own data, automated machine learning enables the user to create net-new models from scratch. AutoML techniques take a dataset as an input and automatically find the best machine learning algorithm, parameters, and data transformations to produce the desired outcome. This process usually involves the data scientist carefully trying multiple combinations, based on their experience. AutoML has the potential to revolutionize machine learning by making it more productive for data scientists and more approachable for nontechnical employees. Microsoft Research has published several papers on this topic, one of them describing a breakthrough that is available today in Azure Machine Learning and the Power Platform, including PowerBI and PowerApps. With this technology, data scientists can be more productive and business users can create their own state-of-the-art models in just a few clicks.
Graphical tools can also simplify the development of machine learning models, making it more accessible to nontechnical users. With this option, the user can create a model instead of customizing an existing one, although some level of familiarity with machine learning is still required. Azure Machine Learning Studio is an example of this approach: users can create machine learning models by dragging, dropping, and connecting elements in a design surface. Promising technologies in incubation such as Lobe are bringing this concept to more complex scenarios, like deep learning.
Another interesting area of research with the potential to democratize AI creation is the concept of machine teaching. At its core, machine learning relies on providing a massive quantity of training inputs and outputs and finding the right algorithm to mimic the transformation. Machine teaching focuses instead on decomposing the problem into smaller pieces that the machine can be trained on individually. It’s similar to the way humans teach other humans, such as children. For example, as I write this book my wife and I are in the process of teaching our daughter Angela how to brush her teeth. A machine learning developer would give her a thousand YouTube videos of kids brushing their teeth, hoping she would learn from these. A reinforcement learning developer would give her a brush, some toothpaste, and a cup and leave her by herself to play with the three. When she happened to brush her teeth correctly, they would give her some candy. In addition to the paradox of using candy as a reward for a child brushing their teeth correctly, that approach would require a lot of experimentation and probably take a very long time. A responsible father like myself would instead take the machine teaching approach, decomposing the problem into smaller pieces (put some toothpaste on the brush, brush the front teeth, brush the back teeth, pour some water in the glass, rinse your mouth, clean the brush and cup), and then teach each step separately, using my own knowledge.
With this approach, the teacher makes the entire process much easier to learn. Machine teaching systems focus on enabling the teacher to transfer their knowledge to the machine through decomposition, generalization, and examples, instead of applying brute force with a huge amount of data or experiments. Although it is still a new concept in the AI space, there are several examples of technologies using this approach today. For example, the language-understanding service in Azure (LUIS) allows users to define intents and entities from plain language using a machine teaching approach, and Bonsai, a technology recently acquired by Microsoft, uses a machine teaching approach to enable business users to train autonomous systems such as manufacturing robots, power mills, or oil drills.
AI Democratization Scenarios
When every employee is empowered to create AI solutions and apply them to their own data, the kinds of business transformations we saw earlier can be done independently at the department or even the individual level. Just as they create Access applications, Excel macros, or SharePoint websites, self-service AI will enable power users in every department to create their own AI.
Often, these users will leverage AI models created by a central technical department or a third-party provider, applying them to their own departmental data—imagine branch offices or departments applying algorithms for product recommendation, lead scoring, or customer feedback analysis to their own regional data.
In other cases, these power users could even create their own AI solutions from scratch. AutoML or easy-to-use graphical tools can enable employees to create custom models for customer churn, sales forecasting, or cold calling. Decision-making processes that were previously supported by departmental self-service business intelligence (BI) tools, dashboards, or spreadsheets can now also be supported by self-service AI.
And at the individual level, employees can automate some of their more repetitive tasks with AI. Task automation, which is traditionally addressed with workflow tools, can be greatly simplified with AI. Robotic Process Automation (RPA) automates individual and team processes by just observing the steps performed by a user as they interact with legacy applications. Instead of learning a programming language or a workflow tool, the user can perform the actions for the machine to learn, and the machine can then can generalize these steps and apply them to any case in a fraction of the time needed by a user. For processes dealing with multiple different legacy applications with a lot of manual data entry, RPA technologies can have a massive impact on employee productivity.
Managing Shadow AI
The empowerment of every department and every employee in an organization to create AI can have an unintended effect: as these self-service projects proliferate, you could wind up with hundreds or thousands of siloed and unmanaged AI solutions. Without management by a central function in the company, the result can be a mess of noncompliant, unsecured, and unreliable AI systems.
The good news is that most organizations are already learning how to deal with this issue in the IT domain. Known as Shadow IT, the use by employees of applications and infrastructure that are not under the control of an organization’s IT department is becoming more widely understood and addressed. Many organizations are working to put solutions in place to enable individuals in every department to bring their own devices to the workplace and to create their own document repositories, applications, dashboards and more, while keeping control over things like security, access, reliability, backups, and privacy.
With AI coming into the hands of every employee, a similar concept known as Shadow AI is emerging. Just like Shadow IT, Shadow AI is a powerful force for enabling innovation at the department and the individual level, but it is not without risk.
Therefore, in addition to providing the tools to empower every employee with AI, you’ll need to think about providing an environment to manage and control the resulting AI projects—in other words, you’ll need to implement an effective Shadow AI strategy. At the very least, this environment should manage the same aspects managed by a Shadow IT policy. Concerns to address include the following:
- Access control
- Manage who has access to the models, data, and outcomes of the AI solutions, and ensure access can be revoked at any moment (for example, when an employee leaves the company).
- Monitoring
- Track the health and usage of every AI solution, including accuracy metrics (especially those relevant to identifying changes in the data that may impact the model’s performance).
- Deployment
- Manage the distribution and versioning of all AI solutions, including traceability back to the development process of the model.
- Reliability
- Assure the availability of these solutions with automatic scaling and failover.
- Security
- Enforce security controls to avoid external attacks or data breaches, including techniques such as encryption and security threat identification.
AI has also unique requirements and challenges that are not present in Shadow IT. AI is more than just a technology; it’s a whole new approach to applications, business, and people that requires a cultural shift in the organization. In the next chapters, we will cover the cultural aspects of an AI organization, but before that, let’s learn the story of how one person changed the culture of a company with almost 100 years of history.
Get The AI Organization now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

