Chapter 4. The AI Ladder: A Path to Organizational Transformation
Despite AI’s enormous potential, it is still underutilized by many industries and organizations. There are several reasons for this, some having to do with data (in one way or another), some with the lack of people with the right skill sets, and some with issues of trust or misunderstanding. Most of them are connected in some way to the broader problem that many organizations are simply not ready—at a process level, a personnel level, or an infrastructure level—or don’t know how to make the changes necessary for a successful transition to becoming an AI-focused entity. One thing we’ve seen: if you start your AI journey without being ready, you’re bound to fail. But if you don’t start because you’re not ready and are unwilling to take the steps to become ready, you’re also bound to fail. So the big question is: how do you become ready? That’s the question managers need to answer.
We all need to remember we’re in a builder’s market. Organizations have to try things out. Pick a problem you’ve always wanted to solve—whether it’s making better predictions, automating something, or optimizing a process—and use AI to solve it. That first project will get you some experience and force you to start collecting (or preparing) data seriously and building the data infrastructure you will need for larger projects. Perhaps more importantly, you will learn a lot about your team, its culture, and yourself, and ultimately your organization’s readiness for AI. So much the better if solving the problem moves the needle on some corporate metric: at this point, you don’t need to demonstrate that AI will revolutionize your business, but you should be able to demonstrate that it can help and is worth further investment. You don’t even need to use advanced AI techniques. Define the problem as precisely as you can, and don’t make it more complex than it has to be. AI rewards people who try to solve specific, well-bounded problems (“supreme clarity” is a favorite phrase we use daily) that are aligned to business unit objectives. That business unit objective might be “Delight customers,” with a key result of “Net promoter score of 50.” This needs to be further broken down into its component parts: for example, “Make pricing simpler,” “Predict lifetime value,” and “Automate first-line customer service.”
The vast majority of AI failures are due to failures in data preparation and organizational science, not the AI models themselves. The failures in data preparation and organization, in turn, can ultimately be traced to the root cause that we have called “organizational unreadiness.” To experience significant success with AI, virtually every aspect of your company’s operations is going to have to change in one way or another. Some companies are not willing to commit to this scale of change, so they attempt to fence their AI projects to limit their impact. Although we recommend starting with small, simple AI projects (the first-base hits we talked about in Chapter 3), you must understand that you will need to go further to score runs. Limiting your use of AI because you’re not willing to change is another way to guarantee failure.
Suitability of AI
Organizations need to understand what AI is suitable (and not suitable) for. By now, everyone in a position of senior leadership has heard about AI, knows that it’s a crucial technology, and is anxious to get started with it. They may have some apprehension, but they also don’t want to miss the boat. Fear of missing out (FOMO) drives many organizations to jump to implement an “AI solution.” Not fully understanding the technology, they assume that it will fix any business problem. This is the “magical thinking” approach that we discussed in the previous chapter. It doesn’t work and it’s bound to fail.
A key component of suitability is measurability. Every AI project must have clear metrics by which to judge whether or not the project was a success. Without clear and agreed-upon measurable goals, projects can devolve into acrimony as different parties argue about vague notions of success or failure. Across our many years in the industry, we continue to marvel at how teams in the same company can have completely different interpretations of the same goal; it’s like one team’s American football touchdown is another’s field goal, and yet another team’s first down. Get a quorum on what success looks like from the very beginning. Trust us on this one—we learned the hard way and have the scar tissue to prove it.
Remember, at its core, AI represents a powerful new set of software and data engineering techniques for making sense out of vast amounts of data of varying complexity. It isn’t a magic wand that can do anything; it must be applied to problems that it is well suited to solve. You therefore must have a general understanding of what kinds of problems AI is good at, and what kinds of problems are best handled in other ways. In other words, as organizations embark on their AI journey, they need to identify the business problems they are trying to solve, ask the right questions, and identify whether AI is a suitable approach to achieve their business goals.
Determining the Right Business Problems to Solve with AI
Not every problem can be solved with AI—just the right ones. Choosing the right project is a key element of success. As we saw in Chapter 3, many AI projects fail because they attempt too much before the organization is ready. Overly ambitious large-scale projects, or projects that entail high risk to the organization if they do not work out, are not good places to start.
To determine the right business problems to solve with AI, consider these best practices:
Specify the business unit objective to which you would like to apply AI.
Determine which key result of that objective will make a noticeable contribution when it succeeds.
Use design thinking to identify and prioritize potential applications of AI.
Understand that failure is not failure (so long as it’s done safely), but a learning experience, when it is identified early and acted on immediately.
Look for parts of the business that have leaders who will require implementation from their team. AI has a negative ROI if it’s never implemented.
Choose metrics that are tied to a quantifiable cost savings, increased revenue, or net new revenue.
Understand that most problems worth solving will likely require multiple AI models.
Use agile methodologies and break each component part into two- to three-week sprints. The goal is to deliver something tangible after two sprints, then build off of that.
Start with data you already have (and can actually be used to solve the problem) that is either not being used or being used to support a mundane workflow by humans (like a quick visual inspection).
Ask your team to propose a project that can show preliminary results in about six weeks. Based on our own experience and the experience of IBM consultants who have done thousands of such projects, we’ve concluded this is about the right length of time for an initial sanity check. Anything much shorter and you won’t have time to get the work organized and going; anything much longer and you run the risk of going off into the weeds.
Building a Data Team
Now let’s consider your team. Depending on the size of your organization, you probably don’t need an army of data scientists. You need a leader who understands the technology, who has experience, and who has a network they can draw upon when the team needs to grow. Again, having well-defined projects of reasonable scale, with well-defined and reasonable criteria for judging success or failure, will help you attract the kind of employees you’re going to need.
You also need—sooner rather than later—specialists in data operations (DataOps) to build and maintain your data infrastructure. They’re responsible for selecting, building, and maintaining tools for data organization (we cover this in Chapter 7), as well as interfacing with the teams responsible for analyzing, deploying, and maintaining applications (detailed in Chapter 8).
It’s worth pointing out that the AI lifecycle often exhibits resource requirements that are the opposite of traditional software development. It is not unusual for a relatively small team of software engineers to develop an application that requires an enormous amount of server “horsepower” to run when it’s deployed to the world. In the AI lifecycle, the training process usually requires more computing resources than running the model in production.
Consider, for example, a massive online retailer. They might have a thousand software developers and quality engineers, but their traditional application might be used by a hundred million or more customers at the same time. The size of the production environment dwarfs that of the development environment. In AI, however, much of the computation is done up front, in the preprocessing of data and the training of models and algorithms that iterate over that data. Whether that computation is done on hardware owned by the corporation, on rented virtual servers in the cloud, or in some kind of hybrid architecture, it is not going to look like a traditional development architecture. With AI, the development environment often dwarfs the production environment because building and training the model requires enormous CPU- and GPU-intensive number crunching and iteration.
Putting the Budget in Place
Management must understand that budgets for AI projects won’t look like those for traditional projects and must fund them accordingly. For one, managers should generally treat AI projects as operating expenses, because for almost all organizations, the best place to run your AI infrastructure is in the cloud (hybrid cloud is perfectly acceptable). This enables you to harness massive amounts of compute power and storage for just a small per-hour charge (or departmental charge-back in the case of a private cloud), so you can spin up tremendous capacity when necessary and shut it all down (and thus avoid paying for it) when you don’t need it. “Cloud is a capability, not a destination” is our mantra; if you’re only thinking of it as another place to store your data or do your computation, you’re not going to get the advantages (we’ll say more about this soon). Managers used to looking for approval for giant capital expenses that got written down over 3, 5, 7, or even 10 years now need to shift into understanding how monthly bills from cloud deployments will hit a profit and loss statement and how those justifications might need to be made to the powers that be in an organization.
Secondly, the people cost for an AI project may be low, at least compared with the headcounts used for, say, an ERP system upgrade or a heavy lift to a new version of a very specific line of business software. AI and machine learning teams need to be smaller and nimbler. They don’t need to build out architectural diagrams and recommend integration plans, and they generally use open source software to experiment.
Developing an Approach
Data scientists have the most fun in the build phase, because it lets them exercise their freedom and explore a set of data to understand patterns, select and engineer features, build and train their models, and optimize hyperparameters. This is where a host of tools and frameworks come together:
- Open languages
- Python, R, Scala, etc.
- Open frameworks and models
- TensorFlow/Keras, PyTorch, XGBoost, Scikit-Learn, etc.
- Approaches and techniques
- Generative adversarial networks (GANs), reinforcement learning (RL), supervised learning (regression, classification), unsupervised learning (clustering), etc.
- Productivity-enhancing capabilities
- Automated AI, visual modeling, feature engineering, principal component analysis (PCA), algorithm selection, activation function selection, and hyperparameter optimization, etc.
- Model development tools
- DataRobot, H2O, IBM Cloud Pak for Data with Watson Studio, Azure ML Studio, Sagemaker, Anaconda, etc.
- Deployment tools
- Cortex, TFX, etc.
Our pro tip: your data science team is best positioned to choose the right tools—the ones they are familiar with, the ones they work quickly in and around, and the ones that will integrate best into your organization’s existing software development infrastructure.
There Is No AI Without IA
But how do you start even a simple AI project? Fortunately, you don’t have to do everything at once. Becoming an AI-centric organization may be a journey, but you can do it in stages. Those stages make up the AI Ladder.
One way to think about starting this process is to remember our tagline, “You can’t have AI without IA.” AI relies on an information architecture (the IA part), a concept we’ll explore in the following chapters. An information architecture is the foundation on which data is organized and structured across a company. For now, think of it as a universal methodology, tailored to your organization’s unique circumstances, that guarantees a steady supply of data that is:
Accessible
Accurate
Secure
Traceable and verifiable
Accessible means that you can get to the data: it isn’t tied to a particular vendor or proprietary tools, nor is it locked up in some silo within the organization. It’s always been true that combining data sources gives results that are much more powerful than results from the data sources taken individually; the whole is greater than the sum of the parts. That’s why we stated earlier that organizational silos result in data silos.
Accurate means that your data is, well, accurate. It’s a mistake to assume that your incoming data is correct, usable, or free of bias. If you look at your data, even casually, you will see plenty of problems: missing values, values that are obviously incorrect, misspelled words in textual data, and plain old ambiguity. Someone once told us how many different ways they’ve seen the corporate name IBM appear in a list from a vendor database: it was well over 100 (Figure 4-1). Spelled out, with capitals, with periods, names of companies that IBM has acquired, “International Business Machines” in various languages—they all map to IBM. It’s been said many times that 80% of a data science project is getting, preparing, and cleaning the data.
Figure 4-1. Various spellings of IBM in a database
Secure means that data is protected from inappropriate access. Many IT executives have left their companies in disgrace after a data theft was discovered. All too often, these thefts could have been prevented by taking minimal security precautions. This has become a huge storyline recently, with the US government declaring cyberattacks as the number one threat to the United States, above terrorism and nuclear attacks (though we suspect in the near future, pandemics will make an appearance for obvious reasons). Our advice: start with the principle of least privilege and apply a defense in depth strategy.
Traceable and verifiable means that you know where your data came from and have confidence that it’s accurate. This is called “data lineage.” Again, it’s something that developers didn’t worry about a few years ago (and many still don’t today because it’s not in their culture), but it’s increasingly important to be able to trace your data to its source, and to know that the source is reliable. Knowing your data’s source is particularly important for AI projects. If your application is trained on bad data, it will give you bad results. If it’s trained with biased data, you’ll get biased results. And if someone can corrupt your data before you use it, they—not you—control what your AI application can do.
Organizations need an information architecture that is modern and open by design: flexible, not tied to any one vendor, and capable of working in public clouds, private clouds, and on your own on-premises investment.
Once you’ve internalized the importance of the phrase “You can’t have AI without IA” you’ll understand that in order to become ready for AI, your organization is going to have to do a wholesale reinvention of itself. If that sounds to you like a pretty tall order, you’re right. It is. That’s where the AI Ladder comes in.
The AI Ladder
We often hear how clients struggle with their skills, and struggle with how to get a quick win with AI. According to Ritika Gunnar, VP of IBM Data and AI, the AI Ladder is a framework to help organizations build an information architecture, and ultimately determine where they are in their AI journey. It’s a model for how we talk to clients about their data maturity, looking at how they collect, organize, and analyze data, and ultimately infuse AI throughout their organization.
The AI Ladder is a unified, proven methodology that leaders can use to overcome the challenges we’ve discussed and accelerate their journey. The idea is that there are “rungs” along the way to a complete transformation, where AI has been scaled throughout every part of the organization.
Note
We acknowledge that our metaphor is not exact. A person with two legs can only stand on one or two rungs of a ladder at the same time, and needs to climb the rungs of a ladder in sequential order. The AI Ladder isn’t exactly like that. Although there is a logical order to the “rungs,” adopting this approach doesn’t necessarily have to be a linear journey. You can start anywhere and build your ladder incrementally, assembling it as you might put together a jigsaw puzzle. The important thing to grasp is that this is a framework by which you can understand the steps involved in reinventing your organization. The best part about this framework is that once it’s in place and practiced, subsequent AI projects get easier and easier, which allows you to expand the impact of AI across your enterprise.
The AI Ladder provides guidance in four key areas, illustrated in Figure 4-2:
How to collect data
How to organize data
How to analyze data
How to infuse AI throughout the organization
How does information architecture relate to the ladder? It’s something you’ll build along the way. It doesn’t make sense to collect data unless you can store it effectively, and you’ll certainly need to clean your data before you can do anything truly useful with it. But if you think this means putting together a substantial infrastructure full of complex tools for data governance and provenance before you can get started, you aren’t likely to get started. Again, begin with a small project. As that project unfolds, you’ll start to see what’s needed and can begin building your data infrastructure. Then, when you tackle a big project, you’ll find that you’ve already done much of the work, and in addition you’ve practiced and refined your skills.
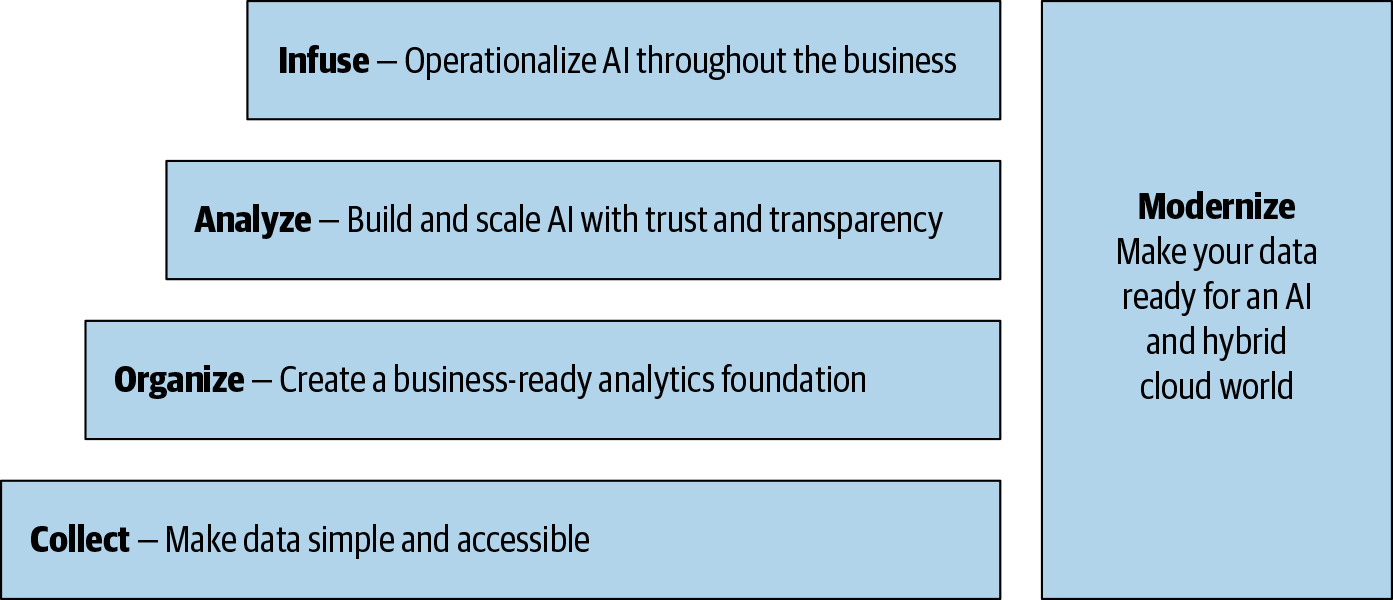
Figure 4-2. The AI Ladder, a guiding strategy for organizations to transform their business by connecting data and AI
Collect
Collecting data simply means gathering and storing it. Collect data of every type, regardless of where it resides, enabling flexibility in the face of ever-changing data sources. Make accessing the data simple. Get data out of corporate silos and be aware of public data sources that may be useful. Find out what data you need but don’t have, and make plans to get it; your company may be discarding important data because nobody has thought about how to use it (like log files from servers). Make the data as broadly accessible as possible, subject to regulation and your own internal policies (which may need to change); democratizing access to data often leads to new insights. Enable people to work with data; don’t put up barriers or leave preexisting barriers standing.
Be prepared to use data of all types. Don’t limit yourself to transactional data that’s stored in a traditional relational database, just because that’s easier to deal with. If you can combine structured transactional data with unstructured clickstream data from customers (like a key/value store or a document database), you’ll be able to build applications that are far more valuable than anything you could construct from either data type on its own.
You may need to think about ongoing data collection, and you may need to build pipelines to manage incoming data. Don’t let data fall on the floor just because collecting it is difficult; the best AI projects sometimes need the data that they need to improve themselves.
Organize
Organizing data means creating a trusted, business-ready foundation with built-in governance, protection, and compliance. The first step is making sure your data is organized and cataloged. It’s surprising how few companies know what data they have, or where to find it. It’s also surprising that many companies don’t really know what their data means; it’s common for different organizations within the same company to use the same terms in slightly different ways. Accounting and Sales could very likely have business unit definitions of a “sale” that mean slightly different things. As part of organizing your data and developing a catalog, you will have to agree on common definitions (an enterprise-wide glossary if you will), how the data is to be accessed, where it’s stored, and how it’s indexed. Accounting might only care about account numbers, while Sales cares about customer names. You have to make sure the data can be accessed both ways.
Next, you need to clean your data to ensure it’s accurate, compliant, and business-ready. If it isn’t, you’ll constantly be stumbling over data problems when you’re trying to do your analysis.
Finally, access to the data needs to be controlled. Only users who have permission should be able to access the data, and they should only be able to access the subset of the data that they need. You need to comply with current regulations, and with your own policies (which may extend beyond regulation). To see what this might entail, think back to our earlier discussion of the GDPR, which has stringent rules about how data can be used. Consider also what might happen if an account manager is tempted to “adjust” some figures in their favor. Data governance protects the entire company.
We’ve seen many companies take a “least effort to comply” approach to data governance, in effect asking “How do we do as little as possible to stay on the right side of the law?” But that’s shortsighted. Sure, it may save some legal bills and keep you from getting fined, but good governance has the potential to create regulatory dividends by repurposing that same data effort for other uses that accelerate your AI journey. If you know what your data is, and can manage the metadata that describes it, you can govern it. And if you can govern it, data scientists will be able to find it and use it more efficiently. The average think “governance for compliance.” The heroes think “governance for insights,” and compliance comes along for the ride.
Analyze
Analyzing data is where you build and deploy your AI models. Start simple; you don’t always need to use complex neural networks where a simple regression will do. We’ve seen this many teams jump to building a “sexy” convolutional neural network (CNN) for a computer vision project when other approaches are simpler and work just fine. Always remember to KISS (keep it simple silly) your AI solutions where you can. Building models often consumes more compute power than using the models in production. While many models seem to be built on a developer’s laptop, it’s usually the case that behind that laptop is a cloud—so think about the kind of cloud (public, private, or hybrid) and what cloud providers you use. There are many platforms and toolkits for building models; most cloud providers support most of these platforms, and even provide hardware acceleration.
It’s sad, but many great AI projects never make it into production; unfortunately, what works on a developer’s laptop frequently doesn’t work at scale. Operations teams are still learning how to manage AI applications. The problem can be as simple as a matter of languages and toolkits (“You built this with R, but to run it at scale we think we need it in Python,”) or as complex as difficult scaling requirements (“You need to retrain the model nightly, but training takes 10 hours.”) To avoid problems with production, it’s wise to integrate developers with your business SMEs and operations (DevOps, DataOps, etc.) teams as soon as possible.
Your teams will inevitably be responsible for monitoring your AI, and in particular monitoring for compliance and fairness. They also need to be concerned about models that become stale over time. Think about it: your model’s accuracy is at its best at the moment you put it in production. From that point on, the forces of nature (the data it was trained on to make predictions in the subject area you’re focused on) are at work to deteriorate its performance (accuracy) because the world is forever changing.
Unlike traditional software, the behavior of AI changes with time. As the environment changes—and as the AI changes the environment—models tend to become less accurate. You have to watch for this gradual degradation in performance (algorithms whose performance worsens over time are said to go “stale”), and see that the model is retrained periodically (how often will depend on the data and the use case of the AI—it could need to be retrained weekly or monthly, or perhaps daily or hourly).
Infuse
Infusing AI is where things get really exciting. Can you use AI to eliminate boring, rote tasks? (And since staff like some easy wins, can you preserve just enough boring, simple tasks to keep employees from thinking AI just made their jobs harder?) Can you build AI systems that give knowledge workers the information they need to make important insights? Can you build tools to optimize your supply chains? There’s no limit to what you do when you reach the top of the AI Ladder.
Breaking an AI strategy down into pieces—or the rungs of a ladder—serves as a guiding principle for organizations. First, the AI Ladder helps organizations understand where they are in their journey: Are they still wrestling with the problems of collecting and organizing data? Or have they had some wins, and are now poised to push AI through the company? Second, it helps them determine where they need to focus. It’s not uncommon for an organization to adopt AI solutions at the Infuse rung, while still building out their Collect and Organize strategies across the organization. It’s important to understand that you never leave any rung behind. You may be building AI tools for every group in the company, but you still have to make sure that you’re collecting the data you need, cleaning it, cataloging it, and controlling access to it. Your processes for those tasks may (and should) be simple at first, but as your use of AI grows, so will your requirements. For example, when you start building tools for finance, you will certainly be met with a different set of of explanation and regulatory requirements that you didn’t face when you were building an intelligent customer service application.
Simplify, Automate, and Transform
The AI Ladder ultimately allows organizations to simplify and automate how they turn data into insights by unifying the collection, organization, and analysis of data regardless of where it lives. By employing the AI Ladder, enterprises can build the foundation for a governed, efficient, and agile approach to AI.
No matter where you are in your AI journey, transforming your organization is still going to take a lot of work. Having the data alone is not enough. Having a team of skilled engineers and data scientists is not enough. (We’ve seen some companies buy boutique data science firms and are still nowhere on their corporate transformation. Why? No AI without IA.) Having the technology and skills is simply not enough. Every rung of the AI Ladder is critical. But when you put everything together, you really can change your company in radical ways. You’ll start realizing that there are possibilities for new ways to engage with your customers, and that will make you more profitable and leave them more satisfied.
Get The AI Ladder now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

