Chapter 1. Streaming Integration
Before we go into depth about what is required to achieve streaming integration, it’s important to understand each of the concepts emphasized (in italics) in this definition. In this chapter, you learn why each of these ideas is important and how streaming integration is not complete without all of them present.
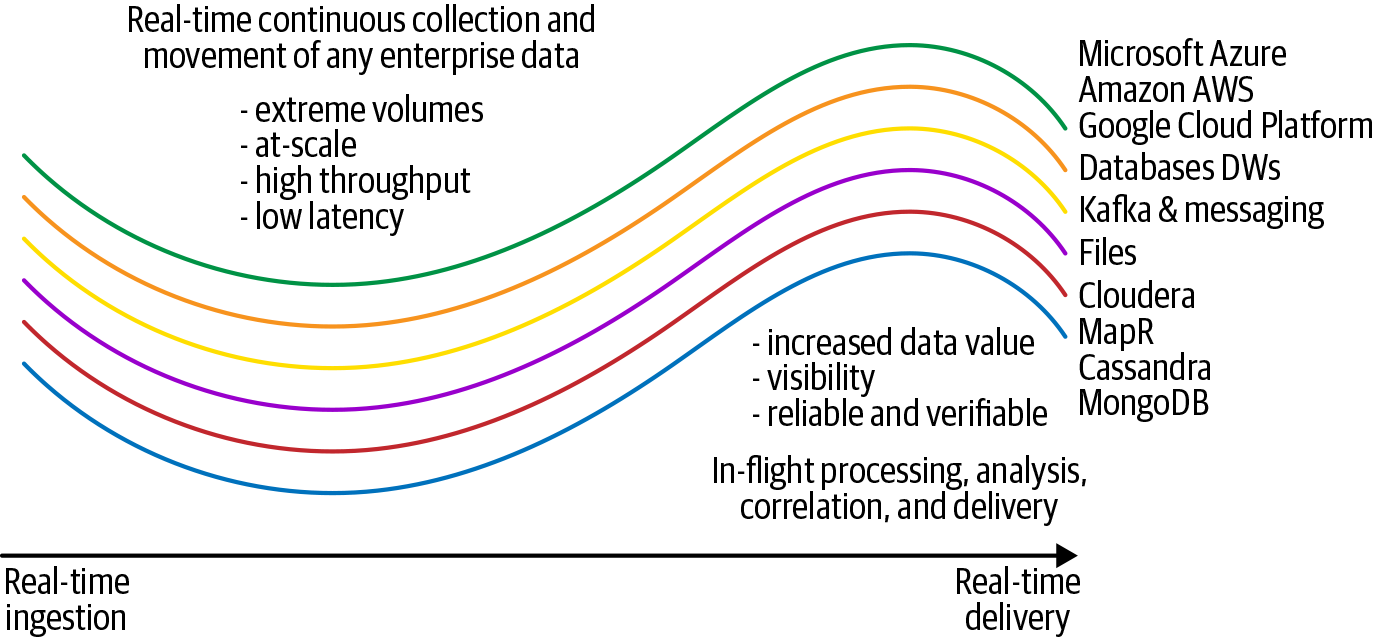
Figure 1-1. Concepts behind streaming integration
Real Time
The overarching principle of streaming integration is that everything happens in real time. There is no delay between data being created, collected, processed, delivered, or viewed such as might be present in traditional Extract, Transform, and Load (ETL) systems or any architecture that uses storage as an intermediary.
This notion means that data must be collected within micro- or milliseconds of being generated. If an organization wants instant insight into its business, any lag will prevent it from understanding what is happening right now.
Continuous Collection
Streaming integration begins with a streaming-first approach to data. Unlike ETL, which runs batch processes as scheduled jobs against already stored data, streaming data collection must be continuous (running forever) and in real time. It involves collecting data as soon as possible after it’s created and before it ever hits a disk. Although some data sources, like message queues and Internet of Things (IoT) devices, can be inherently streaming and push new data immediately, other sources might need special treatment.
We can think of databases as a historical record of what happened in the past. Accessing data from databases through SQL queries is resource-intensive and uses data already stored on disk. To get real-time information from a database you need a technology called change data capture (CDC) that directly intercepts database activity and collects every insert, update, and delete immediately, with very low impact to the database.
Files, whether on disk or in a distributed or cloud filesystem, also cannot be treated as a batch. Collecting real-time file data requires reading at the end of the file and streaming new records as soon as they are written.
Continuous Movement
The result of this continuous collection is a set of data streams. These streams carry the data in real time through processing pipelines and between clustered machines, on-premises and in the cloud. They are used as both the mechanism to continuously process data as it is created and move it from its point of genesis to a final destination.
For speed and low latency, these streams should mostly operate in memory, without writing to disk, but should be capable of persistence when necessary for reliability and recovery purposes.
Any Enterprise Data
Data is generated and stored in a lot of different ways within an enterprise, and requires a lot of different techniques to access it. We’ve already mentioned databases, files, message queues, and IoT devices, but that only scratches the surface. Adding to this list are data warehouses; document, object, and graph databases; distributed data grids; network routers; and many software as a service (SaaS) offerings. All of these can be on-premises, in the cloud, or part of a hybrid-cloud architecture.
For each of these categories, there are numerous providers and many formats. Files alone can be written several different ways, including using delimited text, JSON, XML, Avro, Parquet, or a plethora of other formats.
The integration component of streaming integration requires that any such system must be capable of continuously collecting real-time data from any of these enterprise sources, irrespective of the type of data source or the format the data is in.
Extreme Volumes
When considering data volumes, figures are often quoted in tera-, peta-, or exabytes, but that is the total amount of stored data. We need to think of data volumes for streaming systems differently. Specifically, we need to consider them in terms of the rate at which new data is generated.
The metrics used can be based on the number of new events or the number of bytes created within a certain time period.
For databases, this can be in the order of tens to hundreds of gigabytes per hour stored in transaction logs recording inserts, updates, and deletes – even if the total amount of data stored in the database doesn’t change very much. Security, network devices, and system logs from many machines can easily exceed tens to hundreds of billions of events per day. Many of these logs are discarded after a certain period, so the volume on disk stays fairly constant, but the new data generation rate can be terabytes per day.
There are physical limits to how fast data can be written to disk: on the order of 50 to 100 MBps for magnetic spinning disks, and 200 to 500 MBps for solid-state drives (SSDs). Large-scale enterprise systems often have parallel systems to achieve higher throughput. The largest data generation rates, however, occur when a disk is not involved at all. Reading directly from network ports using protocols such as Transmission Control Protocol (TCP), User Datagram Protocol (UDP), or HyperText Transfer Protocol (HTTP) can achieve higher data volumes up to the speed of the network cards, typically 1 to 10 GBps.
Real-time continuous data collection and the underlying streaming architecture need to be able to handle such data volumes, reading from disk and ports as the data is being generated while imposing low resource usage on the source systems.
At Scale
Scaling streaming integration falls into a number of broad categories, which we dig into deeper later on. Aside from scaling data collection to hundreds of sources, scaling of processing, and handling in-memory context data also needs to be considered.
Streaming integration solutions need to scale up and out. They need to make use of processor threads and memory on a single machine while distributing processing and in-memory storage of data across a cluster. With many distributed nodes within a scaled cluster, it becomes essential that the streaming architecture for moving data between nodes is highly efficient, and can make use of all available network bandwidth.
High Throughput
Dealing with high volumes, at scale, requires that the entire system be tuned to handle enormous throughput of data. It is not sufficient to just be able to keep up with the collection of huge amounts of data as it’s generated. The data also needs to be moved, processed, and delivered at the same rate to eliminate any lag with respect to the source data.
This involves being able to individually scale the collection, processing, and delivery aspects of the system as required. For example, collecting and transforming web logs for delivery into a cloud-based data warehouse might require hundreds of collection nodes, tens of processing nodes, and several parallel delivery nodes, each utilizing multiple threads.
In addition, every aspect of the system needs to be tuned to employ best practices ensuring optimal use of CPU and minimal use of input/output (I/O). In-memory technologies are best suited to this task, especially for processing and data movement. However, persistent data streams might need to be employed sparingly for reliability and recovery purposes.
Low Latency
Latency – or how long the results of a pipeline lag behind the data generation – is not directly related to throughput or scale. It is possible to have a throughput of millions of events per second and yet have a high latency (not the microseconds you would expect). This is because data might need to travel through multiple steps in a pipeline, move between different machines, or be transmitted between on-premises systems and the cloud.
If the goal is to minimize latency, it is necessary to limit the processing steps, I/O, and network hops being utilized. Pipelines that require many steps to achieve multiple simple tasks will have more latency than those that use a single step, rolling the simpler tasks into a single, more complex one. Similarly, architectures that use a hub-and-spoke model will have more latency than point-to-point.
A goal of streaming integration is to minimize latency while maximizing throughput and limiting resource consumption. Simple topologies, such as moving real-time data from a database to the cloud, should have latencies in milliseconds. Adding processing to such pipelines should only marginally increase the latency.
Processing
It is rare that source data is in the exact form required for delivery to a heterogenous target, or to be able to be used for analytics. It is common that some data might need to be eliminated, condensed, reformatted, or denormalized. These tasks are achieved through processing the data in memory, commonly through a data pipeline using a combination of filtering, transformation, aggregation and change detection, and enrichment.
Filtering
Filtering is a very broad capability and uses a variety of techniques. It can range from simple (only allow error and warning messages from a log file to pass through), intermediate (only allow events that match one of a set of regular expressions to pass through), to complex (match data against a machine learning model to derive its relevance and only pass through relevant data). Because filtering acts on individual events – by either including or excluding them – it’s easy to see how we can apply this in real time, in-memory, across one or more data streams.
Transformation
Transformations involve applying some function to the data to modify its structure. A simple transformation would be to concatenate FirstName and LastName fields to create a FullName. The permutations are endless, but common tasks involve things like: converting data types, parsing date and time fields, performing obfuscation or encryption of data to protect privacy, performing lookups based on IP address to deduce location or organization data, converting from one data format to another (such as Avro to JSON), or extracting portions of data by matching with regular expressions.
Aggregation and Change Detection
Aggregation is the common term for condensing or grouping data, usually time-series data, to reduce its granularity. This can involve basic statistical analysis, sampling, or other means that retain the information content, but reduce the frequency of the data. A related notion is change detection which, as the name suggests, outputs data only when it changes. The most appropriate technique depends on the source data and use case.
Aggregation of data, by definition, occurs over multiple events. As such, the scope of aggregation is usually a window of time or defined by other rules to retain events. Aggregation is therefore more memory intensive than filtering given that thousands or millions of events need to be kept in memory and aggregation requires some sizing to determine hardware requirements for edge devices.
Enrichment
Enrichment of data can also be essential for database, IoT, and other use cases. In many instances, the raw data might not contain sufficient context to be deemed useful. It could contain IDs, codes, or other data that would provide little value to downstream analysts. By joining real-time data with some context (about devices, parts, customers, etc.), it’s turned into valuable information. Real-time enrichment of data streams is akin to denormalization in the database world and typically increases the size of data, not decrease it.
Implementation Options
All of these processing tasks need to be accessible to those who build streaming integration pipelines. And those who build pipelines need to understand how to work with data. Here are some options for how these tasks could be implemented:
-
Have individual operators for each simple task, chained to perform processing
-
Use a programming language such as Java or Python to code the processing
-
Use a declarative language such as SQL to define the processing
It is possible to mix-and-match these techniques within a single pipeline, but if you want to minimize processing steps, maximize throughput, and reduce latency, utilizing a language such as SQL – which compiles to high-performance code transparently – provides a good compromise between ease of use, flexibility, and speed.
Analysis
Streaming integration provides more than just the ability to continually move data between sources and targets with in-stream processing. After streaming data pipelines are in place, it’s possible to gain instant value from the streaming data by performing real-time analytics.
This analysis can be in many forms but generally falls into a few broad categories:
-
Time-series and statistical analysis
-
Event processing and pattern detection
-
Real-time scoring of machine learning algorithms
Time-Series and Statistical Analysis
Time-series analysis can be performed naturally on streaming data because streaming data is inherently multitemporal. That is, it can be delineated according to multiple timestamps that can be used to order the data in time. All data will have a timestamp corresponding to when it was collected. In addition, certain collection mechanisms may access an external timestamp, and the data itself can include additional time information.
By keeping a certain amount of data in-memory, or utilizing incremental statistical methods, it is possible to generate real-time statistical measures such as a moving average, standard deviation, or regression. We can use these statistics in conjunction with rules and other context, which themselves can be dynamic, to spot statistically anomalous behavior.
Event Processing and Pattern Detection
Event processing, or what used to be called complex event processing (CEP), enables patterns to be detected in sequences of events. It is a form of time-series analysis, but instead of relying on statistics, it looks for expected and unexpected occurrences. These often rely on data within the events to specify the patterns.
For example, a statistical analysis could spot whether a temperature changed by more than two standard deviations within a certain amount of time. Event processing can utilize that and look for a pattern in which the temperature continues to increase while pressure is increasing and flow rates are dropping, all within a specified amount of time. Event processing is typically used where patterns are known and describable, often derived from the results of previous data analysis.
Real-Time Scoring of Machine Learning Algorithms
Machine learning integration enables pretrained machine learning models to be executed against streaming data to provide real-time analysis of current data. Models could be used for classification, predictions, or anomaly detection. We can use this type of analysis with data that contains many variables, behaves periodically, or for which patterns cannot be specified, only learned.
The great benefit of performing analytics within streaming integration data flows is that the results, and therefore the business insights, are immediate – enabling organizations to be alerted to issues and make decisions in real time.
Correlation
Many use cases collect real-time data from multiple sources. To extract the most value from this data, it might be necessary to join this data together based on the relationship between multiple data streams, such as the way it is correlated through time, data values, location, or more complex associations.
For example, by correlating machine information, such as CPU usage and memory, with information in application logs, such as warnings and response times, it might be possible to spot relationships that we can use for future analytics and predictions.
The most critical aspects of correlation are: first, that it should be able to work across multiple streams of data. Second, it needs to be flexible in the rules that define correlated events and be simple to define and iterate. Ultimately, this means continuous delivery must be considered.
Continuous Delivery
After data has been collected, processed, correlated, and analyzed, the results almost always must be delivered somewhere. That “somewhere” could be a filesystem, database, data warehouse, data lake, message queue, or API, either on-premises or in the cloud. The only exception is when the data is being used solely for in-memory analytics.
Writing data should, wherever possible, also be continuous (not batch) and support almost any enterprise or cloud target and data format. Similar to continuous collection, we should employ parallelization techniques to maximize throughput to ensure the whole end-to-end pipeline does not introduce any lag. An important aspect of delivery is that it should be possible to ensure that all applicable source data is written successfully, once and only once.
Value
The goal of any form of data processing or analytics is to extract business value from the data. The value of data depends on its nature, and it’s important to differentiate between data and information. Although these terms are often used interchangeably, they should not be. Data is a collection of unprocessed facts, whereas information is data processed in such a way as to give it value.
To maximize this value, we need to extract the information content, and with time-sensitive data this needs to happen instantly, upon collection. This can involve filtering out data, performing change detection, enriching it with additional context, or performing analytics to spot anomalies and make predictions. Streaming integration enables this to happen before data is delivered or visualized, ensuring that the value of data is immediately available to the business through visualizations and alerts.
Other patterns for adding value to data include combining both batch and streaming technologies in a single architecture, which has been termed Lambda processing. Streaming integration can both feed an append-only data store used for batch analytics and machine learning as well as provide real-time, in-memory analytics for immediate insight. As an extension to this architecture, stream processing can join historical results to add context to streaming data or invoke pretrained machine learning models to span both batch and real-time worlds.
Visibility
As the name suggests, visibility is the way in which we can present data to the user, often in an interactive fashion. This can involve visualizations in the form of charts and tables, combined together in dashboards. The dashboards and charts can be searchable, filterable, and provide drilldown to secondary pages. As opposed to more traditional BI software, streaming visualizations frequently show up-to-the-second information, but can also be rewound to show historical information.
Visibility in the context of streaming integration can mean one of two things:
-
Visibility into the data itself and the results of analytics
-
Visibility into the data pipelines and integration flows
The former provides insight into business value, whereas the latter gives an operational view of data collection, processing, and delivery, including data volumes, lags, and alerts on anomalous behavior within the data pipeline.
Reliable
It is essential for any system used for mission-critical business operations to be reliable. This means that the system must do what you expect it to do, operate continuously, and recover from failures.
In the scope of streaming integration, it is important to be able to ensure exactly-once processing and delivery of data, independent of the complexity of the flows. All data generated by a source must be collected, processed, and reliably delivered to the target (Figure 1-2). In the case of server, network, system, or other failures, the data flows must recover and continue from where they left off – ensuring that no data is missed and that all processed data is delivered only once.
Additionally, if individual servers in a cluster fail, the system must be capable of resuming data flows on other nodes to ensure continual operations. Ideally, this should all happen transparently to the user without necessitating the intervention of human operatives.
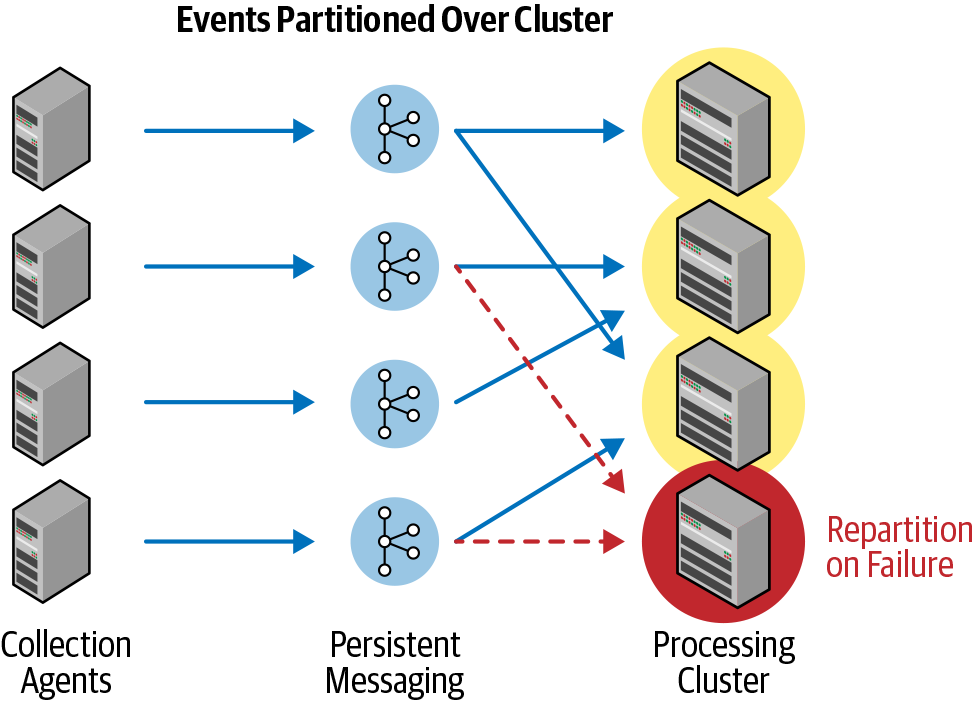
Figure 1-2. Cloud ETL with reliability
Verifiable
Providing reliability guarantees is only half the story. It is also increasingly necessary to be able to prove it and provide insight into the process. Through data flow visibility – including data volumes, number of events, last read and write points, and data lineage – users need to be able to prove that all data that has been read has been both processed and written.
Obviously, this varies by source and target, but the principle is that you need to track data from genesis to destination and verify that it has successfully been written to any targets. This information needs to be accessible to business operations in the form of dashboards and reports, with alerts for any discrepancies.
A Holistic Architecture
In summary, this chapter first defined streaming integration. It then explained its key attributes, which include:
-
Providing real-time continuous collection and movement of any enterprise data
-
Handling extreme volumes at scale
-
Achieving high throughput and low latency
-
Enabling in-flight processing, analysis, correlation, and delivery of data
-
Maximizing both the value and visibility of data
-
Ensuring data is both reliable and verifiable
Streaming Integration should start with a streaming-first approach to collecting data, and then proceed to take advantage of all of these attributes. Any platform that supports streaming integration must provide all of these capabilities to address multiple mission-critical, complex use cases. If any of these attributes are missing, the platform cannot be said to be true streaming integration.
In Chapter 2, we talk about the beginning of the streaming integration pipeline: real-time continuous data collection.
Get Streaming Integration now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

