Gradient descent is a way to minimize an objective function J(θ) parameterized by a model's parameter θ ε Rd by updating the parameters in the opposite direction of the gradient of the objective function with regard to the parameters. The learning rate determines the size of the steps taken to reach the minimum:
- Batch gradient descent (all training observations utilized in each iteration)
- SGD (one observation per iteration)
- Mini batch gradient descent (size of about 50 training observations for each iteration):
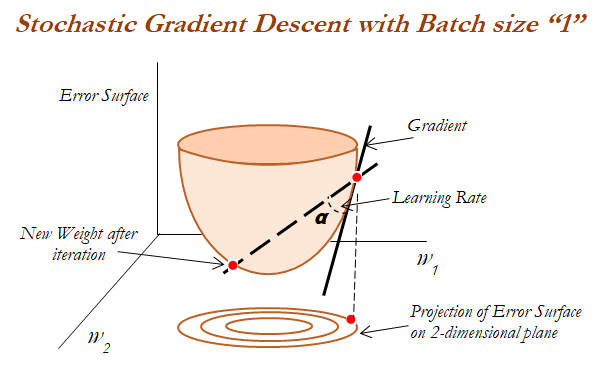
In the following image 2D projection has been observed carefully, in which convergence characteristics ...

