Kapitel 4. Ineffiziente Abfragen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Ineffiziente Abfragen gibt es in jedem System. Sie wirken sich in vielerlei Hinsicht auf die Leistung aus, vor allem durch erhöhte E/A-Last, CPU-Auslastung und Blockierungen. Es ist wichtig, sie zu erkennen und zu optimieren.
In diesem Kapitel werden ineffiziente Abfragen und ihre potenziellen Auswirkungen auf dein System erörtert und Richtlinien für ihre Erkennung gegeben. Außerdem geht es um Extended Events, SQL Traces und den Query Store und endet mit ein paar Gedanken zu Überwachungs-Tools von Drittanbietern. Strategien zur Optimierung ineffizienter Abfragen werden wir in den folgenden Kapiteln behandeln.
Die Auswirkungen ineffizienter Abfragen
Während meiner Karriere als Datenbankingenieur habe ich noch kein System gesehen, das nicht von einer Abfrageoptimierung profitieren würde. Ich bin mir sicher, dass es sie gibt; schließlich ruft mich niemand an, um sich vollkommen gesunde Systeme anzusehen. Trotzdem gibt es nur wenige davon, und es gibt immer Möglichkeiten zur Verbesserung und Optimierung.
Aber nicht jedes Unternehmen legt Wert auf die Optimierung von Abfragen. Es ist ein zeitaufwändiger und mühsamer Prozess, und in vielen Fällen ist es angesichts der Vorteile einer schnelleren Entwicklung und Markteinführung billiger, das Problem mit Hardware zu beheben, als Stunden in die Leistungsoptimierung zu investieren.
Irgendwann führt dieser Ansatz jedoch zu Problemen mit der Skalierbarkeit. Schlecht optimierte Abfragen wirken sich in vielerlei Hinsicht auf das System aus, aber am offensichtlichsten ist vielleicht die Festplattenleistung. Wenn das E/A-Subsystem mit der Belastung durch große Abfragen nicht mithalten kann, leidet die Leistung des gesamten Systems.
Du kannst dieses Problem bis zu einem gewissen Grad umgehen, indem du dem Server mehr Arbeitsspeicher hinzufügst. Dadurch wird der Pufferpool vergrößert und SQL Server kann mehr Daten zwischenspeichern, was die physische E/A reduziert. Wenn die Datenmenge im System im Laufe der Zeit wächst, kann dieser Ansatz jedoch unpraktisch oder sogar unmöglich werden - vor allem in Nicht-Enterprise-Editionen von SQL Server, die die maximale Größe des Pufferpools beschränken.
Ein weiterer Effekt, auf den du achten solltest, ist, dass nicht optimierte Abfragen die CPU auf den Servern belasten. Je mehr Daten du verarbeitest, desto mehr CPU-Ressourcen verbrauchst du. Ein Server braucht vielleicht nur ein paar Mikrosekunden pro logischem Lesevorgang und In-Memory-Datenseiten-Scan, aber das summiert sich schnell, wenn die Anzahl der Lesevorgänge steigt.
Auch hier kannst du dies durch das Hinzufügen weiterer CPUs zum Server ausgleichen. (Beachte jedoch, dass du für zusätzliche Lizenzen bezahlen musst und dass die maximale Anzahl der CPUs in Nicht-Enterprise-Editionen begrenzt ist). Außerdem kann das Hinzufügen von CPUs das Problem nicht immer lösen, da nicht optimierte Abfragen immer noch zum Blockieren beitragen. Es gibt zwar Möglichkeiten, das Blockieren zu reduzieren, ohne ein Abfrage-Tuning durchzuführen, aber das kann das Systemverhalten verändern und hat Auswirkungen auf die Leistung.
Die Quintessenz ist: Wenn du ein System untersuchst, analysiere immer, ob die Abfragen schlecht optimiert sind. Wenn du das getan hast, schätze die Auswirkungen dieser ineffizienten Abfragen.
Die Optimierung von Abfragen ist zwar immer von Vorteil für ein System, aber sie ist nicht immer einfach und bringt auch nicht immer den besten ROI für deine Bemühungen. Trotzdem wirst du in den meisten Fällen zumindest einige Abfragen optimieren müssen.
Um die Dinge ins rechte Licht zu rücken, führe ich Abfrageoptimierungen durch, wenn ich einen hohen Festplattendurchsatz, Blockierungen oder eine hohe CPU-Last im System feststelle. Wenn die Daten im Pufferpool zwischengespeichert werden und die CPU-Belastung akzeptabel ist, kann ich meine Bemühungen jedoch zunächst auf andere Bereiche konzentrieren. Ich muss jedoch vorsichtig sein und an das Datenwachstum denken; es ist möglich, dass die aktiven Daten eines Tages den Pufferpool übersteigen, was zu plötzlichen und ernsthaften Leistungseinbußen führen könnte.
Zum Glück ist bei der Abfrageoptimierung kein Alles-oder-Nichts-Ansatz erforderlich! Du kannst schon durch die Optimierung einer Handvoll häufig ausgeführter Abfragen erhebliche Leistungssteigerungen erzielen. Schauen wir uns ein paar Methoden an, um sie zu erkennen.
Cache-basierte Ausführungsstatistiken planen
In den meisten Fällen speichert SQL Server Ausführungspläne für Abfragen im Cache und verwendet sie wieder. Für jeden Plan im Cache werden außerdem Ausführungsstatistiken geführt, z. B. wie oft die Abfrage ausgeführt wurde, die kumulierte CPU-Zeit und die E/A-Last. Anhand dieser Informationen kannst du schnell die ressourcenintensivsten Abfragen ermitteln und optimieren. (Auf das Plan-Caching gehe ich in Kapitel 6 näher ein.)
Die Analyse von Ausführungsstatistiken aus dem Plan-Cache ist nicht die umfassendste Erkennungstechnik; sie hat einige Einschränkungen. Dennoch ist sie sehr einfach zu verwenden und in vielen Fällen gut genug. Sie funktioniert in allen Versionen von SQL Server und ist immer im System vorhanden. Du musst keine zusätzliche Überwachung einrichten, um die Daten zu sammeln.
Du kannst Ausführungsstatistiken über die Ansicht sys.dm_exec_query_stats abrufen, wie in Listing 4-1 gezeigt. Diese Abfrage ist etwas vereinfacht, aber sie demonstriert die Ansicht in Aktion und zeigt dir die Liste der Metriken, die in der Ansicht angezeigt werden. Ich werde sie verwenden, um später in diesem Kapitel eine anspruchsvollere Version des Codes zu erstellen. Je nach SQL Server-Version und Patching-Level werden einige der Spalten in den Skripten in diesem und anderen Kapiteln möglicherweise nicht unterstützt. Entferne sie, wenn dies der Fall ist.
Der Code liefert dir die Ausführungspläne der Abfragen. Es gibt zwei Funktionen, mit denen du sie erhalten kannst:
sys.dm_exec_query_plan- Diese Funktion gibt den Ausführungsplan des gesamten Ausführungsstapels im Format
XMLzurück. Aufgrund interner Beschränkungen der Funktion kann die Größe des resultierendenXML2 MB nicht überschreiten, und die Funktion kann bei komplexen PlänenNULLzurückgeben. sys.dm_exec_text_query_planDiese Funktion, die ich in Listing 4-1 verwende, gibt eine Textdarstellung des Ausführungsplans zurück. Du kannst sie für den gesamten Stapel oder für eine bestimmte Anweisung aus dem Stapel abrufen, indem du den Offset der Anweisung als Parameter an die Funktion übergibst.
In Listing 4-1 konvertiere ich Pläne in die Darstellung
XMLmit der FunktionTRY_CONVERT, dieNULLzurückgibt, wenn die Größe vonXML2 MB überschreitet. Du kannst die FunktionTRY_CONVERTentfernen, wenn du mit großen Plänen umgehen musst oder wenn du den Code in SQL Server 2005 bis 2008R2 ausführst.
Listing 4-1. Verwendung der Ansicht sys.dm_exec_query_stats
;WITH Queries
AS
(
SELECT TOP 50
qs.creation_time AS [Cached Time]
,qs.last_execution_time AS [Last Exec Time]
,qs.execution_count AS [Exec Cnt]
,CONVERT(DECIMAL(10,5),
IIF
(
DATEDIFF(SECOND,qs.creation_time, qs.last_execution_time) = 0
,NULL
,1.0 * qs.execution_count /
DATEDIFF(SECOND,qs.creation_time, qs.last_execution_time)
)
) AS [Exec Per Second]
,(qs.total_logical_reads + qs.total_logical_writes) /
qs.execution_count AS [Avg IO]
,(qs.total_worker_time / qs.execution_count / 1000)
AS [Avg CPU(ms)]
,qs.total_logical_reads AS [Total Reads]
,qs.last_logical_reads AS [Last Reads]
,qs.total_logical_writes AS [Total Writes]
,qs.last_logical_writes AS [Last Writes]
,qs.total_worker_time / 1000 AS [Total Worker Time]
,qs.last_worker_time / 1000 AS [Last Worker Time]
,qs.total_elapsed_time / 1000 AS [Total Elapsed Time]
,qs.last_elapsed_time / 1000 AS [Last Elapsed Time]
,qs.total_rows AS [Total Rows]
,qs.last_rows AS [Last Rows]
,qs.total_rows / qs.execution_count AS [Avg Rows]
,qs.total_physical_reads AS [Total Physical Reads]
,qs.last_physical_reads AS [Last Physical Reads]
,qs.total_physical_reads / qs.execution_count
AS [Avg Physical Reads]
,qs.total_grant_kb AS [Total Grant KB]
,qs.last_grant_kb AS [Last Grant KB]
,(qs.total_grant_kb / qs.execution_count)
AS [Avg Grant KB]
,qs.total_used_grant_kb AS [Total Used Grant KB]
,qs.last_used_grant_kb AS [Last Used Grant KB]
,(qs.total_used_grant_kb / qs.execution_count)
AS [Avg Used Grant KB]
,qs.total_ideal_grant_kb AS [Total Ideal Grant KB]
,qs.last_ideal_grant_kb AS [Last Ideal Grant KB]
,(qs.total_ideal_grant_kb / qs.execution_count)
AS [Avg Ideal Grant KB]
,qs.total_columnstore_segment_reads
AS [Total CSI Segments Read]
,qs.last_columnstore_segment_reads
AS [Last CSI Segments Read]
,(qs.total_columnstore_segment_reads / qs.execution_count)
AS [AVG CSI Segments Read]
,qs.max_dop AS [Max DOP]
,qs.total_spills AS [Total Spills]
,qs.last_spills AS [Last Spills]
,(qs.total_spills / qs.execution_count) AS [Avg Spills]
,qs.statement_start_offset
,qs.statement_end_offset
,qs.plan_handle
,qs.sql_handle
FROM
sys.dm_exec_query_stats qs WITH (NOLOCK)
ORDER BY
[Avg IO] DESC
)
SELECT
SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2)+1) AS SQL
,TRY_CONVERT(xml,qp.query_plan) AS [Query Plan]
,qs.*
FROM
Queries qs
OUTER APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
OUTER APPLY
sys.dm_exec_text_query_plan
(
qs.plan_handle
,qs.statement_start_offset
,qs.statement_end_offset
) qp
OPTION (RECOMPILE, MAXDOP 1);
Du kannst die Daten je nach deinen Tuning-Zielen unterschiedlich sortieren: nach E/A, wenn du die Festplattenlast reduzieren willst, nach CPU auf CPU-gebundenen Systemen und so weiter.
Abbildung 4-1 zeigt eine Teilausgabe der Abfrage von einem der Server. Wie du siehst, ist es einfach, die zu optimierenden Abfragen anhand der Häufigkeit der Abfrageausführungen und der Daten zum Ressourcenverbrauch in der Ausgabe auszuwählen.
Die Ausführungspläne, die du in der Ausgabe erhältst, enthalten keine tatsächlichen Ausführungsmetriken. In dieser Hinsicht sind sie ähnlich wie geschätzte Ausführungspläne. Dies musst du bei der Optimierung berücksichtigen (mehr dazu in Kapitel 5).
Dieses Problem kann in SQL Server 2019 und höher sowie in Azure SQL-Datenbanken behoben werden, wo du die Sammlung des letzten tatsächlichen Ausführungsplans für die Anweisung in den Datenbanken mit Kompatibilitätsstufe 150 aktivieren kannst. Außerdem musst du die Option LAST_QUERY_PLAN_STATS database aktivieren. Wie bei jeder Datenerfassung führt die Aktivierung dieser Option zu einem Mehraufwand im System, der jedoch relativ gering ist.
Du kannst auf den letzten aktuellen Ausführungsplan über die Funktion sys.dm_exec_query_plan_stats zugreifen. Du kannst die Funktion sys.dm_exec_text_query_plan in allen Codebeispielen in diesem Kapitel durch die neue Funktion ersetzen - sie werden weiterhin funktionieren.
Es gibt noch einige andere wichtige Einschränkungen, an die du dich erinnern solltest. In erster Linie siehst du keine Daten für Abfragen, für die keine Ausführungspläne im Cache gespeichert sind. Es kann sein, dass du einige selten ausgeführte Abfragen verpasst, deren Pläne aus dem Cache entfernt wurden. Normalerweise ist das kein Problem, denn selten ausgeführte Abfragen müssen zu Beginn des Tunings nur selten optimiert werden.
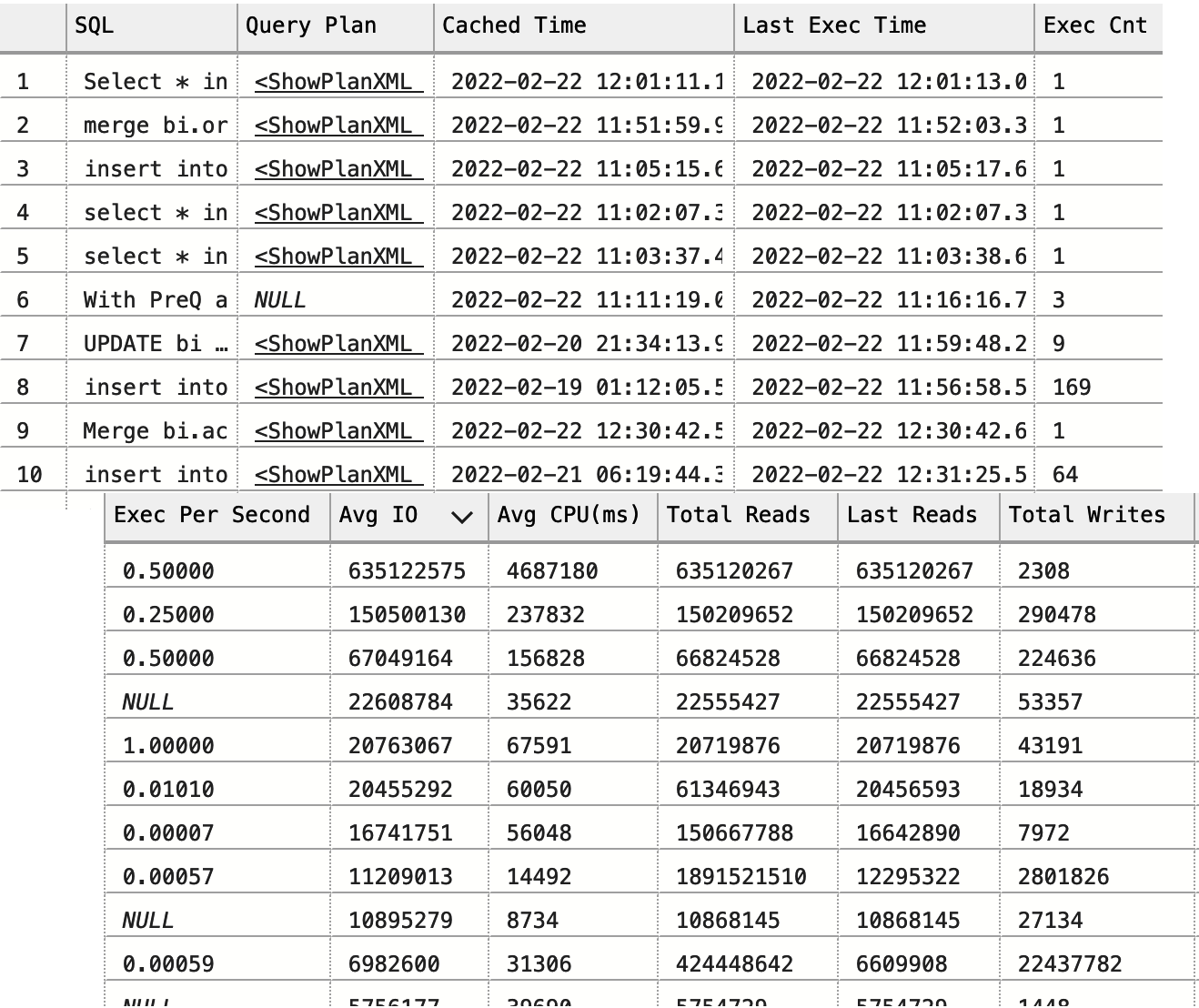
Abbildung 4-1. Teilweise Ausgabe aus der Ansicht sys.dm_exec_query_stats
Es gibt jedoch noch eine andere Möglichkeit. SQL Server speichert die Ausführungspläne nicht, wenn du eine Neukompilierung auf Anweisungsebene mit Ad-hoc-Anweisungen verwendest oder Stored Procedures mit einer RECOMPILE Klausel ausführst. Du musst diese Abfragen mit dem Abfragespeicher oder den erweiterten Ereignissen erfassen, die ich später in diesem Kapitel erläutern werde.
Wenn du eine Neukompilierung auf Anweisungsebene in Stored Procedures oder anderen T-SQL-Modulen verwendest, speichert SQL Server den Ausführungsplan der Anweisung zwischen. Der Plan wird jedoch nicht wiederverwendet, und die Ausführungsstatistik enthält nur die Daten der einzigen (letzten) Ausführung.
Das zweite Problem hängt damit zusammen, wie lange Pläne im Cache bleiben. Dies variiert je nach Plan, was die Ergebnisse verzerren kann, wenn du die Daten nach Gesamtmetriken sortierst. Eine Abfrage mit einer niedrigeren durchschnittlichen CPU-Zeit kann zum Beispiel eine höhere Gesamtzahl an Ausführungen und CPU-Zeit aufweisen als eine Abfrage mit einer höheren durchschnittlichen CPU-Zeit, je nachdem, wann beide Pläne zwischengespeichert wurden.
Du kannst jede dieser Kennzahlen verwenden, aber keine der beiden Methoden ist perfekt. Wenn du die Daten nach Durchschnittswerten sortierst, kann es sein, dass du selten ausgeführte Abfragen an der Spitze der Liste siehst. Denk zum Beispiel an ressourcenintensive nächtliche Aufträge. Wenn du hingegen nach Gesamtwerten sortierst, werden die Abfragen mit den Plänen, die kürzlich zwischengespeichert wurden, möglicherweise nicht berücksichtigt.
Du kannst dir die Spalten creation_time und last_execution_time ansehen, die den letzten Zeitpunkt anzeigen, an dem Pläne zwischengespeichert bzw. ausgeführt wurden. Normalerweise betrachte ich die Daten sortiert nach Gesamt- und Durchschnittsmetrik und berücksichtige dabei die Häufigkeit der Ausführungen (die Gesamt- und die durchschnittliche Anzahl der Ausführungen pro Sekunde). Bevor ich entscheide, was ich optimieren möchte, fasse ich die Daten aus beiden Ausgaben zusammen.
Das letzte Problem ist komplizierter: Es ist möglich, mehrere Ergebnisse für dieselben oder ähnliche Abfragen zu erhalten. Das kann bei Ad-hoc-Workloads passieren, bei Clients, die unterschiedliche SET Einstellungen in ihren Sitzungen haben, wenn Benutzer dieselben Abfragen mit leicht unterschiedlicher Formatierung ausführen, und in vielen anderen Fällen. Dies kann auch in Datenbanken mit Kompatibilitätsstufe 160 (SQL Server 2022) aufgrund der parameterabhängigen Planoptimierung auftreten (mehr dazu in Kapitel 6).
Glücklicherweise kannst du dieses Problem lösen, indem du zwei Spalten, query_hash und query_plan_hash, verwendest, die beide in der Ansicht sys.dm_exec_query_stats angezeigt werden. Die gleichen Werte in diesen Spalten weisen auf ähnliche Abfragen und Ausführungspläne hin. Du kannst diese Spalten verwenden, um Daten zu aggregieren.
Warnung
Die Anweisung DBCC FREEPROCCACHE löscht den Plan-Cache, um die Größe der Ausgabe in der Demo zu verringern. Führe den Code aus Listing 4-2 nicht auf Produktionsservern aus!
Ich möchte das anhand eines einfachen Beispiels demonstrieren. Listing 4-2 führt drei Abfragen aus und prüft dann den Inhalt des Plan-Caches. Die ersten beiden Abfragen sind identisch - sie haben nur eine andere Formatierung. Die dritte ist anders.
Listing 4-2. Die Abfragen query_hash und query_plan_hash in Aktion
DBCC FREEPROCCACHE -- Do not run in production!
GO
SELECT /*V1*/ TOP 1 object_id FROM sys.objects WHERE object_id = 1;
GO
SELECT /*V2*/ TOP 1 object_id
FROM sys.objects
WHERE object_id = 1;
GO
SELECT COUNT(*) FROM sys.objects
GO
SELECT
qs.query_hash, qs.query_plan_hash, qs.sql_handle, qs.plan_handle,
SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2)+1
) as SQL
FROM
sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
ORDER BY query_hash
OPTION (MAXDOP 1, RECOMPILE);
Du kannst die Ergebnisse in Abbildung 4-2 sehen. In der Ausgabe gibt es drei Ausführungspläne. Die letzten beiden Zeilen haben die gleichen Werte query_hash und query_plan_hash und unterschiedliche Werte sql_handle und plan_handle.
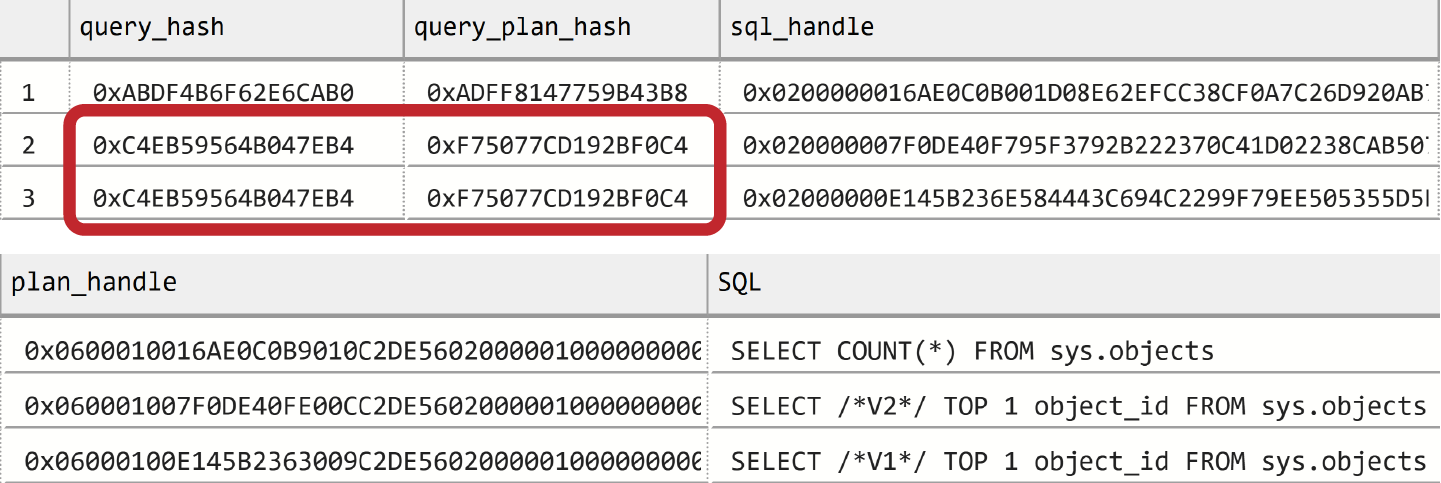
Abbildung 4-2. Mehrere Pläne mit denselben Werten query_hash und query_plan_hash
Listing 4-3 bietet eine anspruchsvollere Version des Skripts aus Listing 4-1, indem es Statistiken von ähnlichen Abfragen zusammenfasst. Die Anweisungs- und Ausführungspläne werden nach dem Zufallsprinzip aus der ersten Abfrage jeder Gruppe entnommen, daher solltest du dies bei deiner Analyse berücksichtigen.
Listing 4-3. Verwendung der Ansicht sys.dm_exec_query_stats mit der Aggregation query_hash
;WITH Data
AS
(
SELECT TOP 50
qs.query_hash
,COUNT(*) as [Plan Count]
,MIN(qs.creation_time) AS [Cached Time]
,MAX(qs.last_execution_time) AS [Last Exec Time]
,SUM(qs.execution_count) AS [Exec Cnt]
,SUM(qs.total_logical_reads) AS [Total Reads]
,SUM(qs.total_logical_writes) AS [Total Writes]
,SUM(qs.total_worker_time / 1000) AS [Total Worker Time]
,SUM(qs.total_elapsed_time / 1000) AS [Total Elapsed Time]
,SUM(qs.total_rows) AS [Total Rows]
,SUM(qs.total_physical_reads) AS [Total Physical Reads]
,SUM(qs.total_grant_kb) AS [Total Grant KB]
,SUM(qs.total_used_grant_kb) AS [Total Used Grant KB]
,SUM(qs.total_ideal_grant_kb) AS [Total Ideal Grant KB]
,SUM(qs.total_columnstore_segment_reads)
AS [Total CSI Segments Read]
,MAX(qs.max_dop) AS [Max DOP]
,SUM(qs.total_spills) AS [Total Spills]
FROM
sys.dm_exec_query_stats qs WITH (NOLOCK)
GROUP BY
qs.query_hash
ORDER BY
SUM((qs.total_logical_reads + qs.total_logical_writes) /
qs.execution_count) DESC
)
SELECT
d.[Cached Time]
,d.[Last Exec Time]
,d.[Plan Count]
,sql_plan.SQL
,sql_plan.[Query Plan]
,d.[Exec Cnt]
,CONVERT(DECIMAL(10,5),
IIF(datediff(second,d.[Cached Time], d.[Last Exec Time]) = 0,
NULL,
1.0 * d.[Exec Cnt] /
datediff(second,d.[Cached Time], d.[Last Exec Time])
)
) AS [Exec Per Second]
,(d.[Total Reads] + d.[Total Writes]) / d.[Exec Cnt] AS [Avg IO]
,(d.[Total Worker Time] / d.[Exec Cnt] / 1000) AS [Avg CPU(ms)]
,d.[Total Reads]
,d.[Total Writes]
,d.[Total Worker Time]
,d.[Total Elapsed Time]
,d.[Total Rows]
,d.[Total Rows] / d.[Exec Cnt] AS [Avg Rows]
,d.[Total Physical Reads]
,d.[Total Physical Reads] / d.[Exec Cnt] AS [Avg Physical Reads]
,d.[Total Grant KB]
,d.[Total Grant KB] / d.[Exec Cnt] AS [Avg Grant KB]
,d.[Total Used Grant KB]
,d.[Total Used Grant KB] / d.[Exec Cnt] AS [Avg Used Grant KB]
,d.[Total Ideal Grant KB]
,d.[Total Ideal Grant KB] / d.[Exec Cnt] AS [Avg Ideal Grant KB]
,d.[Total CSI Segments Read]
,d.[Total CSI Segments Read] / d.[Exec Cnt] AS [AVG CSI Segments Read]
,d.[Max DOP]
,d.[Total Spills]
,d.[Total Spills] / d.[Exec Cnt] AS [Avg Spills]
FROM
Data d
CROSS APPLY
(
SELECT TOP 1
SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2)+1
) AS SQL
,TRY_CONVERT(XML,qp.query_plan) AS [Query Plan]
FROM
sys.dm_exec_query_stats qs
OUTER APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
OUTER APPLY sys.dm_exec_text_query_plan
(
qs.plan_handle
,qs.statement_start_offset
,qs.statement_end_offset
) qp
WHERE
qs.query_hash = d.query_hash AND ISNULL(qt.text,'') <> ''
) sql_plan
ORDER BY
[Avg IO] DESC
OPTION (RECOMPILE, MAXDOP 1);
Ab mit SQL Server 2008 kannst du Ausführungsstatistiken für Stored Procedures über die Ansicht sys.dm_exec_procedure_stats abrufen. Dazu kannst du den Code aus Listing 4-4 verwenden. Wie bei der Ansicht sys.dm_exec_query_stats kannst du die Daten je nach deiner Optimierungsstrategie nach verschiedenen Ausführungsmetriken sortieren. Zu beachten ist, dass die Ausführungsstatistiken auch die Metriken von dynamischem SQL und anderen verschachtelten Modulen (Stored Procedures, Funktionen, Triggers) enthalten, die von den Stored Procedures aufgerufen werden.
Listing 4-4. Verwendung der Ansicht sys.dm_exec_procedure_stats
SELECT TOP 50
IIF (ps.database_id = 32767,
'mssqlsystemresource',
DB_NAME(ps.database_id)
) AS [DB]
,OBJECT_NAME(
ps.object_id,
IIF(ps.database_id = 32767, 1, ps.database_id)
) AS [Proc Name]
,ps.type_desc AS [Type]
,ps.cached_time AS [Cached Time]
,ps.last_execution_time AS [Last Exec Time]
,qp.query_plan AS [Plan]
,ps.execution_count AS [Exec Count]
,CONVERT(DECIMAL(10,5),
IIF(datediff(second,ps.cached_time, ps.last_execution_time) = 0,
NULL,
1.0 * ps.execution_count /
datediff(second,ps.cached_time, ps.last_execution_time)
)
) AS [Exec Per Second]
,(ps.total_logical_reads + ps.total_logical_writes) /
ps.execution_count AS [Avg IO]
,(ps.total_worker_time / ps.execution_count / 1000)
AS [Avg CPU(ms)]
,ps.total_logical_reads AS [Total Reads]
,ps.last_logical_reads AS [Last Reads]
,ps.total_logical_writes AS [Total Writes]
,ps.last_logical_writes AS [Last Writes]
,ps.total_worker_time / 1000 AS [Total Worker Time]
,ps.last_worker_time / 1000 AS [Last Worker Time]
,ps.total_elapsed_time / 1000 AS [Total Elapsed Time]
,ps.last_elapsed_time / 1000 AS [Last Elapsed Time]
,ps.total_physical_reads AS [Total Physical Reads]
,ps.last_physical_reads AS [Last Physical Reads]
,ps.total_physical_reads / ps.execution_count AS [Avg Physical Reads]
,ps.total_spills AS [Total Spills]
,ps.last_spills AS [Last Spills]
,(ps.total_spills / ps.execution_count) AS [Avg Spills]
FROM
sys.dm_exec_procedure_stats ps WITH (NOLOCK)
CROSS APPLY sys.dm_exec_query_plan(ps.plan_handle) qp
ORDER BY
[Avg IO] DESC
OPTION (RECOMPILE, MAXDOP 1);
Abbildung 4-3 zeigt eine Teilausgabe des Codes. Wie du in der Ausgabe sehen kannst, erhältst du Ausführungspläne für die Stored Procedures. Intern sind die Ausführungspläne von Stored Procedures und anderen T-SQL-Modulen nur Sammlungen der individuellen Pläne der einzelnen Anweisungen. In einigen Fällen - zum Beispiel, wenn die Größe des Ausführungsplans 2 MB übersteigt - würde das Skript keinen Plan in die Ausgabe aufnehmen.
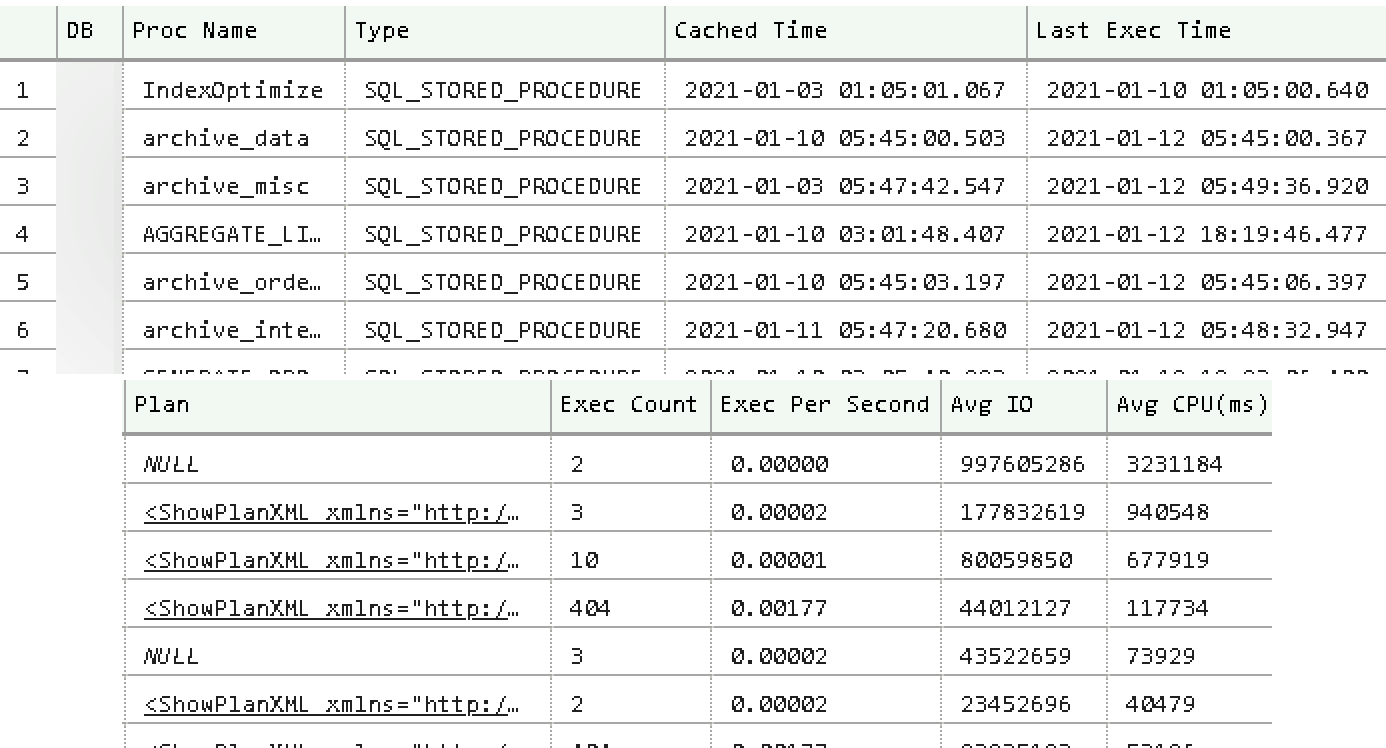
Abbildung 4-3. Teilweise Ausgabe der Ansicht sys.dm_exec_procedure_stats
Listing 4-5 hilft dir bei diesem Problem. Mit kannst du zwischengespeicherte Ausführungspläne und deren Metriken für einzelne Anweisungen von T-SQL-Modulen abrufen. Wenn du das Skript ausführst, musst du den Namen des Moduls in der WHERE Klausel der Anweisung angeben.
Listing 4-5. Abrufen des Ausführungsplans und der Statistiken für Stored-Procedure-Anweisungen
SELECT
qs.creation_time AS [Cached Time]
,qs.last_execution_time AS [Last Exec Time]
,SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2)+1) AS SQL
,TRY_CONVERT(XML,qp.query_plan) AS [Query Plan]
,CONVERT(DECIMAL(10,5),
IIF(datediff(second,qs.creation_time, qs.last_execution_time) = 0,
NULL,
1.0 * qs.execution_count /
datediff(second,qs.creation_time, qs.last_execution_time)
)
) AS [Exec Per Second]
,(qs.total_logical_reads + qs.total_logical_writes) /
qs.execution_count AS [Avg IO]
,(qs.total_worker_time / qs.execution_count / 1000)
AS [Avg CPU(ms)]
,qs.total_logical_reads AS [Total Reads]
,qs.last_logical_reads AS [Last Reads]
,qs.total_logical_writes AS [Total Writes]
,qs.last_logical_writes AS [Last Writes]
,qs.total_worker_time / 1000 AS [Total Worker Time]
,qs.last_worker_time / 1000 AS [Last Worker Time]
,qs.total_elapsed_time / 1000 AS [Total Elapsed Time]
,qs.last_elapsed_time / 1000 AS [Last Elapsed Time]
,qs.total_rows AS [Total Rows]
,qs.last_rows AS [Last Rows]
,qs.total_rows / qs.execution_count AS [Avg Rows]
,qs.total_physical_reads AS [Total Physical Reads]
,qs.last_physical_reads AS [Last Physical Reads]
,qs.total_physical_reads / qs.execution_count
AS [Avg Physical Reads]
,qs.total_grant_kb AS [Total Grant KB]
,qs.last_grant_kb AS [Last Grant KB]
,(qs.total_grant_kb / qs.execution_count)
AS [Avg Grant KB]
,qs.total_used_grant_kb AS [Total Used Grant KB]
,qs.last_used_grant_kb AS [Last Used Grant KB]
,(qs.total_used_grant_kb / qs.execution_count)
AS [Avg Used Grant KB]
,qs.total_ideal_grant_kb AS [Total Ideal Grant KB]
,qs.last_ideal_grant_kb AS [Last Ideal Grant KB]
,(qs.total_ideal_grant_kb / qs.execution_count)
AS [Avg Ideal Grant KB]
,qs.total_columnstore_segment_reads
AS [Total CSI Segments Read]
,qs.last_columnstore_segment_reads
AS [Last CSI Segments Read]
,(qs.total_columnstore_segment_reads / qs.execution_count)
AS [AVG CSI Segments Read]
,qs.max_dop AS [Max DOP]
,qs.total_spills AS [Total Spills]
,qs.last_spills AS [Last Spills]
,(qs.total_spills / qs.execution_count) AS [Avg Spills]
FROM
sys.dm_exec_query_stats qs WITH (NOLOCK)
OUTER APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
OUTER APPLY sys.dm_exec_text_query_plan
(
qs.plan_handle
,qs.statement_start_offset
,qs.statement_end_offset
) qp
WHERE
OBJECT_NAME(qt.objectid, qt.dbid) = <SP Name> -- Add SP Name here
ORDER BY
qs.statement_start_offset, qs.statement_end_offset
OPTION (RECOMPILE, MAXDOP 1);
Ab mit SQL Server 2016 können Sie Ausführungsstatistiken für Trigger und skalare benutzerdefinierte Funktionen erhalten, indem Sie sys.dm_exec_trigger_stats und sys.dm_exec_function_stats Views abrufen. Du kannst denselben Code wie in Listing 4-4 verwenden, du musst nur den DMV-Namen ersetzen. Du kannst den Code auch aus dem Begleitmaterial dieses Buches herunterladen.
Abschließend ist zu erwähnen, dass SQL Server möglicherweise Tausende von Ausführungsplänen zwischenspeichert. Außerdem sind die Funktionen zum Abrufen von Abfrageplänen und SQL-Anweisungen ressourcenintensiv; daher verwende ich den MAXDOP 1 Query Hint, um den Overhead zu reduzieren. In einigen Fällen kann es von Vorteil sein, den Inhalt des Plan-Caches in einer separaten Datenbank mit SELECT INTO Anweisungen zu speichern und die Daten auf nicht produktiven Servern zu analysieren.
Die Fehlersuche auf der Grundlage von Ausführungsstatistiken, die auf dem Plan-Cache basieren, hat einige Einschränkungen, und du könntest einige Abfragen übersehen. Dennoch ist dies ein guter Ausgangspunkt. Am wichtigsten ist, dass die Daten automatisch gesammelt werden und du sofort darauf zugreifen kannst, ohne zusätzliche Überwachungs-Tools einzurichten .
Erweiterte Ereignisse und SQL-Traces
Ich bin sicher, dass jeder SQL Server-Ingenieur die SQL Traces und Extended Events (xEvents) kennt. Sie ermöglichen es dir, verschiedene Ereignisse in einem System zur Analyse und Fehlerbehebung in Echtzeit zu erfassen. Du kannst sie auch verwenden, um langlaufende und teure Abfragen zu erfassen, einschließlich solcher, die keine Ausführungspläne zwischenspeichern und daher von der sys.dm_exec_query_stats Ansicht übersehen werden.
Ich möchte diesen Abschnitt jedoch mit einer Warnung beginnen: Verwende SQL Traces und xEvents nur dann für diesen Zweck, wenn es absolut notwendig ist. Das Erfassen von ausgeführten Anweisungen ist ein kostspieliger Vorgang, der in stark ausgelasteten Systemen zu erheblichen Leistungseinbußen führen kann. (Du hast ein solches Beispiel in Kapitel 1 gesehen.)
Es spielt keine Rolle, wie viele Daten du sammelst. Du kannst die meisten Anweisungen von der Ausgabe ausschließen, indem du Abfragen mit geringem Ressourcenverbrauch herausfilterst. Aber SQL Server muss trotzdem alle Anweisungen erfassen, um sie auszuwerten, zu filtern und unnötige Ereignisse zu verwerfen.
Sammle keine unnötigen Informationen in den Ereignissen, die du sammelst, oder in den xEvent-Aktionen, die du aufzeichnest. Einige Aktionen, wie z. B. callstack, sind teuer und führen zu einem erheblichen Leistungsverlust, wenn sie aktiviert sind. Wenn möglich, verwende xEvents anstelle von SQL Traces. Sie sind leichter und verursachen weniger Overhead im System.
Tabelle 4-1 zeigt verschiedene Extended- und SQL-Trace-Ereignisse, die zur Erkennung ineffizienter Abfragen verwendet werden können. Jedes mit Ausnahme von sqlserver.attention hat ein entsprechendes Ereignis, das zu Beginn der Ausführung ausgelöst wird. Manchmal musst du diese Ereignisse erfassen, um Arbeitslasten aus mehreren Sitzungen zu korrelieren.
| xEvent | SQL-Trace-Ereignis | Kommentare |
|---|---|---|
sqlserver.sql_statement_completed |
SQL:StmtCompleted |
Wird ausgelöst, wenn die Anweisung die Ausführung beendet hat. |
sqlserver.sp_statement_completed
|
SP:StmtCompleted
|
Wird ausgelöst, wenn die SQL-Anweisung innerhalb des T-SQL-Moduls die Ausführung abgeschlossen hat. |
sqlserver.rpc_completed |
RPC:Completed |
Wird ausgelöst, wenn ein Remote Procedure Call (RPC) abgeschlossen ist. RPCs sind parametrisierte SQL-Anfragen, wie z. B. Aufrufe von Stored Procedures oder parametrisierte Batches, die von Anwendungen gesendet werden. Viele Client-Bibliotheken führen Abfragen über sp_executesql Aufrufe aus, die von diesem Ereignis erfasst werden können. |
sqlserver.module_end |
SP:Completed |
Wird ausgelöst, wenn das T-SQL-Modul die Ausführung abgeschlossen hat. |
sqlserver.sql_batch_completed |
SQL:BatchCompleted |
Wird ausgelöst, wenn der SQL-Batch die Ausführung abgeschlossen hat. |
sqlserver.attention |
Error:Attention |
Treten auf, wenn der Client eine Abfrageausführung abbricht, entweder aufgrund einer Zeitüberschreitung oder explizit (z. B. über die rote Abbruchschaltfläche in SSMS). |
Die Auswahl der zu erfassenden Ereignisse hängt von der Systemauslastung, dem Design der Datenzugriffsebene und deiner Fehlerbehebungsstrategie ab. Mit den Ereignissen sqlserver.sql_statement_completed und sqlserver.sp_statement_completed kannst du zum Beispiel ineffiziente Ad-hoc- und T-SQL-Modulabfragen erkennen. Alternativ kannst du mit den Ereignissen sqlserver.rpc_completed und sqlserver.sql_batch_completed ineffiziente Batches und Stored Procedures erfassen und so den Overhead reduzieren.
Das Gleiche gilt für die Auswahl der zu erfassenden xEvent-Aktionen. Du könntest z. B. Informationen über Benutzer und Client-Anwendungen ignorieren, wenn du sie bei der Fehlersuche nicht brauchst. Alternativ könntest du beschließen, query_hash und query_plan_hash Aktionen zu sammeln und sie zu nutzen, um die kumulativen Auswirkungen ähnlicher Abfragen und Ausführungspläne zu ermitteln.
Es gibt zwei Szenarien, in denen ich normalerweise ineffiziente Abfragen erfasse. Ich lasse eine Sitzung ein paar Minuten lang laufen und erfasse die Ergebnisse im Ziel ring_buffer. Normalerweise mache ich das, wenn die Arbeitslast im System relativ statisch ist und durch eine kleine Stichprobe repräsentiert werden kann. Alternativ kann ich eine xEvent-Sitzung für einige Stunden laufen lassen und event_file als Ziel verwenden.
Listing 4-6 zeigt den letzteren Ansatz, bei dem die Daten im Ordner C:\ExtEvents gespeichert werden (ändere ihn in deinem System). Unter werden Anweisungen erfasst, die mehr als 5.000 ms CPU-Zeit verbrauchen oder mehr als 50.000 logische Lese- oder Schreibvorgänge erzeugen. Der Code in Listing 4-6 und Listing 4-7 funktioniert in SQL Server 2012 und höher; in SQL Server 2008, der anders mit dem Dateiziel arbeitet und dem die Aktionen query_hash und query_plan_hash fehlen, sind möglicherweise Änderungen erforderlich.
Ich möchte dich darauf hinweisen, dass diese Sitzung einen Overhead verursacht. Wie viel Overhead du hast, hängt von der Arbeitslast und der Menge der Daten ab, die du erfasst. Lass diese Sitzung nur dann aktiv, wenn du Probleme mit der Leistung beheben willst. Außerdem solltest du die Schwellenwerte cpu_time, logical_reads und writes auf deine Arbeitslast abstimmen und vermeiden, dass zu viele Abfragen erfasst werden.
Definiere auch eine Liste von xEvents-Aktionen, die auf deiner Fehlerbehebungsstrategie basieren. Es ist zum Beispiel nicht nötig, plan_handle zu sammeln, wenn du die Analyse auf einem anderen Server durchführst und keine Ausführungspläne aus dem Plan-Cache abrufen kannst.
Listing 4-6. Erfassen von CPU- und I/O-intensiven Abfragen
CREATE EVENT SESSION [Expensive Queries]
ON SERVER
ADD EVENT sqlserver.sql_statement_completed
(
ACTION
(
sqlserver.client_app_name
,sqlserver.client_hostname
,sqlserver.database_id
,sqlserver.plan_handle
,sqlserver.query_hash
,sqlserver.query_plan_hash
,sqlserver.sql_text
,sqlserver.username
)
WHERE
(
(
cpu_time >= 5000000 or -- Time in microseconds
logical_reads >= 50000 or
writes >= 50000
) AND
sqlserver.is_system = 0
)
)
,ADD EVENT sqlserver.sp_statement_completed
(
ACTION
(
sqlserver.client_app_name
,sqlserver.client_hostname
,sqlserver.database_id
,sqlserver.plan_handle
,sqlserver.query_hash
,sqlserver.query_plan_hash
,sqlserver.sql_text
,sqlserver.username
)
WHERE
(
(
cpu_time >= 5000000 or -- Time in microseconds
logical_reads >= 50000 or
writes >= 50000
) AND
sqlserver.is_system = 0
)
)
ADD TARGET package0.event_file
(
SET FILENAME = 'C:\ExtEvents\Expensive Queries.xel'
)
WITH
(
event_retention_mode=allow_single_event_loss
,max_dispatch_latency=30 seconds
);
Listing 4-7 enthält den Code zum Parsen der gesammelten Daten. In einem ersten Schritt lädt die gesammelten Ereignisse mit der Funktion sys.fn_xe_file_target_read_file in eine temporäre Tabelle. Das Sternchen am Ende des Dateinamens weist SQL Server an, alle Rollover-Dateien von der xEvent-Sitzung zu laden.
Anschließend analysiert der Code die gesammelten Ereignisse und speichert die Ergebnisse in einer anderen temporären Tabelle. Möglicherweise musst du den Code in der EventInfo CTE an die xEvent-Felder und Aktionen anpassen, die du für die Fehlerbehebung benötigst. Parse keine unnötigen Informationen - das Zerlegen von XML ist ein teurer und zeitaufwändiger Vorgang.
Wenn du diesen Code auf SQL Server 2016 oder früheren Versionen ausführst, musst du ihn ändern und die Zeit des Ereignisses aus der event_data XML-Datei abrufen. In SQL Server 2017 gibt die Funktion sys.fn_xe_file_target_read_file dies als Teil der Ausgabe zurück.
Listing 4-7. Parsen von gesammelten xEvent-Daten
CREATE TABLE #EventData
(
event_data XML NOT NULL,
file_name NVARCHAR(260) NOT NULL,
file_offset BIGINT NOT NULL,
timestamp_utc datetime2(7) NOT NULL -- SQL Server 2017+
);
INSERT INTO #EventData(event_data, file_name, file_offset, timestamp_utc)
SELECT CONVERT(XML,event_data), file_name, file_offset, timestamp_utc
FROM sys.fn_xe_file_target_read_file
('c:\extevents\Expensive Queries*.xel',NULL,NULL,NULL);
;WITH EventInfo([Event],[Event Time],[DB],[Statement],[SQL],[User Name]
,[Client],[App],[CPU Time],[Duration],[Logical Reads]
,[Physical Reads],[Writes],[Rows],[Query Hash],[Plan Hash]
,[PlanHandle],[Stmt Offset],[Stmt Offset End],File_Name,File_Offset)
AS
(
SELECT
event_data.value('/event[1]/@name','SYSNAME') AS [Event]
,timestamp_utc AS [Event Time] -- SQL Server 2017+
/*,event_data.value('/event[1]/@timestamp','DATETIME')
AS [Event Time] -- Prior SQL Server 2017 */
,event_data.value
('((/event[1]/action[@name="database_id"]/value/text())[1])'
,'INT') AS [DB]
,event_data.value
('((/event[1]/data[@name="statement"]/value/text())[1])'
,'NVARCHAR(MAX)') AS [Statement]
,event_data.value
('((/event[1]/action[@name="sql_text"]/value/text())[1])'
,'NVARCHAR(MAX)') AS [SQL]
,event_data.value
('((/event[1]/action[@name="username"]/value/text())[1])'
,'NVARCHAR(255)') AS [User Name]
,event_data.value
('((/event[1]/action[@name="client_hostname"]/value/text())[1])'
,'NVARCHAR(255)') AS [Client]
,event_data.value
('((/event[1]/action[@name="client_app_name"]/value/text())[1])'
,'NVARCHAR(255)') AS [App]
,event_data.value
('((/event[1]/data[@name="cpu_time"]/value/text())[1])'
,'BIGINT') AS [CPU Time]
,event_data.value
('((/event[1]/data[@name="duration"]/value/text())[1])'
,'BIGINT') AS [Duration]
,event_data.value
('((/event[1]/data[@name="logical_reads"]/value/text())[1])'
,'INT') AS [Logical Reads]
,event_data.value
('((/event[1]/data[@name="physical_reads"]/value/text())[1])'
,'INT') AS [Physical Reads]
,event_data.value
('((/event[1]/data[@name="writes"]/value/text())[1])'
,'INT') AS [Writes]
,event_data.value
('((/event[1]/data[@name="row_count"]/value/text())[1])'
,'INT') AS [Rows]
,event_data.value(
'xs:hexBinary(((/event[1]/action[@name="query_hash"]/value/text())[1]))'
,'BINARY(8)') AS [Query Hash]
,event_data.value(
'xs:hexBinary(((/event[1]/action[@name="query_plan_hash"]/value/text())[1]))'
,'BINARY(8)') AS [Plan Hash]
,event_data.value(
'xs:hexBinary(((/event[1]/action[@name="plan_handle"]/value/text())[1]))'
,'VARBINARY(64)') AS [PlanHandle]
,event_data.value
('((/event[1]/data[@name="offset"]/value/text())[1])'
,'INT') AS [Stmt Offset]
,event_data.value
('((/event[1]/data[@name="offset_end"]/value/text())[1])'
,'INT') AS [Stmt Offset End]
,file_name
,file_offset
FROM
#EventData
)
SELECT
ei.*
,TRY_CONVERT(XML,qp.Query_Plan) AS [Plan]
INTO #Queries
FROM
EventInfo ei
OUTER APPLY
sys.dm_exec_text_query_plan
(
ei.PlanHandle
,ei.[Stmt Offset]
,ei.[Stmt Offset End]
) qp
OPTION (MAXDOP 1, RECOMPILE);
Jetzt kannst du mit Rohdaten aus der Tabelle #Queries arbeiten und die ineffizientesten Abfragen für die Optimierung aufspüren. In vielen Fällen ist es auch von Vorteil, die Daten auf der Grundlage einer Anweisung, eines Abfrage-Hashes oder eines Plan-Hashes zu aggregieren und die kumulativen Auswirkungen der Abfragen zu analysieren.
Das Begleitmaterial zu diesem Buch enthält ein Skript, mit dem du den Workload im ring_buffer Ziel erfassen kannst. Es gibt jedoch eine wichtige Einschränkung: Die Ansicht sys.dm_xe_session_targets, die die gesammelten Daten des Ziels liefert, kann nur 4 MB XML ausgeben. Das kann dazu führen, dass du einige gesammelte Ereignisse nicht sehen kannst.
Auch hier gilt: Achte auf den Overhead, den xEvents und SQL Traces in Systemen verursachen. Erstelle diese Sitzungen nicht dauerhaft und lass sie laufen. In vielen Fällen kannst du genug Daten zur Fehlerbehebung erhalten, wenn du die Sitzung oder den Trace nur für ein paar Minuten aktivierst .
Abfrage Speicher
So Bisher haben wir in diesem Kapitel zwei Ansätze zur Erkennung ineffizienter Abfragen diskutiert. Beide haben ihre Grenzen. Plan-Cache-basierte Daten können einige Abfragen übersehen; SQL Traces und xEvents erfordern eine komplexe Analyse der Ausgabe und können in stark ausgelasteten Systemen einen erheblichen Leistungs-Overhead verursachen.
Der Query Store, der mit SQL Server 2016 eingeführt wurde, hilft dabei, diese Einschränkungen zu überwinden. Er ist so etwas wie der Flugdatenschreiber (oder "Black Box") im Cockpit eines Flugzeugs, allerdings für SQL Server. Wenn der Query Store aktiviert ist, erfasst und speichert SQL Server die Laufzeitstatistiken und Ausführungspläne der Abfragen in der Datenbank. Er zeigt, wie die Ausführungspläne funktionieren und wie sie sich im Laufe der Zeit entwickeln. Außerdem kannst du bestimmte Ausführungspläne für Abfragen erzwingen, um das Problem des Parameter-Sniffing zu lösen, das wir in Kapitel 6 besprechen werden.
Hinweis
Der Query Store ist in der On-Premises-Version von SQL Server bis SQL Server 2019 standardmäßig deaktiviert. In Azure SQL Databases, Azure SQL Managed Instances und neuen Datenbanken, die in SQL Server 2022 erstellt werden, ist er standardmäßig aktiviert.
Der Query Store ist vollständig in die Abfrageverarbeitungspipeline integriert, wie das High-Level-Diagramm in Abbildung 4-4 zeigt.
Wenn eine Abfrage ausgeführt werden muss, sucht SQL Server nach dem Ausführungsplan im Plan-Cache. Wenn er einen Plan findet, prüft SQL Server, ob die Abfrage neu kompiliert werden muss (aufgrund von Statistikaktualisierungen oder anderen Faktoren), ob ein neuer Forced Plan erstellt wurde und ob ein alter Forced Plan aus dem Query Store gelöscht wurde.
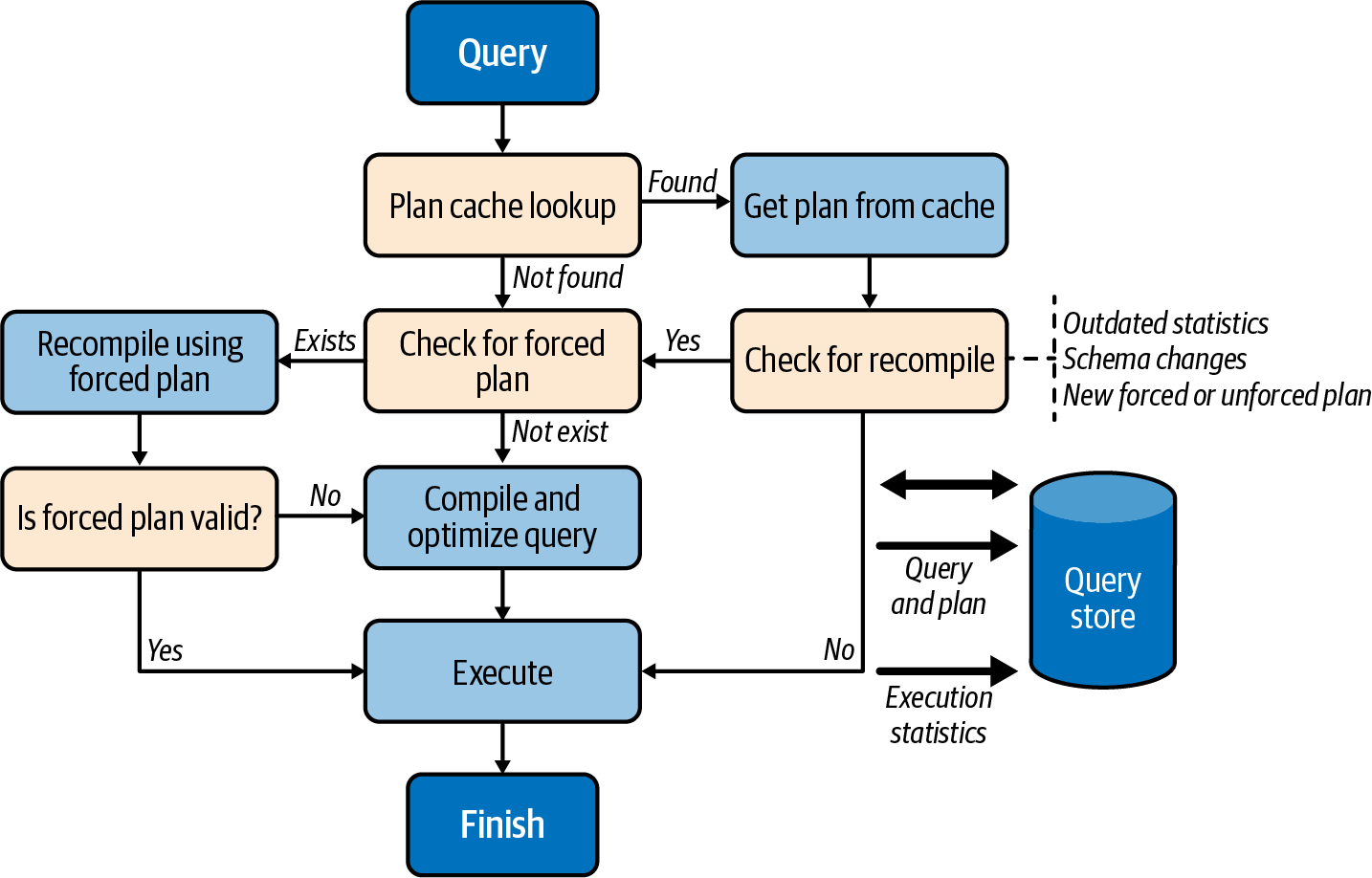
Abbildung 4-4. Pipeline für die Abfrageverarbeitung
Während der Kompilierung prüft SQL Server, ob für die Abfrage ein Forced Plan verfügbar ist. Wenn dies der Fall ist, wird die Abfrage im Wesentlichen mit dem erzwungenen Plan kompiliert, ähnlich wie bei der Verwendung des USE PLAN Hinweises. Wenn der resultierende Plan gültig ist, wird er im Plan-Cache zur Wiederverwendung gespeichert.
Wenn der erzwungene Plan nicht mehr gültig ist (z. B. wenn ein Benutzer einen im erzwungenen Plan referenzierten Index löscht), schlägt SQL Server die Abfrage nicht fehl. Stattdessen kompiliert er die Abfrage erneut ohne den erzwungenen Plan und ohne sie danach zwischenzuspeichern. Der Query Store hingegen behält beide Pläne bei und markiert den erzwungenen Plan als ungültig. All das geschieht für die Anwendungen transparent.
In SQL Server 2022 und SQL Azure Database ermöglicht der Query Store das Hinzufügen von Hints auf Abfrageebene mithilfe der gespeicherten Prozedur sp_query_store_set_hints. Mit Query Store Hints kompiliert SQL Server Abfragen und führt sie so aus, als ob du die Hints mit der OPTION Abfrageklausel eingeben würdest. Das gibt dir zusätzliche Flexibilität bei der Abfrageoptimierung, ohne dass du die Anwendungen ändern musst.
Trotz seiner engen Integration in die Abfrageverarbeitungspipeline und verschiedener interner Optimierungen fügt der Query Store dem System immer noch Overhead zu. Wie hoch der Overhead ist, hängt von den folgenden zwei Hauptfaktoren ab:
- Anzahl der Kompilierungen im System
- Je mehr Kompilierungen SQL Server durchführt, desto mehr Last muss der Query Store bewältigen. Insbesondere funktioniert der Query Store möglicherweise nicht sehr gut in Systemen, die eine sehr hohe, nicht parametrisierte Ad-hoc-Arbeitslast haben.
- Einstellungen für die Datenerfassung
-
In den Konfigurationen des Abfragespeichers kannst du festlegen, ob du alle Abfragen oder nur die teuren Abfragen erfassen willst, sowie die Aggregationsintervalle und die Einstellungen für die Datenspeicherung. Wenn du mehr Daten sammelst und/oder kleinere Aggregationsintervalle verwendest, hast du mehr Overhead.
Achte bei besonders auf die Einstellung
QUERY_CAPTURE_MODE, die bestimmt, welche Abfragen erfasst werden. BeiQUERY_CAPTURE_MODE=ALL(der Standardeinstellung in SQL Server 2016 und 2017) erfasst der Abfragespeicher alle Abfragen im System. Das kann Auswirkungen haben, vor allem bei einer Ad-hoc-Arbeitslast.Mit
QUERY_CAPTURE_MODE=AUTO(der Standardeinstellung in SQL Server 2019 und später) erfasst der Abfragespeicher keine kleinen oder selten ausgeführten Abfragen. Dies ist in den meisten Fällen die beste Option.Ab SQL Server 2019 kannst du
QUERY_CAPTURE_MODE=CUSTOMeinstellen und die Kriterien für die Erfassung von Abfragen noch weiter anpassen.
Wenn er richtig konfiguriert ist, ist der Overhead, den der Abfragespeicher verursacht, normalerweise relativ gering. In manchen Fällen kann er jedoch erheblich sein. Ich habe den Query Store zum Beispiel verwendet, um die Leistung eines Prozesses zu überprüfen, der aus einer sehr großen Anzahl kleiner Ad-hoc-Abfragen besteht. Ich habe alle Abfragen im System im Modus QUERY_CAPTURE_MODE=ALL erfasst und dabei fast 10 GB an Daten im Query Store gesammelt. Mit aktiviertem Query Store dauerte der Prozess 8 Stunden, ohne Query Store nur 2,5 Stunden.
Dennoch, empfehle ich, den Abfragespeicher zu aktivieren, wenn dein System den Overhead verkraften kann. Einige Funktionen aus der IQP-Familie (Intelligent Query Processing) sind beispielsweise auf den Abfragespeicher angewiesen und profitieren davon. Außerdem vereinfacht er die Abstimmung von Abfragen und kann dir viele Stunden Arbeit ersparen, wenn er aktiviert ist.
Hinweis
Überwache QDS* Wartezeiten, wenn du den Query Store aktivierst. Übermäßige QDS* Wartezeiten können ein Zeichen für einen höheren Query Store-Overhead im System sein. Ignoriere QDS_PERSIST_TASK_MAIN_LOOP_SLEEP und QDS_ASYNC_QUEUE Wartezeiten; sie sind harmlos.
Es gibt zwei wichtige Trace-Flags, die du aktivieren solltest, wenn du den Query Store verwendest:
T7745-
Um den Overhead zu reduzieren, speichert SQL Server einige Query Store-Daten im Cache und überträgt sie in regelmäßigen Abständen in die Datenbank. Das Flush-Intervall wird durch die Einstellung
DATA_FLUSH_INTERVAL_SECONDSgesteuert, die festlegt, wie viele Query Store-Daten bei einem SQL Server-Absturz verloren gehen können. Unter normalen Umständen speichert SQL Server die Query Store-Daten beim Herunterfahren des SQL Servers oder beim Failover im Speicher.Dieses Verhalten kann die Abschalt- und Failover-Zeiten in ausgelasteten Systemen verlängern. Du kannst dies mit dem Trace-Flag
T7745deaktivieren, da der Verlust einer kleinen Menge an Telemetrie normalerweise akzeptabel ist. T7752(SQL Server 2016 und 2017)-
SQL Server lädt beim Start der Datenbank einige Query Store-Daten in den Speicher, so dass die Datenbank während dieser Zeit nicht verfügbar ist. Bei großen Query Stores kann dies die Neustart- oder Failover-Zeit des SQL Servers verlängern und die Benutzerfreundlichkeit beeinträchtigen.
Das Trace-Flag
T7752zwingt SQL Server, die Daten des Query Stores asynchron zu laden, so dass die Abfragen parallel ausgeführt werden können. Die Telemetriedaten werden während des Ladevorgangs nicht erfasst, aber das ist normalerweise ein akzeptabler Preis für einen schnelleren Start.Du kannst die Auswirkungen einer synchronen Query Store-Ladung analysieren, indem du dir die Wartezeit für die Warteart
QDS_LOADDBansiehst. Diese Wartezeit tritt nur beim Start der Datenbank auf, daher musst du die Ansichtsys.dm_os_wait_statsabfragen und die Ausgabe nach der Warteart filtern, um die Zahl zu erhalten.
Generell gilt, dass du keinen sehr großen Abfragespeicher anlegen solltest. Außerdem solltest du die Größe des Query Stores überwachen, vor allem bei stark ausgelasteten Systemen. In manchen Fällen ist SQL Server nicht in der Lage, die Daten schnell genug zu bereinigen, vor allem wenn du den Sammelmodus QUERY_CAPTURE_MODE=ALL verwendest.
Schließlich solltest du die neuesten SQL Server-Updates einspielen, insbesondere wenn du SQL Server 2016 und 2017 verwendest. Mehrere Verbesserungen der Skalierbarkeit von Query Store und Fehlerbehebungen wurden nach der ersten Veröffentlichung der Funktion veröffentlicht.
Du kannst auf zwei Arten mit dem Abfragespeicher arbeiten: über die grafische Benutzeroberfläche in SSMS oder indem du dynamische Managementansichten direkt abfragst. Schauen wir uns zuerst die Benutzeroberfläche an.
Abfrage von SSMS-Berichten
Nachdem du den Query Store in der Datenbank aktiviert hast, siehst du im Objekt-Explorer einen Ordner Query Store(Abbildung 4-5). Die Anzahl der Berichte in diesem Ordner hängt von den Versionen von SQL Server und SSMS in deinem System ab. Der Rest dieses Abschnitts führt dich durch die sieben in Abbildung 4-5 gezeigten Berichte.
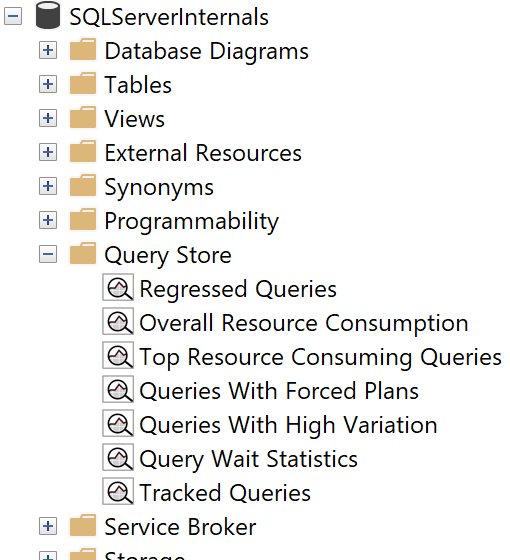
Abbildung 4-5. Query Store Berichte in SSMS
Regressive Abfragen
Dieser Bericht, der in Abbildung 4-6 dargestellt ist, zeigt Abfragen, deren Leistung sich im Laufe der Zeit verschlechtert hat. Du kannst den Zeitrahmen und die Regressionskriterien (wie Festplattenoperationen, CPU-Verbrauch und Anzahl der Ausführungen) für die Analyse konfigurieren.
Wähle die Abfrage in der Grafik im oberen linken Teil des Berichts aus. Im oberen rechten Teil des Berichts werden die gesammelten Ausführungspläne für die ausgewählte Abfrage angezeigt. Du kannst auf die Punkte klicken, die verschiedene Ausführungspläne darstellen, und die Pläne unten sehen. Du kannst auch verschiedene Ausführungspläne miteinander vergleichen.

Abbildung 4-6. Bericht Regressed Queries
Mit der Schaltfläche Plan erzwingen kannst du einen ausgewählten Plan für die Abfrage erzwingen. Sie ruft intern die Stored Procedure sys.sp_query_store_force_plan auf. Die Schaltfläche Plan aufheben hebt einen erzwungenen Plan auf, indem sie die gespeicherte Prozedur sys.sp_query_store_unforce_plan aufruft.
Der Bericht "Regressed Queries" ist ein großartiges Werkzeug, um Probleme im Zusammenhang mit dem Parameter-Sniffing, das wir in Kapitel 6 besprechen werden, zu beheben und sie schnell zu beheben, indem wir bestimmte Ausführungspläne erzwingen.
Die ressourcenintensivsten Abfragen
Mit dem Bericht (Abbildung 4-7) kannst du die ressourcenintensivsten Abfragen im System erkennen. Er funktioniert ähnlich wie die Daten in der Ansicht sys.dm_exec_query_stats, ist aber nicht vom Plan-Cache abhängig. Du kannst die für die Datensortierung verwendeten Metriken und das Zeitintervall anpassen.
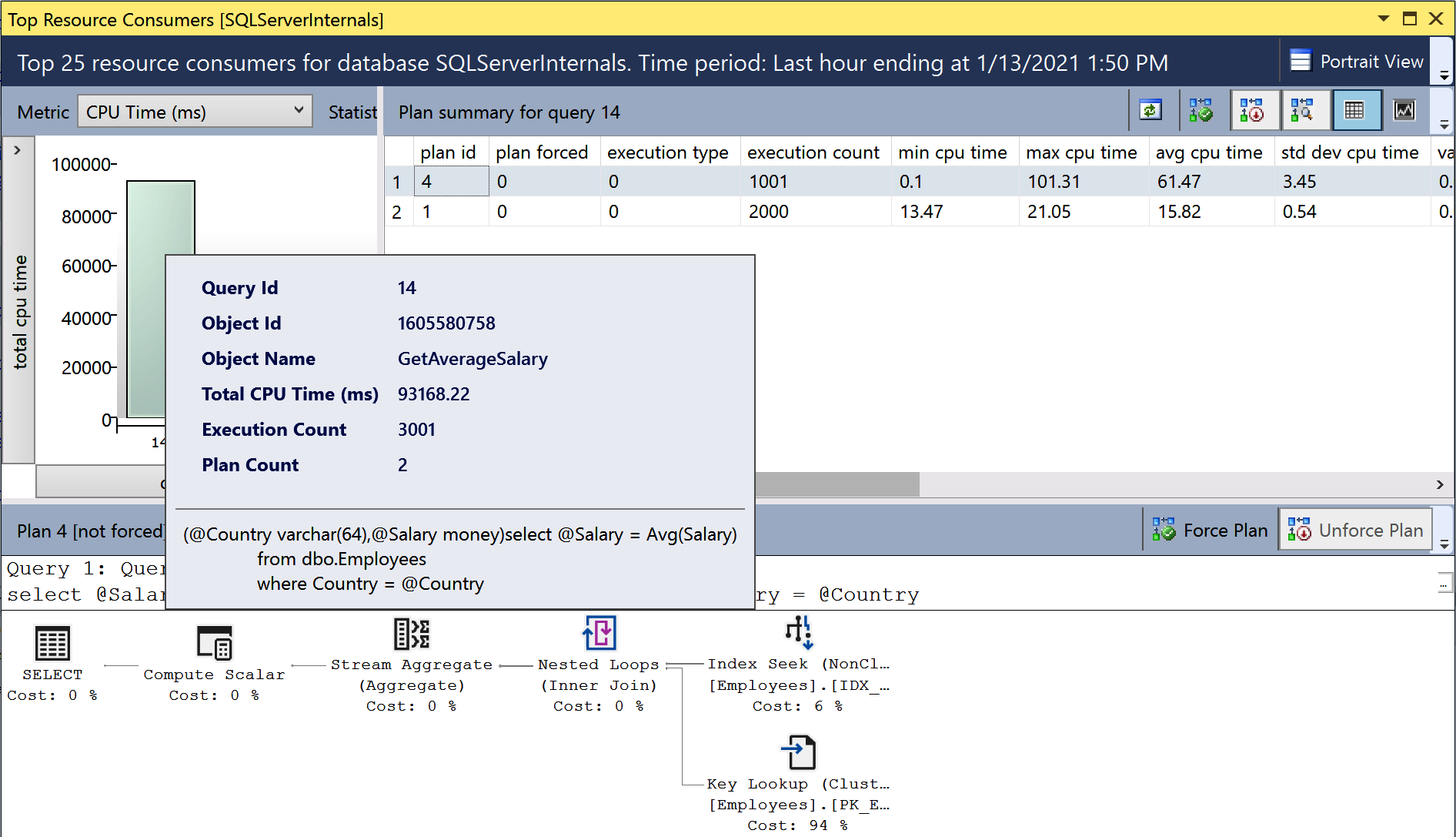
Abbildung 4-7. Bericht über die ressourcenintensivsten Abfragen
Gesamtressourcenverbrauch
Dieser Bericht zeigt die Statistiken und die Ressourcennutzung des Workloads über die angegebenen Zeitintervalle. Er ermöglicht es dir, Spitzen in der Ressourcennutzung zu erkennen und zu analysieren und die Abfragen aufzuschlüsseln, die solche Spitzen verursachen. Abbildung 4-8 zeigt die Ausgabe des Berichts.
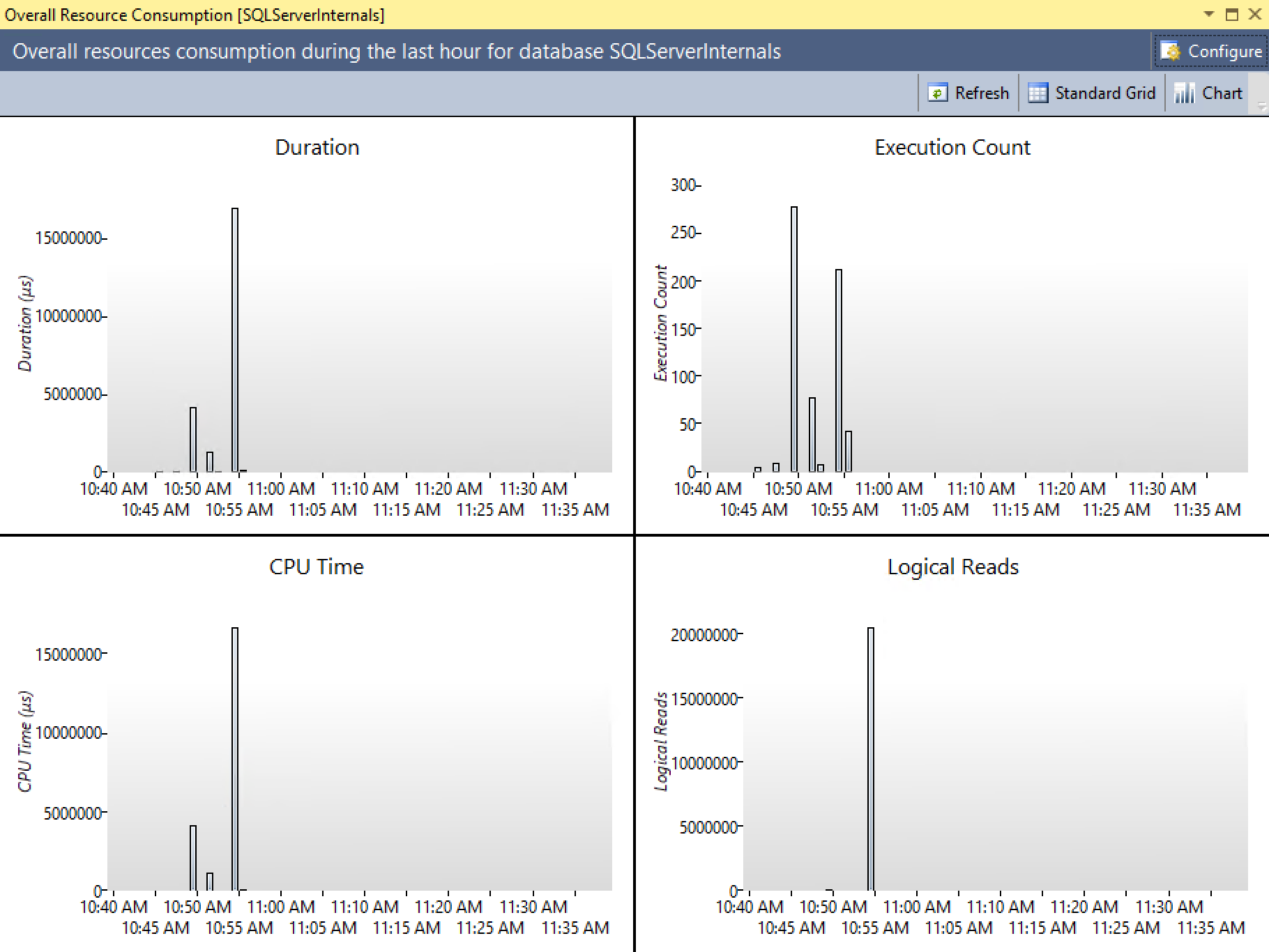
Abbildung 4-8. Bericht zum Gesamtressourcenverbrauch
Abfragen mit hoher Variation
Dieser Bericht ermöglicht es dir, Abfragen mit starken Leistungsschwankungen zu identifizieren. Du kannst ihn nutzen, um Anomalien in der Arbeitslast und mögliche Leistungseinbrüche zu erkennen. Um Platz im Buch zu sparen, verzichte ich darauf, Screenshots von jedem Bericht abzudrucken.
Abfrage-Wartestatistik
Dieser Bericht ermöglicht es dir, Abfragen mit hohen Wartezeiten zu erkennen. Die Daten werden nach verschiedenen Kategorien (z. B. CPU, Festplatte und blockierend) gruppiert, abhängig von der Warteart. Weitere Informationen über die Zuordnung von Wartezeiten findest du in der Microsoft-Dokumentation.
Verfolgte Abfragen
Mit dem Bericht Verfolgte Abfragen kannst du die Ausführungspläne und Statistiken für einzelne Abfragen überwachen. Er liefert ähnliche Informationen wie die Berichte "Regressed Queries" und "Top Resource Consuming Queries", allerdings auf Ebene der einzelnen Abfragen.
Diese Berichte liefern dir eine große Menge an Daten zur Analyse. In manchen Fällen möchtest du jedoch T-SQL verwenden und direkt mit den Daten aus dem Abfragespeicher arbeiten. Schauen wir uns an, wie du das machen kannst.
Arbeiten mit Query Store DMVs
Die dynamischen Verwaltungsansichten von Query Store sind hochgradig normalisiert, wie in Abbildung 4-9 dargestellt. Die Ausführungsstatistiken werden für jeden Ausführungsplan verfolgt und nach Erfassungsintervallen gruppiert, die durch die Einstellung INTERVAL_LENGTH_MINUTES festgelegt werden. Das Standardintervall von 60 Minuten ist in den meisten Fällen akzeptabel.
Wie du dir denken kannst, werden umso mehr Daten gesammelt und im Abfragespeicher gespeichert, je kleiner die Intervalle sind, die du verwendest. Das Gleiche gilt für die Systemauslastung: Eine übermäßige Anzahl von Ad-hoc-Abfragen kann die Größe des Abfragespeichers in die Höhe treiben. Behalte dies im Hinterkopf, wenn du den Abfragespeicher in deinem System konfigurierst.

Abbildung 4-9. Abfrage von Speicher-DMVs
Du kannst die DMVs logisch in zwei Kategorien einteilen: Planspeicher und Laufzeitstatistiken. Zu den Planlager-DMVs gehören die folgenden Ansichten :
sys.query_store_query- Die Ansicht
sys.query_store_queryenthält Informationen über Abfragen und ihre Kompilierungsstatistiken sowie den Zeitpunkt der letzten Ausführung. sys.query_store_query_text- Die Ansicht
sys.query_store_query_textzeigt Informationen über den Abfragetext an. sys.query_context_setting- Die Ansicht
sys.query_context_settingenthält Informationen über die mit der Abfrage verbundenen Kontexteinstellungen. Dazu gehörenSETOptionen, das Standardschema für die Sitzung, die Sprache und andere Attribute. SQL Server kann verschiedene Ausführungspläne für dieselbe Abfrage erstellen und zwischenspeichern, wenn diese Einstellungen unterschiedlich sind. sys.query_store_plan- Die Ansicht
sys.query_store_planenthält Informationen über Abfrageausführungspläne. Die Spalteis_forced_planzeigt an, ob der Plan erzwungen ist. Unterlast_force_failure_reasonerfährst du, warum ein erzwungener Plan nicht auf die Abfrage angewendet wurde.
Wie du sehen kannst, kann jede Abfrage mehrere Einträge in den Ansichten sys.query_store_query und sys.query_store_plan haben. Dies hängt von deinen Sitzungskontextoptionen, Neukompilierungen und anderen Faktoren ab.
Drei weitere Ansichten stellen Laufzeitstatistiken dar :
sys.query_store_runtime_stats_interval- Die Ansicht
sys.query_store_runtime_stats_intervalenthält Informationen über die Erfassungsintervalle der Statistiken. sys.query_store_runtime_stats- Die Ansicht
sys.query_store_runtime_statsverweist auf die Ansichtsys.query_store_planund enthält Informationen über Laufzeitstatistiken für einen bestimmten Plan während eines bestimmtensys.query_store_runtime_stats_intervalIntervalls. Sie enthält Informationen über die Anzahl der Ausführungen, die CPU-Zeit und die Dauer der Aufrufe, logische und physische E/A-Statistiken, die Nutzung des Transaktionsprotokolls, den Grad der Parallelität, die Größe des zugewiesenen Speichers und einige andere nützliche Metriken. sys.query_store_wait_stats- Ab SQL Server 2017 kannst du mit der Ansicht
sys.query_store_wait_statsInformationen über Abfragewartezeiten erhalten. Die Daten werden für jeden Plan und jedes Zeitintervall gesammelt und nach verschiedenen Wartekategorien gruppiert, darunter CPU, Speicher und Blockierung.
Sehen wir uns ein paar Szenarien für die Arbeit mit Query Store-Daten an.
Listing 4-8 enthält Code, der Informationen über die 50 I/O-intensivsten Abfragen des Systems liefert. Da der Query Store Ausführungsstatistiken über Zeitintervalle hinweg aufbewahrt, musst du die Daten aus mehreren sys.query_store_runtime_stats Zeilen zusammenfassen. Die Ausgabe enthält Daten für alle Intervalle, die innerhalb der letzten 24 Stunden endeten, gruppiert nach Abfragen und deren Ausführungsplänen.
Es ist erwähnenswert, dass die Datums-/Zeitangaben im Abfragespeicher den Datentyp datetimeoffset verwenden. Behalte dies im Hinterkopf, wenn du die Daten filterst.
Listing 4-8. Informationen über teure Abfragen aus dem Abfragespeicher abrufen
SELECT TOP 50
q.query_id, qt.query_sql_text, qp.plan_id, qp.query_plan
,SUM(rs.count_executions) AS [Execution Cnt]
,CONVERT(INT,SUM(rs.count_executions *
(rs.avg_logical_io_reads + avg_logical_io_writes)) /
SUM(rs.count_executions)) AS [Avg IO]
,CONVERT(INT,SUM(rs.count_executions *
(rs.avg_logical_io_reads + avg_logical_io_writes))) AS [Total IO]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_cpu_time) /
SUM(rs.count_executions)) AS [Avg CPU]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_cpu_time)) AS [Total CPU]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_duration) /
SUM(rs.count_executions)) AS [Avg Duration]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_duration))
AS [Total Duration]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_physical_io_reads) /
SUM(rs.count_executions)) AS [Avg Physical Reads]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_physical_io_reads))
AS [Total Physical Reads]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_query_max_used_memory) /
SUM(rs.count_executions)) AS [Avg Memory Grant Pages]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_query_max_used_memory))
AS [Total Memory Grant Pages]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_rowcount) /
SUM(rs.count_executions)) AS [Avg Rows]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_rowcount)) AS [Total Rows]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_dop) /
SUM(rs.count_executions)) AS [Avg DOP]
,CONVERT(INT,SUM(rs.count_executions * rs.avg_dop)) AS [Total DOP]
FROM
sys.query_store_query q WITH (NOLOCK)
JOIN sys.query_store_plan qp WITH (NOLOCK) ON
q.query_id = qp.query_id
JOIN sys.query_store_query_text qt WITH (NOLOCK) ON
q.query_text_id = qt.query_text_id
JOIN sys.query_store_runtime_stats rs WITH (NOLOCK) ON
qp.plan_id = rs.plan_id
JOIN sys.query_store_runtime_stats_interval rsi WITH (NOLOCK) ON
rs.runtime_stats_interval_id = rsi.runtime_stats_interval_id
WHERE
rsi.end_time >= DATEADD(DAY,-1,SYSDATETIMEOFFSET())
GROUP BY
q.query_id, qt.query_sql_text, qp.plan_id, qp.query_plan
ORDER BY
[Avg IO] DESC
OPTION (MAXDOP 1, RECOMPILE);
Natürlich kannst du die Daten auch nach anderen Kriterien als dem durchschnittlichen E/A sortieren. Du kannst auch Prädikate zu der WHERE und/oder HAVING Klausel der Abfrage hinzufügen, um die Ergebnisse einzugrenzen. Du kannst z. B. nach DOP-Spalten filtern, wenn du Abfragen erkennen willst, die in einer OLTP-Umgebung Parallelität nutzen, und die Einstellung der Kostenschwelle für Parallelität feinabstimmen.
Ein weiteres Beispiel ist die Erkennung von Abfragen, die den Plan-Cache überlasten. Der Code in Listing 4-9 liefert Informationen über Abfragen, die aufgrund unterschiedlicher Kontexteinstellungen mehrere Ausführungspläne erzeugen. Die beiden häufigsten Gründe dafür sind Sitzungen, die unterschiedliche SET Optionen verwenden, und Abfragen, die auf Objekte ohne Schemanamen verweisen.
Listing 4-9. Abfragen mit unterschiedlichen Kontexteinstellungen
SELECT
q.query_id, qt.query_sql_text
,COUNT(DISTINCT q.context_settings_id) AS [Context Setting Cnt]
,COUNT(DISTINCT qp.plan_id) AS [Plan Count]
FROM
sys.query_store_query q WITH (NOLOCK)
JOIN sys.query_store_query_text qt WITH (NOLOCK) ON
q.query_text_id = qt.query_text_id
JOIN sys.query_store_plan qp WITH (NOLOCK) ON
q.query_id = qp.query_id
GROUP BY
q.query_id, qt.query_sql_text
HAVING
COUNT(DISTINCT q.context_settings_id) > 1
ORDER BY
COUNT(DISTINCT q.context_settings_id)
OPTION (MAXDOP 1, RECOMPILE);
Listing 4-10 zeigt dir, wie du ähnliche Abfragen anhand des query_hash Wertes finden kannst (SQL in der Ausgabe steht für eine zufällig ausgewählte Abfrage aus der Gruppe). Normalerweise gehören diese Abfragen zu einem nicht parametrisierten Ad-hoc-Workload im System. Du kannst diese Abfragen im Code parametrisieren. Wenn das nicht möglich ist, kannst du die erzwungene Parametrisierung verwenden, die ich in Kapitel 6 erläutern werde.
Listing 4-10. Erkennen von Abfragen mit doppelten query_hash Werten
;WITH Queries(query_hash, [Query Count], [Exec Count], qtid)
AS
(
SELECT TOP 100
q.query_hash
,COUNT(DISTINCT q.query_id)
,SUM(rs.count_executions)
,MIN(q.query_text_id)
FROM
sys.query_store_query q WITH (NOLOCK)
JOIN sys.query_store_plan qp WITH (NOLOCK) ON
q.query_id = qp.query_id
JOIN sys.query_store_runtime_stats rs WITH (NOLOCK) ON
qp.plan_id = rs.plan_id
GROUP BY
q.query_hash
HAVING
COUNT(DISTINCT q.query_id) > 1
)
SELECT
q.query_hash
,qt.query_sql_text AS [Sample SQL]
,q.[Query Count]
,q.[Exec Count]
FROM
Queries q CROSS APPLY
(
SELECT TOP 1 qt.query_sql_text
FROM sys.query_store_query_text qt WITH (NOLOCK)
WHERE qt.query_text_id = q.qtid
) qt
ORDER BY
[Query Count] DESC, [Exec Count] DESC
OPTION(MAXDOP 1, RECOMPILE);
Wie du sehen kannst, sind die Möglichkeiten endlos. Verwende den Query Store, wenn du dir den Aufwand in deinem System leisten kannst.
Mit schließlich kannst du mit dem Befehl DBCC CLONEDATABASE einen reinen Schema-Klon der Datenbank erstellen und ihn zur Untersuchung von Leistungsproblemen verwenden. Standardmäßig enthält ein Klon auch die Daten des Query Stores. Du kannst ihn wiederherstellen und eine Analyse auf einem anderen Server durchführen, um den Overhead in der Produktion zu reduzieren .
Tools von Drittanbietern
Wie du jetzt gesehen hast ( ), bietet SQL Server eine Vielzahl von Werkzeugen, um ineffiziente Abfragen aufzuspüren. Dennoch kannst du auch von Überwachungs-Tools anderer Anbieter profitieren. Die meisten stellen dir eine Liste der ressourcenintensivsten Abfragen zur Analyse und Optimierung zur Verfügung. Viele geben dir auch die Basislinie an, die du nutzen kannst, um Trends zu analysieren und rückläufige Abfragen zu erkennen.
Ich werde nicht auf bestimmte Werkzeuge eingehen, sondern möchte dir stattdessen ein paar Tipps für die Auswahl und den Einsatz von Werkzeugen geben.
Der Schlüssel zur Nutzung eines Tools ist, es zu verstehen. Recherchiere, wie es funktioniert, analysiere seine Grenzen und welche Daten es möglicherweise übersieht. Wenn ein Tool z. B. Daten durch zeitgesteuerte Abfragen der Ansicht sys.dm_exec_requests erhält, entgeht ihm möglicherweise ein großer Teil der kleinen, aber häufig ausgeführten Abfragen, die zwischen den Abfragen laufen. Wenn ein Tool hingegen ineffiziente Abfragen durch Sitzungswartezeiten ermittelt, hängen die Ergebnisse stark von der Arbeitslast deines Systems, der Menge der im Pufferpool zwischengespeicherten Daten und vielen anderen Faktoren ab.
Je nach deinen spezifischen Bedürfnissen können diese Einschränkungen akzeptabel sein. Erinnere dich an das Pareto-Prinzip: Du musst nicht alle ineffizienten Abfragen im System optimieren, um eine gewünschte (oder akzeptable) Rendite zu erzielen. Dennoch kannst du von einer ganzheitlichen Sichtweise und von mehreren Perspektiven profitieren. Es ist zum Beispiel sehr einfach, die Liste der ineffizienten Abfragen eines Tools mit den Ausführungsstatistiken im Plan-Cache abzugleichen, um eine vollständigere Liste zu erhalten.
Es gibt aber noch einen weiteren wichtigen Grund, dein Werkzeug zu verstehen: die Abschätzung des Aufwands, den es verursachen könnte. Einige DMVs sind sehr teuer in der Ausführung. Wenn ein Tool z. B. die Funktion sys.dm_exec_query_plan bei jeder Abfrage von sys.dm_exec_requests aufruft, kann dies in stark ausgelasteten Systemen zu einem messbaren Anstieg des Overheads führen. Es ist auch nicht ungewöhnlich, dass Tools ohne dein Wissen Traces und xEvent-Sitzungen erstellen.
Vertraue nicht blind auf Whitepapers und Anbieter, wenn sie behaupten, dass ein Tool harmlos ist. Seine Auswirkungen können in verschiedenen Systemen unterschiedlich sein. Es ist immer besser, den Mehraufwand mit deinem Arbeitsaufwand zu testen, indem du das System mit und ohne das Tool als Grundlage verwendest. Bedenke, dass der Aufwand nicht immer statisch ist und sich erhöhen kann, wenn sich die Arbeitslast ändert.
Schließlich, bedenke die Sicherheitsaspekte bei der Auswahl der Tools. Viele Tools ermöglichen es dir, benutzerdefinierte Monitore zu erstellen, die Abfragen auf dem Server ausführen, was bösartigen Aktivitäten Tür und Tor öffnet. Erteile dem Login des Tools keine unnötigen Rechte und kontrolliere, wer Zugriff auf die Verwaltung des Tools hat.
Wähle schließlich den Ansatz, mit dem du ineffiziente Abfragen am besten erkennen kannst und der mit deinem System am besten funktioniert. Erinnere dich daran, dass die Optimierung von Abfragen in jedem System hilfreich ist.
Zusammenfassung
Ineffiziente Abfragen beeinträchtigen die Leistung von SQL Server und können das Plattensubsystem überlasten. Selbst in Systemen, die über genügend Speicher verfügen, um Daten im Pufferpool zwischenzuspeichern, verbrauchen diese Abfragen CPU, erhöhen die Sperrzeiten und beeinträchtigen das Kundenerlebnis.
SQL Server verfolgt die Ausführungsmetriken für jeden zwischengespeicherten Plan und zeigt sie in der Ansicht sys.dm_exec_query_stats an. Du kannst auch Ausführungsstatistiken für Stored Procedures, Trigger und benutzerdefinierte skalare Funktionen über die Ansichten sys.dm_exec_procedure_stats, sys.dm_exec_trigger_stats, und sys.dm_exec_function_stats abrufen.
Deine auf dem Plan-Cache basierenden Ausführungsstatistiken erfassen keine Laufzeitausführungsmetriken in Ausführungsplänen und enthalten auch keine Abfragen, für die keine Pläne im Cache gespeichert sind. Achte darauf, dass du dies bei deiner Analyse und beim Abfrage-Tuning berücksichtigst.
Du kannst ineffiziente Abfragen in Echtzeit mit Extended Events und SQL Traces erfassen. Beide Ansätze verursachen Overhead, besonders in stark ausgelasteten Systemen. Außerdem liefern sie Rohdaten, die du für weitere Analysen verarbeiten und aggregieren musst.
In SQL Server 2016 und höher kannst du den Query Store nutzen. Dies ist ein großartiges Werkzeug, das nicht vom Plan-Cache abhängt und es dir ermöglicht, Planrückschritte schnell zu erkennen. Der Query Store verursacht einen gewissen Overhead, der in vielen Fällen akzeptabel ist, aber du solltest ihn überwachen, wenn du die Funktion aktivierst.
Schließlich kannst du auch Überwachungs-Tools von Drittanbietern verwenden, um ineffiziente Abfragen zu finden. Erinnere dich daran, die Funktionsweise eines Tools zu recherchieren und seine Grenzen und seinen Overhead zu verstehen.
Im nächsten Kapitel werde ich ein paar gängige Techniken besprechen, mit denen du ineffiziente Abfragen optimieren kannst.
Checkliste zur Fehlersuche
-
Hol dir die Liste der ineffizienten Abfragen aus der Ansicht
sys.dm_exec_query_stats. Sortiere die Daten nach deiner Fehlerbehebungsstrategie (CPU, I/O usw.). -
Erkenne die teuersten Stored Procedures mit der Ansicht
sys.dm_exec_procedure_stats. -
Erwäge, den Abfragespeicher in deinem System zu aktivieren und die gesammelten Daten zu analysieren. (Das kann möglich sein oder auch nicht, wenn du bereits externe Überwachungs-Tools verwendest).
-
Aktiviere die Trace-Flags
T7745und7752, um die Leistung beim Herunterfahren und Starten des SQL Servers zu verbessern, wenn du den Query Store verwendest. -
Analysiere Daten aus Überwachungs-Tools von Drittanbietern und vergleiche sie mit SQL Server-Daten.
-
Analysiere den Overhead, den ineffiziente Abfragen im System verursachen. Setze den Ressourcenverbrauch der Abfragen mit den Wartestatistiken und der Serverlast in Beziehung.
-
Optimiere die Abfragen, wenn du feststellst, dass dies notwendig ist.
Get SQL Server Erweiterte Fehlersuche und Leistungsoptimierung now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

