Kapitel 1. SQL Server Einrichtung und Konfiguration
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Datenbank Server leben nie in einem Vakuum. Sie gehören zu einem Ökosystem aus einer oder mehreren Anwendungen, die von den Kunden genutzt werden. Die Anwendungsdatenbanken werden auf einer oder mehreren Instanzen von SQL Server gehostet, und diese Instanzen wiederum laufen auf physischer oder virtueller Hardware. Die Daten werden auf Festplatten gespeichert, die normalerweise mit anderen Kunden und Datenbanksystemen geteilt werden. Schließlich nutzen alle Komponenten ein Netzwerk für die Kommunikation und Speicherung.
Die Komplexität und die internen Abhängigkeiten von Datenbank-Ökosystemen machen die Fehlerbehebung zu einer sehr anspruchsvollen Aufgabe. Aus Sicht der Kunden stellen sich die meisten Probleme als allgemeine Leistungsprobleme dar: Die Anwendungen sind langsam und reagieren nicht mehr, Datenbankabfragen nehmen Zeit in Anspruch oder die Anwendungen können sich nicht mit der Datenbank verbinden. Die Ursache für diese Probleme kann überall liegen. Die Hardware könnte defekt oder falsch konfiguriert sein; die Datenbank könnte ein ineffizientes Schema, eine ineffiziente Indizierung oder einen ineffizienten Code haben; SQL Server könnte überlastet sein; die Client-Anwendungen könnten Bugs oder Designprobleme haben. Das bedeutet, dass du dein gesamtes System ganzheitlich betrachten musst, um Probleme zu erkennen und zu beheben.
In diesem Buch geht es um die Behebung von SQL Server-Problemen. Allerdings solltest du die Fehlersuche immer mit einer Analyse des Ökosystems deiner Anwendung und der SQL Server-Umgebung beginnen. Dieses Kapitel gibt dir eine Reihe von Richtlinien, wie du diese Überprüfung durchführst und die häufigsten Unzulänglichkeiten in SQL Server-Konfigurationen erkennst .
Zuerst gehe ich auf die Einrichtung der Hardware und des Betriebssystems ein. Als Nächstes spreche ich über den SQL Server und die Datenbankkonfiguration. Außerdem gehe ich auf die Konsolidierung von SQL Server und den Overhead ein, der durch die Überwachung des Systems entstehen kann.
Überlegungen zur Hardware und zum Betriebssystem
In den meisten Fällen finden Fehlerbehebungs- und Leistungsoptimierungsprozesse in Produktionssystemen statt, die viele Daten hosten und unter hoher Last arbeiten. Du musst dich mit den Problemen auseinandersetzen und die Live-Systeme tunen. Trotzdem lässt sich eine Diskussion über die Bereitstellung von Hardware nicht ganz vermeiden, vor allem, weil du nach der Fehlerbehebung vielleicht feststellst, dass deine Server mit der Last nicht mithalten können und aufgerüstet werden müssen .
Ich werde keine bestimmten Hersteller, Teile oder Modellnummern empfehlen; Computerhardware wird schnell verbessert und solche spezifischen Ratschläge wären zum Zeitpunkt der Veröffentlichung dieses Buches bereits veraltet. Stattdessen werde ich mich auf vernünftige Überlegungen konzentrieren, die langfristig relevant sind.
CPU
Die Lizenzkosten einer kommerziellen Datenbank-Engine sind bei weitem der teuerste Teil des Systems. SQL Server ist da keine Ausnahme: Du kannst einen anständigen Server für weniger als den Verkaufspreis von vier Kernen in der SQL Server Enterprise Edition bauen. Du solltest die leistungsstärkste CPU kaufen, die dein Budget zulässt, vor allem, wenn du eine Nicht-Enterprise Edition von SQL Server verwendest, die die Anzahl der Kerne, die du nutzen kannst, begrenzt.
Achte auf das CPU-Modell. Jede neue CPU-Generation bringt Leistungsverbesserungen gegenüber den vorherigen Generationen mit sich. Allein durch die Wahl neuerer CPUs kannst du eine Leistungssteigerung von 10 bis 15 % erzielen, selbst wenn beide CPU-Generationen die gleiche Taktfrequenz haben.
In einigen Fällen, in denen die Lizenzkosten keine Rolle spielen, musst du zwischen langsameren CPUs mit mehr Kernen und schnelleren CPUs mit weniger Kernen wählen. In diesem Fall hängt die Wahl stark von der Arbeitslast des Systems ab. Im Allgemeinen profitieren Systeme für Online Transactional Processing (OLTP) und insbesondere In-Memory OLTP von der höheren Single-Core-Leistung. Ein Data Warehouse und analytische Workloads hingegen können mit einem höheren Grad an Parallelität und mehr Kernen besser laufen.
Speicher
Es gibt einen Witz in der SQL Server Community, der so geht:
- Q. Wie viel Arbeitsspeicher braucht SQL Server normalerweise?
- A. Mehr.
Dieser Scherz hat seine Berechtigung. SQL Server profitiert von einem großen Arbeitsspeicher, der es ihm ermöglicht, mehr Daten zwischenzuspeichern. Das wiederum verringert die Anzahl der Ein-/Ausgabeaktivitäten auf der Festplatte und verbessert die Leistung von SQL Server. Daher kann die Erweiterung des Arbeitsspeichers die billigste und schnellste Methode sein, um einige Leistungsprobleme zu beheben.
Nehmen wir zum Beispiel an, das System leidet unter nicht optimierten Abfragen. Du könntest die Auswirkungen dieser Abfragen verringern, indem du Speicher hinzufügst und die damit verbundenen Lesevorgänge auf der Festplatte eliminierst. Damit wird die Ursache des Problems natürlich nicht behoben. Es ist auch gefährlich, denn wenn die Daten wachsen, passen sie möglicherweise nicht mehr in den Cache. In einigen Fällen kann dies jedoch als vorübergehende Notlösung akzeptabel sein.
Die Enterprise Edition von SQL Server hat keine Begrenzung des Arbeitsspeichers, den sie nutzen kann. Die Nicht-Enterprise-Editionen haben Einschränkungen. Was die Arbeitsspeicherauslastung angeht, kann die Standard Edition von SQL Server 2014 und höher bis zu 128 GB RAM für den Pufferpool, 32 GB RAM pro Datenbank für In-Memory OLTP-Daten und 32 GB RAM für die Speicherung von Columnstore-Indexsegmenten verwenden. Der Speicherbedarf der Web Edition ist auf die Hälfte der Standard Edition begrenzt. Berücksichtige diese Beschränkungen bei deiner Analyse, wenn du Instanzen von SQL Server, die nicht zur Enterprise Edition gehören, bereitstellst oder aktualisierst. Vergiss nicht, anderen SQL Server-Komponenten, wie dem Plan-Cache und dem Lock Manager, zusätzlichen Speicher zuzuweisen.
Am Ende solltest du so viel Speicherplatz hinzufügen, wie du dir leisten kannst. Heutzutage ist er billig. Es gibt keinen Grund, zu viel Speicher zuzuweisen, wenn deine Datenbanken klein sind, aber denke an das zukünftige Datenwachstum.
Disk Subsystem
Ein gesundes , schnelles Festplattensubsystem ist für eine gute SQL Server-Leistung unerlässlich. SQL Server ist eine sehr E/A-intensive Anwendung - es werden ständig Daten von der Festplatte gelesen und auf die Festplatte geschrieben.
Es gibt viele Möglichkeiten, das Plattensubsystem für SQL Server-Installationen zu gestalten. Wichtig ist, dass es so aufgebaut ist, dass die Latenzzeit für E/A-Anfragen gering ist. Für kritische Tier-1-Systeme empfehle ich eine Latenz von 3 bis 5 Millisekunden (ms) für das Lesen und Schreiben von Datendateien und eine Latenz von 1 ms bis 2 ms für das Schreiben von Transaktionsprotokollen. Zum Glück lassen sich diese Werte mit Flash-basierter Speicherung leicht erreichen.
Die Sache hat allerdings einen Haken: Wenn du Probleme mit der E/A-Leistung in SQL Server behebst, musst du die Latenzmetriken innerhalb von SQL Server und nicht auf der Ebene der Speicherung analysieren. Aufgrund der Warteschlangen, die bei E/A-intensiven Arbeitslasten auftreten können, werden in der Regel deutlich höhere Zahlen im SQL Server als in den KPIs (Key Performance Indicators) der Speicherung angezeigt.(In Kapitel 3 wird erläutert, wie E/A-Leistungsdaten erfasst und analysiert werden).
Wenn dein Speichersubsystem mehrere Leistungsstufen anbietet, empfehle ich, die Datenbank tempdb auf das schnellste Laufwerk zu legen, gefolgt vom Transaktionsprotokoll und den Datendateien. Die tempdb Datenbank ist die gemeinsam genutzte Ressource auf dem Server, und es ist wichtig, dass sie einen guten E/A-Durchsatz hat.
Die Schreibvorgänge in die Transaktionsprotokolldateien sind synchron. Es ist wichtig, dass die Schreiblatenz für diese Dateien gering ist. Die Schreibvorgänge in das Transaktionsprotokoll erfolgen ebenfalls sequentiell. Du solltest dich jedoch daran erinnern, dass mehrere Protokoll- und/oder Datendateien auf demselben Laufwerk zu zufälligen E/A über mehrere Datenbanken hinweg führen.
Als bewährte Methode würde ich die Daten und die Protokolldateien aus Gründen der Wartbarkeit und Wiederherstellbarkeit auf verschiedenen physischen Laufwerken speichern. Du musst dir jedoch die zugrunde liegende Konfiguration der Speicherung ansehen. Wenn Disk-Arrays nicht über genügend Spindeln verfügen, kann die Aufteilung auf mehrere LUNs in manchen Fällen die Leistung des Disk-Arrays beeinträchtigen.
In meinen Systemen teile ich geclusterte und nicht geclusterte Indizes nicht auf mehrere Dateigruppen auf, indem ich sie auf verschiedene Laufwerke lege. Das verbessert die E/A-Leistung nur selten, es sei denn, du kannst die Speicherpfade zwischen den Dateigruppen vollständig trennen. Andererseits kann diese Konfiguration die Wiederherstellung im Notfall erheblich erschweren.
Schließlich solltest du dich daran erinnern, dass einige SQL Server-Technologien von einer guten sequenziellen E/A-Leistung profitieren. In-Memory OLTP zum Beispiel verwendet überhaupt keine zufällige E/A, und die Leistung der sequenziellen Lesevorgänge wird in der Regel zum begrenzenden Faktor für das Starten und Wiederherstellen der Datenbank. Auch Data Warehouse-Scans würden von der sequentiellen E/A-Leistung profitieren, wenn B-Tree- und Columnstore-Indizes nicht stark fragmentiert sind. Der Unterschied zwischen sequentieller und zufälliger E/A-Leistung ist bei flashbasierter Speicherung nicht sehr groß; bei magnetischen Laufwerken kann er jedoch ein großer Faktor sein.
Netzwerk
SQL Server kommuniziert mit Clients und anderen Servern über das Netzwerk. Natürlich muss er genügend Bandbreite zur Verfügung stellen, um diese Kommunikation zu unterstützen. In diesem Zusammenhang gibt es einige Punkte, die ich erwähnen möchte.
Zunächst musst du die gesamte Netzwerktopologie analysieren, wenn du Probleme mit der Netzwerkleistung behebst. Erinnere dich daran, dass der Durchsatz eines Netzwerks auf die Geschwindigkeit der langsamsten Komponente begrenzt ist. Du kannst z. B. einen Uplink vom Server mit 10 Gbit/s haben, aber wenn du einen Switch mit 1 Gbit/s im Netzwerkpfad hast, wird dieser zum begrenzenden Faktor. Das ist besonders wichtig für die netzwerkbasierte Speicherung: Stelle sicher, dass der I/O-Pfad zu den Festplatten so effizient wie möglich ist.
Zweitens ist es eine gängige Praxis, ein separates Netzwerk für den Cluster Heartbeat in AlwaysOn Failover Clusters und AlwaysOn Availability Groups aufzubauen. In manchen Fällen kannst du auch ein separates Netzwerk für den gesamten Datenverkehr der Availability Group einrichten. Dies ist ein guter Ansatz, der die Zuverlässigkeit des Clusters in einfachen Konfigurationen verbessert, wenn alle Clusterknoten zum selben Subnetz gehören und Layer-2-Routing nutzen können. In komplexen Multisubnetz-Konfigurationen können mehrere Netzwerke jedoch zu Routing-Problemen führen. Sei bei solchen Konfigurationen vorsichtig und achte darauf, dass die Netzwerke bei der knotenübergreifenden Kommunikation richtig genutzt werden, vor allem in virtuellen Umgebungen, die ich in Kapitel 15 besprechen werde.
Virtualisierung fügt hier eine weitere Ebene der Komplexität hinzu. Stellen Sie sich eine Situation vor, in der Sie einen virtualisierten SQL Server-Cluster mit Knoten auf verschiedenen Hosts haben. Du musst sicherstellen, dass die Hosts den Datenverkehr im Clusternetzwerk vom Client-Datenverkehr trennen und weiterleiten können. Wenn du den gesamten vLan-Verkehr über eine einzige physische Netzwerkkarte leitest, würde das den Zweck eines Heartbeat-Netzwerks zunichte machen.
Betriebssysteme und Anwendungen
Als allgemeine Regel empfehle ich, die neueste Version eines Betriebssystems zu verwenden, das deine Version von SQL Server unterstützt. Vergewissere dich, dass sowohl das Betriebssystem als auch SQL Server gepatcht sind, und implementiere einen Prozess, um regelmäßig Patches zu installieren.
Wenn du eine alte Version von SQL Server (vor 2016) verwendest, nutze die 64-Bit-Variante. In den meisten Fällen ist die 64-Bit-Version leistungsfähiger als die 32-Bit-Version und skaliert besser mit der Hardware.
Seit SQL Server 2017 ist es möglich, Linux als Host für den Datenbankserver zu verwenden. In Bezug auf die Leistung sind die Windows und Linux Versionen von SQL Server sehr ähnlich. Die Wahl des Betriebssystems hängt vom Ökosystem des Unternehmens ab und davon, was dein Team am liebsten unterstützt. Bedenke, dass Linux-basierte Implementierungen eine etwas andere Hochverfügbarkeitsstrategie (HA) erfordern können als eine Windows-Installation. So kann es beispielsweise sein, dass du für automatische Failover auf Pacemaker statt auf Windows Server Failover Cluster (WSFC) zurückgreifen musst.
Verwende, wenn möglich, einen eigenen SQL Server-Host. Erinnere dich daran, dass es einfacher und billiger ist, die Anwendungsserver zu skalieren - verschwende keine wertvollen Ressourcen auf dem Datenbankhost!
Außerdem solltest du keine unwichtigen Prozesse auf dem Server ausführen. Ich sehe immer wieder, wie Datenbankingenieure das SQL Server Management Studio (SSMS) in Remote-Desktop-Sitzungen ausführen. Es ist immer besser, aus der Ferne zu arbeiten und keine Serverressourcen zu verbrauchen.
Wenn du eine Antivirensoftware auf dem Server ausführen musst, schließe alle Datenbankordner von der Überprüfung aus.
Virtualisierung und Clouds
Moderne IT-Infrastrukturen hängen stark von der Virtualisierung ab, die zusätzliche Flexibilität bietet, die Verwaltung vereinfacht und die Hardwarekosten reduziert. Infolgedessen wirst du immer häufiger mit einer virtualisierten SQL Server-Infrastruktur arbeiten müssen.
Daran gibt es nichts auszusetzen. Richtig implementierte Virtualisierung bietet dir viele Vorteile bei akzeptablem Leistungs-Overhead. Sie fügt mit VMware vSphere vMotion oder Hyper-V Live Migration eine weitere HA-Ebene hinzu. Sie ermöglicht es dir, die Hardware nahtlos aufzurüsten und vereinfacht das Datenbankmanagement. Wenn es sich bei deinem System nicht um einen Grenzfall handelt, bei dem du das Maximum aus der Hardware herausholen musst, empfehle ich dir, dein SQL Server-Ökosystem zu virtualisieren.
Hinweis
Auf großen Servern mit vielen CPUs steigt der Overhead durch die Virtualisierung. In vielen Fällen kann er jedoch noch akzeptabel sein.
Durch die Virtualisierung wird die Fehlerbehebung jedoch noch komplexer. Zusätzlich zu den Metriken der virtuellen Gastmaschine (VM) musst du auf den Zustand und die Auslastung des Hosts achten. Erschwerend kommt hinzu, dass die Auswirkungen eines überlasteten Hosts auf die Leistung in den Standard-Leistungskennzahlen eines Gastbetriebssystems möglicherweise nicht klar erkennbar sind.
In Kapitel 15 werde ich verschiedene Ansätze zur Fehlerbehebung in der Virtualisierungsschicht erörtern. Du kannst jedoch damit beginnen, mit den Infrastrukturtechnikern zusammenzuarbeiten, um sicherzustellen, dass der Host nicht überprovisioniert ist. Achte auf die Anzahl der physischen CPUs und zugewiesenen vCPUs auf dem Host sowie auf den physischen und zugewiesenen Speicher. Für geschäftskritische SQL Server-VMs sollten Ressourcen reserviert werden, um Leistungseinbußen zu vermeiden.
Abgesehen von der Virtualisierungsebene ist die Fehlerbehebung bei virtualisierten SQL Server-Instanzen dieselbe wie bei physischen Instanzen. Das Gleiche gilt für Cloud-Installationen, wenn SQL Server innerhalb von VMs ausgeführt wird. Schließlich ist die Cloud nur ein anderes Rechenzentrum, das von einem externen Provider verwaltet wird.
Konfigurieren des SQL Servers
Die Standardkonfiguration für den SQL Server-Setup-Prozess ist relativ anständig und kann für leichte und sogar mittlere Arbeitslasten geeignet sein. Es gibt jedoch einige Dinge, die du überprüfen und anpassen musst.
SQL Server Version und Patching Level
SELECT @@VERSION ist die erste Anweisung, die ich während der SQL Server-Systemüberprüfung ausführe. Dafür gibt es zwei Gründe. Erstens verschafft sie mir einen Einblick in die Patching-Strategie des Systems, sodass ich eventuell Verbesserungen vorschlagen kann. Zweitens hilft sie mir, mögliche bekannte Probleme im System zu identifizieren.
Der letzte Grund ist sehr wichtig. Oft haben mich Kunden gebeten, Probleme zu beheben, die bereits durch Service Packs und kumulative Updates behoben wurden. Sieh dir immer die Versionshinweise an, um zu sehen, ob dir eines der genannten Probleme bekannt vorkommt; möglicherweise wurde dein Problem bereits behoben.
Wenn möglich, solltest du auf die neueste Version von SQL Server aktualisieren. Jede Version bringt Leistungs-, Funktions- und Skalierbarkeitsverbesserungen mit sich. Das gilt besonders, wenn du von älteren Versionen auf SQL Server 2016 oder später umsteigst. SQL Server 2016 war eine Meilensteinversion, die viele Leistungsverbesserungen enthielt. Meiner Erfahrung nach kann ein Upgrade von SQL Server 2012 auf 2016 oder eine neuere Version die Leistung ohne zusätzliche Schritte um 20 bis 40 % verbessern.
Es ist auch erwähnenswert, dass ab SQL Server 2016 SP1 viele Funktionen, die früher nur in der Enterprise Edition enthalten waren, nun auch in den niedrigeren Editionen des Produkts verfügbar sind. Einige von ihnen, wie die Datenkomprimierung, ermöglichen es SQL Server, mehr Daten im Pufferpool zwischenzuspeichern und die Systemleistung zu verbessern.
Natürlich musst du das System vor dem Upgrade testen - es besteht immer die Möglichkeit von Rückschritten. Bei kleineren Patches ist das Risiko in der Regel gering, bei größeren Upgrades steigt es jedoch an. Wie du später in diesem Kapitel sehen wirst, kannst du einige Risiken mit verschiedenen Datenbankoptionen abmildern.
Sofortige Datei-Initialisierung
Jedes Mal, wenn SQL Server Daten- und Transaktionsprotokolldateien vergrößert - entweder automatisch oder als Teil des Befehls ALTER DATABASE - füllt er den neu zugewiesenen Teil der Datei mit Nullen. Dieser Prozess blockiert alle Sitzungen, die versuchen, in die entsprechende Datei zu schreiben, und im Falle des Transaktionsprotokolls werden keine Protokollsätze mehr erzeugt. Er kann auch zu einer Erhöhung der E/A-Schreiblast führen.
Dieses Verhalten kann für Transaktionsprotokolldateien nicht geändert werden; SQL Server löscht sie immer auf Null. Du kannst es jedoch für Datendateien deaktivieren, indem du die Instant File Initialization (IFI) aktivierst. Dies beschleunigt das Wachstum der Datendateien und verkürzt die Zeit, die zum Erstellen oder Wiederherstellen von Datenbanken benötigt wird.
Du kannst IFI aktivieren, indem du dem SQL Server-Startkonto die Berechtigung SA_MANAGE_VOLUME_NAME, auch bekannt als Volume Maintenance Task, erteilst. Dies kannst du in der Anwendung zur Verwaltung der lokalen Sicherheitsrichtlinien(secpol.msc) tun. Du musst SQL Server neu starten, damit die Änderung wirksam wird .
In SQL Server 2016 und höher kannst du diese Berechtigung auch als Teil des SQL Server-Setup-Prozesses erteilen, wie in Abbildung 1-1 dargestellt.
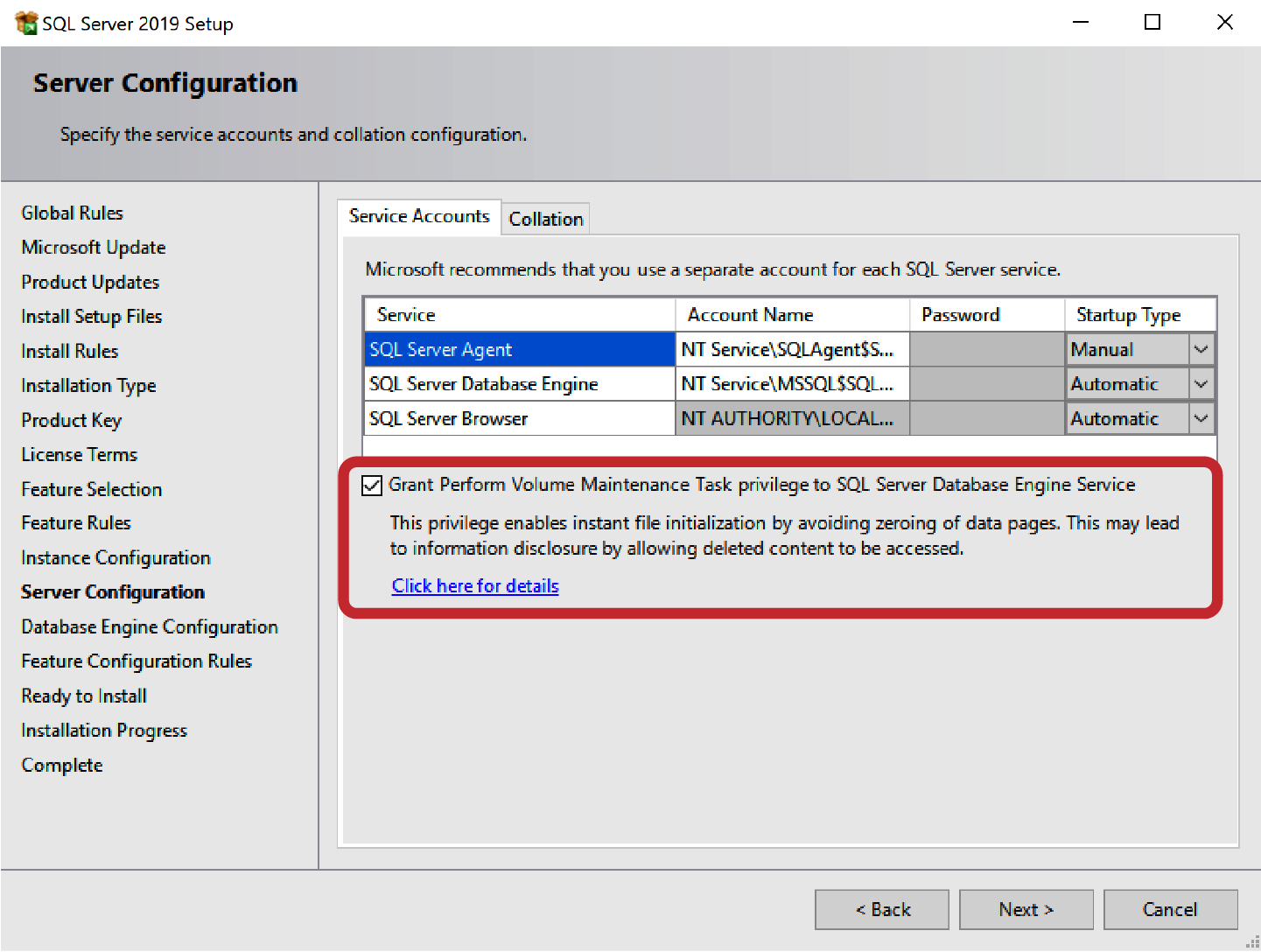
Abbildung 1-1. Aktivieren von IFI während der SQL Server-Einrichtung
Du kannst überprüfen, ob IFI aktiviert ist, indem du die Spalte instant_file_initialization_enabled in der sys.dm_server_services dynamic management view (DMV) untersuchst. Diese Spalte ist in SQL Server 2012 SP4, SQL Server 2016 SP1 und später verfügbar. In älteren Versionen kannst du den in Listing 1-1 gezeigten Code ausführen.
Listing 1-1. Prüfen, ob die sofortige Dateiinitialisierung in alten SQL Server-Versionen aktiviert ist
DBCC TRACEON(3004,3605,-1); GO CREATE DATABASE Dummy; GO EXEC sp_readerrorlog 0,1,N'Dummy'; GO DROP DATABASE Dummy; GO DBCC TRACEOFF(3004,3605,-1); GO
Wenn IFI nicht aktiviert ist, zeigt das SQL Server-Protokoll an, dass SQL Server nicht nur die .mdf-Datendatei, sondern auch die .ldf-Protokolldatei löscht, wie in Abbildung 1-2 dargestellt. Wenn IFI aktiviert ist, wird nur das Löschen der .ldf-Datei im Protokoll angezeigt.
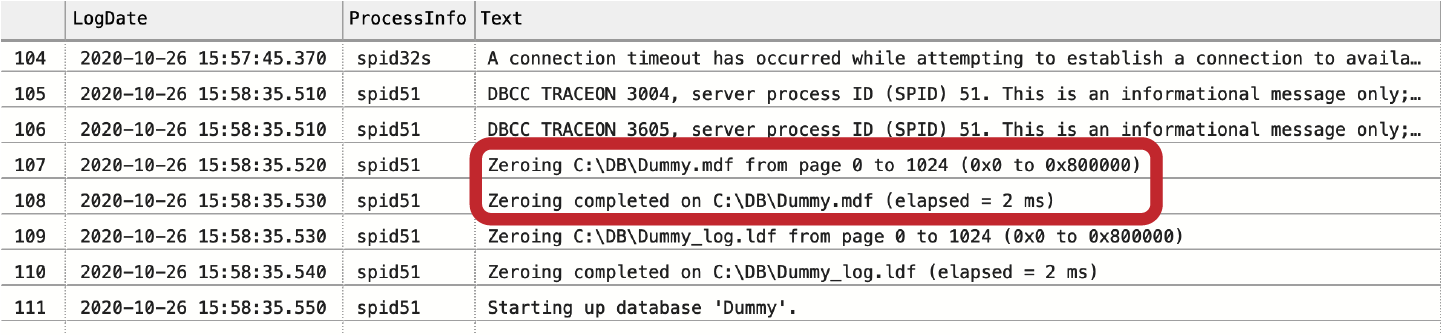
Abbildung 1-2. Prüfen, ob die sofortige Dateiinitialisierung aktiviert ist
Mit dieser Einstellung ist ein kleines Sicherheitsrisiko verbunden. Wenn IFI aktiviert ist, können Datenbankadministratoren einige Daten von zuvor gelöschten Dateien im Betriebssystem sehen, wenn sie sich die neu zugewiesenen Datenseiten in der Datenbank ansehen. Das ist in den meisten Systemen akzeptabel; wenn das der Fall ist, aktiviere es.
tempdb Konfiguration
Die tempdb ist die Systemdatenbank, in der temporäre Objekte gespeichert werden, die von Benutzern und von SQL Server intern erstellt wurden. Es handelt sich um eine sehr aktive Datenbank, die oft zu einer Quelle von Konflikten im System wird. Die Behebung von tempdb-bezogenen Problemen wird in Kapitel 9 besprochen; in diesem Kapitel konzentriere ich mich auf die Konfiguration.
Wie bereits erwähnt, musst du tempdb auf dem schnellsten Laufwerk im System ablegen. Im Allgemeinen muss dieses Laufwerk weder redundant noch persistent sein - die Datenbank wird beim Start von SQL Server neu erstellt. Erinnere dich jedoch daran, dass der SQL Server ausfällt, wenn tempdb nicht verfügbar ist, und berücksichtige dies bei deiner Planung.
Wenn du eine Nicht-Enterprise Edition von SQL Server verwendest und der Server mehr Speicher hat, als SQL Server verbrauchen kann, kannst du tempdb auf das RAM-Laufwerk legen. Bei der SQL Server Enterprise Edition solltest du dies jedoch nicht tun, da du in der Regel eine bessere Leistung erzielst, wenn du den Speicher für den Pufferpool nutzt.
Hinweis
Weisen Sie die Dateien von tempdb der maximalen Größe des RAM-Laufwerks zu und erstellen Sie zusätzliche kleine Daten- und Protokolldateien auf der Festplatte, damit der Platz nicht knapp wird. SQL Server verwendet kleine Dateien auf der Festplatte erst dann, wenn die Dateien auf dem RAM Drive voll sind.
Die Datenbank tempdb sollte immer mehrere Datendateien haben. Leider ist die Standardkonfiguration, die bei der Einrichtung des SQL Servers erstellt wird, nicht optimal, vor allem in den alten Versionen des Produkts. Wie du die Anzahl der Datendateien in tempdb feinabstimmst, erkläre ich in Kapitel 9, aber du kannst bei der Erstkonfiguration folgende Faustregel verwenden:
-
Wenn der Server acht oder weniger CPU-Kerne hat, erstelle die gleiche Anzahl von Datendateien.
-
Wenn der Server mehr als acht CPU-Kerne hat, verwende entweder acht Datendateien oder ein Viertel der Anzahl der Kerne, je nachdem, was größer ist, und runde in Stapeln von vier Dateien auf. Verwende z.B. 8 Datendateien für einen 24-Kern-Server und 12 Datendateien für einen 40-Kern-Server.
Stellen Sie schließlich sicher, dass alle tempdb Datendateien die gleiche Anfangsgröße haben und die Parameter für das automatische Wachstum in Megabyte (MB) statt in Prozent angegeben werden. So kann SQL Server die Nutzung der Datendateien besser ausgleichen und mögliche Konflikte im System verringern.
Trace-Flags
SQL Server verwendet Trace-Flags, um das Verhalten einiger Produktfunktionen zu aktivieren oder zu ändern. Obwohl Microsoft in neuen Versionen von SQL Server immer mehr Datenbank- und Serverkonfigurationsoptionen eingeführt hat, werden Trace-Flags immer noch häufig verwendet. Du musst überprüfen, ob Trace-Flags im System vorhanden sind; eventuell musst du auch einige von ihnen aktivieren.
Du kannst die Liste der aktivierten Trace-Flags erhalten, indem du den Befehl DBCC TRACESTATUS ausführst. Du kannst sie im SQL Server-Konfigurationsmanager und/oder mit der Option -T SQL Server Startup aktivieren.
Schauen wir uns einige gängige Trace-Flags an:
T1118- Dieses Trace-Flag verhindert die Verwendung von gemischten Extents in SQL Server. Dies trägt dazu bei, den
tempdbDurchsatz in SQL Server 2014 und früheren Versionen zu verbessern, indem es die Anzahl der Änderungen und damit die Konkurrenzsituation intempdbSystemkatalogen verringert. Dieses Trace-Flag ist in SQL Server 2016 und neuer nicht erforderlich, datempdbstandardmäßig keine gemischten Extents verwendet. T1117- Mit diesem Trace-Flag vergrößert SQL Server automatisch alle Datendateien in der Dateigruppe, wenn in einer der Dateien kein Platz mehr ist. Dies sorgt für eine gleichmäßigere E/A-Verteilung auf die Datendateien. Du solltest dieses Trace-Flag aktivieren, um den
tempdbDurchsatz in alten Versionen von SQL Server zu verbessern; überprüfe jedoch, ob die Datenbanken der Benutzer Dateigruppen mit mehreren ungleichmäßig großen Datendateien haben. Wie beiT1118ist dieses Trace-Flag in SQL Server 2016 und höher nicht erforderlich, datempdbstandardmäßig alle Datendateien automatisch vergrößert. T2371- Standardmäßig aktualisiert SQL Server die Statistiken erst dann automatisch, wenn 20% der Daten im Index geändert wurden. Das bedeutet, dass die Statistiken bei großen Tabellen selten automatisch aktualisiert werden. Das
T2371trace Flag ändert dieses Verhalten, indem es den Schwellenwert für die Statistikaktualisierung dynamisch macht - je größer die Tabelle ist, desto niedriger ist der Prozentsatz der Änderungen, die erforderlich sind, um die Aktualisierung auszulösen. Ab SQL Server 2016 kannst du dieses Verhalten auch über die Datenbankkompatibilitätsebene steuern. Trotzdem empfehle ich, dieses Trace-Flag zu aktivieren, es sei denn, alle Datenbanken auf dem Server haben eine Kompatibilitätsstufe von 130 oder höher. T3226- Mit diesem Trace-Flag schreibt SQL Server keine Informationen über erfolgreiche Datenbanksicherungen in das Fehlerprotokoll. Dies kann dazu beitragen, die Größe der Protokolle zu reduzieren, so dass sie besser verwaltet werden können.
T1222- Dieses Trace-Flag schreibt Deadlock-Graphen in das SQL Server-Fehlerprotokoll. Dieses Flag ist harmlos, erschwert aber das Lesen und Parsen der SQL Server-Protokolle . Außerdem ist es überflüssig - du kannst bei Bedarf ein Deadlock-Diagramm aus einer
System_HealthExtended Event-Sitzung abrufen. Normalerweise entferne ich dieses Trace-Flag, wenn ich es sehe. T4199- Dieses Trace-Flag und die Option
QUERY_OPTIMIZER_HOTFIXESdatabase (in SQL Server 2016 und höher) steuern das Verhalten von Query Optimizer Hotfixes. Wenn dieses Trace-Flag aktiviert ist, werden die in Service Packs und kumulativen Updates eingeführten Hotfixes verwendet . Dies kann dazu beitragen, einige Fehler im Query Optimizer zu beheben und die Abfrageleistung zu verbessern; es erhöht jedoch auch das Risiko von Planrückschritten nach dem Patching. In der Regel aktiviere ich dieses Trace-Flag in Produktionssystemen nicht, es sei denn, es ist möglich, vor dem Patching gründliche Regressionstests des Systems durchzuführen. T7412- Dieses Trace-Flag ermöglicht ein leichtes Ausführungsprofil der Infrastruktur in SQL Server 2016 und 2017. Damit kannst du mit geringem CPU-Overhead Ausführungspläne und viele Ausführungsmetriken für die Abfragen im System sammeln. Ich werde in Kapitel 5 näher darauf eingehen.
Zusammenfassend lässt sich sagen, dass du in SQL Server 2014 und früher T1118, T2371 und möglicherweise T1117 aktivieren musst. In SQL Server 2016 und später aktivierst du T2371, es sei denn, alle Datenbanken haben eine Kompatibilitätsstufe von 130 oder höher. Danach solltest du dir alle anderen Trace-Flags im System ansehen und verstehen, was sie bewirken. Einige Trace-Flags können versehentlich von Drittanbieter-Tools installiert werden und sich negativ auf die Serverleistung auswirken.
Server Optionen
SQL Server bietet viele Konfigurationseinstellungen. Viele von ihnen werde ich später im Buch ausführlich behandeln, aber ein paar Einstellungen sind es wert, hier erwähnt zu werden.
Optimieren für Ad-hoc-Arbeitslasten
Die erste Konfigurationseinstellung, die ich besprechen werde, ist Optimize for Ad-hoc Workloads. Diese Konfigurationsoption steuert, wie SQL Server die Ausführungspläne von Ad-hoc-Abfragen (ohne Parameter) zwischenspeichert. Wenn diese Einstellung deaktiviert ist (Standardeinstellung), speichert SQL Server die vollständigen Ausführungspläne dieser Anweisungen im Cache, was die Speichernutzung des Plan-Caches erheblich erhöhen kann. Wenn diese Einstellung aktiviert ist, beginnt SQL Server mit der Zwischenspeicherung einer kleinen Struktur (nur ein paar hundert Bytes), dem so genannten Plan-Stub, und ersetzt ihn durch den vollständigen Ausführungsplan, wenn eine Ad-hoc-Abfrage zum zweiten Mal ausgeführt wird.
In den meisten Fällen werden Ad-hoc-Anweisungen nicht wiederholt ausgeführt, und es ist von Vorteil, die Einstellung Optimize for Ad-hoc Workloads in jedem System zu aktivieren. Dadurch kann die Speichernutzung des Plan-Caches erheblich reduziert werden, allerdings um den Preis, dass die Ad-hoc-Abfragen nur selten neu kompiliert werden müssen. Diese Einstellung hat natürlich keine Auswirkungen auf das Caching-Verhalten von parametrisierten Abfragen und T-SQL-Datenbankcode.
Maximaler Server-Speicher
Die zweite wichtige Einstellung ist Max Server Memory, die festlegt, wie viel Speicher SQL Server verbrauchen kann. Datenbankingenieure diskutieren gerne darüber, wie man diese Einstellung richtig konfiguriert, und es gibt verschiedene Ansätze, um den richtigen Wert dafür zu berechnen. Viele Techniker schlagen sogar vor, den Standardwert beizubehalten und SQL Server den Wert automatisch verwalten zu lassen. Meiner Meinung nach ist es am besten, diese Einstellung fein abzustimmen, aber es ist wichtig, dies richtig zu tun(in Kapitel 7 werden die Details besprochen). Eine falsche Einstellung beeinträchtigt die Leistung von SQL Server stärker, als wenn du den Standardwert beibehältst.
Ein besonderes Problem, auf das ich bei Systemüberprüfungen häufig stoße, ist die stark unterdurchschnittliche Bereitstellung dieser Einstellung. Manchmal wird vergessen, diese Einstellung nach Hardware- oder VM-Upgrades zu ändern; manchmal wird sie in nicht dedizierten Umgebungen, in denen SQL Server den Server mit anderen Anwendungen teilt, falsch berechnet. In beiden Fällen kannst du sofortige Verbesserungen erzielen, indem du die Einstellung für den maximalen Serverspeicher erhöhst oder ihn sogar auf den Standardwert zurücksetzt, bis du später eine vollständige Analyse durchführst.
Affinitätsmaske
Du musst die SQL Server-Affinität überprüfen und möglicherweise eine Affinitätsmaske festlegen, wenn SQL Server auf einer Hardware mit mehreren NUMA-Knoten (Non-Uniform Memory Access) läuft. Bei moderner Hardware wird jede physische CPU normalerweise zu einem separaten NUMA-Knoten . Wenn du SQL Server daran hinderst, einige der physischen Kerne zu nutzen, musst du die SQL Server-CPUs (oder Zeitplanungsprogramme; siehe Kapitel 2) gleichmäßig auf die NUMAs verteilen.
Wenn du zum Beispiel SQL Server auf einem Server mit zwei Xeon-Prozessoren mit 18 Kernen ausführst und SQL Server auf 24 Kerne beschränkst, musst du die Affinitätsmaske so einstellen, dass 12 Kerne von jeder physischen CPU genutzt werden. So erzielst du eine bessere Leistung, als wenn SQL Server 18 Kerne des ersten Prozessors und 6 Kerne des zweiten Prozessors nutzen würde.
Listing 1-2 zeigt, wie du die Verteilung der SQL Server Zeitplannungsprogramme (CPUs) auf die NUMA-Knoten analysierst. Sieh dir die Anzahl der Zeitplannungsprogramme für jede Spalte parent_node_id in der Ausgabe an.
Listing 1-2. Überprüfung der Verteilung der Zeitplannungsprogramme für NUMA-Knoten (CPUs)
SELECT parent_node_id ,COUNT(*) as [Schedulers] ,SUM(current_tasks_count) as [Current] ,SUM(runnable_tasks_count) as [Runnable] FROM sys.dm_os_schedulers WHERE status = 'VISIBLE ONLINE' GROUP BY parent_node_id;
Parallelität
Es ist wichtig, die Parallelitätseinstellungen im System zu überprüfen. Die Standardeinstellungen, wie MAXDOP = 0 und Cost Threshold for Parallelism = 5, funktionieren auf modernen Systemen nicht gut. Wie bei Max Server Memory ist es besser, die Einstellungen je nach Arbeitsbelastung des Systems fein abzustimmen(in Kapitel 6 wird dies im Detail besprochen). Meine Faustregel für allgemeine Einstellungen lautet jedoch wie folgt:
-
Setze
MAXDOPin OLTP-Systemen auf ein Viertel und in Data-Warehouse-Systemen auf die Hälfte der Anzahl der verfügbaren CPUs. Bei sehr großen OLTP-Servern sollteMAXDOPbei 16 oder weniger liegen. Die Anzahl der Zeitplannungsprogramme im NUMA-Knoten sollte nicht überschritten werden. -
Setze
Cost Threshold for Parallelismauf 50.
Ab SQL Server 2016 und in der Azure SQL Server-Datenbank können Sie MAXDOP auf Datenbankebene mit dem Befehl ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP einstellen. Dies ist nützlich, wenn die Instanz Datenbanken hostet, die unterschiedliche Arbeitslasten verarbeiten.
Konfigurationseinstellungen
Wie bei den Trace-Flags kannst du auch andere Änderungen der Konfigurationseinstellungen auf dem Server analysieren. Du kannst die aktuellen Konfigurationsoptionen mit in der Ansicht sys.configurations untersuchen. Leider stellt SQL Server keine Liste mit Standardkonfigurationswerten zum Vergleich zur Verfügung, so dass du sie, wie in Listing 1-3 gezeigt, selbst programmieren musst. Um Platz zu sparen, füge ich hier nur einige Konfigurationseinstellungen ein, aber du kannst die vollständige Version des Skripts aus den Begleitmaterialien dieses Buches herunterladen.
Listing 1-3. Erkennen von Änderungen in der Serverkonfiguration
DECLARE
@defaults TABLE
(
name SYSNAME NOT NULL PRIMARY KEY,
def_value SQL_VARIANT NOT NULL
)
INSERT INTO @defaults(name,def_value)
VALUES('backup compression default',0);
INSERT INTO @defaults(name,def_value)
VALUES('cost threshold for parallelism',5);
INSERT INTO @defaults(name,def_value)
VALUES('max degree of parallelism',0);
INSERT INTO @defaults(name,def_value)
VALUES('max server memory (MB)',2147483647);
INSERT INTO @defaults(name,def_value)
VALUES('optimize for ad hoc workloads',0);
/* Other settings are omitted in the book */
SELECT
c.name, c.description, c.value_in_use, c.value
,d.def_value, c.is_dynamic, c.is_advanced
FROM
sys.configurations c JOIN @defaults d ON
c.name = d.name
WHERE
c.value_in_use <> d.def_value OR
c.value <> d.def_value
ORDER BY
c.name;
Abbildung 1-3 zeigt eine Beispielausgabe des vorangegangenen Codes. Die Diskrepanz zwischen den Spalten value und value_in_use weist auf anstehende Konfigurationsänderungen hin, die einen Neustart erfordern, um wirksam zu werden. Die Spalte is_dynamic zeigt an, ob die Konfigurationsoption ohne einen Neustart geändert werden kann.

Abbildung 1-3. Nicht standardmäßige Serverkonfigurationsoptionen
Konfigurieren deiner Datenbanken
Im nächsten Schritt musst du einige Datenbankeinstellungen und Konfigurationsoptionen überprüfen. Schauen wir sie uns an.
Datenbank-Einstellungen
Mit SQL Server kannst du mehrere Datenbankeinstellungen ändern und das Verhalten des Systems an die Arbeitslast und andere Anforderungen anpassen. Auf viele davon werde ich später im Buch eingehen, aber einige Einstellungen möchte ich hier besprechen.
Die erste ist Auto Shrink. Wenn diese Option aktiviert ist, verkleinert SQL Server regelmäßig die Datenbank und gibt ungenutzten freien Speicherplatz aus den Dateien an das Betriebssystem ab. Das sieht zwar verlockend aus und verspricht eine geringere Auslastung des Speicherplatzes, kann aber auch zu Problemen führen.
Der Datenbankschrumpfungsprozess arbeitet auf der physischen Ebene. Er findet leeren Speicherplatz am Anfang der Datei und verschiebt zugewiesene Extents vom Ende der Datei in den leeren Speicherplatz, ohne die Eigentümerschaft der Extents zu berücksichtigen. Dies führt zu einer spürbaren Belastung und zu einer starken Fragmentierung des Index. Außerdem ist es in vielen Fällen nutzlos: Die Datenbankdateien werden einfach wieder größer, wenn die Daten wachsen. Es ist immer besser, den Dateispeicherplatz manuell zu verwalten und die automatische Verkleinerung zu deaktivieren.
Eine weitere Datenbankoption, Auto Close, steuert, wie SQL Server Daten aus der Datenbank zwischenspeichert. Wenn Auto Close aktiviert ist, entfernt SQL Server Datenseiten aus dem Pufferpool und Ausführungspläne aus dem Plan-Cache, wenn die Datenbank keine aktiven Verbindungen hat. Dies führt zu Leistungseinbußen bei den neuen Sitzungen, wenn Daten zwischengespeichert und Abfragen neu kompiliert werden müssen.
Bis auf wenige Ausnahmen solltest du das automatische Schließen deaktivieren. Eine dieser Ausnahmen könnte eine Instanz sein, die eine große Anzahl von Datenbanken beherbergt, auf die nur selten zugegriffen wird. Selbst dann würde ich in Erwägung ziehen, diese Option zu deaktivieren und SQL Server zu erlauben, die zwischengespeicherten Daten auf die normale Weise zurückzuziehen.
Vergewissere dich, dass die Option "Page Verify"auf CHECKSUM eingestellt ist. Dadurch werden Konsistenzfehler effizienter erkannt und Fälle von Datenbankbeschädigungen behoben.
Achte auf das Wiederherstellungsmodell der Datenbank. Wenn die Datenbanken den Wiederherstellungsmodus SIMPLE verwenden, wäre es im Katastrophenfall unmöglich, über die letzte FULL Datenbanksicherung hinaus wiederherzustellen. Wenn du feststellst, dass sich die Datenbank in diesem Modus befindet, besprich dies sofort mit den Beteiligten und vergewissere dich, dass sie das Risiko des Datenverlusts verstehen.
Die Datenbankkompatibilitätsebene steuert die Kompatibilität und das Verhalten von SQL Server auf der Datenbankebene. Wenn du zum Beispiel SQL Server 2019 einsetzt und eine Datenbank mit dem Kompatibilitätslevel 130 (SQL Server 2016) hast, verhält sich SQL Server so, als ob die Datenbank auf SQL Server 2016 laufen würde. Wenn du die Datenbanken auf den niedrigeren Kompatibilitätsstufen belässt, vereinfacht das SQL Server-Upgrades, da mögliche Regressionen reduziert werden; allerdings werden dir dadurch auch einige neue Funktionen und Verbesserungen vorenthalten.
Generell solltest du Datenbanken auf der neuesten Kompatibilitätsebene ausführen, die der SQL Server-Version entspricht. Sei vorsichtig, wenn du sie änderst: Wie bei jeder Versionsänderung kann dies zu Rückschritten führen. Teste das System vor der Änderung und vergewissere dich, dass du die Änderung bei Bedarf wieder rückgängig machen kannst, vor allem wenn die Datenbank eine Kompatibilitätsstufe von 110 (SQL Server 2012) oder darunter hat. Die Erhöhung des Kompatibilitätslevels auf 120 (SQL Server 2014) oder höher ermöglicht ein neues Kardinalitätsschätzungsmodell und kann die Ausführungspläne für die Abfragen erheblich verändern. Teste das System gründlich, um die Auswirkungen der Änderung zu verstehen.
Sie können SQL Server zwingen, die alten Kardinalitätsschätzungsmodelle mit den neuen Datenbankkompatibilitätsebenen zu verwenden, indem Sie die Datenbankoption LEGACY_CARDINALITY_ESTIMATION in SQL Server 2016 und höher auf ON setzen oder indem Sie das Trace-Flag auf Serverebene T9481 in SQL Server 2014 aktivieren. Dieser Ansatz ermöglicht es dir, Upgrades oder Änderungen der Kompatibilitätsstufen schrittweise durchzuführen und so die Auswirkungen auf das System zu reduzieren.(Kapitel 5 befasst sich ausführlicher mit der Kardinalitätsabschätzung und erörtert, wie sich die Risiken bei SQL Server-Upgrades und Änderungen der Kompatibilitätsebene von Datenbanken verringern lassen).
Einstellungen für das Transaktionsprotokoll
SQL Server verwendet eine vorausschauende Protokollierung, bei der Informationen über alle Datenbankänderungen in einem Transaktionsprotokoll gespeichert werden. SQL Server arbeitet mit den Transaktionsprotokollen sequentiell, in einer Art Karussell. In den meisten Fällen brauchst du nicht mehrere Protokolldateien im System - sie machen die Datenbankverwaltung komplizierter und verbessern kaum die Leistung.
Intern teilt SQL Server die Transaktionsprotokolle in so genannte Virtual Log Files (VLFs) auf und verwaltet sie als einzelne Einheiten. So kann SQL Server beispielsweise eine VLF nicht abschneiden und wiederverwenden, wenn sie nur einen einzigen aktiven Protokollsatz enthält. Achte auf die Anzahl der VLFs in der Datenbank. Zu wenige sehr große VLFs machen die Protokollverwaltung und -kürzung suboptimal. Zu viele kleine VLFs verschlechtern die Leistung der Transaktionsprotokolloperationen. Versuche, in Produktionssystemen mehrere hundert VLFs nicht zu überschreiten.
Die Anzahl der VLFs, die SQL Server beim Erweitern eines Protokolls hinzufügt, hängt von der SQL Server-Version und der Größe der Erweiterung ab. In den meisten Fällen werden 8 VLFs erstellt, wenn die Wachstumsgröße zwischen 64 MB und 1 GB liegt, oder 16 VLFs bei einem Wachstum von mehr als 1 GB. Verwende keine prozentuale Konfiguration der automatischen Vergrößerung, da sie viele ungleichmäßig große VLFs erzeugt. Ändere stattdessen die Einstellung für die automatische Vergrößerung des Protokolls so, dass die Datei in Stücken wächst. Normalerweise verwende ich Brocken von 1.024 MB, was 128 MB VLFs erzeugt, es sei denn, ich brauche ein sehr großes Transaktionsprotokoll.
Du kannst die VLFs in der Datenbank mit dem sys.dm_db_log_info DMV in SQL Server 2016 und höher zählen. In älteren Versionen von SQL Server kannst du diese Informationen mit DBCC LOGINFO abrufen. Wenn das Transaktionsprotokoll nicht richtig konfiguriert ist, solltest du es neu erstellen. Dazu kannst du das Protokoll auf die minimale Größe verkleinern und es in Stücken von 1.024 MB bis 4.096 MB vergrößern.
Schrumpfen Sie die Transaktionsprotokolldateien nicht automatisch. Sie werden wieder wachsen und die Leistung beeinträchtigen, wenn SQL Server die Datei löscht. Es ist besser, den Speicherplatz vorab zuzuweisen und die Größe der Protokolldateien manuell zu verwalten. Schränke die maximale Größe und die automatische Vergrößerung nicht ein - du möchtest, dass die Logs im Notfall automatisch wachsen.(In Kapitel 11 erfährst du mehr darüber, wie du Probleme mit dem Transaktionsprotokoll beheben kannst).
Datendateien und Dateigruppen
Standardmäßig erstellt SQL Server neue Datenbanken mit der Single-File PRIMARY Dateigruppe und einer Transaktionsprotokolldatei. Leider ist diese Konfiguration aus Sicht der Leistung, der Datenbankverwaltung und des HA suboptimal.
SQL Server verfolgt die Speicherplatznutzung in den Datendateien über Systemseiten, die sogenannten Allocation Maps. In Systemen mit sehr flüchtigen Daten können Allokationskarten eine Quelle von Konflikten sein: SQL Server serialisiert den Zugriff auf sie während ihrer Änderungen (mehr dazu in Kapitel 10). Jede Datendatei hat ihren eigenen Satz an Allokations-Map-Seiten, und du kannst Konflikte reduzieren, indem du mehrere Dateien in der Dateigruppe mit den aktiv veränderbaren Daten erstellst.
Stellen Sie sicher, dass die Daten gleichmäßig über mehrere Datendateien in derselben Dateigruppe verteilt sind. SQL Server verwendet einen Algorithmus namens Proportional Fill, der die meisten Daten in die Datei schreibt, in der der meiste freie Speicherplatz verfügbar ist. Gleichmäßig große Datendateien tragen dazu bei, diese Schreibvorgänge auszugleichen und den Konflikt zwischen den Allokationskarten zu verringern. Vergewissere dich, dass alle Datendateien in der Dateigruppe die gleiche Größe und die gleichen Auto-Growth-Parameter haben, die in Megabyte angegeben werden.
Möglicherweise möchtest du auch die Option AUTOGROW_ALL_FILES filegroup (verfügbar in SQL Server 2016 und später) aktivieren, die das automatische Wachstum für alle Dateien in der Dateigruppe gleichzeitig auslöst . In früheren Versionen von SQL Server kannst du dafür das Trace-Flag T1117 verwenden, aber erinnere dich daran, dass dieses Flag auf Serverebene gesetzt wird und sich auf alle Datenbanken und Dateigruppen im System auswirkt.
Oft ist es unpraktisch oder unmöglich, das Layout bestehender Datenbanken zu ändern. Es kann jedoch sein, dass du während der Leistungsoptimierung neue Dateigruppen erstellen und Daten verschieben musst. Hier sind ein paar Vorschläge, wie du dies effizient tun kannst:
-
Erstelle mehrere Datendateien in Dateigruppen mit flüchtigen Daten. Ich beginne in der Regel mit vier Dateien und erhöhe die Anzahl, wenn ich Probleme mit dem Einrasten sehe (siehe Kapitel 10). Vergewissere dich, dass alle Datendateien die gleiche Größe haben und die Parameter für das automatische Wachstum in Megabyte angegeben sind; aktiviere die Option
AUTOGROW_ALL_FILES. Bei Dateigruppen mit schreibgeschützten Daten reicht normalerweise eine Datendatei aus. -
Verteile keine geclusterten Indizes, nicht geclusterten Indizes oder große Objektdaten (LOB) auf mehrere Dateigruppen. Dies trägt kaum zur Leistung bei und kann im Falle einer Datenbankbeschädigung zu Problemen führen.
-
Lege zusammengehörige Entitäten (z.B.
OrdersundOrderLineItems) in dieselbe Dateigruppe. Das vereinfacht die Datenbankverwaltung und die Wiederherstellung im Notfall. -
Halte die Dateigruppe
PRIMARYnach Möglichkeit leer.
Abbildung 1-4 zeigt ein Beispiel für ein Datenbanklayout für ein hypothetisches eCommerce-System. Die Daten sind partitioniert und auf mehrere Dateigruppen verteilt, um die Ausfallzeiten zu minimieren und im Katastrophenfall eine teilweise Verfügbarkeit der Datenbank zu gewährleisten.1 Außerdem kannst du die Backup-Strategie verbessern, indem du partielle Datenbanksicherungen durchführst und schreibgeschützte Daten von vollständigen Backups ausschließt .
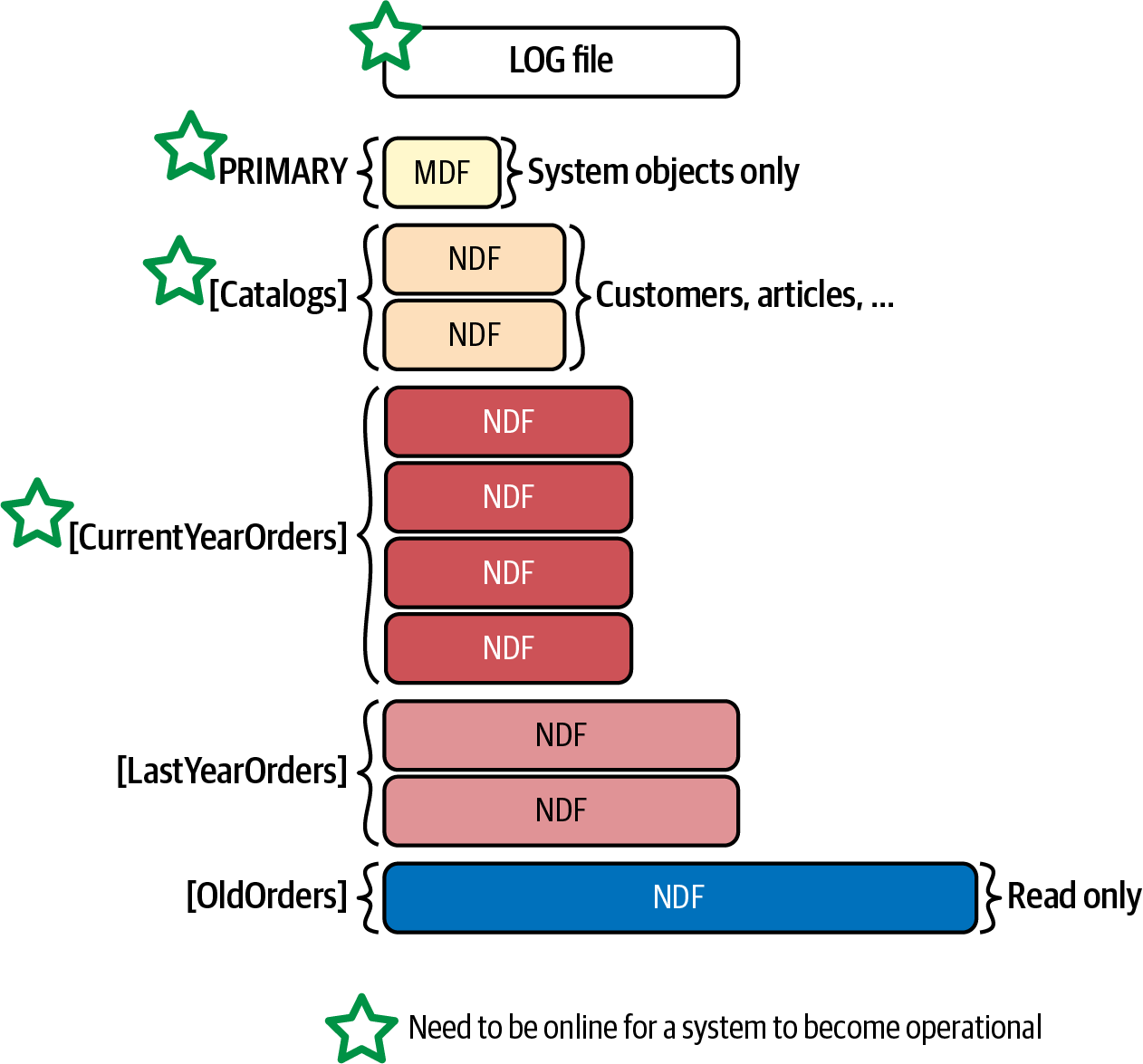
Abbildung 1-4. Datenbank-Layout für ein eCommerce-System
Analysieren des SQL Server-Fehlerprotokolls
Das SQL Server-Fehlerprotokoll ist ein weiterer Ort, den ich normalerweise zu Beginn der Fehlersuche überprüfe. Ich schaue mir gerne alle Fehler an, die auf Bereiche hinweisen, die eine Nachverfolgung erfordern. Die Fehler 823 und 824 können zum Beispiel auf Probleme mit dem Plattensubsystem und/oder auf eine Beschädigung der Datenbank hinweisen.
Du kannst den Inhalt des Fehlerprotokolls in SSMS lesen. Du kannst es auch programmatisch mit der xp_readerrorlog system stored procedure abrufen. Die Herausforderung dabei ist die Menge der Daten im Protokoll: Das Rauschen der Informationsmeldungen kann nützliche Daten verdecken.
Der Code in Listing 1-4 hilft dir, dieses Problem zu lösen. Er ermöglicht es dir, unnötiges Rauschen herauszufiltern und dich auf die Fehlermeldungen zu konzentrieren. Du kannst das Verhalten des Codes mit den folgenden Variablen steuern:
@StartDateund@EndDate- Lege die Zeit für die Analyse fest.
@NumErrorLogs- Gibt die Anzahl der Protokolldateien an, die gelesen werden sollen, wenn SQL Server sie überrollt.
@ExcludeLogonErrors- Lässt die Meldungen zur Anmeldeprüfung aus.
@ShowSurroundingEventsund@ExcludeLogonSurroundingEvents- Ermöglicht es dir, die Informationsmeldungen rund um die Fehlereinträge aus dem Protokoll abzurufen. Das Zeitfenster für diese Meldungen wird durch die Variablen
@SurroundingEventsBeforeSecondsund@SurroundingEventsAfterSecondsgesteuert.
Das Skript erzeugt zwei Ausgaben. Die erste Ausgabe zeigt die Einträge aus dem Fehlerprotokoll, die das Wort Fehler enthalten. Wenn der Parameter @ShowSurroundingEvents aktiviert ist, liefert es auch Log-Einträge um diese Fehlerzeilen herum. Du kannst einige Protokolleinträge, die das Wort Fehler enthalten, von der Ausgabe ausschließen, indem du sie in die Tabelle @ErrorsToIgnore einfügst.
Listing 1-4. Analysieren des SQL Server-Fehlerprotokolls
IF OBJECT_ID('tempdb..#Logs',N'U') IS NOT NULL DROP TABLE #Logs;
IF OBJECT_ID('tempdb..#Errors',N'U') IS NOT NULL DROP TABLE #Errors;
GO
CREATE TABLE #Errors
(
LogNum INT NULL,
LogDate DATETIME NULL,
ID INT NOT NULL identity(1,1),
ProcessInfo VARCHAR(50) NULL,
[Text] NVARCHAR(MAX) NULL,
PRIMARY KEY(ID)
);
CREATE TABLE #Logs
(
[LogDate] DATETIME NULL,
ProcessInfo VARCHAR(50) NULL,
[Text] NVARCHAR(MAX) NULL
);
DECLARE
@StartDate DATETIME = DATEADD(DAY,-7,GETDATE())
,@EndDate DATETIME = GETDATE()
,@NumErrorLogs INT = 1
,@ExcludeLogonErrors BIT = 1
,@ShowSurroundingEvents BIT = 1
,@ExcludeLogonSurroundingEvents BIT = 1
,@SurroundingEventsBeforeSecond INT = 5
,@SurroundingEventsAfterSecond INT = 5
,@LogNum INT = 0;
DECLARE
@ErrorsToIgnore TABLE
(
ErrorText NVARCHAR(1024) NOT NULL
);
INSERT INTO @ErrorsToIgnore(ErrorText)
VALUES
(N'Registry startup parameters:%'),
(N'Logging SQL Server messages in file%'),
(N'CHECKDB for database%finished without errors%');
WHILE (@LogNum <= @NumErrorLogs)
BEGIN
INSERT INTO #Errors(LogDate,ProcessInfo,Text)
EXEC [master].[dbo].[xp_readerrorlog]
@LogNum, 1, N'error', NULL, @StartDate, @EndDate, N'desc';
IF @@ROWCOUNT > 0
UPDATE #Errors SET LogNum = @LogNum WHERE LogNum IS NULL;
SET @LogNum += 1;
END;
IF @ExcludeLogonErrors = 1
DELETE FROM #Errors WHERE ProcessInfo = 'Logon';
DELETE FROM e
FROM #Errors e
WHERE EXISTS
(
SELECT *
FROM @ErrorsToIgnore i
WHERE e.Text LIKE i.ErrorText
);
-- Errors only
SELECT * FROM #Errors ORDER BY LogDate DESC;
IF @@ROWCOUNT > 0 AND @ShowSurroundingEvents = 1
BEGIN
DECLARE
@LogDate DATETIME
,@ID INT = 0
WHILE 1 = 1
BEGIN
SELECT TOP 1 @LogNum = LogNum, @LogDate = LogDate, @ID = ID
FROM #Errors
WHERE ID > @ID
ORDER BY ID;
IF @@ROWCOUNT = 0
BREAK;
SELECT
@StartDate = DATEADD(SECOND, -@SurroundingEventsBeforeSecond, @LogDate)
,@EndDate = DATEADD(SECONd, @SurroundingEventsAfterSecond, @LogDate);
INSERT INTO #Logs(LogDate,ProcessInfo,Text)
EXEC [master].[dbo].[xp_readerrorlog]
@LogNum, 1, NULL, NULL, @StartDate, @EndDate;
END;
IF @ExcludeLogonSurroundingEvents = 1
DELETE FROM #Logs WHERE ProcessInfo = 'Logon';
DELETE FROM e
FROM #Logs e
WHERE EXISTS
(
SELECT *
FROM @ErrorsToIgnore i
WHERE e.Text LIKE i.ErrorText
);
SELECT * FROM #Logs ORDER BY LogDate DESC;
END
Ich werde hier nicht die gesamte Liste möglicher Fehler aufführen; sie könnte zu umfangreich sein und ist in vielen Fällen systembedingt. Aber du musst alle verdächtigen Daten in der Ausgabe analysieren und ihre möglichen Auswirkungen auf das System verstehen.
Abschließend empfehle ich, im SQL Server Agent Warnmeldungen für schwerwiegende Fehler einzurichten, falls dies noch nicht geschehen ist. Du kannst in der Microsoft-Dokumentation nachlesen, wie das geht:.
Konsolidierung von Instanzen und Datenbanken
Man kann nicht über SQL Server-Fehlerbehebung sprechen, ohne die Konsolidierung von Datenbanken und SQL Server-Instanzen zu erwähnen . Die Konsolidierung senkt zwar oft die Hardware- und Lizenzkosten, aber sie ist nicht umsonst; du musst ihre möglichen negativen Auswirkungen auf die aktuelle oder zukünftige Systemleistung analysieren.
Es gibt keine universelle Konsolidierungsstrategie, die bei jedem Projekt angewendet werden kann. Du solltest die Datenmenge, die Last, die Hardwarekonfiguration und deine Geschäfts- und Sicherheitsanforderungen analysieren, wenn du diese Entscheidung triffst. Generell solltest du jedoch vermeiden, OLTP- und Data-Warehouse-/Berichtsdatenbanken auf demselben Server zu konsolidieren, wenn sie stark ausgelastet sind (bzw. wenn sie konsolidiert sind, solltest du sie aufteilen). Data-Warehouse-Abfragen verarbeiten in der Regel große Datenmengen, was zu einer hohen E/A-Aktivität führt und den Inhalt des Pufferpools leert. Insgesamt wirkt sich dies negativ auf die Leistung anderer Systeme aus.
Analysieren Sie außerdem Ihre Sicherheitsanforderungen, wenn Sie Datenbanken konsolidieren. Einige Sicherheitsfunktionen, wie z. B. Audit, wirken sich auf den gesamten Server aus und erhöhen die Leistung aller Datenbanken auf dem Server. Transparente Datenverschlüsselung (TDE) ist ein weiteres Beispiel: Obwohl TDE eine Funktion auf Datenbankebene ist, verschlüsselt SQL Server tempdb, wenn eine der Datenbanken auf dem Server TDE aktiviert hat. Dies führt zu Leistungseinbußen für alle anderen Systeme.
Als allgemeine Regel gilt, dass du Datenbanken mit unterschiedlichen Sicherheitsanforderungen nicht auf derselben Instanz von SQL Server betreiben solltest. Beobachte die Trends und Spitzen in den Metriken und trenne die Datenbanken bei Bedarf voneinander. (Im weiteren Verlauf des Buches stelle ich dir Code zur Verfügung, mit dem du die CPU-, E/A- und Speichernutzung pro Datenbank analysieren kannst).
Ich schlage vor, die Virtualisierung zu nutzen und mehrere VMs auf einem oder mehreren Hosts zu konsolidieren, anstatt mehrere unabhängige und aktive Datenbanken auf eine einzige SQL Server-Instanz zu legen. Dadurch erhältst du eine viel bessere Flexibilität, Verwaltbarkeit und Isolierung zwischen den Systemen, insbesondere wenn mehrere SQL Server-Instanzen auf demselben Server laufen. Es ist viel einfacher, ihren Ressourcenverbrauch zu verwalten, wenn du sie virtualisierst.
Beobachter-Effekt
Der Produktionseinsatz jedes ernstzunehmenden SQL Server-Systems erfordert die Implementierung einer Überwachungsstrategie . Diese kann Überwachungs-Tools von Drittanbietern, Code, der auf Standard-SQL-Server-Technologien basiert, oder beides umfassen.
Eine gute Überwachungsstrategie ist für den SQL Server-Produktionssupport unerlässlich. Sie hilft dir, proaktiv zu handeln, und verkürzt die Zeiten für die Erkennung und Wiederherstellung von Vorfällen. Leider gibt es sie nicht umsonst - jede Art der Überwachung bedeutet einen zusätzlichen Aufwand für das System. In einigen Fällen kann dieser Overhead vernachlässigbar und akzeptabel sein, in anderen Fällen kann er die Serverleistung erheblich beeinträchtigen.
In meiner Laufbahn als SQL Server-Berater habe ich schon viele Fälle von ineffizienter Überwachung erlebt. Ein Kunde verwendete zum Beispiel ein Tool, das Informationen über die Indexfragmentierung lieferte, indem es die Funktion sys.dm_db_index_physical_stats im Modus DETAILED alle vier Stunden für jeden Index in der Datenbank aufrief. Dies führte zu enormen I/O-Spitzen und leerte den Pufferpool, was zu einem spürbaren Leistungsabfall führte. Ein anderer Kunde verwendete ein Tool, das ständig verschiedene DMVs abfragte und den Server dadurch erheblich belastete.
Glücklicherweise kannst du in vielen Fällen diese Abfragen sehen und ihre Auswirkungen bei der Fehlersuche im System bewerten. Bei anderen Technologien ist dies jedoch nicht immer der Fall. Ein Beispiel dafür ist die Überwachung auf Basis von Extended Events (xEvents). Extended Events ist zwar eine großartige Technologie, mit der du komplexe Probleme in SQL Server beheben kannst, aber als Profiling-Tool ist sie nicht die beste Wahl. Einige Ereignisse sind sehr umfangreich und können in stark ausgelasteten Umgebungen einen großen Overhead verursachen.
Schauen wir uns ein Beispiel an, bei dem eine xEvents-Sitzung erstellt wird, die Abfragen im System erfasst, wie in Listing 1-5 gezeigt.
Listing 1-5. Erstellen einer xEvents-Sitzung zur Erfassung von Abfragen im System
CREATE EVENT SESSION CaptureQueries ON SERVER
ADD EVENT sqlserver.rpc_completed
(
SET collect_statement=(1)
ACTION
(
sqlos.task_time
,sqlserver.client_app_name
,sqlserver.client_hostname
,sqlserver.database_name
,sqlserver.nt_username
,sqlserver.sql_text
)
),
ADD EVENT sqlserver.sql_batch_completed
(
ACTION
(
sqlos.task_time
,sqlserver.client_app_name
,sqlserver.client_hostname
,sqlserver.database_name
,sqlserver.nt_username
,sqlserver.sql_text
)
),
ADD EVENT sqlserver.sql_statement_completed
ADD TARGET package0.event_file
(SET FILENAME=N'C:\PerfLogs\LongSql.xel',MAX_FILE_SIZE=(200))
WITH
(
MAX_MEMORY =4096 KB
,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS
,MAX_DISPATCH_LATENCY=5 SECONDS
);
Setze sie dann auf einem Server ein, der unter hoher Last mit einer großen Anzahl gleichzeitiger Anfragen arbeitet. Miss den Durchsatz im System, mit und ohne die xEvents-Sitzung. Sei natürlich vorsichtig und lass sie nicht auf dem Produktionsserver laufen!
Abbildung 1-5 zeigt die CPU-Last und die Anzahl der Batch-Anfragen pro Sekunde in beiden Szenarien auf einem meiner Server. Wie du siehst, hat die Aktivierung der xEvents-Sitzung den Durchsatz um etwa 20 % verringert. Erschwerend kommt hinzu, dass es sehr schwer wäre, die Existenz dieser Sitzung auf dem Server zu erkennen.

Abbildung 1-5. Server-Durchsatz mit und ohne aktive xEvents-Sitzung
Wie stark die Auswirkungen sind, hängt natürlich von der Arbeitsbelastung des Systems ab. In jedem Fall solltest du bei der Fehlersuche nach unnötigen Überwachungs-Tools oder Tools zur Datenerfassung suchen.
Fazit: Beurteile die Überwachungsstrategie und schätze ihren Aufwand als Teil deiner Analyse ab, besonders wenn der Server mehrere Datenbanken beherbergt. xEvents arbeitet zum Beispiel auf Serverebene. Du kannst die Ereignisse zwar nach dem Feld database_id filtern, aber die Filterung erfolgt erst, nachdem ein Ereignis ausgelöst worden ist. Dies kann sich auf alle Datenbanken auf dem Server auswirken.
Zusammenfassung
Die Behebung von Systemproblemen ist ein ganzheitlicher Prozess, bei dem du dein gesamtes Ökosystem analysieren musst. Du musst die Hardware-, Betriebssystem- und Virtualisierungsebenen sowie die SQL Server- und Datenbankkonfigurationen untersuchen und bei Bedarf anpassen.
SQL Server bietet viele Einstellungen, mit denen du die Installation auf die Systemauslastung abstimmen kannst. Es gibt auch bewährte Methoden, die für die meisten Systeme gelten, z. B. die Aktivierung der Einstellungen IFI und Optimize for Ad-Hoc Workloads, die Erhöhung der Anzahl der Dateien in tempdb, die Aktivierung einiger Trace-Flags, die Deaktivierung von Auto Shrink und die Einstellung der richtigen Parameter für das automatische Wachstum der Datenbankdateien.
Im nächsten Kapitel spreche ich über eine der wichtigsten Komponenten von SQL Server - SQLOS - und eine Technik zur Fehlerbehebung namens Wait Statistics.
Checkliste zur Fehlersuche
-
Führe eine umfassende Analyse der Hardware, des Netzwerks und des Festplatten-Subsystems durch.
-
Diskutiere die Hostkonfiguration und -auslastung in virtualisierten Umgebungen mit Infrastrukturingenieuren.
-
Überprüfe die Betriebssystem- und SQL Server-Versionen, -Editionen und Patching-Stände.
-
Prüfe, ob die sofortige Dateiinitialisierung aktiviert ist.
-
Analysiere die Trace-Flags.
-
Aktiviere Optimize for Ad-Hoc Workloads.
-
Überprüfe die Einstellungen für Speicher und Parallelität auf dem Server.
-
Schau dir die Einstellungen von
tempdban (einschließlich der Anzahl der Dateien); überprüfe das Trace-FlagT1118und möglicherweiseT1117in SQL Server-Versionen vor 2016. -
Deaktiviere die automatische Verkleinerung für Datenbanken.
-
Validiere die Einstellungen der Daten- und Transaktionsprotokolldatei.
-
Überprüfe die Anzahl der VLFs in den Transaktionsprotokolldateien.
-
Überprüfe Fehler im SQL Server-Protokoll.
-
Prüfe, ob das System unnötig überwacht wird.
1 Einen tieferen Einblick in Datenpartitionierung und Disaster-Recovery-Strategien findest du in meinem Buch Pro SQL Server Internals, Second Edition (Apress, 2016).
Get SQL Server Erweiterte Fehlersuche und Leistungsoptimierung now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

