Kapitel 4. Spark SQL und Datenrahmen: Einführung in integrierte Datenquellen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Im vorherigen Kapitel haben wir die Entwicklung und die Gründe für die Struktur in Spark erläutert. Insbesondere haben wir erörtert, wie die Spark SQL-Engine eine einheitliche Grundlage für die High-Level-APIs DataFrame und Dataset bietet. Jetzt werden wir unsere Diskussion über den Datenrahmen fortsetzen und seine Interoperabilität mit Spark SQL untersuchen.
In diesem und dem nächsten Kapitel wird auch untersucht, wie Spark SQL mit einigen der in Abbildung 4-1 dargestellten externen Komponenten zusammenarbeitet.
Das gilt insbesondere für Spark SQL:
Stellt die Grundlage für die strukturierten APIs dar, die wir in Kapitel 3 untersucht haben.
Kann Daten in einer Vielzahl von strukturierten Formaten lesen und schreiben (z. B. JSON, Hive-Tabellen, Parquet, Avro, ORC, CSV).
Ermöglicht die Abfrage von Daten über JDBC/ODBC-Konnektoren aus externen Business Intelligence (BI)-Datenquellen wie Tableau, Power BI, Talend oder aus RDBMS wie MySQL und PostgreSQL.
Bietet eine programmatische Schnittstelle zur Interaktion mit strukturierten Daten, die als Tabellen oder Ansichten in einer Datenbank gespeichert sind, aus einer Spark-Anwendung heraus
Bietet eine interaktive Shell, um SQL-Abfragen für deine strukturierten Daten zu erstellen.
Unterstützt ANSI SQL:2003-konforme Befehle und HiveQL.
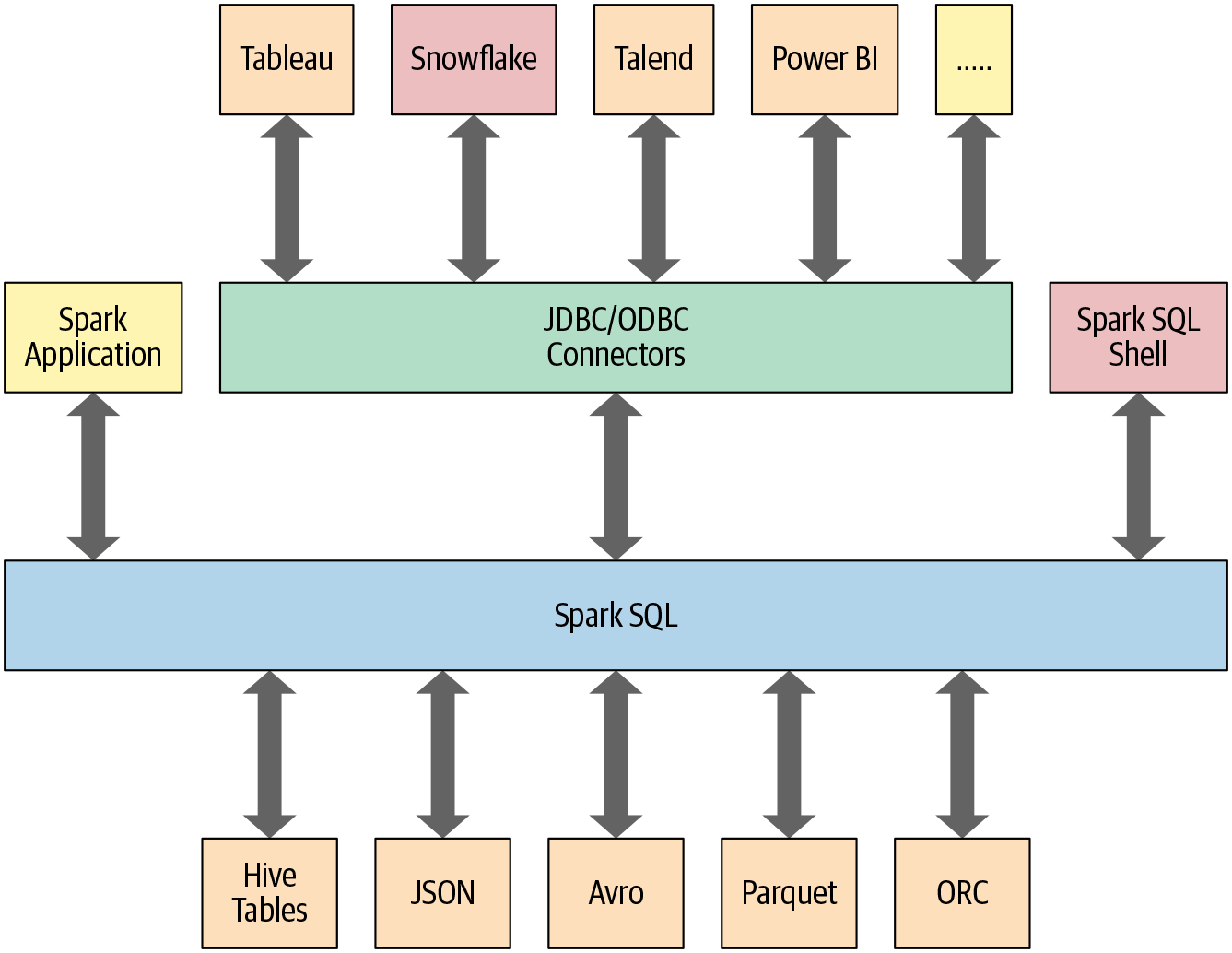
Abbildung 4-1. Spark SQL-Konnektoren und Datenquellen
Beginnen wir damit, wie du Spark SQL in einer Spark-Anwendung verwenden kannst.
Spark SQL in Spark-Anwendungen verwenden
Die SparkSession, die in Spark 2.0 eingeführt wurde, bietet einen einheitlichen Einstiegspunkt für die Programmierung von Spark mit den strukturierten APIs. Du kannst eine SparkSession verwenden, um auf Spark-Funktionen zuzugreifen: Importiere einfach die Klasse und erstelle eine Instanz in deinem Code.
Um eine SQL-Abfrage auszuführen, verwendest du die Methode sql() für die Instanz SparkSession, spark, wie z. B. spark.sql("SELECT * FROM myTableName"). Alle spark.sql Abfragen, die auf diese Weise ausgeführt werden, geben einen Datenrahmen zurück, auf dem du auf Wunsch weitere Spark-Operationen durchführen kannst - die Art, die wir in Kapitel 3 erforscht haben und die du in diesem und dem nächsten Kapitel kennenlernen wirst.
Beispiele für grundlegende Abfragen
In diesem Abschnitt gehen wir ein paar Beispiele für Abfragen des Datensatzes Airline On-Time Performance and Causes of Flight Delays durch, der Daten zu US-Flügen mit Datum, Verspätung, Entfernung, Start- und Zielort enthält. Er ist als CSV-Datei mit über einer Million Datensätzen verfügbar. Mithilfe eines Schemas werden wir die Daten in einen Datenrahmen einlesen und den Datenrahmen als temporäre Ansicht registrieren (mehr zu temporären Ansichten in Kürze), damit wir sie mit SQL abfragen können.
Die Abfragebeispiele werden in Form von Codeschnipseln bereitgestellt und Python- und Scala-Notebooks mit dem gesamten hier vorgestellten Code sind im GitHub-Repository des Buches verfügbar. Diese Beispiele geben dir einen Vorgeschmack darauf, wie du SQL über die Programmierschnittstellespark.sql in deinen Spark-Anwendungen nutzen kannst. Ähnlich wie die DataFrame API in ihrer deklarativen Form ermöglicht dir diese Schnittstelle, strukturierte Daten in deinen Spark-Anwendungen abzufragen .
Normalerweise erstellst du in einer eigenständigen Spark-Anwendung eine SparkSession Instanz manuell, wie im folgenden Beispiel gezeigt. In einer Spark-Shell (oder einem Databricks-Notebook) wird SparkSession jedoch für dich erstellt und ist über die entsprechend benannte Variable spark zugänglich.
Beginnen wir damit, den Datensatz in eine temporäre Ansicht einzulesen:
// In Scalaimportorg.apache.spark.sql.SparkSessionvalspark=SparkSession.builder.appName("SparkSQLExampleApp").getOrCreate()// Path to data setvalcsvFile="/databricks-datasets/learning-spark-v2/flights/departuredelays.csv"// Read and create a temporary view// Infer schema (note that for larger files you may want to specify the schema)valdf=spark.read.format("csv").option("inferSchema","true").option("header","true").load(csvFile)// Create a temporary viewdf.createOrReplaceTempView("us_delay_flights_tbl")
# In Pythonfrompyspark.sqlimportSparkSession# Create a SparkSessionspark=(SparkSession.builder.appName("SparkSQLExampleApp").getOrCreate())# Path to data setcsv_file="/databricks-datasets/learning-spark-v2/flights/departuredelays.csv"# Read and create a temporary view# Infer schema (note that for larger files you# may want to specify the schema)df=(spark.read.format("csv").option("inferSchema","true").option("header","true").load(csv_file))df.createOrReplaceTempView("us_delay_flights_tbl")
Hinweis
Wenn du ein Schema angeben willst, kannst du einen DDL-formatierten String verwenden. Zum Beispiel:
// In Scalavalschema="date STRING, delay INT, distance INT,origin STRING, destination STRING"
# In Pythonschema="`date` STRING, `delay` INT, `distance` INT,`origin`STRING,`destination`STRING"
Jetzt, wo wir eine temporäre Ansicht haben, können wir SQL-Abfragen mit Spark SQL stellen. Diese Abfragen unterscheiden sich nicht von denen, die du an eine SQL-Tabelle in einer MySQL- oder PostgreSQL-Datenbank stellen könntest. Hier geht es darum, zu zeigen, dass Spark SQL eine ANSI:2003-konforme SQL-Schnittstelle bietet und die Interoperabilität zwischen SQL und Datenrahmen demonstriert.
Der US-Flugverspätungsdatensatz hat fünf Spalten:
Die Spalte
dateenthält eine Zeichenfolge wie02190925. Nach der Konvertierung entspricht dies dem Wert02-19 09:25 am.Die Spalte
delaygibt die Verzögerung in Minuten zwischen der geplanten und der tatsächlichen Abfahrtszeit an. Frühe Abflüge zeigen negative Zahlen.Die Spalte
distancegibt die Entfernung in Meilen vom Start- zum Zielflughafen an.Die Spalte
originenthält den IATA-Code des Herkunftsflughafens.Die Spalte
destinationenthält den IATA-Code des Zielflughafens.
Probieren wir also einige Beispielabfragen für diesen Datensatz aus.
Zuerst suchen wir alle Flüge, deren Entfernung größer als 1.000 Meilen ist:
spark.sql("""SELECT distance, origin, destination
FROM us_delay_flights_tbl WHERE distance > 1000
ORDER BY distance DESC""").show(10)
+--------+------+-----------+
|distance|origin|destination|
+--------+------+-----------+
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
+--------+------+-----------+
only showing top 10 rows
Wie die Ergebnisse zeigen, waren die längsten Flüge zwischen Honolulu (HNL) und New York (JFK). Als nächstes finden wir alle Flüge zwischen San Francisco (SFO) und Chicago (ORD) mit mindestens zwei Stunden Verspätung:
spark.sql("""SELECT date, delay, origin, destination
FROM us_delay_flights_tbl
WHERE delay > 120 AND ORIGIN = 'SFO' AND DESTINATION = 'ORD'
ORDER by delay DESC""").show(10)
+--------+-----+------+-----------+
|date |delay|origin|destination|
+--------+-----+------+-----------+
|02190925|1638 |SFO |ORD |
|01031755|396 |SFO |ORD |
|01022330|326 |SFO |ORD |
|01051205|320 |SFO |ORD |
|01190925|297 |SFO |ORD |
|02171115|296 |SFO |ORD |
|01071040|279 |SFO |ORD |
|01051550|274 |SFO |ORD |
|03120730|266 |SFO |ORD |
|01261104|258 |SFO |ORD |
+--------+-----+------+-----------+
only showing top 10 rows
Es scheint, dass es zwischen diesen beiden Städten viele Flüge mit erheblichen Verspätungen gab, und zwar an verschiedenen Tagen. (Als Übung kannst du die Spalte date in ein lesbares Format umwandeln und herausfinden, an welchen Tagen oder in welchen Monaten diese Verspätungen am häufigsten auftraten. Hingen die Verspätungen mit den Wintermonaten oder den Feiertagen zusammen?)
Versuchen wir eine kompliziertere Abfrage, bei der wir die CASE Klausel in SQL verwenden. Im folgenden Beispiel wollen wir alle US-Flüge, unabhängig von Abflug- und Zielort, mit einer Angabe zu den Verspätungen kennzeichnen, die sie hatten: Sehr große Verspätung (> 6 Stunden), große Verspätung (2-6 Stunden), usw. Wir fügen diese für Menschen lesbaren Bezeichnungen in einer neuen Spalte mit dem Namen Flight_Delays ein:
spark.sql("""SELECT delay, origin, destination,
CASE
WHEN delay > 360 THEN 'Very Long Delays'
WHEN delay >= 120 AND delay <= 360 THEN 'Long Delays'
WHEN delay >= 60 AND delay < 120 THEN 'Short Delays'
WHEN delay > 0 and delay < 60 THEN 'Tolerable Delays'
WHEN delay = 0 THEN 'No Delays'
ELSE 'Early'
END AS Flight_Delays
FROM us_delay_flights_tbl
ORDER BY origin, delay DESC""").show(10)
+-----+------+-----------+-------------+
|delay|origin|destination|Flight_Delays|
+-----+------+-----------+-------------+
|333 |ABE |ATL |Long Delays |
|305 |ABE |ATL |Long Delays |
|275 |ABE |ATL |Long Delays |
|257 |ABE |ATL |Long Delays |
|247 |ABE |DTW |Long Delays |
|247 |ABE |ATL |Long Delays |
|219 |ABE |ORD |Long Delays |
|211 |ABE |ATL |Long Delays |
|197 |ABE |DTW |Long Delays |
|192 |ABE |ORD |Long Delays |
+-----+------+-----------+-------------+
only showing top 10 rows
Wie bei den DataFrame- und Dataset-APIs kannst du mit der Schnittstelle spark.sql gängige Datenanalyseoperationen durchführen, wie wir sie im vorherigen Kapitel beschrieben haben. Die Berechnungen durchlaufen einen identischen Weg in der Spark SQL-Engine (siehe "Der Catalyst Optimizer" in Kapitel 3 ) und liefern die gleichen Ergebnisse.
Alle drei vorangegangenen SQL-Abfragen können mit einer entsprechenden DataFrame API-Abfrage ausgedrückt werden. Die erste Abfrage kann zum Beispiel in der Python DataFrame API wie folgt ausgedrückt werden:
# In Pythonfrompyspark.sql.functionsimportcol,desc(df.select("distance","origin","destination").where(col("distance")>1000).orderBy(desc("distance"))).show(10)# Or(df.select("distance","origin","destination").where("distance > 1000").orderBy("distance",ascending=False).show(10))
Dies führt zu den gleichen Ergebnissen wie die SQL-Abfrage:
+--------+------+-----------+ |distance|origin|destination| +--------+------+-----------+ |4330 |HNL |JFK | |4330 |HNL |JFK | |4330 |HNL |JFK | |4330 |HNL |JFK | |4330 |HNL |JFK | |4330 |HNL |JFK | |4330 |HNL |JFK | |4330 |HNL |JFK | |4330 |HNL |JFK | |4330 |HNL |JFK | +--------+------+-----------+ only showing top 10 rows
Als Übung kannst du versuchen, die beiden anderen SQL-Abfragen so zu konvertieren, dass sie die DataFrame API verwenden.
Wie diese Beispiele zeigen, ist die Verwendung der Spark-SQL-Schnittstelle zur Abfrage von Daten ähnlich wie das Schreiben einer regulären SQL-Abfrage für eine relationale Datenbanktabelle. Obwohl die Abfragen in SQL geschrieben sind, kannst du die Ähnlichkeit in der Lesbarkeit und der Semantik zu den Operationen der DataFrame API spüren, die du in Kapitel 3 kennengelernt hast und im nächsten Kapitel weiter erkunden wirst .
Damit du strukturierte Daten wie in den vorangegangenen Beispielen abfragen kannst, verwaltet Spark die komplexe Erstellung und Verwaltung von Views und Tabellen, sowohl im Speicher als auch auf der Festplatte. Das führt uns zu unserem nächsten Thema: wie Tabellen und Views erstellt und verwaltet werden .
SQL-Tabellen und Ansichten
Tabellen enthalten Daten. Zu jeder Tabelle in Spark gehören die entsprechenden Metadaten, d.h. Informationen über die Tabelle und ihre Daten: das Schema, die Beschreibung, der Tabellenname, der Datenbankname, die Spaltennamen, die Partitionen, der physische Ort, an dem die Daten gespeichert sind, usw. All diese Informationen werden in einem zentralen Metaspeicher gespeichert.
Statt eines separaten Metaspeichers für Spark-Tabellen verwendet Spark standardmäßig den Apache Hive-Metaspeicher, der sich unter /user/hive/warehouse befindet, um alle Metadaten über deine Tabellen zu speichern. Du kannst den Standard-Speicherort jedoch ändern, indem du die Spark-Konfigurationsvariable spark.sql.warehouse.dir auf einen anderen Speicherort setzt, der auf eine lokale oder externe verteilte Speicherung eingestellt werden kann.
Verwaltete versus nicht verwaltete Tabellen
Mit Spark kannst du zwei Arten von Tabellen erstellen: verwaltete und nicht verwaltete. Bei einer verwalteten Tabelle verwaltet Spark sowohl die Metadaten als auch die Daten im Dateispeicher. Das kann ein lokales Dateisystem, HDFS oder ein Objektspeicher wie Amazon S3 oder Azure Blob sein. Bei einer nicht verwalteten Tabelle verwaltet Spark nur die Metadaten, während du die Daten selbst in einer externen Datenquelle wie Cassandra verwaltest.
Da Spark bei einer verwalteten Tabelle alles verwaltet, löscht ein SQL-Befehl wie DROP TABLE table_name sowohl die Metadaten als auch die Daten. Bei einer nicht verwalteten Tabelle werden mit demselben Befehl nur die Metadaten gelöscht, nicht aber die eigentlichen Daten. Im nächsten Abschnitt werden wir uns einige Beispiele ansehen, wie verwaltete und nicht verwaltete Tabellen erstellt werden.
Erstellen von SQL-Datenbanken und -Tabellen
Tabellen befinden sich in einer Datenbank. Standardmäßig erstellt Spark Tabellen unter der Datenbank default. Um einen eigenen Datenbanknamen zu erstellen, kannst du einen SQL-Befehl in deiner Spark-Anwendung oder deinem Notebook eingeben. Anhand des US-Flugverspätungsdatensatzes wollen wir eine verwaltete und eine nicht verwaltete Tabelle erstellen. Zunächst erstellen wir eine Datenbank namens learn_spark_db und teilen Spark mit, dass wir diese Datenbank verwenden wollen:
// In Scala/Pythonspark.sql("CREATE DATABASE learn_spark_db")spark.sql("USE learn_spark_db")
Ab diesem Zeitpunkt werden alle Befehle, die wir in unserer Anwendung zum Erstellen von Tabellen geben, dazu führen, dass die Tabellen in dieser Datenbank erstellt werden und unter dem Datenbanknamen learn_spark_db gespeichert werden.
Eine verwaltete Tabelle erstellen
Um eine verwaltete Tabelle in der Datenbank learn_spark_db zu erstellen, kannst du eine SQL-Abfrage wie die folgende stellen:
// In Scala/Pythonspark.sql("CREATE TABLE managed_us_delay_flights_tbl (date STRING, delay INT,distance INT, origin STRING, destination STRING)")
Du kannst dasselbe mit der DataFrame API wie folgt tun:
# In Python# Path to our US flight delays CSV filecsv_file="/databricks-datasets/learning-spark-v2/flights/departuredelays.csv"# Schema as defined in the preceding exampleschema="date STRING, delay INT, distance INT, origin STRING, destination STRING"flights_df=spark.read.csv(csv_file,schema=schema)flights_df.write.saveAsTable("managed_us_delay_flights_tbl")
Mit diesen beiden Anweisungen wird die verwaltete Tabelle us_delay_flights_tbl in der Datenbank learn_spark_db erstellt.
Erstellen einer nicht verwalteten Tabelle
Im Gegensatz dazu kannst du unverwaltete Tabellen aus deinen eigenen Datenquellen erstellen, z. B. aus Parquet-, CSV- oder JSON-Dateien, die in einem für deine Spark-Anwendung zugänglichen Dateispeicher gespeichert sind.
Um eine nicht verwaltete Tabelle aus einer Datenquelle, z. B. einer CSV-Datei, in SQL zu erstellen, verwende:
spark.sql("""CREATE TABLE us_delay_flights_tbl(date STRING, delay INT,
distance INT, origin STRING, destination STRING)
USING csv OPTIONS (PATH
'/databricks-datasets/learning-spark-v2/flights/departuredelays.csv')""")
Und innerhalb der DataFrame API verwenden:
(flights_df
.write
.option("path", "/tmp/data/us_flights_delay")
.saveAsTable("us_delay_flights_tbl"))
Hinweis
Damit du diese Beispiele erkunden kannst, haben wir Python- und Scala-Beispielnotizbücher erstellt, die du im GitHub-Repository des Buches findest.
Ansichten erstellen
Spark kann nicht nur Tabellen erstellen, sondern auch Ansichten auf bestehenden Tabellen. Ansichten können global (für alle SparkSessionin einem bestimmten Cluster sichtbar) oder sitzungsbezogen (nur für eine einzelne SparkSession sichtbar) sein und sind temporär: Sie verschwinden, wenn deine Spark-Anwendung beendet wird.
DasErstellen von Views hat eine ähnliche Syntax wie das Erstellen von Tabellen in einer Datenbank. Sobald du eine Ansicht erstellt hast, kannst du sie wie eine Tabelle abfragen. Der Unterschied zwischen einer View und einer Tabelle besteht darin, dass die Daten in der View nicht gespeichert werden; Tabellen bleiben auch nach Beendigung der Spark-Anwendung erhalten, während die Views verschwinden.
Du kannst mit SQL eine Ansicht aus einer bestehenden Tabelle erstellen. Wenn du zum Beispiel nur die Teilmenge der US-Flugverspätungsdaten mit den Abflughäfen New York (JFK) und San Francisco (SFO) bearbeiten möchtest, erstellen die folgenden Abfragen globale temporäre und temporäre Ansichten, die nur aus diesem Teil der Tabelle bestehen:
-- In SQLCREATEORREPLACEGLOBALTEMPVIEWus_origin_airport_SFO_global_tmp_viewASSELECTdate,delay,origin,destinationfromus_delay_flights_tblWHEREorigin='SFO';CREATEORREPLACETEMPVIEWus_origin_airport_JFK_tmp_viewASSELECTdate,delay,origin,destinationfromus_delay_flights_tblWHEREorigin='JFK'
Das Gleiche kannst du mit der DataFrame API wie folgt erreichen:
# In Pythondf_sfo=spark.sql("SELECT date, delay, origin, destination FROMus_delay_flights_tblWHEREorigin='SFO'")df_jfk=spark.sql("SELECT date, delay, origin, destination FROMus_delay_flights_tblWHEREorigin='JFK'")# Create a temporary and global temporary viewdf_sfo.createOrReplaceGlobalTempView("us_origin_airport_SFO_global_tmp_view")df_jfk.createOrReplaceTempView("us_origin_airport_JFK_tmp_view")
Sobald du diese Ansichten erstellt hast, kannst du Abfragen auf sie stellen, genau wie auf eine Tabelle. Beachte, dass du beim Zugriff auf eine globale temporäre Ansicht das Präfix global_temp.<view_name>verwenden musst, weil Spark globale temporäre Ansichten in einer globalen temporären Datenbank namens global_temp erstellt. Ein Beispiel:
-- In SQLSELECT*FROMglobal_temp.us_origin_airport_SFO_global_tmp_view
Im Gegensatz dazu kannst du die normale temporäre Ansicht ohne das Präfix global_temp aufrufen :
-- In SQLSELECT*FROMus_origin_airport_JFK_tmp_view
// In Scala/Pythonspark.read.table("us_origin_airport_JFK_tmp_view")// Orspark.sql("SELECT * FROM us_origin_airport_JFK_tmp_view")
Du kannst eine Ansicht genauso ablegen wie eine Tabelle:
-- In SQLDROPVIEWIFEXISTSus_origin_airport_SFO_global_tmp_view;DROPVIEWIFEXISTSus_origin_airport_JFK_tmp_view
// In Scala/Pythonspark.catalog.dropGlobalTempView("us_origin_airport_SFO_global_tmp_view")spark.catalog.dropTempView("us_origin_airport_JFK_tmp_view")
Temporäre Ansichten versus globale temporäre Ansichten
Der Unterschied zwischen einer temporären und einer globalen temporären Ansicht ist sehr subtil und kann bei Entwicklern, die neu in Spark sind, zu leichter Verwirrung führen. Eine temporäre Ansicht ist an eine einzelne SparkSession innerhalb einer Spark-Anwendung gebunden. Im Gegensatz dazu ist eine globale temporäre Ansicht für mehrere SparkSessions innerhalb einer Spark-Anwendung sichtbar. Ja, du kannst mehrere SparkSession s innerhalb einer einzigen Spark-Anwendung erstellen - das ist zum Beispiel dann praktisch, wenn du auf Daten aus zwei verschiedenen SparkSessions zugreifen (und sie kombinieren) willst, die nicht dieselben Hive-Metaspeicher-Konfigurationen haben.
Anzeigen der Metadaten
Wie bereits erwähnt, verwaltet Spark die Metadaten, die mit jeder verwalteten oder nicht verwalteten Tabelle verbunden sind. Diese werden in der Catalog, einer High-Level-Abstraktion in Spark SQL zur Speicherung von Metadaten. Die Funktionalität von Catalogwurde in Spark 2.x um neue öffentliche Methoden erweitert, mit denen du die Metadaten deiner Datenbanken, Tabellen und Ansichten untersuchen kannst. In Spark 3.0 wurde die Funktion erweitert, um externe catalog zu verwenden (auf die wir in Kapitel 12 kurz eingehen).
Nachdem du zum Beispiel in einer Spark-Anwendung die Variable SparkSession spark erstellt hast, kannst du mit Methoden wie diesen auf alle gespeicherten Metadaten zugreifen:
// In Scala/Pythonspark.catalog.listDatabases()spark.catalog.listTables()spark.catalog.listColumns("us_delay_flights_tbl")
Importiere das Notizbuch aus dem GitHub Repo des Buches und probiere es aus.
SQL-Tabellen zwischenspeichern
Obwohl wir die Strategien für das Tabellencaching im nächsten Kapitel besprechen werden, ist es hier erwähnenswert, dass du, wie bei Datenrahmen, SQL-Tabellen und Ansichten cachen und uncachen kannst. In Spark 3.0 kannst du zusätzlich zu anderen Optionen eine Tabelle als LAZY angeben, was bedeutet, dass sie nicht sofort, sondern erst bei ihrer ersten Verwendung gecached werden soll:
-- In SQLCACHE[LAZY]TABLE<table-name>UNCACHETABLE<table-name>
Tabellen in Datenrahmen einlesen
Dateningenieure erstellen oft Datenpipelines als Teil ihrer regulären Dateneingabe- und ETL-Prozesse. Sie befüllen Spark SQL-Datenbanken und -Tabellen mit bereinigten Daten, die von nachgelagerten Anwendungen genutzt werden können.
Nehmen wir an, du hast eine bestehende Datenbank, learn_spark_db, und eine Tabelle, us_delay_flights_tbl, die du verwenden kannst. Anstatt aus einer externen JSON-Datei zu lesen, kannst du die Tabelle einfach mit SQL abfragen und das zurückgegebene Ergebnis einem Datenrahmen zuweisen :
// In ScalavalusFlightsDF=spark.sql("SELECT * FROM us_delay_flights_tbl")valusFlightsDF2=spark.table("us_delay_flights_tbl")
# In Pythonus_flights_df=spark.sql("SELECT * FROM us_delay_flights_tbl")us_flights_df2=spark.table("us_delay_flights_tbl")
Jetzt hast du einen bereinigten Datenrahmen, der aus einer bestehenden Spark SQL-Tabelle gelesen wurde. Du kannst auch Daten in anderen Formaten lesen, indem du die in Spark integrierten Datenquellen verwendest. Das gibt dir die Flexibilität, mit verschiedenen gängigen Dateiformaten zu interagierens.
Datenquellen für DataFrames und SQL-Tabellen
Wie in Abbildung 4-1 dargestellt, bietet Spark SQL eine Schnittstelle zu einer Vielzahl von Datenquellen. Außerdem bietet es eine Reihe allgemeiner Methoden zum Lesen und Schreiben von Daten in und aus diesen Datenquellen mithilfe der Datenquellen-API.
In diesem Abschnitt werden wir einige der eingebauten Datenquellen, die verfügbaren Dateiformate und die Möglichkeiten zum Laden und Schreiben von Daten sowie die spezifischen Optionen für diese Datenquellen behandeln. Doch zunächst wollen wir uns zwei übergeordnete Konstrukte der Datenquellen-API genauer ansehen, die die Art und Weise bestimmen, wie du mit verschiedenen Datenquellen interagierst: DataFrameReader und DataFrameWriter.
DataFrameReader
DataFrameReader ist das zentrale Konstrukt für das Lesen von Daten aus einer Datenquelle in einen Datenrahmen (DataFrame). Es hat ein definiertes Format und ein empfohlenes Muster für die Verwendung:
DataFrameReader.format(args).option("key", "value").schema(args).load()
Dieses Muster der Aneinanderreihung von Methoden ist in Spark üblich und leicht zu erkennen. Wir haben es in Kapitel 3 gesehen, als wir gängige Datenanalysemuster untersucht haben.
Beachte, dass du auf DataFrameReader nur über eine Instanz von SparkSession zugreifen kannst. Das heißt, du kannst keine Instanz von DataFrameReader erstellen. Um ein Instanz-Handle zu erhalten, verwende:
SparkSession.read // or SparkSession.readStream
Während read ein Handle an DataFrameReader zurückgibt, um einen Datenrahmen aus einer statischen Datenquelle einzulesen, gibt readStream eine Instanz zurück, um aus einer Streaming-Quelle zu lesen. (Wir werden das strukturierte Streaming später in diesem Buch behandeln).
Die Argumente für jede der öffentlichen Methoden von DataFrameReader können unterschiedliche Werte annehmen. Tabelle 4-1 listet diese auf, mit einer Teilmenge der unterstützten Argumente .
| Methode | Argumente | Beschreibung |
|---|---|---|
format() |
"parquet", "csv", "txt", "json", "jdbc", "orc", "avro", etc. |
Wenn du diese Methode nicht angibst, ist der Standardwert Parquet oder das, was in spark.sql.sources.default eingestellt ist. |
option() |
("mode", {PERMISSIVE | FAILFAST | DROPMALFORMED } )("inferSchema", {true | false})("path", "path_file_data_source") |
Eine Reihe von Schlüssel/Wertpaaren und Optionen. Die Spark-Dokumentation zeigt einige Beispiele und erklärt die verschiedenen Modi und ihre Aktionen. Der Standardmodus ist PERMISSIVE. Die Optionen "inferSchema" und "mode" sind spezifisch für die Dateiformate JSON und CSV. |
schema() |
DDL String oder StructType, z.B. 'A INT, B STRING' oderStructType(...) |
Für das JSON- oder CSV-Format kannst du in der Methode option() angeben, dass das Schema abgeleitet werden soll. Die Angabe eines Schemas für ein beliebiges Format beschleunigt das Laden und stellt sicher, dass deine Daten mit dem erwarteten Schema übereinstimmen. |
load() |
"/path/to/data/source" |
Der Pfad zur Datenquelle. Er kann leer sein, wenn er in option("path", "...") angegeben wird. |
Wir werden hier nicht alle verschiedenen Kombinationen von Argumenten und Optionen aufzählen, aber die Dokumentation für Python, Scala, R und Java bietet Vorschläge und Anleitungen. Es lohnt sich aber, ein paar Beispiele zu zeigen:
// In Scala// Use Parquetvalfile="""/databricks-datasets/learning-spark-v2/flights/summary-data/parquet/2010-summary.parquet"""valdf=spark.read.format("parquet").load(file)// Use Parquet; you can omit format("parquet") if you wish as it's the defaultvaldf2=spark.read.load(file)// Use CSVvaldf3=spark.read.format("csv").option("inferSchema","true").option("header","true").option("mode","PERMISSIVE").load("/databricks-datasets/learning-spark-v2/flights/summary-data/csv/*")// Use JSONvaldf4=spark.read.format("json").load("/databricks-datasets/learning-spark-v2/flights/summary-data/json/*")
Hinweis
In der Regel wird kein Schema benötigt, wenn du aus einer statischen Parkett-Datenquelle liest - die Parkett-Metadaten enthalten normalerweise das Schema, sodass es abgeleitet wird. Für Streaming-Datenquellen musst du jedoch ein Schema angeben. (Das Lesen von Streaming-Datenquellen wird in Kapitel 8 behandelt).
Parquet ist die standardmäßige und bevorzugte Datenquelle für Spark, weil sie effizient ist, eine spaltenbasierte Speicherung verwendet und einen schnellen Kompressionsalgorithmus einsetzt. Weitere Vorteile (wie z. B. Columnar Pushdown) wirst du später kennenlernen, wenn wir uns eingehender mit dem Catalyst-Optimierer beschäftigen.
DataFrameWriter
DataFrameWriter macht das Gegenteil von seinem Gegenstück: Es speichert oder schreibt Daten in eine bestimmte integrierte Datenquelle. Anders als bei DataFrameReader rufst du die Instanz nicht über SparkSession auf, sondern über den Datenrahmen, den du speichern möchtest. Es gibt ein paar empfohlene Verwendungsmuster:
DataFrameWriter.format(args) .option(args) .bucketBy(args) .partitionBy(args) .save(path) DataFrameWriter.format(args).option(args).sortBy(args).saveAsTable(table)
Um ein Instanz-Handle zu erhalten, verwende:
DataFrame.write // or DataFrame.writeStream
Die Argumente für die einzelnen Methoden von DataFrameWriter nehmen ebenfalls unterschiedliche Werte an. Wir führen diese in Tabelle 4-2 auf, mit einer Untermenge der unterstützten Argumente .
| Methode | Argumente | Beschreibung |
|---|---|---|
format() |
"parquet", "csv", "txt", "json", "jdbc", "orc", "avro", etc. |
Wenn du diese Methode nicht angibst, ist der Standardwert Parquet oder das, was in spark.sql.sources.default eingestellt ist. |
option() |
("mode", {append | overwrite | ignore | error or errorifexists} )("mode", {SaveMode.Overwrite | SaveMode.Append, SaveMode.Ignore, SaveMode.ErrorIfExists})("path", "path_to_write_to") |
Eine Reihe von Schlüssel/Wertpaaren und Optionen. Die Spark-Dokumentation zeigt einige Beispiele. Dies ist eine überladene Methode. Die Standardoptionen für den Modus sind error or errorifexists und SaveMode.ErrorIfExists; sie lösen zur Laufzeit eine Ausnahme aus, wenn die Daten bereits existieren. |
bucketBy() |
(numBuckets, col, col..., coln) |
Die Anzahl der Buckets und die Namen der Spalten, nach denen gebuckelt werden soll. Verwendet das Bucket-Schema von Hive auf einem Dateisystem. |
save()
|
"/path/to/data/source" |
Der Pfad, in dem gespeichert werden soll. Er kann leer sein, wenn er in option("path", "...") angegeben wurde. |
saveAsTable() |
"table_name" |
Die Tabelle, in der gespeichert werden soll. |
Hier ist ein kurzes Beispiel, um die Verwendung von Methoden und Argumenten zu veranschaulichen:
// In Scala// Use JSONvallocation=...df.write.format("json").mode("overwrite").save(location)
Parkett
Wir beginnen unsere Erkundung der Datenquellen mit Parquet, da es die Standarddatenquelle in Spark ist. Parquet ist ein Open-Source-Spaltenformat, das von vielen Big-Data-Frameworks und -Plattformen unterstützt wird und weit verbreitet ist. Es bietet viele E/A-Optimierungen (z. B. Komprimierung, die Speicherplatz spart und einen schnellen Zugriff auf Datenspalten ermöglicht).
Aufgrund seiner Effizienz und dieser Optimierungen empfehlen wir, dass du deine Datenrahmen nach der Umwandlung und Bereinigung im Parquet-Format speicherst, um sie später weiterzuverwenden. (Parquet ist auch das standardmäßige offene Tabellenformat für Delta Lake, das wir in Kapitel 9 behandeln werden).
Einlesen von Parquet-Dateien in einen Datenrahmen (DataFrame)
Parkettdateien werden in einer Verzeichnisstruktur gespeichert, die die Datendateien, Metadaten, eine Reihe von komprimierten Dateien und einige Statusdateien enthält. Die Metadaten in der Fußzeile enthalten die Version des Dateiformats, das Schema und Spaltenangaben wie den Pfad usw.
Ein Verzeichnis in einer Parquet-Datei kann zum Beispiel eine Reihe von Dateien wie diese enthalten:
_SUCCESS _committed_1799640464332036264 _started_1799640464332036264 part-00000-tid-1799640464332036264-91273258-d7ef-4dc7-<...>-c000.snappy.parquet
In einem Verzeichnis kann es eine Reihe von part-XXXX komprimierten Dateien geben (die hier gezeigten Namen wurden gekürzt, damit sie auf die Seite passen).
Um Parquet-Dateien in einen Datenrahmen einzulesen, gibst du einfach das Format und den Pfad an:
// In Scalavalfile="""/databricks-datasets/learning-spark-v2/flights/summary-data/parquet/2010-summary.parquet/"""valdf=spark.read.format("parquet").load(file)
# In Pythonfile="""/databricks-datasets/learning-spark-v2/flights/summary-data/parquet/2010-summary.parquet/"""df=spark.read.format("parquet").load(file)
Wenn du nicht aus einer Streaming-Datenquelle liest, musst du das Schema nicht angeben, da Parquet es als Teil der Metadaten speichert.
Lesen von Parquet-Dateien in eine Spark SQL-Tabelle
Du kannst nicht nur Parquet-Dateien in einen Spark-Datenrahmen einlesen, sondern auch eine Spark SQL unmanaged Tabelle oder View direkt mit SQL erstellen:
-- In SQLCREATEORREPLACETEMPORARYVIEWus_delay_flights_tblUSINGparquetOPTIONS(path"/databricks-datasets/learning-spark-v2/flights/summary-data/parquet/2010-summary.parquet/")
Wenn du die Tabelle oder die Ansicht erstellt hast, kannst du die Daten mit SQL in einen Datenrahmen einlesen, wie wir in einigen früheren Beispielen gesehen haben:
// In Scalaspark.sql("SELECT * FROM us_delay_flights_tbl").show()
# In Pythonspark.sql("SELECT * FROM us_delay_flights_tbl").show()
Beide Vorgänge liefern die gleichen Ergebnisse:
+-----------------+-------------------+-----+ |DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count| +-----------------+-------------------+-----+ |United States |Romania |1 | |United States |Ireland |264 | |United States |India |69 | |Egypt |United States |24 | |Equatorial Guinea|United States |1 | |United States |Singapore |25 | |United States |Grenada |54 | |Costa Rica |United States |477 | |Senegal |United States |29 | |United States |Marshall Islands |44 | +-----------------+-------------------+-----+ only showing top 10 rows
Datenrahmen in Parquet-Dateien schreiben
Das Schreiben oder Speichern eines Datenrahmens als Tabelle oder Datei ist ein gängiger Vorgang in Spark. Um einen Datenrahmen zu schreiben, verwendest du einfach die Methoden und Argumente auf DataFrameWriter, die weiter oben in diesem Kapitel beschrieben wurden, und gibst den Speicherort für die Parquet-Dateien an. Zum Beispiel:
// In Scaladf.write.format("parquet").mode("overwrite").option("compression","snappy").save("/tmp/data/parquet/df_parquet")
# In Python(df.write.format("parquet").mode("overwrite").option("compression","snappy").save("/tmp/data/parquet/df_parquet"))
Hinweis
Erinnere dich daran, dass Parquet das Standarddateiformat ist. Wenn du die Methode format() nicht verwendest, wird der Datenrahmen trotzdem als Parquet-Datei gespeichert.
Dies erzeugt eine Reihe von kompakten und komprimierten Parquet-Dateien im angegebenen Pfad. Da wir hier snappy als Komprimierungsmethode gewählt haben, werden wir auch snappy-komprimierte Dateien haben. Aus Gründen der Übersichtlichkeit wurde in diesem Beispiel nur eine Datei erstellt; normalerweise können es ein Dutzend Dateien sein:
-rw-r--r-- 1 jules wheel 0 May 19 10:58 _SUCCESS -rw-r--r-- 1 jules wheel 966 May 19 10:58 part-00000-<...>-c000.snappy.parquet
Datenrahmen in Spark-SQL-Tabellen schreiben
Das Schreiben eines Datenrahmens in eine SQL-Tabelle ist genauso einfach wie das Schreiben in eine Datei - verwende einfach saveAsTable() anstelle von save(). Dadurch wird eine verwaltete Tabelle namens us_delay_flights_tbl erstellt:
// In Scaladf.write.mode("overwrite").saveAsTable("us_delay_flights_tbl")
# In Python(df.write.mode("overwrite").saveAsTable("us_delay_flights_tbl"))
Zusammenfassend lässt sich sagen, dass Parquet das bevorzugte und standardmäßig eingebaute Dateiformat für Datenquellen in Spark ist, das auch von vielen anderen Frameworks übernommen wurde. Wir empfehlen dir, dieses Format in deinen ETL- und Dateningestionsprozessen zu verwenden.
JSON
JavaScript Object Notation (JSON) ist ebenfalls ein beliebtes Datenformat. Es wurde bekannt, weil es im Vergleich zu XML ein leicht zu lesendes und einfach zu parsendes Format ist. Es gibt zwei Darstellungsformate: den einzeiligen Modus und den mehrzeiligen Modus. Beide Modi werden in Spark unterstützt.
Im einzeiligen Modus bezeichnet jede Zeile ein einzelnes JSON-Objekt, während im mehrzeiligen Modus das gesamte mehrzeilige Objekt ein einzelnes JSON-Objekt darstellt. Um in diesem Modus zu lesen, setze multiLine in der Methode option() auf true.
Lesen einer JSON-Datei in einen Datenrahmen (DataFrame)
Du kannst eine JSON-Datei genauso in einen Datenrahmen einlesen, wie du es mit Parquet getan hast - gib einfach "json" in der Methode format() an:
// In Scalavalfile="/databricks-datasets/learning-spark-v2/flights/summary-data/json/*"valdf=spark.read.format("json").load(file)
# In Pythonfile="/databricks-datasets/learning-spark-v2/flights/summary-data/json/*"df=spark.read.format("json").load(file)
Lesen einer JSON-Datei in eine Spark SQL-Tabelle
Du kannst auch eine SQL-Tabelle aus einer JSON-Datei erstellen, genauso wie du es mit Parquet gemacht hast:
-- In SQLCREATEORREPLACETEMPORARYVIEWus_delay_flights_tblUSINGjsonOPTIONS(path"/databricks-datasets/learning-spark-v2/flights/summary-data/json/*")
Sobald die Tabelle erstellt ist, kannst du mit SQL Daten in einen Datenrahmen einlesen:
//InScala/Pythonspark.sql("SELECT * FROM us_delay_flights_tbl").show()+-----------------+-------------------+-----+|DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count|+-----------------+-------------------+-----+|UnitedStates|Romania|15||UnitedStates|Croatia|1||UnitedStates|Ireland|344||Egypt|UnitedStates|15||UnitedStates|India|62||UnitedStates|Singapore|1||UnitedStates|Grenada|62||CostaRica|UnitedStates|588||Senegal|UnitedStates|40||Moldova|UnitedStates|1|+-----------------+-------------------+-----+onlyshowingtop10rows
Datenrahmen in JSON-Dateien schreiben
Einen Datenrahmen als JSON-Datei zu speichern ist ganz einfach. Du gibst die entsprechenden DataFrameWriter Methoden und Argumente an und gib den Ort an, an dem die JSON-Dateien gespeichert werden sollen:
// In Scaladf.write.format("json").mode("overwrite").option("compression","snappy").save("/tmp/data/json/df_json")
# In Python(df.write.format("json").mode("overwrite").option("compression","snappy").save("/tmp/data/json/df_json"))
Es wird ein Verzeichnis im angegebenen Pfad erstellt, das mit einer Reihe von kompakten JSON-Dateien gefüllt wird:
-rw-r--r-- 1 jules wheel 0 May 16 14:44 _SUCCESS -rw-r--r-- 1 jules wheel 71 May 16 14:44 part-00000-<...>-c000.json
Optionen für die JSON-Datenquelle
Tabelle 4-3 beschreibt gängige JSON-Optionen für DataFrameReader und DataFrameWriter. Für eine umfassende Liste verweisen wir auf die Dokumentation .
| Name der Immobilie | Werte | Bedeutung | Umfang |
|---|---|---|---|
compression |
none, uncompressed, bzip2, deflate, gzip, lz4, oder snappy |
Verwende diesen Komprimierungscodec zum Schreiben. Beachte, dass das Lesen die Kompression oder den Codec nur anhand der Dateierweiterung erkennt. | Schreibe |
dateFormat |
yyyy-MM-dd oder DateTimeFormatter |
Verwende dieses Format oder ein beliebiges Format aus Javas DateTimeFormatter. |
Lesen/Schreiben |
multiLine |
true, false |
Verwende den mehrzeiligen Modus. Die Voreinstellung ist false (einzeiliger Modus). |
Lies |
allowUnquotedFieldNames |
true, false |
Erlaubt unquotierte JSON-Feldnamen. Standard ist false. |
Lies |
CSV
Dieses weit verbreitete Textdateiformat erfasst jedes Datum oder Feld, das durch ein Komma getrennt ist; jede Zeile mit durch Komma getrennten Feldern stellt einen Datensatz dar. Auch wenn das Komma das Standardtrennzeichen ist, kannst du auch andere Trennzeichen verwenden, wenn Kommas Teil deiner Daten sind. Gängige Tabellenkalkulationen können CSV-Dateien erstellen, daher ist es ein beliebtes Format bei Daten- und Wirtschaftsanalysten.
Lesen einer CSV-Datei in einen Datenrahmen (DataFrame)
Wie bei den anderen integrierten Datenquellen kannst du die Methoden und Argumente von DataFrameReader verwenden, um eine CSV-Datei in einen Datenrahmen einzulesen:
// In Scalavalfile="/databricks-datasets/learning-spark-v2/flights/summary-data/csv/*"valschema="DEST_COUNTRY_NAME STRING, ORIGIN_COUNTRY_NAME STRING, count INT"valdf=spark.read.format("csv").schema(schema).option("header","true").option("mode","FAILFAST")// Exit if any errors.option("nullValue","")// Replace any null data with quotes.load(file)
# In Pythonfile="/databricks-datasets/learning-spark-v2/flights/summary-data/csv/*"schema="DEST_COUNTRY_NAME STRING, ORIGIN_COUNTRY_NAME STRING, count INT"df=(spark.read.format("csv").option("header","true").schema(schema).option("mode","FAILFAST")# Exit if any errors.option("nullValue","")# Replace any null data field with quotes.load(file))
Lesen einer CSV-Datei in eine Spark SQL-Tabelle
Das Erstellen einer SQL-Tabelle aus einer CSV-Datenquelle unterscheidet sich nicht von der Verwendung von Parquet oder JSON:
-- In SQLCREATEORREPLACETEMPORARYVIEWus_delay_flights_tblUSINGcsvOPTIONS(path"/databricks-datasets/learning-spark-v2/flights/summary-data/csv/*",header"true",inferSchema"true",mode"FAILFAST")
Sobald du die Tabelle erstellt hast, kannst du die Daten wie bisher mit SQL in einen Datenrahmen einlesen:
//InScala/Pythonspark.sql("SELECT * FROM us_delay_flights_tbl").show(10)+-----------------+-------------------+-----+|DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count|+-----------------+-------------------+-----+|UnitedStates|Romania|1||UnitedStates|Ireland|264||UnitedStates|India|69||Egypt|UnitedStates|24||EquatorialGuinea|UnitedStates|1||UnitedStates|Singapore|25||UnitedStates|Grenada|54||CostaRica|UnitedStates|477||Senegal|UnitedStates|29||UnitedStates|MarshallIslands|44|+-----------------+-------------------+-----+onlyshowingtop10rows
Datenrahmen in CSV-Dateien schreiben
Das Speichern eines Datenrahmens als CSV-Datei ist ganz einfach. Gib die entsprechenden DataFrameWriter Methoden und Argumente an und gib den Ort an, an dem die CSV-Dateien gespeichert werden sollen:
// In Scaladf.write.format("csv").mode("overwrite").save("/tmp/data/csv/df_csv")
# In Pythondf.write.format("csv").mode("overwrite").save("/tmp/data/csv/df_csv")
Dies erzeugt einen Ordner am angegebenen Ort, der mit einer Reihe von komprimierten und kompakten Dateien gefüllt wird:
-rw-r--r-- 1 jules wheel 0 May 16 12:17 _SUCCESS -rw-r--r-- 1 jules wheel 36 May 16 12:17 part-00000-251690eb-<...>-c000.csv
Optionen für die CSV-Datenquelle
Tabelle 4-4 beschreibt einige der gängigen CSV-Optionen für DataFrameReader und DataFrameWriter. Da CSV-Dateien komplex sein können, stehen viele Optionen zur Verfügung; für eine umfassende Liste verweisen wir dich auf die Dokumentation .
| Name der Immobilie | Werte | Bedeutung | Umfang |
|---|---|---|---|
compression |
none, bzip2, deflate, gzip, lz4, oder snappy |
Verwende diesen Komprimierungscodec zum Schreiben. | Schreibe |
dateFormat |
yyyy-MM-dd oder DateTimeFormatter |
Verwende dieses Format oder ein beliebiges Format aus Javas DateTimeFormatter. |
Lesen/Schreiben |
multiLine |
true, false |
Verwende den mehrzeiligen Modus. Die Voreinstellung ist false (einzeiliger Modus). |
Lies |
inferSchema |
true, false |
Wenn true, bestimmt Spark die Datentypen der Spalten. Die Voreinstellung ist false. |
Lies |
sep |
Jedes Zeichen | Verwende dieses Zeichen, um Spaltenwerte in einer Zeile zu trennen. Das Standard-Trennzeichen ist ein Komma (,). |
Lesen/Schreiben |
escape |
Jedes Zeichen | Verwende dieses Zeichen, um Anführungszeichen zu vermeiden. Die Voreinstellung ist \. |
Lesen/Schreiben |
header |
true, false |
Gibt an, ob die erste Zeile eine Überschrift ist, die die einzelnen Spaltennamen bezeichnet. Die Voreinstellung ist false. |
Lesen/Schreiben |
Avro
Das Avro-Format wurde in Spark 2.4 als integrierte Datenquelle eingeführt und wird zum Beispiel von Apache Kafka für die Serialisierung und Deserialisierung von Nachrichten verwendet. Es bietet viele Vorteile, darunter die direkte Abbildung auf JSON, Geschwindigkeit und Effizienz sowie Bindungen für viele Programmiersprachen.
Einlesen einer Avro-Datei in einen Datenrahmen (DataFrame)
Das Einlesen einer Avro-Datei in einen Datenrahmen mit DataFrameReader entspricht der Verwendung der anderen Datenquellen, die wir in diesem Abschnitt besprochen haben:
// In Scalavaldf=spark.read.format("avro").load("/databricks-datasets/learning-spark-v2/flights/summary-data/avro/*")df.show(false)
# In Pythondf=(spark.read.format("avro").load("/databricks-datasets/learning-spark-v2/flights/summary-data/avro/*"))df.show(truncate=False)+-----------------+-------------------+-----+|DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count|+-----------------+-------------------+-----+|UnitedStates|Romania|1||UnitedStates|Ireland|264||UnitedStates|India|69||Egypt|UnitedStates|24||EquatorialGuinea|UnitedStates|1||UnitedStates|Singapore|25||UnitedStates|Grenada|54||CostaRica|UnitedStates|477||Senegal|UnitedStates|29||UnitedStates|MarshallIslands|44|+-----------------+-------------------+-----+onlyshowingtop10rows
Einlesen einer Avro-Datei in eine Spark SQL-Tabelle
Auch hier unterscheidet sich die Erstellung von SQL-Tabellen mit einer Avro-Datenquelle nicht von der Verwendung von Parquet, JSON oder CSV:
-- In SQLCREATEORREPLACETEMPORARYVIEWepisode_tblUSINGavroOPTIONS(path"/databricks-datasets/learning-spark-v2/flights/summary-data/avro/*")
Wenn du eine Tabelle erstellt hast, kannst du mit SQL Daten in einen Datenrahmen einlesen:
// In Scalaspark.sql("SELECT * FROM episode_tbl").show(false)
# In Pythonspark.sql("SELECT * FROM episode_tbl").show(truncate=False)+-----------------+-------------------+-----+|DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count|+-----------------+-------------------+-----+|UnitedStates|Romania|1||UnitedStates|Ireland|264||UnitedStates|India|69||Egypt|UnitedStates|24||EquatorialGuinea|UnitedStates|1||UnitedStates|Singapore|25||UnitedStates|Grenada|54||CostaRica|UnitedStates|477||Senegal|UnitedStates|29||UnitedStates|MarshallIslands|44|+-----------------+-------------------+-----+onlyshowingtop10rows
Datenrahmen in Avro-Dateien schreiben
Das Schreiben eines Datenrahmens als Avro-Datei ist ganz einfach. Wie üblich gibst du die entsprechenden DataFrameWriter Methoden und Argumente an und gibst den Speicherort für die Avro-Dateien an:
// In Scaladf.write.format("avro").mode("overwrite").save("/tmp/data/avro/df_avro")
# In Python(df.write.format("avro").mode("overwrite").save("/tmp/data/avro/df_avro"))
Dies erzeugt einen Ordner am angegebenen Ort, der mit einer Reihe von komprimierten und kompakten Dateien gefüllt wird:
-rw-r--r-- 1 jules wheel 0 May 17 11:54 _SUCCESS -rw-r--r-- 1 jules wheel 526 May 17 11:54 part-00000-ffdf70f4-<...>-c000.avro
Optionen für Avro-Datenquellen
Tabelle 4-5 beschreibt gängige Optionen für DataFrameReader und DataFrameWriter. Eine umfassende Liste der Optionen findest du in der Dokumentation .
| Name der Immobilie | Standardwert | Bedeutung | Umfang |
|---|---|---|---|
avroSchema |
Keine | Optionales Avro-Schema, das von einem Benutzer im JSON-Format bereitgestellt wird. Der Datentyp und die Benennung der Datensatzfelder müssen mit den eingegebenen Avro-Daten oder Catalyst-Daten (interner Spark-Datentyp) übereinstimmen, sonst schlägt die Lese-/Schreibaktion fehl. | Lesen/Schreiben |
recordName |
topLevelRecord |
Top-Level-Datensatzname im Schreibergebnis, der in der Avro-Spezifikation vorgeschrieben ist. | Schreibe |
recordNamespace |
"" |
Namensräume im Schreibergebnis aufzeichnen. | Schreibe |
ignoreExtension |
true |
Wenn diese Option aktiviert ist, werden alle Dateien (mit und ohne die Endung .avro ) geladen. Andernfalls werden Dateien ohne die Endung .avro ignoriert. | Lies |
compression |
snappy |
Ermöglicht es dir, den Komprimierungscodec anzugeben, der beim Schreiben verwendet werden soll. Die derzeit unterstützten Codecs sind uncompressed, snappy, deflate, bzip2 und xz.Wenn diese Option nicht gesetzt ist, wird der Wert in spark.sql.avro.compression.codec berücksichtigt. |
Schreibe |
ORC
Als zusätzliches optimiertes spaltenförmiges Dateiformat unterstützt Spark 2.x einen vektorisierten ORC-Reader. Zwei Spark-Konfigurationen legen fest, welche ORC-Implementierung verwendet werden soll. Wenn spark.sql.orc.impl auf native und spark.sql.orc.enableVectorizedReader auf true eingestellt ist, verwendet Spark den vektorisierten ORC-Leser. Ein vektorisierter Leser liest Blöcke von Zeilen (oft 1.024 pro Block) anstatt eine Zeile nach der anderen, was die Abläufe rationalisiert und die CPU-Auslastung für intensive Operationen wie Scans, Filter, Aggregationen und Joins reduziert.
Für Hive ORC SerDe (Serialisierung und Deserialisierung) Tabellen, die mit dem SQL-Befehl USING HIVE OPTIONS (fileFormat 'ORC') erstellt wurden, wird der vektorisierte Reader verwendet, wenn der Spark-Konfigurationsparameter spark.sql.hive.convertMetastoreOrc auf true gesetzt ist.
Einlesen einer ORC-Datei in einen Datenrahmen (DataFrame)
Um einen Datenrahmen mit dem ORC-Vektorleser einzulesen, kannst du einfach die normalen DataFrameReader Methoden und Optionen verwenden:
// In Scalavalfile="/databricks-datasets/learning-spark-v2/flights/summary-data/orc/*"valdf=spark.read.format("orc").load(file)df.show(10,false)
# In Pythonfile="/databricks-datasets/learning-spark-v2/flights/summary-data/orc/*"df=spark.read.format("orc").option("path",file).load()df.show(10,False)+-----------------+-------------------+-----+|DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count|+-----------------+-------------------+-----+|UnitedStates|Romania|1||UnitedStates|Ireland|264||UnitedStates|India|69||Egypt|UnitedStates|24||EquatorialGuinea|UnitedStates|1||UnitedStates|Singapore|25||UnitedStates|Grenada|54||CostaRica|UnitedStates|477||Senegal|UnitedStates|29||UnitedStates|MarshallIslands|44|+-----------------+-------------------+-----+onlyshowingtop10rows
Lesen einer ORC-Datei in eine Spark SQL-Tabelle
Es gibt keinen Unterschied zu Parquet, JSON, CSV oder Avro, wenn du eine SQL-Ansicht mit einer ORC-Datenquelle erstellst:
-- In SQLCREATEORREPLACETEMPORARYVIEWus_delay_flights_tblUSINGorcOPTIONS(path"/databricks-datasets/learning-spark-v2/flights/summary-data/orc/*")
Sobald eine Tabelle erstellt ist, kannst du die Daten wie gewohnt mit SQL in einen Datenrahmen einlesen:
//InScala/Pythonspark.sql("SELECT * FROM us_delay_flights_tbl").show()+-----------------+-------------------+-----+|DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count|+-----------------+-------------------+-----+|UnitedStates|Romania|1||UnitedStates|Ireland|264||UnitedStates|India|69||Egypt|UnitedStates|24||EquatorialGuinea|UnitedStates|1||UnitedStates|Singapore|25||UnitedStates|Grenada|54||CostaRica|UnitedStates|477||Senegal|UnitedStates|29||UnitedStates|MarshallIslands|44|+-----------------+-------------------+-----+onlyshowingtop10rows
Datenrahmen in ORC-Dateien schreiben
Das Zurückschreiben eines transformierten Datenrahmens nach dem Lesen ist ebenso einfach mit den DataFrameWriter Methoden:
// In Scaladf.write.format("orc").mode("overwrite").option("compression","snappy").save("/tmp/data/orc/df_orc")
# In Python(df.write.format("orc").mode("overwrite").option("compression","snappy").save("/tmp/data/orc/flights_orc"))
Das Ergebnis ist ein Ordner am angegebenen Ort, der einige komprimierte ORC-Dateien enthält:
-rw-r--r-- 1 jules wheel 0 May 16 17:23 _SUCCESS -rw-r--r-- 1 jules wheel 547 May 16 17:23 part-00000-<...>-c000.snappy.orc
Bilder
In Spark 2.4 führte die Community eine neue Datenquelle ein, Bilddateien, um Deep Learning und Machine Learning Frameworks wie TensorFlow und PyTorch zu unterstützen. Für Computer Vision-basierte Machine Learning-Anwendungen ist das Laden und Verarbeiten von Bilddatensätzen wichtig.
Einlesen einer Bilddatei in einen Datenrahmen (DataFrame)
Wie bei allen anderen Dateiformaten kannst du die Methoden und Optionen von DataFrameReader verwenden, um eine Bilddatei einzulesen, wie hier gezeigt:
// In Scalaimportorg.apache.spark.ml.source.imagevalimageDir="/databricks-datasets/learning-spark-v2/cctvVideos/train_images/"valimagesDF=spark.read.format("image").load(imageDir)imagesDF.printSchemaimagesDF.select("image.height","image.width","image.nChannels","image.mode","label").show(5,false)
# In Pythonfrompyspark.mlimportimageimage_dir="/databricks-datasets/learning-spark-v2/cctvVideos/train_images/"images_df=spark.read.format("image").load(image_dir)images_df.printSchema()root|--image:struct(nullable=true)||--origin:string(nullable=true)||--height:integer(nullable=true)||--width:integer(nullable=true)||--nChannels:integer(nullable=true)||--mode:integer(nullable=true)||--data:binary(nullable=true)|--label:integer(nullable=true)images_df.select("image.height","image.width","image.nChannels","image.mode","label").show(5,truncate=False)+------+-----+---------+----+-----+|height|width|nChannels|mode|label|+------+-----+---------+----+-----+|288|384|3|16|0||288|384|3|16|1||288|384|3|16|0||288|384|3|16|0||288|384|3|16|0|+------+-----+---------+----+-----+onlyshowingtop5rows
Binäre Dateien
Mit Spark 3.0 wird die Unterstützung für Binärdateien als Datenquelle hinzugefügt. Die DataFrameReader konvertiert jede Binärdatei in eine einzelne DataFrame-Zeile (Datensatz), die den Rohinhalt und die Metadaten der Datei enthält. Die Datenquelle für Binärdateien erzeugt einen DataFrame mit den folgenden Spalten:
Pfad: StringType
modificationTime: ZeitstempelTyp
Länge: LongType
Inhalt: BinaryType
Lesen einer Binärdatei in einen Datenrahmen (DataFrame)
Um Binärdateien zu lesen, gibst du das Datenquellenformat als binaryFile an. Mit der Datenquellenoption pathGlobFilter kannst du Dateien mit Pfaden laden, die einem bestimmten globalen Muster entsprechen, wobei das Verhalten der Partitionserkennung beibehalten wird. Der folgende Code liest zum Beispiel alle JPG-Dateien aus dem Eingabeverzeichnis mit allen partitionierten Verzeichnissen:
// In Scalavalpath="/databricks-datasets/learning-spark-v2/cctvVideos/train_images/"valbinaryFilesDF=spark.read.format("binaryFile").option("pathGlobFilter","*.jpg").load(path)binaryFilesDF.show(5)
# In Pythonpath="/databricks-datasets/learning-spark-v2/cctvVideos/train_images/"binary_files_df=(spark.read.format("binaryFile").option("pathGlobFilter","*.jpg").load(path))binary_files_df.show(5)+--------------------+-------------------+------+--------------------+-----+|path|modificationTime|length|content|label|+--------------------+-------------------+------+--------------------+-----+|file:/Users/jules...|2020-02-1212:04:24|55037|[FFD8FFE0001...|0||file:/Users/jules...|2020-02-1212:04:24|54634|[FFD8FFE0001...|1||file:/Users/jules...|2020-02-1212:04:24|54624|[FFD8FFE0001...|0||file:/Users/jules...|2020-02-1212:04:24|54505|[FFD8FFE0001...|0||file:/Users/jules...|2020-02-1212:04:24|54475|[FFD8FFE0001...|0|+--------------------+-------------------+------+--------------------+-----+onlyshowingtop5rows
Um die Aufteilung der Datenerkennung in einem Verzeichnis zu ignorieren, kannst du recursiveFileLookup auf "true" setzen:
// In ScalavalbinaryFilesDF=spark.read.format("binaryFile").option("pathGlobFilter","*.jpg").option("recursiveFileLookup","true").load(path)binaryFilesDF.show(5)
# In Pythonbinary_files_df=(spark.read.format("binaryFile").option("pathGlobFilter","*.jpg").option("recursiveFileLookup","true").load(path))binary_files_df.show(5)+--------------------+-------------------+------+--------------------+|path|modificationTime|length|content|+--------------------+-------------------+------+--------------------+|file:/Users/jules...|2020-02-1212:04:24|55037|[FFD8FFE0001...||file:/Users/jules...|2020-02-1212:04:24|54634|[FFD8FFE0001...||file:/Users/jules...|2020-02-1212:04:24|54624|[FFD8FFE0001...||file:/Users/jules...|2020-02-1212:04:24|54505|[FFD8FFE0001...||file:/Users/jules...|2020-02-1212:04:24|54475|[FFD8FFE0001...|+--------------------+-------------------+------+--------------------+onlyshowingtop5rows
Beachte, dass die Spalte label nicht vorhanden ist, wenn die Option recursiveFileLookup auf "true" gesetzt ist.
Derzeit unterstützt die Datenquelle für Binärdateien nicht das Zurückschreiben eines Datenrahmens in das ursprüngliche Dateiformat.
In diesem Abschnitt hast du erfahren, wie du Daten aus einer Reihe von unterstützten Dateiformaten in einen Datenrahmen einlesen kannst. Wir haben dir auch gezeigt, wie du temporäre Ansichten und Tabellen aus den vorhandenen integrierten Datenquellen erstellst. Egal, ob du die DataFrame API oder SQL verwendest, die Abfragen führen zu den gleichen Ergebnissen. Du kannst einige dieser Abfragen im Notizbuch im GitHub-Repository für dieses Buch nachlesen.
Zusammenfassung
In diesem Kapitel wurde die Interoperabilität zwischen der DataFrame API und Spark SQL untersucht. Insbesondere hast du einen Eindruck davon bekommen, wie du Spark SQL verwenden kannst, um
Erstelle verwaltete und nicht verwaltete Tabellen mit Spark SQL und der DataFrame API.
Lies von und schreibe in verschiedene integrierte Datenquellen und Dateiformate.
Nutze die Programmierschnittstelle
spark.sql, um SQL-Abfragen auf strukturierte Daten zu stellen, die als Spark SQL-Tabellen oder Ansichten gespeichert sind.Sieh dir die Spark
Catalogan, um die Metadaten von Tabellen und Ansichten zu prüfen.Verwende die APIs
DataFrameWriterundDataFrameReader.
Anhand der Codeschnipsel in diesem Kapitel und der Notebooks, die im GitHub-Repository des Buches verfügbar sind, hast du ein Gefühl dafür bekommen, wie man Datenrahmen und Spark SQL verwendet. Im nächsten Kapitel wird weiter erforscht, wie Spark mit den in Abbildung 4-1 dargestellten externen Datenquellen interagiert. Du wirst einige detailliertere Beispiele für Transformationen und die Interoperabilität zwischen der DataFrame API und Spark SQL sehen .
Get Spark lernen, 2. Auflage now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

