Kapitel 4. Das Dokumentenmanagementsystem
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Die Herausforderung
Nachdem du erfolgreich einen fortschrittlichen Kontoauszugsanalysator für Mark Erbergzuck implementiert hast, beschließt du, ein paar Besorgungen zu machen - einschließlich eines Termins bei deiner Zahnärztin.Dr. Avaj führt ihre Praxis seit vielen Jahren erfolgreich. Ihre zufriedenen Patienten behalten ihre weißen Zähne bis ins hohe Alter. Die Kehrseite einer so erfolgreichen Praxis ist, dass jedes Jahr mehr und mehr Patientenunterlagen anfallen. Jedes Mal, wenn sie eine Aufzeichnung über eine frühere Behandlung finden muss, brauchen ihre Assistentinnen immer länger, um in ihren Aktenschränken zu suchen.
Sie erkennt, dass es an der Zeit ist, die Verwaltung dieser Dokumente zu automatisieren und den Überblick darüber zu behalten. Zum Glück hat sie einen Patienten, der das für sie tun kann! Du wirst ihr helfen, indem du eine Software für sie schreibst, die diese Dokumente verwaltet und es ihr ermöglicht, die Informationen zu finden, mit denen ihre Praxis gedeihen und wachsen kann.
Das Ziel
In diesem Kapitel lernst du eine Reihe verschiedener Prinzipien der Softwareentwicklung kennen. Der Schlüssel zum Design der Verwaltung von Dokumenten ist eine Vererbungsbeziehung, d.h. die Erweiterung einer Klasse oder die Implementierung einer Schnittstelle. Um dies richtig zu tun, lernst du das Liskov-Substitutionsprinzip kennen, benannt nach der berühmten Informatikerin Barbara Liskov.
Dein Verständnis dafür, wann du Vererbung einsetzen solltest, wird durch die Diskussion des Prinzips "Komposition vor Vererbung" vertieft.
Schließlich wirst du dein Wissen über das Schreiben von automatisiertem Testcode erweitern, indem du verstehst, was einen guten und wartbaren Test ausmacht. Nachdem wir nun die Handlung dieses Kapitels verraten haben, wollen wir zurückkommen, um zu verstehen, welche Anforderungen Dr. Avaj an das Dokumentenmanagementsystem stellt.
Hinweis
Wenn du dir irgendwann den Quellcode für dieses Kapitel ansehen möchtest, kannst du das Paket com.iteratrlearning.shu_book.chapter_04im Code-Repository des Buches aufrufen.
Anforderungen an das Dokumentenmanagementsystem
Bei einer freundlichen Tasse Tee mit Dr. Avaj hat sich herausgestellt, dass sie die Dokumente, die sie verwalten möchte, als Dateien auf ihrem Computer hat. Das Dokumentenmanagementsystem muss in der Lage sein, diese Dateien zu importieren und einige Informationen zu jeder Datei zu speichern, die indiziert und durchsucht werden können. Es gibt drei Arten von Dokumenten, die für sie von Bedeutung sind:
- Berichte
-
Ein Text, in dem eine Konsultation einer Operation an einem Patienten beschrieben wird.
- Briefe
-
Ein Textdokument, das an eine Adresse geschickt wird. (Die kennst du wahrscheinlich schon, wenn du daran denkst.)
- Bilder
-
In der Zahnarztpraxis werden oft Röntgenbilder oder Fotos von Zähnen und Zahnfleisch aufgenommen. Diese haben eine bestimmte Größe.
Außerdem müssen alle Dokumente den Pfad zu der verwalteten Datei und den Patienten, um den es in dem Dokument geht, enthalten. Dr. Avaj muss in der Lage sein, diese Dokumente zu durchsuchen und abzufragen, ob jedes der Attribute über eine andere Art von Dokument bestimmte Informationen enthält; zum Beispiel, um nach Briefen zu suchen, in denen der Textkörper "Joe Bloggs" enthält.
Während des Gesprächs hast du auch festgestellt, dass Dr. Avaj in Zukunft vielleicht andere Arten von Dokumenten hinzufügen möchte.
Das Design verfeinern
Bei der Herangehensweise an dieses Problem gibt es viele wichtige Designentscheidungen zu treffen und Modellierungsansätze, die wir wählen können. Diese Entscheidungen sind subjektiv, und du kannst gerne versuchen, eine Lösung für Dr. Avajs Problem zu programmieren, bevor oder nachdem du dieses Kapitel gelesen hast. In "Alternative Ansätze" erfährst du, warum wir verschiedene Entscheidungen vermeiden und welche übergreifenden Prinzipien dahinter stehen.
Ein guter erster Schritt, um sich einem Programm zu nähern, ist es, mit testgetriebener Entwicklung (TDD) zu beginnen, wie wir es beim Schreiben der Beispiellösung in diesem Buch getan haben. Wir werden TDD erst in Kapitel 5 behandeln. Beginnen wir also damit, uns Gedanken über das Verhalten zu machen, das deine Software ausführen soll, und den Code, der dieses Verhalten implementiert, schrittweise auszubauen.
Das Dokumentenmanagementsystem sollte in der Lage sein, Dokumente auf Anfrage zu importieren und sie in den internen Dokumentenspeicher aufzunehmen. Um diese Anforderung zu erfüllen, erstellen wir die Klasse DocumentManagementSystem und fügen zwei Methoden hinzu:
void importFile(String path)-
Nimmt einen Pfad zu einer Datei an, die unser Benutzer in das Dokumentenmanagementsystem importieren möchte. Da es sich um eine öffentliche API-Methode handelt, die Eingaben von Nutzern in einem Produktionssystem annehmen könnte, nehmen wir unseren Pfad als
String, anstatt uns auf eine typsichere Klasse wiejava.nio.Pathoderjava.io.Filezu verlassen. List<Document> contents()-
Gibt eine Liste aller Dokumente zurück, die das Dokumentenverwaltungssystem derzeit speichert.
Du wirst feststellen, dass contents() eine Liste der Klasse Document zurückgibt. Wir haben noch nicht gesagt, was diese Klasse beinhaltet, aber sie wird zu gegebener Zeit wieder auftauchen. Für den Moment kannst du so tun, als wäre es eine leere Klasse.
Importeure
Ein wesentliches Merkmal dieses Systems ist, dass wir in der Lage sein müssen, Dokumente unterschiedlicher Art zu importieren. Für die Zwecke dieses Systems kannst du dich auf die Dateierweiterungen verlassen, um zu entscheiden, wie sie importiert werden sollen, denn Dr. Avaj hat Dateien mit ganz bestimmten Erweiterungen gespeichert. Alle ihre Briefe haben die Endung.letter, Berichte haben die Endung .report und .jpg ist das einzige verwendete Bildformat.
Am einfachsten wäre es, den gesamten Code für den Importmechanismus in eine einzige Methode zu packen, wie in Beispiel 4-1 gezeigt.
Beispiel 4-1. Beispiel für den Wechsel der Erweiterung
switch(extension){case"letter":// code for importing letters.break;case"report":// code for importing reports.break;case"jpg":// code for importing images.break;default:thrownewUnknownFileTypeException("For file: "+path);}
Dieser Ansatz hätte das fragliche Problem gelöst, wäre aber schwer zu erweitern gewesen. Jedes Mal, wenn du einen weiteren Dateityp hinzufügen möchtest, der verarbeitet wird, müsstest du einen weiteren Eintrag in der switch Anweisung implementieren. Mit der Zeit würde diese Methode unüberschaubar lang und schwer zu lesen werden.
Wenn du deine Hauptklasse schön einfach hältst und verschiedene Implementierungsklassen für den Import verschiedener Dokumenttypen aufteilst, ist es einfach, jeden Importeur für sich zu finden und zu verstehen. Um verschiedene Dokumenttypen zu unterstützen, wird eine Importer Schnittstelle definiert. Jede Importer wird eine Klasse sein, die eine andere Art von Datei importieren kann.
Da wir nun wissen, dass wir eine Schnittstelle zum Importieren von Dateien brauchen, stellt sich die Frage, wie wir die zu importierende Datei darstellen sollen. Wir haben mehrere Möglichkeiten: Wir können ein einfaches String verwenden, um den Pfad der Datei darzustellen, oder eine Klasse, die eine Datei repräsentiert, wie java.io.File.
Du könntest argumentieren, dass wir hier das Prinzip der starken Typisierung anwenden sollten: Nimm einen Typ, der die Datei repräsentiert, und reduziere den Spielraum für Fehler gegenüber der Verwendung eines String. Lass uns diesen Ansatz wählen und ein java.io.File Objekt als Parameter in unserer Importer Schnittstelle verwenden, um die zu importierende Datei zu repräsentieren, wie in Beispiel 4-2 gezeigt.
Beispiel 4-2. Importeur
interfaceImporter{DocumentimportFile(Filefile)throwsIOException;}
Du fragst dich vielleicht, warum du dann nicht auch eine File für die öffentliche API von DocumentManagementSystem verwendest? Nun, im Fall dieser Anwendung würde unsere öffentliche API wahrscheinlich in eine Art Benutzeroberfläche eingepackt werden, und wir sind uns nicht sicher, in welcher Form diese Dateien vorliegen. Deshalb haben wir die Dinge einfach gehalten und nur einen String Typ verwendet.
Die Dokumentenklasse
Definieren wir zu diesem Zeitpunkt auch die Klasse Document. Jedes Dokument wird mehrere Attribute haben, nach denen wir suchen können. Verschiedene Dokumente haben verschiedene Arten von Attributen. Wir haben verschiedene Optionen, deren Vor- und Nachteile wir bei der Definition von Document abwägen können.
Die erste und einfachste Art, ein Dokument darzustellen, wäre die Verwendung einerMap<String, String>, einer Zuordnung von Attributnamen zu den Werten, die mit diesen Attributen verbunden sind. Warum also nicht einfach eine Map<String, String> in der Anwendung verwenden? Nun, die Einführung einer Domänenklasse zur Modellierung eines einzelnen Dokuments ist nicht nur eine OOP-Methode, sondern bietet auch eine Reihe praktischer Verbesserungen in Bezug auf die Wartbarkeit und Lesbarkeit der Anwendung.
Zunächst einmal kann man gar nicht genug betonen, wie wichtig es ist, den Komponenten innerhalb einer Anwendung konkrete Namen zu geben. Kommunikation ist König! Gute Teams von Softwareentwicklern verwenden eine allgegenwärtige Sprache, um ihre Software zu beschreiben. Wenn du das Vokabular, das du im Code deiner Anwendung verwendest, mit dem Vokabular abstimmst, das du im Gespräch mit Kunden wie Dr. Avaj benutzt, ist es viel einfacher, die Dinge zu pflegen. Wenn du dich mit einem Kollegen oder Kunden unterhältst, müsst ihr euch immer auf eine gemeinsame Sprache einigen, mit der ihr die verschiedenen Aspekte der Software beschreiben könnt. Wenn du diese Sprache auf den Code selbst abbildest, ist es sehr einfach zu wissen, welchen Teil des Codes du ändern musst. Das nennt manAuffindbarkeit.
Hinweis
Der Begriff Ubiquitous Language wurde von Eric Evans geprägt und stammt aus dem Domain Driven Design. Er bezieht sich auf die Verwendung einer gemeinsamen Sprache, die klar definiert ist und sowohl von Entwicklern als auch von Nutzern verwendet wird.
Ein weiteres Prinzip, das dich ermutigen sollte, eine Klasse zur Modellierung eines Dokuments einzuführen, ist die starke Typisierung. Viele Menschen verwenden diesen Begriff, um sich auf die Beschaffenheit einer Programmiersprache zu beziehen, aber hier geht es um den eher praktischen Nutzen der starken Typisierung bei der Implementierung deiner Software. Mit Typen können wir die Art und Weise, wie Daten verwendet werden, einschränken. Unsere Klasse Document ist zum Beispiel unveränderlich: Sobald sie erstellt wurde, kannst du ihre Attribute nicht mehr ändern oder mutieren. UnsereImporter Implementierungen erstellen die Dokumente; nichts anderes verändert sie. Wenn du jemals ein Document mit einem Fehler in einem seiner Attribute siehst, kannst du die Quelle des Fehlers auf das Importer eingrenzen, das das Document erstellt hat. Aus der Unveränderlichkeit kannst du auch ableiten, dass es möglich ist, alle Informationen, die mit dem Document verbunden sind, zu indizieren oder zwischenzuspeichern, und du weißt, dass sie immer korrekt sein werden, da Dokumente unveränderlich sind.
Eine andere Möglichkeit, die Entwickler bei der Modellierung ihrerDocument in Betracht ziehen könnten, wäre, Document zu einer Erweiterung von HashMap<String, String> zu machen. Auf den ersten Blick scheint das großartig zu sein, weil HashMap alle Funktionen hat, die du für die Modellierung einer Document brauchst. Es gibt jedoch mehrere Gründe, warum das eine schlechte Wahl ist.
Bei der Entwicklung von Software geht es oft darum, unerwünschte Funktionen einzuschränken, aber auch darum, Dinge zu entwickeln, die man haben möchte. Wir hätten die oben erwähnten Vorteile der Unveränderlichkeit sofort wieder zunichte gemacht, wenn wir zugelassen hätten, dass die Klasse Document von jedem in der Anwendung verändert werden könnte, wenn sie nur eine Unterklasse von HashMap wäre. Das Umhüllen der Sammlung gibt uns auch die Möglichkeit, den Methoden aussagekräftigere Namen zu geben, anstatt z. B. ein Attribut durch den Aufruf der Methode get() nachzuschlagen, was nicht wirklich etwas bedeutet! Später werden wir ausführlicher auf Vererbung und Komposition eingehen, denn dies ist wirklich ein spezielles Beispiel für diese Diskussion.
Kurz gesagt: Mit Domänenklassen können wir ein Konzept benennen und die möglichen Verhaltensweisen und Werte dieses Konzepts einschränken, um die Auffindbarkeit zu verbessern und die Gefahr von Fehlern zu verringern. Deshalb haben wir uns entschieden, die Documentwie in Beispiel 4-3 zu modellieren. Falls du dich fragst, warum es nicht wie die meisten Interfaces publicist, wird dies später in "Scoping and Encapsulation Choices" erläutert .
Beispiel 4-3. Dokument
publicclassDocument{privatefinalMap<String,String>attributes;Document(finalMap<String,String>attributes){this.attributes=attributes;}publicStringgetAttribute(finalStringattributeName){returnattributes.get(attributeName);}}
Ein letzter Punkt, den du bei Document beachten solltest, ist, dass sie einen paketübergreifenden Konstruktor hat. Oft machen Java-Klassen ihren Konstruktor public, aber das kann eine schlechte Wahl sein, da es dem Code überall in deinem Projekt erlaubt, Objekte dieses Typs zu erstellen. Nur der Code im Dokumentenverwaltungssystem sollte in der Lage sein, Documents zu erstellen. Deshalb halten wir den Konstruktor paketabhängig und beschränken den Zugriff auf das Paket, in dem sich das Dokumentenverwaltungssystem befindet.
Attribute und hierarchische Dokumente
In unserer Klasse Document haben wir Strings für Attribute verwendet. Verstößt das nicht gegen das Prinzip der starken Typisierung? Die Antwort lautet ja und nein. Wir speichern Attribute als Text, damit sie über eine textbasierte Suche durchsucht werden können. Außerdem wollen wir sicherstellen, dass alle Attribute in einer sehr generischen Form erstellt werden, die unabhängig von der Importer ist, die sie erstellt hat. Strings
sind in diesem Zusammenhang keine schlechte Wahl. Es sei darauf hingewiesen, dass die Weitergabe vonStrings in einer Anwendung zur Darstellung von Informationen oft als schlechte Idee angesehen wird. Im Gegensatz zu etwas, das stark typisiert ist, wird dies als "stringly typed" bezeichnet!
Vor allem, wenn die Attributwerte komplizierter verwendet werden, wäre es nützlich, wenn verschiedene Attributtypen analysiert würden. Wenn wir zum Beispiel Adressen innerhalb einer bestimmten Entfernung oder Bilder mit einer Höhe und Breite unter einer bestimmten Größe finden wollen, wären stark typisierte Attribute ein Segen. Es wäre viel einfacher, Vergleiche mit einem Breitenwert durchzuführen, der eine ganze Zahl ist. Im Fall dieses Dokumentenmanagementsystems brauchen wir diese Funktion jedoch nicht.
Du könntest das Dokumentenmanagementsystem mit einer Klassenhierarchie fürDocuments entwerfen, die die Hierarchie von Importer nachahmt. Ein ReportImporterimportiert zum Beispiel Instanzen der Klasse Report, die die Klasse Document erweitert. Damit wird unsere grundlegende Prüfung der Unterklassenbildung bestanden. Mit anderen Worten, man kann sagen, dass Report ein Document ist und dass der Satz Sinn macht. Wir haben uns jedoch entschieden, diesen Weg nicht einzuschlagen, da die richtige Art, Klassen in einer OOP-Umgebung zu modellieren, darin besteht, in Begriffen von Verhalten und Daten zu denken.
Die Dokumente sind alle sehr generisch in Form von benannten Attributen modelliert und nicht in Form von spezifischen Feldern, die in verschiedenen Unterklassen existieren. Außerdem sind Dokumente in diesem System nur mit sehr wenig Verhalten verbunden. Es hatte einfach keinen Sinn, hier eine Klassenhierarchie einzuführen, wenn sie keinen Nutzen bringt. Man könnte meinen, dass diese Aussage an sich ein wenig willkürlich ist, aber sie zeigt uns ein anderes Prinzip: KISS.
In Kapitel 2 hast du das KISS-Prinzip kennengelernt. KISS bedeutet, dass Entwürfe besser sind, wenn sie einfach gehalten werden. Es ist oft sehr schwer, unnötige Komplexität zu vermeiden, aber es lohnt sich, es zu versuchen. Wenn jemand sagt: "Wir brauchen vielleicht X" oder "Es wäre cool, wenn wir auch Y machen würden", sag einfach Nein. Aufgeblähte und komplexe Entwürfe sind gepflastert mit guten Absichten in Bezug auf Erweiterbarkeit und Code, der eher ein Nice-to-have als ein Must-have ist.
Implementierung und Registrierung von Importeuren
Du kannst die Schnittstelle Importer implementieren, um verschiedene Dateitypen nachzuschlagen.Beispiel 4-4 zeigt, wie Bilder importiert werden. Das Tolle an der Java-Kernbibliothek ist, dass sie eine Menge eingebauter Funktionen gleich mitliefert. Hier lesen wir eine Bilddatei mit der MethodeImageIO.read ein und extrahieren dann die Breite und Höhe des Bildes aus dem resultierenden BufferedImage Objekt.
Beispiel 4-4. ImageImporter
importstaticcom.iteratrlearning.shu_book.chapter_04.Attributes.*;classImageImporterimplementsImporter{@OverridepublicDocumentimportFile(finalFilefile)throwsIOException{finalMap<String,String>attributes=newHashMap<>();attributes.put(PATH,file.getPath());finalBufferedImageimage=ImageIO.read(file);attributes.put(WIDTH,String.valueOf(image.getWidth()));attributes.put(HEIGHT,String.valueOf(image.getHeight()));attributes.put(TYPE,"IMAGE");returnnewDocument(attributes);}}
Attributnamen sind Konstanten, die in der Klasse Attributes definiert sind. Dadurch werden Fehler vermieden, bei denen verschiedene Importeure unterschiedliche Zeichenketten für denselben Attributnamen verwenden, z. B. "Path" gegenüber "path". Java selbst hat kein direktes Konzept für eine Konstante als solche, Beispiel 4-5 zeigt die übliche Redewendung. Diese Konstante ist public, weil wir sie von verschiedenen Importern aus verwenden wollen, obwohl du stattdessen auch eine private oder package scoped Konstante haben kannst. Die Verwendung des Schlüsselworts final stellt sicher, dass die Konstante nicht neu zugewiesen werden kann to und static stellt sicher, dass es nur eine einzige Instanz pro Klasse gibt.
Beispiel 4-5. Wie man eine Konstante in Java definiert
publicstaticfinalStringPATH="path";
Es gibt Importeure für alle drei verschiedenen Dateitypen und du wirst die beiden anderen in "Erweiterung und Wiederverwendung von Code" sehen . Keine Sorge, wir verstecken nichts in unseren Ärmeln. Damit wir die Importer Klassen beim Importieren von Dateien verwenden können, müssen wir auch die Importer registrieren, damit sie nach ihnen suchen. Wir verwenden die Erweiterung der Datei, die wir importieren wollen, als Schlüssel der Map, wie in Beispiel 4-6 gezeigt.
Beispiel 4-6. Registrierung der Importeure
privatefinalMap<String,Importer>extensionToImporter=newHashMap<>();publicDocumentManagementSystem(){extensionToImporter.put("letter",newLetterImporter());extensionToImporter.put("report",newReportImporter());extensionToImporter.put("jpg",newImageImporter());}
Jetzt, wo du weißt, wie du Dokumente importieren kannst, können wir die Suche implementieren. Wir konzentrieren uns hier nicht auf die effizienteste Art und Weise, die Suche nach Dokumenten zu implementieren, da wir nicht versuchen, Google zu implementieren, sondern nur die von Dr. Avaj benötigten Informationen zu erhalten. Ein Gespräch mit Dr. Avaj ergab, dass sie Informationen über verschiedene Attribute eines Document nachschlagen wollte.
Ihre Anforderungen könnten erfüllt werden, wenn sie nur Teilsequenzen innerhalb von Attributwerten finden könnte. So könnte sie zum Beispiel nach Dokumenten suchen, die einen Patienten namens Joe haben und in denen Cola vorkommt. Wir haben daher eine sehr einfache Abfragesprache entwickelt, die aus einer Reihe von Attributnamen und Teilstrings besteht , die durch Kommas getrennt sind. Unsere oben erwähnte Abfrage würde als "patient:Joe,body:Diet Coke" geschrieben werden.
Da die Suchimplementierung einfach gehalten ist und nicht versucht, hochgradig optimiert zu sein, führt sie nur einen linearen Scan über alle im System gespeicherten Dokumente durch und testet jedes einzelne gegen die Abfrage. Die Abfrage String, die an die Methode search übergeben wird, wird in ein Query Objekt geparst, das dann mit jedem Document getestet werden kann.
Das Liskov-Substitutionsprinzip (LSP)
Wir haben über ein paar spezifische Designentscheidungen im Zusammenhang mit Klassen gesprochen - zum Beispiel über die Modellierung von verschiedenen Implementierungen von Importer mit Klassen und warum wir keine Klassenhierarchie für die Klasse Document eingeführt haben und warum wir nicht einfach Document zu HashMap erweitert haben. Aber eigentlich geht es hier um ein breiteres Prinzip, das es uns ermöglicht, diese Beispiele zu einem Ansatz zu verallgemeinern, den du in jeder Software anwenden kannst. Es heißt Liskov-Substitutionsprinzip (LSP) und hilft uns zu verstehen, wie man Subklassen und Schnittstellen richtig implementiert. Das LSP bildet das L der SOLID-Prinzipien, auf die wir uns in diesem Buch beziehen.
Das Liskovsche Substitutionsprinzip wird oft mit diesen sehr formalen Begriffen erklärt, ist aber eigentlich ein sehr einfaches Konzept. Entmystifizieren wir einige dieser Begriffe. Wenn du in diesem Zusammenhang Typ hörst, denkst du einfach an eine Klasse oder eine Schnittstelle. Der Begriff Subtyp bedeutet, dass man eine Eltern-Kind-Beziehung zwischen Typen herstellt; mit anderen Worten, eine Klasse erweitert oder eine Schnittstelle implementiert. Inoffiziell bedeutet das, dass untergeordnete Klassen das Verhalten, das sie von ihren Eltern erben, beibehalten sollten. Wir wissen, dass es sich wie eine offensichtliche Aussage anhört, aber wir können noch genauer werden und LSP in vier verschiedene Teile aufteilen:
- Vorbedingungen können in einem Subtyp nicht verstärkt werden
-
Eine Vorbedingung legt die Bedingungen fest, unter denen ein Code funktionieren wird. Du kannst nicht einfach davon ausgehen, dass das, was du geschrieben hast, sowieso und überall funktioniert. Alle unsere
ImporterImplementierungen haben zum Beispiel die Vorbedingung, dass die zu importierende Datei existiert und lesbar ist. Daher enthält die MethodeimportFileeinen Validierungscode, bevorImporteraufgerufen wird, wie inBeispiel 4-7 zu sehen ist.Beispiel 4-7. importFile Definition
publicvoidimportFile(finalStringpath)throwsIOException{finalFilefile=newFile(path);if(!file.exists()){thrownewFileNotFoundException(path);}finalintseparatorIndex=path.lastIndexOf('.');if(separatorIndex!=-1){if(separatorIndex==path.length()){thrownewUnknownFileTypeException("No extension found For file: "+path);}finalStringextension=path.substring(separatorIndex+1);finalImporterimporter=extensionToImporter.get(extension);if(importer==null){thrownewUnknownFileTypeException("For file: "+path);}finalDocumentdocument=importer.importFile(file);documents.add(document);}else{thrownewUnknownFileTypeException("No extension found For file: "+path);}}LSP bedeutet, dass du keine restriktiveren Vorbedingungen verlangen kannst, als deine Muttergesellschaft sie verlangt. So kannst du zum Beispiel nicht verlangen, dass dein Dokument kleiner als 100 KB ist, wenn dein Elternteil in der Lage sein soll, Dokumente jeder Größe zu importieren.
- Nachbedingungen können in einem Subtyp nicht abgeschwächt werden
-
Das klingt vielleicht ein bisschen verwirrend, weil es sich ähnlich wie die erste Regel liest. Nachbedingungen sind Dinge, die wahr sein müssen, nachdem ein Code ausgeführt wurde. Wenn zum Beispiel
importFile()ausgeführt wurde und die betreffende Datei gültig ist, muss sie in der Liste der Dokumente stehen, die voncontents()zurückgegeben wird. Wenn der übergeordnete Code also einen Nebeneffekt hat oder einen Wert zurückgibt, muss das Kind dies auch tun. - Invarianten des Supertyps müssen in einem Subtyp erhalten bleiben
-
Eine Invariante ist etwas, das sich nie ändert, wie die Ebbe und Flut der Gezeiten. Im Zusammenhang mit der Vererbung wollen wir sicherstellen, dass alle Invarianten, die von der Elternklasse beibehalten werden sollen, auch von den Kindern beibehalten werden.
- Die Regel der Geschichte
-
Dies ist der am schwersten zu verstehende Aspekt von LSP. Im Grunde genommen sollte die Kindklasse keine Zustandsänderungen zulassen, die die Elternklasse nicht zulässt. In unserem Beispielprogramm haben wir also eine unveränderliche Klasse
Document. Mit anderen Worten: Sobald sie instanziiert wurde, kannst du keine Attribute entfernen, hinzufügen oder verändern. Du solltest diese KlasseDocumentnicht untergliedern und eine veränderbare KlasseDocumenterstellen. Der Grund dafür ist, dass jeder Benutzer der Elternklasse ein bestimmtes Verhalten als Reaktion auf den Aufruf von Methoden der KlasseDocumenterwarten würde. Wäre die untergeordnete Klasse veränderbar, könnte sie die Erwartungen der Aufrufer über das Verhalten beim Aufruf dieser Methoden verletzen.
Alternative Ansätze
Du hättest auch einen ganz anderen Ansatz wählen können, wenn es um die Gestaltung des Dokumentenmanagementsystems geht. Wir werfen jetzt einen Blick auf einige dieser Alternativen, da wir sie für lehrreich halten. Keine der Entscheidungen kann als falsch angesehen werden, aber wir denken, dass der gewählte Ansatz der beste ist.
Importer zu einer Klasse machen
Du hättest auch eine Klassenhierarchie für Importeure erstellen können und eine Klasse an der Spitze für die Importer statt einer Schnittstelle verwenden können. Schnittstellen und Klassen bieten unterschiedliche Möglichkeiten. Du kannst mehrere Schnittstellen implementieren, während Klassen Instanzfelder enthalten können und es üblicher ist, Methodenkörper in Klassen zu haben.
In diesem Fall ist der Grund für die Hierarchie, dass verschiedene Importer verwendet werden können. Du hast bereits gehört, warum wir spröde klassenbasierte Vererbungsbeziehungen vermeiden wollen. Es sollte also ziemlich klar sein, dass die Verwendung von Schnittstellen hier die bessere Wahl ist.
Das heißt aber nicht, dass Klassen nicht auch anderswo eine bessere Wahl wären. Wenn du eine starke Beziehung in deiner Problemdomäne modellieren willst, die einen Zustand oder viel Verhalten beinhaltet, dann ist die klassenbasierte Vererbung besser geeignet. Es ist nur nicht die Wahl, die wir hier für am besten geeignet halten.
Auswahl von Scoping und Kapselung
Wenn du dir die Zeit genommen hast, den Code durchzusehen, wirst du feststellen, dass die SchnittstelleImporter, ihre Implementierungen und unsere Klasse Query alle package scoped sind. Wenn du also eine Klassendatei siehst, bei der oben class Query steht, weißt du, dass sie package scoped ist, und wenn da public
class Query steht, ist sie public scoped. Paketscoping bedeutet, dass andere Klassen innerhalb desselben Pakets die Klasse sehen oder auf sie zugreifen können, aber niemand anderes kann das. Es ist eine Tarnvorrichtung.
Eine merkwürdige Sache im Java-Ökosystem ist, dass, obwohl der Paketumfang der Standardumfang ist, es in Softwareentwicklungsprojekten immer mehr public-skalierte Klassen als paket-skalierte gibt. Vielleicht hätte die Vorgabe schon immer public sein sollen, aber so oder so ist der Paketscope ein wirklich nützliches Werkzeug. Es hilft dir, diese Art von Designentscheidungen zu kapseln. In diesem Abschnitt wurde bereits ausführlich auf die verschiedenen Möglichkeiten eingegangen, die dir bei der Gestaltung des Systems zur Verfügung stehen, und vielleicht möchtest du bei der Wartung des Systems auf eines dieser alternativen Designs umstellen. Das wäre schwieriger, wenn wir Details über diese Implementierung außerhalb des betreffenden Pakets durchsickern lassen würden. Durch die sorgfältige Verwendung von Package Scoping kannst du verhindern, dass Klassen außerhalb des Pakets so viele Annahmen über das interne Design machen.
Wir möchten noch einmal darauf hinweisen, dass es sich hierbei lediglich um eine Begründung und Erklärung für diese Designentscheidungen handelt. Es ist nicht grundsätzlich falsch, andere Entscheidungen zu treffen, die in diesem Abschnitt aufgeführt sind - sie können sich als besser geeignet erweisen, je nachdem, wie sich die Anwendung im Laufe der Zeit entwickelt.
Erweitern und Wiederverwenden von Code
Wenn es um Software geht, ist die einzige Konstante der Wandel. Im Laufe der Zeit möchtest du vielleicht Funktionen zu deinem Produkt hinzufügen, die Anforderungen deiner Kunden können sich ändern und Vorschriften können dich dazu zwingen, deine Software zu ändern. Wie wir bereits angedeutet haben, gibt es vielleicht noch mehr Dokumente, die Dr. Avaj gerne in unser Dokumentenmanagementsystem aufnehmen würde. Als wir ihr die Software vorstellten, die wir für sie entwickelt haben, war ihr sofort klar, dass sie auch die Rechnungen ihrer Kunden in diesem System erfassen wollte. Eine Rechnung ist ein Dokument mit einem Text und einem Betrag und hat die Endung .invoice. Beispiel 4-8 zeigt eine Beispielrechnung.
Beispiel 4-8. Beispiel für eine Rechnung
Dear Joe Bloggs Here is your invoice for the dental treatment that you received. Amount: $100 regards, Dr Avaj Awesome Dentist
Zu unserem Glück haben alle Rechnungen von Dr. Avaj das gleiche Format. Wie du siehst, müssen wir daraus einen Geldbetrag extrahieren, und die Betragszeile beginnt mit dem Präfix Amount:. Der Name der Person steht am Anfang des Briefes in einer Zeile mit dem PräfixDear. Tatsächlich implementiert unser System eine allgemeine Methode, um das Suffix einer Zeile mit einem bestimmten Präfix zu finden, wie in Beispiel 4-9 gezeigt. In diesem Beispiel wurde das Feld lines bereits mit den Zeilen der Datei, die wir importieren, initialisiert. Wir übergeben dieser Methode eine prefix- zum Beispiel "Betrag:" - und sie verknüpft den Rest der Zeile, das Suffix, mit einem angegebenen Attributnamen.
Beispiel 4-9. addLineSuffix-Definition
voidaddLineSuffix(finalStringprefix,finalStringattributeName){for(finalStringline:lines){if(line.startsWith(prefix)){attributes.put(attributeName,line.substring(prefix.length()));break;}}}
Tatsächlich haben wir ein ähnliches Konzept, wenn wir versuchen, einen Brief zu importieren. Betrachte den Beispielbrief in Beispiel 4-10. Hier kannst du den Namen des Patienten extrahieren, indem du nach einer Zeile suchst, die mit Dear beginnt. Briefe enthalten auch Adressen und Textabschnitte, die du aus dem Inhalt der Textdatei extrahieren möchtest.
Beispiel 4-10. Briefbeispiel
Dear Joe Bloggs 123 Fake Street Westminster London United Kingdom We are writing to you to confirm the re-scheduling of your appointment with Dr. Avaj from 29th December 2016 to 5th January 2017. regards, Dr Avaj Awesome Dentist
Ein ähnliches Problem haben wir auch, wenn es um den Import von Patientenberichten geht. In Dr. Avajs Berichten wird dem Namen des Patienten das Kürzel Patient: vorangestellt, und sie enthalten einen Textkörper, genau wie Briefe. Ein Beispiel für einen Bericht siehst du inBeispiel 4-11.
Beispiel 4-11. Beispiel für einen Bericht
Patient: Joe Bloggs On 5th January 2017 I examined Joe's teeth. We discussed his switch from drinking Coke to Diet Coke. No new problems were noted with his teeth.
Eine Möglichkeit wäre also, dass alle drei textbasierten Importeure dieselbe Methode implementieren, um die Suffixe von Textzeilen mit einem bestimmten Präfix zu finden, die in Beispiel 4-9 aufgeführt wurde. Wenn wir Dr. Avaj die Anzahl der Codezeilen, die wir geschrieben haben, in Rechnung stellen würden, wäre das eine großartige Strategie. Wir könnten den Geldbetrag verdreifachen, den wir für die gleiche Arbeit erhalten würden!
Leider (oder vielleicht nicht ganz so traurig, wenn man die oben genannten Anreize bedenkt) zahlen die Kunden selten nach der Anzahl der produzierten Codezeilen. Was zählt, sind die Anforderungen, die der Kunde wünscht. Wir wollen diesen Code also wirklich in den drei Importeuren wiederverwenden können. Um den Code wiederverwenden zu können, müssen wir ihn in einer Klasse unterbringen. Du hast im Wesentlichen drei Möglichkeiten, die du in Betracht ziehen kannst, jede mit Vor- und Nachteilen:
-
Eine Hilfsklasse verwenden
-
Vererbung verwenden
-
Eine Domänenklasse verwenden
Die einfachste Möglichkeit ist es, mit einer Hilfsklasse zu beginnen. Diese könntest du ImportUtil nennen. Jedes Mal, wenn du eine Methode haben möchtest, die von verschiedenen Importeuren gemeinsam genutzt werden soll, könnte sie in diese Dienstprogrammklasse aufgenommen werden. Deine Utility-Klasse wäre dann eine Sammlung statischer Methoden.
Eine Utility-Klasse ist zwar nett und einfach, aber nicht gerade der Gipfel der objektorientierten Programmierung. Bei der objektorientierten Programmierung geht es darum, dass Konzepte in deiner Anwendung durch Klassen modelliert werden. Wenn du ein Ding erstellen willst, rufst du new Thing() für dein Ding auf. Attribute und Verhaltensweisen, die mit dem Ding verbunden sind, sollten Methoden der Klasse Thing sein.
Wenn du diesem Prinzip folgst und Objekte der realen Welt als Klassen modellierst, wird deine Anwendung tatsächlich leichter verständlich, weil du eine Struktur erhältst und ein mentales Modell deiner Domäne auf deinen Code übertragen kannst. Wenn du die Art und Weise, wie Buchstaben importiert werden, ändern willst, dann bearbeite die Klasse LetterImporter.
Utility-Klassen verstoßen gegen diese Erwartung und enden oft als Bündel von prozeduralem Code ohne eine einzige Verantwortung oder ein einziges Konzept. Im Laufe der Zeit kann dies dazu führen, dass in unserer Codebasis eine "God Class" auftaucht, d.h. eine einzige große Klasse, die am Ende eine Menge Verantwortung an sich reißt.
Was solltest du also tun, wenn du dieses Verhalten mit einem Konzept verknüpfen willst? Nun, der nächstliegende Ansatz wäre die Vererbung. Bei diesem Ansatz würdest du die verschiedenen Importeure eine TextImporter Klasse erweitern lassen. Du könntest dann alle gemeinsamen Funktionen in dieser Klasse unterbringen und sie in den Unterklassen wiederverwenden.
Vererbung ist unter vielen Umständen eine sehr gute Wahl. Du hast bereits das Liskovsche Substitutionsprinzip kennengelernt und erfahren, wie es die Korrektheit unserer Vererbungsbeziehung einschränkt. In der Praxis ist die Vererbung oft eine schlechte Wahl, wenn die Vererbung bei der Modellierung einer realen Beziehung fehlschlägt.
In diesem Fall ist TextImporter eine Importer und wir können sicherstellen, dass unsere Klassen den LSP-Regeln folgen, aber es scheint nicht wirklich ein starkes Konzept zu sein, mit dem man arbeiten kann. Das Problem mit Vererbungsbeziehungen, die nicht der realen Welt entsprechen, ist, dass sie oft spröde sind. Wenn sich deine Anwendung im Laufe der Zeit weiterentwickelt, solltest du Abstraktionen verwenden, die sich mit der Anwendung weiterentwickeln und nicht gegen sie. Als Faustregel gilt: Es ist keine gute Idee, eine Vererbungsbeziehung einzuführen, nur um die Wiederverwendung von Code zu ermöglichen.
Unsere letzte Möglichkeit ist, die Textdatei mit einer Domänenklasse zu modellieren. Bei diesem Ansatz würden wir ein zugrundeliegendes Konzept modellieren und unsere verschiedenen Importer durch den Aufruf von Methoden auf dem zugrundeliegenden Konzept aufbauen. Um welches Konzept geht es hier also? Eigentlich wollen wir den Inhalt einer Textdatei manipulieren, also nennen wir die Klasse TextFile. Das ist nicht besonders originell oder kreativ, aber darum geht es ja. Du weißt, wo die Funktionalität zur Bearbeitung von Textdateien liegt, denn die Klasse ist ganz einfach benannt.
Beispiel 4-12 zeigt die Definition der Klasse und ihrer Felder. Beachte, dass es sich hierbei nicht um eine Unterklasse von Document handelt, denn ein Dokument sollte nicht nur an Textdateien gekoppelt sein - wir können auch Binärdateien wie Bilder importieren. Es handelt sich lediglich um eine Klasse, die das zugrunde liegende Konzept einer Textdatei modelliert und über entsprechende Methoden zum Extrahieren von Daten aus Textdateien verfügt.
Beispiel 4-12. TextFile Definition
classTextFile{privatefinalMap<String,String>attributes;privatefinalList<String>lines;// class continues ...
Das ist der Ansatz, den wir im Fall der Importeure wählen. Wir denken, dass wir damit unsere Problemdomäne flexibel modellieren können. Es bindet uns nicht in eine spröde Vererbungshierarchie ein, erlaubt uns aber trotzdem, den Code wiederzuverwenden.Beispiel 4-13 zeigt, wie man Rechnungen importiert. Die Suffixe für den Namen und den Betrag werden hinzugefügt, und der Typ der Rechnung wird auf einen Betrag festgelegt.
Beispiel 4-13. Rechnungen importieren
@OverridepublicDocumentimportFile(finalFilefile)throwsIOException{finalTextFiletextFile=newTextFile(file);textFile.addLineSuffix(NAME_PREFIX,PATIENT);textFile.addLineSuffix(AMOUNT_PREFIX,AMOUNT);finalMap<String,String>attributes=textFile.getAttributes();attributes.put(TYPE,"INVOICE");returnnewDocument(attributes);}
Ein weiteres Beispiel für einen Importer, der die Klasse TextFile verwendet, siehst du in Beispiel 4-14. Du brauchst dir keine Gedanken darüber zu machen, wie TextFile.addLines implementiert wird; eine Erklärung dazu findest du in Beispiel 4-15.
Beispiel 4-14. Buchstaben importieren
@OverridepublicDocumentimportFile(finalFilefile)throwsIOException{finalTextFiletextFile=newTextFile(file);textFile.addLineSuffix(NAME_PREFIX,PATIENT);finalintlineNumber=textFile.addLines(2,String::isEmpty,ADDRESS);textFile.addLines(lineNumber+1,(line)->line.startsWith("regards,"),BODY);finalMap<String,String>attributes=textFile.getAttributes();attributes.put(TYPE,"LETTER");returnnewDocument(attributes);}
Diese Klassen wurden aber nicht von Anfang an so geschrieben. Sie haben sich zu dem entwickelt, was sie heute sind. Als wir mit der Programmierung des Dokumentenmanagementsystems begannen, hatte der erste textbasierte Importeur, LetterImporter, seine gesamte Textextraktionslogik inline in die Klasse geschrieben. Die Suche nach wiederverwendbarem Code führt oft zu unangemessenen Abstraktionen. Gehe, bevor du rennst.
Als wir mit dem Schreiben von ReportImporter begannen, wurde immer deutlicher, dass ein Großteil der Textextraktionslogik von den beiden Importeuren gemeinsam genutzt werden kann und dass sie eigentlich in Form von Methodenaufrufen für ein gemeinsames Domänenkonzept geschrieben werden sollten, das wir hier eingeführt haben - TextFile. Tatsächlich haben wir sogar den Code, der von Anfang an von den beiden Klassen gemeinsam genutzt werden sollte, kopiert und eingefügt.
Das heißt nicht, dass das Kopieren und Einfügen von Code gut ist - im Gegenteil. Aber es ist oft besser, ein wenig Code zu kopieren, wenn du anfängst, Klassen zu schreiben. Sobald du mehr von der Anwendung implementiert hast, wird die richtige Abstraktion - z. B. eine TextFile Klasse - offensichtlich. Erst wenn du ein bisschen mehr über den richtigen Weg zur Entfernung von Duplikaten weißt, solltest du den Weg der Entfernung der Duplikate einschlagen.
In Beispiel 4-15 kannst du sehen, wie die Methode TextFile.addLines implementiert wurde. Dies ist ein allgemeiner Code, der von verschiedenen Importer Implementierungen verwendet wird. Das erste Argument ist ein start Index, der dir sagt, in welcher Zeile du beginnen sollst.Dann gibt es ein isEnd Prädikat, das auf die Zeile angewendet wird und true zurückgibt, wenn wir das Ende der Zeile erreicht haben. Schließlich haben wir den Namen des Attributs, das wir mit diesem Wert verknüpfen wollen.
Beispiel 4-15. addLines Definition
intaddLines(finalintstart,finalPredicate<String>isEnd,finalStringattributeName){finalStringBuilderaccumulator=newStringBuilder();intlineNumber;for(lineNumber=start;lineNumber<lines.size();lineNumber++){finalStringline=lines.get(lineNumber);if(isEnd.test(line)){break;}accumulator.append(line);accumulator.append("\n");}attributes.put(attributeName,accumulator.toString().trim());returnlineNumber;}
Test Hygiene
Wie du in Kapitel 2 gelernt hast, hat das Schreiben von automatisierten Tests viele Vorteile für die Wartbarkeit der Software. So können wir den Spielraum für Regressionen verringern und verstehen, welcher Commit sie verursacht hat. Außerdem können wir so unseren Code zuverlässig refaktorisieren. Tests sind jedoch kein Allheilmittel. Sie erfordern, dass wir eine Menge Code schreiben und pflegen, um diese Vorteile zu erhalten. Wie du weißt, ist das Schreiben und Pflegen von Code ein schwieriges Unterfangen, und viele Entwickler/innen stellen fest, dass automatisierte Tests viel Zeit in Anspruch nehmen können, wenn sie zum ersten Mal mit dem Schreiben beginnen.
Um das Problem der Wartbarkeit von Tests zu lösen, musst du dich mit Testhygiene auseinandersetzen. Testhygiene bedeutet, dass du deinen Testcode sauber hältst und sicherstellst, dass er zusammen mit deiner zu testenden Codebasis gepflegt und verbessert wird. Wenn du deine Tests nicht pflegst und behandelst, werden sie mit der Zeit zu einer Belastung für deine Entwicklerproduktivität. In diesem Abschnitt lernst du ein paar wichtige Punkte kennen, die dir helfen können, Tests hygienisch zu halten.
Test Benennung
Das erste, worüber man sich Gedanken machen sollte, wenn es um Tests geht, ist ihre Benennung. Entwicklerinnen und Entwickler können über die Namensgebung sehr geteilter Meinung sein - es ist ein einfaches Thema, über das viel gesprochen wird, weil sich jeder damit identifizieren und über das Problem nachdenken kann. Wir denken, man sollte sich daran erinnern, dass es selten einen eindeutigen, wirklich guten Namen für etwas gibt, dafür aber viele, viele schlechte Namen.
Der erste Test, den wir für das Dokumentenmanagementsystem geschrieben haben, testet, dass wir eine Datei importieren und eine Document erstellen. Dieser Test wurde geschrieben, bevor wir das Konzept einer Importer eingeführt hatten und Document-spezifische Attribute nicht getestet haben. Der Code ist in Beispiel 4-16 zu sehen.
Beispiel 4-16. Test für den Import von Dateien
@TestpublicvoidshouldImportFile()throwsException{system.importFile(LETTER);finalDocumentdocument=onlyDocument();assertAttributeEquals(document,Attributes.PATH,LETTER);}
Dieser Test wurde shouldImportFile genannt. Die wichtigsten Grundsätze für die Benennung von Tests sind Lesbarkeit, Wartbarkeit und die Funktion als ausführbare Dokumentation. Wenn du einen Bericht über die Ausführung einer Testklasse siehst, sollten die Namen wie Aussagen wirken, die dokumentieren, welche Funktionen funktionieren und welche nicht. So kann ein Entwickler das Verhalten der Anwendung leicht auf einen Test abbilden, der bestätigt, dass dieses Verhalten implementiert ist. Indem wir die Impedanzabweichung zwischen Verhalten und Code verringern, machen wir es anderen Entwicklern leichter zu verstehen, was in Zukunft passiert. Dies ist ein Test, der bestätigt, dass das Dokumentenmanagementsystem eine Datei importiert.
Es gibt jedoch viele Anti-Muster bei der Namensgebung. Das schlimmste Anti-Muster ist es, einen Test nach etwas völlig Unbestimmtem zu benennen - zum Beispiel test1. Was in aller Welt testet test1? Die Geduld des Lesers? Behandle die Leute, die deinen Code lesen, so, wie du von ihnen behandelt werden möchtest.
Ein weiteres gängiges Verhaltensmuster bei der Benennung von Tests ist die Benennung nach einem Konzept oder einem Substantiv, z. B. file oder document. Testnamen sollten das zu testende Verhalten beschreiben, nicht ein Konzept. Ein weiteres Anti-Muster bei der Benennung von Tests ist, den Test einfach nach einer Methode zu benennen, die während des Tests aufgerufen wird, und nicht nach dem Verhalten. In diesem Fall könnte der Test importFile heißen.
Du könntest fragen, ob wir diese Sünde nicht begangen haben, indem wir unseren Test shouldImportFile genannt haben? Der Vorwurf ist nicht ganz unberechtigt, aber wir beschreiben hier nur das Verhalten, das getestet wird. Tatsächlich wird die Methode importFile von verschiedenen Tests getestet, zum Beispiel von shouldImportLetterAttributes,shouldImportReportAttributes und shouldImportImageAttributes. Keiner dieser Tests heißt importFile- sie alle beschreiben spezifischere Verhaltensweisen.
OK, jetzt weißt du, wie schlechte Benennungen aussehen. Was sind also gute Testbenennungen? Du solltest drei Faustregeln befolgen und sie bei der Benennung von Tests anwenden:
- Fachterminologie verwenden
-
Passe das Vokabular, das du in deinen Testnamen verwendest, an das Vokabular an, das bei der Beschreibung der Problemdomäne verwendet wird oder auf das sich die Anwendung selbst bezieht.
- Natürliche Sprache verwenden
-
Jeder Testname sollte etwas sein, das man leicht als Satz lesen kann. Er sollte immer ein Verhalten auf lesbare Weise beschreiben.
- Beschreibend sein
-
Code wird viel öfter gelesen, als er geschrieben wird. Deshalb solltest du dir einen guten Namen überlegen, der von Anfang an beschreibend und später leichter zu verstehen ist. Wenn dir kein guter Name einfällt, kannst du auch einen Kollegen fragen. Beim Golf gewinnt man, wenn man die wenigsten Schläge macht. Bei der Programmierung ist das nicht so: Der kürzeste Weg ist nicht unbedingt der beste.
Du kannst dich an die Konvention auf DocumentManagementSystemTest halten und den Namen der Prüfung das Wort "sollte" voranstellen, oder du kannst es auch lassen.
Verhalten statt Umsetzung
Wenn du einen Test für eine Klasse, eine Komponente oder sogar ein System schreibst, dann solltest du nur das öffentliche Verhalten des Getesteten testen. Im Fall des Dokumentenmanagementsystems haben wir nur Tests für das Verhalten unserer öffentlichen API in Form von DocumentManagementSystemTest. In diesem Test testen wir die öffentliche API der Klasse DocumentManagementSystem und damit das gesamte System. Die API ist in Beispiel 4-17 zu sehen.
Beispiel 4-17. Öffentliche API der Klasse DocumentManagementSystem
publicclassDocumentManagementSystem{publicvoidimportFile(finalStringpath){...}publicList<Document>contents(){...}publicList<Document>search(finalStringquery){...}}
Unsere Tests sollten nur diese öffentlichen API-Methoden aufrufen und nicht versuchen, den internen Zustand der Objekte oder das Design zu untersuchen. Dies ist einer der Hauptfehler von Entwicklern, der zu schwer zu wartenden Tests führt. Wenn du dich auf bestimmte Implementierungsdetails verlässt, führt das zu spröden Tests, denn wenn du das betreffende Implementierungsdetail änderst, kann der Test fehlschlagen, auch wenn das Verhalten noch funktioniert. Sieh dir den Test in Beispiel 4-18 an.
Beispiel 4-18. Test für den Import von Briefen
@TestpublicvoidshouldImportLetterAttributes()throwsException{system.importFile(LETTER);finalDocumentdocument=onlyDocument();assertAttributeEquals(document,PATIENT,JOE_BLOGGS);assertAttributeEquals(document,ADDRESS,"123 Fake Street\n"+"Westminster\n"+"London\n"+"United Kingdom");assertAttributeEquals(document,BODY,"We are writing to you to confirm the re-scheduling of your appointment\n"+"with Dr. Avaj from 29th December 2016 to 5th January 2017.");assertTypeIs("LETTER",document);}
Eine Möglichkeit, die Funktion des Buchstabenimports zu testen, wäre gewesen, den Test als Unit-Test für die Klasse LetterImporter zu schreiben. Das hätte ziemlich ähnlich ausgesehen: eine Beispieldatei importieren und dann eine Behauptung über das vom Importer zurückgegebene Ergebnis aufstellen. In unseren Tests ist jedoch die bloße Existenz vonLetterImporter ein Implementierungsdetail. In "Erweiterung und Wiederverwendung von Code" hast du zahlreiche andere Möglichkeiten gesehen, wie wir unseren Importer-Code aufbauen können. Indem wir unsere Tests auf diese Weise gestalten, haben wir die Möglichkeit, unsere Interna auf ein anderes Design umzustellen, ohne unsere Tests zu zerstören.
Wir haben also gesagt, dass man sich auf das Verhalten einer Klasse verlassen kann, wenn man die öffentliche API verwendet, aber es gibt auch einige Teile des Verhaltens, die normalerweise nicht nur dadurch eingeschränkt werden, dass man Methoden öffentlich oder privat macht. Wir wollen uns zum Beispiel nicht auf die Reihenfolge der Dokumente verlassen, die von der Methode contents()zurückgegeben werden. Das ist keine Eigenschaft, die durch die öffentliche API der KlasseDocumentManagementSystem eingeschränkt wird, sondern einfach etwas, das du vermeiden musst.
Ein gängiges Anti-Pattern in diesem Zusammenhang ist die Offenlegung eines ansonsten privaten Zustands durch einen Getter oder Setter, um das Testen zu erleichtern. Das solltest du tunlichst vermeiden, denn es macht deine Tests spröde. Wenn du diesen Zustand offenlegst, um das Testen vordergründig zu vereinfachen, machst du die Wartung deiner Anwendung auf lange Sicht schwieriger. Das liegt daran, dass jede Änderung an deiner Codebasis, die eine Änderung der Darstellung dieses internen Zustands beinhaltet, auch eine Änderung deiner Tests erfordert. Das ist manchmal ein guter Hinweis darauf, dass du eine neue Klasse entwickeln solltest, die einfacher und effektiver getestet werden kann.
Wiederholen Sie sich nicht
In "Erweiterung und Wiederverwendung von Code" wird ausführlich erörtert, wie wir doppelten Code aus unserer Anwendung entfernen können und wo wir den daraus resultierenden Code platzieren. Die gleichen Überlegungen zur Wartung gelten auch für Testcode. Leider machen sich Entwicklerinnen und Entwickler oft nicht die Mühe, doppelten Code aus den Tests zu entfernen, so wie sie es bei Anwendungscode tun würden. In Beispiel 4-19 siehst du einen Test, der wiederholt Aussagen über die verschiedenen Attribute macht, die ein Document hat.
Beispiel 4-19. Test für den Import von Bildern
@TestpublicvoidshouldImportImageAttributes()throwsException{system.importFile(XRAY);finalDocumentdocument=onlyDocument();assertAttributeEquals(document,WIDTH,"320");assertAttributeEquals(document,HEIGHT,"179");assertTypeIs("IMAGE",document);}
Normalerweise müsstest du für jedes Attribut den Attributnamen nachschlagen und sicherstellen, dass er gleich einem erwarteten Wert ist. Im Fall der Tests hier ist dies ein so häufiger Vorgang, dass eine gemeinsame Methode, assertAttributeEquals, mit dieser Logik extrahiert wurde. Ihre Implementierung wird inBeispiel 4-20 gezeigt.
Beispiel 4-20. Eine neue Assertion implementieren
privatevoidassertAttributeEquals(finalDocumentdocument,finalStringattributeName,finalStringexpectedValue){assertEquals("Document has the wrong value for "+attributeName,expectedValue,document.getAttribute(attributeName));}
Gute Diagnostik
Tests wären nicht gut, wenn sie nicht fehlschlagen würden. Wenn du noch nie gesehen hast, dass ein Test fehlschlägt, wie kannst du dann wissen, ob er überhaupt funktioniert? Wenn du Tests schreibst, ist es am besten, wenn du sie für Fehler optimierst. Mit "optimieren" meinen wir nicht, dass der Test schneller abläuft, wenn er fehlschlägt, sondern dass er so geschrieben ist, dass du möglichst leicht verstehen kannst, warum und wie er fehlgeschlagen ist. Der Trick dabei ist eine gute Diagnose.
Unter Diagnose verstehen wir die Meldung und die Informationen, die ausgedruckt werden, wenn ein Test fehlschlägt. Je klarer die Meldung ist, was fehlgeschlagen ist, desto einfacher ist es, den Testfehler zu beheben. Du fragst dich vielleicht, warum du dir die Mühe machen solltest, wenn Java-Tests häufig in modernen IDEs mit eingebauten Debuggern ausgeführt werden? Nun, manchmal werden die Tests in kontinuierlichen Integrationsumgebungen ausgeführt und manchmal über die Kommandozeile. Auch wenn du sie innerhalb einer IDE ausführst, ist es hilfreich, gute Diagnoseinformationen zu haben. Wir haben dich hoffentlich von der Notwendigkeit guter Diagnosen überzeugt, aber wie sehen sie im Code aus?
Beispiel 4-21 zeigt eine Methode, die behauptet, dass das System nur ein einziges Dokument enthält. Wir werden die Methode hasSize() gleich erklären.
Beispiel 4-21. Testen, ob das System ein einzelnes Dokument enthält
privateDocumentonlyDocument(){finalList<Document>documents=system.contents();assertThat(documents,hasSize(1));returndocuments.get(0);}
Der einfachste Typ von Assert, den JUnit uns bietet, ist assertTrue(), der einen booleschen Wert annimmt, von dem er erwartet, dass er wahr ist. Beispiel 4-22 zeigt, wie wir den Test auch mit assertTrue hätten implementieren können. In diesem Fall wird geprüft, ob der Wert gleich 0 ist, so dass der Test shouldImportFile fehlschlägt und somit die Fehlerdiagnose demonstriert wird. Das Problem dabei ist, dass wir keine sehr gute Diagnose erhalten - nur eine AssertionError ohne Informationen in der in Abbildung 4-1 gezeigten Meldung. Du weißt weder, was fehlgeschlagen ist, noch welche Werte verglichen wurden. Du weißt nichts, auch wenn dein Name nicht Jon Snow ist.
Beispiel 4-22. assertTrue Beispiel
assertTrue(documents.size()==0);

Abbildung 4-1. Screenshot des fehlschlagenden assertTrue
Die am häufigsten verwendete Assertion ist assertEquals, die zwei Werte nimmt und prüft, ob sie gleich sind, und die überladen ist, um primitive Werte zu unterstützen. Hier können wir also behaupten, dass die Größe der Liste documents 0 ist, wie inBeispiel 4-23 gezeigt. Dies führt zu einer etwas besseren Diagnose, wie inAbbildung 4-2 zu sehen ist. Du weißt, dass der erwartete Wert 0 und der tatsächliche Wert 1 war, aber es gibt dir immer noch keinen sinnvollen Kontext.
Beispiel 4-23. assertEquals Beispiel
assertEquals(0,documents.size());

Abbildung 4-2. Screenshot des fehlschlagenden assertEquals-Beispiels
Die beste Möglichkeit, eine Aussage über die Größe selbst zu treffen, ist die Verwendung einesMatchers für, der die Größe der Sammlung angibt, da dies die aussagekräftigste Diagnose liefert. In Beispiel 4-24 ist unser Beispiel in diesem Stil geschrieben und zeigt auch die Ausgabe. Wie in Abbildung 4-3 zu sehen ist, lässt sich so viel klarer erkennen, was schief gelaufen ist, ohne dass du noch mehr Code schreiben müsstest.
Beispiel 4-24. assertThat Beispiel
assertThat(documents,hasSize(0));
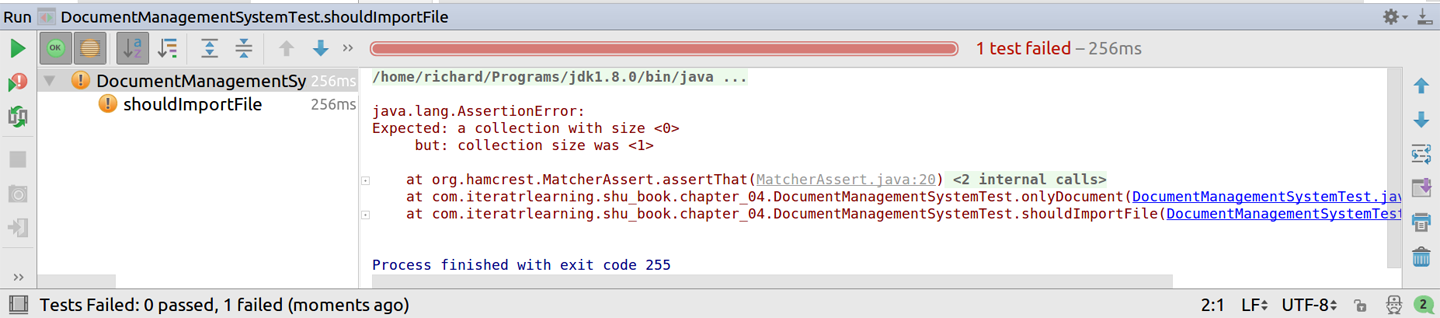
Abbildung 4-3. Screenshot des fehlschlagenden assertThat-Beispiels
Hier wird die Methode assertThat() von JUnit verwendet. Die Methode assertThat()nimmt einen Wert als ersten Parameter und Matcher als zweiten Parameter an. DieMatcher kapselt das Konzept, ob ein Wert mit einer Eigenschaft übereinstimmt, sowie die dazugehörige Diagnose. Der hasSize Matcher wird statisch von einer Matchers Utility-Klasse importiert, die ein Bündel verschiedener Matcher enthält und prüft, ob die Größe einer Sammlung gleich ihrem Parameter ist. Diese Matcher stammen aus der Hamcrest-Bibliothek, einer weit verbreiteten Java-Bibliothek, die sauberere Tests ermöglicht.
Ein weiteres Beispiel dafür, wie du bessere Diagnosen erstellen kannst, wurde inBeispiel 4-20 gezeigt. Hier hätte uns assertEquals die Diagnose für den erwarteten Wert und den tatsächlichen Wert des Attributs geliefert. Der Name des Attributs hätte uns nicht verraten, deshalb wurde er in den Meldungsstring eingefügt, damit wir den Fehler besser verstehen.
Fehlerfälle testen
Einer der absolut schlimmsten und häufigsten Fehler beim Schreiben von Software ist es, nur den schönen, goldenen, glücklichen Pfad deiner Anwendung zu testen - den Codepfad, der ausgeführt wird, wenn die Sonne auf dich scheint und nichts schiefgeht. In der Praxis können viele Dinge schief gehen! Wenn du nicht testest, wie sich deine Anwendung in diesen Situationen verhält, wirst du am Ende keine Software haben, die in einer Produktionsumgebung zuverlässig funktioniert.
Wenn es darum geht, Dokumente in unser Dokumentenmanagementsystem zu importieren, gibt es eine Reihe von Fehlern, die passieren können. Wir könnten versuchen, eine Datei zu importieren, die nicht existiert oder nicht gelesen werden kann, oder wir könnten versuchen, eine Datei zu importieren, von der wir nicht wissen, wie wir den Text extrahieren oder lesen können.
Unser DocumentManagementSystemTest hat ein paar Tests, die inBeispiel 4-25 gezeigt werden, die diese beiden Szenarien testen. In beiden Fällen versuchen wir, eine Pfaddatei zu importieren, die das Problem aufdeckt. Um eine Aussage über das gewünschte Verhalten zu treffen, verwenden wir das Attribut expected = der JUnit-Annotation @Test. Damit kannst du sagen: Hey, hör mal, JUnit, ich erwarte, dass dieser Test eine Ausnahme eines bestimmten Typs auslöst.
Beispiel 4-25. Testen auf Fehlerfälle
@Test(expected=FileNotFoundException.class)publicvoidshouldNotImportMissingFile()throwsException{system.importFile("gobbledygook.txt");}@Test(expected=UnknownFileTypeException.class)publicvoidshouldNotImportUnknownFile()throwsException{system.importFile(RESOURCES+"unknown.txt");}
Vielleicht möchtest du eine Alternative zum einfachen Auslösen einer Exception im Falle eines Fehlers, aber es ist auf jeden Fall hilfreich zu wissen, wie man behauptet, dass eine Exception ausgelöst wird.
Konstanten
Konstanten sind Werte, die sich nicht ändern. Machen wir uns nichts vor - sie sind eines der wenigen gut benannten Konzepte in der Computerprogrammierung. Die Programmiersprache Java verwendet kein explizites constSchlüsselwort wie C++, aber üblicherweise erstellen Entwickler static
field Felder, um Konstanten zu repräsentieren. Da viele Tests aus Beispielen dafür bestehen, wie ein Teil deines Computerprogramms verwendet werden soll, bestehen sie oft aus vielen Konstanten.
Bei Konstanten, die eine nicht offensichtliche Bedeutung haben, ist es ratsam, ihnen einen eigenen Namen zu geben, der in Tests verwendet werden kann. Das machen wir ausgiebig in DocumentManagementSystemTest und haben sogar einen Block ganz oben, der der Deklaration von Konstanten gewidmet ist, wie in Beispiel 4-26 gezeigt.
Beispiel 4-26. Konstanten
publicclassDocumentManagementSystemTest{privatestaticfinalStringRESOURCES="src"+File.separator+"test"+File.separator+"resources"+File.separator;privatestaticfinalStringLETTER=RESOURCES+"patient.letter";privatestaticfinalStringREPORT=RESOURCES+"patient.report";privatestaticfinalStringXRAY=RESOURCES+"xray.jpg";privatestaticfinalStringINVOICE=RESOURCES+"patient.invoice";privatestaticfinalStringJOE_BLOGGS="Joe Bloggs";
Mitbringsel
-
Du hast gelernt, wie man ein Dokumentenmanagementsystem aufbaut.
-
Du hast die unterschiedlichen Kompromisse zwischen den verschiedenen Umsetzungsansätzen erkannt.
-
Du hast mehrere Prinzipien verstanden, die das Design von Software bestimmen.
-
Du hast das Liskovsche Substitutionsprinzip kennengelernt, mit dem du über Vererbung nachdenken kannst.
-
Du hast gelernt, in welchen Situationen das Vererben nicht angebracht ist.
Iteration an dir
Wenn du das Wissen aus diesem Abschnitt vertiefen und festigen willst, kannst du eine der folgenden Aktivitäten ausprobieren:
-
Nimm den vorhandenen Beispielcode und füge eine Implementierung für den Import von Verschreibungsdokumenten hinzu. Ein Rezept sollte einen Patienten, ein Medikament, eine Menge und ein Datum enthalten und die Bedingungen für die Einnahme eines Medikaments angeben. Du solltest auch einen Test schreiben, der überprüft, ob der Import von Rezepten funktioniert.
-
Versuche, die Game of Life Kata umzusetzen.
Die Herausforderung abschließen
Dr. Avaj ist sehr zufrieden mit Ihrem Dokumentenmanagementsystem und nutzt es jetzt ausgiebig. Ihre Bedürfnisse werden durch die Funktionen effektiv erfüllt, weil du dein Design von ihren Anforderungen hin zum Anwendungsverhalten und zu den Implementierungsdetails gelenkt hast. Auf dieses Thema wirst du zurückkommen, wenn TDD im nächsten Kapitel vorgestellt wird.
Get Software-Entwicklung in der realen Welt now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

