Chapter 4. Microkernel Architecture
The microkernel architecture style is a flexible and extensible architecture that allows a developer or end user to easily add additional functionality and features to an existing application in the form of extensions, or “plug-ins,” without impacting the core functionality of the system. For this reason, the microkernel architecture is sometimes referred to as a “plug-in architecture” (another common name for this architecture style). This architecture style is a natural fit for product-based applications (ones that are packaged and made available for download in versions as a typical third-party product), but is also common for custom internal business applications. In fact, many operating systems implement the microkernel architecture style, hence the origin of this style’s name.
Topology
The microkernel architecture style consists of two types of architecture components: a core system and plug-in modules. Application logic is divided between independent plug-in modules and the basic core system, providing extensibility, flexibility, and isolation of application features and custom processing logic. Figure 4-1 illustrates the basic topology of the microkernel architecture style.
The core system of this architecture style can vary significantly in terms of the functionality it provides. Traditionally, the core system contains only the minimal functionality required to make the system operational (such as the case with older IDEs such as Eclipse), but it can also be more full featured (such as with web browsers like Chrome). In either case, the functionality in the core system can then be extended through the use of separate plug-in modules.
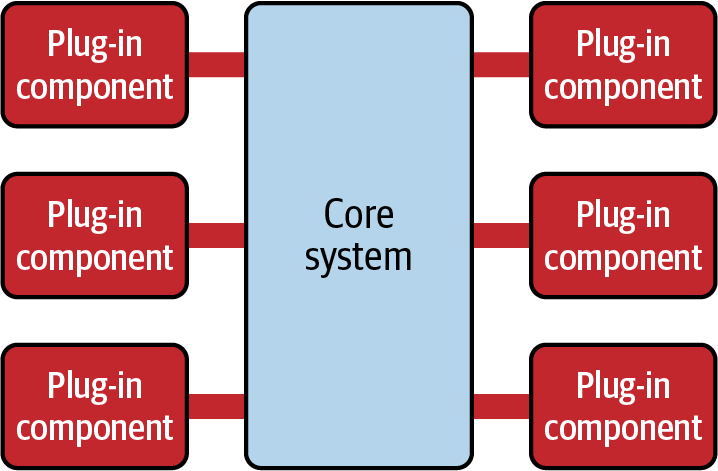
Figure 4-1. Microkernel architecture style
Plug-in modules are standalone, independent components that contain specialized processing, additional features, adapter logic, or custom code that is meant to enhance or extend the core system to provide additional business capabilities. Generally, plug-in modules should be independent of other plug-in modules and not be dependent on other plug-ins to function. It’s also important in this architecture style to keep communication between plug-ins to a minimum to avoid confusing dependency issues.
The core system needs to know which plug-in modules are available and how to get to them. One common way of implementing this is through a plug-in registry. The registry contains information about each plug-in module, including its name, contract details, and remote access protocol details (depending on how the plug-in is connected to the core system). For example, a plug-in for tax software that flags items as a high risk for triggering an audit might have a registry entry that contains the name of the service (AuditChecker), the contract details (input data and output data), and the contract format (XML). In cases where the contracts and access protocol are standard within the system, the registry might only contain the name of the plug-in module and an interface name for how to invoke that plug-in.
Plug-in modules can be connected to the core system in a variety of ways. Traditionally, plug-ins are implemented as separate libraries or modules (such as JAR and DLL files) connected in a point-to-point fashion (such as a method call via an interface). These separate modules can then be managed through frameworks such as OSGi (Open Service Gateway Initiative), Java Modularity, Jigsaw, Penrose, and Prism or .NET environments. When plug-ins are deployed in this manner, the overall deployment model is that of a monolithic (single deployment) architecture. Techniques such as dropping a file in a particular directory and restarting the application are common for the microkernel architecture when using point-to-point plug-ins. Some applications using the previously listed frameworks can also support runtime plug-in capabilities for adding or changing plug-ins without having to restart the core system.
Alternatively, plug-ins can also be implemented as part of a single consolidated codebase, manifested simply through a namespace or package structure. For example, a plug-in that might perform an assessment of a specific electronic device (such as an iPhone 12) for an electronics recycling application might have the namespace app.plugin.assessment.iphone12. Notice that the second node of this namespace specifies that this code is a plug-in, specifically for the assessment of an iPhone 12 device. In this manner, the code in the plug-in is separate from the code in the core system.
Plug-in modules can also be implemented as remote services, and accessed through REST or messaging interfaces from the core system. In this case, the microkernel architecture would be considered a distributed architecture. All requests would still need to go through the core system to reach the plug-in modules, but this type of configuration allows for easier runtime deployment of the plug-in components, and possibly better internal scalability and responsiveness if multiple plug-ins need to be invoked for a single business request.
Examples
A classic example of the microkernel architecture is the Eclipse IDE. Downloading the basic Eclipse product provides you little more than a fancy editor. However, once you start adding plug-ins, it becomes a highly customizable and useful product for software development. Internet browsers are another common example using the microkernel architecture: viewers and other plug-ins add additional capabilities that are not otherwise found in the basic browser (the core system). As a matter of fact, many of the developer and deployment pipeline tools and products such as PMD, Jira, Jenkins, and so on are implemented using microkernel architecture.
The examples are endless for product-based software, but what about the use of the microkernel architecture for small and large business applications? The microkernel architecture applies to these situations as well. Tax software, electronics recycling, and even insurance applications can benefit from this architecture style.
To illustrate this point, consider claims processing in a typical insurance company (filing a claim for an accident, fire, natural disaster, and so on). This software functionality is typically very complicated. Each jurisdiction (for example, a state in the United States) has different rules and regulations for what is and isn’t allowed in an insurance claim. For example, some jurisdictions allow for a free windshield replacement if your windshield is damaged by a rock, whereas other jurisdictions do not. This creates an almost infinite set of conditions for a standard claims process.
Not surprisingly, most insurance claims applications leverage large and complex rules engines to handle much of this complexity. However, these rules engines can grow into a complex big ball of mud where changing one rule impacts other rules, or requires an army of analysts, developers, and testers just to make a simple rule change. Using the microkernel architecture style can mitigate many of these issues.
For example, the stack of folders you see in Figure 4-2 represents the core system for claims processing. It contains the basic business logic required by the insurance company to process a claim (which doesn’t change often), but contains no custom jurisdiction processing. Rather, plug-in modules contain the specific rules for each jurisdiction. Here, the plug-in modules can be implemented using custom source code or separate rules engine instances. Regardless of the implementation, the key point is that jurisdiction-specific rules and processing are separate from the core claims system and can be added, removed, and changed with little or no effect on the rest of the core system or other plug-in modules.
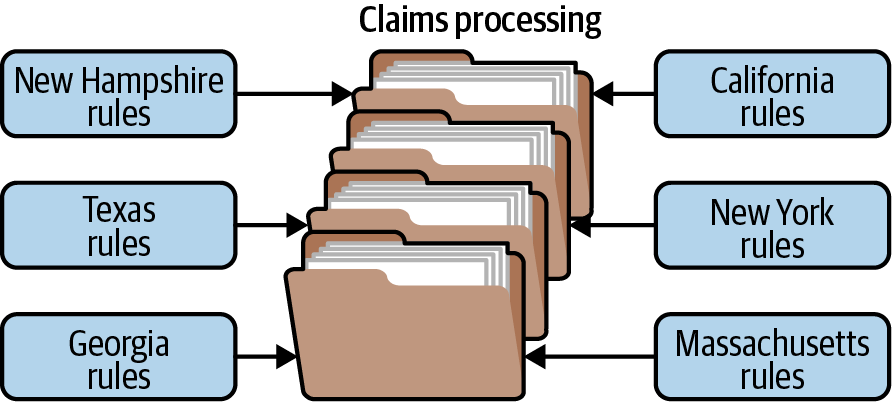
Figure 4-2. Microkernel architecture example of processing an insurance claim
Considerations and Analysis
The microkernel architecture style is very flexible and can vary greatly in granularity. This style can describe the overarching architecture of a system, or it can be embedded and used as part of another architecture style. For example, a particular event processor, domain service, or even a microservice can be implemented using the microkernel architecture style, even though other services are implemented in other ways.
This architecture style provides great support for evolutionary design and incremental development. You can produce a minimal core system that provides some of the primary functionality of a system, and as the system evolves incrementally, you can add features and functionality without having to make significant changes to the core system.
Depending on how this architecture style is implemented and used, it can be considered as either a technically partitioned architecture or a domain partitioned one. For example, using plug-ins to provide adapter functionality or specific configurations would make it a technically partitioned architecture, whereas using plug-ins to provide additional extensions or additional functionality would make it more of a domain partitioned architecture.
When to Consider This Style
The microkernel architecture style is good to consider as a starting point for a product-based application or custom application that will have planned extensions. In particular, it is a good choice for products where you will be releasing additional features over time or you want control over which users get which features.
Microkernel architecture is also a good choice for applications or products that have multiple configurations based on a particular client environment or deployment model. Plug-in modules can specify different configurations and features specific to any particular environment. For example, an application that can be deployed on any cloud environment might have a different set of plug-ins that act as adapters to fit the specific services of that particular cloud vendor, whereas the core system contains the primary functionality and remains completely agnostic as to the actual cloud environment.
As with the layered architecture style, the microkernel architecture style is relatively simple and cost-effective, and is a good choice if you have tight budget and time constraints.
When Not to Consider This Style
All requests must go through the core system, regardless of whether the plug-ins are remote or point-to-point invocations. Because of this, the core system acts as the main bottleneck to this architecture, and is not well suited for highly scalable and elastic systems. Similarly, overall fault tolerance is not good in this architecture style, again due to the need for the core system as an entry point.
One of the goals of the microkernel architecture is to reduce change in the core system and push extended functionality and code volatility out to the plug-in modules, which are more self-contained and easier to test and change. Therefore, if you find that most of your changes are within the core system and you are not leveraging the power of plug-ins to contain additional functionality, this is likely not a good architecture match for the problem you are trying to solve.
Architecture Characteristics
The chart illustrated in Figure 4-3 summarizes the overall capabilities (architecture characteristics) of the microkernel architecture in terms of star ratings. One star means the architecture characteristic is not well supported, whereas five stars means it’s well suited for that particular architecture characteristic.
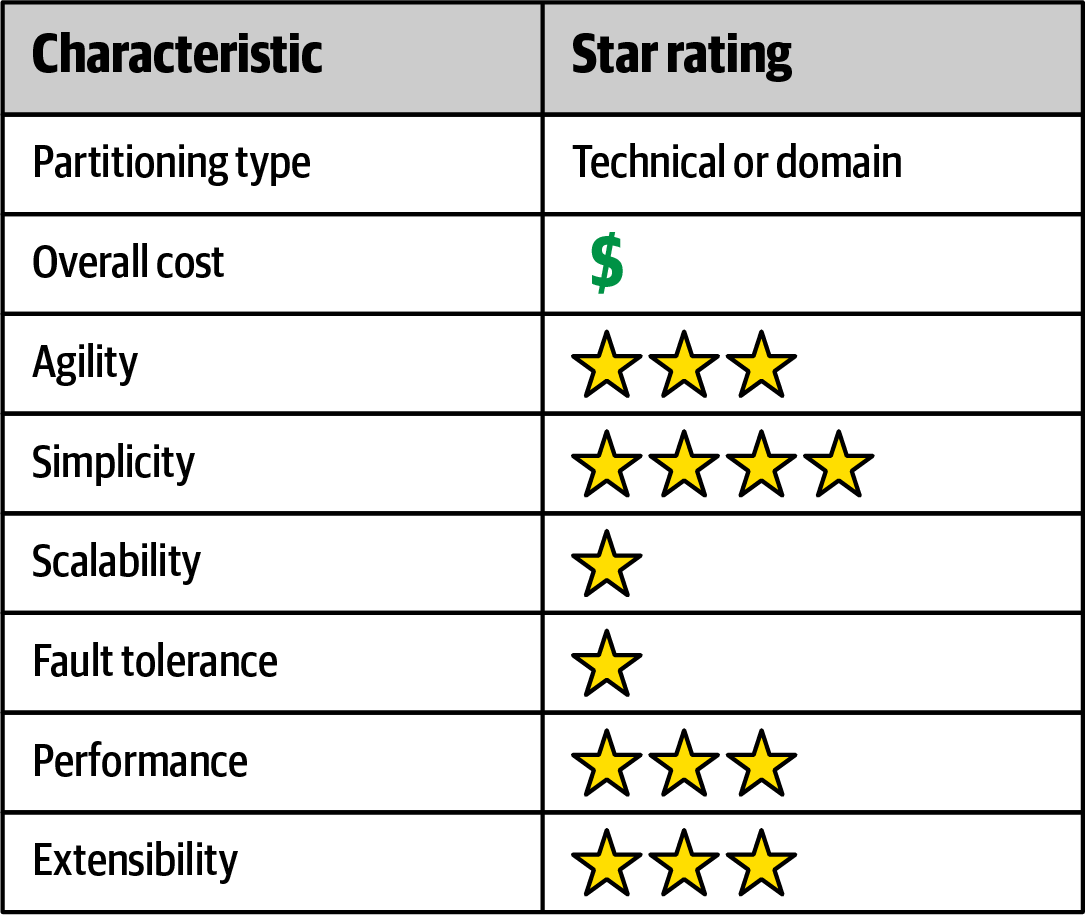
Figure 4-3. Architecture characteristics star ratings for the microkernel architecture
Get Software Architecture Patterns, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

