Vorwort
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Willkommen bei Snowflake SQL und Scripting lernen. Vielleicht bist du ganz neu auf dem Gebiet der Datenbanken und musst Abfragen oder Berichte für eine Snowflake-Datenbank erstellen. Oder vielleicht arbeitest du, wie ich, schon seit Jahren mit Datenbanken wie Oracle, SQL Server oder MySQL und dein Unternehmen hat mit der Umstellung auf cloudbasierte Plattformen begonnen. Wie auch immer, dieses Buch soll dir ein detailliertes Verständnis der SQL-Implementierung von Snowflake vermitteln, damit du so effektiv wie möglich arbeiten kannst.
Um den Zusammenhang zu verdeutlichen, beginne ich mit einem kurzen Überblick über die Geschichte der Datenbanken, beginnend mit der Einführung relationaler Datenbanken in den 1980er Jahren bis hin zur Verfügbarkeit von cloudbasierten Datenbankplattformen wie Snowflake. Wenn du sofort mit dem Erlernen von SQL beginnen möchtest, kannst du mit Kapitel 1 fortfahren, aber du solltest auch "Einrichten einer Beispieldatenbank" lesen, wenn du deine eigene Datenbank zum Experimentieren erstellen möchtest.
Relationale Datenbank Fibel
Computergestützte Datenbanksysteme gibt es seit den 1960er Jahren, aber für die Zwecke dieses Buches beginnen wir mit der Einführung von relationalen Datenbanken, die in den 1980er Jahren mit Produkten wie Oracle, Sybase, SQL Server (Microsoft) und Db2 (IBM) auf den Markt kamen. Relationale Datenbanken basieren auf Datenzeilen, die in Tabellen gespeichert sind, und verwandte Zeilen, die in verschiedenen Tabellen gespeichert sind, werden mit redundanten Werten verknüpft. Der ACME-Großhandelskunde kann z. B. über die Kunden-ID 123 in der Tabelle Customer identifiziert werden, und alle ACME-Bestellungen in der Tabelle Orders würden ebenfalls über die Kunden-ID 123 identifiziert werden.
Eine Tabelle, wie die oben erwähnte Customer oder Orders, besteht aus mehreren Spalten, z. B. Name, Adresse und Telefonnummer. Eine oder mehrere dieser Spalten werden verwendet, um jede Zeile in der Tabelle eindeutig zu identifizieren (der so genannte Primärschlüssel). In der Beispieldatenbank, die für dieses Buch verwendet wird, gibt es eine Tabelle Customer, deren Primärschlüssel aus einer einzigen Spalte namens custkey besteht, und jede Zeile in der Tabelle Customer muss einen eindeutigen Wert custkey haben. Außerdem gibt es eine Tabelle Orders, die die Spalte custkey enthält, um den Kunden zu referenzieren, der die Bestellung aufgegeben hat. Die Spalte Orders.custkey wird als Fremdschlüssel zur Tabelle Customer bezeichnet und muss einen Wert enthalten, der in der Spalte Customer.custkey existiert. Tabelle P-1 zeigt eine kurze Zusammenfassung der bisher eingeführten Terminologie.
| Säule | Eine einzelne Dateneinheit |
| Reihe | Eine Reihe von zusammenhängenden Spalten |
| Tabelle | Eine Reihe von Zeilen |
| Primärschlüssel | Eine oder mehrere Spalten, die als eindeutiger Bezeichner für jede Zeile in einer Tabelle verwendet werden können |
| Fremdschlüssel | Eine oder mehrere Spalten, die zusammen verwendet werden können, um eine einzelne Zeile in einer anderen Tabelle zu identifizieren |
Bisher haben wir die Verwendung von redundanten Spaltenwerten zur Verknüpfung von Tabellen über Primär- und Fremdschlüssel besprochen, aber es gibt Regeln für die Speicherung von redundanten Werten. Es ist zum Beispiel völlig in Ordnung, wenn die Tabelle Orders eine Spalte enthält, die die Werte von Customer.custkey enthält, aber es ist nicht in Ordnung, andere Spalten aus der Tabelle Customer einzubeziehen, wie z. B. die Spalten Name oder Adresse. Wenn du dir eine Zeile in der Tabelle Orders ansiehst und den Namen und die Adresse des Kunden wissen willst, der die Bestellung aufgegeben hat, solltest du diese Werte aus der Tabelle Customer holen, anstatt den Namen und die Adresse des Kunden in der Tabelle Orders zu speichern. Der Prozess, bei dem eine Datenbank so gestaltet wird, dass jede unabhängige Information nur an einem Ort gespeichert wird (außer bei Fremdschlüsseln), wird als Normalisierung bezeichnet.
Normalisierungsregeln gelten auch für einzelne Spalten, d.h. eine Spalte sollte nur einen einzigen unabhängigen Wert enthalten. Ein gängiges Beispiel ist eine Postanschrift, die aus mehreren Elementen wie Straße, Stadt, Bundesland und Postleitzahl besteht. Ein normalisierter Entwurf würde daher mehrere Spalten enthalten, wie in Tabelle P-2 gezeigt.
| Adresse1 | 3 Ahornstraße |
| Adresse2 | Suite 305 |
| Stadt | Anytown |
| Staat | TX |
| Postleitzahl | 12345 |
Unternehmen haben oft mehrere Datenbanken, die für unterschiedliche Zwecke verwendet werden, und der Grad der Normalisierung kann sehr unterschiedlich sein. Eine Datenbank, die ausschließlich von der Versandabteilung eines Unternehmens genutzt wird, kann beispielsweise eine einzige Adressspalte enthalten, die für den Druck von Versandetiketten verwendet wird und im obigen Beispiel den Wert "3 Maple Street, Suite 305, Anytown, TX 12345." enthält. Es kann auch sein, dass die Versanddatenbank täglich aus einer zentralen, normalisierten Datenbank aktualisiert wird.
Schneeflocke
Snowflake wurde 2014 auf den Markt gebracht und ist eine Cloud-basierte, relationale Datenbank mit vollem Funktionsumfang. Snowflake-Datenbanken können auf jeder der drei großen Cloud-Plattformen (Amazon AWS, Microsoft Azure und Google Cloud) gehostet werden, sodass Kunden mit bestehenden Cloud-Implementierungen bei dem bleiben können, was sie kennen. Sowohl die Speicherung als auch die Rechenleistung können bei Bedarf skaliert werden, und das SaaS-Modell (Software as a Service) von Snowflake befreit Unternehmen von der Notwendigkeit, Heerscharen von Netzwerk-, Server- und Datenbankadministratoren einzustellen, sodass sie sich auf ihr Kerngeschäft konzentrieren können.
Es gibt viele Möglichkeiten, mit Snowflake zu interagieren, aber für die Zwecke dieses Buches schlage ich vor, dass du das browserbasierte grafische Tool von Snowflake namens Snowsight verwendest ( ). Snowsight ist ein hervorragendes Tool, das regelmäßig aktualisiert und verbessert wird. Lies die Online-Dokumentation von Snowsight, um dir einen Überblick über seine Möglichkeiten zu verschaffen.
Was ist SQL?
Die Structured Query Language (SQL) ist eine Sprache, die ursprünglich für die Abfrage und Bearbeitung von Daten in relationalen Datenbanken entwickelt wurde. Die SQL-Sprache hat sich weiterentwickelt, um komplexe Daten wie JavaScript Object Notation (JSON)-Dokumente zu verarbeiten, was eine einfachere Integration zwischen SQL und prozeduralen Sprachen wie Java ermöglicht.
Die SQL-Sprache besteht aus mehreren Gruppen von Befehlen, die in Tabelle P-3 aufgeführt sind.
| Kategorie | Verwendung | Beispiele |
|---|---|---|
| Schema-Anweisungen | Erstellen und Ändern von Datenbankstrukturen | Tabelle erstellen, Index erstellen, Tabelle ändern |
| Datenangaben | Abfragen und Bearbeiten von Daten | Auswählen, Einfügen, Aktualisieren, Löschen, Zusammenführen |
| Transaktionsaufstellungen | Transaktionen erstellen und beenden | Commit, Rollback |
Du kannst auch Schema-Anweisungen sehen, die als Datendefinitionssprache (DDL) klassifiziert sind, und Datenanweisungen, die als Datenmanipulationssprache (DML) klassifiziert sind. Die Schema-Anweisungen werden verwendet, um Tabellen, Indizes, Ansichten und verschiedene andere Datenbankstrukturen zu erstellen oder zu ändern. Sobald diese Strukturen eingerichtet sind, verwendest du die Datenanweisungen, um Zeilen in deine Tabellen einzufügen, zu ändern und zu löschen und um Daten abzurufen.
Du wirst in diesem Buch zwar einige Schema-Anweisungen sehen, aber die meisten Beispiele beziehen sich auf die Daten-Anweisungen, die zwar nur wenige sind, aber dafür sehr umfangreich und mächtig, so dass es sich lohnt, sie genauer zu studieren.
SQL ist eine nicht-prozedurale Sprache, d.h. du legst fest, was du tun willst, aber nicht, wie du es tun sollst. Wenn du z.B. einen Bericht erstellst, der die zehn wichtigsten Kunden pro geografischer Region auflistet, würdest du eine select Anweisung schreiben, die die Umsätze für jeden Kunden summiert, aber es liegt am Datenbankserver, wie er die Daten am besten abruft. In der Regel gibt es mehrere Möglichkeiten, eine bestimmte Gruppe von Ergebnissen zu generieren, und einige sind effizienter als andere, so dass es dem Datenbankserver überlassen bleibt, zu bestimmen, wie er die Daten aus mehreren Tabellen auf effiziente Weise abruft.
Was ist SQL Scripting?
Wenn du mit einer prozeduralen Sprache wie Java, C# oder Go programmiert hast, bist du mit Programmierkonstrukten wie Schleifen, if-then-else und Ausnahmebehandlung vertraut. SQL ist eine nicht-prozedurale Sprache und verfügt über keines dieser Konstrukte. Um diese Lücke zu schließen, bieten die meisten Datenbankplattformen sowohl eine nicht-prozedurale SQL-Implementierung als auch eine prozedurale Sprache, die sowohl die SQL-Datenanweisungen wie select und insert als auch alle üblichen prozeduralen Programmierkonstrukte enthält. Oracle bietet zum Beispiel die PL/SQL-Verfahrenssprache an, während Microsoft die Transact-SQL-Sprache bereitstellt.
Snowflake bietet die Snowflake Scripting-Sprache, mit der du Variablen deklarieren, Schleifen und if-then-else-Anweisungen einbauen und Ausnahmen erkennen und behandeln kannst. Die Snowflake Scripting-Sprache wird in den Kapiteln 15, 16 und 17 dieses Buches behandelt.
Einrichten einer Musterdatenbank
Die netten Leute von Snowflake haben mehrere Beispieldatenbanken zur Verfügung gestellt, damit potenzielle Kunden Erfahrungen mit ihrer SQL-Implementierung sammeln können. Eine der Beispieldatenbanken, TPCH_SF1, wird für den Großteil der Beispiele in diesem Buch verwendet. Da die TPCH_SF1-Datenbank jedoch recht groß ist (über 8,7 Millionen Datenzeilen), habe ich mich entschieden, eine kleine Teilmenge (etwa 330.000 Zeilen) von TPCH_SF1 zu verwenden. Du hast zwei Möglichkeiten, deine eigene Beispieldatenbank einzurichten (siehe "Einrichtung der Beispieldatenbank"), die davon abhängen, ob die TPCH_SF1-Beispieldatenbank noch von Snowflake zur Verfügung gestellt wird.
Die Beispieldatenbank enthält acht Tabellen mit Informationen über Kundenbestellungen für eine Reihe von Teilen, die von einer Reihe von Lieferanten geliefert werden. Anhang A enthält eine visuelle Darstellung dieser Tabellen sowie die Beziehungen zwischen den Tabellen.
Wenn du die Beispielabfragen in diesem Buch ausführen möchtest, ist es ganz einfach, ein kostenloses Snowflake-Konto für 30 Tage einzurichten. Sobald dein Konto aktiv ist, kannst du meinen Anweisungen folgen, um deine Beispieldatenbank einzurichten.
Beispielhafte Datenbankeinrichtung
Unabhängig davon, welche der Optionen du für die Erstellung deiner Beispieldatenbanktabellen wählst, gibt es ein paar Dinge, die du zuerst erledigen musst.
Ein Arbeitsblatt erstellen
In Snowsight sind es die Arbeitsblätter, auf denen du mit deiner Datenbank interagierst. Du kannst verschiedene Arbeitsblätter für unterschiedliche Zwecke erstellen. Lass uns also ein Arbeitsblatt mit dem Namen Learning_Snowflake_SQL erstellen. Dazu klickst du im linken Menü auf Arbeitsblätter, dann auf die Schaltfläche "+" oben rechts und wählst SQL-Arbeitsblatt. Ein neues Arbeitsblatt erscheint und erhält einen Standardnamen, der sich nach dem aktuellen Datum/Uhrzeit richtet. Du kannst auf das Menü neben dem Namen des Arbeitsblatts klicken und "Umbenennen" wählen, dann kannst du es so nennen LEARNING_SNOWFLAKE_SQLwie in Abbildung P-2 gezeigt.
Du kannst dieses Arbeitsblatt verwenden, um deine SQL-Befehle auszuführen, beginnend mit der Anweisung create database im nächsten Abschnitt.
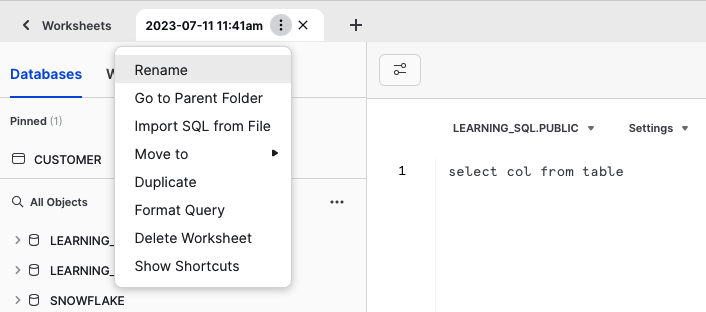
Abbildung P-2. Umbenennen eines Arbeitsblatts
Erstelle deine Datenbank
Jetzt, wo du ein Arbeitsblatt hast, kannst du anfangen, Befehle einzugeben. Die erste Aufgabe besteht darin, deine Beispieldatenbank zu erstellen, wie in Abbildung P-3 dargestellt.
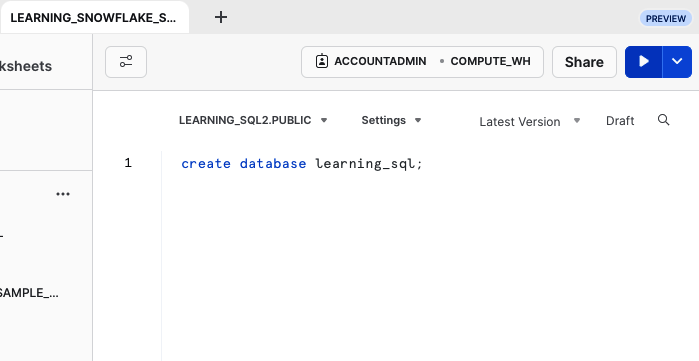
Abbildung P-3. Eine neue Datenbank erstellen
Nach der Eingabe von create database learning_sql in dein Arbeitsblatt eingegeben hast, klicke auf die Schaltfläche Ausführen (der weiße Pfeil mit blauem Hintergrund oben rechts), um deinen Befehl auszuführen. Deine Datenbank wird erstellt und ein Schema namens Public wird standardmäßig angelegt. Hier werden die Tabellen für deine Beispieldatenbank erstellt.
Musterdatenbank Option 1: Kopieren von TPCH_SF1
Um diese Option zu wählen, die die einfachere der beiden Methoden ist, musst du zunächst prüfen, welche Snowflake-Beispieldatenbanken verfügbar sind. Wähle dazu die Menüoption Daten>Datenbanken, um die Liste der verfügbaren Datenbanken anzuzeigen. Wenn du TPCH_SF1 unter der Datenbank SNOWFLAKE_SAMPLE_DATA siehst, hast du Glück, wie du in Abbildung P-4 siehst.

Abbildung P-4. Beispiel einer Datenbankliste
Im nächsten Abschnitt wird beschrieben, wie du die Daten aus TPCH_SF1 in deine eigene Datenbank kopierst.
Erstellen und Auffüllen der Tabellen
Bevor du die Befehle für ausführst, um deine Tabellen zu erstellen, musst du die Datenbank und das Schema angeben, in dem du arbeiten wirst, wie in Abbildung P-5 dargestellt.
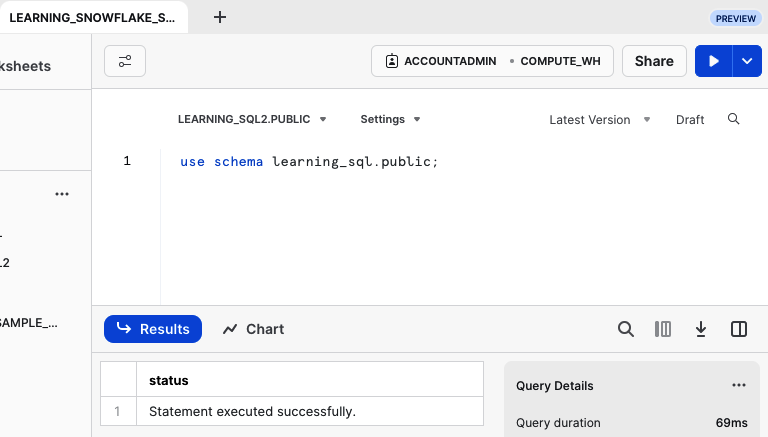
Abbildung P-5. Einstellen der Datenbank und des Schemas
Nachdem du den Befehl use schema eingegeben und die Schaltfläche Ausführen gedrückt hast, kannst du deine Tabellen erstellen. Hier ist der Befehlssatz:
create table region as select * from snowflake_sample_data.tpch_sf1.region; create table nation as select * from snowflake_sample_data.tpch_sf1.nation; create table part as select * from snowflake_sample_data.tpch_sf1.part where mod(p_partkey,50) = 8; create table partsupp as select * from snowflake_sample_data.tpch_sf1.partsupp where mod(ps_partkey,50) = 8; create table supplier as with sp as (select distinct ps_suppkey from partsupp) select s.* from snowflake_sample_data.tpch_sf1.supplier s inner join sp on s.s_suppkey = sp.ps_suppkey; create table lineitem as select l.* from snowflake_sample_data.tpch_sf1.lineitem l inner join part p on p.p_partkey = l.l_partkey; create table orders as with li as (select distinct l_orderkey from lineitem) select o.* from snowflake_sample_data.tpch_sf1.orders o inner join li on o.o_orderkey = li.l_orderkey; create table customer as with o as (select distinct o_custkey from orders) select c.* from snowflake_sample_data.tpch_sf1.customer c inner join o on c.c_custkey = o.o_custkey;
Dieses Skript ist auch auf meiner GitHub-Seite zu finden.
Wenn du diese acht create table Befehle in dein Arbeitsblatt geladen hast, kannst du sie einzeln ausführen, indem du jede Anweisung markierst und ausführst. Du kannst aber auch alle Befehle in einer einzigen Ausführung ausführen, indem du das Menü auf der rechten Seite der Schaltfläche Ausführen ausklappst und Alle ausführen wählst, wie in Abbildung P-6 gezeigt.
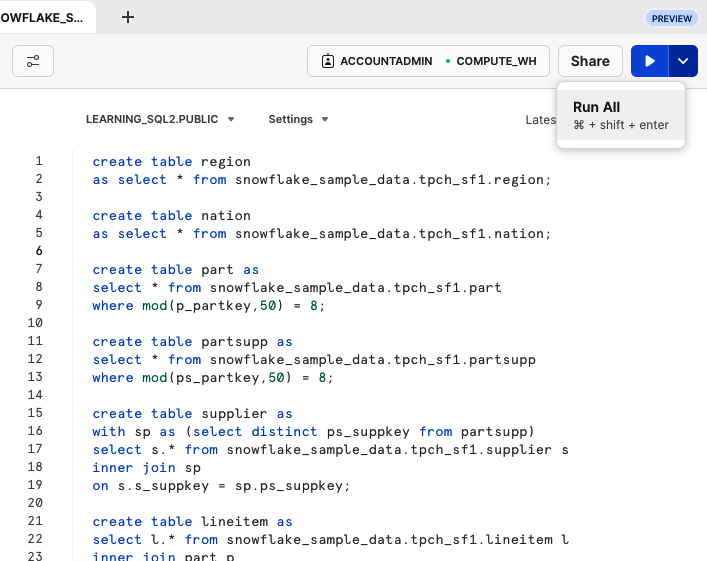
Abbildung P-6. Auswahl der Option Alle ausführen aus dem Menü Ausführen
Egal, ob du sie einzeln oder alle zusammen ausführst, das Endergebnis sollten acht neue Tabellen im öffentlichen Schema deiner Learning_SQL-Datenbank sein. Wenn du auf Probleme stößt, kannst du die Datenbank einfach über create or replace database learning_sql neu erstellen, wodurch alle vorhandenen Tabellen gelöscht werden.
Beispiel-Datenbank Option #2: Daten aus GitHub-Dateien laden
Diese Option musst du verwenden, wenn die Beispieldatenbank TPCH_SF1 nicht mehr in Snowflake verfügbar ist (oder wenn du aus irgendeinem Grund die Option 1 nicht verwenden konntest). Für diese Option musst du acht Tabellen im Schema learning_sql.public erstellen und dann jede Tabelle mithilfe von CSV-Dateien laden, die du auf meiner GitHub-Seite findest. Die folgenden Abschnitte führen dich durch diesen Prozess.
Erstellen von Beispieldatenbanktabellen
Lade die Datei Learning_Snowflake_SQL_Schema.sql von GitHub in dein Arbeitsblatt. Abbildung P-7 zeigt, wie es aussieht.
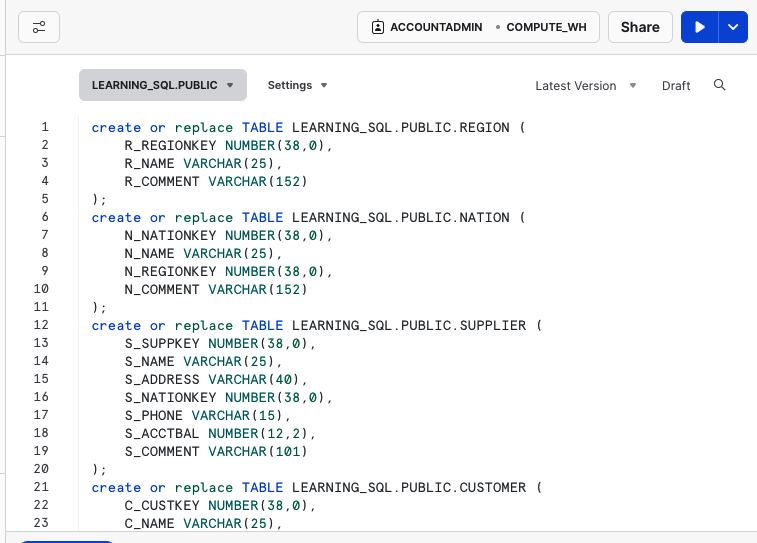
Abbildung P-7. Tabellenanweisungen erstellen
Du kannst jede create table Anweisung markieren und auf die Schaltfläche Ausführen klicken, oder du kannst das Dropdown-Menü neben der Schaltfläche Ausführen verwenden, um die Option Alle ausführen auszuwählen, wodurch alle acht Anweisungen ausgeführt werden. Nach der Ausführung solltest du alle acht Tabellen unter Datenbank>LEARNING_SQL>PUBLIC>Tables sehen können, wie in Abbildung P-8 dargestellt.
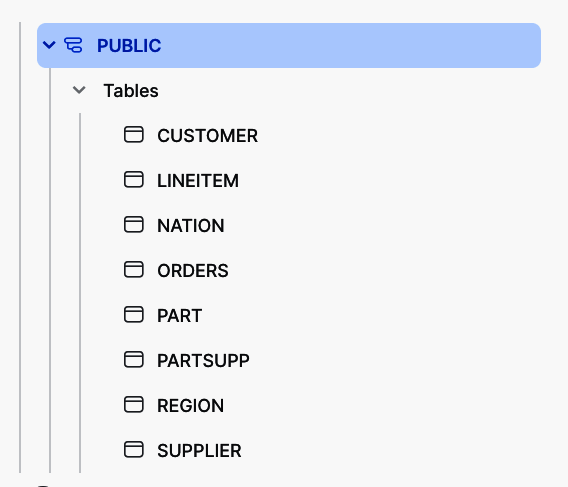
Abbildung P-8. Tabelle Auflistung
Auch hier gilt: Wenn du auf Probleme stößt, kannst du einfach neu anfangen, indem du die Datenbank über create or replace database learning_sql neu erstellst, wodurch alle vorhandenen Tabellen gelöscht werden.
Dateien in Tabellen laden
Jetzt, wo die Tabellen vorhanden sind, kannst du jede einzelne mit Hilfe von CSV-Dateien laden, die du auf meiner GitHub-Seite findest. Jede Tabelle hat eine ähnlich benannte Datei; zum Beispiel lädst du die Tabelle Customer mit der Datei customer.csv.gz, die Tabelle Region mit der Datei region.csv.gz, usw. Tabelle P-4 zeigt die Dateien für jede der acht Tabellen.
Um alle acht Dateien von GitHub herunterzuladen, wähle jede Datei einzeln aus und benutze die Option "Rohdatei herunterladen".
Um die Tabelle Customer zu laden, suche die Tabelle im Menü Datenbank>LEARNING_SQL>PUBLIC>Tabellen und klicke auf die Menüoption Tabelle laden, wie in Abbildung P-9 gezeigt.
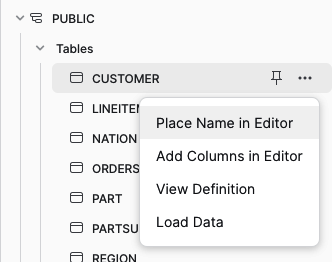
Abbildung P-9. Menüoption Daten laden
Abbildung P-10 zeigt das Pop-up-Fenster, das über die Menüoption Daten laden aufgerufen wird.

Abbildung P-10. Pop-up-Fenster "Daten laden
Klicke auf Durchsuchen und wähle die entsprechende GitHub-Datei aus, wie in Abbildung P-11 dargestellt.
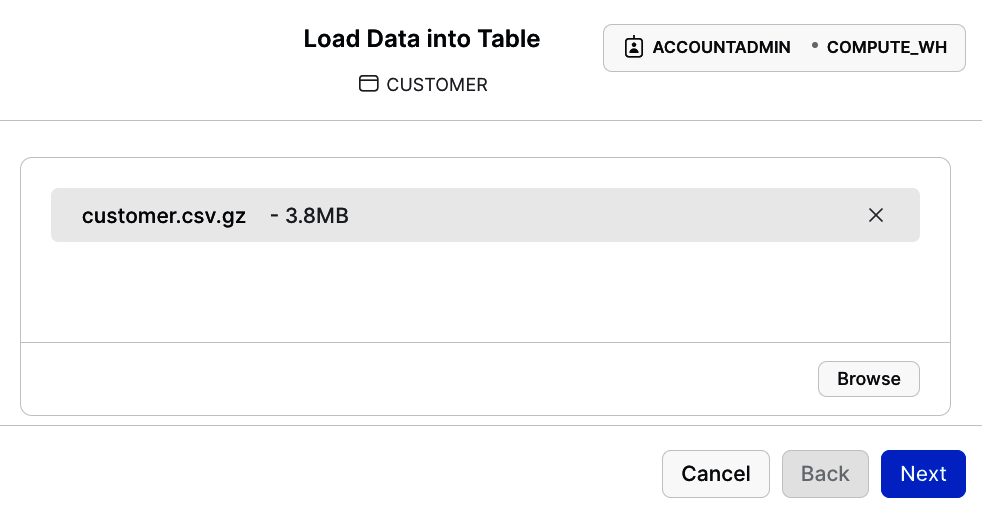
Abbildung P-11. CSV-Datei auswählen
Klicke auf Weiter und wähle die Option "Getrennte Dateien (CSV oder TSV)" in der Dropdown-Liste Dateiformat, wie in Abbildung P-12 dargestellt.
Abbildung P-12. Auswahl der Option "Getrennte Datei
Belasse alle anderen Felder so wie sie sind (Standardoptionen) und klicke auf Weiter. Wenn du fertig bist, solltest du ein Fenster ähnlich wie in Abbildung P-13 sehen.

Abbildung P-13. Erfolgreiches Laden von Daten
Klicke auf Fertig und fahre mit der nächsten Tabelle fort. Achte darauf, dass du für jede der anderen sieben Tabellen die richtige Datei auswählst.
In diesem Buch verwendete Konventionen
In diesem Buch werden die folgenden typografischen Konventionen verwendet:
- Kursiv
-
Weist auf neue Begriffe, URLs, E-Mail-Adressen, Dateinamen und Dateierweiterungen hin.
Constant width-
Wird für Programmlistings sowie innerhalb von Absätzen verwendet, um auf Programmelemente wie Variablen- oder Funktionsnamen, Datenbanken, Datentypen, Umgebungsvariablen, Anweisungen und Schlüsselwörter hinzuweisen.
Constant width bold-
Zeigt Befehle oder anderen Text an, der vom Benutzer wörtlich eingegeben werden sollte, sowie Code, der für die vorliegende Diskussion von besonderem Interesse ist.
Constant width italicoder<constant width in angle brackets>-
Zeigt Text an, der durch vom Benutzer eingegebene Werte oder durch kontextabhängige Werte ersetzt werden soll.
Hinweis
Dieses Element steht für einen allgemeinen Hinweis.
Warnung
Dieses Element weist auf eine Warnung oder einen Warnhinweis hin.
Code-Beispiele verwenden
Zusätzliches Material (Code-Beispiele, Übungen usw.) steht unter https://github.com/alanbeau/learningsnowflakesql zum Download bereit .
Wenn du eine technische Frage oder ein Problem mit den Codebeispielen hast, schicke bitte eine E-Mail an bookquestions@oreilly.com.
Dieses Buch soll dir helfen, deine Arbeit zu erledigen. Wenn in diesem Buch Beispielcode angeboten wird, darfst du ihn in deinen Programmen und deiner Dokumentation verwenden. Du musst uns nicht um Erlaubnis fragen, es sei denn, du reproduzierst einen großen Teil des Codes. Wenn du zum Beispiel ein Programm schreibst, das mehrere Teile des Codes aus diesem Buch verwendet, brauchst du keine Erlaubnis. Der Verkauf oder die Verbreitung von Beispielen aus O'Reilly-Büchern erfordert jedoch eine Genehmigung. Die Beantwortung einer Frage mit einem Zitat aus diesem Buch und einem Beispielcode erfordert keine Genehmigung. Wenn du einen großen Teil des Beispielcodes aus diesem Buch in die Dokumentation deines Produkts aufnimmst, ist eine Genehmigung erforderlich.
Wir freuen uns über eine Namensnennung, verlangen sie aber in der Regel nicht. Eine Quellenangabe umfasst normalerweise den Titel, den Autor, den Verlag und die ISBN. Ein Beispiel: "Learning Snowflake SQL and Scripting von Alan Beaulieu (O'Reilly). Copyright 2024 Alan Beaulieu, 978-1-098-14032-8."
Wenn du der Meinung bist, dass die Verwendung von Code-Beispielen nicht unter die Fair-Use-Regelung oder die oben genannte Erlaubnis fällt, kannst du uns gerne unter permissions@oreilly.com kontaktieren .
O'Reilly Online Learning
Hinweis
Seit mehr als 40 Jahren bietet O'Reilly Media Schulungen, Wissen und Einblicke in Technologie und Wirtschaft, um Unternehmen zum Erfolg zu verhelfen.
Unser einzigartiges Netzwerk von Experten und Innovatoren teilt sein Wissen und seine Erfahrung durch Bücher, Artikel und unsere Online-Lernplattform. Die Online-Lernplattform von O'Reilly bietet dir On-Demand-Zugang zu Live-Trainingskursen, ausführlichen Lernpfaden, interaktiven Programmierumgebungen und einer umfangreichen Text- und Videosammlung von O'Reilly und über 200 anderen Verlagen. Weitere Informationen erhältst du unter http://oreilly.com.
Wie du uns kontaktierst
Bitte richte Kommentare und Fragen zu diesem Buch an den Verlag:
- O'Reilly Media, Inc.
- 1005 Gravenstein Highway Nord
- Sebastopol, CA 95472
- 800-889-8969 (in den Vereinigten Staaten oder Kanada)
- 707-829-7019 (international oder lokal)
- 707-829-0104 (Fax)
- support@oreilly.com
- https://www.oreilly.com/about/contact.html
Wir haben eine Webseite für dieses Buch, auf der wir Errata, Beispiele und zusätzliche Informationen auflisten. Du kannst diese Seite unter https://oreil.ly/learning-snowflake-and-sql aufrufen .
Neuigkeiten und Informationen über unsere Bücher und Kurse findest du unter https://oreilly.com.
Du findest uns auf LinkedIn: https://linkedin.com/company/oreilly-media.
Folge uns auf Twitter: https://twitter.com/oreillymedia.
Sieh uns auf YouTube: https://youtube.com/oreillymedia.
Danksagungen
Ich möchte mehreren Leuten bei O'Reilly Media dafür danken, dass sie mir geholfen haben, dieses Buch zum Leben zu erwecken. Dazu gehören Andy Kwan, der mir bei verschiedenen technischen Problemen geholfen hat, Corbin Collins für seine exzellenten Ratschläge und seine redaktionellen Fähigkeiten sowie Katherine Tozer und Carol Keller für den letzten Anstoß, der uns zum Ziel geführt hat. Ich möchte mich auch bei meinen technischen Prüfern bedanken, darunter Ed Crean und Joyce Kay Avila, deren Fachwissen über das Snowflake-Ökosystem dazu beigetragen hat, dass dieses Buch viel detaillierter ist. Außerdem möchte ich mich bei Pankaj Gupta und Nadir Doctor bedanken, die das Buch zu einem frühen Zeitpunkt sahen und sich mit Begeisterung bereit erklärten, es zu rezensieren. Und schließlich danke ich meiner Frau Nancy, die mich in den letzten 20 Jahren nicht nur bei diesem Buch, sondern auch bei den fünf Ausgaben von Learning SQL und Mastering Oracle SQL unterstützt hat.
Get Snowflake SQL und Skripting lernen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

