Kapitel 4. Serverlos und Sicherheit
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Wir können nur eine kurze Strecke vor uns sehen, aber wir sehen dort eine Menge, was getan werden muss.
Alan Turing
Die Verwendung von serverless Technologien bedeutet, dass einige traditionelle Sicherheitsprobleme wegfallen, wie z.B. das Patchen von Betriebssystemfehlern und die Sicherung von Netzwerkverbindungen. Doch wie jeder technologische Fortschritt bringt auch Serverless neue Herausforderungen mit sich, während bestehende Probleme gelöst werden. Das gilt auch für die Serverless-Sicherheit. In diesem Kapitel werden die Sicherheitsbedrohungen für eine serverlose Anwendung untersucht und die wichtigsten Sicherheitsprimitive und ihre Bedeutung für die serverlose Entwicklung auf AWS erläutert.
Leider denken Softwareentwickler oft erst über die Sicherheit nach, wenn die gesamte Anwendung entwickelt ist, meist in den Wochen oder Tagen vor der Inbetriebnahme. Und selbst dann konzentrieren sie sich in letzter Minute nur auf die Sicherung des Anwendungsumfangs. Dafür gibt es zwei Gründe: Erstens erscheint Sicherheit den Entwicklern von Natur aus komplex, und zweitens haben sie oft das Gefühl, dass die Umsetzung von Sicherheitsmaßnahmen der Praxis der fehlerorientierten Iteration zuwiderläuft.
Auch wenn Softwareentwicklungsteams Sicherheitstools einsetzen und bestimmte Aufgaben an diese Tools delegieren können, muss die Sicherheit immer ein zentrales Anliegen der Entwicklung und des Betriebs sein.
Moderne Softwareentwicklungsteams haben einen lange etablierten Entwicklungsprozess. Traditionell sah dieser in etwa so aus: Entwerfen, Erstellen, Testen, Bereitstellen. Die DevOps-Bewegung hat dafür gesorgt, dass der Betrieb von Software in den Entwicklungslebenszyklus der Software eingebettet wurde. Auch die Sicherheit muss nun Teil des gesamten Entwicklungsprozesses sein.
Die weit verbreitete Empfehlung lautet , die Sicherheit früher in den Entwicklungszyklus einzubeziehen und das Identitäts- und Zugriffsmanagement zu nutzen, um eine umfassende Verteidigung zu gewährleisten, die sich nicht auf die Außengrenzen beschränkt. Serverloses Engineering bietet die Möglichkeit, einen "Secure-by-Design"-Ansatz in deine tägliche Arbeit einzubauen. Wenn du deine Anwendung entwirfst, erstellst und betreibst, solltest du immer die Angriffsvektoren, potenziellen Schwachstellen und die verfügbaren Abhilfemaßnahmen im Blick haben (siehe Abbildung 4-1).
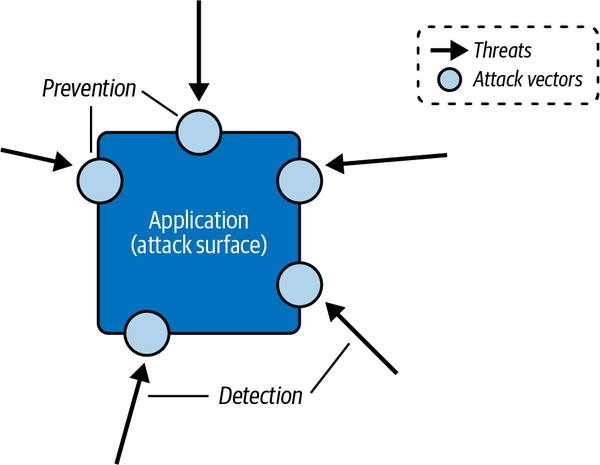
Abbildung 4-1. Anwendungssicherheit umfasst die Erkennung von Bedrohungen und die Anwendung von Präventivmaßnahmen für Angriffsvektoren
Die Praxis der Bedrohungsmodellierung wird immer mehr zu einem unverzichtbaren Werkzeug, um Bedrohungen kontinuierlich zu identifizieren und abzuwehren. Sie wurde 2015 in den angesehenen Thoughtworks Technology Radar aufgenommen, mit der Feststellung, dass "während der gesamten Lebensdauer einer Software neue Bedrohungen auftauchen und sich bestehende Bedrohungen aufgrund von externen Ereignissen und laufenden Änderungen der Anforderungen und der Architektur weiterentwickeln".
Als Softwareentwickler/in musst du auch deine Grenzen erkennen und akzeptieren. Ingenieurteams haben in der Regel nur begrenzte praktische Erfahrungen oder Kenntnisse über die Sicherheit von Anwendungen. Konsultiere die Sicherheitsteams frühzeitig in deinen Software-Design- und Entwicklungszyklen. Sicherheitsteams können in der Regel dabei helfen, Penetrationstests und Sicherheitsaudits zu organisieren, bevor du neue Anwendungen und wichtige Funktionen einführst, und sie können dich bei der Erkennung von Schwachstellen und der Reaktion auf Vorfälle unterstützen. Informiere dich immer über die Cybersicherheitsstrategie deines Unternehmens, die auch Hinweise zur Sicherung von Cloud-Konten und zum Schutz des Datenschutzes enthalten sollte.
Bevor wir weitermachen, sollten wir uns einen Moment Zeit nehmen, um einen wichtigen Punkt festzuhalten: Sicherheit kann einfach sein!
Sicherheit kann einfach sein
Die Sicherheit einer Softwareanwendung zu gewährleisten, kann eine gewaltige Aufgabe sein, wenn man bedenkt, was auf dem Spiel steht. Verstöße gegen die Anwendungsgrenzen und Datenspeicher sind oft dramatisch und verheerend. Abgesehen von den unmittelbaren Folgen wie Datenverlusten und der Notwendigkeit, diese zu beheben, wirken sich diese Vorfälle in der Regel auch negativ auf das Vertrauen zwischen den Verbrauchern und dem Unternehmen sowie zwischen dem Unternehmen und seinen Technikern aus.
Herausforderungen für die Sicherheit
Die Sicherung von cloud-nativen serverlosen Anwendungen kann aus verschiedenen Gründen eine besondere Herausforderung darstellen:
- Verwaltete Dienstleistungen
-
Auf wirst du sehen, dass Managed Services für serverlose Anwendungen von zentraler Bedeutung sind und, wenn sie richtig eingesetzt werden, eine klare Trennung von Belangen, optimale Leistung und effektive Beobachtbarkeit unterstützen können. Managed Services bieten zwar eine solide Grundlage für deine Infrastruktur und einige Sicherheitsvorteile - vor allem durch das Modell der geteilten Verantwortung, das weiter unten in diesem Kapitel besprochen wird -, aber die schiere Anzahl der Services, die für AWS-Teams zur Verfügung stehen, stellt ein Problem dar: Um einen Managed Service zu nutzen (oder auch nur zu bewerten), musst du zunächst die verfügbaren Funktionen, das Preismodell und vor allem die Sicherheitsaspekte verstehen. Wie funktionieren die IAM-Berechtigungen für diesen Service? Wie wird das Modell der geteilten Verantwortung auf diesen Dienst angewendet? Wie funktionieren Zugriffskontrolle und Verschlüsselung?
- Konfigurierbarkeit
-
Ein gemeinsamer Aspekt aller Managed Services ist die Konfigurierbarkeit. Jeder AWS-Service verfügt über eine Reihe von Optionen, die zur Optimierung von Durchsatz, Latenz, Ausfallsicherheit und Kosten angepasst werden können. Durch die Kombination von Diensten können weitere Optimierungen vorgenommen werden, wie z. B. der Einsatz von SQS-Warteschlangen zwischen Lambda-Funktionen, um Batching und Pufferung zu ermöglichen. Einer der Hauptvorteile von Serverless, der in diesem Buch hervorgehoben wird, ist die Granularität von . Wie du gesehen hast, kannst du jeden der verwalteten Dienste in deinen Anwendungen bis ins Detail konfigurieren. Im Hinblick auf die Sicherheit bedeutet dies eine große Angriffsfläche für ungewollte Schwachstellen wie übermäßige Berechtigungen und Privilegienerweiterung.
- Aufkommende Standards
-
AWS liefert ständig neue Services, neue Funktionen und Verbesserungen an bestehenden Funktionen und Services. Diese neuen Dienste und Funktionen können entweder direkt mit der Anwendungs- oder Kontosicherheit zu tun haben oder neue Angriffsvektoren darstellen, die es zu analysieren und zu sichern gilt. Es gibt immer neue Hebel zu ziehen und mehr Dinge zu konfigurieren. Auch die Community rund um AWS und insbesondere um Serverless entwickelt sich relativ schnell weiter: Jeden Tag erscheinen neue Blogbeiträge, Video-Tutorials und Konferenzbeiträge. Der Sicherheitsaspekt der Softwareentwicklung bewegt sich vielleicht etwas langsamer als andere Bereiche, aber es gibt immer noch einen stetigen Strom von Ratschlägen von Cybersecurity-Experten sowie regelmäßige Veröffentlichungen von Schwachstellen und damit verbundenen Forschungsergebnissen. Mit allen AWS-Produktaktualisierungen und bewährten Methoden Schritt zu halten, wenn es um die Sicherung deiner sich ständig weiterentwickelnden Anwendung geht, kann leicht zu einer deiner größten Herausforderungen werden.
Cloud-native serverlose Anwendungen stellen besondere Herausforderungen an die Sicherheit, bieten aber auch viele Vorteile, wenn es um die Sicherung dieser Art von Software geht. Die Architektur von serverlosen Anwendungen schafft einen einzigartigen Sicherheitsrahmen und bietet die Möglichkeit, innerhalb dieses Rahmens auf neuartige Weise zu arbeiten. Du hast die Chance, dein Verhältnis zur Anwendungssicherheit neu zu definieren. Sicherheit kann einfach sein.
Als Nächstes wollen wir uns ansehen, wie du deine serverlose Anwendung sichern kannst.
Erste Schritte
Die Schaffung eines soliden Fundaments für deine serverlose Sicherheitspraxis ist von zentraler Bedeutung. Sicherheit kann und muss ein Hauptanliegen sein. Und es ist nie zu spät, diese Grundlage zu schaffen.
Wie bereits angedeutet, muss Sicherheit ein klar definierter Prozess sein. Es geht nicht darum, eine Checkliste abzuarbeiten, ein Tool einzusetzen oder andere Teams damit zu beauftragen. Sicherheit sollte Teil des Designs, der Entwicklung, der Tests und des Betriebs jedes Teils deines Systems sein.
Die Arbeit innerhalb eines soliden Sicherheits-Frameworks, das gut zu Serverless passt, und die Übernahme vernünftiger technischer Gewohnheiten in Kombination mit der Unterstützung und dem Fachwissen deines Cloud-Providers werden einen großen Beitrag dazu leisten, dass deine Anwendungen sicher bleiben.
Bei der Anwendung auf serverlose Software können zwei moderne Sicherheitstrends eine solide Grundlage für die Sicherung deiner Anwendung bilden: Zero Trust und das Prinzip der geringsten Privilegien. Der nächste Abschnitt befasst sich mit diesen Konzepten.
Sobald du ein Zero-Trust- und Least-Privilege-Sicherheitsframework eingerichtet hast, besteht der nächste Schritt darin, die Angriffsfläche deiner Anwendungen und die Sicherheitsbedrohungen zu identifizieren, für die sie anfällig sind. In den folgenden Abschnitten werden die häufigsten serverlosen Bedrohungen und der Prozess der Bedrohungsmodellierung untersucht.
Das Zero Trust Sicherheitsmodell mit Least Privilege Berechtigungen kombinieren
Es gibt zwei moderne Cybersicherheitsprinzipien, die du als Eckpfeiler deiner serverlosen Sicherheitsstrategie nutzen kannst: die Zero-Trust-Architektur und das Prinzip der geringsten Privilegien.
Zero-Trust-Architektur
Die grundlegende Prämisse der Zero-Trust-Sicherheit ist die Annahme, dass jede Verbindung zu deinem System eine Bedrohung darstellt. Jede einzelne Schnittstelle sollte dann durch eine Schicht von Authentifizierung (wer bist du?) und Autorisierung (was willst du?) geschützt werden. Das gilt sowohl für öffentliche API-Endpunkte, also den Perimeter im traditionellen Burg-und-Mauer-Modell, als auch für private, interne Schnittstellen wie Lambda-Funktionen oder DynamoDB-Tabellen. Zero Trust kontrolliert den Zugriff auf jede einzelne Ressource in deiner Anwendung, während ein Castle-and-Moat-Modell nur den Zugriff auf die Ressourcen am Rande deiner Anwendung kontrolliert.
Stell dir vor, dass ein umherstreifender Ritter zu den Burgmauern galoppiert, den Wachen einen gut aussehenden Ausweis vorlegt und sie von seinen ehrenhaften Absichten überzeugt, bevor er selbstbewusst über die heruntergelassene Zugbrücke die Burg betritt. Wenn diese Wachen das Ausmaß der Sicherheit der Burg ausmachen, kann der Ritter nun frei in den Räumen, Kerkern und Juwelenlagern umherstreifen und sensible Informationen für zukünftige Überfälle sammeln oder an Ort und Stelle wertvolle Gegenstände stehlen. Wenn jedoch jede Tür oder jeder Gang mit zusätzlichen verdächtigen Wachen oder ausgeklügelten Sicherheitskontrollen ausgestattet ist, die standardmäßig null Vertrauen voraussetzen, wäre der Ritter völlig eingeschränkt und würde vielleicht sogar davon abgehalten, überhaupt in die Burg einzudringen.
Ein anderes Szenario ist eine Burg, in der für jede schwere Tür ein einziger Schlüssel angefertigt wird: Sollte der Ritter in den Besitz einer Kopie dieses Schlüssels gelangen, kann er alle Türen öffnen, egal wie dick oder schwer sie sind. Bei Zero Trust gibt es für jede Tür einen eigenen Schlüssel. Abbildung 4-2 zeigt, wie das Burg-und-Moor-Modell im Vergleich zu einer Zero-Trust-Architektur aussieht.
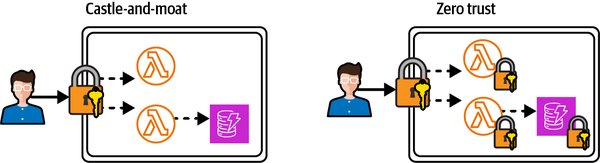
Abbildung 4-2. Castle-and-Moat-Perimeter-Sicherheit im Vergleich zur Zero-Trust-Architektur
Es gibt verschiedene Anwendungen für die Zero-Trust-Architektur, z. B. Remote Computing und die Sicherheit von Unternehmensnetzwerken. Im nächsten Abschnitt wird kurz erläutert, wie das Zero-Trust-Modell interpretiert und auf serverlose Anwendungen angewendet werden kann.
Null Vertrauen und serverlos
Zero Trust wird oft als das nächste große Ding in der Netzwerksicherheit angepriesen. Abgesehen von den Schlagwörtern und dem Hype ist es eine natürliche Lösung für die Sicherheit von verteilten, serverlosen Systemen. Tatsächlich ist Zero Trust oft die De-facto-Methode zur Sicherung von serverlosen Anwendungen. Wenn du die Anwendungssicherheit mit einer Zero-Trust-Mentalität angehst, unterstützt das die Entwicklung guter Gewohnheiten wie die Überprüfung von Nachrichten zwischen den Diensten und die Sicherheit intern zugänglicher APIs.
Du kannst nicht einfach von einem Burg-und-Moat-Modell zu Zero Trust wechseln. Du brauchst zunächst eine unterstützende Anwendungsarchitektur. Wenn zum Beispiel deine API, Geschäftslogik und Datenbank in einer einzigen Container-Anwendung laufen, wird es sehr schwierig sein, die granularen, ressourcenbasierten Berechtigungen anzuwenden, die zur Unterstützung von Zero Trust erforderlich sind. Serverless bietet die optimale Anwendungsarchitektur für Zero Trust, da die Ressourcen auf natürliche Weise zwischen API, Rechenleistung und Speicherung isoliert sind und für jede Ressource eine hochgranulare Zugriffskontrolle in möglich ist.
Das Prinzip des geringsten Privilegs
Identität und Zugriffskontrolle sind für eine effektive Zero-Trust-Architektur unerlässlich. Wenn die Sicherheitsgrenze nun jede Ressource und jeden Vermögenswert in deinem System umschließen muss, brauchst du eine äußerst zuverlässige und granulare Authentifizierungs- und Autorisierungsschicht, um diese Grenze zu implementieren.
Wenn deine Anwendungsressourcen miteinander interagieren, müssen sie mit den minimalen Rechten ausgestattet werden, die für die Ausführung ihrer Operationen erforderlich sind. Dies ist eine Anwendung des Prinzips der geringsten Berechtigung, das in Kapitel 1 vorgestellt wurde.
Lass uns ein relativ einfaches Beispiel nehmen. Angenommen, du hast eine DynamoDB-Tabelle und zwei Lambda-Funktionen, die mit dieser Tabelle interagieren (siehe Abbildung 1-11). Eine Lambda-Funktion muss in der Lage sein, Elemente aus der Tabelle zu lesen, und die andere Funktion sollte in der Lage sein, Elemente in die Tabelle zu schreiben.
Du könntest versucht sein, pauschale Berechtigungen auf eine Zugriffskontrollrichtlinie anzuwenden und sie zwischen den beiden Lambda-Funktionen auszutauschen, etwa so:
{"Version":"2012-10-17","Statement":[{"Sid":"FullAccessToTable","Effect":"Allow","Action":["dynamodb:*"],"Resource":"arn:aws:dynamodb:eu-west-2:account-id:table/TableName"}]}
Dies würde jedoch jeder Funktion mehr Berechtigungen geben, als sie benötigt, und damit gegen das Prinzip der geringsten Rechte verstoßen. Stattdessen würde eine Least Privilege Policy für die schreibgeschützte Lambda-Funktion folgendermaßen aussehen:
{"Version":"2012-10-17","Statement":[{"Sid":"ReadItemsFromTable","Effect":"Allow","Action":["dynamodb:GetItem","dynamodb:Query","dynamodb:Scan"],"Resource":"arn:aws:dynamodb:eu-west-2:account-id:table/TableName"}]}
Und eine Least Privilege Policy für die schreibgeschützte Lambda-Funktion würde wie folgt aussehen:
{"Version":"2012-10-17","Statement":[{"Sid":"WriteItemsToTable","Effect":"Allow","Action":["dynamodb:PutItem","dynamodb:UpdateItem"],"Resource":"arn:aws:dynamodb:eu-west-2:account-id:table/TableName"}]}
Glücklicherweise wendet die zugrundeliegende Berechtigungs-Engine, die von allen AWS-Ressourcen verwendet wird und AWS Identity and Access Management (IAM) heißt, eine standardmäßige Verweigerungshaltung an: Du musst explizit Berechtigungen erteilen und bei Bedarf nach und nach neue Berechtigungen hinzufügen. Schauen wir uns die Möglichkeiten von AWS IAM genauer an.
Die Macht von AWS IAM
AWS IAM ist der eine Dienst, den du überall nutzen wirst - aber er wird auch oft als einer der komplexesten angesehen. Deshalb ist es wichtig, IAM zu verstehen und zu lernen, wie man es nutzen kann. (Du musst aber kein IAM-Experte werden - es sei denn, du willst es!)
Die Stärke von AWS IAM liegt in Rollen und Richtlinien. Richtlinien definieren die Aktionen, die mit bestimmten Ressourcen durchgeführt werden können. Eine Richtlinie kann zum Beispiel die Erlaubnis erteilen, Ereignisse auf einen bestimmten EventBridge-Ereignisbus zu legen. Rollen sind Sammlungen von einer oder mehreren Richtlinien. Rollen können mit IAM-Benutzern verknüpft werden, aber in einer modernen serverlosen Anwendung ist es üblicher, eine Rolle mit einer Ressource zu verknüpfen. Auf diese Weise kann einer EventBridge-Regel die Erlaubnis erteilt werden, eine Lambda-Funktion aufzurufen, die wiederum Elemente in eine DynamoDB-Tabelle stellen darf.
IAM-Aktionen können in zwei Kategorien unterteilt werden: control plane actions und data plane actions. Control-Plane-Aktionen, wie PutEvents und GetItem (z. B. von einer automatisierten Bereitstellungsrolle verwendet), verwalten Ressourcen. Data-Plane-Aktionen wie PutEvents und GetItem (z. B. für eine Lambda-Ausführungsrolle) interagieren mit diesen Ressourcen.
Werfen wir einen Blick auf eine einfache IAM-Richtlinienerklärung und die Elemente, aus denen sie besteht:
{"Sid":"ListObjectsInBucket",# Statement ID, optional identifier for# policy statement"Action":"s3:ListBucket",# AWS service API action(s) that will be allowed# or denied"Effect":"Allow",# Whether the statement should result in an allow or deny"Resource":"arn:aws:s3:::bucket-name",# Amazon Resource Name (ARN) of the# resource(s) covered by the statement"Condition":{# Conditions for when a policy is in effect"StringLike":{# Condition operator"s3:prefix":[# Condition key"photos/",# Condition value]}}}
In der AWS IAM-Dokumentation findest du ausführliche Informationen zu allen Elementen einer IAM-Richtlinie.
Lambda-Ausführungsrollen
Eine wichtige Verwendung von IAM-Rollen in serverlosen Anwendungen sind Lambda-Funktionen Ausführungsrollen. Eine Ausführungsrolle wird an eine Lambda-Funktion angehängt und gewährt der Funktion die für die korrekte Ausführung erforderlichen Berechtigungen, einschließlich des Zugriffs auf alle anderen erforderlichen AWS-Ressourcen. Wenn die Lambda-Funktion zum Beispiel das AWS SDK verwendet, um eine DynamoDB-Anfrage zu stellen, die einen Datensatz in eine Tabelle einfügt, muss die Ausführungsrolle eine Richtlinie mit der Aktion dynamodb:PutItem für die Tabellenressource enthalten.
Die Ausführungsrolle wird vom Lambda-Service bei der Durchführung von Operationen auf der Kontroll- und Datenebene übernommen. Der AWS Security Token Service (STS) wird verwendet, um kurzlebige, temporäre Sicherheitsnachweise abzurufen, die während des Aufrufs über die Umgebungsvariablen der Funktion verfügbar gemacht werden.
Jede Funktion in deiner Anwendung sollte eine eigene, eindeutige Ausführungsrolle mit den Mindestberechtigungen haben, die zur Erfüllung ihrer Aufgabe erforderlich sind. Auf diese Weise sind Einzweckfunktionen (eingeführt in Kapitel 6) auch der Schlüssel zur Sicherheit: Die IAM-Berechtigungen können eng an die Funktion gebunden werden und bleiben entsprechend der begrenzten Funktionalität extrem eingeschränkt.
IAM-Leitplanken
Wie du sicher schon gemerkt hast, geht es bei effektiver serverloser Sicherheit in der Cloud um grundlegende Sicherheitshygiene. Die Festlegung von Leitplanken für die Nutzung von AWS IAM ist ein zentraler Bestandteil der Förderung eines sicheren Ansatzes für die täglichen technischen Aktivitäten. Hier sind einige empfohlene Leitplanken:
- Wende das Prinzip des geringsten Privilegs in den Richtlinien an.
-
IAM Richtlinien sollten nur den minimalen Satz an Berechtigungen enthalten, der für die zugehörige Ressource erforderlich ist, um die notwendigen Operationen auf der Kontroll- oder Datenebene durchzuführen. Generell gilt: Verwende keine Platzhalter (*) in deinen Richtlinienanweisungen. Wildcards sind das Gegenteil von Least Privilege, da sie pauschale Berechtigungen für Aktionen und Ressourcen vergeben. Wenn die Aktion nicht ausdrücklich einen Platzhalter erfordert, solltest du immer spezifisch sein.
- Vermeide die Verwendung von verwalteten IAM-Richtlinien.
-
Diese sind Richtlinien, die von AWS bereitgestellt werden, und sie sind oft verlockende Abkürzungen, besonders wenn du gerade erst anfängst oder einen Service zum ersten Mal nutzt. Du kannst diese Richtlinien zu Beginn des Prototypings oder der Entwicklung verwenden, aber du solltest sie durch eigene Richtlinien ersetzen, sobald du die Integration besser verstehst. Da diese Richtlinien für allgemeine Szenarien entwickelt wurden, sind sie einfach nicht restriktiv genug und verletzen in der Regel das Prinzip der geringsten Privilegien, wenn sie auf Interaktionen innerhalb deiner Anwendung angewendet werden.
- Bevorzuge Rollen gegenüber Benutzern.
-
IAM-Benutzer erhalten statische, langlebige AWS Zugangsdaten (eine Zugangsschlüssel-ID und einen geheimen Zugangsschlüssel). Diese Zugangsdaten können verwendet werden, um direkt auf das AWS-Konto des Anwendungsanbieters zuzugreifen, einschließlich aller Ressourcen und Daten in diesem Konto. Je nach den zugehörigen IAM-Rollen und -Richtlinien kann der authentifizierende Nutzer sogar die Möglichkeit haben, Ressourcen zu erstellen oder zu zerstören. Angesichts der Macht, die sie dem Inhaber verleihen, muss die Verwendung und Verteilung von statischen Anmeldeinformationen eingeschränkt werden, um das Risiko eines unbefugten Zugriffs zu verringern. Wenn möglich, solltest du die Anzahl der IAM-Benutzer auf ein absolutes Minimum beschränken (oder, noch besser, überhaupt keine IAM-Benutzer einrichten).
- Bevorzuge eine Rolle pro Ressource.
-
Jede Ressource in deiner Anwendung, wie z.B. eine EventBridge-Regel, eine Lambda-Funktion und eine SQS-Warteschlange, sollte eine eigene Rolle haben. Die Berechtigungen für diese Rollen sollten feinkörnig sein und am wenigsten privilegiert.
Das AWS-Modell der geteilten Verantwortung
AWS verwendet ein geteiltes Verantwortungsmodell, um die Aufgaben der Anwendungssicherheitskunden und des Cloud-Providers zu definieren (siehe Abbildung 4-3). Wichtig ist hier die Verlagerung der Sicherheitsverantwortung auf AWS bei der Nutzung von Cloud-Diensten. Dies gilt umso mehr, wenn vollständig verwaltete serverlose Dienste nutzt, wie z. B. Compute mit AWS Lambda: AWS verwaltet das Patching der Lambda-Laufzeit, die Isolierung der Funktionsausführung und so weiter.
Serverlose Anwendungen bestehen aus Geschäftslogik, Infrastrukturdefinitionen und verwalteten Services. Das Eigentum an diesen Elementen ist zwischen AWS und den Nutzern der öffentlichen Cloud-Services aufgeteilt. Als Ingenieur für serverlose Anwendungen und AWS-Kunde bist du für die Sicherheit dieser Anwendungen verantwortlich:
-
Dein Funktionscode und die Bibliotheken von Drittanbietern, die in diesem Code verwendet werden
-
Konfiguration der in deiner Anwendung verwendeten AWS-Ressourcen
-
Die IAM-Rollen und Richtlinien, die die Zugriffskontrolle auf die Ressourcen und Funktionen in deiner Anwendung regeln
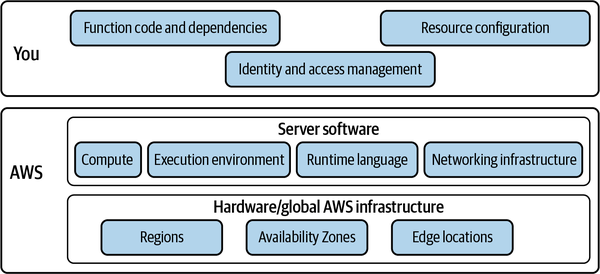
Abbildung 4-3. Das Modell der geteilten Verantwortung für die Cloud-Sicherheit: Du bist für die Sicherheit in der Cloud verantwortlich, und AWS ist für die Sicherheit der Cloud zuständig
Denken wie ein Hacker
Nachdem deine grundlegende Zero-Trust-, Least-Privilege-Sicherheitsstrategie und eine klare Abgrenzung der Verantwortlichkeiten festgelegt hat, besteht der nächste Schritt darin, die potenziellen Angriffsvektoren in deiner Anwendung zu identifizieren und sich der möglichen Bedrohungen für die Sicherheit und Integrität deiner Systeme bewusst zu sein.
Wenn du dir die Bedrohungen für deine Systeme vorstellst, denkst du vielleicht an bösartige Akteure, die außerhalb deines Unternehmens stehen - Hacker. Es gibt zwar externe Bedrohungen, aber sie dürfen nicht die internen Bedrohungen überschatten, vor denen man sich ebenfalls schützen muss. Interne Bedrohungen können natürlich absichtlich böswillig sein, aber das wahrscheinlichere Szenario ist, dass die Schwachstellen unbeabsichtigt eingeführt werden. Die Entwickler/innen einer Anwendung sind oft die Architekten ihrer eigenen Sicherheitslücken und Datenexponierungen, oft durch eine schwache oder fehlende Sicherheitskonfiguration der Cloud-Ressourcen.
Die populäre Darstellung eines Hackers, der einen offensichtlichen denial Service-Angriff auf eine Webanwendung durchführt oder eine Server-Firewall infiltriert, ist immer noch eine sehr reale Möglichkeit, aber subtilere Angriffe auf die Software-Lieferkette sind mittlerweile genauso wahrscheinlich. Bei diesen heimtückischen Angriffen wird bösartiger Code in Bibliotheken von Drittanbietern eingebettet und aus der Ferne automatisiert ausgenutzt, sobald der Code in der Produktionsumgebung eingesetzt wird.
Es ist wichtig, sich in die Denkweise eines Hackers hineinzuversetzen und die potenziellen Bedrohungen für deine serverlosen Anwendungen vollständig zu verstehen, um sie richtig abwehren zu können.
Treffen Sie die OWASP Top 10
Cybersecurity ist ein unglaublich gut erforschter Bereich, in dem Sicherheitsexperten die sich ständig verändernde Softwarelandschaft bewerten, neue Risiken identifizieren und Präventionsmaßnahmen und Ratschläge verbreiten. Als moderner Serverless-Ingenieur musst du die Verantwortung für die Sicherheit der von dir entwickelten Anwendungen übernehmen. Dabei ist es absolut wichtig, dass du deine eigenen Anstrengungen mit der Beachtung professioneller Ratschläge und der Nutzung der umfangreichen, öffentlich zugänglichen Forschung kombinierst.
Die Bedrohungen für die Sicherheit deiner Software zu identifizieren, ist eine Aufgabe, die du nicht alleine angehen solltest. Es gibt mehrere Frameworks zur Kategorisierung von Bedrohungen, die dir dabei helfen können, aber wir wollen uns auf die OWASP Top 10 konzentrieren.
Das Open Web Application Security Project, kurz OWASP, ist eine "gemeinnützige Stiftung, die sich für die Verbesserung der Sicherheit von Software einsetzt". Sie tut dies vor allem durch von der Gemeinschaft geführte Open-Source-Projekte, Tools und Forschung. Die OWASP Foundation hat seit 2003 wiederholt eine Liste der 10 häufigsten und kritischsten Sicherheitsrisiken für Webanwendungen veröffentlicht. Die letzte Version, die 2021 veröffentlicht wurde, ist die aktuellste Liste von Sicherheitsrisiken (zum Zeitpunkt der Erstellung dieses Artikels).
Auch wenn sich eine serverlose Anwendung in mancher Hinsicht von einer typischen Webanwendung unterscheidet, interpretiert Tabelle 4-1 die OWASP Top 10 durch eine serverlose Brille. Beachte, dass die Liste absteigend sortiert ist, wobei das kritischste Anwendungssicherheitsrisiko nach der OWASP-Klassifizierung an erster Stelle steht. Wir haben die Spalte "Serverless Risk Level" als Indikator für das Risiko hinzugefügt, das speziell für serverlose Anwendungen besteht .
| Kategorie Bedrohung | Beschreibung der Bedrohung | Abhilfemaßnahmen | Serverloses Risikoniveau |
|---|---|---|---|
| Unterbrochene Zugriffskontrolle | Die Zugriffskontrolle ist der Torwächter zu deiner Anwendung und ihren Ressourcen und Daten. Durch die Kontrolle des Zugriffs auf deine Ressourcen und Daten kannst du die Benutzer deiner Anwendung so einschränken, dass sie nicht außerhalb der ihnen zugewiesenen Berechtigungen handeln können. |
|
Medium |
| Kryptographische Ausfälle | Eine schwache oder fehlende Verschlüsselung von Daten, sowohl bei der Übertragung zwischen den Komponenten in deiner Anwendung als auch im Ruhezustand in Warteschlangen, Buckets und Tabellen, ist ein großes Sicherheitsrisiko. |
|
Medium |
| Injektion | Das Einschleusen von bösartigem Code in eine Anwendung über vom Benutzer bereitgestellte Daten ist ein beliebter Angriffsvektor. Zu den häufigsten Angriffen gehören SQL- und NoSQL-Injection. |
|
Hoch |
| Unsicheres Design | Die Implementierung und der Betrieb einer Anwendung, bei deren Entwicklung die Sicherheit nicht im Vordergrund stand, ist riskant, da sie anfällig für Sicherheitslücken ist. |
|
Medium |
| Falsche Sicherheitskonfiguration |
Fehlkonfigurationen bei der Verschlüsselung, der Zugriffskontrolle und den Rechenbeschränkungen stellen Schwachstellen dar, die von Angreifern ausgenutzt werden können. Unbeabsichtigter öffentlicher Zugriff auf S3-Buckets ist eine sehr häufige Ursache für Cloud-Datenverletzungen. Lambda-Funktionen mit übermäßiger Zeitüberschreitung können für einen DoS-Angriff ausgenutzt werden. |
|
Medium |
| Anfällige und veraltete Komponenten | Die fortgesetzte Verwendung von anfälliger, nicht unterstützter oder veralteter Software (Betriebssysteme, Webserver, Datenbanken usw.) macht deine Anwendung anfällig für Angriffe, die bekannte Schwachstellen ausnutzen. |
|
Niedrig |
| Fehler bei der Identifizierung und Authentifizierung | Diese Ausfälle können die unbefugte Nutzung von APIs und integrierten Ressourcen wie Lambda-Funktionen, S3-Buckets oder DynamoDB-Tabellen ermöglichen. |
|
Medium |
| Fehler in der Software und der Datenintegrität |
Das Vorhandensein von Schwachstellen oder Exploits im Code von Drittanbietern wird schnell zum häufigsten Risiko für Softwareanwendungen. Da die Anwendungsabhängigkeiten mit dem Lambda-Funktionscode gebündelt und ausgeführt werden, erhalten sie die gleichen Rechte wie deine Geschäftslogik. |
|
Hoch |
| Fehler bei der Sicherheitsprotokollierung und -überwachung |
Angreifer verlassen sich auf das Fehlen von Überwachung und rechtzeitiger Reaktion, um ihre Ziele zu erreichen, ohne entdeckt zu werden. Ohne Protokollierung und Überwachung können Verstöße nicht entdeckt oder analysiert werden. Logs von Anwendungen und APIs werden nicht auf verdächtige Aktivitäten überwacht. |
|
Medium |
| Server-seitige Anfragefälschung (SSRF) | Bei AWS betrifft dies vor allem eine Sicherheitslücke beim Betrieb von Webservern auf EC2-Instanzen. Das verheerendste Beispiel war die Datenpanne bei Capital One im Jahr 2019. |
|
Niedrig |
Es gibt zwei weitere bemerkenswerte Sicherheitsrisiken die für serverlose Anwendungen relevant sind :
- Denial of Service
-
Dies ist ein gängiger Angriff, bei dem eine API ständig mit gefälschten Anfragen bombardiert wird, um die Bearbeitung echter Anfragen zu stören. Öffentliche APIs werden immer mit der Möglichkeit von DoS-Angriffen konfrontiert sein. Deine Aufgabe ist es nicht immer, sie vollständig zu verhindern, sondern sie so schwierig zu machen, dass die Abschreckung allein ausreicht, um die Ressourcen zu sichern. Firewalls, Ratenbegrenzungen und Ressourcendrosselungen (z. B. Lambda, DynamoDB) sind wichtige Maßnahmen, um DoS-Angriffe zu verhindern.
- Verweigerung der Geldbörse
-
Diese Art von Angriffen ist aufgrund des Pay-per-Use-Preismodells und der hohen Skalierbarkeit von Managed Services ziemlich einzigartig für serverlose Anwendungen. Denial-of-Wallet-Angriffe zielen auf die ständige Ausführung von Ressourcen ab, um eine so hohe Nutzungsrechnung anzuhäufen, dass sie dem Unternehmen wahrscheinlich schweren finanziellen Schaden zufügt.
Tipp
Durch die Einrichtung von budget alerts kannst du sicherstellen, dass du vor Denial-of-Wallet-Angriffen gewarnt wirst, bevor sie eskalieren können. Siehe Kapitel 9 für weitere Details.
Nachdem du nun die häufigsten Bedrohungen für serverlose Anwendungen kennst, wirst du als Nächstes erkunden, wie du diese Sicherheitsrisiken mithilfe der Bedrohungsmodellierung auf deine Anwendungen übertragen kannst.
Serverlose Bedrohungsmodellierung
Bevor eine umfassende Sicherheitsstrategie für eine serverlose Anwendung entwickelt wird, ist es wichtig, die Angriffsvektoren zu verstehen und potenzielle Bedrohungen zu modellieren. Dazu müssen die Oberfläche der Anwendung, die schützenswerten Ressourcen und die internen und externen Bedrohungen für die Sicherheit der Anwendung klar definiert werden.
Wie bereits erwähnt, ist Sicherheit ein kontinuierlicher Prozess: Es gibt keinen Endzustand. Um die Sicherheit einer Anwendung aufrechtzuerhalten, während sie wächst, müssen Bedrohungen ständig überprüft und Angriffsvektoren regelmäßig bewertet werden. Im Laufe der Zeit kommen neue Funktionen hinzu, mehr Nutzer werden betreut und mehr Daten gesammelt. Die Bedrohungen werden sich ändern, ihr Schweregrad wird steigen und fallen und das Verhalten der Anwendung wird sich weiterentwickeln. Die verfügbaren Tools und bewährten Methoden der Branche werden sich ebenfalls weiterentwickeln und als Reaktion auf diese Veränderungen effektiver und zielgerichteter werden.
Einführung in die Bedrohungsmodellierung
Zu diesem Zeitpunkt solltest du ein ziemlich klares Verständnis deiner Sicherheitsverantwortung, ein grundlegendes Sicherheitsframework und die wichtigsten Bedrohungen für serverlose Anwendungen haben. Als Nächstes musst du das Framework und die Bedrohungen auf deine Anwendung und ihre Dienste übertragen.
Bei der Bedrohungsmodellierung handelt es sich um einen Prozess, der deinem Team helfen kann, durch Diskussionen und Zusammenarbeit Angriffsvektoren, Bedrohungen und Abhilfemaßnahmen zu identifizieren. Es kann einen Shift-Links- (oder sogar Start-Links-) Sicherheitsansatz unterstützen, bei dem die Sicherheit in erster Linie von dem Team verantwortet wird, das die Anwendung entwirft, erstellt und betreibt, und während des gesamten Lebenszyklus der Softwareentwicklung als Hauptanliegen behandelt wird. Dieser Ansatz wird manchmal auch als DevSecOps bezeichnet.
Um eine kontinuierliche Verbesserung der Sicherheit zu gewährleisten, sollte die Modellierung von Bedrohungen ein Prozess sein, den du regelmäßig durchführst, z. B. bei der Verfeinerung von Aufgaben. Die Bedrohungen sollten bereits in einem frühen Stadium des Lösungsentwurfs modelliert werden (siehe Kapitel 6) und sich auf die Funktions- oder Dienstebene konzentrieren.
Tipp
Threat Composer ist ein Tool von AWS Labs, das dir bei der Anleitung und Visualisierung deines Bedrohungsmodellierungsprozesses helfen kann.
Als Nächstes wirst du einen Rahmen kennenlernen, der dem Prozess der Bedrohungsmodellierung Struktur verleiht: STRIDE.
STRIDE
Das Akronym STRIDE beschreibt sechs Bedrohungskategorien:
- Spoofing
- Manipulationen
-
Ändern von Daten auf der Festplatte, im Speicher, im Netzwerk oder anderswo
- Ablehnung
-
Behauptung , dass du für eine Handlung nicht verantwortlich warst
- Offenlegung von Informationen
-
Erlangung von Informationen, die nicht für dich bestimmt waren
- Denial of Service
-
Zerstörung oder Übermäßiger Verbrauch von endlichen Ressourcen
- Erhöhung des Privilegs
-
Durchführen von Aktionen auf geschützten Ressourcen, die du nicht ausführen darfst
STRIDE-per-Element, oder kurz STRIDE/Element, ist eine Möglichkeit, die STRIDE-Bedrohungskategorien auf Elemente in deiner Anwendung anzuwenden. Das kann helfen, den Prozess der Bedrohungsmodellierung weiter zu fokussieren.
Die Elemente sind Ziele potenzieller Bedrohungen und werden definiert als:
-
Menschliche Akteure/externe Entitäten
-
Prozesse
-
Datenspeicher
-
Datenströme
Es ist wichtig, dass du dich nicht von der Bedrohungsmodellierung überwältigen lässt. Die Absicherung einer Anwendung kann entmutigend sein, aber erinnere dich daran, dass sie, wie zu Beginn dieses Kapitels beschrieben, auch ganz einfach sein kann, vor allem bei serverlosen Anwendungen. Fang klein an, arbeite im Team und befolge den Prozess Schritt für Schritt. Die Identifizierung einer Bedrohung für jedes Element/Bedrohungskombination in der Matrix in Abbildung 4-4 ist ein guter Anfang.
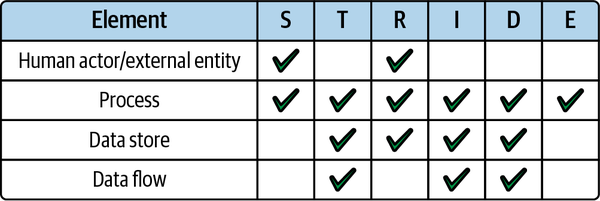
Abbildung 4-4. Anwenden der STRIDE-Bedrohungskategorien pro Element in deiner Anwendung
Ein Verfahren zur Bedrohungsmodellierung
Als Vorbereitung für deine Threat Modeling-Sitzungen kann es für produktive Treffen hilfreich sein, wenn du die folgenden Informationen bereithältst:
-
High-Level-Architektur der Anwendung
-
Dokumente zum Lösungsentwurf
-
Datenmodelle und Schemata
-
Datenflussdiagramme
-
Bereichsspezifische Industriestandards
Ein typischer Bedrohungsmodellierungsprozess umfasst die folgenden Schritte:
-
Identifiziere die Elemente in deiner Anwendung, die Ziele für potenzielle Bedrohungen sein könnten, darunter Datenbestände, externe Akteure, von außen zugängliche Zugangspunkte und Infrastrukturressourcen.
-
Erstelle eine Liste von Bedrohungen für jedes in Schritt 1 identifizierte Element. Achte darauf, dass du dich in dieser Phase auf die Bedrohungen und nicht auf die Abhilfemaßnahmen konzentrierst.
-
Identifiziere für jede in Schritt 2 identifizierte Bedrohung geeignete Schritte, die zur Eindämmung der Bedrohung unternommen werden können. Dazu gehören die Verschlüsselung sensibler Daten, die Zugriffskontrolle für externe Akteure und Zugangspunkte und die Sicherstellung, dass jede Ressource nur die für die Ausführung ihrer Aufgaben erforderlichen Mindestberechtigungen erhält.
-
Beurteile abschließend, ob die vereinbarte Abhilfemaßnahme die Bedrohung angemessen mindert oder ob es ein Restrisiko gibt, das behandelt werden sollte.
Eine umfassende Vorlage zur Modellierung von Bedrohungen findest du in Anhang C.
Sicherung der serverlosen Lieferkette
Anfällige und veraltete Komponenten und Angriffe aus der Lieferkette werden schnell zu einem Hauptanliegen von Softwareentwicklern.
Hinweis
Nach Angaben des Sicherheitsunternehmens Socket sind die Angriffe auf die Lieferkette im letzten Jahr um satte 700% gestiegen, mit über 15.000 registrierten Angriffen. Ein Beispiel, das sie anführen, ereignete sich im Januar 2022, als ein Open-Source-Software-Maintainer absichtlich Malware zu seinem eigenen Paket hinzufügte, das durchschnittlich 100 Millionen Mal pro Monat heruntergeladen wurde. Ein bemerkenswertes Opfer war das offizielle AWS SDK.
Wer ist für den Schutz vor diesen Schwachstellen und Angriffen verantwortlich? Die serverlose Datenverarbeitung auf AWS Lambda ist ein gutes Beispiel für das Modell der geteilten Verantwortung, das weiter oben in diesem Kapitel vorgestellt wurde. AWS ist dafür verantwortlich, die Software in der Laufzeit- und Ausführungsumgebung mit den neuesten Sicherheitspatches und Leistungsverbesserungen auf dem neuesten Stand zu halten, und es liegt in der Verantwortung des Anwendungsentwicklers, den Funktionscode selbst zu sichern. Dazu gehört auch, die von der Funktion verwendeten Bibliotheken auf dem neuesten Stand zu halten.
Da du als Entwickler von Cloud-Anwendungen dafür verantwortlich bist, den Code zu sichern, den du in die Cloud einspeist und in deinen Lambda-Funktionen ausführst, welche Angriffsvektoren und Bedrohungsstufen gibt es hier und wie kannst du die damit verbundenen Sicherheitsprobleme entschärfen?
Sicherung der Abhängigkeitslieferkette
Open-Source-Software ermöglicht eine schnelle Softwareentwicklung und -bereitstellung. Als Softwareentwickler kannst du dich bei der Erstellung deiner Anwendungen auf das Fachwissen und die Arbeit anderer in deiner Community verlassen. Diese Beziehung beruht jedoch auf einer fragilen Vertrauensbasis. Jedes Mal, wenn du eine Abhängigkeit installierst, vertraust du stillschweigend den unzähligen Mitwirkenden an diesem Paket und allem, was sich im Abhängigkeitsbaum dieses Pakets befindet. Der Code von Hunderten von Programmierern wird zu einer Schlüsselkomponente deiner Produktionssoftware.
Du musst dir über die Risiken bewusst sein, die mit der Installation und Ausführung von Open-Source-Software verbunden sind, und über die Schritte, die du unternehmen kannst, um diese Risiken zu verringern.
Denk nach, bevor du installierst
Du kannst mit der Sicherung der serverlosen Lieferkette beginnen, indem du Pakete vor der Installation unter die Lupe nimmst. Dies ist ein einfacher Vorschlag, der einen echten Unterschied bei der Sicherung der Lieferkette deiner Anwendung und bei der allgemeinen Wartung im großen Maßstab machen kann.
Verwende so wenige Abhängigkeiten wie nötig und achte auf Abhängigkeiten, die den Daten- und Kontrollfluss deiner Anwendung verschleiern, wie z.B. Middleware-Bibliotheken. Wenn es eine triviale Aufgabe ist, versuche immer, sie selbst zu erledigen. Es geht auch um Vertrauen. Vertraust du dem Paket? Vertraust du den Mitwirkenden?
Bevor du das nächste Paket in deiner serverlosen Anwendung installierst, solltest du die folgenden Praktiken anwenden:
- Analysiere das GitHub-Repository.
-
Überprüfung die Mitwirkenden an dem Paket. Mehr Mitwirkende bedeuten mehr Kontrolle und Zusammenarbeit. Prüfe, ob das Repository verifizierte Übertragungen verwendet. Beurteile die Geschichte des Pakets: Wie alt ist es? Wie viele Commits wurden gemacht? Analysiere die Repository-Aktivitäten, um herauszufinden, ob das Paket aktiv gewartet und von der Gemeinschaft genutzt wird - GitHub-Sterne sind ein grober Indikator für die Popularität. Vergewissere dich auch, dass die Lizenz des Pakets mit den in deinem Unternehmen geltenden Einschränkungen übereinstimmt.
- Verwende offizielle Paketquellen.
-
Beziehe nur Pakete aus offiziellen Quellen wie NPM, PyPI, Maven, NuGet oder RubyGems über sichere (d.h. HTTPS) Links. Bevorzuge signierte Pakete, die auf Integrität und Authentizität überprüft werden können. Der JavaScript-Paketmanager NPM ermöglicht es dir zum Beispiel, Paketsignaturen zu überprüfen.
- Überprüfe den Abhängigkeitsbaum.
-
Sei dir der Abhängigkeiten des Pakets und des gesamten Abhängigkeitsbaums bewusst. Wähle Pakete mit Null-Laufzeit-Abhängigkeiten, wenn möglich.
- Probiere aus, bevor du kaufst.
-
Teste neue Pakete so isoliert wie möglich und zögere die Einführung in der gesamten Codebasis so lange wie möglich hinaus, bis du dich sicher fühlst.
- Prüfe, ob du es selbst tun kannst.
-
Erfinde das Rad nicht einfach neu, aber eine sehr einfache Möglichkeit, undurchsichtigen Code von Drittanbietern zu entfernen, ist, ihn gar nicht erst einzuführen. Untersuche den Quellcode, um herauszufinden, ob das Paket etwas Einfaches tut, das sich leicht in ein Dienstprogramm eines Drittanbieters übertragen lässt. Logging-Bibliotheken sind ein perfektes Beispiel: Du kannst ganz einfach deinen eigenen Logger implementieren, anstatt eine Bibliothek eines Drittanbieters über deine Codebasis zu verteilen.
- Mach es einfach, auszusteigen.
-
Entwicklungsmuster wie service isolation, single-responsibility Lambda functions und shared code (siehe Kapitel 6 für weitere Informationen zu diesen Mustern) machen es einfacher, deine Architektur weiterzuentwickeln und zu vermeiden, dass allgegenwärtige Antipatterns oder anfällige Software deine Codebase übernehmen.
- Sperre auf den neuesten Stand.
-
Verwende immer die aktuellste Version des Pakets und verwende immer eine explizite Version und nicht einen Bereich oder ein "latest"-Flag.
- Deinstalliere alle nicht verwendeten Pakete.
-
Deinstalliere immer und lösche unbenutzte Pakete aus deinem Abhängigkeitsmanifest. Die meisten modernen Compiler und Bundler nehmen nur die Abhängigkeiten auf, die tatsächlich von deinem Code gebraucht werden.
Pakete auf Schwachstellen scannen
Als Reaktion auf neue Pakete, Paket-Upgrades und Berichte über neue Schwachstellen solltest du außerdem kontinuierlich Schwachstellen-Scans durchführen. Die Scans können mit Tools wie Snyk oder dem GitHub-eigenen Warnsystem Dependabot gegen ein Code-Repository durchgeführt werden.
Abhängigkeits-Upgrades automatisieren
Von allen Vorschlägen zur Sicherung deiner Lieferkette ist dies der wichtigste. Selbst wenn du eine serverlose Anwendung mit zahlreichen Paketen hast, die über mehrere Dienste verteilt sind, solltest du sicherstellen, dass die Upgrades aller Abhängigkeiten automatisiert sind.
Warnung
Auch wenn die Automatisierung von Aktualisierungen der Abhängigkeiten deiner Anwendung im Allgemeinen eine empfehlenswerte Praxis ist, solltest du immer die Checkliste "Denk nach, bevor du installierst" aus dem vorherigen Abschnitt beachten. Du solltest besonders auf die Integrität der eingehenden Updates achten, für den Fall, dass ein bösartiger Akteur eine bösartige Version eines Pakets veröffentlicht hat.
Indem du die Paketversionen auf dem neuesten Stand hältst, stellst du sicher, dass du nicht nur Zugang zu den neuesten Funktionen hast, sondern auch zu den neuesten Sicherheitspatches. Schwachstellen können in früheren Versionen von Software gefunden werden, nachdem viele spätere Versionen veröffentlicht wurden. Ein Upgrade über mehrere kleinere Versionen hinweg kann schon schwierig genug sein, je nachdem, welche Funktionen das Paket hat, ob sich die Autoren an die semantische Versionierung halten und wie verbreitet das Paket in deiner Codebasis ist - aber ein Upgrade von einer Hauptversion auf eine andere ist in der Regel nicht trivial, da die Wahrscheinlichkeit besteht, dass die nächste Version bahnbrechende Änderungen enthält, die sich auf deine Nutzung des Pakets auswirken.
Laufzeit-Updates
Neben der Aktualisierung der Abhängigkeiten ist es sehr empfehlenswert, die neueste Version der AWS Lambda-Laufzeitumgebung, die du verwendest, zu verwenden. Vergewissere dich, dass du Neuigkeiten zur Laufzeitunterstützung abonniert hast und aktualisiere so bald wie möglich.
Warnung
Standardmäßig aktualisiert AWS die Laufzeit deiner Lambda-Funktionen automatisch mit allen Patch-Versionen, die veröffentlicht werden. Darüber hinaus hast du die Möglichkeit, über die Laufzeitverwaltung von Lambda zu steuern, wann die Laufzeit deiner Funktionen aktualisiert wird.
Diese Kontrollen sind vor allem nützlich, um das seltene Auftreten von Fehlern zu vermeiden, die durch eine Laufzeit-Patch-Version verursacht werden, die nicht mit dem Code deiner Funktion kompatibel ist. Da diese Patch-Versionen aber wahrscheinlich Sicherheitsupdates enthalten, solltest du diese Kontrollen mit Vorsicht einsetzen. In der Regel ist es am sichersten, deine Funktionen mit der neuesten Version der Laufzeitumgebung laufen zu lassen.
Das Gleiche gilt für alle Pipelines, die du unterhältst, da diese wahrscheinlich auf virtuellen Maschinen und Laufzeiten laufen, die von Drittanbietern bereitgestellt werden. Und erinnere dich daran, dass du nicht in allen Pipelines und Funktionen dieselbe Laufzeitversion verwenden musst. Du solltest zum Beispiel die neueste Version von Node.js in deinen Pipelines verwenden, noch bevor sie von der Lambda-Laufzeit unterstützt wird.
Weitergehen mit SLSA
Das Sicherheitsrahmenwerk SLSA (sprich: Salsa, kurz für Supply Chain Levels for Software Artifacts) ist "eine Checkliste von Standards und Kontrollen, um Manipulationen zu verhindern, die Integrität zu verbessern und Pakete und Infrastrukturen zu sichern." Bei SLSA geht es darum, von "sicher genug" zu maximaler Widerstandsfähigkeit in der gesamten Software-Lieferkette zu gelangen.
Wenn du einen relativ hohen Sicherheitsstand erreicht hast, kann es nützlich sein, dieses Rahmenwerk zu nutzen, um die Sicherheit deiner Software-Lieferkette zu messen und zu verbessern. Folge der SLSA-Dokumentation, um loszulegen. Der Software Component Verification Standard (SCVS) von OWASP ist ein weiterer Rahmen zur Messung der Sicherheit in der Lieferkette.
Lambda Code Signing
Die letzte Meile in der Software-Lieferkette ist das Verpacken und Bereitstellen deines Funktionscodes in der Cloud. Zu diesem Zeitpunkt besteht deine Funktion in der Regel aus deiner Geschäftslogik (Code, den du verfasst hast) und den Bibliotheken von Drittanbietern, die in den Abhängigkeiten der Funktion aufgeführt sind (Code, den jemand anderes verfasst hat).
Lambda bietet die Möglichkeit, deinen Code zu signieren, bevor du ihn einsetzt. Dadurch kann der Lambda-Dienst überprüfen, dass eine vertrauenswürdige Quelle die Bereitstellung initiiert hat und dass der Code nicht verändert oder manipuliert wurde. Lambda führt mehrere Validierungsprüfungen durch, um die Integrität des Codes zu überprüfen. Dazu gehört auch, dass das Paket seit der Signatur nicht verändert wurde und dass die Signatur selbst gültig ist.
Um deinen Code zu signieren, erstellst du zunächst ein oder mehrere Signing-Profile. Diese Profile können den Umgebungen und Konten zugeordnet werden, die deine Anwendung nutzt - zum Beispiel kannst du ein Signing-Profil pro AWS-Konto erstellen. Alternativ kannst du dich auch für ein Signing-Profil pro Funktion entscheiden, um die Isolierung und Sicherheit zu erhöhen. Die CloudFormation-Ressource für ein Signaturprofil sieht wie folgt aus, wobei PlatformID das Signaturformat und den Signaturalgorithmus angibt, die von dem Profil verwendet werden:
{"Type":"AWS::Signer::SigningProfile","Properties":{"PlatformId":"AWSLambda-SHA384-ECDSA",}}
Sobald du ein Signing-Profil definiert hast, kannst du es verwenden, um Code Signing für deine Funktionen zu konfigurieren:
{"Type":"AWS::Lambda::CodeSigningConfig","Properties":{"AllowedPublishers":[{"SigningProfileVersionArns":["arn:aws:signer:us-east-1:123456789123:/signing-profiles/my-profile"]}],"CodeSigningPolicies":{"UntrustedArtifactOnDeployment":"Enforce"}}}
Weise deiner Funktion schließlich die Konfiguration für das Code Signing zu:
{"Type":"AWS::Lambda::Function","Properties":{"CodeSigningConfigArn":["arn:aws:lambda:us-east-1:123456789123:code-signing-config:csc-config-id",]}}
Wenn du diese Funktion einsetzt, prüft der Lambda-Dienst, ob der Code von einer vertrauenswürdigen Quelle signiert wurde und nicht manipuliert wurde mit seit der Signierung.
Schutz von serverlosen APIs
Laut der OWASP-Top-10-Liste, die wir uns weiter oben in diesem Kapitel angesehen haben, ist die größte Bedrohung für Webanwendungen eine nicht funktionierende Zugriffskontrolle. Auch wenn Serverless dazu beiträgt, einige der Bedrohungen durch eine lückenhafte Zugriffskontrolle zu entschärfen, gibt es in diesem Bereich noch einiges zu tun.
Wenn du das Zero-Trust-Sicherheitsmodell anwendest, musst du die Zugriffskontrolle auf jede isolierte Komponente sowie auf den Perimeter deines Systems anwenden. Für die meisten serverlosen Anwendungen wird die Sicherheitsgrenze ein API Gateway Endpunkt sein. Wenn du eine serverlose Anwendung entwickelst, die eine API für das öffentliche Internet bereitstellt, musst du einen geeigneten Mechanismus zur Zugriffskontrolle für diese API entwerfen und implementieren.
In diesem Abschnitt werden wir die verfügbaren Autorisierungsstrategien für die Anwendung der Zugriffskontrolle auf serverlose APIs untersuchen und herausfinden, wann die einzelnen Strategien eingesetzt werden sollten. Die Optionen für die Zugriffskontrolle für API Gateway sind in Tabelle 4-2 zusammengefasst.
Hinweis
Amazon API Gateway bietet zwei Arten von APIs: REST-APIs und HTTP-APIs. Sie bieten unterschiedliche Funktionen zu unterschiedlichen Kosten. Einer der Unterschiede sind die verfügbaren Optionen für die Zugriffskontrolle. Die Kompatibilität der einzelnen Methoden der Zugriffskontrolle, die wir in diesem Abschnitt untersuchen werden, ist in Tabelle 4-2 angegeben.
| Strategie für die Zugriffskontrolle | Beschreibung | REST-API | HTTP-API |
|---|---|---|---|
| Cognito-Autorinnen und -Autoren | Direkte Integration mit dem Zugangsverwaltungsdienst Amazon Cognito und API Gateway REST APIs. Die Anmeldedaten der Cognito-Kunden werden gegen Zugriffstoken ausgetauscht, die direkt mit Cognito validiert werden. | Ja | Nein |
| JWT-Autorisierer | Kann verwendet werden, um einen Zugriffsverwaltungsdienst, der JSON Web Tokens (JWTs) für die Zugriffskontrolle verwendet, wie z. B. Amazon Cognito oder Okta, mit API Gateway HTTP APIs zu integrieren. | Neina | Ja |
| Lambda-Autoren | Lambda-Funktionen können verwendet werden, um eine benutzerdefinierte Autorisierungslogik zu implementieren, wenn ein anderer Zugangsverwaltungsdienst als Cognito verwendet wird, oder um eingehende Webhook-Nachrichten zu überprüfen, wenn keine benutzerbasierte Authentifizierung verfügbar ist. | Ja | Ja |
a Du kannst immer noch JWTs verwenden, um REST-API-Anfragen zu autorisieren und zu authentifizieren, aber du musst einen benutzerdefinierten Lambda-Authorizer schreiben, der die eingehenden Token verifiziert. | |||
Absicherung von REST-APIs mit Amazon Cognito
Es gibt von natürlich viele Zugangsmanagementdienste und Identitätsanbieter, darunter Okta und Auth0. Wir werden uns auf die Verwendung von Cognito konzentrieren, um eine REST-API zu sichern, da es AWS-eigen ist und aus diesem Grund nur minimalen Overhead verursacht.
Amazon Cognito
Bevor wir eintauchen, lass uns die Bausteine definieren, die du brauchst. Cognito wird oft als einer der komplexesten AWS-Services angesehen. Deshalb ist es wichtig, dass du ein grundlegendes Verständnis der Komponenten von Cognito und eine klare Vorstellung von der Architektur der Zugriffskontrolle hast, die du anstrebst. Hier sind die wichtigsten Komponenten für die Implementierung der Zugriffskontrolle mit Cognito:
- Benutzer-Pools
-
Ein Benutzerpool ist ein Benutzerverzeichnis in Amazon Cognito. Normalerweise hast du einen einzigen Benutzerpool in deiner Anwendung. Mit diesem Benutzerpool kannst du alle Benutzer deiner Anwendung verwalten, unabhängig davon, ob du nur einen oder mehrere Benutzer hast.
- Anwendung Kunden
-
Du kannst eine traditionelle Client/Server-Webanwendung entwickeln, bei der du eine Frontend-Webanwendung und eine Backend-API verwaltest. Oder du betreibst eine mandantenfähige Business-to-Business-Plattform, bei der die Backend-Dienste der Mandanten einen Client Credentials Grant verwenden, um auf deine Dienste zuzugreifen. In diesem Fall kannst du für jeden Mandanten einen Anwendungsclient erstellen und die Client-ID und das Geheimnis für die Machine-to-Machine-Authentifizierung mit dem Mandanten-Backend-Dienst teilen.
- Geltungsbereiche
-
Geltungsbereiche werden verwendet, um den Zugriff eines Anwendungsclients auf bestimmte Ressourcen in der API deiner Anwendung zu kontrollieren.
Cognito und API Gateway
Cognito-Autorisierer bieten eine vollständig verwaltete Integration der Zugriffskontrolle mit API Gateway, wie in Abbildung 4-5 dargestellt. API-Kunden tauschen ihre Anmeldedaten (eine Client-ID und ein Geheimnis) über einen Cognito-Endpunkt gegen Zugangstoken aus. Diese Zugangstoken werden dann in die API-Anfragen aufgenommen und über den Cognito-Autorisierer validiert.
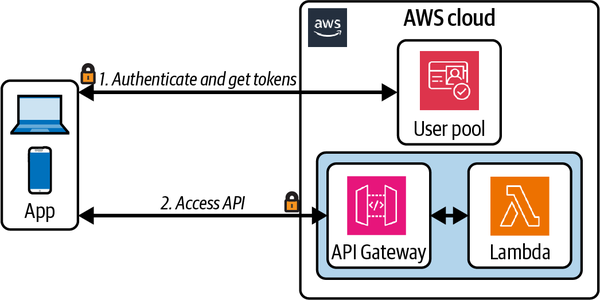
Abbildung 4-5. API Gateway Cognito Autorisierer
Außerdem kann einem API-Endpunkt ein Bereich zugewiesen werden. Bei der Autorisierung einer Anfrage an den Endpunkt überprüft der Cognito-Autorisierer, ob der Bereich des Endpunkts in der Liste der erlaubten Bereiche enthalten ist.
Absicherung von HTTP-APIs
Wenn du eine API-Gateway-HTTP-API und nicht eine REST-API verwendest, kannst du den nativen Cognito-Autorisierer nicht nutzen. Stattdessen hast du ein paar alternative Möglichkeiten. Wir werden uns Beispiele für die beiden praktischsten ansehen: Lambda-Autorisierer und JWT-Autorisierer.
Tipp
JWT-Authorizer können auch verwendet werden, um API-Anfragen mit Amazon Cognito zu authentifizieren, wenn HTTP-APIs verwendet werden.
JWT-Autorisierer
Wenn deine Autorisierungsstrategie lediglich darin besteht, dass ein Kunde ein JSON-Web-Token zur Überprüfung übermittelt, ist die Verwendung eines JWT-Autorisierers eine gute Option. Wenn du einen JWT-Autorisierer verwendest, wird der gesamte Autorisierungsprozess vom API-Gateway-Dienst verwaltet.
Hinweis
JWT ist ein offener Standard, der eine kompakte, in sich geschlossene Methode zur sicheren Übermittlung von Informationen zwischen Parteien in Form von JSON-Objekten definiert. JWTs können verwendet werden, um die Integrität einer Nachricht und die Authentifizierung des Nachrichtenerstellers und -abnehmers sicherzustellen.
JWTs können kryptografisch signiert und verschlüsselt werden, so dass die Integrität der im Token enthaltenen Angaben überprüft werden kann, während diese Angaben vor anderen Parteien verborgen bleiben.
Du konfigurierst zunächst den JWT-Autorisierer und fügst ihn dann einer Route hinzu. Die CloudFormation-Ressource sieht dann etwa so aus:
{"Type":"AWS::ApiGatewayV2::Authorizer","Properties":{"ApiId":"ApiGatewayId","AuthorizerType":"JWT","IdentitySource":["$request.header.Authorization"],"JwtConfiguration":{"Audience":["https://my-application.com"],"Issuer":"https://cognito-idp.us-east-1.amazonaws.com/userPoolID"},"Name":"my-authorizer"}}
Der IdentitySource sollte mit dem Ort des JWT übereinstimmen, den der Kunde in der API-Anfrage angegeben hat, z. B. der Authorization HTTP-Header. Die JwtConfiguration sollte den erwarteten Werten in den Token entsprechen, die von den Kunden übermittelt werden. Dabei ist Audience die HTTP-Adresse des Empfängers des Tokens (in der Regel deine API-Gateway-Domäne) und Issuer die HTTP-Adresse des Dienstes, der für die Ausstellung der Token zuständig ist, wie z. B. Cognito oder Okta.
Lambda-Autoren
Lambda-Funktionen mit benutzerdefinierter Autorisierungslogik können an API Gateway HTTP-API-Routen angehängt und bei jeder Anfrage aufgerufen werden. Diese Funktionen werden als Lambda-Autorisierer bezeichnet und können verwendet werden, wenn du Zugriffskontrollstrategien anwenden musst, die über die von den verwalteten Cognito oder JWT-Autorisierern unterstützten Strategien hinausgehen. In den Antworten der Funktionen wird der Zugriff auf die angeforderten Ressourcen entweder genehmigt oder verweigert (siehe Abbildung 4-6).
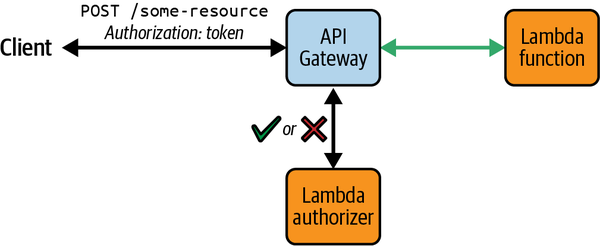
Abbildung 4-6. Kontrolle des Zugriffs auf API-Gateway-Ressourcen mit einem Lambda-Autorisierer
Lambda-Autorisierer unterstützen verschiedene Stellen für die Bereitstellung von Autorisierungsansprüchen in API-Anfragen. Diese werden als Identitätsquellen bezeichnet und umfassen HTTP-Header und Query-String-Parameter (zum Beispiel den Authorization Header). Die Identitätsquelle, die du verwendest, ist für Anfragen an API Gateway erforderlich; alle Anfragen ohne die erforderliche Eigenschaft erhalten sofort eine 401 Unauthorized Antwort und der Lambda-Authorizer wird nicht aufgerufen.
Die Antworten des Lambda-Authorizers können auch zwischengespeichert werden. Die Antworten werden entsprechend der von den API-Kunden bereitgestellten Identitätsquelle zwischengespeichert. Wenn ein Client die gleichen Werte für die erforderlichen Identitätsquellen innerhalb des konfigurierten Cache-Zeitraums oder der TTL bereitstellt, verwendet API Gateway das zwischengespeicherte Autorisierungsergebnis von , anstatt die Autorisierungsfunktion aufzurufen.
Tipp
Das Zwischenspeichern der Antworten deiner Lambda-Authorizer führt zu einer schnelleren Beantwortung von API-Anfragen und zu einer Reduzierung der Kosten, da die Lambda-Funktion deutlich seltener aufgerufen wird.
Die Lambda-Funktion, die zur Autorisierung von Anfragen verwendet wird, kann eine IAM-Richtlinie oder eine so genannte einfache Antwort zurückgeben. Die einfache Antwort reicht in der Regel aus, es sei denn, dein Anwendungsfall erfordert eine IAM-Richtlinienantwort oder detailliertere Berechtigungen. Wenn du die einfache Antwort verwendest, muss die Autorisierungsfunktion eine Antwort im folgenden Format zurückgeben, wobei isAuthorized ein boolescher Wert ist, der das Ergebnis deiner Autorisierungsprüfungen angibt, und context optional ist und zusätzliche Informationen enthalten kann, die an API-Zugriffsprotokolle und Lambda-Funktionen weitergegeben werden, die mit der API-Ressource integriert sind:
{"isAuthorized":true/false,"context":{"key":"value"}}
Validieren und Überprüfen von API-Anfragen
gibt es weitere Möglichkeiten, deine serverlose API zu schützen, die über die Zugriffskontrollmechanismen hinausgehen, die wir bisher in diesem Abschnitt untersucht haben. Insbesondere öffentlich zugängliche APIs sollten immer vor absichtlichem oder unabsichtlichem Missbrauch geschützt werden, und eingehende Anfragedaten an diese APIs sollten immer validiert und bereinigt werden.
Schutz von API-Gateway-Anfragen
API Gateway bietet zwei Möglichkeiten zum Schutz vor Denial-of-Service- und Denial-of-Wallet-Angriffen.
Erstens können die Anfragen von einzelnen API-Kunden über API Gateway-Nutzungspläne gedrosselt werden. Mithilfe von Nutzungsplänen kann der Zugang zu API-Stufen und -Methoden kontrolliert und die Rate der Anfragen an diese Methoden begrenzt werden. Durch die Begrenzung der API-Anfragen kannst du verhindern, dass deine API-Kunden deinen Dienst absichtlich oder unabsichtlich missbrauchen. Nutzungspläne können auf alle Methoden in einer API oder auf bestimmte Methoden angewendet werden. Die Kunden erhalten einen API-Schlüssel, den sie bei jeder Anfrage an deine API angeben müssen. Wenn ein Kunde zu viele Anfragen stellt und deshalb gedrosselt wird, erhält er die HTTP-Fehlerantwort 429 Too Many Requests.
API Gateway integriert außerdem mit AWS WAF, um granularen Schutz auf Anfrageebene zu bieten. Mit der WAF kannst du eine Reihe von Regeln festlegen, die auf jede eingehende Anfrage angewendet werden, z. B. die Drosselung der IP-Adresse.
Hinweis
WAF-Regeln werden immer vor anderen Zugriffskontrollmechanismen wie Cognito-Autorisierern oder Lambda-Autorisierern angewendet.
Validierung von API-Gateway-Anfragen
Anfragen an API-Gateway-Methoden können validiert werden, bevor sie weiterverarbeitet werden. Angenommen, du hast eine Lambda-Funktion, die an eine API-Route angehängt ist, die die API-Anfrage als Eingabe akzeptiert und einige Operationen auf den Anfragebody anwendet. Du kannst eine JSON-Schema-Definition der erwarteten Eingabestruktur und des Formats bereitstellen, und API Gateway wendet diese Datenvalidierungsregeln auf den Körper einer Anfrage an, bevor es die Funktion aufruft. Wenn die Validierung der Anfrage fehlschlägt, wird die Funktion nicht aufgerufen und der Client erhält eine 400 Bad Request HTTP-Antwort.
Hinweis
Die Implementierung der Anforderungsvalidierung über API Gateway kann besonders nützlich sein, wenn du direkte Integrationen zu anderen AWS-Diensten als Lambda verwendest. Du könntest zum Beispiel eine API-Gateway-Ressource haben, die direkt mit Amazon EventBridge integriert ist und auf API-Anfragen reagiert, indem sie Ereignisse an einen Event-Bus weiterleitet. In dieser Architektur möchtest du die Nutzdaten der Anfrage immer validieren und bereinigen, bevor du sie an nachgelagerte Verbraucher weiterleitest.
Weitere Informationen über funktionslose Integrationsmuster findest du in Kapitel 5.
Im folgenden JSON-Beispiel ist die Eigenschaft message erforderlich, und die Anfrage wird abgelehnt, wenn dieses Feld im Anfragetext fehlt:
{"$schema":"http://json-schema.org/draft-07/schema#","title":"my-request-model","type":"object","properties":{"message":{"type":"string"},"status":{"type":"string"}},"required":["message"]}
In Lambda-Funktionen, in denen Daten umgewandelt, in einer Datenbank gespeichert oder an einen Event-Bus oder eine Nachrichtenwarteschlange weitergeleitet werden, sollte eine tiefere Eingabevalidierung und -sanitisierung durchgeführt werden. Dadurch kann deine Anwendung vor SQL-Injection-Angriffen geschützt werden, der Bedrohung Nr. 3 in der OWASP Top 10 (siehe Tabelle 4-1).
Nachrichtenüberprüfung in ereignisgesteuerten Architekturen
Die meisten der Zugriffskontrolltechniken, die wir kennengelernt haben, gelten im Allgemeinen für synchrone Anfrage/Antwort-APIs. Aber wie du in Kapitel 3 gelernt hast, ist es sehr wahrscheinlich, dass du und die Teams oder Drittparteien, mit denen du interagierst, ereignisgesteuerte Anwendungen entwickeln und dabei irgendwann auf eine asynchrone API stoßen werden.
Die Überprüfung von Nachrichten ist in der Regel an den Integrationspunkten zwischen Systemen erforderlich - zum Beispiel bei eingehenden Nachrichten von Drittanbietern Webhooks und bei Nachrichten, die von deiner Anwendung an andere Systeme oder Konten gesendet werden. In einer Zero-Trust-Architektur ist die Nachrichtenüberprüfung auch für den Nachrichtenaustausch zwischen den Diensten in deiner Anwendung wichtig.
Überprüfung von Nachrichten zwischen Verbrauchern und Produzenten
Um die Dienste zu entkoppeln, weiß der Produzent eines Ereignisses in der Regel absichtlich nichts von den nachgelagerten Konsumenten des Ereignisses. Du könntest zum Beispiel eine organisationsweite Event-Backbone-Architektur haben, bei der mehrere Produzenten Ereignisse an einen zentralen Event-Broker senden und mehrere Konsumenten diese Ereignisse abonnieren, wie in Abbildung 4-7 dargestellt.
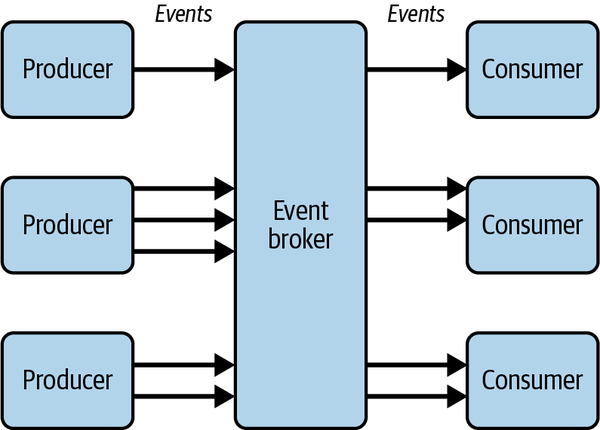
Abbildung 4-7. Entkoppelte Produzenten und Konsumenten in einer ereignisgesteuerten Architektur
Die Absicherung von Verbrauchern asynchroner APIs hängt von der Kontrolle eingehender Nachrichten ab. Die Verbraucher sollten immer die Kontrolle über das Abonnement einer asynchronen API haben, und es wird bereits ein gewisses Maß an Vertrauen zwischen den Ereignisproduzenten und dem Ereignisbroker bestehen, aber die Ereignisverbraucher müssen sich auch gegen Absender-Spoofing und Nachrichtenmanipulation schützen. Die Verifizierung eingehender Nachrichten ist in ereignisgesteuerten Systemen entscheidend.
Nehmen wir an, der Event Broker in Abbildung 4-7 ist ein Amazon EventBridge Event Bus in einem zentralen Konto, das Teil der Kerndomäne deines Unternehmens ist. Die Produzenten sind Services, die in separaten AWS-Konten bereitgestellt werden, ebenso wie die Konsumenten. Ein Verbraucher muss sicherstellen, dass jede Nachricht von einer vertrauenswürdigen Quelle stammt. Ein Produzent muss sicherstellen, dass Nachrichten nur von zugelassenen Verbrauchern gelesen werden können. In einer wirklich entkoppelten Architektur könnte der Event Broker selbst für die Nachrichtenverschlüsselung und die Schlüsselverwaltung zuständig sein (und nicht der Producer), aber um das Beispiel kurz zu halten, machen wir dies zum Aufgabenbereich des Producers.
Verschlüsselte und überprüfbare Nachrichten mit JSON Web Tokens
Du kannst JWT als Transportprotokoll für deine Nachrichten verwenden. Um die Nachrichten zu signieren und zu verschlüsseln, kannst du eine Technik verwenden, die als verschachtelte JWTs bezeichnet und in Abbildung 4-8 dargestellt ist.
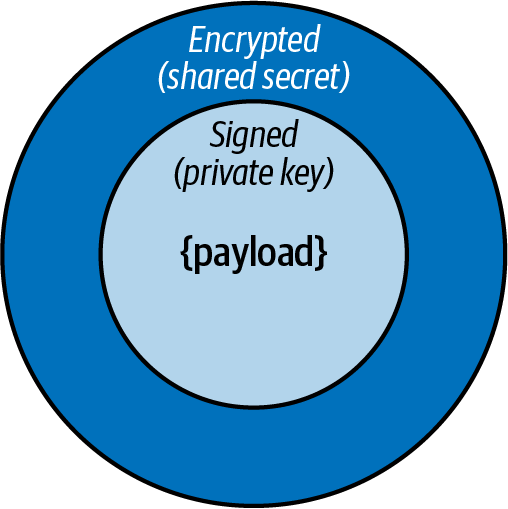
Abbildung 4-8. Ein verschachteltes JSON-Web-Token
Der Produzent muss die Nutzdaten der Nachricht zunächst mit dem privaten Schlüssel signieren und dann die signierte Nachricht mit einem gemeinsamen Geheimnis verschlüsseln:
constpayload={data:{hello:"world"}};constsignedJWT=awaitnewSignJWT(payload).setProtectedHeader({alg:"ES256"}).setIssuer("urn:example:issuer").setAudience("urn:example:audience").setExpirationTime("2h").sign(privateKey);constencryptedJWT=awaitnewEncryptJWT(signedJWT).setProtectedHeader({alg:"dir",cty:"JWT",enc:"A256GCM"}).encrypt(sharedSecret);
Tipp
Öffentliche/private Verschlüsselung Schlüsselpaare und gemeinsame Geheimnisse sollten getrennt von der Produktion der Nachricht zur Laufzeit erstellt und im AWS Key Management Service (KMS) oder AWS Secrets Manager gespeichert werden. Die Schlüssel und Geheimnisse können dann zur Laufzeit abgerufen werden, um die Nachricht zu signieren und zu verschlüsseln.
Beim Empfang einer Nachricht muss der Verbraucher zunächst die Signatur mit dem öffentlichen Schlüssel des Produzenten überprüfen und dann die Nutzdaten mit dem gemeinsamen Geheimnis entschlüsseln:
constdecryptedJWT=awaitDecryptJWT(encryptedJWT,sharedSecret);constdecodedJWT=awaitVerifyJWT(decryptedJWT,publicKey);// if verified, original payload available at decodedJWT.payload
Warnung
Nur der öffentliche Schlüssel des Produzenten und das gemeinsame Geheimnis sollten an die Verbraucher der Nachricht weitergegeben werden. Der private Schlüssel sollte niemals weitergegeben werden.
Integrierte Nachrichtenüberprüfung für SNS
Zusätzlich zu dem Ansatz, der im vorherigen Abschnitt beschrieben wurde, beginnen einige AWS-Services, wie Amazon Simple Notification Service (SNS), jetzt damit, Nachrichtensignaturen nativ zu unterstützen. SNS signiert die von deinem Topic übermittelten Nachrichten und ermöglicht es den abonnierten HTTP Endpunkten, ihre Authentizität zu überprüfen.
Daten schützen
Daten sind das wertvollste Gut, das jede Softwareanwendung anhäuft. Dazu gehören persönliche Daten der Nutzer/innen der Anwendung, Daten über die Integration von Drittanbietern in die Anwendung und Daten über die Anwendung selbst.
Kryptographisches Versagen ist die zweitwichtigste der OWASP Top 10 Bedrohungen für Webanwendungen, nach der fehlenden Zugriffskontrolle. In diesem Abschnitt geht es um die entscheidende Rolle der Datenverschlüsselung bei der Sicherung einer serverlosen Anwendung und darum, wie du deine Daten verschlüsseln kannst, während sie dein System durchlaufen.
Datenverschlüsselung überall
Während du deine serverlose Anwendung entwickelst und betreibst, wirst du sowohl die Möglichkeiten als auch die Herausforderungen entdecken, die sich aus der Verbindung von Komponenten mit Ereignissen ergeben. Ereignisse ermöglichen es dir, Komponenten zu entkoppeln und umfangreiche Daten in ihre Nachrichten aufzunehmen. Serverless Compute ist von Natur aus zustandslos. Das bedeutet, dass die Daten, die eine Lambda-Funktion oder ein Step Functions-Workflow benötigt, um seine Operationen auszuführen, entweder von einem Datenspeicher wie DynamoDB oder S3 abgefragt oder in der Payload des Aufrufs bereitgestellt werden müssen.
In ereignisgesteuerten Systemen sind die Daten überall. Das bedeutet, dass auch die Datenverschlüsselung überall sein muss. Die Daten werden in Datenbanken und Objektspeichern gespeichert. Sie werden durch Nachrichtenwarteschlangen und Ereignisbusse bewegt. Dr. Werner Vogels, der CTO und VP von Amazon, sagte einmal auf der Bühne der re:Invent: "Tanze, als ob niemand zusieht. Verschlüssele, als ob jeder zuschaut."
Was ist Verschlüsselung?
Verschlüsselung ist eine Technik, um den Zugriff auf Daten einzuschränken, indem man sie ohne Schlüssel unlesbar macht. Kryptografische Algorithmen werden verwendet, um Klartextdaten mit einem Verschlüsselungsschlüssel zu verbergen. Die verschlüsselten Daten können nur mit demselben Schlüssel wieder entschlüsselt werden.
Die Verschlüsselung ist dein wichtigstes Werkzeug zum Schutz der Daten in deiner Anwendung. Sie ist besonders wichtig bei ereignisgesteuerten Anwendungen, bei denen Daten ständig zwischen Konten, Diensten, Funktionen, Datenspeichern, Bussen und Warteschlangen fließen. Verschlüsselung kann in zwei Kategorien unterteilt werden: Verschlüsselung im Ruhezustand und Verschlüsselung während der Übertragung. Indem du Daten sowohl bei der Übertragung als auch im Ruhezustand verschlüsselst, stellst du sicher, dass deine Daten während ihres gesamten Lebenszyklus und von Anfang bis Ende geschützt sind, wenn sie dein System durchlaufen und in andere Systeme gelangen.
Die meisten AWS Managed Services bieten native Unterstützung für Verschlüsselung sowie eine direkte Integration mit AWS Secrets Manager und AWS KMS. Das bedeutet, dass der Prozess der Ver- und Entschlüsselung von Daten und die Verwaltung der zugehörigen Verschlüsselungsschlüssel weitgehend von dir abstrahiert wird. Allerdings ist die Verschlüsselung in der Regel nicht standardmäßig aktiviert, sodass du für die Aktivierung und Konfiguration der Verschlüsselung auf Ressourcenebene verantwortlich bist.
Verschlüsselung bei der Übertragung
Daten sind in einer serverlosen Anwendung unterwegs, wenn sie von Service zu Service übertragen werden. Alle AWS-Services bieten sichere, verschlüsselte HTTP-Endpunkte über Transport Layer Security (TLS). Wann immer du mit der API eines AWS-Services interagierst, solltest du den HTTPS-Endpunkt verwenden. Standardmäßig verwenden die Vorgänge, die du mit dem AWS SDK durchführst, die HTTPS-Endpunkte aller AWS-Services. Wenn deine Lambda-Funktion zum Beispiel von einer API-Gateway-Anfrage aufgerufen wird und du von der Funktion aus einen EventBridge PutEvents -Aufruf tätigst, werden die Nutzdaten während der Übertragung vollständig verschlüsselt.
Zusätzlich zu TLS werden alle AWS-API-Anfragen, die mit dem AWS SDK gestellt werden, durch ein Anfrage-Signierungsverfahren geschützt, das unter als Signature Version 4 bekannt ist. Dieser Prozess soll vor Manipulationen von Anfragen und Spoofing des Absenders schützen.
Verschlüsselung im Ruhezustand
Die Verschlüsselung im Ruhezustand wird auf Daten angewendet, wenn sie gespeichert oder zwischengespeichert werden. In einer serverlosen Anwendung können dies Daten in einem EventBridge-Ereignisbus oder -Archiv, eine Nachricht in einer SQS-Warteschlange, ein Objekt in einem S3-Bucket oder ein Element in einer DynamoDB-Tabelle sein.
Generell gilt: Wann immer ein Managed Service die Möglichkeit bietet, Daten im Ruhezustand zu verschlüsseln, solltest du davon Gebrauch machen. Dies ist jedoch besonders wichtig, wenn du die Daten im Ruhezustand als sensibel eingestuft hast.
Du solltest die Speicherung von Daten im Ruhezustand und bei der Übertragung immer begrenzen. Je mehr Daten gespeichert werden und je länger sie gespeichert werden, desto größer sind die Angriffsfläche und das Sicherheitsrisiko. Speichere oder transportiere Daten nur, wenn es unbedingt notwendig ist, und überprüfe deine Datenmodelle und Ereignis-Nutzdaten kontinuierlich, um sicherzustellen, dass überflüssige Attribute entfernt werden.
Tipp
Es hat auch Vorteile für die Nachhaltigkeit, weniger Daten zu speichern. In Kapitel 10 findest du weitere Informationen zu diesem Thema.
AWS KMS
Der wichtigste (Wortspiel beabsichtigt) AWS Service, wenn es um Verschlüsselung geht, ist der AWS Key Management Service. AWS KMS ist ein vollständig verwalteter Service, der die Erzeugung und Verwaltung der kryptografischen Schlüssel unterstützt, die zum Schutz deiner Daten verwendet werden. Wenn du die nativen Verschlüsselungsfunktionen eines AWS-Services wie Amazon SQS oder S3 verwendest, wie in den vorangegangenen Abschnitten beschrieben, nutzt du den KMS, um die erforderlichen Verschlüsselungsschlüssel zu erstellen und zu verwalten. Wann immer ein Service Daten ver- oder entschlüsseln muss, stellt er eine Anfrage an KMS, um auf die entsprechenden Schlüssel zuzugreifen. Der Zugang zu den Schlüsseln wird den Diensten über ihre zugehörigen IAM-Rollen gewährt.
Es gibt verschiedene Arten von KMS-Schlüsseln, z. B. HMAC-Schlüssel und asymmetrische Schlüssel, die im Allgemeinen in zwei Kategorien eingeteilt werden: Von AWS verwaltete Schlüssel und vom Kunden verwaltete Schlüssel. AWS-verwaltete Schlüssel sind Verschlüsselungsschlüssel, die von einem AWS-Service, der in das AWS KMS integriert ist, in deinem Namen erstellt, verwaltet, gedreht und verwendet werden. Vom Kunden verwaltete Schlüssel sind Verschlüsselungsschlüssel, die du erstellst, besitzt und verwaltest. Für die meisten Anwendungsfälle solltest du dich für AWS-verwaltete Schlüssel entscheiden, wenn sie verfügbar sind. Vom Kunden verwaltete Schlüssel können in Fällen verwendet werden, in denen du die Verwendung der Schlüssel überprüfen oder eine zusätzliche Kontrolle über behalten musst.
Hinweis
In der AWS-Dokumentation findest du eine ausführliche Erklärung der KMS-Konzepte, wenn du mehr über dieses Thema lesen möchtest.
Sicherheit in der Produktion
Die Integration von Sicherheit in deinen Entwicklungsprozess ist der Schlüssel zu einer ganzheitlichen Sicherheitsstrategie. Aber was passiert, wenn deine Anwendung produktionsreif ist und in der Produktion läuft?
Wenn du in Produktion gehst, stellt sich oft die Frage: Ist meine Anwendung sicher? Um dir den Prozess zu erleichtern, haben wir eine abschließende Sicherheits-Checkliste erstellt, die du durchgehen kannst, bevor du deine Anwendung für deine Nutzer/innen freigibst, und die dich darauf vorbereitet, deine Anwendung kontinuierlich auf Schwachstellen zu überwachen. Erinnere dich daran, dass Sicherheit ein Prozess ist, an dem du ständig arbeiten musst, genau wie an jedem anderen Aspekt deiner Software.
Sicherheits-Checkliste für serverlose Anwendungen zum Start
Hier ist eine praktische Liste von Dingen, die vor dem Start einer serverlosen Anwendung überprüft werden sollten. Sie kann auch Teil einer Sicherheitsautomatisierungspipeline und der Sicherheitsleitplanken deines Teams sein:
-
Beauftrage Penetrationstests und Sicherheitsprüfungen in einem frühen Stadium der Entwicklung deiner Anwendung.
-
Aktiviere die serverseitige Verschlüsselung (SSE) für alle S3-Buckets mit wertvollen Daten.
-
Aktiviere kontoübergreifende Backups oder Objektreplikation für S3-Buckets mit geschäftskritischen Daten.
-
Aktiviere die Verschlüsselung im Ruhezustand für alle SQS-Warteschlangen.
-
Aktiviere WAF auf API Gateway REST APIs mit baseline-verwalteten Regeln.
-
Aktiviere Zugriffs- und Ausführungsprotokolle für API Gateway APIs.
-
Entferne sensible Daten aus den Umgebungsvariablen von Lambda-Funktionen.
-
Speichere Geheimnisse im AWS Secrets Manager.
-
Verschlüssle die Umgebungsvariablen der Lambda-Funktion.
-
Aktiviere Backups für alle DynamoDB-Tabellen, die geschäftskritische Daten enthalten.
-
Überprüfe Abhängigkeiten auf Schwachstellen: Behebe alle kritischen und hohen Sicherheitswarnungen und minimiere mittlere und niedrige Warnungen.
-
Richte Budgetalarme in CloudWatch ein, um gegen Denial of Wallet-Angriffe zu schützen.
-
Entferne nach Möglichkeit alle IAM-Benutzer.
-
Entferne Wildcards aus den IAM-Richtlinien, wo immer es möglich ist, um die geringsten Rechte zu wahren .
-
Erstelle einen IAM-Anmeldungsbericht, um ungenutzte Rollen und Benutzer zu identifizieren, die entfernt werden können.
-
Erstelle einen CloudTrail-Pfad, um Logs an S3 zu senden.
-
Führe eine Überprüfung des Well-Architected Frameworks durch, wobei der Schwerpunkt auf der Säule Sicherheit und den Sicherheitsempfehlungen der Serverless Lens liegt.
Aufrechterhaltung der Sicherheit in der Produktion
In einem Unternehmen gibt es mehrere AWS-Services, die du nutzen kannst, um den Prozess der Sicherung deiner Anwendung fortzusetzen, sobald sie in der Produktion läuft.
Sicherheitsüberwachung mit CloudTrail
AWS CloudTrail zeichnet alle Aktionen auf, die von IAM-Benutzern, IAM-Rollen oder einem AWS-Service in einem Konto durchgeführt werden. CloudTrail erfasst Aktionen über die AWS-Konsole, CLI, SDK und Service-APIs. Dieser Strom von Ereignissen kann verwendet werden, um deine serverlose Anwendung auf ungewöhnliche oder unbeabsichtigte Zugriffe zu überwachen und sich vor Angriff Nr. 9 auf der OWASP Top 10 Liste zu schützen: Sicherheit Protokollierung und Überwachungsfehler.
Tipp
CloudTrail ist ein wichtiges Instrument zur Abwehr von Ablehnungsangriffen, wie in "STRIDE" beschrieben .
Du kannst Amazon CloudWatch zur Überwachung von CloudTrail-Ereignissen verwenden. CloudWatch Logs Metrikfilter können auf CloudTrail-Ereignisse angewandt werden, um bestimmte Begriffe zu finden, wie z.B. ConsoleLogin events. Diese Metrikfilter können dann CloudWatch-Metriken zugewiesen werden, die zum Auslösen von Alarmen verwendet werden können.
CloudTrail ist standardmäßig für dein AWS-Konto aktiviert. Damit kannst du CloudTrail-Protokolle über den Ereignisverlauf in der AWS-Konsole durchsuchen. Um die Protokolle jedoch über 90 Tage hinaus aufzubewahren und eine detaillierte Analyse und Prüfung der Protokolle durchzuführen, musst du einen Trail konfigurieren. Ein Trail ermöglicht es CloudTrail, Protokolle an einen S3-Bucket zu liefern.
Sobald deine CloudTrail-Protokolle in S3 gespeichert sind, kannst du Amazon Athena verwenden, um die Protokolle zu durchsuchen und detaillierte Analysen und Korrelationen durchzuführen. Weitere Informationen zu den bewährten Methoden von CloudTrail findest du in Chloe Goldsteins Artikel im AWS-Blog.
Kontinuierliche Sicherheitsprüfungen mit Security Hub
Du kannst AWS Security Hub nutzen, um die Sicherheitspraktiken deines Teams zu unterstützen und um Sicherheitserkenntnisse aus anderen Diensten wie Macie zusammenzufassen, die du im nächsten Abschnitt kennenlernen wirst.
Security Hub ist besonders nützlich, um potenzielle Fehlkonfigurationen wie öffentliche S3-Buckets oder fehlende Verschlüsselung im Ruhezustand in einer SQS-Warteschlange zu identifizieren, die sonst schwer aufzuspüren wären. In den Berichten des Security Hubs werden die Feststellungen nach Schweregrad geordnet und eine vollständige Beschreibung jeder Feststellung mit einem Link zu Informationen über Abhilfemaßnahmen, sofern vorhanden, sowie eine Gesamtsicherheitsbewertung geliefert.
Schwachstellenprüfung mit Amazon Inspector
Amazon Inspector kann verwendet werden, um Lambda-Funktionen kontinuierlich auf bekannte Schwachstellen zu überprüfen und die Ergebnisse nach Schweregrad geordnet zu melden. Die Ergebnisse können auch im Security Hub angezeigt werden, um ein zentrales Dashboard zur Sicherheitslage zu erstellen.
Warnung
Die Sicherheitsvorteile von Amazon Inspector sind mit Kosten verbunden. Du solltest das Preismodell verstehen, bevor du Inspector aktivierst.
Inspector kann zusätzlich zu automatischen Schwachstellen-Scannern verwendet werden, die du vielleicht schon früher im Entwicklungsprozess einsetzt, z. B. im Code-Repository selbst.
Aufspüren sensibler Datenlecks
Wie du im vorherigen Abschnitt über den Schutz von Daten gesehen hast, ist die Sicherheit deiner Produktionsdaten entscheidend. Insbesondere Daten, die als sensibel eingestuft sind, müssen mit der höchsten Sicherheitsstufe behandelt werden.
Das Ausmaß, in dem deine Anwendung sensible Daten wie Namen, Adressen, Passwörter und Kreditkartennummern empfängt, verarbeitet und speichert, hängt vom Zweck der Anwendung ab. Aber alle Anwendungen, mit Ausnahme der einfachsten, werden wahrscheinlich in irgendeiner Form mit sensiblen Daten umgehen.
Es gibt vier Schritte, um sensible Daten zu verwalten:
-
Verstehe Protokolle, Richtlinien und Gesetze, die sich auf das Datenmanagement beziehen. Dabei kann es sich um organisatorische Richtlinien zum Datenschutz oder um Datenschutzvorschriften wie den Health Insurance Portability and Accountability Act (HIPAA), die General Data Privacy Regulation (GDPR), den Payment Card Industry Data Security Standard (PCI-DSS) und das Federal Risk and Authorization Management Program (FedRAMP) handeln.
-
Identifiziere und klassifiziere sensible Daten in deinem System. Dabei kann es sich um Daten handeln, die in API-Anfragekörpern empfangen, von internen Funktionen erzeugt, in Ereignisströmen verarbeitet, in einer Datenbank gespeichert oder an Dritte gesendet werden.
-
Implementiere Maßnahmen, um den unsachgemäßen Umgang mit und die Speicherung von sensiblen Daten zu verhindern. Oft gibt es Vorschriften, die es verbieten, Daten über einen bestimmten Zeitraum hinaus zu speichern, sensible Daten zu protokollieren oder Daten zwischen geografischen Regionen zu verschieben.
-
Implementiere ein System zur Erkennung und Beseitigung von unsachgemäßer Speicherung sensibler Daten.
Entschärfung von Datenlecks
Es gibt Maßnahmen, die das Potenzial der Speicherung sensibler Daten in Datenbanken, Objektspeichern oder Protokollen einschränken können, z. B. explizite Protokolle und Protokollredaktion. Es ist jedoch wichtig, die Systeme so zu gestalten, dass eine versehentliche Speicherung sensibler Daten toleriert wird, und so schnell wie möglich zu reagieren und Abhilfe zu schaffen, wenn dies geschieht. In jedem System, das mit sensiblen Daten arbeitet, besteht die Möglichkeit, dass sie falsch gehandhabt werden.
Es ist außerdem ratsam, nur Daten zu speichern, die für den Betrieb deiner Anwendung unbedingt erforderlich sind, und diese Daten nur so lange zu speichern, wie sie benötigt werden. Das Löschen von Daten nach einer bestimmten Zeitspanne kann in verschiedenen AWS-Datenspeichern automatisiert werden. Zum Beispiel sollten CloudWatch-Protokollgruppen mit einer Mindestaufbewahrungsfrist konfiguriert werden, DynamoDB-Datensätze können mit einem TTL-Wert versehen werden und der Lebenszyklus von S3-Objekten kann mit Ablaufrichtlinien gesteuert werden.
In den folgenden Abschnitten werden einige Techniken beschrieben, um sensible Datenlecks in Anwendungsprotokollen und in der Speicherung von Objekten aufzudecken.
Verwaltete Erkennung sensibler Daten
Einige AWS-Dienste bieten bereits eine verwaltete Erkennung sensibler Daten an, und weitere Dienste könnten in der Zukunft folgen. Amazon SNS bietet nativen Datenschutz für Nachrichten, die über SNS-Themen gesendet werden. Amazon CloudWatch bietet eine integrierte Erkennung von sensiblen Daten in Anwendungsprotokollen, z. B. von Lambda-Funktionen.
Amazonas Macie
Amazon Macie ist ein vollständig verwalteter Datensicherheitsdienst, der maschinelles Lernen nutzt, um sensible Daten in AWS-Arbeitslasten zu entdecken. Macie ist in der Lage, in S3-Buckets gespeicherte Daten zu extrahieren und zu analysieren, um verschiedene Arten von sensiblen Daten wie AWS-Anmeldedaten, persönliche Daten, Kreditkartennummern und mehr zu erkennen.
Daten können von verschiedenen Komponenten in deiner Anwendung an S3 weitergeleitet und von Macie kontinuierlich auf sensible Attribute überwacht werden. Dazu können Ereignisse gehören, die an EventBridge gesendet werden, API-Antworten, die von Lambda-Funktionen erzeugt werden, oder Nachrichten, die an SQS-Warteschlangen gesendet werden. Ereignisse, die Macie feststellt, werden an EventBridge gesendet und können von dort weitergeleitet werden, um dich zu warnen, wenn sensible Daten gespeichert oder von deiner Anwendung übertragen werden.
Zusammenfassung
Das Sicherheitsparadoxon besagt, dass die Sicherheit von Software zwar von größter Bedeutung für ein Unternehmen sein sollte, aber oft nicht das Hauptanliegen der Entwicklungsteams ist. Diese Diskrepanz wird in der Regel durch einen Mangel an umsetzbaren Prozessen verursacht.
Sicherheit muss und kann ein integraler Bestandteil des Lebenszyklus deiner serverlosen Softwarebereitstellung sein. Dies kannst du erreichen, indem du wichtige Sicherheitsstrategien wie die Zero-Trust-Architektur, das Prinzip der geringsten Privilegien und die Bedrohungsmodellierung anwendest, Branchenstandards für Datenverschlüsselung, API-Schutz und Lieferkettensicherheit befolgst und die von AWS bereitgestellten Sicherheitstools wie IAM und Security Hub nutzt.
Am wichtigsten ist, dass du dich daran erinnerst, dass Sicherheit ganz einfach sein kann. Indem du einen klaren Rahmen für die Sicherung deiner serverlosen Anwendung festlegst, kannst du deinen Ingenieuren viele der üblichen Ängste und Unsicherheiten nehmen.
Interview mit einem Branchenexperten
Nicole Yip, leitende Ingenieurin
Nicole Yip hat viele Jahre damit verbracht, Entwicklungsteams in AWS zum Laufen zu bringen und ihnen dabei zu helfen, in Australien und dem Vereinigten Königreich zur Betriebsreife zu gelangen. Ihre Interessen in den Bereichen DevOps (in seinen vielen Definitionen), Sicherheit, Zuverlässigkeit, Infrastruktur und allgemeines Systemdesign haben dazu beigetragen, Teams so zu formen, dass sie ihre Anwendungen und Dienste sicher in die Produktion bringen und gleichzeitig ihr Verständnis und ihre Prozesse rund um den Betrieb von Produktionssystemen (vor allem einer sehr beliebten globalen Einzelhandelswebsite) weiterentwickeln können.
Du kannst einige Konferenzvorträge und Blogbeiträge über ihre verschiedenen Interessengebiete online finden, aber ihr Hauptaugenmerk liegt darauf, die Teams in den Unternehmen, mit denen sie zu tun hatte, zu inspirieren, herauszufordern und Wachstum zu realisieren.
F: In der Softwarebranche herrscht die Meinung, dass Sicherheit schwierig ist und Cybersecurity-Spezialisten überlassen werden sollte. Hat die Cloud das geändert, oder sollten Ingenieure immer noch Angst vor Sicherheit haben?
In der Softwarebranche gilt Sicherheit zwar als schwierig und einschüchternd, aber ich würde sagen, dass sie als "eine weitere Anforderung" und ein Kaninchenloch angesehen wird.
Sicherheit gilt als "schwierig", weil sie eine weitere nichtfunktionale Anforderung ist, die in jeder Phase berücksichtigt werden muss, vom Entwurf über die Implementierung bis hin zum laufenden Betrieb. Sicherheit ist auch deshalb schwierig, weil es viel zu entdecken gibt, wenn du in die Welt der Sicherheit einsteigst - es geht nicht nur um den Code, den du schreibst, die Architektur, die du entwirfst, oder die Zugriffskontrollen für die Anwendungen, die du verwendest, um bestimmte Standards und Protokolle zu erfüllen. Es gibt auch ganze Kategorien von Bedrohungen, wie z. B. physische Sicherheit und Social Engineering, an die man nicht denkt, wenn man die Sicherheit nur aus der Sicht der Softwareentwicklung betrachtet, die aber genauso schädlich sein können, wenn nicht sogar noch schädlicher, wenn sie in dein System eindringen.
Für die Sicherheitsteams hat sich das InfoSec-Tooling, das früher manuell und umständlich war und monatlich oder seltener geplant werden musste, verbessert und ist jetzt viel benutzerfreundlicher und in den Softwareentwicklungszyklus integriert, so dass es einfacher ist, Probleme zu erkennen, bevor sie in die Produktion gelangen, oder sogar automatisch Patches für verwundbare Abhängigkeiten zu erstellen, sobald sie in der Community gemeldet werden.
Softwareentwickler sind in der Regel sehr neugierig und sollten daher keine Angst vor dem Thema Sicherheit haben - je mehr du darüber weißt, desto fundiertere Entscheidungen triffst du, wenn es darum geht, wie du eine Anwendung hostest oder ob du auf einen Link klickst. Jede Codezeile, die geschrieben wird, und jede Designentscheidung, die getroffen wird, verändert die Sicherheitslage des Systems. Je sicherheitsbewusster alle an der Softwareentwicklung Beteiligten sind, desto unwahrscheinlicher ist es, dass ein Bösewicht genug Schwachstellen findet, um Schaden anzurichten.
Bei der Cloud liegt die Verantwortung für die Sicherung von Teilen deines Systems beim Cloud-Provider - die Sicherheit deiner Rechenzentren und gespeicherten Daten wird vertraglich mit dem Cloud-Provider vereinbart. Für kleine Unternehmen ist das ein Segen, denn es ist ein weiterer Punkt, der geklärt und durchgesetzt werden müsste, wenn sie sich für einen eigenen Serverraum entschieden hätten.
Wenn du einen Cloud-Provider nutzt, konfigurierst du standardmäßig ein sichereres System, ohne dir dessen bewusst zu sein. Die Entscheidung, eine Anwendung in der Cloud einzurichten, kann bereits dazu führen, dass du Entscheidungen über die Sicherheit triffst, weil du bei der Konfiguration der Dienste vor diese Entscheidungen gestellt wirst.
Du kannst immer noch ein System mit Schwachstellen in der Cloud bauen, also bleibe neugierig; lerne so viel wie möglich über Angriffsvektoren (Bedrohungsmodelle helfen dabei, diese zu identifizieren) und die tatsächlichen geschäftlichen Auswirkungen auf dein System, wenn jemand sie entdeckt und ausnutzt. Es geht nicht um das "ob", sondern um das "wann".
Was bedeutet "Sicherheit"?
Das Endziel ist, dass dein System auf die vorgesehene Art und Weise genutzt werden kann, und alle anderen potenziellen Missbräuche und Zugriffe sollten eingedämmt (eingeschränkt) oder gar nicht erst möglich sein.
Es ist eine Risikoakzeptanzskala - du sicherst ein System bis zu dem Punkt, an dem du als Unternehmen die Wahrscheinlichkeit und die Auswirkungen der potenziellen Angriffsvektoren in deinem System akzeptierst. Warum? Weil es Angriffsvektoren gibt, die du nicht verhindern kannst, wie z. B. Insider-Bedrohungen durch einen bösartigen Akteur in deinem Entwicklungsteam!
F: Serverless verlagert die Verantwortung für die Verwaltung der Infrastruktur auf AWS, sodass sich die Ingenieure auf den Code konzentrieren können, der in dieser Infrastruktur bereitgestellt wird. Wird die Sicherheit durch die Delegation der Infrastrukturverwaltung bei Serverless einfacher oder schwieriger?
Es kommt darauf an, aus welchem Blickwinkel du das Ganze betrachtest: als Infrastruktur-/Netzwerkingenieur oder als Softwareentwickler. Insgesamt denke ich, dass Serverless die Sicherheit ein wenig einfacher macht, da die Umgebungen in einer Sandbox laufen, was die Möglichkeit verringert, dass ein Einbruchspunkt bestehen bleibt. Aber wenn du anfängst, komplexere Anwendungsfälle einzuführen, die z. B. Netzwerke (wenn sie in einer VPC laufen), Authentifizierung und Autorisierung von Clients (die deine APIs aufrufen)... einbeziehen, dann bleibt das erforderliche Maß an Sicherheitsexpertise gleich. Anstatt dass die Verantwortung bei einem Betriebs- oder Infrastrukturteam liegt, das sich bereits mit Bedrohungen auf Netzwerkebene befasst, wird diese Aufgabe vom Team für Softwareentwicklung übernommen.
Wir müssen uns bewusst darum bemühen, die Erwartungen an Softwareentwickler zu erhöhen, die sich weiter nach unten in den Stack von Serverless und Infrastruktur wagen. Es reicht nicht aus, die verwendeten Bibliotheken gemäß den empfohlenen Sicherheitsstufen zu konfigurieren, sondern du musst auch überlegen, wie viele Berechtigungen der Container, in dem dein Code läuft, tatsächlich braucht, um zu funktionieren, wie viel Konnektivität er zu anderen Ressourcen braucht - sollten sie sich im selben Netzwerk befinden oder können sie isoliert werden?
F: Du hast viele Jahre lang Software-Teams geleitet und eine aktive Rolle in der Cloud- und DevOps-Community gespielt. Hast du beobachtet, dass sich die Rolle eines Softwareentwicklers verändert hat, da er zunehmend für die Sicherung seiner Anwendungen verantwortlich ist, wenn er serverlose Technologien einsetzt?
Ja, aber nicht unbedingt, weil Softwareentwickler/innen immer mehr Verantwortung für die Sicherheit ihrer Anwendungen übernehmen. Softwareentwickler/innen fangen in der Regel in einem Spezialgebiet an - Frontend, Backend, Datenbankadministrator/in usw. - und lernen die führenden Frameworks, Muster und nichtfunktionalen Anforderungen (einschließlich Sicherheit) für die Entwicklung zuverlässiger Lösungen in diesem Spezialgebiet. Dann fangen sie an, sich auszudehnen und Spezialgebiete zu sammeln, mit dem Ziel, der mythische "Full Stack"-Ingenieur zu werden. Früher umfasste der Begriff "Full Stack" im Wesentlichen die Bereiche Frontend, Backend und Datenbanken, aber mit der Verbreitung von Cloud-Hosting-Plattformen können auch Betrieb, Netzwerk und Infrastruktur dazugehören. Vor allem mit Serverless hat sich die Einstiegshürde für neue Fachgebiete gesenkt, wie z. B. Daten (Migration und Management), maschinelles Lernen und vieles mehr.
Wie ich bereits erwähnt habe, ist Sicherheit eine dieser nicht-funktionalen Anforderungen, die in allen Teilen des Stacks vorhanden ist, und all diese Spezialgebiete, die ich zuvor erwähnt habe, müssen Sicherheit und Datenschutz mit unterschiedlichen Augen für ihre Bereiche des Stacks verstehen.
Mit Serverless können Softwareentwickler/innen einen Fuß in die Tür bekommen, um sich mit Netzwerken und Infrastrukturen vertraut zu machen, wobei Sicherheit und Datenschutz in die Nutzung der Plattform integriert werden.
Wenn du eine AWS VPC anforderst und deine Subnetze und Routing-Tabellen einrichtest, sind diese standardmäßig gesperrt und du gibst die Ports und Netzwerke an, auf die du zugreifen musst (ignorieren wir mal die Tatsache, dass die Standard-Netzwerkressourcen in neuen AWS-Konten sich nicht daran halten).
Die Möglichkeiten und Wege für Softwareentwickler/innen, sich weiterzuentwickeln, werden immer größer. Alle paar Jahre werden neue Technologien auftauchen (derzeit GenAI und Prompt-Engineering), die die Einstiegshürde für andere Fachrichtungen senken (z. B. Data Science und Kreativwirtschaft) und dann eine neue Zeile in der Beschreibung eines Full-Stack-Ingenieurs hinzufügen können.
F: Du hast eine entscheidende Rolle bei der Einführung von Serverless und DevOps in großen Unternehmen gespielt. Wie können Teams und Organisationen deiner Erfahrung nach eine Kultur der Sicherheit fördern?
Es gibt zwei Dinge, die ich genutzt habe, um eine Kultur der Sicherheit zu fördern. Erstens, indem ich eine starke Kultur im Entwicklungsteam aufgebaut und Sicherheitsthemen in die täglichen Gespräche eingebracht habe, um das Sicherheitsbewusstsein zu erhalten.
Leistungsstarke Ingenieurskulturen zeichnen sich in der Regel durch Transparenz, schnelles Fehlschlagen und "No Blame"-Prinzipien aus. Das schafft nicht nur Vertrauen, sondern ermöglicht es den Teams auch, gemeinsam zu lernen. Niemand kann eine Architektur überprüfen und sie zu 100 % abschließen, ohne Risiken in Kauf zu nehmen. Jeder hat unbekannte Unbekannte, und es gibt einfach einige Angriffsvektoren, die man nicht ausschließen kann. Wenn also etwas passiert, wird eine Kultur, die klare Regeln hat, was zu tun ist, wenn ein Verstoß auftritt, und die niemanden dafür bestraft, einen Verstoß zu erkennen und zu melden, viel schneller sicherheitsreif werden als ein Team, in dem diese Prinzipien nicht aktiv gefördert werden.
Der zweite Punkt ist, die Sicherheit im Gespräch zu halten und genügend Zeit für Slack, Innovation und Neugierde zu haben. Tooling und Shift-Links-Prinzipien machen schon früh im Softwareentwicklungszyklus auf Sicherheitsbedenken aufmerksam, was die Diskussion anregt, wenn sie auf konstruktive Weise auftauchen. Die Einführung von Anforderungen für die Bedrohungsmodellierung als Teil des Entwurfsprozesses bringt die Diskussion über Sicherheit noch weiter nach links. Darüber hinaus brauchst du aber auch Ingenieure, die neugierig sind, die sich ständig fragen, was wäre wenn, und die genug Zeit haben, diesen Gedankengängen nachzugehen. Regelmäßige "Lunch and Learn "-Sitzungen über die letzte Sicherheitslücke, die in der Branche gemeldet wurde, oder ein Sicherheitskonzept können diese Momente des "Was wäre wenn...?" auslösen. Diese kleine Eingabeaufforderung an einen Ingenieur, über die Sache nachzudenken, an der er gerade arbeitet, und zu erkennen, dass die Schwachstelle, die diese Sicherheitslücke oder dieses Konzept ermöglichte, auch auf die Sache zutreffen könnte, an der er gerade arbeitet, ist das, was du suchst - und dann stellst du sicher, dass sie unterstützt werden, wenn sie es ausprobieren oder das "Was wäre wenn...?"-Szenario durchspielen. Sie könnten sogar eine Entschärfung einbauen, bevor das Feature in Produktion geht!
Es sind diese Linsen auf dem Code von einer hohen Ebene (Bedrohungsmodellierung) bis zu einer niedrigen Ebene (Abhängigkeits- und statische Analysetools), die das sichere Design und die Implementierung eines Systems ergänzen können, aber es sind die Ingenieure, die in der Lage sein werden, das System mit der Geschäftslogik und den Einschränkungen im Hinterkopf zu sichern, während jede Codezeile geschrieben und jeder Teil des Systems konfiguriert wird. Gib ihnen den Raum und das Wissen, um ihre Neugierde zu wecken und dies zu tun!
F: Es gibt mehrere Standards und bewährte Methoden für die Sicherheit bei AWS, darunter das Prinzip der geringsten Privilegien, das Modell der gemeinsamen Verantwortung für die Cloud-Sicherheit und das AWS Well-Architected Framework. Wo kann ein Unternehmen, das Serverless einführt, deiner Meinung nach mit dem Sicherheitsbewusstsein beginnen?
Als Erstes solltest du bedenken, dass jeder für die Sicherheit verantwortlich ist.
Ich würde sagen, fang auf der Unternehmensebene an und geh davon aus, dass du morgen einen Einbruch erleidest. Gibt es in deinem Unternehmen eine gute Sicherheitsgrundlage? Würdest du wissen, ob und wann du verletzt wirst und wie du reagieren und Abhilfe schaffen kannst?
Präventions- und Entschärfungsmaßnahmen sind immer notwendig, können aber das Risiko eines Einbruchs nie auf 0 % reduzieren. Wie ich bereits erwähnt habe, gibt es einige Angriffsvektoren, die du nicht schließen kannst und die du nur so gut wie möglich entschärfen kannst, um sie auf ein akzeptables Risikoniveau zu senken.
Zu den grundlegenden Sicherheitsfunktionen auf Unternehmensebene gehören:
- Erkennung
-
SIEM-Warnungen (Security Information and Event Management), die an ein reaktionsschnelles Team gehen
- Antwort
-
Integritätsgesichertes Beweissicherungssystem, Sandboxes und isolierte Netzwerke, Erfahrung in Sicherheitsmaßnahmen
- Prävention
-
Leitplanken, Schulungen, goldene Pfade, Audits, Penetrationstests
Wenn man von der Unternehmensebene auf die Plattformteams übergeht, sollten die Plattformteams goldene Sicherheitspfade in ihre Produkte einbauen, die alles, was auf der Plattform entwickelt wird, in das SIEM des Unternehmens einspeisen und den Teams priorisierte Warnmeldungen anzeigen. Sie können auch die Anwendungsteams unterstützen, indem sie Sicherheitstools in ihre Toolchain und Deployment-Pipelines integrieren und die Ergebnisse auf effektive Art und Weise weitergeben.
Anwendungsteams sollten regelmäßig an Sicherheitsschulungen teilnehmen, um über die neuesten Bedrohungen auf dem Laufenden zu bleiben - sei es durch die Teilnahme an Präsentationen, in denen die neuesten Hacks auf einer relevanten Anwendungsebene aufgedeckt werden, durch die Teilnahme an Unternehmensschulungen oder durch die Neugierde, mehr über die bewährten Methoden der verwendeten Tools zu erfahren (AWS Well-Architected Framework, GitHub Dependabot-Ergebnisse, statische und/oder dynamische Analysetools, penetration tests, usw.).
Get Serverlose Entwicklung auf AWS now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

